1.1. Development Status
With the development of communication technology, the “time and frequency” domain overlap and signal reception, especially wideband signal reception, bring excellent interference. In the complex electromagnetic environment, wide-open receivers often encounter co-channel multi-source signals, that is, in the receiving bandwidth, the same period, there is the existence of multiple communication or non-communication signals [
1]. Single-signal identification techniques are more maturely developed, and the traditional method of identifying multi-source aliased signals requires separation followed by identification. It takes a lot of steps and a long time, and the recognition effect is restricted by the separation effect. Especially when the time-frequency aliasing degree of multi-source signals is high, the traditional separation method has a large error under underdetermined conditions, which leads to the failure of the traditional single-signal recognition method. Therefore, exploring a more effective separation method for co-channel time-frequency aliasing signal identification is urgent.
In 2006, Hinton et al., proposed a Deep Belief Network (DBN) and applied it to speech recognition tasks and achieved good results [
2]. In 2012, Krizhevsky et al., proposed the concept of a convolutional neural network (CNN), and achieved breakthrough results in image recognition tasks, which laid a foundation for subsequent signal recognition research [
3]. In 2016, O’Shea et al., took the lead in applying a CNN to the automatic feature extraction and classification of complex time-domain radio signals [
4]. The research team designed a four-layer neural network architecture consisting of two convolutional layers and two fully connected layers, and successfully recognized signals with three analog modulation modes and eight digital modulation modes. Compared with the traditional feature extraction method based on an expert system, this method shows significant performance advantages. The results not only show the high adaptability of a CNN in processing time series data, but also confirm its efficiency and accuracy in automatic feature extraction and classification tasks. With the successful application of a CNN in the field of signal recognition, more and more algorithms have been proposed. Ref. [
5] compare the performance of Long Short-Term Memory (LSTM) and a CNN in radio signal modulation recognition tasks in detail. The