

Multi-Task Foreground-Aware Network with Depth Completion for Enhanced RGB-D Fusion Object Detection Based on Transformer



Abstract
1. Introduction
- We introduce a real-time object recognition and depth completion approach using a single Transformer backbone network, allowing the simultaneous extraction of RGB and sparse LIDAR features. Compared to the 32 ms required when serializing the depth completion network and object detection network, our integrated network, inclusive of object detection functionality, totals an inference time of 26 ms.
- During the Feature Pyramid Network (FPN) stage, we use a weight matrix based on dense depth map features to enhance the detection of small and challenging objects. This approach yields significant improvements in detection accuracy for vehicles, bicycles, and pedestrians within the Kitti dataset, showing relative enhancements of 4.78%, 8.93%, and 15.54%, respectively, over the baseline.
- We generate masks for regions with target recognition labels, calculate depth completion loss separately, and reduce the weight of depth completion loss in environmental areas to mitigate noise impact on the neural network.
2. Related Work
2.1. General 2D Image Object Detection
2.2. Multi-Sensor Fused Object Detection
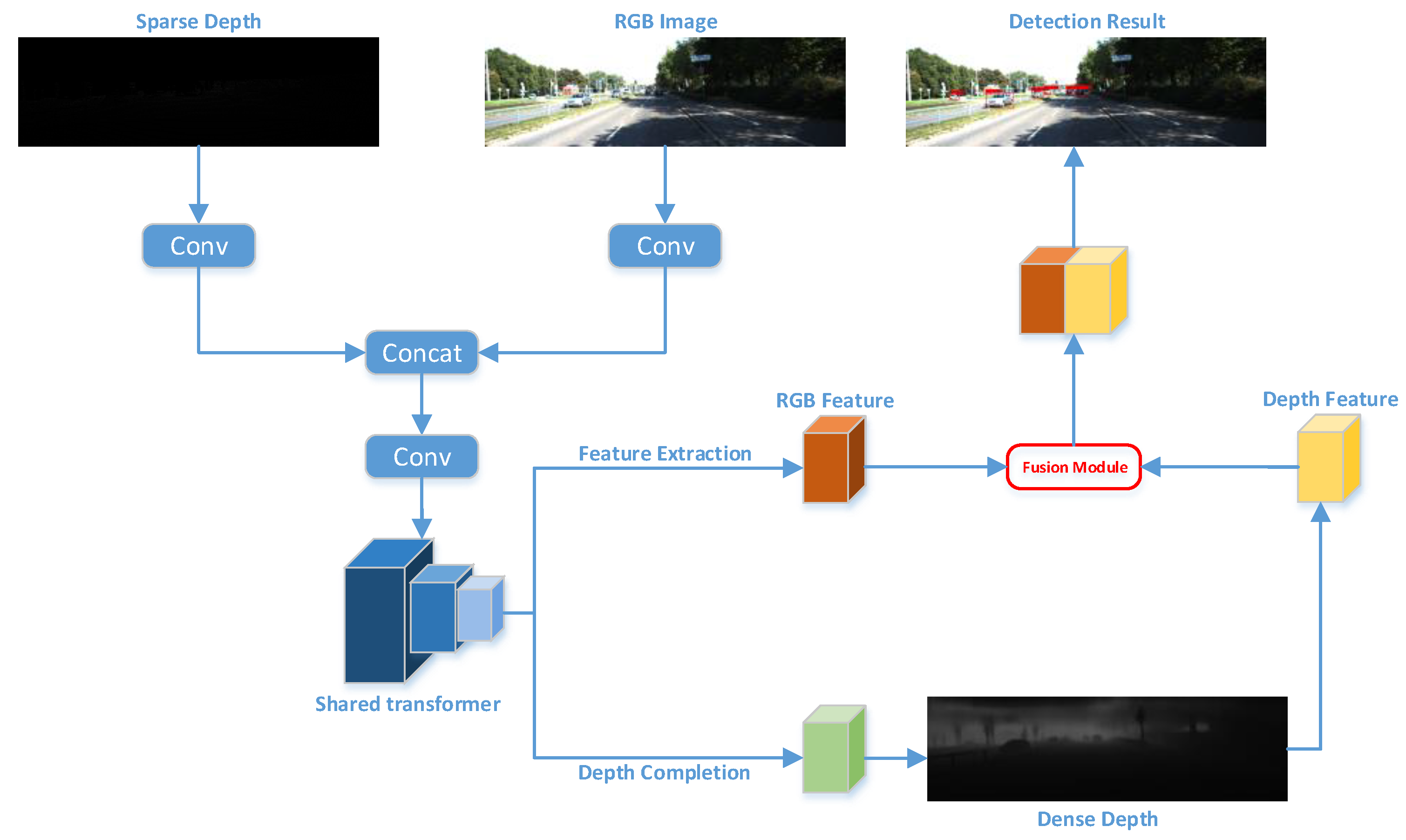
