
Goal-Guided Graph Attention Network with Interactive State Refinement for Multi-Agent Trajectory Prediction

 , , , and
, , , and
Abstract
:1. Introduction
- Leveraging prior research, our study introduces SRGAT, a cutting-edge trajectory prediction framework that innovatively merges HD maps with dynamic vehicle data. This method not only addresses the challenge of fixed stride by adapting to vehicle context and environmental objectives, but also comprehensively evaluates the road environment’s influence on trajectory forecasts.
- Our model significantly boosts the accuracy of trajectory predictions in intricate traffic scenarios by exploiting HD maps’ spatial constraints and vehicles’ dynamic states, effectively addressing the challenge of dynamic goal estimation.
- By introducing a dual-branch multimodal prediction architecture that generates multiple potential future trajectories and assigns a confidence score to each, the model’s accuracy and diversity in trajectory prediction in complex traffic situations are significantly enhanced. It increases both the accuracy and variety of the predictions.
- We conducted evaluations of the proposed model on both Argoverse and nuScenes datasets and engaged in a detailed comparison with the current state-of-the-art methods. The results demonstrate that our model exhibits substantial performance improvements over these methods across a range of critical performance metrics.
2. Problem Formulation
3. Data Preprocessing
4. Structure of SRGAT Model
4.1. Model Framework
4.2. Encoder
4.2.1. Scenario Encoder
4.2.2. Social Encoder
4.3. Goal Areas’ Estimation
4.4. Trajectory Decoding and Generation
4.5. Training Details
5. Performance Evaluation and Comparative Analysis
5.1. Experiment Setup
5.2. Evaluation Metrics
5.3. Results and Ablation Studies
5.3.1. Performance Comparison to Other Methods
5.3.2. Ablation Study
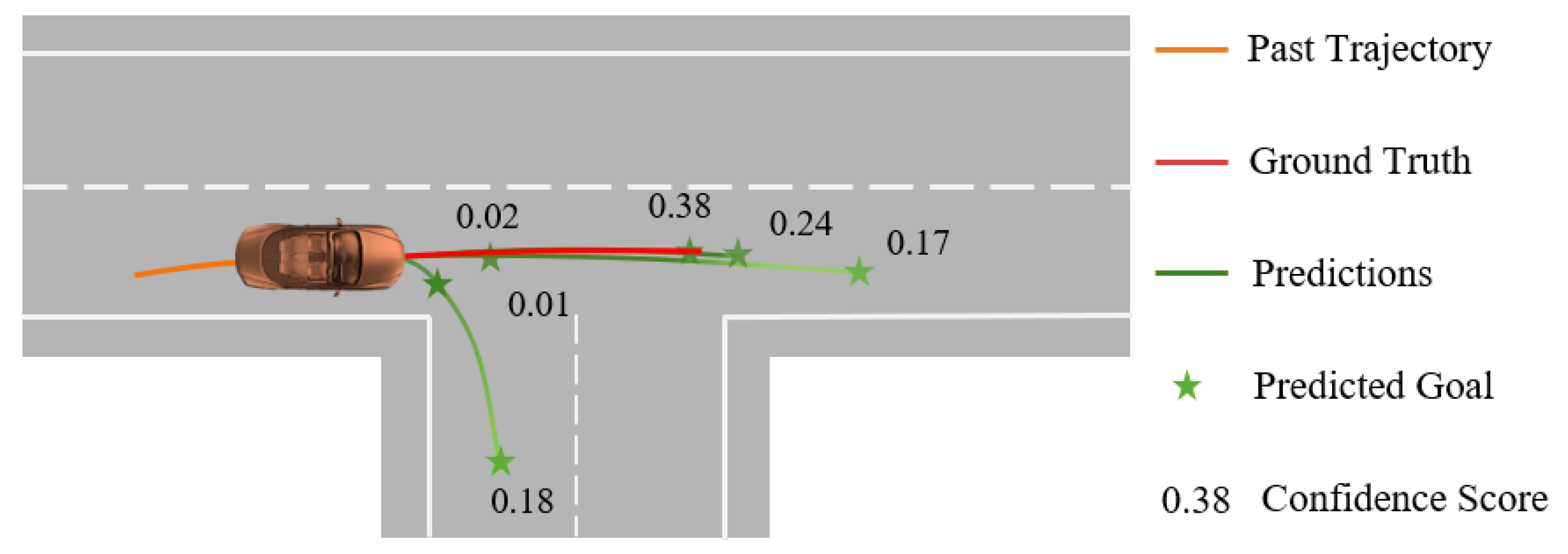
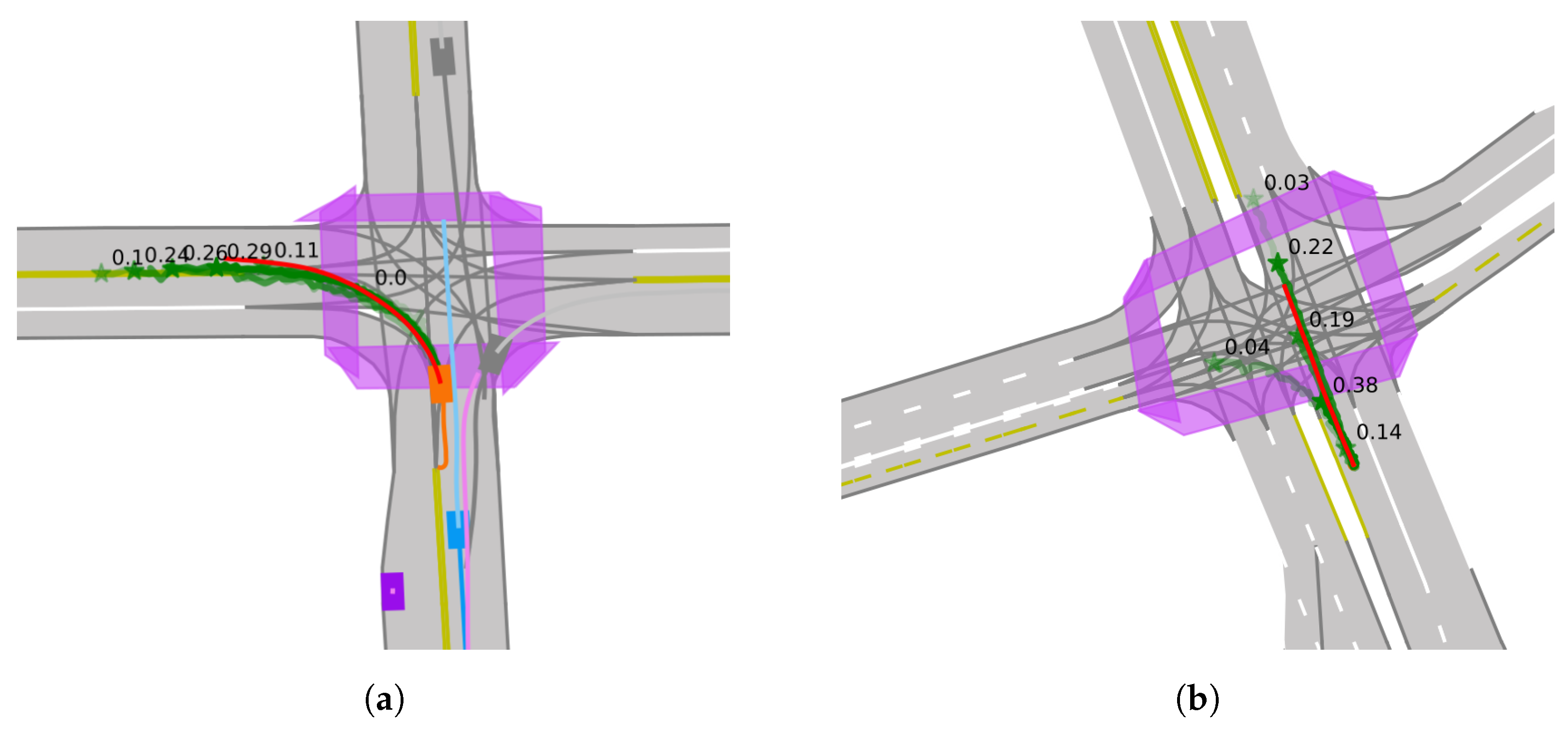
5.3.3. Qualitative Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Conde, M.V.; Barea, R.; Bergasa, L.M.; Gómez-Huélamo, C. Improving Multi-Agent Motion Prediction With Heuristic Goals and Motion Refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5322–5331. [Google Scholar]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D tracking and forecasting with rich maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 8748–8757. [Google Scholar]
- Ettinger, S.; Cheng, S.; Caine, B.; Liu, C.; Zhao, H.; Pradhan, S.; Chai, Y.; Sapp, B.; Qi, C.R.; Zhou, Y.; et al. Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9710–9719. [Google Scholar]
- Zeng, W.; Luo, W.; Suo, S.; Sadat, A.; Yang, B.; Casas, S.; Urtasun, R. End-to-end interpretable neural motion planner. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8660–8669. [Google Scholar]
