
Skeleton-Based Activity Recognition for Process-Based Quality Control of Concealed Work via Spatial–Temporal Graph Convolutional Networks

Abstract
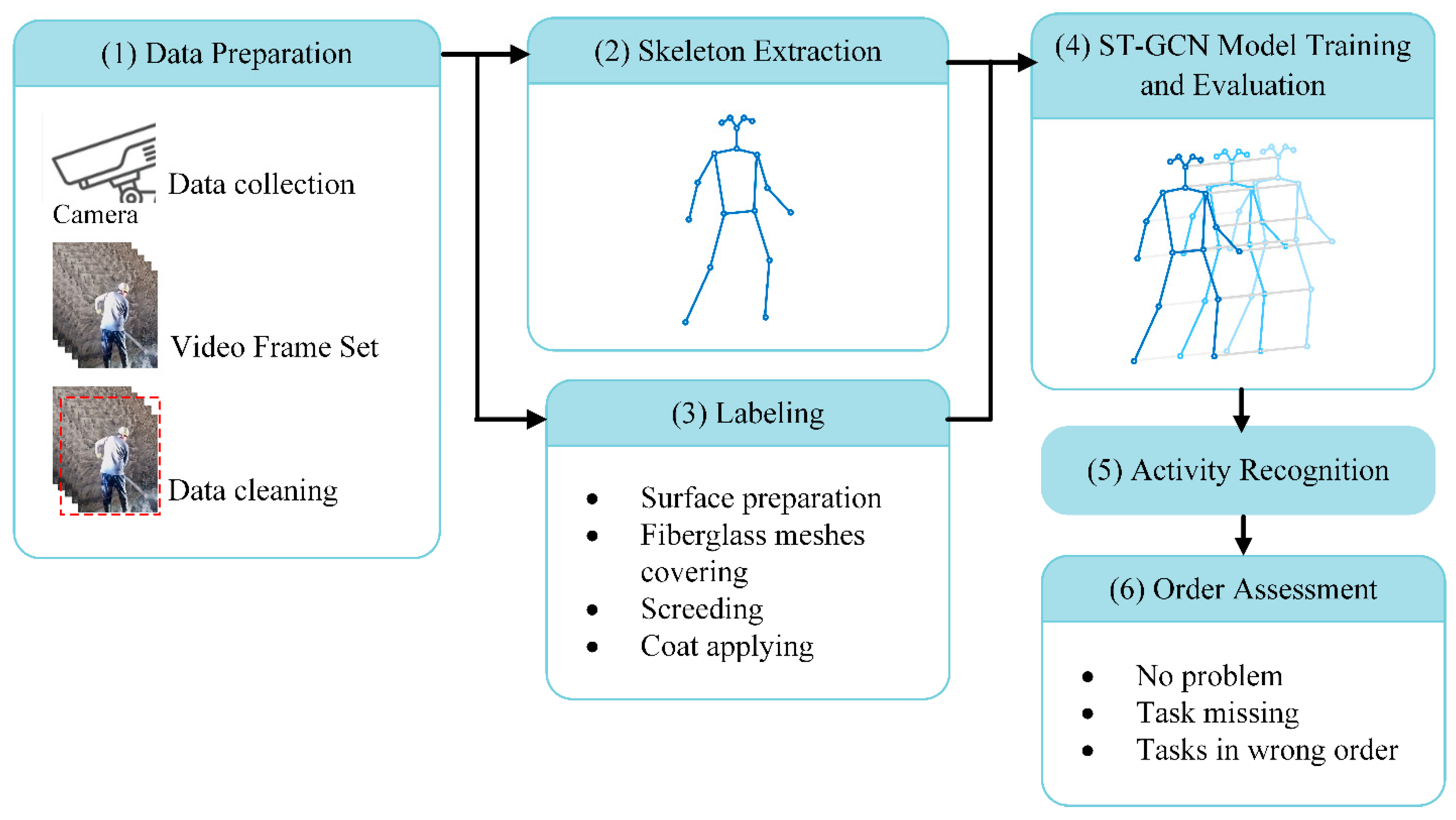
:1. Introduction
- (1)
- Provide a practical activity-order evaluation framework based on ST-GCNs which can facilitate process-based construction quality control. The experimental results highlight the accuracy of the approach and the feasibility of the framework.
- (2)
- Release a new plastering work video dataset containing both RGB and skeleton data to verify our model.
2. Related Works
2.1. Computer Vision in Construction
2.2. Skeleton-Based Human Activity Recognition
3. Methodology
3.1. Framework Overview
3.2. Dataset Preparation
- (1)
- Video collection: To feasibly automatically recognize activities of particular construction works in real scenarios with the proposed method, the video dataset was collected based on surveillance videos from real construction sites.