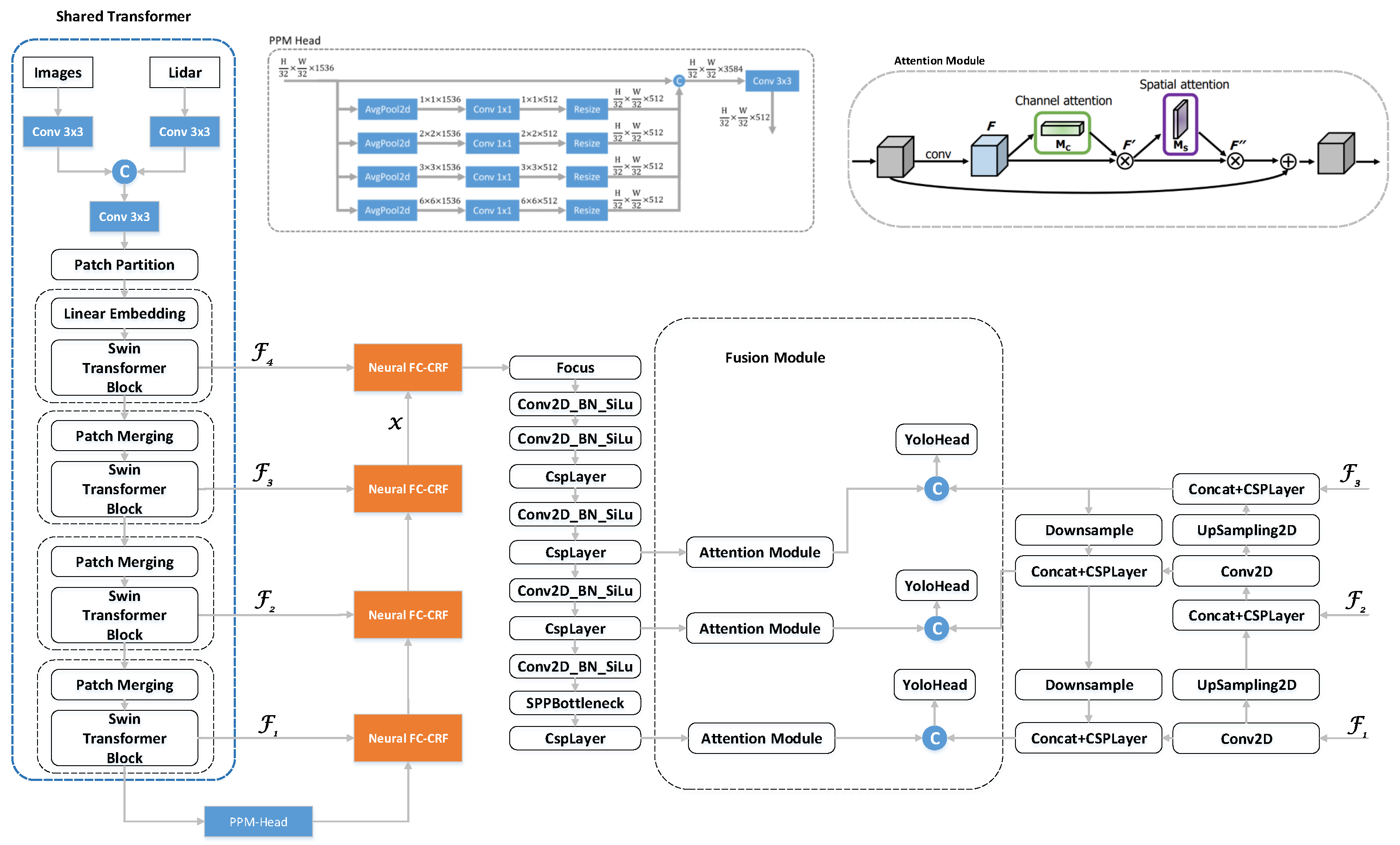
3. Methodology
3.1. Data Augmentation
3.2. Preprocessing Module
3.3. Depth Completion
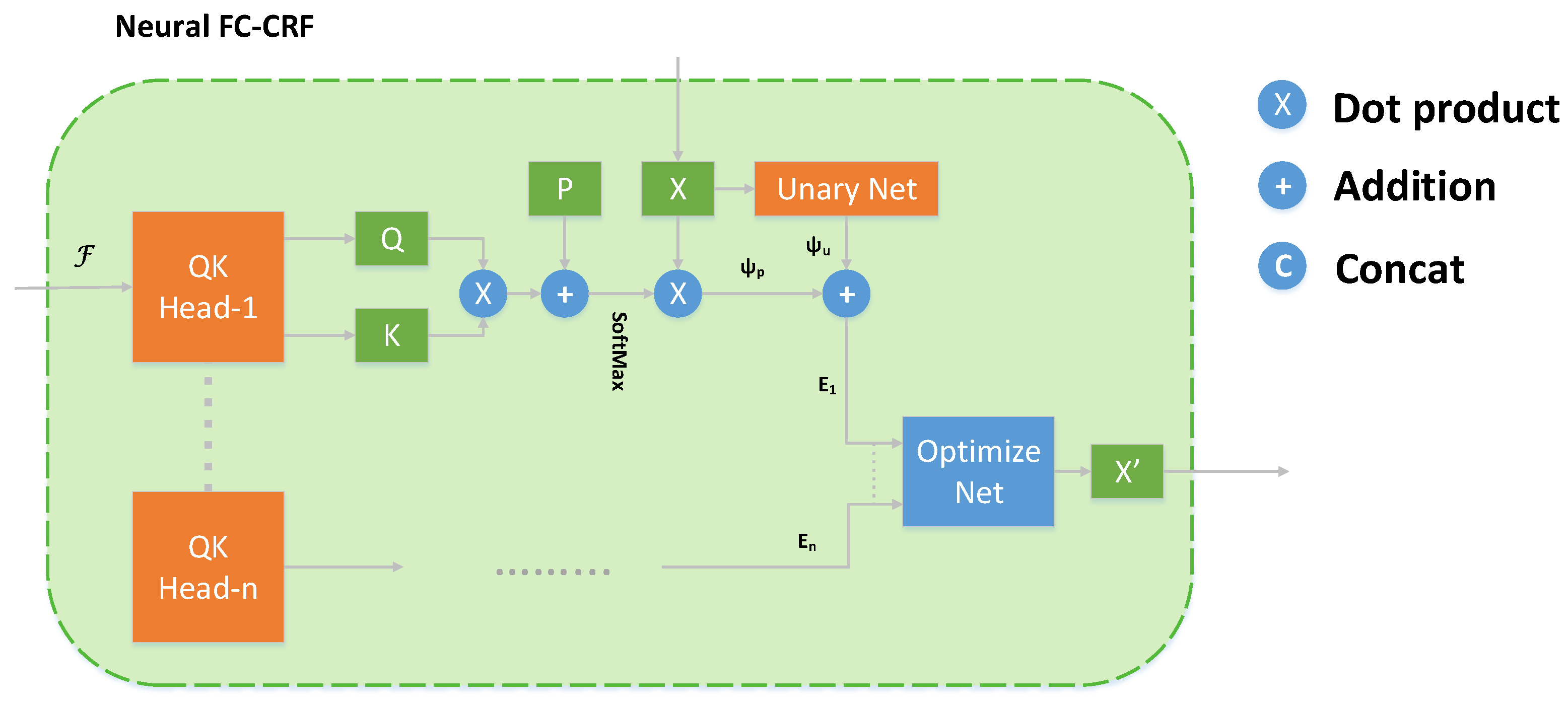
3.4. Fusion Module
3.5. Loss Function Design
3.6. Dataset and Metric
3.7. Implementation Details
3.8. Evaluation Metrics
4. Results
4.1. Evaluation Results
4.2. Ablation Study
- The advantages of employing the preprocessing network in the context of fused object detection.
- The efficacy of multi-scale fusion during the Feature Pyramid Network (FPN) stage for our fused object detection.
- The impact on object detection performance due to the design of the loss function.
