
PSMOT: Online Occlusion-Aware Multi-Object Tracking Exploiting Position Sensitivity


Abstract
:1. Introduction
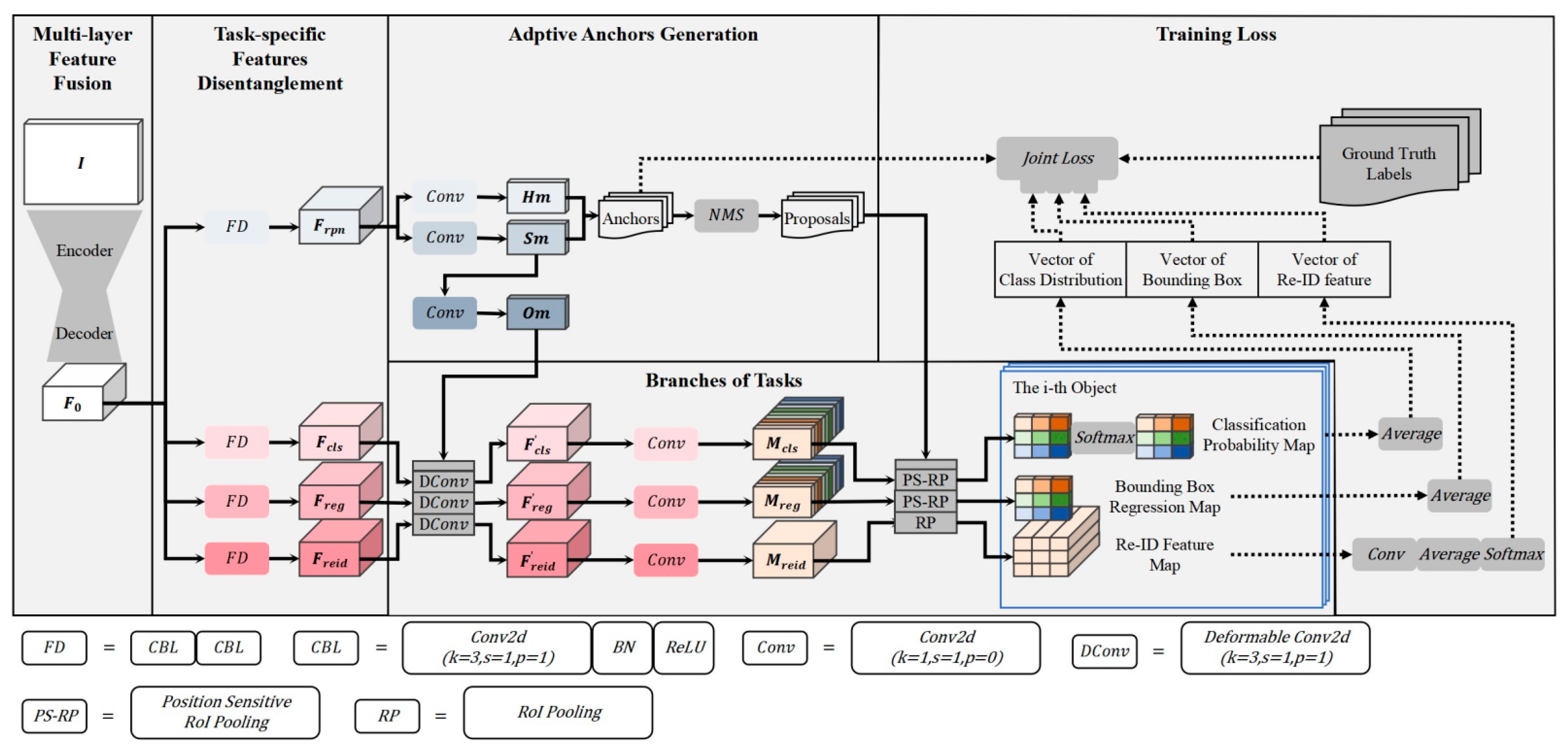
- Reuses the two-stage model in multi-object tracking and leverages its inherent advantages in RoI-wise and region-based mechanisms to handle feature misalignment and provide conditions for anti-occlusion;
- The two-stage JDE model, extended from R-FCN, adopts a fully convolutional network structure that significantly reduces the computational burden in RoI-wise processing;
- Replaces the original RPN network, which relies on dense and predefined anchors, with a network based on adaptive sparse anchors, enabling the production of more high-quality proposals with fewer anchors. This replacement further improves the model’s efficiency;
- An efficient encoder–decoder network with multi-layer feature fusion is employed as the model’s backbone and additional convolutional layers are added at the entry of each task branch. Therefore, the highly informative shared features are first generated and then disentangled into effective task-specific features. This feature process effectively mitigates the conflicts between tasks and significantly improves the overall performance;
- Extends the application of position sensitivity to determine whether a specific part of an object is occluded. Leveraging this cue helps in active anti-occlusion by excluding the corresponding interference.
