Self-Supervised Open-Set Speaker Recognition with Laguerre–Voronoi Descriptors



Abstract
:1. Introduction
- A novel Laguerre–Voronoi descriptor deep neural network (LVDNet) architecture, realizing a self-supervised learning approach, is proposed. The architecture allows operating efficiently with short speech segments.
- A novel Laguerre–Voronoi-based vector of locally aggregated descriptors, namely Laguerre–Voronoi descriptors (LVD), is introduced to extract essential speech features while filtering out noise.
- A unique clustering criterion is developed to help the DNN generate clusterable speaker representation.
2. Related Works
3. Methodology
3.1. Laguerre–Voronoi Descriptor Deep Neural Network (LVDNet) Architecture
3.1.1. Large-Kernel Attention (LKA)
3.1.2. Squeeze–Excitation Attention (SEA)
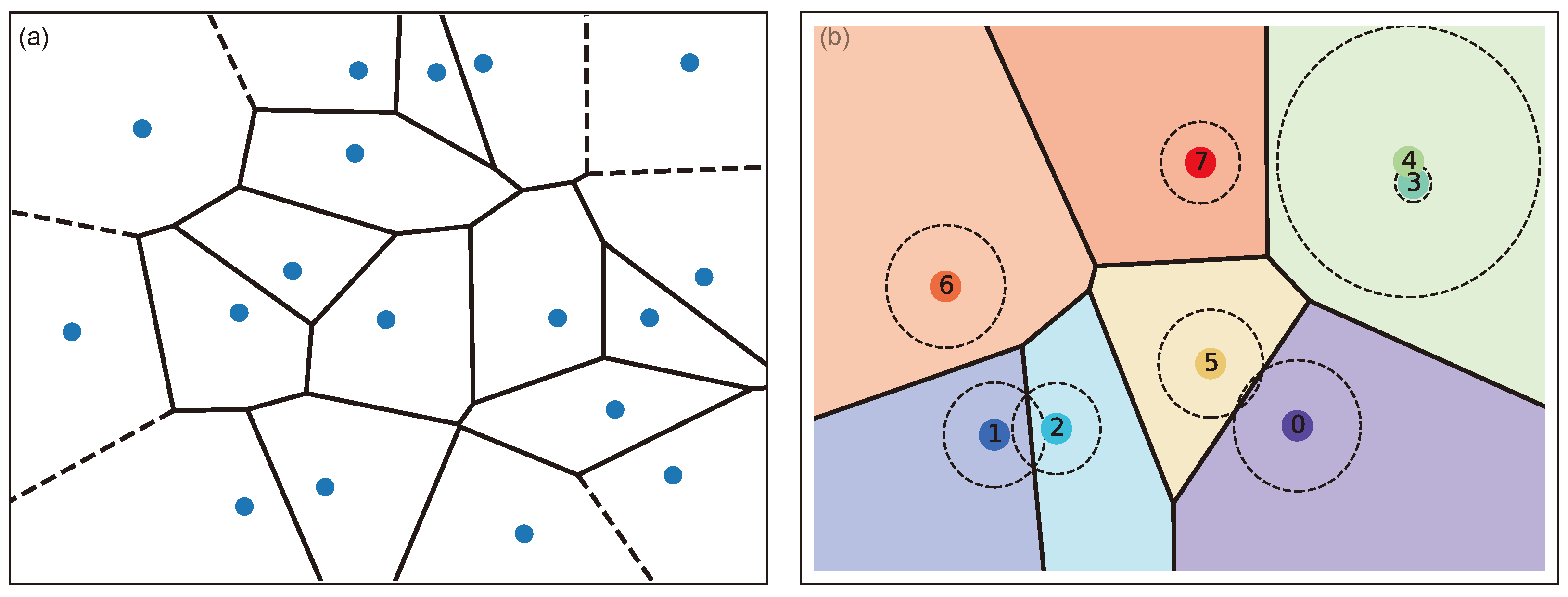
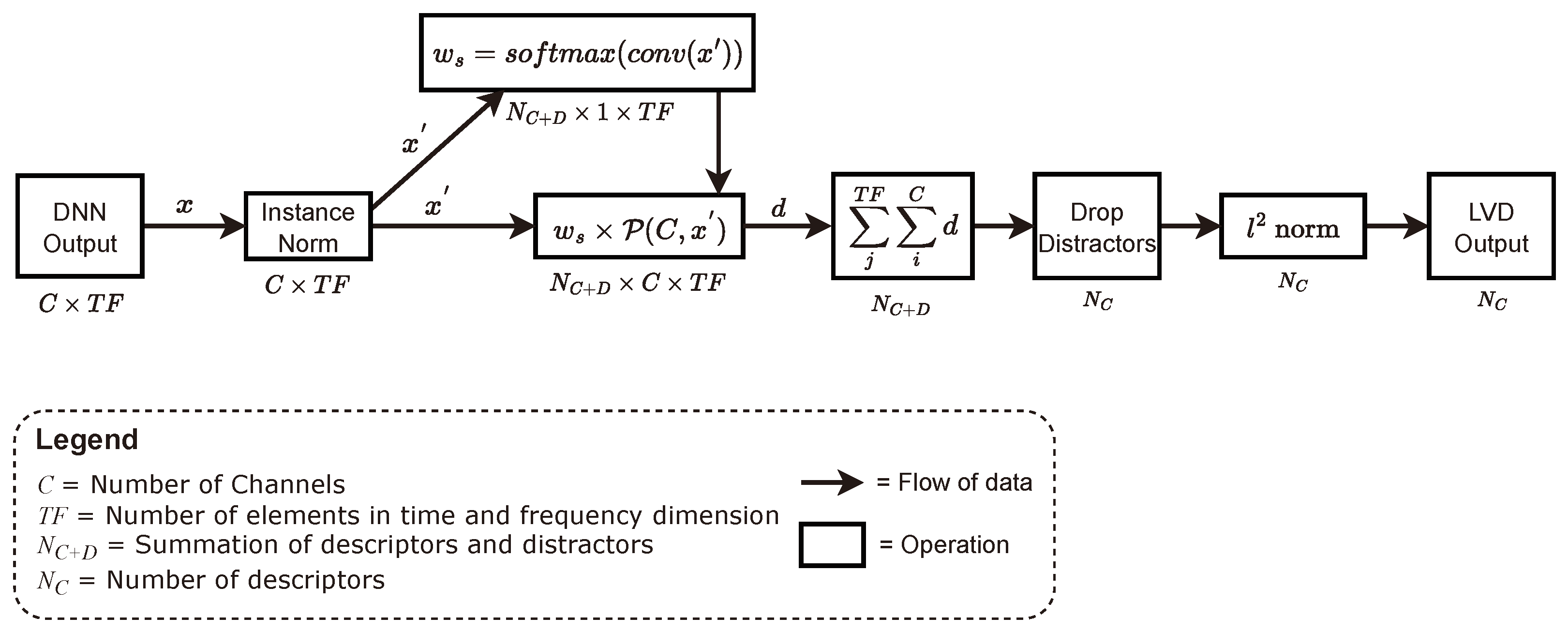
3.2. Laguerre–Voronoi Descriptors (LVDs)
3.3. Scaling
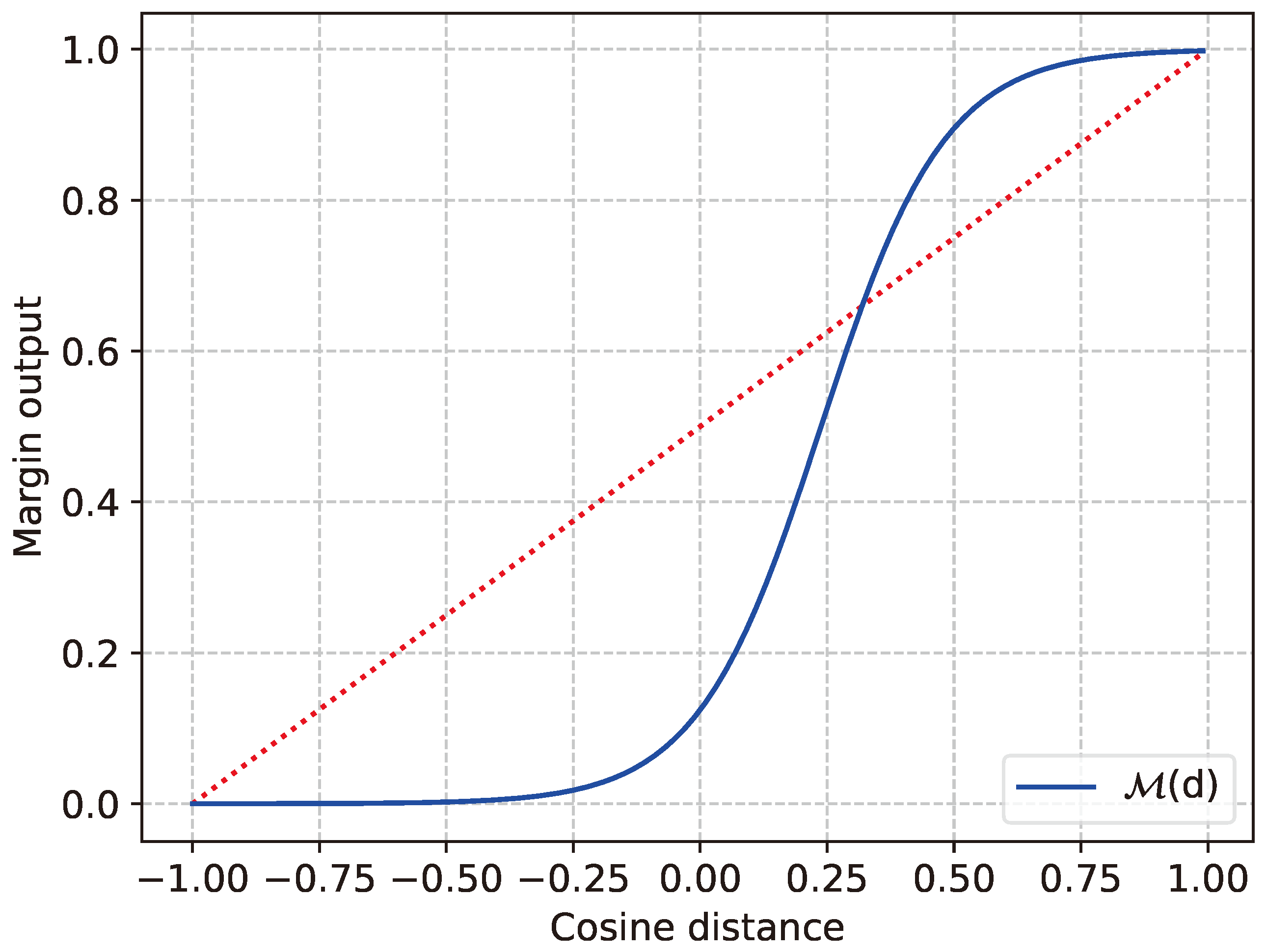
3.4. Cluster Criterion
4. Experimental Results
4.1. Datasets and Experimental Setup
4.2. Ablation Study
4.3. Comparison of Feature-Aggregation Strategies
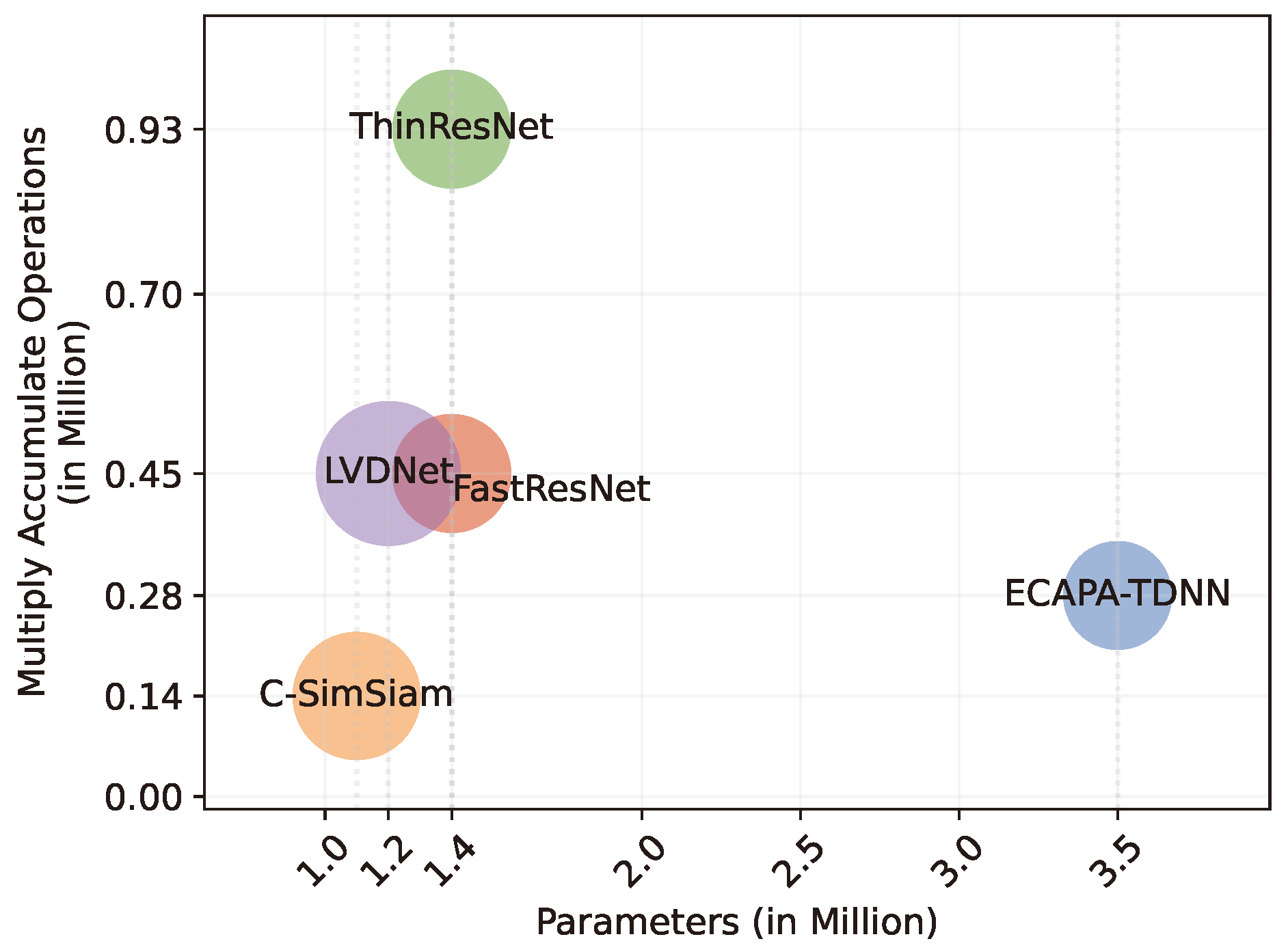
4.4. Comparison of DNN Models
4.5. Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SSL | self-supervised Learning |
| DNN | deep neural network |
| LVD | Laguerre–Voronoi descriptors |
| LVDNet | Laguerre–Voronoi descriptor deep neural network |
| VLAD | vector of locally aggregated descriptors |
| SAP | self-attentive pooling |