- Jeong, Y.; Yi, K. Target vehicle motion prediction-based motion planning framework for autonomous driving in uncontrolled intersections. IEEE Trans. Intell. Transp. Syst. 2019, 22, 168–177. [Google Scholar] [CrossRef]
- Frasch, J.V.; Gray, A.; Zanon, M.; Ferreau, H.J.; Sager, S.; Borrelli, F.; Diehl, M. An auto-generated nonlinear MPC algorithm for real-time obstacle avoidance of ground vehicles. In Proceedings of the 2013 European Control Conference (ECC), Zurich, Switzerland, 17–19 July 2013; pp. 4136–4141. [Google Scholar]
- Gindele, T.; Brechtel, S.; Dillmann, R. A probabilistic model for estimating driver behaviors and vehicle trajectories in traffic environments. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Portugal, 19–22 September 2010; pp. 1625–1631. [Google Scholar]
- Schreier, M.; Willert, V.; Adamy, J. Bayesian, maneuver-based, long-term trajectory prediction and criticality assessment for driver assistance systems. In Proceedings of the 17th international IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 334–341. [Google Scholar]
- Deo, N.; Rangesh, A.; Trivedi, M.M. How would surround vehicles move? a unified framework for maneuver classification and motion prediction. IEEE Trans. Intell. Veh. 2018, 3, 129–140. [Google Scholar] [CrossRef]
- Zhang, K.; He, Z.; Zheng, L.; Zhao, L.; Wu, L. A generative adversarial network for travel times imputation using trajectory data. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 197–212. [Google Scholar] [CrossRef]
- Qiao, S.; Gao, F.; Wu, J.; Zhao, R. An Enhanced Vehicle Trajectory Prediction Model Leveraging LSTM and Social-Attention Mechanisms. IEEE Access 2023, 12, 1718–1726. [Google Scholar] [CrossRef]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar]
- Deo, N.; Trivedi, M.M. Convolutional social pooling for vehicle trajectory prediction. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1468–1476. [Google Scholar]
- Sheng, Z.; Xu, Y.; Xue, S.; Li, D. Graph-based spatial-temporal convolutional network for vehicle trajectory prediction in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17654–17665. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Messaoud, K.; Yahiaoui, I.; Verroust-Blondet, A.; Nashashibi, F. Attention based vehicle trajectory prediction. IEEE Trans. Intell. Veh. 2020, 6, 175–185. [Google Scholar]
- Messaoud, K.; Deo, N.; Trivedi, M.M.; Nashashibi, F. Trajectory prediction for autonomous driving based on multi-head attention with joint agent-map representation. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 165–170. [Google Scholar]
- Zhang, C.; Berger, C. Pedestrian Behavior Prediction Using Deep Learning Methods for Urban Scenarios: A Review. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10279–10301. [Google Scholar] [CrossRef]
