
EHNet: Efficient Hybrid Network with Dual Attention for Image Deblurring


Abstract
1. Introduction
- The EHNet leverages a combination of CNN encoders and Transformer decoders to achieve efficient image deblurring.
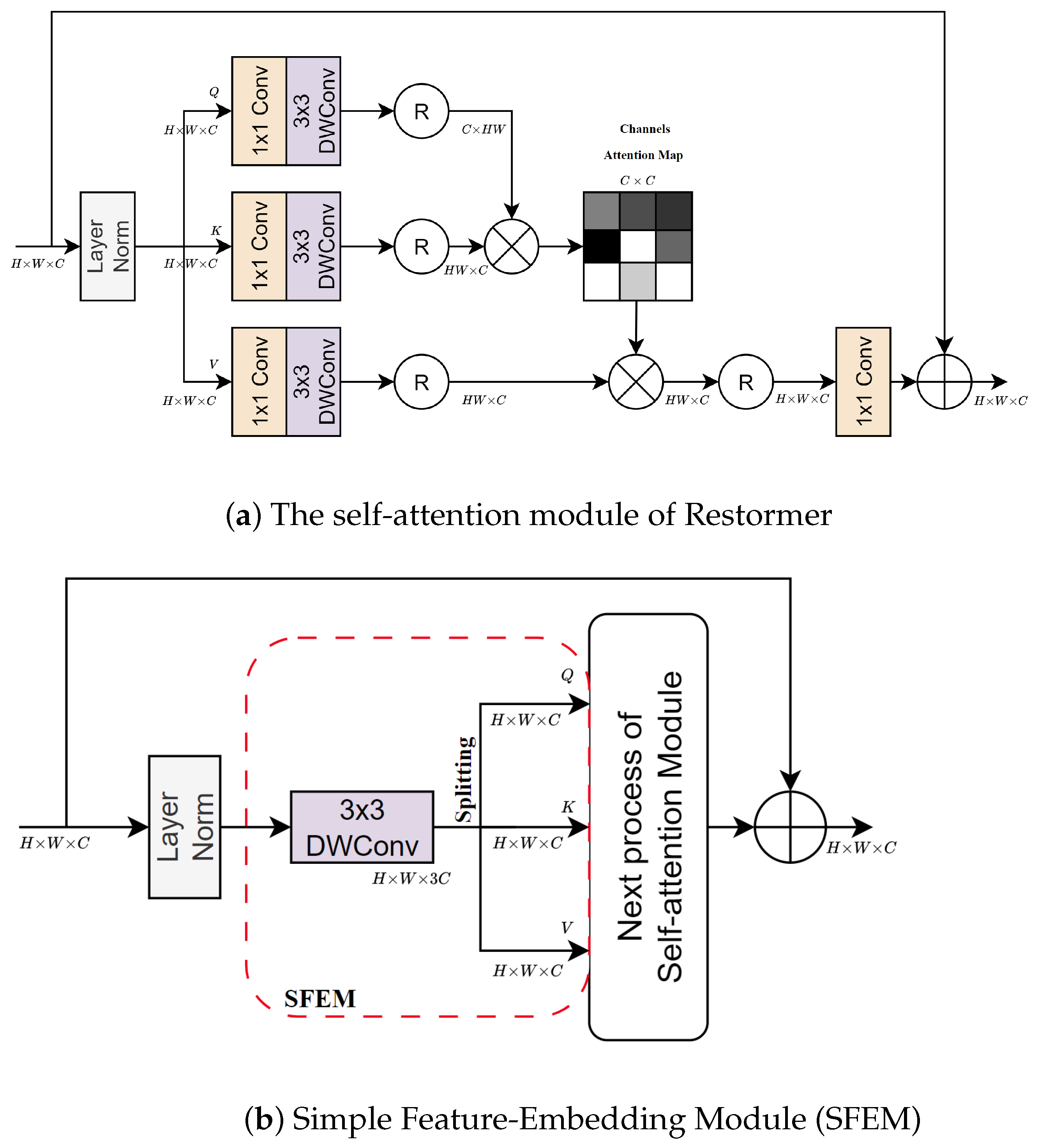
- Transformer Blocks are improved to address the limitations of previous methods. The proposed blocks include the following: (1) The MHTA refines features by modeling channel dependencies. (2) The MWSA captures blur patterns at various spatial scales. (3) The SFEM generates simplified embedding features in each self-attention module.
