
Automated Region of Interest-Based Data Augmentation for Fallen Person Detection in Off-Road Autonomous Agricultural Vehicles

Abstract
1. Introduction
2. Related Work
2.1. Object Detection in Off-Road Environment
2.2. Data Augmentation for Object Detection
2.3. Instance Segmentation
3. Materials and Methods
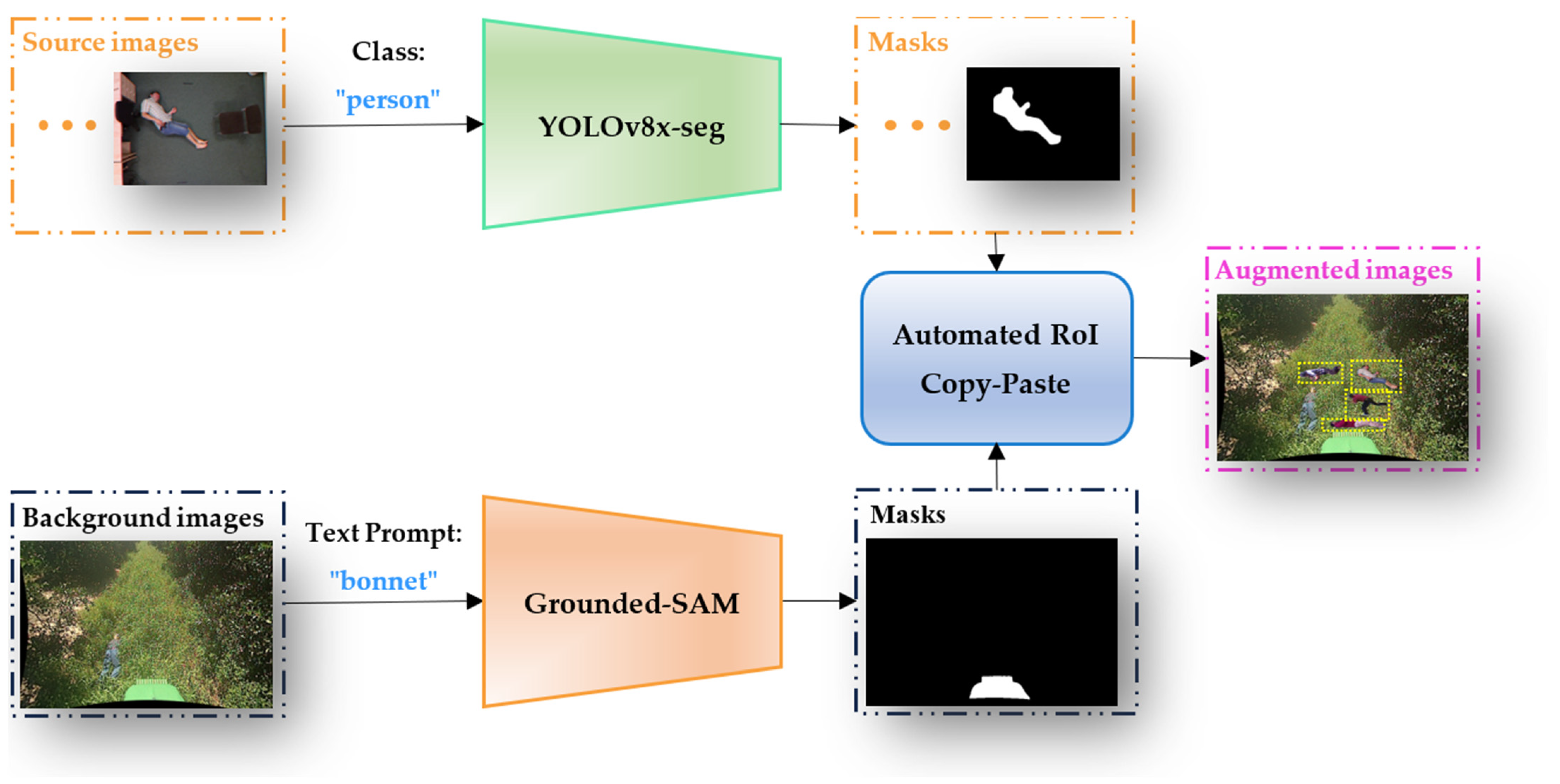
3.1. Framework
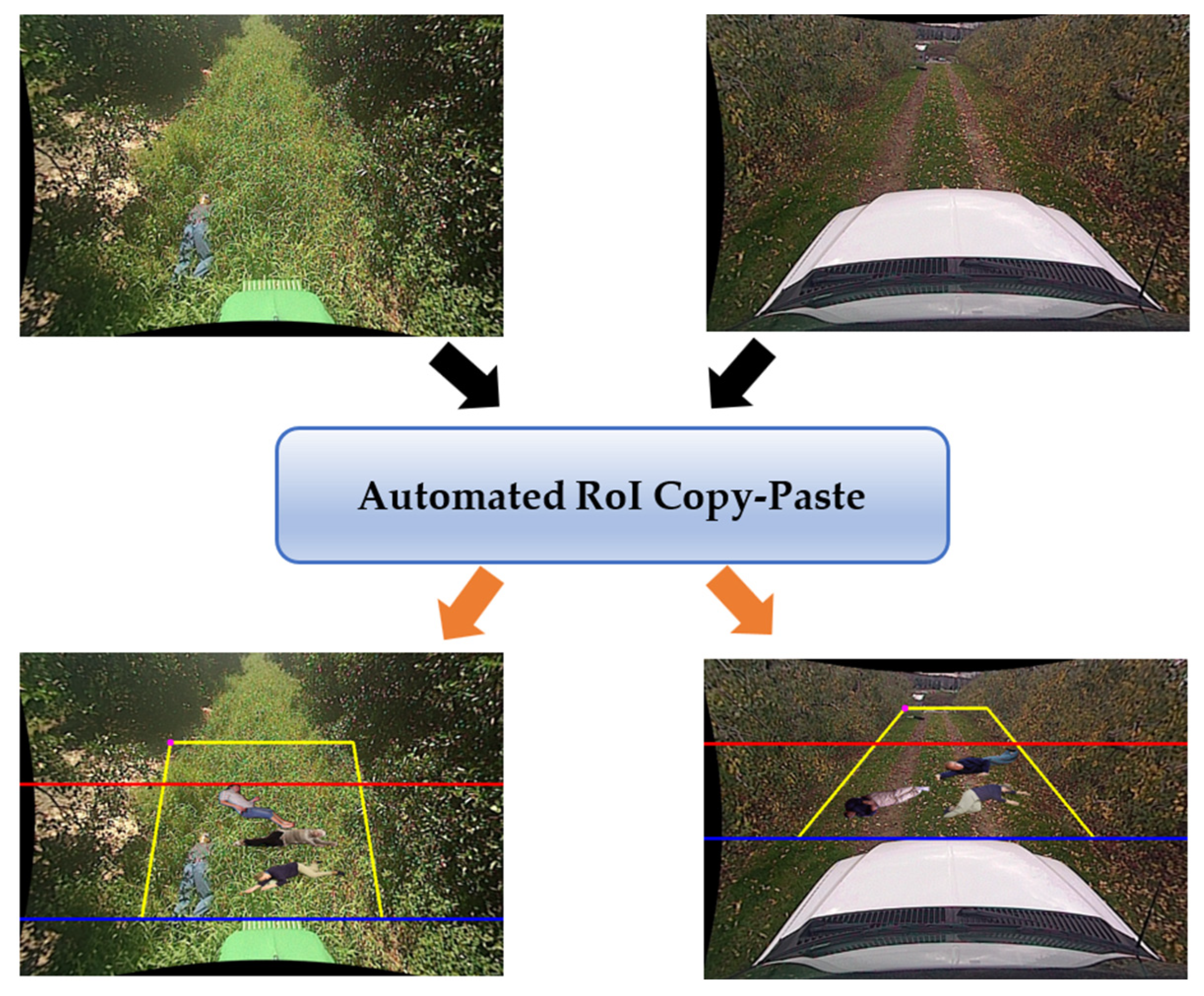
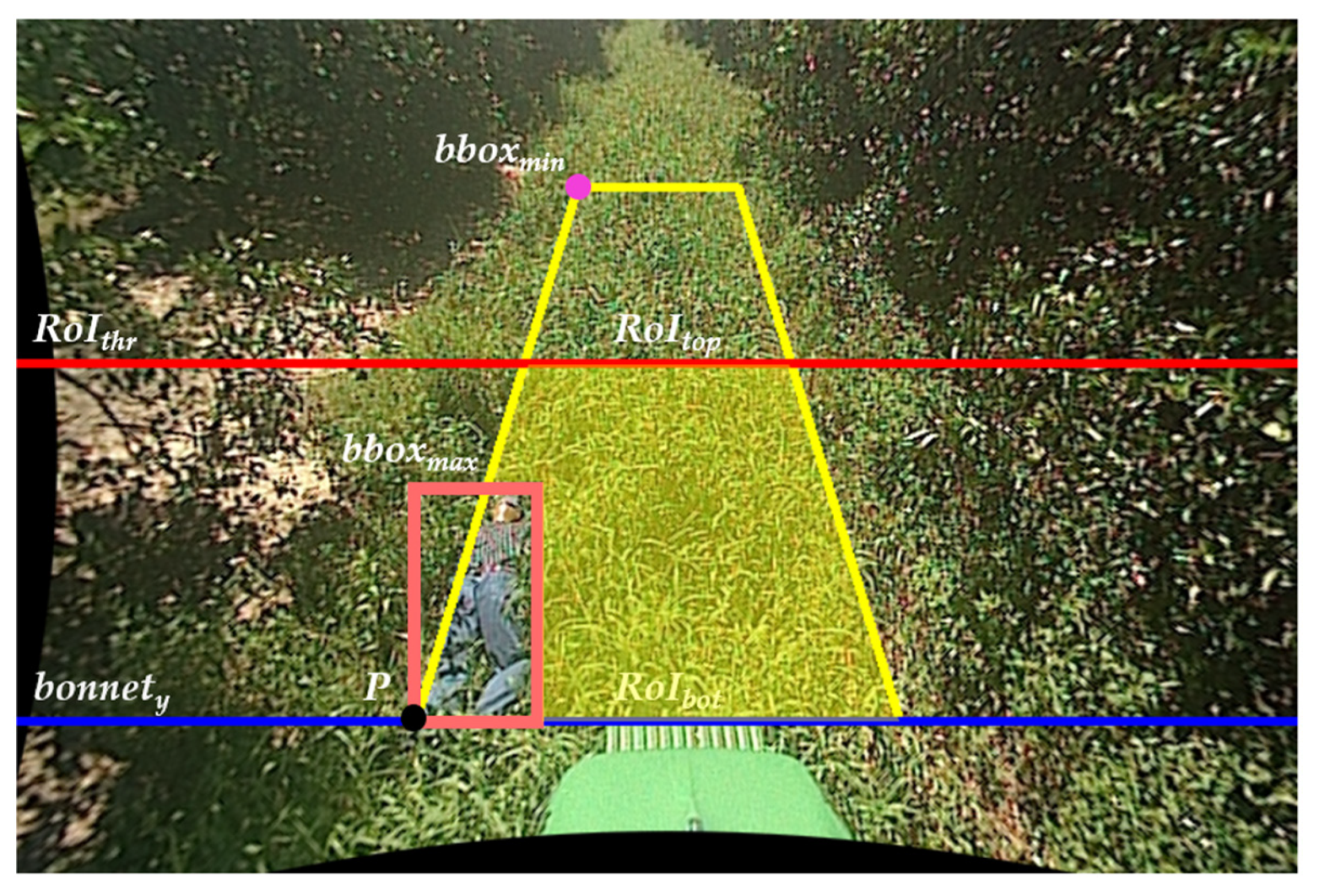
3.2. Automated RoI Copy-Paste (ARCP)
| Algorithm 1. Set Up Maximum and Minimum Bounding Boxes for Each Section |
| Input: - ‘bg_imgs’: List of background images - ‘bg_txts’: List of text files corresponding to ‘bg_imgs’ Output: - ‘results’: Dictionary of containing bounding box statistics |
| For each ‘bg_img’ in ‘bg_imgs’ do Open the corresponding file in ‘bg_txts’ and read lines into ‘bg_lines’ For each ‘bg_line’ in ‘bg_lines’ do Parse ‘x’, ‘y’, ‘w’, ‘h’ as floats from ‘bg_line’ Adjust ‘y’ to (‘y’ − ‘h’/2) Create ‘bbox’ as a tensor [‘x’, ‘y’, ‘w’, ‘h’] Calculate ‘area’ as ‘w’ * ‘h’ Increment ‘count’ Update bounding box statistics: ‘ymin’, ‘ymax’, ‘bboxmin’, ‘bboxmax’ based on ‘y’ ‘areamax’, ‘widthmax’, ‘heightmax’, ‘widthmin’, ‘heightmin’ based on ‘w’, ‘h’, and ‘area’ If ‘prev_bbox’ exists, then Calculate ‘iou’ If ‘iou’ equals 0, then Store current statistics in ‘results’ for ‘section_num’ Reset statistics Increment ‘section_num’ Set ‘prev_bbox’ to ‘bbox’ Store final statistics in ‘results’ for the last ‘section_num’ Return ‘results’ |
| Algorithm 2. Copy-Paste Objects from Multiple Images |
| Input: - ‘results’: Output of Algorithm 1 - ‘fallen_person_imgs’: List of fallen person images Output: - Augmented image |
