
BodyFlow: An Open-Source Library for Multimodal Human Activity Recognition

 , , , , , , , and
, , , , , , , and
Abstract
1. Introduction
2. Related Work
2.1. Multimodal HAR
2.2. Related Frameworks
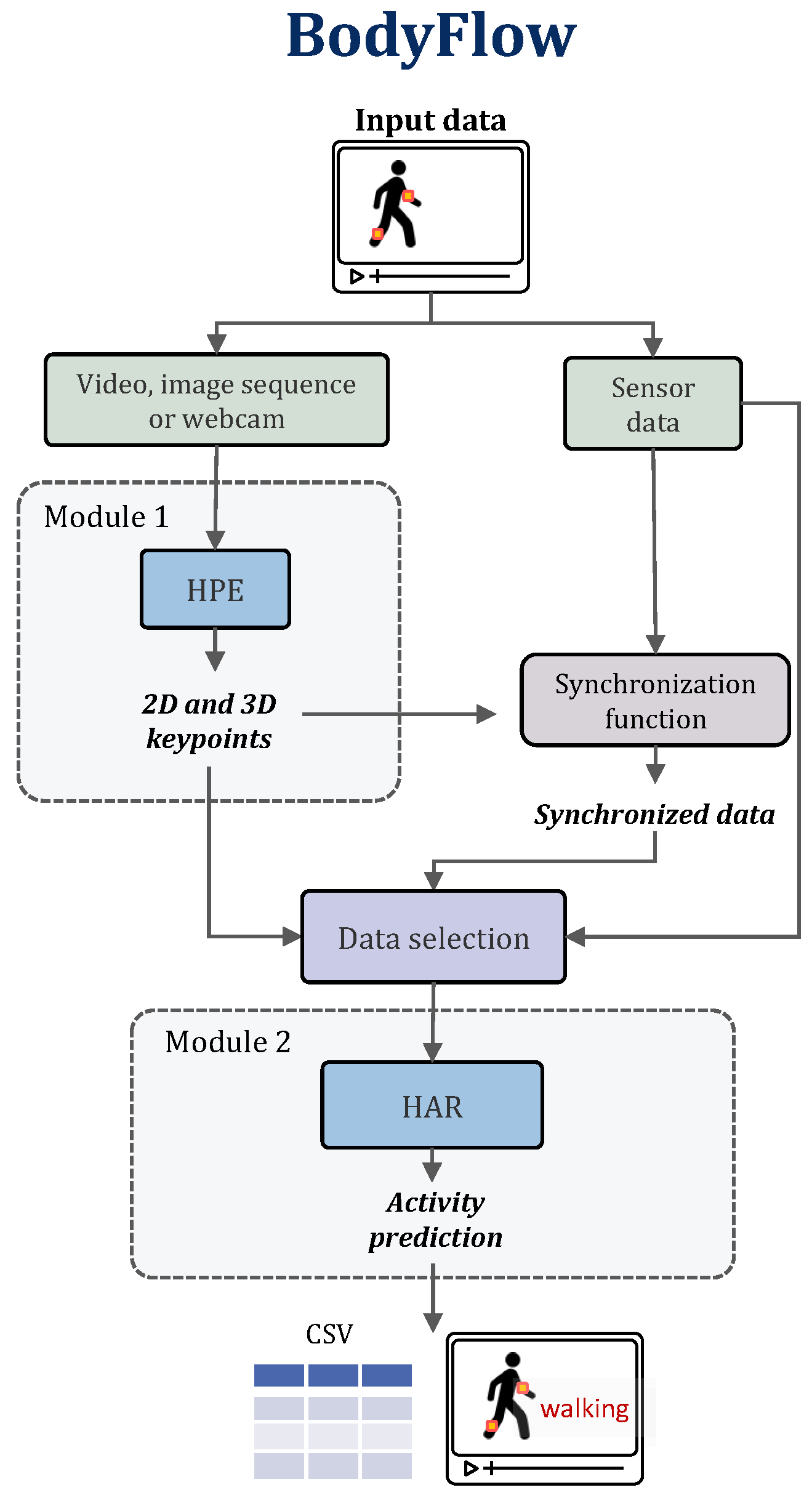
3. BodyFlow
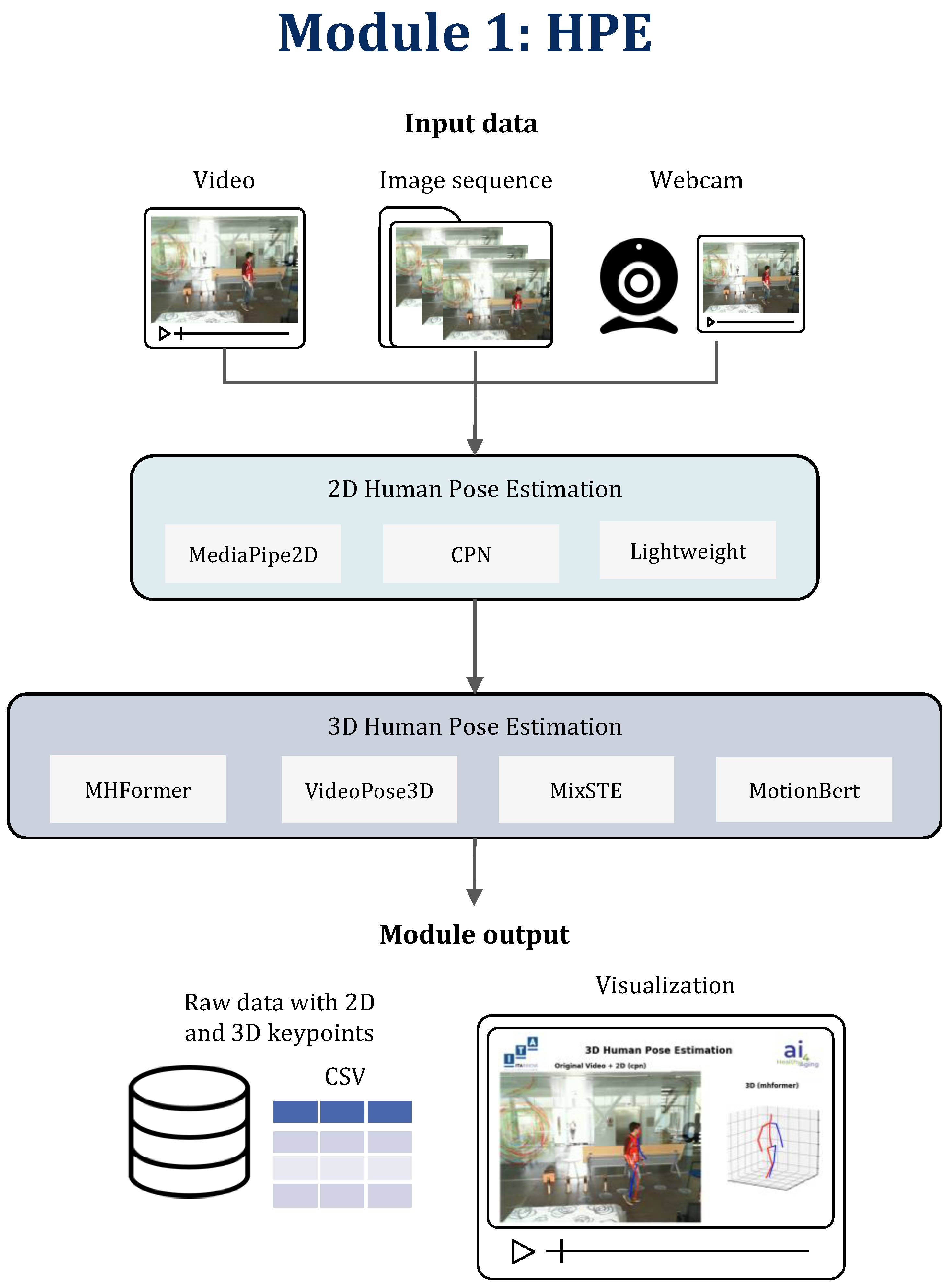
3.1. Module 1: Human Pose Estimation
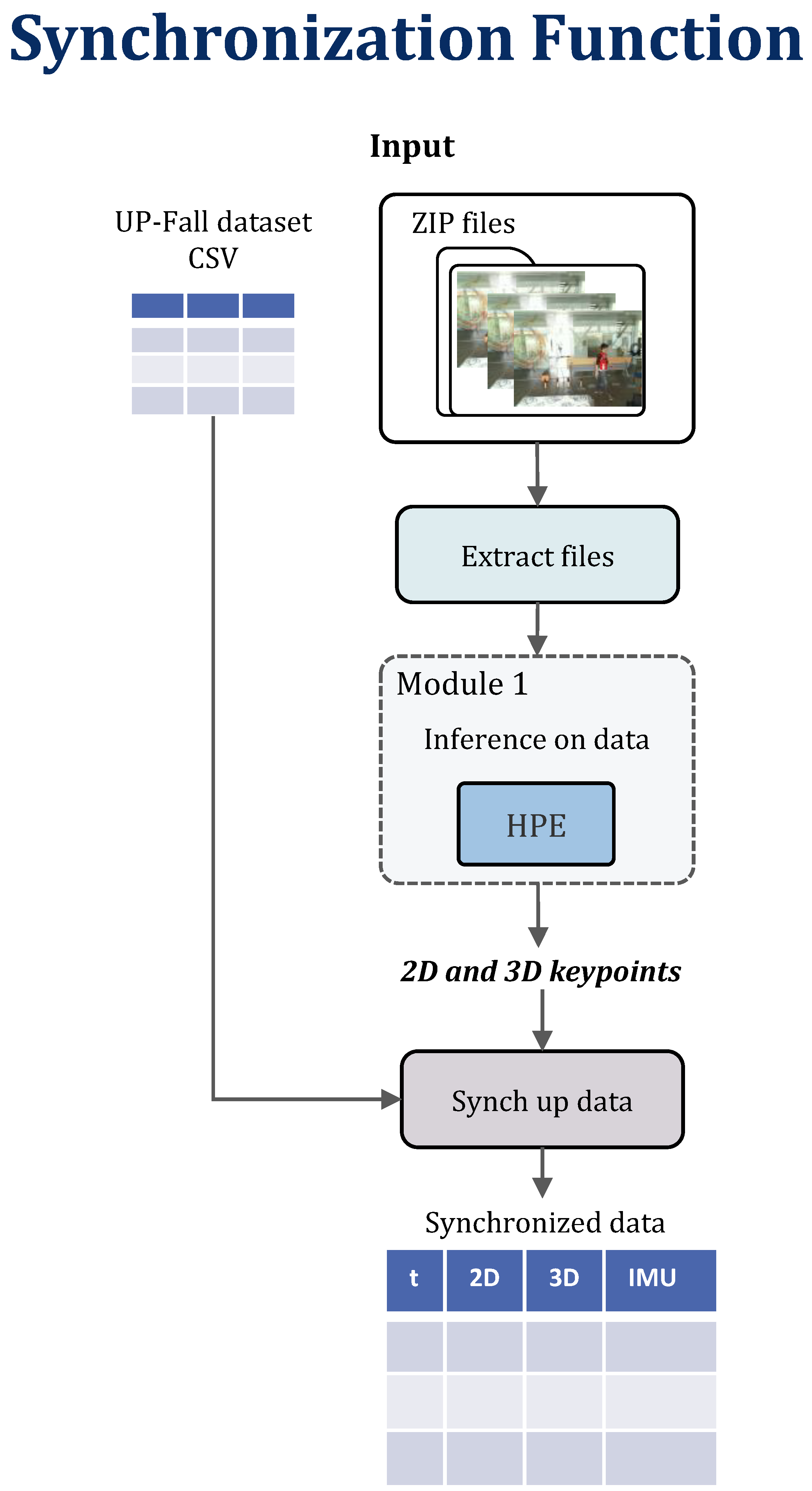
3.2. Synchronization Function
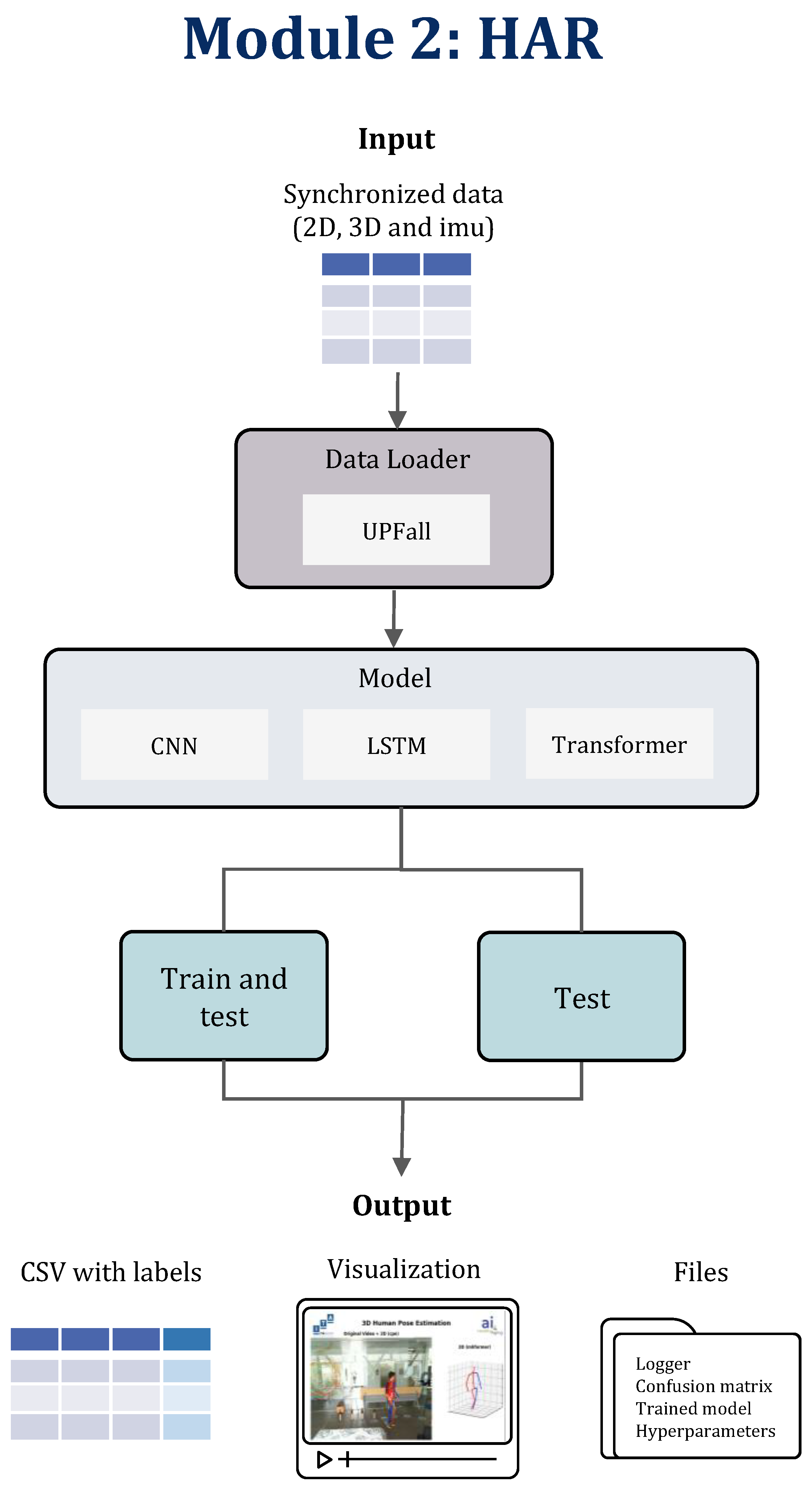
3.3. Module 2: Human Activity Recognition
4. Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| CNN | Convolutional neural network |
| CPN | Cascade Pyramid Network |
| HAR | Human activity recognition |
| HPE | Human pose estimation |
| IMU | Inertial measurement unit |
| LSTM | Long short-term memory |
References
- Aznar-Gimeno, R.; Labata-Lezaun, G.; Adell-Lamora, A.; Abadía-Gallego, D.; del Hoyo-Alonso, R.; González-Muñoz, C. Deep Learning for Walking Behaviour Detection in Elderly People Using Smart Footwear. Entropy 2021, 23, 777. [Google Scholar] [CrossRef] [PubMed]
- Qi, W.; Wang, N.; Su, H.; Aliverti, A. DCNN Based Human Activity Recognition Framework with Depth Vision Guiding. Neurocomputing 2022, 486, 261–271. [Google Scholar] [CrossRef]
- Bibbò, L.; Carotenuto, R.; Della Corte, F. An Overview of Indoor Localization System for Human Activity Recognition (HAR) in Healthcare. Sensors 2022, 22, 8119. [Google Scholar] [CrossRef] [PubMed]
- Patiño-Saucedo, J.A.; Ariza-Colpas, P.P.; Butt-Aziz, S.; Piñeres-Melo, M.A.; López-Ruiz, J.L.; Morales-Ortega, R.C.; De-la-hoz Franco, E. Predictive Model for Human Activity Recognition Based on Machine Learning and Feature Selection Techniques. Int. J. Environ. Res. Public Health 2022, 19, 12272. [Google Scholar] [CrossRef]