4.2.1. Impact of the Preprocessing Module
4.2.2. Impact of the Multi-Scale Depth Completion Fusion Module
4.2.3. The Combined Impact of the Preprocessing Module and Multi-Scale Fusion Module
4.2.4. Impact of the Loss Function Design
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.L.; Han, S. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2774–2781. [Google Scholar]
- Hamid, M.S.; Abd Manap, N.; Hamzah, R.A.; Kadmin, A.F. Stereo matching algorithm based on deep learning: A survey. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 1663–1673. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Wu, J.; Xu, Y.; Chang, E.; Tu, Z. Unsupervised object class discovery via saliency-guided multiple class learning. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 862–875. [Google Scholar] [CrossRef] [PubMed]
- Fan, D.P.; Li, T.; Lin, Z.; Ji, G.P.; Zhang, D.; Cheng, M.M.; Fu, H.; Shen, J. Re-thinking co-salient object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4339–4354. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human action recognition from various data modalities: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3200–3225. [Google Scholar] [CrossRef] [PubMed]
- Fan, D.P.; Wang, W.; Cheng, M.M.; Shen, J. Shifting more attention to video salient object detection. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8554–8564. [Google Scholar]
- Wang, W.; Shen, J.; Yang, R.; Porikli, F. Saliency-aware video object segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 20–33. [Google Scholar] [CrossRef]
- Song, H.; Wang, W.; Zhao, S.; Shen, J.; Lam, K.M. Pyramid dilated deeper convlstm for video salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 715–731. [Google Scholar]
- Wang, W.; Shen, J.; Shao, L. Video salient object detection via fully convolutional networks. IEEE Trans. Image Process. 2017, 27, 38–49. [Google Scholar] [CrossRef] [PubMed]
- Hoyer, L.; Dai, D.; Chen, Y.; Koring, A.; Saha, S.; Van Gool, L. Three ways to improve semantic segmentation with self-supervised depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 11130–11140. [Google Scholar]
- Wang, Q.; Dai, D.; Hoyer, L.; Van Gool, L.; Fink, O. Domain adaptive semantic segmentation with self-supervised depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 8515–8525. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Zhou, T.; Chen, G.; Fu, H.; Shen, J.; Shao, L. Pranet: Parallel reverse attention network for polyp segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; pp. 263–273. [Google Scholar]
- Shamim, S.; Awan, M.J.; Mohd Zain, A.; Naseem, U.; Mohammed, M.A.; Garcia-Zapirain, B. Automatic COVID-19 lung infection segmentation through modified unet model. J. Healthc. Eng. 2022, 2022, 6566982. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.H.; Gao, S.H.; Mei, J.; Xu, J.; Fan, D.P.; Zhang, R.G.; Cheng, M.M. Jcs: An explainable covid-19 diagnosis system by joint classification and segmentation. IEEE Trans. Image Process. 2021, 30, 3113–3126. [Google Scholar] [CrossRef] [PubMed]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Kämäräinen, J.K.; Danelljan, M.; Zajc, L.Č.; Lukežič, A.; Drbohlav, O.; et al. The eighth visual object tracking VOT2020 challenge results. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; pp. 547–601. [Google Scholar]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online tracking by learning discriminative saliency map with convolutional neural network. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 597–606. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Sun, G.; Cheng, M.M.; Shen, J.; Shao, L. Camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 14–19 June 2020; pp. 2777–2787. [Google Scholar]
- Liu, G.; Fan, D. A model of visual attention for natural image retrieval. In Proceedings of the 2013 International Conference on Information Science and Cloud Computing Companion, Guangzhou, China, 7–8 December 2013; pp. 728–733. [Google Scholar]
- Li, J.; Zhang, X.; Li, J.; Liu, Y.; Wang, J. Building and optimization of 3D semantic map based on Lidar and camera fusion. Neurocomputing 2020, 409, 394–407. [Google Scholar] [CrossRef]
