3.1. Original Vision Transformer
ViT processes a 2D image into a 1D sequence, similar to the string format commonly used in NLP, and then feeds it to an encoder stacked by transformer layers, with the core structure within the transformer layers being the self-attention mechanism, which allows the model to realize global feature dependency modeling with data specificity.
The computational process of the self-attention mechanism can be described as mapping features into query vectors, key vectors, and value vectors, obtaining global attention by computing the dot product between query vectors and key vectors, considering the attention weights after scaling and normalization as weighted weights of the value vectors, and computing the weighted results to obtain the new feature representation. Specifically,
,
, and
are obtained by feature mapping of input
, and the mapping matrices are
,
, and
, where
c is the number of channels in the feature and
N is the number of tokens obtained in the original image. For any query vector
, it is necessary to interact with all key vectors; then, the complete self-attention computation can be represented as follows:
where
is a scaling factor.
Based on self-attention, feature channels are assigned to multiple heads within separate self-attention computations for multi-head self-attention (MSA). The feedforward network (FFN) has two fully connected layers with residual connections. A transformer encoder block can be constructed using the MSA layer and the FFN layer. The forward propagation of the
k-th layer is calculated as follows:
where
indicates the Layer Normalization operation [
53],
, and
L is the number of layers.
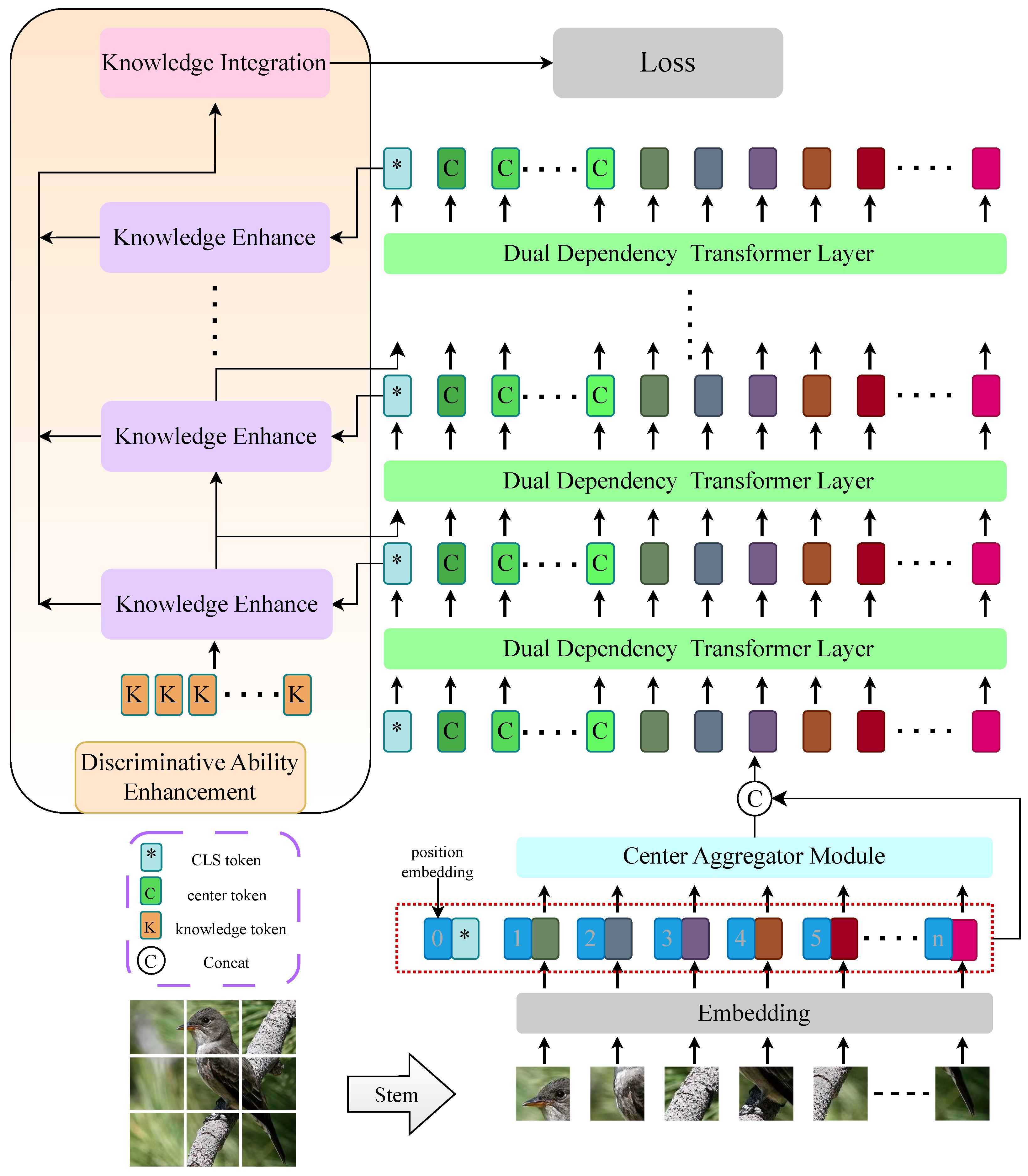
3.2. Center Token Aggregation Module
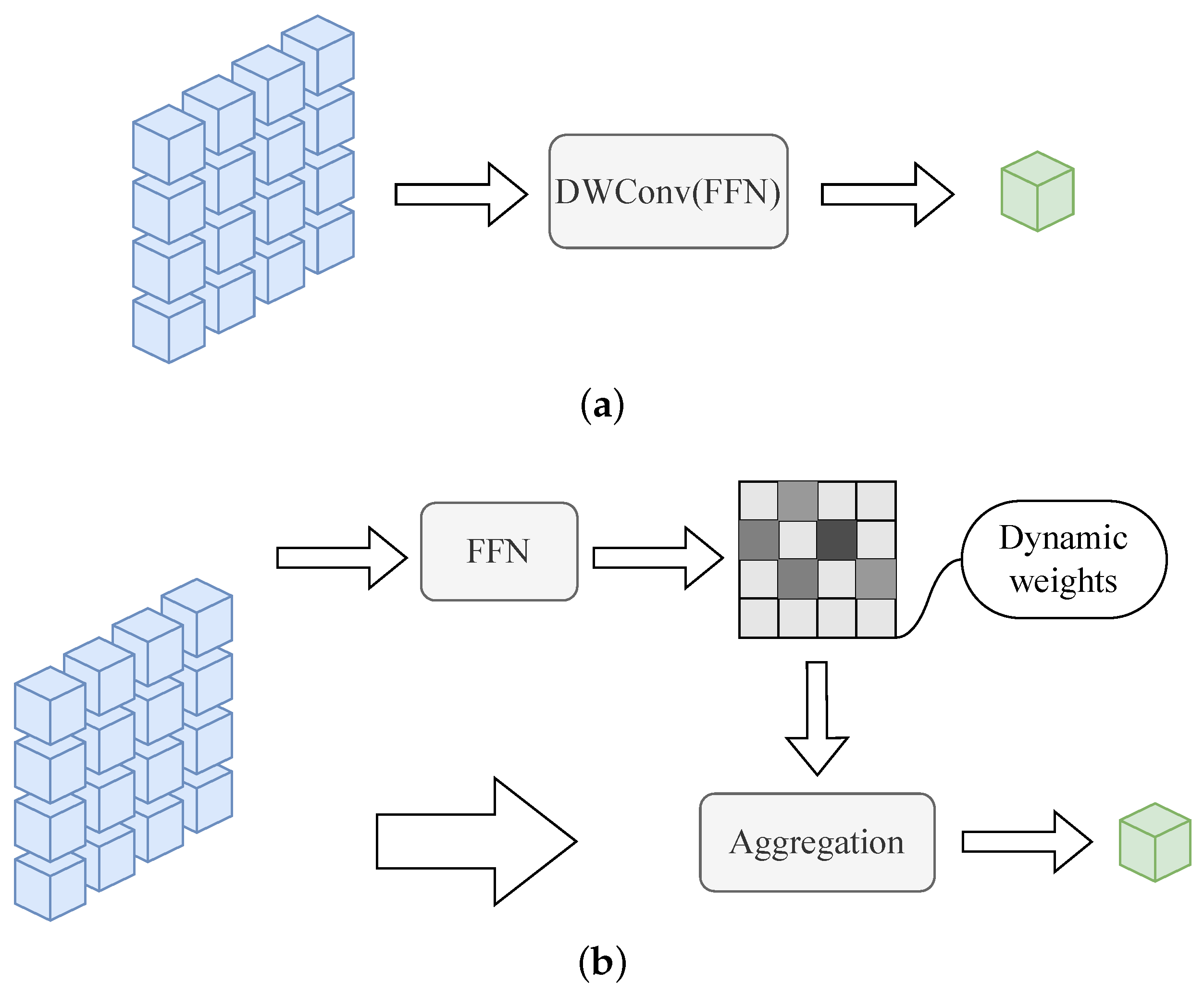
The guiding role of the center feature in dual-dependency attention (DDA) is crucial for determining the semantic window construction of the semantic-dependency attention pathway (SDA). The effective play of DDA in each layer of the model largely depends on the ability of the center token feature to capture the key information. Due to the specificity of data distribution in fine-grained visual classification, the aggregation method of the center token needs to be dynamically adjusted according to the specificity of the data. Therefore, traditional static weighting methods may not be applicable in this case, and the model needs to explore more flexible aggregation strategies. This is to enable the model to adapt to the dynamic nature of fine-grained data and to fully exploit the information of the key features.
