1. Introduction
High-precision environment sensing is essential in advancing autonomous driving technology. It necessitates the integration of multiple sensors such as cameras, millimeter-wave radar, and LiDAR [
1]. LiDAR utilizes a restricted set of scanning beams to perceive the environment, leading to the generation of a sparsely populated point cloud. The inadequate semantic information provided by a sparsely populated point cloud significantly impacts the efficacy of 3D perception tasks, including 3D object detection, scene semantic segmentation [
2], and 3D object tracking [
3]. Point cloud densification is crucial in comprehending 3D environments as it offers supplementary structural and semantic information to improve the accuracy of 3D perception tasks. Nevertheless, existing densification methods based on registration prove inadequate for dynamic targets due to the inherent limitations of the point cloud, such as incompleteness and deformation. To tackle this concern, we propose a Kalman-based scene flow estimation method for point cloud densification and 3D object detection in dynamic scenes.
Generally speaking, point cloud densification aims to reconstruct a dense and precise point cloud frame from a given sequence of sparse point clouds. This process is particularly challenging due to the variability and complexity of spatial data in real-world environments. Many registration-based methods [
4,
5,
6,
7,
8] are currently being investigated for aligning multi-frame point clouds to obtain dense point cloud maps. The Iterative Closest Point (ICP) algorithm [
9] is a classical point cloud alignment algorithm that optimizes the correspondence between two point clouds by minimizing their differences. However, its reliance on static geometries makes it less effective in scenarios where objects or the environment change over time. While the ICP family of algorithms is efficient at aligning large-scale point clouds, it often overlooks the dynamic attributes of the objects within the scene. These dynamic attributes include aspects such as the movement, rotation, and deformation of objects over time, which are crucial in dynamic environments. With the emergence of deep learning, several works [
10,
11,
12,
13,
14] have started to exploit feature correspondences and spatial relationships within point clouds.
Advancements in feature matching techniques, such as SSL-Net’s approach to sparse semantic learning [
15] and PGFNet’s strategy for preference-guided filtering [
16], have been instrumental in enhancing the accuracy of feature correspondence in complex scenarios. These methods demonstrate the importance of accurately identifying and filtering key features, a concept that can significantly augment traditional methods like ICP in point cloud densification processes, especially in dynamic scenes. The ability to discern and track these dynamic attributes accurately is crucial for understanding changes in the scene over time, thereby enhancing 3D perception in applications like autonomous driving.
Scene flow estimation aims to fundamentally understand the evolving dynamics of the environment without making any assumptions about the scene structure or object motion. Early works [
17,
18,
19,
20] focused on stereo vision cameras, where 3D motion fields were estimated using a knowledge-driven approach. Flownet3D [
21] is the first deep learning-based end-to-end scene flow estimation network. It utilizes PointNet++ [
22] as the backbone network while introducing a novel stream embedding layer. NSFP [
23] is the first method for estimating scene flow based on runtime optimization. It represents the scene flow using a unique implicit regularizer and is not constrained by data-driven limitations. However, when estimating long sequence point cloud scene flow, the estimator is limited by the motion relationships between two frames of point clouds, which can lead to the point cloud being guided to the wrong location. To overcome this localization error, an effective correction mechanism is necessary.
With the development of multi-modality techniques, several studies have proposed utilizing additional information to improve the performance of 3D object detectors. The authors of [
7] propose a framework based on an improved ICP method to enhance the performance of deep learning-based classification by incorporating the shape information of the LiDAR point cloud. The authors of [
24] explore a motion detection method based on point cloud registration. This method detects motion by analyzing the overlapping relationship between the registered source and target point clouds. The authors of [
25] propose a point cloud feature fusion module based on scene flow estimation to enhance the performance of 3D object tracking.
