1. Introduction
Over the last decade, major advances in wireless communication technology, microelectronics, and (big) data analytics have caused a significant increase in the application of Wireless Sensor Networks (WSNs) [
1,
2]. A WSN comprises a network of many spatially distributed sensors that monitor certain parameters of a physical system and engage in wireless data communication. The WSN is made up of sensor nodes, sometimes also called sensor motes, which are essentially microcomputers with the ability to collect data, process these data internally, and finally transmit these data to a centralized location. WSNs have numerous applications in different fields, including environmental monitoring, health monitoring, logistics, and smart cities [
3,
4]. With the increasing use of WSNs, there is a growing demand for performant data analysis techniques capable of handling the vast volumes of collected data.
An important challenge within WSN research concerns missing value imputation for the extensive spatiotemporal datasets that are generated. Unavoidably, networks tend to lose readings from sensors for reasons that are difficult or impossible to anticipate, such as sensor failure due to power depletion, network outages, and communication errors, but also destruction due to storms or vandalism [
5]. These missing readings can have important consequences for real-time monitoring, for example, in an emergency setting. Likewise, environmental monitoring applications relying on WSN data can suffer from missing data, which might lead to delayed or incorrect responses to environmental changes. Additionally, missing values can weaken the reliability of sensor data and increase the difficulty of sensor calibration. Finally, incomplete data can also compromise the performance of subsequent modeling and statistical analysis, which may result in biased conclusions or inaccurate predictions. A concrete example can be found in environmental research, where a WSN is commonly leveraged to measure variables such as temperature, humidity, atmosphere pressure, and sunlight, among others. Despite the wealth of data collected by sensor nodes, they often exist in raw form. Analytical tools commonly employed in such fields, such as support vector machines, principal component analysis, and singular value decomposition, face limitations when confronted with datasets containing missing data. Consequently, addressing the issue of missing data in these datasets presents a significant hurdle, impacting the efficacy of analyses and hindering the ability to draw meaningful conclusions [