To address the above problems, we design the central aggregation (CTA) approach shown in
Figure 3 to pay full attention to global features as a prerequisite, transform the commonly used static aggregation approach into self-directed dynamic aggregation, and learn the mapping from feature description to aggregation weights. The efficient aggregation approach guarantees that the center token realizes the complete inheritance of semantic representations of foreground targets and background details, avoiding discrimination-irrelevant semantic dependencies in the subsequent attention learning.
Specifically, we obtain the feature token
with positional embedding, where
N is the number of patch tokens, feed it into the fully connected network to obtain the token weights, and use the normalized weights to weight the global token to obtain the center token; the mapping process can be expressed as follows:
where
ACT is the GELU,
and
are the learnable parameter,
m is the hyperparameter as center token number,
indicates the Layer Normalization operation [
53], and
is the token weight. It can then be obtained as follows:
where
denotes the transpose of
and
is the center token.
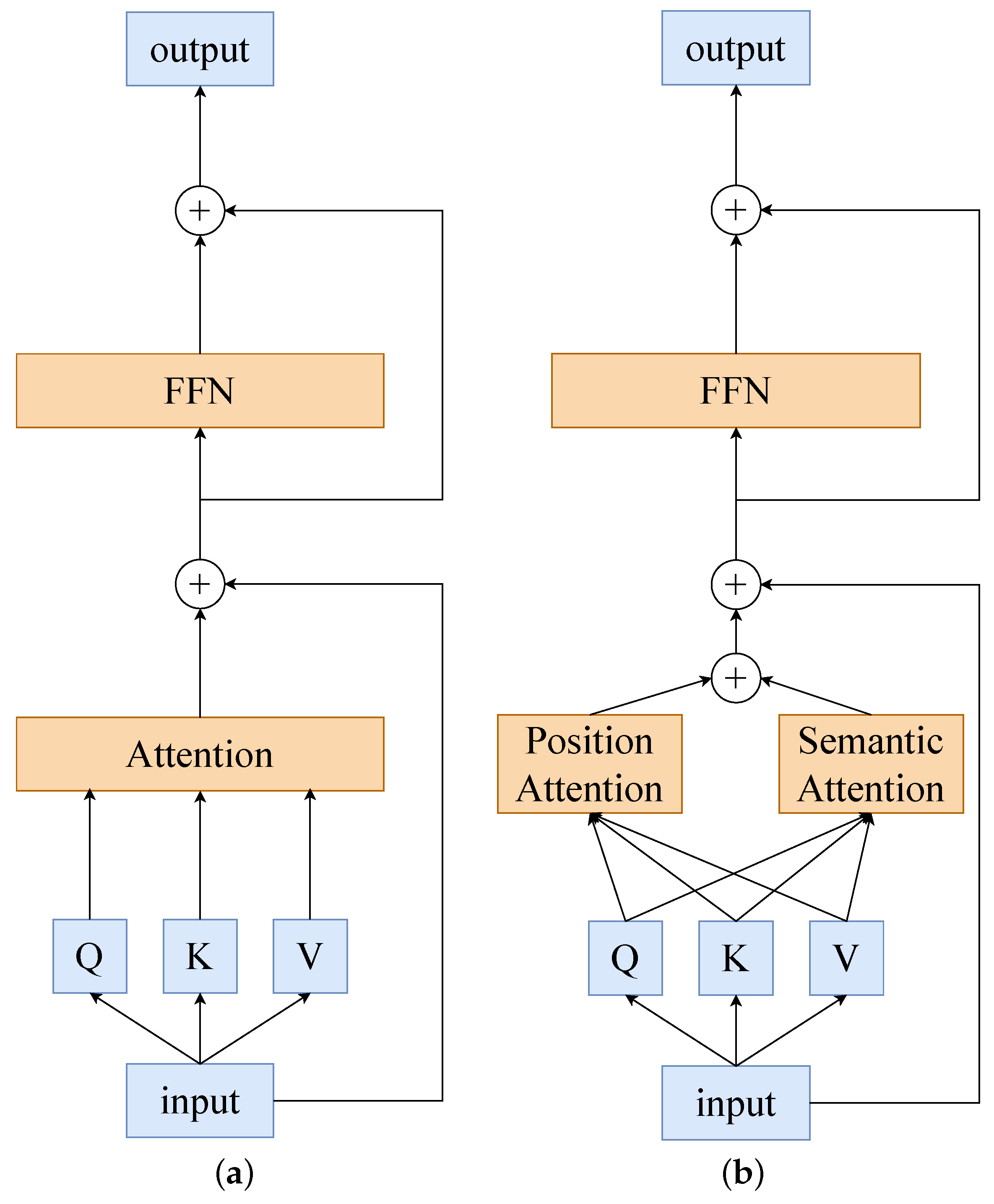
3.3. Dual-Dependency Attention
The original self-attention mechanism allows each token to interact with all tokens to form a global token dependency and to address its huge computational cost. We decouple it into a dual-dependency learning in position space (PDA) and semantic space (SDA), which achieves an alternative to the original method with a linear positive correlation computational cost. In
