
A Self-Adaptive Automatic Incident Detection System for Road Surveillance Based on Deep Learning

 ,
,  ,
,
Abstract
:
1. Introduction
- The proposed AID system is self-adaptive and fully automated in contrast to currently operating AIDS. The attributes that event detection algorithms rely on (road segmentation and identification of driving trajectories) are automatically obtained using the output of the AI-based modules and simple algorithms. This leads to a self-calibrated system that quickly adapts to any change in the environment, thus requiring no human interaction.
- Since the event detection modules rely on object detection and tracking, these subsystems are implemented using deep learning algorithms to improve accuracy. In order to keep computational complexity low, the tracker has been notably optimised—see Section 3.2.2.
- Event detection is based on novel algorithms that have been implemented to seize all the information available from the preceding AI modules, specifically (i) existing lane delineation and shoulder detection are based on a simple yet efficient segmentation algorithm that relies on manual identification of foreground objects. A novel feature of our proposal consists of the automation of this interactive process by using the moving objects from the scene as foreground. Those objects are previously identified by a deep learning-based object detector. (ii) Driving trajectories are obtained after tracking the detected moving objects in the scene using a deep learning-based tracker. This approach is in principle more accurate than conventional methods based on optical flow, which are more sensitive to changes in light conditions, and (iii) detection of non-moving objects has been achieved by first discarding moving ones using a novel algorithm based on inpainting techniques [3].
2. Related Work: State of the Art
2.1. AID and Smart Roads