| ASP | attentive statistics pooling |
| CEL | Contrastive Equilibrium Learning |
| DINO | self-distillation with no Labels |
| LKA | large-kernel attention |
| SEA | squeeze0-excitation attention |
| TDNN | time-delay neural network |
References
- Balestriero, R.; Ibrahim, M.; Sobal, V.; Morcos, A.; Shekhar, S.; Goldstein, T.; Bordes, F.; Bardes, A.; Mialon, G.; Tian, Y.; et al. A cookbook of self-supervised learning. arXiv 2023, arXiv:2304.12210. [Google Scholar]
- Chen, H.; Gouin-Vallerand, C.; Bouchard, K.; Gaboury, S.; Couture, M.; Bier, N.; Giroux, S. Enhancing Human Activity Recognition in Smart Homes with Self-Supervised Learning and Self-Attention. Sensors 2024, 24, 884. [Google Scholar] [CrossRef] [PubMed]
- Geng, C.; Huang, S.j.; Chen, S. Recent advances in open set recognition: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3614–3631. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.S.; Huh, J.; Mun, S.; Lee, M.; Heo, H.S.; Choe, S.; Ham, C.; Jung, S.; Lee, B.J.; Han, I. In defence of metric learning for speaker recognition. arXiv 2020, arXiv:2003.11982. [Google Scholar]
- Palo, H.K.; Behera, D. Analysis of Speaker’s Age Using Clustering Approaches with Emotionally Dependent Speech Features. In Critical Approaches to Information Retrieval Research; IGI Global: Pennsylvania, PA, USA, 2020; pp. 172–197. [Google Scholar]
- Ravanelli, M.; Bengio, Y. Speaker recognition from raw waveform with sincnet. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1021–1028. [Google Scholar]
