
FPIRST: Fatigue Driving Recognition Method Based on Feature Parameter Images and a Residual Swin Transformer

Abstract
1. Introduction
- (1)
- Different drivers show different facial features. Judging whether the driver is fatigued by using a fixed statistical threshold is not a universal approach. The threshold method for fatigue driving recognition necessitates calculating an adaptive threshold for each driver in their normal driving state in advance. However, determining whether their current driving state is their normal driving state is difficult in practical applications.
- (2)
- The SVM method judges fatigue driving through data classification. The computational complexity of this method depends on the number of support vectors, and predictive time is proportional to the number of support vectors. Thus, it is more sensitive to missing data. Finding a suitable nuclear function to transform data dimensions is difficult, thus affecting the accuracy of classification.
- (3)
- The LSTM network selectively remembers or forgets information through gating units. It learns to enter long-term dependencies in the sequence, effectively controlling the flow and outflow of information, and passes this information to the next time step. However, it needs improvement in accurately capturing important information in the input sequence.
- (1)
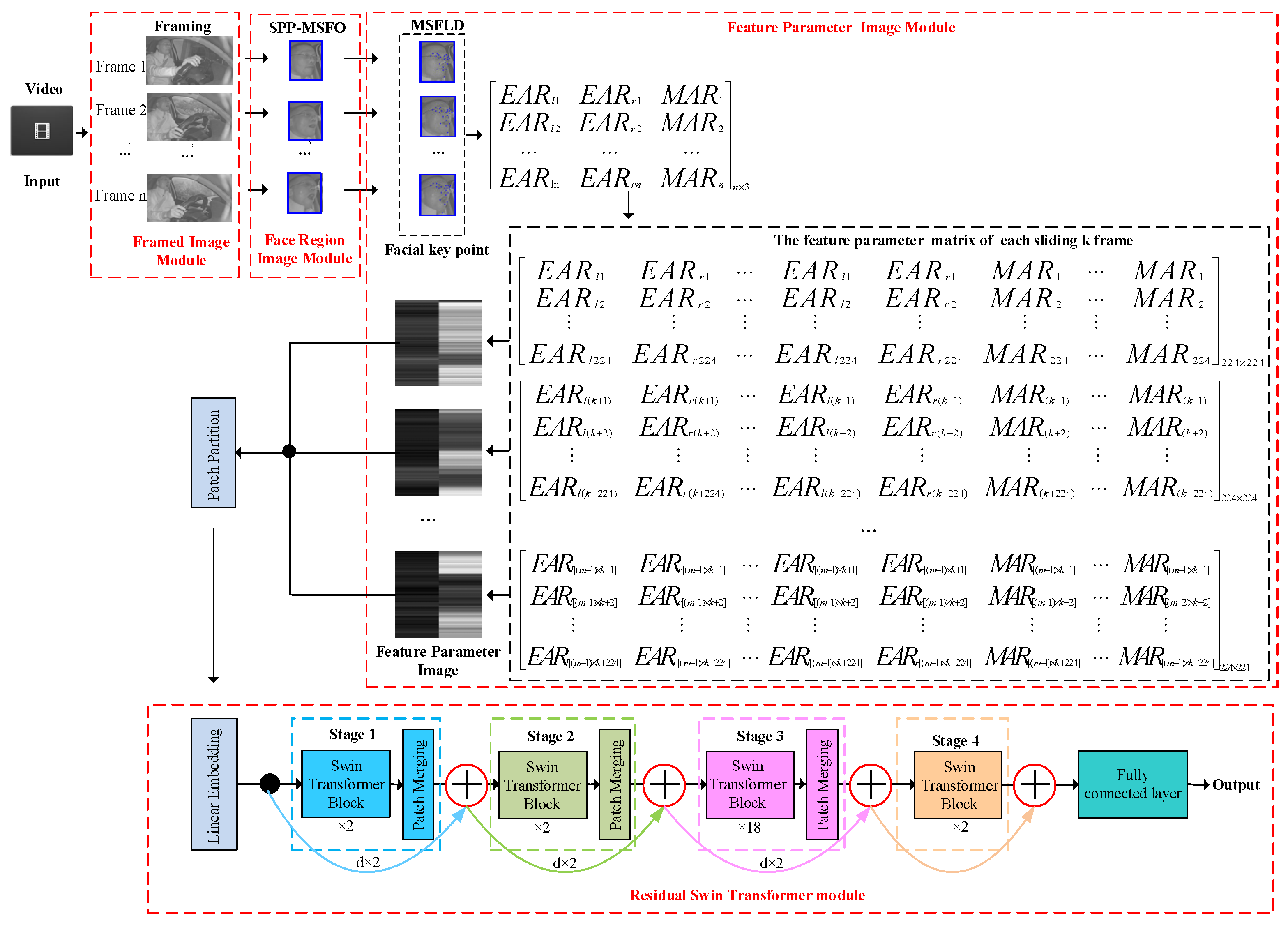
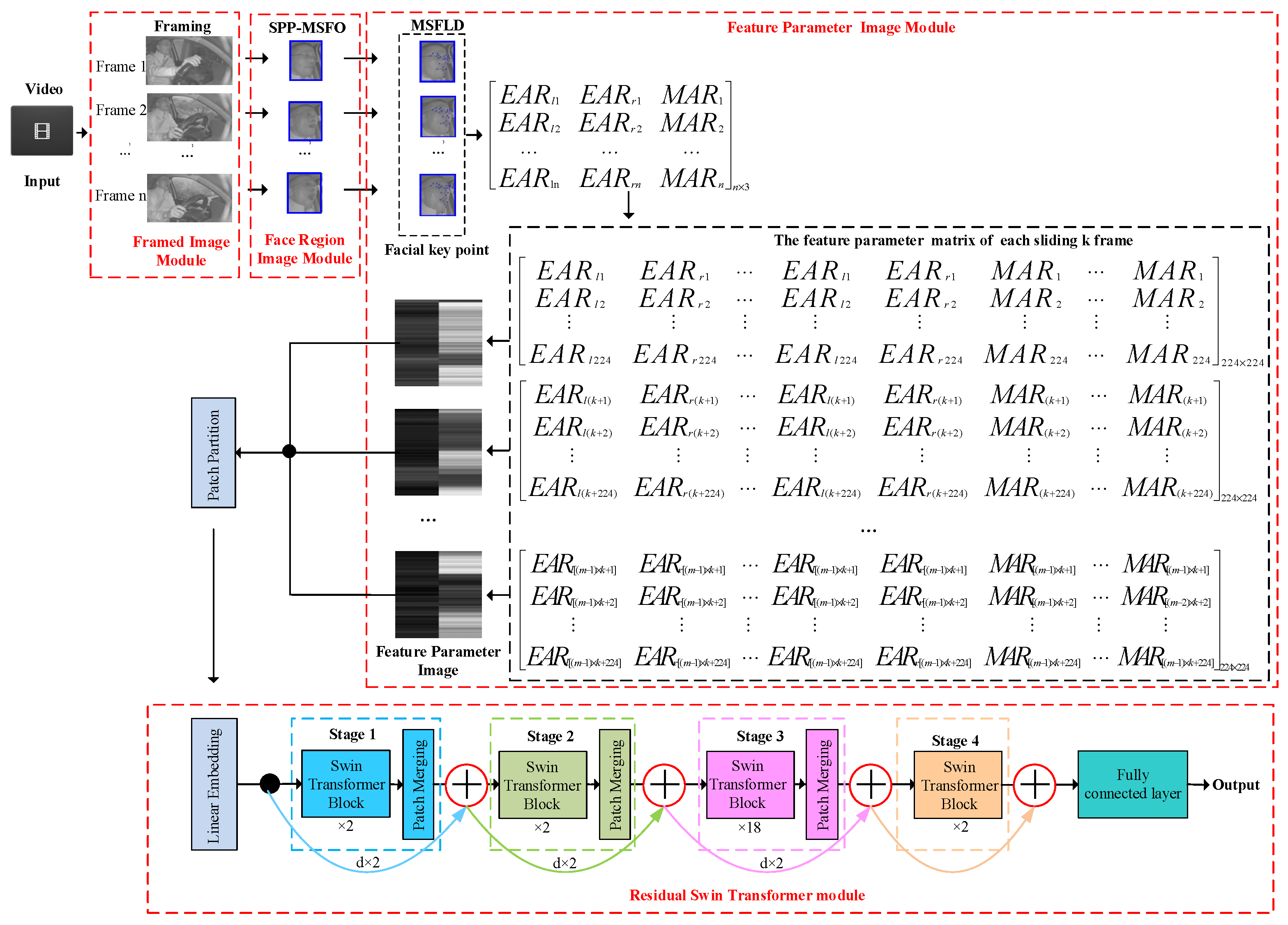
- A fatigue driving recognition framework based on feature parameter images and a residual Swin Transformer is designed. In the FPIRST, SPP-MSFO is used to detect the face region, and MSFLD is adopted to locate facial key points. On the basis of the key points, the feature parameter images are formulated, and the residual Swin Transformer network is used to recognize fatigue driving.
- (2)
- The aspect ratios of the mouth, left eye, and right eye are computed based on facial 23 key point coordinates to formulate feature parameter images. The feature parameter matrix of n × 3 can be obtained from n-frame images. Subsequently, the technique of sliding k frames is used to expand the n × 3 feature parameter matrix into an m 224 × 224 matrix. Each feature parameter matrix of 224 × 224 is converted into a feature parameter image. Such images contain not only the characteristics of feature parameters but also the duration information of fatigue driving behavior.