- (2)
- Video segmentation: Video segmentation is the process of slicing a continuous video into discrete portions for feature extraction. The videos were first converted to a frame rate of 30 frames per second (FPS), and then divided into segments of consecutive frames according to the categories of activities to build a dataset for each activity.
- (3)
- Data cleaning: Invalid frames where the body or the operation of the worker was not fully captured by the camera or where irrelevant people were captured were removed.
- (4)
- Annotation: The activity class labels were assigned to video segments according to the categories of activities. This step was intended to ensure that the skeletons over a period would correctly represent actual construction activities. In addition, this serves as the ground truth for the learning algorithm [3].
3.3. Skeleton Extraction
3.4. ST-GCN-Based Activity Recognition
4. Preliminary Experiments for Activity Recognition
4.1. Data Collection and Pre-Process
- (1)
- Surface area preparation, including cleaning the wall, removing all dust, and applying an interface agent;
- (2)
- Covering fiberglass meshes to prevent cracks;
- (3)
- Screeding to guide the even application of plaster;
- (4)
- Applying the coat to make the surface uniform and level.
4.2. Feature Extraction
4.3. Model Training Details
4.4. Network Architecture
4.5. Performance Metrics and Evaluation
5. Experiments for Activity Order Assessment
6. Discussion and Conclusions
6.1. Performance of Skeleton-Based Activity Order Assessment
6.2. Potential Applications
- (1)
- Process-based quality control
- (2)
- E-learning in construction training
- (1)
- Designing labor training exercises and training delivery methods;
- (2)
- Measuring the relative weights of labor training exercises;
- (3)
- Assessing labor competencies;
- (4)
- Developing a performance score system and grading scheme for laborers;
- (5)
- Training reinforcement.
6.3. Limitations and Future Directions
6.4. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Asadi, K.; Ramshankar, H.; Noghabaei, M.; Han, K. Real-time image localisation and registration with BIM using perspective alignment for indoor monitoring of construction. J. Comput. Civ. Eng. 2019, 33, 04019031. [Google Scholar] [CrossRef]
- Sherafat, B.; Ahn, C.R.; Akhavian, R.; Behzadan, A.H.; Golparvar-Fard, M.; Kim, H.; Lee, Y.-C.; Rashidi, A.; Azar, E.R. Automated methods for activity recognition of construction workers and equipment: State-of-the-art review. J. Constr. Eng. Manag. 2020, 146, 03120002. [Google Scholar] [CrossRef]
- Akhavian, R.; Behzadan, A.H. Smartphone-based construction workers’ activity recognition and classification. Autom. Constr. 2016, 71, 198–209. [Google Scholar] [CrossRef]
- Sherafat, B.; Rashidi, A.; Asgari, S. Sound-based multiple-equipment activity recognition using convolutional neural networks. Autom. Constr. 2022, 135, 104104. [Google Scholar] [CrossRef]
- Rashid, K.M.; Louis, J. Activity identification in modular construction using audio signals and machine learning. Autom. Constr. 2020, 119, 103361. [Google Scholar] [CrossRef]
- Zhang, S.; Wei, Z.; Nie, J.; Huang, L.; Wang, S.; Li, Z. A review on human activity recognition using vision-based method. J. Healthc. Eng. 2017, 2017, 3090343. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Lee, S.; Peña-Mora, F. Vision-based detection of unsafe actions of a construction worker: Case study of ladder climbing. J. Comput. Civ. Eng. 2013, 27, 635–644. [Google Scholar] [CrossRef]
- Ding, L.; Fang, W.; Luo, H.; Love, P.E.; Zhong, B.; Ouyang, X. A deep hybrid learning model to detect unsafe behavior: Integrating convolution neural networks and long short-term memory. Autom. Constr. 2018, 86, 118–124. [Google Scholar] [CrossRef]
- Kim, K.; Cho, Y.K. Effective inertial sensor quantity and locations on a body for deep learning-based worker’s motion recognition. Autom. Constr. 2020, 113, 103126. [Google Scholar] [CrossRef]
- Khan, N.; Saleem, M.R.; Lee, D.; Park, M.W.; Park, C. Utilising safety rule correlation for mobile scaffolds monitoring leveraging deep convolution neural networks. Comput. Ind. 2021, 129, 103448. [Google Scholar] [CrossRef]
- Xu, W.; Wang, T.-K. Dynamic safety prewarning mechanism of human–machine–environment using computer vision. Eng. Constr. Archit. Manag. 2020, 27, 1813–1833. [Google Scholar] [CrossRef]
