1. Introduction
Anomaly detection has been a central focus in machine learning research for many years. An anomaly in time series data is a deviation from the expected pattern or trend within a given time frame, showing up as outliers, fluctuations, or changes in the data, indicating unusual behavior [
1]. Livestock anomalies refer to unexpected changes in trends or patterns, such as irregularities in population dynamics, production metrics, or environmental factors like temperature, humidity, and gases. It has widespread applications across various domains, including livestock farming [
2], cyber-intrusion detection, healthcare, sensor networks, and image anomaly detection. The expansion of livestock farms and the number of animals necessitate advanced management techniques for optimizing productivity with limited manpower. Failure to address the irregularities in livestock data can lead to various consequences, including untreated illnesses, reduced productivity, and heightened mortality rates, posing significant risks to animal welfare and farm profitability [
3]. Detection and management of these anomalies are crucial for ensuring optimal farm management and animal well-being. Precision farming emerges as a solution, propelling the transition toward automated livestock smart farms [
4]. Central to this is anomaly detection, which is crucial in sectors like finance and healthcare but pivotal in livestock management. Farmers can gain valuable insights by detecting outliers in data points that deviate significantly from typical patterns, which are frequently caused by discrepancies and errors in the sensors. Organizations are exploring methods to enhance pig productivity with minimal human involvement. Livestock health, well-being, and productivity can be significantly improved by paying close attention to them and promptly detecting anomalies. This can help in identifying potential health issues or environmental inconsistencies in livestock settings, allowing for swift interventions to maintain animal welfare and farm productivity. Studies have demonstrated that focusing on the livestock sector can result in positive outcomes, as evidenced by a wealth of research [
4,
5]. Given the increasing scale of livestock rearing, adopting intelligent agricultural solutions is essential to ensuring optimal farm and livestock housing conditions, especially in pig farming, where it is crucial. The seamless integration of different equipment within and around barns is essential for creating and maintaining optimal growth conditions for livestock. Gas sensors in pig barns ensure the safety and health of animals and workers. Conventional outlier detection techniques lack efficacy when dealing with large, multi-dimensional datasets. Autoencoders, representing a type of deep learning technique, have excelled in detecting outliers due to their ability to identify complex patterns and relationships in the data. Autoencoders have revolutionized anomaly detection and prediction [
6]. Advanced analytical techniques have the capability to identify complex, nonlinear relationships within data. These techniques allow for the precise identification of anomalies in offering predictive insights essential for improving the efficiency and productivity of livestock management.
Having accurate data is essential for making informed decisions. Several factors can cause variations in data quality, including measurement errors, inaccurate data entries, sensor failures, or deliberate sabotage. These challenges can be complex to manage using sophisticated methodologies. Analyzing spatial interconnections within multi-sensor datasets is crucial for making informed decisions in the current era. The complexity lies in differentiating between noise, typical, and atypical data. Therefore, there is a need for a dependable mechanism that enables precise identification and interpretation of such data. Several approaches for analyzing spatial dependencies in multiple sensors have been studied [
7,
8]. To deal with such challenges, researchers have developed various methods, e.g., data-driven anomaly detection [
9] and maximum mean discrepancy (MMD) [
10]. Deep learning approaches, especially those involving autoencoders, have surfaced as potent solutions for outlier detection, although some may fall short in performance. Their performance is often tied to their adeptness in unraveling intricate nonlinear relationships within data [
11,
12]. Through learning intricate data patterns, these techniques facilitate enhanced anomaly identification, fostering a more accurate and insightful analysis.
Pig house sensors collect real-time management data, ensuring optimal growth and animal welfare. Equipment inside and outside the house maintains a suitable environment and boosts productivity. Gas sensors monitor hazardous gases like carbon dioxide CO
2 and ammonia NH
3 which can accumulate due to animal respiration and waste. Integrating gas sensors with ventilation systems helps control the indoor climate and maintain a healthy environment for animals and workers. High carbon dioxide CO
2 levels can pose a suffocation risk [
13,
14]. Using mechanisms that capture spatial–temporal correlations and dependencies among diverse data streams has proven highly effective. Traditional models like RNNs, VAEs, or GANs may need to become more capable of addressing this challenge with the same level of efficiency [
15]. Using our proprietary dataset from the pig farm, we show that pig diseases are the most critical factor affecting productivity. Preventing infections is crucial for maintaining pig productivity. Proper maintenance of the pig house and equipment can create a healthier environment and decrease the chances of infection [
16,
17].
Autoencoder-based models are effective in smart farming, especially in anomaly detection. A study found that they can detect anomalies in agricultural vehicles by identifying obstructive objects in the field. The study also introduced a semi-supervised autoencoder trained with a max-margin-inspired loss function that outperformed basic and denoising autoencoders in the generation of anomaly maps using relative-perceptual–L1 loss [
18]. According to the research, autoencoders are identified as a versatile tool for anomaly detection. Autoencoders use an encoder and a decoder to minimize reconstruction errors for normal data. Anomalies result in higher reconstruction errors and are identifiable as outliers [
19,
20].
Several techniques have been proposed to overcome the limitations of outlier detection: LSTM, LSTM-AE, ConvLSTM, and GRU. These standard techniques have limitations in identifying the capacity to detect a wider range of subtle and complex anomalies, especially in intricate, dynamic industrial environments [
21,
22]. One such technique is represented by ensemble methods which combine the outputs of multiple models to improve accuracy and robustness. Like in any technology, there is always a chance of malfunction, probably leading to undetected hazardous conditions [
23]. Advanced analytics and machine learning improve the speed and accuracy of real-time data processing, enabling precise anomaly detection and interpretation of complex data relationships in livestock farming. However, the growing use of IoT devices in agriculture raises security and privacy concerns that must be addressed. Current anomaly detection methods in agriculture, especially in livestock farming and industrial settings, must handle real-time, multi-dimensional data. Traditional autoencoder architectures struggle to adapt to the complexities of dynamic and noisy farm environments. Unpredictable variables often affect data in this field, resulting in a higher rate of false positives or negatives.
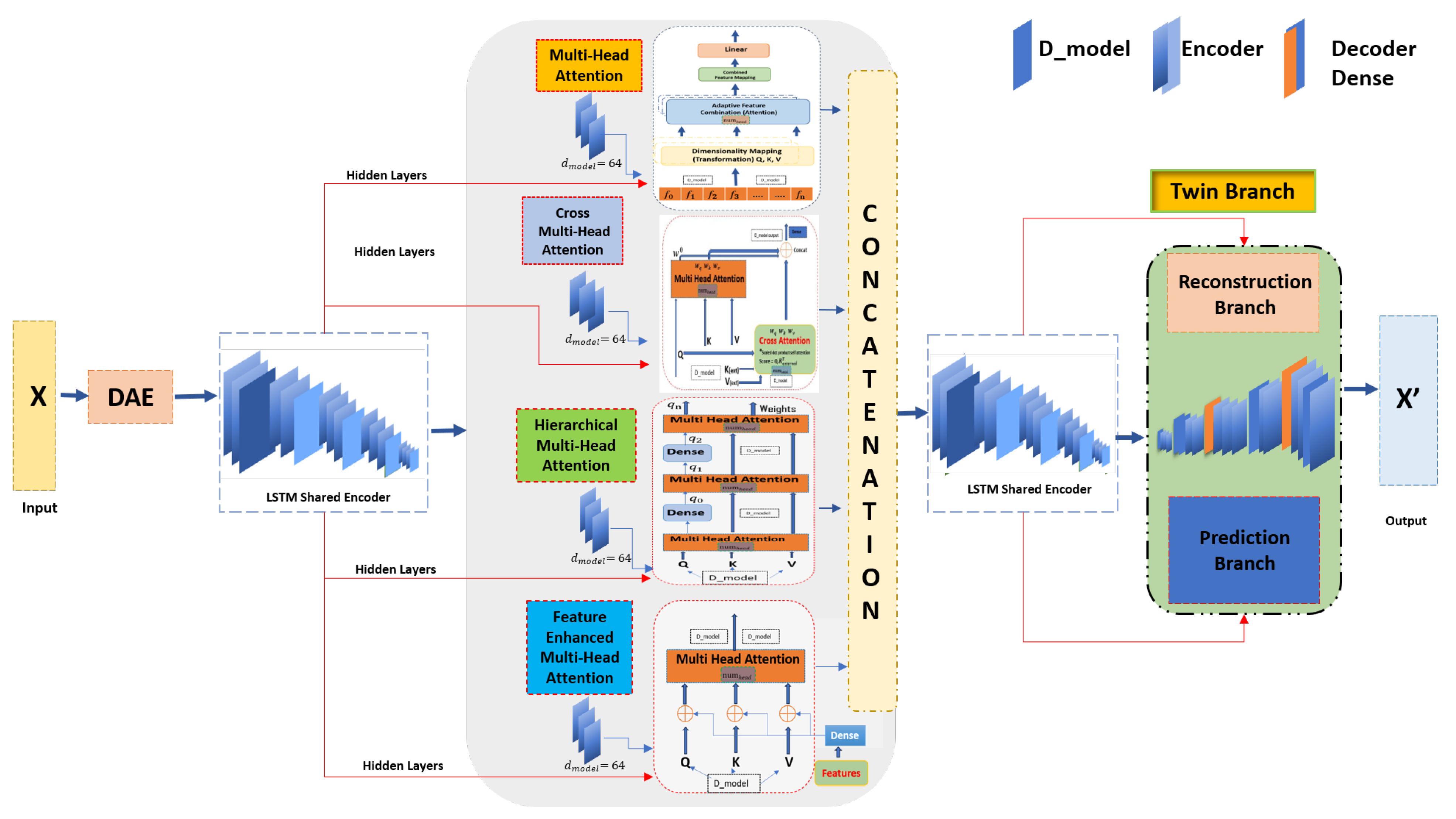
