
SmartLaundry: A Real-Time System for Public Laundry Allocation in Smart Cities


Abstract
1. Introduction
- A real-time system design for smart public laundry recommendation allocation.
- Data-driven forecasting for device usages.
- A resource allocation algorithm for smart washing center recommendations
2. Related Work
2.1. Smart City Solutions
2.2. Time Series Forecasting
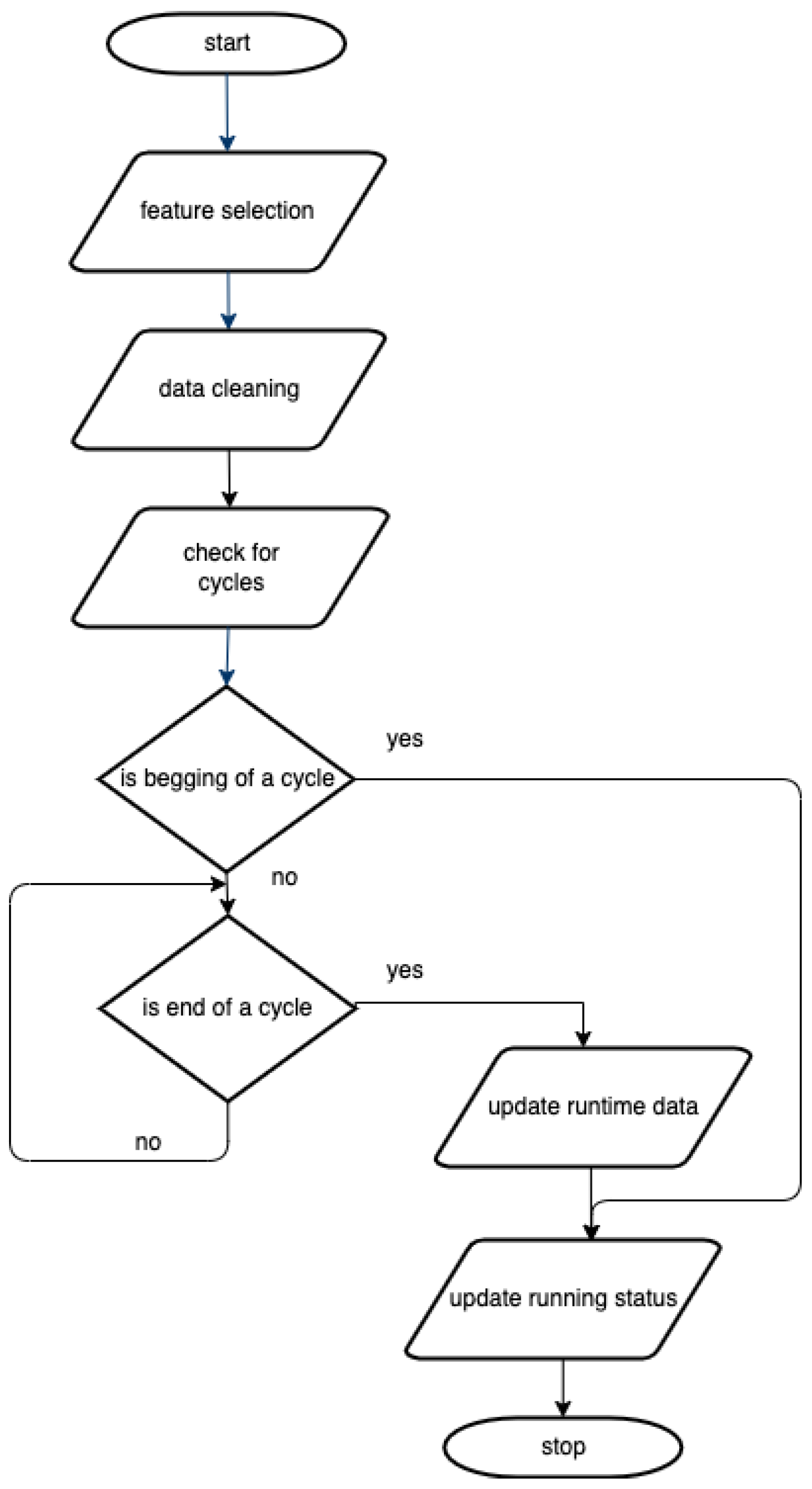
3. System Design
3.1. Proposed Terminology
- Raw real-time sensors’ data = raw data recorded by sensors attached to washing machines in a real-time manner.
