The construction of beautiful rural areas is a significant aspect of China’s rural revitalization strategy. Accurate surveying and investigation of rural buildings facilitate more effective rural planning and the development of livable and productive, beautiful rural areas [
1]. The primary methods for extracting buildings from high-spatial-resolution remote sensing images are categorized into classical computer vision methods and machine learning methods. Classical computer vision methods, such as edge detection [
2] and region-based segmentation algorithms [
3], primarily extract buildings by analyzing intuitive features like shape, spectrum, and texture in remote sensing images. Meanwhile, machine learning methods, including random forests [
4] and support vector machines (SVMs) [
5], automatically identify buildings by learning complex features from image data. While these methods can effectively identify and learn from large datasets, their success is highly reliant on domain expertise in remote sensing and extensive practical experience in feature selection. With high-spatial-resolution remote sensing images becoming ever more complex and detailed, both classical computer vision and machine learning methods encounter significant challenges in enhancing extraction accuracy, automation, and processing speed [
6].
In recent years, deep learning algorithms have gained prominence in applications such as image classification, object detection, and semantic segmentation [
7]. Their powerful feature extraction and recognition capabilities have led to revolutionary progress in the automatic extraction of ground information from remote sensing images. In 2015, Long et al. [
8] introduced a seminal work in the field of semantic segmentation with the Fully Convolutional Network (FCN), which replaced the fully connected layers in traditional Convolutional Neural Networks (CNNs) with convolutional layers, achieving pixel-level classification of images. The field has since seen the emergence of a series of classic networks, such as U-Net [
9], PSPNet [
10], and the DeepLab series [
11,
12,
13]. These networks can autonomously learn complex spectral and texture features in remote sensing images and automatically extract features of buildings, roads, and other targets [
14]. They have improved segmentation accuracy through various means, including the skip-connection structure in U-Net that retains details, the pyramid pooling structure in PSPNet that aggregates contextual information at multiple scales, and the Atrous Spatial Pyramid Pooling (ASPP) module in DeepLab V3+, which uses atrous convolution to expand the receptive field [
15]. Numerous scholars have built upon the design concepts of these traditional networks and proposed new network architecture modules to enhance semantic segmentation performance for specific tasks. Gong et al. [
16] designed a context-aware module that captures long-range dependencies between building locations using a self-attention mechanism while extracting multi-scale building features, thus enhancing the model’s capacity to represent building features. Yu et al. [
17] introduced an attention gate module added to the skip-connection structure of U-Net, which suppresses irrelevant features and noise in the input image, emphasizing the primary features of buildings. Further developing U-Net, Yu et al. [
18] created the CC-Net module to connect the encoder and decoder, capturing essential building features, adding multi-scale semantic information to the network, and using multiple attention gates to model global dependencies between buildings. Wang et al. [
19] presented a global feature information perception module that addresses the semantic gap between low-level and high-level features and utilizes a spatial attention mechanism, improving the model’s interpretation of spatial feature information. Compared to the CNN-based methods, Transformer-based methods are more adept at handling long-range dependencies in images. Gibril et al. utilized the self-attention mechanism in Transformers, which allows the model to consider information from the entire image when processing each image patch, effectively capturing global dependencies [
20]. Chen et al. proposed a Transformer-based dual-branch network called ADF-Net, which not only enhances the recognition of building features and the expression of spatial information but also captures global dependencies between buildings effectively [
21]. Although Transformer-based methods have shown strong performance in image segmentation tasks, they generally require more computational resources and larger training datasets to achieve optimal performance. Therefore, when selecting a suitable method for a specific remote sensing image processing task, it is important to consider the model’s complexity, training cost, and execution efficiency comprehensively. Future research could explore combining Transformers and CNNs and finding ways to reduce their computational demands while maintaining model performance. This will be crucial for achieving efficient and accurate surveying of rural buildings.