- Ulrich, L.; Vezzetti, E.; Moos, S.; Marcolin, F. Analysis of RGB-D camera technologies for supporting different facial usage scenarios. Multimed. Tools Appl. 2020, 79, 29375–29398. [Google Scholar] [CrossRef]
- Brahmanage, G.; Leung, H. Outdoor RGB-D Mapping Using Intel-RealSense. In Proceedings of the 2019 IEEE SENSORS, Montreal, QC, Canada, 27–30 October 2019; pp. 1–4. [Google Scholar]
- Halmetschlager-Funek, G.; Suchi, M.; Kampel, M.; Vincze, M. An empirical evaluation of ten depth cameras: Bias, precision, lateral noise, different lighting conditions and materials, and multiple sensor setups in indoor environments. IEEE Robot. Autom. Mag. 2018, 26, 67–77. [Google Scholar] [CrossRef]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3d object detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 35–52. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.H.; Kautz, J. Splatnet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 2530–2539. [Google Scholar]
- Wang, Y.; Chao, W.L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8445–8453. [Google Scholar]
- You, Y.; Wang, Y.; Chao, W.L.; Garg, D.; Pleiss, G.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar++: Accurate depth for 3d object detection in autonomous driving. arXiv 2019, arXiv:1906.06310. [Google Scholar]
- Simon, M.; Amende, K.; Kraus, A.; Honer, J.; Samann, T.; Kaulbersch, H.; Milz, S.; Michael Gross, H. Complexer-yolo: Real-time 3d object detection and tracking on semantic point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Multimodal virtual point 3d detection. In Proceedings of the Thirty-Fifth Annual Conference on Neural Information Processing Systems, virtual, 6–14 December 2021; Volume 34, pp. 16494–16507. [Google Scholar]
- Ophoff, T.; Van Beeck, K.; Goedemé, T. Exploring RGB+ Depth fusion for real-time object detection. Sensors 2019, 19, 866. [Google Scholar] [CrossRef] [PubMed]
- Chu, F.; Pang, Y.; Cao, J.; Nie, J.; Li, X. Improving 2D object detection with binocular images for outdoor surveillance. Neurocomputing 2022, 505, 1–9. [Google Scholar] [CrossRef]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-task multi-sensor fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7345–7353. [Google Scholar]
- Shen, J.; Liu, Q.; Chen, H. An optimized multi-sensor fused object detection method for intelligent vehicles. In Proceedings of the 2020 IEEE 5th International Conference on Intelligent Transportation Engineering (ICITE), virtual, 11–13 September 2020; pp. 265–270. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Jiang, D.; Li, G.; Tan, C.; Huang, L.; Sun, Y.; Kong, J. Semantic segmentation for multiscale target based on object recognition using the improved Faster-RCNN model. Future Gener. Comput. Syst. 2021, 123, 94–104. [Google Scholar] [CrossRef]
- Zheng, W.; Tang, W.; Chen, S.; Jiang, L.; Fu, C.W. Cia-ssd: Confident iou-aware single-stage object detector from point cloud. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 3555–3562. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Sünderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B.; Milford, M. On the performance of convnet features for place recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 29 September–2 October 2015; pp. 4297–4304. [Google Scholar]
- Cai, G.; Chen, B.M.; Lee, T.H. Unmanned Rotorcraft Systems; Springer Science & Business Media: London, UK, 2011. [Google Scholar]
- Garcia Rubio, V.; Rodrigo Ferran, J.A.; Menendez Garcia, J.M.; Sanchez Almodovar, N.; Lalueza Mayordomo, J.M.; Álvarez, F. Automatic change detection system over unmanned aerial vehicle video sequences based on convolutional neural networks. Sensors 2019, 19, 4484. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Kim, J.H.; Kim, N.; Park, Y.W.; Won, C.S. Object detection and classification based on YOLO-V5 with improved maritime dataset. J. Mar. Sci. Eng. 2022, 10, 377. [Google Scholar] [CrossRef]
- Aufrère, R.; Gowdy, J.; Mertz, C.; Thorpe, C.; Wang, C.C.; Yata, T. Perception for collision avoidance and autonomous driving. Mechatronics 2003, 13, 1149–1161. [Google Scholar] [CrossRef]
- Monteiro, G.; Premebida, C.; Peixoto, P.; Nunes, U. Tracking and classification of dynamic obstacles using laser range finder and vision. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Beijing, China, 9–15 October 2006; pp. 1–7. [Google Scholar]