- Ramos, R.G.; Domingo, J.D.; Zalama, E.; Gómez-García-Bermejo, J.; López, J. SDHAR-HOME: A Sensor Dataset for Human Activity Recognition at Home. Sensors 2022, 22, 8109. [Google Scholar] [CrossRef]
- Adewopo, V.; Elsayed, N.; ElSayed, Z.; Ozer, M.; Abdelgawad, A.; Bayoumi, M. Review on Action Recognition for Accident Detection in Smart City Transportation Systems. arXiv 2022, arXiv:2208.09588. [Google Scholar] [CrossRef]
- Wang, Y.; Cang, S.; Yu, H. A survey on wearable sensor modality centred human activity recognition in health care. Expert Syst. Appl. 2019, 137, 167–190. [Google Scholar] [CrossRef]
- Liu, R.; Ramli, A.A.; Zhang, H.; Henricson, E.; Liu, X. An overview of human activity recognition using wearable sensors: Healthcare and artificial intelligence. In International Conference on Internet of Things; Springer: Cham, Switzerland, 2021; pp. 1–14. [Google Scholar] [CrossRef]
- Zitouni, M.; Pan, Q.; Brulin, D.; Campo, E. Design of a smart sole with advanced fall detection algorithm. J. Sens. Technol. 2019, 9, 71–90. [Google Scholar] [CrossRef]
- Newaz, N.T.; Hanada, E. The methods of fall detection: A literature review. Sensors 2023, 23, 5212. [Google Scholar] [CrossRef]
- Requena, S.H.; Nieto, J.M.G.; Popov, A.; Delgado, I.N. Human Activity Recognition from Sensorised Patient’s Data in Healthcare: A Streaming Deep Learning-Based Approach. Int. J. Interact. Multimed. Artif. Intell. 2023, 8, 23–37. [Google Scholar] [CrossRef]
- Cheng, W.Y.; Scotland, A.; Lipsmeier, F.; Kilchenmann, T.; Jin, L.; Schjodt-Eriksen, J.; Wolf, D.; Zhang-Schaerer, Y.P.; Garcia, I.F.; Siebourg-Polster, J.; et al. Human activity recognition from sensor-based large-scale continuous monitoring of Parkinson’s disease patients. In Proceedings of the 2017 IEEE/ACM International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Philadelphia, PA, USA, 17–19 July 2017; pp. 249–250. [Google Scholar] [CrossRef]
