1. Introduction
In the era of Industry 4.0 [
1,
2,
3], the industrial sector urgently needs to introduce transmission protocols characterized by high transmission rates, low latency, and high reliability [
4] to meet the demand for massive data transmission in factories [
1]. Unlike wired protocols, wireless networks better meet the current industrial demand for device mobility, leading researchers to explore their applications in the sector [
5,
6,
7,
8,
9] and propose standards such as industrial wireless sensor networks [
5] and WIA-FA for factory automation [
6], which feature lower transmission latency. In these applications, WIA-FA has achieved the lowest transmission delay of 25 ms in multi-AGV synchronous motion scenarios. However, most of these wireless networks have limited coverage and narrow bandwidth, making it difficult to ensure the determinism of information transmission.
The commercially available 5G network is renowned for its low latency and high reliability, offering broad application prospects [
10]. The current state-of-the-art 6G network outperforms 5G in terms of real-time performance and reliability, but it is still in the theoretical research phase. Ref. [
11] proposed a dual-function radar-communication base station beamforming design method to address joint communication and signal optimization issues in the 6G environment. Ref. [
12] identified 12 key scientific challenges facing 6G. Overall, 6G technology is still far from practical application. Against this backdrop, researching the application potential of 5G in the industrial sector is particularly necessary.
The measurement and performance analysis of 5G RTT data can provide a basis for assessing its application potential in specific industrial scenarios. Therefore, selecting appropriate 5G RTT measurement methods based on different scenario requirements is crucial. References [
13,
14] focus on the characteristics of the network itself, using precise but complex measurement tools or methods to analyze 5G RTT under different network conditions. However, these methods are not suitable for engineering practice due to their lack of convenience. Among researchers focusing on industrial applications, the author [
15] conducted 5G RTT measurements and characteristic analyses on highways. Ref. [
16] improved urban positioning accuracy by measuring 5G RTT in the Global Navigation Satellite System (GNSS). Although these findings demonstrate the potential of 5G, there is a lack of research on its RTT performance in real factory environments.
In industrial fields with high real-time requirements, accurately predicting 5G RTT helps improve system performance. For instance, in scenarios involving dual AGV (Kunshan Huaheng Welding Co., Ltd., Kunshan, China) synchronized control, precise 5G RTT predictions assist in maintaining the accuracy and stability of the synchronized control system [
17]. The author of [
18] utilized the specialized measurement software Nemo Handy (Keysight Technologies, Inc., Santa Rosa, CA, USA) to obtain real-time data on radio layer and physical layer parameters and combined it with machine learning algorithms to predict 5G RTT. The author of [
19] proposed a URLLC time delay prediction method based on unbalanced regression algorithms and LSTM to address sporadic large time delay issues. These studies demonstrate the effectiveness of 5G prediction methods within their respective research contexts, but there is a lack of research on 5G time delay prediction in real factory environments.
To address the research gap in existing literature regarding the application of 5G in factory environments, we designed a 5G RTT measurement method suitable for factories, analyzed the measured RTT performance, and proposed a method for predicting 5G RTT. Our study confirms the feasibility of applying 5G in factory environments with low latency requirements, which is of significant importance in the current context of Industry 4.0 and provides a valuable reference for future exploration of 6G industrial applications.
The rest of the paper is organized as follows.
Section 2 briefly provides an overview of research works related to this study.
Section 3 details the test environment setting for 5G network performance. In
Section 4, statistical analysis is conducted on the 5G RTT data, and the results indicate that the low latency performance of 5G technology is superior to existing standards. At the same time, the statistical results provide a basis for assessing whether 5G networks can be applied to specific industrial scenarios.
Section 5 demonstrates that the RTT data are a series of non-stationary random time sequences. In
Section 6, first-order differencing is first used on the original 5G RTT series to obtain the stationary differential sequences. Then, a time series analysis-based variational mode decomposition (VMD)–long short-term memory (LSTM) prediction method is proposed, in which VMD is used to decompose the differential sequences into a series of different modes to reduce the impact of the complexity and volatility of the original data on prediction accuracy. After that, LSTM is used to predict the differential sequences, and finally, the inverse difference is performed to obtain the predicted value of 5G RTT.
Section 7 first introduces two metrics for evaluating model prediction performance based on the accuracy and stability requirements of industrial control systems. Then, a sensitivity analysis of the model to different hyperparameters is conducted, providing a basis for hyperparameter selection. Finally, by comparing different prediction methods, it proves that the proposed method has a better performance in the prediction of RTT. Finally, conclusions are presented in
Section 8.
4. Statistical Analysis of 5G RTT Data
According to different packet sending intervals and packet lengths, eight RTT datasets (dataset 1 to dataset 8 in
Table 3) were statistically analyzed, and the results are reported in
Table 3. To apply 5G networks to industrial scenarios, it is necessary to first determine the required network service capabilities based on business requirements and then plan a 5G network that can achieve such network service capabilities. There are already relevant standardized regulations for network planning. Therefore, for 5G networks in different industrial scenarios, as long as they have the same network service capabilities as the network used in our research, the characteristics of the network after standardized network planning will be approximately the same. Consequently, our research results can be generalized for other industrial scenarios with the same business requirements.
It can be seen that the minimum values of the eight sets of data were relatively close and all less than 7 ms. Due to the uncertainty caused by factors such as the network signal-to-noise ratio (SNR) and network load, the maximum RTT had a strong randomness, yet the average values of the eight sets of data were about 11 ms. Generally speaking, when the packet lengths are the same, the longer the packet sending intervals, the larger the average values of RTT, yet the increase is relatively small. It can be seen from the standard deviation data that when the packet sending intervals increased while the packet lengths were the same, the variability in the 5G RTT increased. All eight sets of data had positive skewness because of the long tailing and the large number of great RTT data, and this situation was influenced by the SNR as well as the load of the network.