The method proposed in this paper is based on scene flow estimation and aims to improve the density of dynamic objects in a long sequence of point clouds to enhance the performance of 3D object detection. This will allow multiple frames of these objects to converge into the same frame. However, existing scene flow estimators suffer from localization errors when estimating a long sequence of point clouds. These errors disrupt the structural information of the target and render it unsuitable for 3D perception tasks. Therefore, we introduce a Kalman filter to correct the scene flow estimation results and eliminate the localization errors frame by frame. This approach leads to improved performance in point cloud densification. Our contributions in this study are as follows:
We propose a novel method for densifying point clouds by utilizing motion information from multi-frame point clouds with a novel scene flow estimator using a two-branch pyramid network as the implicit regularizer.
We address the issue of localization error in long-sequence scene flow estimation by utilizing a Kalman filter to precisely adjust the position of dynamic objects.
We compare our point cloud densification method with the ICP-based point cloud densification method, and our method outperforms in terms of accuracy and precision.
We conduct extensive experiments on the KITTI 3D tracking dataset to demonstrate that our method effectively improves the LiDAR-only detectors’ performance by achieving superior results to the baselines.
3. Proposed Method
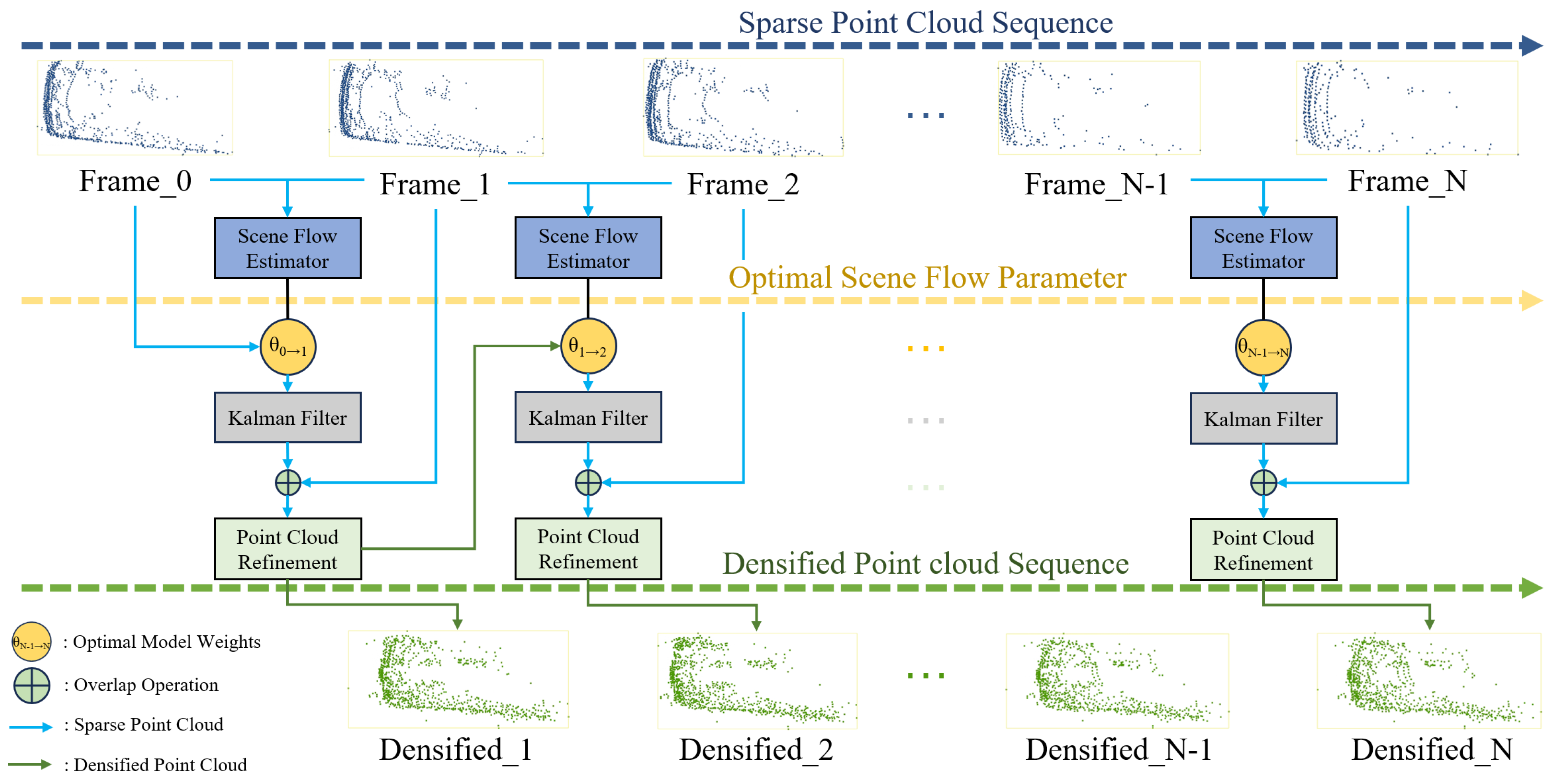
In this paper, a two-branch pyramid network is modeled as the scene flow estimator, and the adopted dataset is the KITTI tracking dataset [
46]. Scene flow estimation is first performed on pairs of point cloud frames to obtain an optimal estimate of the motion field and store the corresponding optimal model weights; then, these saved optimal model weights are utilized to perform a long sequence of scene flow estimation. In this process, the Kalman filter is employed to rectify the position of dynamic targets obtained from estimation, thereby mitigating the cumulative localization error. The results after correction are refined according to the point cloud density of the current frame to streamline the number of point clouds and minimize the impact of cumulative noise on the results. Finally, the aforementioned operations are recursively applied to the sequence of point clouds from the initial frame to the final frame, resulting in the densification of the dynamic point cloud targets of the dataset. The overall architecture of the densification method is depicted in
Figure 1. The pseudocode is presented in Algorithm 1.