2.2. Object Detection
2.3. Object Tracking
2.4. Automatic Incident Detection
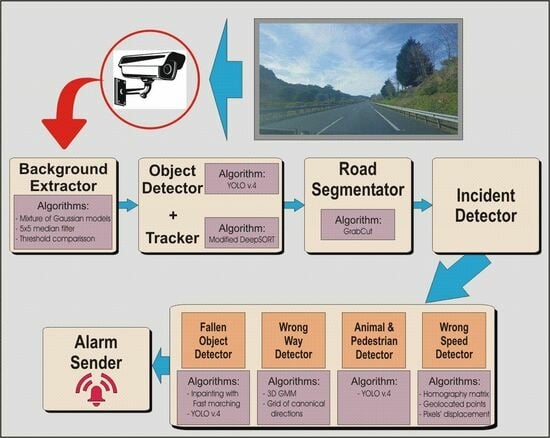
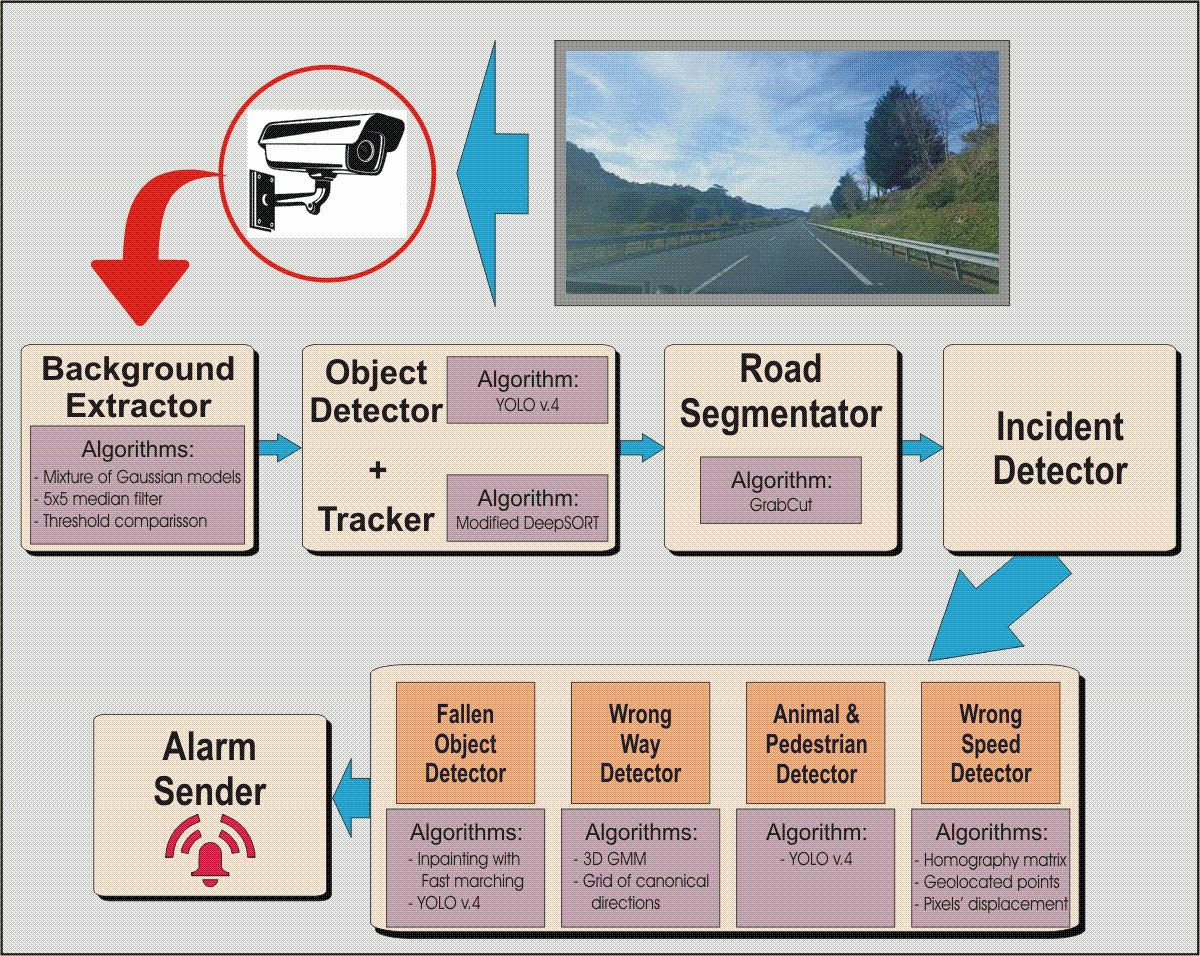
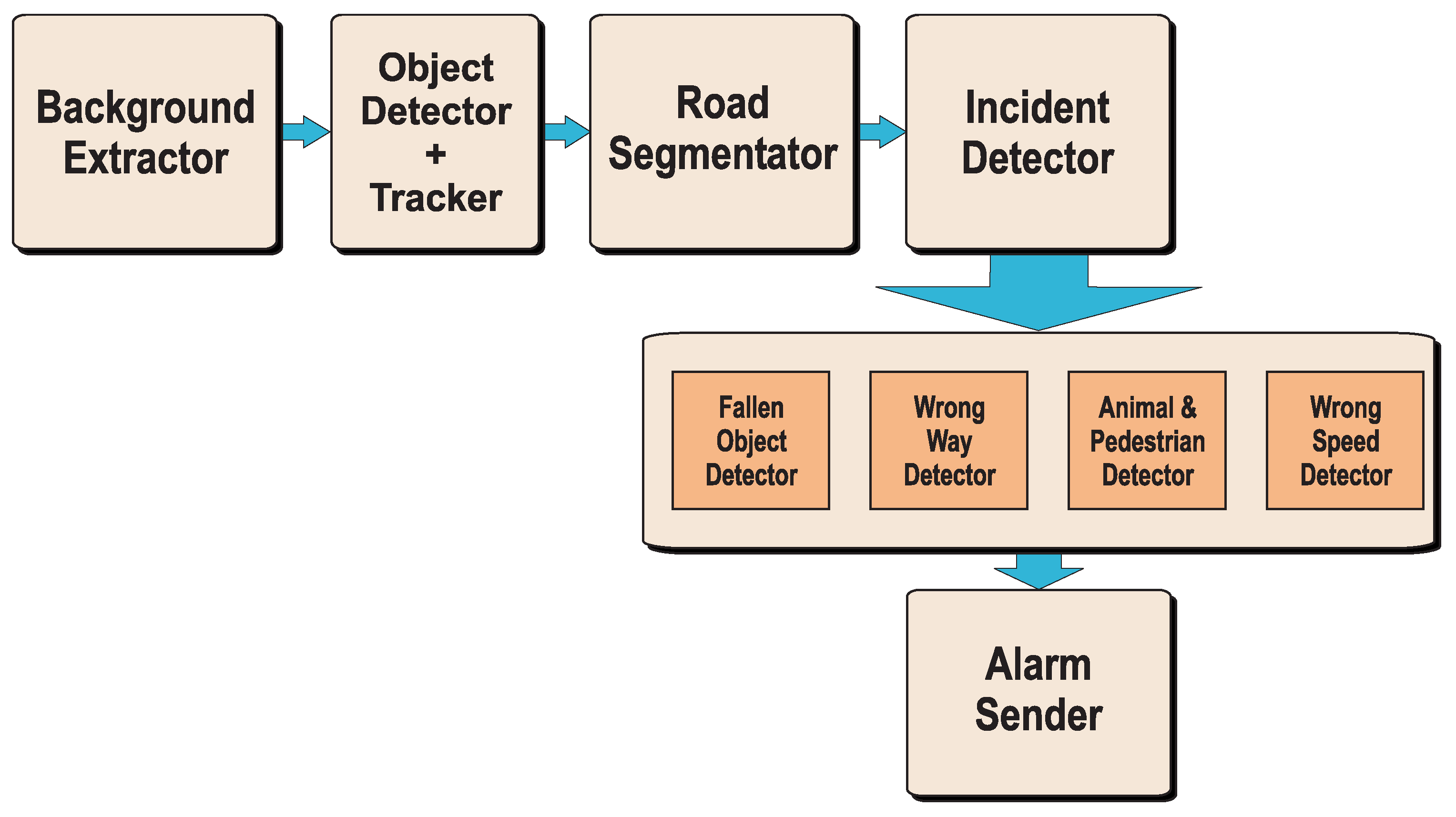
3. Self-Adaptive AID System for Road Surveillance
3.1. Background Detector
3.2. Object Detector and Tracker
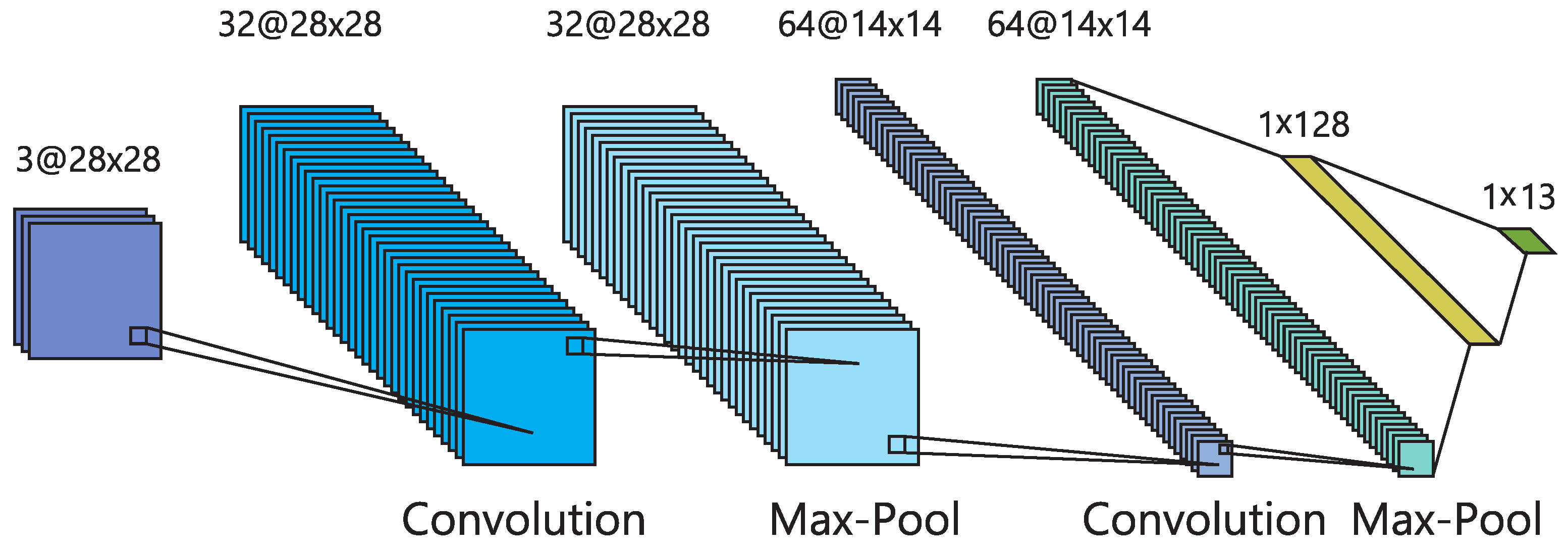
3.2.1. Object Detector
3.2.2. Tracker
3.3. Road Segmentation
3.4. Detection of Vehicles with Wrong Direction
3.4.1. Detection Based on a 3D Gaussian Mixture Model
3.4.2. Detection Based on a Grid of Canonical Directions
3.5. Abnormal Speed Detection
3.6. Fallen-Object Detection
3.7. Animal and Pedestrian Detection
4. Results and Discussion
4.1. Background Extractor
4.2. Object Detection
4.3. Detection of Kamikaze Vehicles
4.3.1. Modification of the Gaussian Mixture Model
4.3.2. Detector Based on Grid of Canonical Directions
4.3.3. Semi-Automatic Detector
4.4. Anomalous Speed Estimation
