Abstract
Two-wheeled non-motorized vehicles (TNVs) have become the primary mode of transportation for short-distance travel among residents in many underdeveloped cities in China due to their convenience and low cost. However, this trend also brings corresponding risks of traffic accidents. Therefore, it is necessary to analyze the driving behavior characteristics of TNVs through their trajectory data in order to provide guidance for traffic safety. Nevertheless, the compact size, agile steering, and high maneuverability of these TNVs pose substantial challenges in acquiring high-precision trajectories. These characteristics complicate the tracking and analysis processes essential for understanding their movement patterns. To tackle this challenge, we propose an enhanced You Only Look Once Version X (YOLOx) model, which incorporates a median pooling-Convolutional Block Attention Mechanism (M-CBAM). This model is specifically designed for the detection of TNVs, and aims to improve accuracy and efficiency in trajectory tracking. Furthermore, based on this enhanced YOLOx model, we have developed a micro-trajectory data mining framework specifically for TNVs. Initially, the paper establishes an aerial dataset dedicated to the detection of TNVs, which then serves as a foundational resource for training the detection model. Subsequently, an augmentation of the Convolutional Block Attention Mechanism (CBAM) is introduced, integrating median pooling to amplify the model’s feature extraction capabilities. Subsequently, additional detection heads are integrated into the YOLOx model to elevate the detection rate of small-scale targets, particularly focusing on TNVs. Concurrently, the Deep Sort algorithm is utilized for the precise tracking of vehicle targets. The process culminates with the reconstruction of trajectories, which is achieved through a combination of video stabilization, coordinate mapping, and filtering denoising techniques. The experimental results derived from our self-constructed dataset reveal that the enhanced YOLOx model demonstrates superior detection performance in comparison to other analogous methods. The comprehensive framework accomplishes an average trajectory recall rate of 85% across three test videos. This significant achievement provides a reliable method for data acquisition, which is essential for investigating the micro-level operational mechanisms of TNVs. The results of this study can further contribute to the understanding and improvement of traffic safety on mixed-use roads.
1. Introduction
As China’s urbanization accelerates, it is accompanied by the escalating challenges of traffic congestion and safety concerns. Within this context, two-wheeled non-motorized vehicles (TNVs) have risen to prominence as a primary transportation mode for urban dwellers. Their appeal largely stems from the low travel costs and flexibility they offer, especially on the flat roads of the southern cities of China. According to publicly available statistics, by the end of 2021 the total number of electric bicycles in China had surpassed 340 million [1]. This statistic is expected to increase because of their low cost and ease of use. However, this could also worsen traffic safety risks on mixed-use roads. Incidents such as running red lights, speeding, and hit-and-run occurrences have become increasingly frequent [2,3,4]. Data from the National Bureau of Statistics indicates that in 2021 there were a total of 35,141 traffic accidents involving TNVs nationwide [5]. This statistic reflects a staggering 128% increase in the accident occurrence rate compared to the year 2015. Therefore, it becomes essential to examine the behavioral characteristics of TNVs in order to understand their operational mechanisms and inform decision-making processes in traffic safety, management, and control. Nonetheless, achieving a comprehensive understanding of TNV behavior and associated accident risks remains challenging, largely due to limitations in data collection.
Driving trajectories, which encompass both temporal and spatial information, are crucial for studying the behavioral characteristics of vehicles [6]. The effective utilization of spatio-temporal data to extract the potential operating characteristics of targets can provide robust data support for the prevention and management of traffic safety issues. For instance, within an intelligent networked environment, self-driving cars leverage spatio-temporal data to perceive the actions of nearby vehicles and adapt their driving strategies accordingly. This approach significantly contributes to the reduction in traffic congestion [7]. Furthermore, forecasting the movement of people using spatio-temporal data can assist in proactively managing traffic in critical areas [8]. In a similar vein, if high-quality trajectory data for TNVs can be effectively obtained, it can provide invaluable support for comprehensively understanding the microscopic movement patterns of TNVs. This knowledge could then be instrumental in guiding road traffic safety, particularly in areas without mixed traffic.
One of the most prevalent trajectory datasets is the Next Generation Simulation (NGSIM) dataset, which was introduced by the United States Federal Highway Administration [9]. NGSIM is compiled through the processing of traffic videos captured using cameras mounted on roadside buildings, encompassing sections of both highways and urban streets. It includes continuous trajectories of motor vehicles, along with details like vehicle speeds, accelerations, coordinates, and types. However, the NGSIM dataset lacks data pertaining to TNVs. Furthermore, it is constrained by the positioning of fixed cameras, which results in coverage of only fixed road segments, limited overall coverage, and a singular vehicle type focus.
In recent years, the swift advancement of unmanned aerial vehicle (UAV) technology has offered a novel method for trajectory data acquisition. Its benefits include lower costs and expansive aerial perspectives, yielding trajectory data characterized by enhanced continuity and precision. UAVs have, thus, emerged as the mainstream medium for trajectory data collection. Nonetheless, when compared to motor vehicles like cars and buses, TNVs often present challenges due to their smaller size, higher density, and less distinctive features in aerial videos, complicating their accurate detection and rapid identification. Additionally, the process of aerial photography introduces complexities due to the simultaneous motion of both the target and the UAV, making the positioning task more challenging. This paper introduces a methodological framework designed for mining micro-trajectories of TNVs in urban road environments. The key contributions of this work are outlined as follows:
1. We propose a novel method for mining TNVs trajectory data, utilizing the You Only Look Once Version X (YOLOx) [10] target detection model coupled with the Deep Sort multi-target tracking algorithm. This approach facilitates frame-by-frame vehicle location tracking. The selection of YOLOx is a comprehensive outcome, balancing between model detection performance and model size.
2. We propose the integration of a Convolutional Block Attention Mechanism (CBAM) based on median pooling into the YOLOX framework, specifically designed to detect TNVs with small-sized targets. This enhancement significantly improves the model’s detection performance for small target vehicles.
3. We employ a range of techniques, including video stabilization, coordinate mapping, and filter denoising, to accurately reconstruct the vehicle’s motion trajectory.
The remainder of this paper is organized as follows: Section 2 provides a review of research on mining vehicle trajectories and analyzes efforts to enhance detection performance for small target objects. Section 3 describes the specific methodology and experimental program and Section 4 presents the experiment results and analyzes them objectively.
2. Related Works
The evolution of urban transportation in China began relatively late, leading to a conspicuous discrepancy and imbalance between the advancement of transportation management and the pace of rapid urbanization. Notably, TNVs present significant challenges to urban traffic management, primarily due to their inherent mobility and flexibility. Exploring the microscopic behavioral characteristics of TNVs and conducting in-depth analysis of their microscopic traffic mechanisms have emerged as pressing issues for many scholars and city managers. However, due to constraints in data acquisition, existing research has not been able to fully capture the microscopic driving behavior characteristics of non-motor vehicles. Certain studies have utilized GPS data from shared bicycles and delivery workers [11,12,13], but this data tends to be of coarse granularity and is limited by the issue of a single type of sample. Utilizing computer vision technology to extract vehicle trajectories from aerial videos represents a highly efficient method. However, the TNVs examined in this study are characterized by their small size and high density in high-altitude videos, which presents significant challenges for feature extraction. Numerous studies have focused on video-based trajectory extraction of medium and large vehicles, such as cars, but have neglected small targets like TNVs. This section will review research related to video trajectory extraction and efforts to enhance recognition performance for small targets. The related work and methodologies also provide a substantial reference foundation for this article.
2.1. Progress of Trajectory Data of Drone Aerial Photography
Compared to the traditional methods of manual statistics and camera-based data capture for acquiring micro-traffic flow data, the emerging approach that combines UAV aerial photography with computer vision has garnered widespread attention from researchers due to its high efficiency and low error rate. Liu et al. [14] utilized UAV to collect traffic videos in urban highway exit areas and proposed a composite framework to extract vehicle trajectories. This framework integrates the YOLOv4 vehicle detection algorithm, SORT vehicle tracking algorithm, and the KD-tree trajectory data reconstruction algorithm. Experiments demonstrate that this framework can effectively capture most car trajectories. However, the SORT algorithm struggles with effectively handling obstructions in the background. Lin et al. [15] proposed a method for acquiring traffic data, such as vehicle flow and speed at intersections, using aerial videos captured using unmanned aerial vehicles. This method employs background subtraction and image morphological operations to detect vehicles in the video and utilizes the KCF algorithm for tracking vehicle targets to extract their trajectories. However, this method lacks the ability to distinguish between different types of vehicles, resulting in all moving objects being recorded indiscriminately. To identify the formation and triggering factors of congestion bottlenecks in fast road weaving areas in real-time, Li et al. [16] constructed vehicle trajectory data based on aerial videos captured using UAVs. They proposed a congestion identification method for weaving areas, incorporating an analysis of unstable traffic flow. However, the effectiveness of this method has not been confirmed in mixed traffic sections involving both motorized and non-motorized vehicles. Wang et al. [17] utilized target detection algorithms and Kalman filtering to capture and analyze traffic flow from unmanned aerial vehicle videos. However, Kalman filtering is notably sensitive to initial values, which may significantly impact the results. Li et al. [18] developed an adaptive framework for estimating the ground speed of multiple vehicles in UAV aerial videos. They proposed a homography-based motion compensation method to determine the actual motion trajectories of vehicles in the current video frame. This method necessitates the real dimensions of the cars as prior information for guidance.