- Preprocessed real-time data = data collected by sensors after the preprocessing step, which includes data selection and cleaning of the data.
- Historical data = the historical preprocessed data that were recorded and stored in the cloud system.
- Forecasted data = the forecasted usage data for the machines connected to the system.
- Data acquisition module = a module that receives the raw real-time data from sensors, extracts the information of interest, cleans it, and returns preprocessed real-time data.
- Forecasting module = a module that predicts the usage on a given time interval per each device.
- Real-time recommendation module = a module that communicates with the mobile device via an application. It uses preprocessed real-time data and forecasted data and sends recommendations regarding possible laundries.
3.2. SmartLaundry—Real-Time System Architecture
- represents the maximum load a machine allows. It is a parameter set depending on the number of machines and overall system usage.
- represents the targeted minimum number of machines recommended for the user of the system at a given moment of time. The user should select it according to the possibility of movement and could incorporate the distance from a suggested location (not yet incorporated).
3.3. Algorithmic Method for Smart Real-Time Recommendations of Machines
| Algorithm 1: GetPenalizedDevices: Determination of the list of the devices with high forecasted usage. |
 |
| Algorithm 2: GetRecommendedDevices: Determination of the list of the recommended devices to be used. |
 |
4. Proof of Concept Evaluation
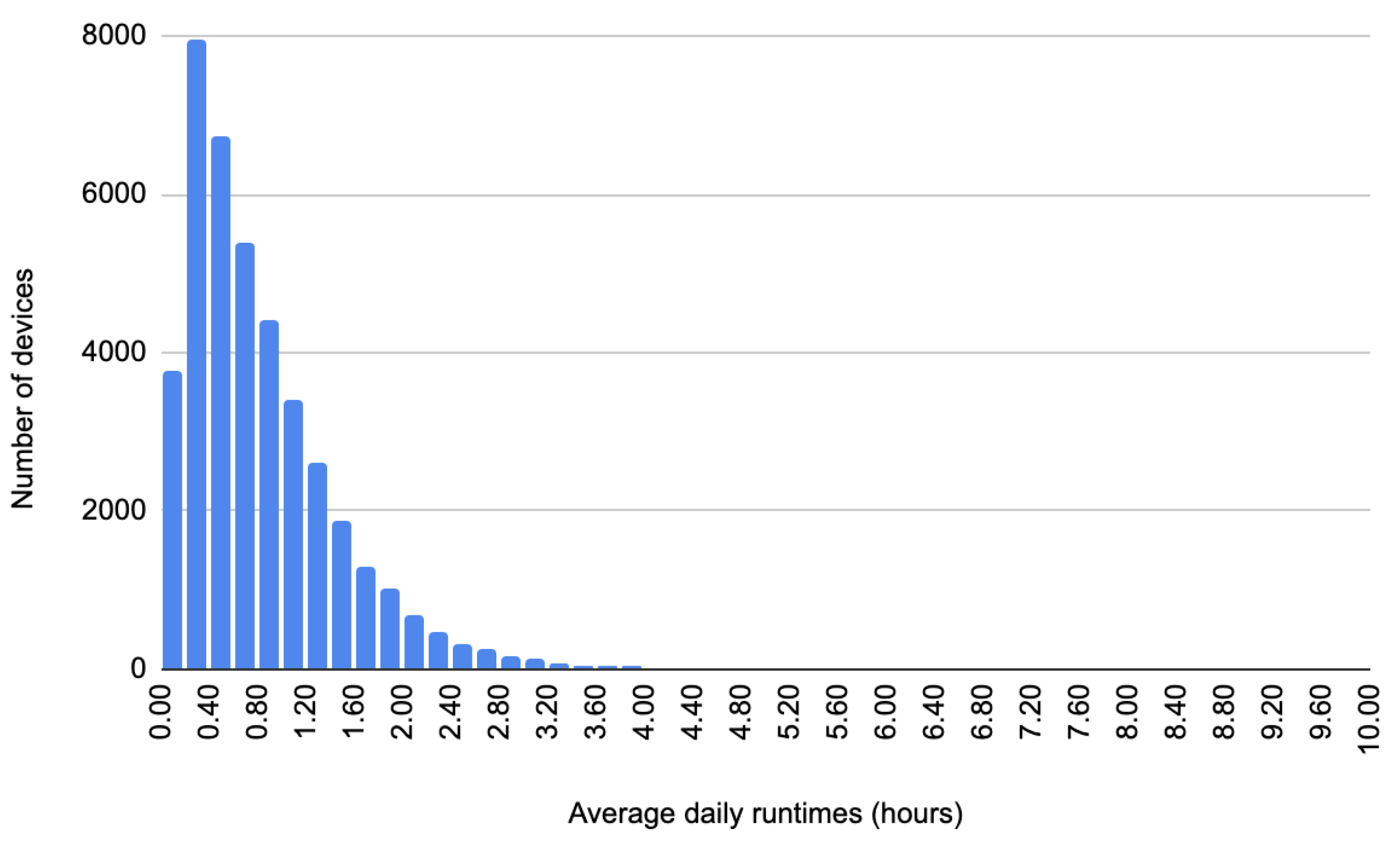
4.1. Data Acquisition and Forecasting on Real Devices’ Data
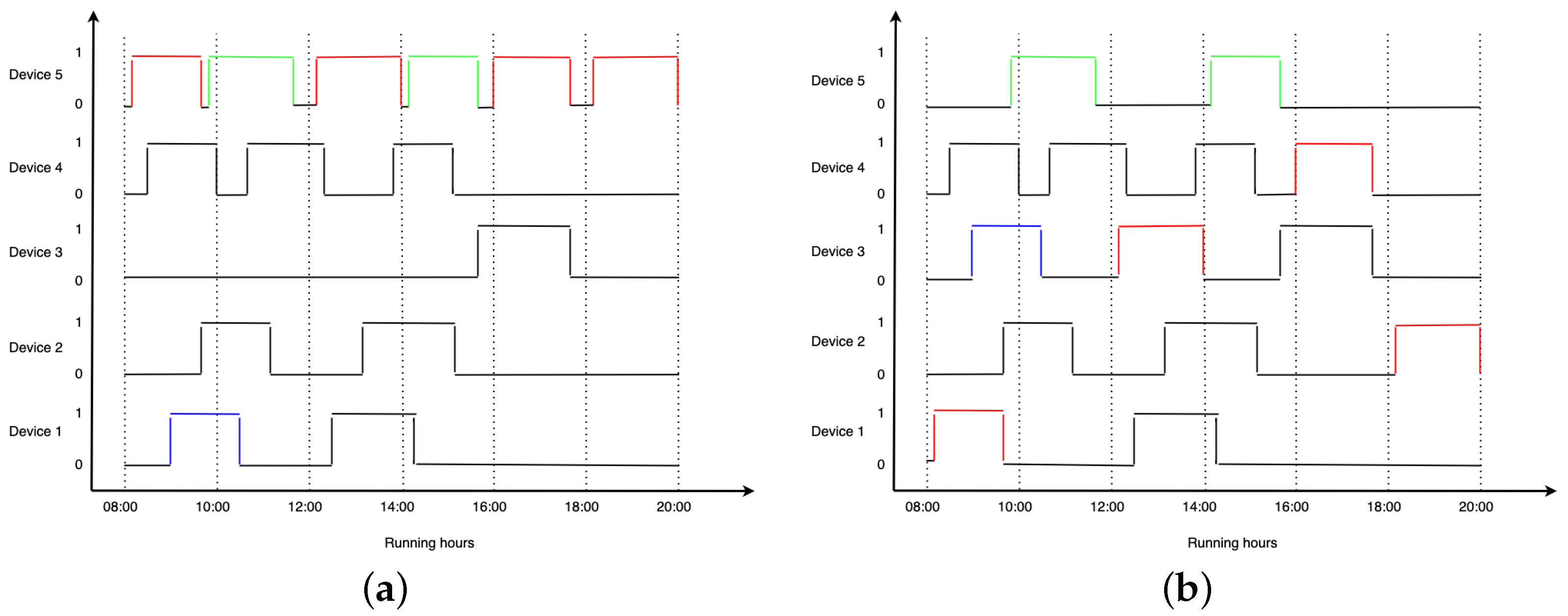
4.2. Simulation of the Interaction with the Recommendation System
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Worldometers. World Population Forecast-Worldometers. 2024. Available online: https://www.worldometers.info/world-population/#table-forecast (accessed on 10 February 2024).