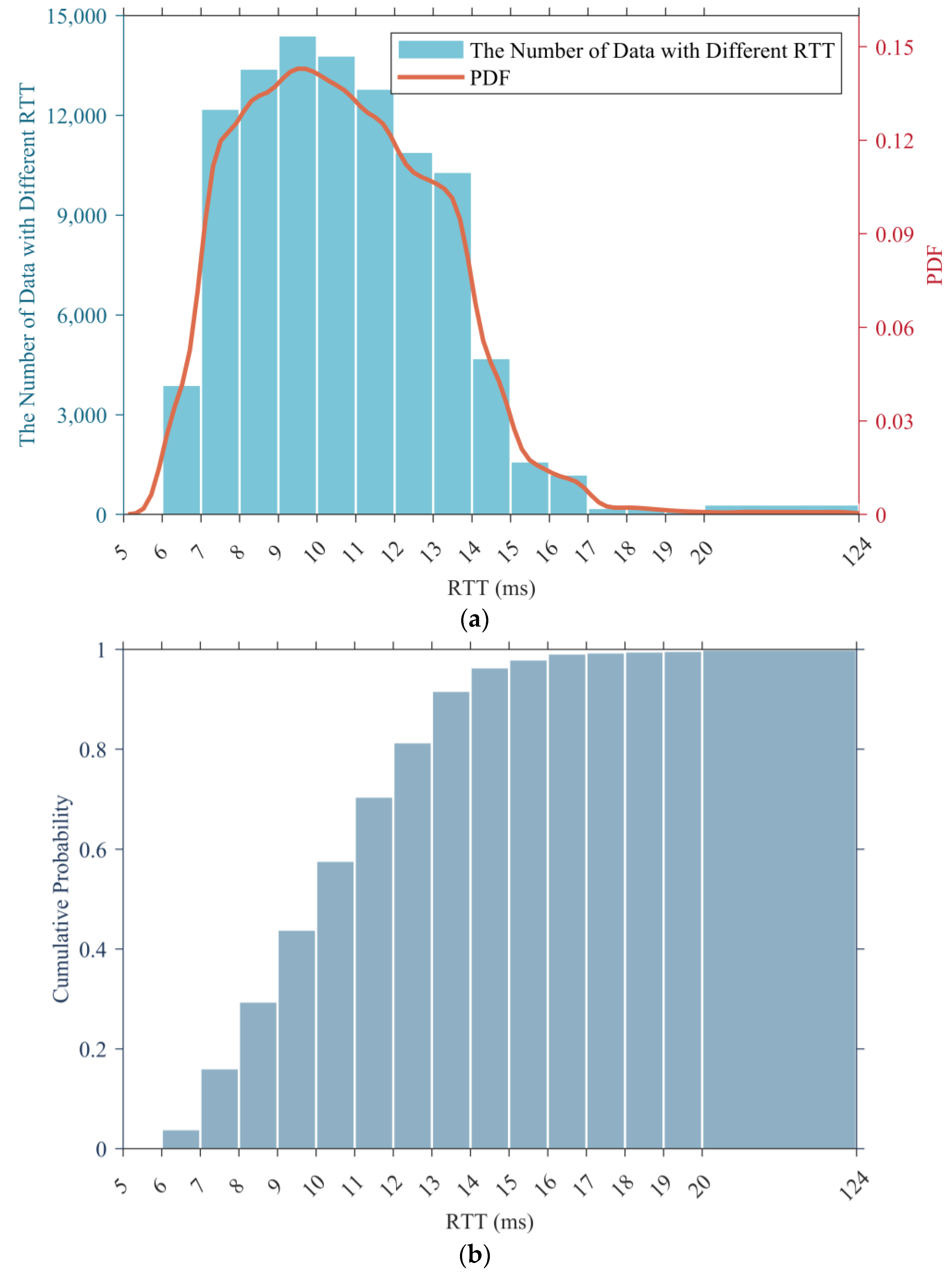
We used dataset 1 as an example to draw its histogram and probability density function (PDF), and the results are presented in
Figure 2a, while
Figure 2b displays its cumulative histogram.
According to the statistical results, the RTT data with values within the range of (7, 14] accounted for the vast majority of the total sample, reaching 87.8%, yet the RTT data with a value greater than 15 ms only accounted for 3.6%. In addition, the RTT data with a value greater than 20 ms (which is regarded as a large delay) were even less, accounting for only 0.3%.
Through the statistical analysis of 5G RTT data in this section, it can be seen that their average value was around 11 ms, which is better than the 25 ms of WIA-FA and can better meet the low latency requirements of machine tools or robot control in factory environments.
6. 5G RTT Prediction with the Time Series Analysis-Based VMD-LSTM Method
We propose a 5G RTT prediction method based on time series analysis and VMD-LSTM, to use a sequence of
m + 1 RTT data
obtained through measurement to predict a sequence of
n RTTs
that will be generated in the future.
represents the
kth subsequence of the
K subsequences obtained after the VMD process conducted on
. In addition, the terms related to LSTM networks are defined as follows:
represents the LSTM unit at time
t −
i in the LSTM network corresponding to the
kth subsequence. Among them,
represents the cell state of the LSTM unit at time
t −
i − 1,
represents the output of the LSTM unit at time
t −
i − 1,
represents the
kth component of the known DRTT data input to the LSTM unit at time
t −
i,
represents the cell state of the LSTM unit at time
t −
i,
represents the output of the LSTM unit at time
t −
i. These LSTM units (
) make up the training phase of the LSTM network.