Relevant literature indicates that using UAVs to acquire traffic flow data is both feasible and reliable. The implementation primarily involves two steps. First, based on the principles of computer vision, feature extraction is conducted in aerial videos to detect and recognize vehicles. Subsequently, target tracking of the detected vehicles is achieved through relevant filtering algorithms and deep learning algorithms. However, the aforementioned methods have not been validated in urban road sections with mixed motorized and non-motorized traffic. Moreover, the focus of trajectory extraction has been limited to cars, without consideration for other types of vehicles, such as TNVs.
2.2. Small Target Detection
The TNVs analyzed in this paper are characterized by their small size, dense grouping, and blurred features in aerial videos, which pose significant challenges for their detection and recognition. Efficiently detecting small targets against a large background has emerged as a current research hotspot. Presently, research on small target detection primarily revolves around the utilization of feature pyramid networks, attention mechanisms, and their collaborative integration. Some researchers have enhanced feature extraction for small targets by improving residual structures and adding multi-branch cross-scale modules in feature pyramid networks [18,19,20]. However, this also implies increased model complexity, leading to excessive consumption of computational resources. In the realm of attention mechanisms, Cao et al. [21] introduced a multi-dimensional attention gate network by integrating spatial, channel, and multi-dimensional feature map inputs. This network captures the global distribution of semantic information across spatial and channel dimensions, facilitating enhanced feature response. Wang et al. [22] developed a bidirectional attention network by merging multi-channel attention modules and multi-attention fusion modules. This network provides an abundance of information for the feature fusion of small targets. However, overly complex attention mechanisms may lead to overemphasis on certain features while neglecting other crucial ones, potentially resulting in decreased performance. Many studies have integrated both approaches to augment the feature extraction capabilities for small objects. For instance, in studies [23,24,25], researchers have enhanced the network’s perception of fine details on small objects by combining various attention mechanisms within the feature pyramid network, yielding promising results. However, this does not imply that a more complex model is necessarily better. On the contrary, more intricate models require substantial prior knowledge to fine-tune their hyperparameters, and they also tend to reduce the detection speed of the model. Additionally, some researchers have approached small target detection from alternative perspectives. For instance, Bosquet et al. [26] introduced a data augmentation method that combines generative adversarial networks (GANs) to achieve high-quality data synthesis. However, it is important to note that excessive data augmentation can introduce more noise. This makes it more susceptible to overfitting. Kim et al. [27] introduced a novel loss function based on the Wasserstein distance to specifically address the detection of small target objects. This approach effectively overcomes issues related to sensitivity of intersection and union in narrow scenarios. Although the method is effective for detecting small targets, it may be necessary to use a larger sample size for more accurate learning and evaluation. Shan et al. [28] designed a bidirectional feedback framework (GKB) that optimizes the interplay between Gaussian mixture models and kernelized correlation filters to enhance vehicle detection. The method also places a greater computational burden on the model.
In summary, existing trajectory extraction methods are primarily tailored for medium to large targets such as cars, with limited research focused on the trajectory mining of TNVs. Additionally, in the realm of small target detection, there is a lack of an effective balance between detection performance and the consumption of computational resources.
3. Methods
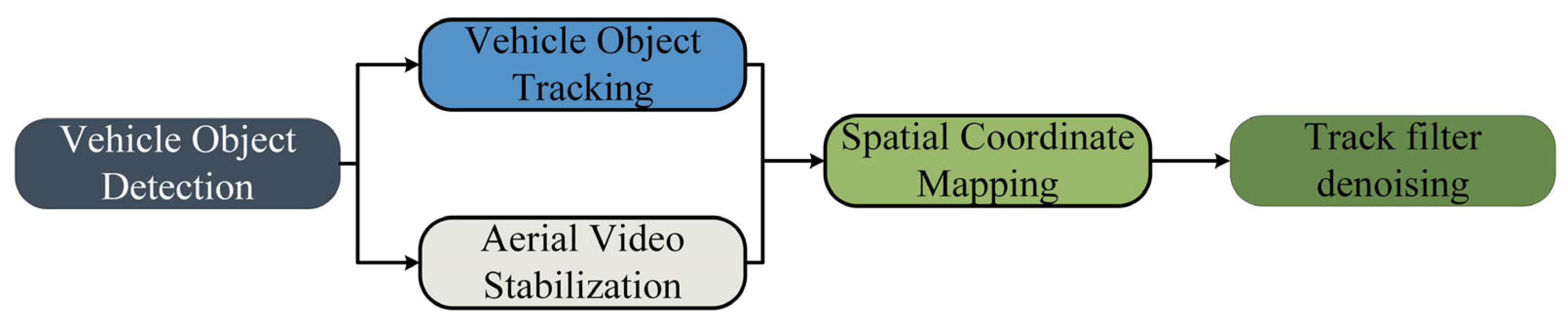
The primary objective of this paper is to construct a methodological framework for extracting the trajectories of TNVs at urban road intersections and mixed traffic flow bottleneck segments. Our study focuses on non-motorized vehicles, which are often overlooked in traditional trajectory extraction studies. This class of vehicles presents a challenge due to their small size, and our research aims to address this lack in the field of mining TNV trajectories. The data obtained can be utilized to study the microscopic driving behavior of non-motorized vehicles, addressing the current challenge of acquiring fine-grained trajectory data for these vehicles. The framework consists of five modules: vehicle object detection, vehicle object tracking, aerial video stabilization, spatial coordinate mapping, and trajectory filtering denoising. The overall structure of the framework is shown in Figure 1. In the video stabilization phase, the optical flow method is employed to perform feature-based stabilization of UAV aerial videos, resulting in a stable video for subsequent detection. In the vehicle target detection module, an optimized and improved single-stage object detection algorithm YOLOx is used as the vehicle target detector to obtain the vehicle bounding boxes. Subsequently, the Deep Sort multi-object tracking algorithm is employed to track the successfully detected vehicles. Vehicle target detection and target tracking work simultaneously to form the initial vehicle trajectories. After obtaining the coordinate location information of vehicles, pixel coordinates are transformed into real-world physical coordinates, and vehicle coordinates are correlated to obtain a continuous trajectory. Finally, Kalman filtering is applied to denoise the trajectory, eliminating errors and improving trajectory quality.
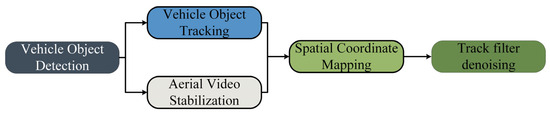
Figure 1.
Overview of the framework structure.