- Nations, U. Sustainable Development Goals-United Nations Sustainable Development. 2024. Available online: https://www.un.org/sustainabledevelopment/sustainable-development-goals/ (accessed on 10 February 2024).
- Zhou, J.; Wang, P.; Xie, L. Research on resource allocation optimization of smart city based on big data. IEEE Access 2020, 8, 158852–158861. [Google Scholar] [CrossRef]
- Elfaki, A.O.; Messoudi, W.; Bushnag, A.; Abuzneid, S.; Alhmiedat, T. A Smart Real-Time Parking Control and Monitoring System. Sensors 2023, 23, 9741. [Google Scholar] [CrossRef] [PubMed]
- Li, J. Resource optimization scheduling and allocation for hierarchical distributed cloud service system in smart city. Future Gener. Comput. Syst. 2020, 107, 247–256. [Google Scholar] [CrossRef]
- Mazidi, M.; Malakhatka, E.; Steen, D.; Wallbaum, H. Real-time rolling-horizon energy management of public laundries: A case study in HSB living lab. Energy Convers. Manag. X 2023, 20, 100462. [Google Scholar] [CrossRef]
- Qureshi, M.S.; Qureshi, M.B.; Fayaz, M.; Zakarya, M.; Aslam, S.; Shah, A. Time and cost efficient cloud resource allocation for real-time data-intensive smart systems. Energies 2020, 13, 5706. [Google Scholar] [CrossRef]
- Kashpruk, N.; Piskor-Ignatowicz, C.; Baranowski, J. Time Series Prediction in Industry 4.0: A Comprehensive Review and Prospects for Future Advancements. Appl. Sci. 2023, 13, 12374. [Google Scholar] [CrossRef]
- Portase, R.; Tolas, R.; Lemnaru, C.; Potolea, R. Prediction Pipeline on Time Series Data Applied for Usage Prediction on Household Devices. In Proceedings of the eKNOW 2023: The Fifteenth International Conference on Information, Process, and Knowledge Management, Venice, Italy, 24–28 April 2023. [Google Scholar]
- Deb, C.; Zhang, F.; Yang, J.; Lee, S.E.; Shah, K.W. A review on time series forecasting techniques for building energy consumption. Renew. Sustain. Energy Rev. 2017, 74, 902–924. [Google Scholar] [CrossRef]
- Sami, M.A.; Khan, T.A. Forecasting failure rate of IoT devices: A deep learning way to predictive maintenance. Comput. Electr. Eng. 2023, 110, 108829. [Google Scholar] [CrossRef]
- Chui, K.T.; Lytras, M.D.; Visvizi, A. Energy sustainability in smart cities: Artificial intelligence, smart monitoring, and optimization of energy consumption. Energies 2018, 11, 2869. [Google Scholar] [CrossRef]
- Ordouei, M.; Broumandnia, A.; Banirostam, T.; Gilani, A. Optimization of energy consumption in smart city using reinforcement learning algorithm. Int. J. Nonlinear Anal. Appl. 2024, 15, 277–290. [Google Scholar]
- Hur, C.H.; Lee, H.E.; Kim, Y.J.; Kang, S.G. Semi-supervised domain adaptation for multi-label classification on nonintrusive load monitoring. Sensors 2022, 22, 5838. [Google Scholar] [CrossRef]
- Ibrahim, B.; Rabelo, L. A deep learning approach for peak load forecasting: A case study on panama. Energies 2021, 14, 3039. [Google Scholar] [CrossRef]
- Calvillo, C.F.; Sánchez-Miralles, A.; Villar, J. Energy management and planning in smart cities. Renew. Sustain. Energy Rev. 2016, 55, 273–287. [Google Scholar] [CrossRef]
