
Voice Analysis in Dogs with Deep Learning: Development of a Fully Automatic Voice Analysis System for Bioacoustics Studies


Abstract
1. Introduction
2. Materials and Methods (Background)
2.1. Dataset
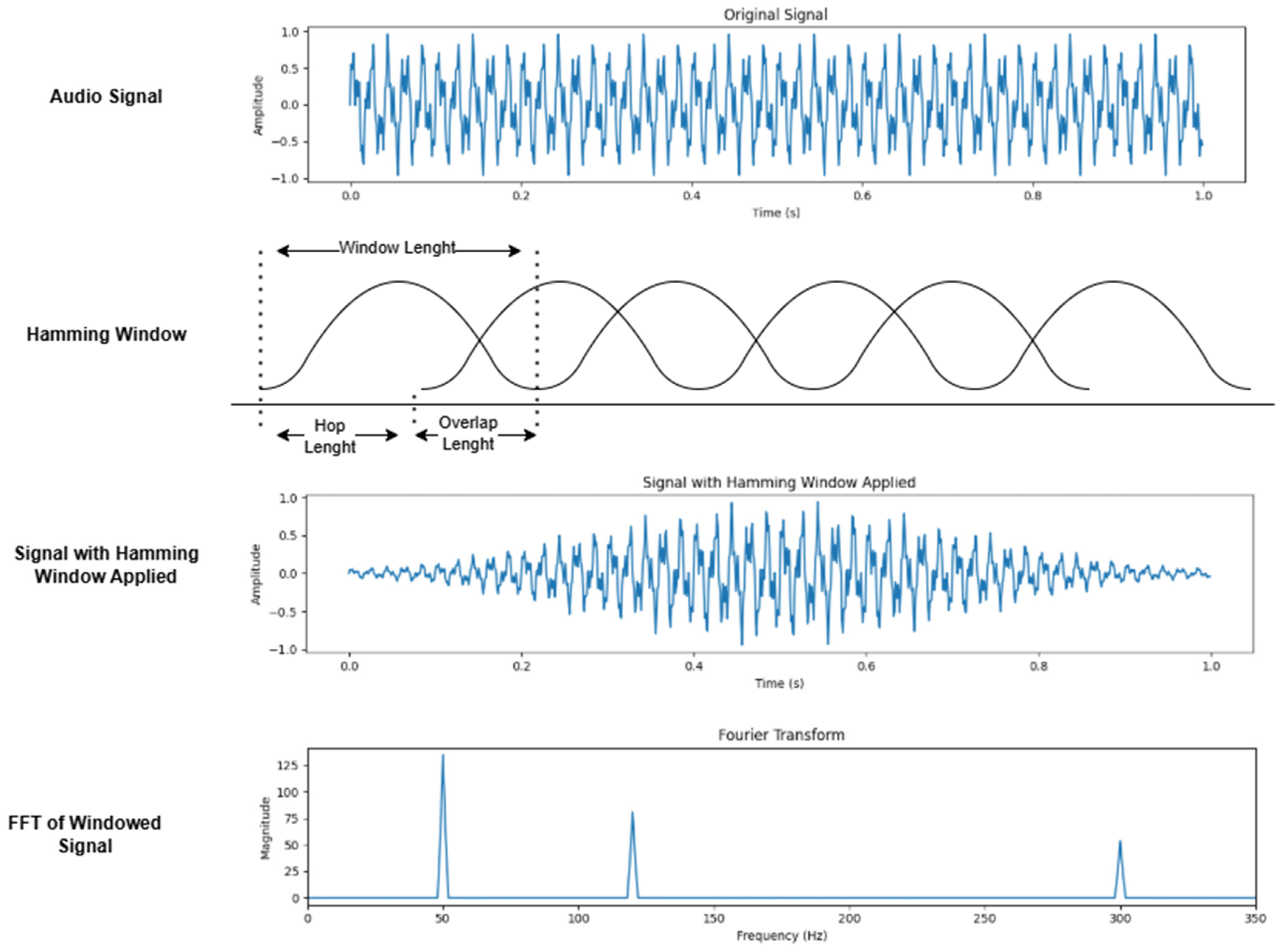
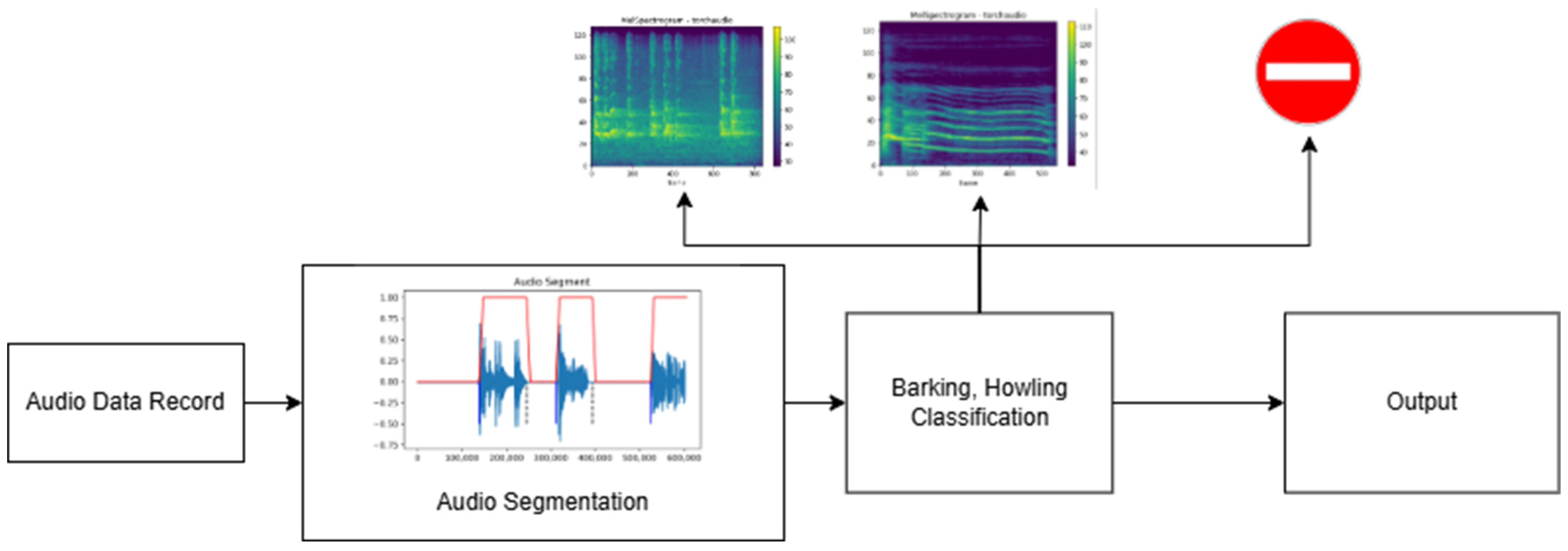
2.2. Preprocessing (Audio Segmentation)
- : represents the root mean square energy, which indicates the average power of the sound signal.
- denotes the sample of the sound signal. These samples represent the varying values of the signal over time.
- : indicates the number of samples within a frame. This represents the small portions of the sound signal being analyzed.
- : represents the index of the frames.
