

NeoSLAM: Long-Term SLAM Using Computational Models of the Brain

 , ,
, ,  and
and
Abstract
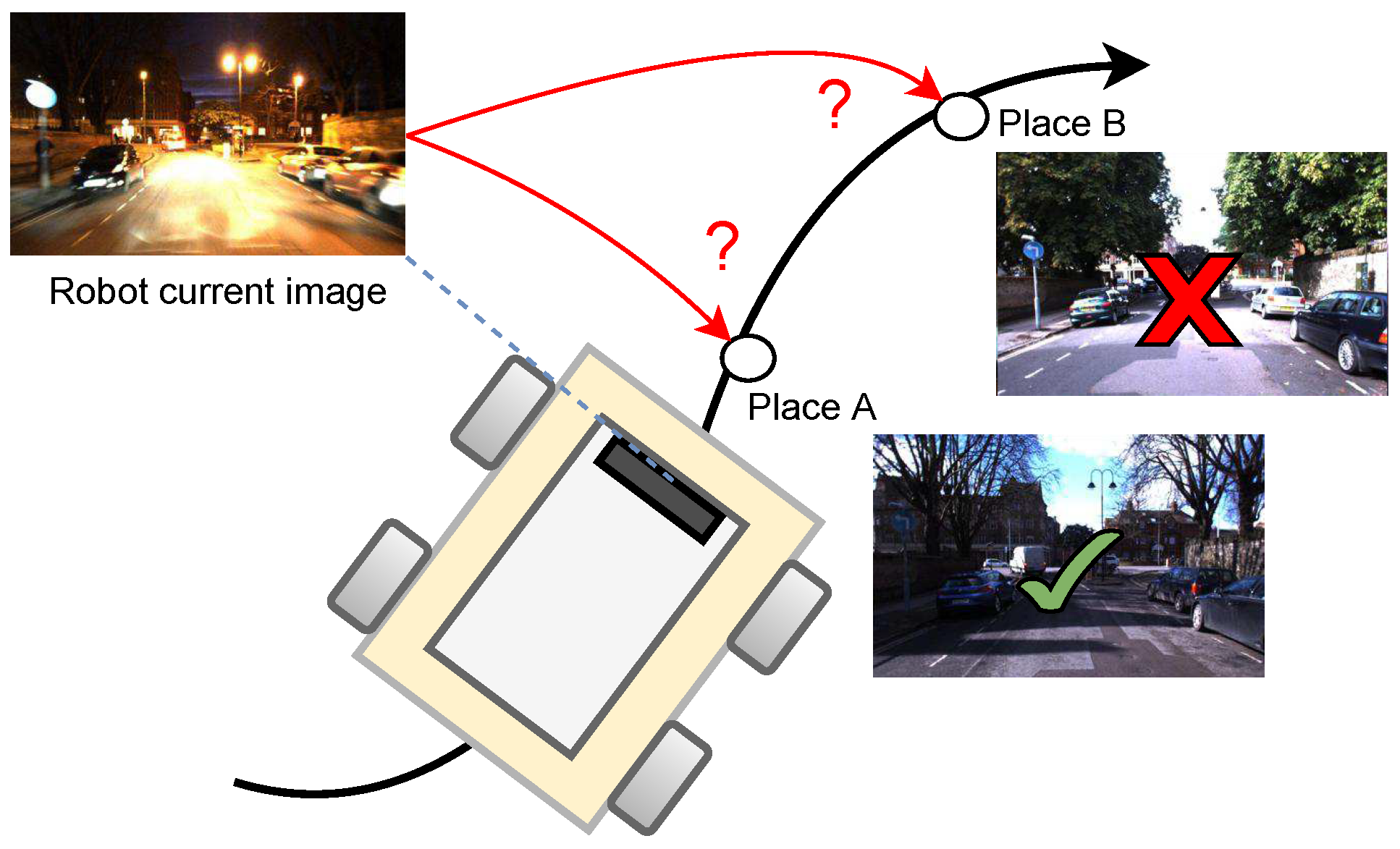
:1. Introduction
- We present NeoSLAM, a novel long-term visual SLAM that integrates computational models of the neocortex and hippocampal–entorhinal system in order to enhance the efficiency and robustness to changes in the robot’s environment caused by different conditions.
- A new loop-closure detector based on spatial-view cells is presented. The method uses binary sparse distributed representations, offering a compact and powerful way to encode complex patterns in data. Unlike traditional dense representations, which require substantial computational resources, our method significantly reduces the computational load, making it particularly suitable for real-time applications.