- (3)
- A residual Swin Transformer module is used to recognize fatigue driving behavior. The residual Swin Transformer can represent features more compactly and obtain richer semantic information, therefore better locating targets. The skip connection in the residual Swim Transformer realizes selective multi-scale learning of local discriminative features in diving video sequences. The experimental results on the HNUFD dataset verify the proposed method.
2. Related Work
2.1. Fatigue Driving Recognition Methods
2.2. Image Classification Methods
3. Proposed Method
3.1. Overview of the Architecture
3.2. Feature Parameter Image Module
3.2.1. Feature Extraction of Eye Fatigue
3.2.2. Feature Extraction of Mouth Fatigue
3.2.3. Generating the Feature Parameter Matrix of
3.2.4. Generating Feature Parameter Image of
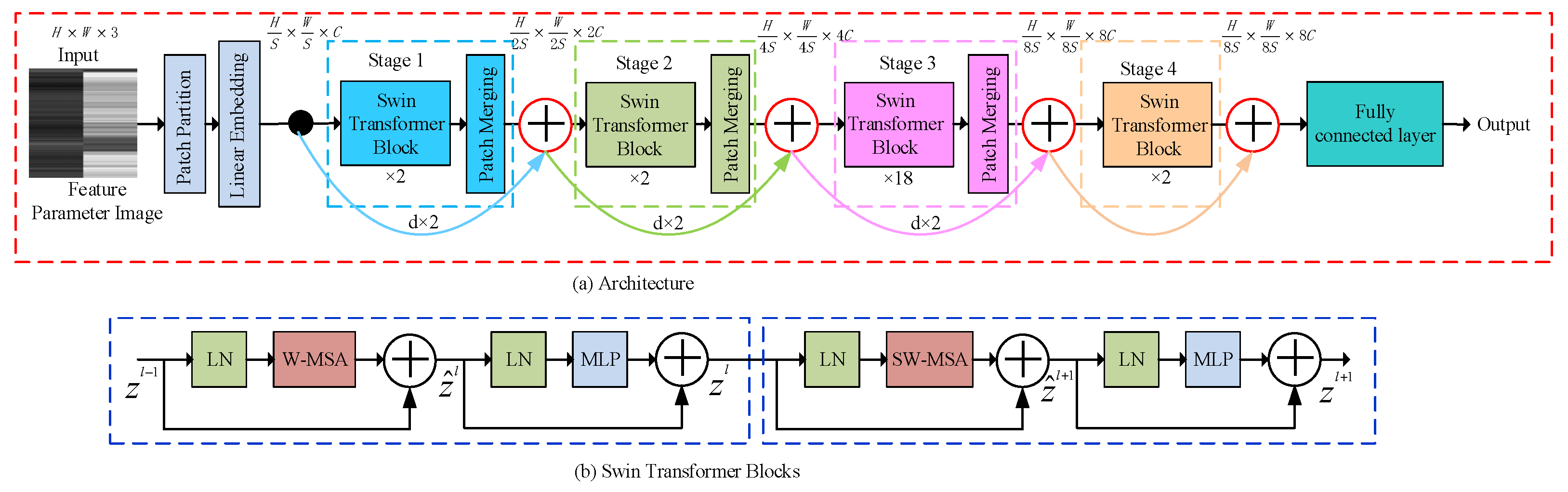
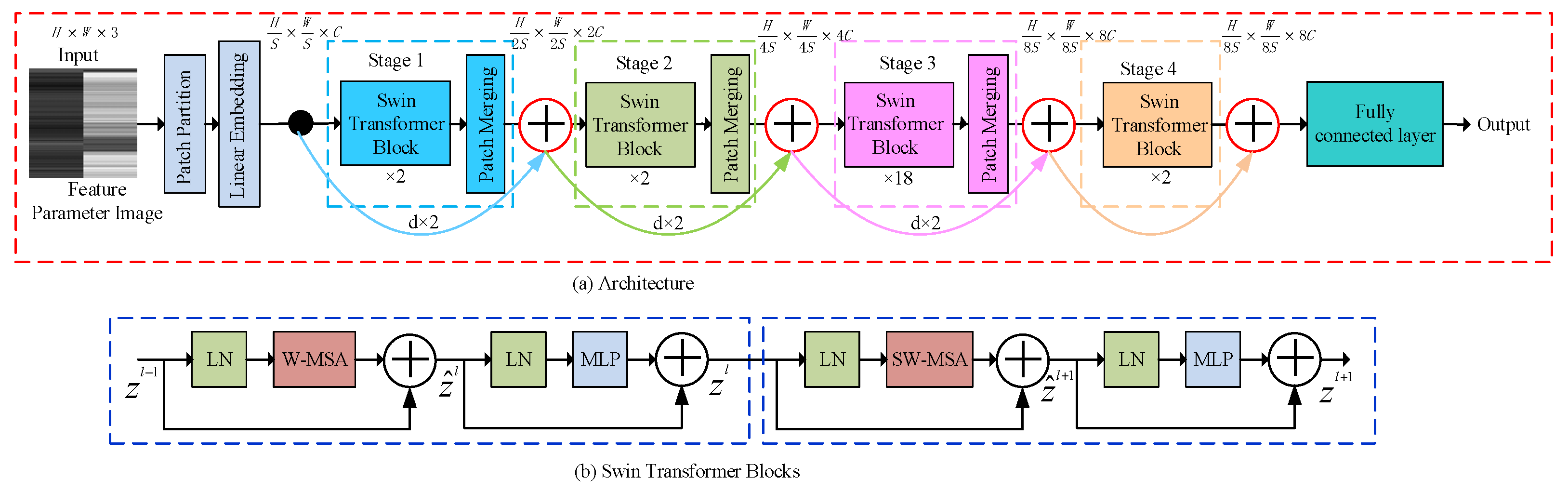
3.3. Residual Swin Transformer Module
3.4. Learning Algorithm of FPIRST
- (1)
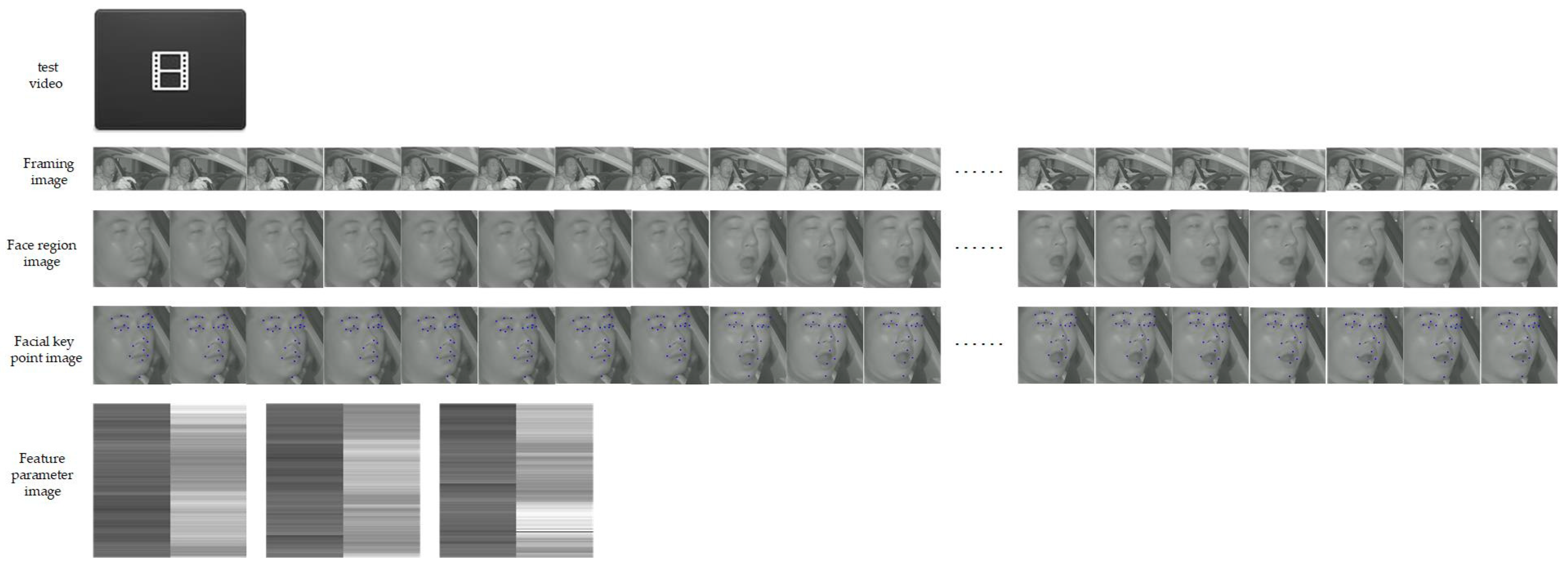
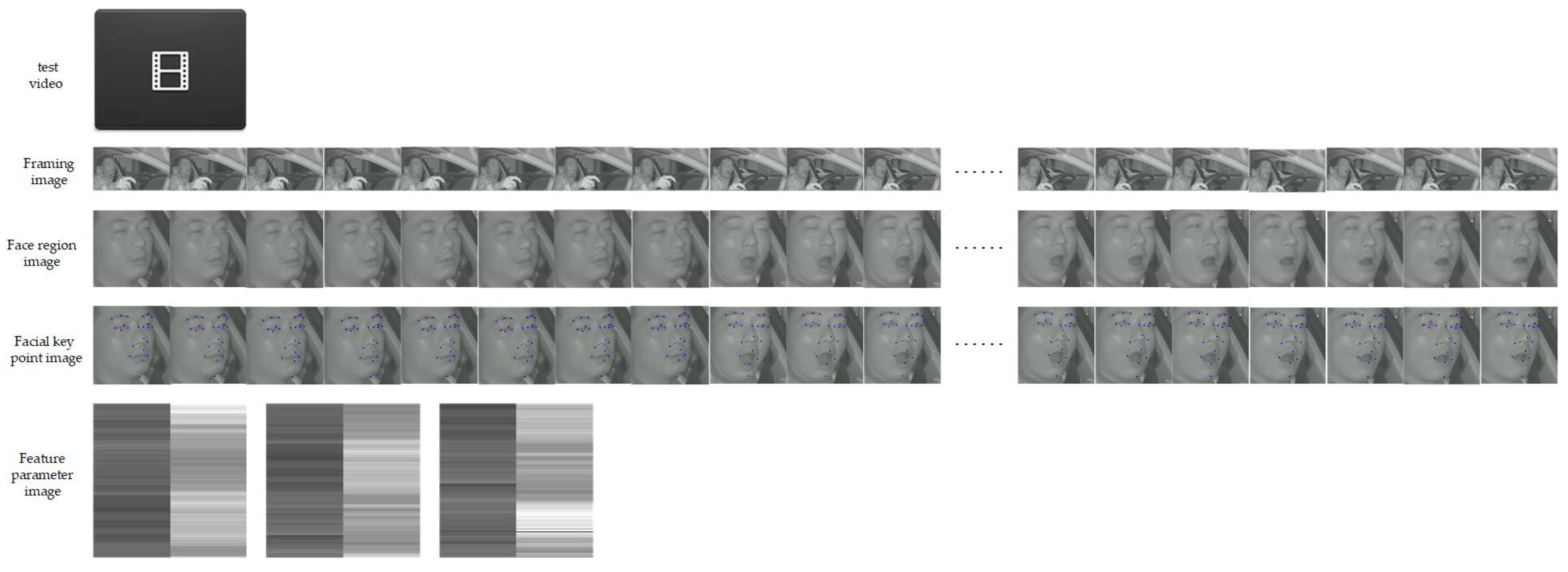
- In Line 1, the structure of the FPIRST model is constructed. This model consists of SPP-MSFO, MSFLD, the feature parameter matrix and image, and the residual Swin Transformer. The overview of the FPIRST model architecture is shown in Figure 1. The data processing procedure is as follows. Through the getThreeRatioFromvideo (yolo, keyPointModel, videoFile) function, the video is divided into frames, face area detection, and 23 key points on the face location, and the aspect ratios of the left eye, right eye, and mouth are calculated by Formulas (1), (2), and (3), respectively, to form an