2. Related Work
2.1. Early Tracking-by-Detection MOT Methods
2.2. Joint Detection and Embedding (JDE) MOT Methods
2.3. Anti-Occlusion in MOT
3. Our Approach
3.1. The Two-Stage JDE Model
3.1.1. Multi-Layer Feature Fusion
3.1.2. Task-Specific Disentanglement
3.1.3. Adaptive Sparse Anchors
3.1.4. Branches of Tasks
- (1)
- Classification
- (2)
- Bounding Box Regression
- (3)
- ReID Feature Extraction
3.1.5. Loss Function
3.2. Online Tracking
3.2.1. Anti-Occlusion Inference
3.2.2. Online Association
3.2.3. Anti-Occlusion Tracking
4. Experiments
4.1. Datasets
4.2. Metrics
4.3. Implementation
4.4. Ablastion Studies
4.4.1. Multi-Layer Feature Fusion
4.4.2. Feature Disentanglement
4.4.3. Generation of Adaptive Anchors
4.4.4. Position Sensitivity
4.4.5. Association Scheme
4.5. Comparisons with State-of-the-Art MOT Methods
4.5.1. Comparisons with Typical Methods
4.5.2. Comparisons with Methods for MOT Benchmarks
4.6. Visualization
4.6.1. Visualization of the Visibility Map
4.6.2. Visualization of Detection and Tracking of Occluded Targets
4.6.3. Visualization of Online Tracking
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Teng, S.; Hu, X.; Deng, P.; Li, B.; Li, Y.; Yang, D.; Ai, Y.; Li, L.; Zhe, X.; Zhu, F.; et al. Motion Planning for Autonomous Driving: The State of the Art and Future Perspectives. IEEE Trans. Intell. Veh. 2023, 8, 3692–3711. [Google Scholar] [CrossRef]
- Varghese, E.B.; Thampi, S.M. A Comprehensive Review of Crowd Behavior and Social Group Analysis Techniques in Smart Surveillance. In Intelligent Image and Video Analytics; Routledge: London, UK, 2023; pp. 57–84. [Google Scholar]
- Wu, H.; Nie, J.; Zhang, Z.; He, Z.; Gao, M. Deep Learning-based Visual Multiple Object Tracking: A Review. Comput. Sci. 2023, 50, 77–87. [Google Scholar] [CrossRef]
- Voigtlaender, P.; Krause, M.; Osep, A.; Luiten, J.; Sekar, B.B.G.; Geiger, A.; Leibe, B. Mots: Multi-object tracking and segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7942–7951. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards real-time multi-object tracking. In Proceedings of the Computer Vision-ECCV2020: European Conference, Glasgow, UK, 23–28 August 2020; pp. 107–122. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the Fairness of Detection and Re-identification in Multiple Object Tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Liang, C.; Zhang, Z.; Lu, Y.; Li, B.; Zhu, S.; Hu, W. Rethinking the competition between detection and ReID in Multi-Object Tracking. arXiv 2020, arXiv:2010.12138. [Google Scholar]
- Yu, E.; Li, Z.; Han, S.; Wang, H. RelationTrack: Relation-aware Multiple Object Tracking with Decoupled Representation. arXiv 2021, arXiv:2105.04322. [Google Scholar] [CrossRef]