- Syed, A.; Morris, B. STGT: Forecasting pedestrian motion using spatio-temporal graph transformer. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 1553–1558. [Google Scholar]
- Mercat, J.; Gilles, T.; El Zoghby, N.; Sandou, G.; Beauvois, D.; Gil, G.P. Multi-head attention for multi-modal joint vehicle motion forecasting. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 9638–9644. [Google Scholar]
- Girgis, R.; Golemo, F.; Codevilla, F.; Weiss, M.; D’Souza, J.A.; Kahou, S.E.; Heide, F.; Pal, C. Latent variable sequential set transformers for joint multi-agent motion prediction. arXiv 2021, arXiv:2104.00563. [Google Scholar]
- Zhao, H.; Gao, J.; Lan, T.; Sun, C.; Sapp, B.; Varadarajan, B.; Shen, Y.; Shen, Y.; Chai, Y.; Schmid, C.; et al. Tnt: Target-driven trajectory prediction. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2021; pp. 895–904. [Google Scholar]
- Choi, S.; Kim, J.; Yun, J.; Choi, J.W. R-Pred: Two-Stage Motion Prediction Via Tube-Query Attention-Based Trajectory Refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 8525–8535. [Google Scholar]
- Cui, H.; Radosavljevic, V.; Chou, F.C.; Lin, T.H.; Nguyen, T.; Huang, T.K.; Schneider, J.; Djuric, N. Multimodal trajectory predictions for autonomous driving using deep convolutional networks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2090–2096. [Google Scholar]
- Chai, Y.; Sapp, B.; Bansal, M.; Anguelov, D. Multipath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction. arXiv 2019, arXiv:1910.05449. [Google Scholar]
- Casas, S.; Luo, W.; Urtasun, R. Intentnet: Learning to predict intention from raw sensor data. In Proceedings of the Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; pp. 947–956. [Google Scholar]
- Hong, J.; Sapp, B.; Philbin, J. Rules of the road: Predicting driving behavior with a convolutional model of semantic interactions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8454–8462. [Google Scholar]
- Wang, M.; Zhu, X.; Yu, C.; Li, W.; Ma, Y.; Jin, R.; Ren, X.; Ren, D.; Wang, M.; Yang, W. Ganet: Goal area network for motion forecasting. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 1609–1615. [Google Scholar]
- Gao, J.; Sun, C.; Zhao, H.; Shen, Y.; Anguelov, D.; Li, C.; Schmid, C. Vectornet: Encoding hd maps and agent dynamics from vectorized representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11525–11533. [Google Scholar]
- Shi, S.; Jiang, L.; Dai, D.; Schiele, B. Mtr++: Multi-agent motion prediction with symmetric scene modeling and guided intention querying. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Liang, M.; Yang, B.; Hu, R.; Chen, Y.; Liao, R.; Feng, S.; Urtasun, R. Learning lane graph representations for motion forecasting. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 541–556. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Kim, W.; Son, B.; Kim, I. Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 5583–5594. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11621–11631. [Google Scholar]