| Algorithm 1 Dynamic Point Cloud Densification Algorithm |
Require: Point cloud Sequence:
Ensure: Densification Results: - 1:
Initiate the optimal scene flow parameters - 2:
function F(, , ) - 3:
Define the model to calculate the scene flow from to - 4:
return estimated scene flow - 5:
end function - 6:
for to N do - 7:
, where is the scene flow from to - 8:
Perform Kalman Filter to to eliminate the cumulative localization error - 9:
Overlap with and perform point cloud refinement - 10:
Obtain densified result - 11:
end for - 12:
return Densification Results:
|
3.1. Long Sequence Scene Flow Estimation
Scene flow estimation is the process of determining the motion vectors that describe the dynamic changes between consecutive point cloud frames in a scene. These vectors provide insights into the relative movement of objects and surfaces from one frame to the next.
Let and denote the point cloud frames at consecutive time steps t and . The scene flow is the vector field that represents the estimated movement of each point from to its new position in .
The scene flow quantifies the displacement of points between consecutive frames in a point cloud sequence, capturing the dynamic changes within the scene from time t to . This concept extends beyond the straightforward difference between coordinates, encompassing complex movements, including the translation, rotation, and deformation of objects in the environment.
In practice, there is not always a direct one-to-one correspondence between
and
, so the scene flow
represents the motion vector from each point in
to its closest matching position in
. This relationship is modeled by the function
F:
where
denotes the scene flow estimation model and
represents the model weights. Scene flow estimation is performed for each pair of point cloud frames in the sequence
, sequentially calculating the optimal scene flow model weights
.
For comprehensive multi-frame analysis, the scene flow estimation from any frame
i to frame
j is iteratively updated as follows:
where
is the cumulative scene flow from the initial frame to frame
j, refined with the latest estimation of movement between frames
and
i. This process ensures that each new frame contributes to the overall scene dynamics by updating the cumulative scene flow with the latest available data. Consequently, the scene flow at any given frame
j is the result of aggregating the motion observed up to that point, thus reflecting a more accurate depiction of the movement patterns over time.
The above formulation ensures that scene flow estimation is treated as an iterative and cumulative process that refines our understanding of the scene dynamics over time rather than defining the point cloud frames themselves.
