

COVID-19 Infection Percentage Estimation from Computed Tomography Scans: Results and Insights from the International Per-COVID-19 Challenge
 ,
,  , ,
, ,  , , , , , , , , , , , ,
, , , , , , , , , , , ,  and
and 
Abstract
:1. Introduction
2. Regression vs. Segmentation

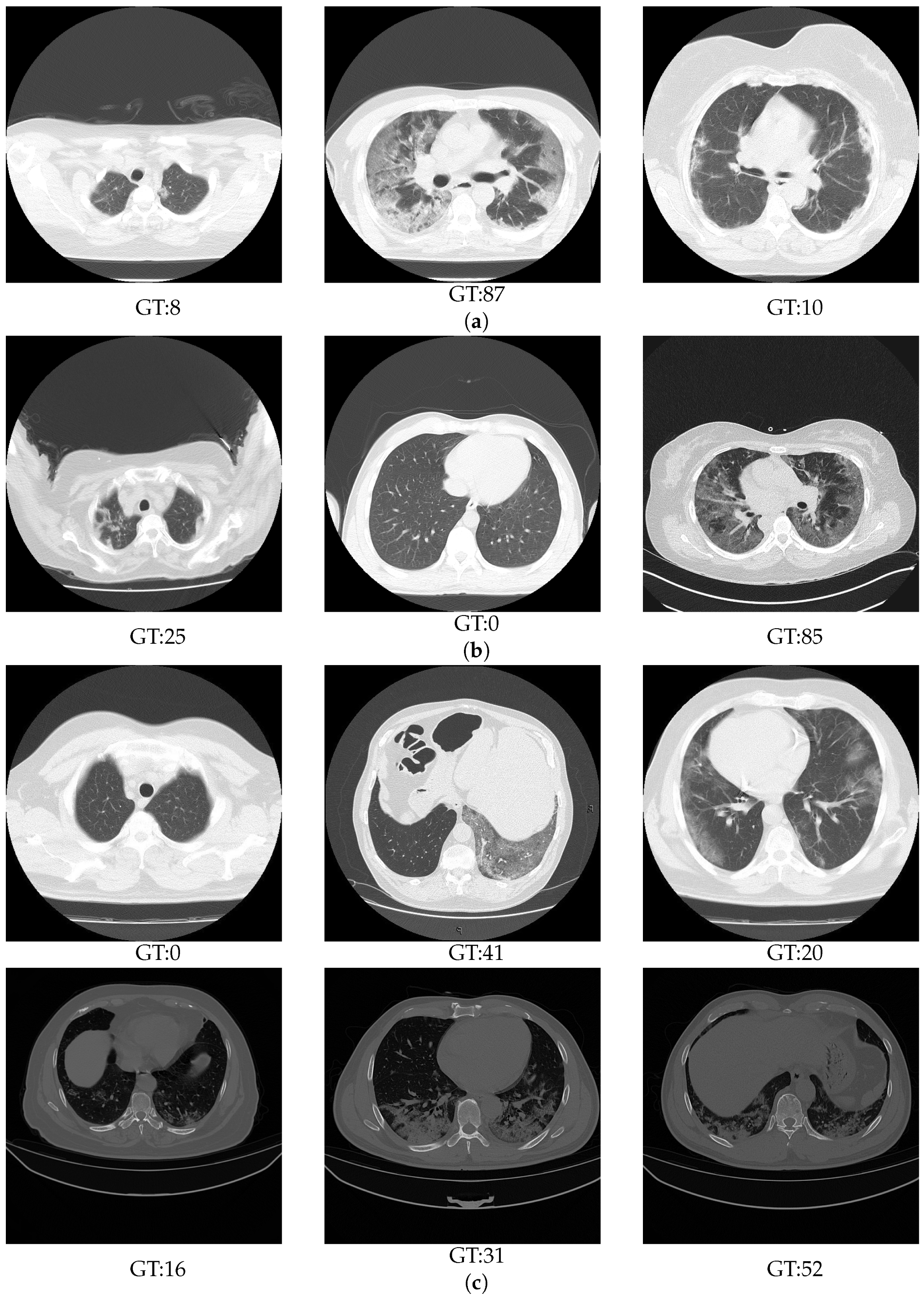{kind=link}
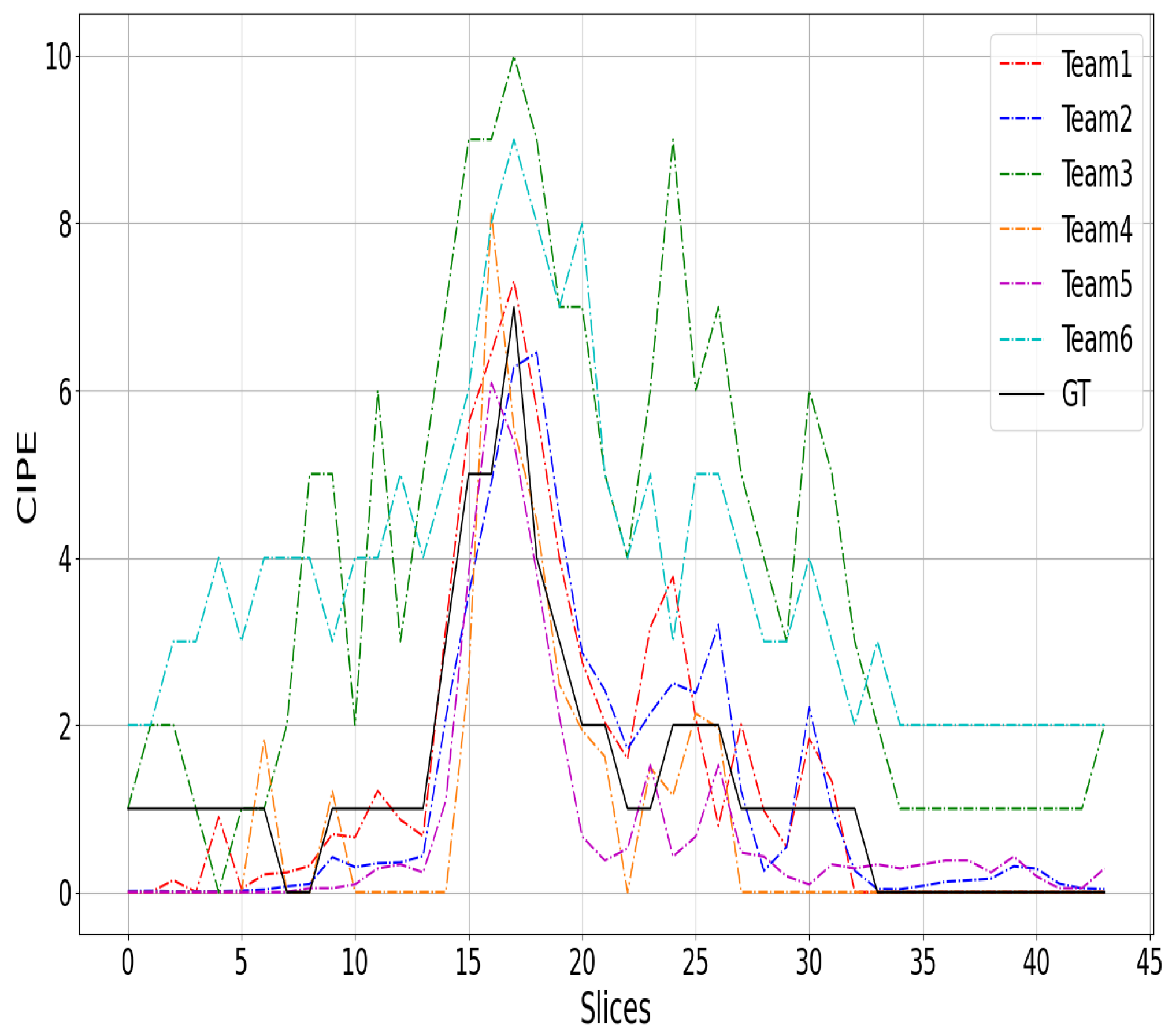{kind=link}
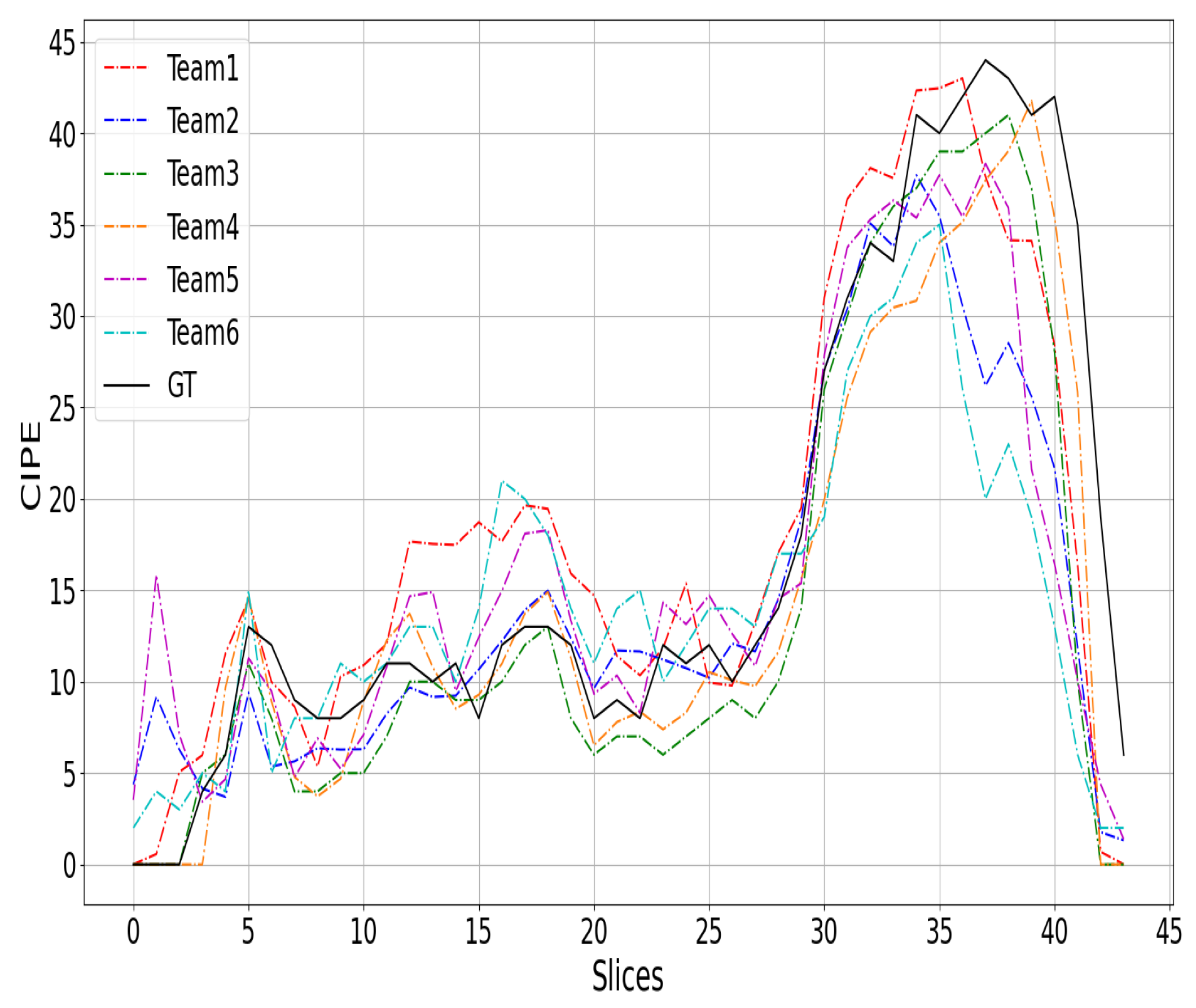{kind=link}
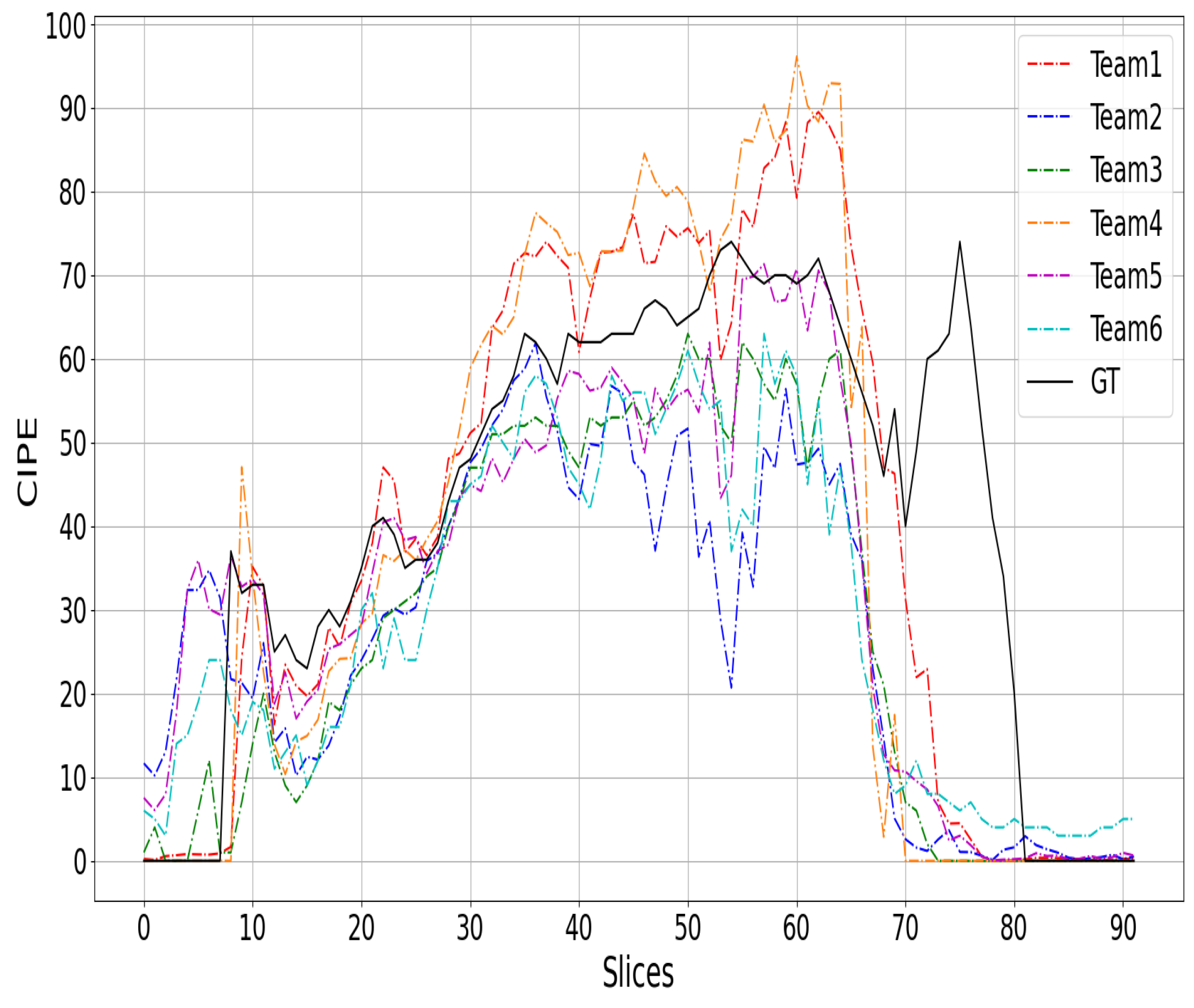{kind=link}
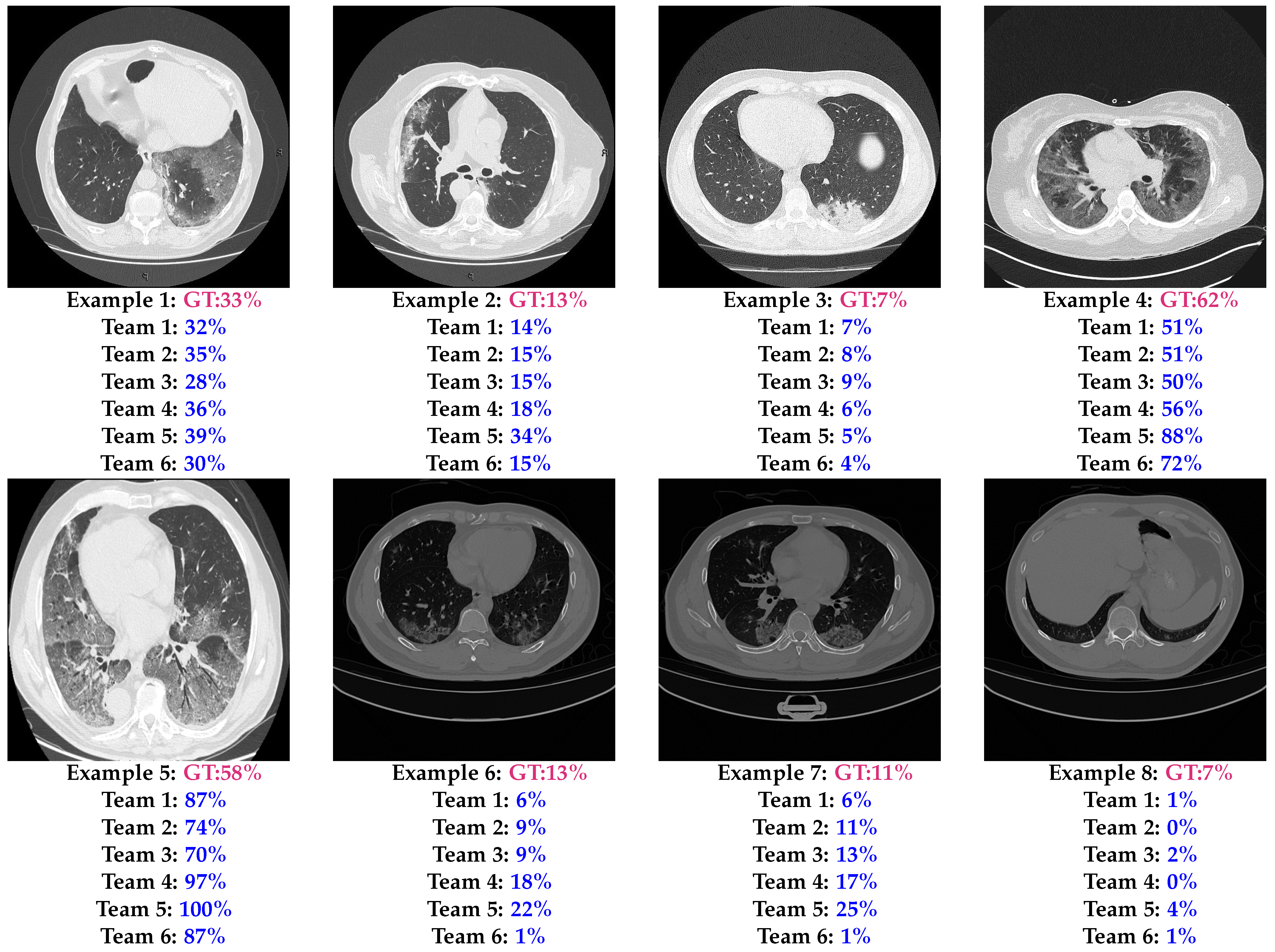{kind=link}
| Name | Dataset | #CT-Scans | #Slices |
|---|---|---|---|
| Dataset_1 | COVID-19 CT segmentation [25] | 40 | 100 |
| Dataset_2 | Segmentation dataset nr. 2 [25] | 9 | 829 |
| Dataset_3 | COVID-19-CT-Seg dataset [14] | 20 | 3520 |
| Architecture | MAE | PC | RMSE |
|---|---|---|---|
| Unet | 5.2 | 0.8931 | 10.62 |
| AttUnet | 4.98 | 0.8292 | 12.02 |
| Unet++ | 4.94 | 0.8509 | 11.30 |
| ResNext-50 (MSE) | 3.15 | 0.9653 | 5.85 |
| ResNext-50 (Huber) | 2.65 | 0.9696 | 5.31 |
| DenseNet-161 (MSE) | 3.18 | 0.9688 | 5.48 |
| DenseNet-161 (Huber) | 2.72 | 0.9718 | 5.14 |
3. Challenge Framework
3.1. Data Preparation
3.2. The Competition Challenges
3.3. Model Training

3.4. Model Evaluation
