
Multilingual Framework for Risk Assessment and Symptom Tracking (MRAST)
 , , , , , ,
, , , , , ,
Abstract
1. Introduction
2. Related Work
3. Methodology
3.1. Environment
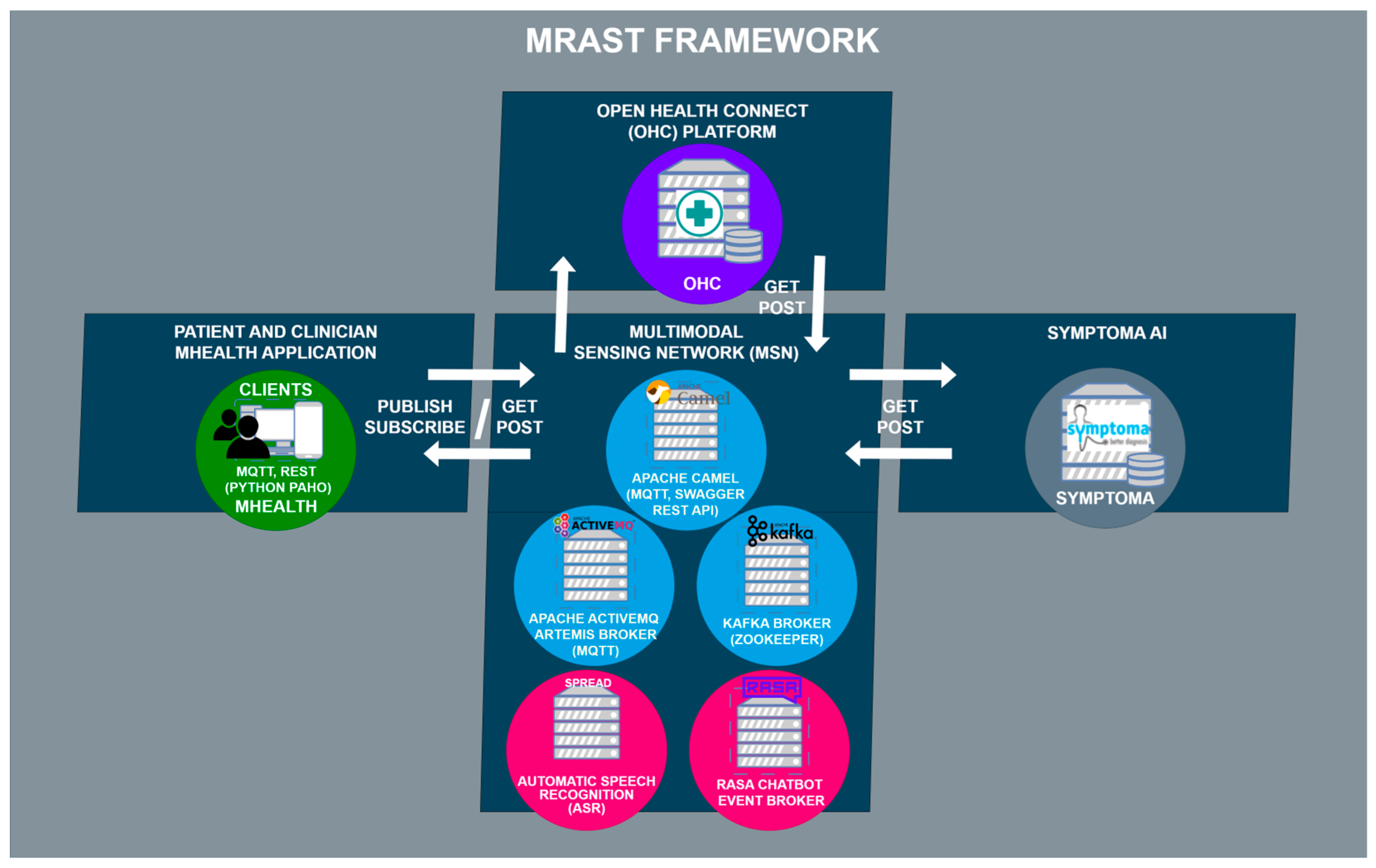
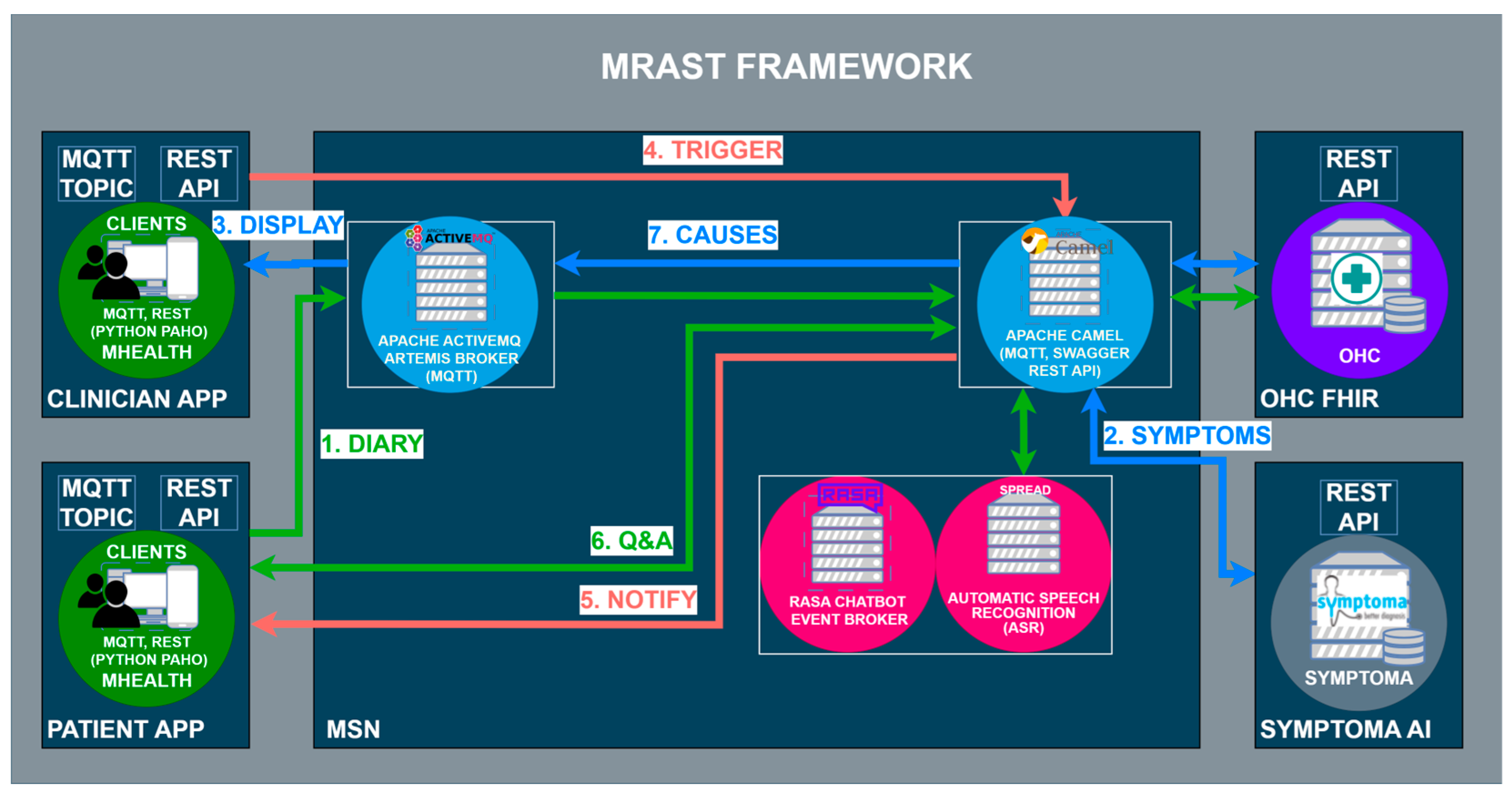
3.2. The MRAST Framework
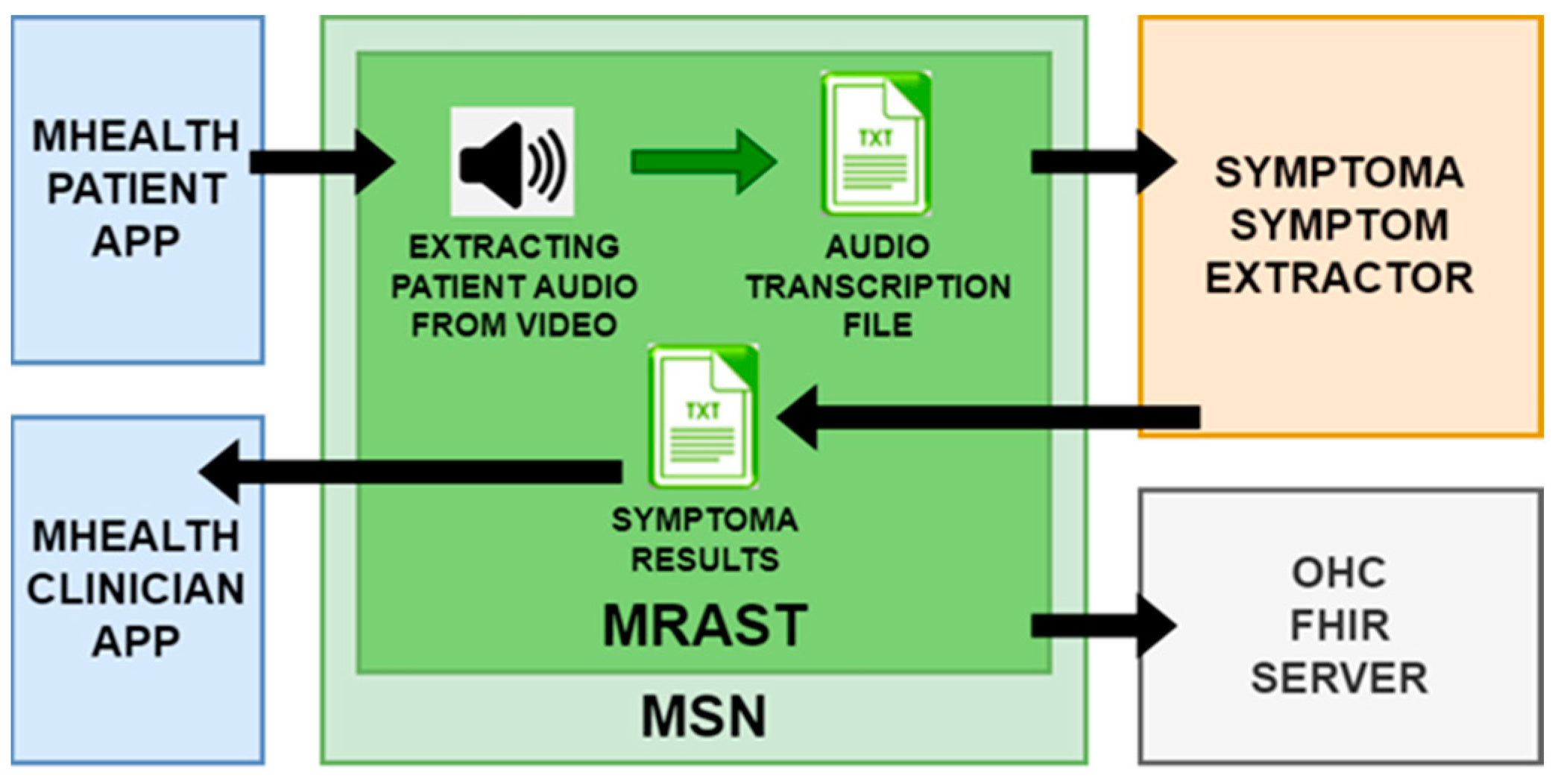
3.2.1. Speech Recognition Engine
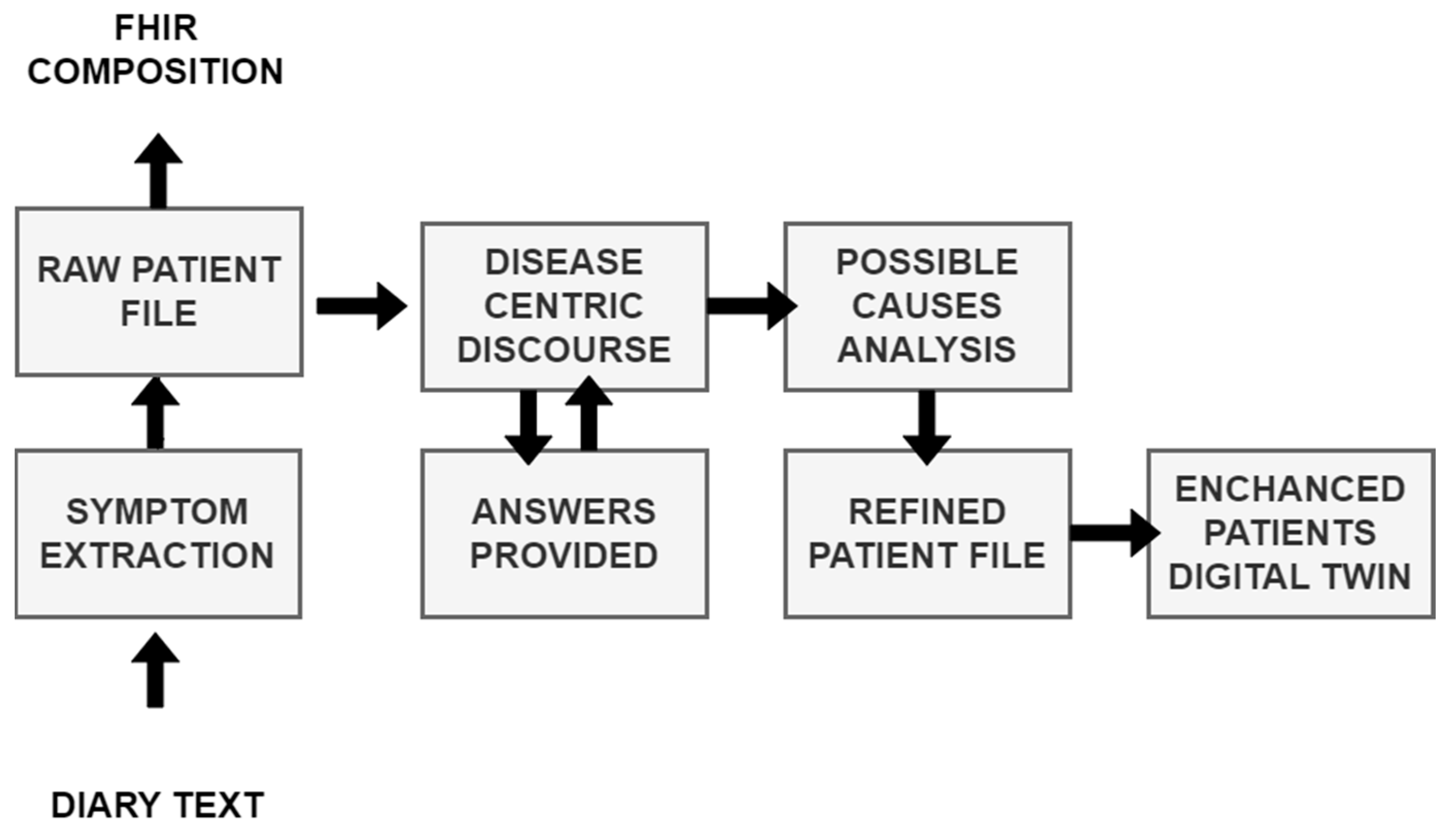
3.2.2. From Diary Recording to Updated Insights on Patient Condition
3.2.3. Big Data Platform and HL7 FHIR Server
3.3. Case Study with Full Patient Journey
4. Results
4.1. ASR Results
4.2. FHIR Server and Connectivity Tests
4.3. Patient Evaluation
4.4. Feasibility of MRAST Framework in the Real World
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Salmond, S.W.; Echevarria, M. Healthcare Transformation and Changing Roles for Nursing. Orthop Nurs 2017, 36, 12–25. [Google Scholar] [CrossRef]
- Anderson, G. Chronic Conditions: Making the Case for Ongoing Care. Partnersh. Solut. Johns Hopkins Univ. 2002. Available online: https://www.policyarchive.org/handle/10207/21756 (accessed on 18 December 2023).