| For each ‘bg_img’ in ‘bg_imgs’ do Initialize an ‘occlusion_mask’ to 0 Iw, Ih = size of ‘bg_img’ Open corresponding file in ‘bg_txts’, read lines into ‘bg_lines’ For each ‘bg_line’ in ‘bg_lines’ do Update the corresponding ‘occlusion_mask’ to 255 If the section changes, then Update ‘heightmax’, ‘widthmax’, ‘heightmin’, ‘widthmin’, ‘areamax’ Create a ‘bonnet’ mask with Grounded-SAM If ‘’ > 0.5, then For each ‘fallen_person_img’ in ‘fallen_person_imgs’ do Break if you encounter the maximum paste object value during the loop Create a ‘fallen person’ mask with the YOLOv8x-seg Adjust position and size for fallen person within RoI Randomly rotate ‘fallen person’ with a probability of 0.25 Each ‘fallen person’ is flipped vertically and horizontally with a probability of 0.5 if ‘occlusion_mask’ exists at the current position, then continue Paste a ‘fallen person’ into the background image Apply alpha blending Save the augmented image |
4. Experimental Results and Discussion
4.1. Experimental Setup
4.2. Evaluation Metrics
4.3. Experimental Analysis
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Calicioglu, O.; Flammini, A.; Bracco, S.; Bellù, L.; Sims, R. The Future Challenges of Food and Agriculture: An Integrated Analysis of Trends and Solutions. Sustainability 2019, 11, 222. [Google Scholar] [CrossRef]
- Ma, J.; Ushiku, Y.; Sagara, M. The Effect of Improving Annotation Quality on Object Detection Datasets: A Preliminary Study. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4850–4859. [Google Scholar] [CrossRef]
- Oliveira, L.; Moreira, A.; Silva, M. Advances in Agriculture Robotics: A State-of-the-Art Review and Challenges Ahead. Robotics 2021, 10, 52. [Google Scholar] [CrossRef]
- Kumar, A.; Mohan, D.; Mahajan, P. Studies on Tractor Related Injuries in Northern India. Accid. Anal. Prev. 1998, 30, 53–60. [Google Scholar] [CrossRef] [PubMed]
- Frank, A.; McKnight, R.; Kirkhorn, S.; Gunderson, P. Issues of Agricultural Safety and Health. Annu. Rev. Public Health 2004, 25, 225–245. [Google Scholar] [CrossRef]
