Abstract
Ship detection is vital for maritime safety and vessel monitoring, but challenges like false and missed detections persist, particularly in complex backgrounds, multiple scales, and adverse weather conditions. This paper presents YOLO-Vessel, a ship detection model built upon YOLOv7, which incorporates several innovations to improve its performance. First, we devised a novel backbone network structure called Efficient Layer Aggregation Networks and Omni-Dimensional Dynamic Convolution (ELAN-ODConv). This architecture effectively addresses the complex background interference commonly encountered in maritime ship images, thereby improving the model’s feature extraction capabilities. Additionally, we introduce the space-to-depth structure in the head network, which can solve the problem of small ship targets in images that are difficult to detect. Furthermore, we introduced ASFFPredict, a predictive network structure addressing scale variation among ship types, bolstering multiscale ship target detection. Experimental results demonstrate YOLO-Vessel’s effectiveness, achieving a 78.3% mean average precision (mAP), surpassing YOLOv7 by 2.3% and Faster R-CNN by 11.6%. It maintains real-time detection at 8.0 ms/frame, meeting real-time ship detection needs. Evaluation in adverse weather conditions confirms YOLO-Vessel’s superiority in ship detection, offering a robust solution to maritime challenges and enhancing marine safety and vessel monitoring.
1. Introduction
Ship image detection technology is widely applied in various domains, such as maritime ship monitoring, shipping supervision, and maritime cruise search and rescue. However, in practical applications, different lighting conditions, complex backgrounds at sea, and stormy weather all increase the difficulty of ship detection [1]. This places higher demands on both accuracy and real-time ship detection. As computer vision technology rapidly advances, its applications are becoming increasingly widespread. These techniques have been gradually applied to ship detection and identification [2], which provides a new direction for maritime ship detection.
Ship image detection methods fall into traditional and deep learning methods. Traditional methods generally adopt support vector machine (SVM), histogram of oriented gradients (HOG), local binary pattern, and other algorithms for ship feature extraction and detection. For example, Feng et al. [3] present a multi-branch SVM approach to enhance the rapid detection of moving ships by incorporating effective multi-scale features. However, waves or changes in the background introduced higher computational costs to the model. Shi et al. [4] proposed an extended HOG method for detecting actual ships in candidate regions by computing a histogram of oriented gradients of local image regions. This method has the advantage of geometric invariance but increases the computational time, making it unsuitable for real-time applications. Zhu et al. [5] introduced a new texture operator to enhance feature extraction capabilities. However, in environments characterized by clouds, sea waves, and clutter, the method failed to extract detailed ship information, thereby reducing ship detection performance. Traditional methods exhibit limited portability and robustness across diverse scenes, and they are often susceptible to interference from complex backgrounds, noise, and low-light conditions [6]. Their real-time performance and accuracy are insufficient to meet task requirements. In the context of ship detection under adverse weather conditions, a series of methods for improving detection models have been proposed in references [7,8]. These methods are applied in complex maritime vessel monitoring systems under haze and low visibility conditions. The authors employ a direct detection technique. Another approach involves a two-step process: preprocessing the image to remove haze, and then conducting ship recognition. Song et al. [9] introduced a method for ship detection in hazy marine remote-sensing images. This method uses color polarization classification and haze concentration clustering to balance the remote sensing image (RSI) color and eliminate haze interference. The subsequent recognition of the processed image reduces the difficulty, but this method results in the loss of more image details. Liu et al. [10] proposed a novel image-dehazing algorithm based on color prior knowledge. This method achieves a higher accuracy in ship detection in thin cloud and mist environments, albeit with an increased computational burden due to the intricate preprocessing steps.
In contrast, deep learning possesses formidable feature learning capabilities, rendering it the prevailing approach in current ship detection technology. Object detection techniques in deep learning can be classified into two-stage and one-stage methods. For the two-stage detection method, Escorcia-Gutierrez et al. [11] introduced an enhanced Mask R-CNN model for improved recognition and classification of small ships in shipping. However, there remains a significant error in locating the ship’s contour edge region, indicating the necessity for further model accuracy improvement. Yu et al. [12] proposed an enhanced R-CNN method called Ship R-CNN, which improves ship detection accuracy in scenarios with complex backgrounds and minimal differentiation between ships and distant shores. However, this method did not account for ship recognition under nighttime conditions. Li et al. [13] improved the Cascade R-CNN method for more accurate small-ship detection. However, it faces efficiency challenges in recognizing redundant features. In the one-stage detection methods, the most representative algorithm is the You Only Look Once (YOLO) family. The algorithms employ a direct regression approach to make predictions over the entire image, effectively improving detection speed while maintaining accuracy, and are thus widely used in ship detection. Specifically, Guo et al. [14] presented LVENet, an enhancement network for improved low-light maritime vessel detection by enhancing image channel luminance. However, the network does not account for the challenges of rainy and foggy weather conditions, and its model exhibits limited generalization. Guo et al. [15] improved the deblurring and defogging performance of the model by enhancing the fused image feature information, but their method is limited by the dark light environment and noise interference, which increases the uncertainty of the prediction results.
In summary, although some research results have been achieved in ship image detection under complex sea conditions, challenges persist. First, the presence of various ship types with significant size variations between classes and small target scales poses difficulties for target detection. Secondly, adverse factors like sea haze, uneven illumination, and low visibility in complex backgrounds can degrade imaging quality. Extracting effectively ship features from the ocean background remains a challenge for algorithms. This paper presents a ship detection model tailored for complex sea state images, with three key contributions.
- We propose an improved real-time ship detection model based on YOLOv7 (YOLO-Vessel), specifically designed to address ship detection challenges in the complex sea conditions mentioned above.
- A backbone network called Efficient Layer Aggregation Networks and Omni-Dimensional Dynamic Convolution (ELAN-ODConv) with strong feature extraction capability is designed to reduce false and missed detections. Then, a network termed Efficient Layer Aggregation Networks Head and Space-to-depth and Convolution (ELANH-SPDC) is introduced at the head to achieve fine-grained detection and identification of ships. In addition, a new prediction network structure named ASFFPredict is designed, which adaptively learns each feature layer’s weights and can fuse each scale’s feature information more efficiently.
- To adapt ship detection under different adverse weather conditions, this paper proposes a ship dataset under adverse weather conditions, which is then artificially synthesized using physical haze, rain, snow, and low light algorithms, and experiments are conducted in real scenarios to verify the detection accuracy and operation efficiency of this model.
2. Related Work
The YOLO series of models has garnered extensive attention in recent years, and researchers have achieved a series of advancements in ship detection research based on the YOLO framework. For example, Yao et al. [16] employed the YOLOv8 model for multi-class ship detection, improving ship recognition accuracy. However, their dataset was not comprehensive enough and lacked training data for large-sized vessels. Furthermore, Zhao et al. [17] proposed a detection model named YOLOv7-sea, incorporating attention mechanisms to enhance focus on regions containing vessels of interest. However, this approach fails to extract multi-scale ship features and may lead to erroneous detections. To tackle inadequate feature extraction, dynamic convolutions have gradually found applications across various domains in deep learning. The representative omni-dimensional dynamic convolution (ODConv) [18] is a novel convolutional operation capable of dynamically adjusting convolution kernels to effectively capture multi-dimensional features in data, thereby enhancing the model’s performance in detection tasks. Cheng et al. [19] integrated dynamic convolution modules into shallow networks, enhancing the model’s efficiency in ship recognition under complex backgrounds. However, this approach encounters issues such as false positives for small-sized vessels and prolonged model training times. Complex maritime ship target recognition often results in false positives, and due to intricate backgrounds and noise interference, it may also fail to recognize small-sized vessels. Chen et al. [20] presented a multi-scale ship detection model for complex scenes. They incorporated the ASPP module to expand the receptive field while reducing feature loss for small-sized vessels. However, this model did not take into account the time cost.
To further improve the detection of small ships in complex sea conditions, SPDC has unique advantages in detecting small targets and low-resolution images. The SPDC structure consists of space-to-depth and convolution [21], where space-to-depth is a transformation layer that downsamples the feature maps in the CNN using image transformation techniques while retaining all the channel information to enhance small-size feature extraction. Ma and Pang et al. [22] presented an SP-YOLOv8s detection model that enhances the fine-grained feature information during downsampling, improving the accuracy of detecting small objects. However, this gain in accuracy comes at the cost of increased computational complexity. Multi-scale fusion networks have found widespread application in deep learning models. Zhang et al. [23] presented an improved model built upon YOLOv7-tiny. This model integrates multi-scale residual modules, enhancing ship detection performance in complex water surface environments. However, its performance may degrade when detecting target vessels at more minor scales.
To enhance multi-scale feature information, the adaptive spatial feature fusion (ASFF) mechanism dynamically tunes the weights assigned to feature maps. This dynamic adjustment empowers the model to get information at varying scales and hierarchical levels [24], resulting in a more comprehensive feature fusion [25]. Guo et al. [26] proposed a lightweight LMSD-YOLO model to create a real-time maritime vessel detection model with a reduced parameter count. The model achieves an adaptive fusion of multi-scale features. However, its feature extraction capability falls short in low-visibility images and noise interference, leading to potential false negatives for small vessels.
The current YOLO algorithm has been developed to version 8 (YOLOv8). Compared to the previous version, YOLOv7, YOLOv8 introduces the convolution to fusion structure, reducing the number of convolution modules, resulting in faster detection speeds. However, this speed enhancement comes at the cost of sacrificing some detection accuracy. Consequently, YOLOv8 might exhibit reduced ship detection accuracy in complex environments. YOLOv7 incorporates the efficient layer aggregation networks (ELAN) structure to facilitate multi-branch gradient flow feature extraction [27]. This design enhances the model’s detection performance, making it better suited for ship detection in complex maritime conditions. The YOLOv7 consists primarily of four parts: input, backbone network, head network, and prediction network. The ELAN [28] combines VoVNet and CSPNet [29]. It enables the deep network to converge more effectively without changing the original model structure gradient propagation path and continuously enhances its learning capability. The head network enhances its feature fusion capability with the SPPCSPC module and path aggregation network (PANet).
Given the challenges related to work poses and the difficulty of detecting small vessels in complex environments, further improvements are needed for the YOLOv7 model. Dynamic convolutions offer advantages in capturing multi-dimensional features, and SPDC is adept at enhancing small object detection at low resolutions. Both of these techniques contribute to improving feature information extraction. ASFF can effectively merge multi-scale features to enrich feature detection information. Therefore, this study introduces dynamic convolutions, SPDC, and ASFF networks to the basic YOLOv7 model to enhance detection outcomes.
3. Proposed Detection Framework
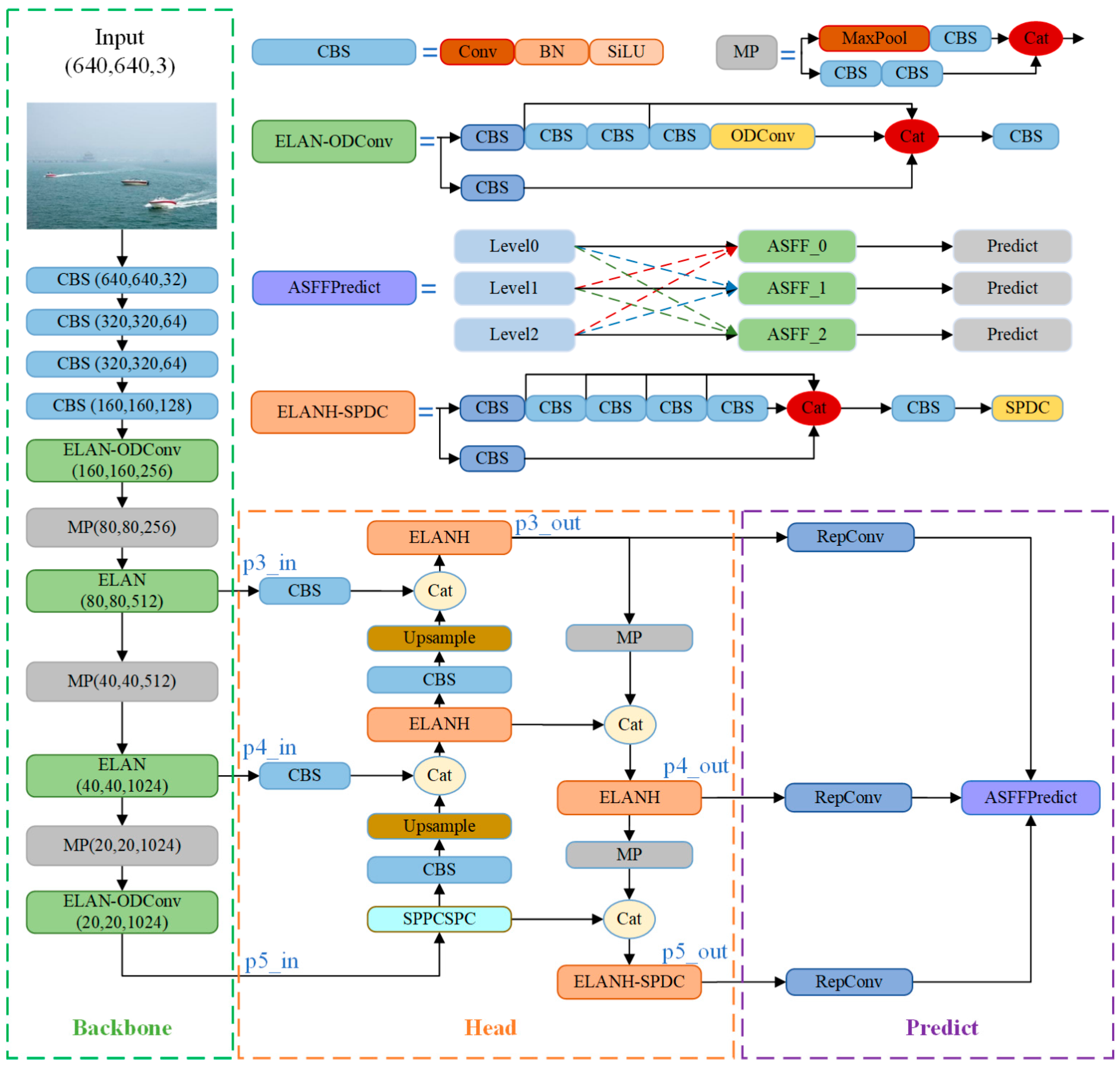
One needs to strengthen the network’s feature extraction capabilities and optimize information flow to enhance the model’s effectiveness in detecting ships under challenging sea conditions. Therefore, this paper optimizes the backbone, head, and prediction network components of YOLOv7 by leveraging the advantages of ODConv, SPDC, and ASFF. As illustrated in Figure 1, the YOLO-Vessel model comprises three main components: the ELAN-ODConv backbone network structure, ELANH-SPDC head structure, and ASFFPredict prediction network structure.