simulation results show that the recognition rate of the neural network to the signal is not affected by the depth of the network and the size of the filter, thus revealing the flexibility and robustness of the network structure selection in the field of modulation recognition. Ref. [
6] proposed a classification algorithm based on a transformer and denoising autoencoder (DAE). The algorithm combines the denoising autoencoder component in the DAE_LSTM model and the Residual Stack design in the Res-Net architecture, and finally integrates the attention mechanism of the transformer to enhance the feature extraction and sequence modeling capabilities. The experimental results show that the proposed algorithm performs well on the public dataset RadioML2018.01A. Ref. [
7] proposed a multimodal attention mechanism signal modulation recognition method based on Generative Adversarial Networks (GANs), a CNN, and LSTM to solve the problem of the low recognition accuracy of spread spectrum signals under low signal-to-noise (SNR) conditions. In this method, the GAN is used to denoise the time-frequency image, and then the time-frequency image and I/Q data are input into the recognition model based on a CNN and LSTM, and the attention mechanism is added to the model to realize the high-precision recognition of ten kinds of signals such as MASK and MFSK.
To sum up, time-frequency aliasing signal separation based on machine learning has become a research hotspot [
8], mainly divided into two identification methods based on decision trees and neural networks. In the decision tree-based recognition method, Ref. [