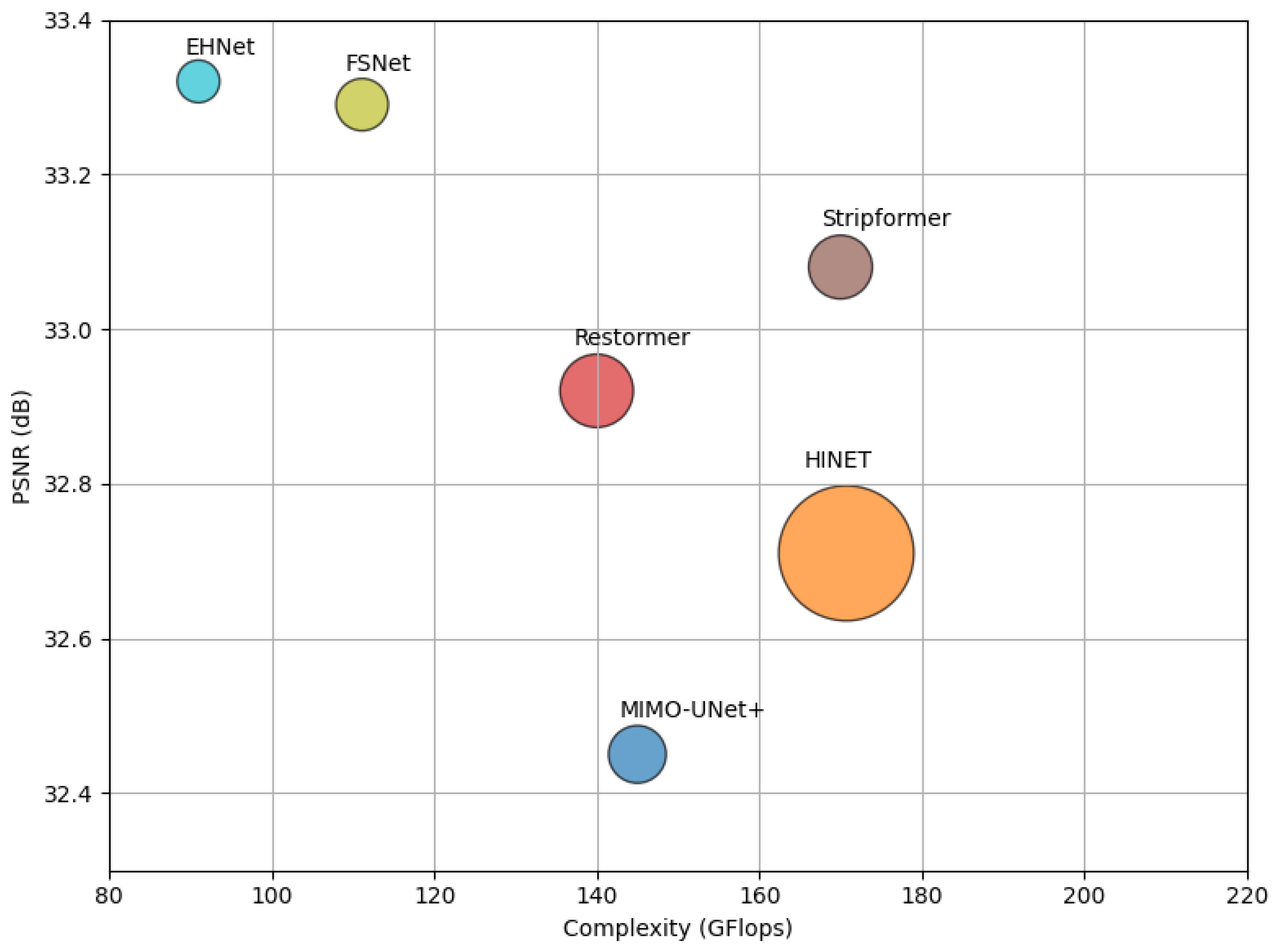
- Our comprehensive evaluation reveals that EHNet outperforms existing state-of-the-art deep-learning methods in image deblurring. This superior performance is achieved through a compact model size and reduced computational demands.