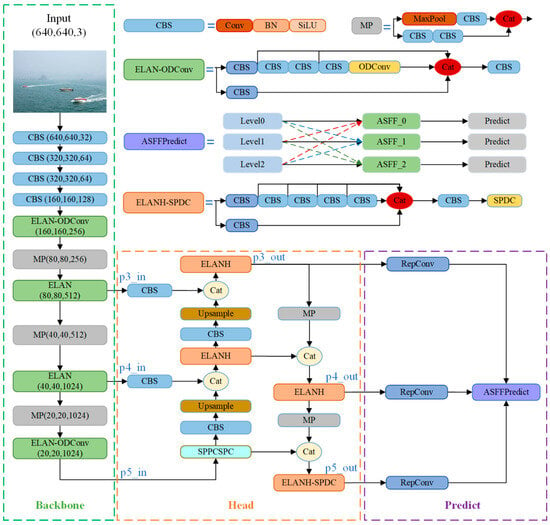
Figure 1.
Entire structure of the YOLO-Vessel.
3.1. Backbone Network
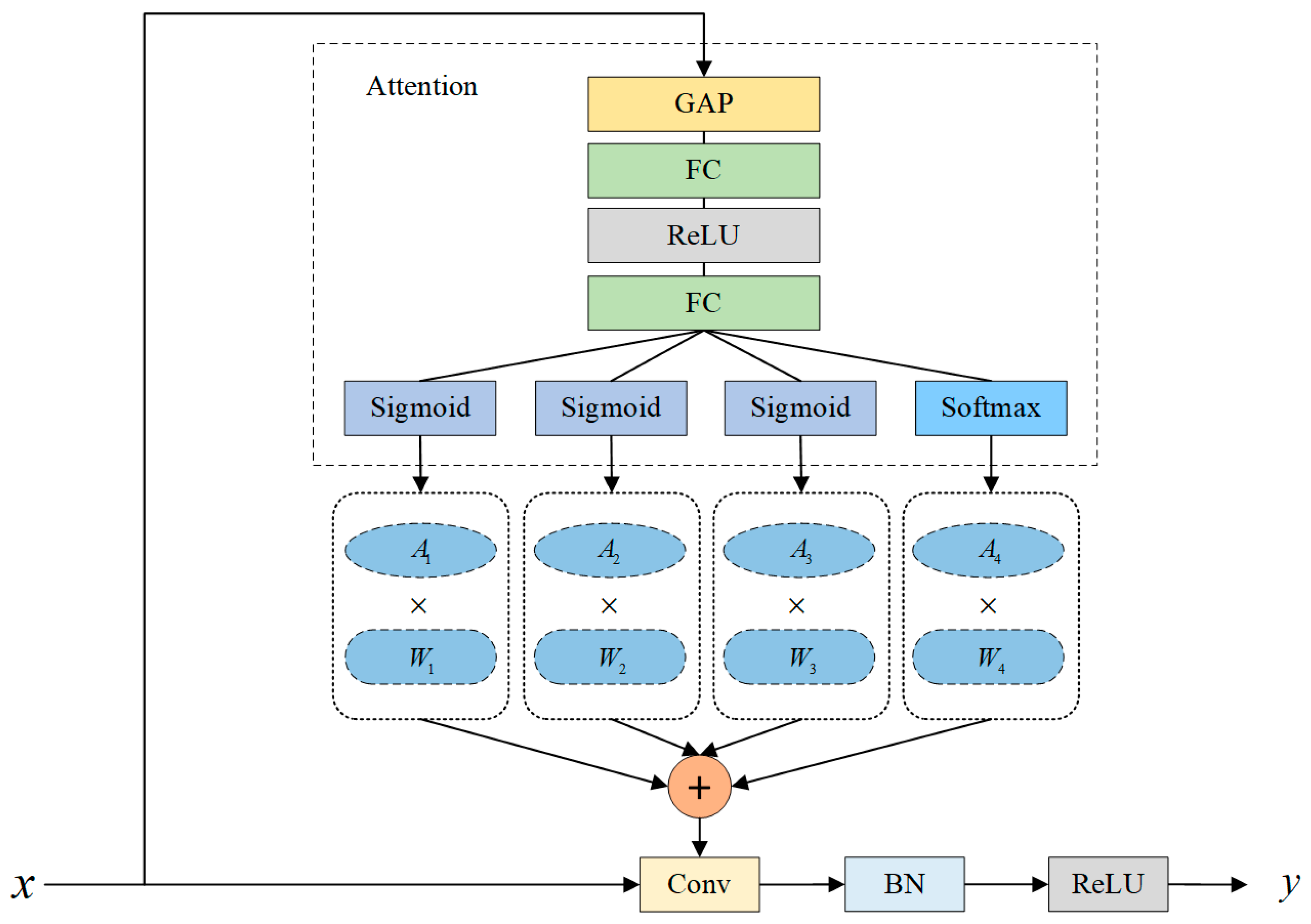
The YOLO-Vessel backbone network incorporates CBS, ELAN-ODConv, and MP modules. The CBS module comprises a convolution layer, with the SiLU activation function applied afterward, followed by the addition of a batch normalization (BN) layer. The ELAN-ODConv module includes the CBS module and the ODConv unit. This design enhances the network’s learning capabilities by extending and merging bases while preserving the original gradient path. In each ELAN-ODConv structure, downsampling is achieved by compressing the feature map scale using a 3 × 3 convolution kernel with a stride of 1 and zero padding. Then, the feature map passes through two branches: one enters the CBS module, and the other enters multiple CBS modules and an ODConv structure. Finally, the outputs of the two branches are operated with Concat and partially transformed using a 1 × 1 convolution module to improve the learnability of the model. As shown in Figure 2, the design idea of ODConv is to generate a new feature map by performing element-wise multiplication and addition of four convolution kernels, each of the same size and dimension, while considering their corresponding attention weights, and finally, by using a convolution operation.
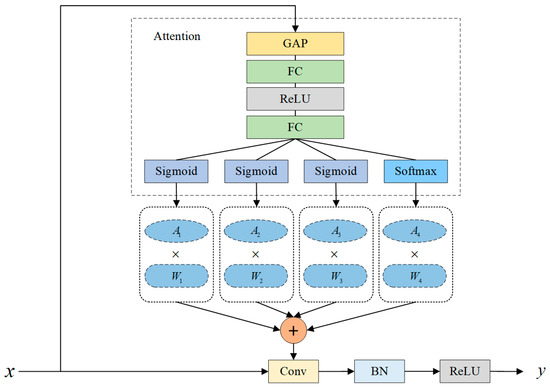
Figure 2.
Structure of ODConv.
ODConv is a more generalized form of dynamic convolution, with its computational form as follows:
, , and are three newly introduced attention weights, representing the weights associated with the spatial position of the convolution kernel, input channels, and output channels, respectively. is the attention weight corresponding to the number of convolutional kernels.
Figure 2 shows that ODConv learns the four attention weights of the convolutional kernel in parallel along four dimensions. The input feature map is first subjected to a global average pooling (GAP) operation and then passed through a Fully Connected (FC) Layer—ReLU Activation Layer—Fully Connected (FC) Layer structure. Finally, a set of attention weights is obtained at the output of the sigmoid and softmax activation function layers. Specifically, , , and are generated by the Sigmoid activation function, i.e.,
This function maps input values to the interval (0,1). is generated by the Softmax activation function, i.e.,
Here, represents the ith element of the input vector. Softmax produces a set of probability values, introducing normalized constraints to simplify the learning of . The final weighted values of each group of convolutional kernels are used to generate output features. Compared with ordinary dynamic convolution, which only considers the single factor of the number of convolution kernels, ODConv adds multiple-dimensional information so that the input features can obtain rich contextual information.
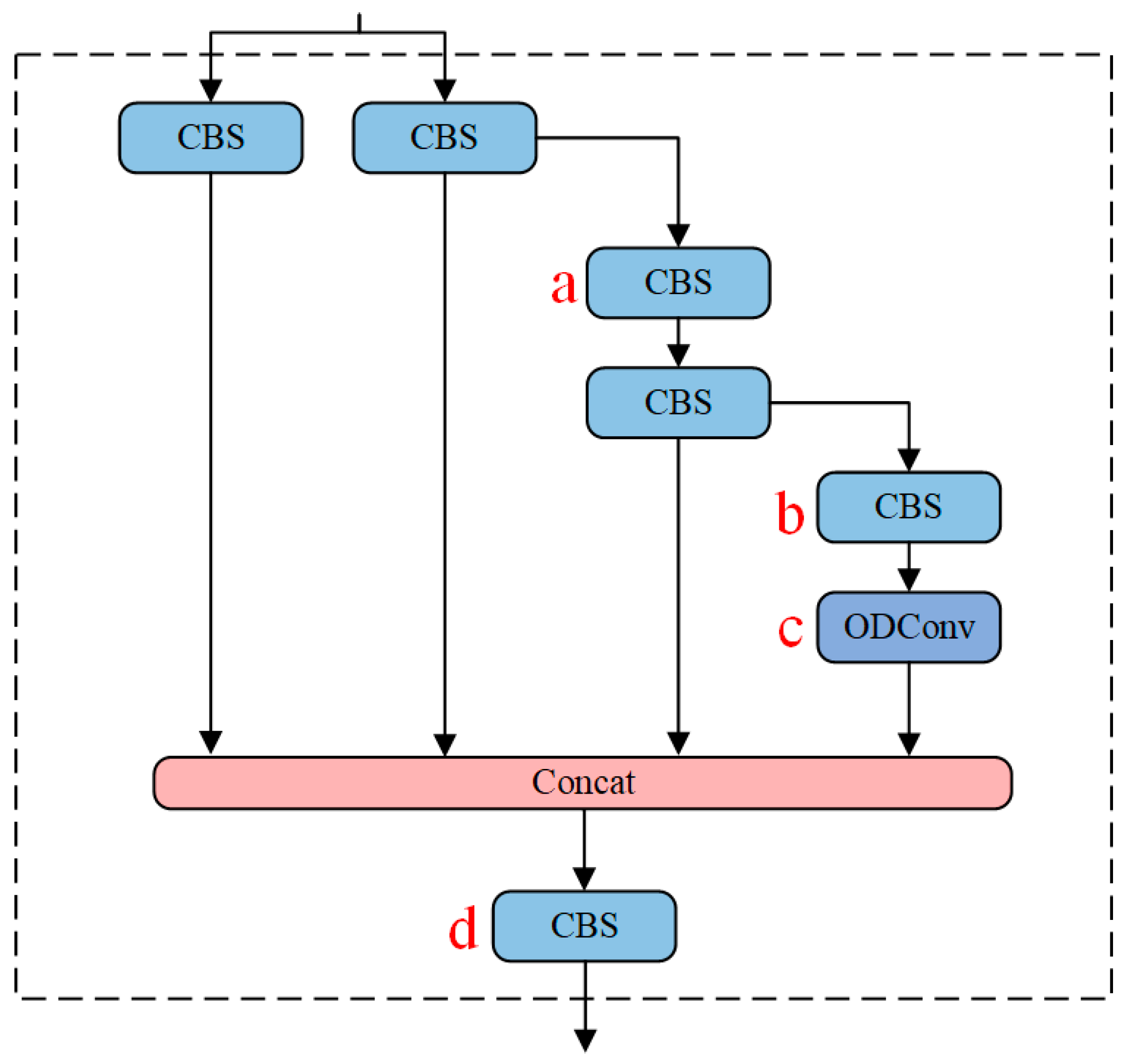
In this study, ODConv is employed to achieve the goal of a more precise model without increasing the network’s width and depth. Figure 3 presents four variations of ELAN-ODConv types, namely ELAN-ODConv-a, ELAN-ODConv-b, ELAN-ODConv-c, and ELAN-ODConv-d, designed with ODConv at different positions in the backbone network of the YOLOv7-Vessel. Experimental results (as detailed in Section 4.5.2) indicate that replacing the ordinary convolution module with ODConv at position c within the ELAN module results in the maximum mAP value. Therefore, ELAN-ODConv-c is selected as the preferred ELAN-ODConv configuration.