In our research, we present a new model called the “TimeTector (TT-TBAD)”, which offers a revolutionary approach to detecting anomalies in agricultural environments. Our innovative methodology is specifically designed to handle the complexities and nuances of multi-sensor and real-time series data that are common in farming settings, thereby providing a robust and advanced autoencoder ensemble approach that addresses the unique challenges of monitoring pig farm environments. It is capable of detecting outliers with remarkable accuracy and can also make predictive inferences, which is a feature that is often absent in traditional models. As a result, “TimeTector (TT-TBAD)” represents a significant advancement in the field, providing an effective and precise solution for detecting anomalies in critical agricultural applications. Our innovative TT-TBAD methodology is designed to detect anomalies in livestock sensor data using advanced techniques. It utilizes a Twin-Branch Shared LSTM Autoencoder framework, incorporating a Denoising Autoencoder (DAE) and several Multi-Head Attention mechanisms. This approach can be used to effectively handle the noisy data commonly found in agricultural settings. The model captures complex spatial–temporal correlations and hierarchical relationships while minimizing reconstruction and prediction errors. Real-time performance insights are provided via a dynamic feedback loop. Optimized for multi-sensor time series data, TT-TBAD enhances data quality by reducing noise and providing accurate forecasts, enabling proactive farm management and improved productivity and animal welfare. In summary, this study makes three key contributions:
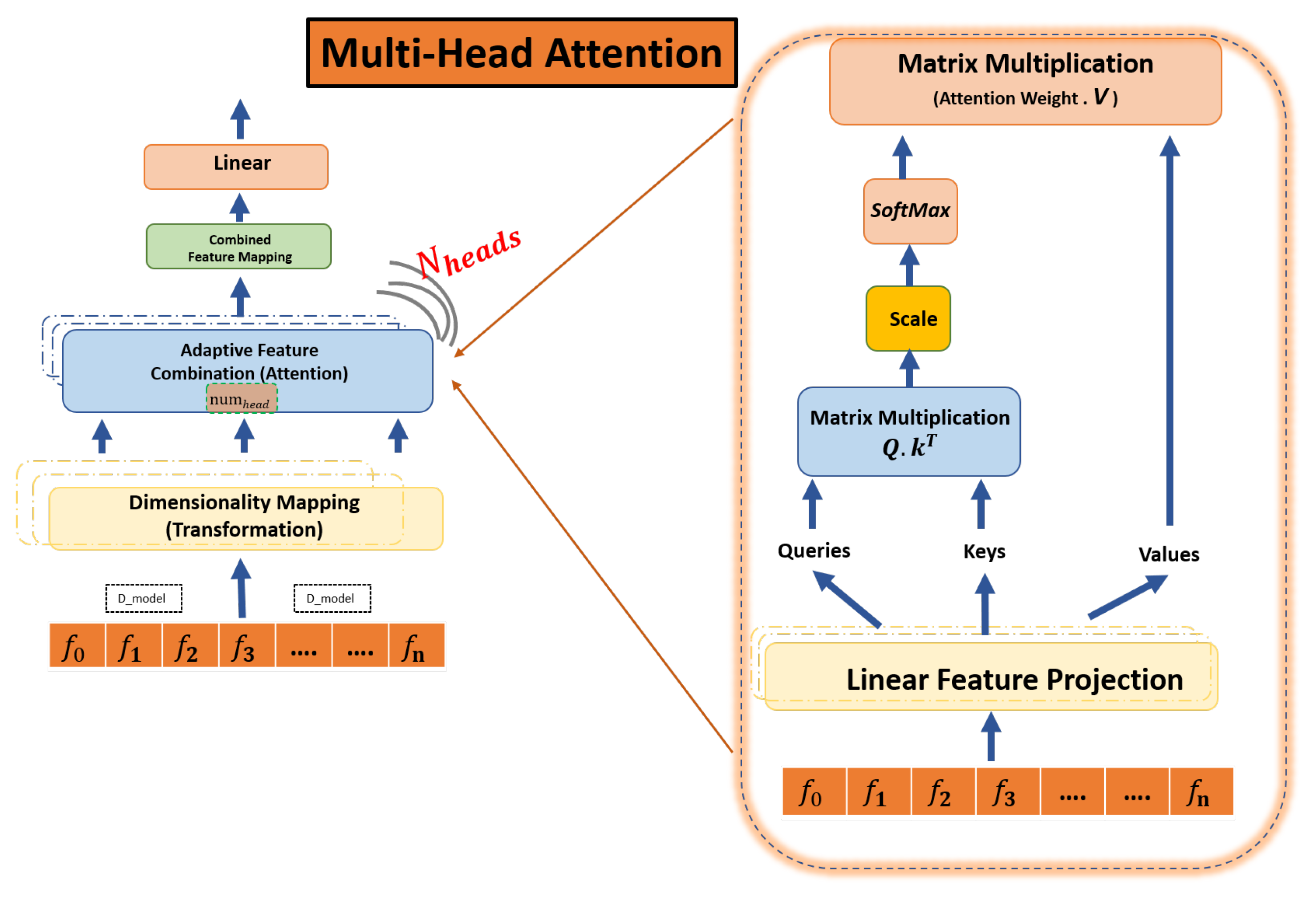
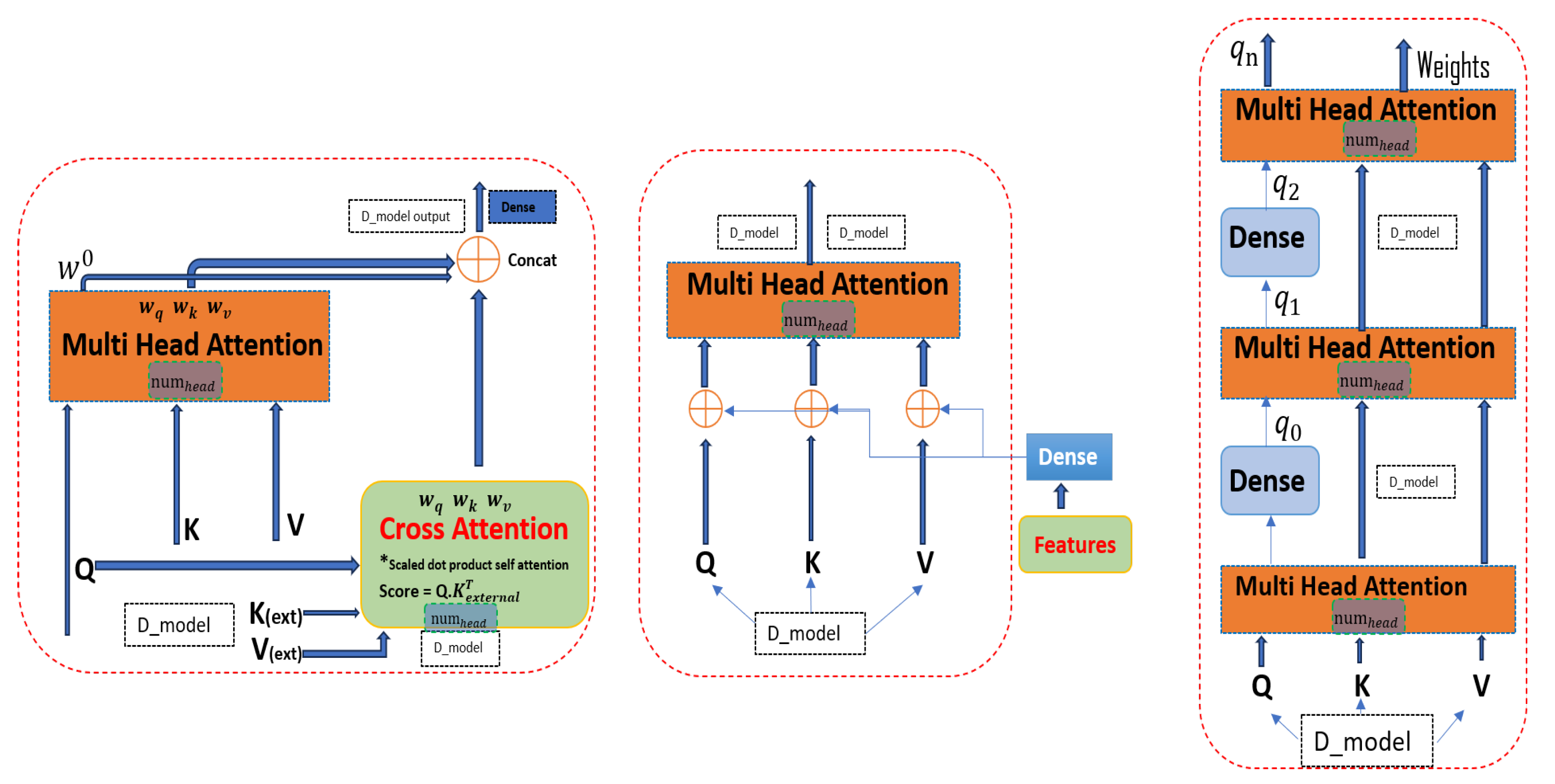
This model integrates advanced mechanisms, including Multi-Head Attention, Hierarchical Multi-Head Attention, Cross Multi-Head Attention, and Feature-Enhanced Multi-Head Attention. These features enable the analysis of hierarchical data, identification of complex relationships, and interpretation of auxiliary features. Moreover, the model’s dual-branch LSTM structure enhances spatial–temporal data analysis, resulting in improved accuracy for anomaly detection in livestock farming, a capability not adequately addressed by traditional models.
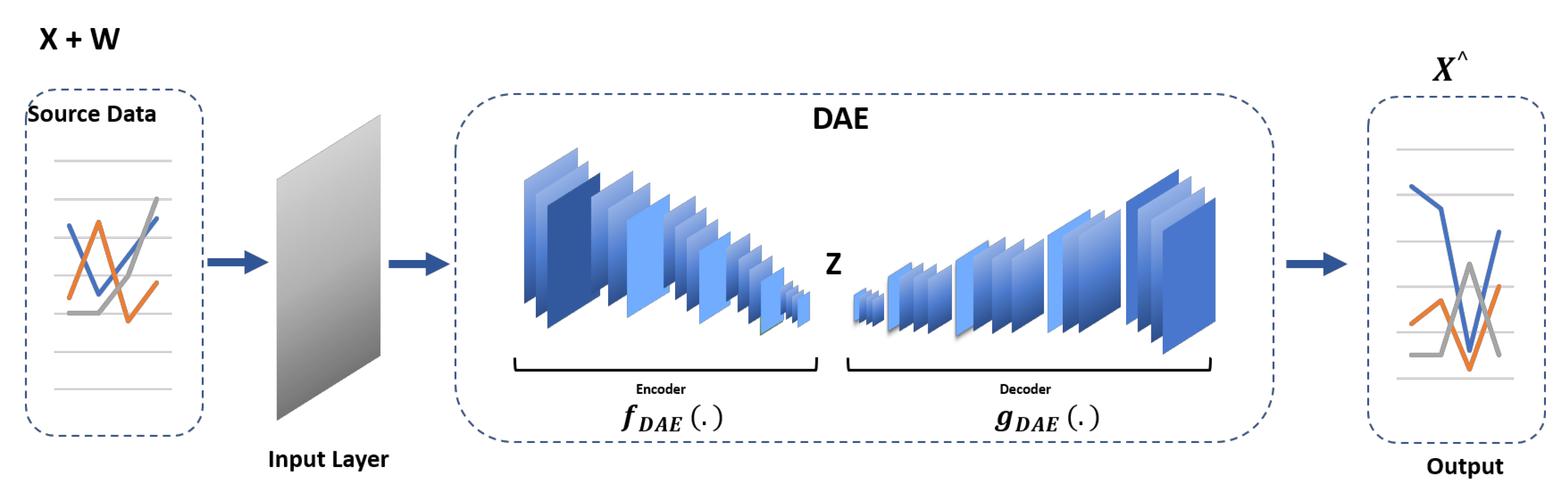
The integration of a Denoising Autoencoder (DAE) with Shared LSTM encoder branches manages noisy agricultural sensor data during training, mitigating overfitting and enhancing adaptability. The development of a Twin-Branch structure for multi-task learning enables simultaneous data reconstruction and future prediction, distinguishing between normal operations, noisy data, and anomalies. This dual-task learning approach generates precise, actionable insights in real time, a capability not typically found in traditional models.
The developed model uses a feedback loop based on reconstruction and prediction errors to continuously monitor and adjust its performance, through a dynamic rather than static threshold-based mechanism. This adaptive mechanism significantly improves the detection accuracy and the model’s adaptability to evolving farm conditions by boosting the accuracy and adaptability in anomaly detection, aiding decision-making. Finally, evaluation results showed a lower construction on error (MSE, MAE, and RMSE) and high accuracy (precision, recall, and F1) when evaluated against the benchmark and baseline anomaly detection models.
The rest of the paper is organized as follows:
Section 2 provides related work, exploring state-of-the-art techniques for anomaly detection in sensor data.
Section 3 and
Section 4 describe our proposed methodology and detailed framework. The dataset explanation and analysis are described in
Section 5. Performance evaluation, results, and analysis of the experiment follow in
Section 6. Finally,
Section 8 concludes the paper with directions for possible future work.
2. Related Work
Several research studies have been performed on existing state-of-the-art techniques for detecting anomalies in indoor and outdoor pig farm environment datasets and other similar fields [
24]. This detection process has been studied for decades in natural language processing (NLP) and images and videos [
25]. Various methods are available for anomaly detection, including statistical, supervised machine learning-based, and unsupervised deep learning-based approaches. These methods have been explored in detail through literature reviews in similar studies; as such, our focus is on unsupervised learning due to the lack of labels. Outlier detection in real-time series data has unique challenges that require efficient processing and handling of data drift or concept drift [
26]. Machine learning and deep learning advancements in analyzing time series data from sensor networks show that spatial information from sensor locations can be leveraged to improve predictions [
27].
The use of techniques such as sliding windows, feature selection, and online learning algorithms for handling real-time series data in outlier detection tasks has been explored in previous research, where challenges specific to real-time series data in outlier detection have been acknowledged [
28]. These challenges include handling the data drift, where the statistical properties of the data change over time, and the concept drift, where there is the evolution of the underlying concepts being monitored. To address these challenges, techniques like sliding windows, which limit the data window for analysis, and feature selection, which focuses on the most relevant attributes, have been explored [
29]. Additionally, online learning and multilayer neurocontrol of high-order uncertain nonlinear systems with active disturbance rejection algorithms, which adapt to changing data distributions and solve real-world problems, have been investigated to improve the efficiency of outlier detection in real-time scenarios [
30,
31].
Additionally, autoencoder-based anomaly detection has proven to be highly effective in IoT-based smart farming systems, exhibiting exceptional performance in accurately detecting anomalies in key variables such as soil moisture, air temperature, and air humidity. The integration of this technology has shown superior performance, making it a valuable tool for precision agriculture. This study proposes a new approach for anomaly detection using autoencoder-based reconstructed inputs. The proposed method outperforms existing techniques and facilitates the creation of supervised datasets for further research. The hourly forecasting models for soil moisture and air temperature demonstrate low numbers of estimation errors, indicating the effectiveness of this method [
32].
In order to improve the accuracy of intrusion detection on the Internet of Things (IoT), intrusion labels are integrated into the decoding layers of the model. However, this approach may not effectively handle the data and concept drift challenges frequently encountered in real-time anomaly detection. Additionally, multi-sensor technology IoT devices can be used in both cloud and edge computing infrastructure to provide remote control of watering and fertilization, real-time monitoring of farm conditions, and solutions for more sustainable practices. However, these improvements in efficiency and ease of use come with increased risks to security and privacy. Combining vulnerable IoT devices with the critical infrastructure of the agriculture domain broadens the attack surface for adversaries, making it easier for them to launch cyber-attacks [
33]. An end-to-end deep learning framework for extracting fault-sensitive features from multi-sensor time series data showcases data-driven methods to handle spatiotemporal cases [
34].