- Li, J.; Porock, D. Resident Outcomes of Person-Centered Care in Long-Term Care: A Narrative Review of Interventional Research. Int. J. Nurs. Stud. 2014, 51, 1395–1415. [Google Scholar] [CrossRef]
- Calvert, M.; Kyte, D.; Price, G.; Valderas, J.M.; Hjollund, N.H. Maximising the Impact of Patient Reported Outcome Assessment for Patients and Society. BMJ 2019, 364, k5267. [Google Scholar] [CrossRef]
- Nguyen, H.; Butow, P.; Dhillon, H.; Sundaresan, P. A Review of the Barriers to Using Patient-Reported Outcomes (PROs) and Patient-Reported Outcome Measures (PROMs) in Routine Cancer Care. J. Med. Radiat. Sci. 2021, 68, 186–195. [Google Scholar] [CrossRef] [PubMed]
- Black, N. Patient Reported Outcome Measures Could Help Transform Healthcare. BMJ 2013, 346, f167. [Google Scholar] [CrossRef] [PubMed]
- Greenhalgh, J. The Applications of PROs in Clinical Practice: What Are They, Do They Work, and Why? Qual. Life Res. 2009, 18, 115–123. [Google Scholar] [CrossRef] [PubMed]
- Snyder, C.F.; Aaronson, N.K.; Choucair, A.K.; Elliott, T.E.; Greenhalgh, J.; Halyard, M.Y.; Hess, R.; Miller, D.M.; Reeve, B.B.; Santana, M. Implementing Patient-Reported Outcomes Assessment in Clinical Practice: A Review of the Options and Considerations. Qual. Life Res. 2012, 21, 1305–1314. [Google Scholar] [CrossRef]
- Churruca, K.; Pomare, C.; Ellis, L.A.; Long, J.C.; Henderson, S.B.; Murphy, L.E.D.; Leahy, C.J.; Braithwaite, J. Patient-Reported Outcome Measures (PROMs): A Review of Generic and Condition-Specific Measures and a Discussion of Trends and Issues. Health Expect. 2021, 24, 1015–1024. [Google Scholar] [CrossRef] [PubMed]
- Foster, A.; Croot, L.; Brazier, J.; Harris, J.; O’Cathain, A. The Facilitators and Barriers to Implementing Patient Reported Outcome Measures in Organisations Delivering Health Related Services: A Systematic Review of Reviews. J. Patient-Rep. Outcomes 2018, 2, 46. [Google Scholar] [CrossRef] [PubMed]
- Ju, A.; Tong, A. Considerations and Challenges in Selecting Patient-Reported Outcome Measures for Clinical Trials in Nephrology. Clin. J. Am. Soc. Nephrol. 2017, 12, 1882–1884. [Google Scholar] [CrossRef]
- Montgomery, N.; Bartlett, S.J.; Brundage, M.D.; Bryant-Lukosius, D.; Howell, D.; Ismail, Z.; Krzyzanowska, M.K.; Moody, L.; Snyder, C.F.; Staley Liang, M.; et al. Defining a Patient-Reported Outcome Measure (PROM) Selection Process: What Criteria Should Be Considered When Choosing a PROM for Routine Symptom Assessment in Clinical Practice? J. Clin. Oncol. 2018, 36, 187. [Google Scholar] [CrossRef]
- Keller, S.; Dy, S.; Wilson, R.; Dukhanin, V.; Snyder, C.; Wu, A. Selecting Patient-Reported Outcome Measures to Contribute to Primary Care Performance Measurement: A Mixed Methods Approach. J. Gen. Intern. Med. 2020, 35, 2687–2697. [Google Scholar] [CrossRef] [PubMed]
- Patients’ Reasons for Non-Use of Digital Patient-Reported Outcome Concepts: A Scoping Review—Amalie Søgaard Nielsen, Kristian Kidholm, Lars Kayser, 2020. Available online: https://journals.sagepub.com/doi/full/10.1177/1460458220942649 (accessed on 26 October 2023).