3.1. Improved YOLOx Model
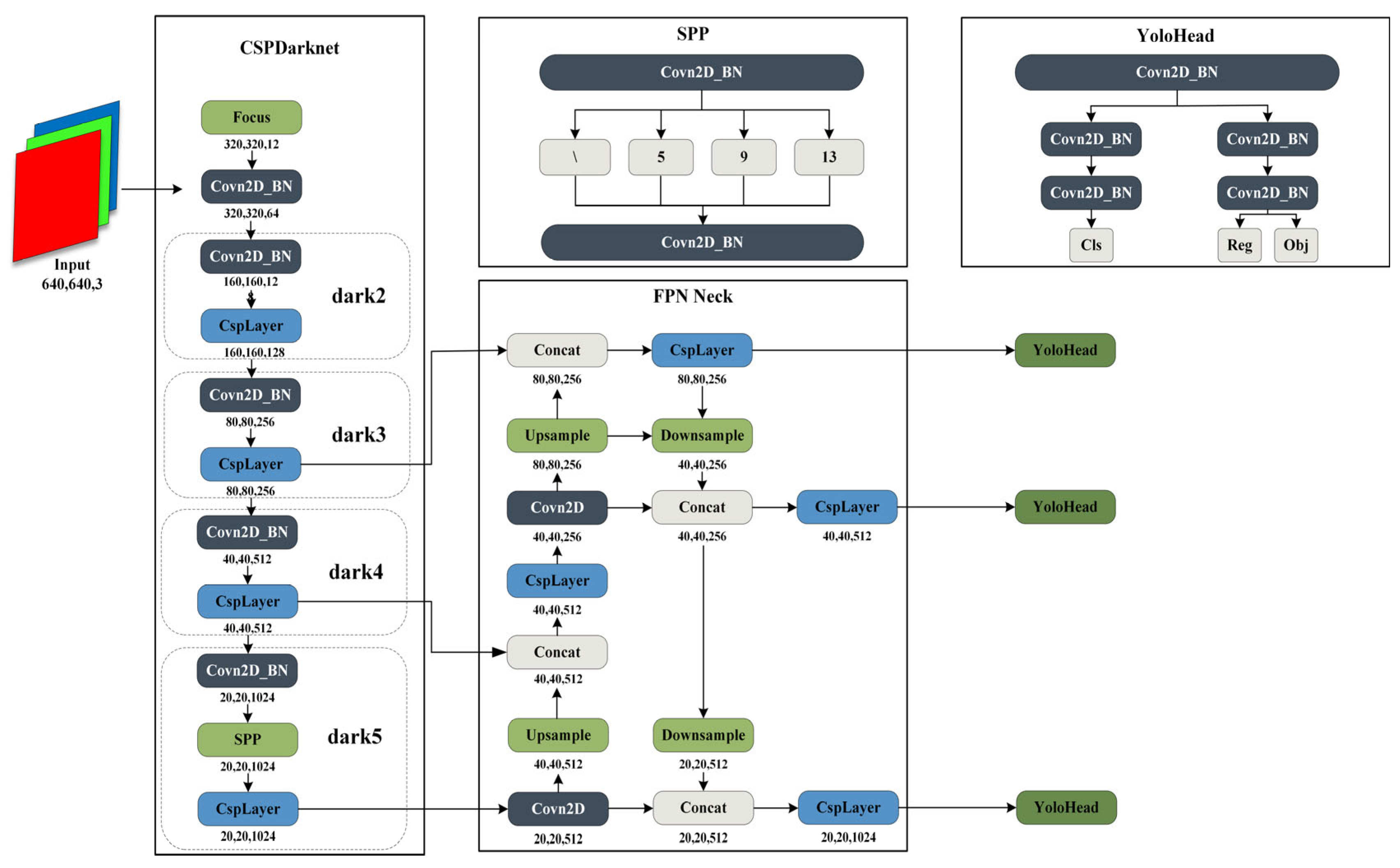
YOLOx [10], initially introduced by Megvii Technology in 2021, falls within the YOLO series of single-stage detection algorithms. In contrast to multi-object detection algorithms such as YOLOv3 [29] and YOLOv5 [30], YOLOx distinguishes itself by integrating several noteworthy techniques, including SimOTA (dynamic sample matching), decoupled detection heads, and the incorporation of the Focusstructure. The network architecture is illustrated in Figure 2.
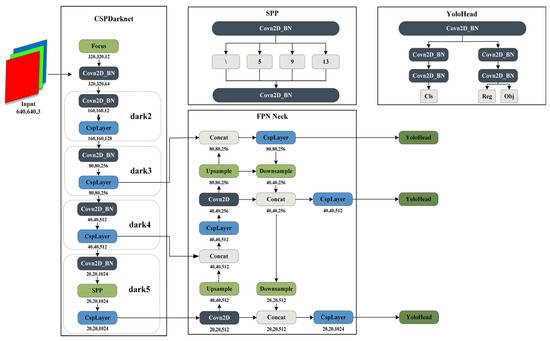
Figure 2.
YOLOx is composed of four parts: input, backbone, neck, and head.
3.1.1. Convolutional Block Attention Module Based on Median Pooling
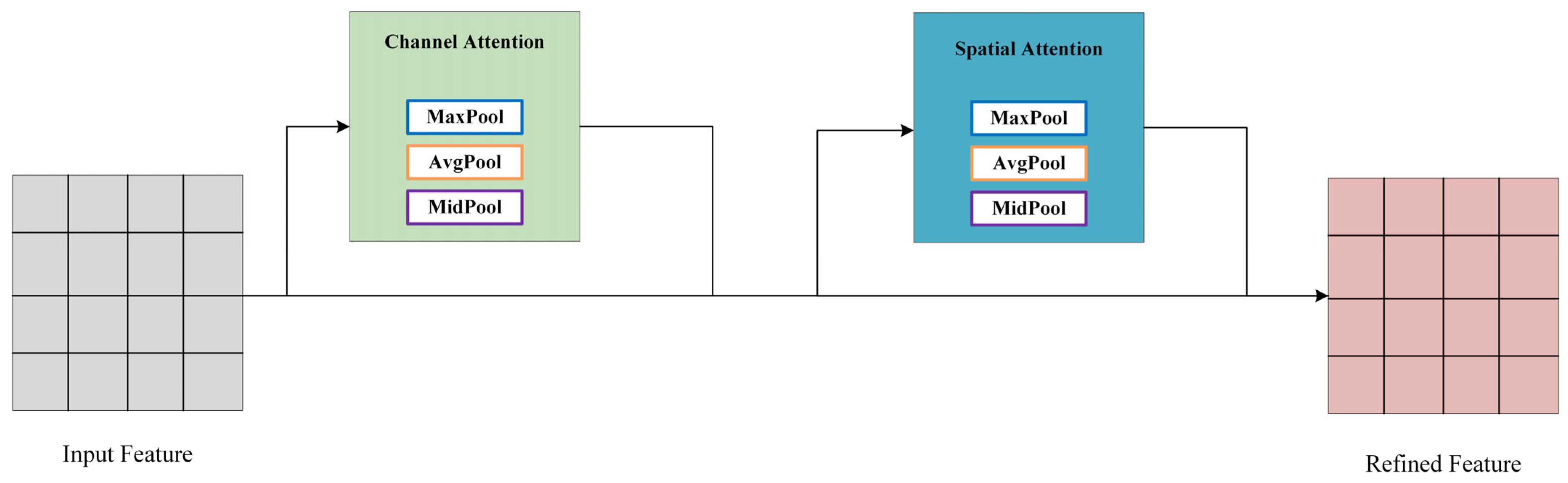
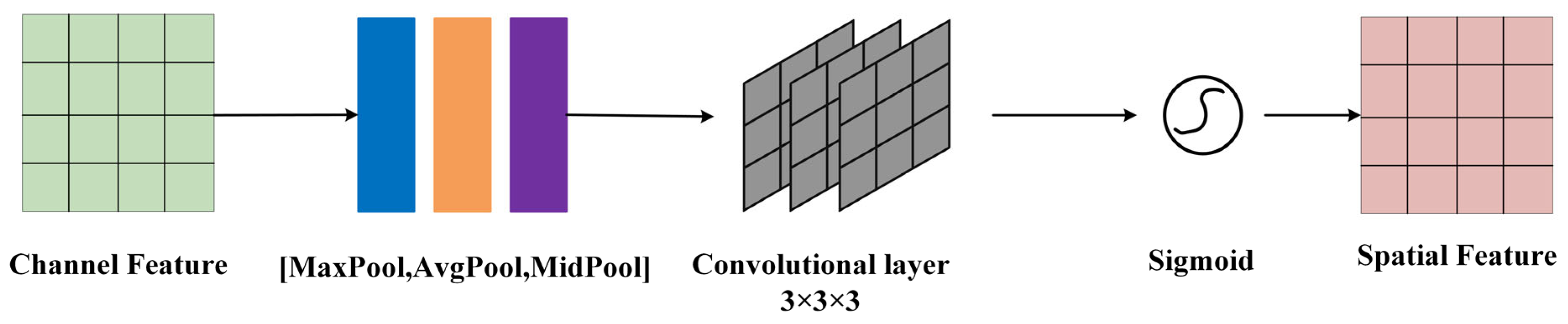
Convolutional Block Attention Module (CBAM) is a lightweight attention module designed for feedforward convolutional neural networks [31]. This section introduces an enhancement to CBAM, presenting a median pooling-based CBAM (M-CBAM), as shown in the structure diagram in Figure 3.
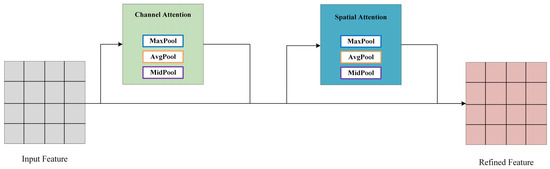
Figure 3.
M-CBAM generates features through the combined action of a channel attention mechanism and a spatial attention mechanism.
The M-CBAM introduced in this paper comprises a channel attention module and a spatial attention module. The output of the convolutional layer initially passes through the channel attention module to obtain weighted results and subsequently enters the spatial attention module, ultimately resulting in the overall weighted output.
The channel attention module processes the input feature map by applying global max pooling, global average pooling, and global median pooling based on width and height. The resulting features are then fed into a fully connected neural network to obtain output features, which are subsequently activated using the sigmoid function. The channel attention features are illustrated in Figure 4 and expressed using the following equation:
where represents the channel attention map; represents the intermediate feature map; represents the sigmoid function; represents the multilayer perceptron; denotes average pooling; denotes maximum pooling; and denotes median pooling.