represents the LSTM unit at time
t +
j in the LSTM network corresponding to the
kth subsequence. Among them,
represents the cell state of the LSTM unit at time
t + j − 1,
represents the output of the LSTM unit at time
t + j − 1,
represents the
kth component of the predicted DRTT data input to the LSTM unit at time
t +
j,
represents the cell state of the LSTM unit at time
t +
j,
represents the output of the LSTM unit at time
t +
j, i.e., the predicted DRTT data for the next moment (time
t +
j + 1). These LSTM units (
) make up the prediction phase of the LSTM network. In the framework diagram shown in
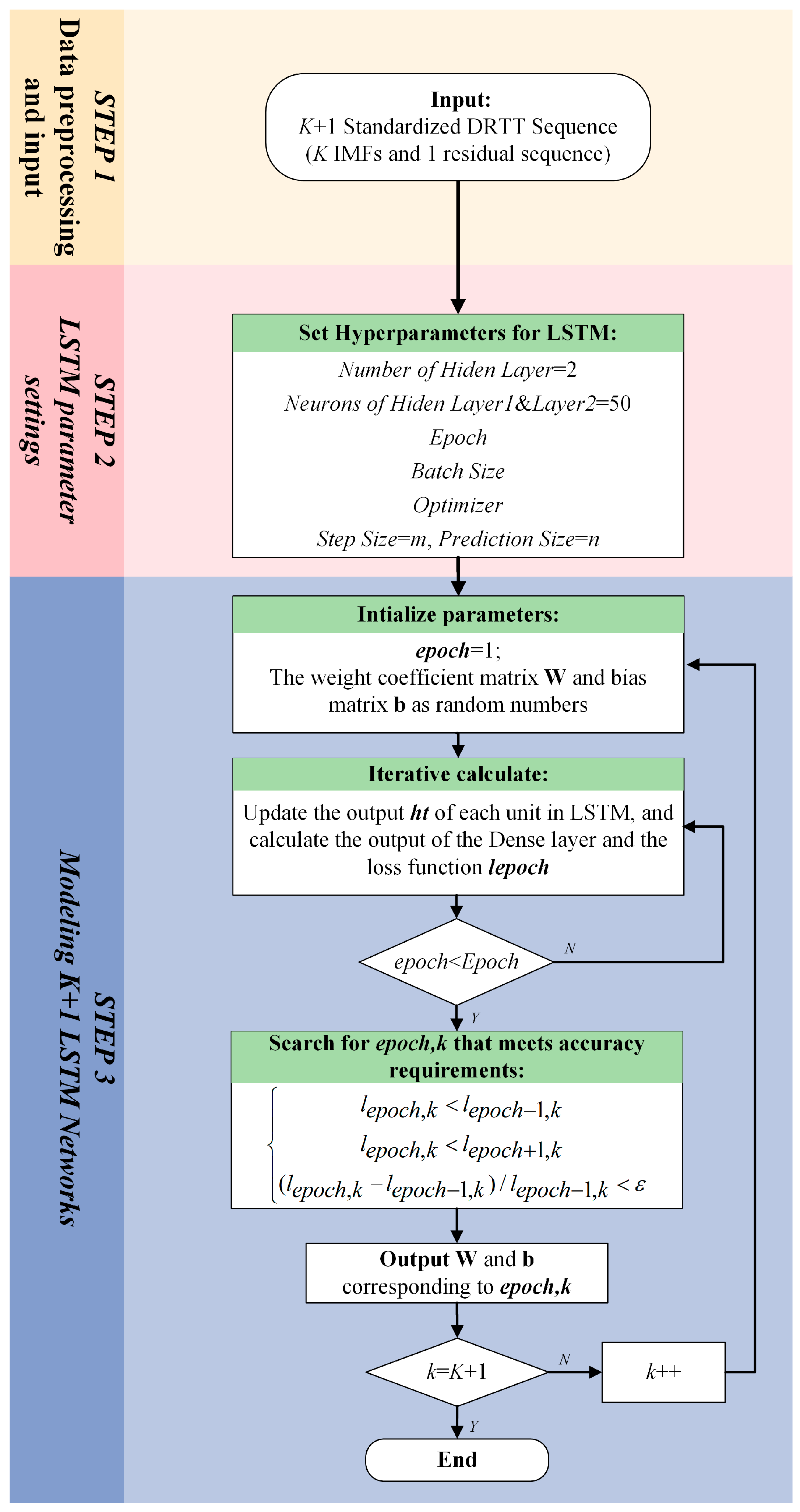
Figure 4, it can be seen that the four main steps of this time series analysis-based VMD-LSTM method are as follows:
Step 1. First-order differencing is performed on the 5G RTT series to obtain the DRTT series , where is calculated according to (1).
Step 2. VMD is performed on the 5G DRTT series.
According to the analysis in
Section 5, it can be concluded that due to the nonlinearity of the 5G DRTT series, the accuracy of directly predicting DRTT data is relatively low. Therefore, in the prediction method proposed in this paper, the VMD method is first used to decompose the DRTT series
into
K subsequences
and a residual sequence
, where
and
. Besides,
and
.
Step 3. LSTM prediction is performed separately on the decomposed K + 1 subsequences.
After completing step 2, we obtain K IMFs and 1 residual sequence, totaling K + 1 subsequences. As these subsequences possess different frequency domain characteristics, it is necessary to establish individual LSTM networks for each of the K + 1 subsequences before making predictions on them separately. Subsequently, these K + 1 LSTM networks will be used for predicting the corresponding subsequences, respectively.
Taking the first subsequence as an example, the prediction process can be described as follows: by substituting m DRTT values, i.e., in , into the already modelled network LSTM1, the predicted values for the next n unknown DRTT values can be calculated.
Define as the predicted sequence of the first subsequence. For other K subsequences, their respective LSTM networks can be used to calculate n predicted values. These predicted values respectively constitute the prediction sequences and . Among them, represents the predicted sequence of K IMFs, while represents the predicted sequence of the residual sequence.
Step 4. The prediction results of the original sequence are reconstructed.
After steps 1–3, we obtain the prediction results
and
for each IMF and residual sequence of
. As described in step 2, the DRTT value at a certain moment is equal to the sum of the values of each IMF and the residual value at that moment, i.e.,
. Thus, the predicted DRTT value at a certain time in the future is also equal to the predicted values of each IMF plus the predicted residual value at that time, i.e.,
. Therefore, the predicted sequence of the DRTT series can be represented by the following formula:
As mentioned earlier, the unknown sequence
can be predicted using the known sequence
, and the predicted sequence composed of predicted values is
. By performing an inverse operation on (1), we can obtain:
Meanwhile, as mentioned in step 1, the known sequence
is obtained using the first-order difference of the known sequence
. Therefore, in (3), only
is known. So, we incorporate the predicted values of
and the corresponding first-order difference of RTT into (3) and rewrite it as:
By using (4), the predicted values of n future RTTs can be calculated.
6.1. Decomposing the 5G DRTT Series with the VMD Method
VMD is a method that utilizes an iterative search for the optimal solution of a variational model to extract the intrinsic mode function (IMF) components of a signal. It is suitable for decomposing time series with nonlinear and non-stationary characteristics [
33]. Using the VMD method, the first-order differential sequence
of the 5G RTT series can be decomposed into
K modes
. The principle is to find a set of subsequences, under the condition that the sum of each subsequence is equal to the original sequence so that the sum of the estimated bandwidth of the subsequences is minimized [
33]:
in which
represents the
tth element of the DRTT series,
represents the
tth element in the
kth DRTT subsequence,
represents the center frequency of the
kth DRTT subsequence. The symbol * represents convolution.
The problem can be transformed into the following variational problem using the Lagrange equation:
In which
represents a vector composed of Lagrange multipliers,
represents the quadratic penalty factor. Iteratively calculate the value
in the frequency domain of the
kth DRTT subsequence, as well as the corresponding center frequency of the
kth differential subsequence
and the Lagrange multipliers
, through the process shown in
Figure 5. Among them,
l represents the number of iterations. When the convergence condition
is met, the iteration process can be stopped, and
K DRTT subsequences
in the time domain can be obtained through inverse Fourier transform.