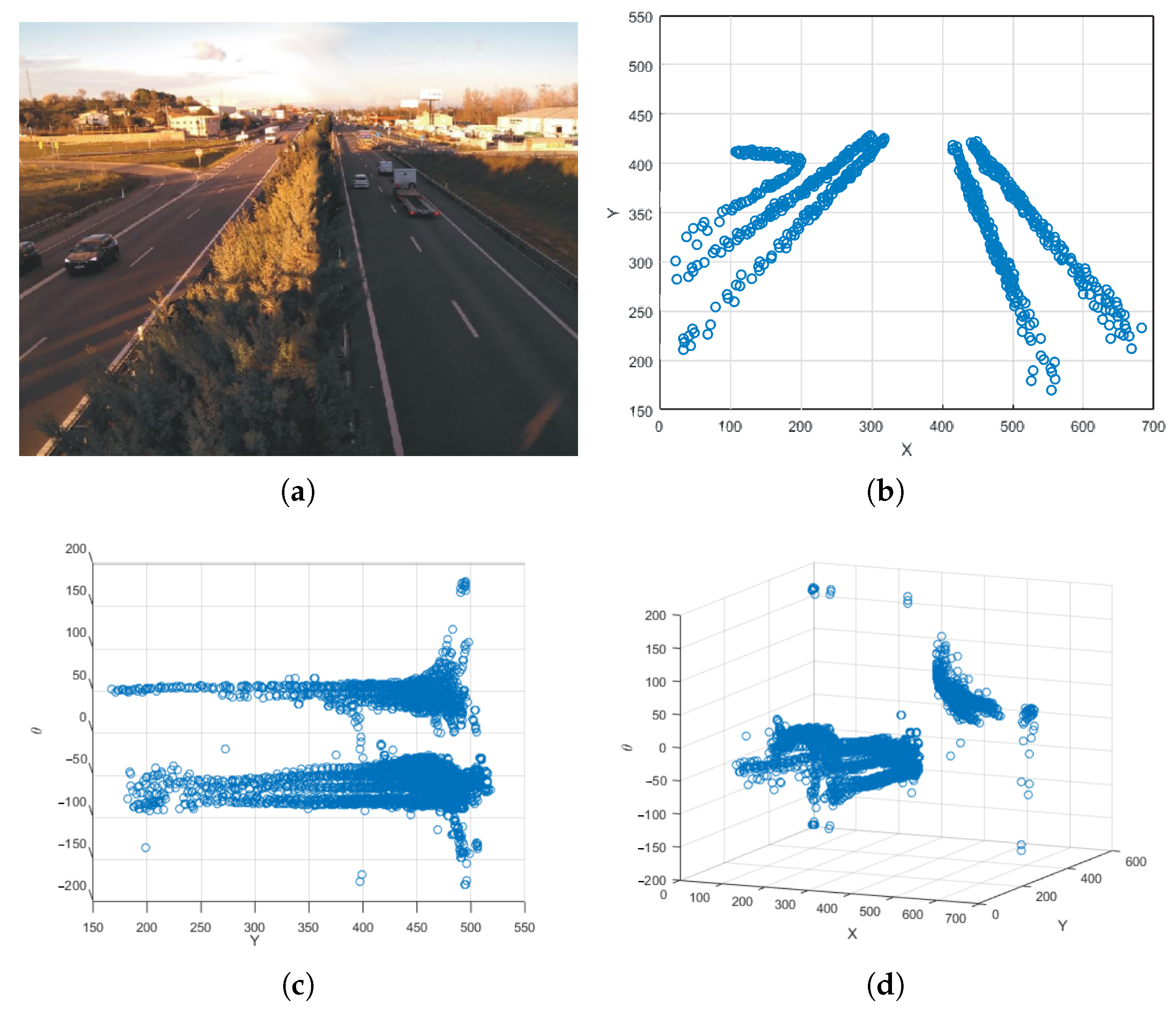
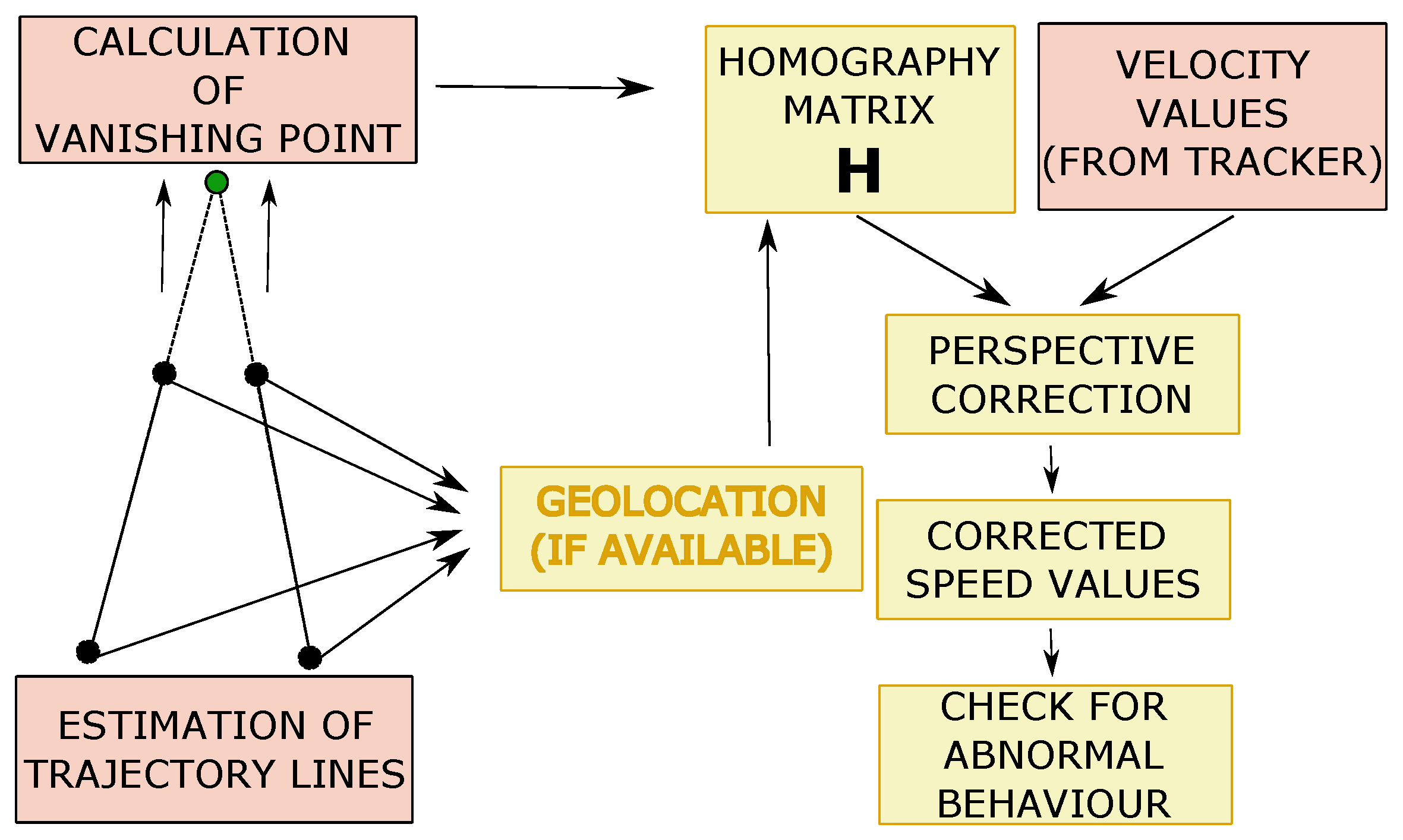
- Perspective Calibration: First of all, to illustrate some of the drawbacks of existing approaches based on vanishing points, we show in Figure 11 an example where not enough leak lines could be detected using the Hough transform method [26], and no vanishing point could be identified.The Hough transform is too dependent on the characteristics of the image. The proposed method based on trajectory lines generated by the vehicles offers better results as can be seen in Figure 12, where the ROI and the intersection points with this, which will be used to find the homography matrix, are shown as well. In Figure 12b, the trajectory lines perfectly match the vanishing lines present in the image.After the homography matrix H is calculated, the image is reconstructed to check if track lanes maintain a constant width, i.e., if perspective has been corrected—see Figure 13.