2.3. Feature Extraction
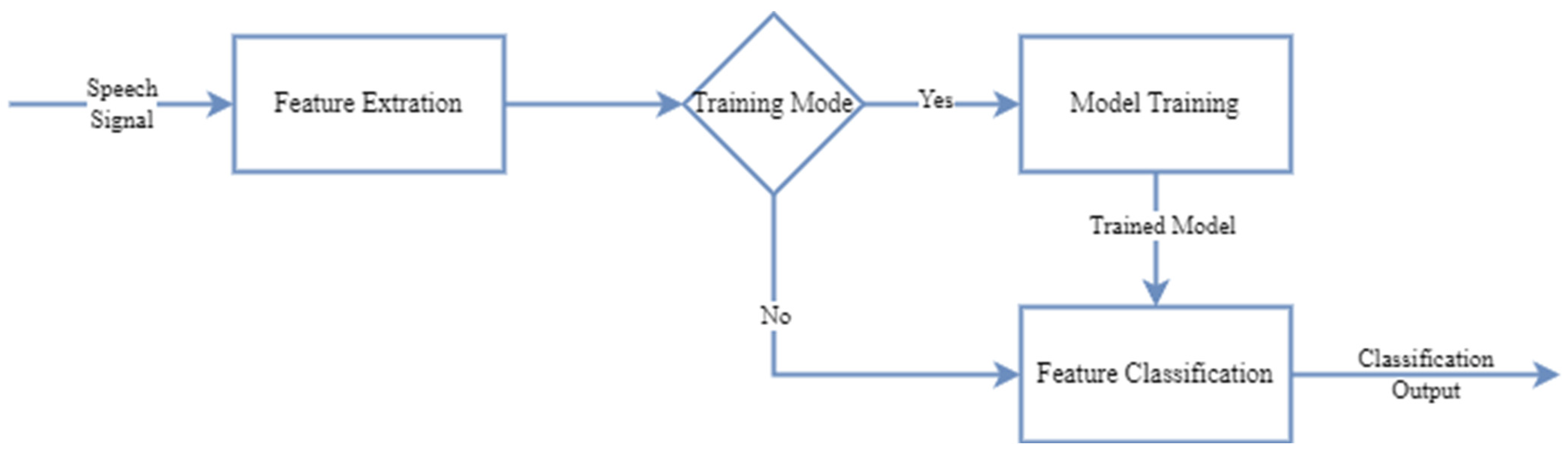
2.4. Classification
2.4.1. Convolutional Neural Network (CNN)
2.4.2. Classification Systems
2.4.3. Model Training
2.4.4. Classification Evaluations Metrics
- TP: correctly classifies barking minutes.
- TN: correctly classifies howling minutes.
- FP: howling minutes classified as barking.
- FN: barking minutes classified as howling.
- Precision: proportion of correctly identified positive samples among predicted positives.
- Recall: proportion of actual positive samples correctly identified.
- F1-Score: harmonic mean of precision and recall.
- Accuracy: proportion of correctly classified instances overall.
- Macro Average: arithmetic mean of metric values (precision, recall, or F1-score) calculated independently for each class.
- Weighted Average: the average of metric values weighted by the number of samples (support) in each class.
2.5. Full Automatically Vocalization Analysis System
3. Experimental Results and Discussion
- SVMs: exhibited consistent performance across all feature sets, with weighted average F1-scores around 0.81 (Mel), 0.86 (MFCCs), and 0.85 (LFCCs). Although robust, SVMs did not surpass the top-performing CNN configurations, which reached or exceeded 0.90 on some feature sets.
- KNNs: demonstrated comparatively weaker performance, with weighted average F1-scores of 0.64 (Mel) and around 0.76 (MFCCs, LFCCs). This method struggled to match the effectiveness of both the CNN-based models and the other classical approaches, indicating that KNNs may be less suited to the given data and feature distributions.
- Naive Bayes: achieved competitive results, particularly with MFCC and LFCC features, reaching a weighted average F1-score of 0.87. Although Naive Bayes approached the performance of some CNN models, it still fell short of the best CNN scores (e.g., 0.90+), suggesting that deep learning architectures better capture the complexity of the underlying representations.