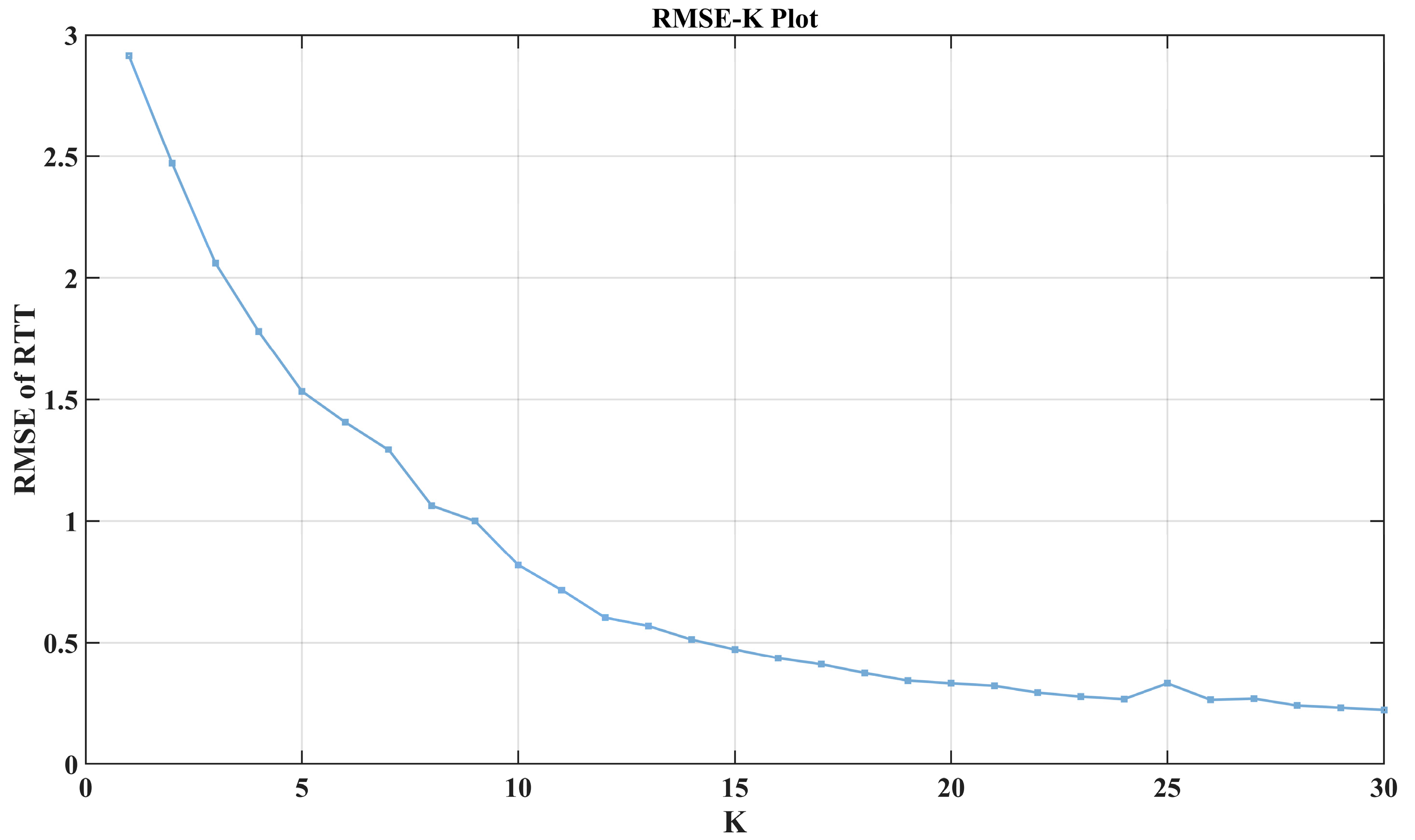
In the above decomposition process, the number of DRTT subsequences
K, the quadratic penalty factor
, and the update coefficient
have a significant impact on the decomposition effect. Among them,
is used to update the Lagrange multiplier vector in the iterative calculation shown in
Figure 5.
We referred to the method in [
19] and set the value of
K to 7. Since the optimization process for the quadratic penalty factor
and the update coefficient
in [
24] adopted the GOA method [
55], which optimizing the mean of the residual, i.e.,
REI shown in (7) to minimum, this will cause the VMD to focus on obtaining the minimum residual while ignoring the consideration of the stationarity or randomness of the IMFs, which has a significant impact on prediction accuracy.
in which
LN represents the length of the residual sequence.
To simplify the optimization process for
and
while improving the predictability of the sequence, we propose a parameter optimization method based on correlation coefficients. As stated in
Section 5.2, when the partial autocorrelation coefficient of the sequence has an
m-order truncation, it indicates that the DRTT value at time
t (i.e.,
) has a high correlation with the DRTT values at
m previous moments (i.e.,
), while the correlation with the DRTT values at other previous moments is weak. Based on this feature, the more accurate the relationship between
and
we establish is, the closer the predicted value
based on this relationship will be to the true value
. Therefore, when conducting VMD, our optimization goal is to search for a set of
and
so that the partial autocorrelation coefficients of each subsequence conform to the characteristic of
m-order truncation as closely as possible. The steps are as follows:
Step 1. Initial values of 3000 and −0.1 are assigned to and , respectively.
Step 2. VMD is executed, and the partial autocorrelation coefficients of K IMFs and residual sequences are respectively calculated, which form a matrix with rows and K + 1 columns. represents the maximum lag of the partial autocorrelation coefficient to be calculated. The element of the matrix represents the partial autocorrelation coefficient of the jth subsequence with ith lag.
Step 3. Search for whether there exists a lag
m that all subsequences satisfy the following conditions:
The calculation formulas for
,
, and
are as follows:
Among them, k = 1, …, K represents the kth subsequence, is two times the standard deviation for the correlation analysis, while , , and limit the degree of deviation of the partial autocorrelation coefficients of the subsequence from the m-order truncation. and constrain the sum of partial autocorrelation coefficients, and constrains the individual partial autocorrelation coefficients.
Step 4. If the value of m that meets the condition cannot be found in step 3, set and return to step 2 to restart the search. If the value of m cannot be found until , proceed to step 5.
Step 5. Let , and return to step 2 to restart the search.