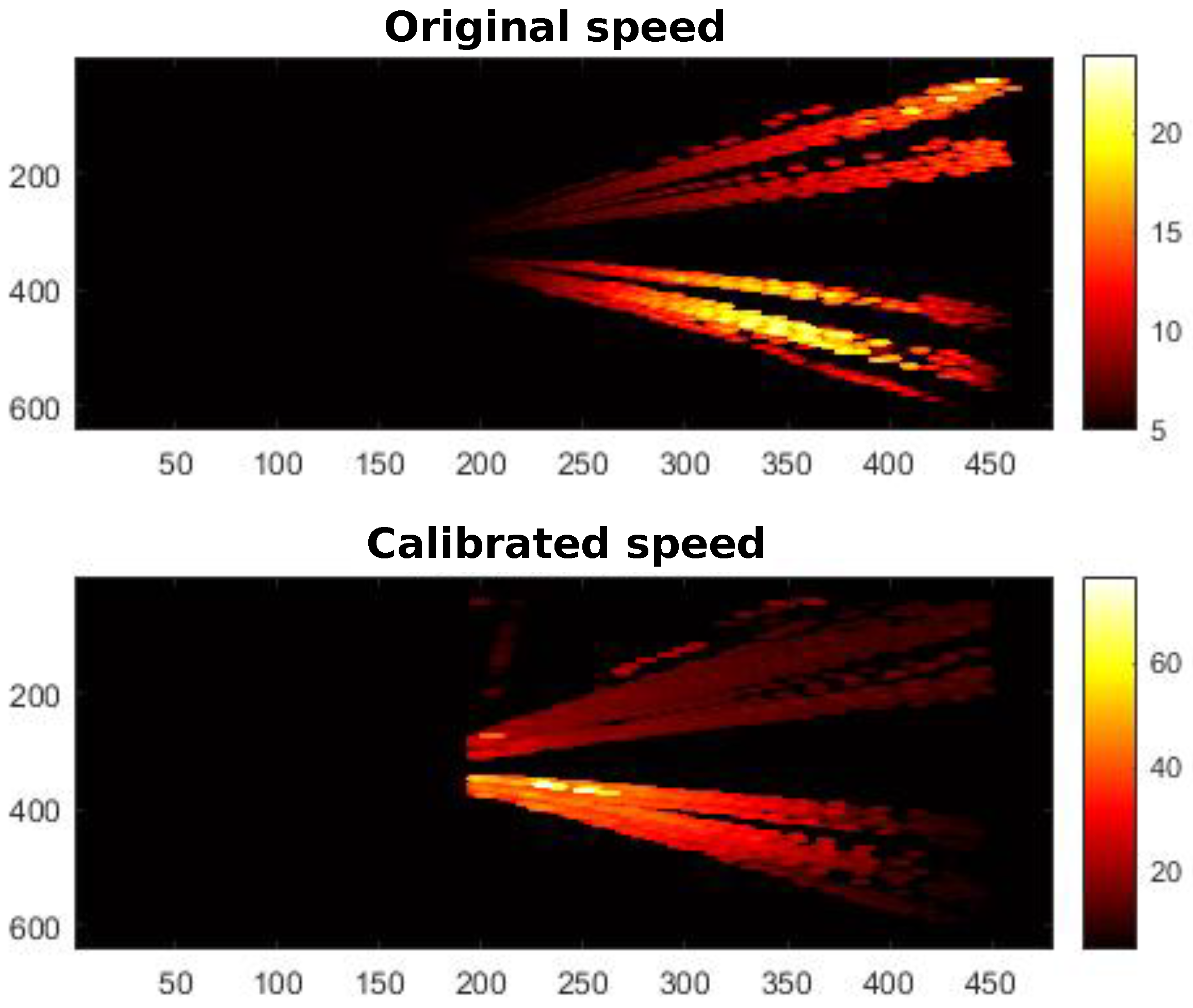
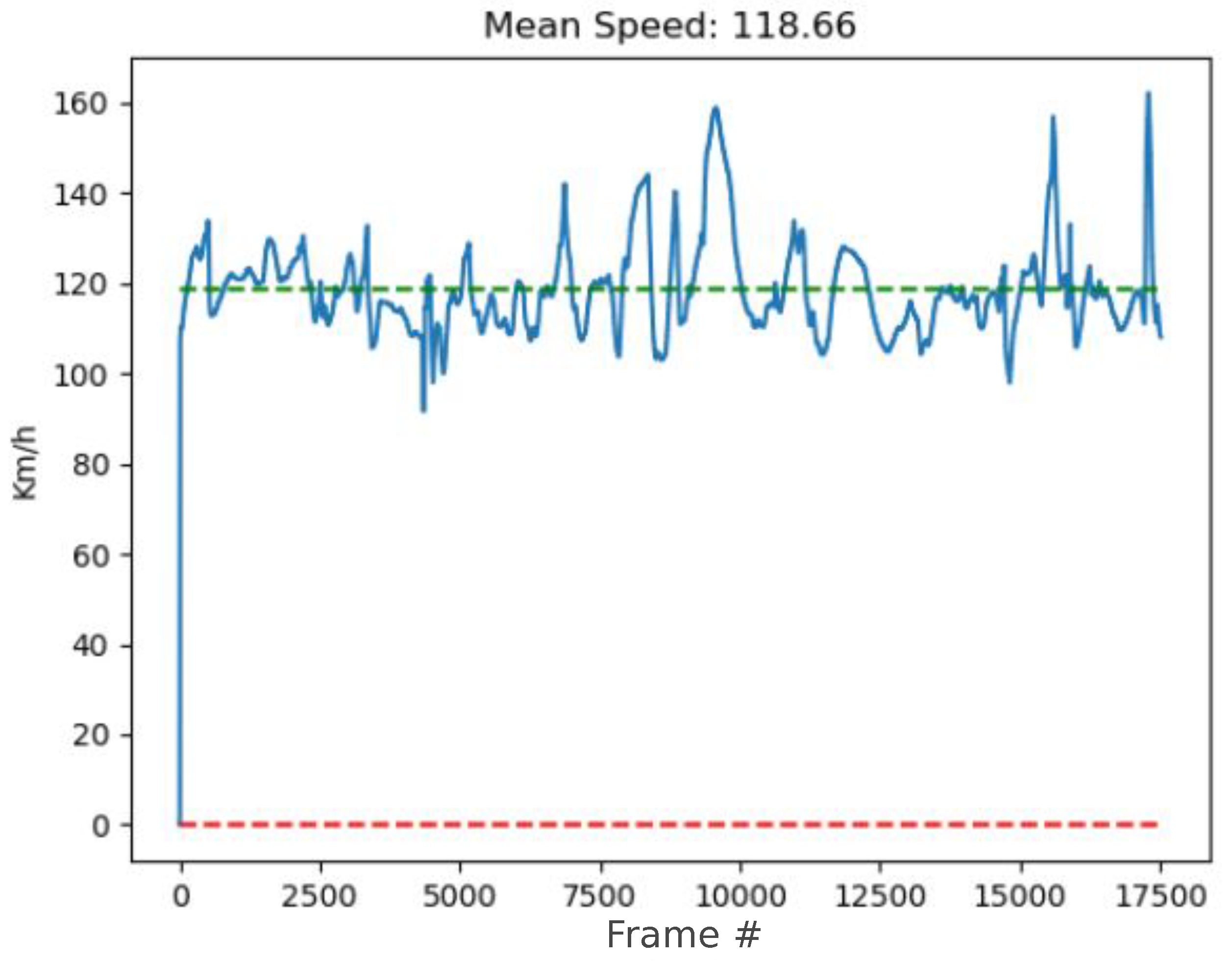
- Speed estimation: Once the homography matrix H has been obtained, Equation (3) is used to calibrate the speed of each vehicle, previously calculated with Deep-SORT. The aim pursued is to avoid dependence of the estimated speed with respect to the position in the image. To verify these results, we used heat maps representing the speed measured before and after calibration for the different scenarios. Heat maps of speed along the road are shown in Figure 14, both before calibration (top) and after (bottom).
4.5. Detection of Objects on the Road
4.6. Execution Speed and Model Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- True Positive (TP): The system detects something correctly.
- True Negative (TN): The system detects nothing because there is really nothing to detect.
- False Positive (FP): The system detects something when there is nothing to detect, a Type 1 error.
- False Negative (FN): The system detects nothing when there is something to detect, that is, the detection is skipped, a Type 2 error.
- Precision: Ratio of correct positive predictions to total positive predictions. Accuracy is important if false positives are to be avoided. This metric is also known as Positive Predictive Value (PPV).
- Sensitivity (Recall): Also called the True Positive Rate (TPR). It is the percentage of true positives detected versus total true positives. Sensitivity is important if false negatives are to be avoided.
- Specificity: also called the True Negative Rate (TNR). It is the percentage of true negatives detected versus all true negatives.
- False Positive Rate (FPR): ratio of false positives to the total number of negatives.