- Zeng, W.; Liang, M.; Liao, R.; Urtasun, R. Lanercnn: Distributed representations for graph-centric motion forecasting. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 532–539. [Google Scholar]
- Wang, X.; Su, T.; Da, F.; Yang, X. ProphNet: Efficient agent-centric motion forecasting with anchor-informed proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21995–22003. [Google Scholar]
- Zhou, Z.; Wang, J.; Li, Y.H.; Huang, Y.K. Query-centric trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17863–17873. [Google Scholar]
- Gu, J.; Sun, C.; Zhao, H. Densetnt: End-to-end trajectory prediction from dense goal sets. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 15303–15312. [Google Scholar]
- Liu, Y.; Zhang, J.; Fang, L.; Jiang, Q.; Zhou, B. Multimodal motion prediction with stacked transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7577–7586. [Google Scholar]
- Gilles, T.; Sabatini, S.; Tsishkou, D.; Stanciulescu, B.; Moutarde, F. Home: Heatmap output for future motion estimation. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 500–507. [Google Scholar]
- Gilles, T.; Sabatini, S.; Tsishkou, D.; Stanciulescu, B.; Moutarde, F. Gohome: Graph-oriented heatmap output for future motion estimation. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 9107–9114. [Google Scholar]
- Ye, M.; Cao, T.; Chen, Q. Tpcn: Temporal point cloud networks for motion forecasting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 11318–11327. [Google Scholar]
- Phan-Minh, T.; Grigore, E.C.; Boulton, F.A.; Beijbom, O.; Wolff, E.M. Covernet: Multimodal behavior prediction using trajectory sets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 14074–14083. [Google Scholar]
- Salzmann, T.; Ivanovic, B.; Chakravarty, P.; Pavone, M. Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 683–700. [Google Scholar]
- Wang, C.; Wang, Y.; Xu, M.; Crandall, D.J. Stepwise goal-driven networks for trajectory prediction. IEEE Robot. Autom. Lett. 2022, 7, 2716–2723. [Google Scholar] [CrossRef]
- Luo, C.; Sun, L.; Dabiri, D.; Yuille, A. Probabilistic multi-modal trajectory prediction with lane attention for autonomous vehicles. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 2370–2376. [Google Scholar]
- Deo, N.; Trivedi, M.M. Trajectory forecasts in unknown environments conditioned on grid-based plans. arXiv 2020, arXiv:2001.00735. [Google Scholar]
