Research on Pig Sound Recognition Based on Deep Neural Network and Hidden Markov Models

Abstract
:1. Introduction
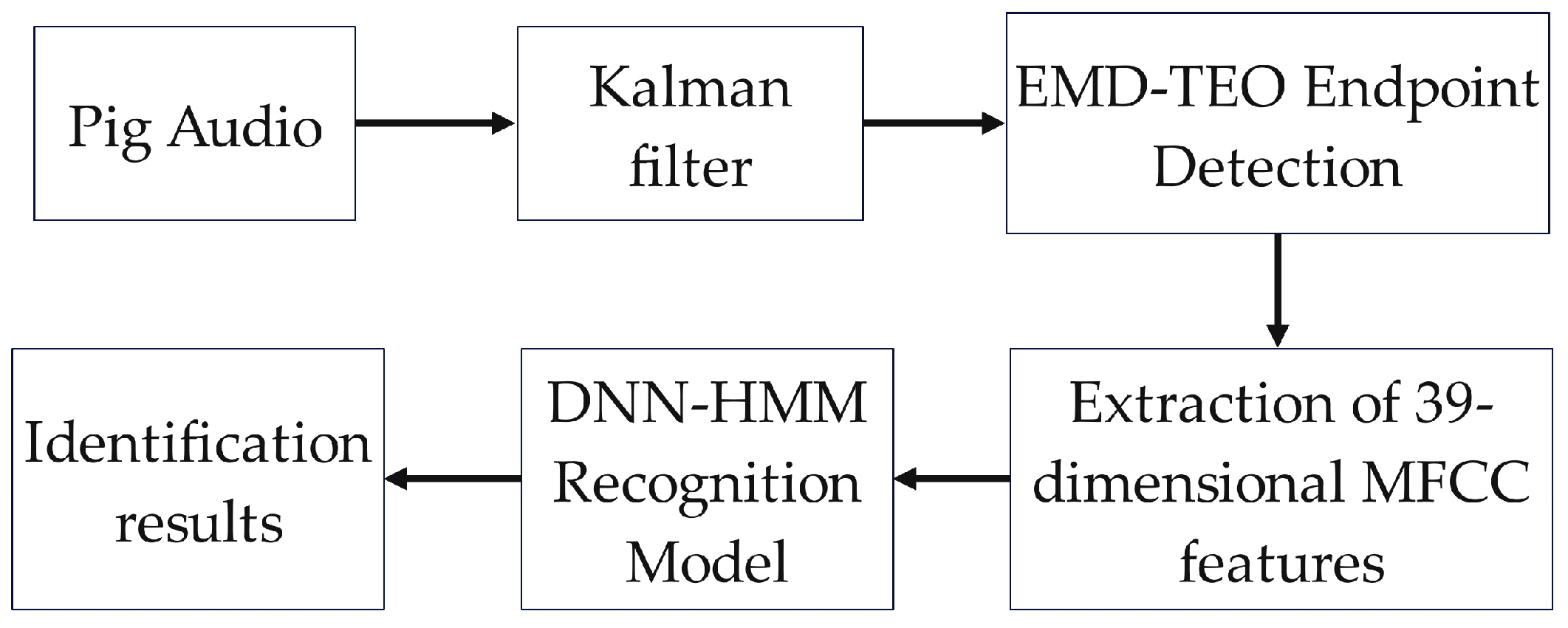
2. Materials and Methods
2.1. Materials
2.2. Sound Signal Preprocessing and Feature Extraction
2.2.1. Kalman Filtering
- (1)
- Defining a system of discrete control processes that can be described by linear stochastic differential equations and the measured values of the system :where is the system state at time k. is the control quantity of the system at time k. A and B are system parameters. is the measured value at time k. H is the parameter of the measurement system. is the process noise assumed to be Gaussian white noise and its covariance is Q. is the measurement noise assumed to be Gaussian white noise and its covariance is R.
- (2)
- Using the process model of the system to predict the current state based on the previous state,where is the optimal result of the previous state.
