

YOLO-OD: Obstacle Detection for Visually Impaired Navigation Assistance

Abstract
1. Introduction
2. Related Work
2.1. One-Stage Detectors
2.2. Two-Stage Detectors
2.3. Similar Works
3. Methodology
3.1. Architecture of the Proposed Method
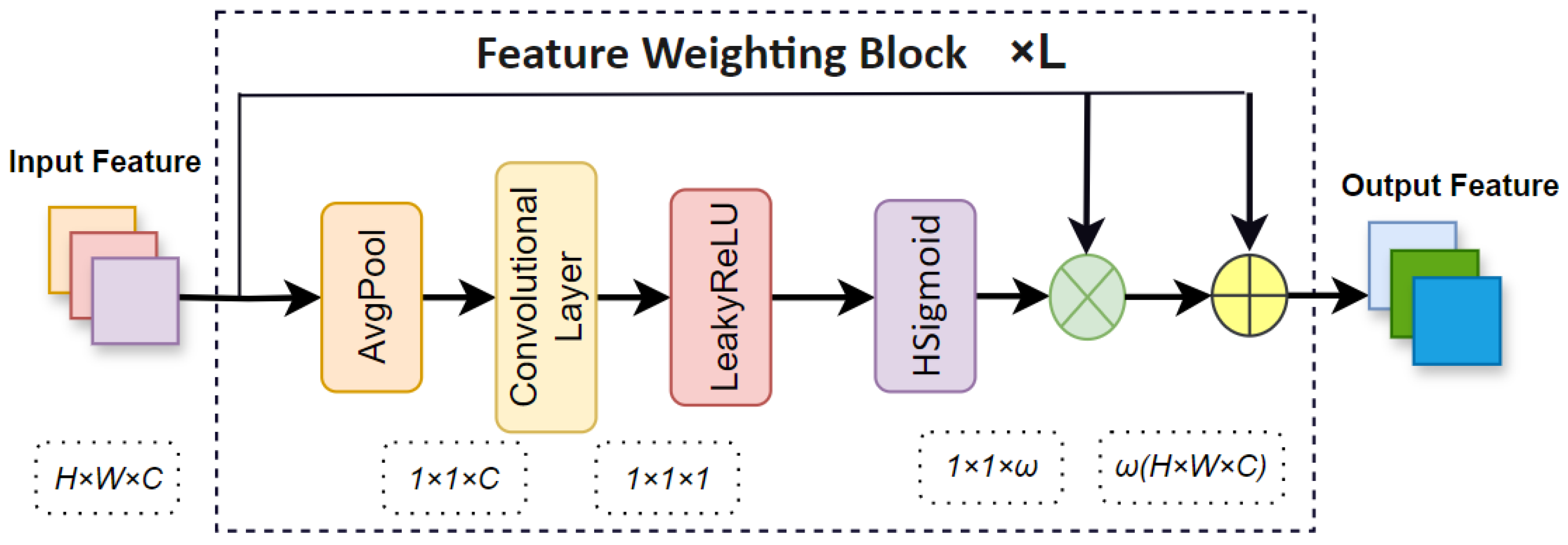
3.2. Feature Weighting Block