- Ohi, A.Q.; Gavrilova, M.L. A Novel Self-Supervised Representation Learning Model for an Open-set Speaker Recognition. In Proceedings of the Computer Information Systems and Industrial Management, Tokyo, Japan, 22–24 September 2023; Volume 14164. [Google Scholar]
- Sang, M.; Li, H.; Liu, F.; Arnold, A.O.; Wan, L. Self-supervised speaker verification with simple siamese network and self-supervised regularization. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 6127–6131. [Google Scholar]
- Chen, Y.; Zheng, S.; Wang, H.; Cheng, L.; Chen, Q. Pushing the limits of self-supervised speaker verification using regularized distillation framework. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Zisserman, A. Voxceleb: A large-scale speaker identification dataset. arXiv 2017, arXiv:1706.08612. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 5206–5210. [Google Scholar]
- Dehak, N.; Kenny, P.J.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-end factor analysis for speaker verification. IEEE Trans. Audio, Speech, Lang. Process. 2010, 19, 788–798. [Google Scholar] [CrossRef]
- Variani, E.; Lei, X.; McDermott, E.; Moreno, I.L.; Gonzalez-Dominguez, J. Deep neural networks for small footprint text-dependent speaker verification. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 4052–4056. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5329–5333. [Google Scholar]
- Li, C.; Ma, X.; Jiang, B.; Li, X.; Zhang, X.; Liu, X.; Cao, Y.; Kannan, A.; Zhu, Z. Deep speaker: An end-to-end neural speaker embedding system. arXiv 2017, arXiv:1705.02304. [Google Scholar]