- Cicirelli, G.; Impedovo, D.; Dentamaro, V.; Marani, R.; Pirlo, G.; D’Orazio, T.R. Human gait analysis in neurodegenerative diseases: A review. IEEE J. Biomed. Health Inform. 2021, 26, 229–242. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.K.; Bae, M.N.; Lee, K.B.; Hong, S.G. Identification of patients with sarcopenia using gait parameters based on inertial sensors. Sensors 2021, 21, 1786. [Google Scholar] [CrossRef] [PubMed]
- Antonaci, F.G.; Olivetti, E.C.; Marcolin, F.; Castiblanco Jimenez, I.A.; Eynard, B.; Vezzetti, E.; Moos, S. Workplace Well-Being in Industry 5.0: A Worker-Centered Systematic Review. Sensors 2024, 24, 5473. [Google Scholar] [CrossRef] [PubMed]
- Sheikholeslami, S.; Ng, P.; Liu, H.; Yu, Y.; Plataniotis, K. Towards Collaborative Multimodal Federated Learning for Human Activity Recognition in Smart Workplace Environment. In Proceedings of the 2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), Seoul, Republic of Korea, 14–19 April 2024; pp. 635–639. [Google Scholar] [CrossRef]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View Adaptive Neural Networks for High Performance Skeleton-based Human Action Recognition. arXiv 2018, arXiv:1804.07453. [Google Scholar] [CrossRef]
- Martínez-Villaseñor, L.; Ponce, H.; Brieva, J.; Moya-Albor, E.; Núñez-Martínez, J.; Peñafort-Asturiano, C. UP-Fall Detection Dataset: A Multimodal Approach. Sensors 2019, 19, 1988. [Google Scholar] [CrossRef]