2. Related Work
2.1. CNN-Based Image Deblurring
2.2. Transformer-Based Image Deblurring
3. Proposed Method
3.1. Overall Architecture
3.2. Convolution Blocks
3.3. Transformer Blocks
3.3.1. Simple Feature-Embedding Module (SFEM)
3.3.2. Multi-Head Transposed Attention (MHTA)
3.3.3. Multi-Window Self-Attention (MWSA)
3.4. Loss Function
4. Experiments
4.1. Dataset and Evaluation Metrics
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.2. Implementation Details
4.3. Performance Comparison
4.3.1. EHNet
4.3.2. EHNet-S
4.4. Ablation Studies
4.4.1. Effectiveness of MHTA and MWSA
4.4.2. Effectiveness of SFEM
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pham, T.-D.; Duong, M.-T.; Ho, Q.-T.; Lee, S.; Hong, M.-C. CNN-based facial expression recognition with simultaneous consideration of inter-class and intra-class variations. Sensors 2023, 23, 9658. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Ren, W.; Luo, W.; Lai, W.S.; Stenger, B.; Yang, M.H.; Li, H. Deep image deblurring: A survey. Int. J. Comput. Vis. 2022, 130, 2103–2130. [Google Scholar] [CrossRef]
- Koh, J.; Lee, J.; Yoon, S. Single-image deblurring with neural networks: A comparative survey. Comput. Vis. Image Underst. 2021, 203, 103134. [Google Scholar] [CrossRef]
- Cho, S.; Lee, S. Fast motion deblurring. ACM Trans. Graph. 2009, 28, 1–8. [Google Scholar] [CrossRef]
- Fergus, R.; Singh, B.; Hertzmann, A.; Roweis, S.; Freeman, W. Removing camera shake from a single photograph. ACM Trans. Graph. 2006, 25, 787–794. [Google Scholar] [CrossRef]
- Gong, D.; Tan, M.; Zhang, Y.; Van den Hengel, A.; Shi, Q. Blind image deconvolution by automatic gradient activation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1827–1836. [Google Scholar]
- Whyte, O.; Sivic, J.; Zisserman, A.; Ponce, J. Non-uniform deblurring for shaken images. Int. J. Comput. Vis. 2012, 98, 168–186. [Google Scholar] [CrossRef]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Deblurring Images via Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2315–2328. [Google Scholar] [CrossRef] [PubMed]
- Oh, J.; Hong, M.-C. Low-light image enhancement using hybrid deep-learning and mixed-norm loss functions. Sensors 2022, 22, 6904. [Google Scholar] [CrossRef]
- Duong, M.-T.; Lee, S.; Hong, M.-C. DMT-Net: Deep Multiple Networks for Low-Light Image Enhancement Based on Retinex Model. IEEE Access 2023, 11, 132147–132161. [Google Scholar] [CrossRef]
- Duong, M.-T.; Nguyen Thi, B.-T.; Lee, S.; Hong, M.-C. Multi-branch network for color image denoising using dilated convolution and attention mechanisms. Sensors 2024, 24, 3608. [Google Scholar] [CrossRef]
- Duong, M.T.; Lee, S.; Hong, M.C. Learning to Concurrently Brighten and Mitigate Deterioration in Low-Light Images. IEEE Access 2024, 12, 132891–132903. [Google Scholar] [CrossRef]
- Younesi, A.; Ansari, M.; Fazli, M.; Ejlali, A.; Shafique, M.; Henkel, J. A comprehensive survey of convolutions in deep-learning: Applications, challenges, and future trends. IEEE Access 2024, 12, 41180–41218. [Google Scholar] [CrossRef]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 7–9 May 2015; pp. 769–777. [Google Scholar]
- Vasu, S.; Maligireddy, V.R.; Rajagopalan, A. Non-blind deblurring: Handling kernel uncertainty with CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3272–3281. [Google Scholar]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8174–8182. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Stenger, B.; Liu, W.; Li, H. Deblurring by realistic blurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2737–2746. [Google Scholar]
- Gao, H.; Tao, X.; Shen, X.; Jia, J. Dynamic scene deblurring with parameter selective sharing and nested skip connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3843–3851. [Google Scholar]