3.5. Baseline Method
4. Challenge Phases
4.1. Validation Phase
4.2. Testing Phase
4.3. After the Challenge Ended
5. Participating Teams
5.1. Taiyuan_university_lab713
5.2. TAC
5.3. SenticLab.UAIC
5.4. ACVLab
5.5. EIDOSlab_Unito
5.6. IPLab
6. Challenge Results
6.1. Results
6.2. Analysis
7. Discussion
8. Conclusions
9. Limitations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kucirka, L.M.; Lauer, S.A.; Laeyendecker, O.; Boon, D.; Lessler, J. Variation in False-Negative Rate of Reverse Transcriptase Polymerase Chain Reaction–Based SARS-CoV-2 Tests by Time Since Exposure. Ann. Intern. Med. 2020, 173, 262–267. [Google Scholar] [CrossRef] [PubMed]
- Vantaggiato, E.; Paladini, E.; Bougourzi, F.; Distante, C.; Hadid, A.; Taleb-Ahmed, A. COVID-19 Recognition Using Ensemble-CNNs in Two New Chest X-ray Databases. Sensors 2021, 21, 1742. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Liu, X.; Shen, J.; Wang, C.; Li, Z.; Ye, L.; Wu, X.; Chen, T.; Wang, K.; Zhang, X. A deep-learning pipeline for the diagnosis and discrimination of viral, non-viral and COVID-19 pneumonia from chest X-ray images. Nat. Biomed. Eng. 2021, 5, 509–521. [Google Scholar] [CrossRef] [PubMed]