Anomaly detection involves a comprehensive survey of deep learning techniques for anomaly detection, covering various methods and their applications across different domains. However, the survey might not delve deep into real-time series data anomaly detection [
35]. A survey on anomaly detection that focused on time series using deep learning and covered a range of applications, including healthcare and manufacturing, provided specific insights into livestock health monitoring or multi-task learning [
36]. Knowledge distillation for compressing an unsupervised anomaly detection model and addressing the challenge of deploying models on resource-constrained devices are examples of the challenges associated with real-time data processing and multi-task learning in anomaly detection [
37]. One learning-based study introduced a simple yet effective method for anomaly detection by learning small perturbations to perturb normal data and subsequently classifying the normal and perturbed data into two different classes using deep neural networks. The focus on perturbation learning might not align with the Multi-Head Attention and memory-driven multi-task learning approaches in our work [
38].
5. Dataset Analysis and Explanation
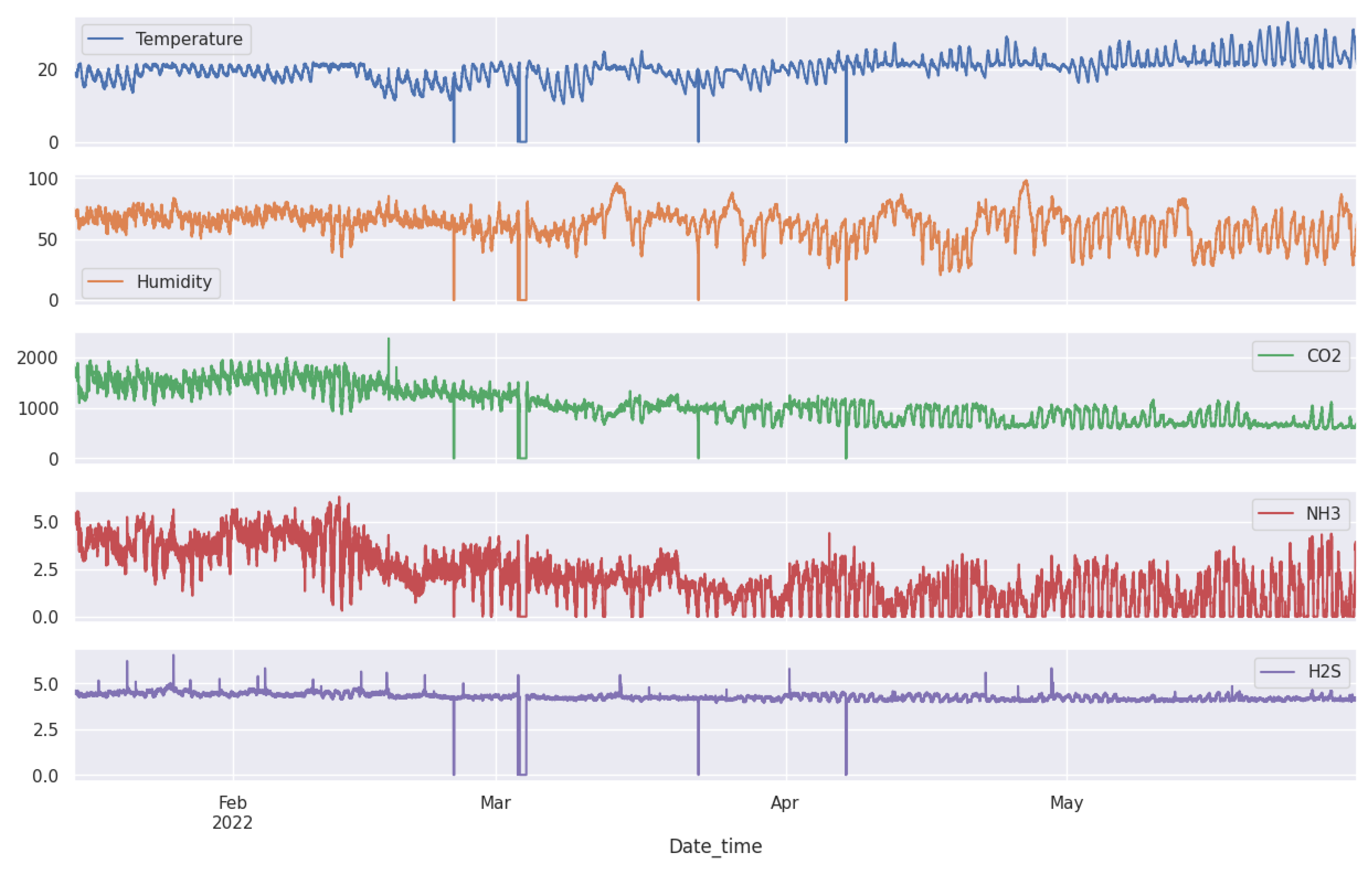
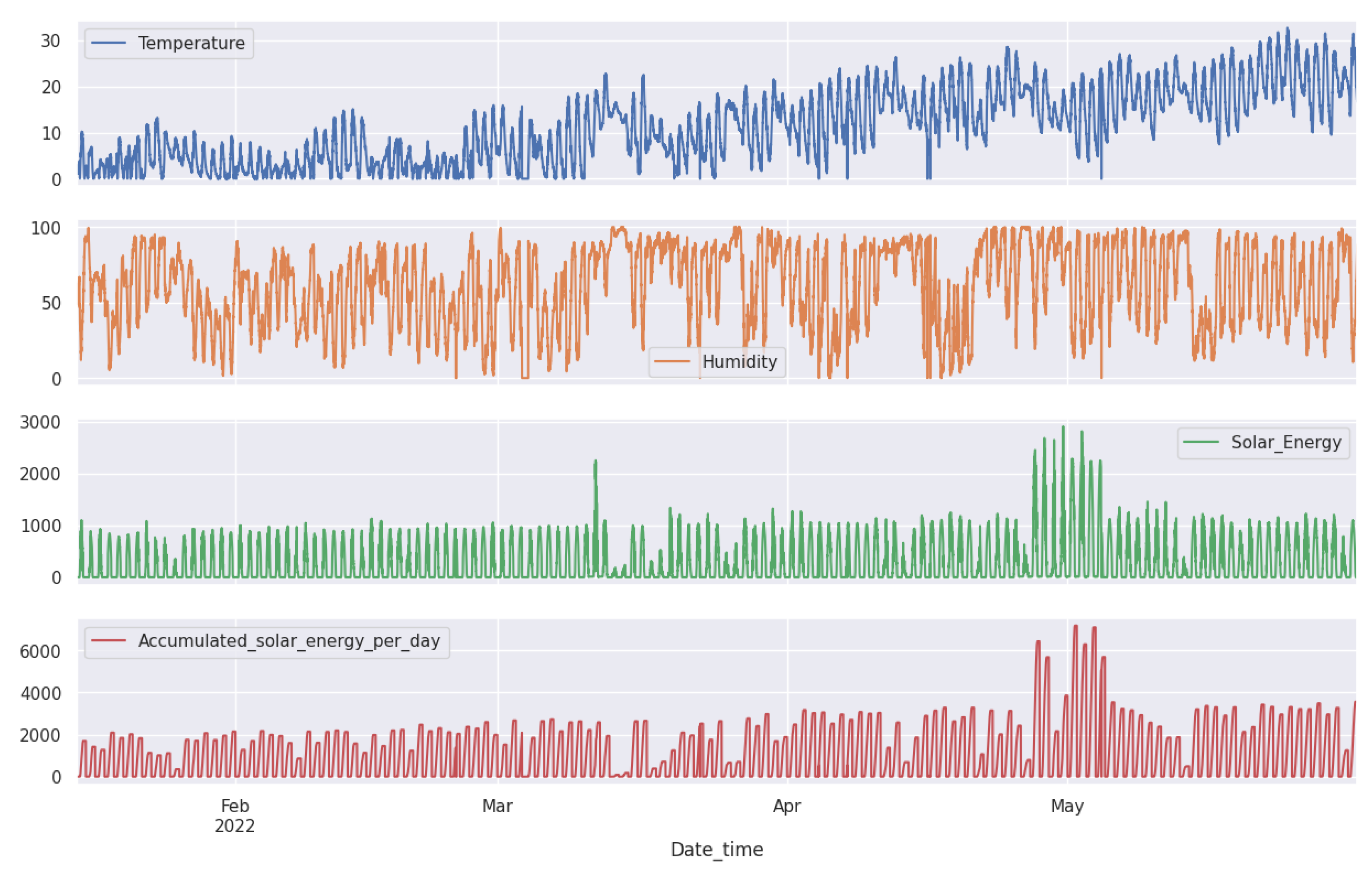
The datasets as shown in
Figure 7 and
Figure 8 are composed of multiple time series produced by different sensors. These sensors help us maintain a comfortable environment for the pigs. We installed several sensors inside our pig barn to monitor temperature (°C), humidity (%), carbon dioxide CO
2 (ppm), ammonia NH
3 (ppm), and hydrogen sulfide H
2S (ppm).
We installed weather forecasting devices outside to obtain accurate weather readings. These devices include temperature (°C), humidity (%), carbon dioxide CO
2 (ppm), ammonia NH
3 (ppm), and hydrogen sulfide H
2S (ppm). By monitoring both the inside and outside environment, we can make informed decisions to ensure the well-being of our pigs, as shown in
Figure 9. Our setup consists of interconnected sensors that generate copious amounts of data, up to 39,456 data points per sensor. Additional details are found in
Table 1.
All these sensors converge at a local server, Jetson Nano, where the data are immediately stored as they are collected. Acting as an intermediate repository and processing node, this Jetson Nano is then connected to a central server, which serves as a comprehensive data hub for all the collected data. This includes sensor data, imagery, and video feeds from cameras, all securely stored in real-time to ensure seamless consolidation, correlation, and analysis. As mentioned in the introduction in
Section 1, the dataset is sourced from our pig barn farm project. The sensors produce data with a 5-min delay, creating a multivariate time series of nine features. These features include information about the indoor conditions of the barn, such as fattening and outdoor weather forecasts. For more detailed information, please refer to
Table 1.
5.1. Data Analysis and Correlation
In livestock farming, environmental parameters play a vital role in animal health, growth, and productivity. Even minor changes in temperature or CO
2 levels can drastically affect the well-being of these animals as shown in
Figure 10. Therefore, it is crucial to study moderate correlations that may seem insignificant at first glance.
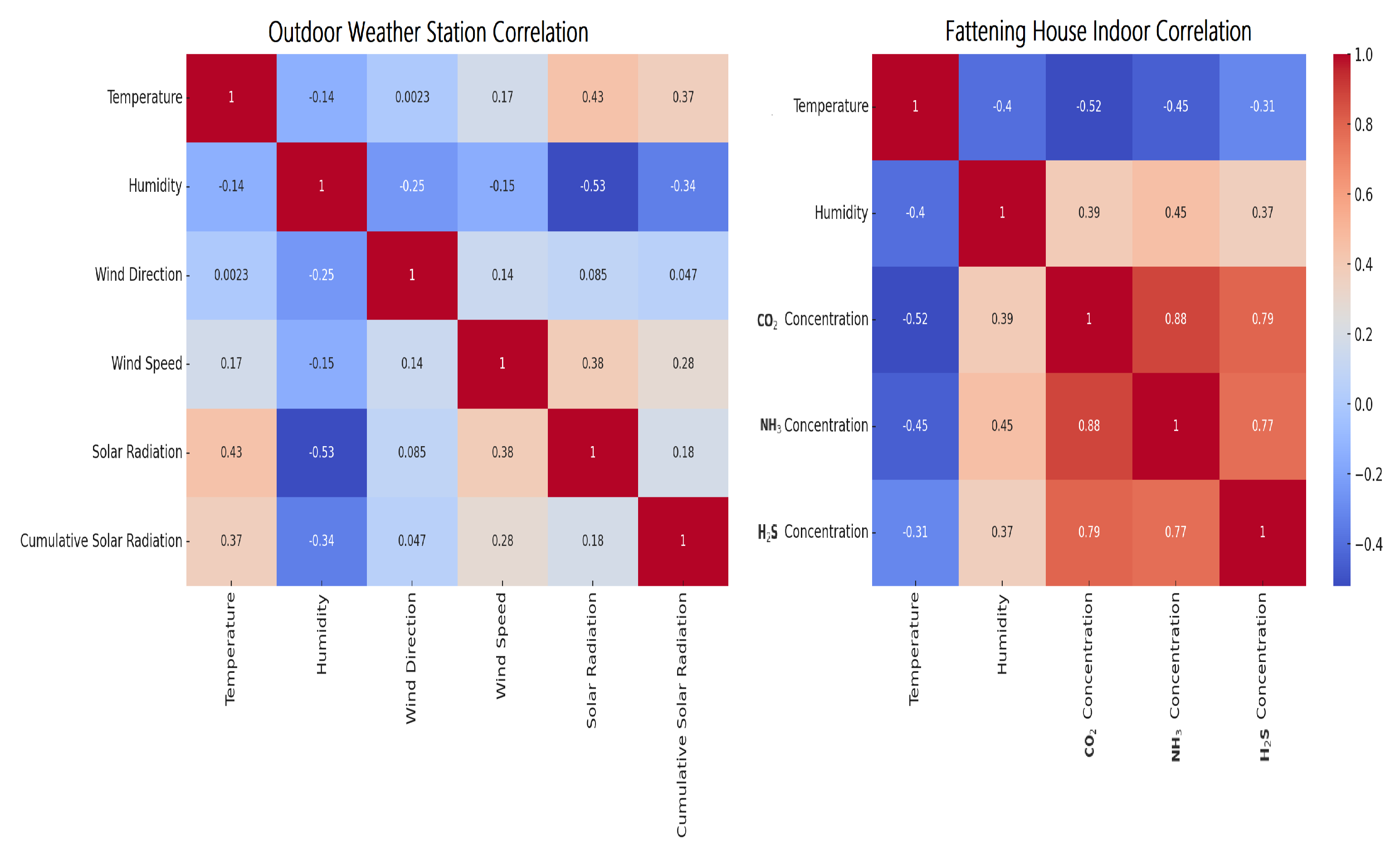
5.2. Outdoor Weather Station Correlation
Our research shows that temperature and humidity are negatively correlated, indicating that when temperature increases, humidity tends to decrease, and vice versa. On the other hand, solar radiation is positively correlated with cumulative solar radiation, which is expected as the latter is a cumulative measure. The other features do not exhibit strong correlations as shown in
Figure 10 (left).