- Negative Predictive Value (NPV): relationship between the true negatives and the total number of predicted negatives.
- Accuracy: Percentage of correct predictions. However, for a dataset with different frequency of classes (unbalanced), it is not a good performance metric and others such as PPV and NPV should be used.
- F1 score: Represents a trade-off between precision and sensitivity. It indicates how many data are classified correctly without losing a significant number of them.
- Intersection over the Union (IoU): compares the area and position detected with the true area and position of the object.
- Average Precision (AP): Measures the overall precision of the system taking into account all classes. The IoU metric is usually first used with a set threshold to classify the detection as true positive or false positive. Typical thresholds are IoU = 0.5, IoU = 0.75 and IoU = 0.95. Precision and sensitivity are then calculated for a single class, and their relationship is plotted. As this function is usually zigzagging, the curve is smoothed, that is, interpolated, usingThis result is an approximate (and easier to integrate) function of the relationship between precision and sensitivity for a single class. With the interpolated curve, it is immediate to calculate the mean precision as the area under the curve.However, since the PASCAL VOC [50] competition, another much simpler way for the AP calculation was proposed. In this case, the value of the curve is averaged over 11 points.With the AP calculated for each class, averaging of all the classes is performed, resulting in the mean value of the AP (mAP), which is widely used in object detection competitions.
