Abstract
Object detection is an essential computer vision task that identifies and locates objects within images or videos and is crucial for applications such as autonomous driving, robotics, and augmented reality. Light Detection and Ranging (LiDAR) and camera sensors are widely used for reliable object detection. These sensors produce heterogeneous data due to differences in data format, spatial resolution, and environmental responsiveness. Existing review articles on object detection predominantly focus on the statistical analysis of fusion algorithms, often overlooking the complexities of aligning data from these distinct modalities, especially dynamic environment data alignment. This paper addresses the challenges of heterogeneous LiDAR-camera alignment in dynamic environments by surveying over 20 alignment methods for three-dimensional (3D) object detection, focusing on research published between 2019 and 2024. This study introduces the core concepts of multimodal 3D object detection, emphasizing the importance of integrating data from different sensor modalities for accurate object recognition in dynamic environments. The survey then delves into a detailed comparison of recent heterogeneous alignment methods, analyzing critical approaches found in the literature, and identifying their strengths and limitations. A classification of methods for aligning heterogeneous data in 3D object detection is presented. This paper also highlights the critical challenges in aligning multimodal data, including dynamic environments, sensor fusion, scalability, and real-time processing. These limitations are thoroughly discussed, and potential future research directions are proposed to address current gaps and advance the state-of-the-art. By summarizing the latest advancements and highlighting open challenges, this survey aims to stimulate further research and innovation in heterogeneous alignment methods for multimodal 3D object detection, thereby pushing the boundaries of what is currently achievable in this rapidly evolving domain.
1. Introduction
The development of autonomous driving, intelligent transport systems, and environmental sensing technology has received widespread attention and occupies a pivotal position [1,2,3,4,5]. The main task of perception is to accurately and precisely understand the complex environment surrounding a vehicle and minimize the potential risk of collision, which is the cornerstone of safe and efficient mobility [6,7]. Environmental perceptions and object detection are closely linked. In scenarios such as highway driving, three-dimensional (3D) object detection can accurately identify vehicles and obstacles at different distances, while in urban traffic, even in cluttered environments, 3D object detection can support the accurate detection of smaller objects such as bicycles and pedestrians. As a result, 3D object detection technology is becoming increasingly important. It has become a driving force for the development of autonomous driving and intelligent transportation systems to a higher stage.
Multisensor fusion integrating data from Light Detection and Ranging, or LiDAR, camera, and radar, plays a crucial role in overcoming the limitations of single-mode systems and ensuring robust object detection in diverse, dynamic environments [8,9,10]. For example, in autonomous driving, the fusion of LIDAR and a camera enables advanced functions such as lane detection in poorly lit conditions, while in dense urban environments, sudden changes in light or pedestrian occlusion also challenge existing single-mode systems.
1.1. Motivation
With the rapid development of autonomous driving and intelligent transportation systems, precise 3D object detection in dynamic environments has become one of the key technologies for ensuring safety and reliability. In the 3D object detection task, LiDAR and cameras, as complementary sensors, provide sparse and precise geometric information and rich semantic visual information, respectively, and their fusion helps improve the accuracy and robustness of target detection. However, achieving efficient cross-modal alignment and fusion is still challenging due to the significant differences in modal data characteristics, especially in dynamic scenes, where fast-moving targets, difficulties in temporal and spatial synchronization of modal data, and the exploitation of characteristics under noise interference limit the applicability of existing methods [11].
On the other hand, the complexity of objects in dynamic environments imposes higher requirements on multimodal data representation. In dynamic environments, object detection faces the following challenges: rapid target motion, occlusion, interaction, and environmental changes. Uncertainty in dynamic scenes makes multimodal heterogeneous alignment methods vital tools for coping with target detection accuracy and real-time performance. The difference between the sparseness of LiDAR point clouds and the denseness of camera images makes it particularly difficult to construct uniform and robust feature representations of dynamic scenes. Existing feature extraction and fusion methods may suffer from delays or information loss in rapidly changing scenes, thus affecting the real-time reliability of detection. Therefore, a systematic review of feature alignment and data representation methods for LiDAR cameras is important for promoting efficient 3D object detection in dynamic environments.
This review aims to comprehensively summarize existing research, explore the technical difficulties and solutions for LiDAR-camera alignment and fusion in dynamic environment detection, and identify the advantages and shortcomings of the current technologies. By systematically analyzing the current status and challenges of multimodal fusion in dynamic scenes, it is hoped to provide theoretical support and practical references for future research, promote the development of more robust and efficient 3D object detection methods, and lay the foundation for practical applications in the fields of autonomous driving and intelligent transportation.
1.2. Existing Surveys
Existing surveys focus on either camera, LiDAR, or multimodal object detection network methods. As shown in Table 1, most relevant studies have been conducted in the last few years. They cover multiple components of datasets, sensor technologies (e.g., LiDAR and cameras), deep learning techniques for feature extraction and object localization, data representation, and alignment methods for object detection networks. While they provide valuable insights into specific aspects, such as sensor modalities, LiDAR data representations, and general pipelines for 3D detection, they exhibit notable limitations. Specifically, they need comprehensive discussions on the intricate details of multimodal data representation and alignment, which are crucial for integrating heterogeneous sensor inputs.
The primary challenge lies in the differences between camera-recorded information, which projects the real world onto a two-dimensional (2D) plane, and point clouds, which directly store spatial geometric information. The main issue to overcome is multimodal fusion, followed by addressing the disparity in data representation. Point clouds are irregular, unordered, and continuous, whereas images are regular, orderly, and discrete. These fundamental differences pose obstacles in developing algorithms for processing point cloud and image data, including the need for calibration between the two systems. Overcoming these disparities is crucial for advancing the study of LiDAR and camera data fusion in perception systems [12,13,14]. The Convolutional Neural Network (CNN) method extracts and fuses features from LiDAR point clouds and camera images by stacking multiple convolutional layers to achieve data alignment. However, this can lead to issues of high computational complexity and limited real-time performance [15,16,17]. Furthermore, the aforementioned surveys need to address the challenges and methods of multimodal object detection in dynamic and complex environments, where real-time adaptability, occlusion handling, and sensor fusion robustness are critical. This gap underscores the need for a more detailed review of heterogeneous alignment in this area.

Table 1.
Comparison of surveys on object detection. (√) indicates that the topic has been covered. (×) indicates that the topic was not covered. (⊙) indicates that the topic is partially covered.
Table 1.
Comparison of surveys on object detection. (√) indicates that the topic has been covered. (×) indicates that the topic was not covered. (⊙) indicates that the topic is partially covered.
| Year | Surveys | Representation | Alignment | Datasets | Challenges | Main Topic |
|---|---|---|---|---|---|---|
| 2019 | [18] | ⊙ | × | √ | × | Multimodal detection methods. |
| 2020 | [19] | ⊙ | × | √ | × | LiDAR-based deep networks. |
| 2021 | [20] | √ | × | ⊙ | √ | LiDAR-based detection. |
| [21] | × | × | √ | × | Electric vehicles detection. | |
| [22] | ⊙ | × | √ | √ | LiDAR-based detection. | |
| 2022 | [23] | ⊙ | × | √ | √ | Case study detection methods. |
| [24] | × | × | √ | × | LiDAR-based detection. | |
| 2023 | [7] | √ | ⊙ | √ | √ | Multimodal detection methods. |
| [25] | √ | ⊙ | √ | √ | Images-based detection. | |
| [6] | × | × | √ | √ | Multimodal detection methods. | |
| 2024 | [26] | ⊙ | ⊙ | √ | √ | Multimodal detection methods. |
| [27] | ⊙ | ⊙ | √ | √ | Multimodal detection methods. | |
| This study | √ | √ | √ | √ | Representation and alignment. | |
1.3. Contributions
Current research on object detection primarily focuses on the statistical analysis of fusion algorithms, while in real-world dynamic scenarios, the detection performance of these algorithms depends on the unified representation and alignment of multimodal data.
This review focuses primarily on the statistical analysis of fusion algorithms in object detection, emphasizing the advancements in heterogeneous data processing and classification. It begins by summarizing key developments in the field and identifying primary studies. These studies are analyzed, including categorizing data representation and alignment methods. The review concludes with a discussion of the challenges and recommendations for future research. This paper addresses four research questions (RQ) left unresolved by previous reviews:
- What are 3D object detection, related autonomous driving datasets, and their heterogeneous alignment?
- How many studies on data representation and heterogeneous alignment methods for 3D object detection have been conducted between 2019 and 2024?
- How do we categorize 3D object detection data representation and heterogeneous alignment methods?
- What are the challenges, limitations, and recommendations for future research on 3D object detection?
In this paper, current articles on heterogeneous alignment methods for 3D object detection proposed in recent years are discussed. Firstly, the basic concepts of 3D object detection and the screening method are described. Secondly, the 3D object detection heterogeneous alignment methods are classified according to different characteristics. Finally, the shortcomings of current 3D object detection algorithms for heterogeneous data alignment are analyzed, and future development trends are predicted. The contributions of this study are as follows.
- Provide an analytical comparison of 3D object detection and heterogeneous alignment, focusing on recent research articles published between 2019 and 2024.
- Summarize the latest research trends and a method for classifying the alignment of heterogeneous data for 3D object detection.
- Highlight critical challenges in the heterogeneous alignment of 3D object detection and potential avenues for future exploration in this domain.
1.4. Organization
The structure of this paper is shown in Figure 1. Section 1 provides a complete introduction. Section 2 provides an overview of 3D object detection, covering the definition of object detection, sensor characteristics, various detection methods, and relevant datasets (RQ1). Section 3 outlines the steps for identifying significant studies between 2019 and 2024 (RQ2). Section 4 and Section 5 then present the representation methods and alignment strategies, including the heterogeneity of multimodal data in the 3D object detection addressed (RQ3). Section 6 summarizes the analytical discussion of this review and outlines the directions for future research (RQ4). Section 7 concludes this review.
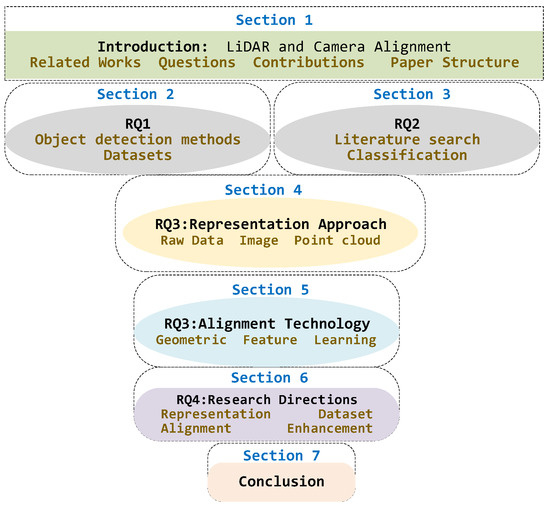
Figure 1.
