
Edge-Triggered Three-Dimensional Object Detection Using a LiDAR Ring


Abstract
1. Introduction
2. Background Knowledge
2.1. Ring Data of LiDAR
2.2. Edge Trigger
2.3. Analysis of Object Features in Point Cloud
3. Ring Edge-Triggered Detection Method
3.1. Noise Filtering
3.2. Object Points Extraction with Ring Edge
| Algorithm 1. Algorithm to detect objects with edges | |||||
| Input: Point cloud in multiple areas divided by azimuths | |||||
| Output: Point cloud recognized as obstacle | |||||
| for each point cloud area in P do | |||||
| := p (sorted by ring id) | |||||
| initialize | |||||
| for each ring in R do | |||||
| := [ring == each ring] | |||||
| th := arctan(.y/.x) | |||||
| = (sorted by th) | |||||
| := list of zeros (size : number of ) | |||||
| diff := difference of z value between neighbor points of | |||||
| edges := index of where diff > | |||||
| if diff[ first edge ] < 0 then // if first edge is falling edge | |||||
| [before first edge] = 1 | |||||
| end if | |||||
| for each edge in edges do | |||||
| if diff[each edge] > 0 then // if edge is the rising edge | |||||
| [after each edge] = 1 | |||||
| else then // if edge is the falling edge | |||||
| [after each edge] = 0 | |||||
| end if | |||||
| end for | |||||
| = +[] | |||||
| end for | |||||
| end for | |||||
3.3. Covering Edge Cases
3.4. Results of Processes of Ring Edge
3.5. Estimation of Bounding Boxes
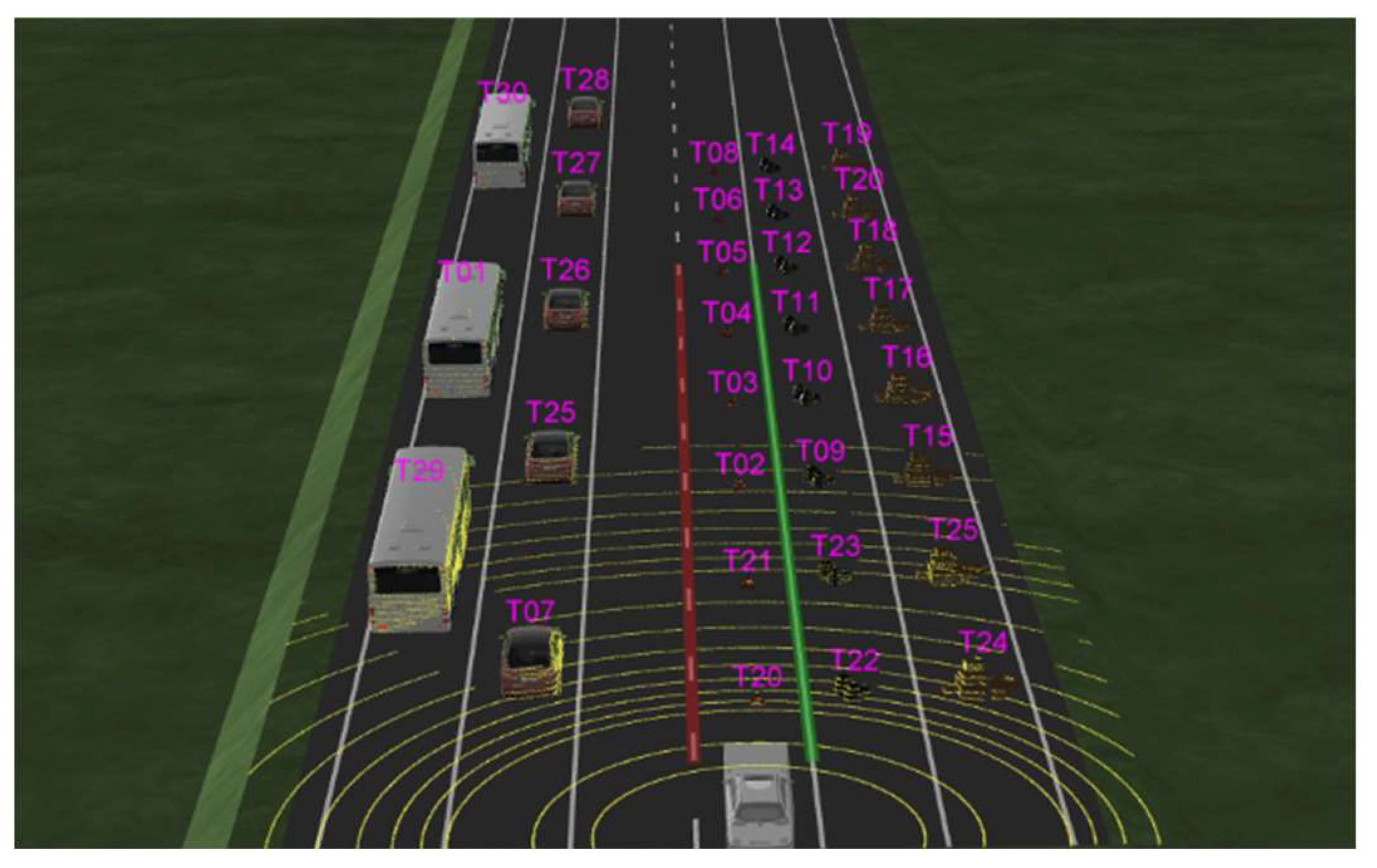
4. Environments of Experiments
