From Pixels to Precision: A Survey of Monocular Visual Odometry in Digital Twin Applications †





Abstract
:1. Introduction
1.1. Visual Odometry for Digital Twin

2. Basics of Monocular Visual Odometry
- Feature detection: In the initial phase of VO, the focus is on identifying and capturing key visual features from the first camera frame, which are essential for tracking movements across frames. This process, fundamental for the accurate monitoring of camera movement, traditionally relies on algorithms like Harris, SIFT, ORB, and BRISK to pinpoint precise and durable features, such as corners or edges. However, it is crucial to expand beyond these to include line and planar features, which have proven to be invaluable in enhancing the robustness and completeness of feature detection and matching in monocular VO systems. These additions are essential for capturing the full complexity and variety of real-world environments [26,27,28,29].
- Feature tracking: Following feature detection, the VO algorithm focuses on tracking these identified features across consecutive frames. This tracking establishes correspondences between features in successive frames, creating a continuity that facilitates motion analysis. Techniques such as KLT (Kanade–Lucas–Tomasi) tracking or optical flow have proven effective in this context, enabling accurate alignment and correspondence mapping [30].
- Motion estimation: With the correspondences between features in consecutive frames established, the next task is to estimate the camera’s motion. This process involves mathematical techniques, such as determining the essential matrix or, if needed, the fundamental matrix. These methods leverage the correspondences to ascertain the relative motion between frames, providing a snapshot of how the camera’s position changes over time [31].
- Triangulation: Based on the estimated camera motion, the algorithm then moves to determine the 3D positions of the tracked features by triangulation. This technique involves estimating the spatial location of a point by measuring angles from two or more distinct viewpoints. The result is a three-dimensional mapping of features that adds depth and context to the analysis [32].
- Trajectory estimation: The final step in the basic VO algorithm involves synthesizing the previously gathered information to estimate the camera’s overall trajectory within the environment and map the surroundings. This composite task draws upon both the estimated camera motion from step (iii) and the 3D positioning of the tracked features from step (iv). Together, these elements coalesce into a coherent picture of the camera’s path, contributing to a broader understanding of the spatial context [33].
3. Research Challenges in Monocular Visual Odometry
- Feature Detection and Tracking: The efficacy of monocular VO hinges on the precise detection and tracking of image features, which are critical measurements in the VO process. Uncertainties in these measurements arise under conditions of low-texture or nondescript environments, which can be exacerbated by inadequate lighting and complex motion dynamics, challenging the robustness of feature-matching algorithms and leading to measurement inaccuracies [34].
- Motion Estimation: Robust motion estimation is central to VO, with its accuracy contingent upon the reliability of feature correspondence measurements. Uncertainty in these measurements can occur due to outliers from incorrect feature matching and drift resulting from cumulative errors in successive estimations, significantly complicating the attainment of precise motion measurements [35].
- Non-static Scenes: The premise of VO algorithms typically involves the assumption of static scenes, thereby simplifying the measurement process. However, uncertainty is introduced in dynamic environments where moving objects induce variances in the measurements, necessitating advanced methods to discern and correctly interpret camera motion amidst these uncertainties.
- Camera Calibration: The accurate calibration of camera parameters is foundational for obtaining precise VO measurements. Uncertainties in calibration—due to factors such as environmental temperature changes, light conditions, lens distortions, or mechanical misalignments—can significantly distort measurement accuracy, impacting the reliability of subsequent VO estimations [36].
- Scaling Challenges: In VO, the lack of an absolute reference frame introduces uncertainty in scale measurements, a pivotal component for establishing the camera’s absolute trajectory. Inaccuracies in these scale measurements can arise from ambiguous geometries, limited visual cues, and the monocular nature of the data, which may lead to scale drift and wrong trajectory computations [37].
- Ground Plane Considerations: The ground plane is often used as a reference in VO measurements for scale estimation. However, uncertainties in these measurements can be attributed to ambiguous ground features, variable lighting conditions that affect feature visibility, and scaling complexities relative to object heights, challenging the accuracy of VO scale measurements [38].
- Perspective Projection: The perspective projection in monocular VO introduces inherent uncertainties due to the transformation of 3D scenes into 2D images, leading to challenges such as depth information loss and scale ambiguity. This projection results in the foreshortening and distortion of objects, complicating the estimation of relative distances and sizes. Additionally, the overlapping of features in the 2D plane can cause occlusions, disrupting the feature tracking crucial for motion estimation. The projection of 3D points onto a 2D plane also introduces feature perspective errors, especially when features are distant from the camera center or when the camera is close to the scene.
