


Large Span Sizes and Irregular Shapes Target Detection Methods Using Variable Convolution-Improved YOLOv8

Abstract
1. Introduction
2. Methods
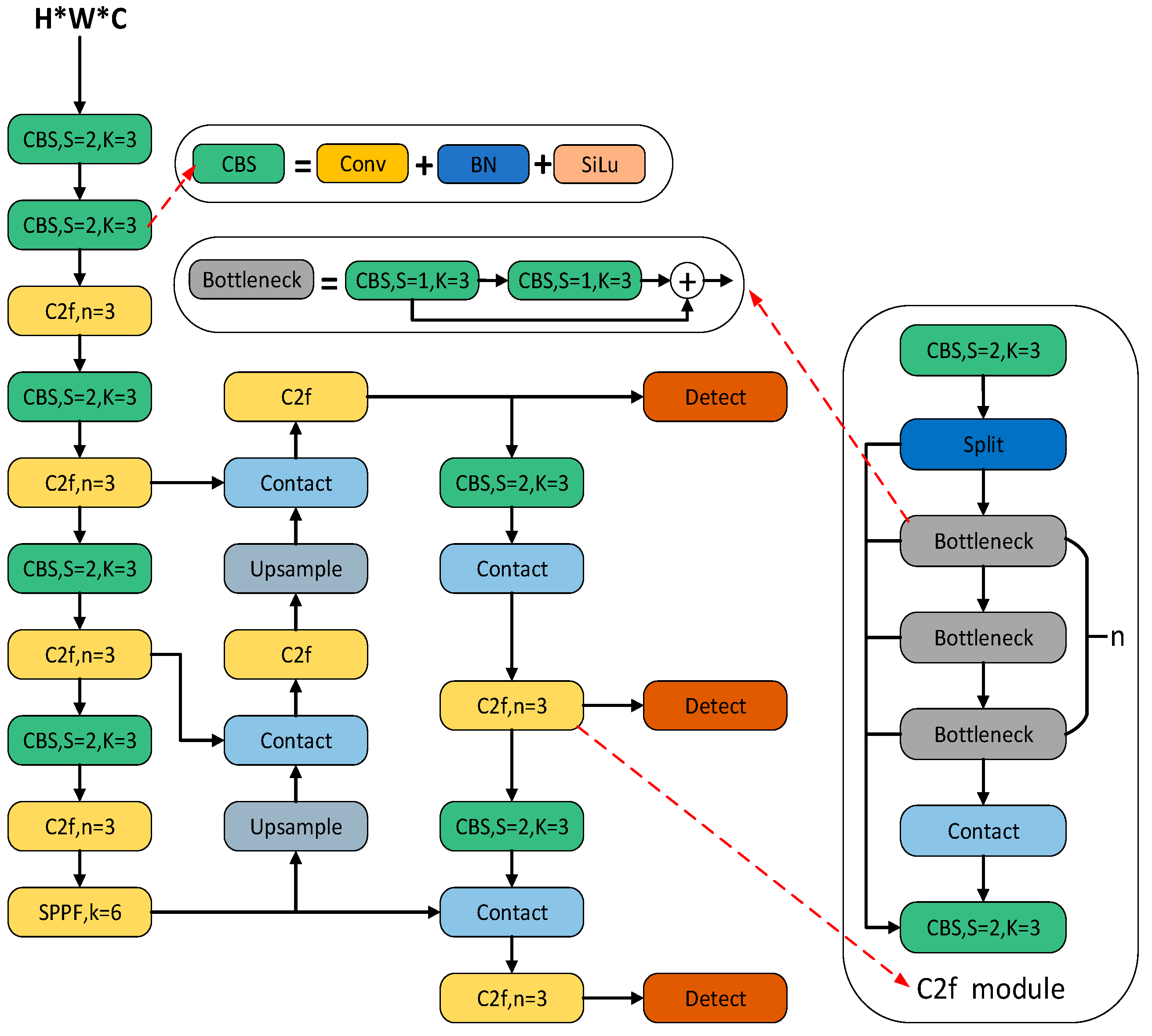
2.1. YOLOv8 Network Model
2.1.1. Data Preprocessing
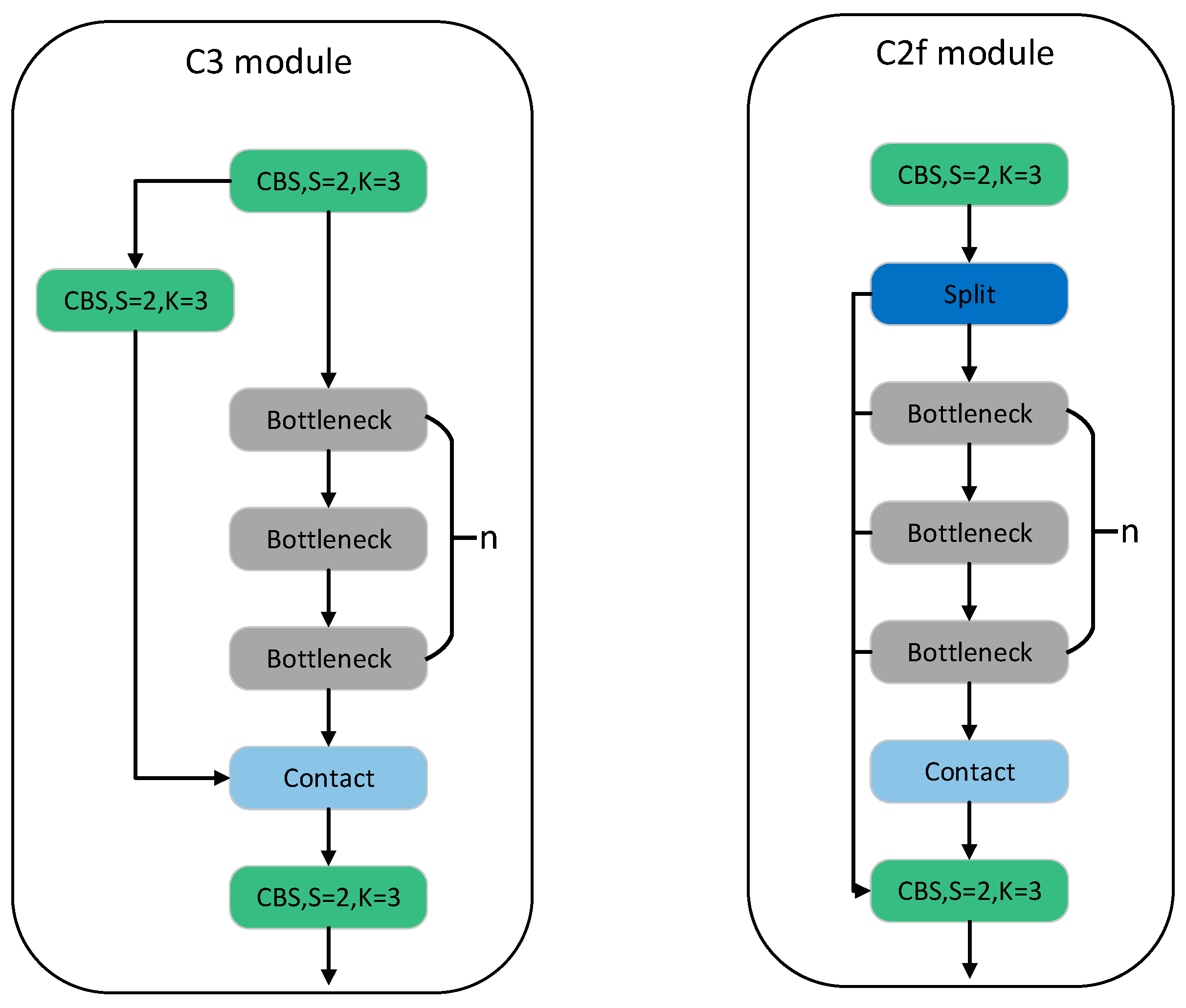
2.1.2. YOLOv8 Backbone Network
2.1.3. Label Assignment Strategy
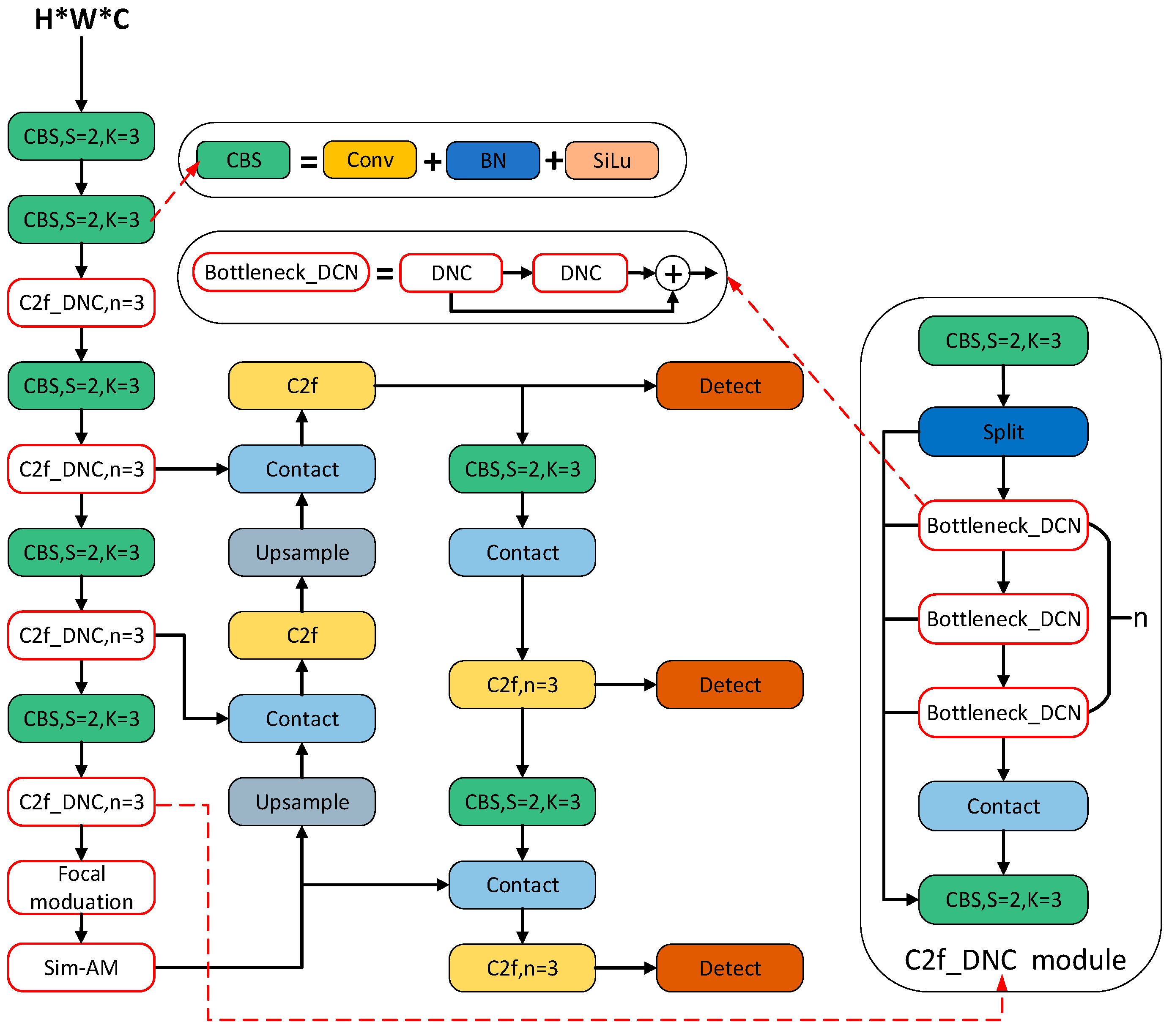
2.2. YOLOv8 Network Model Improved Based on Adaptive Convolution
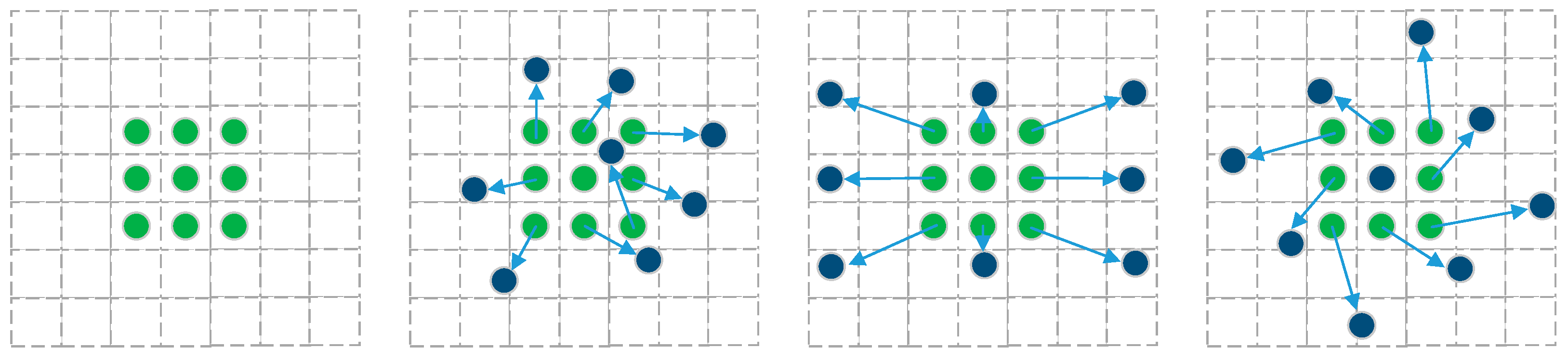
2.2.1. Deformable Convolution Network
2.2.2. Simple Parameter-Free Attention Mechanism
2.2.3. Focal Modulation Networks
2.2.4. Large Span Sizes and Irregular Shapes Target Detection Methods
3. Experiment and Result
3.1. Dataset Creation and Preprocessing
3.2. Evaluation Indicators
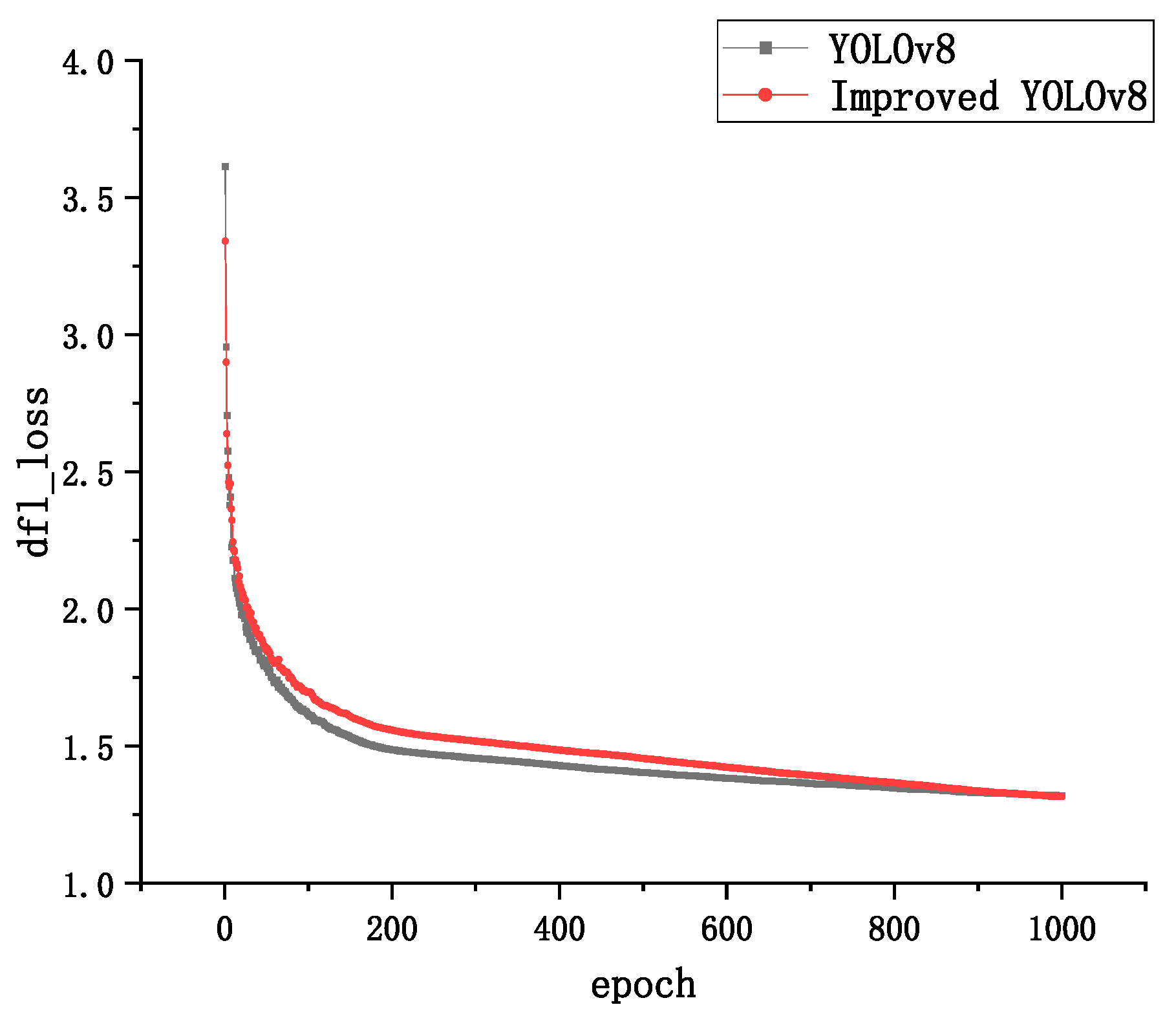
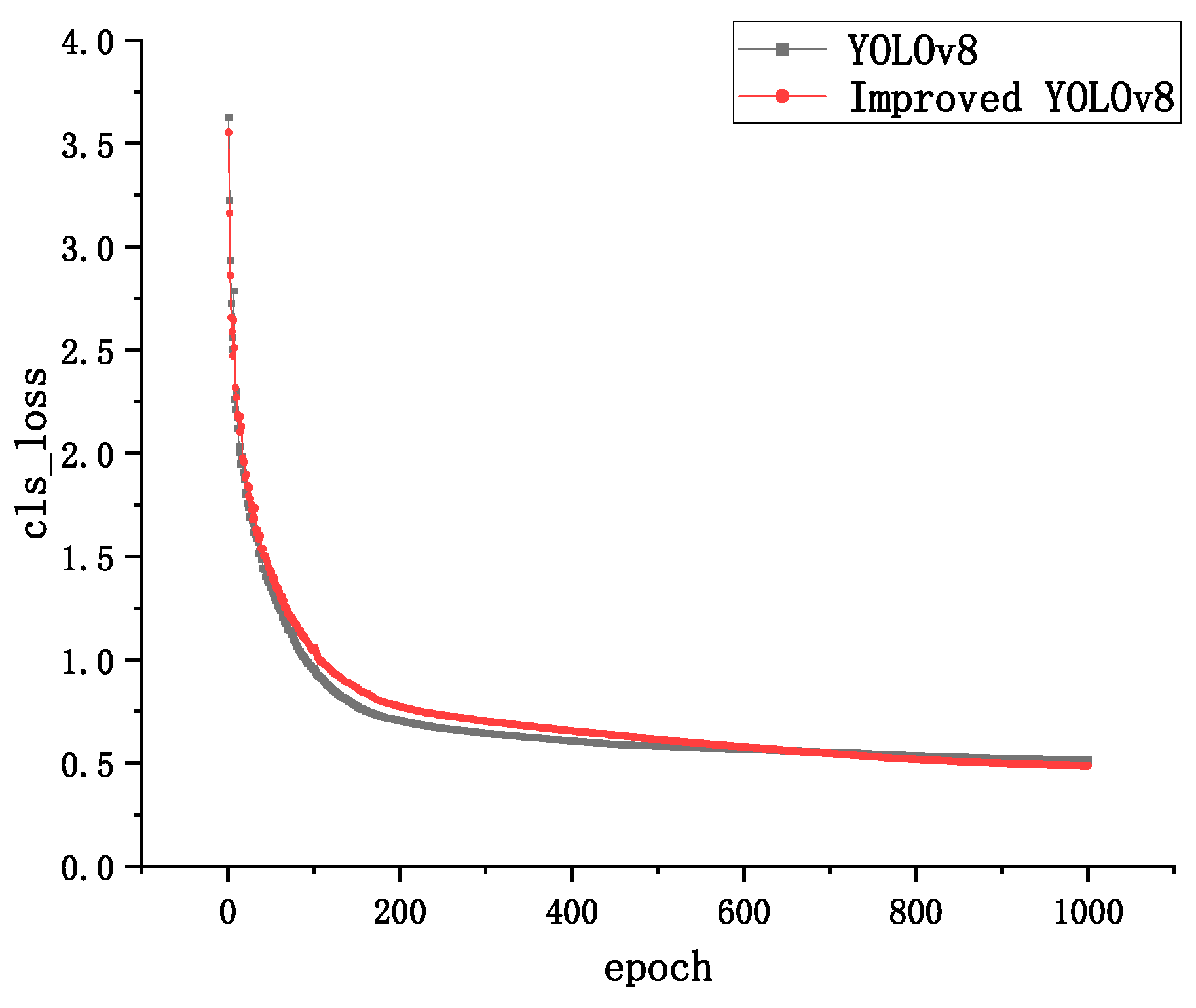
3.3. Convergence Analysis
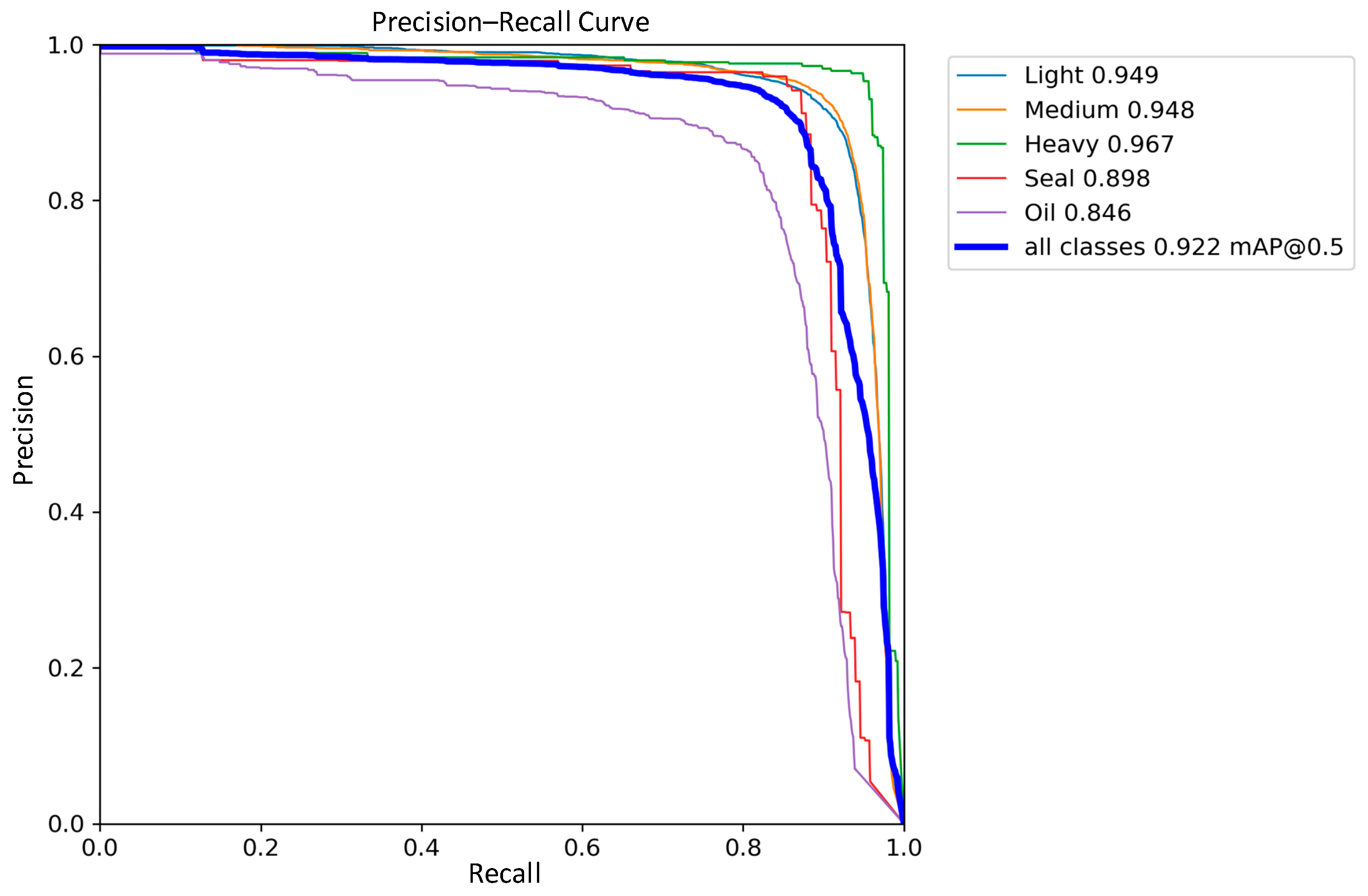
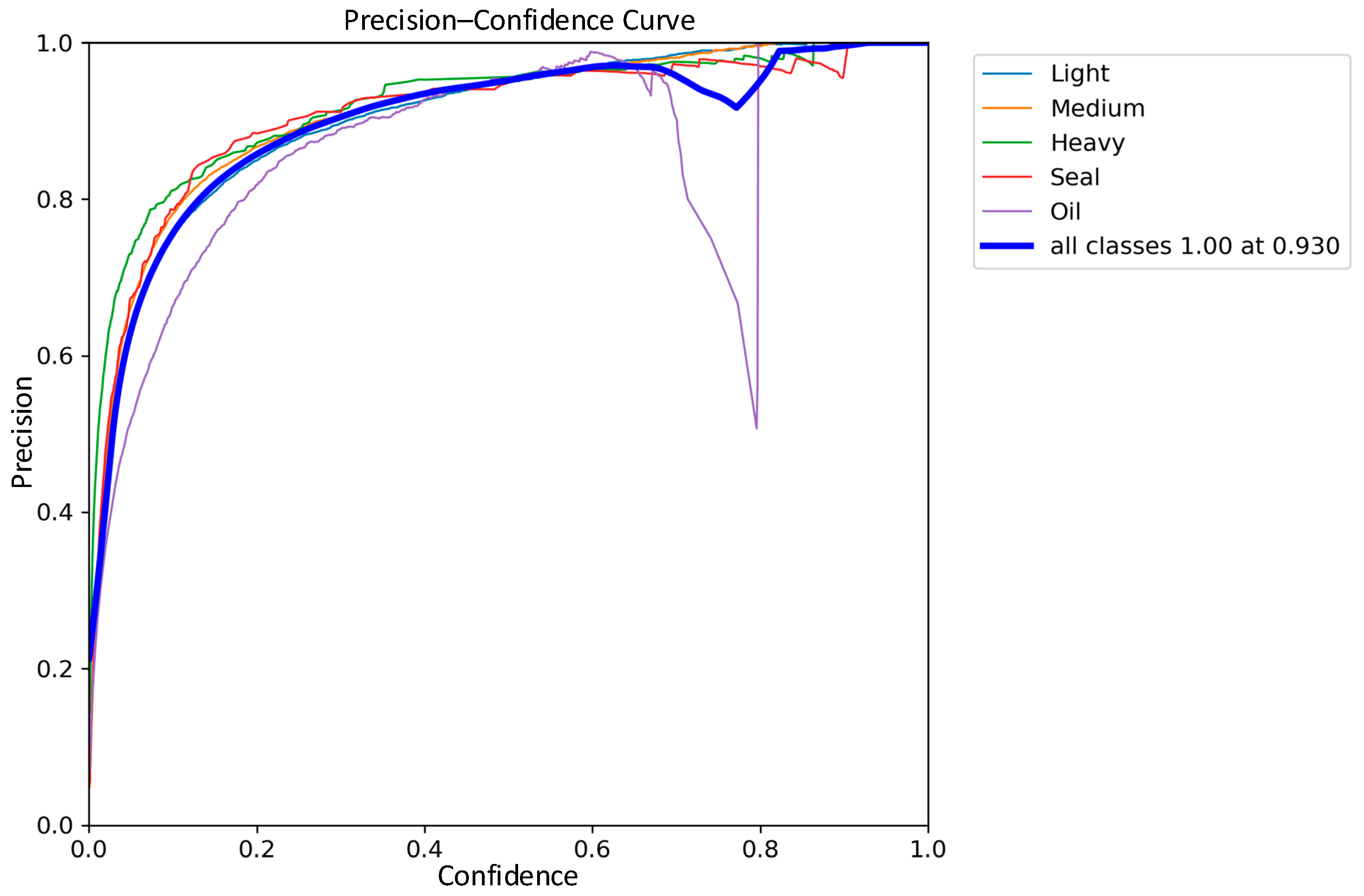
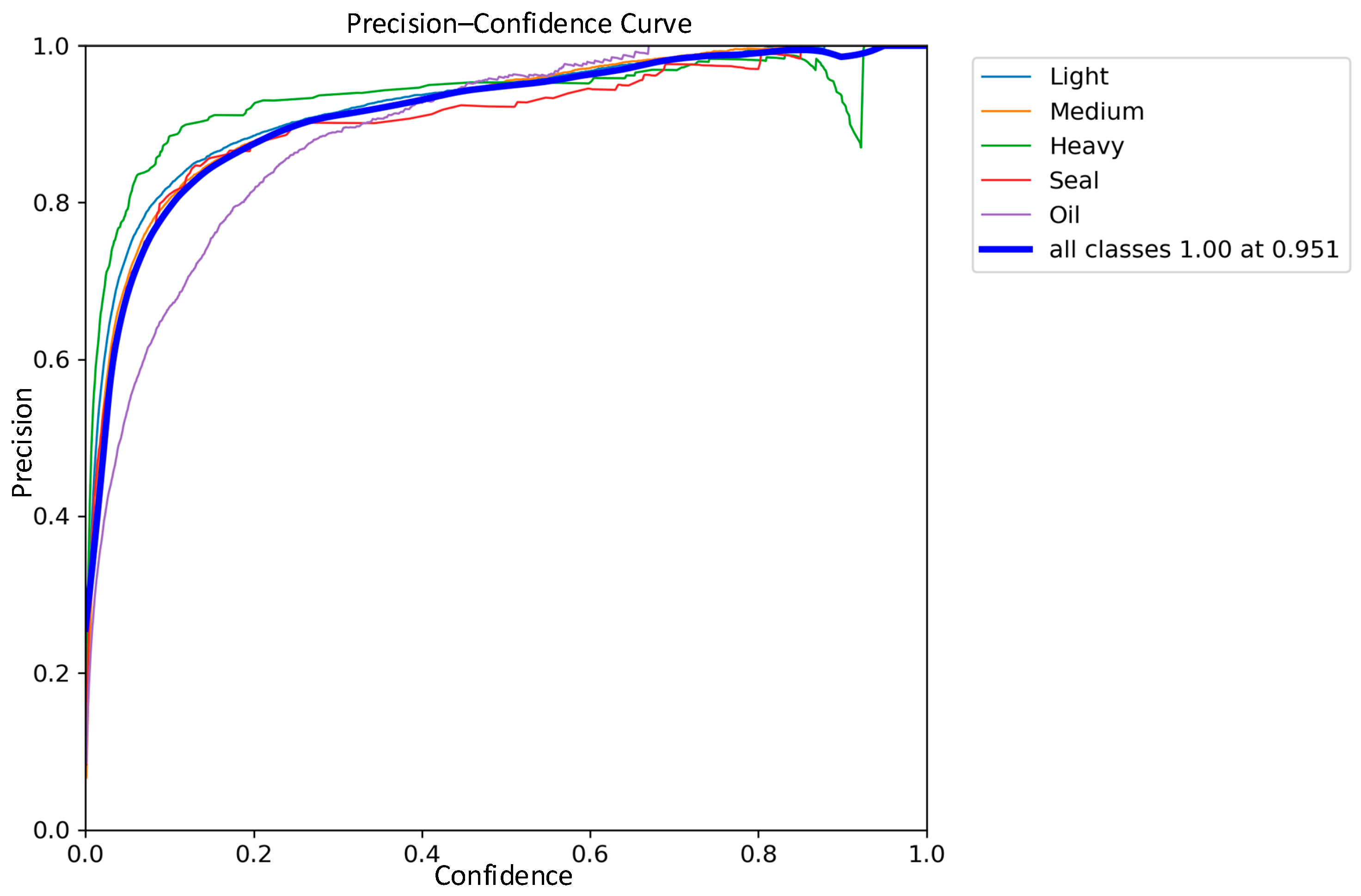
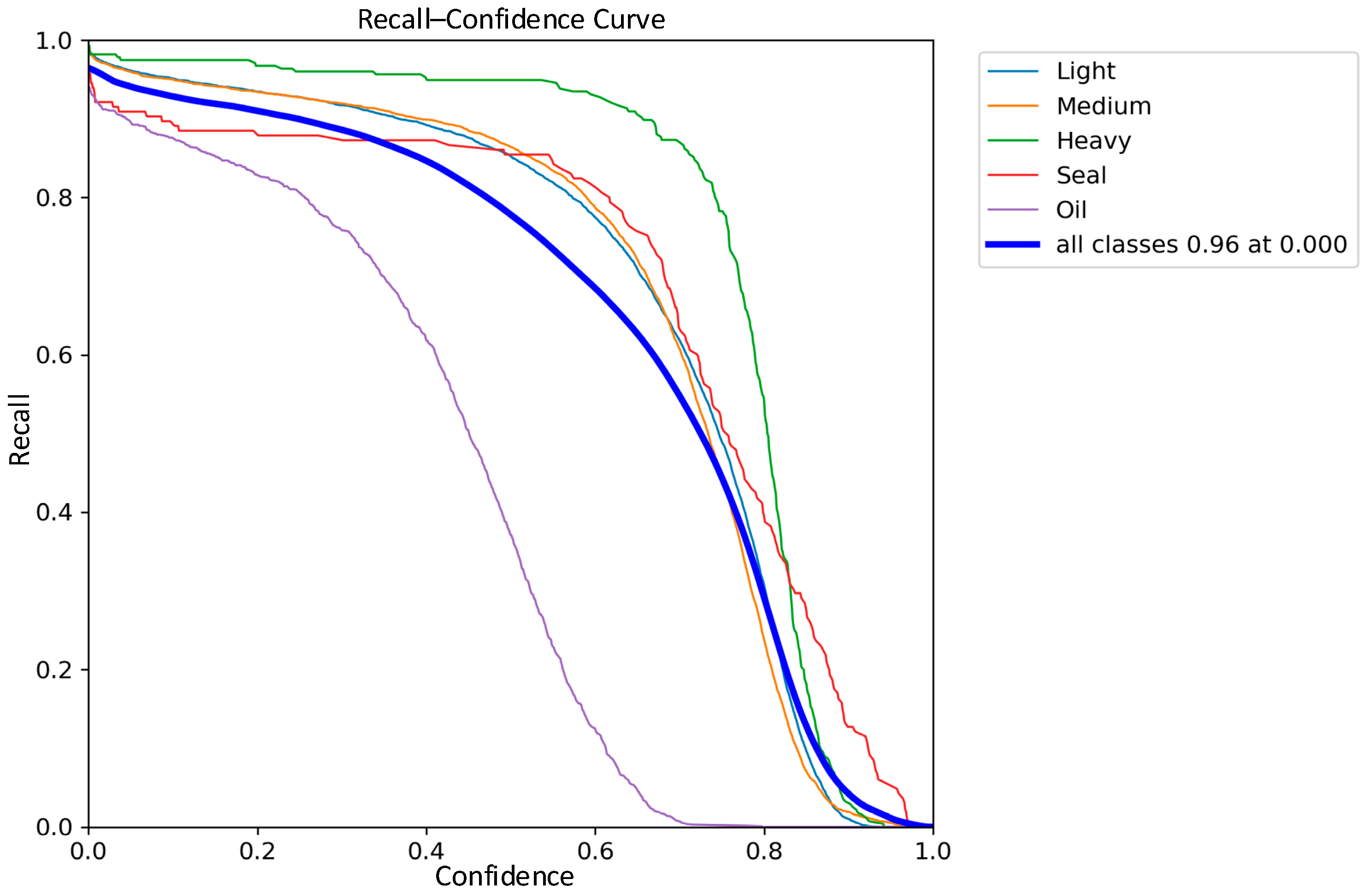