- Moorehead, S. Unsettled Issues Regarding the Commercialization of Autonomous Agricultural Vehicles; SAE Technical Paper; SAE International: Warrendale, PA, USA, 2022. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F. Deep Learning in Agriculture: A Survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.; Cubuk, E.; Le, Q.; Zoph, B. Simple Copy-Paste Is a Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar] [CrossRef]
- Wolf, M.; Douat, L.; Erz, M. Safety-Aware Metric for People Detection. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–20 September 2021; pp. 2759–2765. [Google Scholar] [CrossRef]
- Chen, L.; Lin, S.; Lu, X.; Cao, D.; Wu, H.; Guo, C.; Liu, C.; Wang, F. Deep Neural Network Based Vehicle and Pedestrian Detection for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3234–3246. [Google Scholar] [CrossRef]
- Feng, D.; Harakeh, A.; Waslander, S.; Dietmayer, K. A Review and Comparative Study on Probabilistic Object Detection in Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2021, 23, 9961–9980. [Google Scholar] [CrossRef]
- Zamanakos, G.; Tsochatzidis, L.; Amanatiadis, A.; Pratikakis, I. A Comprehensive Survey of LIDAR-Based 3D Object Detection Methods with Deep Learning for Autonomous Driving. Comput. Graph. 2021, 99, 153–181. [Google Scholar] [CrossRef]
- Gupta, A.; Anpalagan, A.; Guan, L.; Khwaja, A. Deep Learning for Object Detection and Scene Perception in Self-Driving Cars: Survey, Challenges, and Open Issues. Array 2021, 10, 100057. [Google Scholar] [CrossRef]
- Dai, D.; Chen, Z.; Bao, P.; Wang, J. A Review of 3D Object Detection for Autonomous Driving of Electric Vehicles. World Electr. Veh. J. 2021, 12, 139. [Google Scholar] [CrossRef]
- Tang, X.; Zhang, Z.; Qin, Y. On-Road Object Detection and Tracking Based on Radar and Vision Fusion: A Review. IEEE Intell. Transp. Syst. Mag. 2021, 14, 103–128. [Google Scholar] [CrossRef]