- Calvert, M.J.; Cruz Rivera, S.; Retzer, A.; Hughes, S.E.; Campbell, L.; Molony-Oates, B.; Aiyegbusi, O.L.; Stover, A.M.; Wilson, R.; McMullan, C.; et al. Patient Reported Outcome Assessment Must Be Inclusive and Equitable. Nat. Med. 2022, 28, 1120–1124. [Google Scholar] [CrossRef] [PubMed]
- Garcia Farina, E.; Rowell, J.; Revette, A.; Haakenstad, E.K.; Cleveland, J.L.F.; Allende, R.; Hassett, M.; Schrag, D.; McCleary, N.J. Barriers to Electronic Patient-Reported Outcome Measurement Among Patients with Cancer and Limited English Proficiency. JAMA Netw. Open 2022, 5, e2223898. [Google Scholar] [CrossRef] [PubMed]
- Lavallee, D.C.; Chenok, K.E.; Love, R.M.; Petersen, C.; Holve, E.; Segal, C.D.; Franklin, P.D. Incorporating Patient-Reported Outcomes into Health Care to Engage Patients And Enhance Care. Health Aff. 2016, 35, 575–582. [Google Scholar] [CrossRef] [PubMed]
- Sanders, C.; Rogers, A.; Bowen, R.; Bower, P.; Hirani, S.; Cartwright, M.; Fitzpatrick, R.; Knapp, M.; Barlow, J.; Hendy, J.; et al. Exploring Barriers to Participation and Adoption of Telehealth and Telecare within the Whole System Demonstrator Trial: A Qualitative Study. BMC Health Serv. Res. 2012, 12, 220. [Google Scholar] [CrossRef] [PubMed]
- Long, C.; Beres, L.K.; Wu, A.W.; Giladi, A.M. Patient-Level Barriers and Facilitators to Completion of Patient-Reported Outcomes Measures. Qual. Life Res. 2022, 31, 1711–1718. [Google Scholar] [CrossRef] [PubMed]
- Miller, D.; Steele Gray, C.; Kuluski, K.; Cott, C. Patient-Centered Care and Patient-Reported Measures: Let’s Look Before We Leap. Patient 2015, 8, 293–299. [Google Scholar] [CrossRef]
- Fan, X.; Miller, B.C.; Park, K.-E.; Winward, B.W.; Christensen, M.; Grotevant, H.D.; Tai, R.H. An Exploratory Study about Inaccuracy and Invalidity in Adolescent Self-Report Surveys. Field Methods 2006, 18, 223–244. [Google Scholar] [CrossRef]
- Stuart, A.L.; Pasco, J.A.; Jacka, F.N.; Brennan, S.L.; Berk, M.; Williams, L.J. Comparison of Self-Report and Structured Clinical Interview in the Identification of Depression. Compr. Psychiatry 2014, 55, 866–869. [Google Scholar] [CrossRef]
- Dell’Osso, L.; Carmassi, C.; Rucci, P.; Conversano, C.; Shear, M.K.; Calugi, S.; Maser, J.D.; Endicott, J.; Fagiolini, A.; Cassano, G.B. A Multidimensional Spectrum Approach to Post-Traumatic Stress Disorder: Comparison between the Structured Clinical Interview for Trauma and Loss Spectrum (SCI-TALS) and the Self-Report Instrument (TALS-SR). Compr. Psychiatry 2009, 50, 485–490. [Google Scholar] [CrossRef]
- McColl, E. Best Practice in Symptom Assessment: A Review. Gut 2004, 53 (Suppl. S4), iv49–iv54. [Google Scholar] [CrossRef] [PubMed]
- Raskin, S.A. Memory for Intentions Screening Test: Psychometric Properties and Clinical Evidence. Brain Impair. 2009, 10, 23–33. [Google Scholar] [CrossRef]
- Sato, H.; Kawahara, J. Selective Bias in Retrospective Self-Reports of Negative Mood States. Anxiety Stress Coping 2011, 24, 359–367. [Google Scholar] [CrossRef] [PubMed]
- Robinson, M.A.; Boies, K. On the Quest for Quality Self-Report Data: HEXACO and Indicators of Careless Responding. Can. J. Behav. Sci. Rev. Can. Des Sci. Du Comport. 2021, 53, 377–380. [Google Scholar] [CrossRef]
- Maniaci, M.R.; Rogge, R.D. Caring about Carelessness: Participant Inattention and Its Effects on Research. J. Res. Personal. 2014, 48, 61–83. [Google Scholar] [CrossRef]
- Okupa, A.Y.; Sorkness, C.A.; Mauger, D.T.; Jackson, D.J.; Lemanske, R.F. Daily Diaries vs Retrospective Questionnaires to Assess Asthma Control and Therapeutic Responses in Asthma Clinical Trials: Is Participant Burden Worth the Effort? Chest 2013, 143, 993–999. [Google Scholar] [CrossRef]
- Jeong, H.; Yim, H.W.; Lee, S.-Y.; Lee, H.K.; Potenza, M.N.; Kwon, J.-H.; Koo, H.J.; Kweon, Y.-S.; Bhang, S.; Choi, J.-S. Discordance between Self-Report and Clinical Diagnosis of Internet Gaming Disorder in Adolescents. Sci. Rep. 2018, 8, 10084. [Google Scholar] [CrossRef] [PubMed]
- Siggeirsdottir, K.; Aspelund, T.; Sigurdsson, G.; Mogensen, B.; Chang, M.; Jonsdottir, B.; Eiriksdottir, G.; Launer, L.J.; Harris, T.B.; Jonsson, B.Y.; et al. Inaccuracy in Self-Report of Fractures May Underestimate Association with Health Outcomes When Compared with Medical Record Based Fracture Registry. Eur. J. Epidemiol. 2007, 22, 631–639. [Google Scholar] [CrossRef]
- Okura, Y.; Urban, L.H.; Mahoney, D.W.; Jacobsen, S.J.; Rodeheffer, R.J. Agreement between Self-Report Questionnaires and Medical Record Data Was Substantial for Diabetes, Hypertension, Myocardial Infarction and Stroke but Not for Heart Failure. J. Clin. Epidemiol. 2004, 57, 1096–1103. [Google Scholar] [CrossRef]
- Kim, A.; Chung, K.C.; Keir, C.; Patrick, D.L. Patient-Reported Outcomes Associated with Cancer Screening: A Systematic Review. BMC Cancer 2022, 22, 223. [Google Scholar] [CrossRef] [PubMed]
- Merlo, J.; Berglund, G.; Wirfält, E.; Gullberg, B.; Hedblad, B.; Manjer, J.; Hovelius, B.; Janzon, L.; Hanson, B.S.; Ostergren, P.O. Self-Administered Questionnaire Compared with a Personal Diary for Assessment of Current Use of Hormone Therapy: An Analysis of 16,060 Women. Am. J. Epidemiol. 2000, 152, 788–792. [Google Scholar] [CrossRef] [PubMed]
- Bolger, N.; Davis, A.; Rafaeli, E. Diary Methods: Capturing Life as It Is Lived. Annu. Rev. Psychol. 2003, 54, 579–616. [Google Scholar] [CrossRef] [PubMed]
- Janssens, K.A.M.; Bos, E.H.; Rosmalen, J.G.M.; Wichers, M.C.; Riese, H. A Qualitative Approach to Guide Choices for Designing a Diary Study. BMC Med. Res. Methodol. 2018, 18, 140. [Google Scholar] [CrossRef] [PubMed]
- Saeidzadeh, S.; Gilbertson-White, S.; Kwekkeboom, K.; Babaieasl, F.; Seaman, A. Using Online Self-Management Diaries for Qualitative Research. Int. J. Qual. Methods 2021, 20, 160940692110388. [Google Scholar] [CrossRef]
- Timmers, T.; Janssen, L.; Stohr, J.; Murk, J.L.; Berrevoets, M.a.H. Using eHealth to Support COVID-19 Education, Self-Assessment, and Symptom Monitoring in the Netherlands: Observational Study. JMIR Mhealth Uhealth 2020, 8, e19822. [Google Scholar] [CrossRef]
- Mendoza, J.; Seguin, M.L.; Lasco, G.; Palileo-Villanueva, L.M.; Amit, A.; Renedo, A.; McKee, M.; Palafox, B.; Balabanova, D. Strengths and Weaknesses of Digital Diaries as a Means to Study Patient Pathways: Experiences With a Study of Hypertension in the Philippines. Int. J. Qual. Methods 2021, 20, 16094069211002746. [Google Scholar] [CrossRef]