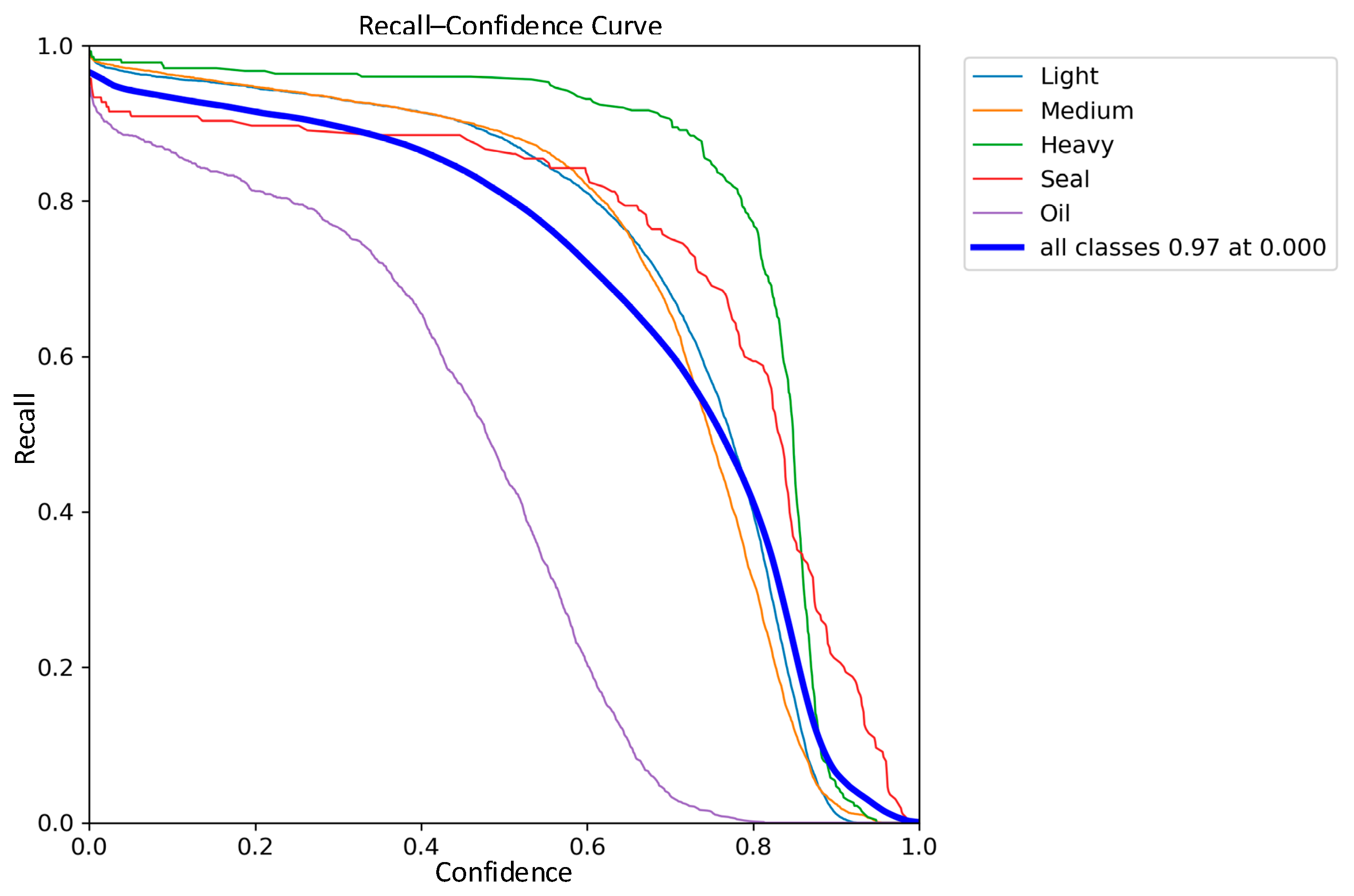
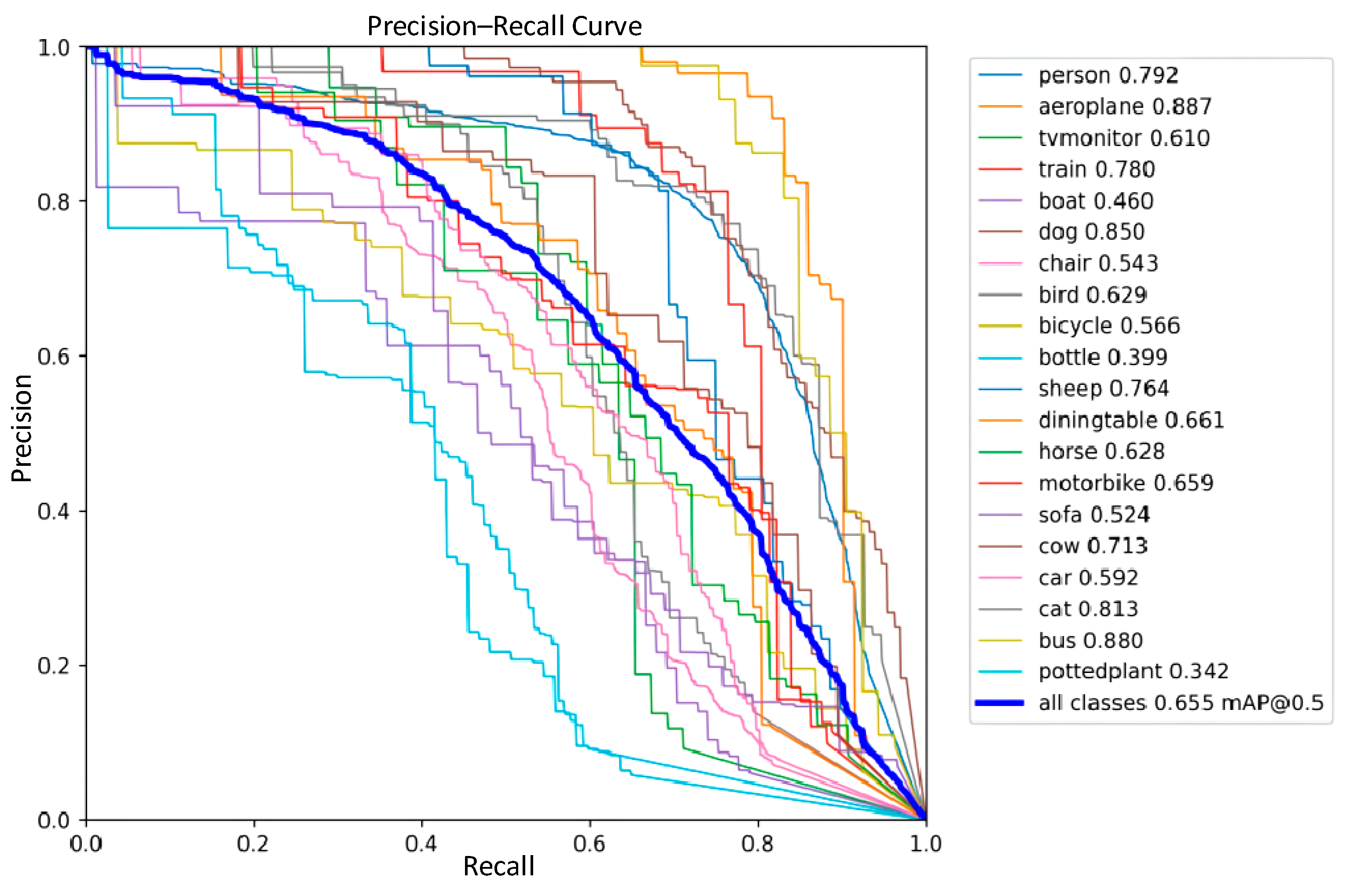
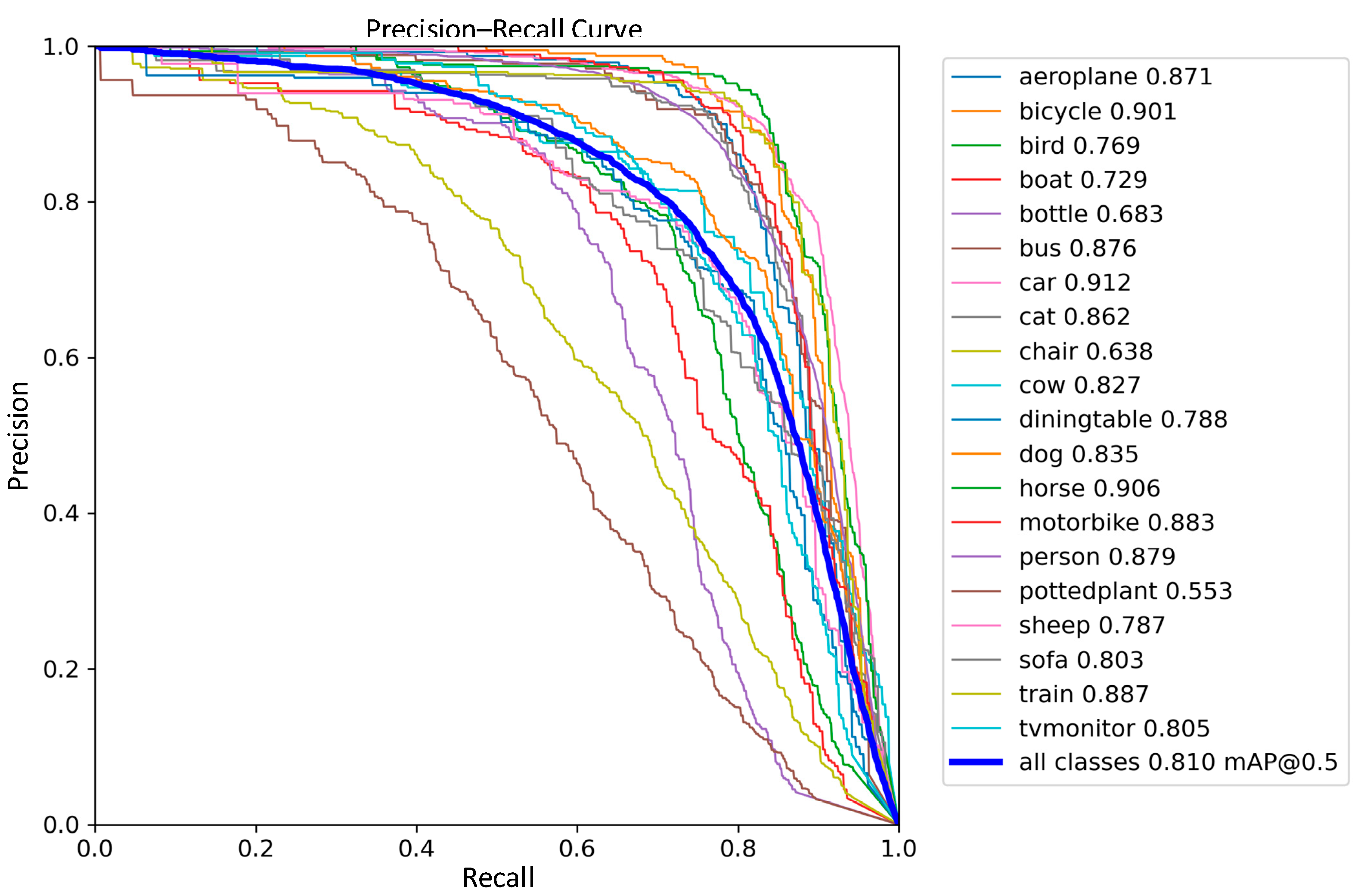
3.4. Comparative Analysis of Detection Performance
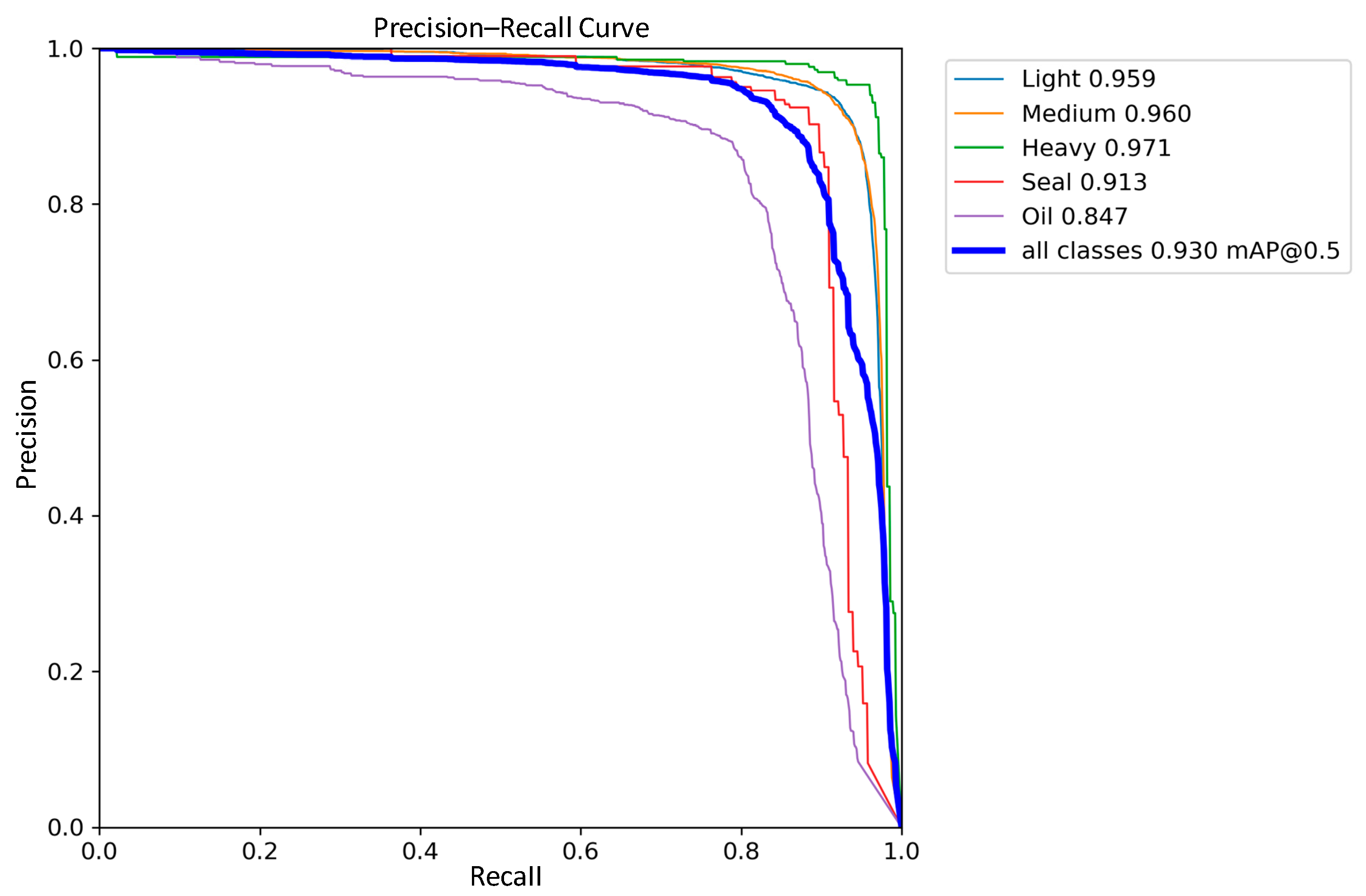
3.5. Generalization Experiment
3.6. Detection Effect
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yan, M.Y.; Sun, J.B. A Dim-small Target Real-time Detection Method Based on Enhanced YOLO. In Proceedings of the IEEE International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, 27–29 February 2022. [Google Scholar]
- Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W. Fire-YOLO: A Small Target Object Detection Method for Fire Inspection. Sustainability 2022, 14, 4930. [Google Scholar] [CrossRef]
- Yu, H.; Li, Y.; Zhang, D. An Improved YOLO v3 Small-Scale Ship Target Detection Algorithm. In Proceedings of the 6th International Conference on Smart Grid and Electrical Automation (ICSGEA), Kunming, China, 29–30 May 2021. [Google Scholar]