After optimizing the VMD parameters mentioned above, we have obtained a set of subsequences with good predictability. After calculation, the value of
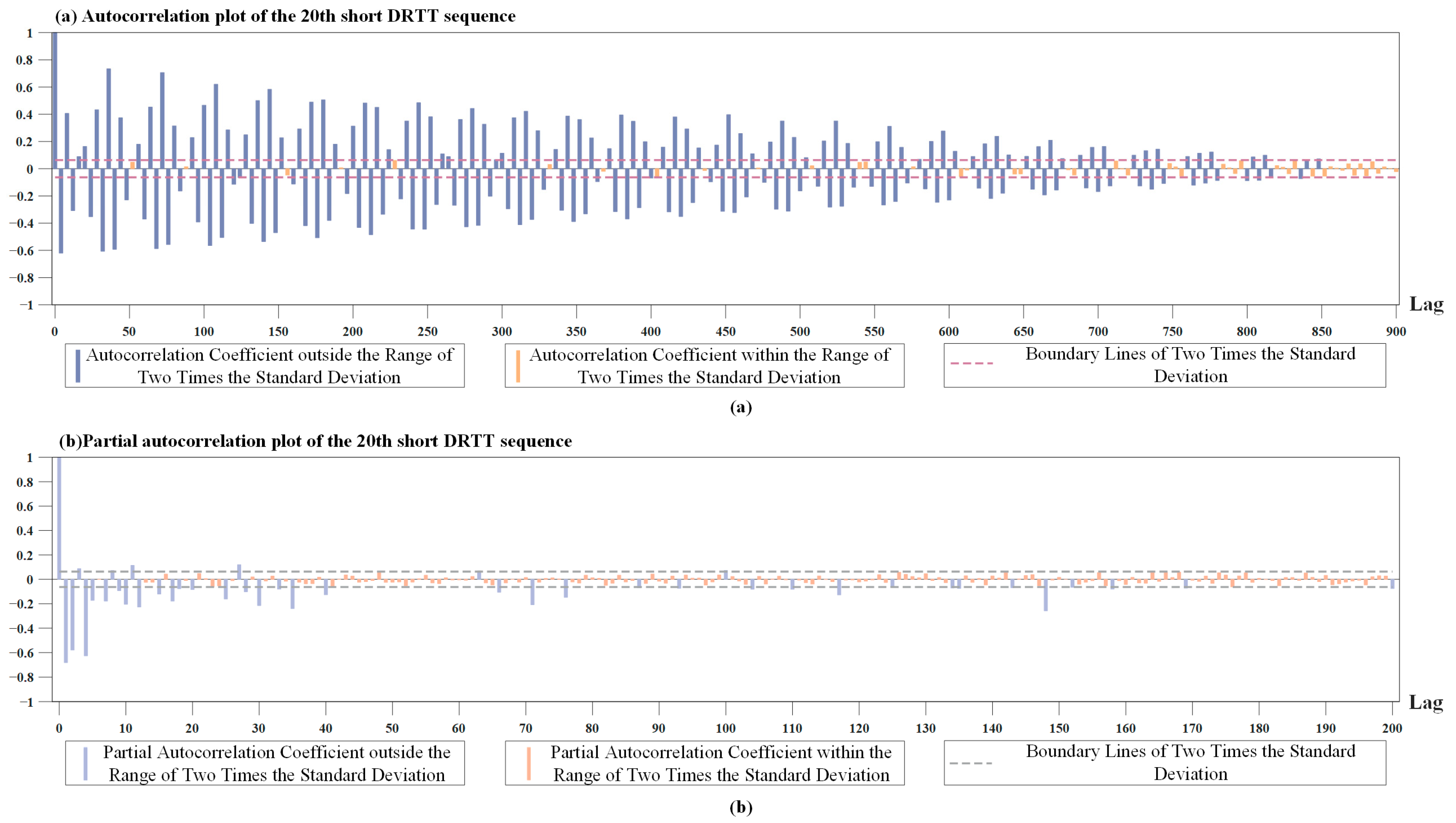
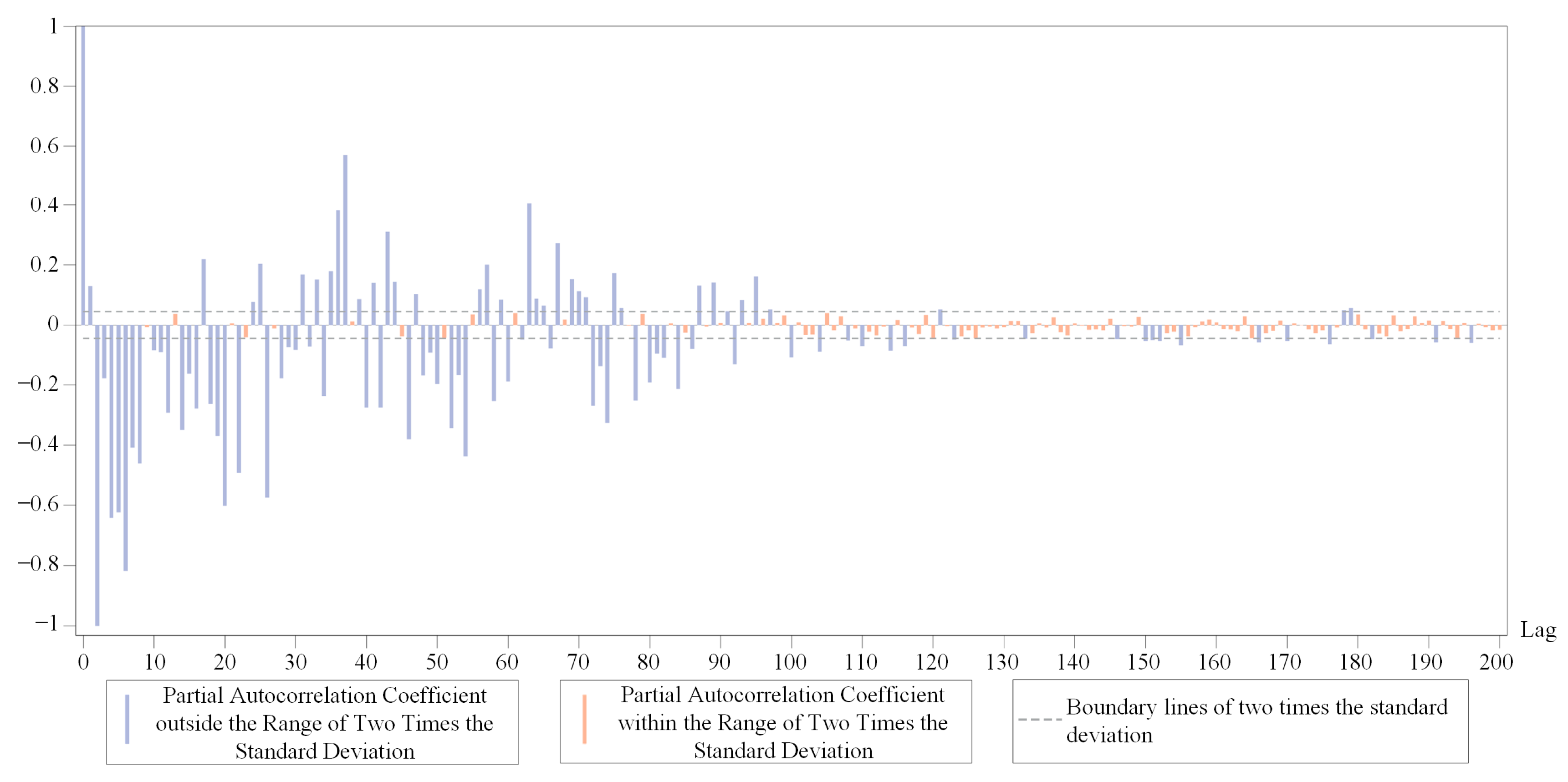
m is 82 for the chosen DRTT series. We plot the partial autocorrelation coefficient of one of the subsequences in
Figure 6. It can be seen that after approximately 82nd lag, the value of the partial autocorrelation coefficient is relatively small, which can be roughly considered to have 82nd lag truncation characteristics.
