
Dual-Modal Illumination System for Defect Detection of Aircraft Glass Canopies

Abstract
:1. Introduction
- An automated prototype system with a dual-modal illumination structure is proposed. For the same sampling point, the system sequentially uses forward lighting and backward lighting to capture defect images. By integrating the information from both types of images, more accurate defect detection is achieved.
- A curated dataset is presented, which, to the best of our knowledge, is the first benchmark in the field of defect detection for aircraft transparent materials.
- A dual-modal baseline is designed and proved to be competitive, in which we designed two fusion detection methods: a data-level fusion method named RGB Channel Fusion, and an attention-based dual-branch modal fusion network using feature-level fusion. Both methods achieved excellent results on our dataset.
2. Related Work
2.1. Traditional Machine Vision Method for Defect Detection in Transparent Materials
2.2. Deep Learning-Based Visual Defect Detection
2.3. Multi-Modal Fusion in Object Detection
3. Methodology
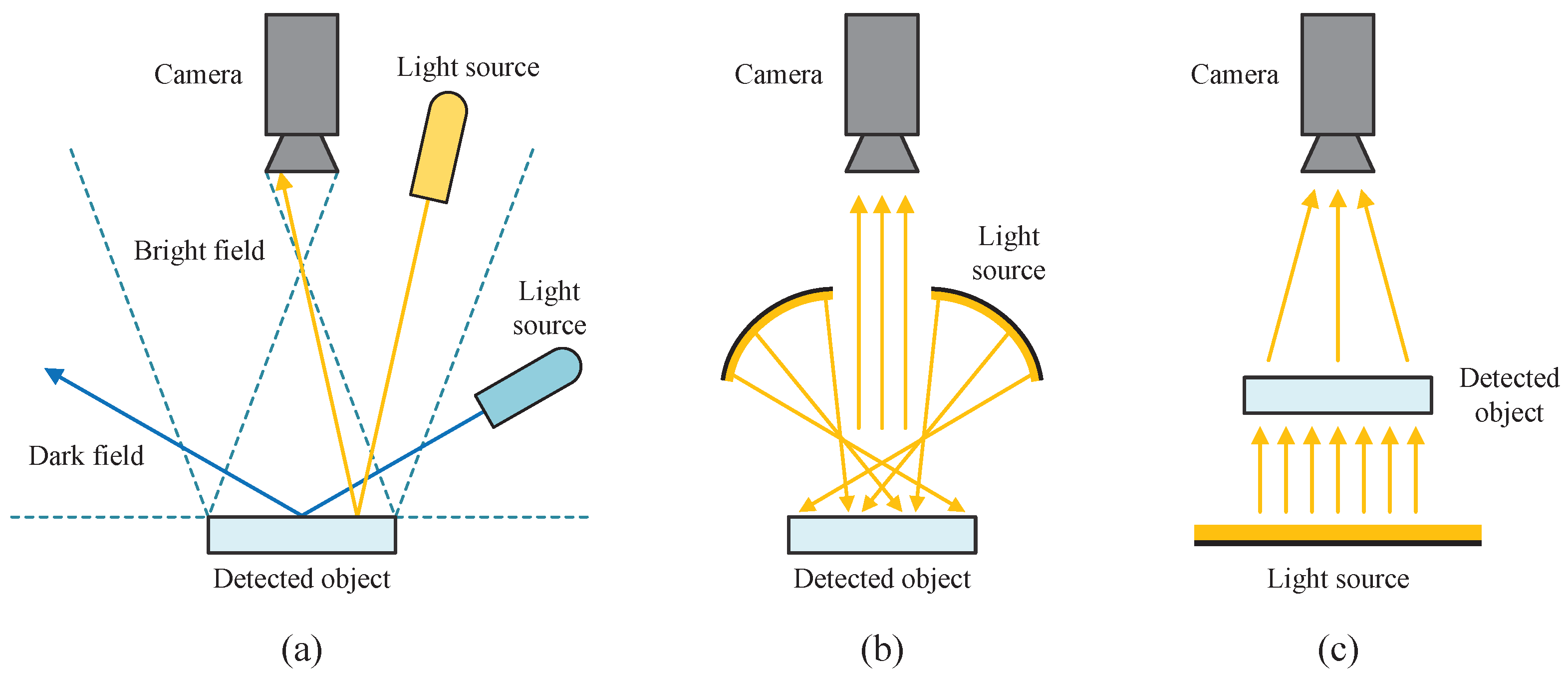
3.1. Dual-Modal Illumination Structure
3.2. Image Acquisition Platform
3.3. Dataset Construction
- If all four points of the bounding box are outside the field of view, delete the target (process ends), otherwise go to step 2.