- Random Forest: showed similar trends to Naive Bayes, achieving weighted average F1-scores around 0.86–0.87 with different feature sets. While Random Forest can leverage ensemble learning to yield strong results, it did not consistently outperform the strongest CNN configurations.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Anders, F.; Hlawitschka, M.; Fuchs, M. Automatic classification of infant vocalization sequences with convolutional neural networks. Speech Commun. 2020, 119, 36–45. [Google Scholar] [CrossRef]
- Valente, D.; Wang, H.; Andrews, P.; Mitra, P.P.; Saar, S.; Tchernichovski, O.; Golani, I.; Benjamini, Y. Characterizing animal behavior through audio and video signal processing. IEEE Multimed. 2007, 14, 32–41. [Google Scholar] [CrossRef]
- Teixeira, D.; Maron, M.; van Rensburg, B.J. Bioacoustic monitoring of animal vocal behavior for conservation. Conserv. Sci. Pract. 2019, 1, e72. [Google Scholar] [CrossRef]
- Bain, M.; Nagrani, A.; Schofield, D.; Berdugo, S.; Bessa, J.; Owen, J.; Hockings, K.J.; Matsuzawa, T.; Hayashi, M.; Biro, D. Automated audiovisual behavior recognition in wild primates. Sci. Adv. 2021, 7, eabi4883. [Google Scholar] [CrossRef]
- Siegford, J.M.; Steibel, J.P.; Han, J.; Benjamin, M.; Brown-Brandl, T.; Dórea, J.R.; Morris, D.; Norton, T.; Psota, E.; Rosa, G.J. The quest to develop automated systems for monitoring animal behavior. Appl. Anim. Behav. Sci. 2023, 265, 106000. [Google Scholar] [CrossRef]
- Penar, W.; Magiera, A.; Klocek, C. Applications of bioacoustics in animal ecology. Ecol. Complex. 2020, 43, 100847. [Google Scholar] [CrossRef]
- Ovaskainen, O.; Moliterno de Camargo, U.; Somervuo, P. Animal Sound Identifier (ASI): Software for automated identification of vocal animals. Ecol. Lett. 2018, 21, 1244–1254. [Google Scholar] [CrossRef] [PubMed]
- Nolasco, I.; Singh, S.; Morfi, V.; Lostanlen, V.; Strandburg-Peshkin, A.; Vidaña-Vila, E.; Gill, L.; Pamuła, H.; Whitehead, H.; Kiskin, I. Learning to detect an animal sound from five examples. Ecol. Inform. 2023, 77, 102258. [Google Scholar] [CrossRef]
- Mcloughlin, M.P.; Stewart, R.; McElligott, A.G. Automated bioacoustics: Methods in ecology and conservation and their potential for animal welfare monitoring. J. R. Soc. Interface 2019, 16, 20190225. [Google Scholar] [CrossRef] [PubMed]
- Tami, G.; Gallagher, A. Description of the behaviour of domestic dog (Canis familiaris) by experienced and inexperienced people. Appl. Anim. Behav. Sci. 2009, 120, 159–169. [Google Scholar] [CrossRef]
- Pongrácz, P.; Molnár, C.; Miklosi, A. Acoustic parameters of dog barks carry emotional information for humans. Appl. Anim. Behav. Sci. 2006, 100, 228–240. [Google Scholar] [CrossRef]
- Pongrácz, P.; Molnár, C.; Miklósi, Á. Barking in family dogs: An ethological approach. Vet. J. 2010, 183, 141–147. [Google Scholar] [CrossRef]
- Yeon, S.C. The vocal communication of canines. J. Vet. Behav. 2007, 2, 141–144. [Google Scholar] [CrossRef]
- Kakabutr, P.; Chen, K.S.; Wangvisavawit, V.; Padungweang, P.; Rojanapornpun, O. Dog cough sound classification using artificial neural network and the selected relevant features from discrete wavelet transform. In Proceedings of the 2017 9th International Conference on Knowledge and Smart Technology (KST), Chonburi, Thailand, 1–4 February 2017; pp. 121–125. [Google Scholar]