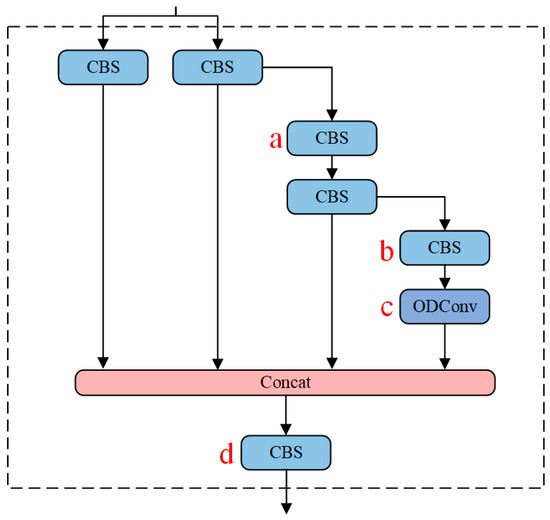
Figure 3.
Structure of ELAN-ODConv. The ODConv is introduced into the ELAN module, where positions a, b, c, and d are highlighted in red, representing the locations where ordinary convolutions are replaced with ODConv.
3.2. Head Network
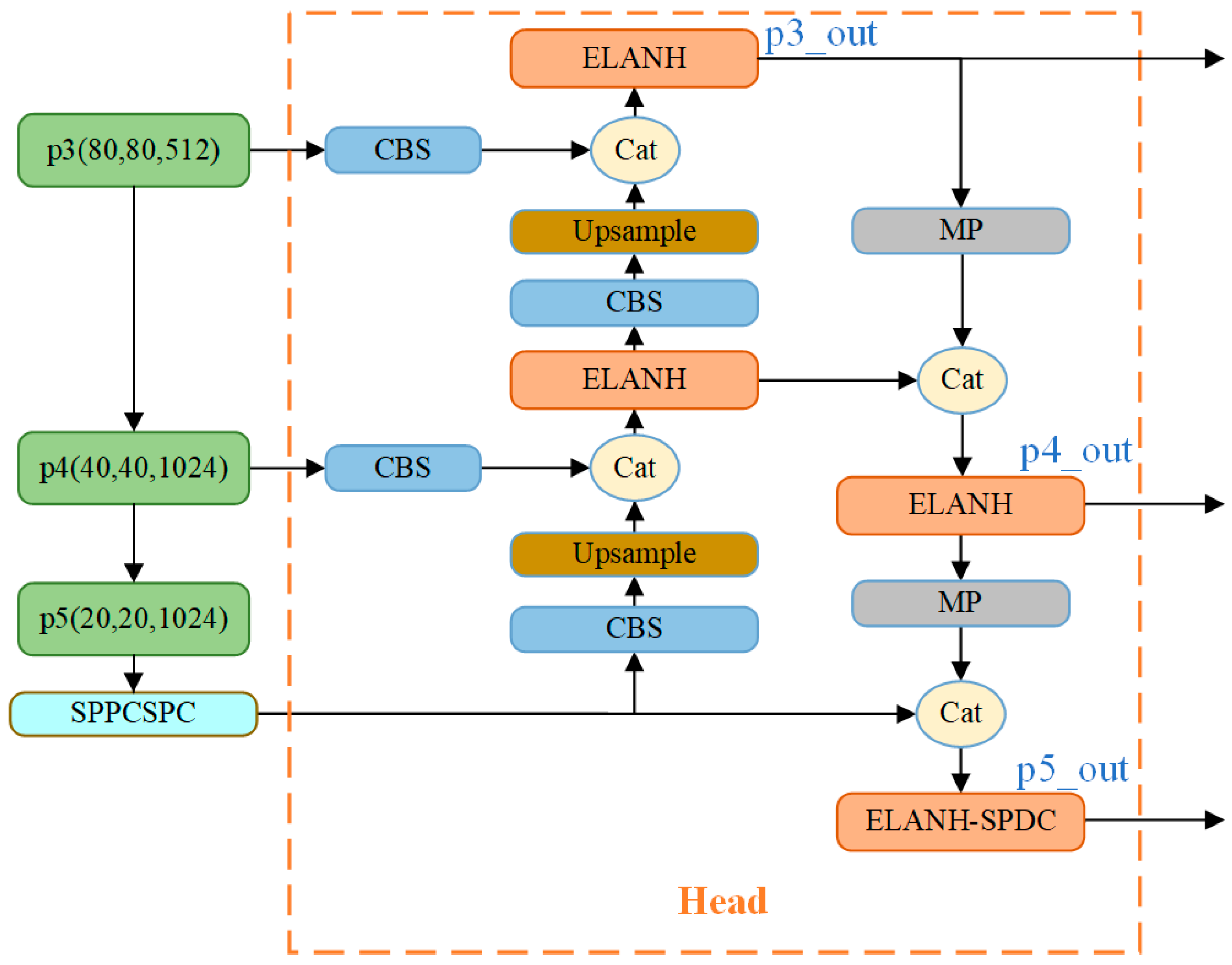
YOLO-Vessel’s head network consists of the PANet structure, the SPPCSPC module, and the ELANH-SPDC module. The feature information extracted from the backbone network is generated in the p3_in, p4_in, and p5_in layers at the three scales of 80 × 80, 40 × 40, and 20 × 20, respectively, and output to the head network. Subsequently, the 20 × 20 scale feature map is first upsampled using the SPPCPSC module to perform a Concat operation with the 40 × 40 scale feature map. Then, the output features are upsampled to perform a second fusion with the 80 × 80 scale feature map to further the fusion between adjacent scales of the feature map. However, in the multiscale structure, as the depth of the network grows, the location information of the feature map is weakened, and the resolution of the map gradually decreases, which leads to the degradation of the model’s detection performance. Accordingly, we introduce an ELANH-SPDC module, incorporating the SPDC module into the head network’s tail. This enhancement aims to sharpen the model’s attention towards low-resolution and small objects, particularly in remote sea areas, while also boosting recognition performance for low-resolution feature maps.
As shown in Figure 4, this study incorporates the SPDC module into three head network positions: p3_out, p4_out, and p5_out. When the feature maps enter the Head, the channel dimension reaches its maximum while the network resolution reaches its minimum. Introducing features learned by SPDC at this stage is crucial for detecting low-resolution features. Experimental results (as detailed in Section 4.5.1) indicate that inserting SPDC at position p5_out in the head network yields the optimal detection performance for the model. Therefore, the SPDC designed at position p5_out is employed to create the ELANH-SPDC module, which is then integrated into the overall head network structure.
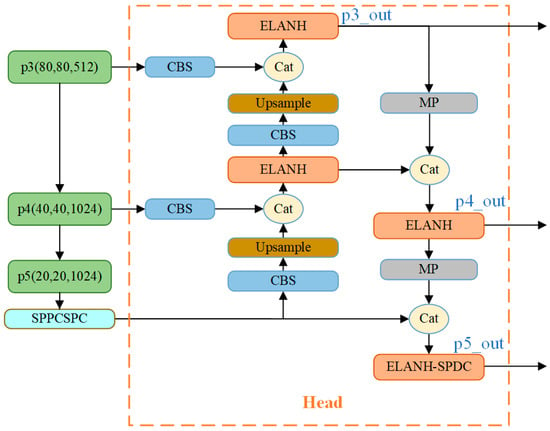
Figure 4.
The head network is equipped with the ELANH-SPDC module.
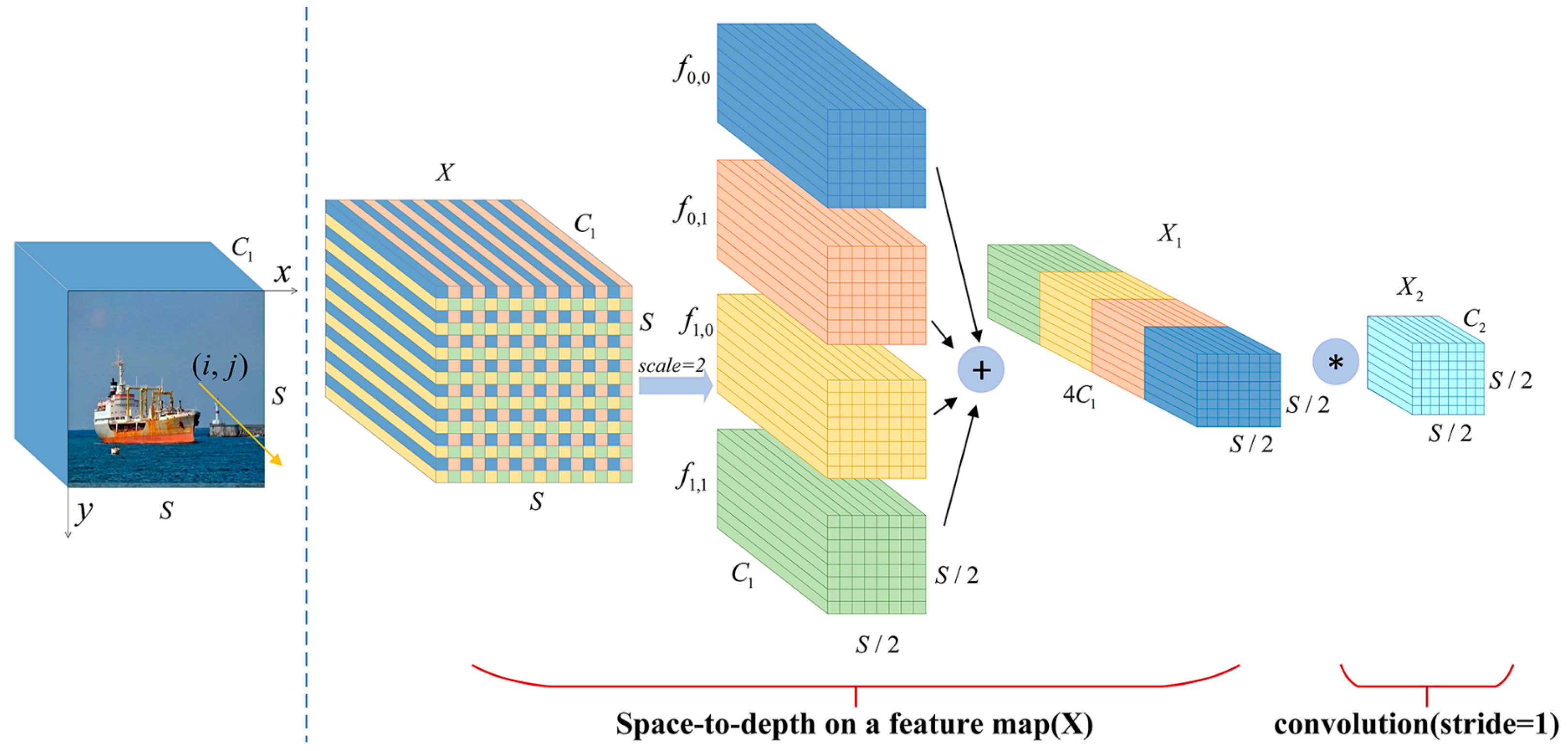
The ELANH-SPDC module is the main feature extraction module located at the output position of p5_out in the head network, which divides the gradient stream into network paths of different lengths. The Concat operation fuses the features of each branch, ultimately replacing the original 1 × 1 standard convolution with the SPDC module to obtain more effective feature information. This approach preserves more fused, detailed features and optimizes the model’s detection accuracy. We set as the original feature map, as the intermediate feature map, as the final feature map, as the subfeature map, as the feature map scale scaling factor, as the feature map length and width dimension values, as the feature map depth value, and as the convolution kernel depth value. Space-to-depth cuts a feature map of size into a series of subfeature maps, and each subfeature map is formed by all entries of and divided by scale. The SPDC calculation equation is as follows:
The graphical process is given in Figure 5, where four subfeature maps , , , are obtained when , each with size , which is equivalent to twice the downsampling of the original feature map . Then, all the subfeature maps are connected along the channel dimension to obtain the intermediate feature map , where the spatial dimension is reduced by a scale factor, and the channel dimension is increased by a scale factor. The space-to-depth layer converts the original feature map into an intermediate feature map with feature discrimination information. A convolutional layer with a filter is added in Figure 5 to achieve further transformation from the intermediate feature map to the final feature map . The step size of this convolutional layer is set to 1 to retain the maximum amount of discriminative feature information. Therefore, we introduce the SPDC structure into the ELANH structure of the head network, which can effectively improve the detection performance of the model for low-resolution and small ships at sea.