- Yadav, S.K.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. A review of multimodal human activity recognition with special emphasis on classification, applications, challenges and future directions. Knowl.-Based Syst. 2021, 223, 106970. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances. Sensors 2022, 22, 1476. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2012, 15, 1192–1209. [Google Scholar] [CrossRef]
- Ramanujam, E.; Perumal, T.; Padmavathi, S. Human activity recognition with smartphone and wearable sensors using deep learning techniques: A review. IEEE Sens. J. 2021, 21, 13029–13040. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A Tutorial on Human Activity Recognition Using Body-Worn Inertial Sensors. ACM Comput. Surv. 2014, 46, 1–33. [Google Scholar] [CrossRef]
- Preece, S.J.; Goulermas, J.Y.; Kenney, L.P.; Howard, D. A comparison of feature extraction methods for the classification of dynamic activities from accelerometer data. IEEE Trans. Biomed. Eng. 2008, 56, 871–879. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.J.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 22 August 2024).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Arshad, M.H.; Bilal, M.; Gani, A. Human Activity Recognition: Review, Taxonomy and Open Challenges. Sensors 2022, 22, 6463. [Google Scholar] [CrossRef]
- Hochreiter, S. Long Short-term Memory. In Neural Computation; MIT-Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Dirgová Luptáková, I.; Kubovčík, M.; Pospíchal, J. Wearable Sensor-Based Human Activity Recognition with Transformer Model. Sensors 2022, 22, 1911. [Google Scholar] [CrossRef]
- Shuchang, Z. A Survey on Human Action Recognition. arXiv 2022, arXiv:2301.06082. [Google Scholar] [CrossRef]