3.2. Two-Branch Pyramid Network
We have developed a two-branch pyramid network to serve as the model for the scene flow estimator, as illustrated in
Figure 2. Frame
is initially inputted into a pyramid feature extractor, which comprises a bottom-up and top-down pathway for the point cloud. The number of sampling layers is configured as 4 for both the bottom-up and top-down pathways, while the scale rate is set to 2. The output of each downsampled layer will be combined with the results of the upsampling layer and passed as input to the subsequent layer for the next upsampling operation. The final output, noted as
, is fed into an implicit regularizer for optimization.
In the implicit regularizer, the backbone is constructed using a neural network based on an MLP. We include a position head and a flow head to encode the positional and motion information of the input point cloud. We adopt the LeakyReLU(Leaky Rectified Linear Unit) [
47] as the activation function. Unlike the traditional ReLU activation function, which blocks negative input values, LeakyReLU allows a small, non-zero gradient when the unit is not active. This means that it passes a small fraction of the negative values, thus addressing the issue of ‘dead neurons’ that can occur in ReLU. This characteristic helps in maintaining the flow of gradients through the network, making it particularly useful for models where the preservation of information from negative input values is crucial. The input layer of the backbone consists of three channels, while there are six hidden layers with 128 hidden units each. The backbone is equipped with a 128-channel output, which is subsequently connected to the position head and flow head. Each head comprises two hidden layers, each containing 128 hidden units. The output of each head consists of three channels, which correspond to the estimated coordinates and motion vectors in the XYZ coordinate system. Given the
, the position head outputs the estimated coordinates noted as
, and the flow head outputs the estimated flow vectors noted as
.
In the regularizer constraints, we formulate the contraints as two parts. On the one hand, the
combined with the
should be consistent with the
. On the other hand, the
substracted from the
should be consistent with
. Thus, the objective function can be defined as
where
(.,.) denotes the Chamfer distance function [
48], which is defined as
where
a and
b are s from point clouds
A and
B.
During the optimization process, we follow the gradient descent technique and obtain the optimal scene flow model weights
, as shown in Equation (5).
3.3. Kalman Filter Correction
However, although all scene flow model weights {
,
, …,
} are the optimal estimation of the corresponding point cloud pairs, these parameters tend to suffer from the problem of accumulating localization errors when performing long sequences of scene flow estimation, as depicted in
Figure 3.
As depicted in
Figure 3, the scene flow estimation model’s performance is visualized. In
Figure 3a, we observe that the red point cloud, representing the estimated scene flow, closely aligns with the green point cloud, which represents the ground truth. This alignment indicates a precise estimation without localization error. Conversely,
Figure 3b reveals the challenges posed by cumulative localization errors. Despite the estimator maintaining the overall shape of the point cloud, there is a noticeable drift towards the lower left, underscoring the significance of robust error correction mechanisms in long sequence estimations.
To eliminate the cumulative localization error of point cloud during the long sequence estimation process, the Kalman filter [
49] is introduced to correct the dynamic targets’ position.
The cluster center of the dynamic target is represented as the state quantity
, where
denote the spatial coordinates and
represent the velocity components. Assuming that the dynamic target adheres to uniform motion, the transition matrix
A is constructed to reflect this. In the matrix,
represents the time interval between successive observations or states. It is used to integrate the effect of time on the movement and velocity of the target. The transition matrix
A is thus defined as:
The Kalman filter consists of prediction and updating, as depicted in
Figure 4:
is the optimal outcome of the previous state, A and B are the system parameters, is the control quantity of the present state, and is the prediction of . is the covariance of , is the transpose matrix of A, Q is the covariance of the system process noise, and is the covariance of . H is the observation matrix, R is the noise covariance of the system measurements, and is the Kalman gain. is the measured value, is the optimal predicted value at the current moment, and is the covariance of .
The center of dynamic target is corrected using the optimal Kalman filter prediction value , which eliminates the localization error frame by frame and obtains accurate scene flow estimation results for a long sequence of point clouds.
3.4. Point Cloud Refinement
After accumulating multi-frame point clouds, duplicate points exist in the same part of the target. We propose refining and deduplicating the point cloud to reduce the noise accumulation on the densification result and ensure the uniformity of the target object’s density.