- (3)
- Updating covariance P,where is the corresponding covariance of . is the corresponding covariance of . is the transpose matrix of . is the covariance of the system process.
- (4)
- The optimal estimated value of the current state k can be obtained by combining the predicted value and measured value:where is the transposition of in its expression, and is the Kalman gain, defined as .
- (5)
- In order to keep the Kalman filter running until the end of the system, the covariance in the state k should be updated:where is a matrix of 1. will change to when the system enters the state k + 1.
2.2.2. Endpoint Detection
- (1)
- The EMD algorithm is used to decompose the denoised pig sound signal into multiple single-modal functions (IMFs).
- (2)
- TEO is used to process the modal components with special meaning, obtain the energy spectrum of the modal components, and extract the characteristic frequency parameters of pig sounds.
- (3)
- The short-time cepstral distance method is introduced to calculate the cepstral distance parameters to obtain more accurate endpoint values.
- (4)
- The endpoint detection of two-level parameters is adopted to identify the start value and end value of the effective signal.
2.2.3. Signal Feature Extraction
2.3. Construction and Evaluation of Sound Classification Model
2.3.1. DNN-HMM Model
2.3.2. Training GMM-HMM
2.3.3. Supervised DNN Training
2.3.4. Construction and Test of Pig Sound Model
- (1)
- GMM-HMM training. Based on the theoretical knowledge in Section 2.3.2, five hidden states were used to simulate the pig sounds of eating, estrus, humming, howling and panting. The given initial probability length was the same as the number of states, the first element was 1, and the other elements were set to 0. The hidden state transition probability matrix was set to 5 × 5 and the total value to 1. The observation state transition probability matrix was initialized by evenly dividing the pig sound feature training samples and estimating their global mean and variance. The Baum–Welch algorithm was used to optimize and re-evaluate the GMM parameters, and the alignment information was obtained by the Viterbi algorithm to update the HMM parameters. In this process, the number of iterations was set to 40 and the convergence threshold is 10−6. After this process, based on the GMM-HMM system, the alignment between the data frame of the training sound and the corresponding states of the relevant syllable was achieved.
- (2)
- Supervised DNN training. We imported the data labels aligned between the completed frames and the hidden states into DNN. In order to reduce network redundancy, splice was set to 3, which means that in addition to the current frame, three frames before and three frames after it were included to generate a 7-frame vector, so that the information of adjacent frames could be used to model the relationship between context features. Considering the sound number and feature dimension of training, a neural network with three hidden layers was set. In order to speed up the calculation, 128 nodes were set in each layer, and the softmax layer was set as the output layer. The output probability was obtained through forward propagation, and the error loss was calculated with the training label obtained in the first step. Throughout the process, the activation function used the rectified linear unit (ReLU) [37], whose expression is [38,39]
- (3)
- Model testing. After the DNN-HMM model was trained, we used the MFCC features extracted from the test sound samples corresponding to several pig behavior states to input into the five sound models obtained from the training. The best hidden-state transition path of the test samples in the recognition model was searched through the Viterbi algorithm, and the cumulative output probability was calculated. Finally, we compared the output probability of the test sample in five models to obtain the sound recognition results.