- Wang, C.; Yan, J. A comprehensive survey of rgb-based and skeleton-based human action recognition. IEEE Access 2023, 11, 53880–53898. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. arXiv 2014, arXiv:1406.2199. [Google Scholar] [CrossRef]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar] [CrossRef]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the IEEE CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1297–1304. [Google Scholar] [CrossRef]
- Presti, L.L.; La Cascia, M. 3D skeleton-based human action classification: A survey. Pattern Recognit. 2016, 53, 130–147. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3288–3297. [Google Scholar] [CrossRef]
- Giannakos, I.; Mathe, E.; Spyrou, E.; Mylonas, P. A study on the Effect of Occlusion in Human Activity Recognition. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 29 June–2 July 2021; pp. 473–482. [Google Scholar] [CrossRef]
- Vernikos, I.; Spyropoulos, T.; Spyrou, E.; Mylonas, P. Human activity recognition in the presence of occlusion. Sensors 2023, 23, 4899. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.H.; Kim, M.J.; Yoo, S.B. Occluded Part-aware Graph Convolutional Networks for Skeleton-based Action Recognition. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 7310–7317. [Google Scholar] [CrossRef]
- Bai, X.; Yang, M.; Chen, B.; Zhou, F. REMI: Few-Shot ISAR Target Classification via Robust Embedding and Manifold Inference. IEEE Trans. Neural Netw. Learn. Syst. 2024, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Zhou, H.; Shi, X.; Ran, R.; Tian, C.; Zhou, F. An Evidential-enhanced Tri-Branch Consistency Learning Method for Semi-supervised Medical Image Segmentation. arXiv 2024, arXiv:2404.07032. [Google Scholar] [CrossRef]
- Liu, W.; Bao, Q.; Sun, Y.; Mei, T. Recent Advances in Monocular 2D and 3D Human Pose Estimation: A Deep Learning Perspective. arXiv 2021, arXiv:2104.11536. [Google Scholar]