The search radius essentially defines the maximum distance within which a point in the scene flow estimation result
, corrected by the Kalman filter, is considered to be a duplicate of a point in
. The average point cloud distance
D of point cloud
is used as the search radius, and the average point cloud distance
D is calculated by Equation (7):
where
,
,
are the mean values of point cloud in
x,
y,
z dimensions, respectively, and
n is the number of point clouds.
If a point in is found within this radius of a point p, then p is replaced with the nearest point in ; otherwise, p is retained. This approach allows us to efficiently deduplicate and refine the point cloud, enhancing the overall quality of the densification results. By iterating this process for all values of i ranging from 0 to , we obtain the refined densification results for the first j frames.
4. Experiments
In this section, we provide a detailed description of the parameter settings used in the scene flow estimation model, along with the hardware and software configuration employed. In the second part, we have finetuned our model on the KITTI scene flow dataset and compared our method against other state-of-the-art scene flow estimation techniques. Next, we proceed to compare the proposed method with the ICP algorithm in terms of the densification outcomes. For the purpose of conducting a comprehensive analysis, we have employed five distinct LiDAR detectors to assess their performance. This evaluation was carried out on both the raw and densified KITTI tracking dataset. The overall methodology and sequential analysis steps in our approach are summarized in
Figure 5.
4.1. Experimental Setup
The hardware and software configurations utilized in this paper are outlined in
Table 1.
In our experimental setup, parallel computing techniques were employed to accelerate the processing, primarily utilizing GPU computation. The workflow involved two key computational stages. Firstly, the scene flow estimation was carried out using GPU-based computations. This step leverages the powerful parallel processing capabilities of the GPU to efficiently handle the complex calculations required by the scene flow model. Following the scene flow estimation, the point cloud positions were corrected using the Kalman filter, a process that was executed on the CPU. For dynamic targets identified in the point cloud space through clustering, multiple CPU threads were allocated to perform Kalman filter operations in parallel. This parallelization on the CPU allowed for efficient handling of multiple dynamic targets simultaneously. Once all the corrections for a particular frame were completed, the process proceeded to the next frame, maintaining this sequence throughout the experiment.
For the task of object detection, our experimental phase primarily focused on the training and validation of the models. This component was conducted separately and predominantly utilized GPU computations. The use of GPUs in this phase was crucial due to their ability to handle the intensive calculations required for deep learning tasks, significantly speeding up the training and validation process of the detection models.
This combination of GPU and CPU parallel processing not only optimized our computational workflow but also ensured the efficient handling of both the scene flow estimation and object detection tasks, crucial for the success of our experiment.
The optimization of the scene flow estimatior is achieved through the utilization of the Adam optimizer, which aims to minimize the objective function. Considering the abundance of point clouds and the issue of overfitting, the learning rate has been set to 1 × 10−3, and the optimization rounds have been limited to 5000 iterations.
4.2. Scene Flow Results and Analysis
To thoroughly assess our proposed scene flow estimation model, we conducted experiments on the KITTI Scene Flow dataset [
50], which comprises 100 training and 50 test scenarios. Each scenario consists of several consecutive stereo image pairs along with corresponding LiDAR point cloud data and precise ground truth annotations, covering diverse driving environments such as urban streets, rural roads, and highways.
The performance of the scene flow estimator was evaluated using a set of established metrics from previous works [
51,
52]: End-Point Error in 3D (EPE3D), which measures the average Euclidean distance between the estimated and ground truth flow vectors; strict 3D accuracy (acc3d_strict), the proportion of estimated points with an error below 5 cm or 5%; relaxed 3D accuracy (acc3d_relax), considering a threshold of 10 cm or 10%; and the outlier ratio, the percentage of points where the estimation error exceeds 30 cm or 10%. These metrics provide a comprehensive assessment of the estimator’s accuracy and robustness in estimating scene flow, offering a detailed framework for benchmarking against other state-of-the-art techniques. The detailed evaluation metrics are as follows:
End-Point Error in 3D (EPE3D): The average Euclidean distance between the estimated flow field and the ground truth , which provides a measure of the model’s predictive accuracy.