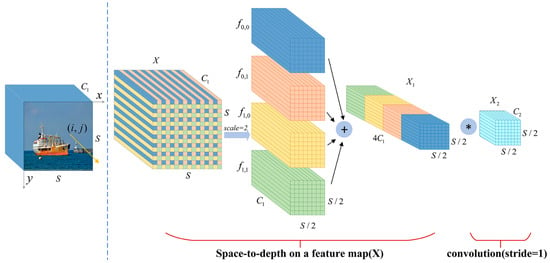
Figure 5.
Structure of SPDC. The symbol “*” represents the convolution operation.
3.3. Prediction Network
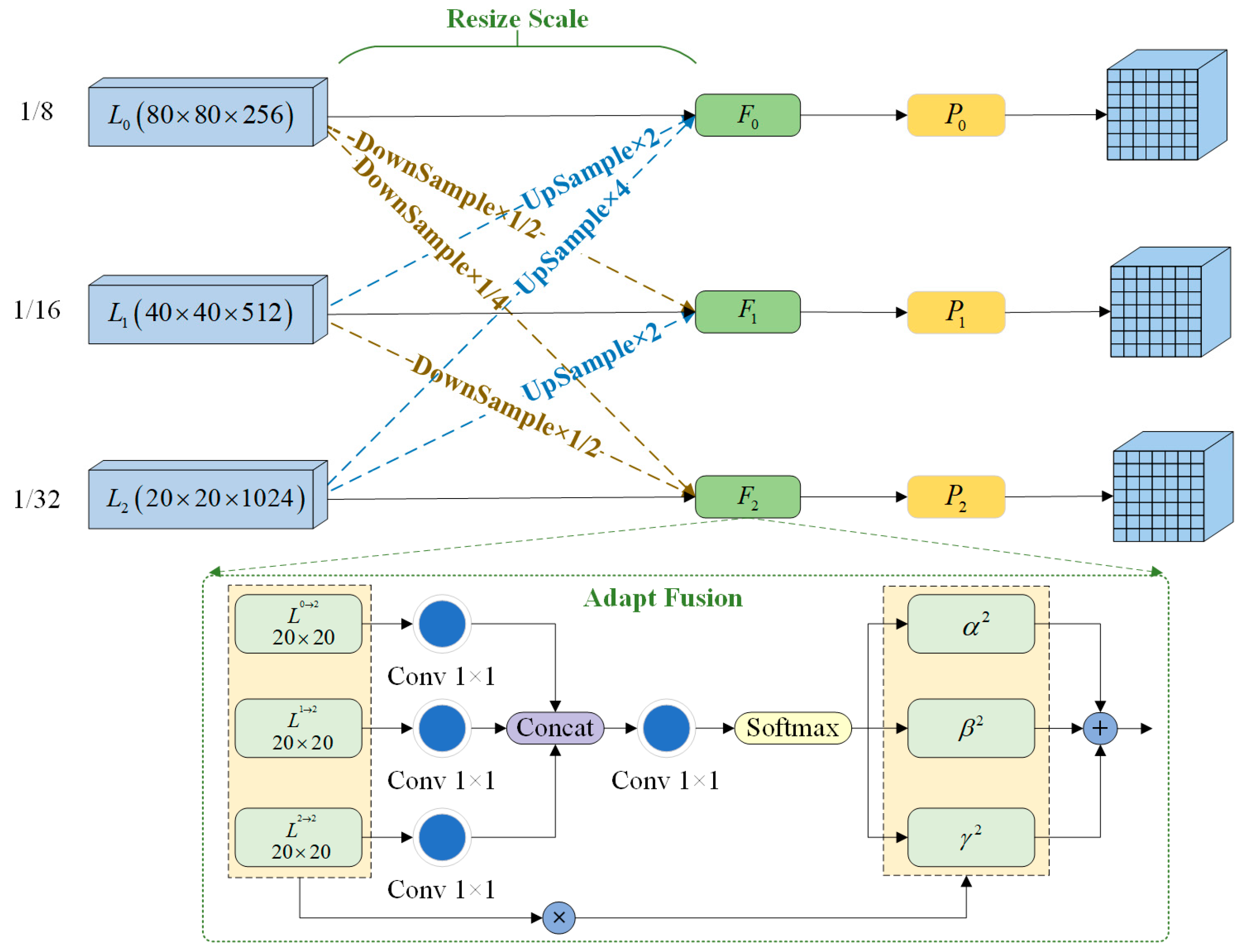
The YOLO-Vessel model uses a multiscale prediction method in the prediction network part, where the input 640 × 640 scale images are downsampled in the backbone structure by factors of 8×, 16×, and 32×. Then, the output of the head network yields 80 × 80 scale feature maps p3_out, 40 × 40 scale feature maps p4_out, and 20 × 20 scale feature maps p5_out. Among them, p3_out is used for small-scale target detection, p4_out is used for medium-scale target detection, and p5_out is used for large-scale target detection. As depicted in Figure 6, this paper introduces an adaptively spatial feature fusion network structure named ASFFPredict. Utilizing ASFF, the network learns optimal fusion weights to accentuate feature layers that contain more information about small targets. Subsequently, features from each feature layer are fused to ensure that elements with higher weights dominate the expression in the resulting feature map. The introduction of ASFF between the head network and YOLO head aims to enhance the model’s detection performance for small maritime targets, providing an innovative solution for ship detection problems in maritime regions.
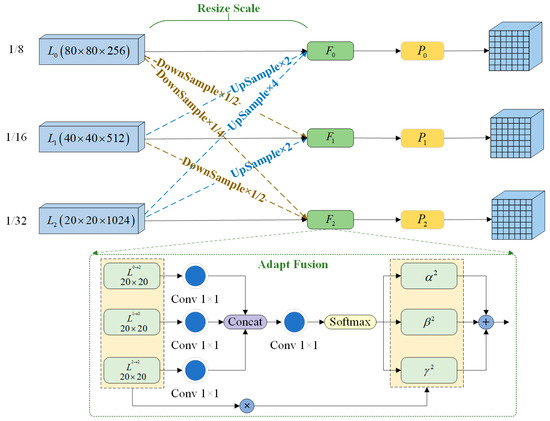
Figure 6.
The process of adaptively spatial feature fusion.
We select three layers of feature map output from the head network for fusion. In Figure 6, , , and denote the feature maps involved in adaptive fusion. Direct feature fusion cannot be performed since these three feature maps have different scales and channels. Therefore, the resolution and channels of each feature layer need to first be adjusted to be the same. Taking layer fusion as an example, the fused feature map is labeled , and then, the three spatial weights from , , and to are labeled , , and , respectively. The expressions are as follows:
where , , and , , and are normalized scalars that are calculated using the Softmax function. The expressions are as follows:
and denote the feature maps with transformed scales, which are transformed from the feature maps of the layer to the layer and from the feature maps of the layer to the layer. In this process, a 3 × 3 convolution is first used to downsample the layer four times and the layer two times, thus adjusting the feature maps of all layers to a 20 × 20 scale size. Then, the other feature layers are fused and upsampled using nearest neighbor interpolation. Next, the feature channels of and are adjusted to 1024 using 1 × 1 convolution, and the feature map scale is kept constant. Finally, and the transformed and are subjected to the Concat operation, and each of the three feature maps are multiplied by their respective weights; the results are then summed to get the feature map . The weight parameters are learned from the convolutional layer output using gradient back-propagation, and the weights can be adaptively adjusted in the feature fusion process. The adaptively spatial feature fusion process achieves a better fusion of features at different scales, effectively recognizes small and multiscale objects, and enhances the capability for maritime vessel detection.
4. Experiments
4.1. Dataset Preparation and Data Augmentation
The datasets we use are derived from two public datasets and one handcrafted dataset, including the public ship dataset SeaShips7000 [30] and the ship dataset provided by the 2nd International Challenge for Intelligent Perception of Marine Targets in 2021, with 200 and 4300 images, respectively. The mixed public dataset covers six ship categories: bulk carrier, sailboat, container ship, yacht, cruises, and fishing boat. This dataset is divided into an 8:1:1 ratio for training, validation, and testing. There are 415 pictures in the homemade dataset collected using a fixed shooting device in the Yangtze River waters of the Chongqing section. The shooting device used a Hikvision 23× zoom monitoring dome with a resolution of 2560 pixels (horizontal) × 1440 (vertical) pixels and shot ship images containing three real scenes of normal, rain, haze, and dawn from different positions and angles. Due to the lack of snowy weather, the ship images in snowy weather come from real snowy ship pictures collected by web crawlers. The homemade dataset includes ship pictures captured in various weather conditions: normal clear, rain, haze, snow, and dawn. Each weather type constitutes 20% of the dataset, allowing the model’s performance in detecting ships under real-world environmental conditions to be evaluated.
Usually, images acquired in complex adverse weather are visually richer and better match the actual complex sea-going ship conditions. However, acquiring large quantities of realistic ship images in adverse weather conditions in real sea environments is challenging, which makes it necessary to use synthetic images. In this paper, the above-mixed public dataset is artificially synthesized with images of ships under severe weather conditions [31], and the synthesized dataset is named “SeaShips_weather.” It is a synthesis of rain, haze, snow, and dawn weather images based on the RGB layer stacking algorithm, atmospheric scattering model, and retinex theory, as shown in Figure 7.

Figure 7.
Synthesized ship images in adverse maritime weather conditions. (a) Rainy weather images, including the original and rainy images with rain streak angles of −45 degrees, 0 degrees, and 45 degrees. (b) Haze images, including the original image and images with haze concentrations of 0.02, 0.04, and 0.06. (c) Snowy weather images, including the original and snowy images with 1, 3, and 5 snow levels. (d) Dawn images, including the original and dawn images, have low light coefficients of 0.25, 0.55, and 0.85.
- Rain patterns with different tilt angles of −45, 0, and 45 degrees are randomly added to the preprocessed image to synthesize the rain ship image. The expressions of synthetic rain are as follows:denotes the synthesized rain image, denotes any pixel in the image, denotes the original image, denotes the rain pattern layer, and denotes a random luminance value, as shown in Figure 7a.
- The haze can significantly degrade image quality during detection. To simulate ship scenes in such conditions, we employ an atmospheric scattering model to synthesize hazy sky images. The formula for creating artificial haze is as follows:is the synthesized dense haze image, is the original image, the parameter is any pixel in the image, is the wavelength of light, is the value of scattered atmospheric light at infinity, and is the light propagation function, in which is the atmospheric scattering factor and is the distance of the target object. Adjusting the atmospheric scattering factor synthesizes the sea haze images of different degrees, as shown in Figure 7b.
- As depicted in Figure 7c, the snowflake texture is randomly added to the original image by adjusting the snow amount value to synthesize a ship image on a snowy day. The expression of the synthesized snowflake is as follows:denotes the synthesized snow day image, denotes any pixel in the image, denotes the original image, denotes the rain pattern layer, and denotes the random luminance value in the image.
- Dawn weather tends to cause low brightness, low contrast, and detail loss in the image. The ship image under dawn weather is synthesized using the retinex algorithm, as shown in Figure 7d, where the attenuation coefficient changes the image brightness value. The expression of the synthesized dawn image is as follows:is the synthesized dawn image, is the original image, and is the spatially smoothed luminance function.
4.2. Experimental Environment
The experiments were conducted with the following configurations: an Ubuntu 18.04.6 operating system, a Tesla V100 GPU with 32GB of memory (Austin, TX, USA), and an Intel(R) Xeon(R) Platinum 8163 CPU (Santa Clara, CA, USA). To accelerate the computations, we employed CUDA 10.2 and cuDNN 7.6.5. The training of our proposed model and the comparison models was carried out using the PyTorch 1.7.1 framework.
4.3. Experimental Setup
The crucial details of the key parameters for training the network model in this study are as follows: the input image size is set to 640 × 640, the initial learning rate is 0.001, momentum is 0.937, weight decay is 0.0005, the batch size is 4, each training epoch duration is 62 s, Mosaic is set to 1.0, and the optimizer employs stochastic gradient descent (SGD) with cosine learning rate decay strategy. Other parameters adopt default values from YOLOv7. Mosaic data augmentation enriched the training dataset by introducing four images simultaneously, which underwent flipping, zooming, and splicing operations to diversify the detection scenarios. The training process comprised 150 epochs, totaling 135,000 iterations.
4.4. Evaluation Index
To quantitatively evaluate the detection effectiveness of the proposed model, seven evaluation metrics are introduced to examine the performance, including precision (P), recall (R), average precision (AP), mean average precision (mAP), giga floating point operations per second (GFLOPS), inference time (Infer), and F-Measure (F1). Their calculation formulae are shown below.
where denotes the P-R curve, denotes the number of detected ship categories, denotes the number of correctly detected ships, denotes the number of mis-detected ships, and denotes the number of undetected ships.