- Xie, W.; Nagrani, A.; Chung, J.S.; Zisserman, A. Utterance-level aggregation for speaker recognition in the wild. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 5791–5795. [Google Scholar]
- Zhong, Y.; Arandjelović, R.; Zisserman, A. Ghostvlad for set-based face recognition. In Proceedings of the Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part II 14. Springer: Berlin/Heidelberg, Germany, 2019; pp. 35–50. [Google Scholar]
- Cai, W.; Chen, J.; Li, M. Exploring the encoding layer and loss function in end-to-end speaker and language recognition system. arXiv 2018, arXiv:1804.05160. [Google Scholar]
- Okabe, K.; Koshinaka, T.; Shinoda, K. Attentive statistics pooling for deep speaker embedding. arXiv 2018, arXiv:1803.10963. [Google Scholar]
- Chen, L.; Liu, Y.; Xiao, W.; Wang, Y.; Xie, H. SpeakerGAN: Speaker identification with conditional generative adversarial network. Neurocomputing 2020, 418, 211–220. [Google Scholar] [CrossRef]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Dawalatabad, N.; Madikeri, S.; Sekhar, C.C.; Murthy, H.A. Novel architectures for unsupervised information bottleneck based speaker diarization of meetings. IEEE/Acm Trans. Audio Speech Lang. Process. 2020, 29, 14–27. [Google Scholar] [CrossRef]
- Mridha, M.F.; Ohi, A.Q.; Monowar, M.M.; Hamid, M.A.; Islam, M.R.; Watanobe, Y. U-vectors: Generating clusterable speaker embedding from unlabeled data. Appl. Sci. 2021, 11, 10079. [Google Scholar] [CrossRef]