6].
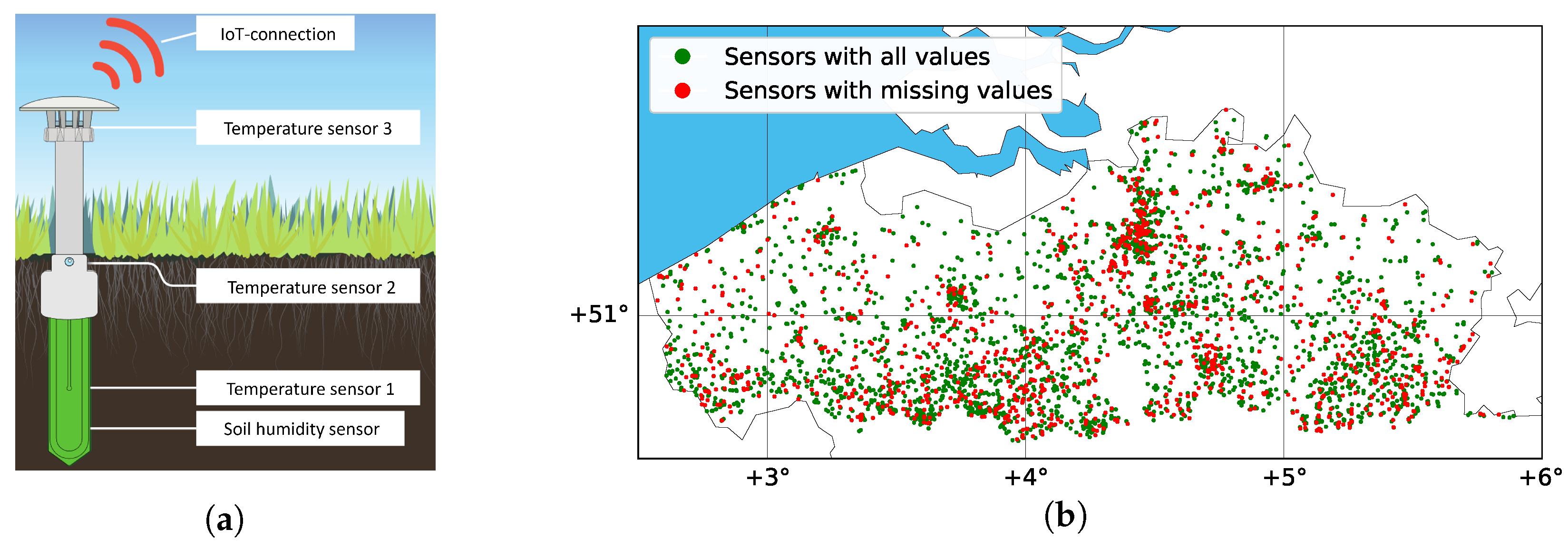
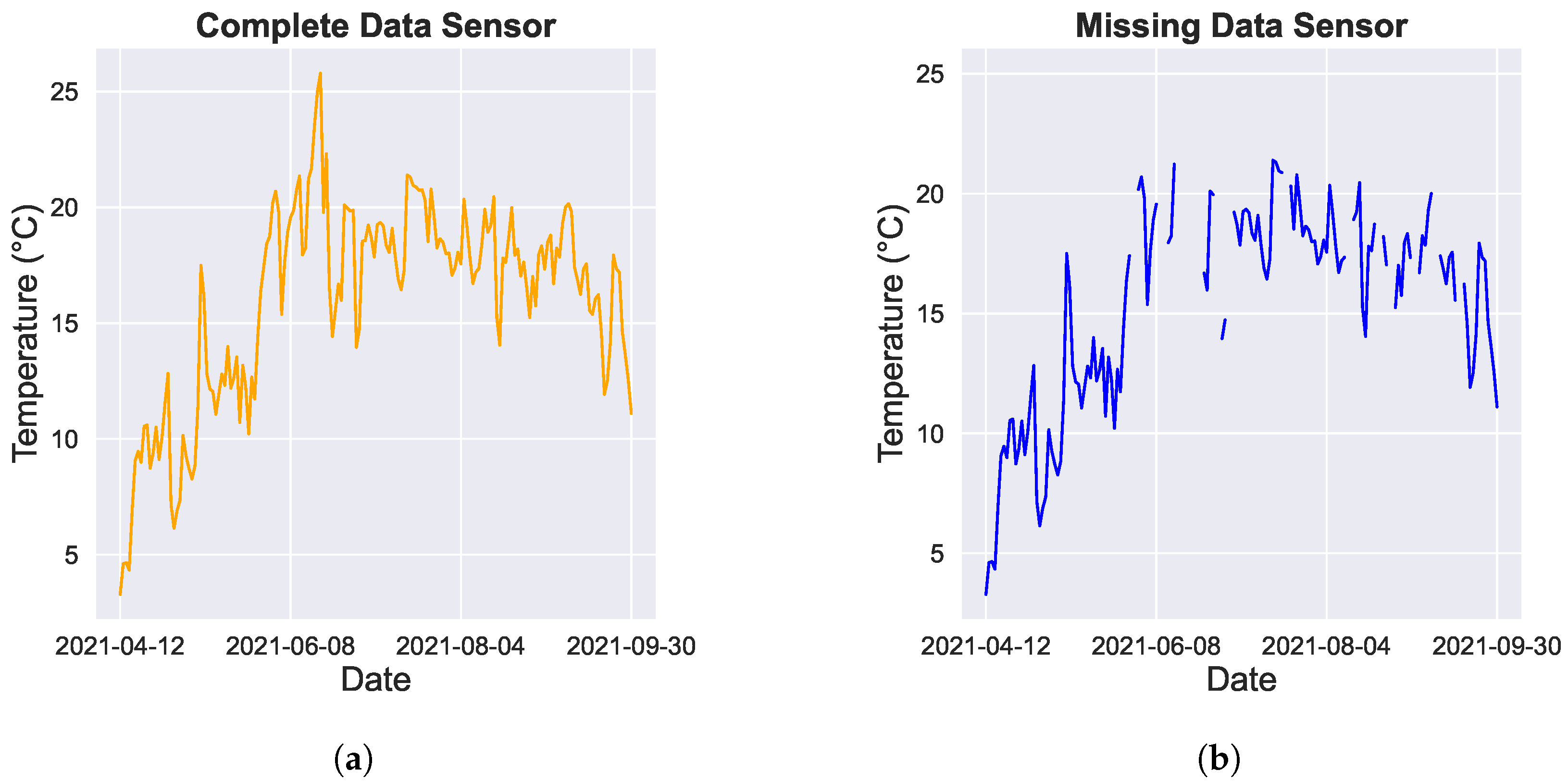
The objective of this study was to evaluate the performance of missing value imputation techniques on a dataset generated by a WSN for environmental monitoring. To this end, we employ a unique dataset that originated from one of the largest citizen science projects to date involving Internet of Things (IoT) monitoring. Throughout the summers of 2021 and 2022, 4400 citizens within the region of Flanders (Belgium) installed IoT sensors in their gardens to measure the temperature and soil moisture at a high temporal frequency (every 15 min). The goal of this citizen science project, called Curieuze-Neuzen in de Tuin; Nosy Parkers in the Garden (CNidT), was to gain insight into how garden ecosystems can provide cooling for climate adaptation and mitigate the impacts of extreme weather events like heat waves. In projects like CNidT, missing values in the sensor time series are undesirable, both from a scientific and from a citizen perspective. From a scientific perspective, the data incompleteness reduces the power of the ensuing statistical analysis, which here aimed to uncover the factors that drive local garden cooling during extreme weather events. Likewise, data incompleteness was also highly unwanted from the citizen perspective: participating citizens were updated daily through personal dashboards, while society at large was informed through real-time maps on the website of a national newspaper. However, missing values were common in the recorded time series due to a combination of random sensor failure (e.g., battery problems), failed data transfers (e.g., due to network outages), and errors made by the citizens (e.g., destruction or damaging of the sensor). For these reasons, the dataset from the CNidT project was especially suitable as a case study for missing value imputation in WSN data. The CNidT dataset is an integral component of the SoilTemp project, which is a publicly available database outlined in Lembrechts et al. (2020) [