feature parameter matrix. The feature parameter matrix is processed by the Li_n_3toLi224_224 (Li375_3, n, k, p) function, and feature parameter matrices are formed. The calculation formula is shown in (6). The feature parameter matrix of 224 × 224 is converted into a feature parameter image () with a resolution of 224 × 224 by the array2img (dataArray, imgSavePath) function.
- (2)
- In Line 2, the parameters in the FPIRST model are initialized. The parameters include the weight , bias , learning rate , batch size, number of classes, and epochs. These parameters are initialized, as described in Section 4.
- (3)
- In Lines 3–9, the FPIRST model is trained, using forward learning and backward propagation.
- (4)
- In Line 9, model training is completed when the end condition is satisfied. The end conditions include the number of iterations and an early stopping strategy.
| Algorithm 1 Training strategy of FPIRST |
| Input: Given videos from the HNUFD video dataset, feature parameter image training sample after data processing and their type labels .
Output: The well-trained model FPIRST. 1: Construct the FPIRST method shown in Figure 1; 2: Initialize the parameters; 3: Repeat 4: Randomly select a batch of instances from ; 5: Forward learn training samples through the FPIST model; 6: Compute the error by 7: Propagate the error back through FPIST and update the parameters; 8: Find by minimizing with ; 9: Until the end condition is satisfied. |
4. Experiments
4.1. Setting
4.1.1. Experimental Conditions
4.1.2. Evaluation Metrics
4.2. Datasets
4.3. Ablation Studies
4.3.1. Architecture of the FPIRST Method
4.3.2. Residual Swin Transformer Model