- Liu, Q.; Chen, D.; Chu, Q.; Yuan, L.; Liu, B.; Zhang, L.; Yu, N. Online Multi-Object Tracking with Unsupervised Re-IDentification Learning and Occlusion Estimation. Neurocomputing 2022, 483, 333–347. [Google Scholar] [CrossRef]
- Tsai, C.Y.; Shen, G.Y.; Nisar, H. Swin-JDE: Joint Detection and Embedding Multi-Object Tracking Based on Swin-Transformer. Eng. Appl. Artif. Intell. 2023, 119, 105770. [Google Scholar] [CrossRef]
- Mostafa, R.; Baraka, H.; Bayoumi, A. LMOT: Efficient Light-Weight Detection and Tracking in Crowds. IEEE Access 2022, 10, 83085–83095. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, J.; Li, B.; Gao, L.; Zhang, J. RetinaMOT: Rethinking anchor-free YOLOv5 for online multiple object tracking. Complex Intell. Syst. 2023, 9, 5115–5133. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Wang, J.; Kai, C.; Shuo, Y.; Loy, C.C.; Lin, D. Region Proposal by Guided Anchoring. arXiv 2019, arXiv:1901.03278. [Google Scholar]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep Layer Aggregation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 18–23. [Google Scholar]
- Dai, J.; He, K.; Li, Y.; Ren, S.; Sun, J. Instance-sensitive Fully Convolutional Networks. arXiv 2016, arXiv:1603.08678. [Google Scholar]
- Chen, L.; Ai, H.; Zhuang, Z.; Shang, C. Real-Time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple Online and Realtime Tracking. arXiv 2016, arXiv:1602.00763. [Google Scholar]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Li, W.; Li, Q.; Liu, Y.; Shi, X.; Yan, J. POI: Multiple Object Tracking with High Performance Detection and Appearance Feature. arXiv 2016, arXiv:1610.06136. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Lee, S.; Kim, E. Multiple Object Tracking via Feature Pyramid Siamese Networks. IEEE Access 2019, 7, 8181–8194. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Li, Z.; Cai, S.; Wang, X.; Shao, H.; Niu, L.; Xue, N. Multiple Object Tracking with GRU Association and Kalman Prediction. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Sener, O.; Koltun, V. Multi-Task Learning as Multi-Objective Optimization. arXiv 2018, arXiv:1810.04650. [Google Scholar]
- Cipolla, R.; Gal, Y.; Kendall, A. Multi-task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7482–7491. [Google Scholar]
- Jocher, G. YOLOv5 Release V6.1. 2022. Available online: https://github.com/ultralytics/yolov5/releases/tag/v6.1 (accessed on 22 February 2022).
- Hu, W.; Li, X.; Luo, W.; Zhang, X.; Maybank, S.; Zhang, Z. Single and Multiple Object Tracking Using Log-Euclidean Riemannian Subspace and Block-Division Appearance Model. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2420–2440. [Google Scholar]
- Izadinia, H.; Saleemi, I.; Li, W.; Shah, M. (MP)2T: Multiple People Multiple Parts Tracker. In Proceedings of the Computer Vision-ECCV2020: European Conference, Glasgow, UK, 23–28 August 2020; pp. 100–114. [Google Scholar]