5.3. Fattening House Indoor Correlation
Figure 10 (right) shows that temperature and humidity are negatively correlated, which is the same as at the outdoor weather station, with similar data for outdoors. CO
2 concentration has a slight negative correlation with humidity. The other features in the fattening house data do not have strong correlations.
When analyzing data, it is crucial to consider the correlation between variables. The strength of the correlation can be classified into three categories.
5.3.1. Weak Correlation
Even if the correlation is weak, it should still be considered if the variable has practical significance, such as CO
2 levels. General interpretations for the strength of the correlation coefficient (
rr) can be
5.3.2. Moderate Correlation
Moderate correlations should be closely examined, as their combined effects or interactions with other variables may be important as shown in Equation (
32).
5.3.3. Strong Correlation
Strong correlations are obviously significant and should be included in the analysis. However, if using linear models, caution should be observed regarding multicollinearity as given in Equation (
33).
6. Experimental Results and Discussion
6.1. Implementation Details
We developed and tested anomaly detection models for multivariate time series using a Shared LSTM Twin-Branch technique and a Multi-Head Attention mechanism. The models were implemented in Python 3.7 using popular frameworks such as Pandas, NumPy, Scikit-Learn, TensorFlow 2, and the Keras API. The experiments were performed on a PC equipped with an Intel (R) CoreTM i7-10700 CPU @ 2.90 GHz and 32 GB of RAM. The model architecture parameters are explained in
Table 2.
6.2. Performance Metrics
The process of evaluating an unlabeled anomaly detection model involves using various performance metrics, including mean squared error (MSE), mean absolute error (MAE), root mean squared error (RMSE), and the
score as shown in Equations (
34)–(
37). These metrics are instrumental in the accurate assessment of the model’s performance. While MSE and MAE capture the reconstruction errors vital for anomaly detection, RMSE provides additional information on the magnitude of errors. In addition, the
score, although unusual in anomaly detection, helps in comparing the ability of our model to capture data variance with that of baseline models as given in the equations below. This comprehensive set of metrics ensures that our model’s anomaly detection performance is robust, even in the absence of ground truth labels [
11].
The model parameters and their respective values are detailed in
Table 2. We split the raw data into training and validation sets to train our model, with an 80% and 10% split, respectively. Since we do not have separate data for testing, we set aside 10% of the data for testing the model, as given in
Table 1. To normalize the data, we utilized the MinMaxScaler from the scikit–learn library in Python, which scales each feature to a specified range, usually between zero and one. Normalization guarantees that each feature contributes equally to the final prediction, which is particularly useful when dealing with features of varying magnitudes. It also aids in model convergence during training and ensures accurate model performance evaluation through reported metrics such as MSE, MAE, RMSE, and
Score across all features. The batch sizes of the dataset used for training the model varied from 24 to 32. To enhance the ability of the model to learn data representation and make the training more robust, we included Gaussian noise using DAE in the training set. The progress of model training was analyzed using a sophisticated monitoring technique known as the feedback loop paradigm [
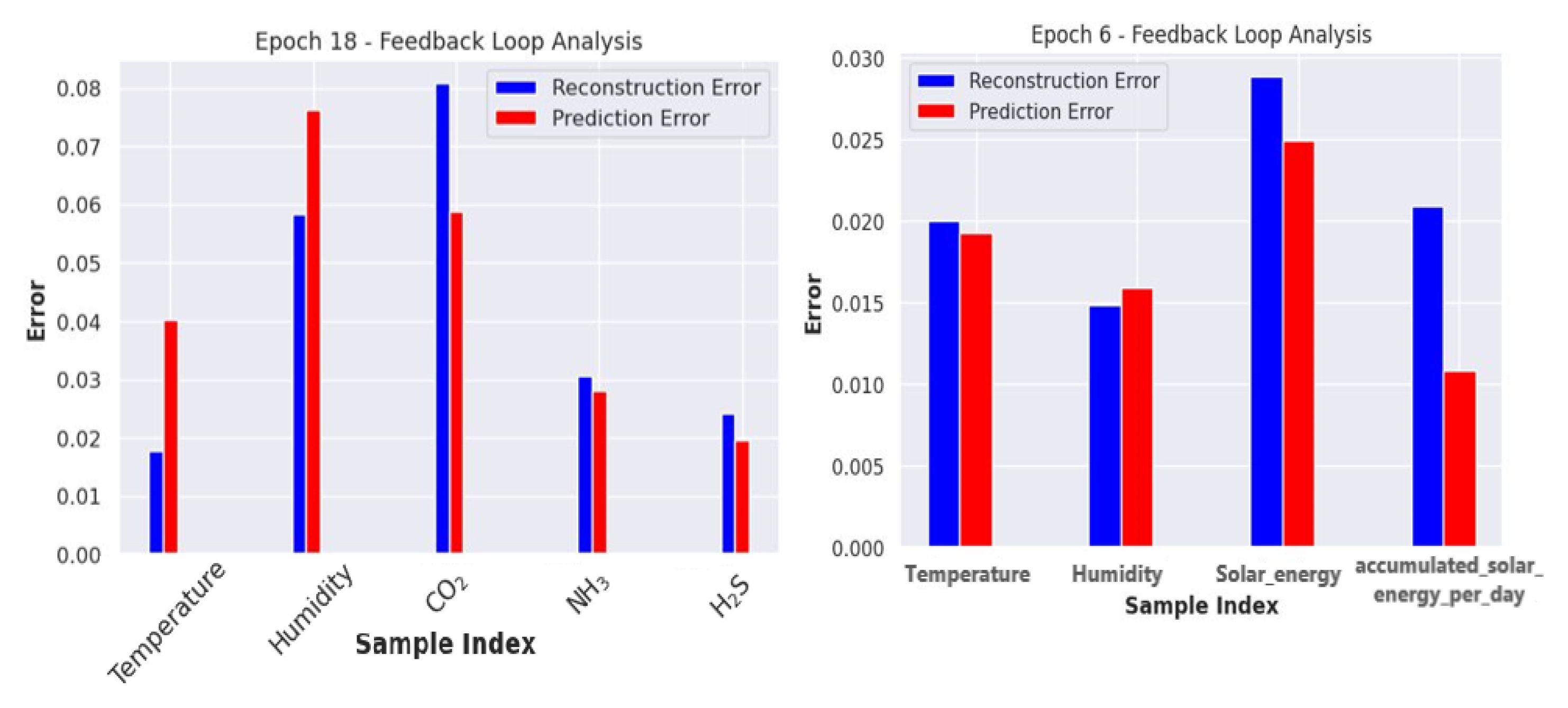
44], which allowed for a meticulous examination of the process. The reconstruction and prediction errors were comprehensively evaluated throughout each epoch and systematically recorded. These errors were visualized as a bar graph, revealing feature-specific and iteration-specific nuances, as demonstrated in
Figure 11. This in-depth analysis facilitated a nuanced understanding of the model’s learning dynamics, providing insights into the complex challenges encountered and overcome during training. Eventually, the model was successfully trained on the validation set after employing specific techniques.
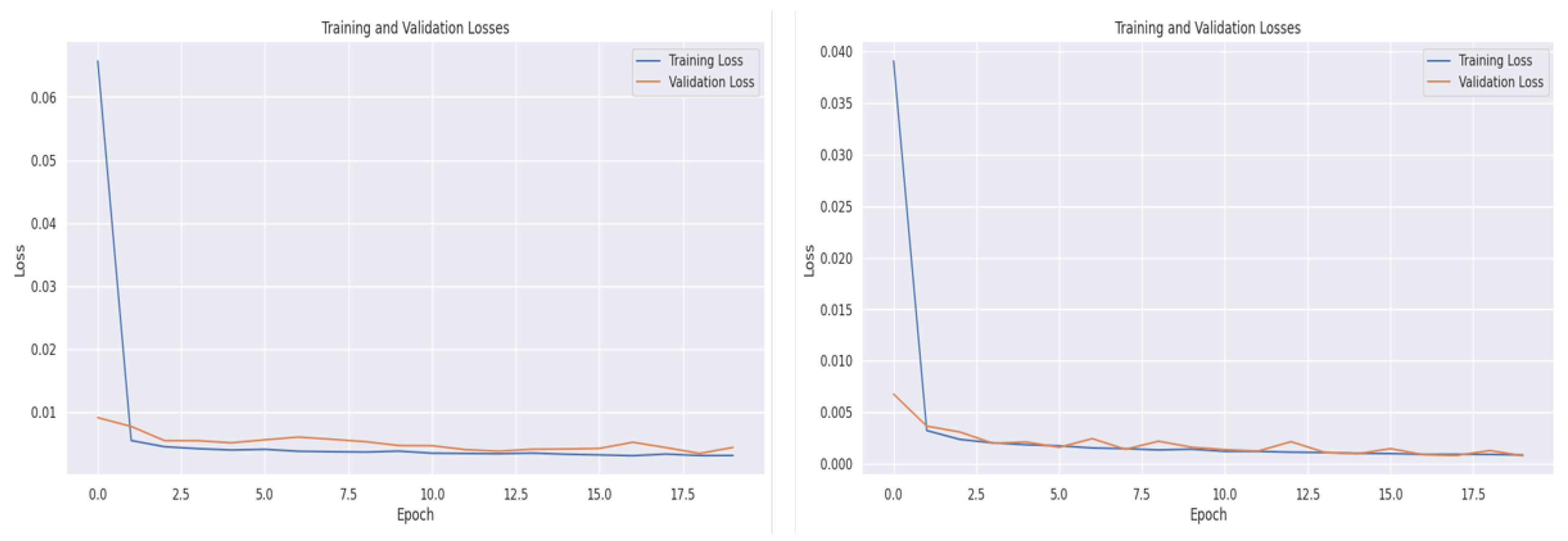
During the training of our model, we evaluated its performance on the validation dataset for each epoch. The graph in
Figure 12 shows the model performance on the indoor fatten barn dataset and the outdoor weather forecast dataset. The graph highlights that the model learned quickly at the beginning of the training process, but the loss curves stabilized in the later epochs to avoid overfitting. We employed the
kernelregularization technique to prevent overfitting, which is elaborated in
Table 2. Additionally, we applied the early stopping technique to save computational resources.
6.3. Anomaly Detection and Prediction for the Indoor Fattening Barn Environment Dataset
Our model is trained using a shared LSTM encoder with several Multi-Head Attention mechanisms and reconstructed with Twin-Branch techniques, which utilize reconstruction errors to identify abnormalities and prediction errors that enable accurate predictions of the following values in the sequence during runtime. The method assigns loss weights of 0.5 and 1.0, respectively, for the two branches involved in the process.
We comprehensively evaluated our proposed method by comparing it with several baseline models. To ensure a fair comparison between different models, we made sure to maintain identical experimental conditions. This involved using the same data splits for training and testing, applying the same preprocessing routines, and utilizing the exact architectures and parameters as specified in the original papers. This ensured that any observed differences in performance were solely due to the inherent properties of the models themselves, rather than any discrepancies in the methodology used to evaluate them. This validates the credibility of our approach and facilitates a fair comparison, underscoring the reliability and thoroughness of our study. TT-TBAD was conducted and compared against various state-of-the-art baseline models across multiple features.
Table 3 displays the MSE, MAE, RMSE, and
scores for each feature. Our proposed “TT-TBAD” methodology outperforms the other analyzed baseline models. Regarding predicting humidity, our model achieves an over
score = 0.93 accuracy in almost all feature cases except for H
2S.
This could indicate potential data discrepancies. Unlike other models such as Attention and Bi-LSTM [
39], which struggle with the complexities of their attention mechanisms, our model utilizes the power of the Multi-Head Attention technique and achieves higher precision. Through this distinction, the strength and ingenuity of our approach are highlighted.