6.2. 5G RTT Prediction Method Based on VMD-LSTM
LSTM is a special type of recurrent neural network (RNN) that not only takes the state of the previous moment as the input for the current moment but also takes the state of the past
m moments as the input for the current moment. Therefore, it has good predictive performance for time series [
44]. In the method proposed in this paper, the LSTM network is used to predict the various VMD modes
and the residual sequence
of the 5G DRTT series. It is crucial to model the LSTM network for the 5G DRTT series before implementing predictions. The flow chart shown in
Figure 7 illustrates the three main steps of the LSTM network modeling process:
Step 1. Data preprocessing and input:
Considering that a large sample size will result in a long training time, 2000 DRTT data were selected as the training and prediction dataset for the LSTM network. We used the first 80% of the dataset as the training set and the remaining 20% as the test set to evaluate the predictive performance of the modeled LSTM network. Then, the following min–max normalization method was used to standardize the data to within [0, 1]:
in which
is the DRTT series composed of all DRTT data, and
is the standardized DRTT series,
, represents the time range of the chosen DRTT series.
Step 2. LSTM parameter settings:
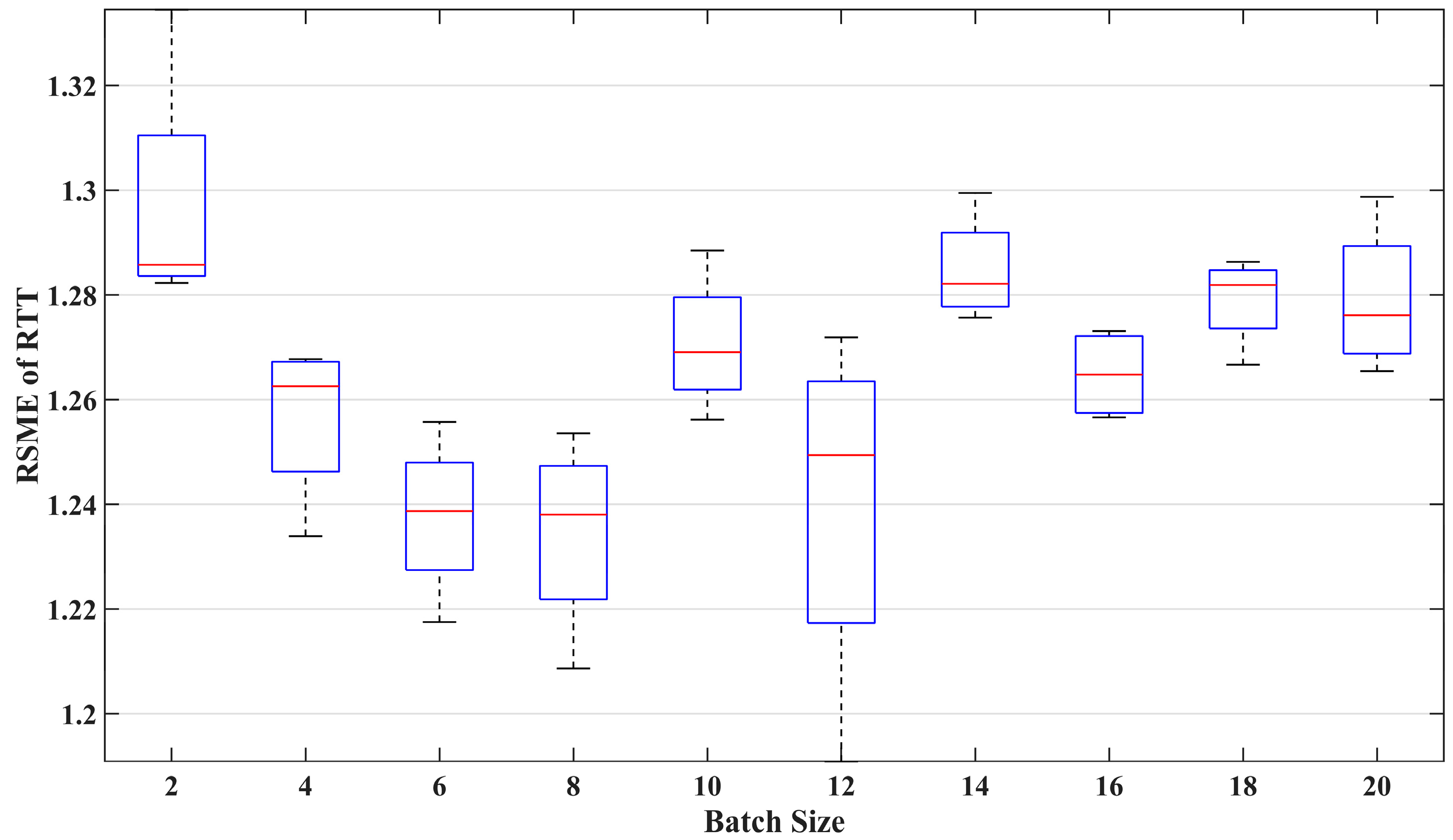
In this study, the LSTM network used to predict standardized DRTT values was defined as a four-layer network consisting of an input layer, a fully connected layer, and two hidden layers. Each hidden layer contained 50 neurons. The other hyperparameters that need to be set include Epoch, Batch Size, and Optimizer. The values of these hyperparameters can be determined using complex hyperparameter optimization methods, such as grid search. In this study, the specific values of the aforementioned hyperparameters were determined through sensitivity analysis of the model, as detailed in
Section 7.2.