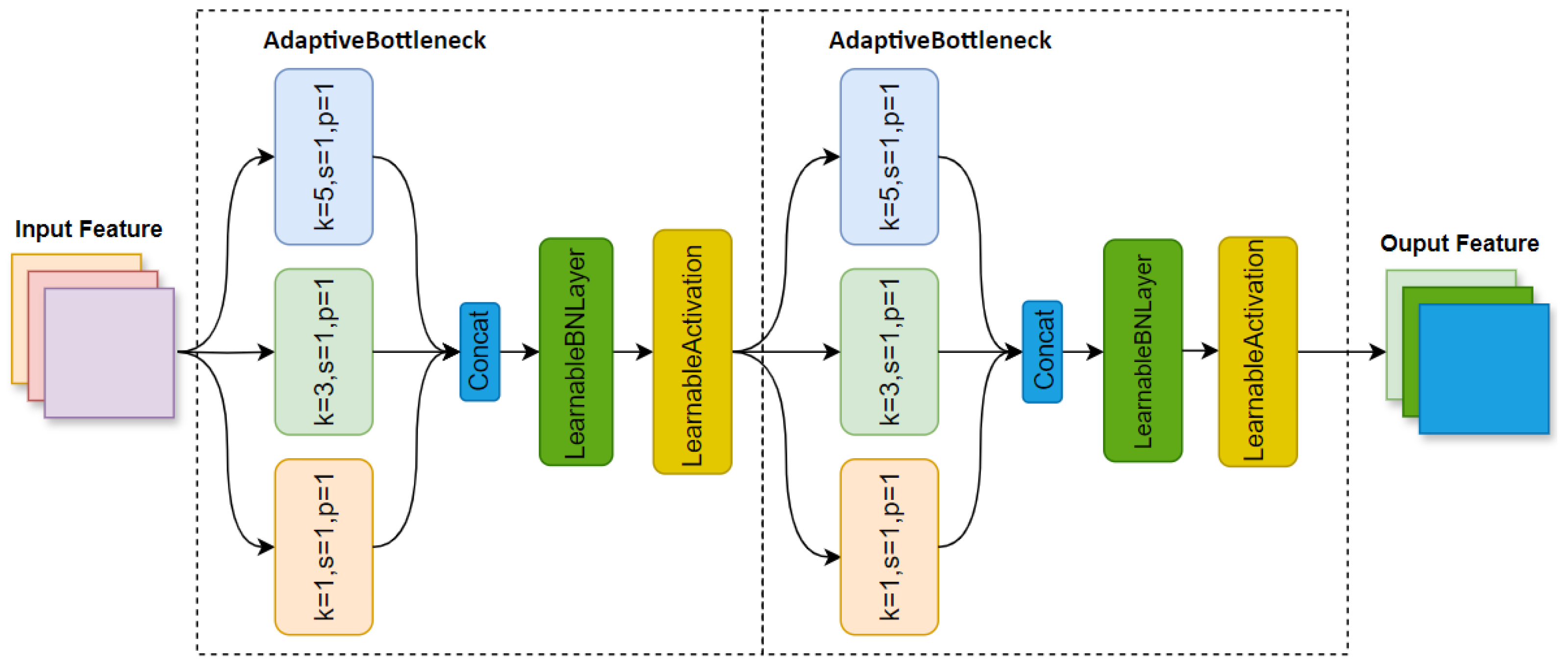
3.3. Adaptivebottleneck Block
- acts as a learnable shift to the batch mean , allowing the model to modify the mean in response to changes in data distribution.
- adjusts the batch variance , allowing the model to fine-tune the spread of the data distribution.