- Timestamp Synchronization Uncertainty: This type of uncertainty arises when there are discrepancies in the timing of the data capture and processing among different components of a system, such as cameras, inertial measurement units (IMUs), and LiDAR scanners. In systems that rely on precise timing for data integration and analysis, such as visual–inertial navigation systems, this uncertainty can significantly impact accuracy [9].
4. Traditional Approaches
5. Machine Learning-Based Approaches
5.1. Full Deep Learning Approaches
5.2. Semi-Deep Learning Approaches
6. Uncertainty of Positioning Provided by Monocular Visual Odometry
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Zou, D.; Tan, P.; Yu, W. Collaborative visual SLAM for multiple agents: A brief survey. Virtual Real. Intell. Hardw. 2019, 1, 461–482. [Google Scholar] [CrossRef]
- Yang, G.; Wang, Y.; Zhi, J.; Liu, W.; Shao, Y.; Peng, P. A Review of Visual Odometry in SLAM Techniques. In Proceedings of the 2020 International Conference on Artificial Intelligence and Electromechanical Automation (AIEA), Tianjin, China, 26–28 June 2020; pp. 332–336. [Google Scholar]
- Razali, M.R.; Athif, A.; Faudzi, M.; Shamsudin, A.U. Visual Simultaneous Localization and Mapping: A review. PERINTIS eJournal 2022, 12, 23–34. [Google Scholar]
- Agostinho, L.R.; Ricardo, N.M.; Pereira, M.I.; Hiolle, A.; Pinto, A.M. A Practical Survey on Visual Odometry for Autonomous Driving in Challenging Scenarios and Conditions. IEEE Access 2022, 10, 72182–72205. [Google Scholar] [CrossRef]
- Couturier, A.; Akhloufi, M.A. A review on absolute visual localization for UAV. Robot. Auton. Syst. 2021, 135, 103666. [Google Scholar] [CrossRef]
- Ma, L.; Meng, D.; Zhao, S.; An, B. Visual localization with a monocular camera for unmanned aerial vehicle based on landmark detection and tracking using YOLOv5 and DeepSORT. Int. J. Adv. Robot. Syst. 2023, 20. [Google Scholar] [CrossRef]
- Yousif, K.; Bab-Hadiashar, A.; Hoseinnezhad, R. An overview to visual odometry and visual SLAM: Applications to mobile robotics. Intell. Ind. Syst. 2015, 1, 289–311. [Google Scholar] [CrossRef]
- Gadipudi, N.; Elamvazuthi, I.; Lu, C.K.; Paramasivam, S.; Su, S.; Yogamani, S. WPO-Net: Windowed Pose Optimization Network for Monocular Visual Odometry Estimation. Sensors 2021, 21, 8155. [Google Scholar] [CrossRef]
- Xu, Z. Stereo Visual Odometry with Windowed Bundle Adjustment; University of California: Los Angeles, CA, USA, 2015. [Google Scholar]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. The revisiting problem in simultaneous localization and mapping: A survey on visual loop closure detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19929–19953. [Google Scholar] [CrossRef]
- Civera, J.; Davison, A.J.; Montiel, J.M.M. Inverse Depth Parametrization for Monocular SLAM. IEEE Trans. Robot. 2008, 24, 932–945. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Graeter, J.; Wilczynski, A.; Lauer, M. LIMO: Lidar-Monocular Visual Odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7872–7879. [Google Scholar]