For LSTM networks, except for the above hyperparameters, there were two important hyperparameters, which were the input size
m (also known as the time step) and the output size
n. After the above hyperparameters were determined, other parameters in the LSTM network could be identified. Subsequently,
m known DRTT values could be used to predict
n unknown DRTT data. In the field of deep learning, the selection of
m and
n, like other hyperparameters, requires a lot of experimentation, such as using grid search [
56] to find the appropriate values. During this search process, once the set of hyperparameters is changed, we have to retrain the LSTM network and analyze whether its prediction results meet the requirements. Therefore, common deep learning parameter tuning methods are time-consuming and complex. To this end, we propose a method for determining the input and output sizes of LSTM networks based on time series analysis results.
In the tuning process of VMD parameters in
Section 6.1, we conducted correlation analysis on this
K + 1 subsequence. The analysis indicated that
. Therefore, we set the input and output sizes of these
K + 1 LSTM networks to
m = 82 and
n = 1.
Step 3. Modeling K + 1 LSTM networks:
LSTM network modeling is a complex process of parameter identification. The basic unit of the LSTM network is shown in
Figure 8.
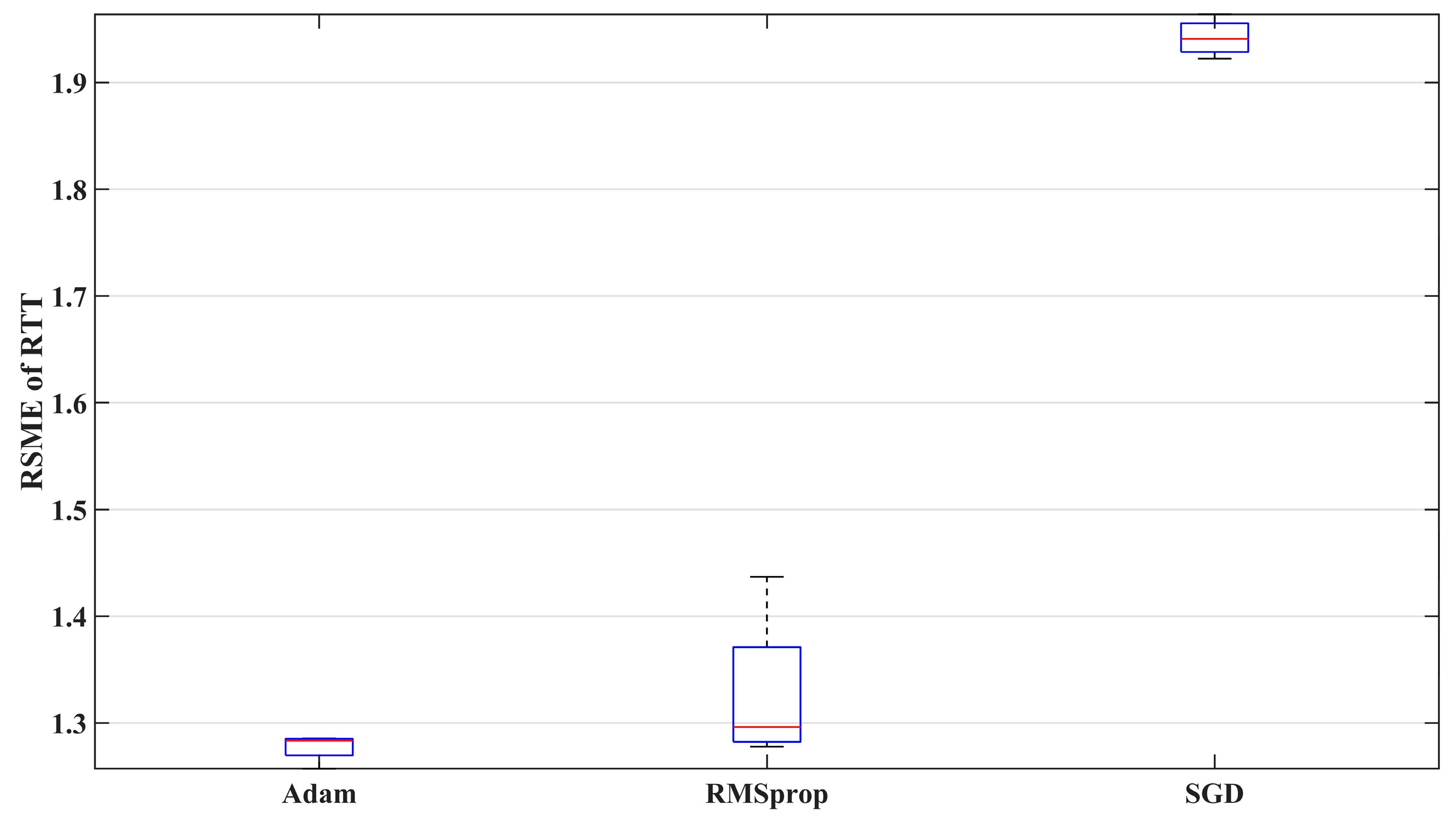
In this paper, the gradient descent method Adam was used to iteratively update the weight coefficient matrices
,
,
, and
, as well as the bias matrices
,
,
, and
. These parameters were used to update the output value
of the unit. From the third step in
Figure 7, it can be seen that in the proposed VMD-LSTM modeling method the parameters of each LSTM network corresponding to
K VMD subsequences
and residual sequence
(i.e., a total of
K + 1 subsequences) are iteratively updated. Compared with the method in [
28] that set the stopping condition as the sum of the output values of
K + 1 sequences meeting the fitting accuracy requirement, our training method for network parameters is to stop fitting the current subsequence only when the epoch, the number of iterations, reaches the set maximum number of iterations. After the iteration calculation of a single subsequence is completed, the epoch value that meets the accuracy requirements of the current subsequence is determined by backtracking the historical information during the network training process of this subsequence. In the former method, as all subsequences use the same number of iterations, overfitting can easily occur, thereby affecting prediction accuracy. As a comparison, our method will adaptively select the number of iterations for each of the
K + 1 LSTM networks based on the changes in their respective loss functions during the iteration process to avoid overfitting.