Structure and organization of this paper.
2. Background
This section introduces the background of 3D object detection and common dataset indicators encompassing RQ1. It also highlights the rationale behind the focus of this review. Unlike previous works that primarily concentrated on single-modal or multimodal object detection methods, our review emphasizes the representation and alignment of multimodal data. This perspective addresses the foundational challenges of effectively integrating and utilizing multimodal information, thereby providing a more holistic understanding of the field.
2.1. Object Detection
2.1.1. Sensory
Object detection aims to predict objects’ bounding boxes and properties, including their position, size, and category. Sensors can provide raw data for 3D object detection. Cameras and LiDAR sensors are the two most commonly used sensors. Cameras have advantages such as low cost, easy accessibility, and high frame rate, which are crucial for understanding semantics. The camera generates an image Icam ∈ RW×H×3, which can be used for feature extraction, where W and H are the width and height of the image, respectively. The captured image has rich texture and color characteristics. However, cameras have notable limitations: they capture only 2D appearance information and cannot directly provide the 3D structural details of a scene. While depth information can be inferred from images, it often involves significant errors. Furthermore, image-based detection is sensitive to lighting conditions and extreme weather, making nighttime detection considerably more challenging than daytime detection, which affects the robustness of object detection.
In contrast, a point cloud is data consisting of many points in the same spatial reference system, expressing the spatial distribution of objects. The point cloud can be represented as Ipoint ∈ RN×3, and can be used for feature extraction in object detection. LiDAR sensors provide highly accurate, dense, and high-resolution point cloud data. However, LiDAR sensors are significantly more expensive than cameras, which limits their widespread adoption, particularly in cost-sensitive applications. Additionally, their resolution is lower than that of cameras, making the detection of small or distant objects challenging.
A comparison of cameras and LiDAR sensors highlights their complementary strengths and weaknesses. Cameras are well suited for capturing detailed appearance and semantic information, whereas LiDAR provides superior depth, accuracy, and robustness under varied lighting conditions. This comparison is crucial for understanding the trade-offs involved in sensor selection and motivates the exploration of multimodal approaches that integrate data from both types of sensors. By leveraging the complementary strengths of cameras and LiDAR, researchers have aimed to address the limitations of each individual sensor and enhance the performance of 3D object detection systems, especially in dynamic and complex environments.
2.1.2. Camera-Based
In recent years, several well-established methods for 2D object detection have been developed for 3D object detection [28,29,30]. For example, image-based detection methods have a low cost [31,32]. Monocular cameras provide shape and texture in the form of pixels and therefore lack depth information [33,34,35]. Stereo cameras can provide accurate depth at the cost of complexity and cost increase [36,37]. Multiview cameras can generate depth maps covering different scene ranges than other cameras [38,39]. However, camera-based detection can be affected by unfavorable conditions, such as low light [40,41]. For the KITTI [42] dataset, the top monocular image-based method, DD3D [43], and the top stereo image-based method, LIGA-Stereo [44], achieved low reliability at 16.87% and 64.66% mean Average Precision (mAP), respectively. Further exploration is needed to achieve more reliable visual monitoring.
2.1.3. LiDAR-Based
LiDAR provides robust 3D geometric information compared to camera images, which is critical for 3D object detection. Additionally, LiDAR sensors can better adapt to external factors, such as glare, resulting in more reliable detection under extreme lighting conditions. However, LiDAR-only algorithms have not been widely used in vision for the following reasons: (1) LiDAR is very expensive and bulky, especially compared to cameras [45]; (2) LiDAR has a minimal operating distance, and the point cloud away from LiDAR is very sparse [46]; and (3) LIDAR systems face significant challenges in extreme weather conditions such as heavy rain, as water droplets can disrupt the depth sensing of the LIDAR [47]. Moreover, the visibility of the camera image is reduced. Therefore, even with data fusion, extracting meaningful information under these conditions remains a challenge.
2.1.4. Fusion-Based
Multimodal 3D object detection combines the advantages of multiple modalities by integrating various sensors to achieve better performance. Compared to unimodal detection, it can fully utilize depth information from point clouds and texture information from images. However, several challenges remain unsolved. Early pioneers in multimodal 3D object detection included MV3D [12]. They focused on combining data from two modalities for applications but overlooked the heterogeneous modal gap.
2.1.5. Discussion and Analysis
Each sensor has unique characteristics, and their advantages sometimes complement each other. More methods are being developed to fuse networks of images and point clouds to achieve better performance than single-sensor methods in 3D object detection tasks. However, 3D object detection methods with fused networks must deal with heterogeneous data representations. The detection of point clouds and images requires specialized fusion mechanisms. 3D object detection methods typically utilize different projection views, such as bird’s-eye, cylindrical, and point views, to generate object predictions. Additionally, more research is now focusing on using modeling approaches for object prediction.
2.2. Datasets
2.2.1. Definition and Comparative Analysis
Many driving datasets have been created in the past few years, facilitating research on 3D object detection by providing multimodal sensory data and 3D annotations. We present a survey of existing datasets (Table 2) and review the characteristics of popular datasets.
Table 2.
Summary of driving datasets for 3D object detection.
Existing popular datasets can be analyzed according to three groups. In the first group, the datasets are grouped by their size. In group 1, the sizes of the KITTI [48], KAIST [49], and Cirrus [56] datasets are less than 50 k. The second group classifies the datasets by class number. The class number of three datasets is more than 10. In the third group, datasets are categorized by the number of sensors. The numerator represents the LiDAR number, and the denominator expresses the number of sensors. The KITTI [48], KAIST [49], H3D [44], Argoverse [51], nuScenes [52], A*3D [54], and ONCE [57] datasets include only one LiDAR, whereas others use more than one LiDAR. The KITTI [48], Argoverse [51], A*3D [54], and ONCE [57] datasets include two sensor types, whereas the other datasets have three sensor types. The frequency distribution of the groupings is summarized in Figure 2.
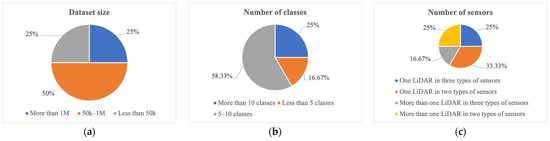
Figure 2.
Frequency distribution of datasets based on (a) dataset size, (b) number of classes, and (c) number of sensors.
2.2.2. Discussion and Analysis
Autonomous driving datasets have different characteristics. The KITTI [48], Argoverse [51], A*3D [54], and Cirrus [56] datasets contain only driving data obtained during the daytime and in good weather. Recent datasets, such as KAIST [49], ApolloScap [43], H3D [44], Lyft Level 5 [50], nuScenes [52], Waymo [53], PandaSet [55], and ONCE [57], provide data captured at night or during rainy weather. Some datasets, like Argoverse [51], PandaSet [55], and nuScenes [52], offer finer object categories with more than 10 classes, while fewer than 10 categories are detected in two other datasets.
Precision and recall are the most commonly used metrics for object detection. Precision is the ratio of the number of instances correctly identified as positive samples by the model to the total number of instances correctly identified as positive samples. In contrast, recall is the ratio of the number of instances correctly identified as positive samples by the model to the total number of instances that are positive samples. The mAP and Normalized Detection Score (NDS) are also commonly used metrics for evaluating object detection tasks, measuring the average performance of the model across multiple categories. A higher mAP indicates better model performance on the detection task. The NDS considers the degree of overlap (IoU) between the object detection results and the ground truth. It weighs the recall and false alarm rates according to the size and distance of the target. Evaluation metrics may be adjusted, updated, or expanded as autonomous driving technologies and datasets evolve.
2.3. Heterogenous Alignment Discussion and Analysis
In the context of 3D object detection for autonomous driving, heterogeneous alignment refers to the process of aligning and fusing data from different sensors. This alignment integrates the complementary characteristics of data from various sensors, enhancing object detection and recognition accuracy and robustness. By leveraging the strengths of each sensor type, heterogeneous alignment provides a more comprehensive understanding of the surrounding environment, which is crucial for the safe and effective operation of autonomous vehicles. The alignment is represented throughout the alignment and fusion process, as shown in Figure 3.
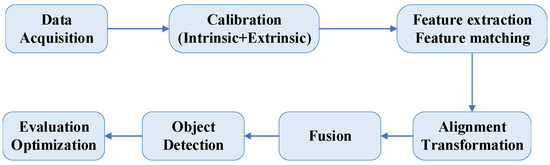
Figure 3.
Magnetization frame of multimodal alignment and fusion.
LiDAR and camera heterogeneous alignment aim to synchronize and integrate sensory input data from both LiDAR and camera systems to enhance the accuracy and robustness of 3D object detection. LiDAR sensors provide precise depth information and a detailed 3D point cloud representation of the environment, capturing the spatial structure of objects. In contrast, camera systems offer rich color and texture details, which are crucial for accurate object classification and identification. By aligning the data from these two heterogeneous sources, we can leverage the strengths of both modalities to achieve a more comprehensive understanding of the scene.
In dynamic autonomous driving environments, these sensors need to be effectively fused to compensate for the limitations of a single sensor and provide accurate environmental sensing. The alignment of heterogeneous sensor data plays a crucial role in system perception, decision-making, and planning. Although the data alignment of heterogeneous sensors can theoretically improve the performance of autonomous driving systems, it still faces many challenges in practice. In recent years, significant progress has been made in the application of deep learning and multimodal learning to image processing and point cloud processing. Data alignment from different sensors can be performed more efficiently using deep neural network models. However, in the face of dynamic and complex driving environments, overcoming the challenges of temporal synchronization, spatial alignment, and resolution differences in sensor data will be an important research topic in future autonomous driving.
3. Protocol and Strategies for Studies
This study aims to summarize the process of reviewing heterogeneous alignment and classifying LiDAR and camera fusion to answer RQ2.
3.1. Literature Search and Screening Strategies
In this study, we focused on the literature published between 2019 and 2024. A five-year time span is sufficient to analyze recent trends and draw conclusions. Databases searched for articles are WoS, SpringerLink, IEEE Xplore, ProQuest, ACM Digital Library, Scopus, Science Director, and Google Scholar. These databases were selected for research after considering expert opinions on the literature search strategies. The search keywords used were ‘machine learning’, ‘fusion or alignment’, ‘LiDAR’, ‘Camera’, and ‘object detection’, excluding terms such as ‘medicine’, ‘infrared’, ‘remote sensing’, and ‘mapping’. Boolean operators such as ‘AND’, ‘OR’, and ‘NOT’ were used to refine the search, with the ‘-’ operator in Google Scholar functioning as an equivalent to ‘NOT’.