- Aiyegbusi, O.L.; Nair, D.; Peipert, J.D.; Schick-Makaroff, K.; Mucsi, I. A Narrative Review of Current Evidence Supporting the Implementation of Electronic Patient-Reported Outcome Measures in the Management of Chronic Diseases. Ther. Adv. Chronic. Dis. 2021, 12, 20406223211015958. [Google Scholar] [CrossRef]
- Papapetropoulos, S.S. Patient Diaries as a Clinical Endpoint in Parkinson’s Disease Clinical Trials. CNS Neurosci. Ther. 2012, 18, 380–387. [Google Scholar] [CrossRef]
- Broderick, J.E. Electronic Diaries: Appraisal and Current Status. Pharm. Med. 2008, 22, 69–74. [Google Scholar] [CrossRef]
- Piasecki, T.M.; Hufford, M.R.; Solhan, M.; Trull, T.J. Assessing Clients in Their Natural Environments with Electronic Diaries: Rationale, Benefits, Limitations, and Barriers. Psychol. Assess. 2007, 19, 25–43. [Google Scholar] [CrossRef]
- Lizée, T.; Basch, E.; Trémolières, P.; Voog, E.; Domont, J.; Peyraga, G.; Urban, T.; Bennouna, J.; Septans, A.-L.; Balavoine, M.; et al. Cost-Effectiveness of Web-Based Patient-Reported Outcome Surveillance in Patients with Lung Cancer. J. Thorac. Oncol. 2019, 14, 1012–1020. [Google Scholar] [CrossRef]
- Mlakar, I.; Šafran, V.; Hari, D.; Rojc, M.; Alankuş, G.; Pérez Luna, R.; Ariöz, U. Multilingual Conversational Systems to Drive the Collection of Patient-Reported Outcomes and Integration into Clinical Workflows. Symmetry 2021, 13, 1187. [Google Scholar] [CrossRef]
- Nateqi, J.; Lin, S.; Krobath, H.; Gruarin, S.; Lutz, T.; Dvorak, T.; Gruschina, A.; Ortner, R. From symptom to diagnosis-symptom checkers re-evaluated: Are symptom checkers finally sufficient and accurate to use? An update from the ENT perspective. HNO 2019, 67, 334–342. [Google Scholar] [CrossRef] [PubMed]
- Martin, A.; Nateqi, J.; Gruarin, S.; Munsch, N.; Abdarahmane, I.; Zobel, M.; Knapp, B. An Artificial Intelligence-Based First-Line Defence against COVID-19: Digitally Screening Citizens for Risks via a Chatbot. Sci. Rep. 2020, 10, 19012. [Google Scholar] [CrossRef] [PubMed]
- Munsch, N.; Martin, A.; Gruarin, S.; Nateqi, J.; Abdarahmane, I.; Weingartner-Ortner, R.; Knapp, B. Diagnostic Accuracy of Web-Based COVID-19 Symptom Checkers: Comparison Study. J. Med. Internet Res. 2020, 22, e21299. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.; Nateqi, J.; Weingartner-Ortner, R.; Gruarin, S.; Marling, H.; Pilgram, V.; Lagler, F.B.; Aigner, E.; Martin, A.G. An Artificial Intelligence-Based Approach for Identifying Rare Disease Patients Using Retrospective Electronic Health Records Applied for Pompe Disease. Front. Neurol. 2023, 14, 1108222. [Google Scholar] [CrossRef]
- HAPI FHIR—The Open Source FHIR API for Java. Available online: https://hapifhir.io/ (accessed on 19 June 2021).
- Fox Insight Collects Online, Longitudinal Patient-Reported Outcomes and Genetic Data on Parkinson’s Disease|Scientific Data. Available online: https://www.nature.com/articles/s41597-020-0401-2 (accessed on 27 October 2023).
- Jones, J.B.; Snyder, C.F.; Wu, A.W. Issues in the Design of Internet-Based Systems for Collecting Patient-Reported Outcomes. Qual. Life Res. Int. J. Qual. Life Asp. Treat. Care Rehabil. 2007, 16, 1407–1417. [Google Scholar] [CrossRef] [PubMed]
- Frost, J.; Okun, S.; Vaughan, T.; Heywood, J.; Wicks, P. Patient-Reported Outcomes as a Source of Evidence in off-Label Prescribing: Analysis of Data from PatientsLikeMe. J. Med. Internet Res. 2011, 13, e6. [Google Scholar] [CrossRef] [PubMed]
- Haun, J.N.; Alman, A.C.; Melillo, C.; Standifer, M.; McMahon-Grenz, J.; Shin, M.; Lapcevic, W.A.; Patel, N.; Elwy, A.R. Using Electronic Data Collection Platforms to Assess Complementary and Integrative Health Patient-Reported Outcomes: Feasibility Project. JMIR Med. Inf. 2020, 8, e15609. [Google Scholar] [CrossRef]
- Penedo, F.J.; Oswald, L.B.; Kronenfeld, J.P.; Garcia, S.F.; Cella, D.; Yanez, B. The Increasing Value of eHealth in the Delivery of Patient-Centred Cancer Care. Lancet Oncol. 2020, 21, e240–e251. [Google Scholar] [CrossRef] [PubMed]
- Lu, D.J.; Girgis, M.; David, J.M.; Chung, E.M.; Atkins, K.M.; Kamrava, M. Evaluation of Mobile Health Applications to Track Patient-Reported Outcomes for Oncology Patients: A Systematic Review. Adv. Radiat. Oncol. 2021, 6, 100576. [Google Scholar] [CrossRef] [PubMed]
- Benze, G.; Nauck, F.; Alt-Epping, B.; Gianni, G.; Bauknecht, T.; Ettl, J.; Munte, A.; Kretzschmar, L.; Gaertner, J. PROutine: A Feasibility Study Assessing Surveillance of Electronic Patient Reported Outcomes and Adherence via Smartphone App in Advanced Cancer. Ann. Palliat. Med. 2019, 8, 104–111. [Google Scholar] [CrossRef] [PubMed]
- Werhahn, S.M.; Dathe, H.; Rottmann, T.; Franke, T.; Vahdat, D.; Hasenfuß, G.; Seidler, T. Designing Meaningful Outcome Parameters Using Mobile Technology: A New Mobile Application for Telemonitoring of Patients with Heart Failure. ESC Heart Fail 2019, 6, 516–525. [Google Scholar] [CrossRef]
- Juengst, S.B.; Terhorst, L.; Nabasny, A.; Wallace, T.; Weaver, J.A.; Osborne, C.L.; Burns, S.P.; Wright, B.; Wen, P.-S.; Kew, C.-L.N.; et al. Use of mHealth Technology for Patient-Reported Outcomes in Community-Dwelling Adults with Acquired Brain Injuries: A Scoping Review. Int. J. Environ. Res. Public Health 2021, 18, 2173. [Google Scholar] [CrossRef]
- Sato, Y.; Maruyama, T. Examining Difference between Paper- and Web-Based Self-Reported Departure/Arrival Time Using Smartphone-Based Survey. Transp. Res. Procedia 2020, 48, 1390–1400. [Google Scholar] [CrossRef]
- Descamps, J.; Le Hanneur, M.; Bouché, P.-A.; Boukebous, B.; Duranthon, L.-D.; Grimberg, J. Do Web-Based Follow-up Surveys Have a Better Response Rate than Traditional Paper-Based Questionnaires Following Outpatient Arthroscopic Rotator Cuff Repair? A Randomized Controlled Trial. Orthop. Traumatol. Surg. Res. 2023, 109, 103479. [Google Scholar] [CrossRef]
- Meirte, J.; Hellemans, N.; Anthonissen, M.; Denteneer, L.; Maertens, K.; Moortgat, P.; Van Daele, U. Benefits and Disadvantages of Electronic Patient-Reported Outcome Measures: Systematic Review. JMIR Perioper Med. 2020, 3, e15588. [Google Scholar] [CrossRef]
- Petracca, F.; Tempre, R.; Cucciniello, M.; Ciani, O.; Pompeo, E.; Sannino, L.; Lovato, V.; Castaman, G.; Ghirardini, A.; Tarricone, R. An Electronic Patient-Reported Outcome Mobile App for Data Collection in Type A Hemophilia: Design and Usability Study. JMIR Form Res 2021, 5, e25071. [Google Scholar] [CrossRef]