- Shu, G.; Dehghan, A.; Oreifej, O.; Hand, E.; Shah, M. Part-based multiple-person tracking with partial occlusion handling. In Proceedings of the 2012 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1815–1821. [Google Scholar]
- Tang, S.; Andriluka, M.; Schiele, B. Detection and Tracking of Occluded People. Int. J. Comput. Vis. 2014, 110, 58–69. [Google Scholar] [CrossRef]
- Wu, B.; Nevatia, R. Detection and Tracking of Multiple, Partially Occluded Humans by Bayesian Combination of Edgelet based Part Detectors. Int. J. Comput. Vis. 2007, 75, 247–266. [Google Scholar] [CrossRef]
- Chu, Q.; Ouyang, W.; Li, H.; Wang, X.; Liu, B.; Yu, N. Online Multi-Object Tracking Using CNN-based Single Object Tracker with Spatial-Temporal Attention Mechanism. arXiv 2017, arXiv:1708.02843. [Google Scholar]
- Ess, A.; Leibe, B.; Schindler, K.; Van Gool, L. A mobile vision system for robust multi-person tracking. In Proceedings of the 2008 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. CityPersons: A Diverse Dataset for Pedestrian Detection. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4457–4465. [Google Scholar]
- Zhang, S.; Xie, Y.; Wan, J.; Xia, H.; Li, S.Z.; Guo, G. WiderPerson: A Diverse Dataset for Dense Pedestrian Detection in the Wild. IEEE Trans. Multimed. 2020, 22, 380–393. [Google Scholar] [CrossRef]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: A benchmark. In Proceedings of the 2009 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 304–311. [Google Scholar]
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. Joint Detection and Identification Feature Learning for Person Search. arXiv 2016, arXiv:1604.01850. [Google Scholar]
- Zheng, L.; Zhang, H.; Sun, S.; Chandraker, M.; Yang, Y.; Tian, Q. Person Re-identification in the Wild. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3346–3355. [Google Scholar]
- Dave, A.; Khurana, T.; Tokmakov, P.; Schmid, C.; Ramanan, D. TAO: A Large-Scale Benchmark for Tracking Any Object. arXiv 2020, arXiv:2005.10356. [Google Scholar]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. MOT20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar]
- Luiten, J.; Osep, A.; Dendorfer, P.; Torr, P.; Geiger, A.; Leal-Taixe, L.; Leibe, B. HOTA: A Higher Order Metric for Evaluating Multi-object Tracking. Int. J. Comput. Vis. 2021, 129, 548–578. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Huang, C.; Nevatia, R. Learning to associate: HybridBoosted multi-target tracker for crowded scene. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2953–2960. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Ristani, E.; Solera, F.; Zou, S.; Cucchiara, R.; Tomasi, C. Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking. arXiv 2016, arXiv:1609.01775. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-Based Object Detectors with Online Hard Example Mining. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Dvornik, N.; Mairal, J.; Schmid, C. Modeling Visual Context is Key to Augmenting Object Detection Datasets. arXiv 2018, arXiv:1807.07428. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Peng, J.; Wang, T.; Lin, W.; Wang, J.; See, J.; Wen, S.; Ding, E. TPM: Multiple Object Tracking with Tracklet-Plane Matching. Pattern Recognit. 2020, 107, 107480. [Google Scholar] [CrossRef]
- Girbau, A.; Giró-i-Nieto, X.; Rius, I.; Marqués, F. Multiple Object Tracking with Mixture Density Networks for Trajectory Estimation. arXiv 2021, arXiv:2106.10950. [Google Scholar]
- Li, W.; Xiong, Y.; Yang, S.; Xu, M.; Wang, Y.; Xia, W. Semi-TCL: Semi-Supervised Track Contrastive Representation Learning. arXiv 2021, arXiv:2107.02396. [Google Scholar]
- Pang, B.; Li, Y.; Zhang, Y.; Li, M.; Lu, C. TubeTK: Adopting Tubes to Track Multi-Object in a One-Step Training Model. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6307–6317. [Google Scholar]
- Zhou, X.; Koltun, V. Tracking Objects as Points. arXiv 2020, arXiv:2004.01177. [Google Scholar]
- Xu, Y.; Ban, Y.; Delorme, G.; Gan, C.; Rus, D.; Alameda-Pineda, X. TransCenter: Transformers with Dense Representations for Multiple-Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 7820–7835. [Google Scholar] [CrossRef] [PubMed]
- Meinhardt, T.; Kirillov, A.; Leal-Taixe, L.; Feichtenhofer, C. TrackFormer: Multi-Object Tracking with Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8834–8844. [Google Scholar]
- Lee, S.H.; Park, D.H.; Bae, S.H. Decode-MOT: How Can We Hurdle Frames to Go Beyond Tracking-by-Detection? IEEE Trans. Image Processs. 2023, 32, 4378–4392. [Google Scholar] [CrossRef] [PubMed]
- Gao, R.; Wang, L. MeMOTR: Long-Term Memory-Augmented Transformer for Multi-Object Tracking. arXiv 2023, arXiv:2307.15700. [Google Scholar]
- Zhang, Y.; Sheng, H.; Wu, Y.; Wang, S.; Ke, W.; Xiong, Z. Multiplex Labeling Graph for Near-Online Tracking in Crowded Scenes. IEEE Internet Things J. 2020, 7, 7892–7902. [Google Scholar] [CrossRef]
- Sun, P.; Cao, J.; Jiang, Y.; Zhang, R.; Xie, E.; Yuan, Z.; Wang, C.; Luo, P. TransTrack: Multiple Object Tracking with Transformer. arXiv 2020, arXiv:2012.15460. [Google Scholar]
- Wang, Y.; Kitani, K.; Weng, X. Joint Object Detection and Multi-Object Tracking with Graph Neural Networks. arXiv 2020, arXiv:2006.13164. [Google Scholar]
- Fukui, H.; Miyagawa, T.; Morishita, Y. Multi-Object Tracking as Attention Mechanism. arXiv 2023, arXiv:2307.05874. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | MOTA ↑ | IDF1 ↑ | AssA ↑ | DetA ↑ | LocA ↑ | IDs ↓ | Frag ↓ |
|---|---|---|---|---|---|---|---|
| ResNet-34 | 69.6 | 70.4 | 57.8 | 56.2 | 78.7 | 303 | 631 |
| FPN-34 | 71.4 | 72.8 | 61.1 | 59.8 | 81.7 | 237 | 370 |
| DLA-34 (ours) | 75.1 | 75.8 | 62.2 | 62.5 | 83.8 | 167 | 269 |