3.4. Enhanced Feature Attention Head
4. Experiment
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Ablation Studies
4.4. Comparisons
4.5. Visualization
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| TLA | Three letter acronym |
| LD | Linear dichroism |
References
- Li, F.; Li, X.; Liu, Q.; Li, Z. Occlusion handling and multi-scale pedestrian detection based on deep learning: A review. IEEE Access 2022, 10, 19937–19957. [Google Scholar] [CrossRef]
- Khan, S.D.; Salih, Y.; Zafar, B.; Noorwali, A. A deep-fusion network for crowd counting in high-density crowded scenes. Int. J. Comput. Intell. Syst. 2021, 14, 168. [Google Scholar]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Real, S.; Araujo, A. Navigation systems for the blind and visually impaired: Past work, challenges, and open problems. Sensors 2019, 19, 3404. [Google Scholar] [CrossRef] [PubMed]
- Saegusa, S.; Yasuda, Y.; Uratani, Y.; Tanaka, E.; Makino, T.; Chang, J.Y.J. Development of a guide-dog robot: Leading and recognizing a visually-handicapped person using a LRF. J. Adv. Mech. Des. Syst. Manuf. 2010, 4, 194–205. [Google Scholar] [CrossRef]
- dos Santos, A.D.P.; Medola, F.O.; Cinelli, M.J.; Garcia Ramirez, A.R.; Sandnes, F.E. Are electronic white canes better than traditional canes? A comparative study with blind and blindfolded participants. Univers. Access Inf. Soc. 2021, 20, 93–103. [Google Scholar] [CrossRef]
- Arakeri, M.P.; Keerthana, N.; Madhura, M.; Sankar, A.; Munnavar, T. Assistive technology for the visually impaired using computer vision. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; IEEE: Piscataway, NY, USA, 2018; pp. 1725–1730. [Google Scholar]
- Said, Y.; Atri, M.; Albahar, M.A.; Ben Atitallah, A.; Alsariera, Y.A. Obstacle detection system for navigation assistance of visually impaired people based on deep learning techniques. Sensors 2023, 23, 5262. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhao, L.; Li, S.; Jia, Y. Real-time object detection method based on improved YOLOv4-tiny. arXiv 2020, arXiv:2011.04244. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, X.; Shrivastava, A.; Gupta, A. A-fast-rcnn: Hard positive generation via adversary for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2606–2615. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, G.; Hu, Y.; Chen, Z.; Guo, J.; Ni, P. Lightweight object detection algorithm for robots with improved YOLOv5. Eng. Appl. Artif. Intell. 2023, 123, 106217. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Cheng, B.; Wei, Y.; Shi, H.; Feris, R.; Xiong, J.; Huang, T. Revisiting rcnn: On awakening the classification power of faster rcnn. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 453–468. [Google Scholar]
- Ren, Y.; Zhu, C.; Xiao, S. Object detection based on fast/faster RCNN employing fully convolutional architectures. Math. Probl. Eng. 2018, 2018, 3598316. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Liu, B.; Zhao, W.; Sun, Q. Study of object detection based on Faster R-CNN. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; IEEE: Piscataway, NY, USA, 2017; pp. 6233–6236. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Chandna, S.; Singhal, A. Towards outdoor navigation system for visually impaired people using YOLOv5. In Proceedings of the 2022 12th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Virtual, 27–28 January 2022; IEEE: Piscataway, NY, USA, 2022; pp. 617–622. [Google Scholar]
- Elgendy, M.; Sik-Lanyi, C.; Kelemen, A. A novel marker detection system for people with visual impairment using the improved tiny-yolov3 model. Comput. Methods Programs Biomed. 2021, 205, 106112. [Google Scholar] [CrossRef]
- Atitallah, A.B.; Said, Y.; Atitallah, M.A.B.; Albekairi, M.; Kaaniche, K.; Boubaker, S. An effective obstacle detection system using deep learning advantages to aid blind and visually impaired navigation. Ain Shams Eng. J. 2024, 15, 102387. [Google Scholar] [CrossRef]
- Khan, W.; Hussain, A.; Khan, B.M.; Crockett, K. Outdoor mobility aid for people with visual impairment: Obstacle detection and responsive framework for the scene perception during the outdoor mobility of people with visual impairment. Expert Syst. Appl. 2023, 228, 120464. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. Kan: Kolmogorov-Arnold networks. arXiv 2024, arXiv:2404.19756. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NY, USA, 2010; pp. 2528–2535. [Google Scholar]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the 2020 IEEE Symposium on Computers and communications (ISCC), Rennes, France, 7–10 June 2020; IEEE: Piscataway, NY, USA, 2020; pp. 1–7. [Google Scholar]
- Cui, Z.; Chen, W.; Chen, Y. Multi-scale convolutional neural networks for time series classification. arXiv 2016, arXiv:1603.06995. [Google Scholar]
- Zyh. Road Obstacle Dataset in COCO Format. Baidu AI Studio. 2023. Available online: https://aistudio.baidu.com/datasetdetail/198589 (accessed on 13 October 2024).