4.5. Experimental Results and Analysis
4.5.1. Impact of SPDC Integration on Network Performance
Incorporating the SPDC module into the YOLOv7 model enables effective learning of ship features under complex weather conditions, which is particularly crucial for detecting low-resolution images. A meticulous evaluation and pre-selection of three potential scenarios was conducted to determine the optimal location for introducing SPDC into the network. The objective was to identify the optimal scenario that achieves the highest performance regarding mAP and F1 metrics while minimizing the computational complexity of the model’s GFLOPS. The first scenario involves introducing SPDC at the p3_out output position of the head network, the second scenario selects the p4_out output position, and the third scenario opts for the p5_out output position. As shown in Table 1, through a comparative analysis of these scenarios, the performance is optimal when SPDC is positioned at p5_out. Despite a slight increase in inference time, the model achieves an mAP of 77.6%, F1 of 76, and a significant reduction in model complexity, with GFLOPS reaching 94.8.

Table 1.
Detection results of SPDC applied at different positions in the YOLOv7 head network.
4.5.2. Results of Replacing Standard Convolution with ODConv
This section analyzes the performance of applying ODConv at different positions in the ELAN module of YOLOv7. The ELAN layer in YOLOv7 consists of seven positions for ordinary convolutions. The third, fifth, sixth, and seventh positions are selected as potential locations for replacing ordinary convolutions with ODConv. As illustrated in Figure 3, four positions in the ELAN module are labeled as a, b, c, and d, representing four improved modules. The comparative detection results are presented in Table 2.
Table 2.
Detection results of replacing ordinary convolutions with ODConv at different positions in the ELAN module.
The experimental results indicate that the YOLOv7-ODConv-c model achieves better performance at position c. Compared to the YOLOv7 model, the YOLOv7-ODConv-c model shows a slight increase in inference time due to the increased learning weight dimensions of ODConv. However, it achieves an improvement of 1.6% in mAP, a 2% increase in F1, and a reduction in GFLOPS to 100.9. In summary, with a marginal sacrifice in speed, the YOLOv7-ODConv-c model significantly enhances ship detection accuracy.
4.5.3. Ablation Experiment
This section verifies the effectiveness of ELAN-ODConv, ELANH-SPDC, and ASFFPredict for ship detection tasks in adverse weather conditions at sea. Based on the YOLOv7 model, three different network models were constructed sequentially, introducing new modules combined with varying network structures, as shown in Table 3. Here, √ indicates the incorporation of the corresponding improvement module, while × suggests the absence of the respective improvement module.
Table 3.
YOLOv7 models with different improvements.
YOLO-ES introduces a single new module, YOLO-OS introduces two new modules, and YOLO-Vessel incorporates all three new modules.
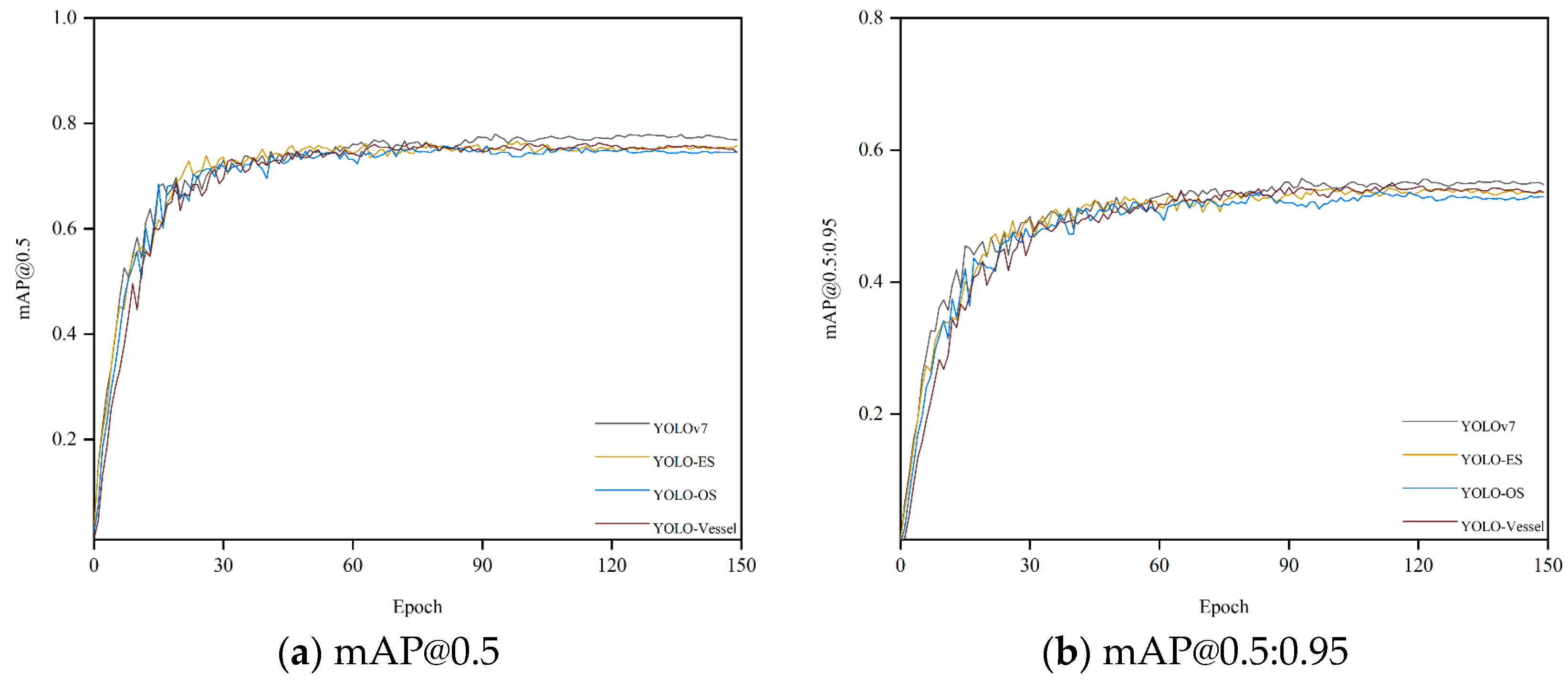
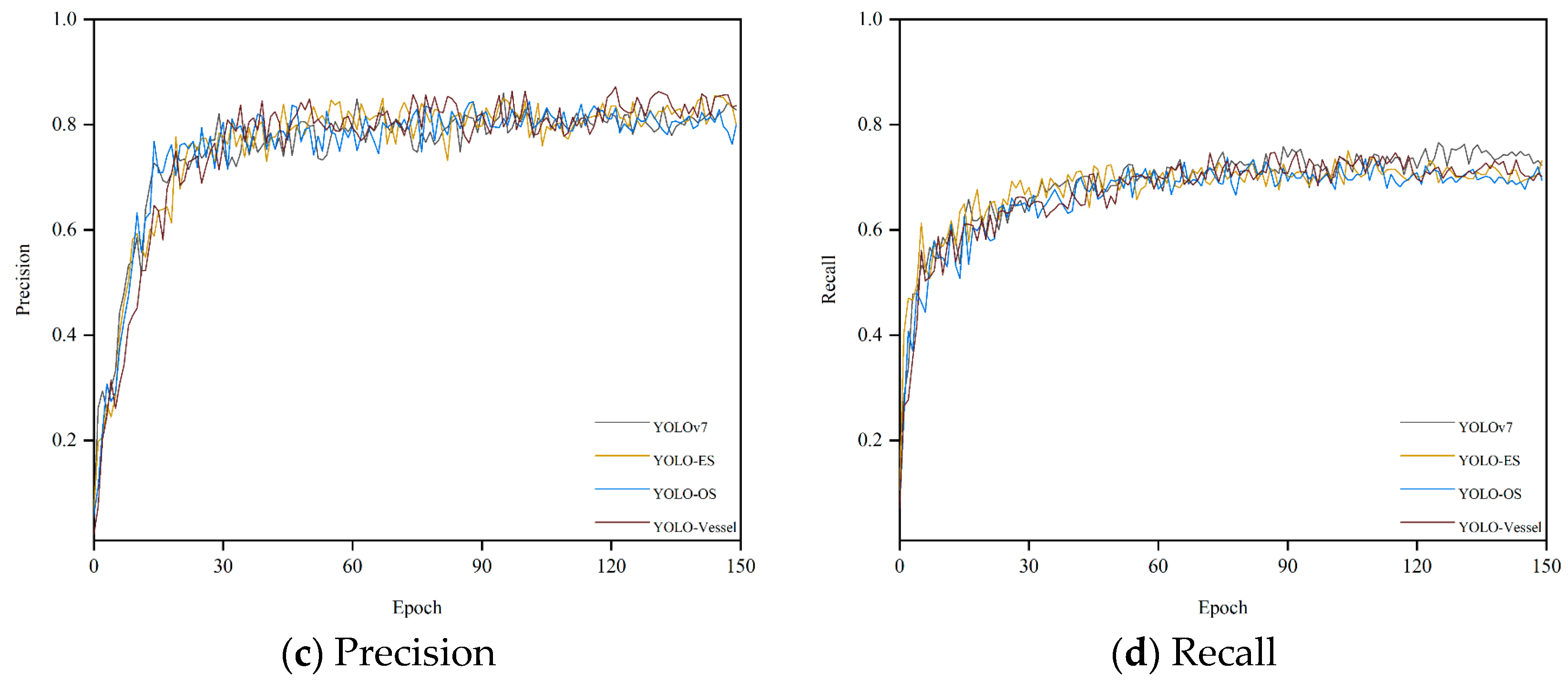
We conducted several experiments on a synthetic weather ship dataset. Figure 8 shows the mAP, precision, and recall curves for all detectors during model training. All curves rise gently and converge quickly, indicating that the model is well-trained and not overfitted. As depicted in Figure 8a,b, the overall training curves exhibit minimal fluctuations. However, Figure 8c,d reveal more significant volatility during the ascending phase of the overall training curve, although these fluctuations minimally impact detection accuracy. Due to the introduction of ODConv and SPDC, the model’s detection capability has been enhanced. YOLO-Vessel improves precision from 82.8% to 83.7% compared to the original YOLOv7 model. Additionally, after training for 150 epochs, the recall, mAP@0.5, and mAP@0.5:0.95 indices reach 70.2%, 74.5%, and 53.6%, respectively. The model performs well in detecting ship images.
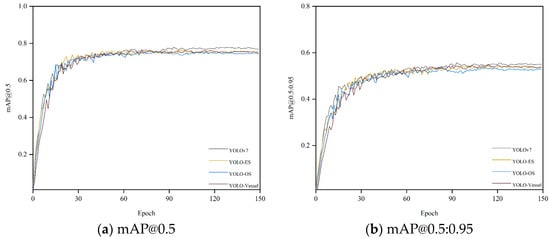
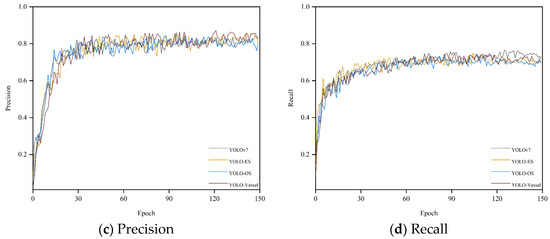
Figure 8.
Performance comparison of training different improved models on the synthetic weather ship dataset.
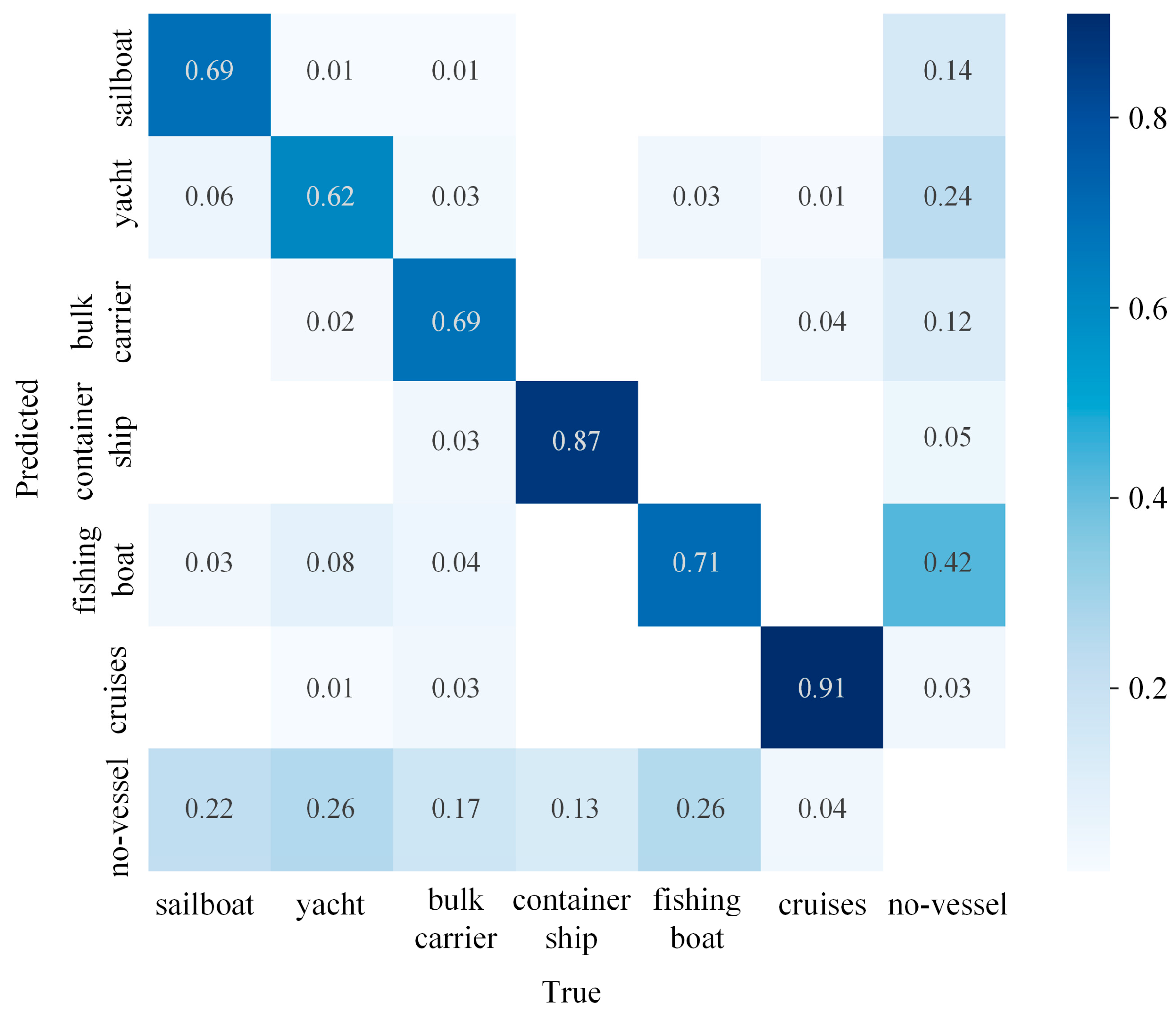
During the individual testing process for each image, predictions and actual values for each category were recorded, resulting in a confusion matrix, as shown in Figure 9. It can be observed that there are misclassifications between cargo ships and cruise ships, primarily due to the similar features of these two types of vessels and the blurriness of ships in adverse maritime weather conditions, making them easily confused. To address this, a “no-vessel” category has been added to the detection, representing the absence of any vessel. Fishing boats also experience misclassifications, mainly due to their small size. In complex maritime weather conditions, interference from background noise can easily result in misidentifying fishing boat classes as “no-vessel” classes. Therefore, adverse weather conditions significantly impact the detection of ships.