After conducting a thorough collective comparison with other baseline models, as shown in
Table 4 and
Table 5, our advanced TT-TBAD technique achieved a remarkable performance
score of 0.993 and 0.994, indicating its superior predictive capabilities. On the other hand, the “Attention Bi-LSTM” model falls behind. In addition, traditional approaches like LSTM [
22] are not as effective, as their high error rates illustrate the challenges they face in understanding the complex dynamics of the barn environment.
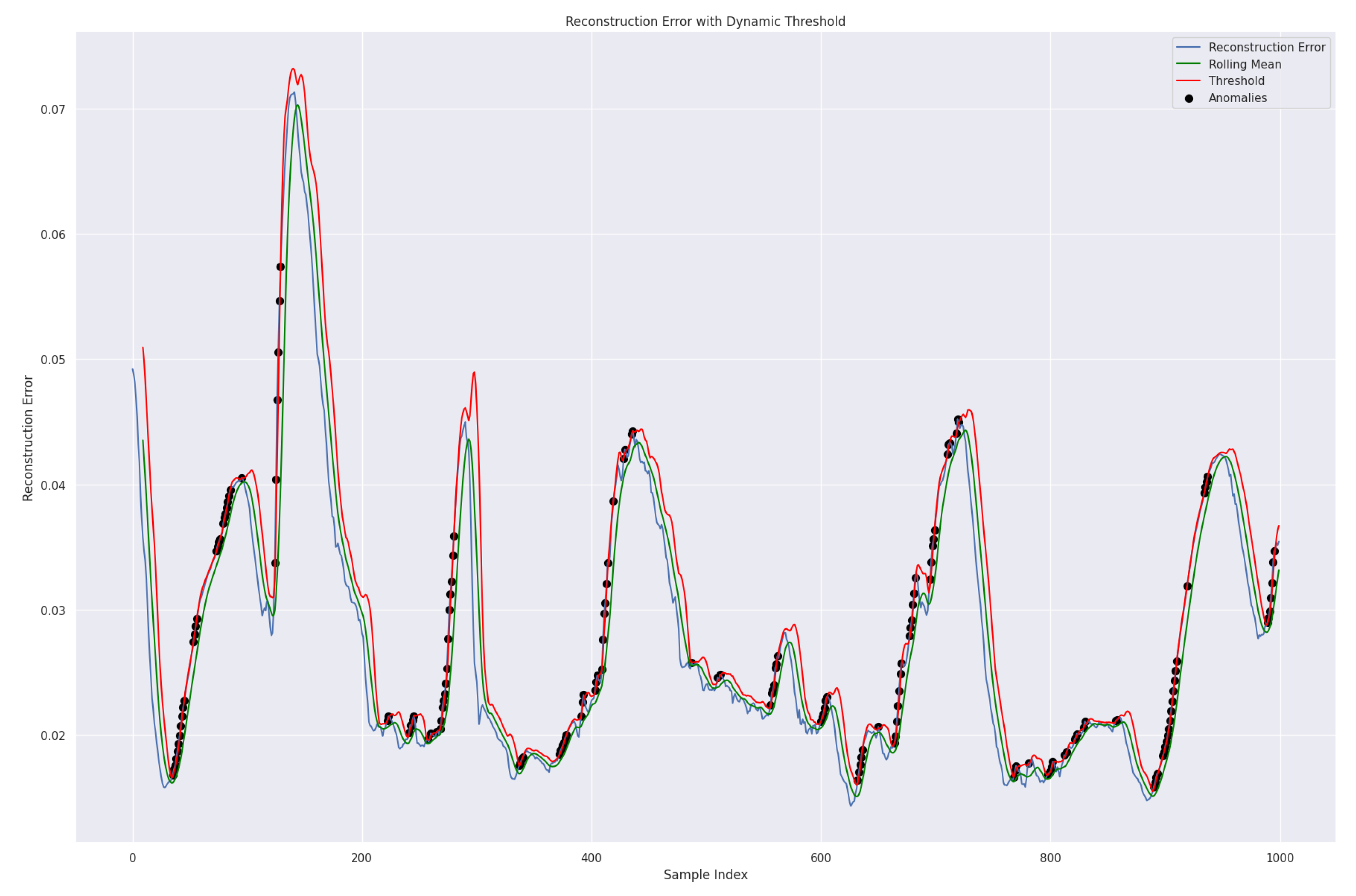
We used the dynamic threshold approach based on rolling mean addition to
k standard deviation to determine the threshold for the reconstruction error. This is a flexible method for anomaly detection in time series data. It can adjust to changing data patterns and is suitable for many applications, especially in dynamic environments, as shown in Equation (
38). This approach is more effective than the traditional technique of taking the average of the five highest loss values from the validation set [
45]. Our model can identify anomalies in the data by using the predetermined dynamic threshold. If the reconstruction loss exceeds this threshold, the model will recognize those values as abnormal; Ref. [
39], as shown in
Figure 13.
Meanwhile, the RollingMean represents the reconstruction error, and the RollingStdDev is the standard deviation of observations over a specified window and time. k, a predefined constant, determines the number of standard deviations from the rolling mean required to qualify a point as an anomaly.
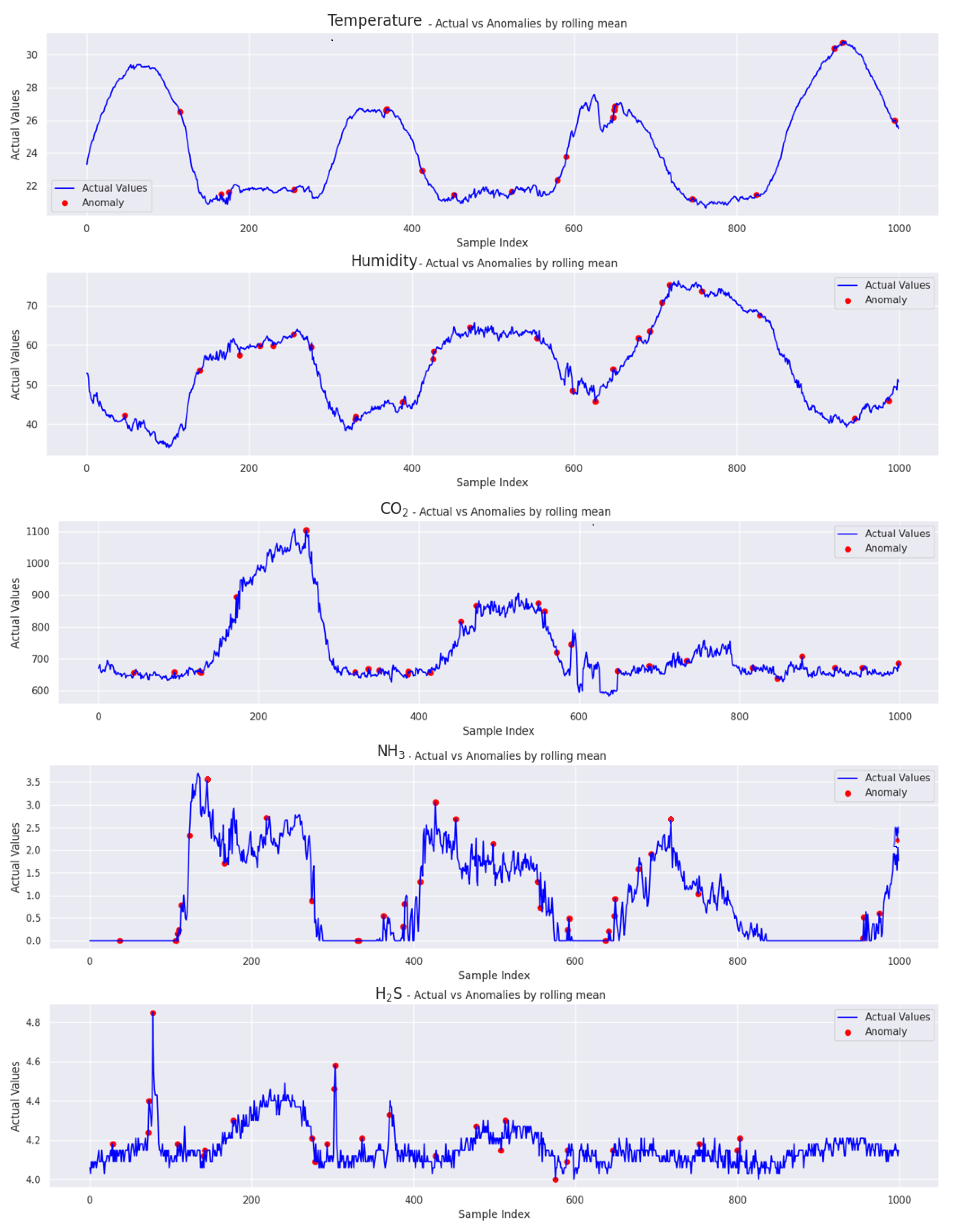
Smoothing the errors by averaging during the rolling mean calculation over a specified data window helps to reduce the reconstruction error. As a result, the green line representing the rolling mean appears smooth. Validation data were utilized for testing purposes, and we present the results in
Figure 14.
The figure includes five line charts that display the comparison between the anomalies and actual values for each feature separately, based on a small portion of the validation set. Each chart plots data points over a common x-axis, with several samples for each feature, including temperature, humidity, CO2, NH3, and H2S. After analyzing 39,456 samples, we identified anomalies in varying percentages across different metrics. The temperature metric showed a 3.29% anomaly rate, humidity at 3.39%, CO2 at 3.58%, and NH3 stood out with a higher rate of 4.19%.
Interestingly, H2S displayed the lowest anomaly rate at 2.62%. This is due to the model’s higher reconstruction and prediction error, with an score = 0.71. In comparison, other features exhibited metrics indicating better performance. This discrepancy emphasizes how model accuracy and prediction errors can impact anomaly detection.
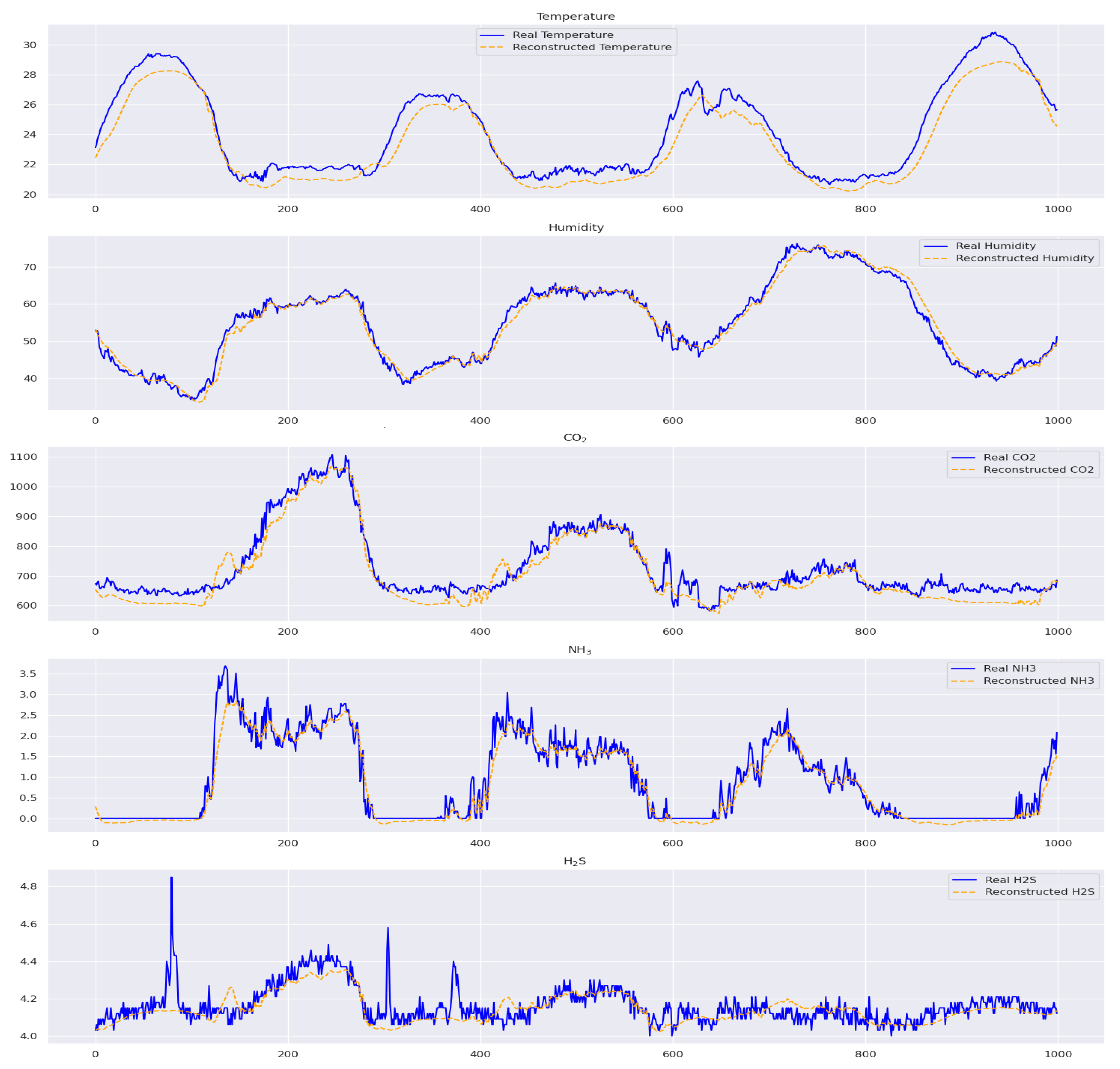
The model predictions for temperature and humidity in the prediction phase are quite accurate, indicating its reliability. However, there are some noticeable discrepancies in temperature around indices 200, 600, and 800 and humidity near 800, which may be due to external factors or model limitations. CO
2 predictions match well with actual data, but some deviations at indices 200 and 600 could be attributed to environmental changes. On the other hand, predicting NH
3 and H
2S levels is more challenging, with more pronounced fluctuations, particularly around indices 200–800 for NH
3 and 200–400 for H
2S, highlighting potential challenges or sporadic environmental events. Moreover, predicting the lines using H
2S presents challenges, making the model’s future job more challenging. The deviations in these metrics underscore the areas for model improvement, as depicted in
Figure 15.