- Roth, H.R.; Xu, Z.; Tor-Díez, C.; Jacob, R.S.; Zember, J.; Molto, J.; Li, W.; Xu, S.; Turkbey, B.; Turkbey, E.; et al. Rapid artificial intelligence solutions in a pandemic—The COVID-19-20 Lung CT Lesion Segmentation Challenge. Med. Image Anal. 2022, 82, 102605. [Google Scholar] [CrossRef] [PubMed]
- Goncharov, M.; Pisov, M.; Shevtsov, A.; Shirokikh, B.; Kurmukov, A.; Blokhin, I.; Chernina, V.; Solovev, A.; Gombolevskiy, V.; Morozov, S.; et al. CT-Based COVID-19 triage: Deep multitask learning improves joint identification and severity quantification. Med. Image Anal. 2021, 71, 102054. [Google Scholar] [CrossRef] [PubMed]
- Bougourzi, F.; Distante, C.; Dornaika, F.; Taleb-Ahmed, A.; Hadid, A. ILC-Unet++ for COVID-19 Infection Segmentation. In Lecture Notes in ComputerScience, Proceedings of the International Conference on Image Analysis and Processing, ICIAP 2022 Workshops—Image Analysis and Processing, Lecce, Italy, 23–27 May 2022; Mazzeo, P.L., Frontoni, E., Sclaroff, S., Distante, C., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 461–472. [Google Scholar] [CrossRef]
- Ghayvat, H.; Awais, M.; Bashir, A.; Pandya, S.; Zuhair, M.; Rashid, M.; Nebhen, J. AI-enabled radiologist in the loop: Novel AI-based framework to augment radiologist performance for COVID-19 chest CT medical image annotation and classification from pneumonia. Neural Comput. Appl. 2023, 35, 14591–14609. [Google Scholar] [CrossRef] [PubMed]