4.4. Comparison of the Accuracy of the Proposed Method under Different Sliding Frame Numbers
4.4.1. Building A Training Image Dataset for the Residual Swin Transformer Model
4.4.2. Training the Residual Swin Transformer Model
4.4.3. Comparing the Accuracy of the Proposed Method under Different Numbers of Sliding Frames
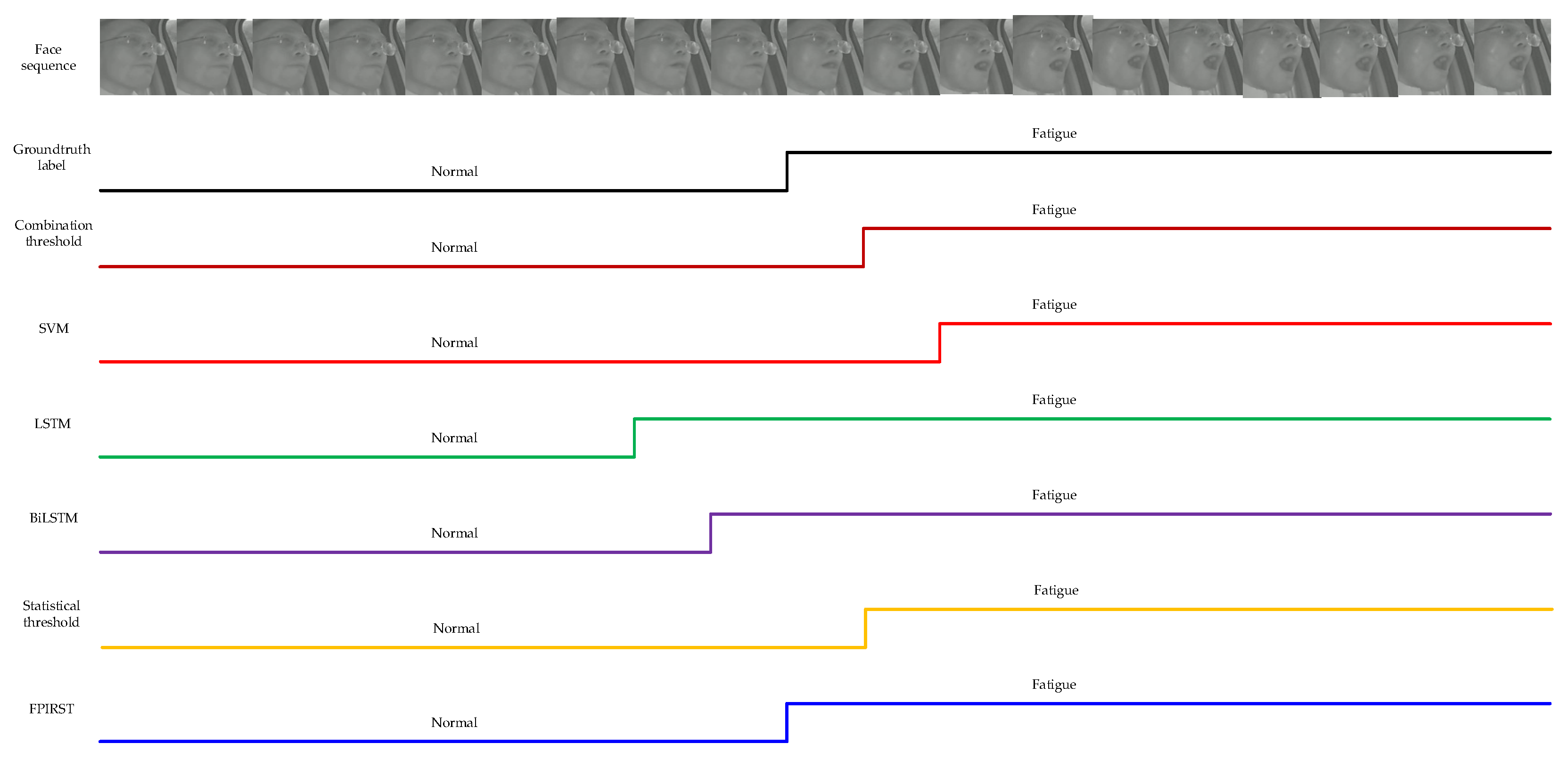
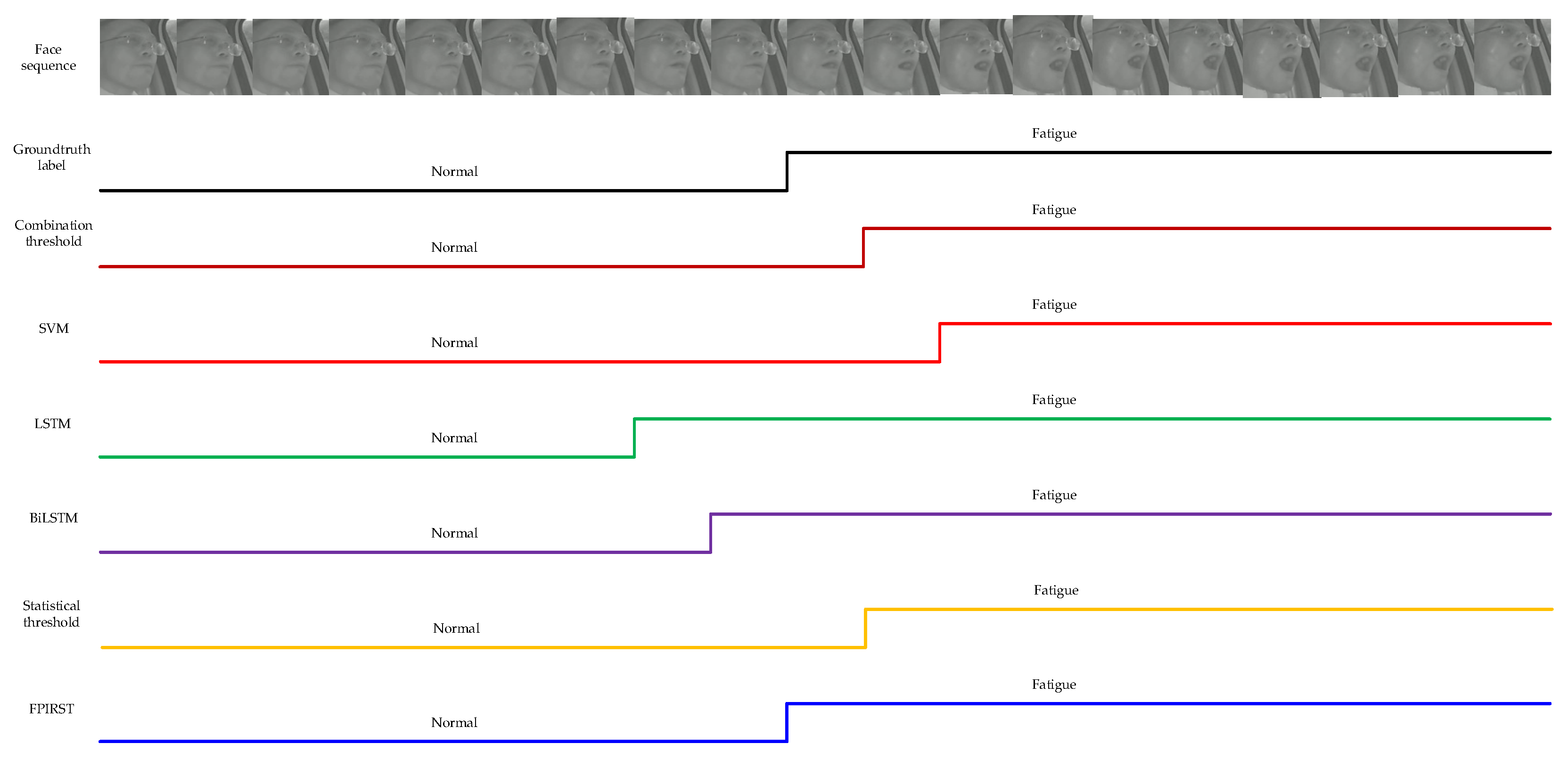
4.5. Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, C.; Subramanian, R. Factors Related to Fatal Single-Vehicle Run-Off-Road Crashes; Report HS-811 232; URC Enterprises: Washington, DC, USA, 2009. [Google Scholar]
- Li, D.H.; Liu, Q.; Yuan, W.; Liu, H.X. Relationship between fatigue driving and traffic accident. J. Traffic transp. Eng. 2010, 10, 104–109. [Google Scholar]
- Niu, Q.; Zhou, Z.; Jin, L. Fatigue driving detection method based on eye movement feature. J. Harbin Eng. Univ. 2015, 39, 394–398. [Google Scholar]
- Zhang, Z.; Ning, H.; Zhou, F. A systematic survey of driving fatigue monitoring. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19999–20020. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Xiao, W.; Liu, H.; Ma, Z.; Chen, W.; Sun, C.; Shi, B. Fatigue Driving Recognition Method Based on Multi-Scale Facial Landmark Detector. Electronics 2022, 11, 4103. [Google Scholar] [CrossRef]
- Guo, X.; Li, S.; Yu, J.; Zhang, J.; Ma, J.; Ma, L.; Liu, W.; Ling, H. PFLD: A Practical Facial Landmark Detector. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1–11. [Google Scholar]