Figure 4.
Median pooling layer embedded in the channel attention module.
The input of the spatial attention module consists of channel attention features and image input features. First, the input features undergo channel-based max pooling, average pooling, and median pooling. The pooled features are stacked and then subjected to dimension reduction through three layers of convolutional operations. The resulting feature is activated through the sigmoid function to obtain the final spatial attention feature as shown in Figure 5, represented as follows:
where represents the channel attention map; represents the intermediate feature map; represents the sigmoid function; represents the multilayer perceptron; denotes average pooling; denotes maximum pooling; and denotes median pooling.
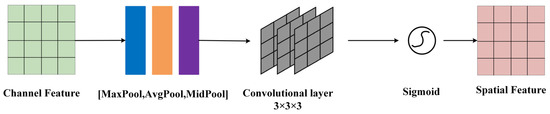
Figure 5.
Median pooling implanted in the spatial attention module and replacing the convolutional layer.
The proposed median pooling in this article possesses the following characteristics: compared to max pooling and min pooling, median pooling exhibits stronger noise resistance, enabling better exploration of target and background features in image information; simultaneously, median pooling can fully utilize spatial and temporal neighboring information in images, especially for closely located small target objects, showing excellent resolution and recognition effects.
The M-CBAM proposed in this paper, based on the original model, incorporates a median pooling layer into the channel attention module and spatial attention module. This addition effectively enhances the network’s capability to learn target edges and texture structure characteristics, while also improving noise resistance. Furthermore, in the channel attention module, the original single 7 × 7 convolution is replaced with three layers of 3 × 3 convolutions, reducing model parameters and saving computational costs.
3.1.2. The Fourth Small Object Detection Head
The design of decoupled detection heads improves the performance of YOLOx in terms of bounding box regression and target classification, but it does not directly benefit the localization of small objects. Additionally, YOLOx may suffer from feature loss of small target objects when used in conjunction with downsampling layers for feature extraction. Consequently, to improve the model’s detection performance for small objects, an additional small target detection head connected to the backbone network has been incorporated into the network architecture. This additional detection head predicts on larger feature maps and retains more small target objects, partially compensating for the feature loss that occurred during the small target feature extraction in the original network. However, this does not imply that more detection heads are better, as additional detection heads increase the model’s computational burden. In this paper, the addition of only one extra detection head is a balanced consideration of model performance and computational cost.
3.1.3. Loss Function Optimization
The original YOLOx uses IoU [32] loss to measure the overlap between the ground truth box and the predicted box, which is the intersection over union (IoU). However, when the predicted box and the ground truth box do not intersect, the IOU is 0, which cannot reflect the distance between the two anchor boxes. In this case, the loss function becomes non-differentiable, leading to gradient vanishing issues, preventing the neural network from further learning. The formula for calculating IOU is as follows:
where A represents the predicted box and B represents the ground truth box.
Based on the issues with the IoU loss mentioned above, this paper introduces the CIoU [33] loss as an improvement over the IoU loss in the model. It incorporates penalties for both the distance between the predicted box and the ground truth box centers and aspect ratio in addition to considering the overlap area between the prediction and the actual bounding boxes. The formula for calculating CIoU loss is as follows:
Within the formula, signifies the distance between the centroids of the predicted box and the ground truth box, corresponds to the length of the diagonal of the minimum enclosing rectangle, serves as a weighting parameter, and is employed to quantify the consistency of the aspect ratio between the ground truth box and the predicted box.
3.2. Vehicle Motion Trajectory Extraction
3.2.1. Vehicle Tracking Based on the Deep Sort Algorithm
To acquire trajectory information for moving vehicles, dynamic tracking and positioning of the vehicles are required. Considering the issue of occlusion caused by factors such as roadside greenery and traffic signals in urban road traffic, this paper utilizes the Deep Sort multi-object tracking algorithm to achieve the tracking and positioning of moving vehicles [34]. Deep Sort is an enhancement of the SORT object tracking algorithm, which incorporates additional appearance feature information of moving targets [35], which is characterized using the cosine distance with the following equation:
where denotes the minimal cosine distance between the appearance features, denotes the cosine similarity of the appearance features between the j-th detection image and the i-th tracking image, and denotes the library of appearance features. The smaller represents the higher similarity of the appearance features between the tracking frame and the detection frame.
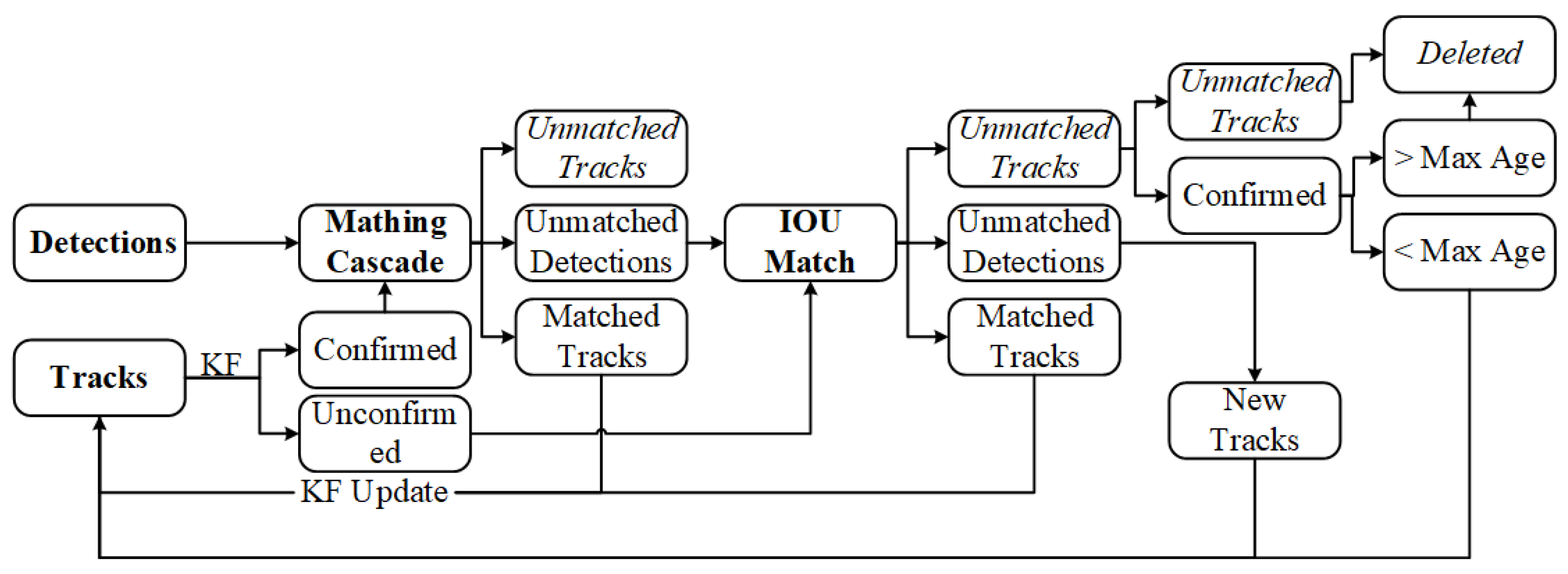
The tracking process of Deep Sort for vehicles is outlined in Figure 6 and consists of the following steps:
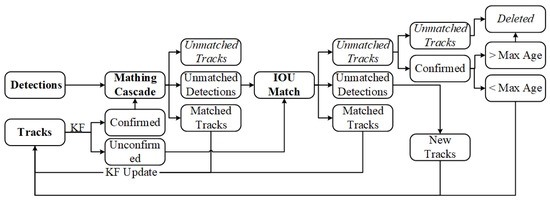
Figure 6.
Flowchart of Deep Sort algorithm.
- Object Detection: Based on the detection results of YOLOx in the first frame of the video, corresponding initial tracks are created, and the Kalman filter is used to predict the potential locations of vehicle targets in the second frame of the image.
- Cascade Matching: In the second frame, predicted trajectories are divided into two states: confirmed state (CS) and unconfirmed state (US). CS is considered as a vehicle target, while the US is uncertain whether it is a vehicle target. CS is associated with the detection results in the second frame, taking into account the motion state and appearance of CS and whether they match the detection box. The matching method uses cascade matching, resulting in three preliminary outcomes for the second frame: matched tracks, unmatched tracks, and unmatched detections. Among these, the matched tracks are directly updated with Kalman filtering into the vehicle target trajectories, while unmatched track boxes and unmatched detection boxes represent matching failures and await further processing.