- Scaramuzza, D.; Fraundorfer, F. Visual Odometry [Tutorial]. IEEE Robot. Autom. Mag. 2011, 18, 80–92. [Google Scholar] [CrossRef]
- Fraundorfer, F.; Scaramuzza, D. Visual Odometry: Part II: Matching, Robustness, Optimization, and Applications. IEEE Robot. Autom. Mag. 2012, 19, 78–90. [Google Scholar] [CrossRef]
- Basiri, A.; Mariani, V.; Glielmo, L. Enhanced V-SLAM combining SVO and ORB-SLAM2, with reduced computational complexity, to improve autonomous indoor mini-drone navigation under varying conditions. In Proceedings of the IECON 2022—48th Annual Conference of the IEEE Industrial Electronics Society, Brussels, Belgium, 17–20 October 2022; pp. 1–7. [Google Scholar] [CrossRef]
- He, M.; Zhu, C.; Huang, Q.; Ren, B.; Liu, J. A review of monocular visual odometry. Vis. Comput. 2020, 36, 1053–1065. [Google Scholar] [CrossRef]
- Aqel, M.O.; Marhaban, M.H.; Saripan, M.I.; Ismail, N.B. Review of visual odometry: Types, approaches, challenges, and applications. SpringerPlus 2016, 5, 1897. [Google Scholar] [CrossRef]
- Pottier, C.; Petzing, J.; Eghtedari, F.; Lohse, N.; Kinnell, P. Developing digital twins of multi-camera metrology systems in Blender. Meas. Sci. Technol. 2023, 34, 075001. [Google Scholar] [CrossRef]
- Feng, W.; Zhao, S.Z.; Pan, C.; Chang, A.; Chen, Y.; Wang, Z.; Yang, A.Y. Digital Twin Tracking Dataset (DTTD): A New RGB+ Depth 3D Dataset for Longer-Range Object Tracking Applications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 3288–3297. [Google Scholar]
- Sundby, T.; Graham, J.M.; Rasheed, A.; Tabib, M.; San, O. Geometric Change Detection in Digital Twins. Digital 2021, 1, 111–129. [Google Scholar] [CrossRef]
- Döbrich, O.; Brauner, C. Machine vision system for digital twin modeling of composite structures. Front. Mater. 2023, 10, 1154655. [Google Scholar] [CrossRef]
- Benzon, H.H.; Chen, X.; Belcher, L.; Castro, O.; Branner, K.; Smit, J. An Operational Image-Based Digital Twin for Large-Scale Structures. Appl. Sci. 2022, 12, 3216. [Google Scholar] [CrossRef]
- Wang, X.; Xue, F.; Yan, Z.; Dong, W.; Wang, Q.; Zha, H. Continuous-time stereo visual odometry based on dynamics model. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 388–403. [Google Scholar]
- Yang, Q.; Qiu, C.; Wu, L.; Chen, J. Image Matching Algorithm Based on Improved FAST and RANSAC. In Proceedings of the 2021 IEEE International Conference on Mechatronics and Automation (ICMA), Takamatsu, Japan, 8–11 August 2021; pp. 142–147. [Google Scholar] [CrossRef]
- Lam, S.K.; Jiang, G.; Wu, M.; Cao, B. Area-Time Efficient Streaming Architecture for FAST and BRIEF Detector. IEEE Trans. Circuits Syst. II Express Briefs 2019, 66, 282–286. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust invariant scalable keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the IJCAI’81, 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; Volume 2, pp. 674–679. [Google Scholar]