- Tian, D.; Han, Y.; Wang, B.; Guan, T.; Wei, W. A Review of Intelligent Driving Pedestrian Detection Based on Deep Learning. Comput. Intell. Neurosci. 2021, 2021, 5410049. [Google Scholar] [CrossRef] [PubMed]
- Trabelsi, R.; Khemmar, R.; Decoux, B.; Ertaud, J.-Y.; Butteau, R. Recent Advances in Vision-Based on-Road Behaviors Understanding: A Critical Survey. Sensors 2022, 22, 2654. [Google Scholar] [CrossRef]
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3D Object Detection for Autonomous Driving: A Review and New Outlooks. arXiv 2022, arXiv:2206.09474. [Google Scholar] [CrossRef]
- Qian, R.; Lai, X.; Li, X. 3D Object Detection for Autonomous Driving: A Survey. Pattern Recognit. 2022, 130, 108796. [Google Scholar] [CrossRef]
- Ma, X.; Ouyang, W.; Simonelli, A.; Ricci, E. 3D Object Detection from Images for Autonomous Driving: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 3537–3556. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; He, H.; Wang, Y.; Mao, Z.; Wang, H. Multi-Modality 3D Object Detection in Autonomous Driving: A Review. Neurocomputing 2023, 553, 126587. [Google Scholar] [CrossRef]
- Wang, Y.; Mao, Q.; Zhu, H.; Deng, J.; Zhang, Y.; Ji, J.; Li, H.; Zhang, Y. Multi-Modal 3D Object Detection in Autonomous Driving: A Survey. Int. J. Comput. Vis. 2023, 131, 2122–2152. [Google Scholar] [CrossRef]
- Karangwa, J.; Liu, J.; Zeng, Z. Vehicle Detection for Autonomous Driving: A Review of Algorithms and Datasets. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11568–11594. [Google Scholar] [CrossRef]
- Berwo, M.; Khan, A.; Fang, Y.; Fahim, H.; Javaid, S.; Mahmood, J.; Abideen, Z.; M.S., S. Deep Learning Techniques for Vehicle Detection and Classification from Images/Videos: A Survey. Sensors 2023, 23, 4832. [Google Scholar] [CrossRef] [PubMed]
- Tabor, T.; Pezzementi, Z.; Vallespi, C.; Wellington, C. People in the Weeds: Pedestrian Detection Goes Off-Road. In Proceedings of the 2015 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), West Lafayette, IN, USA, 18–20 October 2015; pp. 1–7. [Google Scholar] [CrossRef]