Figure 4, a comparison of our novel attention with the original method can be found.
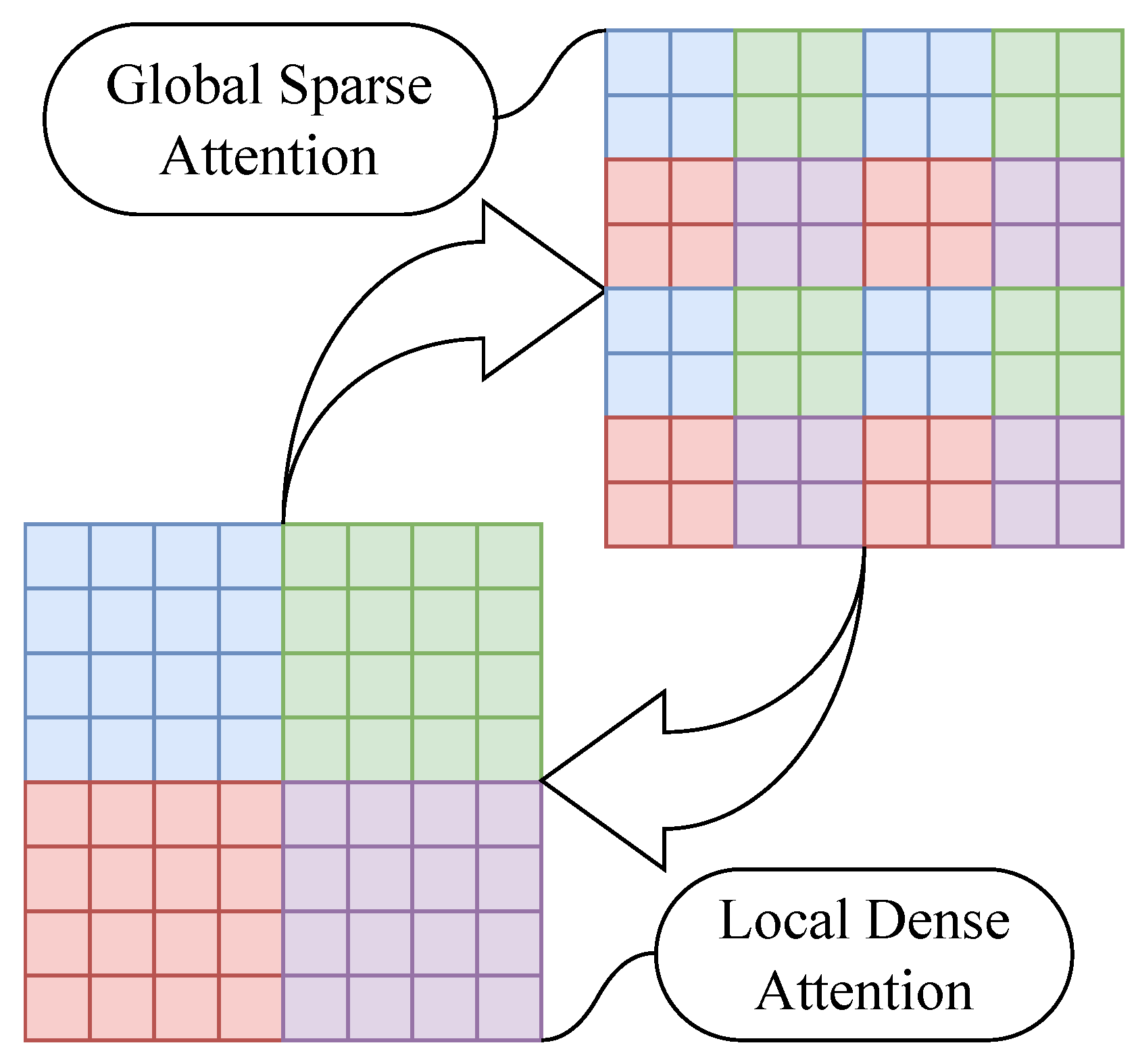
In the position space pathway (PDA), we design two types of grouping token interactions, namely, local dense attention (LDA) and global sparse attention (GSA), and these interactions are shown in
Figure 5. In LDA, tokens are grouped according to their relative positions in space by windowing, and each token only needs to interact with all tokens within its window. In GSA, all tokens within each window are grouped again so that each new group contains tokens from each window, and the scope of token interactions is restricted to the group. We design to allow these two types of attention to stack up in the backbone network, making the model perform global token interactions within two neighboring layers.
Specifically, we obtain the feature map
and determine the number
g of tokens within each group, its shape transforms to the same
when the feature map is fed into local dense interactions and global sparse interactions in the location-space pathway. In addition, to enhance the information interaction between intragroup tokens and global tokens, the keys and values of cls tokens and center tokens are shared within each group; therefore, we obtain
,
, and
, where
, and the positional dependency attention is calculated as follows:
It is worth noting that although LDA and GSA are consistent in the computational process, they differ significantly in the windowing strategy of feature tokens. Specifically, in the LDA, the feature space is directly divided equally according to a predetermined number of windows, such that feature tokens belonging to the same window are spatially adjacent. This partitioning facilitates the capture of subtle feature changes in the local region, which is conducive to increasing the sensitivity to local structures. In contrast, the GSA uses a more globalized window partitioning strategy that achieves global feature fusion by uniformly distributing the tokens within each local window to each global window. This strategy allows each global window to absorb information from different local regions, enhancing the ability to understand the global structure and contextual information.
In the semantic space pathway (SDA), global tokens interact semantically by extracting information from the center token, and the center token updates itself by extracting information from the global tokens. The center token serves as a medium for information propagation, allowing each token to interact with the global token with linear computational complexity. It is worth noting that this dependency modeling is based on the cross-attention relationship between the center token and the global token, which means that the method of information propagation depends on the distribution of the center token in the semantic space of the entire image features. In other words, our proposed semantic space attention can be viewed as an overlapping partition of the image semantic space based on the center token, and the dependency modeling of the semantic information in the partitioned subspace guarantees a high-quality feature representation of the semantics of the image object. Furthermore, the demonstration of the visualization results for the model principle supports this assertion.