4.1. Experiments Environment Setting
4.1.1. Open-Source Datasets
4.1.2. Virtual Driving Environments Setting
4.1.3. Real Driving Environments Setting
4.1.4. Voxelization Setting
4.2. Evaluation Metrics
4.2.1. F1 Score
4.2.2. Voxel Detection Rate and Point Detection Rate
5. Results
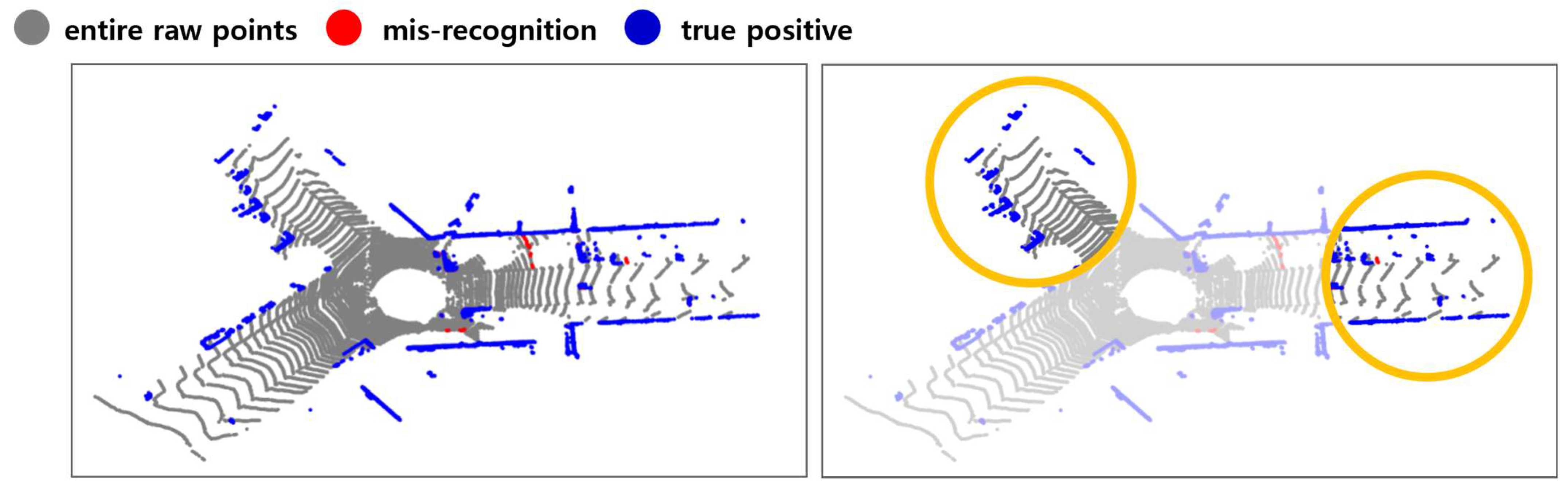
5.1. Results of Point Extraction Performance
5.1.1. Real-Time Performance
5.1.2. Detection Performance with F1 Score
5.1.3. Detection Performance with VDR
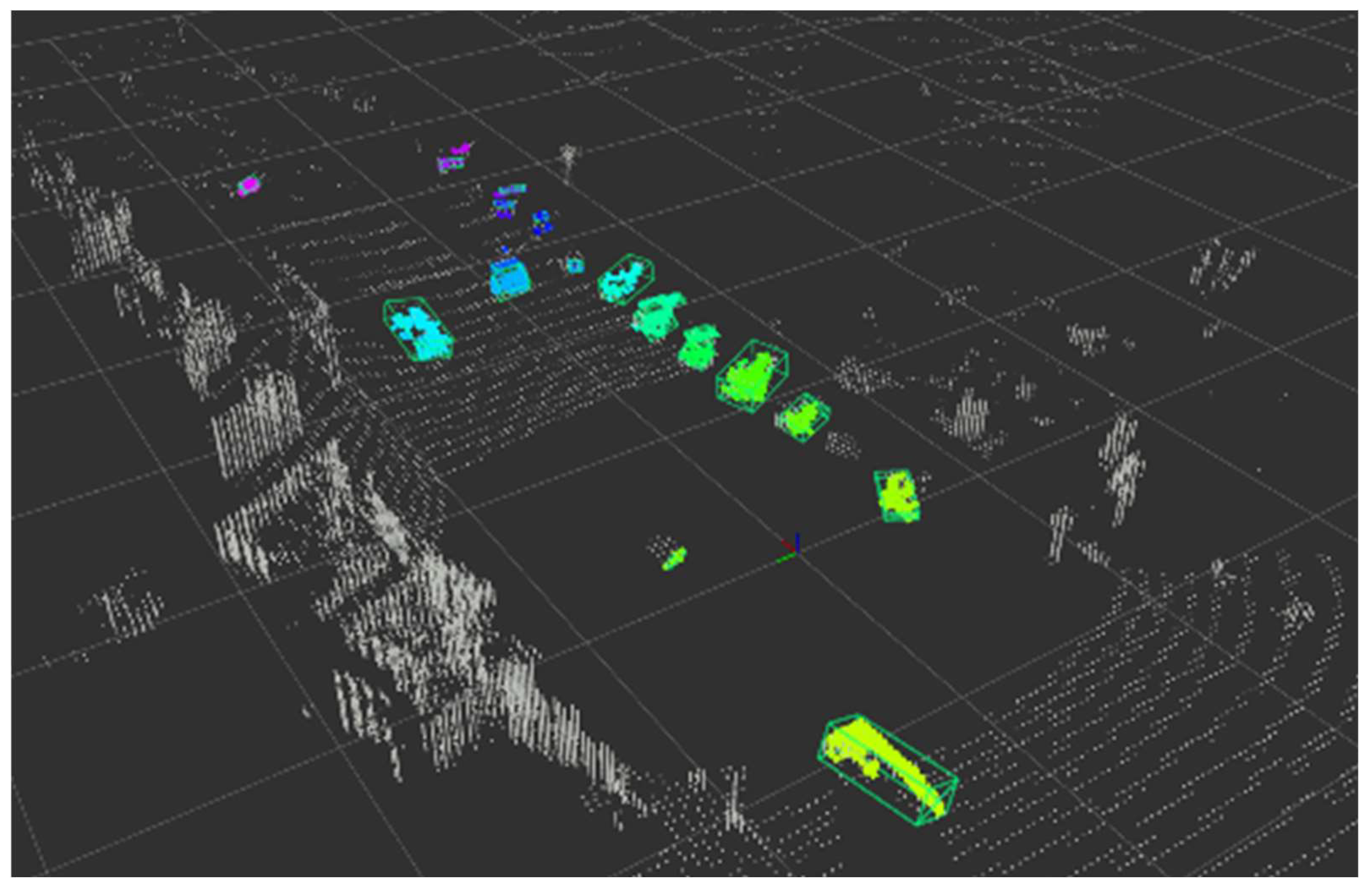
5.2. Bounding Box Estimation Results
5.2.1. Results with WOD
5.2.2. Virtual Driving Test Results of Performance
5.2.3. Real Driving Test Results of Performance
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- SAE J3016_202104; Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles. SAE International: Warrendale, PA, USA, 2021.
- Alaba, S.Y.; Ball, J.E. A Survey on Deep-Learning-Based LiDAR 3D Object Detection for Autonomous Driving. Sensors 2022, 22, 9577. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Lee, J.; Gwak, G.; Kim, K.; Kang, W.; Shin, D.; Hwang, S. Development of virtual simulator and database for deep learning-based object detection. J. Drive Control 2021, 18, 9–18. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Zheng, W.; Tang, W.; Jiang, L.; Fu, C.W. SE-SSD: Self-Ensembling Single-Stage Object Detector from Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14494–14503. [Google Scholar]