- IoU Matching: The unmatched track boxes and unmatched detection boxes mentioned above are further associated using IoU matching, where a higher IoU value indicates greater proximity and a higher likelihood of belonging to the same vehicle target. By setting an IoU threshold, three outcomes are filtered: matched tracks, unmatched track boxes, and unmatched detection boxes. Among these, the matched tracks are updated into vehicle target trajectories through Kalman filtering. The further filtered unmatched track boxes and unmatched detection boxes await subsequent processing.
- Processing of Unmatched Detection Boxes: For the remaining unmatched detection boxes, new trajectories must be reconstructed. Simultaneously, these newly established trajectories are confirmed. If they are determined to be vehicle targets and not other objects, they are likewise updated into the existing vehicle target trajectories.
- Processing of Unmatched Track Boxes: Due to missed detections in the detection stage, situations with unmatched track boxes can occur. It is necessary to confirm the unmatched track boxes. If they do not represent vehicle targets, they are deleted. If they are identified as vehicle targets, they are initially retained. Within 30 frames, if they successfully match with detection boxes in subsequent frames, they are updated into the vehicle target trajectories. If no successful match occurs, they are deleted. This process is repeated to achieve multi-object tracking in the video stream.
3.2.2. Aerial Video Stabilization
During high-altitude video capture using UAV, the action of propellers and external wind forces can disrupt the stability of the aircraft, leading to video jitter. Such jitter can lead to drifting in the relative positions of vehicles, hindering vehicle tracking and the subsequent extraction of trajectories. This section aims to stabilize drone aerial videos through a method based on feature points. The specific procedures include:
(1) Input the video for detection and identify the image’s feature points.
(2) Utilize optical flow to track the image’s feature points and construct a motion affine transformation matrix based on the alterations in feature points between the previous and current frames.
(3) Calculate motion trajectories using the motion affine transformation matrix and apply motion trajectory smoothing.
(4) Generate a smoothed affine transformation matrix based on the smoothed motion trajectories.
(5) Ultimately, the stabilized video image is produced through the smoothed affine transformation matrix.
3.2.3. Spatial Coordinate Mapping
Initially, the camera coordinate system and image coordinate system are established. Through the pinhole imaging principle, the camera coordinate system can be projected onto the image coordinate system.
Subsequently, the pixel coordinate system is established, and the following relationship exists between the image coordinate system and the pixel coordinate system :
where represents the scaling factor for pixel coordinates along the -axis, represents the scaling factor for pixel coordinates along the -axis, and denotes the pixel coordinates of the image plane center in the pixel coordinate system. The equation can be rewritten in matrix multiplication form as follows:
where represents the camera’s intrinsic matrix, which can be obtained by referring to the drone’s specification parameters.
3.3. Experimental Arrangements
3.3.1. Data Source
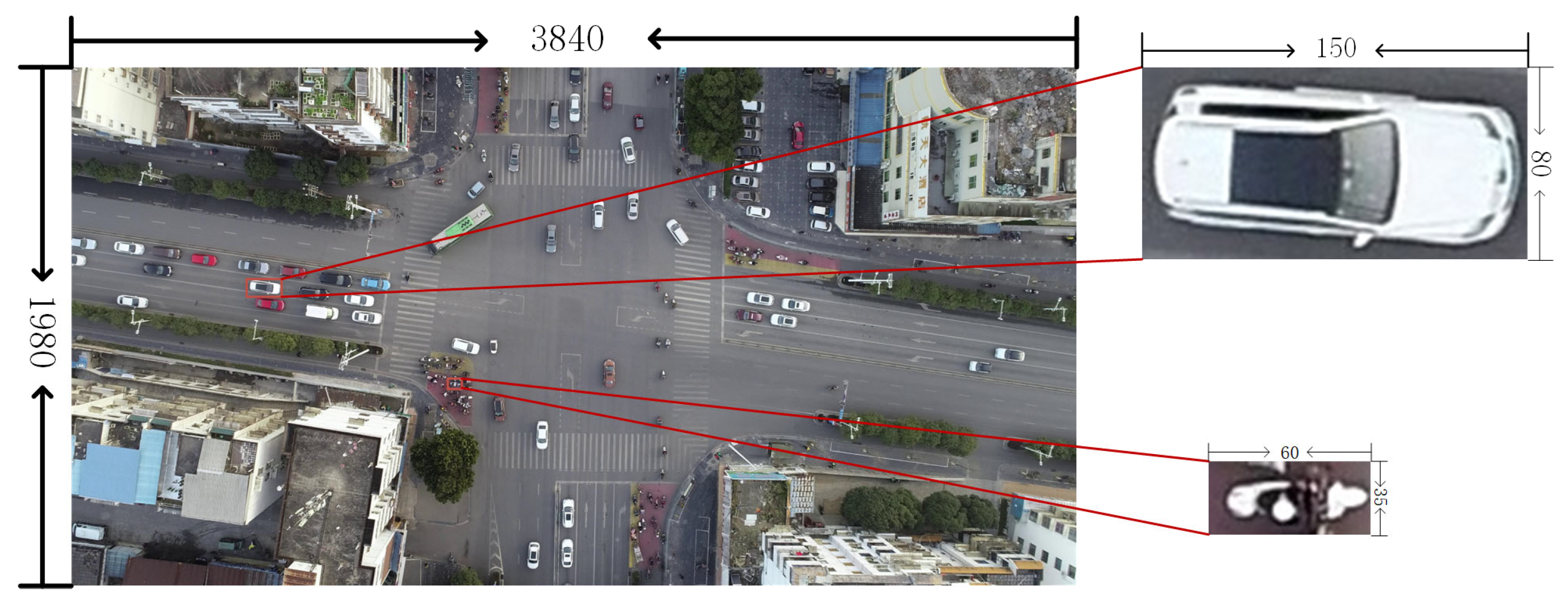
During the research expedition in cities Guilin and Nanning, China, the team identified road segments and intersections with expansive visibility and limited roadside obstructions for capturing aerial videos. The UAV used was the DJI Mavic 3, with a video frame rate of 60 fps and dimensions of 3840 × 1980 pixels, recording at altitudes ranging from 70 m to 80 m. Frame extraction is performed on the recorded video to obtain images for network training. Image annotation for object recognition is a prerequisite for model training. Image annotation for object recognition serves as a fundamental prerequisite for model training. In this experiment, a total of 515 images were annotated. Based on real road conditions, this study categorizes traffic targets into five types: non-motorized vehicles, cars, buses, trucks, and pedestrians. An example of the dataset is shown in Figure 7.
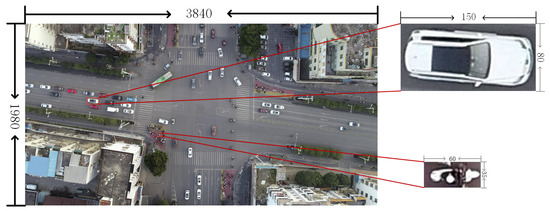
Figure 7.
The size of the two-wheeled non-motorized vehicle target in the dataset is 60 × 35 pixels, which is much smaller than the automobile target.
3.3.2. Experimental Configuration and Evaluation Metrics
The experiments in this study were carried out on a Windows system using the Python programming language. The experimental configuration parameters are detailed in Table 1.

Table 1.
Experimental configuration parameters.
To validate the performance of the model in this paper, the evaluation metrics employed include recall, precision, average precision (AP), F1 score, and model parameters [36].
Among these, TP represents true positive cases, indicating the number of instances where the model predicts a positive sample and it is indeed a positive sample; FP denotes false positive cases, signifying the number of instances where the model predicts a positive sample but it is actually a negative sample; and FN stands for false negative cases, denoting the number of instances where the model predicts a negative sample but it is actually a positive sample.
Precision and recall are conflicting metrics; generally, when classification confidence is high, precision tends to be high, whereas when classification confidence is low, recall tends to be high. Therefore, to provide a comprehensive evaluation of these two metrics, the F1 score is also employed to assess model performance.
AP is a metric used to measure the overall correctness of a specific category. It is calculated as the area under the precision–recall curve and represents the average precision of the model across the entire range of recall levels. A higher AP value indicates superior model performance.
The precision–recall curves (PR curves) are constructed by calculating cumulative precision values of TP or FP and recall values.
3.3.3. Experimental Design
In this study, 12 experiments were conducted to assess the model’s performance. Table 2 outlines the experimental design, with experiment 1 serving as the control group, utilizing the original YOLOx model as the baseline. Experiments 2 to 5 aim to validate the effectiveness of the model improvement methods proposed in this paper, while experiments 6 to 12 provide comparisons with prevalent object detection algorithms currently in use.
Table 2.
Experiment schedule.