- Foster, T. Object Detection and Sensor Data Processing for Off-Road Autonomous Vehicles; Mississippi State University: Starkville, MS, USA, 2021. [Google Scholar]
- Kim, E.; Park, K.; Yang, H.; Oh, S. Training Deep Neural Networks with Synthetic Data for Off-Road Vehicle Detection. In Proceedings of the 2020 20th International Conference on Control, Automation and Systems (ICCAS), Busan, Republic of Korea, 13–16 October 2020; pp. 427–431. [Google Scholar] [CrossRef]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar] [CrossRef]
- Kumar, T.; Mileo, A.; Brennan, R.; Bendechache, M. Image Data Augmentation Approaches: A Comprehensive Survey and Future Directions. arXiv 2023, arXiv:2301.02830. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q. Randaugment: Practical Automated Data Augmentation with a Reduced Search Space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- Kim, J.; Hwang, Y. GAN-Based Synthetic Data Augmentation for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5002512. [Google Scholar] [CrossRef]
- Kim, Y.; Lee, J.; Kim, C.; Jin, K.; Park, C. GAN Based ROI Conditioned Synthesis of Medical Image for Data Augmentation. In Medical Imaging 2023: Image Processing; SPIE: Bellingham, WA, USA, 2023; Volume 12464, pp. 739–745. [Google Scholar] [CrossRef]
- Eker, T. Classifying Objects from Unseen Viewpoints Using Novel View Synthesis Data Augmentation. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 19 October 2021. Available online: https://fse.studenttheses.ub.rug.nl/id/eprint/26208 (accessed on 13 December 2023).
- Jian, Y.; Yu, F.; Singh, S.; Stamoulis, D. Stable Diffusion for Aerial Object Detection. arXiv 2023, arXiv:2311.12345. [Google Scholar]