The screening process for retrieving relevant articles consisted of four steps: removing duplicates, screening by title, screening by abstract, and screening for relevance to the research questions. The inclusion criteria for article screening are shown in Table 3. The screening results are presented in Table 4.
Table 3.
Inclusion and exclusion criteria for article screening.
Table 4.
Overview of the systematic screening.
3.2. Classification and Analytical Framework
To provide a thorough overview of the current research on heterogeneous data alignment for multimodal 3D object detection, this study presents a systematic analysis of 21 representative papers published between 2019 and 2024. The analysis framework encompasses key dimensions, including country of origin, publication year, datasets utilized, methodological approaches, primary contributions, and the identified limitations in Table 5. The examined studies predominantly originate from China (17 papers, or 80.9%) [58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74], with additional contributions from the United Kingdom [75], Germany [76], the United States [77], and Brazil [78]. The KITTI dataset is the most frequently employed benchmark (11 papers, or 52.3%) [58,59,61,63,64,66,67,68,75,78], supplemented by other datasets such as CADC, SUN-RGB [65], FlyingThings3D [73], Waymo [53], and nuScenes [52,71,72,73,74,77]. This highlights the importance of the KITTI dataset, followed by the nuScenes dataset.
Table 5.
Summary of contribution, applicability, and limitations of the primary studies.
4. Heterogeneous Data Representation Approaches
RQ3 is discussed in two parts: 3D object detection data representation and heterogeneous alignment methods. In this section, data representation approaches are examined.
4.1. Categorization Summary
The previous subsection analyzed the literature from 2019 to 2024, focusing on multimodal data, primarily point clouds, and images collected by LiDAR and cameras. These data types are not uniformly represented. This subsection expands the analysis to the past decade, summarizing the fact that heterogeneous data representations in 3D object detection can be categorized into primitive and projective representations. This categorization is based on a literature review from the last five years. Table 6 provides a detailed summary of these findings.
Table 6.
Summary of data representations for object detection.
The data representations from LiDAR and cameras used in 3D object detection vary, each with advantages and disadvantages. These are generally categorized into raw data representation, project representation, and bird’s eye view (BEV) representation.
Raw data representation includes raw image data and raw point cloud data. Raw image data is a two-dimensional representation of an image that provides much information and improves detection accuracy, but requires a lot of computation and long inference time [45,67,71,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112]. Raw point cloud data are three-dimensional data directly generated by LiDAR sensors, which are usually rich in spatial information and highly accurate in practical applications [81,82,84,85,86,89,90,91,94,99,100,102,106,107,108].
Project representations include pseudo-point cloud 3D representations generated from images, which have the advantages of low computational effort and fast processing speed, but contain less information and lose geometric details in the conversion process [96,113]. The BEV representation consists of BEV feature data and BEV map data [114,115,116,117]. BEV feature data are 2D representations derived from an image suitable for feature extraction and global analysis.
A voxel is a typical representation derived from point clouds, characterized by its ability to discretize the 3D space into uniform grids, allowing for efficient spatial indexing and processing of large-scale data [71,83,92,94,95,97,98,100,101,103,104,105,109,110,111,112,113,114,115]. Front (range) view data are a 2D representation generated from a point cloud that simplifies the computation [87,88]. BEV map data are a 2D representation derived from point clouds, which can provide more intuitive spatial information for vehicle path planning and environment understanding [12,45,96,107,117,118,119].
4.2. Discussion and Analysis
Different data representations, such as images and point clouds, exhibit distinct strengths and weaknesses that influence their suitability for various application scenarios. Images typically contain rich information, such as color and texture, which contributes to improved accuracy in object detection. However, the computational costs and inference times associated with image processing are often significant. In contrast, point clouds generated by sensors like LiDAR are computationally efficient and offer faster processing speeds, but they generally lack the detailed contextual and semantic information found in images. Additionally, point clouds may suffer from geometric information loss during processing. While BEV representations derived from point clouds enhance real-time performance, they introduce projection errors, which may reduce accuracy, especially for detecting small or distant objects. These trade-offs highlight the importance of selecting appropriate data representations based on the specific demands of multimodal object detection in dynamic environments.
Since input data for multimodal fusion are often heterogeneous, constructing correspondences between the features of different modalities is critical. Researchers have proposed various alignment methods to address this challenge, enabling effective data integration from different sensors. For instance, a common approach is to represent LiDAR point clouds and camera images in a shared feature space, as illustrated in Figure 4. By analyzing the strengths and weaknesses of these data representations, we aim to facilitate advancements in solving the complex problem of multimodal object detection in dynamic environments.
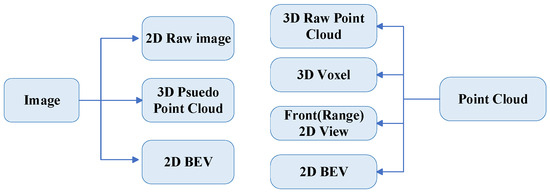
Figure 4.
Magnetization Frame of Multimodal alignment and fusion.
5. Heterogeneous Alignment Techniques
To answer RQ3, this section categorizes the alignment methods from reviewed papers into three types: (1) geometric alignment, (2) project alignment, and (3) learning alignment. This paper identified several studies that incorporate similar approaches. Analyzed from Table 5, three papers implemented the geometric and project alignment approach. The primary studies implemented 3D object detection through feature matching [58,60,67,68,69], achieved feature alignment of both sensors by feature selection [66,75], mapped 3D features into 2D features to achieve feature alignment [59,78], and directly fused the data generated by LiDAR and camera sensors after extracting features [64]. Pang et al. [73] directly processes the 3D detector head as a 2D detector head. Finally, other works have used an attention mechanism to achieve multimodal heterogeneous data alignment [61,63,65]. Figure 5 presents a summary of the alignment approach.
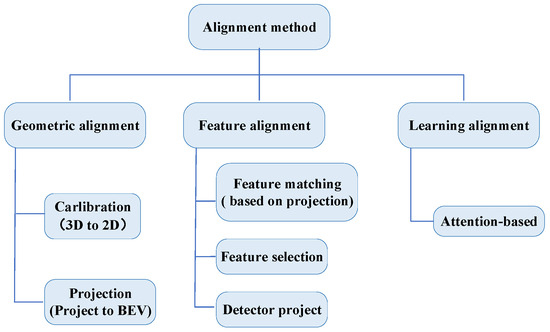
Figure 5.
Summary of alignment approaches.
The geometric alignment method has high computational efficiency and good real-time performance; however, its accuracy is limited, and its ability to adapt to environmental changes is poor. The project alignment method can obtain higher accuracy and better adapt to environmental changes but requires a large amount of a priori knowledge and computational resources. The learning alignment method combines the advantages of project alignment and model alignment, which can trade-off accuracy and efficiency, but increases the algorithm’s complexity and the parameter’s difficulty.
5.1. Geometric Alignment
Geometric alignment methods can be roughly divided into Calibration and Projection.
Calibration: This is a crucial preprocessing step in multimodal heterogeneous data processing using a projection matrix that includes intrinsic and extrinsic parameters to project 3D world coordinates to 2D image coordinates [67,68], especially when combining 3D data with 2D data. It is important for multimodal data fusion to ensure the spatial consistency of different modal data (e.g., RGB images and LiDAR point cloud data) through calibration [59,78].
Projection: This is another preprocessing step for multimodal heterogeneous data. When 3D information needs to be recovered from a 2D image, points in the 2D image can be inversely mapped into the 3D space using the camera’s internal and external references, called a pseudo-point cloud [58]. This typically requires additional depth information or assumptions, such as the use of depth images or stereo vision, to recover 3D points. Alternativey projecting heterogeneous sensor data into a unified geographic coordinate system and achieving alignment through local feature matching, e.g., a uniform project into the BEV space [64], which is more efficient but less resilient to large-scale environmental changes.
5.2. Feature Alignment
Projection alignment after feature extraction is known as the feature alignment. It generally performs better for detection than for data alignment before feature extraction. Feature alignment can be divided into three categories based on specific methods.
Feature matching: Ouyang et al. [60] achieved multimodal data alignment by projecting a LIDAR point cloud onto a 2D image plane, generating a depth range diagram (DRD), and then combining these 2D features with camera images. Specifically, it first generates DRD maps from the sparse LIDAR point cloud using an up-sampling algorithm and then fuses the DRD maps with the image to enhance the accuracy of object detection. Wang et al. [69] fuses the semantic features of view voxels with the geometric features of the point cloud by projecting each point cloud onto an image feature map. In this way, PVFusion can better utilize the semantic information of the image, thus improving the detection accuracy of small objects (e.g., pedestrians) in sparse point clouds.
Feature selection: Features are fused by generating 3D and 2D regions of interest (RoIs) in point clouds and images, respectively, and then aligning these two RoIs. Specifically, RoIFusion generates 3D RoIs in the point cloud and corresponding 2D RoIs in the image, extracts geometric and texture features through the 3D RoIs pooling layer and 2D RoIs pooling layer, and finally fuses these features for 3D object detection. This approach effectively reduces the computational cost and viewpoint misalignment problems and improves the detection performance [71].
Detector project: Significantly improves the accuracy and real-time performance of 3D object detection by introducing a lightweight 3D-Q-2D image detector that combines 3D detection of candidate regions with image feature extraction, resulting in efficient alignment and fusion of point clouds and images [73].
5.3. Learning Alignment
Learning alignment has primarily focused on attention-based methods. Many researchers have leveraged deep learning methods for feature alignment and enhancing model alignment without sacrificing semantic information, mainly using attention [71,102,103,104,105]. AutoAlign [71] converts voxels into a query q and camera features into a key k and a value v. For each voxel cell, an inner product is computed between the query and the key, generating a correlation matrix between the voxel and all its corresponding camera features. This is followed by normalization, where the value v, containing the camera information, is weighted. To reduce the computational effort, Chen et al. [96] drew inspiration from deformable DETR [110] and proposed a cross-alignment algorithm called DeformCAFA, which employs a deformable cross-attention mechanism. In this method, the query q and key k are similar to AutoAlign, but the value v is modified. A projection matrix is used to query the image features corresponding to voxel features, and offsets are learned by an MLP, extracting the image features associated with these offsets as the value v. This enables each voxel to perceive the entire image, thereby facilitating feature alignment between the two modalities. Several studies have proposed projection and deep attention mechanisms for multimodal heterogeneous data alignment that effectively learn the significance of different modal features and adaptively fuse features based on a depth threshold [72,73,74,114]. The Graph Feature Alignment (GFA) module and Self-Attention Feature Alignment (SAFA) module introduced by Song et al. [73] improve the alignment accuracy of point cloud and image features by leveraging neighborhood relationships and attention mechanisms, ultimately boosting detection performance. Extensive experiments on the KITTI and nuScenes datasets demonstrate that GraphAlign enhances detection accuracy, particularly for small objects at long distances, in high-precision scenarios.