References
- C-ITS Organisation. Ecosystem for Fully Operational C-ITS Service Delivery; Technical Report; European Commission, EU: Brussels, Belgium, 2022. [Google Scholar]
- C-ITS Organisation. C-Roads Annual Pilot Overview Report; Technical Report; European Commission, EU: Brussels, Belgium, 2021. [Google Scholar]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH 2000), New Orleans, LA, USA, 23–28 July 2000; pp. 417–424. [Google Scholar] [CrossRef]
- Pompigna, A.; Mauro, R. Smart roads: A state of the art of highways innovations in the Smart Age. Eng. Sci. Technol. Int. J. 2022, 25, 100986. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1, p. 1. [Google Scholar] [CrossRef]
- Girshick, R.B. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 379–387. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Etten, A.V. You Only Look Twice: Rapid Multi-Scale Object Detection In Satellite Imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence (IJCAI-81), San Francisco, CA, USA, 24–28 August 1981; Volume 2, pp. 674–679. [Google Scholar]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Buxton, B.F.; Buxton, H. Computation of optic flow from the motion of edge features in image sequences. Image Vis. Comput. 1984, 2, 59–75. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 14–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Osher, S.; Fedkiw, R.P. Level Set Methods: An Overview and Some Recent Results. J. Comput. Phys. 2001, 169, 463–502. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI)—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, Z.; Ellis, T. Automatic lane detection from vehicle motion trajectories. In Proceedings of the 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance, Krakow, Poland, 27–30 August 2013; pp. 466–471. [Google Scholar] [CrossRef]
- Usmankhujaev, S.; Baydadaev, S.; Woo, K.J. Real-Time, Deep learning based wrong direction detection. Appl. Sci. 2020, 10, 2453. [Google Scholar] [CrossRef]
- Rahman, Z.; Ami, A.M.; Ullah, M.A. A real-time wrong-way vehicle detection based on YOLO and centroid tracking. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 July 2020; pp. 916–920. [Google Scholar] [CrossRef]
- Monteiro, G.; Ribeiro, M.; Marcos, J.; Batista, J. Wrongway drivers detection based on optical flow. In Proceedings of the 2007 IEEE International Conference on Image Processing (ICIP), San Antonio, TX, USA, 16–19 September 2007; Volume 5, p. V-141. [Google Scholar] [CrossRef]
- Piciarelli, C.; Micheloni, C.; Foresti, G.L. Trajectory-Based Anomalous Event Detection. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1544–1554. [Google Scholar] [CrossRef]
- Grammatikopoulos, L.; Karras, G.; Petsa, E. Geometric information from single uncalibrated images of roads. Int. Arch. Photogr. Remote Sens. Spat. Inform. Sci. 2002, 34, 21–26. [Google Scholar]
- Grammatikopoulos, L.; Karras, G.; Petsa, E. An automatic approach for camera calibration from vanishing points. ISPRS Photogramm. Remote Sens. 2007, 62, 64–76. [Google Scholar] [CrossRef]
- Doğan, S.; Temiz, M.S.; Külür, S. Real time speed estimation of moving vehicles from side view images from an uncalibrated video camera. Sensors 2010, 10, 4805–4824. [Google Scholar] [CrossRef]
- Gao, X.S.; Hou, X.R.; Tang, J.; Cheng, H.F. Complete solution classification for the perspective-three-point problem. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 930–943. [Google Scholar] [CrossRef]
- Mammeri, A.; Zhou, D.; Boukerche, A. Animal-Vehicle Collision Mitigation System for Automated Vehicles. IEEE Trans. Syst. Man Cybern. Syst. 2016, 46, 1287–1299. [Google Scholar] [CrossRef]
- Varagula, J.; Kulproma, P.-A.-N.; ITOb, T. Object Detection Method in Traffic by On-Board Computer Vision with Time Delay Neural Network. Procedia Comput. Sci. 2017, 112, 127–136. [Google Scholar] [CrossRef]
- Galvao, L.G.; Abbod, M.; Kalganova, T.; Palade, V.; Huda, M.N. Pedestrian and Vehicle Detection in Autonomous Vehicle Perception Systems—A Review. Sensors 2021, 21, 7267. [Google Scholar] [CrossRef]
- Zivkovic, Z. Improved adaptive Gaussian mixture model for background subtraction. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR 2004), Cambridge, UK, 23–26 August 2004; Volume 2, pp. 28–31. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Michael, K.; TaoXie; Fang, J.; imyhxy; et al. YOLOv5 by Ultralytics, Version 7.0; Zenodo: Geneva, Switzerland, 2020. [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8; Zenodo: Geneva, Switzerland, 2023. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Chan, F.H.; Chen, Y.T.; Xiang, Y.; Sun, M. Anticipating Accidents in Dashcam Videos. In Proceedings of the 13th Asian Conference on Computer Vision (ACCV 2016), Taipei, Taiwan, 20–24 November 2016; pp. 136–153. [Google Scholar]
- Shah, A.P.; Lamare, J.B.; Nguyen-Anh, T.; Hauptmann, A. CADP: A Novel Dataset for CCTV Traffic Camera based Accident Analysis. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Fang, J.; Yan, D.; Qiao, J.; Xue, J.; Wang, H.; Li, S. DADA-2000: Can Driving Accident be Predicted by Driver Attention? Analyzed by A Benchmark. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 4303–4309. [Google Scholar] [CrossRef]