2.3.5. Performance Test Indices
3. Results and Analysis
3.1. Pre-Enhancement of Sound Samples
3.2. Test Results and Comparative Analysis of Pig Sound Model
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zha, W.; Li, H.; Wu, G.; Zhang, L.; Pan, W.; Gu, L.; Jiao, J.; Zhang, Q. Research on the recognition and tracking of group-housed pigs’ posture based on edge computing. Sensors 2023, 23, 8952. [Google Scholar] [CrossRef]
- Yin, Y.; Ji, N.; Wang, X.; Shen, W.; Dai, B.; Kou, S.; Liang, C. An investigation of fusion strategies for boosting pig cough sound recognition. Comput. Electron. Agric. 2023, 205, 107645. [Google Scholar] [CrossRef]
- Wu, Y.; Shao, R.; Li, M.; Zhang, F.; Tao, H.; Gu, L.; Jiao, J. Endpoint detection of live pig audio signal based on improved emd-teo cepstrum distance. J. China Agric. Univ. 2021, 26, 104–116. [Google Scholar]
- Wu, X.; Zhou, S.L.; Chen, M.W.; Zhao, Y.H.; Wang, Y.F.; Zhao, X.M.; Li, D.Y.; Pu, H.B. Combined spectral and speech features for pig speech recognition. PLoS ONE 2022, 17, 22. [Google Scholar] [CrossRef]
- Ji, N.; Shen, W.Z.; Yin, Y.L.; Bao, J.; Dai, B.S.; Hou, H.D.; Kou, S.L.; Zhao, Y.Z. Investigation of acoustic and visual features for pig cough classification. Biosyst. Eng. 2022, 219, 281–293. [Google Scholar] [CrossRef]
- Sun, H.; Tong, Z.; Xie, Q.; Li, J. Recognition of pig coughing sound based on bp neural network. J. Chin. Agric. Mech. 2022, 43, 148–154. [Google Scholar]
- Chung, Y.; Oh, S.; Lee, J.; Park, D.; Chang, H.-H.; Kim, S. Automatic detection and recognition of pig wasting diseases using sound data in audio surveillance systems. Sensors 2013, 13, 12929–12942. [Google Scholar] [CrossRef]
- Liu, Z.; He, X.; Sang, J.; Li, Y.; Wu, Z.; Lu, Z. Research on pig coughing sound recognition based on hidden markov model. In Proceedings of the 10th Symposium of Information Technology Branch of Chinese Society of Animal Husbandry and Veterinary Medicine, Beijing, China, 7 August 2015; p. 6. [Google Scholar]
- Cho, Y.; Jonguk, L.; Hee, P.D.; Chung, Y. Noise-robust porcine respiratory diseases classification using texture analysis and cnn. KIPS Trans. Softw. Data Eng. 2018, 7, 91–98. [Google Scholar]
- Shen, W.Z.; Ji, N.; Yin, Y.L.; Dai, B.S.; Tu, D.; Sun, B.H.; Hou, H.D.; Kou, S.L.; Zhao, Y.Z. Fusion of acoustic and deep features for pig cough sound recognition. Comput. Electron. Agric. 2022, 197, 7. [Google Scholar] [CrossRef]
- Liao, J.; Li, H.X.; Feng, A.; Wu, X.; Luo, Y.J.; Duan, X.L.; Ni, M.; Li, J. Domestic pig sound classification based on transformercnn. Appl. Intell. 2023, 53, 4907–4923. [Google Scholar] [CrossRef]
- Yin, Y.; Tu, D.; Shen, W.; Bao, J. Recognition of sick pig cough sounds based on convolutional neural network in field situations. Inf. Process. Agric. 2021, 8, 369–379. [Google Scholar] [CrossRef]
- Shen, W.; Tu, D.; Yin, Y.; Bao, J. A new fusion feature based on convolutional neural network for pig cough recognition in field situations. Inf. Process. Agric. 2021, 8, 573–580. [Google Scholar] [CrossRef]
- Gong, Y.; Li, X.; Gao, Y.; Lei, M.; Liu, W.; Yang, Z. Recognition of pig cough sound based on vector quantization. J. Huazhong Agric. Univ. 2017, 36, 119–124. [Google Scholar]
- Wang, Y.; Li, S.; Zhang, H.; Liu, T. A lightweight cnn-based model for early warning in sow oestrus sound monitoring. Ecol. Inform. 2022, 72, 101863. [Google Scholar] [CrossRef]
- Min, K.-J.; Lee, H.-J.; Hwang, H.; Lee, S.; Lee, K.; Moon, S.; Lee, J.; Lee, J.-W. A study on classification of pig sounds based on supervised learning. J. Inst. Electr. Eng. 2021, 70, 805–822. [Google Scholar] [CrossRef]
- Wegner, B.; Spiekermeier, I.; Nienhoff, H.; Grosse-Kleimann, J.; Rohn, K.; Meyer, H.; Plate, H.; Gerhardy, H.; Kreienbrock, L.; Beilage, E.G.; et al. Status quo analysis of noise levels in pig fattening units in germany. Livest. Sci. 2019, 230, 9. [Google Scholar] [CrossRef]
- Cao, L. Overview of speech enhancement algorithms. J. Hebei Acad. Sci. 2020, 37, 30–36. [Google Scholar]
- da Silva, L.A.; Joaquim, M.B. Noise reduction in biomedical speech signal processing based on time and frequency kalman filtering combined with spectral subtraction. Comput. Electr. Eng. 2008, 34, 154–164. [Google Scholar] [CrossRef]
- Fu, W.; Zhou, Y.; Zhang, X.; Liu, N. Single-channel blind source separation algorithm based on parameter estimation and kalman filter. Syst. Eng. Electron. 2023, 1–9. Available online: https://kns.cnki.net/kcms/detail/11.2422.TN.20231206.1112.002.html (accessed on 14 February 2024).