- Mohr, R.; Triggs, B. Projective Geometry for Image Analysis. In Proceedings of the XVIIIth International Symposium on Photogrammetry & Remote Sensing (ISPRS ’96), Vienna, Austria, 9–19 July 1996. Tutorial given at International Symposium on Photogrammetry & Remote Sensing. [Google Scholar]
- Ma, Y.; Soatto, S.; Kosecká, J.; Sastry, S. An Invitation to 3-D Vision: From Images to Geometric Models; Interdisciplinary Applied Mathematics; Springer: New York, NY, USA, 2012. [Google Scholar]
- Lozano, R. Unmanned Aerial Vehicles: Embedded Control; ISTE, Wiley: Denver, CO, USA, 2013. [Google Scholar]
- Abaspur Kazerouni, I.; Fitzgerald, L.; Dooly, G.; Toal, D. A survey of state-of-the-art on visual SLAM. Expert Syst. Appl. 2022, 205, 117734. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Yang, K.; Fu, H.T.; Berg, A.C. Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3403–3412. [Google Scholar]
- Zhou, D.; Dai, Y.; Li, H. Ground-Plane-Based Absolute Scale Estimation for Monocular Visual Odometry. IEEE Trans. Intell. Transp. Syst. 2020, 21, 791–802. [Google Scholar] [CrossRef]
- Cao, L.; Ling, J.; Xiao, X. Study on the influence of image noise on monocular feature-based visual slam based on ffdnet. Sensors 2020, 20, 4922. [Google Scholar] [CrossRef] [PubMed]
- Qiu, X.; Zhang, H.; Fu, W.; Zhao, C.; Jin, Y. Monocular visual-inertial odometry with an unbiased linear system model and robust feature tracking front-end. Sensors 2019, 19, 1941. [Google Scholar] [CrossRef] [PubMed]
- Jinyu, L.; Bangbang, Y.; Danpeng, C.; Nan, W.; Guofeng, Z.; Hujun, B. Survey and evaluation of monocular visual-inertial SLAM algorithms for augmented reality. Virtual Real. Intell. Hardw. 2019, 1, 386–410. [Google Scholar] [CrossRef]
- Chiodini, S.; Giubilato, R.; Pertile, M.; Debei, S. Retrieving Scale on Monocular Visual Odometry Using Low-Resolution Range Sensors. IEEE Trans. Instrum. Meas. 2020, 69, 5875. [Google Scholar] [CrossRef]
- Lee, H.; Lee, H.; Kwak, I.; Sung, C.; Han, S. Effective Feature-Based Downward-Facing Monocular Visual Odometry. IEEE Trans. Control. Syst. Technol. 2024, 32, 266–273. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B.; Ratti, C.; Daniela, R. LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping. In Proceedings of the IEEE International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2021; pp. 5692–5698. [Google Scholar] [CrossRef]
- Wisth, D.; Camurri, M.; Das, S.; Fallon, M. Unified Multi-Modal Landmark Tracking for Tightly Coupled Lidar-Visual-Inertial Odometry. IEEE Robot. Autom. Lett. 2021, 6, 1004–1011. [Google Scholar] [CrossRef]
- Fang, B.; Pan, Q.; Wang, H. Direct Monocular Visual Odometry Based on Lidar Vision Fusion. In Proceedings of the 2023 WRC Symposium on Advanced Robotics and Automation (WRC SARA), Beijing, China, 19 August 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 256–261. [Google Scholar]