- Krug, P.; Birkholz, P.; Gerazov, B.; van Niekerk, D.; Xu, A.; Xu, Y. Articulatory Synthesis for Data Augmentation in Phoneme Recognition. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH; International Speech Communication Association (ISCA): Incheon, Republic of Korea, 2022; Volume 2022, pp. 1228–1232. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar] [CrossRef]
- Zhao, H.; Sheng, D.; Bao, J.; Chen, D.; Chen, D.; Wen, F.; Yuan, L.; Liu, C.; Zhou, W.; Chu, Q.; et al. X-Paste: Revisiting Scalable Copy-Paste for Instance Segmentation Using CLIP and StableDiffusion. arXiv 2023, arXiv:2212.03863. [Google Scholar] [CrossRef]
- Xie, J.; Li, W.; Li, X.; Liu, Z.; Ong, Y.; Loy, C. MosaicFusion: Diffusion Models as Data Augmenters for Large Vocabulary Instance Segmentation. arXiv 2023, arXiv:2309.13042. [Google Scholar] [CrossRef]
- Dhariwal, P.; Nichol, A. Diffusion Models Beat Gans on Image Synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar] [CrossRef]
- Lee, S.; Lee, S.; Seong, H.; Hyun, J.; Kim, E. Fallen Person Detection for Autonomous Driving. Expert Syst. Appl. 2023, 213, 119242. [Google Scholar] [CrossRef]
- Ruiz-Ponce, P.; Ortiz-Perez, D.; Garcia-Rodriguez, J.; Kiefer, B. Poseidon: A Data Augmentation Tool for Small Object Detection Datasets in Maritime Environments. Sensors 2023, 23, 3691. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.; Chung, K. STAug: Copy-Paste Based Image Augmentation Technique Using Salient Target. IEEE Access 2022, 10, 123605–123613. [Google Scholar] [CrossRef]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, Paste and Learn: Surprisingly Easy Synthesis for Instance Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1301–1310. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.; Lo, W.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar] [CrossRef]
- IDEA-Research/Grounded-Segment-Anything. Available online: https://github.com/IDEA-Research/Grounded-Segment-Anything (accessed on 29 November 2023).