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | mAP | mAP50 | mAPs | mAPm | mAPl | Flops/G | Parameters/M |
|---|---|---|---|---|---|---|---|
| YOLOv8-s (baseline) | 28.51 | 42.02 | 18.93 | 28.93 | 34.01 | 14.27 | 11.14 |
| YOLOv8-s + FWB | 29.33 | 42.54 | 20.02 | 30.42 | 34.72 | 14.28 | 11.14 |
| YOLOv8-s + ABB | 29.55 | 42.85 | 20.23 | 29.94 | 35.14 | 58.52 | 40.09 |
| YOLOv8-s + EFAH | 29.44 | 42.46 | 19.25 | 29.86 | 35.06 | 14.90 | 11.37 |
| YOLOv8-s + FWB + ABB | 30.00 | 42.33 | 20.87 | 30.41 | 35.74 | 58.53 | 48.09 |
| YOLOv8-s + ABB + EFAH | 29.78 | 42.86 | 19.98 | 30.05 | 35.37 | 59.14 | 48.32 |
| YOLOv8-s + FWB + EFAH | 29.72 | 42.72 | 19.92 | 30.35 | 35.08 | 14.90 | 11.37 |
| YOLOv8-s + FWB + ABB + EFAH | 30.02 | 43.32 | 20.96 | 31.07 | 35.58 | 59.15 | 48.32 |
| Models | mAP | mAP50 | mAPs | mAPm | mAPl | Flops/G | Parameters/M |
|---|---|---|---|---|---|---|---|
| YOLOv5-s | 14.23 | 28.52 | 10.65 | 17.71 | 12.83 | 8.12 | 12.33 |
| YOLOv5-s + FWB | 15.22 | 29.41 | 11.24 | 19.05 | 14.45 | 8.13 | 12.34 |
| YOLOv5-s + EFAH | 15.34 | 28.84 | 12.17 | 19.16 | 13.78 | 8.23 | 12.39 |
| YOLOv7-tiny | 21.91 | 37.61 | 13.02 | 24.01 | 25.92 | 6.56 | 6.02 |
| YOLOv7-tiny + FWB | 23.43 | 38.85 | 14.66 | 25.32 | 27.67 | 6.57 | 6.03 |
| YOLOv7-tiny + EFAH | 22.12 | 38.26 | 13.68 | 23.65 | 27.09 | 6.67 | 6.12 |
| YOLO X-s | 23.22 | 40.31 | 14.51 | 25.06 | 27.52 | 13.32 | 8.94 |
| YOLO X-s + FWB | 23.54 | 40.82 | 14.76 | 25.67 | 27.61 | 13.33 | 8.94 |
| YOLO X-s + ABB | 24.76 | 41.76 | 15.25 | 26.23 | 30.27 | 47.92 | 38.56 |
| YOLO X-s + EFAH | 23.91 | 41.12 | 14.65 | 25.42 | 28.47 | 15.80 | 9.83 |
| SSD300 | 21.22 | 39.04 | 8.52 | 21.95 | 28.61 | 30.58 | 24.15 |
| SSD300 + FWB | 22.06 | 40.12 | 9.26 | 23.23 | 29.47 | 30.58 | 24.15 |
| SSD300 + EFAH | 21.63 | 39.37 | 8.63 | 22.67 | 29.09 | 44.72 | 56.23 |
| Models | mAP | mAP50 | mAPs | mAPm | mAPl | Flops/G | Parameters/M |
|---|---|---|---|---|---|---|---|
| Cascade R-CNN | 27.23 | 40.95 | 17.12 | 27.26 | 34.01 | 14.27 | 11.14 |
| Cascade R-CNN + FWB | 27.12 | 41.85 | 18.06 | 27.62 | 34.72 | 14.28 | 11.14 |
| Cascade R-CNN + EFAH | 27.63 | 41.66 | 18.45 | 28.47 | 35.14 | 58.52 | 48.09 |
| Faster R-CNN | 25.90 | 41.61 | 17.72 | 25.94 | 33.04 | 236.00 | 69.16 |