- Campos, C.; Elvira, R.; Rodriguez, J.J.; Montiel, J.M.; Tardos, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Huang, W.; Wan, W.; Liu, H. Optimization-Based Online Initialization and Calibration of Monocular Visual-Inertial Odometry Considering Spatial-Temporal Constraints. Sensors 2021, 21, 2673. [Google Scholar] [CrossRef]
- Zhou, L.; Wang, S.; Kaess, M. DPLVO: Direct Point-Line Monocular Visual Odometry; DPLVO: Direct Point-Line Monocular Visual Odometry. IEEE Robot. Autom. Lett. 2021, 6, 7113. [Google Scholar] [CrossRef]
- Li, R.; Wang, S.; Long, Z.; Gu, D. UnDeepVO: Monocular Visual Odometry Through Unsupervised Deep Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar]
- Ban, X.; Wang, H.; Chen, T.; Wang, Y.; Xiao, Y. Monocular Visual Odometry Based on Depth and Optical Flow Using Deep Learning. IEEE Trans. Instrum. Meas. 2021, 70, 2501619. [Google Scholar] [CrossRef]
- Lin, L.; Wang, W.; Luo, W.; Song, L.; Zhou, W. Unsupervised monocular visual odometry with decoupled camera pose estimation. Digit. Signal Process. Rev. J. 2021, 114. [Google Scholar] [CrossRef]
- Kim, U.H.; Kim, S.H.; Kim, J.H. SimVODIS: Simultaneous Visual Odometry, Object Detection, and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 428–441. [Google Scholar] [CrossRef]
- Almalioglu, Y.; Turan, M.; Saputra, M.R.U.; de Gusmão, P.P.; Markham, A.; Trigoni, N. SelfVIO: Self-supervised deep monocular Visual–Inertial Odometry and depth estimation. Neural Netw. 2022, 150, 119–136. [Google Scholar] [CrossRef]
- Tian, R.; Zhang, Y.; Zhu, D.; Liang, S.; Coleman, S.; Kerr, D. Accurate and Robust Scale Recovery for Monocular Visual Odometry Based on Plane Geometry. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar] [CrossRef]
- Fan, C.; Hou, J.; Yu, L. A nonlinear optimization-based monocular dense mapping system of visual-inertial odometry. Meas. J. Int. Meas. Confed. 2021, 180, 109533. [Google Scholar] [CrossRef]
- Yang, N.; von Stumberg, L.; Wang, R.; Cremers, D. D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1278–1289. [Google Scholar] [CrossRef]
- Aksoy, Y.; Alatan, A.A. Uncertainty modeling for efficient visual odometry via inertial sensors on mobile devices. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 3397–3401. [Google Scholar]
- Ross, D.; De Petrillo, M.; Strader, J.; Gross, J.N. Uncertainty estimation for stereo visual odometry. In Proceedings of the 34th International Technical Meeting of the Satellite Division of The Institute of Navigation (ION GNSS+ 2021), Online, 20–24 September 2021; pp. 3263–3284. [Google Scholar]
- Gakne, P.V.; O’Keefe, K. Tackling the scale factor issue in a monocular visual odometry using a 3D city model. In Proceedings of the ITSNT 2018, International Technical Symposium on Navigation and Timing, Toulouse, France, 13–16 November 2018. [Google Scholar]