7]. This extensive database comprises data from 7538 temperature sensors spanning 51 countries and encompassing diverse biomes. The primary objective of the SoilTemp project is to enhance the global comprehension of microclimates and to address discrepancies between existing climate data and the finer spatiotemporal resolutions pertinent to organisms and ecosystem dynamics [
7].
Given that missing data within WSNs pose a fundamental challenge, the development of methods capable of imputing these missing values represents an active area of research. Within our study, several imputation approaches were evaluated to analyze their performance. An overview of all considered approaches and their imputation strategies is given in
Table 1. A first approach involves techniques that take advantage of the temporal correlation between data, thus imputing missing values for a given sensor using the available data of that same sensor at different time steps. Evaluated methods for this approach include mean and linear spline imputation [
8]. A second class of techniques utilizes spatial correlation to impute values, focusing on data from other sensors in the network at the same time step to impute the missing values of one sensor. Evaluated methods for this approach include k Nearest Neighbors (KNN) imputation [
9], Multiple Imputation (MI) techniques such as Multiple Imputation using Chained Equations (MICE) and Markov Chain Monte Carlo (MCMC) [
10,
11,
12], and Random Forests (RFs) to replace missing data (MissForest) [
13]. The last strategy combines both the spatial and temporal aspects, taking full advantage of the patterns and intricacies present within the data. For this, specific methods for WSNs have been developed, such as Data Estimation using Statistical Models (DESM) and Applying k-Nearest Neighbor Estimation (AKE). Matrix Completion (MC) methods can also be exploited here as they use correlations within one sensor and across multiple sensors but assume that the data is static, i.e., they ignore the temporal component of the data [
14,
15]. Other methods in this class tend to leverage deep learning to impute missing values, for example Multiple Imputation using Denoising Autoencoders (MIDA) [
16] or Recurrent Neural Network (RNN)-based approaches such as Bidirectional Recurrent Imputation for Time Series (BRITS) and Multi-directional Recurrent Neural Network (M-RNN) [
15,
17]. For a detailed explanation of all imputation methods evaluated in this study, we refer to
Section 2.3.