- Ma, D.; Orner, D.; Ghaly, M.M.; Parashar, B.; Ames, J.W.; Chen, W.C.; Potters, L.; Teckie, S. Automated Health Chats for Symptom Management of Head and Neck Cancer Patients Undergoing Radiation Therapy. Oral Oncol. 2021, 122, 105551. [Google Scholar] [CrossRef]
- Chaix, B.; Bibault, J.-E.; Romain, R.; Guillemassé, A.; Neeral, M.; Delamon, G.; Moussalli, J.; Brouard, B. Assessing the Performances of a Chatbot to Collect Real-Life Data of Patients Suffering from Primary Headache Disorders. Digit Health 2022, 8, 20552076221097783. [Google Scholar] [CrossRef]
- Bibault, J.-E.; Chaix, B.; Nectoux, P.; Pienkowski, A.; Guillemasé, A.; Brouard, B. Healthcare Ex Machina: Are Conversational Agents Ready for Prime Time in Oncology? Clin. Transl. Radiat. Oncol. 2019, 16, 55–59. [Google Scholar] [CrossRef]
- Te Pas, M.E.; Rutten, W.G.M.M.; Bouwman, R.A.; Buise, M.P. User Experience of a Chatbot Questionnaire Versus a Regular Computer Questionnaire: Prospective Comparative Study. JMIR Med. Inf. 2020, 8, e21982. [Google Scholar] [CrossRef]
- Schamber, E.M.; Takemoto, S.K.; Chenok, K.E.; Bozic, K.J. Barriers to Completion of Patient Reported Outcome Measures. J. Arthroplast. 2013, 28, 1449–1453. [Google Scholar] [CrossRef] [PubMed]
- Veloso Costa, A.; Padfield, O.; Elliott, S.; Hayden, P. Improving Patient Diary Use in Intensive Care: A Quality Improvement Report. J. Intensive Care Soc. 2021, 22, 27–33. [Google Scholar] [CrossRef] [PubMed]
- Knott, E.; Rao, A.H.; Summers, K.; Teeger, C. Interviews in the Social Sciences. Nat. Rev. Methods Primers 2022, 2, 1–15. [Google Scholar] [CrossRef]
- Thomas, J.A. Using Unstructured Diaries for Primary Data Collection. Nurse Res. 2015, 22, 25–29. [Google Scholar] [CrossRef] [PubMed]
- Ahlin, E. Semi-Structured Interviews with Expert Practitioners: Their Validity and Significant Contribution to Translational Research. In Sage Research Methods Cases Part 2; Sage Publications Ltd.: London, UK, 2019. [Google Scholar] [CrossRef]
- Henriksen, M.G.; Englander, M.; Nordgaard, J. Methods of Data Collection in Psychopathology: The Role of Semi-Structured, Phenomenological Interviews. Phenomenol. Cogn. Sci. 2022, 21, 9–30. [Google Scholar] [CrossRef]
- Kakilla, C. Strengths and Weaknesses of Semi-Structured Interviews in Qualitative Research: A Critical Essay. Preprints 2021, 2021060491. [Google Scholar] [CrossRef]
- DeJonckheere, M.; Vaughn, L.M. Semistructured Interviewing in Primary Care Research: A Balance of Relationship and Rigour. Fam. Med. Community Health 2019, 7, e000057. [Google Scholar] [CrossRef] [PubMed]
- You, Y.; Gui, X. Self-Diagnosis through AI-Enabled Chatbot-Based Symptom Checkers: User Experiences and Design Considerations. AMIA Annu. Symp. Proc. 2021, 2020, 1354–1363. [Google Scholar]
- Sharma, D.; Kaushal, S.; Kumar, H.; Gainder, S. Chatbots in Healthcare: Challenges, Technologies and Applications. In Proceedings of the 4th International Conference on Artificial Intelligence and Speech Technology (AIST), Delhi, India, 9–10 December 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Bemmann, F.; Schoedel, R. Chatbots for Experience Sampling—Initial Opportunities and Challenges. In Proceedings of the Joint ACM Conference on Intelligent User Interfaces Workshops, ACMIUI-WS 2021, College Station, TX, USA, 13–17 April 2021. [Google Scholar]
- Xiao, Z.; Zhou, M.X.; Liao, Q.V.; Mark, G.; Chi, C.; Chen, W.; Yang, H. Tell Me About Yourself: Using an AI-Powered Chatbot to Conduct Conversational Surveys with Open-Ended Questions. ACM Trans. Comput.-Hum. Interact. 2020, 27, 1–37. [Google Scholar] [CrossRef]
- Jannach, D.; Manzoor, A.; Cai, W.; Chen, L. A Survey on Conversational Recommender Systems. ACM Comput. Surv. 2021, 54, 36. [Google Scholar] [CrossRef]
- Valtolina, S.; Barricelli, B.R.; Di Gaetano, S. Communicability of Traditional Interfaces VS Chatbots in Healthcare and Smart Home Domains. Behav. Inf. Technol. 2020, 39, 108–132. [Google Scholar] [CrossRef]
- Beam, E.A. Social Media as a Recruitment and Data Collection Tool: Experimental Evidence on the Relative Effectiveness of Web Surveys and Chatbots. J. Dev. Econ. 2023, 162, 103069. [Google Scholar] [CrossRef]
- Chaix, B.; Bibault, J.-E.; Pienkowski, A.; Delamon, G.; Guillemassé, A.; Nectoux, P.; Brouard, B. When Chatbots Meet Patients: One-Year Prospective Study of Conversations Between Patients With Breast Cancer and a Chatbot. JMIR Cancer 2019, 5, e12856. [Google Scholar] [CrossRef] [PubMed]
- Han, X.; Zhou, M.; Turner, M.; Yeh, T. Designing Effective Interview Chatbots: Automatic Chatbot Profiling and Design Suggestion Generation for Chatbot Debugging. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 6 May 2021; pp. 1–15. [Google Scholar]
- Wei, J.; Kim, S.; Jung, H.; Kim, Y.-H. Leveraging Large Language Models to Power Chatbots for Collecting User Self-Reported Data. arXiv 2023, arXiv:2301.05843. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Lin, B.; Cecchi, G.; Bouneffouf, D. Psychotherapy AI Companion with Reinforcement Learning Recommendations and Interpretable Policy Dynamics. In Proceedings of the Companion Proceedings of the ACM Web Conference 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 932–939. [Google Scholar]
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for Good? On Opportunities and Challenges of Large Language Models for Education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Floridi, L.; Chiriatti, M. GPT-3: Its Nature, Scope, Limits, and Consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling Language Modeling with Pathways. J. Mach. Learn. Res. 2023, 24, 1–113. [Google Scholar]
- Rae, J.W.; Borgeaud, S.; Cai, T.; Millican, K.; Hoffmann, J.; Song, F.; Aslanides, J.; Henderson, S.; Ring, R.; Young, S.; et al. Scaling Language Models: Methods, Analysis & Insights from Training Gopher. arXiv 2021, arXiv:2112.11446. [Google Scholar] [CrossRef]
- Teubner, T.; Flath, C.; Weinhardt, C.; Aalst, W.; Hinz, O. Welcome to the Era of ChatGPT et al.: The Prospects of Large Language Models. Bus. Inf. Syst. Eng. 2023, 65, 95–101. [Google Scholar] [CrossRef]
- BioMedLM: A Domain-Specific Large Language Model for Biomedical Text. Available online: https://www.mosaicml.com/blog/introducing-pubmed-gpt (accessed on 27 October 2023).