- Mun, S.H.; Kang, W.H.; Han, M.H.; Kim, N.S. Unsupervised representation learning for speaker recognition via contrastive equilibrium learning. arXiv 2020, arXiv:2010.11433. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Han, B.; Chen, Z.; Qian, Y. Self-supervised speaker verification using dynamic loss-gate and label correction. arXiv 2022, arXiv:2208.01928. [Google Scholar]
- Desplanques, B.; Thienpondt, J.; Demuynck, K. Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification. arXiv 2020, arXiv:2005.07143. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Chung, J.S.; Huh, J.; Mun, S. Delving into Voxceleb: Environment Invariant Speaker Recognition. arXiv 2019, arXiv:1910.11238. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual attention network. In Computational Visual Media; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–20. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Imai, H.; Iri, M.; Murota, K. Voronoi diagram in the Laguerre geometry and its applications. Siam J. Comput. 1985, 14, 93–105. [Google Scholar] [CrossRef]
- Snyder, D.; Chen, G.; Povey, D. Musan: A music, speech, and noise corpus. arXiv 2015, arXiv:1510.08484. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Components | Clustering Performance (ARI ↑) | |||||
|---|---|---|---|---|---|---|
| LKA + SEA | Margin | Scaling | LVD | VoxCeleb1 | LibriSpeech-Clean | LibriSpeech-Other |
| ✗ | ✓ | ✓ | ✓ | 84.98 | 92.33 | 91.97 |