- Deo, N.; Wolff, E.; Beijbom, O. Multimodal trajectory prediction conditioned on lane-graph traversals. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 203–212. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Learning Rate | |
| Epoch Number | 50 |
| Batch Size | 64 |
| Self-Attention Unit Number | 128 |
| Activation | ReLU |
| Number of attentions | 4 |
| Method | brierFDE6 | minFDE6 | minFDE1 | minADE6 | minADE1 |
|---|---|---|---|---|---|
| LaneRCNN [35] | 2.14 | 1.45 | 3.69 | 0.90 | 1.68 |
| TNT [22] | 2.14 | 1.44 | 4.95 | 0.91 | 2.17 |
| DenseTNT (MR) [38] | 2.07 | 1.38 | 3.69 | 0.91 | 1.70 |
| LaneGCN [31] | 2.05 | 1.36 | 3.77 | 0.86 | 1.70 |
| mmTransformer [39] | 2.03 | 1.33 | 4.00 | 0.84 | 1.77 |
| HOME [40] | - | 1.45 | 3.73 | 0.94 | 1.73 |
| GOHOME [41] | 1.98 | 1.45 | 3.64 | 0.94 | 1.68 |
| DenseTNT (FDE) [38] | 1.97 | 1.28 | 3.63 | 0.85 | 1.67 |
| TPCN [42] | 1.92 | 1.24 | 3.48 | 0.81 | 1.57 |
| GANet [25] | 1.79 | 1.16 | 3.45 | 0.80 | 1.59 |
| R-Pred [23] | 1.77 | 1.12 | 3.47 | 0.76 | 1.58 |
| ProphNet [36] | 1.73 | 1.14 | 3.33 | 0.77 | 1.52 |
| QCNet [37] | 1.69 | 1.07 | - | 0.73 | - |
| Ours | 1.62 | 1.05 | 3.25 | 0.73 | 1.45 |
| Method | MinADE5 | minADE10 | MissRate5,2 | MissRate10,2 | Offroad Rate |
| CoverNet [43] | 1.96 | 1.48 | 0.67 | - | - |
| Trajectron++ [44] | 1.88 | 1.51 | 0.70 | 0.57 | 0.25 |
| SG-Net [45] | 1.86 | 1.40 | 0.67 | 0.52 | 0.04 |
| MHA-JAM [17] | 1.81 | 1.24 | 0.59 | 0.46 | 0.07 |
| CXX [46] | 1.63 | 1.29 | 0.69 | 0.60 | 0.08 |
| P2T [47] | 1.45 | 1.16 | 0.64 | 0.46 | 0.03 |
| PGP [48] | 1.30 | 1.00 | 0.61 | 0.37 | 0.03 |
| Ours | 1.22 | 0.95 | 0.58 | 0.33 | 0.03 |
| Scene-En | Social-En | L-Seed | ADE6 | FDE6 |
|---|---|---|---|---|
| ✓ | - | - | 1.49 | 5.31 |
| - | ✓ | - | 1.41 | 5.10 |
| - | - | ✓ | 1.33 | 4.72 |
| ✓ | ✓ | - | 1.04 | 2.40 |
| ✓ | ✓ | ✓ | 0.83 | 1.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Qiao, S.; Li, H.; Sun, B.; Gao, F.; Hu, H.; Zhao, R. Goal-Guided Graph Attention Network with Interactive State Refinement for Multi-Agent Trajectory Prediction. Sensors 2024, 24, 2065. https://doi.org/10.3390/s24072065
Wu J, Qiao S, Li H, Sun B, Gao F, Hu H, Zhao R. Goal-Guided Graph Attention Network with Interactive State Refinement for Multi-Agent Trajectory Prediction. Sensors. 2024; 24(7):2065. https://doi.org/10.3390/s24072065
Chicago/Turabian StyleWu, Jianghang, Senyao Qiao, Haocheng Li, Boyu Sun, Fei Gao, Hongyu Hu, and Rui Zhao. 2024. "Goal-Guided Graph Attention Network with Interactive State Refinement for Multi-Agent Trajectory Prediction" Sensors 24, no. 7: 2065. https://doi.org/10.3390/s24072065
APA StyleWu, J., Qiao, S., Li, H., Sun, B., Gao, F., Hu, H., & Zhao, R. (2024). Goal-Guided Graph Attention Network with Interactive State Refinement for Multi-Agent Trajectory Prediction. Sensors, 24(7), 2065. https://doi.org/10.3390/s24072065