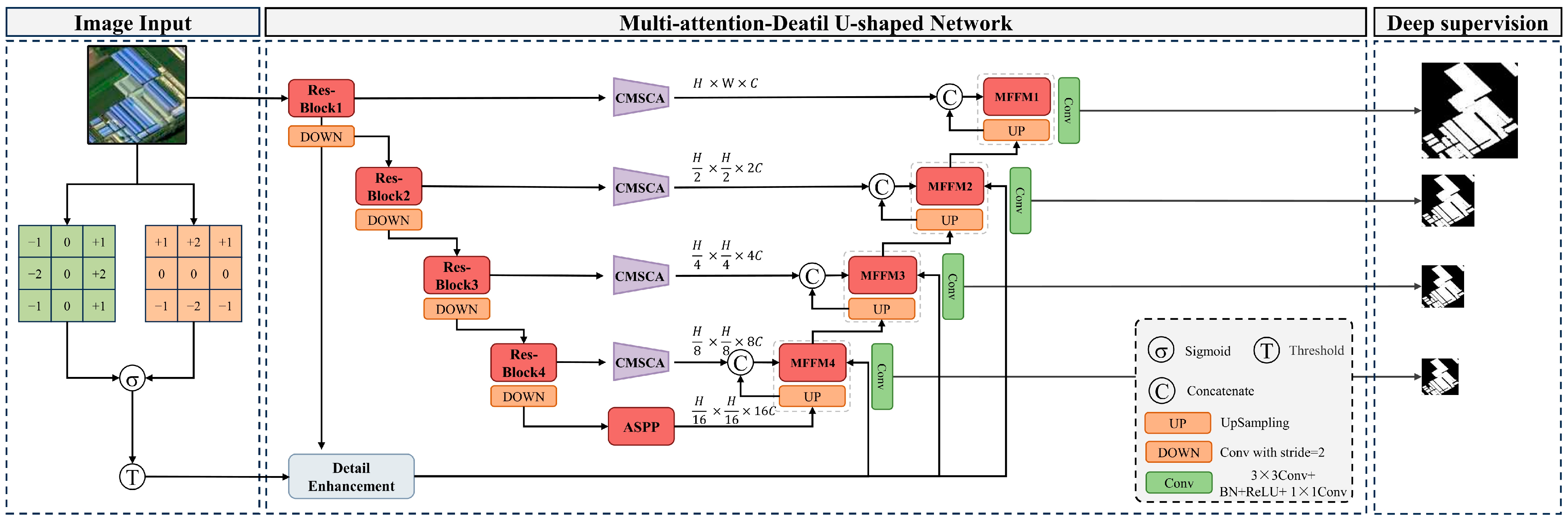
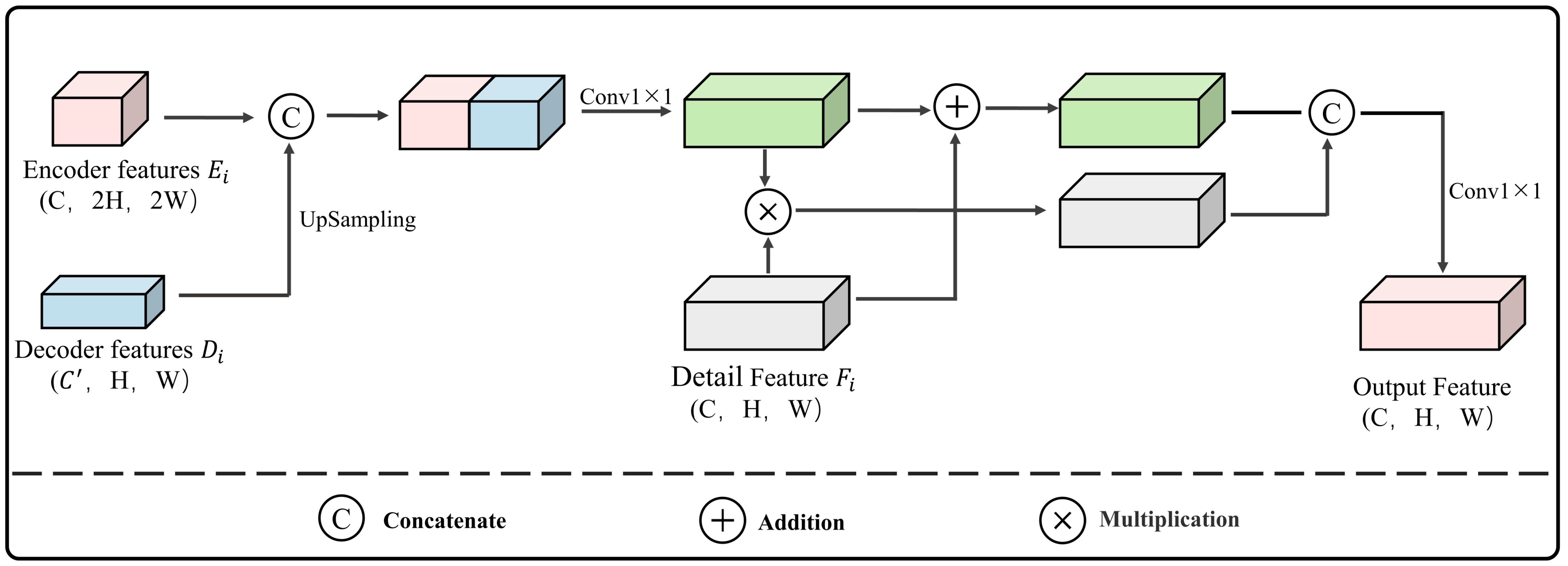
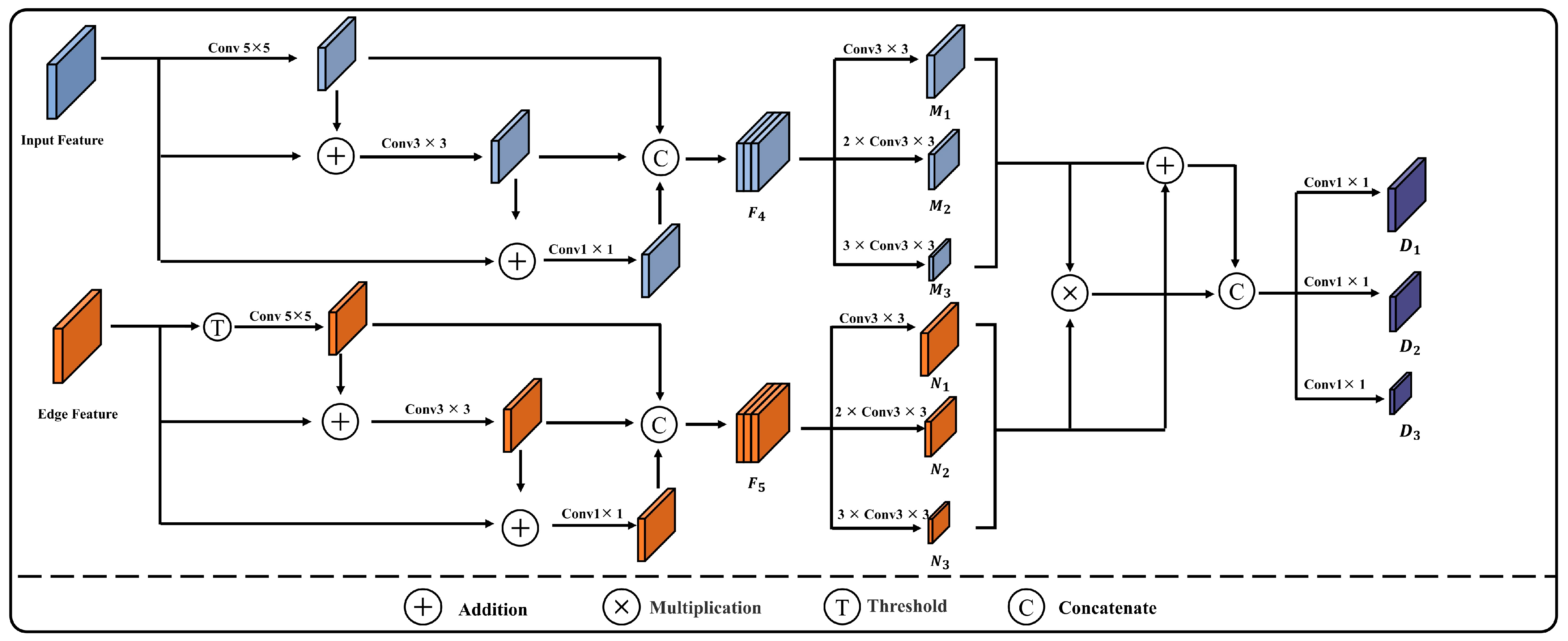
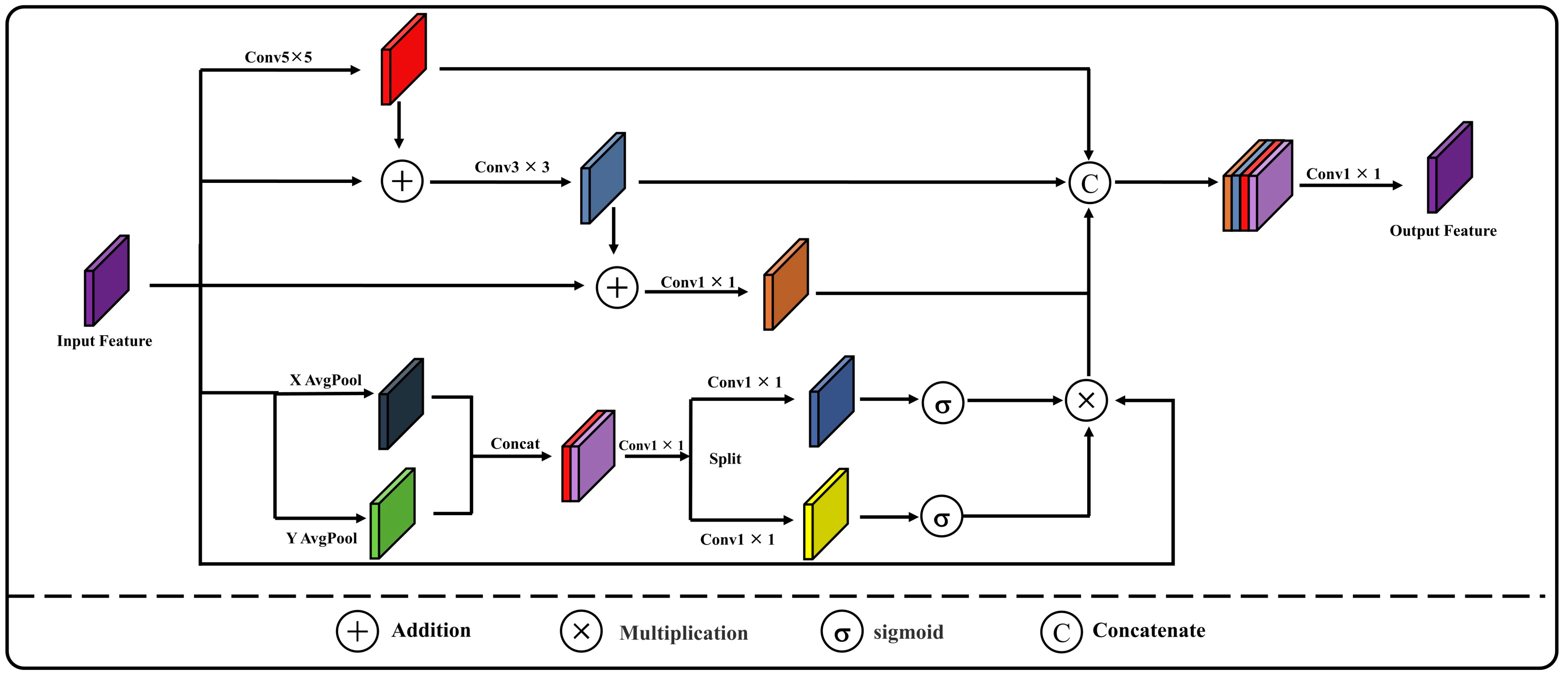
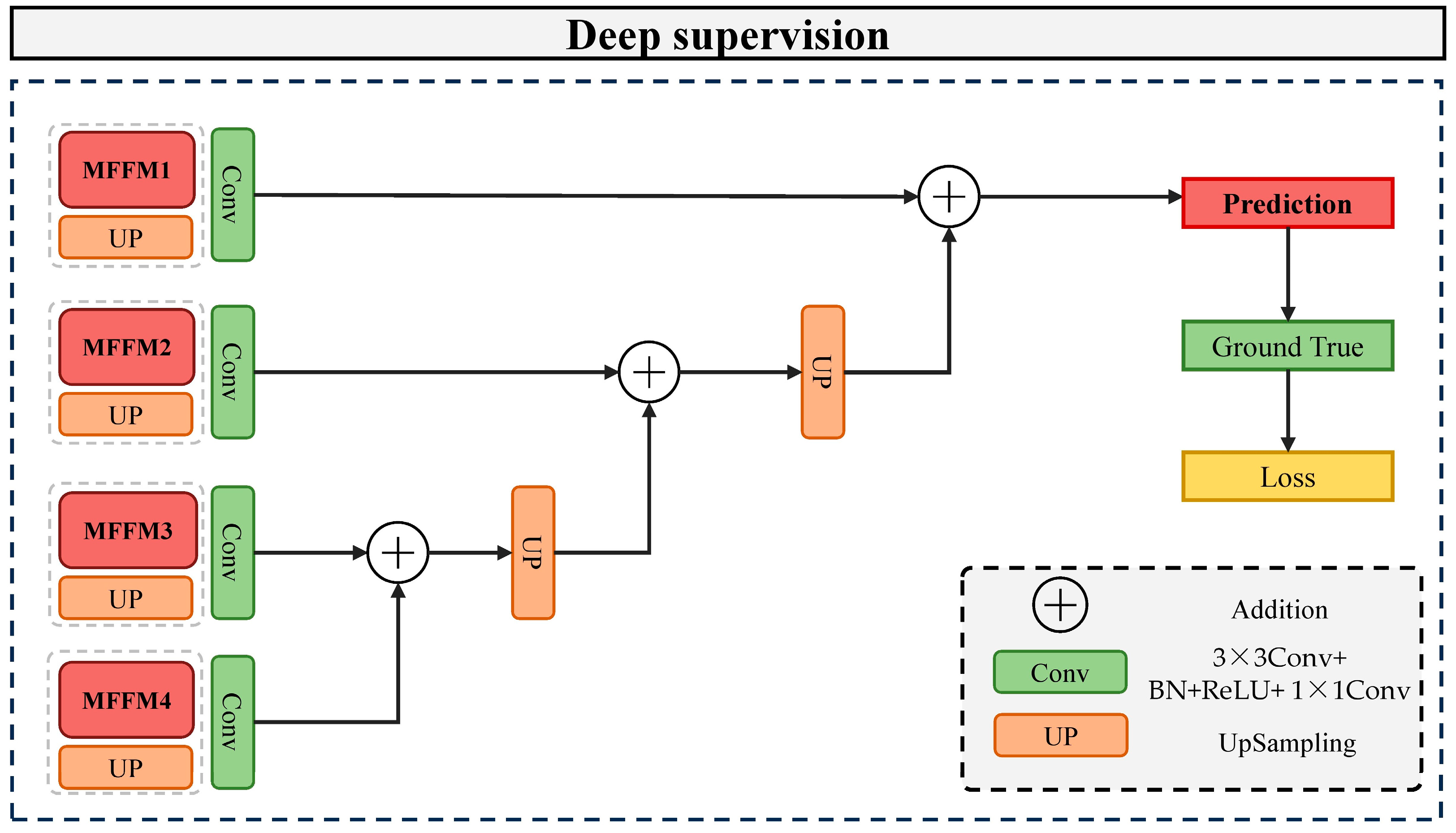
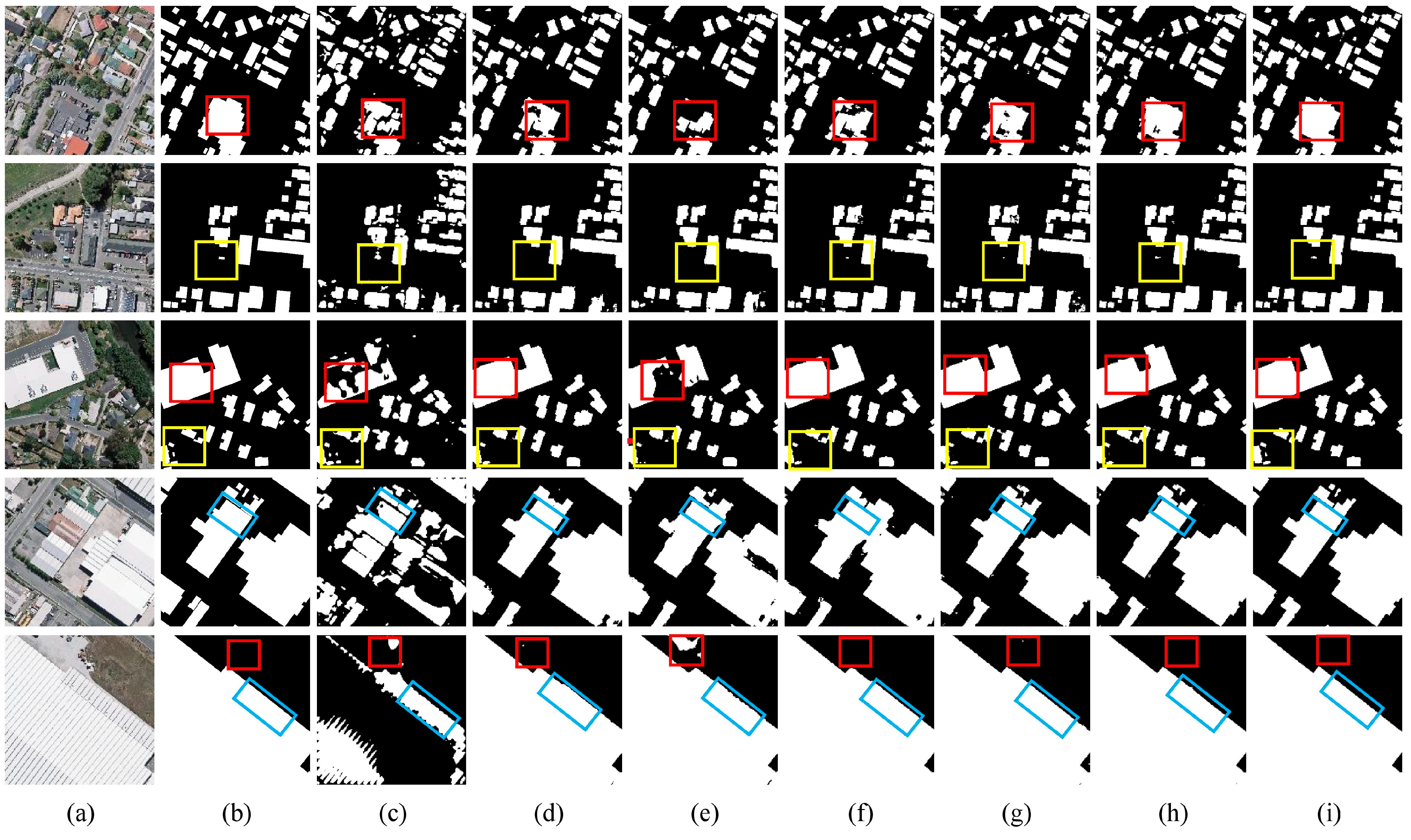
Although numerous researchers have investigated the semantic segmentation of buildings in high-spatial-resolution remote sensing images and have achieved favorable results in urban building extraction, there is limited research on the extraction of rural buildings in different provinces of China, which feature various construction styles [