- Hamme, D.V.; Goeman, W.; Veelaert, P.; Philips, W. Robust monocular visual odometry for road vehicles using uncertain perspective projection. EURASIP J. Image Video Process. 2015, 2015, 10. [Google Scholar] [CrossRef]
- Van Hamme, D.; Veelaert, P.; Philips, W. Robust visual odometry using uncertainty models. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Ghent, Belgium, 22–25 August 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–12. [Google Scholar]
- Brzozowski, B.; Daponte, P.; De Vito, L.; Lamonaca, F.; Picariello, F.; Pompetti, M.; Tudosa, I.; Wojtowicz, K. A remote-controlled platform for UAS testing. IEEE Aerosp. Electron. Syst. Mag. 2018, 33, 48–56. [Google Scholar] [CrossRef]
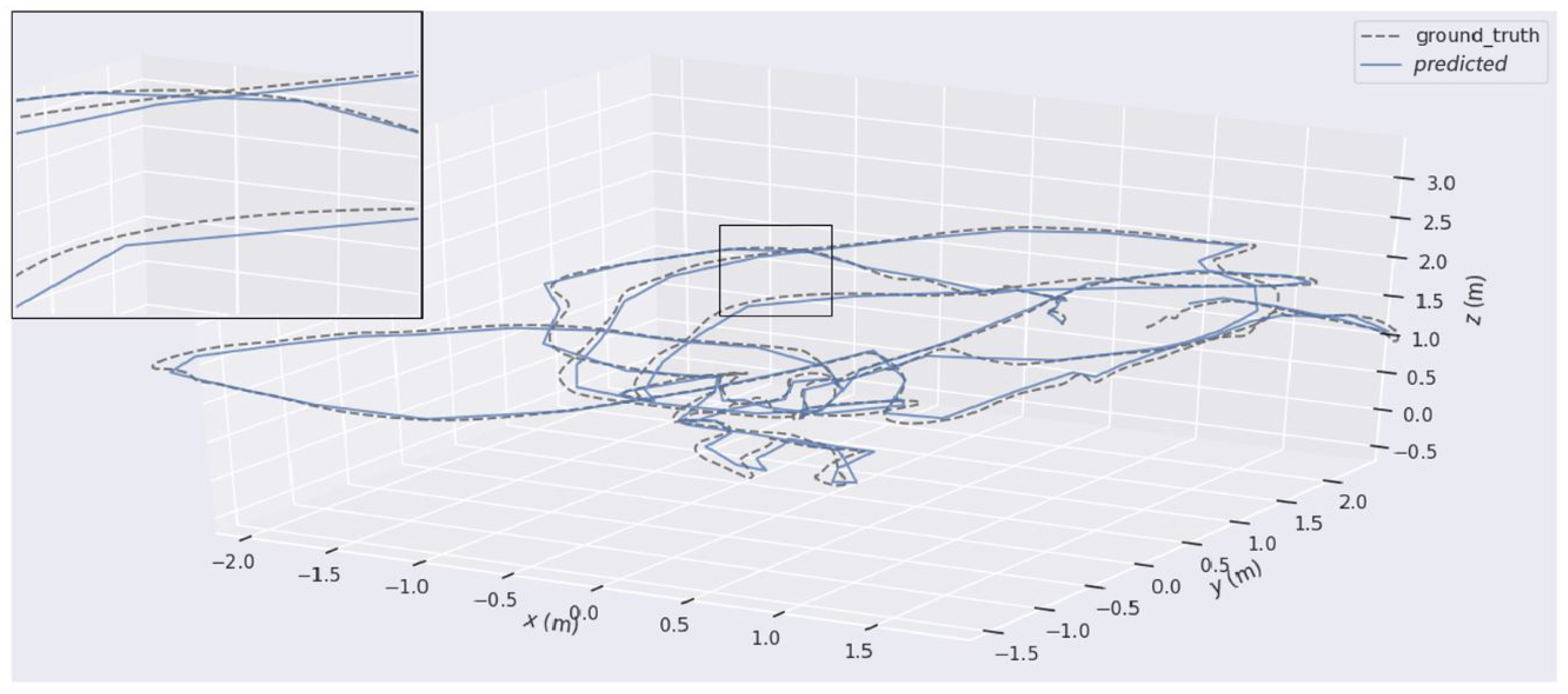

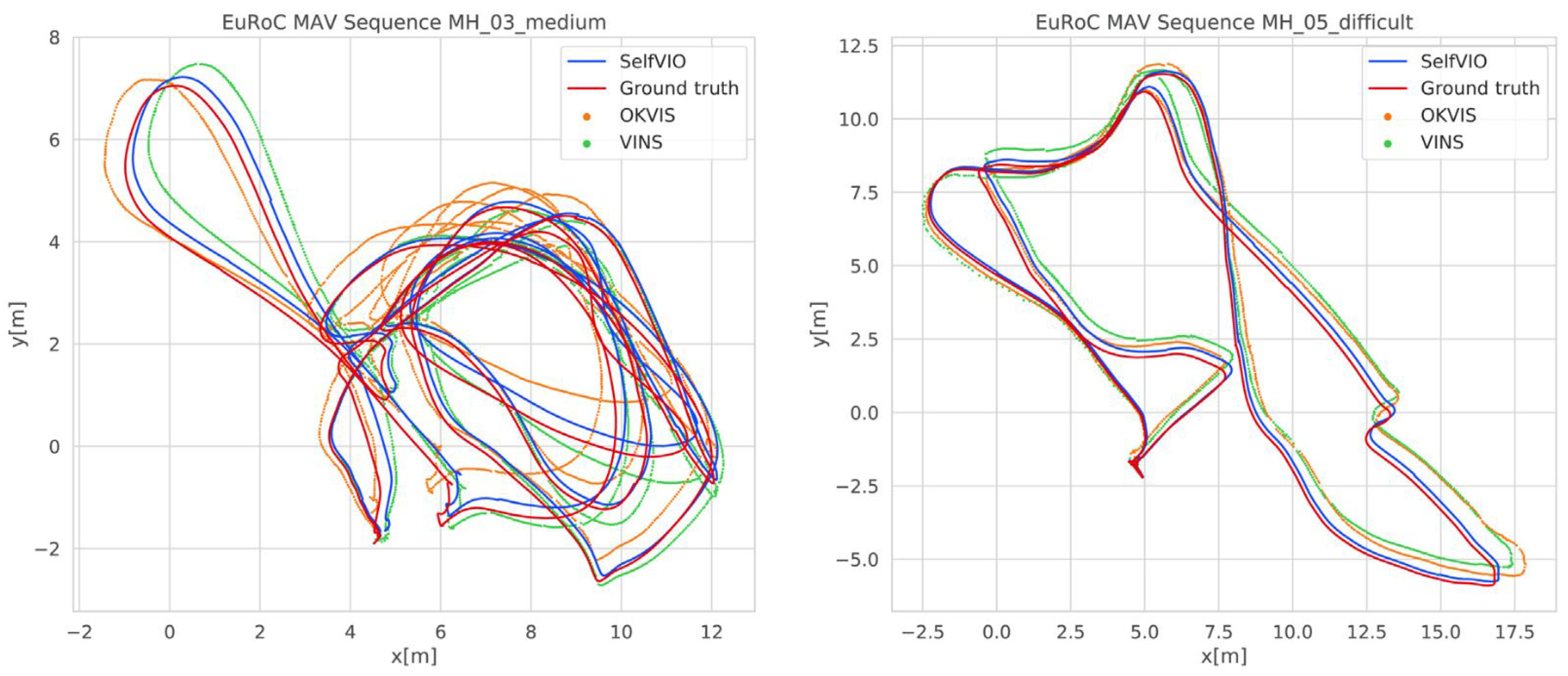

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Sensor Type | Method | Environmental Structure | Open Source | Key Points |
|---|---|---|---|---|---|
| [14] | LiDAR | Bundle Adjustment | Outdoor | Yes | Using LiDAR for camera feature tracks and keyframe-based motion estimation. Labeling is used for outlier rejection and landmark weighting. |
| [38] | Monocular | Ground Plane-Based Deep Learning | Outdoor | No | A ground plane and camera height-based divide-and-conquer method. A scale correction strategy reduces scale drift in VO. |
| [42] | LiDAR | Feature Extraction | Outdoor | No | A VO algorithm using a standard front end with camera tracking relative to triangulated landmarks optimizing the camera poses and landmark map with range sensor depth information resolves monocular scale ambiguity and drift. |
| [43] | Monocular | Feature Extraction | Indoor | No | A VO system utilizing a downward-facing camera, feature extraction, velocity-aware masking, and nonconvex optimization, enhanced with LED illumination and a ToF sensor, for improved accuracy and efficiency in mobile robot navigation. |
| [44] | LiDAR | Feature Extraction | Outdoor | Yes | LVI-SAM achieves real-time state estimation and map building with high accuracy and robustness. |
| [45] | LiDAR | Feature Extraction | Outdoor–Indoor | No | A multi-sensor odometry system for mobile platforms that integrates visual, LiDAR, and inertial data. Real time with fixed lag smoothing. |
| [46] | LiDAR | Feature Extraction | Outdoor | No | A method combining LiDAR depth with monocular visual odometry, using photometric error minimization and point-line feature refinement, alongside LiDAR-based segmentation for improved pose estimation and drift reduction. |
| [47] | Monocular | Feature Extraction | Outdoor | Yes | The main innovation is a visual–inertial SLAM system that uses MAP estimation even during IMU initialization. |
| [48] | Monocular | Feature Extraction | Outdoor | No | The authors developed a lightweight scale recovery framework using an accurate ground plane estimate. The framework includes ground point extraction and aggregation algorithms for selecting high-quality ground points. |