- We provide a thorough experimental evaluation that involves deploying the system in practical scenarios, enabling a thorough examination of its performance and capabilities within the Robot Operating System (ROS) framework.
2. NeoSLAM
2.1. Neocortex Model
2.1.1. Sparse Distributed Representations
2.1.2. Notation
- Cell state: each cell can be in an active state, in a predictive (depolarized) state, or in a nonactive state.
- Active state: Matrix of active cells, , where is the active state of the i’th cell in the j’th column at any time step t. A value of 1 indicates an active state and a value of 0 indicates an inactive state.
- Predictive state: Matrix of predictive cells, , where is the predictive state of the i’th cell in the j’th column at any time step t. A value of 1 indicates a predicted state and a value of 0 indicates an unpredicted state.
- Winner cells: Matrix of winner cells, , where is the winner i’th cell in the j’th column at any time step t. A winner cell is an active cell that was predicted or selected from the bursting minicolumn.
- Minicolumn state: Each minicolumn has a binary state variable , where a value of 1 indicates an active state and a value of 0 indicates an inactive state.
- Dendrite segments: Each cell has one proximal dendrite segment and one or more distal dendrite segments. The proximal dendrite segment is a single shared dendrite segment per each minicolumn of cells and receives feed-forward connections from dimensions of the input I. The distal dendrite segments receive lateral input from nearby cells through the synapses on each segment.
- Synapse: Connection between an axon of one neuron and a dendrite of the other. The dendrite segments contain a number of potential synapses that have an associated permanence value. The permanence value of a synapse is a scalar value ranging from 0.0 to 1.0. If the permanence value of the potential synapse is greater than a threshold , it becomes a functional synapse, as can be seen in Figure 4. In HTM theory, synapses have binary weights.
- Learning: the process of learning involves incrementing or decrementing the permanence values of potential synapses on a dendrite segment.
2.1.3. Hierarchical Temporal Memory
2.2. Encoder
2.3. Spatial-View-Cells Module
2.4. Pose Cell Network
2.5. Experience Map
3. Experimental Validation
3.1. Experimental Setup
3.2. Environments
3.2.1. Robotarium
3.2.2. Heriot-Watt University
3.2.3. Cow Barn on the Farmland
3.3. Evaluation Metrics
- Precision (P);
- Recall (R); and
- Area under the precision–recall curve ().
3.4. General Procedures
3.5. Parameter Configurations
4. Results
4.1. Robotarium
4.2. Heriot-Watt University
4.3. Cow Barn
5. Discussion and Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BC | Border Cells |
| BoVW | Bag-of-Visual-Words |
| BRIEF | Binary Robust Independent Elementary Features |
| BRISK | Binary Robust Invariant Scalable Keypoints |
| CANN | Continuous Attractor Neural Network |
| CNN/ConvNet | Convolutional Neural Network |
| FAB-MAP | Fast-Appearance-Based Mapping technique |
| FAST | Features from accelerated segment test |
| GC | Grid cells |
| HD | Head-direction cells |
| HP | Hippocampus |
| HTM | Hierarchical temporal memory |
| LCD | Loop-closure detection |
| LIO-SAM | LiDAR-Inertial Odometry Smoothing and Mapping |
| MAP | Maximum a Posteriori Probability |
| MEC | Medial Entorhinal Cortex |
| ORB | Oriented FAST and Rotated BRIEF |
| ORE | Offshore Renewable Energy sector |
| PC | Place cell |
| ROS | Robot Operating System |
| SLAM | Simultaneous Localization and Mapping |
| SDR | Sparse distributed representations |
| SIFT | Scale-Invariant Feature Transform |
| SP | Spatial Pooler |
| SURF | Speeded-Up Robust Features |
| TM | Temporal memory |
| VLAD | Vector of Locally Aggregated Descriptors |
| VPR | Visual place recognition |
References