- Zhu, D.C.; Wen, H.Y.; Deng, Y.C. Pro-active warning system for the crossroads at construction sites based on computer vision. Eng. Constr. Archit. Manag. 2020, 27, 1145–1168. [Google Scholar] [CrossRef]
- Piao, Y.; Xu, W.; Wang, T.-K.; Chen, J.-H. Dynamic fall risk assessment framework for construction workers based on dynamic Bayesian network and computer vision. J. Constr. Eng. Manag. 2021, 147, 04021171. [Google Scholar] [CrossRef]
- Rashid, K.M.; Louis, J. Automated activity identification for construction equipment using motion data from articulated members. Front. Built Environ. 2020, 5, 144. [Google Scholar] [CrossRef]
- Slaton, T.; Hernandez, C.; Akhavian, R. Construction activity recognition with convolutional recurrent networks. Autom. Constr. 2020, 113, 103138. [Google Scholar] [CrossRef]
- Deng, H.; Hong, H.; Luo, D.; Deng, Y.; Su, C. Automatic indoor construction process monitoring for tiles based on BIM and computer vision. J. Constr. Eng. Manag. 2020, 146, 04019095. [Google Scholar] [CrossRef]
- Luo, H.; Lin, L.; Chen, K.; Antwi-Afari, M.F.; Chen, L. Digital technology for quality management in construction: A review and future research directions. Dev. Built Environ. 2022, 12, 100087. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Gao, X.; Hu, W.; Tang, J.; Liu, J.; Guo, Z. Optimised skeleton-based action recognition via sparsified graph regression. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Duan, W.; Wang, Y.; Li, J.; Zheng, Y.; Ning, C.; Duan, P. Real-time surveillance-video-based personalised thermal comfort recognition. Energy Build. 2021, 244, 110989. [Google Scholar] [CrossRef]
- Seo, J.; Han, S.; Lee, S.; Kim, H. Computer vision techniques for construction safety and health monitoring. Adv. Eng. Inform. 2015, 29, 239–251. [Google Scholar] [CrossRef]
- Xu, S.; Wang, J.; Shou, W.; Ngo, T.; Sadick, A.-M.; Wang, X. Computer vision techniques in construction: A critical review. Arch. Comput. Methods Eng. 2021, 28, 3383–3397. [Google Scholar] [CrossRef]
- Paneru, S.; Jeelani, I. Computer vision applications in construction: Current state, opportunities & challenges. Autom. Constr. 2021, 132, 103940. [Google Scholar]
- Zhang, M.; Shi, R.; Yang, Z. A critical review of vision-based occupational health and safety monitoring of construction site workers. Saf. Sci. 2020, 126, 104658. [Google Scholar] [CrossRef]
- Guo, B.H.; Zou, Y.; Fang, Y.; Goh, Y.M.; Zou, P.X. Computer vision technologies for safety science and management in construction: A critical review and future research directions. Saf. Sci. 2021, 135, 105130. [Google Scholar] [CrossRef]
- Fang, W.; Love, P.E.; Luo, H.; Ding, L. Computer vision for behaviour-based safety in construction: A review and future directions. Adv. Eng. Inform. 2020, 43, 100980. [Google Scholar] [CrossRef]
- Reja, V.K.; Varghese, K.; Ha, Q.P. Computer vision-based construction progress monitoring. Autom. Constr. 2022, 138, 104245. [Google Scholar] [CrossRef]
- Omar, T.; Nehdi, M.L. Data acquisition technologies for construction progress tracking. Autom. Constr. 2016, 70, 143–155. [Google Scholar] [CrossRef]
- Ma, Z.; Liu, S. A review of 3D reconstruction techniques in civil engineering and their applications. Adv. Eng. Inform. 2018, 37, 163–174. [Google Scholar] [CrossRef]
- Ekanayake, B.; Wong, J.K.W.; Fini, A.A.F.; Smith, P. Computer vision-based interior construction progress monitoring: A literature review and future research directions. Autom. Constr. 2021, 127, 103705. [Google Scholar] [CrossRef]
- Braun, A.; Tuttas, S.; Borrmann, A.; Stilla, U. Improving progress monitoring by fusing point clouds, semantic data and computer vision. Autom. Constr. 2020, 116, 103210. [Google Scholar] [CrossRef]
- Kim, J.; Chi, S. Multi-camera vision-based productivity monitoring of earthmoving operations. Autom. Constr. 2020, 112, 103121. [Google Scholar] [CrossRef]
- Kim, H.; Bang, S.; Jeong, H.; Ham, Y.; Kim, H. Analysing context and productivity of tunnel earthmoving processes using imaging and simulation. Autom. Constr. 2018, 92, 188–198. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, Z.; Hammad, A. Automated excavators activity recognition and productivity analysis from construction site surveillance videos. Autom. Constr. 2020, 110, 103045. [Google Scholar] [CrossRef]