- Puspasari, M.A.; Iridiastadi, H.; Sutalaksana, I.Z.; Sjafruddin, A. Fatigue Classification of Ocular Indicators using Support Vector Machine. In Proceedings of the International Conference on Intelligent Informatics and Biomedical Science (ICIIBMS), Bangkok, Thailand, 21–24 October 2018; pp. 66–69. [Google Scholar]
- Chen, L.; Xin, G.; Liu, Y.; Huang, J. Driver fatigue detection based on facial key points and LSTM. Secur. Commun. Netw. 2021, 2021, 5383573. [Google Scholar] [CrossRef]
- Hu, Y.; Lu, M.; Xie, C.; Lu, X. Driver Drowsiness Recognition via 3D Conditional GAN and Two-Level Attention Bi-LSTM. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4755–4768. [Google Scholar] [CrossRef]
- Sikander, G.; Anwar, S. Driver Fatigue Detection Systems: A Review. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2339–2352. [Google Scholar] [CrossRef]
- Zhang, N.; Zhang, H.; Huang, J. Driver Fatigue State Detection Based on Facial Key Points. In Proceedings of the of the 6th International Conference on Information Systems (ICSAI), Shanghai, China, 2–4 November 2019; pp. 144–149. [Google Scholar] [CrossRef]
- Qin, X.; Yang, P.; Shen, Y.; Li, M.; Hu, J.; Yun, J. Classification of driving fatigue based on EEG signals. In Proceedings of the International Symposium on Computer, Consumer and Control (IS3C), Taichung City, Taiwan, 13–16 November 2020; pp. 508–512. [Google Scholar] [CrossRef]
- Ye, Q.; Huang, P.; Zhang, Z.; Zhang, Z.; Fu, L.; Yang, W. Multiview learning with robust double-sided twin SVM. IEEE Trans. Cybern. 2022, 52, 12745–12758. [Google Scholar] [CrossRef] [PubMed]