- Yin, S.; McCowan, B. Barking in domestic dogs: Context specificity and individual identification. Anim. Behav. 2004, 68, 343–355. [Google Scholar] [CrossRef]
- Taylor, A.M.; Reby, D.; McComb, K. Context-related variation in the vocal growling behaviour of the domestic dog (Canis familiaris). Ethology 2009, 115, 905–915. [Google Scholar] [CrossRef]
- Yeo, C.Y.; Al-Haddad, S.; Ng, C.K. Dog voice identification (ID) for detection system. In Proceedings of the 2012 Second International Conference on Digital Information Processing and Communications (ICDIPC), Klaipeda, Lithuania, 10–12 July 2012; pp. 120–123. [Google Scholar]
- Tani, Y.; Yokota, Y.; Yayota, M.; Ohtani, S. Automatic recognition and classification of cattle chewing activity by an acoustic monitoring method with a single-axis acceleration sensor. Comput. Electron. Agric. 2013, 92, 54–65. [Google Scholar] [CrossRef]
- Bishop, J.C.; Falzon, G.; Trotter, M.; Kwan, P.; Meek, P.D. Livestock vocalisation classification in farm soundscapes. Comput. Electron. Agric. 2019, 162, 531–542. [Google Scholar] [CrossRef]
- Nunes, L.; Ampatzidis, Y.; Costa, L.; Wallau, M. Horse foraging behavior detection using sound recognition techniques and artificial intelligence. Comput. Electron. Agric. 2021, 183, 106080. [Google Scholar] [CrossRef]
- Tsai, M.-F.; Huang, J.-Y. Sentiment analysis of pets using deep learning technologies in artificial intelligence of things system. Soft Comput. 2021, 25, 13741–13752. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Abdel-Hamid, O.; Mohamed, A.-r.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Palanisamy, K.; Singhania, D.; Yao, A. Rethinking CNN models for audio classification. arXiv 2020, arXiv:2007.11154. [Google Scholar]
- Dewi, S.P.; Prasasti, A.L.; Irawan, B. The study of baby crying analysis using MFCC and LFCC in different classification methods. In Proceedings of the 2019 IEEE International Conference on Signals and Systems (ICSigSys), Bandung, Indonesia, 16–18 July 2019; pp. 18–23. [Google Scholar]
- Noda, J.J.; Travieso-González, C.M.; Sánchez-Rodríguez, D.; Alonso-Hernández, J.B. Acoustic classification of singing insects based on MFCC/LFCC fusion. Appl. Sci. 2019, 9, 4097. [Google Scholar] [CrossRef]
- Panagiotakis, C.; Tziritas, G. A speech/music discriminator based on RMS and zero-crossings. IEEE Trans. Multimed. 2005, 7, 155–166. [Google Scholar] [CrossRef]
- Sharma, G.; Umapathy, K.; Krishnan, S. Trends in audio signal feature extraction methods. Appl. Acoust. 2020, 158, 107020. [Google Scholar] [CrossRef]
- Yang, C.; Hu, S.; Tang, L.; Deng, R.; Zhou, G.; Yi, J.; Chen, A. A barking emotion recognition method based on Mamba and Synchrosqueezing Short-Time Fourier Transform. Expert Syst. Appl. 2024, 258, 125213. [Google Scholar] [CrossRef]
- Hantke, S.; Cummins, N.; Schuller, B. What is my dog trying to tell me? The automatic recognition of the context and perceived emotion of dog barks. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5134–5138. [Google Scholar]
- Gómez-Armenta, J.R.; Pérez-Espinosa, H.; Fernández-Zepeda, J.A.; Reyes-Meza, V. Automatic classification of dog barking using deep learning. Behav. Process. 2024, 218, 105028. [Google Scholar] [CrossRef]
- Salah, E.; Amine, K.; Redouane, K.; Fares, K. A Fourier transform based audio watermarking algorithm. Appl. Acoust. 2021, 172, 107652. [Google Scholar] [CrossRef]