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large Language Models Encode Clinical Knowledge. Nature 2022, 620, 172–180. [Google Scholar] [CrossRef]
- Lin, B.; Bouneffouf, D.; Cecchi, G.; Varshney, K.R. Towards Healthy AI: Large Language Models Need Therapists Too. arXiv 2023, arXiv:2304.00416. [Google Scholar] [CrossRef]
- Yeung, J.A.; Kraljevic, Z.; Luintel, A.; Balston, A.; Idowu, E.; Dobson, R.J.; Teo, J.T. AI Chatbots Not yet Ready for Clinical Use. Front. Digit. Health 2023, 5, 60. [Google Scholar] [CrossRef] [PubMed]
- Omar, R.; Mangukiya, O.; Kalnis, P.; Mansour, E. ChatGPT versus Traditional Question Answering for Knowledge Graphs: Current Status and Future Directions Towards Knowledge Graph Chatbots. arXiv 2023, arXiv:2302.06466. [Google Scholar] [CrossRef]
- Shojania, K.G. The Frustrating Case of Incident-Reporting Systems. Qual. Saf. Health Care 2008, 17, 400–402. [Google Scholar] [CrossRef]
- O’Hara, J.K.; Reynolds, C.; Moore, S.; Armitage, G.; Sheard, L.; Marsh, C.; Watt, I.; Wright, J.; Lawton, R. What Can Patients Tell Us about the Quality and Safety of Hospital Care? Findings from a UK Multicentre Survey Study. BMJ Qual. Saf. 2018, 27, 673–682. [Google Scholar] [CrossRef]
- McIntosh, M.J.; Morse, J.M. Situating and Constructing Diversity in Semi-Structured Interviews. Glob. Qual. Nurs. Res. 2015, 2, 2333393615597674. [Google Scholar] [CrossRef]
- Short, C.E.; Finlay, A.; Sanders, I.; Maher, C. Development and Pilot Evaluation of a Clinic-Based mHealth App Referral Service to Support Adult Cancer Survivors Increase Their Participation in Physical Activity Using Publicly Available Mobile Apps. BMC Health Serv. Res. 2018, 18, 27. [Google Scholar] [CrossRef]
- Loh, K.P.; Ramsdale, E.; Culakova, E.; Mendler, J.H.; Liesveld, J.L.; O’Dwyer, K.M.; McHugh, C.; Gilles, M.; Lloyd, T.; Goodman, M.; et al. Novel mHealth App to Deliver Geriatric Assessment-Driven Interventions for Older Adults with Cancer: Pilot Feasibility and Usability Study. JMIR Cancer 2018, 4, e10296. [Google Scholar] [CrossRef] [PubMed]
- Moorthy, P.; Weinert, L.; Harms, B.C.; Anders, C.; Siegel, F. German Version of the mHealth App Usability Questionnaire in a Cohort of Patients with Cancer: Translation and Validation Study. JMIR Hum. Factors 2023, 10, e51090. [Google Scholar] [CrossRef]
- Teckie, S.; Solomon, J.; Kadapa, K.; Sanchez, K.; Orner, D.; Kraus, D.; Kamdar, D.P.; Pereira, L.; Frank, D.; Diefenbach, M. A Mobile Patient-Facing App for Tracking Patient-Reported Outcomes in Head and Neck Cancer Survivors: Single-Arm Feasibility Study. JMIR Form. Res. 2021, 5, e24667. [Google Scholar] [CrossRef] [PubMed]
- Paulissen, J.M.J.; Zegers, C.M.L.; Nijsten, I.R.; Reiters, P.H.C.M.; Houben, R.M.; Eekers, D.B.P.; Roelofs, E. Performance and Usability Evaluation of a Mobile Health Data Capture Application in Clinical Cancer Trials Follow-Up. Tech. Innov. Patient Support Radiat. Oncol. 2022, 24, 107–112. [Google Scholar] [CrossRef]
- Open Health Connect. Building Connected Health and Care Systems: Integrating Services with Actionable Data. Available online: https://www.dedalus.com/na/our-offer/products/open-health-connect/ (accessed on 10 December 2023).
- Šafran, V.; Hari, D.; Ariöz, U.; Mlakar, I. PERSIST Sensing Network: A Multimodal Sensing Network Architecture for Collection of Patient-Generated Health Data in The Clinical Workflow. In Proceedings of the 2021 International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), Mauritius, Mauritius, 7–8 October 2021; pp. 1–6. [Google Scholar]
- Rojc, M.; Mlakar, I.; Kačič, Z. The TTS-Driven Affective Embodied Conversational Agent EVA, Based on a Novel Conversational-Behavior Generation Algorithm. Eng. Appl. Artif. Intell. 2017, 57, 80–104. [Google Scholar] [CrossRef]
- Miner, A.S.; Laranjo, L.; Kocaballi, A.B. Chatbots in the Fight against the COVID-19 Pandemic. NPJ Digit. Med. 2020, 3, 65. [Google Scholar] [CrossRef]
- Li, J.; Lavrukhin, V.; Ginsburg, B.; Leary, R.; Kuchaiev, O.; Cohen, J.M.; Nguyen, H.; Gadde, R.T. Jasper: An End-to-End Convolutional Neural Acoustic Model. arXiv 2019, arXiv:1904.03288. [Google Scholar] [CrossRef]
- Del Rio, M.; Delworth, N.; Westerman, R.; Huang, M.; Bhandari, N.; Palakapilly, J.; McNamara, Q.; Dong, J.; Zelasko, P.; Jette, M. Earnings-21: A Practical Benchmark for ASR in the Wild. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August 2021; pp. 3465–3469. [Google Scholar]
- Heafield, K. KenLM: Faster and Smaller Language Model Queries. In Proceedings of the Sixth Workshop on Statistical Machine Translation; Association for Computational Linguistics: Edinburgh, Scotland, 2011; pp. 187–197. [Google Scholar]
- Ginsburg, B.; Castonguay, P.; Hrinchuk, O.; Kuchaiev, O.; Lavrukhin, V.; Leary, R.; Li, J.; Nguyen, H.; Zhang, Y.; Cohen, J.M. Stochastic Gradient Methods with Layer-Wise Adaptive Moments for Training of Deep Networks. arXiv 2019, arXiv:1905.11286. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Hori, T.; Watanabe, S.; Zhang, Y.; Chan, W. Advances in Joint CTC-Attention Based End-to-End Speech Recognition with a Deep CNN Encoder and RNN-LM. arXiv 2017, arXiv:1706.02737. [Google Scholar] [CrossRef]
- Picone, M.; Inoue, S.; DeFelice, C.; Naujokas, M.F.; Sinrod, J.; Cruz, V.A.; Stapleton, J.; Sinrod, E.; Diebel, S.E.; Wassman, E.R. Social Listening as a Rapid Approach to Collecting and Analyzing COVID-19 Symptoms and Disease Natural Histories Reported by Large Numbers of Individuals. Popul. Health Manag. 2020, 23, 350–360. [Google Scholar] [CrossRef]
- Eureka|Symptoma: The World’s Most Accurate AI Symptom Checker. Available online: https://www.eurekanetwork.org/blog/symptoma-the-world-s-most-accurate-ai-symptom-checker (accessed on 16 November 2023).
- Hong, N.; Wen, A.; Stone, D.J.; Tsuji, S.; Kingsbury, P.R.; Rasmussen, L.V.; Pacheco, J.A.; Adekkanattu, P.; Wang, F.; Luo, Y.; et al. Developing a FHIR-Based EHR Phenotyping Framework: A Case Study for Identification of Patients with Obesity and Multiple Comorbidities from Discharge Summaries. J. Biomed. Inform. 2019, 99, 103310. [Google Scholar] [CrossRef]
- The Dedalus Platform. Dedalus Ways to Digital Connect 4 Healthcare (DC4H). Available online: https://www.dedalus.com/global/en/our-offer/continuum-of-care/newdedalus-platform/ (accessed on 10 December 2023).