Strict 3D Accuracy (Acc3d_strict): The percentage of points with an end-point error of less than 5 cm or a relative end-point error of less than 5%, measuring the model’s accuracy under stringent conditions.
Relaxed 3D Accuracy (Acc3d_relax): The percentage of points with an end-point error of less than 10 cm or a relative end-point error of less than 10%, assessing the model’s performance under more lenient conditions.
Outlier Ratio (Out.): The percentage of points where the end-point error exceeds 30 cm or the relative end-point error is greater than 10%, identifying predictions with substantial errors.
Following the presentation of evaluation metrics, we now introduce the comparative methods used in our experiments to benchmark our scene flow estimator against current leading techniques in the field, including four distinct scene flow estimation models: Graph Prior [
53] employs a graph-based approach for spatial consistency and geometric coherence, beneficial for large-scale datasets in driving contexts. Neural Prior [
23] leverages deep learning to encode motion patterns, aiming for robust flow estimation amidst environmental noise and occlusions. SCOOP [
54] represents a novel, minimally supervised technique that learns point features and refines flow via soft correspondences, making it suitable for training with limited data. Lastly, OptFlow [
55] utilizes an optimization strategy with local correlation and graph constraints, efficiently differentiating between static and dynamic points and showcasing rapid convergence with high accuracy.
The effectiveness of our scene flow estimation model was rigorously evaluated on the KITTI Scene Flow dataset, with the results being compared against several state-of-the-art methods. The comparative results are summarized in
Table 2.
Our method achieved the lowest End-Point Error in 3D (EPE3D) of 0.027, indicating the highest precision in estimating the motion vectors. While OptFlow excelled in terms of strict and relaxed 3D accuracy, our method demonstrated competitive performance with a balanced approach towards accuracy (94.3% in Acc3d_strict and 96.8% in Acc3d_relax) and outlier management, evidenced by the lowest outlier ratio of 10.4%. These results signify our method’s capability to accurately estimate scene flow while maintaining robustness against errors. Notably, the non-learning-based nature of our method, alongside Graph Prior, Neural Prior, and OptFlow, reflects the potential of algorithmic approaches without extensive reliance on large training datasets.
To further substantiate the efficacy of our scene flow estimatior, particularly emphasizing the improved localization accuracy provided by the Kalman filter, we include a set of visualization results.
Figure 6 concretely demonstrates the scene flow estimation over extended sequences, revealing the trajectories and point cloud data before and after Kalman filter correction.
Figure 6a,b illustrate the marked contrast in trajectory prediction and point cloud localization with and without the use of the Kalman filter. In
Figure 6a, we observe the corrected trajectories that exhibit high coherence and precision, affirming the filter’s role in enhancing localization accuracy, especially in complex urban and highway scenarios. Conversely,
Figure 6b highlights the discrepancies and increased localization errors when the Kalman filter is not employed. The bottom sections of both figures provide a clear side-by-side trajectory comparison, with the corrected paths presenting a compelling case for the Kalman filter’s impact. These visual comparisons not only bolster the quantitative results but also deliver qualitative, intuitive confirmation of our model’s improved performance in dynamic settings. The enhanced flow coherence and diminished error presented in these visual outcomes effectively address the reviewer’s call for more robust visual evidence, thus substantiating our claims of superior scene flow estimation capabilities.
4.3. Densification Results and Analysis
The densification experiments are particularly focused on mobile entities like cars, trucks, and cyclists because these entities typically exhibit significant movement and variation in point clouds, presenting unique challenges in terms of densification and accuracy. To disrupt the structure of the raw point cloud, we employ random cropping. Subsequently, we evaluate the performance of our proposed method and the ICP algorithm on these data by conducting a comparative analysis.
In our implementation of the ICP algorithm, the objective was to align the point clouds from consecutive frames. This involved iteratively adjusting the transformation matrix to minimize the distance between corresponding points in the point clouds. The algorithm accounted for rotations and translations to best fit the point clouds from frame to frame. This iterative process continued until the changes in the transformation matrix were below our predefined threshold of 0.005, indicating an adequate alignment had been achieved.