4. Results
4.1. Object Detection Results
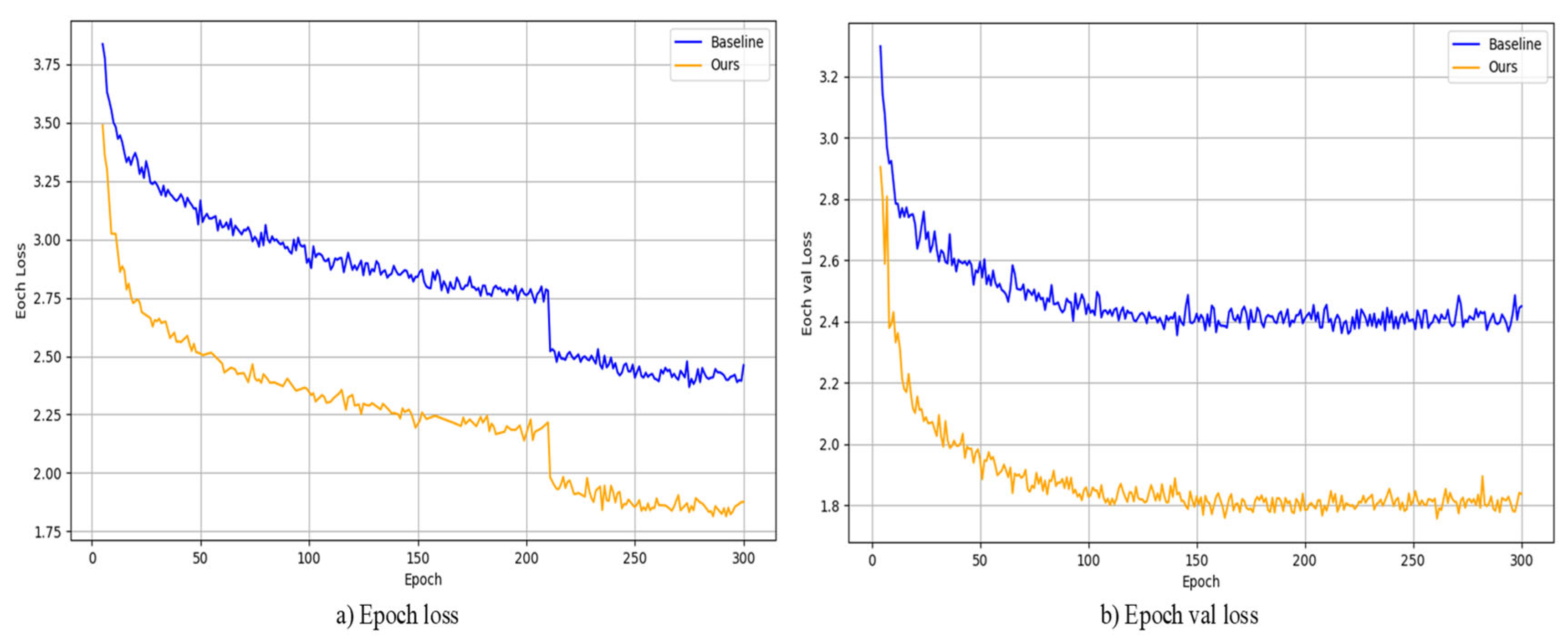
During model training, this paper employed a transfer learning strategy, using YOLOx-s as the pretrained weights and fine-tuning the model on a custom dataset. Figure 8 shows the reduction in loss during the training of the model, and the decrease in loss on the training and validation sets are shown in (a) and (b), respectively. In both sets of experiments, the loss function gradually decreases with an increase in training epochs. Compared to the baseline model, the improved model in this paper exhibits faster loss reduction and reduced oscillation in the loss curve, resulting in improved network convergence speed.
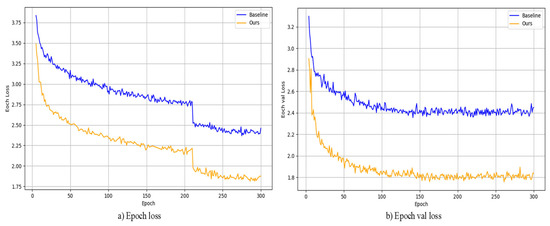
Figure 8.
(a,b) show the loss function decreases for the baseline model and our model, respectively, and our model converges faster.
Table 3 presents the enhancement effects of the improvement strategies proposed in this paper on model performance. From experiment 2 to experiment 5, the improvement strategies introduced in this paper were gradually integrated for validation. It is noteworthy that the main focus of this study is TNVs. Additionally, due to the scarcity of buses and trucks in actual road scenarios, the model’s performance evaluation is conducted only with TNVs and passenger cars as representatives. In experiment 2, after incorporating CIoU, the model showed improvements in various evaluation metrics for both TNVs and cars. In experiment 3, the introduction of CBAM led to enhancements in AP, recall, and F1 for TNVs, but resulted in a decline for cars. In experiment 4, after incorporating the proposed M-CBAM, it compensated for the decline in car evaluation metrics observed in experiment 3 while also improving the metrics for TNVs. Experiment 5 incorporates all the improvement strategies from this paper and represents the best performing group among the five sets of experiments. Compared to the baseline model, experiment 5 achieved a 2.34% increase in recall and a 1.56% increase in precision for TNVs, as well as a 4.28% increase in recall and a 2.22% increase in precision for automobiles. The AP for TNVs reached 64.26%, showing a growth of 1.58%, while the AP for automobiles improved by 3.13%. The improvement strategies in this paper effectively enhance the model’s detection performance for small TNV targets.
Table 3.
Assessment results of improvement strategies’ effectiveness.
In order to evaluate the improvement strategies in this paper, performance comparisons were conducted with prevalent object detection models currently in use. Table 4 displays the performance comparison results between the model introduced in this paper and the prevalent object detection models in current use. It can be seen that the baseline model before the improvement of the TNVs detection on the recall reached the best among other algorithms in the same category, in addition to its smaller model parameters and faster detection speed, which also provides guidance for us to choose YOLOx as the baseline model. Remarkably, the model in this paper achieved the best performance in both the AP and recall metrics for TNVs. In terms of model parameters, the improvement strategies in this paper have only increased by 0.83 M compared to the baseline model, which is lower than the parameters of other object detection models except YOLOv5. Detection efficiency is measured using the fps metric. The most recent YOLOv8 algorithm achieves the highest detection speed, yet its performance on TNV small targets is suboptimal. This may be attributed to YOLOv8 being pre-trained on the coco dataset, which lacks sufficient small target objects. Consequently, this affects the model’s detection rate of non-motorized vehicles. Additionally, the increased complexity of YOLOv8’s network and its frequent downsampling contribute to the loss of features of tiny targets. On the other hand, the SSD algorithm, while slightly slower in detection speed compared to YOLOv8, exhibits an exceedingly low recall on TNVs. The detection performance of the two-stage object detection algorithm Faster-RCNN is the lowest, possibly because in methods based on candidate box regression, anchor boxes correspond to the original image, and anchor boxes lose the features of small targets after multiple downsampling operations. Therefore, this leads to ineffectiveness in high-density small object detection tasks. The detection speed of our model is 28.7 FPS, which, while not the fastest, still satisfies the requirements for real-time detection. Detection speed is influenced by the complexity of the model structure. In this paper, the addition of the fourth detection head increased the size of the model and added extra parameters relative to the baseline model. This is also one of the reasons for the decrease in FPS.
Table 4.
Comparison with results of advanced models.
The detection results of different models are illustrated as shown in Figure 9. Compared to other similar object detection models, the model in this paper is capable of effectively detecting non-motorized vehicle targets, and it can even detect smaller objects such as “pedestrians”. This demonstrates the effectiveness of the improvement strategies proposed in this paper for small target objects.
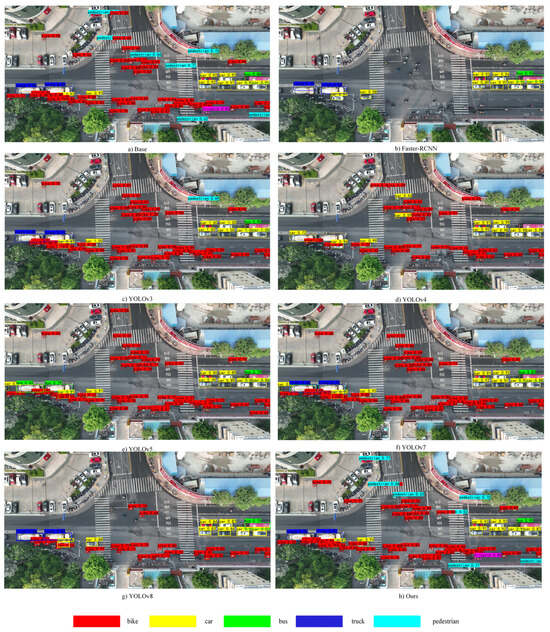
Figure 9.
In the comparison of the detection effect with other models, our model achieves better results in terms of detection rate and correctness rate.