- Miller, I.F.; Becker, A.D.; Grenfell, B.T.; Metcalf, C.J.E. Disease and healthcare burden of COVID-19 in the United States. Nat. Med. 2020, 26, 1212–1217. [Google Scholar] [CrossRef]
- Wang, G.; Liu, X.; Li, C.; Xu, Z.; Ruan, J.; Zhu, H.; Meng, T.; Li, K.; Huang, N.; Zhang, S. A Noise-Robust Framework for Automatic Segmentation of COVID-19 Pneumonia Lesions From CT Images. IEEE Trans. Med. Imaging 2020, 39, 2653–2663. [Google Scholar] [CrossRef]
- Kumar, S.; Raut, R.D.; Narkhede, B.E. A proposed collaborative framework by using artificial intelligence-internet of things (AI-IoT) in COVID-19 pandemic situation for healthcare workers. Int. J. Healthc. Manag. 2020, 13, 337–345. [Google Scholar] [CrossRef]
- Wang, X.; Deng, X.; Fu, Q.; Zhou, Q.; Feng, J.; Ma, H.; Liu, W.; Zheng, C. A Weakly-Supervised Framework for COVID-19 Classification and Lesion Localization From Chest CT. IEEE Trans. Med. Imaging 2020, 39, 2615–2625. [Google Scholar] [CrossRef]