5.4. Discussion and Analysis
Multimodal data representations for object detection are categorized into raw and projected representations. Projected representation transforms data to enhance alignment and performance, particularly in BEV-based detectors, whereas raw representation retains the original data to preserve maximal information. Ongoing developments in multimodal representation suggest future advancements toward more efficient representations. However, heterogeneous sensor fusion remains an active research field, with new methods and algorithms continually emerging. In practical applications, it is essential to consider various factors, such as specific scenarios, required accuracy, and computational resources, when choosing the appropriate alignment method. For example, increasing the weight of lidar to achieve good detection in dynamic nighttime driving environments is a solution to this challenge.
The alignment of multimodal heterogeneous data is essential in the process of data fusion. The goal of data alignment is to effectively fuse heterogeneous data from different sensors and different modalities so that they have good correspondence in the same representation space and provide a unified multimodal input for subsequent sensing and prediction tasks. For heterogeneous data modalities, such as images and point clouds, it is difficult to fuse them directly due to the huge differences in their original representations. Therefore, it is necessary to map them to an intermediate representation space first, so that different modal data have similar representation forms in this space. The fusion of heterogeneous data into a unified representation space involves cross-modal data alignment and fusion. Common practices include using autoencoders to encode the data into the latent space, and using projection methods to map the data to the common space.
This review also summarizes the model alignment methods, and the common methods include the attention mechanism and the deformable attention mechanism. After data fusion, a unified multimodal representation not only facilitates complementary and synergistic information from different modalities, but also facilitates the application of machine learning models for subsequent perceptual inference tasks. Therefore, the core idea of the multimodal heterogeneous data alignment method is to fuse different modal data to generate a unified multimodal representation to achieve efficient fusion and utilization of inter-modal information. This is the basis and key to multimodal perception.
6. Challenges and Future Directions
Despite many alignment techniques, the fusion of image and point cloud data in autonomous driving scenarios still faces challenges such as accuracy, robustness, and real-time processing requirements. Currently, improving the alignment accuracy between point cloud and image data is one of the main focuses of multimodal object detection research, and it is also the main challenge and limitation that the field is currently facing, and it still needs to fully mature. This section explores the current difficulties and emerging trends in the field of multimodal 3D object detection alignment techniques. The structure of future research directions follows the framework illustrated in Figure 6.
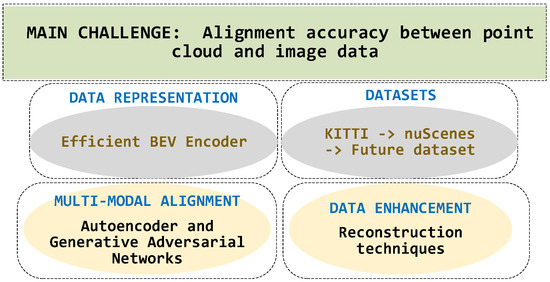
Figure 6.
Structure and keywords of the challenges and research directions.
6.1. Data Representation
The heterogeneous nature of data acquired by different sensors can lead to problems, such as information desynchronization in data representation. Some recent studies by Liang et al. [114] and Liu et al. [115] attempted to use BEV representation to unify different modalities, which provides a new perspective to solve this problem and is worth further exploration.
The BEV representation can naturally fuse data from different sensors by projecting 3D data onto a horizontal plane and presenting scene information in a top-down view. Compared with the direct fusion of point cloud and image, BEV indicates that while preserving the rich semantic information of the camera, it also contains precise depth information of the point cloud, which is expected to resolve the differences between heterogeneous modalities better. Some recent works, such as BEVFusion and BEVFormer [120], are based on this idea and have achieved good results. However, there are some potential limitations of the BEV representation, such as the possibility of introducing additional errors in the projection process and the ability to model objects perpendicular to the ground is somewhat affected. Therefore, designing an efficient BEV encoder, solving the occlusion problem, and combining it with the original sensor data are all worthy of attention. More work is still needed to fully explore the potential of BEV representation to address challenges, such as projection error and occlusion. In addition, it can be combined with other techniques to obtain a more robust and accurate multimodal 3D object detection system.
6.2. Datasets
Most of the literature analyzed achieved better recognition results using KITTI datasets. However, KITTI datasets do not include data from outdoor scenes, such as nighttime. nuScenes datasets have attracted much attention due to their multimodal characteristics and wide coverage, which is expected to solve the challenge of the limited field of view of the current publicly available datasets in complex environments. In addition, traditional datasets are often limited to specific sensor types, such as a single camera or LIDAR, resulting in blind spots in complex scenes. By contrast, nuScenes integrates data from multiple sensors, including cameras, LiDAR, and radar, thereby providing a valuable resource for studying multimodal fusion perception.
Although nuScenes provides rich multimodal data, object detection still has some deficiencies. A complex urban scene and multiple object classes make detection more difficult. The calibration error and time delay between different sensor data also challenge data processing. Therefore, the focus of current research is on how to make full use of the advantages of multimodal data to improve the accuracy and robustness of object detection. Several studies have found that existing datasets still have some deficiencies in the object detection task. Some researchers have also pointed out that the poor quality of annotation and inconsistent format of annotation have brought some obstacles to the utilization of the dataset.
The development of future datasets needs to focus on the following aspects: (1) constructing datasets containing more scale variations to promote the performance of detection algorithms at different scales; (2) expanding the types of scenes for data collection, such as increasing the number of indoor, confined space, and other complex environments; (3) improving the quality of the annotation and adopting semiautomatic or automated annotation to reduce the error of manual annotation; (4) unifying the annotation format to facilitate the fusion of different datasets; and (5) exploring the use of fewer samples or unlabeled data to reduce the cost of labeling. Improving the multimodal sensing dataset will provide a more solid data foundation for the fields of automatic driving and robotics.
6.3. Multimodal Alignment
Although existing studies have attempted to encode sparse 3D representations into 2D representations [87,88], a large amount of information is often lost during the encoding process. This information loss not only affects the final perceptual accuracy but also increases the difficulty of subsequent processing. Therefore, encoding 3D features efficiently, reducing information loss, and achieving effective alignment of multimodal data becomes the key to improving the performance of multimodal perception.
Advanced coding techniques such as Autoencoder and Generative Adversarial Networks (GAN) can play an important role in deep learning to solve this challenge. Through unsupervised learning, the Autoencoder can learn the intrinsic feature representation of the data, encode high-dimensional sparse data into low-dimensional compact representations, and reconstruct the original data approximately when decoding. GAN learns the data distribution through adversarial training between generators and discriminators and generates synthetic data that are highly similar to the actual data, thus achieving efficient encoding and decoding.
By combining techniques such as autoencoders and GANs, researchers can develop more compact 3D representations that accurately align multimodal data while reducing information loss. For example, 3D point cloud data are encoded into a low-dimensional potential space, and then a reconstruction that is highly consistent with the original data is generated by a decoding network, thus preserving the key feature information. In addition, the GAN-based coding method can also generate more detailed and smooth correspondences for mapping between different modal data to improve the quality of multimodal fusion. In conclusion, the innovative application of efficient coding technology will promote the development of multimodal sensing algorithms and open new possibilities for autonomous driving in complex environments.
6.4. Data Enhancement
Data enhancement techniques are mainly applied to single-modal scenarios, with less consideration for multimodal situations [121,122,123,124,125,126]. Traditional data enhancement tools, such as rotation, translation, and scaling, mainly operate on a single data modality. It is difficult to capture and enhance the intrinsic connections between multiple modalities. Therefore, effectively enhancing multimodal data while preserving cross-modal correlation has become a key challenge in improving the performance of multimodal algorithms.
In response to the above challenges, some research works have attempted cross-modal data enhancement methods. For example, Wang et al. [106] proposed Point Enhancement, which is a more complex cross-modal data enhancement scheme for generating enhanced point cloud and image data pairs by adding additional mask annotations to image branches. However, this method requires additional manual labeling and is sensitive to noise, which still has some limitations. Therefore, better solutions are urgently needed to address cross-modal data enhancement’s synchronization and alignment challenges.
Reconstruction techniques may provide an effective way to solve this problem. By transforming heterogeneous multimodal data into a unified representation, the linkages between different modalities can be fully preserved. Based on this unified representation, we can perform data augmentation operations in the latent space to generate new representations, which can then be decoded into augmented multimodal data. This approach not only avoids the need for manual annotation but also effectively eliminates the influence of noise, thus achieving high quality cross-modal data enhancement. In the future, the integration of reconstruction technology and other machine learning models will provide better solutions for multimodal data enhancement and promote the development of multimodal perception algorithms.
7. Conclusions
This paper has provided a comprehensive examination of heterogeneous LiDAR-camera alignment methods in the context of multimodal 3D object detection. We explored the motivation and background of the field by presenting the existing datasets and evaluation metrics. In addition, we analyzed various datasets and evaluation metrics and compared the alignment and representation methods. Additionally, we presented a novel classification for data representation and feature alignment. We also discussed the advantages and disadvantages of different approaches. We provided an overview of recent trends, challenges, and future research directions. To overcome the deficiency of the traditional calibration method, we suggest a new alignment fusion method that maps the point cloud neighborhoods to the image neighborhoods by projection and then uses the self-attention mechanism to enhance the weights of essential relationships in the fused features.
It is important to acknowledge the limitations of this review, particularly regarding its scope. This review primarily addresses alignment methods without extensively exploring other critical aspects of object detection, such as data augmentation strategies, real-time processing capabilities, and the impact of emerging technologies like deep learning. Future reviews should consider a broader temporal scope to enhance our understanding of heterogeneous alignment methods and their applications in object detection. It would be beneficial to include discussions on the integration of novel machine learning techniques, implications of multimodal data processing on performance, and case studies from various domains, such as autonomous driving and robotics.