- Gwak, S.; Na, H.; Kim, K.; Song, E.; Jeong, S.; Lee, K.; Jeong, J.; Hwang, S. Validation of semantic segmentation dataset for autonomous driving. J. Drive Control 2022, 19, 104–109. [Google Scholar]
- Yan, X.; Gao, J.; Zheng, C.; Zheng, C.; Zhang, R.; Cui, S.; Li, Z. 2DPAS: 2D priors assisted semantic segmentation on lidar point clouds. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 677–695. [Google Scholar]
- Alonso, I.; Riazuelo, L.; Montesano, L.; Murillo, A.C. 3d-mininet: Learning a 2d representation from point clouds for fast and efficient 3d lidar semantic segmentation. IEEE Robot. Autom. Lett. 2020, 5, 5432–5439. [Google Scholar] [CrossRef]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation. arXiv 2020, arXiv:2004.02147. [Google Scholar] [CrossRef]
- Singh, A.; Kamireddypalli, A.; Gandhi, V.; Krishna, K.M. LiDAR guided Small obstacle Segmentation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 8513–8520. [Google Scholar]
- Wang, L.; Zhao, C.; Wang, J. A LiDAR-based obstacle-detection framework for autonomous driving. In Proceedings of the European Conference (ECC), St. Petersburg, Russia, 12–15 May 2020; pp. 901–905. [Google Scholar]
- Lee, S.; Lim, H.; Myung, H. Patchwork++: Fast and Robust Ground Segmentation Solving Partial Under-Segmentation Using 3D Point Cloud. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 13276–13283. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Ouster Sensor Docs v0.3. Available online: https://static.ouster.dev/sensor-docs/index.html (accessed on 12 February 2023).