- If all four points of the bounding box are within the field of view, no adjustment is required (process ends), otherwise go to step 3.
- Select a point that is outside the field of view. Calculate the distance between the point and its adjacent two points to find the long and short sides connected to the point on the rectangle. Translate the short side along the direction of the long side until the point falls on the image boundary. The translation amount is determined by solving a linear programming problem. After adjustment, return to step 2 to re-evaluate.
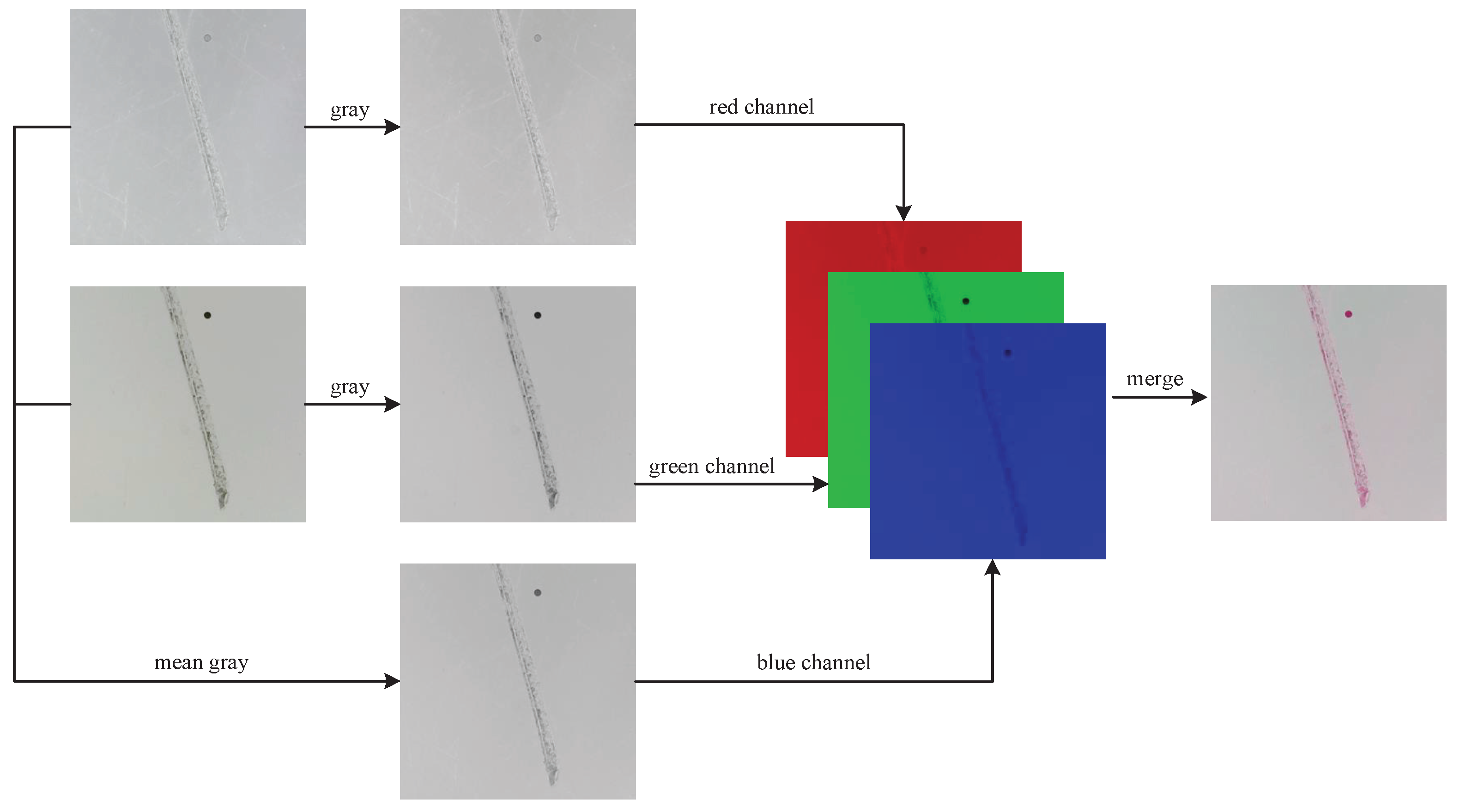
3.4. RGB Channel Fusion Method
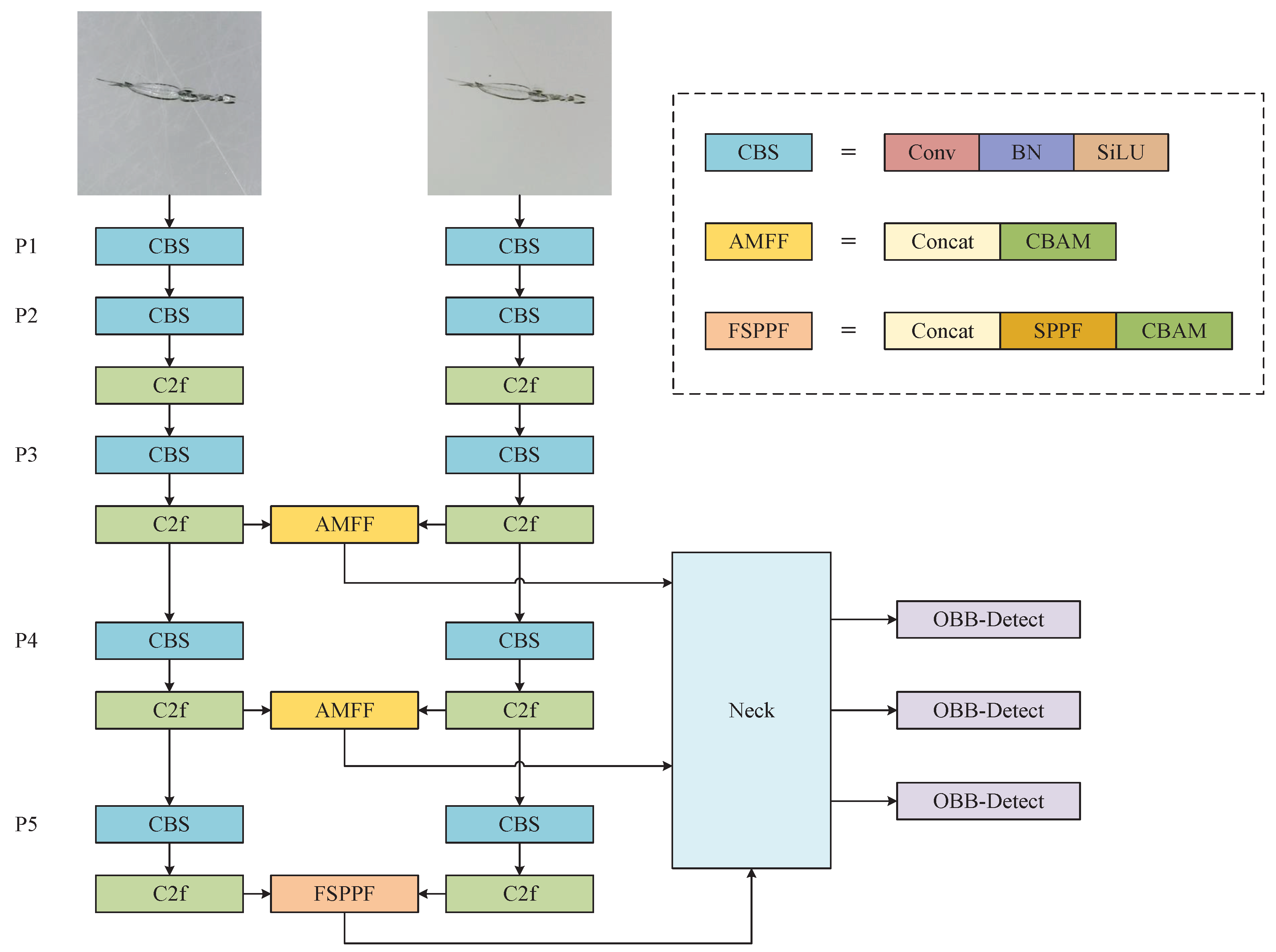
3.5. Attention-Based Dual-Branch Modal Fusion Network (ADMF-Net)
4. Experiments
4.1. Evaluation Metrics
4.2. Implementation Details
4.3. Results and Discussion
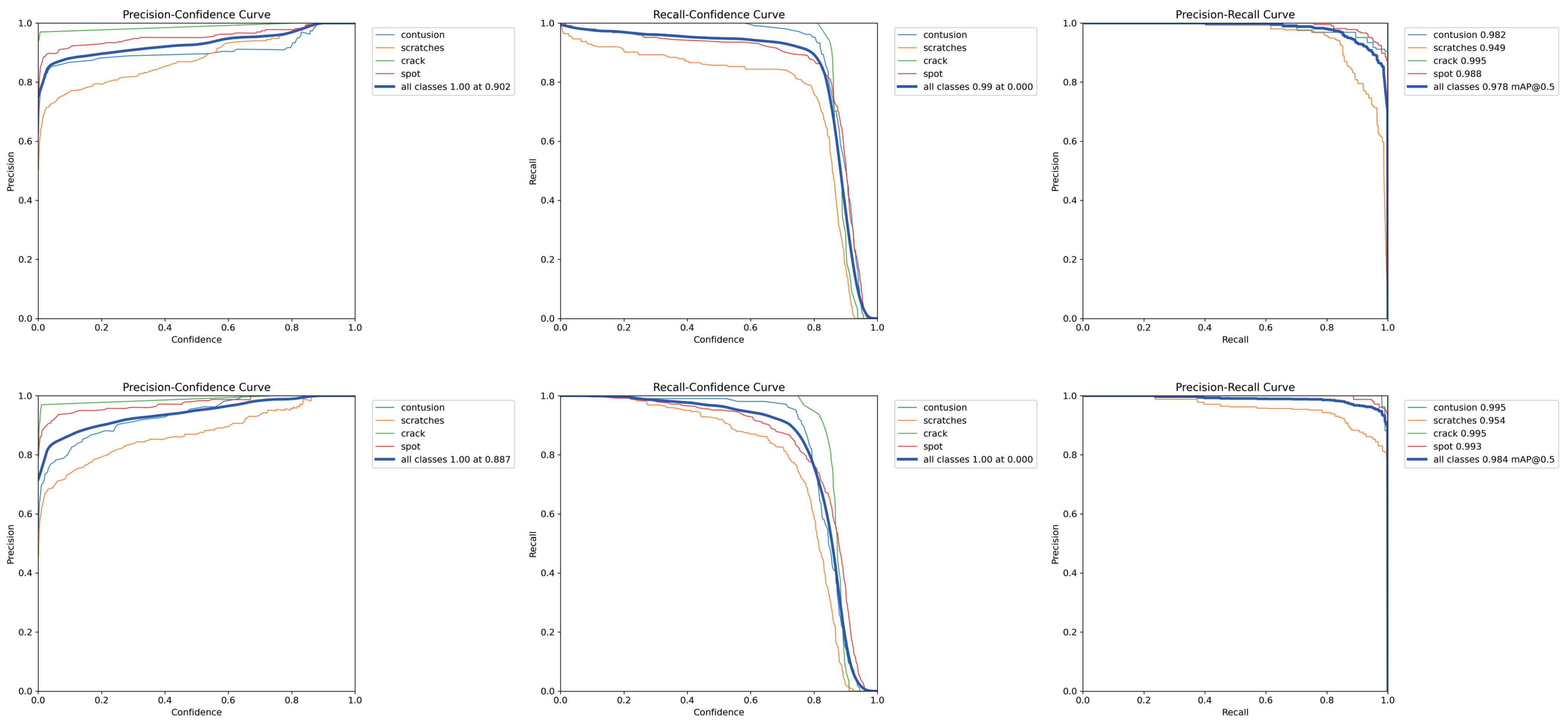
4.3.1. Baseline and Dual-Modal Validity Discussion
4.3.2. ADMF-Net Experiment
4.3.3. Interpretability Experiment
4.3.4. Comparative Analysis of Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Towsyfyan, H.; Biguri, A.; Boardman, R.; Blumensath, T. Successes and challenges in non-destructive testing of aircraft composite structures. Chin. J. Aeronaut. 2020, 33, 771–791. [Google Scholar] [CrossRef]
- Keršienė, N.; Raslavičius, L.; Keršys, A.; Kažys, R.; Žukauskas, E. Energo-mechanical evaluation of damage growth and fracture initiation in aviation composite structures. Polym.-Plast. Technol. Eng. 2016, 55, 1137–1144. [Google Scholar] [CrossRef]