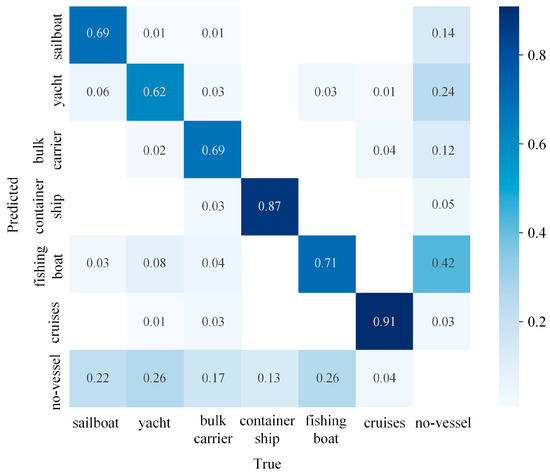
Figure 9.
Confusion matrix for the YOLO-Vessel model.
Next, the results of different improved models of YOLOv7 were compared, as shown in Table 4.
Table 4.
Performance comparison of the original model with different improved models.
The following conclusions were drawn from Table 4:
- YOLO-Vessel is the best performer in the YOLO series regarding mAP. Compared with the original YOLOv7, its mAP performance improved by 2.3%. It can be observed that the original YOLOv7 has the lowest mAP value and unsatisfactory detection results. Compared with the original YOLOv7 model, all three improved network models have improved mAP. Among them, the overall mAP values for ship detection increased by 1.6%, 1.7%, and 2.3%, respectively. The analysis shows that YOLO-ES demonstrates higher accuracy in recognizing cruise ships. Additionally, the improved models offer better recognition performance for small to medium-sized sailboats, yachts, and fishing boats. Compared to YOLOv7, YOLO-ES exhibits improved recognition of fishing boats, with an increase in AP value by 0.9%, indicating that the ELANH-SPDC structure can enhance the feature information for low-resolution targets during feature fusion, demonstrating exemplary performance in detecting low-resolution targets in complex backgrounds. Continuing to introduce the ODConv structure into the model, YOLO-OS is more advantageous in fishing boat detection accuracy, with AP values improved by 1.0% compared to YOLO-ES. This demonstrates that combining the ELAN-ODConv and ELANH-SPDC structures enhances the model’s performance in detecting small targets. YOLO-Vessel surpasses YOLOv7, YOLO-ES, and YOLO-OS in detecting fishing boats, highlighting the ASFF network’s effectiveness in improving detection performance for the IDetect head. In addition, YOLO-Vessel also demonstrates an advantage in detecting large-scale vessels such as bulk carriers and container ships. Its AP values for these categories are improved by 3.7% and 2.7%, respectively, compared to YOLOv7. This indicates that the combination of ELANH-SPDC structure, ELAN-ODConv structure, and ASFFPredict structure can fully learn more visual features of ships and thus improve the model’s performance of ship detection in adverse weather, especially detecting critical hull parts and reducing the number of false alarms. The final YOLO-Vessel has good performance for overall ship detection and can significantly improve the accuracy of ship detection under adverse weather conditions at sea.
- In terms of inference speed, the YOLO-ES model achieves the fastest detection speed. However, with the introduction of the ELAN-ODConv module, the network’s inference speed slightly decreases, but the model’s accuracy improves. Therefore, the YOLO-Vessel model trades off accuracy and inference speed, compensating for the slight reduction in speed to enhance detection accuracy.
- Regarding model computation, compared to the original model, YOLO-ES, YOLO-OS, and YOLO-Vessel reduced GFLOPS by 8.4, 10.7, and 2.4, respectively. The significant reduction in computational demands alleviates the computational burden on the machine. Furthermore, the YOLO-Vessel model incorporates adaptively spatial feature fusion and dynamic convolution techniques for ship detection, enhancing detection performance. It achieves the highest F1 score in ship image detection, surpassing the original model by 3%.
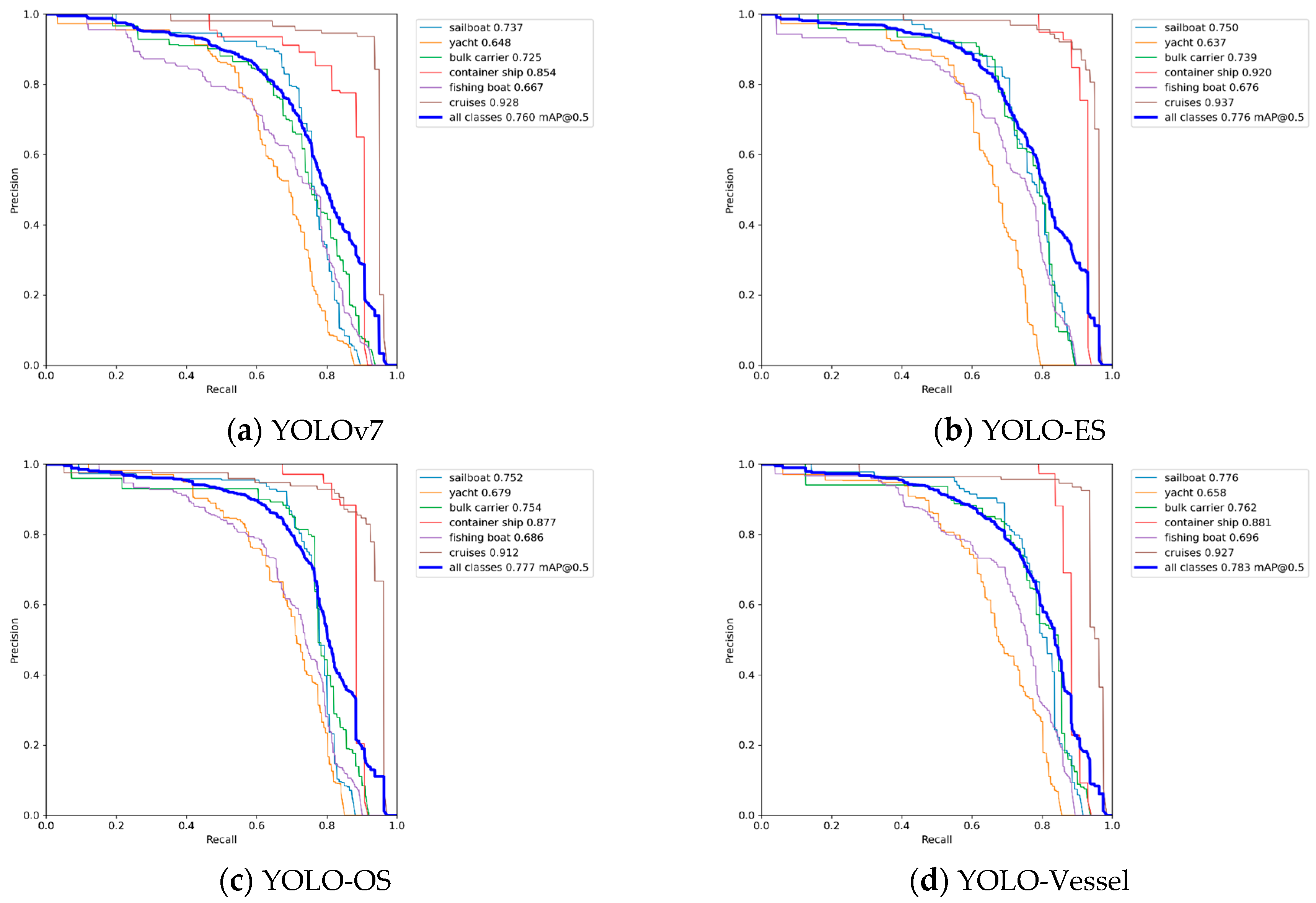
Figure 10 illustrates the Precision-Recall (P-R) curve. The area enclosed by the P-R curve and the coordinate axes in the image represent the mAP value. It can be observed that the mAP value of the YOLO-Vessel is higher than that of other improved models. The improved model shows a slight enhancement at different recall rates, indicating the effectiveness of the proposed improvements in enhancing the ship detection performance of the model.
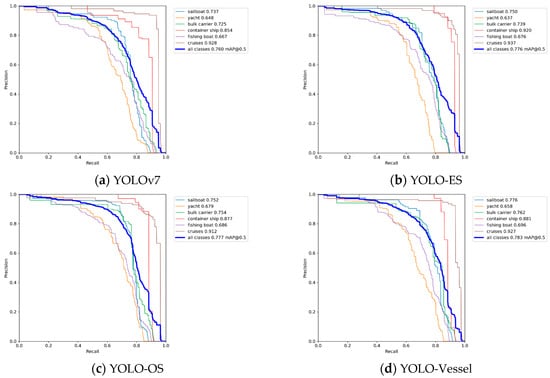
Figure 10.
Precision-Recall curves for different improved models.
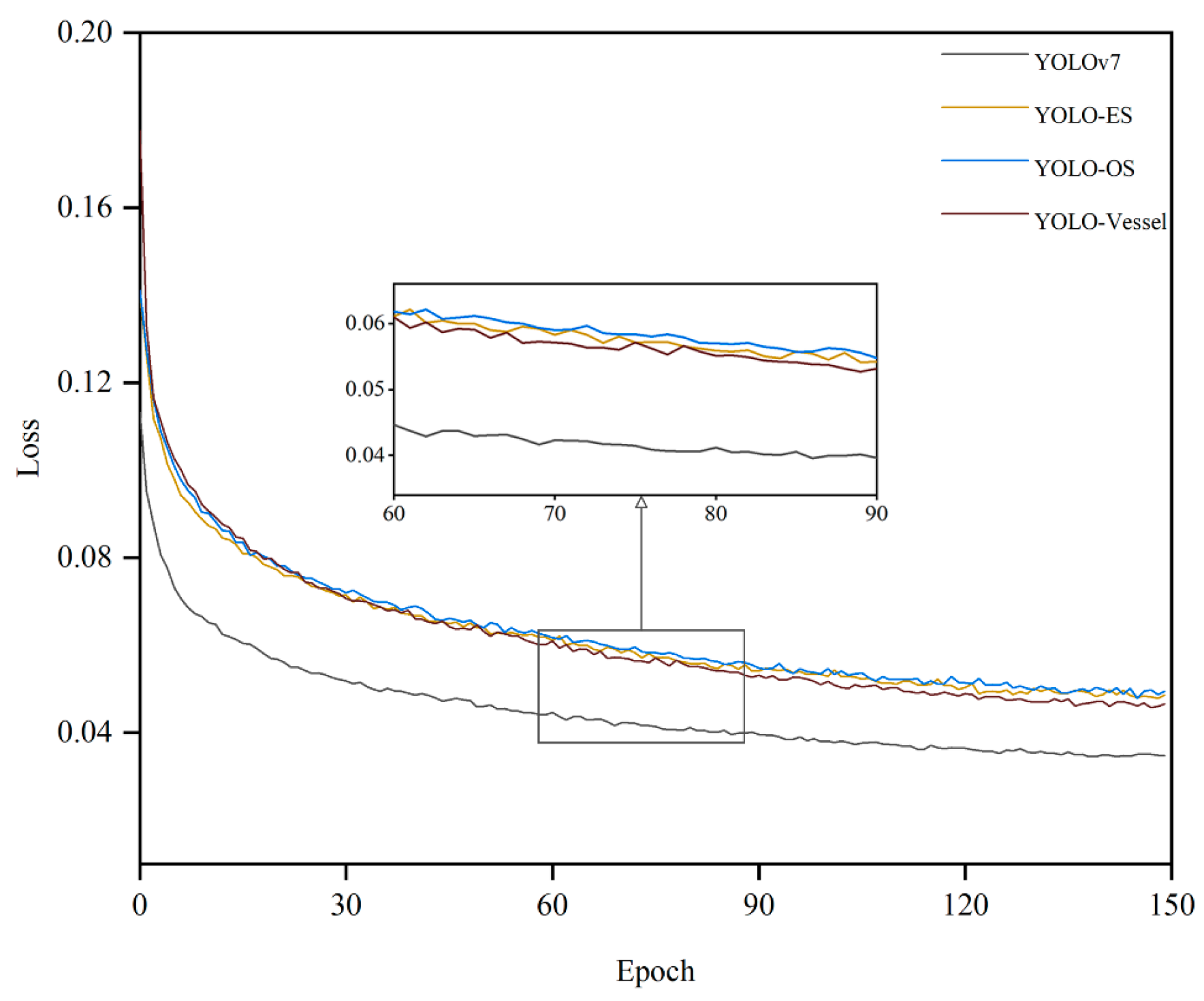
As Figure 11 demonstrates the comparison of the loss values of the original model with different improvements. Specifically, the loss curve of the YOLO-Vessel exhibits a swifter decline during initial training and converges more stably in the final phase compared to the other models, indicating that ELAN-ODConv and ELANH-SPDC can effectively extract features, resulting in a faster decrease in loss values and optimal model detection performance.