- Elbir, A.; İlhan, H.O.; Serbes, G.; Aydın, N. Short Time Fourier Transform based music genre classification. In Proceedings of the 2018 Electric Electronics, Computer Science, Biomedical Engineerings’ Meeting (EBBT), Istanbul, Turkey, 18–19 April 2018; pp. 1–4. [Google Scholar]
- Er, M.B. A novel approach for classification of speech emotions based on deep and acoustic features. IEEE Access 2020, 8, 221640–221653. [Google Scholar] [CrossRef]
- Sahidullah, M.; Saha, G. A novel windowing technique for efficient computation of MFCC for speaker recognition. IEEE Signal Process. Lett. 2012, 20, 149–152. [Google Scholar] [CrossRef]
- Jeon, H.; Jung, Y.; Lee, S.; Jung, Y. Area-efficient short-time fourier transform processor for time–frequency analysis of non-stationary signals. Appl. Sci. 2020, 10, 7208. [Google Scholar] [CrossRef]
- Chapaneri, S.V. Spoken digits recognition using weighted MFCC and improved features for dynamic time warping. Int. J. Comput. Appl. 2012, 40, 6–12. [Google Scholar]
- Stevens, S.S.; Volkmann, J.; Newman, E.B. A scale for the measurement of the psychological magnitude pitch. J. Acoust. Soc. Am. 1937, 8, 185–190. [Google Scholar] [CrossRef]
- Deng, M.; Meng, T.; Cao, J.; Wang, S.; Zhang, J.; Fan, H. Heart sound classification based on improved MFCC features and convolutional recurrent neural networks. Neural Netw. 2020, 130, 22–32. [Google Scholar] [CrossRef]
- Jung, D.-H.; Kim, N.Y.; Moon, S.H.; Jhin, C.; Kim, H.-J.; Yang, J.-S.; Kim, H.S.; Lee, T.S.; Lee, J.Y.; Park, S.H. Deep learning-based cattle vocal classification model and real-time livestock monitoring system with noise filtering. Animals 2021, 11, 357. [Google Scholar] [CrossRef] [PubMed]
- Lalitha, S.; Geyasruti, D.; Narayanan, R.; Shravani, M. Emotion detection using MFCC and cepstrum features. Procedia Comput. Sci. 2015, 70, 29–35. [Google Scholar] [CrossRef]
- Bhatia, S.; Devi, A.; Alsuwailem, R.I.; Mashat, A. Convolutional Neural Network Based Real Time Arabic Speech Recognition to Arabic Braille for Hearing and Visually Impaired. Front. Public Health 2022, 10, 898355. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bark | Howl | Macro Avg | Weighted Avg | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Feature | Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support | Accuracy | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| AlexNet | Mel Spectrogram | 0.83 | 0.83 | 0.83 | 12 | 0.78 | 0.78 | 0.78 | 9 | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 |
| AlexNet | MFCC | 0.92 | 0.92 | 0.92 | 12 | 0.89 | 0.89 | 0.89 | 9 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 |
| AlexNet | LFCC | 0.90 | 0.75 | 0.82 | 12 | 0.73 | 0.89 | 0.80 | 9 | 0.81 | 0.81 | 0.82 | 0.81 | 0.83 | 0.81 | 0.81 |
| DenseNet | Mel Spectrogram | 0.92 | 0.92 | 0.92 | 12 | 0.89 | 0.89 | 0.89 | 9 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 |
| DenseNet | MFCC | 0.91 | 0.83 | 0.87 | 12 | 0.89 | 0.89 | 0.89 | 9 | 0.86 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
| DenseNet | LFCC | 0.91 | 0.83 | 0.87 | 12 | 0.80 | 0.89 | 0.84 | 9 | 0.86 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
| EfficientNet | Mel Spectrogram | 0.90 | 0.75 | 0.82 | 12 | 0.73 | 0.89 | 0.80 | 9 | 0.81 | 0.82 | 0.81 | 0.81 | 0.83 | 0.81 | 0.81 |
| EfficientNet | MFCC | 0.91 | 0.83 | 0.87 | 12 | 0.80 | 0.89 | 0.84 | 9 | 0.86 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
| EfficientNet | LFCC | 0.92 | 0.92 | 0.92 | 12 | 0.89 | 0.89 | 0.89 | 9 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 |