Specifically, we use cross-attention learning of center tokens with global tokens to achieve semantically relevant interactions of global tokens and clustering updates of center tokens, with the structure shown in
Figure 6. We take the global tokens
and the center tokens
; after feature mapping, we obtain
,
, and
and
,
, and
, and the semantic-dependency attention is calculated as follows:
It is interesting to note that in the SDA, we do not perform center token interaction (CI). The purpose of this design is to ensure that the center token can serve as the core of the information transfer, preserving as much as possible the discreteness of interest of each semantic window. This discreteness is crucial because it ensures that the semantic information of the subject instances in the global image feature can be learned in its entirety. By maintaining the independence of the central token, the model gains an enhanced ability to recognize critical details in the image by effectively freeing it from unnecessary information obfuscation.
Otherwise, the generation of the cls token has not changed; we take
and
to form
,
,
,
, and
, and the new cls token is calculated as follows:
where
is the output of the cls token in the dual-dependency attention.
After the dual-dependency attention, we obtain two feature representations for the global tokens, and each token needs to be evaluated for its weight in both pathways. Specifically, in the semantic-dependency attention pathway, we consider that the significant tendency of patch tokens to pay attention to all center tokens indicates that their semantic information is more relevant to the image subject, so we compute the variance of the attentional weights of each patch token for all center tokens and map it to
and expand the dimension of the weight vector as
; the fusion is then calculated as follows:
where ⊗ implies element-wise multiplication,
and
are two learnable parameters that are used as scaling factors, and
and
are the output of global tokens and center tokens in the dual-dependency attention.
3.4. Complexity Analysis for Dual-Dependency Attention
In the field of fine-grained image classification, the Vision Transformer has been studied due to its computational cost, which is quadratically positively correlated with the resolution of the input image; however, there is a lack of substitutes that can be used for the linear complexity attention of the FGVC without the need for targeted pre-training. In the following, we compare the computational complexity of our dual-dependency attention with the standard global self-attention.
For the global self-attention, query mapping, key mapping, value mapping, self-attentive learning, and output mapping are required for the input feature map
, where
N is the number of patch tokens and cls tokens; the global self-attention can be expressed as follows:
where the corresponding computational complexity can be expressed as follows:
where it is obvious that the original global attention approach has a significant computational cost.
For our dual-dependency attention, the method is the same as the original method regarding query mapping, key mapping, value mapping, and output mapping, so we mainly analyze the attention calculation process.
In the position space–dependency attention pathway, attention is computed with the feature map
as follows:
where the corresponding computational complexity can be expressed as follows:
In the semantic space–dependency attention pathway, attention is computed with the feature map
and
as follows:
where the corresponding computational complexity can be expressed as follows:
Thus, the computational complexity of our dual-dependency attention can be expressed as follows:
It is clear that the computational cost of our proposed dual-dependency attention has only a linear positive correlation with the input image resolution and that g and m are much smaller than N, implying significant computational reductions.
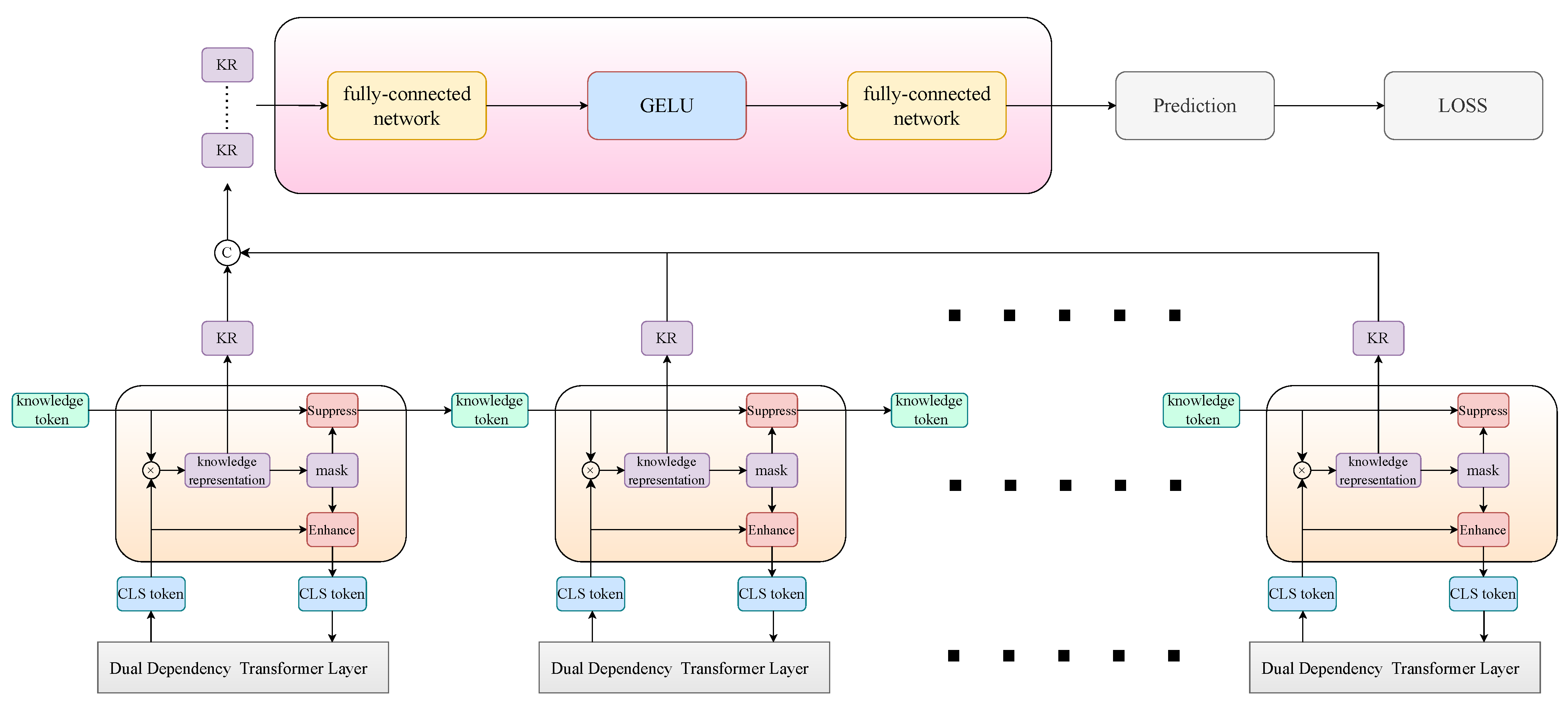
3.5. Discriminative Ability Enhancement Module
The detailed structure of the module is shown in
Figure 7. The discriminative accuracy of the model depends on the sensitivity of the fine-grained feature extraction strategy to the discriminatively relevant refinement information in the feature space. Based on our dual-attention–dependent high-fidelity feature representation, our proposed discriminative ability enhancement module implements guidance for the tendency change in the fine-grained feature extraction strategy in the backbone network by taking advantage of the knowledge-based modeling of classification recognition cues.
Observation of the classification results of the model shows that in most misclassification cases, the confidence level of the correct category is usually only slightly lower than the highest confidence level, suggesting that these misclassification cases are caused by insufficient extraction of relevant discriminative features for a small number of categories. Therefore, we decided to strengthen the ability of the model to capture discriminative cues for high-confidence classes.
Specifically, we designed serial-connected knowledge enhancement learning to connect with each layer in the backbone network and augment the cls token output from each layer with discriminative knowledge. The model suppresses high-confidence class representations of knowledge tokens to guarantee the richness of fine-grained feature extraction for cls tokens and transfer and fuse the knowledge representation of the cls tokens. In single knowledge enhancement learning, we take the knowledge token
and the cls token
, where
k is the number of classes, and the knowledge representation
corresponding to the cls token can be computed in the following:
Based on the sorting of the knowledge representation according to the confidence value, we obtain the mask
corresponding to the top
t classes and the mask
corresponding to the other classes, and the output is computed as follows:
where ⊗ implies element-wise multiplication with broadcasting and
and
are two learnable parameters that are used as scaling factors. It accurately assesses the deflection of the model discrimination results by the knowledge enhancement module and absorbs the multi-level fine-grained features to exploit the learning richness of the model features. The knowledge representation
s of each layer of the cls tokens is spliced into
, where
L is the number of backbone layers, and the final discrimination
of the model is obtained by employing the learnable knowledge integration method, which is calculated as follows:
where ACT is the GELU,
and
are the learnable parameter, and
P is the output of the model.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