9] extract eight kinds of features to identify twelve kinds of signals, and the feature selection is complicated. In the neural network-based recognition method, Ref. [
10] extracts instantaneous features and higher-order cumulative volume features and uses the BP network for the intra-class recognition of phase-shift keying (PSK) and quadrature amplitude modulation (QAM) signals, but the complexity of the algorithm is high. Ref. [
11] dataset’s SNR is fixed at 4 dB and 10 dB, and Ref. [
12] does not investigate mixed signals composed of source signals with different code rates; all of them have the problem of poor dataset generalization ability. Refs. [
13,
14] use the Deep Convolutional Neural Network (DCNN) network and Seg-Net network to extract time-frequency graph features to achieve signal separation and identification, respectively, but the features are selected singly, and the intra-class identification of modulated signals cannot be achieved.
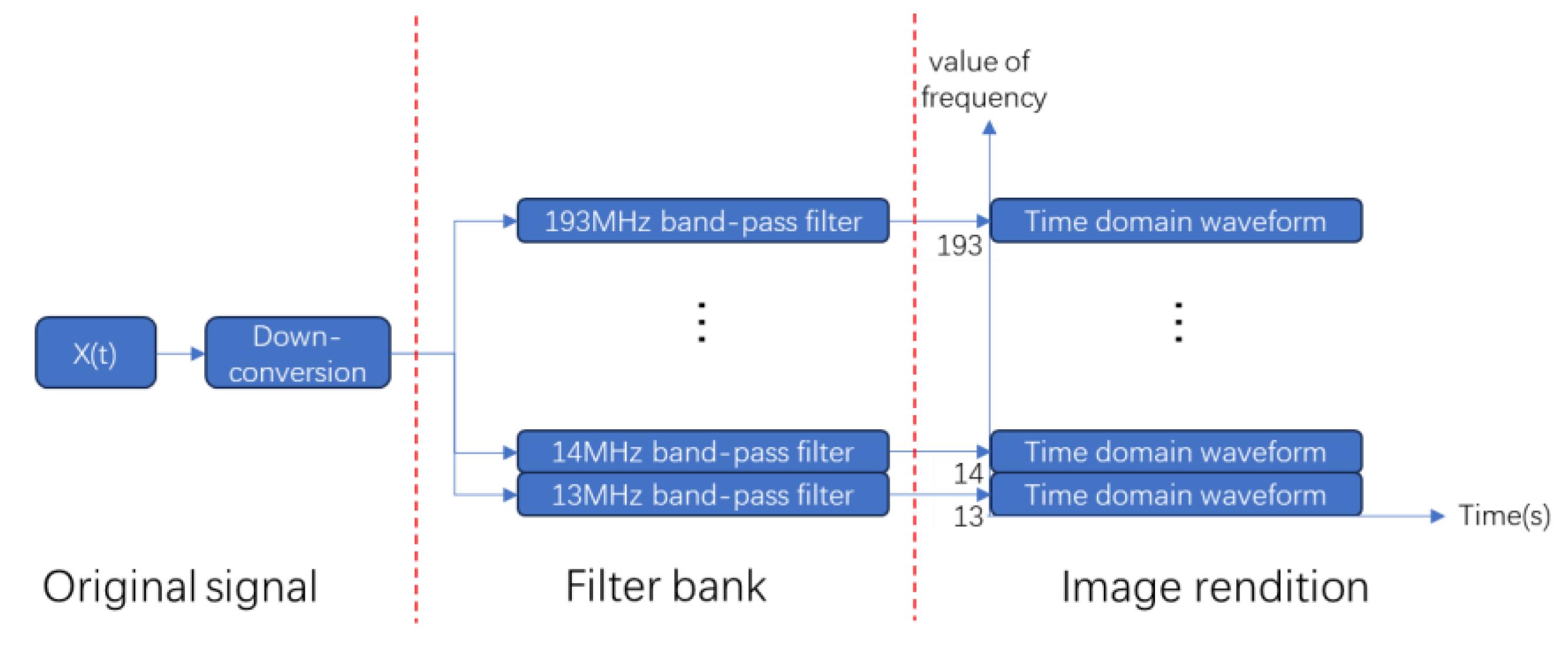
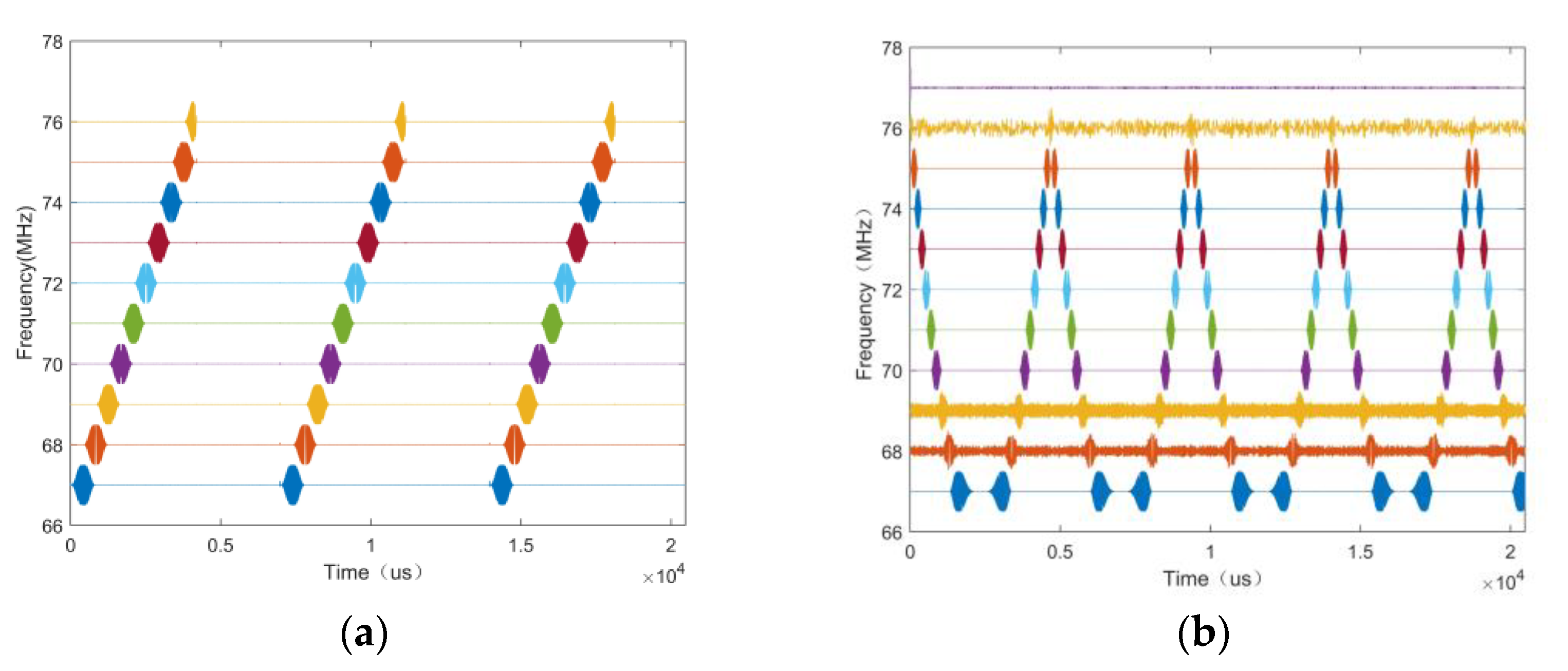
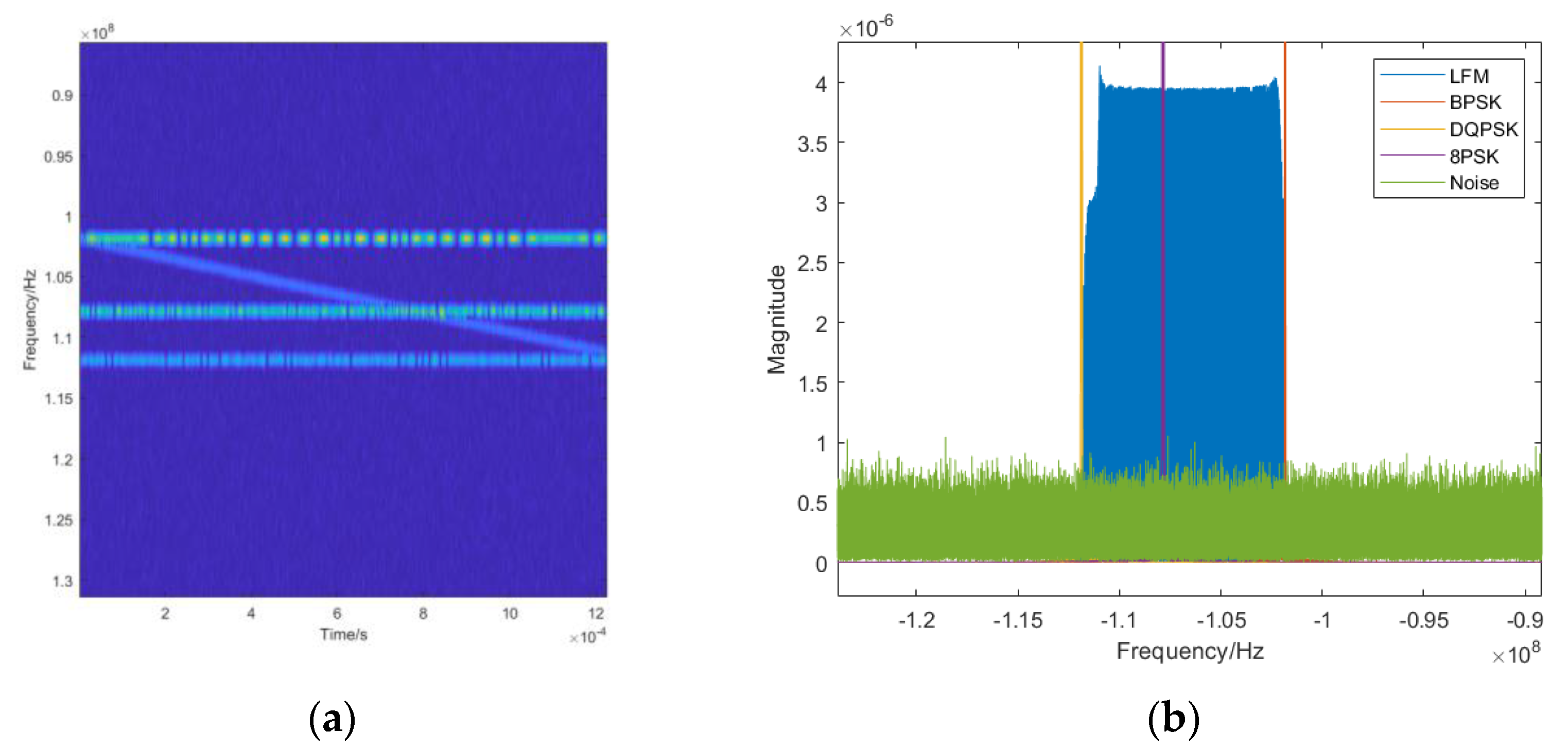
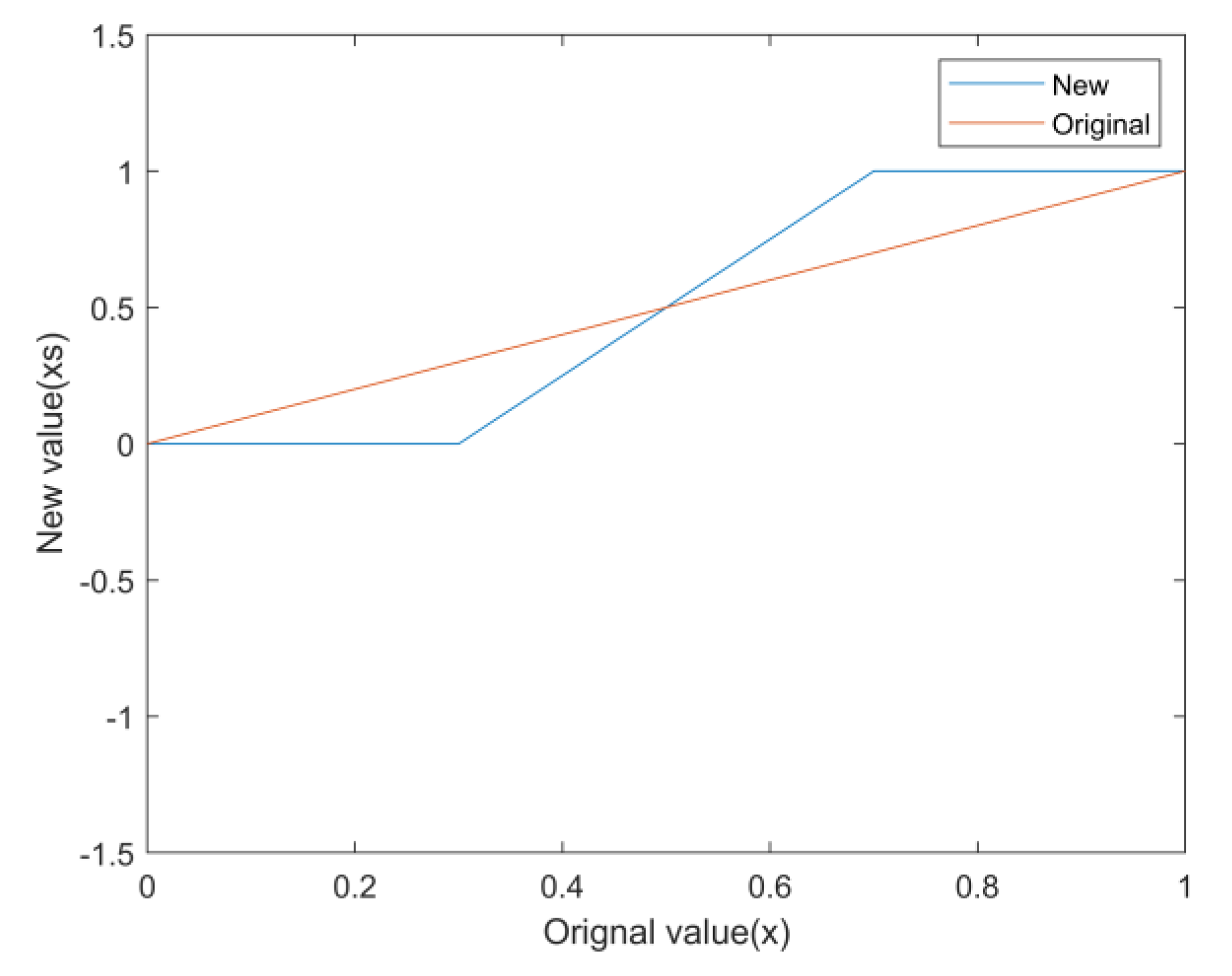
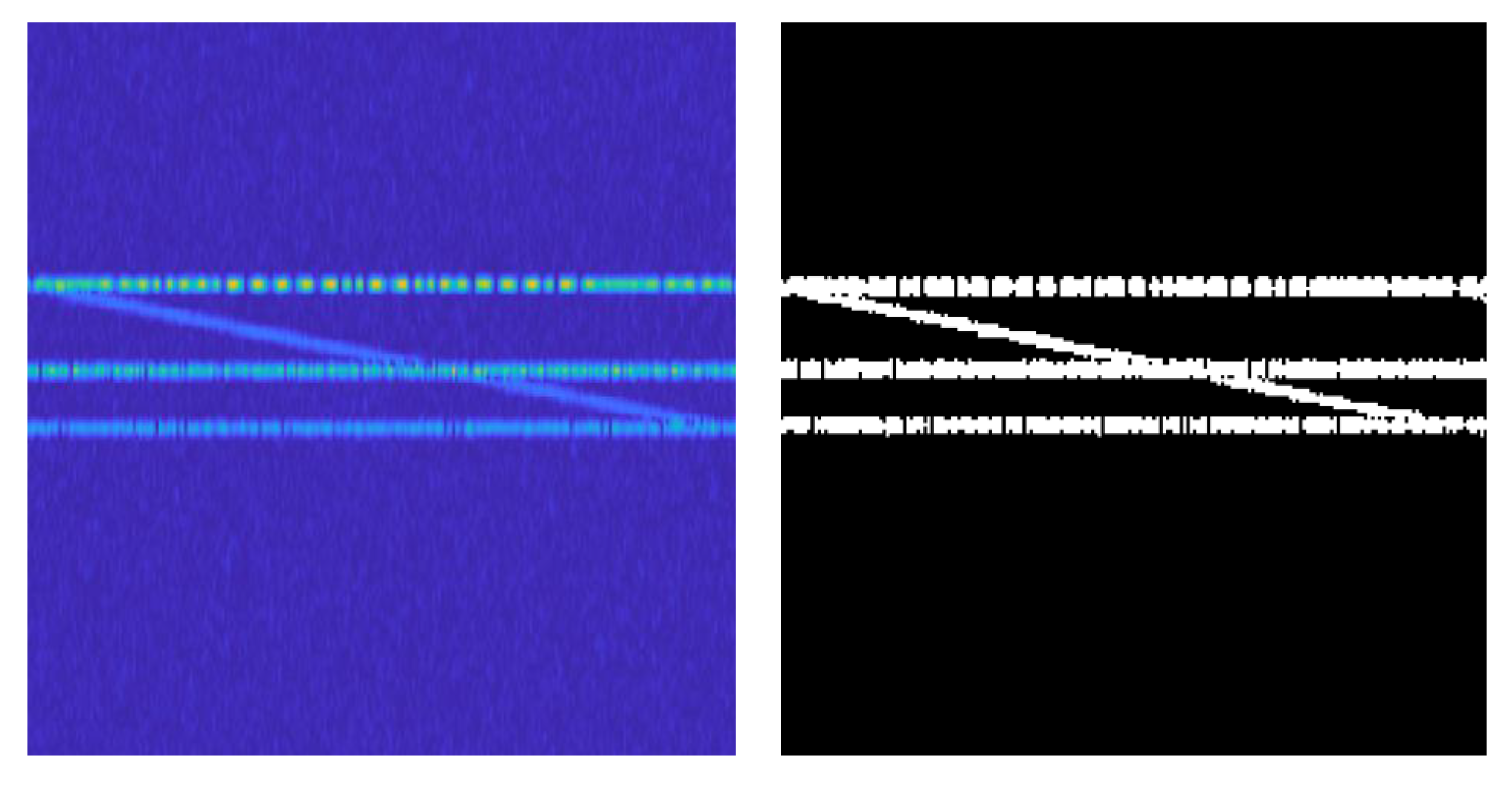
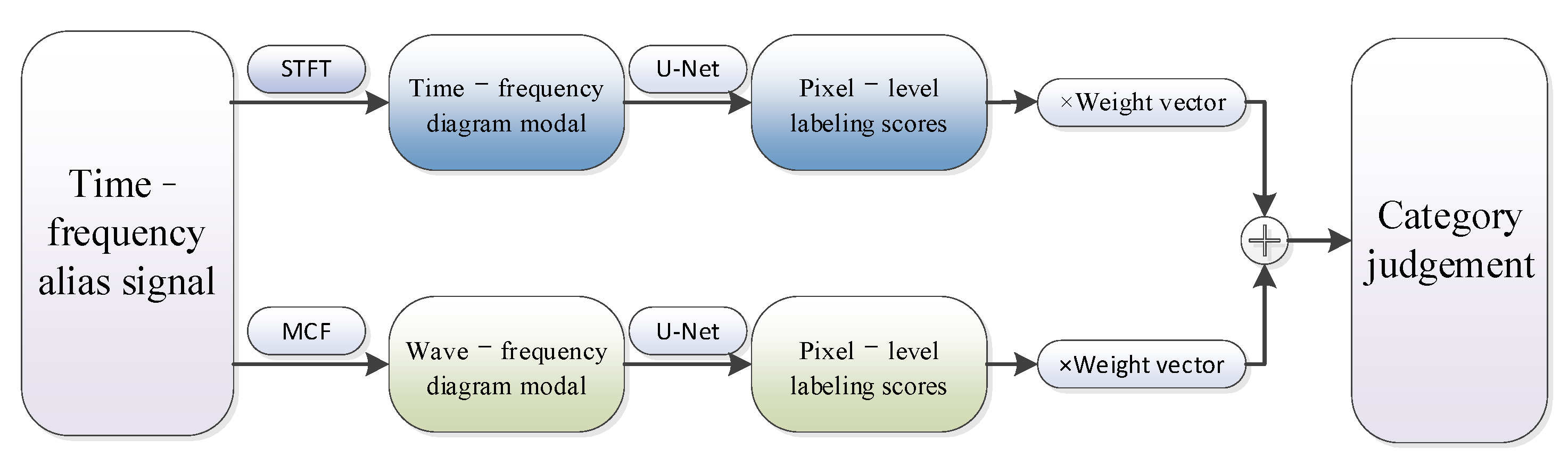
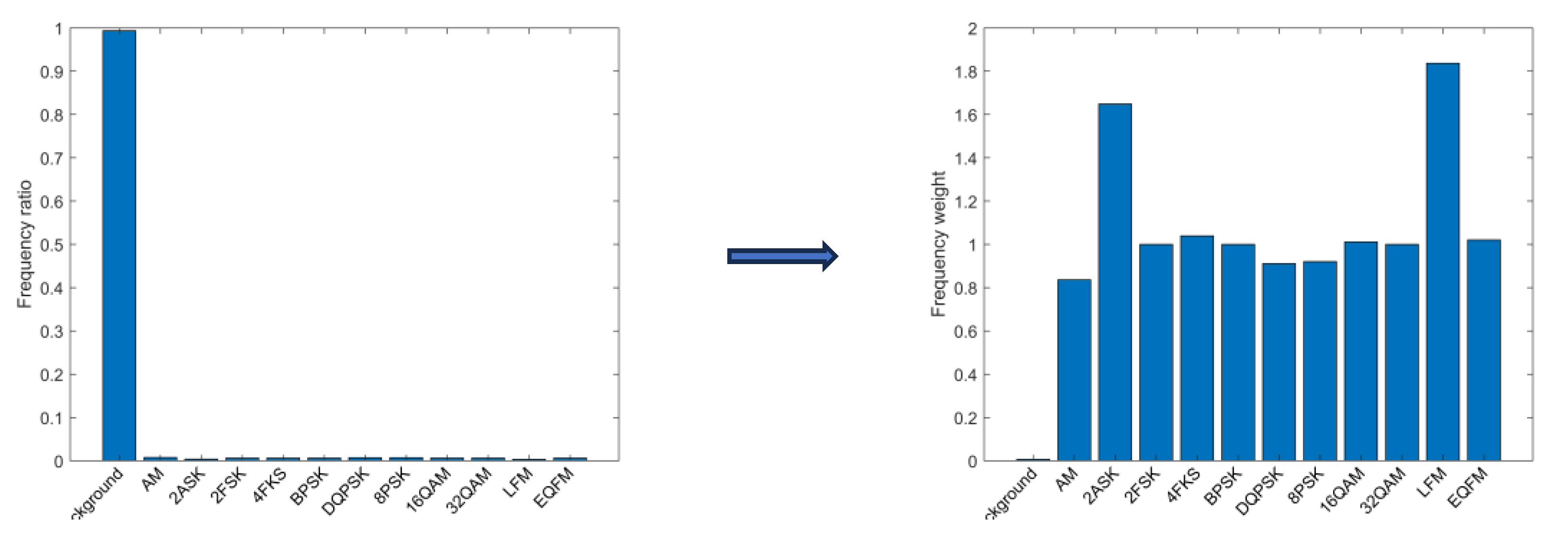
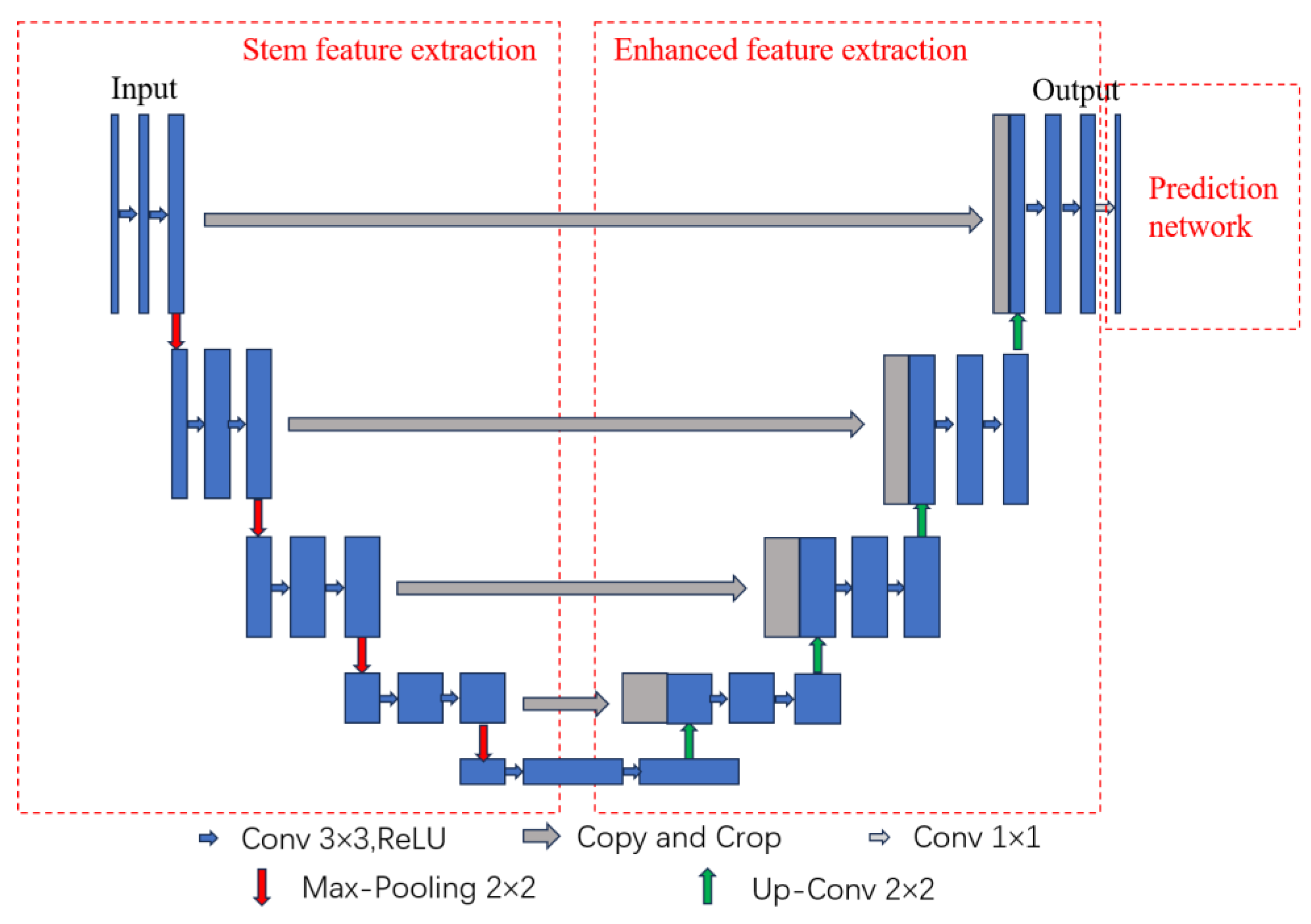
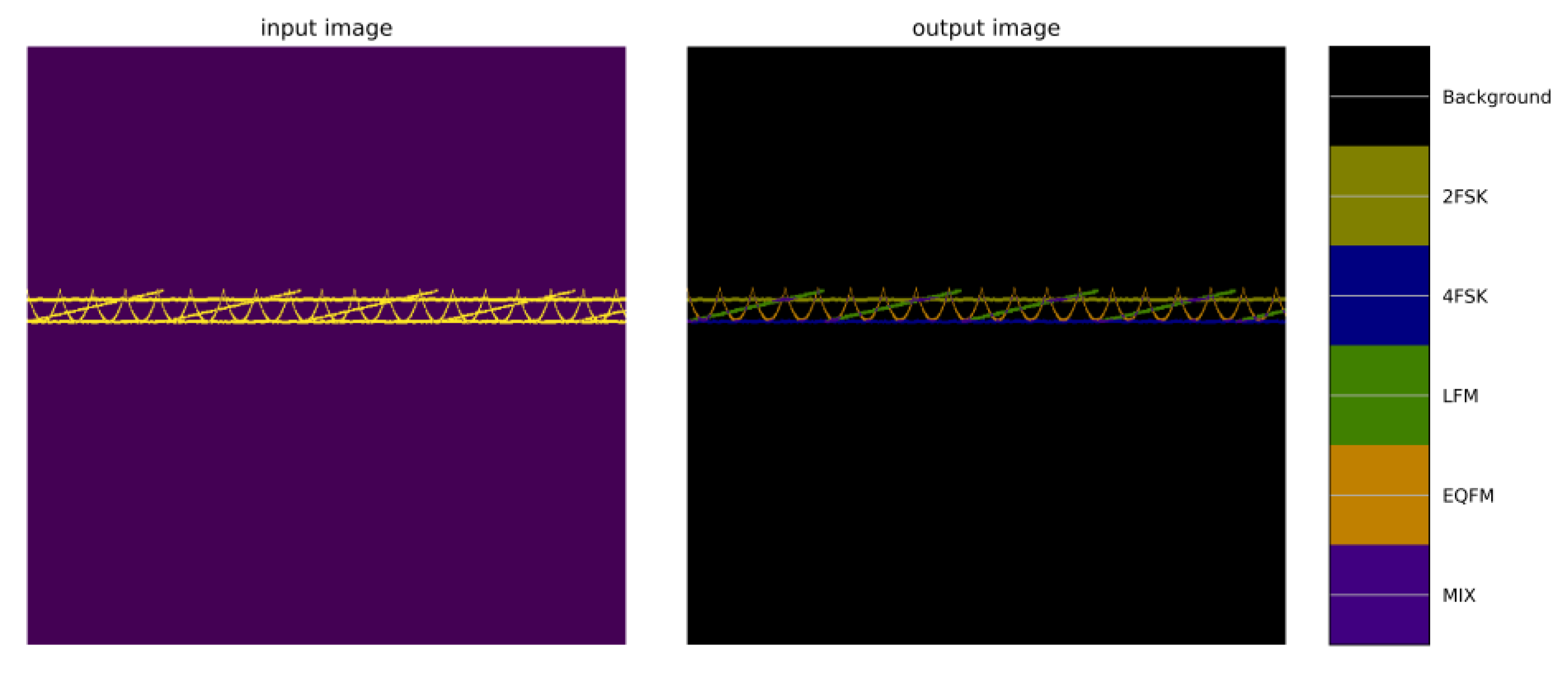
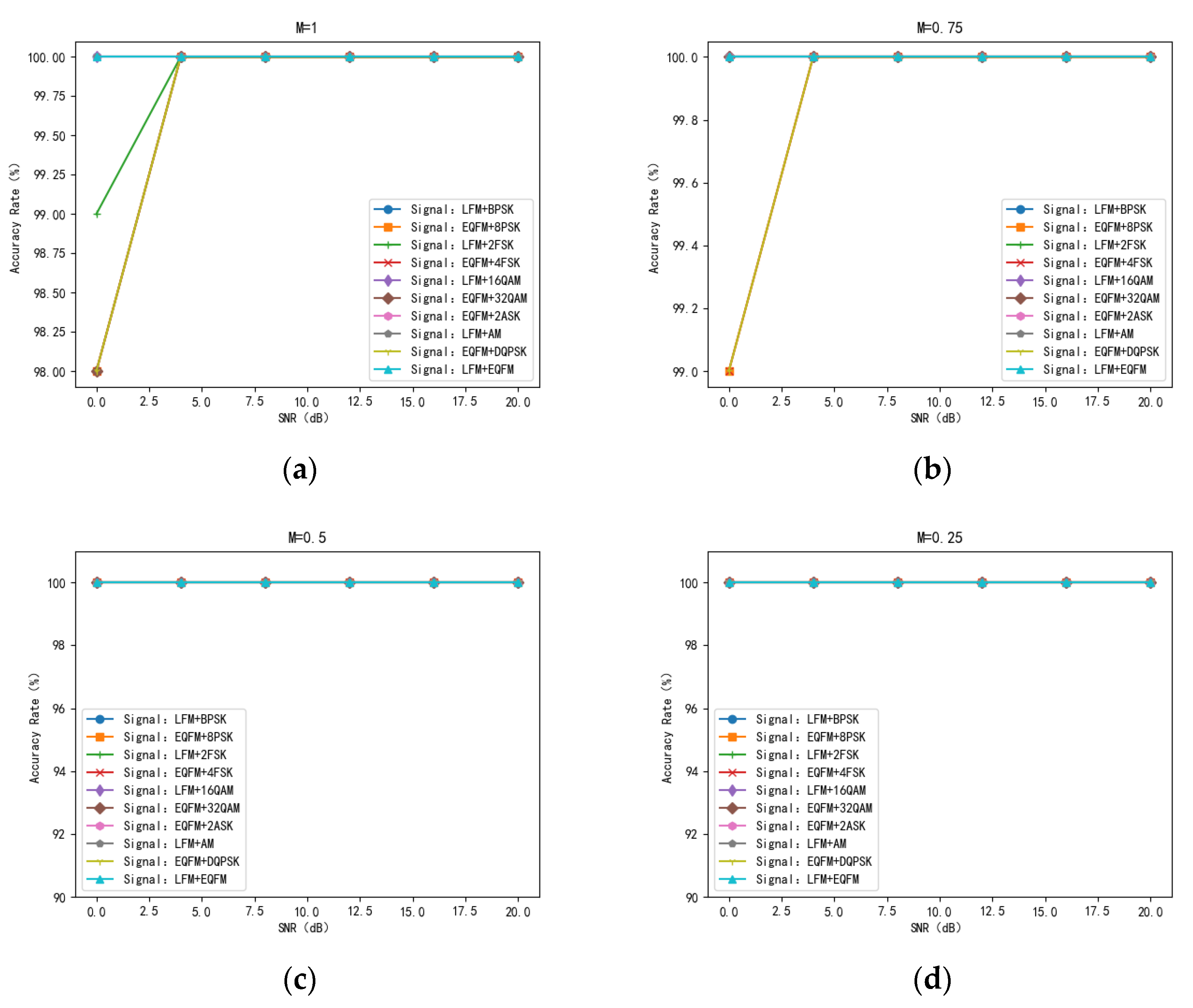
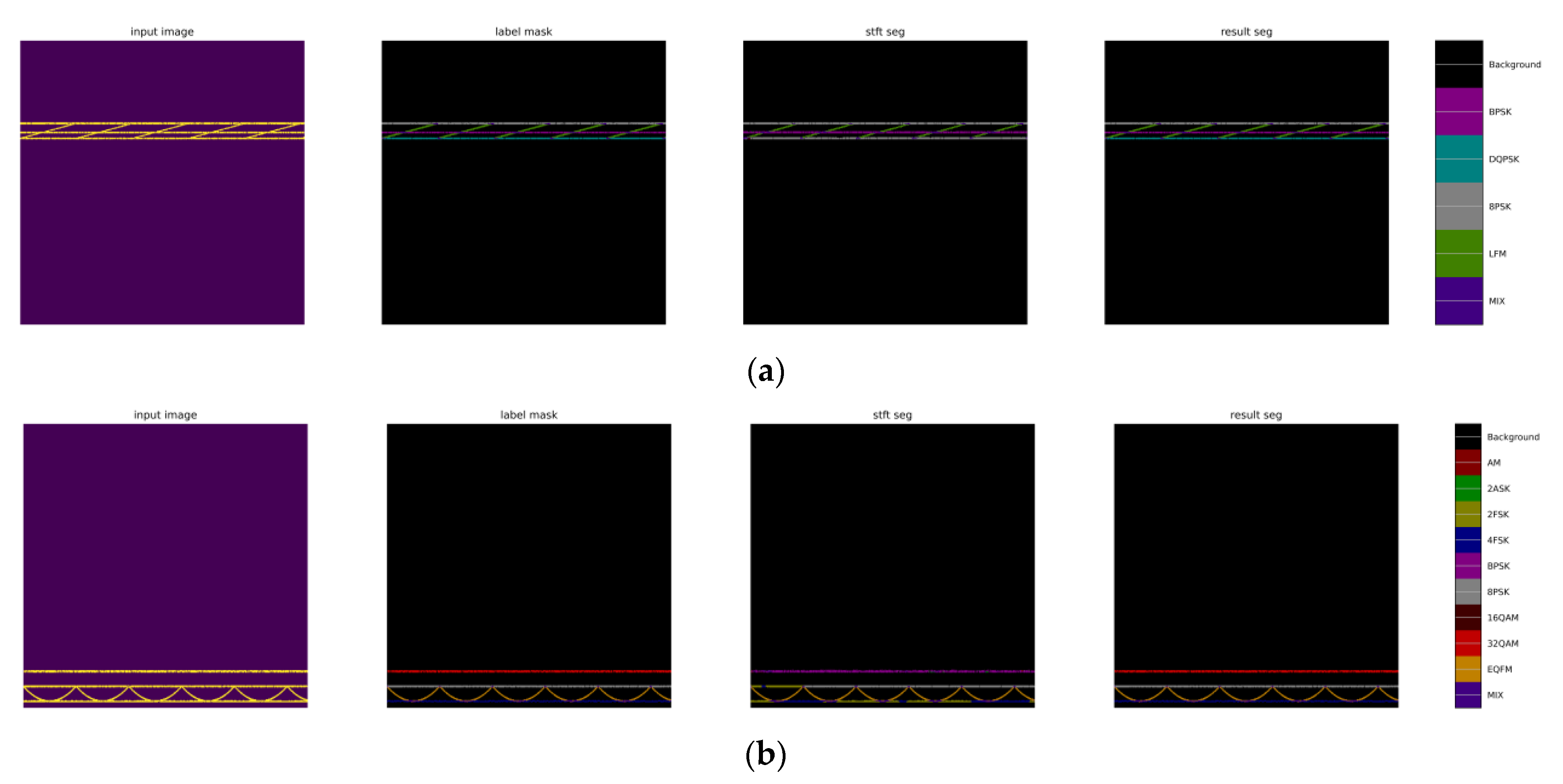
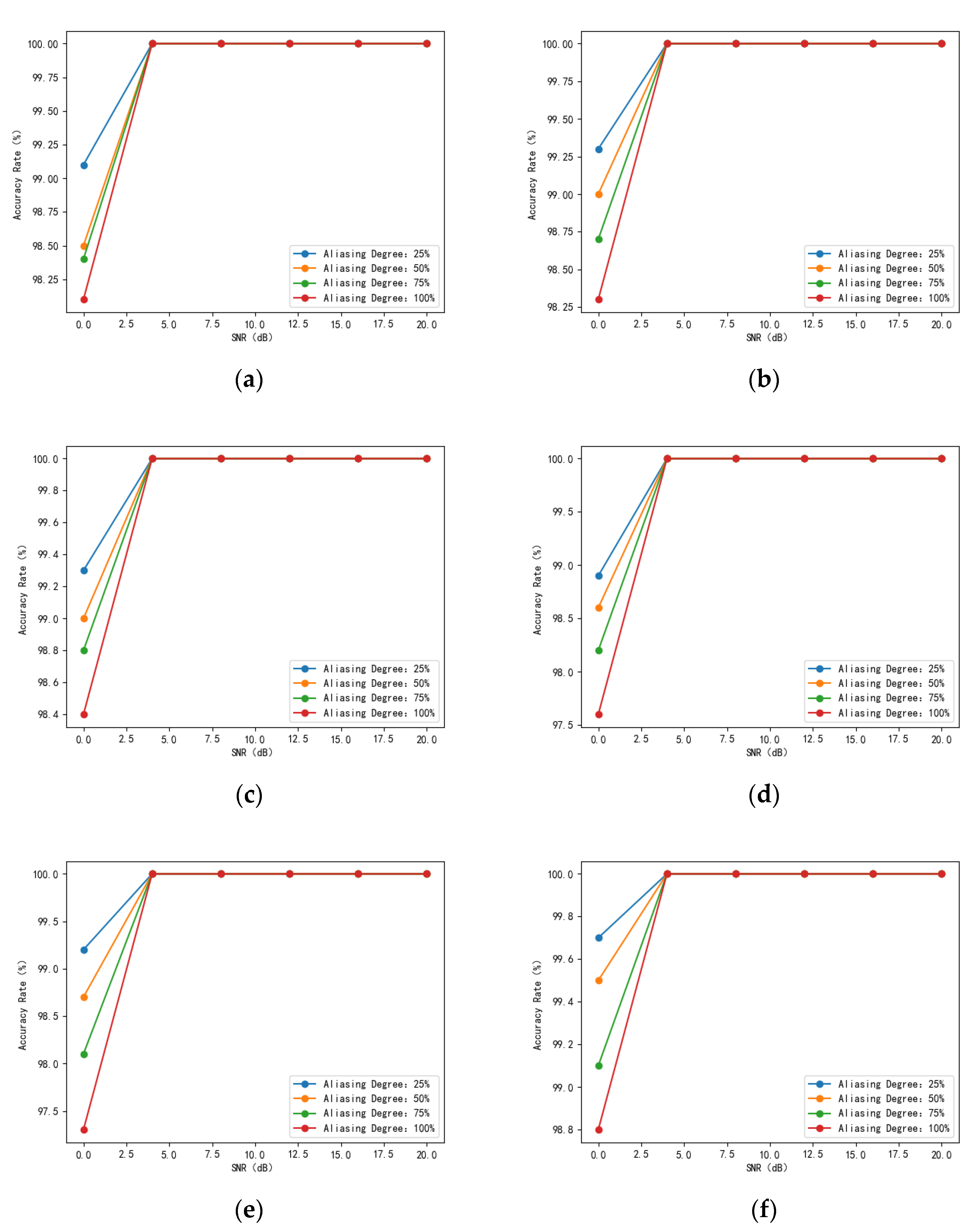
Currently, machine learning-based signal recognition methods are ineffective for intra-class signals in practical applications, mainly because intra-class signals are challenging to recognize due to the same modulation of the