- Meng, Y.; Bridge, J.; Addison, C.; Wang, M.; Merritt, C.; Franks, S.; Mackey, M.; Messenger, S.; Sun, R.; Fitzmaurice, T.; et al. Bilateral adaptive graph convolutional network on CT based COVID-19 diagnosis with uncertainty-aware consensus-assisted multiple instance learning. Med. Image Anal. 2022, 84, 102722. [Google Scholar] [CrossRef] [PubMed]
- Asnawi, M.H.; Pravitasari, A.A.; Darmawan, G.; Hendrawati, T.; Yulita, I.N.; Suprijadi, J.; Nugraha, F.A.L. Lung and Infection CT-Scan-Based Segmentation with 3D UNet Architecture and Its Modification. Healthcare 2023, 11, 213. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Wang, Y.; An, X.; Ge, C.; Yu, Z.; Chen, J.; Zhu, Q.; Dong, G.; He, J.; He, Z.; et al. Toward data-efficient learning: A benchmark for COVID-19 CT lung and infection segmentation. Med. Phys. 2021, 48, 1197–1210. [Google Scholar] [CrossRef] [PubMed]
- Fan, D.P.; Zhou, T.; Ji, G.P.; Zhou, Y.; Chen, G.; Fu, H.; Shen, J.; Shao, L. Inf-Net: Automatic COVID-19 Lung Infection Segmentation From CT Images. IEEE Trans. Med. Imaging 2020, 39, 2626–2637. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Xu, Z.; Li, W.; Myronenko, A.; Roth, H.R.; Harmon, S.; Xu, S.; Turkbey, B.; Turkbey, E.; Wang, X.; et al. Federated semi-supervised learning for COVID region segmentation in chest CT using multi-national data from China, Italy, Japan. Med. Image Anal. 2021, 70, 101992. [Google Scholar] [CrossRef] [PubMed]
- Bougourzi, F.; Distante, C.; Ouafi, A.; Dornaika, F.; Hadid, A.; Taleb-Ahmed, A. Per-COVID-19: A Benchmark Dataset for COVID-19 Percentage Estimation from CT-Scans. J. Imaging 2021, 7, 189. [Google Scholar] [CrossRef] [PubMed]
- Pavao, A.; Guyon, I.; Letournel, A.C.; Baró, X.; Escalante, H.; Escalera, S.; Thomas, T.; Xu, Z. Codalab Competitions: An Open Source Platform to Organize Scientific Challenges. Ph.D. Thesis, Université Paris-Saclay, Paris, France, 2022. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science, Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Lecture Notes in Computer Science, Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Granada, Spain, 20 September 2018; Stoyanov, D., Taylor, Z., Carneiro, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Huber, P.J. Robust estimation of a location parameter. In Breakthroughs in Statistics; Springer: Berlin/Heidelberg, Germany, 1992; pp. 492–518. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- RADIOLOGISTS. COVID-19 CT-Scans Segmentation Datasets. 2019. Available online: http://medicalsegmentation.com/covid19/ (accessed on 18 August 2021).