- Snyder, C.; Do, M. Data for STREETS: A Novel Camera Network Dataset for Traffic Flow; University of Illinois at Urbana-Champaign: Urbana/Champaign, IL, USA, 2019. [Google Scholar] [CrossRef]
- Stepanyants, V.; Andzhusheva, M.; Romanov, A. A Pipeline for Traffic Accident Dataset Development. In Proceedings of the 2023 International Russian Smart Industry Conference (SmartIndustryCon), Sochi, Russia, 27–31 March 2023; pp. 621–626. [Google Scholar] [CrossRef]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut” Interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. (TOG) 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Kumar, A.; Khorramshahi, P.; Lin, W.A.; Dhar, P.; Chen, J.C.; Chellappa, R. A semi-automatic 2D solution for vehicle speed estimation from monocular videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops), Salt Lake City, UT, USA, 18–22 June 2018; pp. 137–144. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Telea, A. An image inpainting technique based on the fast marching method. J. Graph. Tools 2004, 9, 23–34. [Google Scholar] [CrossRef]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Code No. | COCO | Deep-Drive |
|---|---|---|---|
| Bicycle | 0 | Yes | Yes |
| Bus | 1 | Yes | Yes |
| Car | 2 | Yes | Yes |
| Motorbike | 3 | Yes | Yes |
| Person | 4 | Yes | Yes |
| Biker | 5 | No | Yes |
| Truck | 6 | Yes | Yes |
| Cat | 7 | Yes | No |
| Dog | 8 | Yes | No |
| Horse | 9 | Yes | No |
| Sheep | 10 | Yes | No |
| Cow | 11 | Yes | No |
| Bear | 12 | Yes | No |
| Video No. | One Way/Two Way | Location | Traffic Density | Characteristics |
|---|---|---|---|---|
| 1 | 2 | Singapore | Medium | Additional lane on the left |
| 2 | 2 | N/A | Medium/High | Occasional traffic jams |
| 3 | 2 | N/A | Medium | Aux. lane on left Lorries hiding cars |
| 4 | 1 | London | Curve Wind gusts | |
| 5 | 2 | N/A | Heterogeneous High on the right | Urban Aux. lanes on both sides |
| 6 | 1 | N/A | Heterogeneous | Curve Aux. lane on right |
| 7 | Soria, Spain | Low | Tunnel entrance Lighting changes | |
| 8 | Soria, Spain | Low | Inside a tunnel Poor lighting Glares |
| TP | FP | TN | FN | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|
| 23 | 0 | 577 | 0 | 100% | 100% | 100% | 100% |
| Model | mAP | Recall | Precision |
|---|---|---|---|
| YOLOv4 (new training) | 0.52 | 0.71 | 0.78 |
| YOLOv4Tiny (new training) | 0.37 | 0.40 | 0.71 |
| YOLOv4 (COCO) | 0.36 | 0.61 | 0.64 |
| YOLOv4Tiny (COCO) | 0.23 | 0.35 | 0.70 |
| Video No. | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| 1 | 0.84 | 0.83 | 0.86 | 0.84 |
| 2 | 0.86 | 0.89 | 0.90 | 0.84 |
| 3 | 0.83 | 0.82 | 0.84 | 0.83 |
| 4 | 0.88 | 0.97 | 0.79 | 0.87 |
| 5 | 0.86 | 0.92 | 0.78 | 0.85 |
| Mean ± std. dev. |
| Video No. | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| 1 | 0.90 | 0.96 | 0.82 | 0.89 |
| 2 | 0.91 | 0.98 | 0.83 | 0.90 |
| 3 | 0.90 | 1.00 | 0.80 | 0.89 |
| 4 | 0.88 | 0.99 | 0.76 | 0.86 |
| 5 | 0.87 | 0.99 | 0.75 | 0.85 |
| Mean ± Std.Dev. |
| Video No. | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| 1 | 0.91 | 0.93 | 0.89 | 0.91 |
| 2 | 0.87 | 0.96 | 0.78 | 0.86 |
| 3 | 0.96 | 0.96 | 0.95 | 0.95 |
| 4 | 0.92 | 0.94 | 0.89 | 0.91 |
| 5 | 0.88 | 0.99 | 0.77 | 0.87 |
| Mean ± Std.Dev. |
| Model | Speed (FPS) | Memory (Weights) | Memory (Inference) |
|---|---|---|---|
| YOLOv4 | 61.40 ± 5.16 | 250 | 1871 |
| YOLOv4 Tiny | 110.03 ± 25.80 | 25 | 763 |
| Model | Speed (FPS) | Memory (Weights) | Memory (Inference) |
|---|---|---|---|
| Original [17] | 5.00 ± 3.4 | 11.2 | 3.83 |
| Proposed Encoder | 10.65 ± 4.56 | 1.2 | 2.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bartolomé-Hornillos, C.; San-José-Revuelta, L.M.; Aguiar-Pérez, J.M.; García-Serrada, C.; Vara-Pazos, E.; Casaseca-de-la-Higuera, P. A Self-Adaptive Automatic Incident Detection System for Road Surveillance Based on Deep Learning. Sensors 2024, 24, 1822. https://doi.org/10.3390/s24061822
Bartolomé-Hornillos C, San-José-Revuelta LM, Aguiar-Pérez JM, García-Serrada C, Vara-Pazos E, Casaseca-de-la-Higuera P. A Self-Adaptive Automatic Incident Detection System for Road Surveillance Based on Deep Learning. Sensors. 2024; 24(6):1822. https://doi.org/10.3390/s24061822
Chicago/Turabian StyleBartolomé-Hornillos, César, Luis M. San-José-Revuelta, Javier M. Aguiar-Pérez, Carlos García-Serrada, Eduardo Vara-Pazos, and Pablo Casaseca-de-la-Higuera. 2024. "A Self-Adaptive Automatic Incident Detection System for Road Surveillance Based on Deep Learning" Sensors 24, no. 6: 1822. https://doi.org/10.3390/s24061822
APA StyleBartolomé-Hornillos, C., San-José-Revuelta, L. M., Aguiar-Pérez, J. M., García-Serrada, C., Vara-Pazos, E., & Casaseca-de-la-Higuera, P. (2024). A Self-Adaptive Automatic Incident Detection System for Road Surveillance Based on Deep Learning. Sensors, 24(6), 1822. https://doi.org/10.3390/s24061822