| Faster R-CNN + FWB | 26.03 | 41.52 | 19.04 | 27.16 | 32.77 | 236.00 | 69.17 |
| Faster R-CNN + EFAH | 26.32 | 41.74 | 18.12 | 26.55 | 32.82 | 236.00 | 69.38 |
| Deformable-DETR | 27.92 | 44.75 | 15.92 | 29.93 | 30.36 | 208.00 | 41.36 |
| Deformable-DETR + FWB | 28.52 | 45.24 | 16.95 | 30.31 | 30.38 | 208.00 | 41.38 |
| Deformable-DETR + EFAH | 28.32 | 45.02 | 16.73 | 30.44 | 31.65 | 231.00 | 41.63 |
| Models | Backbone | mAP | mAP50 | mAPs | mAPm | mAPl | Flops/G | Parameters/M |
|---|---|---|---|---|---|---|---|---|
| YOLOv5-s | YOLOv5CSPDarknet | 14.23 | 28.52 | 10.65 | 17.71 | 12.83 | 8.12 | 12.33 |
| YOLOv7-tiny | E-ELAN | 21.91 | 37.61 | 13.02 | 24.01 | 25.92 | 6.56 | 6.02 |
| YOLO X-s | YOLOXCSPDarknet | 23.22 | 40.31 | 14.51 | 25.06 | 27.52 | 13.32 | 8.94 |
| SSD300 | SSDVGG | 21.22 | 39.04 | 8.52 | 21.95 | 28.61 | 30.58 | 24.15 |
| YOLOv8-s | YOLOv8CSPDarknet | 28.51 | 42.02 | 18.93 | 28.93 | 34.01 | 14.27 | 11.14 |
| YOLOv10-n | CSPDarknet | 29.1 | 42.3 | 19.9 | 30.1 | 35.2 | 8.25 | 2.69 |
| Faster R-CNN | ResNet-50 | 25.90 | 41.6 | 17.7 | 25.9 | 30.3 | 208.00 | 41.36 |
| Cascade R-CNN | ResNet-50 | 27.23 | 40.95 | 17.12 | 27.26 | 33.04 | 236.00 | 69.16 |
| Deformable DETR | ResNet-50 | 27.9 | 44.7 | 15.9 | 29.9 | 35.4 | 193.00 | 40.10 |
| Ours | CSPDarknet | 30.01 | 43.32 | 20.96 | 31.07 | 35.58 | 59.15 | 48.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Jing, B.; Yu, X.; Sun, Y.; Yang, L.; Wang, C. YOLO-OD: Obstacle Detection for Visually Impaired Navigation Assistance. Sensors 2024, 24, 7621. https://doi.org/10.3390/s24237621
Wang W, Jing B, Yu X, Sun Y, Yang L, Wang C. YOLO-OD: Obstacle Detection for Visually Impaired Navigation Assistance. Sensors. 2024; 24(23):7621. https://doi.org/10.3390/s24237621
Chicago/Turabian StyleWang, Wei, Bin Jing, Xiaoru Yu, Yan Sun, Liping Yang, and Chunliang Wang. 2024. "YOLO-OD: Obstacle Detection for Visually Impaired Navigation Assistance" Sensors 24, no. 23: 7621. https://doi.org/10.3390/s24237621
APA StyleWang, W., Jing, B., Yu, X., Sun, Y., Yang, L., & Wang, C. (2024). YOLO-OD: Obstacle Detection for Visually Impaired Navigation Assistance. Sensors, 24(23), 7621. https://doi.org/10.3390/s24237621