6.4. Comparative Analysis of Anomaly Detection in Indoor Environment
The proposed TT-TBAD for anomaly detection is evaluated against state-of-the-art models, including LSTM-AE, GRU, LSTM, ConvLSTM-AE, and Attention-Bi-LSTM, with an assessment based on accuracy [
46], precision [
47], recall [
48], and the F1 score [
49]. The comparative study involves the utilization of a data annotation mechanism to label the partial test dataset, ensuring suitability for the detection evaluation. The results are presented in
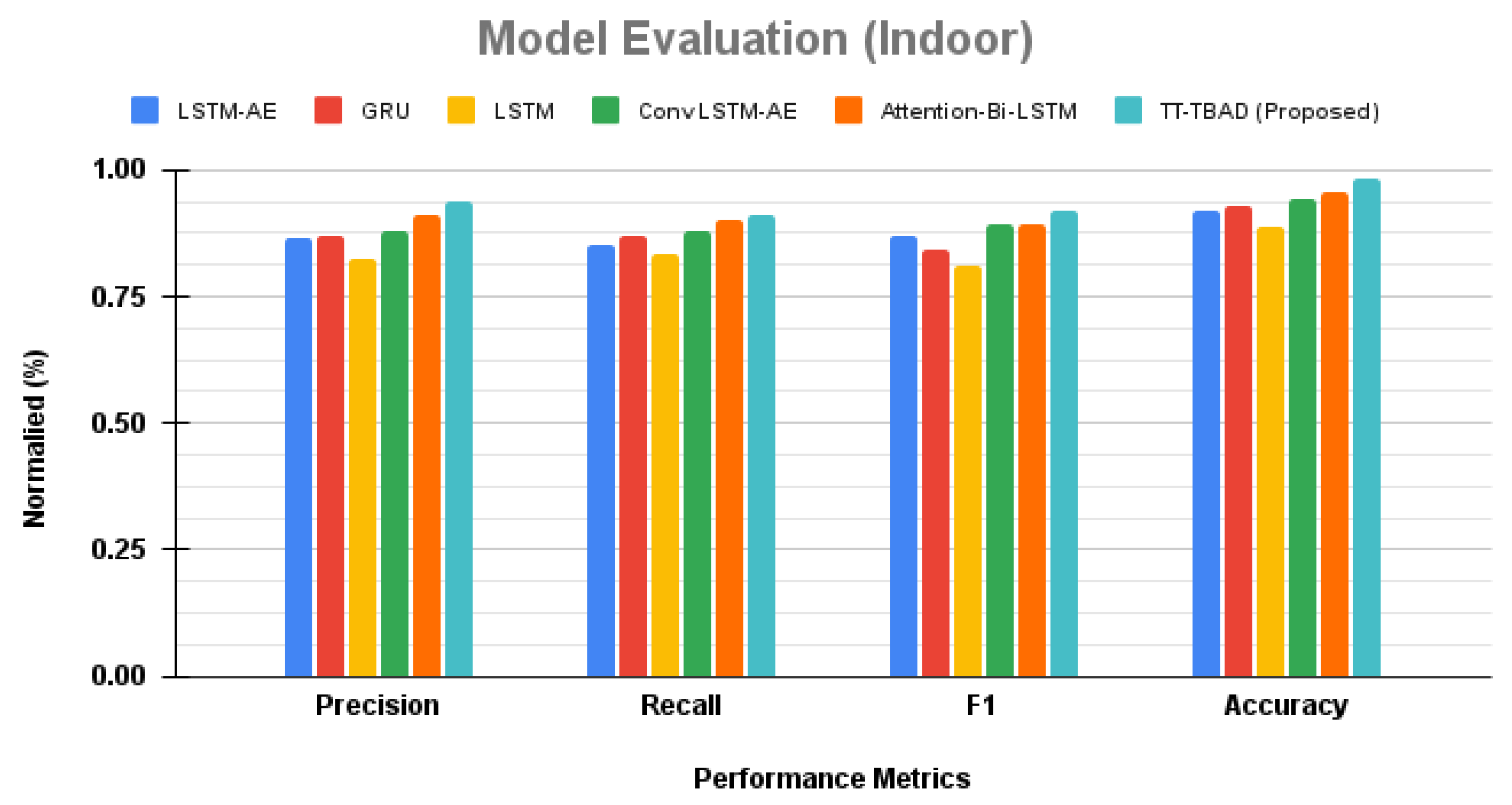
Figure 16, revealing that the LSTM-AE model demonstrated a robust balance between precision (0.867) and recall (0.853), resulting in a solid F1 score of 0.868. The GRU slightly outperformed, achieving precision and recall values of 0.87 and 0.871, respectively, although there was a modest dip in the F1 score to 0.844. The standard LSTM lagged behind, with precision and recall scores of 0.824 and 0.835, hinting at a potential decrease in anomaly classification accuracy, as reflected by an F1 score of 0.809. In contrast, the ConvLSTM-AE model excelled, boasting precision and recall scores of 0.881 and 0.879, along with an impressive F1 score of 0.893, indicating enhanced anomaly detection capability. Additionally, the Attention-Bi-LSTM model achieved the highest precision at 0.91 and a recall of 0.902, resulting in an F1 score of 0.891, showcasing strong predictive confidence. However, the spotlight is on our TT-TBAD model, surpassing all others with outstanding precision (0.94), recall (0.913), and F1 score (0.92), coupled with an unmatched accuracy of 0.983. This establishes a new standard in anomaly detection, highlighting our model’s exceptional precision and reliability.
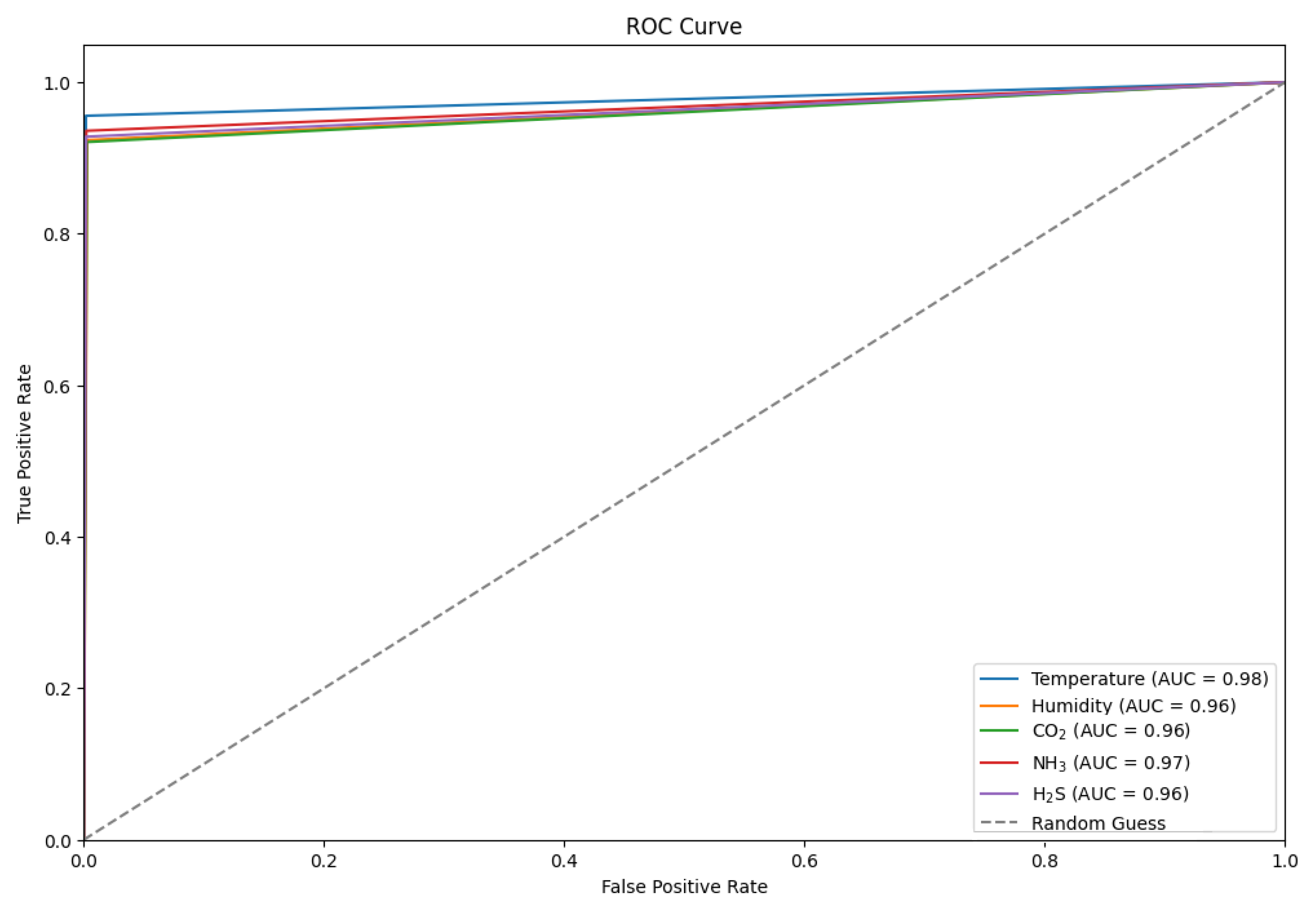
The Receiver Operating Characteristic (ROC) curve highlights the effectiveness of environmental classifiers in detecting gases within an enclosed setting. Among the classifiers, temperature demonstrated the highest performance with an AUC score of 0.98. NH3, CO2, and H2S classifiers also performed exceedingly well with AUC scores ranging from 0.96 to 0.97. The humidity classifier had an AUC score of 0.96, indicating its potential effectiveness in detecting gases.
These AUC values presented in
Figure 17, markedly higher than the random guess baseline (AUC = 0.5), reflect the classifiers’ high accuracy and confirm their potential for reliable indoor air quality monitoring, offering substantial benefits for safety and hazard prevention in controlled environments.
6.5. Anomaly Detection and Prediction for Outdoor Weather Forecast for the Barn Environment Dataset
Utilizing the same effective methodology employed in the previous dataset, we applied our method with great attention to detail to ensure uniformity and comparability in our analysis. Upon thoroughly examining
Table 6, it is evident that the TT-TBAD method consistently outperforms its counterparts.
The performance of various models was evaluated based on different features such as temperature, humidity, solar energy, and accumulated solar energy per day. The TT-TBAD method displayed superior precision for temperature and humidity, with the lowest MSE, MAE, and RMSE values and scores = 0.99 and 0.99, respectively. In solar energy, the TT-TBAD method outperforms other models with its impressive score = 0.94 for Attention-Bi-LSTM and 0.98 for accumulated solar energy/day. Although Attention-Bi-LSTM has slightly better error metrics, TT-TBAD stands out for its adaptability and resilience, making it a reliable and versatile model for predictive analysis. Its consistency in performance across various datasets underlines its potential as an excellent choice for predictive analysis of solar energy.
The study used various modeling techniques for outdoor weather forecasting in a fattening barn environment. The results showed that our TT-TBAD method performed the best with the lowest mean squared error (MSE) of 0.000618 and an excellent Score = 0.99. This demonstrates the exceptional predictive accuracy of our method in this particular setting. Other methods, such as LSTM-AE and ConvLSTM-AE, also performed well, with Scores = 0.95 and 0.96, respectively. However, Attention-Bi-LSTM achieved the highest score = 0.97. GRU slightly surpassed LSTM-AE with an score = 0.90.