- Park, D.; Kang, D.U.; Kim, J.; Chun, S.Y. Multi-temporal recurrent neural networks for progressive non-uniform single image deblurring with incremental temporal training. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Proceedings, Part VI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 327–343. [Google Scholar]
- Purohit, K.; Rajagopalan, A.N. Region-adaptive dense network for efficient motion deblurring. Proc. AAAI Artif. Intell. 2020, 34, 11882–11889. [Google Scholar] [CrossRef]
- Suin, M.; Purohit, K.; Rajagopalan, A. Spatially attentive patch-hierarchical network for adaptive motion deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3606–3615. [Google Scholar]
- Zhang, S.; Shen, X.; Lin, Z.; Měch, R.; Costeira, J.P.; Moura, J.M. Learning to understand image blur. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6586–6595. [Google Scholar]
- Zhang, H.G.; Dai, Y.C.; Li, H.D.; Koniusz, P. Deep stacked hierarchical multi-patch network for image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5971–5979. [Google Scholar]
- Cho, S.-J.; Ji, S.-W.; Hong, J.-P.; Jung, S.-W.; Ko, S.-J. Rethinking coarse-to-fine approach in single image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4641–4650. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. HINet: Half instance normalization network for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 182–192. [Google Scholar]
- Kim, K.; Lee, S.; Cho, S. MSSNet: Multi-scale-stage network for single image deblurring. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XIX. Springer: Berlin/Heidelberg, Germany, 2022; pp. 514–539. [Google Scholar]
- Tsai, F.-J.; Peng, Y.-T.; Tsai, C.-C.; Lin, Y.-Y.; Lin, C.-W. BANet: A Blur-aware attention network for dynamic scene deblurring. IEEE Trans. Image Process 2022, 31, 6789–6799. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Chu, X.; Zhang, X.; Sun, J. Simple baselines for image restoration. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 17–33. [Google Scholar]
- Mao, X.; Liu, Y.; Liu, F.; Li, Q.; Shen, W.; Wang, Y. Intriguing findings of frequency selection for image deblurring. Proc. AAAI Artif. Intell. 2023, 37, 1905–1913. [Google Scholar] [CrossRef]
- Cui, Y.; Ren, W.; Cao, X.; Knoll, A. Image restoration via frequency selection. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 1093–1108. [Google Scholar] [CrossRef]
- Su, H.; Jampani, V.; Sun, D.; Gallo, O.; Learned-Miller, E.; Kautz, J. Pixel-adaptive convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11166–11175. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Zhao, H.; Gou, Y.; Li, B.; Peng, D.; Lv, J.; Peng, X. Comprehensive and Delicate: An Efficient Transformer for Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14122–14132. [Google Scholar]
- Lee, H.; Choi, H.; Sohn, K.; Min, D. Cross-scale KNN image transformer for image restoration. IEEE Access 2023, 11, 13013–13027. [Google Scholar] [CrossRef]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Tsai, F.-J.; Peng, Y.-T.; Lin, Y.-Y.; Tsai, C.-C.; Lin, C.-W. Stripformer: Strip Transformer for fast image deblurring. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XIX. Springer: Berlin/Heidelberg, Germany, 2022; pp. 146–162. [Google Scholar]
- Yan, Q.; Gong, D.; Wang, P.; Zhang, Z.; Zhang, Y.; Shi, J.Q. SharpFormer: Learning Local Feature Preserving Global Representations for Image Deblurring. IEEE Trans. Image Process 2023, 32, 2857–2866. [Google Scholar] [CrossRef]
- Zhao, Q.; Yang, H.; Zhou, D.; Cao, J. Rethinking image deblurring via CNN-transformer multiscale hybrid architecture. IEEE Trans. Instrum. Meas. 2022, 72, 1–15. [Google Scholar] [CrossRef]