- Zheng, C.; Wu, W.; Yang, T.; Zhu, S.; Chen, C.; Liu, R.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep Learning-Based Human Pose Estimation: A Survey. arXiv 2020, arXiv:2012.13392. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar] [CrossRef]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A simple yet effective baseline for 3d human pose estimation. arXiv 2017, arXiv:1705.03098. [Google Scholar]
- Cheng, Y.; Yang, B.; Wang, B.; Tan, R.T. 3D Human Pose Estimation using Spatio-Temporal Networks with Explicit Occlusion Training. arXiv 2020, arXiv:2004.11822. [Google Scholar] [CrossRef]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zeng, A.; Sun, X.; Yang, L.; Zhao, N.; Liu, M.; Xu, Q. Learning Skeletal Graph Neural Networks for Hard 3D Pose Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 11436–11445. [Google Scholar]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3D Human Pose Estimation with Spatial and Temporal Transformers. arXiv 2021, arXiv:2103.10455. [Google Scholar]
- Zhang, J.; Tu, Z.; Yang, J.; Chen, Y.; Yuan, J. MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Li, W.; Liu, H.; Tang, H.; Wang, P.; Van Gool, L. MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 13147–13156. [Google Scholar]
- Zhu, W.; Ma, X.; Liu, Z.; Liu, L.; Wu, W.; Wang, Y. MotionBERT: Unified Pretraining for Human Motion Analysis. arXiv 2022, arXiv:2210.06551. [Google Scholar] [CrossRef]
- Kiran, S.; Khan, M.; Javed, M.; Alhaisoni, M.; Tariq, U.; Nam, Y.; Damaševičius, R.; Sharif, M. Multi-Layered Deep Learning Features Fusion for Human Action Recognition. Comput. Mater. Contin. 2021, 69, 4061–4075. [Google Scholar] [CrossRef]
- Contributors, M. OpenMMLab Pose Estimation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmpose (accessed on 22 August 2024).