22]. Compared to urban areas, rural buildings in different regions exhibit diverse backgrounds, and building structures and layouts can vary significantly due to differences in geographical landscapes and cultural practices. This variation presents challenges in automatic building extraction [
23,
24] and may lead to issues such as omissions, incorrect extractions, and unclear boundaries between buildings [
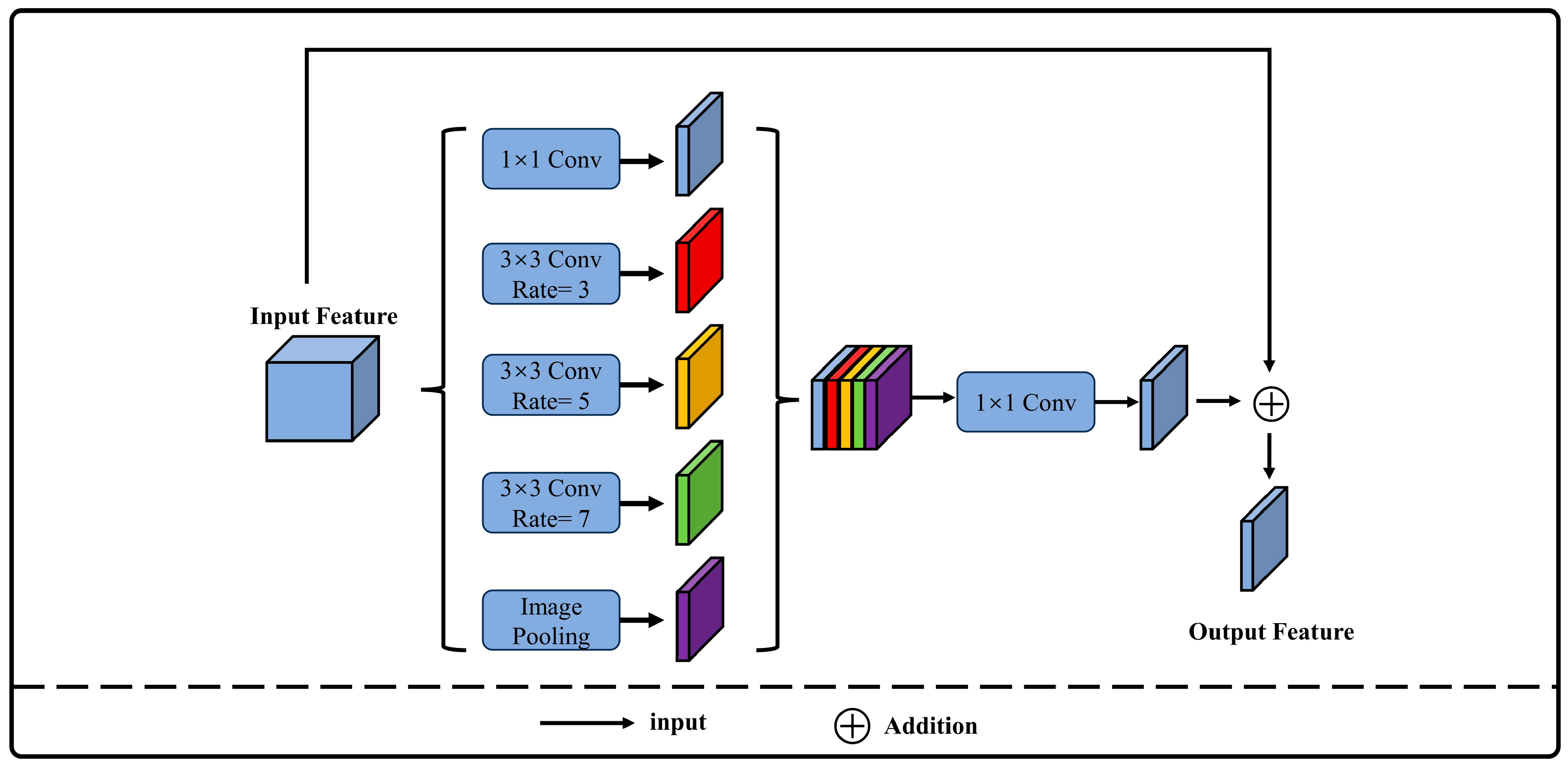