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Li, C.; Yang, J.; Su, H.; Zhu, J.; et al. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. arXiv 2023, arXiv:2303.05499. [Google Scholar] [CrossRef]
- Ultralytics/Ultralytics. Available online: https://github.com/ultralytics/ultralytics (accessed on 2 May 2023).
- Pezzementi, Z.; Tabor, T.; Hu, P.; Chang, J.; Ramanan, D.; Wellington, C.; Babu, B.; Herman, H. Comparing Apples and Oranges: Off-Road Pedestrian Detection on the NREC Agricultural Person-Detection Dataset. arXiv 2017, arXiv:1707.07169. [Google Scholar] [CrossRef]
- Fall Detection Dataset. Available online: https://www.kaggle.com/datasets/uttejkumarkandagatla/fall-detection-dataset (accessed on 8 November 2023).
- Fall Detection Dataset. Available online: https://falldataset.com (accessed on 8 November 2023).
- UR Fall Detection Dataset. Available online: http://fenix.ur.edu.pl/~mkepski/ds/uf.html (accessed on 8 November 2023).
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-Cam: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- FieldSAFE—Dataset for Obstacle Detection in Agriculture. Available online: https://vision.eng.au.dk/fieldsafe/ (accessed on 8 November 2023).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision↑ (%) | Recall↑ (%) | AP↑ (%) | F1 Score↑ (%) |
|---|---|---|---|---|
| YOLOv7x [58] | 75.4 | 70.7 | 77.8 | 73.0 |
| YOLOv7x w/RandAug [35] | 93.0 | 76.2 | 87.0 | 83.8 |
| YOLOv7x w/X-Paste [42] | 79.0 | 79.1 | 84.0 | 79.0 |
| YOLOv7x w/Copy-Paste [9] | 84.9 | 82.9 | 88.7 | 83.9 |
| YOLOv7x w/ARCP | 97.3 | 88.6 | 95.6 | 92.7 |
| Model | Precision↑ (%) | Recall↑ (%) | AP↑ (%) | F1 Score↑ (%) |
|---|---|---|---|---|
| YOLOv8x [53] | 87.9 | 75.0 | 83.8 | 80.9 |
| YOLOv8x w/RandAug [35] | 88.1 | 77.3 | 85.0 | 82.3 |
| YOLOv8x w/X-Paste [42] | 75.3 | 89.1 | 84.1 | 81.6 |
| YOLOv8x w/Copy-Paste [9] | 87.4 | 77.8 | 87.9 | 82.3 |
| YOLOv8x w/ARCP | 90.8 | 91.0 | 96.2 | 90.9 |
| Model | Precision↑ (%) | Recall↑ (%) | AP↑ (%) | F1 Score↑ (%) |
|---|---|---|---|---|
| YOLOv8x [53] | 25.3 | 28.9 | 13.5 | 26.6 |
| YOLOv8x w/RandAug [35] | 34.0 | 22.3 | 13.2 | 26.9 |
| YOLOv8x w/X-Paste [42] | 31.6 | 28.7 | 18.6 | 30.1 |
| YOLOv8x w/Copy-Paste [9] | 54.9 | 66.2 | 44.6 | 60.0 |
| YOLOv8x w/ARCP | 82.9 | 63.8 | 72.3 | 72.1 |
| Model | (a) | (b) | (c) | (b) + (c) | (a) + (c) |
|---|---|---|---|---|---|