Previous studies have conducted various comparative analyses, assessing different datasets, classes of algorithms, setups, and types or scenarios of missingness. However, in most studies, the focus is more on multivariate time series rather than on specific WSN data. Jadhav et al. [
18] compared seven imputation methods across five publicly available datasets, concluding that KNN imputation exhibited the highest performance. Similarly, Jäger et al. [
19] evaluated six imputation techniques on 69 datasets, noting that random forest-based solutions generally outperformed others. Notably, their study also evaluated performance in downstream Machine Learning (ML) tasks, finding that the imputation rendered a 10–20% performance increase. Khayati et al. [
20] focused on sensor time series imputation, comparing 16 recovery algorithms on six public and two synthetic datasets, including block missings, which are more reflective of WSN data characteristics. Their findings suggested that the optimal recovery method often depends on dataset-specific characteristics. Yozgatligil et al. [
21] assessed six imputation techniques using Turkish State Meteorological Service data, introducing the correlation dimension technique to account for spatiotemporal dependencies in imputation evaluation. Their study indicated that the MCMC approach yielded the most favorable results.
Table 1.
The imputation techniques that were considered in this study, together with their respective imputation strategy.
Table 1.
The imputation techniques that were considered in this study, together with their respective imputation strategy.
| Method | Imputation Strategy |
|---|
| AKE [6] | WSN-specific |
| BRITS [17] | Deep learning |
| DESM [22] | WSN-specific |
| KNN [9] | Spatial correlations |
| MC [14] | Temporal and spatial correlations (static) |
| MCMC [12] | Spatial correlations |
| MICE [11] | Spatial correlations |
| MIDA [16] | Deep learning |
| MRNN [15] | Deep learning |
| Mean imputation | Temporal correlations |
| MissForest [13] | Spatial correlations |
| Spline [8] | Temporal correlations |
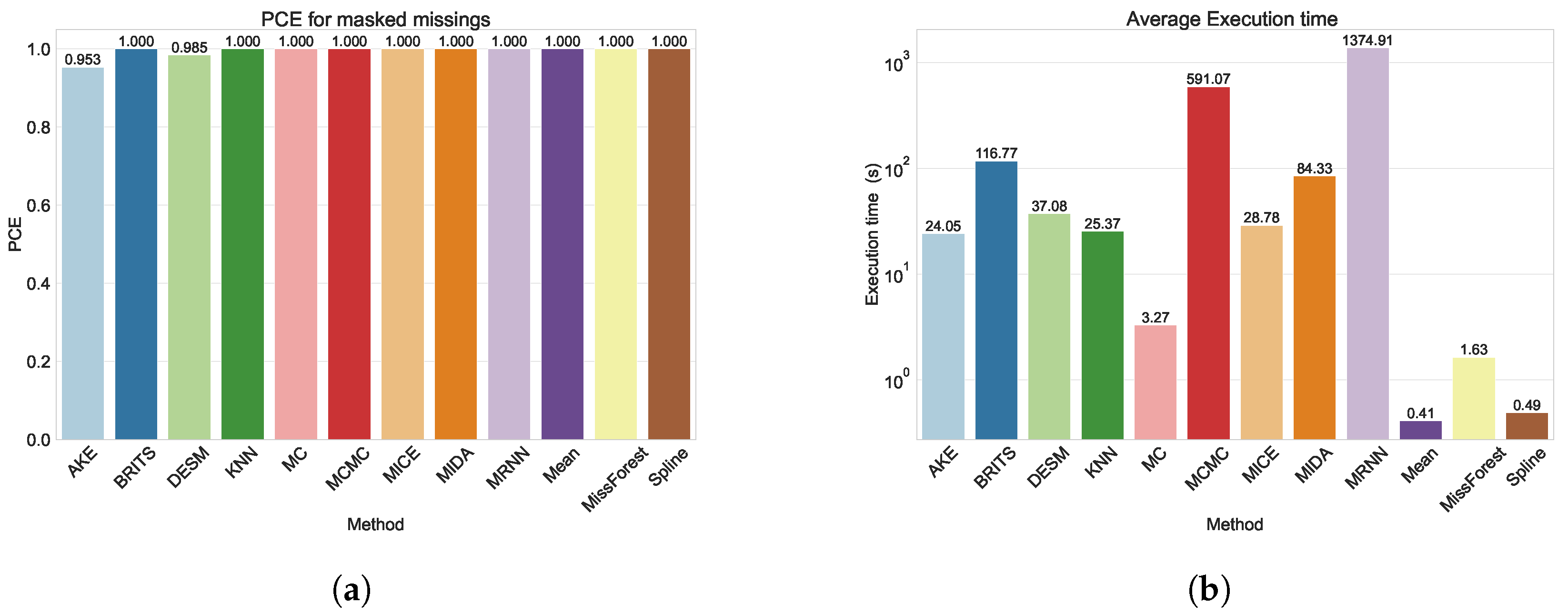
In this study, we evaluated 12 imputation techniques for different artificial missing scenarios (by inducing 10%, 20%, 30%, 40%, and 50% data removal), as well as a more realistic scenario defined as “masked” missings. In this scenario, we replicated the missing patterns observed in sensors with incomplete data onto sensors with complete information, simulating a real-world missings scenario. In this way, we created a standardized scenario through which we can evaluate how effective every method is in compensating for the missing patterns. Comparisons are made based on the Root-Mean-Square Error (RMSE) and Mean Absolute Error (MAE) to assess the accuracy of the imputed values. Our study advances the existing literature by conducting a comprehensive comparison of various missing value imputation methods, employing different strategies and model types. Moreover, we analyze a genuine WSN dataset featuring a substantial sensor count (1500) and expand the assessment of these techniques from random missing values to masked missing values, offering a more realistic evaluation scenario for practical deployment.