Author Contributions
Conceptualization, Y.W. and A.H.A.R.; methodology, Y.W.; formal analysis, Y.W.; investigation, Y.W.; writing—original draft preparation, Y.W.; writing—review and editing, A.H.A.R., F.’A.N.R. and M.K.M.R.; visualization, Y.W. and M.K.M.R.; supervision, A.H.A.R. and F.’A.N.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Faculty of Information Science and Technology Universiti Kebangsaan Malaysia, innovation grant number TT-2023-012.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable in this article.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Abd Rahman, A.H.; Sulaiman, R.; Sani, N.S.; Adam, A.; Amini, R. Evaluation of Peer Robot Communications Using Cryptoros. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 658–663. [Google Scholar] [CrossRef]
- Abd Rahman, A.H.; Ariffin, K.A.Z.; Sani, N.S.; Zamzuri, H. Pedestrian Detection Using Triple Laser Range Finders. Int. J. Electr. Comput. Eng. (IJECE) 2017, 7, 3037–3045. [Google Scholar] [CrossRef]
- Shahrim, K.A.; Abd Rahman, A.H.; Goudarzi, S. Hazardous Human Activity Recognition in Hospital Environment Using Deep Learning. IAENG Int. J. Appl. Math. 2022, 52, 748–753. [Google Scholar]
- Wang, L.; Zhang, X.; Song, Z.; Bi, J.; Zhang, G.; Wei, H.; Tang, L.; Yang, L.; Li, J.; Jia, C.; et al. Multimodal 3d Object Detection in Autonomous Driving: A Survey and Taxonomy. IEEE Trans. Intell. Veh. 2023, 8, 3781–3798. [Google Scholar] [CrossRef]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Wang, Y.; Mao, Q.; Zhu, H.; Deng, J.; Zhang, Y.; Ji, J.; Li, H.; Zhang, Y. Multimodal 3d Object Detection in Autonomous Driving: A Survey. Int. J. Comput. Vis. 2023, 131, 2122–2152. [Google Scholar] [CrossRef]
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3d Object Detection for Autonomous Driving: A Comprehensive Survey. Int. J. Comput. Vis. 2023, 131, 1909–1963. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Y.; Niu, Q. Multi-Sensor Fusion in Automated Driving: A Survey. IEEE Access 2019, 8, 2847–2868. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multimodal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1341–1360. [Google Scholar] [CrossRef]
- Cui, Y.; Chen, R.; Chu, W.; Chen, L.; Tian, D.; Li, Y.; Cao, D. Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review. IEEE Trans. Intell. Transp. Syst. 2021, 23, 722–739. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3d Object Detection Network for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Advances in Neural Information Processing Systems 30; Neural Information Processing Systems Foundation, Inc. (NeurIPS): San Diego, CA, USA, 2017. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep Learning on Point Sets for 3d Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. Clocs: Camera-Lidar Object Candidates Fusion for 3d Object Detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- He, C.; Zeng, H.; Huang, J.; Hua, X.-S.; Zhang, L. Structure Aware Single-Stage 3d Object Detection from Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A Survey on 3d Object Detection Methods for Autonomous Driving Applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, Y.; Zhang, S.; Ogai, H. Deep 3d Object Detection Networks Using Lidar Data: A Review. IEEE Sens. J. 2020, 21, 1152–1171. [Google Scholar] [CrossRef]
- Fernandes, D.; Silva, A.; Névoa, R.; Simões, C.; Gonzalez, D.; Guevara, M.; Novais, P.; Monteiro, J.; Melo-Pinto, P. Point-Cloud Based 3d Object Detection and Classification Methods for Self-Driving Applications: A Survey and Taxonomy. Inf. Fusion 2021, 68, 161–191. [Google Scholar] [CrossRef]
- Dai, D.; Chen, Z.; Bao, P.; Wang, J. A Review of 3d Object Detection for Autonomous Driving of Electric Vehicles. World Electr. Veh. J. 2021, 12, 139. [Google Scholar] [CrossRef]
- Zamanakos, G.; Tsochatzidis, L.; Amanatiadis, A.; Pratikakis, I. A Comprehensive Survey of Lidar-Based 3d Object Detection Methods with Deep Learning for Autonomous Driving. Comput. Graph. 2021, 99, 153–181. [Google Scholar] [CrossRef]
- Qian, R.; Lai, X.; Li, X. 3d Object Detection for Autonomous Driving: A Survey. Pattern Recognit. 2022, 130, 108796. [Google Scholar] [CrossRef]
- Hasan, M.; Hanawa, J.; Goto, R.; Suzuki, R.; Fukuda, H.; Kuno, Y.; Kobayashi, Y. Lidar-Based Detection, Tracking, and Property Estimation: A Contemporary Review. Neurocomputing 2022, 506, 393–405. [Google Scholar] [CrossRef]
- Ma, X.; Ouyang, W.; Simonelli, A.; Ricci, E. 3d Object Detection from Images for Autonomous Driving: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 3537–3556. [Google Scholar] [CrossRef]
- Pravallika, A.; Hashmi, M.F.; Gupta, A. Deep Learning Frontiers in 3d Object Detection: A Comprehensive Review for Autonomous Driving. IEEE Access 2024, 12, 173936–173980. [Google Scholar] [CrossRef]
- Song, Z.; Liu, L.; Jia, F.; Luo, Y.; Jia, C.; Zhang, G.; Yang, L.; Wang, L. Robustness-Aware 3d Object Detection in Autonomous Driving: A Review and Outlook. IEEE Trans. Intell. Transp. Syst. 2024, 25, 15407–15436. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, T.; Ma, Y.; Wei, L. 3d Street Object Detection from Monocular Images Using Deep Learning and Depth Information. J. Adv. Comput. Intell. Intell. Inform. 2023, 27, 198–206. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-Level Control through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Carr, P.; Sheikh, Y.; Matthews, I. Monocular Object Detection Using 3d Geometric Primitives. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. Proceedings, Part I 12 2012. [Google Scholar]