25]. To address these issues and challenges, this study proposes an improved network based on U-Net, the Multi-attention-Detail U-shaped Network (MAD-UNet), which integrates multi-scale contextual information with detail feature enhancement through the design of Multi-scale Fusion Modules and Detail Feature Extraction Modules (DFEM). This integration optimizes the extraction of building edges and addresses the issue of building boundary adhesion in the extraction of rural buildings across different regions. Additionally, a pyramid pooling structure with atrous convolution is introduced to enhance the feature extraction ability of the backbone network. A Cascade Multi-Scale Coordinate Attention (CMSCA) module is designed to enhance attention to multi-scale semantics and spatial information, thereby reducing the occurrence of missed and incorrect segmentations during the extraction of rural buildings in various regions. Furthermore, deep supervision is proposed, supervising different levels of features within the decoder to improve the model’s robustness. This approach makes the model more suitable for tasks such as building recognition and segmentation in high-spatial-resolution drone remote sensing images with a spatial resolution of 0.5 m. The main contributions of this research can be summarized as follows:
The main sections of this article are arranged as follows:
Section 2 provides a detailed introduction to the overall architecture of the MAD-UNet network, the design of the Multi-scale Feature Fusion Module (MFFM), the design of the CMSCA module, and the incorporation of the ASPP module and deep supervision mechanism.
Section 3 describes the collection and construction of experimental data and the selection of evaluation metrics.
Section 4 presents the experimental parameter settings, displays the experimental results, and provides a comparative analysis.
Section 5 summarizes the advantages of the network and prospects for future work.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}