- Wu, H.Y.; Wang, Y.; Zhao, P.; Qian, M. Small-target weed-detection model based on YOLO-V4 with improved backbone and neck structures. Precis. Agric. 2023, 24, 2149–2170. [Google Scholar] [CrossRef]
- Mou, X.A.; Lei, S.; Zhou, X. YOLO-FR: A YOLOv5 Infrared Small Target Detection Algorithm Based on Feature Reassembly Sampling Method. Sensors 2023, 23, 2710. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Meng, Y.; Yu, X.; Bi, H.; Chen, Z.; Li, H.; Yang, R.; Tian, J. MBAB-YOLO: A Modified Lightweight Architecture for Real-Time Small Target Detection. IEEE Access 2023, 11, 78384–78401. [Google Scholar] [CrossRef]
- Shabbir, S.; Zhang, Y.; Sun, C.; Yue, Z.; Xu, W.; Zou, L.; Chen, F.; Yu, J. Transfer learning improves the prediction performance of a LIBS model for metals with an irregular surface by effectively correcting the physical matrix effect. J. Anal. At. Spectrom. 2021, 36, 1441–1454. [Google Scholar] [CrossRef]
- Ji, S.; Xu, D.; Guo, L.; Li, M.; Zhang, D. The Seeding Algorithm for Spherical k-Means Clustering with Penalties. In Proceedings of the 13th International Conference on Algorithmic Aspects in Information and Management (AAIM), Beijing, China, 6–8 August 2019; Springer International Publishing Ag: Cham, Switzerland, 2019. [Google Scholar]