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Mitchell, D.; Blanche, J.; Zaki, O.; Roe, J.; Kong, L.; Harper, S.; Robu, V.; Lim, T.; Flynn, D. Symbiotic System of Systems Design for Safe and Resilient Autonomous Robotics in Offshore Wind Farms. IEEE Access 2021, 9, 141421–141452. [Google Scholar] [CrossRef]
- Mitchell, D.; Blanche, J.; Harper, S.; Lim, T.; Gupta, R.; Zaki, O.; Tang, W.; Robu, V.; Watson, S.; Flynn, D. A review: Challenges and opportunities for artificial intelligence and robotics in the offshore wind sector. Energy AI 2022, 8, 100146. [Google Scholar] [CrossRef]
- Harper, S.T.; Mitchell, D.; Nandakumar, S.C.; Blanche, J.; Lim, T.; Flynn, D. Addressing Non-Intervention Challenges via Resilient Robotics Utilizing a Digital Twin. In Proceedings of the 2023 IEEE International Conference on Omni-Layer Intelligent Systems (COINS), Berlin, Germany, 23–25 July 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Cheah, W.; Garcia-Nathan, T.B.; Groves, K.; Watson, S.; Lennox, B. Path Planning for a Reconfigurable Robot in Extreme Environments. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 10087–10092. [Google Scholar] [CrossRef]
- Mitchell, D.; Emor Baniqued, P.D.; Zahid, A.; West, A.; Nouri Rahmat Abadi, B.; Lennox, B.; Liu, B.; Kizilkaya, B.; Flynn, D.; Francis, D.J.; et al. Lessons learned: Symbiotic autonomous robot ecosystem for nuclear environments. IET Cyber-Syst. Robot. 2023, 5, e12103. [Google Scholar] [CrossRef]
- Baskoro, C.H.A.H.B.; Saputra, H.M.; Mirdanies, M.; Susanti, V.; Radzi, M.F.; Aziz, R.I.A. An Autonomous Mobile Robot Platform for Medical Purpose. In Proceedings of the 2020 International Conference on Sustainable Energy Engineering and Application (ICSEEA), Tangerang, Indonesia, 18–20 November 2020; pp. 41–44. [Google Scholar] [CrossRef]
- Siegwart, R.; Nourbakhsh, I.R.; Scaramuzza, D. Introduction to Autonomous Mobile Robots; MIT Press: Cambridge, UK, 2011. [Google Scholar]
- Lowry, S.; Sünderhauf, N.; Newman, P.; Leonard, J.J.; Cox, D.; Corke, P.; Milford, M.J. Visual Place Recognition: A Survey. IEEE Trans. Robot. 2016, 32, 1–19. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust invariant scalable keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar] [CrossRef]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 2, pp. 1470–1477. [Google Scholar] [CrossRef]
- Sünderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B.; Milford, M. On the performance of ConvNet features for place recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 4297–4304. [Google Scholar] [CrossRef]
- Perronnin, F.; Liu, Y.; Sánchez, J.; Poirier, H. Large-scale image retrieval with compressed Fisher vectors. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3384–3391. [Google Scholar] [CrossRef]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar] [CrossRef]
- Sousa, R.B.; Sobreira, H.M.; Moreira, A.P. A systematic literature review on long-term localization and mapping for mobile robots. J. Field Robot. 2023, 40, 1245–1322. [Google Scholar] [CrossRef]
- Skrede, S. Nordlandsbanen: Minute by Minute, Season by Season. 2013. Available online: https://nrkbeta.no/2013/01/15/nordlandsbanen-minute-by-minute-season-by-sea/son (accessed on 21 June 2020).
- Schubert, S.; Neubert, P. What makes visual place recognition easy or hard? arXiv 2021, arXiv:2106.12671. [Google Scholar]
- Milford, M.; Wyeth, G. Hippocampal models for simultaneous localisation and mapping on an autonomous robot. In Proceedings of the 2003 Australasian Conference on Robotics and Automation, Brisbane, Australia, 1–3 December 2003; Wyeth, G., Roberts, J., Eds.; Australian Robotics and Automation Association: Brisbane, Australia, 2003; pp. 1–10. [Google Scholar]
- Milford, M.; Wyeth, G. Mapping a Suburb With a Single Camera Using a Biologically Inspired SLAM System. IEEE Trans. Robot. 2008, 24, 1038–1053. [Google Scholar] [CrossRef]
- Ball, D.; Heath, S.; Wiles, J.; Wyeth, G.; Corke, P.; Milford, M. OpenRatSLAM: An open source brain-based SLAM system. Auton. Robot. 2013, 34, 149–176. [Google Scholar] [CrossRef]