- Andriluka, M.; Roth, S.; Schiele, B. Monocular 3d Pose Estimation and Tracking by Detection. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Chen, L.; Zou, Q.; Pan, Z.; Lai, D.; Zhu, L.; Hou, Z.; Wang, J.; Cao, D. Surrounding Vehicle Detection Using an Fpga Panoramic Camera and Deep Cnns. IEEE Trans. Intell. Transp. Syst. 2019, 21, 5110–5122. [Google Scholar] [CrossRef]
- Lee, C.-H.; Lim, Y.-C.; Kwon, S.; Lee, J.-H. Stereo Vision–Based Vehicle Detection Using a Road Feature and Disparity Histogram. Opt. Eng. 2011, 50, 027004-04-23. [Google Scholar] [CrossRef]
- Kemsaram, N.; Das, A.; Dubbelman, G. A Stereo Perception Framework for Autonomous Vehicles. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020. [Google Scholar]
- Kim, K.; Woo, W. A Multi-View Camera Tracking for Modeling of Indoor Environment. In Proceedings of the Pacific-Rim Conference on Multimedia, Tokyo, Japan, 30 November–3 December 2004. [Google Scholar]
- Park, J.Y.; Chu, C.W.; Kim, H.W.; Lim, S.J.; Park, J.C.; Koo, B.K. Multi-View Camera Color Calibration Method Using Color Checker Chart. U.S. Patent 12/334,095, 18 June 2009. [Google Scholar]
- Zhou, Y.; Wan, G.; Hou, S.; Yu, L.; Wang, G.; Rui, X.; Song, S. Da4ad: End-to-End Deep Attention-Based Visual Localization for Autonomous Driving. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. Proceedings, Part XXVIII 16 2020. [Google Scholar]
- Zhang, Y.; Carballo, A.; Yang, H.; Takeda, K. Perception and Sensing for Autonomous Vehicles under Adverse Weather Conditions: A Survey. ISPRS J. Photogramm. Remote Sens. 2023, 196, 146–177. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The Kitti Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The Apolloscape Dataset for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Patil, A.; Malla, S.; Gang, H.; Chen, Y.-T. The H3d Dataset for Full-Surround 3d Multi-Object Detection and Tracking in Crowded Urban Scenes. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d Proposal Generation and Object Detection from View Aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Meyer, G.P.; Charland, J.; Hegde, D.; Laddha, A.; Vallespi-Gonzalez, C. Sensor Fusion for Joint 3d Object Detection and Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Geiger, A.; Lenzp, U.R. Are We Ready for Autonomous Driving? The Kitti Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Visionand Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Choi, Y.; Kim, N.; Hwang, S.; Park, K.; Yoon, J.S.; An, K.; Kweon, I.S. Kaist Multi-Spectral Day/Night Data Set for Autonomous and Assisted Driving. IEEE Trans. Intell. Transp. Syst. 2018, 19, 934–948. [Google Scholar] [CrossRef]
- Li, G.; Jiao, Y.; Knoop, V.L.; Calvert, S.C.; Van Lint, J.W.C. Large Car-Following Data Based on Lyft Level-5 Open Dataset: Following Autonomous Vehicles Vs. Human-Driven Vehicles. In Proceedings of the 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2023. [Google Scholar]
- Chang, M.-F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3d Tracking and Forecasting with Rich Maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Pham, Q.-H.; Sevestre, P.; Pahwa, R.S.; Zhan, H.; Pang, C.H.; Chen, Y.; Mustafa, A.; Chandrasekhar, V.; Lin, J. A* 3d Dataset: Towards Autonomous Driving in Challenging Environments. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar]
- Xiao, P.; Shao, Z.; Hao, S.; Zhang, Z.; Chai, X.; Jiao, J.; Li, Z.; Wu, J.; Sun, K.; Jiang, K. Pandaset: Advanced Sensor Suite Dataset for Autonomous Driving. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021. [Google Scholar]
- Wang, Z.; Ding, S.; Li, Y.; Fenn, J.; Roychowdhury, S.; Wallin, A.; Martin, L.; Ryvola, S.; Sapiro, G.; Qiu, Q. Cirrus: A Long-Range Bi-Pattern Lidar Dataset. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Mao, J.; Niu, M.; Jiang, C.; Liang, H.; Chen, J.; Liang, X.; Li, Y.; Ye, C.; Zhang, W.; Li, Z. One Million Scenes for Autonomous Driving: Once Dataset. arXiv 2021, arXiv:2106.11037. [Google Scholar]
- Ma, J.; Wang, X.; Duan, H.; Wang, R. 3d Object Detection Based on the Fusion of Projected Point Cloud and Image Features. In Proceedings of the 2022 6th International Conference on Electronic Information Technology and Computer Engineering, Xiamen, China, 21–23 October 2022. [Google Scholar]
- Xu, X.; Zhang, L.; Yang, J.; Cao, C.; Tan, Z.; Luo, M. Object Detection Based on Fusion of Sparse Point Cloud and Image Information. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Ouyang, Z.; Cui, J.; Dong, X.; Li, Y.; Niu, J. Saccadefork: A Lightweight Multi-Sensor Fusion-Based Target Detector. Inf. Fusion 2022, 77, 172–183. [Google Scholar] [CrossRef]
- Hong, D.-S.; Chen, H.-H.; Hsiao, P.-Y.; Fu, L.-C.; Siao, S.-M. Crossfusion Net: Deep 3d Object Detection Based on Rgb Images and Point Clouds in Autonomous Driving. Image Vis. Comput. 2020, 100, 103955. [Google Scholar] [CrossRef]
- Rjoub, G.; Wahab, O.A.; Bentahar, J.; Bataineh, A.S. Improving Autonomous Vehicles Safety in Snow Weather Using Federated Yolo Cnn Learning. In Proceedings of the International Conference on Mobile Web and Intelligent Information Systems, Virtual Event, 23–25 August 2021. [Google Scholar]
- Liu, L.; He, J.; Ren, K.; Xiao, Z.; Hou, Y. A Lidar–Camera Fusion 3d Object Detection Algorithm. Information 2022, 13, 169. [Google Scholar] [CrossRef]
- Liu, Q.; Li, X.; Zhang, X.; Tan, X.; Shi, B. Multi-View Joint Learning and Bev Feature-Fusion Network for 3d Object Detection. Appl. Sci. 2023, 13, 5274. [Google Scholar] [CrossRef]
- Yong, Z.; Xiaoxia, Z.; Nana, D. Research on 3d Object Detection Method Based on Convolutional Attention Mechanism. J. Phys. Conf. Ser. 2021, 1848, 012097. [Google Scholar] [CrossRef]