| Module | MOTA ↑ | IDF1 ↑ | AssA ↑ | DetA ↑ | LocA ↑ | IDs ↓ | Frag ↓ |
|---|---|---|---|---|---|---|---|
| General | 72.9 | 73.8 | 59.6 | 60.1 | 81.3 | 224 | 332 |
| Ours | 75.1 | 75.8 | 62.2 | 62.5 | 83.8 | 167 | 269 |
| Module | Number | MOTA ↑ | IDF1 ↑ | AssA ↑ | DetA ↑ | LocA ↑ | FPS ↑ |
|---|---|---|---|---|---|---|---|
| Vanilla RPN | 300 | 72.1 | 72.5 | 58.5 | 59.1 | 79.3 | 14.3 |
| 1000 | 73.5 | 73.9 | 60.1 | 60.3 | 80.6 | 5.1 | |
| GA-RPN (ours) | 300 | 73.2 | 74.4 | 59.5 | 60.2 | 82.3 | 22.4 |
| 500 | 75.1 | 75.8 | 62.2 | 62.5 | 83.8 | 16.6 | |
| 1000 | 75.6 | 76.5 | 63.5 | 64.1 | 85.3 | 7.4 |
| K × K | MOTA ↑ | IDF1 ↑ | IDs ↓ | Frag ↓ | FPS ↑ |
|---|---|---|---|---|---|
| 1 × 1 | 64.9 | 63 | 535 | 878 | 20.3 |
| 3 × 3 | 74.6 | 75 | 252 | 504 | 18.6 |
| 5 × 5 | 75.1 | 75.8 | 167 | 269 | 16.6 |
| 7 × 7 | 75.4 | 76.4 | 133 | 196 | 10.3 |
| 9 × 9 | 75.4 | 76.6 | 122 | 183 | 4.1 |
| ReID | IoU and Kalman | Hierarchy | MOTA ↑ | IDF1 ↑ | IDs ↓ | Frag ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | 75.1 | 75.8 | 167 | 269 | 16.6 |
| ✓ | ✓ | 74.0 | 73.6 | 217 | 326 | 19.0 | |
| ✓ | 72.7 | 72.6 | 279 | 446 | 20.3 |
| Versions | Max Proposals | Dims of PS Maps |
|---|---|---|
| PSMOT-Fast | 300 | 3 |
| PSMOT-Balance | 500 | 5 |
| PSMOT-Pro | 1000 | 7 |
| Tracker | MOTA ↑ | IDF1 ↑ | AssA ↑ | DetA ↑ | LocA ↑ | IDs ↓ | Frag ↓ | FPS ↑ | Params ↓ |
|---|---|---|---|---|---|---|---|---|---|
| FairMOT [6] | 73.3 | 72.3 | 58.0 | 60.9 | 83.6 | 3303 | 8073 | 25.9 | 24.4 M |
| RelationTrack [8] | 73.8 | 74.7 | 61.5 | 60.6 | 83.4 | 1374 | 2166 | 8.5 | 22.7 M |
| PSMOT-Fast | 73.9 | 74.1 | 59.1 | 61.6 | 83.5 | 3052 | 4883 | 20.0 | 24.8 M |
| PSMOT-Balance | 75.1 | 75.8 | 62.2 | 62.5 | 83.8 | 1896 | 2804 | 16.6 | 24.9 M |
| PSMOT-Pro | 75.9 | 76.3 | 63.9 | 64.3 | 84.4 | 1309 | 2114 | 6.2 | 25.0 M |
| Dataset | Tracker | Time | Arch | MOTA ↑ | IDF1 ↑ | AssA ↑ | DetA ↑ | LocA ↑ | IDs ↓ | Frag ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MOT17 | TPM [54] | 2020 | SDE | 54.2 | 52.6 | 40.9 | 42.5 | 80.0 | 1824 | 2472 | 0.8 |
| TrajE [55] | 2021 | SDE | 67.4 | 61.2 | 46.6 | 53.5 | 81.5 | 4019 | 6613 | 1.4 | |
| FairMOT [6] | 2020 | JDE | 73.3 | 72.3 | 58.0 | 60.9 | 83.6 | 3303 | 8073 | 25.9 | |
| CSTrack [7] | 2020 | JDE | 74.9 | 72.6 | 57.9 | 61.1 | 83.3 | 3567 | 7668 | 15.8 | |
| Semi-TCL [56] | 2021 | JDE | 73.3 | 73.2 | 59.4 | 60.4 | 83.7 | 2790 | 8010 | -- | |
| RelationTrack [8] | 2021 | JDE | 73.8 | 74.7 | 61.5 | 60.6 | 83.4 | 1374 | 2166 | 8.5 | |
| OUTrack [9] | 2022 | JDE | 73.5 | 70.2 | 56.7 | 61.1 | 83.8 | 4122 | 7500 | 25.9 | |
| Swin_JDE [10] | 2023 | JDE | 72.3 | 70.7 | 57.4 | 58.5 | 83.0 | 2679 | 3903 | 4.5 | |
| TubeTK [57] | 2020 | JDT | 63.0 | 58.6 | 45.1 | 51.4 | 81.1 | 4137 | 5727 | 3.0 | |