- Silveira, L.; Guth, F.; Drews-Jr, P.; Ballester, P.; Machado, M.; Codevilla, F.; Duarte-Filho, N.; Botelho, S. An Open-source Bio-inspired Solution to Underwater SLAM. IFAC-PapersOnLine 2015, 48, 212–217. [Google Scholar] [CrossRef]
- Yuan, M.; Tian, B.; Shim, V.A.; Tang, H.; Li, H. An Entorhinal-Hippocampal Model for Simultaneous Cognitive Map Building. In Proceedings of the AAAI, Austin, TX, USA, 25–30 January 2015; Bonet, B., Koenig, S., Eds.; AAAI Press: Washington, DC, USA, 2015; pp. 586–592. [Google Scholar]
- Lu, H.; Xiao, J.; Zhang, L.; Yang, S.; Zell, A. Biologically inspired visual odometry based on the computational model of grid cells for mobile robots. In Proceedings of the 2016 IEEE International Conference on Robotics and Biomimetics (ROBIO), Qingdao, China, 3–7 December 2016; pp. 595–601. [Google Scholar] [CrossRef]
- Kazmi, S.M.A.M.; Mertsching, B. Gist+RatSLAM: An Incremental Bio-inspired Place Recognition Front-End for RatSLAM. EAI Endorsed Trans. Creat. Technol. 2016, 3, e3. [Google Scholar] [CrossRef]
- Zhou, S.C.; Yan, R.; Li, J.X.; Chen, Y.K.; Tang, H. A brain-inspired SLAM system based on ORB features. Int. J. Autom. Comput. 2017, 14, 564–575. [Google Scholar] [CrossRef]
- Zeng, T.; Si, B. Cognitive Mapping Based on Conjunctive Representations of Space and Movement. Front. Neurorobotics 2017, 11, 61. [Google Scholar] [CrossRef]
- Yu, F.; Chancan, M.; Shang, J.; Hu, Y.; Milford, M. NeuroSLAM: A Brain Inspired SLAM System for 3D Environments. Biol. Cybern. 2019, 113, 515–545. [Google Scholar] [CrossRef] [PubMed]
- Çatal, O.; Jansen, W.; Verbelen, T.; Dhoedt, B.; Steckel, J. LatentSLAM: Unsupervised multi-sensor representation learning for localization and mapping. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA 2021, Xi’an, China, 30 May–5 June 2021; pp. 6739–6745. [Google Scholar] [CrossRef]
- Salimpour Kasebi, S.; Seyedarabi, H.; Musevi Niya, J. Hybrid navigation based on GPS data and SIFT-based place recognition using Biologically-inspired SLAM. In Proceedings of the 2021 11th International Conference on Computer Engineering and Knowledge (ICCKE), Mashhad, Iran, 28–29 October 2021; pp. 260–266. [Google Scholar] [CrossRef]
- Fan, C.; Chen, Z.; Jacobson, A.; Hu, X.; Milford, M. Biologically-Inspired Visual Place Recognition with Adaptive Multiple Scales. Robot. Auton. Syst. 2017, 96, 224–237. [Google Scholar] [CrossRef]
- Neubert, P.; Ahmad, S.; Protzel, P. A Sequence-Based Neuronal Model for Mobile Robot Localization. In Proceedings of the KI 2018: Advances in Artificial Intelligence, Berlin, Germany, 24–28 September 2018; Trollmann, F., Turhan, A.Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 117–130. [Google Scholar]
- Neubert, P.; Schubert, S.; Protzel, P. A Neurologically Inspired Sequence Processing Model for Mobile Robot Place Recognition. IEEE Robot. Autom. Lett. 2019, 4, 3200–3207. [Google Scholar] [CrossRef]
- Hawkins, J.; Ahmad, S. Why Neurons Have Thousands of Synapses, a Theory of Sequence Memory in Neocortex. Front. Neural Circuits 2016, 10, 23. [Google Scholar] [CrossRef]
- Li, J.; Tang, H.; Yan, R. A Hybrid Loop Closure Detection Method Based on Brain-Inspired Models. IEEE Trans. Cogn. Dev. Syst. 2022, 14, 1532–1543. [Google Scholar] [CrossRef]
- Squire, L.; Berg, D.; Bloom, F.; du Lac, S.; Ghosh, A.; Spitzer, N.; Squire, L. Fundamental Neuroscience; Elsevier Science: Amsterdam, The Netherlands, 2008. [Google Scholar]
- Rolls, E.T. Cerebral Cortex: Principles of Operation; Oxford University Press: Oxford, UK, 2016. [Google Scholar]
- Rolls, E.T. Chapter 4.2—The primate hippocampus and episodic memory. In Handbook of Behavioral Neuroscience; Dere, E., Easton, A., Nadel, L., Huston, J.P., Eds.; Elsevier: Amsterdam, The Netherlands, 2008; Volume 18, pp. 417–626. [Google Scholar] [CrossRef]
- Hawkins, J.; Ahmad, S.; Dubinsky, D. Hierarchical Temporal Memory including HTM Cortical Learning Algorithms. Version 0.2.1. Available online: https://www.numenta.com/assets/pdf/whitepapers/hierarchical-temporal-memory-cortical-learning-algorithm-0.2.1-en.pdf (accessed on 30 November 2023).