- Xaviar, S.; Yang, X.; Ardakanian, O. Robust Multimodal Fusion for Human Activity Recognition. arXiv 2023, arXiv:2303.04636. [Google Scholar] [CrossRef]
- Ouyang, X.; Shuai, X.; Zhou, J.; Shi, I.W.; Xie, Z.; Xing, G.; Huang, J. Cosmo: Contrastive Fusion Learning with Small Data for Multimodal Human Activity Recognition. In Proceedings of the 28th Annual International Conference on Mobile Computing and Networking (MobiCom ’22), Sydney, Australia, 17–21 October 2022; pp. 324–337. [Google Scholar] [CrossRef]
- Mollyn, V.; Ahuja, K.; Verma, D.; Harrison, C.; Goel, M. SAMoSA: Sensing Activities with Motion and Subsampled Audio. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2022, 6, 1–19. [Google Scholar]
- Noori, F.M.; Wallace, B.; Uddin, M.Z.; Torresen, J. A robust human activity recognition approach using openpose, motion features, and deep recurrent neural network. In Scandinavian Conference on Image Analysis; Springer: Cham, Switzerland, 2019; pp. 299–310. [Google Scholar]
- Duhme, M.; Memmesheimer, R.; Paulus, D. Fusion-gcn: Multimodal action recognition using graph convolutional networks. In DAGM German Conference on Pattern Recognition; Springer: Cham, Switzerland, 2021; pp. 265–281. [Google Scholar]
- Islam, M.; Nooruddin, S.; Karray, F.; Muhammad, G. Multi-level feature fusion for multimodal human activity recognition in Internet of Healthcare Things. Inf. Fusion 2023, 94, 17–31. [Google Scholar] [CrossRef]
- Andriluka, M.; Iqbal, U.; Milan, A.; Insafutdinov, E.; Pishchulin, L.; Gall, J.; Schiele, B. PoseTrack: A Benchmark for Human Pose Estimation and Tracking. arXiv 2017, arXiv:1710.10000. [Google Scholar]
- Pang, H.E.; Cai, Z.; Yang, L.; Zhang, T.; Liu, Z. Benchmarking and Analyzing 3D Human Pose and Shape Estimation Beyond Algorithms. Adv. Neural Inf. Process. Syst. 2022, 35, 26034–26051. [Google Scholar]
- Khannouz, M.; Glatard, T. A benchmark of data stream classification for human activity recognition on connected objects. arXiv 2020, arXiv:2008.11880. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded Pyramid Network for Multi-Person Pose Estimation. arXiv 2017, arXiv:1711.07319. [Google Scholar]
- Osokin, D. Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose. arXiv 2018, arXiv:1811.12004. [Google Scholar]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.; Yong, M.G.; Lee, J.; et al. MediaPipe: A Framework for Building Perception Pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Choutas, V.; Pavlakos, G.; Bolkart, T.; Tzionas, D.; Black, M.J. Monocular expressive body regression through body-driven attention. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part X 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 20–40. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. arXiv 2018, arXiv:1812.08008. [Google Scholar] [CrossRef] [PubMed]
- Bazarevsky, V.; Grishchenko, I.; Raveendran, K.; Zhu, T.; Zhang, F.; Grundmann, M. BlazePose: On-device Real-time Body Pose tracking. arXiv 2020, arXiv:2006.10204. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar]
- Suarez, J.J.P.; Orillaza, N.; Naval, P. AFAR: A Real-Time Vision-Based Activity Monitoring and Fall Detection Framework Using 1D Convolutional Neural Networks. In Proceedings of the 2022 14th International Conference on Machine Learning and Computing (ICMLC) (ICMLC 2022), Shenzhen, China, 18–21 February 2022; pp. 555–559. [Google Scholar] [CrossRef]
- Falcon, W.; Team, T.P.L. PyTorch Lightning. 2019. Available online: https://zenodo.org/records/3828935 (accessed on 22 August 2024).
- The MLflow Development Team. MLflow: A Machine Learning Lifecycle Platform. Open Source Platform for the Machine Learning Lifecycle. 2023. Available online: https://github.com/mlflow/mlflow (accessed on 22 August 2024).
- Espinosa, R.; Ponce, H.; Gutiérrez, S.; Martínez-Villaseñor, L.; Brieva, J.; Moya-Albor, E. A vision-based approach for fall detection using multiple cameras and convolutional neural networks: A case study using the UP-Fall detection dataset. Comput. Biol. Med. 2019, 115, 103520. [Google Scholar] [CrossRef]