| ✓ | ✗ | ✓ | ✓ | 91.43 | 84.58 | 90.47 |
| ✓ | ✓ | ✗ | ✓ | 92.67 | 92.76 | 94.33 |
| ✓ | ✓ | ✓ | ✗ | 90.08 | 90.32 | 89.61 |
| ✓ | ✓ | ✓ | ✓ | 94.98 | 94.93 | 95.43 |
| Model Components | Verification Performance (EER ↓) | |||||
|---|---|---|---|---|---|---|
| LKA + SEA | Margin | Scaling | LVD | VoxCeleb1 | LibriSpeech-Clean | LibriSpeech-Other |
| ✗ | ✓ | ✓ | ✓ | 19.16 | 8.27 | 7.54 |
| ✓ | ✗ | ✓ | ✓ | 18.14 | 8.18 | 7.79 |
| ✓ | ✓ | ✗ | ✓ | 17.42 | 9.38 | 9.33 |
| ✓ | ✓ | ✓ | ✗ | 17.05 | 12.08 | 12.35 |
| ✓ | ✓ | ✓ | ✓ | 12.87 | 7.66 | 6.26 |
| Feature-Aggregation Strategy | Performance | |||||
|---|---|---|---|---|---|---|
| VoxCeleb1 | LibriSpeech-Clean | LibriSpeech-Other | ||||
| EER (↓) | ARI (↑) | EER (↓) | ARI (↑) | EER (↓) | ARI (↑) | |
| Avg-Pooling | 17.05 | 90.08 | 12.08 | 90.32 | 12.35 | 89.61 |
| SAP [18] | 14.77 | 92.07 | 9.66 | 92.03 | 9.59 | 92.35 |
| ASP [19] | 15.66 | 91.40 | 10.41 | 91.43 | 8.83 | 92.44 |
| Ghost-VLAD [17] | 17.05 | 90.08 | 8.04 | 92.32 | 8.35 | 92.61 |
| LVD | 12.87 | 94.98 | 7.66 | 94.93 | 6.26 | 95.43 |
| DNN Models | Performance | Parameters (in Millions) | Multiply Accumulate Operations (in Millions) | |||||
|---|---|---|---|---|---|---|---|---|
| VoxCeleb1 | LibriSpeech-Clean | LibriSpeech-Other | ||||||
| EER (↓) | ARI (↑) | EER (↓) | ARI (↑) | EER (↓) | ARI (↑) | |||
| ThinResNet [32] | 14.88 | 90.29 | 10.28 | 91.28 | 9.8 | 92.40 | 1.4 | 0.93 |
| FastResNet [4] | 14.55 | 90.37 | 10.37 | 91.23 | 9.83 | 92.43 | 1.4 | 0.45 |