- Cui, Y.; Ahmad, S.; Hawkins, J. Continuous Online Sequence Learning with an Unsupervised Neural Network Model. Neural Comput. 2016, 28, 2474–2504. [Google Scholar] [CrossRef] [PubMed]
- Hawkins, J.; Ahmad, S.; Cui, Y. A Theory of How Columns in the Neocortex Enable Learning the Structure of the World. Front. Neural Circuits 2017, 11, 81. [Google Scholar] [CrossRef]
- Cui, Y.; Ahmad, S.; Hawkins, J. The HTM Spatial Pooler—A Neocortical Algorithm for Online Sparse Distributed Coding. Front. Comput. Neurosci. 2017, 11, 111. [Google Scholar] [CrossRef] [PubMed]
- Mnatzaganian, J.; Fokoue, E.; Kudithipudi, D. A Mathematical Formalization of Hierarchical Temporal Memory’s Spatial Pooler. Front. Robot. AI 2016, 3, 81. [Google Scholar] [CrossRef]
- Celeghin, A.; Borriero, A.; Orsenigo, D.; Diano, M.; Guerrero, C.A.M.; Perotti, A.; Petri, G.; Tamietto, M. Convolutional neural networks for vision neuroscience: Significance, developments, and outstanding issues. Front. Comput. Neurosci. 2023, 17, 1153572. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ahmad, S.; Hawkins, J. Properties of Sparse Distributed Representations and their Application to Hierarchical Temporal Memory. arXiv 2015, arXiv:1503.07469. [Google Scholar]
- Wyeth, G.; Milford, M. Spatial cognition for robots. IEEE Robot. Autom. Mag. 2009, 16, 24–32. [Google Scholar] [CrossRef]
- Hawkins, J.; Ahmad, S.; Purdy, S.; Lavin, A. Biological and Machine Intelligence (BAMI). Initial Online Release 0.4. Available online: https://numenta.com/resources/biological-and-machine-intelligence/ (accessed on 30 November 2023).
- Shan, T.; Englot, B.; Meyers, D.; Wang, W.; Ratti, C.; Rus, D. LIO-SAM: Tightly-coupled Lidar Inertial Odometry via Smoothing and Mapping. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 5135–5142. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Robot | Environment | Ground Truth |
|---|---|---|---|
| 1 | Clearpath Husky | Robotarium | Annotated manually |
| 2 | Clearpath Husky | Robotarium | Annotated manually |
| 3 | Hay-cleaning robot | Cow barn | LiDAR-based SLAM |
| Parameter | Module | Robotarium | HWU | Cow Barn |
|---|---|---|---|---|
| input-, columnDimensions | Spatial Pooler | 2048 | 2048 | 2048 |
| numActiveColumnsPerInhArea | Spatial Pooler | 40 | 40 | 40 |
| columnDimensions | Temporal memory | 2048 | 2048 | 2048 |
| cellsPerColumn | Temporal memory | 32 | 32 | 32 |
| activationThreshold | Temporal memory | 4 | 4 | 4 |
| maximum size of the interval | Spatial-view cells | 1 | 3 | 2 |
| maximum overlap | Spatial-view cells | - | 384 | 384 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pizzino, C.A.P.; Costa, R.R.; Mitchell, D.; Vargas, P.A. NeoSLAM: Long-Term SLAM Using Computational Models of the Brain. Sensors 2024, 24, 1143. https://doi.org/10.3390/s24041143
Pizzino CAP, Costa RR, Mitchell D, Vargas PA. NeoSLAM: Long-Term SLAM Using Computational Models of the Brain. Sensors. 2024; 24(4):1143. https://doi.org/10.3390/s24041143
Chicago/Turabian StylePizzino, Carlos Alexandre Pontes, Ramon Romankevicius Costa, Daniel Mitchell, and Patrícia Amâncio Vargas. 2024. "NeoSLAM: Long-Term SLAM Using Computational Models of the Brain" Sensors 24, no. 4: 1143. https://doi.org/10.3390/s24041143