- Zimmermann, N.; Wang, P.H. A review of failure modes and fracture analysis of aircraft composite materials. Eng. Fail. Anal. 2020, 115, 104692. [Google Scholar] [CrossRef]
- Kopardekar, P.; Mital, A.; Anand, S. Manual, Hybrid and Automated Inspection Literature and Current Research. Integr. Manuf. Syst. 1993, 4, 18–29. [Google Scholar] [CrossRef]
- Ebayyeh, A.A.R.M.; Mousavi, A. A Review and Analysis of Automatic Optical Inspection and Quality Monitoring Methods in Electronics Industry. IEEE Access 2020, 8, 183192–183271. [Google Scholar] [CrossRef]
- Costa, R.D.; Maia, J.M.; Assef, A.A.; Pichorim, S.F.; Gewehr, P.M.; Costa, E.T. Defect Detection in Aluminum Bars Using Impedance and Ultrasonic Attenuation. IEEE Sens. J. 2020, 20, 7400–7413. [Google Scholar] [CrossRef]
- Yao, H.B.; Ping, J.; Ma, G.D.; Li, L.W.; Gu, J.N. The system research on automatic defect detection of glasses. Appl. Mech. Mater. 2013, 437, 362–365. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, Y.; Zhu, Q.; Mao, J.; Xiao, C.; Lu, X.; Zhang, H. A Surface Defect Detection Framework for Glass Bottle Bottom Using Visual Attention Model and Wavelet Transform. IEEE Trans. Ind. Inform. 2020, 16, 2189–2201. [Google Scholar] [CrossRef]
- Jian, C.; Gao, J.; Ao, Y. Automatic surface defect detection for mobile phone screen glass based on machine vision. Appl. Soft Comput. J. 2017, 52, 348–358. [Google Scholar] [CrossRef]