- Abdel-Basset, M.; Chang, V.; Hawash, H.; Chakrabortty, R.K.; Ryan, M. FSS-2019-nCov: A deep learning architecture for semi-supervised few-shot segmentation of COVID-19 infection. Knowl.-Based Syst. 2021, 212, 106647. [Google Scholar] [CrossRef]
- Botchkarev, A. Performance metrics (error measures) in machine learning regression, forecasting and prognostics: Properties and typology. arXiv 2018, arXiv:1809.03006. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Chaudhary, S.; Yang, W.; Qiang, Y. Swin Transformer for COVID-19 Infection Percentage Estimation from CT-Scans. In Lecture Notes in Computer Science, Proceedings of the Image Analysis and Processing, ICIAP 2022 Workshops, Lecce, Italy, 23–27 May 2022; Mazzeo, P.L., Frontoni, E., Sclaroff, S., Distante, C., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 520–528. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Anwar, T. SEnsembleNet: A Squeeze and Excitation based Ensemble Network for COVID-19 Infection Percentage Estimation from CT-Scans. 2022. Available online: https://www.techrxiv.org/doi/full/10.36227/techrxiv.19497467.v1 (accessed on 27 February 2024).
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 2735–2745. [Google Scholar] [CrossRef]
- Bello, I.; Fedus, W.; Du, X.; Cubuk, E.D.; Srinivas, A.; Lin, T.Y.; Shlens, J.; Zoph, B. Revisiting ResNets: Improved Training and Scaling Strategies. Adv. Neural Inf. Process. Syst. 2021, 34, 22614–22627. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Miron, R.; Breaban, M.E. Revitalizing Regression Tasks Through Modern Training Procedures: Applications in Medical Image Analysis for Covid-19 Infection Percentage Estimation. In Lecture Notes in Computer Science, Proceedings of the Image Analysis and Processing, ICIAP 2022 Workshops, Lecce, Italy, 23–27 May 2022; Mazzeo, P.L., Frontoni, E., Sclaroff, S., Distante, C., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 473–482. [Google Scholar] [CrossRef]
- Hsu, C.C.; Dai, S.J.; Chen, S.N. COVID-19 Infection Percentage Prediction via Boosted Hierarchical Vision Transformer. In Lecture Notes in Computer Science, Proceedings of the Image Analysis and Processing, ICIAP 2022 Workshops, Lecce, Italy, 23–27 May 2022; Mazzeo, P.L., Frontoni, E., Sclaroff, S., Distante, C., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 529–535. [Google Scholar] [CrossRef]
- Tricarico, D.; Chaudhry, H.A.H.; Fiandrotti, A.; Grangetto, M. Deep Regression by Feature Regularization for COVID-19 Severity Prediction. In Lecture Notes in Computer Science, Proceedings of the Image Analysis and Processing, ICIAP 2022 Workshops, Lecce, Italy, 23–27 May 2022; Mazzeo, P.L., Frontoni, E., Sclaroff, S., Distante, C., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 496–507. [Google Scholar] [CrossRef]
- Napoli Spatafora, M.A.; Ortis, A.; Battiato, S. Mixup Data Augmentation for COVID-19 Infection Percentage Estimation. In Lecture Notes in Computer Science, Proceedings of the Image Analysis and Processing, ICIAP 2022 Workshops, Lecce, Italy, 23–27 May 2022; Mazzeo, P.L., Frontoni, E., Sclaroff, S., Distante, C., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 508–519. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30.
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Berkeley, CA, USA, 13–18 July 2020; pp. 1597–1607. [Google Scholar]




| Hospital | Hakim Saidane Biskra | Ziouch Mohamed Tolga |
|---|---|---|
| #CT-scans | 154 | 35 |
| Device Scanner | Hitachi ECLOS CT Scanner | Toshiba Alexion CT Scanner |
| Slice Thickness | 5 mm | 3 mm |
| Split | #CT Scans | #Slices |
|---|---|---|
| Train | 132 | 3054 |
| Val | 57 | 1301 |
| Name | Dataset | #CT-Scans | #Slices |
|---|---|---|---|
| Dataset_1 | COVID-19 CT segmentation [25] | 40 | 100 |
| Dataset_2 | Segmentation dataset nr. 2 [25] | 9 | 829 |
| Dataset_3 | COVID-19-CT-Seg dataset [14] | 20 | 3520 |
| Test Set | Total | 69 | 4449 |