In
Figure 7, the process of proposed point cloud densification method is illustrated.
Figure 7a shows the original sparse point cloud with missing data sections.
Figure 7b demonstrates how the proposed algorithm adds new points to these sections. These new points are generated based on the estimated motion and shape information derived from adjacent frames and the algorithm’s predictive modeling. The points are not imported from other point clouds but are instead synthesized by the algorithm to fill in gaps and enhance the overall density and completeness of the point cloud.
The proposed method and the ICP algorithm are utilized to analyze the dynamic targets that have been segmented from the KITTI tracking dataset. The qualitative comparison results are illustrated in
Figure 8. Based on the analysis of the experimental results, it is apparent that our method successfully maintains the shape of the densified point cloud while minimizing the occurrence of noise points.
To evaluate the effectiveness of the method proposed in this correspondence, the evaluation metrics utilized consist of Chamfer Distance (CD) [
48] and Root Mean Square Error (RMSE). The Chamfer Distance (CD) is defined by Equation (8). The Root Mean Square Error (RMSE) is defined as
The Root Mean Square Error (RMSE) measures the deviation between predicted and true values and is more sensitive to outliers in the data. Based on the above two metrics, a comparative analysis of the performance of the method across different object classes is presented in
Table 3.
The Chamfer Distance (CD) measures the consistency of the densification outcome and the ground truth. The Root Mean Square Error (RMSE) is employed to assess the accuracy of the densification result in comparison to the actual values of the inner points.
Table 3 demonstrates that the method proposed in this paper achieves lower results for all three classes in both metrics. As shown in
Figure 9, we statistically compare the results of densification using one-frame point clouds to twenty-frame point clouds. In most cases, our method achieves better results than the traditional ICP method. The proposed method exhibits superior performance in comparison to the conventional ICP algorithm by effectively improving the density and completeness of the point cloud.
In our ablation studies, we specifically assessed the impact of key components in our proposed method: scene flow, Kalman filter, and point cloud refinement. The analysis of Chamfer Distance results, presented in
Table 4, highlights the importance of these components in ensuring spatial accuracy in point cloud densification. Notably, the Kalman filter’s contribution was more pronounced than that of the refinement module; this was especially evident in the results for truck1 and truck2. While the combination of scene flow, Kalman filter, and point cloud refinement provided the most accurate outcomes with the lowest Chamfer Distance across all categories, the Kalman filter alone significantly improved spatial accuracy, underscoring its critical role in our method. The increased Chamfer Distance in configurations without the Kalman filter reaffirms its substantial impact on achieving optimal densification.
In the analysis of Root Mean Square Error (RMSE), detailed in
Table 5, we found that the contributions of the Kalman filter and point cloud refinement to the overall precision of densification were similar. The integration of scene flow, Kalman filter, and refinement resulted in the lowest RMSE values, denoting the highest precision. The inclusion of both the Kalman filter and refinement was essential for enhancing localization accuracy and maintaining temporal alignment accuracy in dynamic scenes. This was particularly important for moving objects such as cars and cyclists. The similar performance improvements observed in configurations with either the Kalman filter or refinement alone highlight the balanced contribution of these components to the accuracy of the densification process.
4.4. 3D Object Detection Results and Analysis
To evaluate the performance impact of densification on LiDAR-based object detection, we carried out a series of experiments using the KITTI tracking dataset. This dataset was partitioned into a training set with 4001 point cloud frames and a validation set with 3900 frames. The division facilitates a robust evaluation framework, allowing for an in-depth analysis of the detector’s performance under varied conditions.