- Nand, G.K.; Noopur; Neogi, N. Defect detection of steel surface using entropy segmentation. In Proceedings of the 11th IEEE India Conference: Emerging Trends and Innovation in Technology, INDICON 2014, Pune, India, 11–13 December 2014. [Google Scholar] [CrossRef]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P. Visual-based defect detection and classification approaches for industrial applications—A SURVEY. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef]
- Park, J.; Riaz, H.; Kim, H.; Kim, J. Advanced cover glass defect detection and classification based on multi-DNN model. Manuf. Lett. 2020, 23, 53–61. [Google Scholar] [CrossRef]
- Cheng, L.; Tong, Z.; Xie, S.; Kersemans, M. IRT-GAN: A generative adversarial network with a multi-headed fusion strategy for automated defect detection in composites using infrared thermography. Compos. Struct. 2022, 290, 115543. [Google Scholar] [CrossRef]
- Zhu, Y.; Ding, R.; Huang, W.; Wei, P.; Yang, G.; Wang, Y. HMFCA-Net: Hierarchical multi-frequency based Channel attention net for mobile phone surface defect detection. Pattern Recognit. Lett. 2022, 153, 118–125. [Google Scholar] [CrossRef]
- Pan, Z.; Yang, J.; Wang, X.; Wang, F.; Azim, I.; Wang, C. Image-based surface scratch detection on architectural glass panels using deep learning approach. Constr. Build. Mater. 2021, 282, 122717. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Zhang, M.; Yin, L. Solar Cell Surface Defect Detection Based on Improved YOLO v5. IEEE Access 2022, 10, 80804–80815. [Google Scholar] [CrossRef]
- Xie, Y.; Hu, W.; Xie, S.; He, L. Surface Defect Detection Algorithm Based on Feature-Enhanced YOLO. Cogn. Comput. 2023, 15, 565–579. [Google Scholar] [CrossRef]