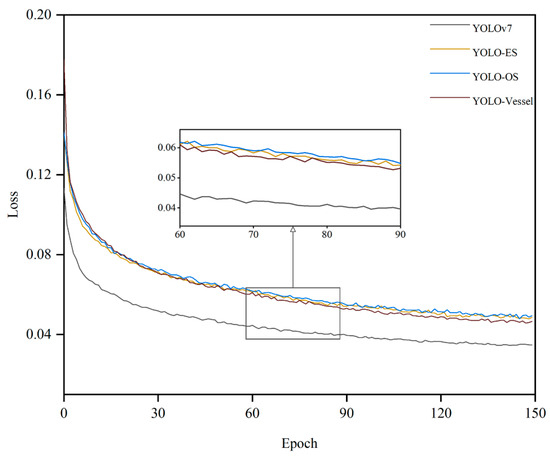
Figure 11.
Comparison of loss values for different improved models of YOLOv7.
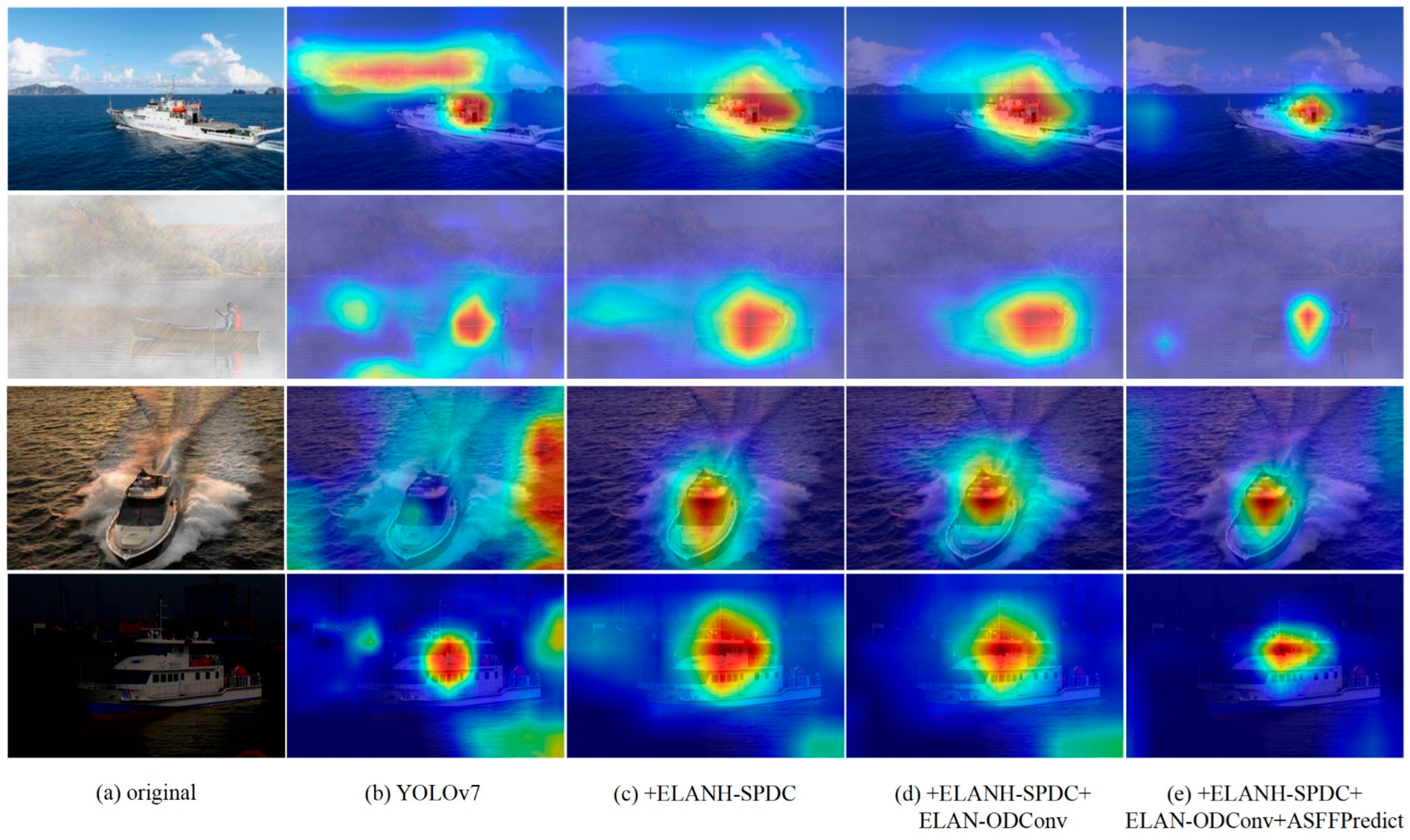
We also validate the effectiveness of introducing SPDC, ODConv, and ASFF. We employ gradient-weighted class activation mapping (Grad-CAM) to visualize heatmaps for the four models, explaining the significance of feature capture in the improved models. In the Grad-CAM heatmaps, deeper colors indicate regions contributing more to ship detection in the heatmap. Figure 12a displays the original image of the target to be detected. As depicted in Figure 12b, the heatmaps of YOLOv7 exhibit poor ship detection performance under adverse weather conditions, with instances of heatmap region misalignment or sparsity. In Figure 12c, introducing the ELANH-SPDC module mitigates the impact of adverse weather or noise to some extent, capturing the approximate location of ships and reducing interference in learning ship features under low resolution. Figure 12d illustrates the continued improvement by introducing the ELAN-ODConv, enhancing the backbone network’s ability to extract ship features and reducing the number of irrelevant regions in the heatmap. Finally, in Figure 12e, introducing the ASFFPredict structure further refines the localization of ship targets, narrowing the heatmap range and indicating an increased focus on ship features.
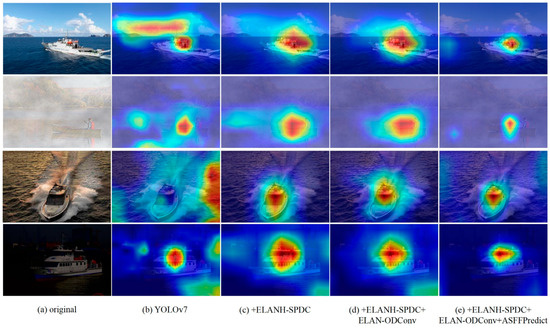
Figure 12.
The heat map of the improved model of YOLOv7 introduces different modules for detecting ships.
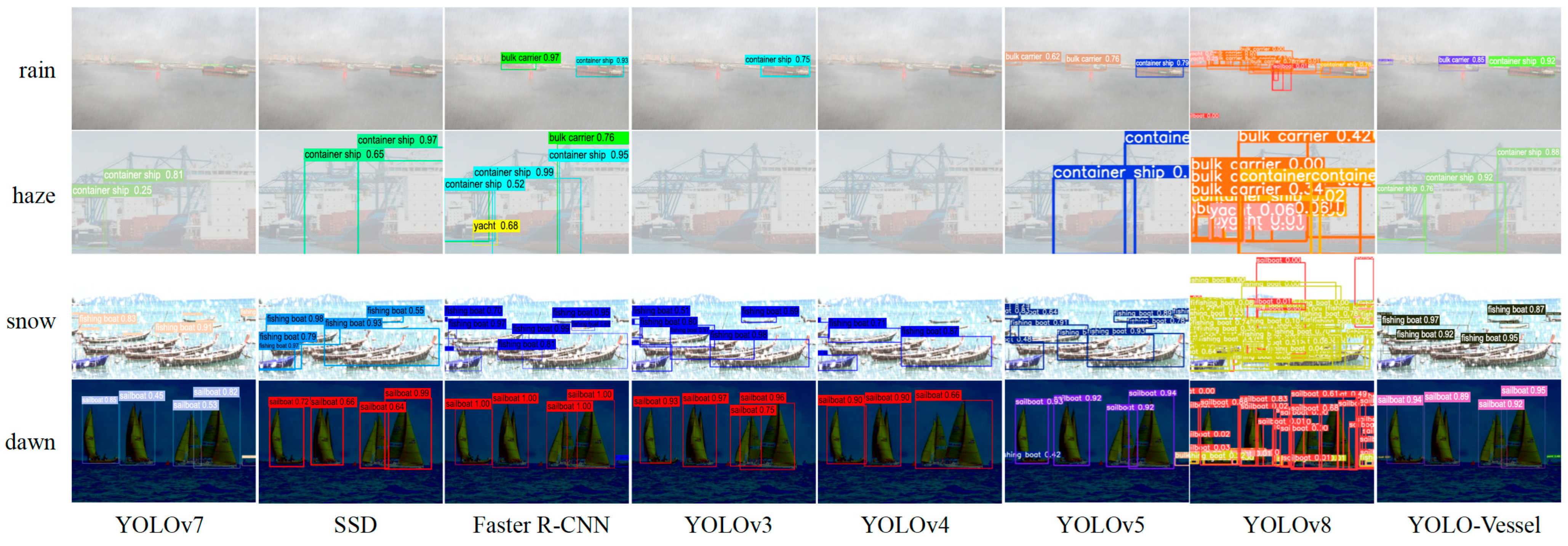
Figure 13 compares ship image detection performance under challenging conditions, including adverse weather, small target occlusion, and low lighting. This comparison involves YOLOv7, YOLO-ES, YOLO-OS, and YOLO-Vessel. As shown in Figure 13, YOLOv7 has problems with missed and false ship detection in all types of images. The same is true for YOLO-EO and YOLO-OA, and problems include, for example, insufficient accuracy in identifying frame positioning. However, YOLO-Vessel can successfully perform the identification task and locate the target vessel more accurately in the images.

Figure 13.
The experimental comparison of YOLO-Vessel with YOLOv7, YOLO-ES, and YOLO-OS models is presented in maritime vessel detection. From top to bottom, they represent vessel detection in rainy, hazy, snowy, and dawn weather conditions.
In the rainy and hazy conditions shown in Figure 13, YOLOv7 has missed ships because of the small size of individual vessels and the less distinct hull outline, which is very close to the texture of the background. In addition, in the snow and dawn conditions shown in Figure 13, the detection performance remains poor because YOLOv7 does not locate the target size well, and hence the confidence level of detecting the ship targets is low. In contrast, YOLO-ES has good detection results and can detect multiple and small ships simultaneously, indicating the effectiveness of ELANH-SPDC, but it detects frame calibration imprecisely. In Figure 13, YOLO-OS and YOLO-Vessel can successfully identify the small target position, demonstrating the efficacy of ASFFPredict and ELANH-ODConv. In addition, YOLO-Vessel can identify more small target ship positions with smaller objects, proving that YOLO-Vessel is more robust in images of ships under extreme adverse weather conditions.