- Gao, Z.; Sridhar, S.; Spiller, D.E.; Taylor, P.R. Applying Improved Optical Recognition with Machine Learning on Sorting Cu Impurities in Steel Scrap. J. Sustain. Metall. 2020, 6, 785–795. [Google Scholar] [CrossRef]
- Selvakumar, K.; Jerome, J.; Shankar, N.; Sarathkumar, T. Robust embedded vision system for face detection and identification in smart surveillance. Int. J. Signal Imaging Syst. Eng. 2015, 8, 356. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Y.; Li, L.-P.; You, Z.-H.; Huang, W.-Z. Self-Interacting Proteins Prediction from PSSM Based on Evolutionary Information. Sci. Program. 2021, 2021, 6677758. [Google Scholar] [CrossRef]
- Dange, A.D.; Momin, B.F. The CNN and DPM based approach for multiple object detection in images. In Proceedings of the International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019. [Google Scholar]
- Hua, X.; Wang, X.Q.; Wang, D.; Ma, Z.; Shao, F. Multi-Objective Detection of Traffic Scenes Based on Improved SSD. Acta Opt. Sin. 2018, 38, 1215003. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Wang, H.; Cao, D.; Velenis, E.; Wang, F.-Y. Driver Activity Recognition for Intelligent Vehicles: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2019, 68, 5379–5390. [Google Scholar] [CrossRef]
- Zheng, M.J.; Lei, Z.J.; Zhang, K. Intelligent detection of building cracks based on deep learning. Image Vis. Comput. 2020, 103, 103987. [Google Scholar] [CrossRef]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Zhang, W.; Fu, C.; Xie, H.; Zhu, M.; Tie, M.; Chen, J. Global Context Aware RCNN for Object Detection. Neural Comput. Appl. 2020, 33, 11627–11639. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, X.; Dong, J.; Chen, C.; Lv, Q. GPNet: Gated pyramid network for semantic segmentation. Pattern Recognit. 2021, 115, 107940. [Google Scholar] [CrossRef]