- Zhang, Y.; Sidibé, D.; Morel, O.; Mériaudeau, F. Deep multimodal fusion for semantic image segmentation: A survey. Image Vis. Comput. 2021, 105, 104042. [Google Scholar] [CrossRef]
- Chen, H.; Li, Y.; Su, D. Multi-modal fusion network with multi-scale multi-path and cross-modal interactions for RGB-D salient object detection. Pattern Recognit. 2019, 86, 376–385. [Google Scholar] [CrossRef]
- Wang, Q.; Chi, Y.; Shen, T.; Song, J.; Zhang, Z.; Zhu, Y. Improving RGB-Infrared Object Detection by Reducing Cross-Modality Redundancy. Remote Sens. 2022, 14, 2020. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schutz, C.; Rosenbaum, L.; Hertlein, H.; Glaser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1341–1360. [Google Scholar] [CrossRef]
- Li, M.; Yao, N.; Liu, S.; Li, S.; Zhao, Y.; Kong, S.G. Multisensor Image Fusion for Automated Detection of Defects in Printed Circuit Boards. IEEE Sens. J. 2021, 21, 23390–23399. [Google Scholar] [CrossRef]
- Zhou, T.; Ruan, S.; Canu, S. A review: Deep learning for medical image segmentation using multi-modality fusion. Array 2019, 3–4, 100004. [Google Scholar] [CrossRef]
- Ren, Z.; Fang, F.; Yan, N.; Wu, Y. State of the Art in Defect Detection Based on Machine Vision. Int. J. Precis. Eng. and Manuf.-Green Tech. 2022, 9, 661–691. [Google Scholar] [CrossRef]
- Ming, W.; Shen, F.; Li, X.; Zhang, Z.; Du, J.; Chen, Z.; Cao, Y. A comprehensive review of defect detection in 3C glass components. Measurement 2020, 158, 107722. [Google Scholar] [CrossRef]
- Wang, W. Advanced Auto Labeling Solution with Added Features. 2023. Available online: https://github.com/CVHub520/X-AnyLabeling (accessed on 14 October 2024).