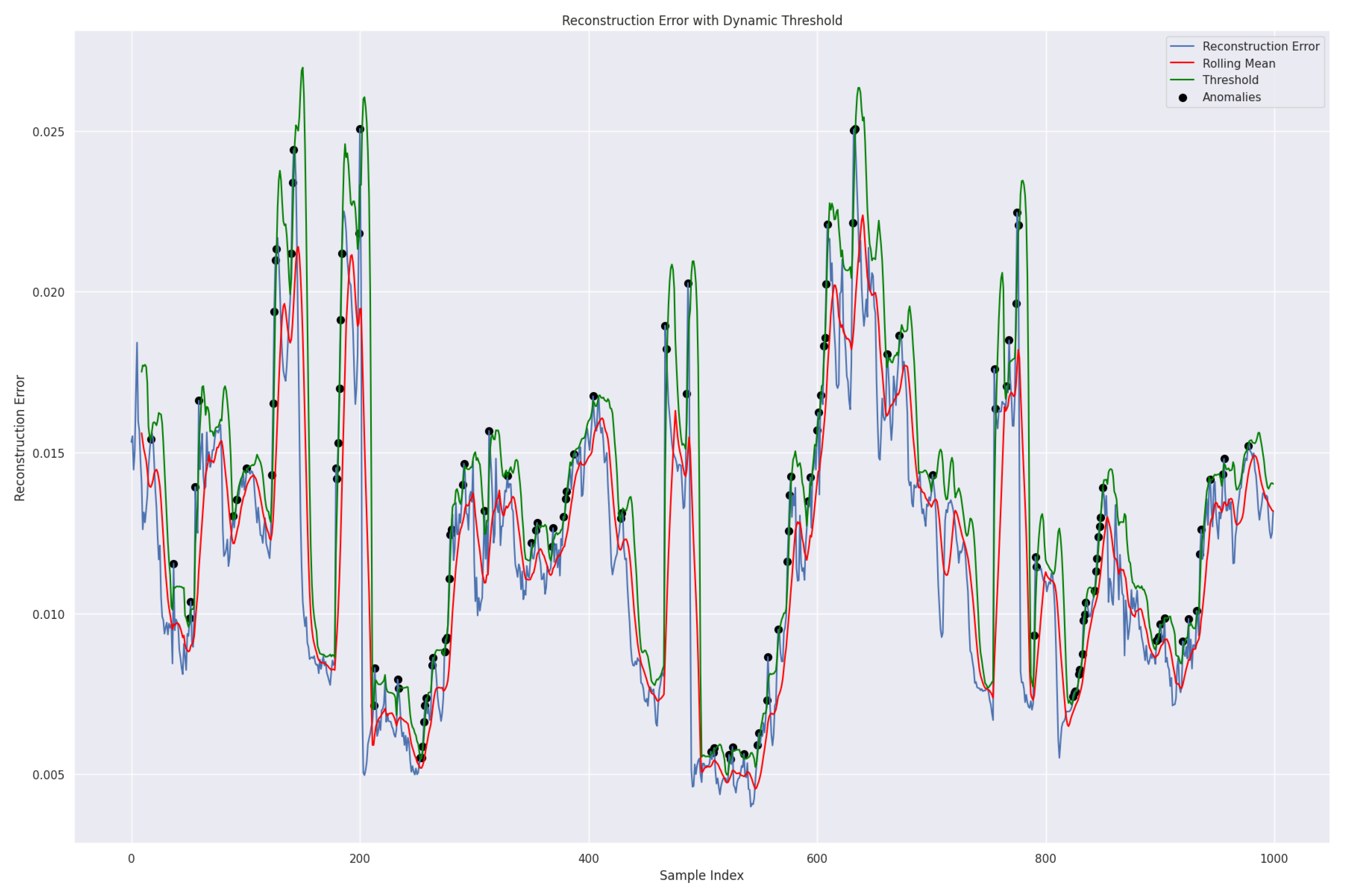
Figure 18 illustrates the same dynamic threshold approach is used for outdoor weather forecast datasets to identify anomalies in the data compared to the reconstruction error. The black data points indicate the anomalies, meaning the model finds it difficult to reconstruct them accurately. The blue line represents the difference between the original and reconstructed data.
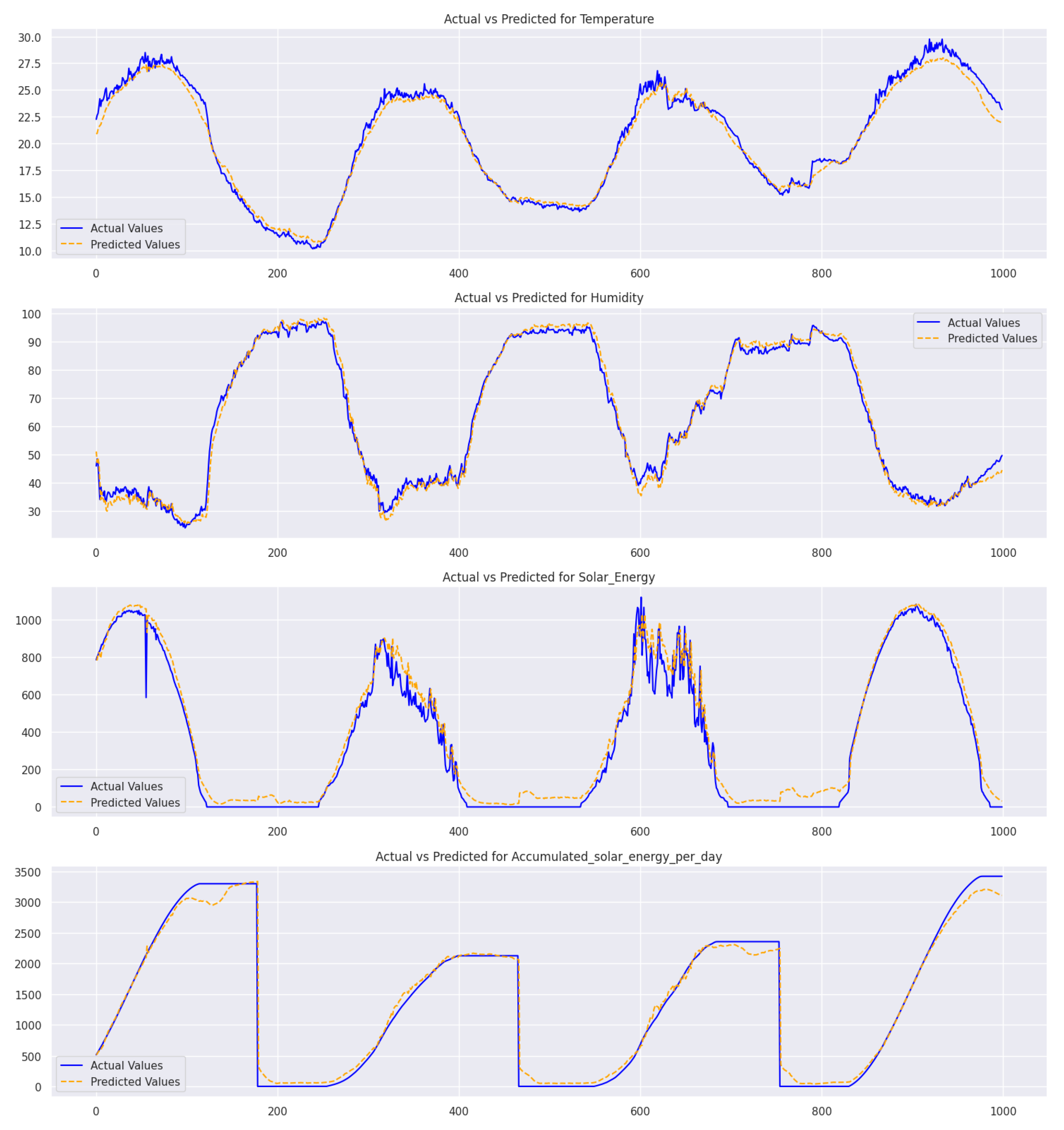
The solar energy graph has pronounced fluctuations with several anomalies, and the accumulated solar energy chart has a step-like pattern, with anomalies signifying unexpected drops or surges. These graphs emphasize the need to monitor environmental and energy parameters for consistency. The graphs in
Figure 19 compare actual and predicted values. While the model predictions for temperature and humidity are highly accurate, noticeable discrepancies are evident in the solar energy graph. These inconsistencies underscore the imperative need to develop and refine prediction mechanisms, particularly in the context of solar energy parameters. It is crucial to address these discrepancies to enhance the accuracy of the model predictions.
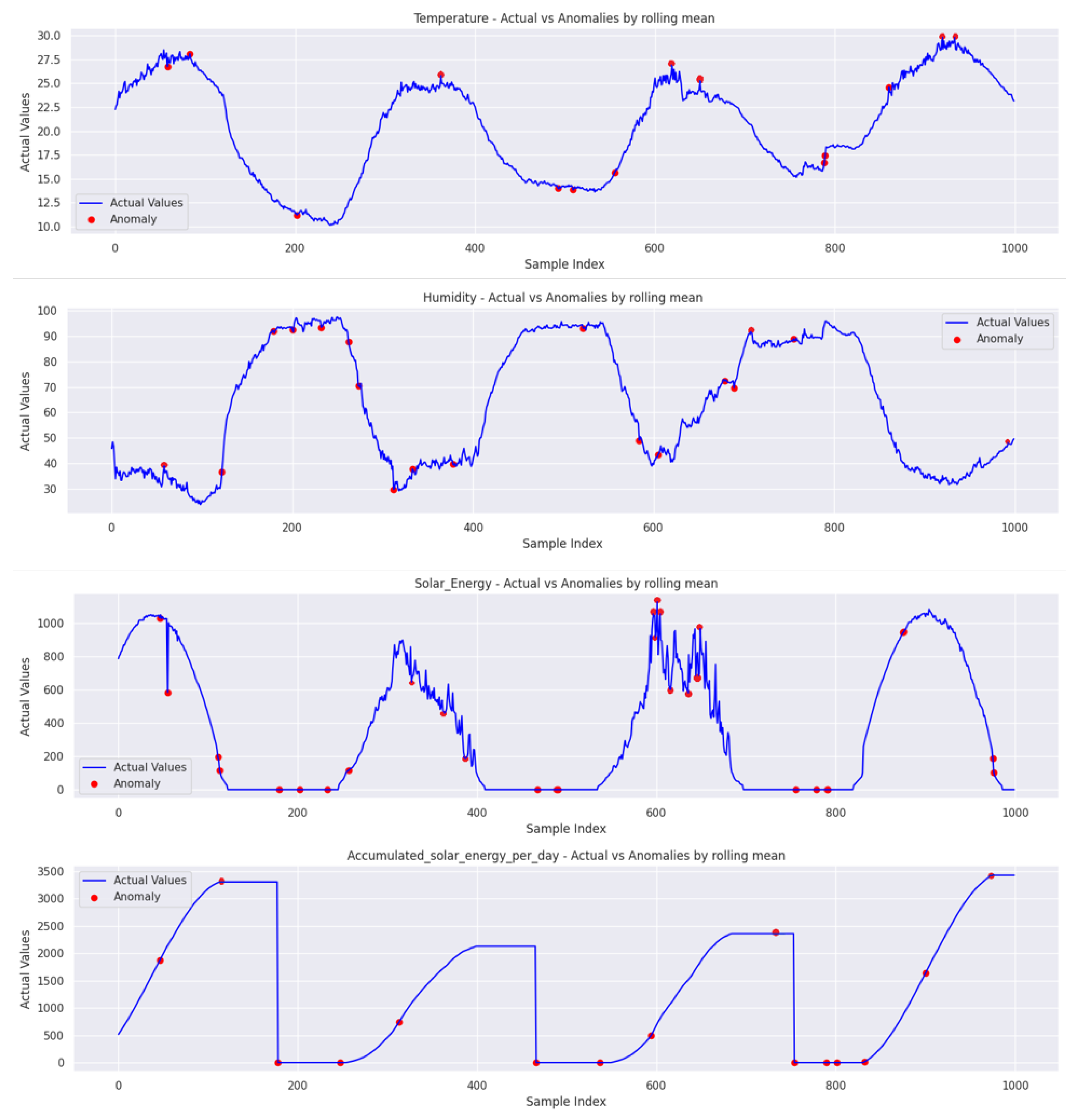
Upon analyzing the data using the rolling mean approach, it becomes evident that metrics related to solar energy, such as solar energy and accumulated solar energy per day, exhibit a slightly higher percentage of anomalies, approximately 4.43% and 4.54%, respectively, as shown in
Figure 20. In contrast, anomalies in temperature and humidity are only slightly lower, at around 3.36% and 3.44%, respectively. This discrepancy suggests that the solar metrics may be more susceptible to abnormalities or external factors influencing their readings when compared to the more consistent readings of temperature and humidity.