4.2. Vehicle Motion Trajectory Extraction Results
In this section, three test videos were used to evaluate the performance of the trajectory extraction framework. In the first test video, the research team manually counted 14 (car) and 116 (bike) real trajectories; in the second video, it was 14 (car) and 102 (bike); and in the third test video, it was 25 (car) and 37 (bike). As shown in Table 5, the recall rate for car trajectories is almost the same in the three test videos, and is 92.86%, 92.86%, and 92.00%, respectively. The recall rate for bike trajectories is 81.90%, 85.29%, and 72.97%, all lower than that of cars. This is because the model performs better when detecting cars during the detection process.
Table 5.
Results of trajectory extraction.
In the three test videos, a total of 50 trajectories for both cars and bikes were lost or not correctly associated. Most of the lost trajectories were due to detection failures. Additionally, the research team observed that trajectory losses were lower on straight road segments like bridges compared to intersections, indicating that target density also affects trajectory construction.
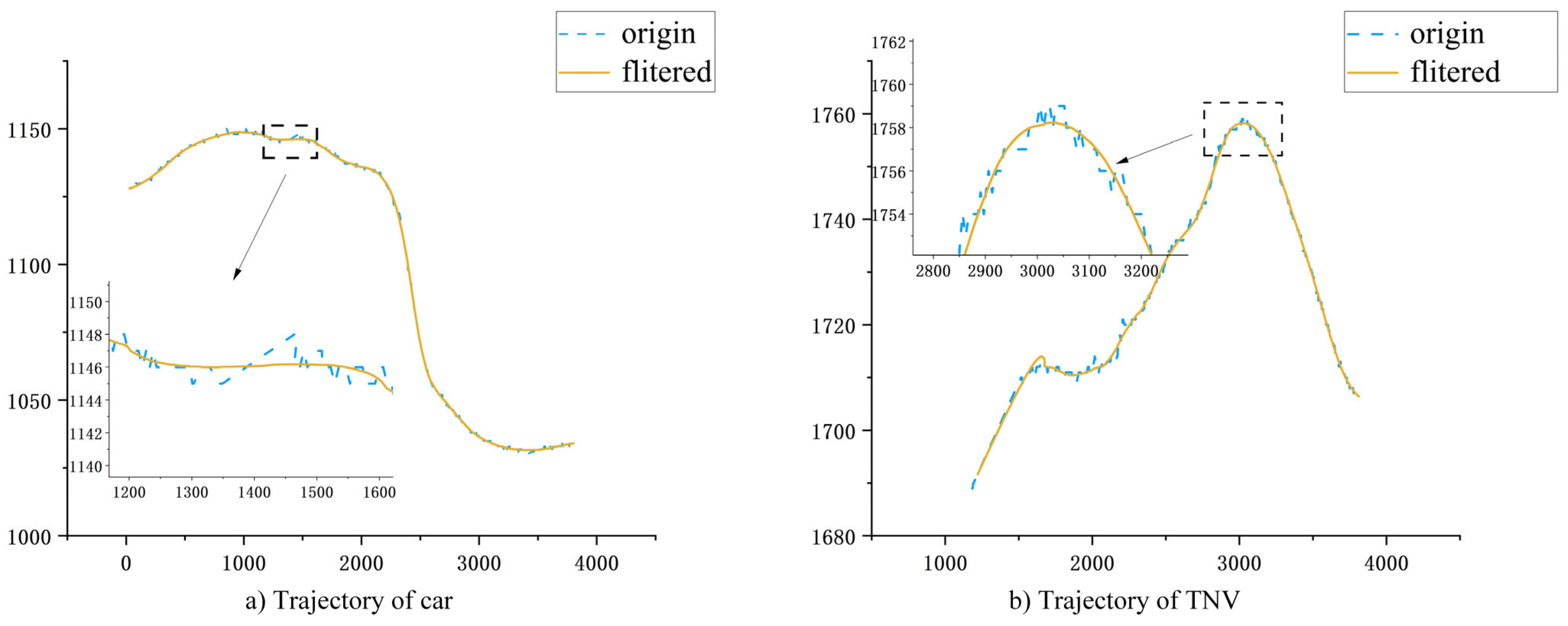
The results of denoised car and TNV trajectories are presented in Figure 10. In the coordinate plot, the blue dashed line and the orange line, respectively, represent the original trajectories and the smoothed trajectories. Figure 10 demonstrates that the smoothed trajectory data has reduced fluctuations. In fact, the trajectory construction method proposed in this paper enables frame-by-frame tracking and construction, effectively mitigating the initial trajectory data’s volatility.
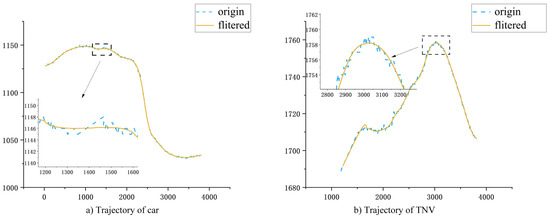
Figure 10.
(a,b) are the results of car and TNV trajectory construction, respectively, and the trajectory extraction method in this paper can realistically restore the vehicle’s motion trajectory.
5. Discussion
This study presents a method for extracting vehicle trajectories in dedicated non-mixed traffic lanes, thereby reducing the workload for relevant researchers. Additionally, the method can contribute to enriching trajectory data for traffic flow studies. Based on the video data from this study, more detailed research on the microscopic operational mechanisms of vehicles can be conducted, providing relevant data support for the field of traffic safety.
However, this study still has some limitations that need to be further addressed and improved by researchers, including but not limited to the following aspects:
The dataset used for model training in this study is relatively small, with an uneven sample distribution. Future research can explore the application of the current method in more diverse traffic environments, such as on different types of roads, in various cities, and even within the transportation systems of different countries. This would enable the validation of the method’s generalizability and practicality.
Considering the real-time performance and accuracy of the existing framework, future work could focus on algorithmic optimization to enhance the speed and accuracy of trajectory reconstruction. For instance, researchers could develop new algorithms to mitigate the impact of lighting variations, or employ machine learning methods to predict and correct errors in the trajectories.
Based on the extracted trajectory data, future research could delve deeper into analyzing the microscopic behavior patterns of vehicles, identifying potential risky behaviors, and providing data support for traffic safety management and urban planning.
With the rapid advancement in the field of computer vision, future research could integrate more sophisticated image processing and object recognition technologies. This includes utilizing deep learning for image segmentation and feature extraction, thereby enhancing the accuracy of small target detection.
6. Conclusions
This paper presents a framework for extracting vehicle trajectories based on aerial videos, particularly focusing on the trajectories of small target TNVs. The proposed framework integrates high-precision vehicle object detection, vehicle object tracking, aerial video stabilization, coordinate mapping, and trajectory filtering denoising. Testing was conducted on three different videos, and the main contributions are as follows:
(1) This paper proposes an improved YOLOx object detection method for detecting small non-motorized vehicle targets. Compared to advanced object detection algorithms, the improved YOLOx in this paper achieves the best overall detection performance for small targets such as TNVs, with an AP of 64.26% and a recall of 63.5%. Furthermore, it achieves a detection speed of 28.7 fps, meeting the requirements for real-time detection.
(2) This paper presents enhancements to the CBAM attention mechanism by incorporating median pooling layers in both the channel attention module and the spatial attention module, thereby strengthening the feature extraction capacity for small target objects. Furthermore, the original single 7 × 7 convolution layer is replaced with three layers of 3 × 3 convolution, maintaining detection performance while reducing the model parameters to 9.77 M.
(3) This paper verifies the performance when a fourth additional detection head is incorporated in the network for detecting small TNV targets. Experimental results show that after adopting the improvement strategies proposed in this paper the recall rate for TNV targets has increased by 2.43%, and the category AP has improved by 1.58%.
(4) This paper extracts vehicle trajectories based on the Deep Sort multi-object tracking algorithm. Experimental results indicate that the average recall rate of the proposed method for the trajectories of TNVs can exceed 80%.
(5) This paper has constructed a new aerial non-motorized small target dataset which contains 38,728 non-motorized small target objects, and the dataset is continuously being enriched.
The primary contribution of this study is the development of a vehicle trajectory extraction method with a specific emphasis on small non-motorized vehicle targets. This method provides an effective way to acquire data for analyzing the intricate operational mechanisms of TNVs. These vehicles pose a significant challenge due to their small size, and our research aims to bridge this gap in the domain of TNV trajectory analysis. The outcomes of this study offer substantial data support for an in-depth understanding and application of the micro-motion patterns of electric bicycles. This understanding is crucial for guiding traffic safety management in mixed traffic conditions. Additionally, the advancements achieved in detecting small targets such as TNVs in this paper can provide insights and serve as a benchmark for similar challenges in other industries or fields.