- Zhang, T.; Shao, Y.Y.; Wu, Y.Q.; Geng, Y.Z.; Fan, L. An overview of speech endpoint detection algorithms. Appl. Acoust. 2020, 160, 16. [Google Scholar] [CrossRef]
- Li, L.; Zhu, Y.; Qi, Y.; Zhao, J.; Ma, K. Multilevel emotion recognition of audio features based on multitask learning and attention mechanism. Intell. Comput. Appl. 2024, 14, 85–94+101. [Google Scholar]
- Maganti, H.K.; Matassoni, M. Enhancing robustness for speech recognition through bio-inspired auditory filter-bank. Int. J. Bio-Inspired Comput. 2012, 4, 271–277. [Google Scholar] [CrossRef]
- Lokesh, S.; Devi, M.R. Speech recognition system using enhanced mel frequency cepstral coefficient with windowing and framing method. Cluster Comput. 2019, 22, 11669–11679. [Google Scholar] [CrossRef]
- Mor, B.; Garhwal, S.; Kumar, A. A systematic review of hidden markov models and their applications. Arch. Comput. Method Eng. 2021, 28, 1429–1448. [Google Scholar] [CrossRef]
- Zhu, J.; Yao, G.; Zhang, G.; Li, J.; Yang, Q.; Wang, S.; Ye, S. Survey of few shot learning of deep neural network. Comput. Eng. Appl. 2021, 57, 22–33. [Google Scholar]
- Rascon, C. Characterization of deep learning-based speech-enhancement techniques in online audio processing applications. Sensors 2023, 23, 4394. [Google Scholar] [CrossRef]
- Smit, P.; Virpioja, S.; Kurimo, M. Advances in subword-based hmm-dnn speech recognition across languages. Comput. Speech Lang. 2021, 66, 101158. [Google Scholar] [CrossRef]
- Vetráb, M.; Gosztolya, G. Using hybrid HMM/DNN embedding extractor models in computational paralinguistic tasks. Sensors 2023, 23, 5208. [Google Scholar] [CrossRef]
- Zhang, M.C.; Chen, X.M.; Li, W. A hybrid hidden markov model for pipeline leakage detection. Appl. Sci. 2021, 11, 3183. [Google Scholar] [CrossRef]
- Kim, D.; Jang, L.C.; Heo, S.; Wongsason, P. Note on fuzzifying probability density function and its properties. AIMS Math. 2023, 8, 15486–15498. [Google Scholar] [CrossRef]
- Yan, H.; Yang, S. Blind demodulation algorithm for short burst signals based on maximun likelihood rules. Radio Commun. Technol. 2016, 42, 52–55. [Google Scholar]
- Gilbert, D.F. A Comparative Analysis of Machine Learning Algorithms for Hidden Markov Models. Master’s Thesis, California State University, Sacramento, CA, USA, 2012. [Google Scholar]
- Chen, J.; Mao, Y.W.; Hu, M.F.; Guo, L.X.; Zhu, Q.M. Decomposition optimization method for switching models using em algorithm. Nonlinear Dyn. 2023, 111, 9361–9375. [Google Scholar] [CrossRef]
- Zhang, Y.; Kuang, S.; Liang, J.; Xu, J. A recognition method for multi-reconnaissance data based on error back propagation algorithm. Electron. Inf. Warf. Technol. 2019, 34, 18–22+60. [Google Scholar]