6.6. Comparative Analysis of Anomaly Detection Models in Outdoor Environment
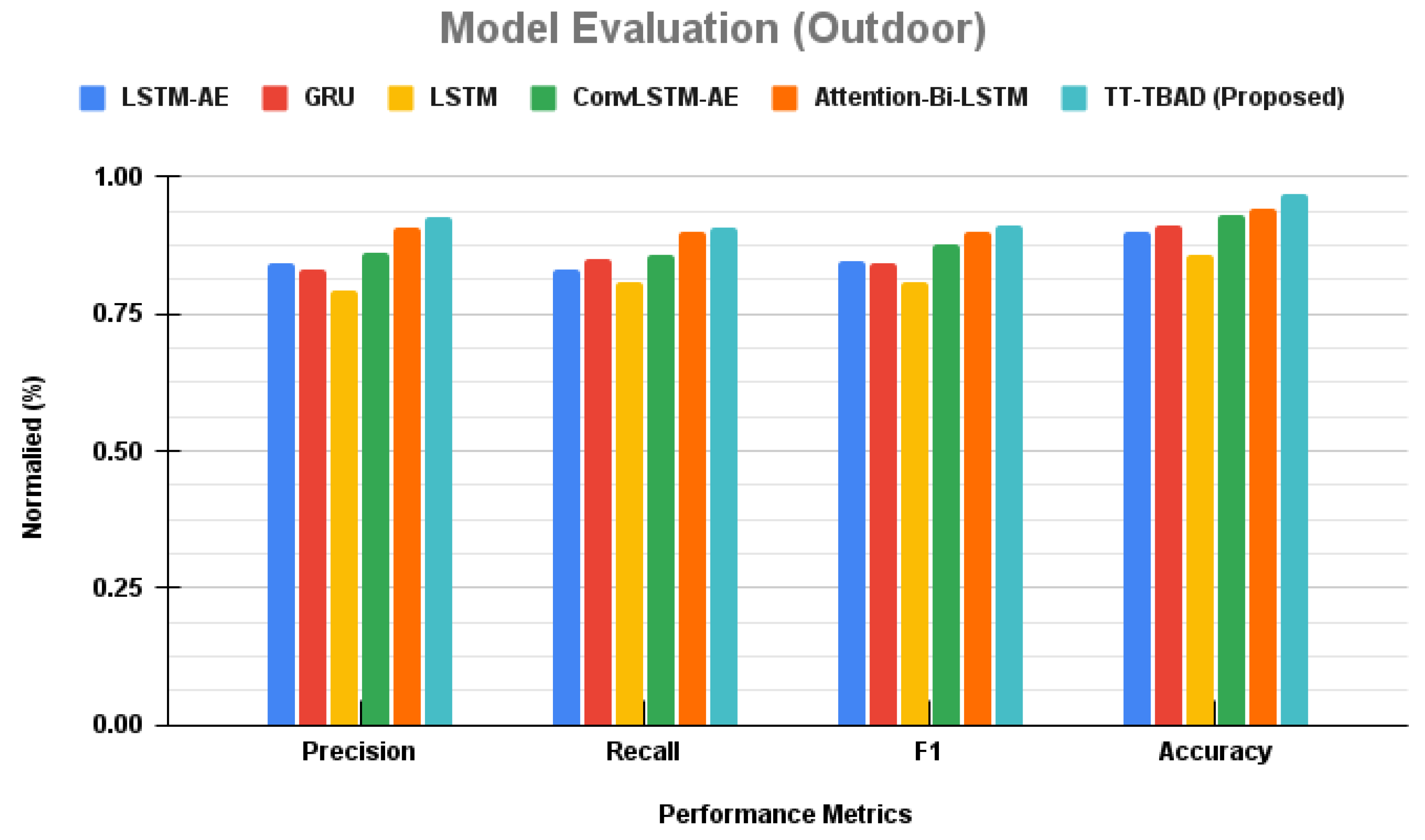
A comparative study of anomaly detection is performed for various models, and the results are presented in
Figure 21. The figure shows that the LSTM-AE model achieves a solid precision rate of 0.842 paired with a recall of 0.83, harmonizing into an F1 score of 0.848. Nipping at its heels, the GRU model registers a precision of 0.83 with an incrementally higher recall of 0.851, achieving an F1 score of 0.841. Transitioning to the LSTM model, we observe a dip in precision to 0.792 and recall to 0.809, reflected in a modest F1 score of 0.81. In contrast, the ConvLSTM-AE model emerges stronger, with a precision of 0.862 and recall of 0.859, coalescing into a solid F1 score of 0.876. A leap forward is seen with the Attention-Bi-LSTM model, which achieves a notable precision of 0.909 and a recall of 0.899, commanding an F1 score of 0.901. The crescendo of our analysis is reached with the introduction of our TT-TBAD model. It sets a new benchmark with a precision of 0.927 and a recall of 0.909, melding into an F1 score of 0.91. This performance is further underscored by a remarkable accuracy of 0.971, positioning our model at the apex of anomaly detection capabilities.
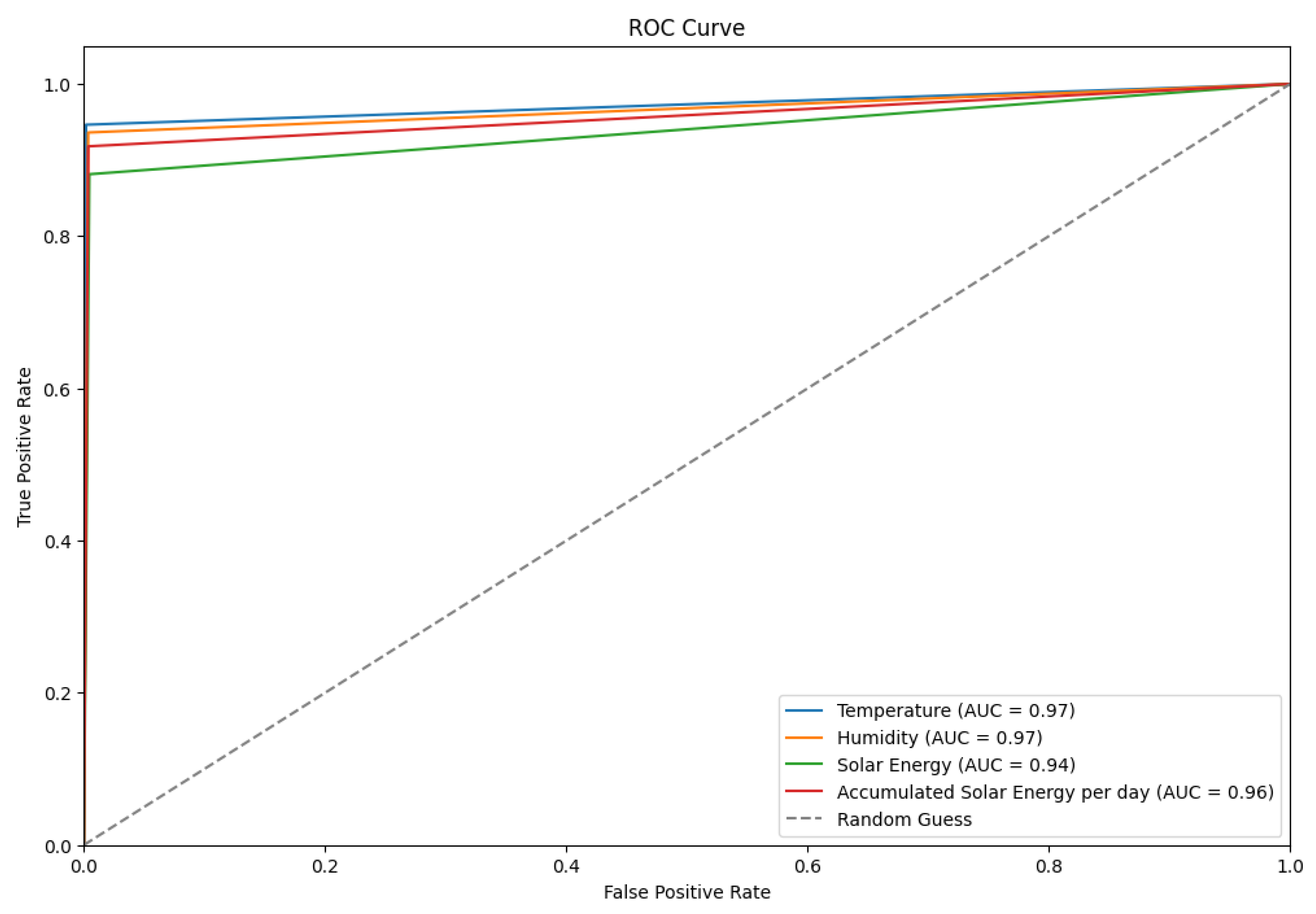
Moreover, the ROC curve presented in
Figure 22 demonstrates the discriminative power of four classifiers based on environmental parameters. The figure shows AUC scores of 0.97 for both temperature and humidity, followed closely by accumulated solar energy per day at 0.96 and solar energy at 0.94. The classifiers exhibit robust predictive capabilities, with their performance significantly surpassing the random classification benchmark (AUC = 0.5). This underscores their potential utility in sophisticated environmental sensing and prediction applications.
7. Discussion
The TimeTector-Twin-Branch Shared LSTM encoder (TT-TBAD) is a revolutionary development in the field of agricultural data analytics. It is particularly useful for detecting anomalies in time series data, which can be noisy and difficult to analyze. This model is designed to understand agricultural datasets and redefine the standards of anomaly detection by identifying genuine irregularities that are crucial for operational farm decision making.
At its core, the proposed method uses a shared LSTM encoder, which is known for its ability to comprehend temporal data, along with advanced attention mechanisms. These mechanisms filter through data to eliminate irrelevant noise and highlight critical anomalies. This is especially important in agriculture, where distinguishing between benign fluctuations and significant outliers is essential for crop yield and livestock health. TT-TBAD also uses a Denoising Autoencoder (DAE) to counter the challenge of overfitting. This ensures that the model remains robust and generalizable, even when faced with new data. The Twin-Branch design of the model allows for it to simultaneously reconstruct data and predict future environmental and biological shifts, providing valuable predictive foresight for farmers which traditional models failed to provide. What sets TT-TBAD apart is its ability to balance architectural complexity with computational efficiency. Despite its advanced design, TT-TBAD has commendable training durations between 380 and 400 s, meaning that it respects the time-sensitive demands of agricultural operations. This efficiency is achieved without sacrificing the depth and breadth of its data analysis, maintaining high fidelity in anomaly detection and prediction. TT-TBAD introduces a dynamic thresholding technique based on a rolling mean, which adapts to evolving data patterns. This fine-tunes the model’s sensitivity to fluctuations and enhances its accuracy, making it an indispensable asset in precision farming technologies. In sum, TT-TBAD is an excellent example of meticulous data analysis, advanced predictive modeling, and practical computational application. Its unmatched accuracy in detecting and predicting anomalies, underpinned by a dynamic and adaptive thresholding strategy, makes it a valuable tool for precision farming technologies that work in harmony with nature and machine learning innovation.
Limitations and Assumptions
The model is tested and found to be efficient in identifying any unusual or abnormal data points within the current datasets. However, its scalability and complexity make it challenging to process larger datasets, which requires longer training periods and more computational power. Moreover, parameter tuning has become more complex, and refined optimization techniques are necessary. The model’s anomaly detection capability depends on the quality of the input data, and it is crucial to judiciously integrate noise to preserve its effectiveness. The model’s design is based on fundamental assumptions about input data and training parameters, such as noise levels, sequence sizing, and batch processing, which aim to improve its performance in detecting anomalies within agricultural contexts.
8. Conclusions
In our research paper, we introduce the TimeTector-Twin-Branch Shared LSTM encoder (TT-TBAD) model which employs a Twin-Branch Shared LSTM encoder and multiple Multi-Head Attention mechanisms to detect anomalies and make real-time predictions from multivariate time series sensor data. With the advent of deep learning algorithms, the challenge of capturing spatial–temporal correlations in multi-sensor time series data is efficiently addressed. These algorithms excel at generalizing normal, noisy, and abnormal data patterns, making them an ideal solution for handling complex data structures. Our model is a fusion of several robust frameworks. It incorporates the Denoising Autoencoder (DAE) to characterize multi-sensor time series signals, thus minimizing the risk of overfitting caused by noise and anomalies in the training data. Additionally, we utilize various Multi-Head Attention mechanisms such as Multi-Head Attention (MHA), Cross-Multi-Head Attention (C-MHA), Hierarchical Multi-Head Attention (Hi-MHA), and Feature-Enhanced Multi-Head Attention (FH-MHA). These mechanisms enable the model to capture diverse and hierarchical relationships, recognize cross-sequence patterns, and leverage external features, resulting in a comprehensive understanding of complex datasets. Our experimental evaluation is conducted on proprietary livestock barn environmental datasets using performance metrics for both anomaly detection and future prediction, where our model demonstrates outstanding performance compared to benchmark traditional models with detection accuracies and scores of 97.1%, 98.3% and 0.994%, 0.993%.
In our future work, we aim to develop a smart agriculture livestock environment that allows real-time monitoring through the barn sensors. The ultimate aim is to automate livestock farming to the greatest possible extent.





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}