- Liu, Z.; Cheng, J.; Fan, J.; Lin, S.; Wang, Y.; Zhao, X. Multimodal Fusion Based on Depth Adaptive Mechanism for 3d Object Detection. IEEE Trans. Multimed. 2023. [Google Scholar] [CrossRef]
- Zhu, A.; Xiao, Y.; Liu, C.; Cao, Z. Robust Lidar-Camera Alignment with Modality Adapted Local-to-Global Representation. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 59–73. [Google Scholar] [CrossRef]
- Wu, Y.; Zhu, M.; Liang, J. Psnet: Lidar and Camera Registration Using Parallel Subnetworks. IEEE Access 2022, 10, 70553–70561. [Google Scholar] [CrossRef]
- Wang, K.; Zhou, T.; Zhang, Z.; Chen, T.; Chen, J. Pvf-Dectnet: Multimodal 3d Detection Network Based on Perspective-Voxel Fusion. Eng. Appl. Artif. Intell. 2023, 120, 105951. [Google Scholar] [CrossRef]
- Carranza-García, M.; Galán-Sales, F.J.; Luna-Romera, J.M.; Riquelme, J.C. Object Detection Using Depth Completion and Camera-Lidar Fusion for Autonomous Driving. Integr. Comput.-Aided Eng. 2022, 29, 241–258. [Google Scholar] [CrossRef]
- Chen, Z.; Li, Z.; Zhang, S.; Fang, L.; Jiang, Q.; Zhao, F.; Zhou, B.; Zhao, H. Autoalign: Pixel-Instance Feature Aggregation for Multi-Modal 3d Object Detection. arXiv 2022, arXiv:2201.06493. [Google Scholar]
- Song, Z.; Jia, C.; Yang, L.; Wei, H.; Liu, L. Graphalign++: An Accurate Feature Alignment by Graph Matching for Multimodal 3d Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 2619–2632. [Google Scholar] [CrossRef]
- Song, Z.; Wei, H.; Bai, L.; Yang, L.; Jia, C. Graphalign: Enhancing Accurate Feature Alignment by Graph Matching for Multimodal 3d Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023. [Google Scholar]
- Song, Z.; Yang, L.; Xu, S.; Liu, L.; Xu, D.; Jia, C.; Jia, F.; Wang, L. Graphbev: Towards Robust Bev Feature Alignment for Multimodal 3d Object Detection. arXiv 2024, arXiv:2403.11848. [Google Scholar]
- Chen, C.; Fragonara, L.Z.; Tsourdos, A. Roifusion: 3d Object Detection from Lidar and Vision. IEEE Access 2021, 9, 51710–51721. [Google Scholar] [CrossRef]
- Rishav, R.; Battrawy, R.; Schuster, R.; Wasenmüller, O.; Stricker, D. Deeplidarflow: A Deep Learning Architecture for Scene Flow Estimation Using Monocular Camera and Sparse Lidar. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. Fast-Clocs: Fast Camera-Lidar Object Candidates Fusion for 3d Object Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022. [Google Scholar]
- Melotti, G.; Premebida, C.; Gonçalves, N. Multimodal Deep-Learning for Object Recognition Combining Camera and Lidar Data. In Proceedings of the 2020 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Ponta Delgada, Portugal, 15–17 April 2020. [Google Scholar]
- Dou, J.; Xue, J.; Fang, J. Seg-Voxelnet for 3d Vehicle Detection from Rgb and Lidar Data. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Ku, J.; Pon, A.D.; Walsh, S.; Waslander, S.L. Improving 3d Object Detection for Pedestrians with Virtual Multi-View Synthesis Orientation Estimation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019. [Google Scholar]
- Zhang, H.; Yang, D.; Yurtsever, E.; Redmill, K.A.; Özgüner, Ü. Faraway-Frustum: Dealing with Lidar Sparsity for 3d Object Detection Using Fusion. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021. [Google Scholar]
- Wang, Z.; Jia, K. Frustum Convnet: Sliding Frustums to Aggregate Local Point-Wise Features for Amodal 3d Object Detection. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019. [Google Scholar]
- Paigwar, A.; Sierra-Gonzalez, D.; Erkent, Ö.; Laugier, C. Frustum-Pointpillars: A Multi-Stage Approach for 3d Object Detection Using Rgb Camera and Lidar. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum Pointnets for 3d Object Detection from Rgb-D Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Shin, K.; Kwon, Y.P.; Tomizuka, M. Roarnet: A Robust 3d Object Detection Based on Region Approximation Refinement. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep Sensor Fusion for 3d Bounding Box Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, X.; Wang, L.; Zhang, G.; Lan, T.; Zhang, H.; Zhao, L.; Li, J.; Zhu, L.; Liu, H. Ri-Fusion: 3d Object Detection Using Enhanced Point Features with Range-Image Fusion for Autonomous Driving. IEEE Trans. Instrum. Meas. 2022, 72, 1–13. [Google Scholar] [CrossRef]
- Zhang, Z.; Liang, Z.; Zhang, M.; Zhao, X.; Li, H.; Yang, M.; Tan, W.; Pu, S. Rangelvdet: Boosting 3d Object Detection in Lidar with Range Image and Rgb Image. IEEE Sens. J. 2021, 22, 1391–1403. [Google Scholar] [CrossRef]
- Yin, T.; Zhou, X.; Krähenbühl, P. Multimodal Virtual Point 3d Detection. Adv. Neural Inf. Process. Syst. 2021, 34, 16494–16507. [Google Scholar]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing Point Features with Image Semantics for 3d Object Detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. Proceedings, Part XV 16 2020. [Google Scholar]
- Zhang, Z.; Shen, Y.; Li, H.; Zhao, X.; Yang, M.; Tan, W.; Pu, S.; Mao, H. Maff-Net: Filter False Positive for 3d Vehicle Detection with Multimodal Adaptive Feature Fusion. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022. [Google Scholar]
- Fei, J.; Chen, W.; Heidenreich, P.; Wirges, S.; Stiller, C. Semanticvoxels: Sequential Fusion for 3d Pedestrian Detection Using Lidar Point Cloud and Semantic Segmentation. In Proceedings of the 2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Karlsruhe, Germany, 14–16 September 2020. [Google Scholar]
- Wang, G.; Tian, B.; Zhang, Y.; Chen, L.; Cao, D.; Wu, J. Multi-View Adaptive Fusion Network for 3d Object Detection. arXiv 2020, arXiv:2011.00652. [Google Scholar]