- Xu, H.; Wang, A.; Du, Y.; Sun, Y. Discussion on the basic models and application of deep learning. J. Chang. Norm. Univ. 2020, 39, 47–54+93. [Google Scholar]
- Wang, S.H.; Chen, Y. Fruit category classification via an eight-layer convolutional neural network with parametric rectified linear unit and dropout technique. Multimed. Tools Appl. 2020, 79, 15117–15133. [Google Scholar] [CrossRef]
- Zhao, J. Pig Cough Sounds Recognition Based on Deep Learning. Master’s Thesis, Huazhong Agricultural University, Wuhan, China, 2020. [Google Scholar]
- Zhao, J.; Li, X.; Liu, W.H.; Gao, Y.; Lei, M.G.; Tan, H.Q.; Yang, D. Dnn-hmm based acoustic model for continuous pig cough sound recognition. Int. J. Agric. Biol. Eng. 2020, 13, 186–193. [Google Scholar] [CrossRef]
- Jamin, A.; Humeau-Heurtier, A. (Multiscale) cross-entropy methods: A review. Entropy 2020, 22, 45. [Google Scholar] [CrossRef]
- Zhao, W.; Jin, C.; Tu, Z.; Krishnan, S.; Liu, s. Support vector machine for acoustic scene classification algorith research based on multi-features fusion. Trans. Beijing Inst. Technol. 2020, 40, 69–75. [Google Scholar]
- Xu, J.; Yu, H.; Li, H.; Chen, S.; Zhen, G.; Gu, L.; Li, X.; Gong, D.; Xing, B.; Ying, L. Fish behavior recognition based on mfcc and resnet. J. Mar. Inf. Technol. Appl. 2022, 37, 21–27. [Google Scholar]
- Kong, Q.Q.; Yu, C.S.; Xu, Y.; Iqbal, T.; Wang, W.W.; Plumbley, M.D. Weakly labelled audioset tagging with attention neural networks. IEEE-ACM Trans. Audio Speech Lang. 2019, 27, 1791–1802. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Recall | Accuracy | Specificity |
|---|---|---|---|
| Base-HMM | 0.653 | 0.61 | 0.873 |
| GMM-HMM | 0.709 | 0.66 | 0.916 |
| DNN-HMM | 0.833 | 0.83 | 0.958 |
| Models | Recall | Accuracy | Specificity |
|---|---|---|---|
| SVM | 0.725 | 0.71 | 0.932 |
| ResNet18 | 0.759 | 0.75 | 0.938 |
| DNN-HMM | 0.798 | 0.79 | 0.945 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, W.; Li, H.; Zhou, X.; Jiao, J.; Zhu, C.; Zhang, Q. Research on Pig Sound Recognition Based on Deep Neural Network and Hidden Markov Models. Sensors 2024, 24, 1269. https://doi.org/10.3390/s24041269
Pan W, Li H, Zhou X, Jiao J, Zhu C, Zhang Q. Research on Pig Sound Recognition Based on Deep Neural Network and Hidden Markov Models. Sensors. 2024; 24(4):1269. https://doi.org/10.3390/s24041269
Chicago/Turabian StylePan, Weihao, Hualong Li, Xiaobo Zhou, Jun Jiao, Cheng Zhu, and Qiang Zhang. 2024. "Research on Pig Sound Recognition Based on Deep Neural Network and Hidden Markov Models" Sensors 24, no. 4: 1269. https://doi.org/10.3390/s24041269
APA StylePan, W., Li, H., Zhou, X., Jiao, J., Zhu, C., & Zhang, Q. (2024). Research on Pig Sound Recognition Based on Deep Neural Network and Hidden Markov Models. Sensors, 24(4), 1269. https://doi.org/10.3390/s24041269