- Fu, L.; Li, Z.; Ye, Q.; Yin, H.; Liu, Q.; Chen, X.; Fan, X.; Yang, W.; Yang, G. Learning Robust Discriminant Subspace Based on Joint L2,p- and L2,s-Norm Distance Metrics. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 130–144. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.H.; Tian, Y.B.; Searyoh, P.K.; Yu, G.; Yong, Y.-T. Deep reinforcement learning-based resource allocation strategy for energy harvesting-powered cognitive machine-to-machine networks. Comput. Commun. 2020, 160, 706–717. [Google Scholar] [CrossRef]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of image classification algorithms based on convolutional neural networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May2015; pp. 1–14. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognitio (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations(ICLR), Virtual Event, 3–7 May 2021; pp. 1–22. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yang, W.; Tan, C.; Chen, Y.; Xia, H.; Tang, X.; Cao, Y.; Zhou, W.; Lin, L.; Dai, G. BiRSwinT: Bilinear full-scale residual swin-transformer for fine-grained driver behavior recognition. J. Frankl. Inst. 2023, 360, 1166–1183. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device or Parameter | Details | |
|---|---|---|
| Experimental conditions | CPU (Santa Clara, CA, USA) | Intel x299 Core i9-10900X @3.7 GH |
| Memory | 32 G | |
| Motherboard | Z690 DDR4 | |
| GPU (Santa Clara, CA, USA) | NVIDIA RTX 3090 48 G | |
| Platform | 64-bit Ubuntu | |
| parameter settings | Language | Python |
| Framework | PyTorch | |
| Learning rate | 0.0001 | |
| Batch size | 8 | |
| Epoch | 100 |
| Formulation | Accuracy (%) |
|---|---|
| FI + ST | 82.7338 |
| FI + FRI + ST | 82.7338 |
| FI + FRI + FPI + ST | 84.8921 |
| FI + RST | 82.7338 |
| FI + FRI + RST | 87.0504 |
| FI + FRI + FPI + RST (Proposed) | 96.4029 |