The remainder of this paper is structured as follows:
Section 2.1 introduces the CNidT project, while
Section 2.2 describes the dataset collected in the project, as well as the preprocessing steps that were used. In
Section 2.3, the imputation methods evaluated in this study are described, and the evaluation criteria are detailed in
Section 2.4.
Section 3 presents the results and discusses the implications of these results. In
Section 4, we summarize our findings, list the most important insights and conclusions, and provide possible directions for future research.
4. Conclusions
During the last decade, sensors have become increasingly important across scientific fields and industries. Unfortunately, sensor data often contain missing values, which can significantly hamper the interpretation and possible analysis of the collected data. Consequently, the importance of methods capable of imputing these missing values with accurate estimates has grown considerably. In this study, we conducted a comparison of twelve imputation methods on a unique environmental microclimate monitoring dataset collected by the CNidT citizen science project. We extend the current literature by providing an extensive comparison of different missing value imputation methods originating from different backgrounds and imputation strategies. In addition, our work considers a real WSN dataset with a large number of sensors (1500), which is uncommon in the literature. Furthermore, we extend the evaluation of the evaluated techniques from random missings to masked missings, which provides a highly realistic evaluation scenario for practical implementations.
We evaluated the imputation methods for two different missing patterns: random missings, with the degree of missingness ranging from 10% to 50%, and masked missings, which were obtained using realistic missing value patterns. For all missing patterns, the MC method outperformed all other methods. MissForest and MCMC also performed relatively well in both scenarios, while MICE only achieved good results for random missings. The methods that are designed for WSNs specifically also performed well in both scenarios; however, they were not able to provide imputations for all missing values in the masked missings scenario. Finally, the deep learning-based methods, M-RNN, MIDA, and BRITS, performed poorly for both missing patterns, which can be attributed to the characteristics of our dataset. We can conclude from the results obtained that the methods that exploit spatial correlations within the dataset tend to perform better than the other methods. This can be explained by the relatively small distance between sensors, as well as the granularity of the temporal component. Moreover, since the data encompassed the period from April to September, temperatures predominantly experienced an upward trajectory, making it challenging to discern a clear trend in the temporal aspects of the data. These results can be extrapolated to similar scenarios where the number of sensors is high and densely distributed with a comparable length of time. The success of methods such as MC, MissForest, and MCMC, particularly in capturing spatial correlations within the dataset, suggests that they would generalize well to such environments. Despite challenges posed by masked missing values, these methods still demonstrated robust performance, implying their potential applicability in scenarios with complex missing data patterns.