- Xie, L.; Xiang, C.; Yu, Z.; Xu, G.; Yang, Z.; Cai, D.; He, X. Pi-Rcnn: An Efficient Multi-Sensor 3d Object Detector with Point-Based Attentive Cont-Conv Fusion Module. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, New York, USA, 7–12 February 2020. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential Fusion for 3d Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-Task Multi-Sensor Fusion for 3d Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Simon, M.; Amende, K.; Kraus, A.; Honer, J.; Samann, T.; Kaulbersch, H.; Milz, S.; Michael Gross, H. Complexer-Yolo: Real-Time 3d Object Detection and Tracking on Semantic Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Sindagi, V.A.; Zhou, Y.; Tuzel, O. Mvx-Net: Multimodal Voxelnet for 3d Object Detection. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Wang, Z.; Zhao, Z.; Jin, Z.; Che, Z.; Tang, J.; Shen, C.; Peng, Y. Multi-Stage Fusion for Multi-Class 3d Lidar Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Chen, X.; Zhang, T.; Wang, Y.; Wang, Y.; Zhao, H. Futr3d: A Unified Sensor Fusion Framework for 3d Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; Tai, C.-L. Transfusion: Robust Lidar-Camera Fusion for 3d Object Detection with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zhang, Y.; Chen, J.; Huang, D. Cat-Det: Contrastively Augmented Transformer for Multimodal 3d Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V. Deepfusion: Lidar-Camera Deep Fusion for Multimodal 3d Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Chen, Z.; Li, Z.; Zhang, S.; Fang, L.; Jiang, Q.; Zhao, F. Deformable Feature Aggregation for Dynamic Multimodal 3d Object Detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Li, Y.; Qi, X.; Chen, Y.; Wang, L.; Li, Z.; Sun, J.; Jia, J. Voxel Field Fusion for 3d Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Wang, C.; Ma, C.; Zhu, M.; Yang, X. Pointaugmenting: Cross-Modal Augmentation for 3d Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, Z.; Zhan, W.; Tomizuka, M. Fusing Bird’s Eye View Lidar Point Cloud and Front View Camera Image for 3d Object Detection. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018. [Google Scholar]
- Zhu, M.; Ma, C.; Ji, P.; Yang, X. Cross-Modality 3d Object Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021. [Google Scholar]
- Xu, S.; Zhou, D.; Fang, J.; Yin, J.; Bin, Z.; Zhang, L. Fusionpainting: Multimodal Fusion with Adaptive Attention for 3d Object Detection. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021. [Google Scholar]
- Zhu, H.; Deng, J.; Zhang, Y.; Ji, J.; Mao, Q.; Li, H.; Zhang, Y. Vpfnet: Improving 3d Object Detection with Virtual Point Based Lidar and Stereo Data Fusion. IEEE Trans. Multimed. 2022, 25, 5291–5304. [Google Scholar] [CrossRef]
- Chen, Y.; Li, Y.; Zhang, X.; Sun, J.; Jia, J. Focal Sparse Convolutional Networks for 3d Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Yang, H.; Liu, Z.; Wu, X.; Wang, W.; Qian, W.; He, X.; Cai, D. Graph R-Cnn: Towards Accurate 3d Object Detection with Semantic-Decorated Local Graph. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Wu, X.; Peng, L.; Yang, H.; Xie, L.; Huang, C.; Deng, C.; Liu, H.; Cai, D. Sparse Fuse Dense: Towards High Quality 3d Detection with Depth Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Liang, T.; Xie, H.; Yu, K.; Xia, Z.; Lin, Z.; Wang, Y.; Tang, T.; Wang, B.; Tang, Z. Bevfusion: A Simple and Robust Lidar-Camera Fusion Framework. Adv. Neural Inf. Process. Syst. 2022, 35, 10421–10434. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.L.; Han, S. Bevfusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-Cvf: Generating Joint Camera and Lidar Features Using Cross-View Spatial Feature Fusion for 3d Object Detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. Proceedings, Part XXVII 16 2020. [Google Scholar]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep Continuous Fusion for Multi-Sensor 3d Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lu, H.; Chen, X.; Zhang, G.; Zhou, Q.; Ma, Y.; Zhao, Y. Scanet: Spatial-Channel Attention Network for 3d Object Detection. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Deng, J.; Czarnecki, K. Mlod: A Multi-View 3d Object Detection Based on Robust Feature Fusion Method. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019. [Google Scholar]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Qiao, Y.; Dai, J. Bevformer: Learning Bird’s-Eye-View Representation from Multi-Camera Images Via Spatiotemporal Transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time Series Data Augmentation for Deep Learning: A Survey. arXiv 2020, arXiv:2002.12478. [Google Scholar]
- Lu, W.; Zhao, D.; Premebida, C.; Zhang, L.; Zhao, W.; Tian, D. Improving 3d Vulnerable Road User Detection with Point Augmentation. IEEE Trans. Intell. Veh. 2023, 8, 3489–3505. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Zoph, B.; Cubuk, E.D.; Ghiasi, G.; Lin, T.-Y.; Shlens, J.; Le, Q.V. Learning Data Augmentation Strategies for Object Detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. Proceedings, Part XXVII 16 2020. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised Data Augmentation for Consistency Training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- Zhao, T.; Liu, Y.; Neves, L.; Woodford, O.; Jiang, M.; Shah, N. Data Augmentation for Graph Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021. [Google Scholar]
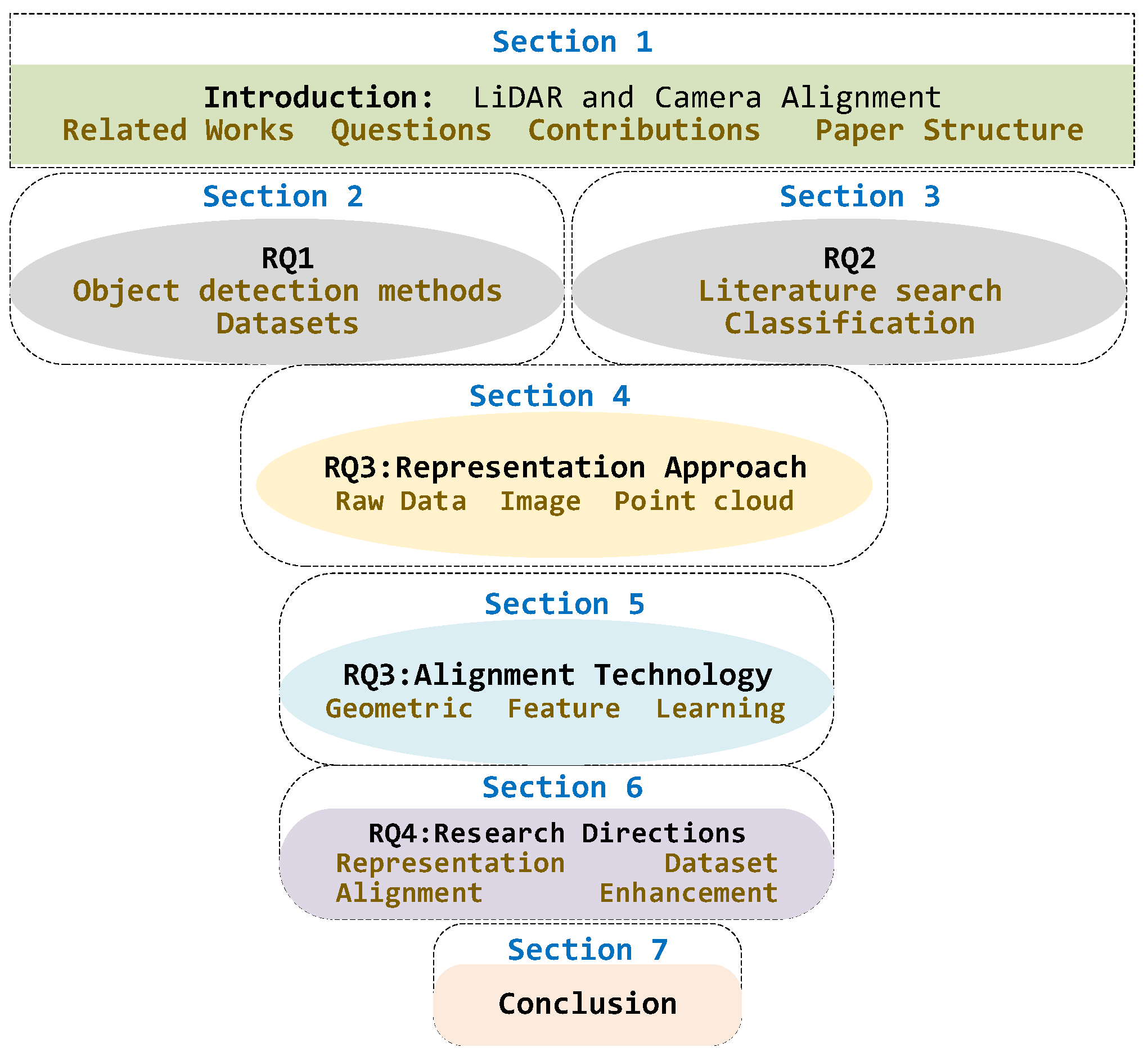
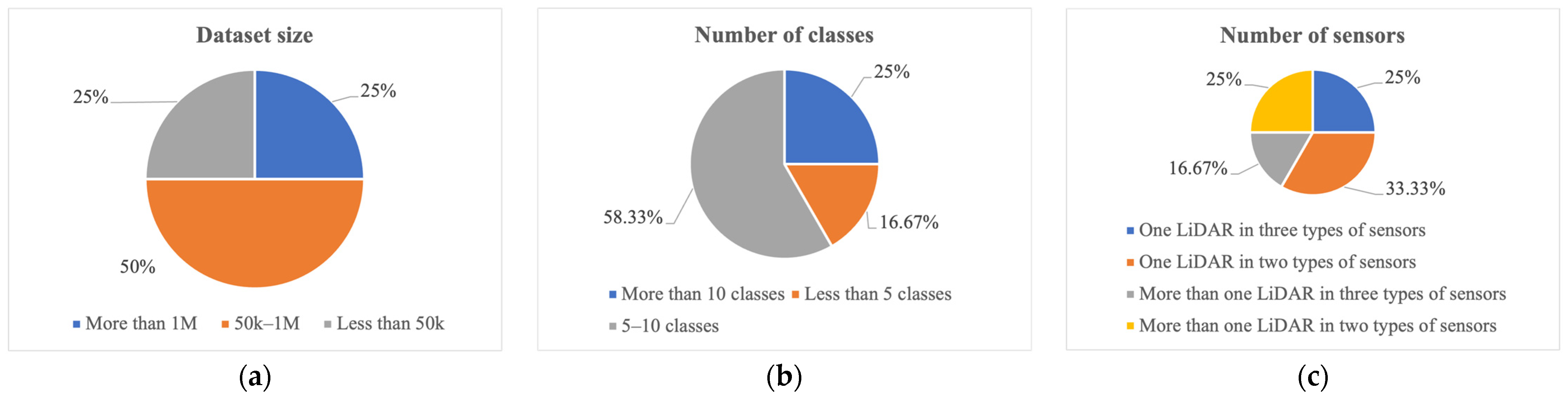
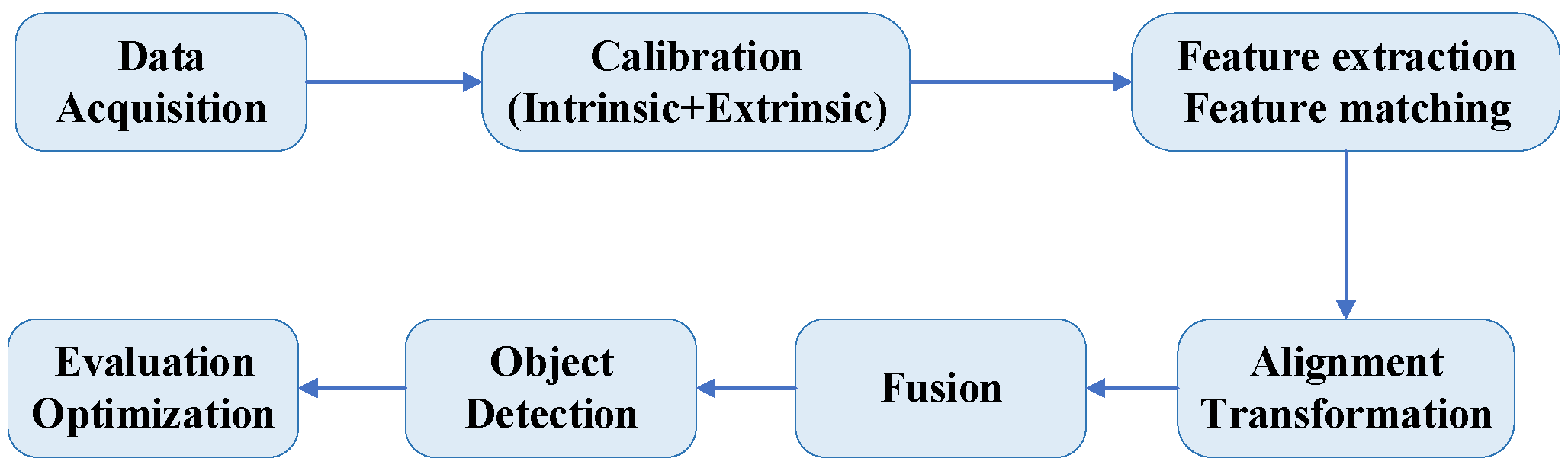
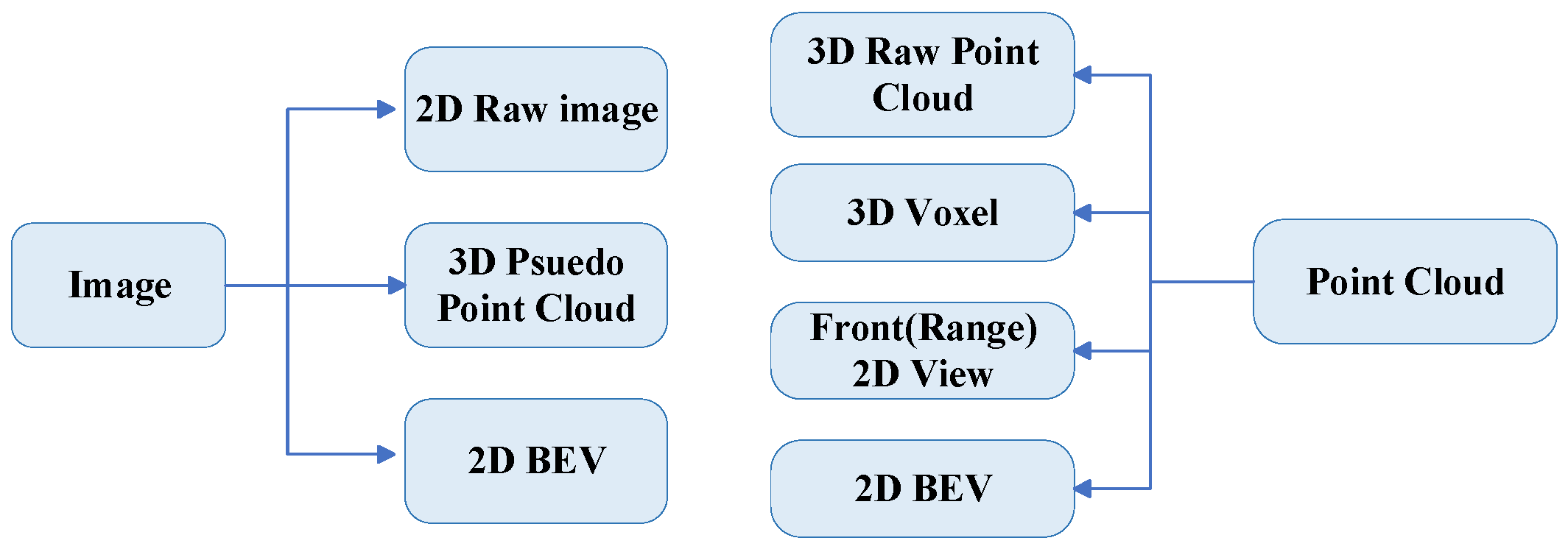
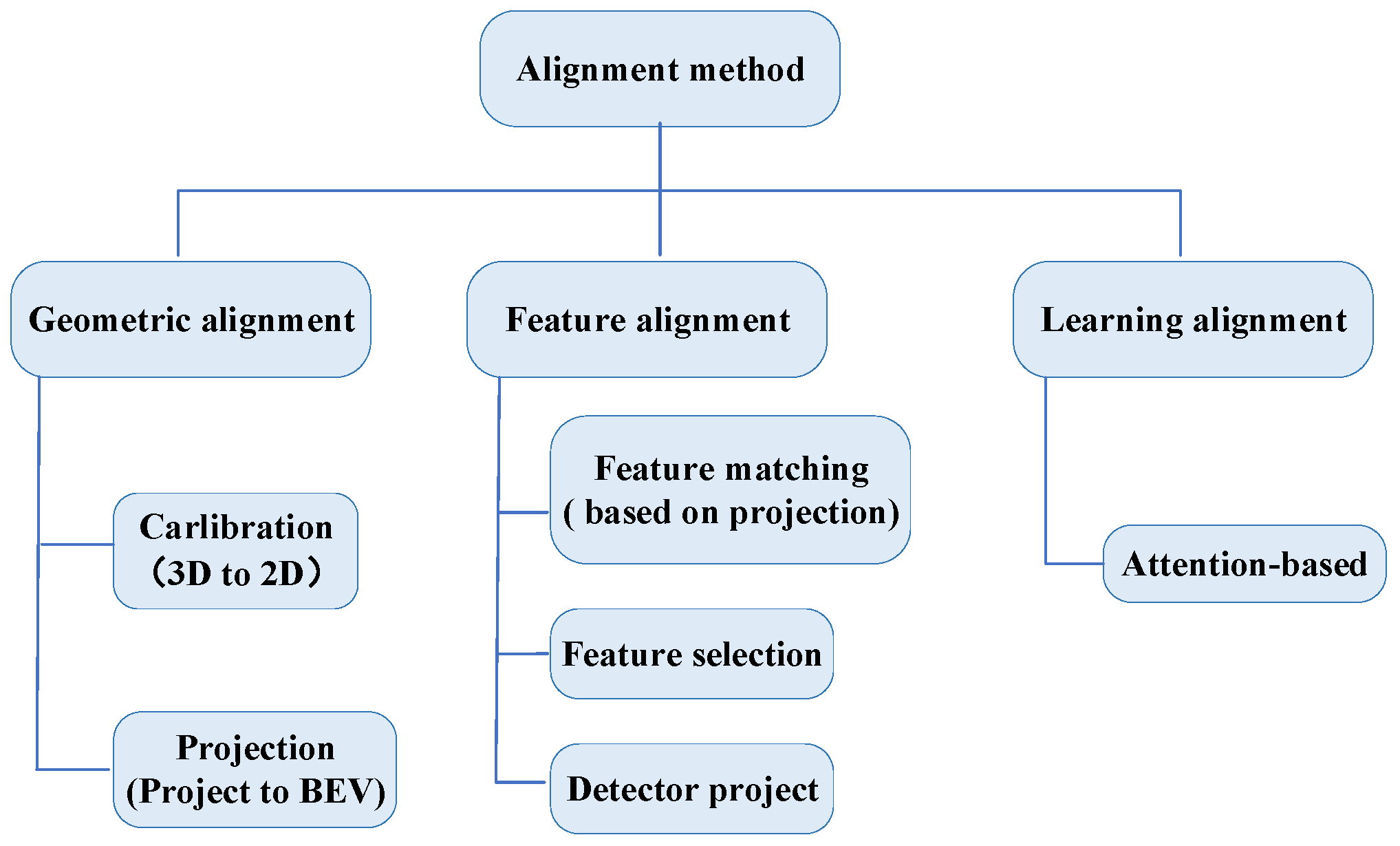
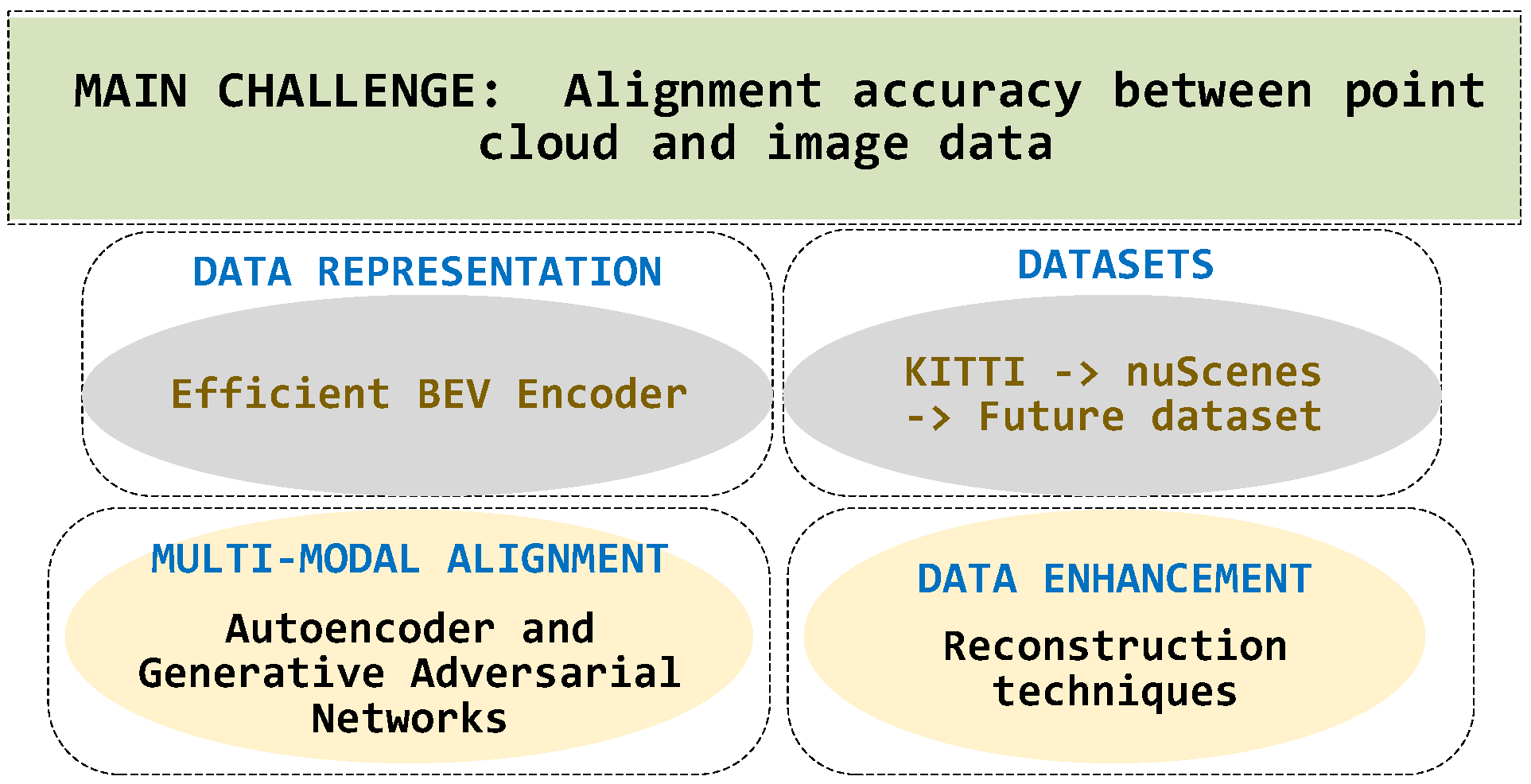
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).