| Model | Accuracy (%) |
|---|---|
| Swin Transformer [20] | 84.8921 |
| Full-scale Residual Swin Transformer [21] | 84.8921 |
| Residual Swin Transformer | 96.4029 |
| Frame Numbers | Accuracy (%) |
|---|---|
| 25 (1 s) | 84.8921 |
| 50 (2 s) | 84.1727 |
| 75 (3 s) | 96.4029 |
| 100 (4 s) | 87.7698 |
| 125 (5 s) | 84.1727 |
| Methodology | Accuracy (%) | Model Size (MiB) | Test Time (s) |
|---|---|---|---|
| Combination threshold [6] | 86.3309 | - | 25.6132 |
| SVM [8] | 74.1007 | 0.211 | 25.9192 |
| LSTM [9] | 82.7338 | 0.292 | 29.9493 |
| BiLSTM [10] | 85.6115 | 3.2 | 33.9743 |
| Statistical threshold [12] | 90.6475 | - | 25.6205 |
| FPIRST | 96.4029 | 343.1 | 26.7026 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, W.; Liu, H.; Ma, Z.; Chen, W.; Hou, J. FPIRST: Fatigue Driving Recognition Method Based on Feature Parameter Images and a Residual Swin Transformer. Sensors 2024, 24, 636. https://doi.org/10.3390/s24020636
Xiao W, Liu H, Ma Z, Chen W, Hou J. FPIRST: Fatigue Driving Recognition Method Based on Feature Parameter Images and a Residual Swin Transformer. Sensors. 2024; 24(2):636. https://doi.org/10.3390/s24020636
Chicago/Turabian StyleXiao, Weichu, Hongli Liu, Ziji Ma, Weihong Chen, and Jie Hou. 2024. "FPIRST: Fatigue Driving Recognition Method Based on Feature Parameter Images and a Residual Swin Transformer" Sensors 24, no. 2: 636. https://doi.org/10.3390/s24020636
APA StyleXiao, W., Liu, H., Ma, Z., Chen, W., & Hou, J. (2024). FPIRST: Fatigue Driving Recognition Method Based on Feature Parameter Images and a Residual Swin Transformer. Sensors, 24(2), 636. https://doi.org/10.3390/s24020636