Densification was applied to the raw KITTI tracking dataset by aggregating data from one and three consecutive point cloud frames. The rationale behind this choice is twofold. Firstly, the original dataset annotations are based on single-frame data, where ground truth labels are provided for each frame in isolation. Introducing more frames for densification would require a complex re-annotation process to include the additional temporal context, a task that would be both labor-intensive and outside the scope of this study. Secondly, the choice of three frames specifically serves to provide a deeper temporal insight while maintaining computational efficiency. It allows us to capture more dynamic changes in the scene than single-frame densification while avoiding the exponential increase in computational load and potential data misalignment that could arise from processing many frames. Our approach, therefore, carefully balances the depth of temporal context with practical constraints such as the availability of labeled data and computational resources.
In our experiments, both one-frame and three-frame densified datasets were used during the training and testing phases to ensure consistency in model evaluation. The training followed the protocol established by the Openpcdet [
56] framework, with a designated 200 epochs to achieve detector convergence.
To provide a comprehensive understanding of the detectors used in our study, we briefly describe each:
PointPillars [
40] is a novel 3D object detection framework for point cloud data. It converts point clouds into a pseudo-image of pillars, enabling efficient detection through 2D convolutional neural networks.
SECOND [
57] employs sparse convolutional networks to process spatially sparse but information-rich regions in point clouds, thereby enhancing both speed and accuracy in 3D object detection.
PointRCNN [
58] is a two-stage 3D object detector that operates directly on raw point clouds. It generates 3D bounding box proposals and refines them for precise object localization and classification.
PV-RCNN [
59] integrates voxel-based and point-based neural networks. This hybrid approach extracts rich contextual features from point clouds, leading to significant improvements in detection accuracy.
[
60] focuses on detailed part-level features for robust object recognition in point cloud data. It enhances detection precision by aggregating these fine-grained features effectively.
Our results, as tabulated in
Table 6, demonstrate that densification contributes to noticeable performance improvements across these detectors. The PV-RCNN detector, in particular, showcased an enhancement of up to 7.95% in detecting cyclists in challenging scenarios.
However, the performance gains observed with the three-frame densified dataset were marginal compared to those with the single-frame dataset. This outcome suggests that while additional frames do provide more context, there is a threshold beyond which the benefits plateau, likely due to the increased complexity without a corresponding increase in labeled information. In essence, the modest performance gains from additional frames are potentially offset by the introduction of unlabeled objects, leading to a trade-off between temporal context and the quality of training data.
Qualitative comparisons in
Figure 10 illustrate the advantages of our densification method.
Figure 10b is derived from the PV-RCNN detector trained on the three-frame densified dataset, while
Figure 10a pertains to the same detector trained on the raw dataset. Our method enriches the dataset with additional structural and semantic information, leading to a reduction in false positives across various environmental conditions, as highlighted in the image sections. This underscores our densification approach’s ability to mitigate false detections for vehicles, pedestrians, and cyclists.
4.5. Limitations and Future Work
Following the detailed presentation of our experimental results and their comparative analysis, it is imperative to acknowledge the limitations of our approach and propose avenues for future advancements.
Limitations:
Kalman Filter Integration: Our method uses a Kalman filter to correct localization errors in dynamic targets within point cloud scenes, especially in long sequence scene flows. However, this module’s integration with the deep learning-based scene flow estimator is not as tight as it could be, leading to additional computational overhead.
Scene Flow Estimator Constraints: The constraints of our scene flow estimator require further exploration. The model currently faces significant computational challenges when estimating point cloud scene flows in large scenes, indicating a need for further optimization.
Validation on 3D Object Detection Models: There is a need for more extensive validation across various 3D object detection models to ensure the method’s adaptability to different applications.
Future Work:
Integrating Kalman Filter into Scene Flow Estimation: One avenue for improvement involves embedding the Kalman filter module directly into the scene flow estimation model. This integration, along with developing appropriate constraints, could be advantageous for long sequence point cloud scene flow estimation.
Lightweight Data Representation: Adopting more lightweight data representation mechanisms could significantly reduce the overall latency of the algorithm.
Experiments with Additional 3D Object Detection Models: Expanding our experiments to include a wider range of 3D object detection models is crucial. Given the issues of multi-frame label mismatch, implementing an appropriate label modification mechanism will be essential to maintain the accuracy of model training.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}