When the optimal epochs are determined, their corresponding weight coefficient matrix and bias matrix are also calculated accordingly. During the process of modeling the LSTM network, the output value of the LSTM unit is updated and calculated according to the following formulas:
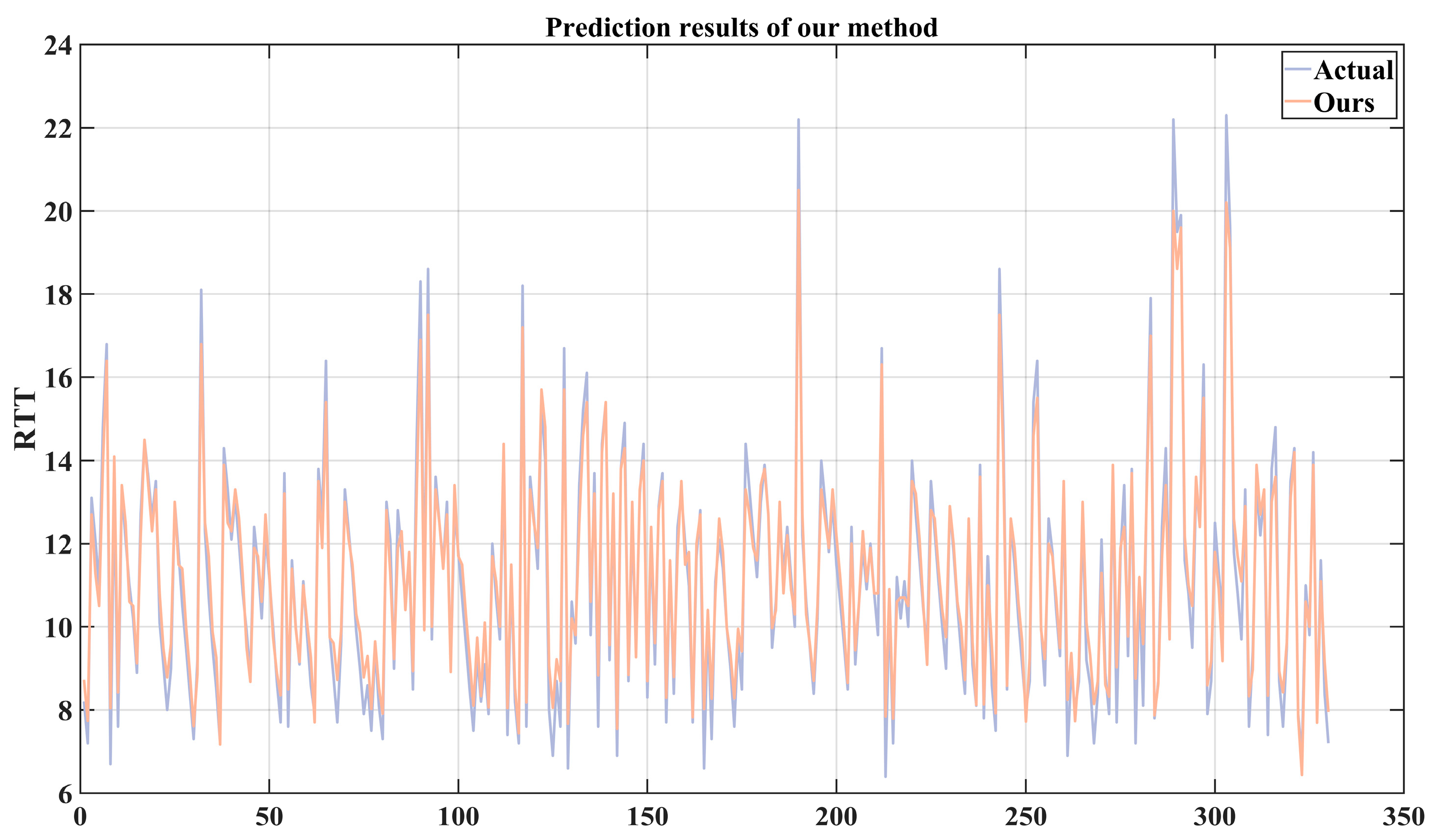
At this point, the LSTM network has been modeled. According to the prediction method for a single sequence in
Figure 4, the predicted sequences
and the predicted residual sequence
can be obtained using (10)–(15) based on their respective weight coefficients and biases. By using (2) to predict the DRTT series and finally performing inverse difference according to (4), the predicted sequence
of the 5G RTT series can be obtained.
8. Conclusions
In order to apply 5G technology to factory environments with low latency requirements for data transmission, we proposed a 5G RTT time series analysis-based VMD-LSTM prediction method. To obtain the performance data of 5G technology applied in real factory scenarios, we designed an on-site testbed from SPLC contracting (pinging a packet) to MPLC and recorded 5G RTT data. All the devices in the test network were existing commercial products rather than prototypes, and the RTT measurement method is also relatively simple. The statistical analysis of the 5G RTT data indicated that their average value was around 11 ms, which is better than the WIA-FA standard [
57] and can better meet the low latency requirements of industrial data transmission. The ADF test method was used to prove that the 5G RTT time series is non-stationary. The DRTT series, after the first-order difference, was transformed into a stationary sequence. Combining the autocorrelation and partial autocorrelation coefficients of the sequence, we proposed a VMD-LSTM prediction method based on time series analysis. Compared with other prediction methods that combine EEMD, VMD, and LSTM, this method has the best prediction accuracy.
The time series analysis-based VMD-LSTM prediction method proposed in this paper can be used to evaluate network performance based on business requirements. In the 5G network, by establishing a corresponding VMD-LSTM model for RTT prediction and comparing the actual RTT with the predicted one, abnormal values can be identified, and their causes can be analyzed, guiding the improvement of the 5G network. Furthermore, we have defined an indicator TC related to the control cycle to characterize whether the prediction method can accurately predict whether the RTT value exceeds the control cycle. In the field of industrial control, this method can be used for RTT prediction and motion control compensation in the sampling period of control systems, reducing the impact of control instruction packet loss caused by RTT, as well as improving the robustness of the control algorithms. In addition, TC can also be used to indicate when to retrain the model and to indicate the setting of the control cycle.
The work in this paper is based on the real experimental data of the 5G-R15 version, and the proposed method can also be used for higher versions of 5G networks. To achieve real-time prediction, single multi-step prediction can be carried out in the future. Considering that the accuracy of multi-step prediction usually decreases with an increase in the prediction step size, indicators such as signal-to-noise ratio, load, and RTT can be used as inputs for multi-factor LSTM prediction, thus balancing prediction accuracy and real-time prediction performance.



 and
and 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}