4.5.4. Comparison with Other Algorithms
To further evaluate the detection performance of YOLO-Vessel, this paper compares the algorithms with several mainstream algorithms, employing the same synthetic ship dataset, and including Faster R-CNN, Fast R-CNN, Mask R-CNN, Cascade R-CNN, SSD, YOLOv3, YOLOv4, YOLOv5, YOLOv7, and YOLOv8. The experimental results in Table 5 demonstrate that the proposed YOLO-Vessel outperforms other mainstream algorithms. Specifically, the performance of Faster R-CNN, Fast R-CNN, Mask R-CNN, Cascade R-CNN, SSD, YOLOv3, and YOLOv4 is significantly worse than that of other algorithms, and it is usually challenging to perform ship detection robustly at sea level in adverse weather in marine ship detection applications. In comparison, the detection based on YOLOv5, YOLOv7, and YOLOv8 performs better. Regarding recall, while Faster R-CNN, YOLOv5m, and YOLOv5x show slightly better performance, YOLO-Vessel achieves the highest F1 score at 78%. In terms of model complexity, YOLO-Vessel has 100.3 GFLOPS, which is less than YOLOv5l, YOLOv5x, YOLOv7, YOLOv7x, YOLOv8l, and YOLOv8x, although greater than YOLOv8m at 78.7 MB. However, it achieves excellent results in mAP. Regarding inference time, YOLOv8n has the shortest inference time and the fastest speed but has insufficient detection accuracy. YOLO-Vessel has a trade-off between detection accuracy and inference speed, achieving an mAP of 78.3%, making it more advantageous than other algorithms. Furthermore, its accuracy in detecting sailboats, a crucial aspect of maritime surveillance, excelled, reaching a remarkable 77.6%. This indicates that YOLO-Vessel is also more accurate and robust for small ship detection in complex sea conditions. In conclusion, compared with other mainstream models, YOLO-Vessel has a higher accuracy advantage and is more suitable for ship detection in adverse weather.
Table 5.
Comparison of experimental results.
Comparisons of ship detection performance in rainy, hazy, snowy, and dawn weather are shown in Figure 14, Figure 15 and Figure 16. The other models in the comparison can achieve accurate ship detection in adverse weather, but errors can occur in other complex sea conditions. Due to the sizeable similar ship outline background interference and small ship occlusion, YOLOv8 cannot capture the features of small ships well, and multiple misidentified detection frames appear, resulting in less accurate ship detection at sea. In the dawn environment, the SSD algorithm misses many ships. The Faster R-CNN algorithm has improved at detecting localization recognition, but the target confidence still needs to be higher. YOLOv4 misses ship detection in the snowy environment, while YOLOv3 and YOLOv5 have better feature extraction ability, but there is a false detection situation, which may mistakenly detect the background as a ship. In contrast, the YOLO-Vessel model improves the prediction network by using ASFF, enabling it to fuse targets’ structural features at different scales, detect more ships in complex sea conditions, and achieve better detection performance.

Figure 14.
From top to bottom: representing the results of complex background ship detection at sea in rainy, hazy, snowy, and dawn weather, respectively.
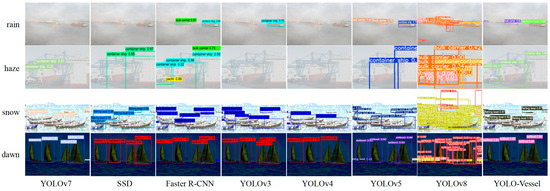
Figure 15.
From top to bottom: the results of multi-objective ship detection at sea representing rainy, hazy, snowy, and dawn weather, respectively.

Figure 16.
From top to bottom: small target ship detection results at sea representing rainy, hazy, snowy, and dawn weather, respectively.
4.5.5. Experiments on Realistic Ship Detection
This section further demonstrates the YOLO-Vessel model’s detection performance in a realistic environment, as illustrated in Figure 17.

Figure 17.
Ship detection experiments in authentic adverse weather images. From left to right: ship detection results for (a) YOLOv7 and (b) YOLO-Vessel in rainy images, haze, snow, and dawn weather, respectively.
Compared with the YOLOv7 algorithm, YOLO-Vessel can extract different types of ship features under different adverse weather conditions and perform target detection for six common types of ships with good recognition results. From the ship detection results in rainy, hazy, snowy, and dawn weather, we can conclude the following:
- As shown in the rain of Figure 17, YOLOv7 mistakenly identifies the house building background as a ship in a rainy environment; in the same case, as shown in the snow in Figure 17, YOLOv7 incorrectly detects street light as some other vessels in snowy weather, while YOLO-Vessel can correctly detect the ship category and location with 94% confidence, which solves the complex background interference problem.
- As shown in the haze of Figure 17, under hazy weather conditions, YOLOv7 successfully detected large bulk carriers and cruise ships near the shore but failed to detect small target vessels in the distance. In contrast, YOLO-Vessel significantly improved recognition of small ships in haze weather, effectively reducing the probability of missed detections.
- As shown in the dawn of Figure 17, in the dawn environment, YOLOv7 only detects one ship, and the YOLO-Vessel model avoids missed detection and detects all the cruise ships and bulk carrier in the picture.
In conclusion, YOLO-Vessel outperforms YOLOv7 on the real adverse weather dataset, demonstrating its superiority in challenging conditions and further validating the effectiveness of YOLO-Vessel for ship detection in complex backgrounds.
5. Conclusions
In addressing the challenges posed by adverse weather, complex background interference in ship detection images, and multiscale ship target detection, this paper introduces ODConv to optimize the YOLOv7 model. It fully uses four-dimensional weights to learn image features, achieving efficient feature extraction and addressing the challenges of missed and false detections in complex backgrounds. Moreover, the model’s detection accuracy is enhanced by introducing the ELANH-SPDC module, guided by SPDC, in the head network to preserve finer feature details. Furthermore, incorporating ASFFPredict into the detection head allows for aggregating more semantic information, enabling more comprehensive feature fusion. This effectively tackles the issues related to detecting ships at various scales, addressing the uneven distribution of target features and enhancing the detection performance for smaller targets. Under the sample constraint, this paper improves the robustness of YOLO-Vessel for target detection in adverse weather using a mixed weather ship image training mechanism. Compared with other YOLO series models, the YOLO-Vessel method trades off complexity and detection accuracy. It can detect many maritime vessels in real-time with high accuracy. In general, the mAP of YOLO-Vessel reaches 78.3%, the detection speed is 8.0 ms/frame, and the GFLOPS is 100.8, thus satisfying real-time ship detection at sea. In our future research, we plan to explore lightweight techniques for the primary backbone of the model to reduce parameter count and model size. This may include methodologies such as model pruning, quantization, and utilizing lightweight convolution modules. We aim to develop models better suited for deployment on mobile devices, enhancing their applicability to maritime ship detection tasks.
Author Contributions
Conceptualization, Z.L. and Z.D.; methodology, Z.L. and Z.D.; software, Z.D.; validation, Z.L., K.H., Z.J. and X.Z.; formal analysis, Z.L.; investigation, Z.L.; resources, Z.L. and K.H.; data curation, Z.D. and K.H.; writing—original draft preparation, Z.D.; writing—review and editing, Z.L., K.H., Z.J. and X.Z.; visualization, Z.L. and Z.D.; supervision, X.Z., Z.J. and K.H.; project administration, Z.L. and K.H.; funding acquisition, K.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (grant number 61902273), the Chunhui Cooperation Program of the Ministry of Education (grant number HZKY20220590-202200265), and the Collaborative education program of Tianjin institute of software engineering (grant number TJISE2017026). The authors acknowledge the anonymous reviewers for their helpful comments on the manuscript.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
The authors would like to thank Tianjin Chengjian University for technical support and all the members of our team for their contribution to the marine ship detection experiments.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Xu, Q.; Li, Y.; Zhang, M.; Li, W. COCO-Net: A Dual-Supervised Network with Unified ROI-Loss for Low-Resolution Ship Detection from Optical Satellite Image Sequences. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5629115. [Google Scholar] [CrossRef]
- Liu, R.W.; Yuan, W.; Chen, X.; Lu, Y. An enhanced CNN-enabled learning method for promoting ship detection in maritime surveillance system. Ocean. Eng. 2021, 235, 109435. [Google Scholar] [CrossRef]
- Feng, J.; Li, B.; Tian, L.; Dong, C. Rapid ship detection method on movable platform based on discriminative multi-size gradient features and multi-branch support vector machine. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1357–1367. [Google Scholar] [CrossRef]
- Shi, Z.; Yu, X.; Jiang, Z.; Li, B. Ship detection in high-resolution optical imagery based on anomaly detector and local shape feature. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4511–4523. [Google Scholar]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Y.; Li, Z.; Yan, X.; Guan, Q.; Zhong, Y.; Zhang, L.; Li, D. Oil spill contextual and boundary-supervised detection network based on marine SAR images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5213910. [Google Scholar] [CrossRef]
- Chen, M.; Sun, J.; Aida, K.; Takefusa, A. Weather-aware object detection method for maritime surveillance systems. Future Gener. Comput. Syst. 2024, 151, 111–123. [Google Scholar] [CrossRef]
- Chen, X.; Wei, C.; Xin, Z.; Zhao, J.; Xian, J. Ship Detection under Low-Visibility Weather Interference via an Ensemble Generative Adversarial Network. J. Mar. Sci. Eng. 2023, 11, 2065. [Google Scholar] [CrossRef]
- Song, R.; Li, T.; Li, T. Ship detection in haze and low-light remote sensing images via colour balance and DCNN. Appl. Ocean Res. 2023, 139, 103702. [Google Scholar] [CrossRef]
- Liu, T.; Zhang, Z.; Lei, Z.; Huo, Y.; Wang, S.; Zhao, J.; Zhang, J.; Jin, X.; Zhang, X. An approach to ship target detection based on combined optimization model of dehazing and detection. Eng. Appl. Artif. Intell. 2024, 127, 107332. [Google Scholar] [CrossRef]
- Escorcia-Gutierrez, J.; Gamarra, M.; Beleño, K.; Soto, C.; Mansour, R.F. Intelligent deep learning-enabled autonomous small ship detection and classification model. Comput. Electr. Eng. 2022, 100, 107871. [Google Scholar] [CrossRef]
- Yu, M.; Han, S.; Wang, T.; Wang, H. An approach to accurate ship image recognition in a complex maritime transportation environment. J. Mar. Sci. Eng. 2022, 10, 1903. [Google Scholar] [CrossRef]
- Li, M.; Lin, S.; Huang, X. SAR Ship Detection Based on Enhanced Attention Mechanism. In Proceedings of the 2021 2nd International Conference on Artificial Intelligence and Computer Engineering (ICAICE), Hangzhou, China, 5–7 November 2021; pp. 759–762. [Google Scholar]
- Guo, Y.; Lu, Y.; Liu, R.W. Lightweight deep network-enabled real-time low-visibility enhancement for promoting vessel detection in maritime video surveillance. J. Navig. 2022, 75, 230–250. [Google Scholar] [CrossRef]
- Guo, J.; Feng, H.; Xu, H.; Yu, W.; Shuzhi, G.S. D3-Net: Integrated multi-task convolutional neural network for water surface deblurring, dehazing and object detection. Eng. Appl. Artif. Intell. 2023, 117, 105558. [Google Scholar] [CrossRef]
- Yao, Z.; Chen, X.; Shi, C. Research on Surface Environment Perception via Camera-LiDAR Sensor Fusion. In Proceedings of the 2023 6th International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 26–29 May 2023; pp. 895–899. [Google Scholar]
- Zhao, H.; Zhang, H.; Zhao, Y. Yolov7-sea: Object detection of maritime uav images based on improved yolov7. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 233–238. [Google Scholar]
- Li, C.; Zhou, A.; Yao, A. Omni-dimensional dynamic convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Cheng, S.; Zhu, Y.; Wu, S. Deep learning based efficient ship detection from drone-captured images for maritime surveillance. Ocean. Eng. 2023, 285, 115440. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, C.; Filaretov, V.; Yukhimets, D. Multi-Scale Ship Detection Algorithm Based on YOLOv7 for Complex Scene SAR Images. Remote Sens. 2023, 15, 2071. [Google Scholar] [CrossRef]
- Sunkara, R.; Luo, T. No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Grenoble, France, 19–23 September 2022; pp. 443–459. [Google Scholar]
- Ma, M.; Pang, H. SP-YOLOv8s: An Improved YOLOv8s Model for Remote Sensing Image Tiny Object Detection. Appl. Sci. 2023, 13, 8161. [Google Scholar] [CrossRef]
- Zhang, L.; Du, X.; Zhang, R.; Zhang, J. A Lightweight Detection Algorithm for Unmanned Surface Vehicles Based on Multi-Scale Feature Fusion. J. Mar. Sci. Eng. 2023, 11, 1392. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Zhou, Z.; Chen, J.; Huang, Z.; Lv, J.; Song, J.; Luo, H.; Wu, B.; Li, Y.; Diniz, P.S. HRLE-SARDet: A Lightweight SAR Target Detection Algorithm Based on Hybrid Representation Learning Enhancement. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5203922. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, S.; Zhan, R.; Wang, W.; Zhang, J. LMSD-YOLO: A Lightweight YOLO Algorithm for Multi-Scale SAR Ship Detection. Remote Sens. 2022, 14, 4801. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Yeh, I.-H. Designing Network Design Strategies through Gradient Path Analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. Seaships: A large-scale precisely annotated dataset for ship detection. IEEE Trans. Multimed. 2018, 20, 2593–2604. [Google Scholar] [CrossRef]
- Fei, B.; Lyu, Z.; Pan, L.; Zhang, J.; Yang, W.; Luo, T.; Zhang, B.; Dai, B. Generative Diffusion Prior for Unified Image Restoration and Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9935–9946. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).