| YOLOv7x [58] | 37.9 | 32.9 | 30.7 | 32.1 | 38.5 |
| YOLOv7x w/Copy-Paste [9] (a) | - | 66.2 | 28.2 | 64.4 | - |
| YOLOv7x w/Copy-Paste [9] (b) | 57.1 | - | 17.6 | - | 51.3 |
| YOLOv7x w/Copy-Paste [9] (a) + (b) | - | - | 22.9 | - | - |
| YOLOv7x w/ARCP (a) | - | 68.2 | 33.1 | 66.2 | - |
| YOLOv7x w/ARCP (b) | 68.7 | - | 36.4 | - | 64.9 |
| YOLOv7x w/ARCP (a) + (b) | - | - | 38.0 | - | - |
| Model | (a) | (b) | (c) | (b) + (c) | (a) + (c) |
|---|---|---|---|---|---|
| YOLOv8x [53] | 37.3 | 37.4 | 25.4 | 32.1 | 35.6 |
| YOLOv8x w/Copy-Paste [9] (a) | - | 71.9 | 34.8 | 70.3 | - |
| YOLOv8x w/Copy-Paste [9] (b) | 52.2 | - | 24.4 | - | 44.6 |
| YOLOv8x w/Copy-Paste [9] (a) + (b) | - | - | 29.9 | - | - |
| YOLOv8x w/ARCP (a) | - | 78.0 | 50.2 | 75.7 | - |
| YOLOv8x w/ARCP (b) | 66.0 | - | 30.5 | - | 60.8 |
| YOLOv8x w/ARCP (a) + (b) | - | - | 28.0 | - | - |
| Model | Precision↑ (%) | Recall↑ (%) | AP↑ (%) | F1 Score↑ (%) |
|---|---|---|---|---|
| YOLOv7x [58] | 46.6 | 27.1 | 23.6 | 34.3 |
| YOLOv7x w/Copy-Paste [9] | 21.3 | 24.8 | 13.0 | 22.9 |
| YOLOv7x w/ARCP | 40.4 | 52.5 | 34.2 | 45.7 |
| Model | Precision↑ (%) | Recall↑ (%) | AP↑ (%) | F1 Score↑ (%) |
|---|---|---|---|---|
| YOLOv8x [53] | 25.0 | 24.9 | 12.8 | 24.9 |
| YOLOv8x w/Copy-Paste [9] | 30.8 | 27.0 | 14.7 | 28.8 |
| YOLOv8x w/ARCP | 37.2 | 34.6 | 19.0 | 35.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baek, H.; Yu, S.; Son, S.; Seo, J.; Chung, Y. Automated Region of Interest-Based Data Augmentation for Fallen Person Detection in Off-Road Autonomous Agricultural Vehicles. Sensors 2024, 24, 2371. https://doi.org/10.3390/s24072371
Baek H, Yu S, Son S, Seo J, Chung Y. Automated Region of Interest-Based Data Augmentation for Fallen Person Detection in Off-Road Autonomous Agricultural Vehicles. Sensors. 2024; 24(7):2371. https://doi.org/10.3390/s24072371
Chicago/Turabian StyleBaek, Hwapyeong, Seunghyun Yu, Seungwook Son, Jongwoong Seo, and Yongwha Chung. 2024. "Automated Region of Interest-Based Data Augmentation for Fallen Person Detection in Off-Road Autonomous Agricultural Vehicles" Sensors 24, no. 7: 2371. https://doi.org/10.3390/s24072371
APA StyleBaek, H., Yu, S., Son, S., Seo, J., & Chung, Y. (2024). Automated Region of Interest-Based Data Augmentation for Fallen Person Detection in Off-Road Autonomous Agricultural Vehicles. Sensors, 24(7), 2371. https://doi.org/10.3390/s24072371