| CenterTrack [58] | 2020 | JDT | 67.8 | 64.7 | 51.0 | 53.8 | 81.5 | 3039 | 6102 | 3.8 | |
| TransCenter [59] | 2021 | JDT | 73.2 | 62.2 | 49.7 | 60.1 | 83.5 | 4614 | 9519 | 1.0 | |
| TrackFormer [60] | 2022 | JDT | 74.1 | 68 | 54.1 | 60.9 | 82.8 | 2829 | 4221 | 5.7 | |
| Decode_MOT [61] | 2023 | JDT | 73.2 | 72 | 58.9 | 60.5 | 83.6 | 3363 | 6051 | 1.8 | |
| MeMOTR [62] | 2023 | JDT | 72.8 | 71.5 | 58.4 | 59.6 | 83.0 | 1902 | 4770 | 29.6 | |
| PSMOT-Fast | --- | JDE | 73.9 | 74.1 | 59.1 | 61.6 | 83.5 | 3052 | 4883 | 20.0 | |
| PSMOT-Balance | 75.1 | 75.8 | 62.2 | 62.5 | 83.8 | 1896 | 2804 | 16.6 | |||
| PSMOT-Pro | 75.9 | 76.3 | 63.9 | 64.3 | 84.4 | 1309 | 2114 | 6.2 | |||
| MOT20 | FairMOT [6] | 2020 | JDE | 61.8 | 67.3 | 54.7 | 54.7 | 81.1 | 5243 | 7874 | 13.2 |
| CSTrack [7] | 2020 | JDE | 66.6 | 68.6 | 54.0 | 54.2 | 81.5 | 3196 | 7632 | 4.5 | |
| Semi-TCL [10] | 2021 | JDE | 65.2 | 70.1 | 56.3 | 54.6 | 81.2 | 4139 | 8508 | 22.4 | |
| RelationTrack [8] | 2021 | JDE | 67.2 | 70.5 | 56.4 | 56.8 | 81.8 | 4243 | 8236 | 4.3 | |
| OUTrack [9] | 2022 | JDE | 68.6 | 69.4 | 55.6 | 57.0 | 82.5 | 2223 | 5683 | 12.4 | |
| LMOT [11] | 2022 | JDE | 59.1 | 61.1 | 46.8 | 48.4 | 83.1 | 1398 | 2446 | 22.4 | |
| RetinaMOT [8] | 2023 | JDE | 66.8 | 67.5 | 53.8 | 54.5 | 82.0 | 1739 | 3217 | 22.4 | |
| Swin_JDE [10] | 2023 | JDE | 70.4 | 69.5 | 54.8 | 56.9 | 82.1 | 2026 | 3165 | 4.1 | |
| MLT [63] | 2020 | JDT | 48.9 | 54.6 | 44.1 | 42.7 | 80.6 | 2187 | 3067 | 3.7 | |
| TransTrack [64] | 2020 | JDT | 65.0 | 59.4 | 45.2 | 53.3 | 82.8 | 3608 | 11,352 | 14.9 | |
| TransCenter [59] | 2021 | JDT | 58.5 | 49.6 | 37.0 | 51.7 | 81.1 | 4695 | 9581 | 1.0 | |
| GSDT [65] | 2021 | JDT | 67.1 | 67.5 | 52.7 | 54.7 | 81.7 | 3230 | 9878 | 1.5 | |
| TrackFormer [60] | 2022 | JDT | 68.6 | 65.7 | 53.0 | 56.7 | 83.7 | 1532 | 2474 | 5.7 | |
| TicrossNet [66] | 2023 | JDT | 60.6 | 59.3 | 44.9 | 51.9 | 81.4 | 4266 | 6969 | 31.0 | |
| Decode_MOT [61] | 2023 | JDT | 67.2 | 69.0 | 54.6 | 54.5 | 81.4 | 2805 | 7084 | 12.2 | |
| PSMOT-Fast | --- | JDE | 66.6 | 68.2 | 55.2 | 55.1 | 81.2 | 2295 | 3442 | 13.2 | |
| PSMOT-Balance | 68.2 | 70.4 | 56.3 | 56.3 | 82.3 | 1426 | 2339 | 10.1 | |||
| PSMOT-Pro | 69.2 | 72.0 | 58.3 | 58.4 | 83.4 | 1210 | 2032 | 3.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, R.; Zhang, X.; Zhang, J. PSMOT: Online Occlusion-Aware Multi-Object Tracking Exploiting Position Sensitivity. Sensors 2024, 24, 1199. https://doi.org/10.3390/s24041199
Zhao R, Zhang X, Zhang J. PSMOT: Online Occlusion-Aware Multi-Object Tracking Exploiting Position Sensitivity. Sensors. 2024; 24(4):1199. https://doi.org/10.3390/s24041199
Chicago/Turabian StyleZhao, Ranyang, Xinyan Zhang, and Jianwei Zhang. 2024. "PSMOT: Online Occlusion-Aware Multi-Object Tracking Exploiting Position Sensitivity" Sensors 24, no. 4: 1199. https://doi.org/10.3390/s24041199