- Maalek, R.; Lichti, D.D.; Ruwanpura, J.Y. Automatic Recognition of Common Structural Elements from Point Clouds for Automated Progress Monitoring and Dimensional Quality Control in Reinforced Concrete Construction. Remote Sens. 2019, 11, 1102. [Google Scholar] [CrossRef]
- Mechtcherine, V.; van Tittelboom, K.; Kazemian, A.; Kreiger, E.; Nematollahi, B.; Nerella, V.N.; Santhanam, M.; de Schutter, G.; Van Zijl, G.; Lowke, D.; et al. A roadmap for quality control of hardening and hardened printed concrete. Cem. Concr. Res. 2022, 157, 106800. [Google Scholar] [CrossRef]
- Iglesias, C.; Martínez, J.; Taboada, J. Automated vision system for quality inspection of slate slabs. Comput. Ind. 2018, 99, 119–129. [Google Scholar] [CrossRef]
- Chai, Y.T.; Wang, T.-K. Evaluation and decision-making framework for concrete surface quality based on computer vision and ontology. Eng. Constr. Archit. Manag. 2022. ahead-of-print. [Google Scholar] [CrossRef]
- Luo, X.; Li, H.; Yang, X.; Yu, Y.; Cao, D. Capturing and understanding workers’ activities in far-field surveillance videos with deep action recognition and Bayesian nonparametric learning. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 333–351. [Google Scholar] [CrossRef]
- Chin, S.; Kim, K.; Kim, Y.-S. A process-based quality management information system. Autom. Constr. 2004, 13, 241–259. [Google Scholar] [CrossRef]
- Zhong, B.; Ding, L.; Luo, H.; Zhou, Y.; Hu, Y.; Hu, H. Ontology-based semantic modeling of regulation constraint for automated construction quality compliance checking. Autom. Constr. 2012, 28, 58–70. [Google Scholar] [CrossRef]
- Plizzari, C.; Cannici, M.; Matteucci, M. Skeleton-based action recognition via spatial and temporal transformer networks. Comput. Vis. Image Underst. 2021, 208, 103219. [Google Scholar] [CrossRef]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 1–11. [Google Scholar]
- Han, S.; Lee, S. A vision-based motion capture and recognition framework for behavior-based safety management. Autom. Constr. 2013, 35, 131–141. [Google Scholar] [CrossRef]
- Ray, S.J.; Teizer, J. Real-time construction worker posture analysis for ergonomics training. Adv. Eng. Inform. 2012, 26, 439–455. [Google Scholar] [CrossRef]
- Guo, H.; Yu, Y.; Ding, Q.; Skitmore, M. Image-and-Skeleton-Based Parameterized Approach to Real-Time Identification of Construction Workers’ Unsafe Behaviors. J. Constr. Eng. Manag. 2018, 144, 04018042. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Luo, H.; Wang, M.; Wong, P.K.-Y.; Cheng, J.C. Full body pose estimation of construction equipment using computer vision and deep learning techniques. Autom. Constr. 2020, 110, 103016. [Google Scholar] [CrossRef]
- Manoharan, K.; Dissanayake, P.; Pathirana, C.; Deegahawature, D.; Silva, R. A competency-based training guide model for labourers in construction. Int. J. Constr. Manag. 2021, 23, 1323–1333. [Google Scholar] [CrossRef]
- Li, Z.; Li, D. Action recognition of construction workers under occlusion. J. Build. Eng. 2022, 45, 103352. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activity | Number of Videos | Duration in Total (s) | Maximum Duration (s) | Minimum Duration (s) |
|---|---|---|---|---|
| Surface preparation | 20 | 1189 | 122 | 7 |
| Fiberglass mesh covering | 12 | 1151 | 269 | 14 |
| Screeding | 29 | 725 | 182 | 7 |
| Coat applying | 28 | 3185 | 442 | 9 |
| Index | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Training | 0.9947 | 0.9890 | 0.9930 | 0.9909 |
| Validation | 0.9948 | 0.9890 | 0.9931 | 0.9909 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, L.; Yang, X.; Peng, T.; Li, H.; Guo, R. Skeleton-Based Activity Recognition for Process-Based Quality Control of Concealed Work via Spatial–Temporal Graph Convolutional Networks. Sensors 2024, 24, 1220. https://doi.org/10.3390/s24041220
Xiao L, Yang X, Peng T, Li H, Guo R. Skeleton-Based Activity Recognition for Process-Based Quality Control of Concealed Work via Spatial–Temporal Graph Convolutional Networks. Sensors. 2024; 24(4):1220. https://doi.org/10.3390/s24041220
Chicago/Turabian StyleXiao, Lei, Xincong Yang, Tian Peng, Heng Li, and Runhao Guo. 2024. "Skeleton-Based Activity Recognition for Process-Based Quality Control of Concealed Work via Spatial–Temporal Graph Convolutional Networks" Sensors 24, no. 4: 1220. https://doi.org/10.3390/s24041220