- Pandiyan, P.; Saravanan, S.; Usha, K.; Kannadasan, R.; Alsharif, M.H.; Kim, M.K. Technological advancements toward smart energy management in smart cities. Energy Rep. 2023, 10, 648–677. [Google Scholar] [CrossRef]
- Song, F.; Ma, Y.; You, I.; Zhang, H. Smart Collaborative Evolvement for Virtual Group Creation in Customized Industrial IoT. IEEE Trans. Netw. Sci. Eng. 2022, 8, 5114–5128. [Google Scholar] [CrossRef]
- Mahmood, O.A.; Abdellah, A.R.; Muthanna, A.; Koucheryavy, A. Distributed Edge Computing for Resource Allocation in Smart Cities Based on the IoT. Information 2022, 13, 328. [Google Scholar] [CrossRef]
- Anagnostopoulos, C.; Aladwani, T.; Alghamdi, I.; Kolomvatsos, K. Data-driven analytics task management reasoning mechanism in edge computing. Smart Cities 2022, 5, 562–582. [Google Scholar] [CrossRef]
- Wang, D.; Tan, D.; Liu, L. Particle swarm optimization algorithm: An overview. Soft Comput. 2018, 22, 387–408. [Google Scholar] [CrossRef]
- Deng, R.; Luo, F.; Ranzi, G.; Qiu, J. Real-time energy management system for public laundries with demand charge tariff. J. Eng. 2021, 2021, 49–59. [Google Scholar] [CrossRef]
- Lin, J.; Williamson, S.; Borne, K.; DeBarr, D. Pattern recognition in time series. Adv. Mach. Learn. Data Min. Astron. 2012, 1, 3. [Google Scholar]
- Spencer, D.E. Developing a Bayesian vector autoregression forecasting model. Int. J. Forecast. 1993, 9, 407–421. [Google Scholar] [CrossRef]
- González-Vidal, A.; Moreno-Cano, V.; Terroso-Sáenz, F.; Skarmeta, A.F. Towards energy efficiency smart buildings models based on intelligent data analytics. Procedia Comput. Sci. 2016, 83, 994–999. [Google Scholar] [CrossRef]
- Mussumeci, E.; Coelho, F.C. Large-scale multivariate forecasting models for Dengue-LSTM versus random forest regression. Spat. Spatio-Temporal Epidemiol. 2020, 35, 100372. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhai, N.; Yao, P.; Zhou, X. Multivariate time series forecast in industrial process based on XGBoost and GRU. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; Volume 9, pp. 1397–1400. [Google Scholar]
- Abbasi, R.A.; Javaid, N.; Ghuman, M.N.J.; Khan, Z.A.; Ur Rehman, S. Short term load forecasting using XGBoost. In Proceedings of the Web, Artificial Intelligence and Network Applications: Proceedings of the Workshops of the 33rd International Conference on Advanced Information Networking and Applications (WAINA-2019), Matsue, Japan, 27–29 March 2019; pp. 1120–1131. [Google Scholar]
- Casolaro, A.; Capone, V.; Iannuzzo, G.; Camastra, F. Deep Learning for Time Series Forecasting: Advances and Open Problems. Information 2023, 14, 598. [Google Scholar] [CrossRef]
- Zahid, M.; Ahmed, F.; Javaid, N.; Abbasi, R.A.; Zainab Kazmi, H.S.; Javaid, A.; Bilal, M.; Akbar, M.; Ilahi, M. Electricity price and load forecasting using enhanced convolutional neural network and enhanced support vector regression in smart grids. Electronics 2019, 8, 122. [Google Scholar] [CrossRef]