broad classes and similar single-dimensional features. To solve this problem, this article proposes a time-frequency aliasing signal recognition method based on multi-mode fusion (TRMM); the method first performs multidimensional feature extraction from two modes, a time-frequency diagram and wave-frequency diagram, and then establishes a pixel-level weighted fusion decision-maker to adjudicate each pixel; the method achieves inter-class recognition as well as satisfactory intra-class recognition. At an SNR of 0 dB, the recognition rate of the four-signal aliasing model can reach more than 97.3%.




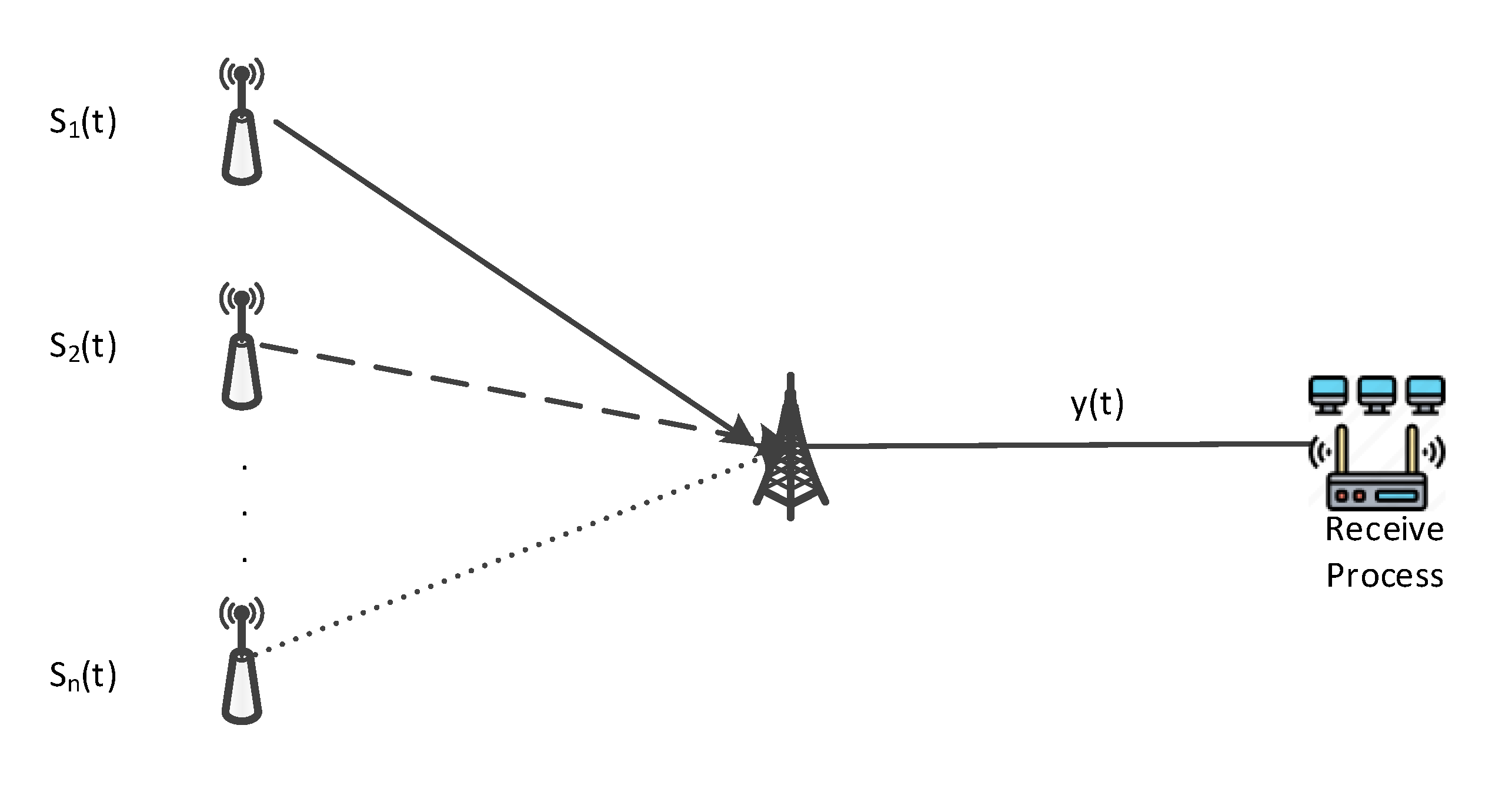





















{kind=link}
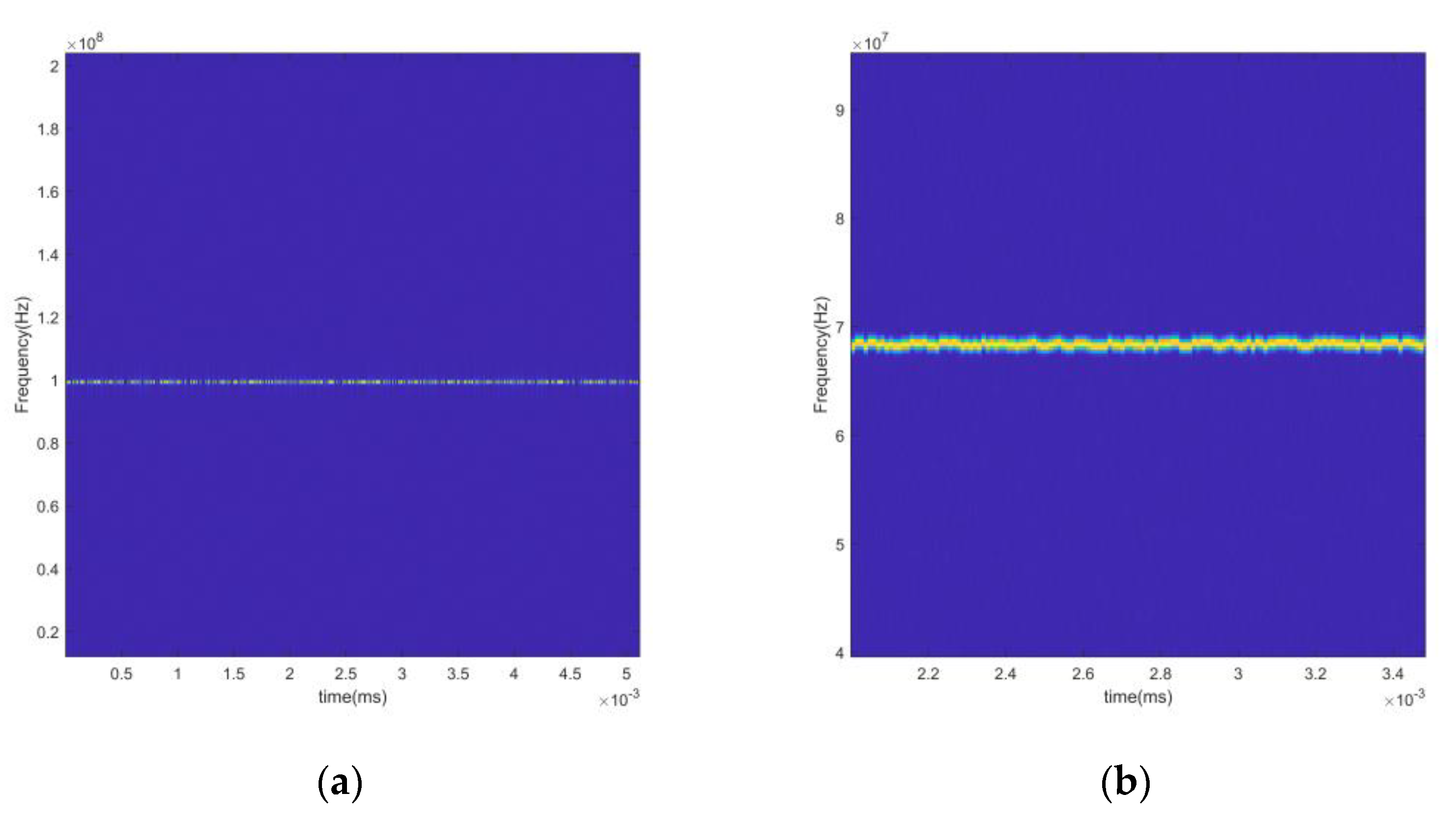{kind=link}
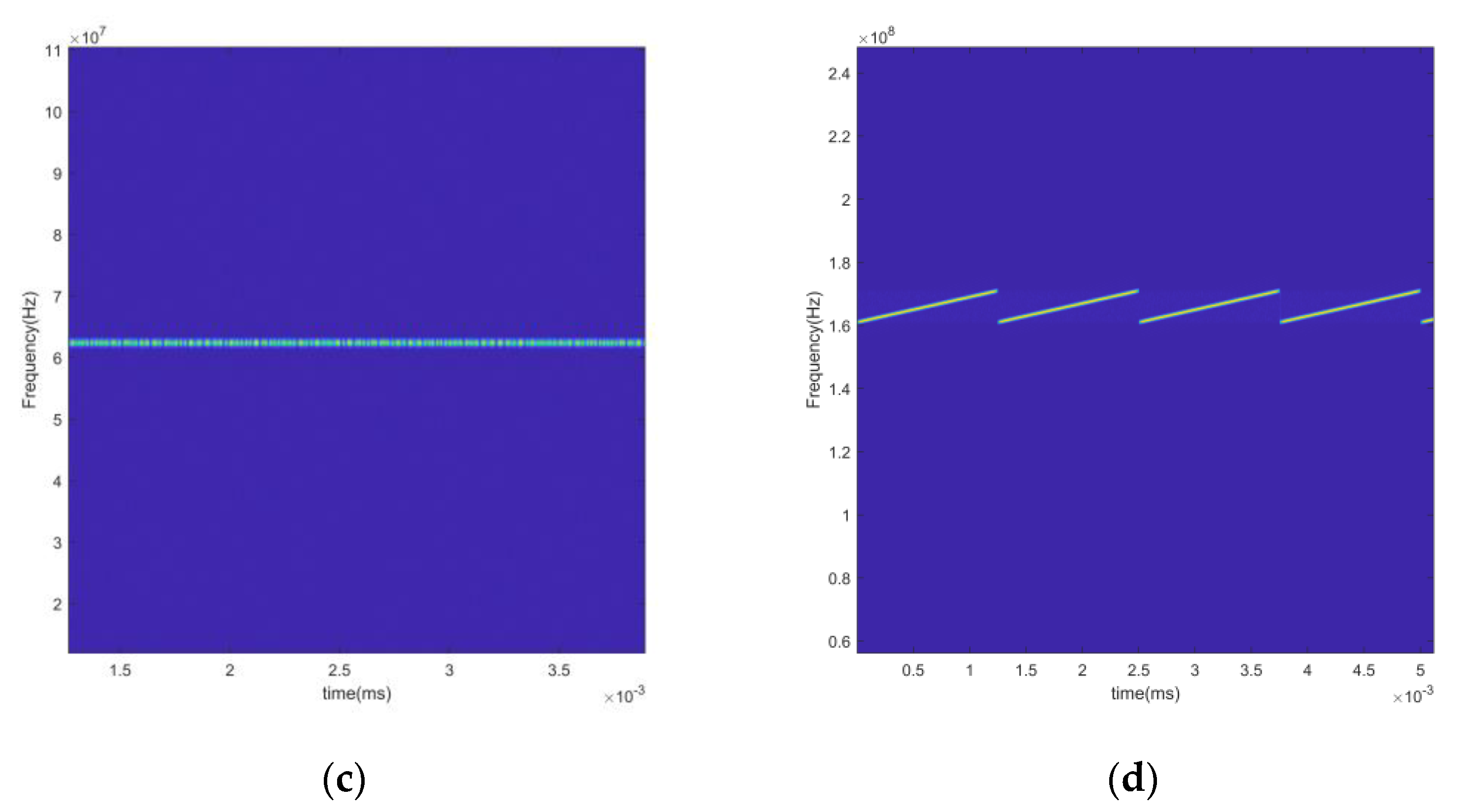{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}