- Shim, S.; Chun, C.; Ryu, S. Road Surface Damage Detection based on Object Recognition using Fast R-CNN. J. Korea Inst. Intell. Transp. Syst. 2019, 18, 104–113. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Barreiros, M.O.; Dantas, D.d.O.; Silva, L.C.d.O.; Ribeiro, S.; Barros, A.K. Zebrafish tracking using YOLOv2 and Kalman filter. Sci. Rep. 2021, 11, 14. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Gan, H.; Yan, Y. Study on Improvement of YOLOv3 Algorithm. J. Phys. Conf. Ser. 2021, 1884, 012031. [Google Scholar] [CrossRef]
- Sun, X.; Hao, H.; Liu, Y.; Zhao, Y.; Wang, Y.; Du, Y. Research on the Application of YOLOv4 in Power Inspection. IOP Conf. Ser. Earth Environ. Sci. 2021, 693, 012038. [Google Scholar] [CrossRef]
- Zhang, L.; Li, J.M.; Zhang, F.Q. An Efficient Forest Fire Target Detection Model Based on Improved YOLOv5. Fire 2023, 6, 291. [Google Scholar] [CrossRef]
- Pullakandam, M.; Loya, K.; Salota, P.; Yanamala, R.M.; Javvaji, P.K. Weapon Object Detection Using Quantized YOLOv8. In Proceedings of the 2023 5th International Conference on Energy, Power and Environment: Towards Flexible Green Energy Technologies (ICEPE), Shillong, India, 15–17 June 2023; pp. 1–5. [Google Scholar]