- Aksan, F.; Li, Y.; Suresh, V.; Janik, P. CNN-LSTM vs. LSTM-CNN to Predict Power Flow Direction: A Case Study of the High-Voltage Subnet of Northeast Germany. Sensors 2023, 23, 901. [Google Scholar] [CrossRef] [PubMed]
- Botchkarev, A. Performance metrics (error measures) in machine learning regression, forecasting and prognostics: Properties and typology. arXiv 2018, arXiv:1809.03006. [Google Scholar]
- De Myttenaere, A.; Golden, B.; Le Grand, B.; Rossi, F. Mean absolute percentage error for regression models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef]
- Makridakis, S. Accuracy measures: Theoretical and practical concerns. Int. J. Forecast. 1993, 9, 527–529. [Google Scholar] [CrossRef]
- Portase, R.; Tolas, R.; Potolea, R. MEDIS: Analysis Methodology for Data with Multiple Complexities. In Proceedings of the 13th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2021), Online, 25–27 October 2021; pp. 191–198. [Google Scholar]
- Olariu, E.M.; Tolas, R.; Portase, R.; Dinsoreanu, M.; Potolea, R. Modern approaches to preprocessing industrial data. In Proceedings of the 2020 IEEE 16th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2020; pp. 221–226. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Size | No of Devices |
|---|---|---|
| Initial raw sensors dataset | 8.1 millions | 49 k |
| Selected raw sensors dataset | 530 k | 482 |
| Appliance | Average Usage/Day (s) | No of Days without Usage/Year |
|---|---|---|
| App 1 | 36.718 | 39 |
| App 2 | 31.492 | 38 |
| App 3 | 21.159 | 48 |
| App 4 | 23.916 | 39 |
| App 5 | 21.475 | 50 |
| Random Forest | XGBoost | SVR | ||||
|---|---|---|---|---|---|---|
| Metrics | MAE | SMAPE | MAE | SMAPE | MAE | SMAPE |
| App 1 | 9119 | 12.14% | 9119 | 12.14% | 14,539 | 36.51% |
| App 2 | 6045 | 9.66% | 6075 | 9.76% | 9669 | 28.67% |
| App 3 | 4042 | 22.02% | 4012 | 8.69% | 6153 | 13.81% |
| App 4 | 10,198 | 15.37% | 10,198 | 15.37% | 15,048 | 37.42% |
| App 5 | 8522 | 29.22% | 8432 | 20.89% | 9728 | 40.34% |
| CNN | LSTM | |||
|---|---|---|---|---|
| Metrics | MAE | SMAPE | MAE | SMAPE |
| App 1 | 8168 | 12.37% | 6659 | 20.86% |
| App 2 | 4423 | 6.43% | 4311 | 6.34% |
| App 3 | 4428 | 22.41% | 4348 | 9.63% |
| App 4 | 11,466 | 19.77% | 11,021 | 19.41% |
| App 5 | 5956 | 26.61% | 4846 | 26.22% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Portase, R.L.; Tolas, R.; Potolea, R. SmartLaundry: A Real-Time System for Public Laundry Allocation in Smart Cities. Sensors 2024, 24, 2159. https://doi.org/10.3390/s24072159
Portase RL, Tolas R, Potolea R. SmartLaundry: A Real-Time System for Public Laundry Allocation in Smart Cities. Sensors. 2024; 24(7):2159. https://doi.org/10.3390/s24072159
Chicago/Turabian StylePortase, Raluca Laura, Ramona Tolas, and Rodica Potolea. 2024. "SmartLaundry: A Real-Time System for Public Laundry Allocation in Smart Cities" Sensors 24, no. 7: 2159. https://doi.org/10.3390/s24072159
APA StylePortase, R. L., Tolas, R., & Potolea, R. (2024). SmartLaundry: A Real-Time System for Public Laundry Allocation in Smart Cities. Sensors, 24(7), 2159. https://doi.org/10.3390/s24072159