| ResNet50 | Mel Spectrogram | 0.91 | 0.83 | 0.87 | 12 | 0.80 | 0.89 | 0.84 | 9 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
| ResNet50 | MFCC | 0.91 | 0.83 | 0.87 | 12 | 0.80 | 0.89 | 0.84 | 9 | 0.86 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
| ResNet50 | LFCC | 0.91 | 0.83 | 0.87 | 12 | 0.80 | 0.89 | 0.84 | 9 | 0.86 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
| ResNet152 | Mel Spectrogram | 0.90 | 0.75 | 0.82 | 12 | 0.73 | 0.89 | 0.80 | 9 | 0.81 | 0.81 | 0.82 | 0.81 | 0.83 | 0.81 | 0.81 |
| ResNet152 | MFCC | 0.91 | 0.83 | 0.87 | 12 | 0.80 | 0.89 | 0.84 | 9 | 0.86 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
| ResNet152 | LFCC | 0.91 | 0.83 | 0.87 | 12 | 0.80 | 0.89 | 0.84 | 9 | 0.86 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
| SVM | Mel Spectrogram | 0.83 | 0.83 | 0.83 | 12 | 0.78 | 0.78 | 0.78 | 9 | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 |
| SVM | MFCC | 0.91 | 0.83 | 0.87 | 12 | 0.80 | 0.89 | 0.84 | 9 | 0.86 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
| SVM | LFCC | 0.90 | 0.83 | 0.87 | 12 | 0.80 | 0.85 | 0.82 | 9 | 0.85 | 0.85 | 0.84 | 0.85 | 0.85 | 0.85 | 0.85 |
| KNN | Mel Spectrogram | 0.70 | 0.70 | 0.70 | 12 | 0.50 | 0.63 | 0.56 | 9 | 0.64 | 0.60 | 0.67 | 0.63 | 0.64 | 0.64 | 0.64 |
| KNN | MFCC | 0.81 | 0.80 | 0.80 | 12 | 0.70 | 0.70 | 0.70 | 9 | 0.76 | 0.76 | 0.75 | 0.75 | 0.76 | 0.76 | 0.76 |
| KNN | LFCC | 0.81 | 0.80 | 0.80 | 12 | 0.70 | 0.70 | 0.70 | 9 | 0.76 | 0.76 | 0.75 | 0.75 | 0.76 | 0.76 | 0.76 |
| Naive Bayes | Mel Spectrogram | 0.91 | 0.83 | 0.87 | 12 | 0.80 | 0.89 | 0.84 | 9 | 0.86 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
| Naive Bayes | MFCC | 0.90 | 0.83 | 0.86 | 12 | 0.78 | 0.89 | 0.84 | 9 | 0.87 | 0.84 | 0.86 | 0.85 | 0.87 | 0.87 | 0.87 |
| Naive Bayes | LFCC | 0.90 | 0.83 | 0.86 | 12 | 0.78 | 0.89 | 0.84 | 9 | 0.87 | 0.84 | 0.86 | 0.85 | 0.87 | 0.87 | 0.87 |
| Random Forest | Mel Spectrogram | 0.91 | 0.83 | 0.87 | 12 | 0.80 | 0.89 | 0.84 | 9 | 0.86 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
| Random Forest | MFCC | 0.90 | 0.83 | 0.86 | 12 | 0.78 | 0.89 | 0.84 | 9 | 0.87 | 0.84 | 0.86 | 0.85 | 0.87 | 0.87 | 0.87 |
| Random Forest | LFCC | 0.91 | 0.83 | 0.87 | 12 | 0.80 | 0.89 | 0.84 | 9 | 0.86 | 0.85 | 0.86 | 0.86 | 0.86 | 0.86 | 0.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karaaslan, M.; Turkoglu, B.; Kaya, E.; Asuroglu, T. Voice Analysis in Dogs with Deep Learning: Development of a Fully Automatic Voice Analysis System for Bioacoustics Studies. Sensors 2024, 24, 7978. https://doi.org/10.3390/s24247978
Karaaslan M, Turkoglu B, Kaya E, Asuroglu T. Voice Analysis in Dogs with Deep Learning: Development of a Fully Automatic Voice Analysis System for Bioacoustics Studies. Sensors. 2024; 24(24):7978. https://doi.org/10.3390/s24247978
Chicago/Turabian StyleKaraaslan, Mahmut, Bahaeddin Turkoglu, Ersin Kaya, and Tunc Asuroglu. 2024. "Voice Analysis in Dogs with Deep Learning: Development of a Fully Automatic Voice Analysis System for Bioacoustics Studies" Sensors 24, no. 24: 7978. https://doi.org/10.3390/s24247978
APA StyleKaraaslan, M., Turkoglu, B., Kaya, E., & Asuroglu, T. (2024). Voice Analysis in Dogs with Deep Learning: Development of a Fully Automatic Voice Analysis System for Bioacoustics Studies. Sensors, 24(24), 7978. https://doi.org/10.3390/s24247978