- Guzov, V.; Mir, A.; Sattler, T.; Pons-Moll, G. Human poseitioning system (hps): 3d human pose estimation and self-localization in large scenes from body-mounted sensors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4318–4329. [Google Scholar]
- Dao, N.D.; Le, T.V.; Tran, H.T.; Nguyen, Y.T.; Duy, T.D. The combination of face identification and action recognition for fall detection. J. Sci. Technol. Issue Inf. Commun. Technol. 2022, 20, 37–44. [Google Scholar] [CrossRef]
- Zhang, C.; Tian, Y.; Capezuti, E. Privacy preserving automatic fall detection for elderly using RGBD cameras. In Proceedings of the Computers Helping People with Special Needs: 13th International Conference, ICCHP 2012, Linz, Austria, 11–13 July 2012; Proceedings, Part I 13. Springer: Berlin/Heidelberg, Germany, 2012; pp. 625–633. [Google Scholar] [CrossRef]
- El Maachi, I.; Bilodeau, G.A.; Bouachir, W. Deep 1D-Convnet for accurate Parkinson disease detection and severity prediction from gait. Expert Syst. Appl. 2020, 143, 113075. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Protocol 1 | Protocol 2 | No. Parameters |
|---|---|---|---|
| VideoPose3D (2019) | 46.8 mm | 36.5 mm | 16.95 M |
| MHFormer (2022) | 43.1 mm | 34.5 mm | 25.15 M |
| MixSTE (2022) | 40.9 mm | 32.6 mm | 33.78 M |
| MotionBert (2022) | 39.1 mm | 33.2 mm | 16 M |
| 3D/2D | MediaPipe2D | CPN | Lightweight |
|---|---|---|---|
| VideoPose3D | 0.92 | 0.94 | 0.90 |
| MHFormer | 1 | 0.95 | 0.95 |
| MixSTE | 0.96 | 0.97 | 0.95 |
| MotionBert | 0.99 | 1 | 0.97 |
| Algorithm | Number of Layers | No. Parameters | Size (MB) |
|---|---|---|---|
| CNN | 16 | 2.3 M | 10 |
| LSTM | 8 | 1.6 M | 8 |
| Transformer | 56 | 135 M | 540 |
| HAR Model | Features | F1 | Accuracy | Precision | Recall |
|---|---|---|---|---|---|
| LSTM | All | 0.811 | 0.904 | 0.813 | 0.813 |
| LSTM | 3D | 0.792 | 0.898 | 0.804 | 0.784 |
| LSTM | 2D | 0.476 | 0.682 | 0.649 | 0.473 |
| LSTM | IMUs | 0.783 | 0.887 | 0.807 | 0.766 |
| LSTM | Ankle | 0.572 | 0.744 | 0.576 | 0.572 |
| CNN | All | 0.749 | 0.887 | 0.751 | 0.752 |
| CNN | 3D | 0.772 | 0.885 | 0.772 | 0.776 |
| CNN | 2D | 0.763 | 0.865 | 0.766 | 0.765 |
| CNN | IMUs | 0.698 | 0.856 | 0.737 | 0.688 |
| CNN | Ankle | 0.603 | 0.788 | 0.623 | 0.595 |
| Transformer | All | 0.815 | 0.913 | 0.816 | 0.819 |
| Transformer | 3D | 0.766 | 0.871 | 0.758 | 0.778 |
| Transformer | 2D | 0.769 | 0.877 | 0.767 | 0.778 |
| Transformer | IMUs | 0.778 | 0.887 | 0.793 | 0.767 |
| Transformer | Ankle | 0.611 | 0.777 | 0.613 | 0.612 |
| Espinosa et al. [83] | 0.729 | 0.822 | 0.742 | 0.716 | |
| Martinez-Villasenor et al. [18] | 0.712 | 0.951 | 0.718 | 0.713 | |
| Suarez et al. [80] | 0.836 | 0.893 | 0.848 | 0.834 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
del-Hoyo-Alonso, R.; Hernández-Ruiz, A.C.; Marañes-Nueno, C.; López-Bosque, I.; Aznar-Gimeno, R.; Salvo-Ibañez, P.; Pérez-Lázaro, P.; Abadía-Gallego, D.; Rodrigálvarez-Chamarro, M.d.l.V. BodyFlow: An Open-Source Library for Multimodal Human Activity Recognition. Sensors 2024, 24, 6729. https://doi.org/10.3390/s24206729
del-Hoyo-Alonso R, Hernández-Ruiz AC, Marañes-Nueno C, López-Bosque I, Aznar-Gimeno R, Salvo-Ibañez P, Pérez-Lázaro P, Abadía-Gallego D, Rodrigálvarez-Chamarro MdlV. BodyFlow: An Open-Source Library for Multimodal Human Activity Recognition. Sensors. 2024; 24(20):6729. https://doi.org/10.3390/s24206729
Chicago/Turabian Styledel-Hoyo-Alonso, Rafael, Ana Caren Hernández-Ruiz, Carlos Marañes-Nueno, Irene López-Bosque, Rocío Aznar-Gimeno, Pilar Salvo-Ibañez, Pablo Pérez-Lázaro, David Abadía-Gallego, and María de la Vega Rodrigálvarez-Chamarro. 2024. "BodyFlow: An Open-Source Library for Multimodal Human Activity Recognition" Sensors 24, no. 20: 6729. https://doi.org/10.3390/s24206729
APA Styledel-Hoyo-Alonso, R., Hernández-Ruiz, A. C., Marañes-Nueno, C., López-Bosque, I., Aznar-Gimeno, R., Salvo-Ibañez, P., Pérez-Lázaro, P., Abadía-Gallego, D., & Rodrigálvarez-Chamarro, M. d. l. V. (2024). BodyFlow: An Open-Source Library for Multimodal Human Activity Recognition. Sensors, 24(20), 6729. https://doi.org/10.3390/s24206729