- González-Castro, L.; Cal-González, V.M.; Del Fiol, G.; López-Nores, M. CASIDE: A Data Model for Interoperable Cancer Survivorship Information Based on FHIR. J. Biomed. Inform. 2021, 124, 103953. [Google Scholar] [CrossRef]
- Mukhiya, S.K.; Rabbi, F.; I Pun, V.K.; Rutle, A.; Lamo, Y. A GraphQL Approach to Healthcare Information Exchange with HL7 FHIR. Procedia Comput. Sci. 2019, 160, 338–345. [Google Scholar] [CrossRef]
- Documents Download Module. Available online: https://ec.europa.eu/research/participants/documents/downloadPublic?documentIds=080166e5f99add65&appId=PPGMS (accessed on 24 January 2024).
- Alwakeel, L.; Lano, K. Functional and Technical Aspects of Self-Management mHealth Apps: Systematic App Search and Literature Review. JMIR Hum. Factors 2022, 9, e29767. [Google Scholar] [CrossRef]
- Cao, J.; Ganesh, A.; Cai, J.; Southwell, R.; Perkoff, E.M.; Regan, M.; Kann, K.; Martin, J.H.; Palmer, M.; D’Mello, S. A Comparative Analysis of Automatic Speech Recognition Errors in Small Group Classroom Discourse. In Proceedings of the 31st ACM Conference on User Modeling, Adaptation and Personalization; Association for Computing Machinery: New York, NY, USA, 2023; pp. 250–262. [Google Scholar]
- Denby, B.; Csapó, T.G.; Wand, M. Future Speech Interfaces with Sensors and Machine Intelligence. Sensors 2023, 23, 1971. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zhou, Z.; Li, B.; Li, Z.; Kan, Z. Multi-Modal Interaction with Transformers: Bridging Robots and Human with Natural Language. Robotica 2024, 42, 415–434. [Google Scholar] [CrossRef]
- Verbraeken, J.; Wolting, M.; Katzy, J.; Kloppenburg, J.; Verbelen, T.; Rellermeyer, J.S. A Survey on Distributed Machine Learning. ACM Comput. Surv. 2020, 53, 1–33. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Language | Training Data | Testing Data | Training Time | Model Size | Platform | Batch WER | Test WER |
|---|---|---|---|---|---|---|---|
| Slovenian | 336.74 h | 85.84 h | 55 days | 2.6 GB | HPC GPU 2xRTX8000 | 0.0032% | 2.3% |
| Latvian | 782.65 h | 197.08 h | 93 days | 2.6 GB | HPC GPU 2xRTX8000 | 2.03% | 0.35% |
| English | 1272.87 h | 319.97 h | 81 days | 2.6 GB | HPC GPU 8xA100 | 0.7% | 2.92% |
| Spanish | 1272.87 h | 319.97 h | 81 days | 2.6 GB | HPC GPU 8xA100 | 0.7% | 2.92% |
| Russian | 2796.00 h | 709.42 h | 145 days | 2.6 GB | HPC GPU 6xA100 | 9.1% | 2.7% |
| French | 1272.48 h | 335.49 h | 185 days | 2.6 GB | HPC GPU 4xV100 | 5.3% | 7.6% |
| Clinical Partner | Recruited Patients | Mean Age | Breast Cancer | Colorectal Cancer | Male | Female |
|---|---|---|---|---|---|---|
| UL | 46 | 54 | 24 | 22 | 7 | 39 |
| UKCM | 40 | 57 | 20 | 20 | 11 | 29 |
| CHU | 41 | 55 | 21 | 20 | 7 | 34 |
| SERGAS | 39 | 56 | 20 | 19 | 12 | 27 |
| TOTAL | 166 | 55 | 85 | 81 | 37 | 129 |
| First | Middle | Last | |
|---|---|---|---|
| Mean | 7.600 | 7.250 | 7.600 |
| Median | 8.000 | 8.000 | 8.000 |
| Std. deviation | 1.635 | 2.023 | 1.789 |
| Minimum | 5.000 | 2.000 | 4.000 |
| Maximum | 10.000 | 10.000 | 10.000 |
| 25th percentile | 6.000 | 6.750 | 6.000 |
| 50th percentile | 8.000 | 8.000 | 8.000 |
| 75th percentile | 8.250 | 8.000 | 9.000 |
| First | Middle | Last | |
|---|---|---|---|
| Mean | 7.600 | 7.350 | 7.900 |
| Median | 7.500 | 8.000 | 8.000 |
| Std. deviation | 1.667 | 1.899 | 1.553 |
| Minimum | 5.000 | 3.000 | 5.000 |
| Maximum | 10.000 | 10.000 | 10.000 |
| 25th percentile | 6.000 | 6.000 | 7.000 |
| 50th percentile | 7.500 | 8.000 | 8.000 |
| 75th percentile | 9.000 | 8.250 | 9.000 |
| First | Middle | Last | |
|---|---|---|---|
| Mean | 6.650 | 7.000 | 7.000 |
| Median | 7.000 | 8.000 | 8.000 |
| Std. deviation | 2.455 | 2.753 | 2.695 |
| Minimum | 1.000 | 1.000 | 1.000 |
| Maximum | 10.000 | 10.000 | 10.000 |
| 25th percentile | 5.750 | 6.750 | 6.000 |
| 50th percentile | 7.000 | 8.000 | 8.000 |
| 75th percentile | 8.000 | 9.000 | 9.000 |
| Study | Questionnaires | Patient Sample | Patient Feedback |
|---|---|---|---|
| Short et. al. [101] | Self-defined | 10 | Strongly positive |
| Loh et. al. [102] | SUS | 18 | Positive |
| Moorthy et. al. [103] | SUS, MAUQ | 133 | Strongly positive |
| Teckie et. al. [104] | SUS | 17 | Positive |
| Paulissen et. al. [105] | SUS | 15 | Strongly positive |
| PERSIST [122] | SUS, Self-defined | 166 | Strongly positive |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Šafran, V.; Lin, S.; Nateqi, J.; Martin, A.G.; Smrke, U.; Ariöz, U.; Plohl, N.; Rojc, M.; Bēma, D.; Chávez, M.; et al. Multilingual Framework for Risk Assessment and Symptom Tracking (MRAST). Sensors 2024, 24, 1101. https://doi.org/10.3390/s24041101
Šafran V, Lin S, Nateqi J, Martin AG, Smrke U, Ariöz U, Plohl N, Rojc M, Bēma D, Chávez M, et al. Multilingual Framework for Risk Assessment and Symptom Tracking (MRAST). Sensors. 2024; 24(4):1101. https://doi.org/10.3390/s24041101
Chicago/Turabian StyleŠafran, Valentino, Simon Lin, Jama Nateqi, Alistair G. Martin, Urška Smrke, Umut Ariöz, Nejc Plohl, Matej Rojc, Dina Bēma, Marcela Chávez, and et al. 2024. "Multilingual Framework for Risk Assessment and Symptom Tracking (MRAST)" Sensors 24, no. 4: 1101. https://doi.org/10.3390/s24041101
APA StyleŠafran, V., Lin, S., Nateqi, J., Martin, A. G., Smrke, U., Ariöz, U., Plohl, N., Rojc, M., Bēma, D., Chávez, M., Horvat, M., & Mlakar, I. (2024). Multilingual Framework for Risk Assessment and Symptom Tracking (MRAST). Sensors, 24(4), 1101. https://doi.org/10.3390/s24041101