- Shen, J.; Chen, Y.; Liu, Y.; Zuo, X.; Fan, H.; Yang, W. ICAFusion: Iterative cross-attention guided feature fusion for multispectral object detection. Pattern Recognit. 2024, 145, 109913. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Defect Type Name | Count |
|---|---|---|
| 0 | contusion | 1104 |
| 1 | scratches | 1728 |
| 2 | crack | 232 |
| 3 | spot | 1720 |
| Parameter Name | Parameter Value |
|---|---|
| Epoch | 300 |
| Batch size | 16 |
| Image size | |
| Data augmentation | Mosaic-4 |
| Optimizer | SGD |
| Learning rate | 0.01 |
| Momentum | 0.937 |
| Weight decay | 0.0005 |
| Index | Dataset Name | Model | mAP50 | mAP50-95 |
|---|---|---|---|---|
| 1 | forward_only | YOLOv8m | 0.928 | 0.641 |
| 2 | backward_only | YOLOv8m | 0.790 | 0.538 |
| 3 | ag_composite_obb | RGB Channel Fusion (ours) 1 | 0.979 | 0.691 |
| 4 | ag_dual_obb | ADMF-Net (ours) | 0.984 | 0.669 |
| Index | Contusion | Scratches | Crack | Spot |
|---|---|---|---|---|
| 1 | 0.908/0.649 | 0.900/0.517 | 0.995/0.743 | 0.908/0.652 |
| 2 | 0.951/0.679 | 0.233/0.118 | 0.995/0.685 | 0.980/0.669 |
| 3 | 0.980/0.716 | 0.957/0.556 | 0.995/0.737 | 0.984/0.754 |
| 4 | 0.995/0.686 | 0.954/0.520 | 0.995/0.714 | 0.993/0.756 |
| Index | Dataset Name | Model | mAP50 | mAP50-95 |
|---|---|---|---|---|
| 5 | ag_composite_diff_obb | RGB Channel Fusion 1 | 0.977 | 0.684 |
| 6 | ag_dual_obb | ADMF-Net 2 | 0.983 | 0.639 |
| 7 | ag_dual_obb | ADMF-Net 3 | 0.976 | 0.668 |
| 8 | ag_dual_rect | ICAFusion [28] 4 | 0.963 | 0.640 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Yao, Y.; Wen, R.; Liu, Q. Dual-Modal Illumination System for Defect Detection of Aircraft Glass Canopies. Sensors 2024, 24, 6717. https://doi.org/10.3390/s24206717
Li Z, Yao Y, Wen R, Liu Q. Dual-Modal Illumination System for Defect Detection of Aircraft Glass Canopies. Sensors. 2024; 24(20):6717. https://doi.org/10.3390/s24206717
Chicago/Turabian StyleLi, Zijian, Yong Yao, Runyuan Wen, and Qiyang Liu. 2024. "Dual-Modal Illumination System for Defect Detection of Aircraft Glass Canopies" Sensors 24, no. 20: 6717. https://doi.org/10.3390/s24206717
APA StyleLi, Z., Yao, Y., Wen, R., & Liu, Q. (2024). Dual-Modal Illumination System for Defect Detection of Aircraft Glass Canopies. Sensors, 24(20), 6717. https://doi.org/10.3390/s24206717