| [49] | Monocular | Feature Extraction | Indoor | No | This paper presents VO using points and lines. Direct methods choose pixels with enough gradients to minimize photometric errors. |
| [50] | Monocular | Deep Learning Based | Outdoor | No | The approach of this paper combines unsupervised deep learning and scale recovery, which is trained with stereo image pairs but tested with monocular images. |
| [3] | Monocular | Deep Learning Based | Outdoor–Indoor | No | The authors proposed a self-supervised monocular depth estimation network for stereo videos, which aligns training image pairs with predictive brightness transformation parameters. |
| [51] | Monocular | Deep Learning Based | Outdoor | No | A VO system called DL Hybrid is proposed, which uses DL networks in image processing and geometric localization theory based on hybrid pose estimation methods. |
| [52] | Monocular | Deep Learning Based | Outdoor | No | The authors created a decoupled cascade structure and residual-based posture refinement in an unsupervised VO framework that estimates 3D camera positions by decoupling the rotation, translation, and scale. |
| [9] | Monocular | Deep Learning Based | Outdoor | No | The suggested network in this work is built on supervised learning-based approaches with a feature encoder and pose regressor that takes multiple successive two grayscale picture stacks for training and enforces composite pose restrictions. |
| [53] | Monocular | Deep Learning Based | Outdoor | Yes | A neural architecture that performs VO, object detection, and instance segmentation in a single thread (SimVODIS). |
| [54] | Monocular | Deep Learning Based | Outdoor | Yes | The proposed method is called SelfVIO, which is a self-supervised deep learning-based VO and depth map recovery method using adversarial training and self-adaptive visual sensor fusion. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Neyestani, A.; Picariello, F.; Ahmed, I.; Daponte, P.; De Vito, L. From Pixels to Precision: A Survey of Monocular Visual Odometry in Digital Twin Applications. Sensors 2024, 24, 1274. https://doi.org/10.3390/s24041274
Neyestani A, Picariello F, Ahmed I, Daponte P, De Vito L. From Pixels to Precision: A Survey of Monocular Visual Odometry in Digital Twin Applications. Sensors. 2024; 24(4):1274. https://doi.org/10.3390/s24041274
Chicago/Turabian StyleNeyestani, Arman, Francesco Picariello, Imran Ahmed, Pasquale Daponte, and Luca De Vito. 2024. "From Pixels to Precision: A Survey of Monocular Visual Odometry in Digital Twin Applications" Sensors 24, no. 4: 1274. https://doi.org/10.3390/s24041274
APA StyleNeyestani, A., Picariello, F., Ahmed, I., Daponte, P., & De Vito, L. (2024). From Pixels to Precision: A Survey of Monocular Visual Odometry in Digital Twin Applications. Sensors, 24(4), 1274. https://doi.org/10.3390/s24041274