Author Contributions
Conceptualization, D.Z. and Z.Z.; methodology, R.Y.; validation, S.H.; writing—original draft preparation, Z.Z.; writing—review and editing, Z.W.; supervision, D.Z.; funding acquisition, D.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant number (71861005) and The Innovation Project of GUET Graduate Education, grant number (2022YCXS226).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Production and Application Status, Challenges and Measures of Electric Two-Wheeler Vehicles in China. 2022, p. 14. Available online: http://www.itdp-china.org/media/publications/PDFs/%E4%B8%AD%E5%9B%BD%E7%94%B5%E5%8A%A8%E4%B8%A4%E8%BD%AE%E8%BD%A6%E7%94%9F%E4%BA%A7%E5%BA%94%E7%94%A8%E7%8A%B6%E5%86%B5%E3%80%81%E6%8C%91%E6%88%98%E4%B8%8E%E5%AF%B9%E7%AD%96.pdf (accessed on 10 January 2024).
- Hu, L.; Hu, X.; Wang, J.; Kuang, A.; Hao, W.; Lin, M. Casualty Risk of E-Bike Rider Struck by Passenger Vehicle Using China in-Depth Accident Data. Traffic Inj. Prev. 2020, 21, 283–287. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Kuai, C.; Lv, H.; Li, W. Investigating Different Types of Red-Light Running Behaviors among Urban e-Bike Rider Mixed Groups. J. Adv. Transp. 2021, 2021, 1977388. [Google Scholar] [CrossRef]
- Jiang, C.; Tay, R.; Lu, L. A Skewed Logistic Model of Two-Unit Bicycle-Vehicle Hit-and-Run Crashes. Traffic Inj. Prev. 2021, 22, 158–161. [Google Scholar] [CrossRef] [PubMed]
- China Statistical Yearbook—2022. Available online: http://www.stats.gov.cn/sj/ndsj/2022/indexch.htm (accessed on 26 September 2023).
- Zhao, J.; Sartipi, M. Automatic Identification of Anomalous Driving Events from Trajectory Data. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; IEEE: New York, NY, USA, 2022; pp. 851–856. [Google Scholar]
- Zhu, L.; Lu, L.; Wang, X.; Jiang, C.; Ye, N. Operational Characteristics of Mixed-Autonomy Traffic Flow on the Freeway with On- and Off-Ramps and Weaving Sections: An RL-Based Approach. IEEE Trans. Intell. Transp. Syst. 2022, 23, 13512–13525. [Google Scholar] [CrossRef]
- Xiao, G.; Chen, L.; Chen, X.; Jiang, C.; Ni, A.; Zhang, C.; Zong, F. A Hybrid Visualization Model for Knowledge Mapping: Scientometrics, SAOM, and SAO. IEEE Trans. Intell. Transp. Syst. 2023. early access. [Google Scholar] [CrossRef]
- Next Generation Simulation (NGSIM) Open Data. Available online: https://datahub.transportation.gov/stories/s/Next-Generation-Simulation-NGSIM-Open-Data/i5zb-xe34 (accessed on 11 April 2023).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Shen, Y.; Zhang, X.; Zhao, J. Understanding the Usage of Dockless Bike Sharing in Singapore. Int. J. Sustain. Transp. 2018, 12, 686–700. [Google Scholar] [CrossRef]
- Dane, G.; Feng, T.; Luub, F.; Arentze, T. Route Choice Decisions of E-Bike Users: Analysis of GPS Tracking Data in the Netherlands. In Proceedings of the Geospatial Technologies for Local and Regional Development; Kyriakidis, P., Hadjimitsis, D., Skarlatos, D., Mansourian, A., Eds.; Springer International Publishing AG: Cham, Switzerland, 2020; pp. 109–124. [Google Scholar]
- Lopez, A.J.; Astegiano, P.; Gautama, S.; Ochoa, D.; Tampere, C.M.J.; Beckx, C. Unveiling E-Bike Potential for Commuting Trips from GPS Traces. ISPRS Int. Geo-Inf. 2017, 6, 190. [Google Scholar] [CrossRef]
- Liu, Z.; He, J.; Zhang, C.; Yan, X.; Wang, C.; Qiao, B. Vehicle Trajectory Extraction at the Exit Areas of Urban Freeways Based on a Novel Composite Algorithms Framework. J. Intell. Transport. Syst. 2023, 27, 295–313. [Google Scholar] [CrossRef]
- Zhou, L.J.; Wang, H. Approach to Obtaining Traffic Volume and Speed Based on Video-Extracted Trajectories. In Proceedings of the International Conference on Transportation and Development 2020—Emerging Technologies and Their Impacts; Zhang, G., Ed.; American Society of Civil Engineers: New York, NY, USA, 2020; pp. 140–151. [Google Scholar]
- Li, X.; Liang, J.; Zhang, W.; Hao, T.; Chen, L. Congestion identification method in intersection area based on aerial video construction risk index. J. Railw. Sci. Eng. 2023, 20, 494–505. [Google Scholar] [CrossRef]
- Wang, J.; Simeonova, S.; Shahbazi, M. Orientation- and Scale-Invariant Multi-Vehicle Detection and Tracking from Unmanned Aerial Videos. Remote Sens. 2019, 11, 2155. [Google Scholar] [CrossRef]
- Li, J.; Chen, S.; Zhang, F.; Li, E.; Yang, T.; Lu, Z. An Adaptive Framework for Multi-Vehicle Ground Speed Estimation in Airborne Videos. Remote Sens. 2019, 11, 1241. [Google Scholar] [CrossRef]
- Luo, T.; Wang, H.; Cai, Y.; Chen, L.; Wang, K.; Yu, Y. Binary Residual Feature Pyramid Network: An Improved Feature Fusion Module Based on Double-Channel Residual Pyramid Structure for Autonomous Detection Algorithm. IET Intell. Transp. Syst. 2023, 17, 1288–1301. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, H.; Lu, X. Adaptive Feature Fusion for Small Object Detection. Appl. Sci. 2022, 12, 11854. [Google Scholar] [CrossRef]
- Cao, L.; Li, J.; Chen, S. Multi-Target Segmentation of Pancreas and Pancreatic Tumor Based on Fusion of Attention Mechanism. Biomed. Signal Process. Control 2023, 79, 104170. [Google Scholar] [CrossRef]
- Wang, S.; Qu, Z.; Li, C.; Gao, L. BANet: Small and Multi-Object Detection with a Bidirectional Attention Network for Traffic Scenes. Eng. Appl. Artif. Intell. 2023, 117, 105504. [Google Scholar] [CrossRef]
- Min, K.; Lee, G.-H.; Lee, S.-W. Attentional Feature Pyramid Network for Small Object Detection. Neural Netw. 2022, 155, 439–450. [Google Scholar] [CrossRef]
- Chen, X.; Li, Y.; Nakatoh, Y. Pyramid Attention Object Detection Network with Multi-Scale Feature Fusion. Comput. Electr. Eng. 2022, 104, 108436. [Google Scholar] [CrossRef]
- Jiao, L.; Kang, C.; Dong, S.; Chen, P.; Li, G.; Wang, R. An Attention-Based Feature Pyramid Network for Single-Stage Small Object Detection. Multimed. Tools Appl. 2023, 82, 18529–18544. [Google Scholar] [CrossRef]
- Bosquet, B.; Cores, D.; Seidenari, L.; Brea, V.M.; Mucientes, M.; Del Bimbo, A. A Full Data Augmentation Pipeline for Small Object Detection Based on Generative Adversarial Networks. Pattern Recognit. 2023, 133, 108998. [Google Scholar] [CrossRef]
- Kim, J.; Huh, J.; Park, I.; Bak, J.; Kim, D.; Lee, S. Small Object Detection in Infrared Images: Learning from Imbalanced Cross-Domain Data via Domain Adaptation. Appl. Sci. 2022, 12, 11201. [Google Scholar] [CrossRef]
- Shan, X.; Wu, Q.; Li, Z.; Wang, C. Bidirectional Feedback of Optimized Gaussian Mixture Model and Kernel Correlation Filter for Enhancing Simple Detection of Small Pixel Vehicles. Neural Comput. Appl. 2023, 35, 8747–8761. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW 2021), Montreal, BC, Canada, 11–17 October 2021; IEEE Computer Society: Los Alamitos, CA, USA, 2021; pp. 2778–2788. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Pt VII; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing AG: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. In Proceedings of the Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 516–520. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. arXiv 2017, arXiv:1703.07402. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple Online and Realtime Tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Ferrer, L. Analysis and Comparison of Classification Metrics. arXiv 2023, arXiv:2209.05355. [Google Scholar]
- SSD: Single Shot MultiBox Detector | SpringerLink. Available online: https://link.springer.com/chapter/10.1007/978-3-319-46448-0_2 (accessed on 3 January 2024).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 12 January 2024).

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).