Future research can expand upon our study with a more detailed assessment of (other) methods on different datasets. More specifically, different numbers of sensors and temporal granularity can be evaluated to more clearly identify the impact of these dataset specific features on the evaluated models. This can aid in the identification of a general best imputation technique across different WSNs. Furthermore, in future studies concerning missing data imputation for WSNs, additional features of the sensors or locations can be used to address missing values, such as the type of microclimate location, or other measured variables, such as the humidity in our specific use case. Also, the development of novel WSN-specific methods that efficiently exploit all structures (spatial and temporal) that are available in the data, carry significant potential. For example, a method could use an MI approach by first imputing all missing values using temporal correlations and subsequently using these imputations to obtain a more accurate spatial imputation, or vice versa. Additionally, cost-sensitive methods for missing value imputation can be evaluated, where over- or underestimations of the actual value can be penalized more heavily. Moreover, the evaluation of the temporal and spatial granularity and its impact on the imputation performance for various methods could be a valuable addition. Finally, our comparative study focuses on daily temperature values, whereas it may be interesting to evaluate it per 15-min interval or hourly and assess the imputation performance.
In conclusion, we were able to successfully impute missing values in our unique environmental monitoring dataset and provided guidelines for researchers who want to impute missing values in a similar dataset. Ultimately, we found that the best method to impute missing values is often dataset-specific and should be identified using a set of artificially induced missings, preferably both randomly generated and based on a realistic missing pattern.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
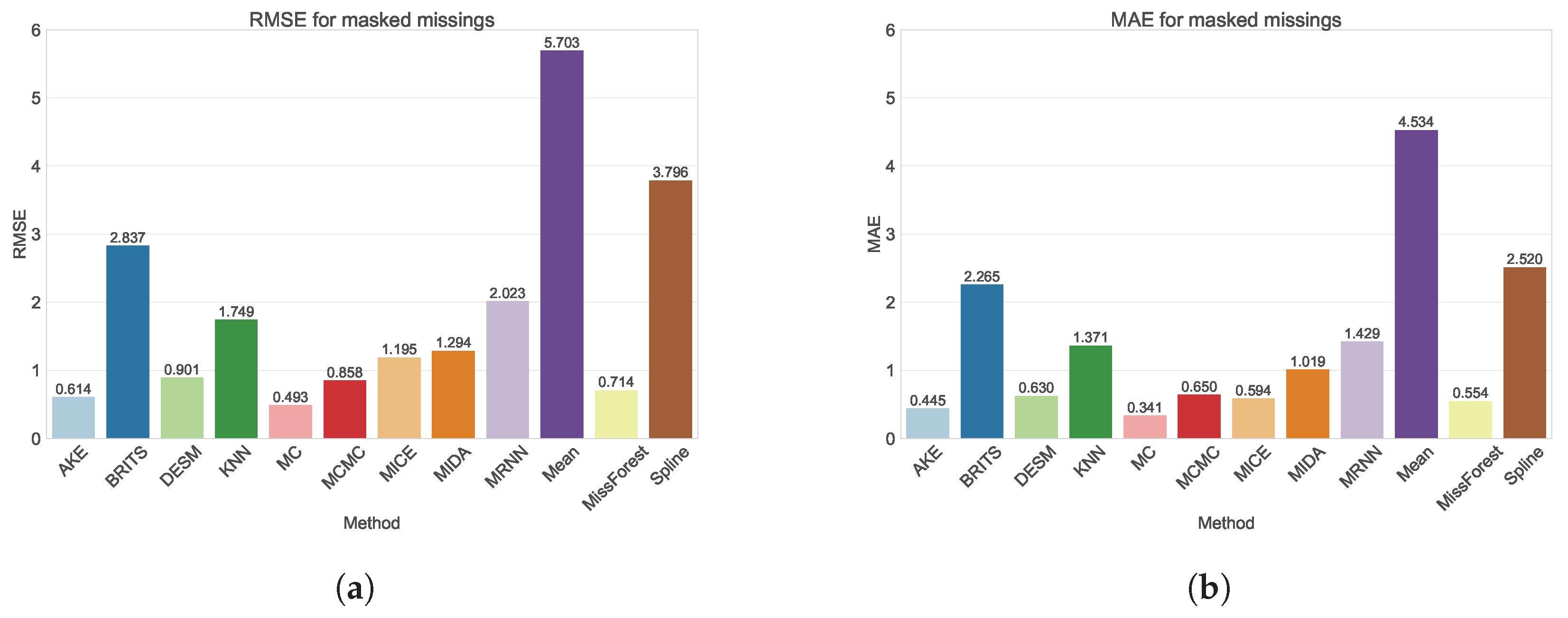{kind=link}
{kind=link}