| Rank | Team | MAE | PC | RMSE |
|---|---|---|---|---|
| 1 | SenticLab.UAIC | 4.17 | 0.9487 | 8.19 |
| 2 | TAC | 4.48 | 0.9460 | 8.54 |
| 3 | Taiyuan_university_lab713 | 4.50 | 0.9490 | 8.09 |
| 4 | EIDOSlab_Unito | 4.91 | 0.9429 | 8.70 |
| 5 | ausilianapoli94 | 4.95 | 0.9435 | 8.60 |
| 6 | ACVLab | 4.99 | 0.9364 | 9.08 |
| - | Baseline | 5.24 | 0.9322 | 9.45 |
| Rank | Team | MAE | PC | RMSE |
|---|---|---|---|---|
| 1 | Taiyuan_university_lab713 | 3.55 | 0.8547 | 7.51 |
| 2 | TAC | 3.64 | 0.8022 | 8.57 |
| 3 | SenticLab.UAIC | 4.61 | 0.7634 | 9.09 |
| 4 | ACVLab | 4.86 | 0.7287 | 10.27 |
| 5 | EIDOSlab_Unito | 5.02 | 0.7977 | 9.01 |
| 6 | IPLab | 6.53 | 0.7091 | 9.97 |
| - | Baseline | 8.57 | 0.6344 | 12.62 |
| Rank | Team | MAE | PC | RMSE |
|---|---|---|---|---|
| 1 | Taiyuan_university_lab713 | 3.84 | 0.8830 | 7.92 |
| 2 | TAC | 3.89 | 0.8453 | 8.55 |
| 3 | SenticLab.UAIC | 4.48 | 0.8190 | 8.46 |
| 4 | ACVLab | 4.90 | 0.7910 | 9.43 |
| 5 | EIDOSlab_Unito | 4.98 | 0.8413 | 8.79 |
| 6 | IPLab | 6.06 | 0.7794 | 9.01 |
| - | Baseline | 7.57 | 0.7237 | 11.66 |
| Team | Preprocessing | Backbone | Architecture | Loss Function | Deep Features | Pretraining | Ensemble | Data Augmentation |
|---|---|---|---|---|---|---|---|---|
| 1. Taiyuan _university _lab713 | None | Transformer | Swin-L MLP | MSE | ✓ | ImageNet | ✗ | Hue Saturation Brightness Contrast |
| 2. TAC | None | CNN | ResNest-50d ResNetrs-50 SeresNext-50 EcaresNet-50t Skresnext-50 Seresnet-50 SEnsemble-Net | Smooth- | ✓ | ImageNet | ✓ | Horizontal flipping Shift scale rotation |
| 3. SenticLab.UAIC | None | CNN | ResNeSt-50 with Hybrid Pooling | Smooth- Distribution loss KL-divergence | ✗ | ImageNet | ✓ | Rotation Color Jittering Contrast Brightness Sharpness ShearX -ShearY Cutout TranslateX TranslateY |
| 4. ACVLab | Maximum- Rectangle Extraction | Trans-former | Hybrid Swin | MSE Cross-Entropy | ✗ | None | ✗ | Horizontal flipping Random shifting Random scaling Rotation Hue Saturation Brightness Contrast adjustment |
| 5. EIDOSlab _Unito | Pixel intensity scaling | CNN | DenseNet-121 Contrastive learning | Euclidean distance | ✓ | ImageNet | ✗ | Horizontal flipping -Random Cropping |
| 6. IPLab | None | CNN | Inception-v3 | Huber | ✗ | ImageNet | ✗ | Mix-up Gaussian blurring Color jittering Vertical flipping |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bougourzi, F.; Distante, C.; Dornaika, F.; Taleb-Ahmed, A.; Hadid, A.; Chaudhary, S.; Yang, W.; Qiang, Y.; Anwar, T.; Breaban, M.E.; et al. COVID-19 Infection Percentage Estimation from Computed Tomography Scans: Results and Insights from the International Per-COVID-19 Challenge. Sensors 2024, 24, 1557. https://doi.org/10.3390/s24051557
Bougourzi F, Distante C, Dornaika F, Taleb-Ahmed A, Hadid A, Chaudhary S, Yang W, Qiang Y, Anwar T, Breaban ME, et al. COVID-19 Infection Percentage Estimation from Computed Tomography Scans: Results and Insights from the International Per-COVID-19 Challenge. Sensors. 2024; 24(5):1557. https://doi.org/10.3390/s24051557
Chicago/Turabian StyleBougourzi, Fares, Cosimo Distante, Fadi Dornaika, Abdelmalik Taleb-Ahmed, Abdenour Hadid, Suman Chaudhary, Wanting Yang, Yan Qiang, Talha Anwar, Mihaela Elena Breaban, and et al. 2024. "COVID-19 Infection Percentage Estimation from Computed Tomography Scans: Results and Insights from the International Per-COVID-19 Challenge" Sensors 24, no. 5: 1557. https://doi.org/10.3390/s24051557
APA StyleBougourzi, F., Distante, C., Dornaika, F., Taleb-Ahmed, A., Hadid, A., Chaudhary, S., Yang, W., Qiang, Y., Anwar, T., Breaban, M. E., Hsu, C. -C., Tai, S. -C., Chen, S. -N., Tricarico, D., Chaudhry, H. A. H., Fiandrotti, A., Grangetto, M., Spatafora, M. A. N., Ortis, A., & Battiato, S. (2024). COVID-19 Infection Percentage Estimation from Computed Tomography Scans: Results and Insights from the International Per-COVID-19 Challenge. Sensors, 24(5), 1557. https://doi.org/10.3390/s24051557