- Li, Y.T.; Fan, Q.; Huang, H.; Han, Z.; Gu, Q. A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition. Drones 2023, 7, 304. [Google Scholar] [CrossRef]
- Yun, S.; Han, D. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Yang, L.X.; Zhang, R.Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning (ICML), Online, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Öztürk, S.; Çukur, T. Focal modulation network for lung segmentation in chest X-ray images. Turk. J. Electr. Eng. Comput. Sci. 2023, 31, 1006–1020. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Input image resolution | 640 × 640 × 3 |
| Epoch | 1000 |
| Learning rate | 0.01 |
| Batch size | 8 |
| P (Positive) | N (Negative) | |
|---|---|---|
| T (True) | True positive (TP) | True negative (TN) |
| F (False) | False positive (FP) | False negative (FN) |
| Framework | mAP | Recall Rate | Accuracy |
|---|---|---|---|
| SSD | 84.9% | 77.8% | 90.1% |
| Faster-RCNN | 90.1% | 86.9% | 91.2% |
| YOLO | 78.3% | 71.2% | 87.5% |
| YOLOv3 | 80.7% | 74.7% | 89.2% |
| YOLOv5 | 82.2% | 83.0% | 92.9% |
| Classic YOLOv8 | 92.2% | 96.0% | 93.0% |
| Improved YOLOv8 | 93.0% | 97.0% | 95.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Liu, W.; Chui, H.-C.; Chen, X. Large Span Sizes and Irregular Shapes Target Detection Methods Using Variable Convolution-Improved YOLOv8. Sensors 2024, 24, 2560. https://doi.org/10.3390/s24082560
Gao Y, Liu W, Chui H-C, Chen X. Large Span Sizes and Irregular Shapes Target Detection Methods Using Variable Convolution-Improved YOLOv8. Sensors. 2024; 24(8):2560. https://doi.org/10.3390/s24082560
Chicago/Turabian StyleGao, Yan, Wei Liu, Hsiang-Chen Chui, and Xiaoming Chen. 2024. "Large Span Sizes and Irregular Shapes Target Detection Methods Using Variable Convolution-Improved YOLOv8" Sensors 24, no. 8: 2560. https://doi.org/10.3390/s24082560
APA StyleGao, Y., Liu, W., Chui, H.-C., & Chen, X. (2024). Large Span Sizes and Irregular Shapes Target Detection Methods Using Variable Convolution-Improved YOLOv8. Sensors, 24(8), 2560. https://doi.org/10.3390/s24082560