- Charles, H.R.; Kinney, L.L. Cengage Learning. Fundamentals of Logic Design, 6th ed.; Cengage: Stamford, CT, USA, 2009. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Jörg, S.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, IAAI, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Hafiz, D.A.; Youssef, B.A.B.; Sheta, W.M.; Hassan, H.A. Interest Point Detection in 3D Point Cloud Data Using 3D Sobel-Harris Operator. Int. J. Pattern Recognit. Artif. Intell. 2015, 29, 1555014. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Zhang, J.; Zhao, X.; Chen, Z.; Lu, Z. A Review of Deep Learning-Based Semantic Segmentation for Point Cloud. IEEE Access 2019, 7, 179118–179133. [Google Scholar] [CrossRef]
- Pandar40P 40-Channel Mechanical LiDAR. Available online: https://www.hesaitech.com/product/pandar40P (accessed on 26 April 2023).
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Edge-Triggered 3D Object Detecion for Small Objects Using LiDAR Ring. Available online: https://youtu.be/lKLvyVGrqDs (accessed on 15 April 2023).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kind | Length (m) | Width (m) | Height (m) |
|---|---|---|---|
| Warning tripod | 0.16 | 0.44 | 0.39 |
| Garbage bags | 1.12 | 1.12 | 0.7 |
| Boxes | 1.46 | 2.55 | 1.18 |
| Car | 4.83 | 1.8 | 1.3 |
| Bus | 11.89 | 2.55 | 2.65 |
| Precision (%) | Recall (%) | F1 Score (%) | |
|---|---|---|---|
| Ring Edge | 95.59 | 87.86 | 91.56 |
| RANSAC | 93.09 | 89.14 | 91.07 |
| Precision (%) | Recall (%) | F1 Score (%) | |
|---|---|---|---|
| Ring Edge | 94.18 | 85.48 | 89.62 |
| RANSAC | 87.02 | 74.48 | 80.26 |
| Scenario | 1 Flatland | 2 Slope |
|---|---|---|
| True positive | 87,417 | 12,286 |
| False negative | 2347 | 410 |
| Entire points | 89,764 | 12,696 |
| PDR | 0.974 | 0.968 |
| Kind | Length (m) | Width (m) | Height (m) | Detection Distance (m) |
|---|---|---|---|---|
| Warning tripod | 0.16 | 0.44 | 0.39 | 20 |
| Garbage bags | 1.12 | 1.12 | 0.7 | 70 |
| Boxes | 1.46 | 2.55 | 1.18 | 80 |
| Car | 4.83 | 1.8 | 1.3 | 90 |
| Bus | 11.89 | 2.55 | 2.65 | 90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, E.; Jeong, S.; Hwang, S.-H. Edge-Triggered Three-Dimensional Object Detection Using a LiDAR Ring. Sensors 2024, 24, 2005. https://doi.org/10.3390/s24062005
Song E, Jeong S, Hwang S-H. Edge-Triggered Three-Dimensional Object Detection Using a LiDAR Ring. Sensors. 2024; 24(6):2005. https://doi.org/10.3390/s24062005
Chicago/Turabian StyleSong, Eunji, Seyoung Jeong, and Sung-Ho Hwang. 2024. "Edge-Triggered Three-Dimensional Object Detection Using a LiDAR Ring" Sensors 24, no. 6: 2005. https://doi.org/10.3390/s24062005
APA StyleSong, E., Jeong, S., & Hwang, S.-H. (2024). Edge-Triggered Three-Dimensional Object Detection Using a LiDAR Ring. Sensors, 24(6), 2005. https://doi.org/10.3390/s24062005