| ECAPA-TDNN [28] | 14.86 | 90.98 | 11.05 | 90.71 | 12.38 | 90.26 | 3.5 | 0.28 |
| C-SimSiam [7] | 14.79 | 91.76 | 9.86 | 92.47 | 8.88 | 93.55 | 1.1 | 0.14 |
| LVDNet | 12.87 | 94.98 | 7.66 | 94.93 | 6.26 | 95.43 | 1.2 | 0.45 |
| Methods | Speech Seg. | Performance | |||||
|---|---|---|---|---|---|---|---|
| VoxCeleb | LibriSpeech-Clean | LibriSpeech-Other | |||||
| EER (↓) | ARI (↑) | EER (↓) | ARI (↑) | EER (↓) | ARI (↑) | ||
| DINO-Reg [9] | 3.0 | 29.61 | 48.05 | 26.04 | 45.79 | 25.22 | 55.19 |
| CEL [24] | 1.8 | 17.8 | 83.85 | 10.7 | 84.69 | 9.92 | 87.95 |
| SimSiamReg [24] | 1.8 | 19.33 | 83.92 | 10.03 | 82.86 | 9.98 | 88.36 |
| C-SimSiam [7] | 1.8 | 15.4 | 90.26 | 9.87 | 90.65 | 9.09 | 90.38 |
| LVDNet | 1.8 | 12.87 | 94.98 | 7.66 | 94.93 | 6.26 | 95.43 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ohi, A.Q.; Gavrilova, M.L. Self-Supervised Open-Set Speaker Recognition with Laguerre–Voronoi Descriptors. Sensors 2024, 24, 1996. https://doi.org/10.3390/s24061996
Ohi AQ, Gavrilova ML. Self-Supervised Open-Set Speaker Recognition with Laguerre–Voronoi Descriptors. Sensors. 2024; 24(6):1996. https://doi.org/10.3390/s24061996
Chicago/Turabian StyleOhi, Abu Quwsar, and Marina L. Gavrilova. 2024. "Self-Supervised Open-Set Speaker Recognition with Laguerre–Voronoi Descriptors" Sensors 24, no. 6: 1996. https://doi.org/10.3390/s24061996
APA StyleOhi, A. Q., & Gavrilova, M. L. (2024). Self-Supervised Open-Set Speaker Recognition with Laguerre–Voronoi Descriptors. Sensors, 24(6), 1996. https://doi.org/10.3390/s24061996