- Premebida, C.; Ludwig, O.; Nunes, U. LIDAR and vision-based pedestrian detection system. J. Field Robot. 2009, 26, 696–711. [Google Scholar] [CrossRef]
- Du, X.; Ang, M.H.; Karaman, S.; Rus, D. A general pipeline for 3d detection of vehicles. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3194–3200. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 918–927. [Google Scholar]
- Ochs, M.; Kretz, A.; Mester, R. Sdnet: Semantically guided depth estimation network. In Proceedings of the Pattern Recognition: 41st DAGM German Conference, DAGM GCPR 2019, Dortmund, Germany, 10–13 September 2019; pp. 288–302. [Google Scholar]
- Klingner, M.; Termöhlen, J.A.; Mikolajczyk, J.; Fingscheidt, T. Self-supervised monocular depth estimation: Solving the dynamic object problem by semantic guidance. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 582–600. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, virtual, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yuan, W.; Gu, X.; Dai, Z.; Zhu, S.; Tan, P. New crfs: Neural window fully-connected crfs for monocular depth estimation. arXiv 2022, arXiv:2203.01502. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the Twenty-Eighth Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Condat, R.; Rogozan, A.; Bensrhair, A. Gfd-retina: Gated fusion double retinanet for multimodal 2d road object detection. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Wang, C.H.; Chen, H.W.; Fu, L.C. Vpfnet: Voxel-pixel fusion network for multi-class 3d object detection. arXiv 2021, arXiv:2111.00966. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Runtime | Input Data | Car (%) | Pedestrian (%) | Cyclist (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | |||
| MMF [32] | 43 ms | Image + Lidar | 91.82 | 90.17 | 88.54 | N/A | N/A | N/A | N/A | N/A | N/A |
| MSF-YOLO [33] | 32 ms * | Image + Lidar | 95.34 | 91.12 | 84.55 | 75.04 | 59.03 | 54.65 | 66.53 | 48.23 | 42.61 |
| Faster R-CNN [35] | 24 ms | Image | 88.97 | 83.16 | 72.62 | 79.97 | 66.24 | 61.09 | 72.40 | 62.86 | 54.97 |
| GFD-Retina [60] | 376 ms * | Image + Lidar | 94.36 | 88.54 | 78.74 | 77.43 | 60.00 | 56.01 | 79.90 | 60.43 | 53.62 |
| VPF [61] | 72 ms | Image + Lidar | 96.06 | 95.17 | 92.66 | 75.03 | 65.68 | 61.95 | 82.60 | 74.52 | 66.04 |
| YOLOX [62] | 18 ms | Image | 93.15 | 87.26 | 84.49 | 73.80 | 65.93 | 57.81 | 79.49 | 71.83 | 59.38 |
| YOLOV7 [63] | 15 ms | Image | 94.20 | 88.13 | 86.34 | 73.62 | 65.91 | 57.13 | 79.83 | 74.15 | 62.05 |
| Ours | 26 ms | Image + Lidar | 96.41 | 90.01 | 89.89 | 80.84 | 73.67 | 66.54 | 87.55 | 83.19 | 77.36 |
| Method | Car (%) | Pedestrian (%) | Cyclist (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | |
| Basaeline | 93.59 | 87.92 | 85.11 | 73.49 | 65.71 | 57.61 | 80.31 | 73.79 | 61.82 |
| + P | 93.74 | 88.12 | 85.73 | 73.66 | 65.95 | 58.37 | 80.92 | 74.58 | 62.75 |
| + M | 94.37 | 88.82 | 87.05 | 77.92 | 70.53 | 63.36 | 85.28 | 80.29 | 74.53 |
| + P + M | 94.63 | 89.19 | 88.02 | 78.28 | 71.01 | 64.47 | 85.73 | 81.13 | 75.59 |
| + M + L | 94.85 | 89.33 | 88.59 | 80.15 | 72.82 | 65.35 | 86.79 | 82.25 | 76.08 |
| + P + M + L | 96.41 | 90.01 | 89.89 | 80.84 | 73.67 | 66.54 | 87.55 | 83.19 | 77.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, J.; Zhong, S.; Yue, T.; Yin, Y.; Tang, Y. Multi-Task Foreground-Aware Network with Depth Completion for Enhanced RGB-D Fusion Object Detection Based on Transformer. Sensors 2024, 24, 2374. https://doi.org/10.3390/s24072374
Pan J, Zhong S, Yue T, Yin Y, Tang Y. Multi-Task Foreground-Aware Network with Depth Completion for Enhanced RGB-D Fusion Object Detection Based on Transformer. Sensors. 2024; 24(7):2374. https://doi.org/10.3390/s24072374
Chicago/Turabian StylePan, Jiasheng, Songyi Zhong, Tao Yue, Yankun Yin, and Yanhao Tang. 2024. "Multi-Task Foreground-Aware Network with Depth Completion for Enhanced RGB-D Fusion Object Detection Based on Transformer" Sensors 24, no. 7: 2374. https://doi.org/10.3390/s24072374
APA StylePan, J., Zhong, S., Yue, T., Yin, Y., & Tang, Y. (2024). Multi-Task Foreground-Aware Network with Depth Completion for Enhanced RGB-D Fusion Object Detection Based on Transformer. Sensors, 24(7), 2374. https://doi.org/10.3390/s24072374