- Chen, M.; Yi, S.; Lan, Z.; Duan, Z. An efficient image deblurring network with a hybrid architecture. Sensors 2023, 16, 7260. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision Transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Xu, Q.; Qian, Y. Bidirectional transformer for video deblurring. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8450–8461. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Howard, A.; Pang, R.; Adam, H.; Le, Q.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Ba, J.-L.; Kiros, J.-R.; Hinton, G.-E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shen, Z.; Wang, W.; Lu, X.; Shen, J.; Ling, H.; Xu, T.; Shao, L. Human-aware motion deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5571–5580. [Google Scholar]
- Rim, J.; Lee, H.; Won, J.; Cho, S. Real-world blur dataset for learning and benchmarking deblurring algorithms. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; Volume 12370, pp. 184–201. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | GoPro [16] | HIDE [52] | RealBlur-J [53] | RealBlur-R [53] | Params↓ (M) | Complexity↓ (GFLOPs) | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | |||
| DeblurGAN-v2 [19] | 29.55 | 0.934 | 26.61 | 0.875 | 28.70 | 0.866 | 35.26 | 0.944 | 60.9 | 411 |
| DBGAN [20] | 31.10 | 0.942 | 28.94 | 0.915 | 24.93 | 0.745 | 33.78 | 0.909 | 11.6 | 760 |
| MIMO-UNet+ [27] | 32.45 | 0.958 | 29.99 | 0.930 | 27.63 | 0.837 | 35.54 | 0.947 | 16.1 | 145 |
| MPRNet [28] | 32.66 | 0.959 | 30.96 | 0.939 | 28.70 | 0.873 | 35.99 | 0.952 | 20.1 | 778 |
| HINet [29] | 32.71 | 0.959 | 30.32 | 0.932 | 28.17 | 0.849 | 35.75 | 0.950 | 88.7 | 171 |
| Restormer [37] | 32.92 | 0.961 | 31.22 | 0.942 | 28.96 | 0.879 | 36.19 | 0.957 | 26.1 | 140 |
| BANet+ [31] | 33.03 | 0.961 | 30.58 | 0.935 | 28.10 | 0.852 | 35.78 | 0.950 | 40.0 | 588 |
| Stripformer [41] | 33.08 | 0.962 | 31.03 | 0.939 | 28.82 | 0.876 | 36.08 | 0.954 | 19.7 | 170 |
| FSNet [34] | 33.28 | 0.963 | 31.05 | 0.941 | 28.47 | 0.868 | 35.84 | 0.952 | 13.28 | 111 |
| EHNet | 33.32 | 0.964 | 31.34 | 0.943 | 28.22 | 0.854 | 36.06 | 0.954 | 8.78 | 91 |
| Methods | RealBlur-J [53] | RealBlur-R [53] | Params↓ (M) | Complexity↓ (GFLOPs) | ||
|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | |||
| SRN [17] | 31.38 | 0.909 | 38.65 | 0.965 | 6.8 | 167 |
| DeblurGAN-v2 [19] | 29.69 | 0.870 | 36.44 | 0.935 | 60.9 | 411 |
| MSSNet [30] | 32.10 | 0.928 | 39.76 | 0.972 | 15.6 | 154 |
| Stripformer [41] | 32.48 | 0.929 | 39.84 | 0.974 | 19.7 | 170 |
| BANet+ [31] | 32.40 | 0.929 | 39.90 | 0.972 | 40.0 | 588 |
| EHNet | 32.50 | 0.931 | 40.06 | 0.974 | 8.78 | 91 |
| Methods | GoPro [16] | Params↓ (M) | Complexity↓ (GFLOPs) | |
|---|---|---|---|---|
| PSNR↑ | SSIM↑ | |||
| PSS-NSC [21] | 30.92 | 0.935 | 2.84 | 29.11 |
| MT-RNN [22] | 31.15 | 0.945 | 2.64 | 164.00 |
| MIMO-UNet [27] | 31.73 | 0.951 | 6.80 | 67.17 |
| SAPHN † [24] | 31.85 | 0.948 | 23.00 | - |
| CODE † [38] | 31.94 | - | 12.18 | 22.52 |
| EHNet-S | 32.04 | 0.954 | 1.58 | 16.85 |
| Model | MHTA | MWSA | PSNR↑ | SSIM↑ | Params↓ (M) | Complexity↓ (GFLOPs) |
|---|---|---|---|---|---|---|
| I | ✓ | ✗ | 31.12 | 0.945 | 1.45 | 14.97 |
| II | ✗ | ✓ | 31.60 | 0.949 | 1.48 | 15.34 |
| EHNet-S | ✓ | ✓ | 32.04 | 0.954 | 1.58 | 16.85 |
| Model | PW + DW | SFEM | PSNR↑ | SSIM↑ | Params↓ (M) | Complexity↓ (GFLOPs) |
|---|---|---|---|---|---|---|
| III | ✓ | ✗ | 32.09 | 0.954 | 2.03 | 23.08 |
| EHNet-S | ✗ | ✓ | 32.04 | 0.954 | 1.58 | 16.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ho, Q.-T.; Duong, M.-T.; Lee, S.; Hong, M.-C. EHNet: Efficient Hybrid Network with Dual Attention for Image Deblurring. Sensors 2024, 24, 6545. https://doi.org/10.3390/s24206545
Ho Q-T, Duong M-T, Lee S, Hong M-C. EHNet: Efficient Hybrid Network with Dual Attention for Image Deblurring. Sensors. 2024; 24(20):6545. https://doi.org/10.3390/s24206545
Chicago/Turabian StyleHo, Quoc-Thien, Minh-Thien Duong, Seongsoo Lee, and Min-Cheol Hong. 2024. "EHNet: Efficient Hybrid Network with Dual Attention for Image Deblurring" Sensors 24, no. 20: 6545. https://doi.org/10.3390/s24206545
APA StyleHo, Q.-T., Duong, M.-T., Lee, S., & Hong, M.-C. (2024). EHNet: Efficient Hybrid Network with Dual Attention for Image Deblurring. Sensors, 24(20), 6545. https://doi.org/10.3390/s24206545