



An Analytical Model of IaaS Architecture for Determining Resource Utilization †


Abstract
:1. Introduction
1.1. Related Works
1.2. Research Contribution
- An analytical model in the form of a method, called ARU method, is developed to determine the average use of each cloud system resource (RAM (R), disk (D), processor (P), bandwidth (B)) during its operation.
- In order to develop the proposed algorithm, models of multi-service systems were used: a model of multi-service resources with full availability, a model of multi-service resources with limited availability, and the methodology of fixed points.
- A simulation model of a cloud system based is developed on requests for four parameters (R, D, P, B) in order to obtain information on the use of individual resources of physical machines and indicate the impact of individual resources on the rejection of requests;
- The results obtained using the model are compared with the results obtained using the simulator developed by the authors.
2. Cloud Computing Structure
2.1. Management in the Cloud
- Round-robin: This algorithm distributes VMs in a round-robin fashion across the available PMs. It ensures an even distribution of VMs across the PMs and prevents the overloading of any single PM.
- Opportunistic load balancing (OLB): This algorithm dynamically monitors the load on each PM and migrates VMs from overloaded PMs to underloaded ones to balance the load. It makes use of statistical models to predict the future load on PMs.
- Central load balancing decision model (CLBDM): This algorithm uses a central controller to balance the load across the PMs. The controller has access to the load information of all PMs and makes decisions on where to place VMs based on the current and predicted future load.
- Ant Colony Optimization (ACO): This algorithm is inspired by the behavior of ants in finding the shortest path between two points. In the cloud computing environment, ACO can be used to find the optimal placement of VMs based on resource utilization, energy consumption, and other criteria.
- Genetic algorithm (GA): This algorithm uses a population-based approach to find the optimal solution for VM placement. It starts with an initial population of VM placement solutions and evolves them using mutation, crossover, and selection operations to find the fittest solution.
- Uniform distribution: This is an even distribution that tends to average each device’s resource usage. This approach was taken into account by the authors during the research.
2.2. Physical Machine
- —the number of processors (cores),
- —the total capacity of RAM,
- —the total capacity of the hard disk,
- —the total bitrate of a network link.
- —the number of demanded processors (cores),
- —the demands for capacity of RAM,
- —the demanded capacity of the hard disk,
- —the demanded speed of a network link,
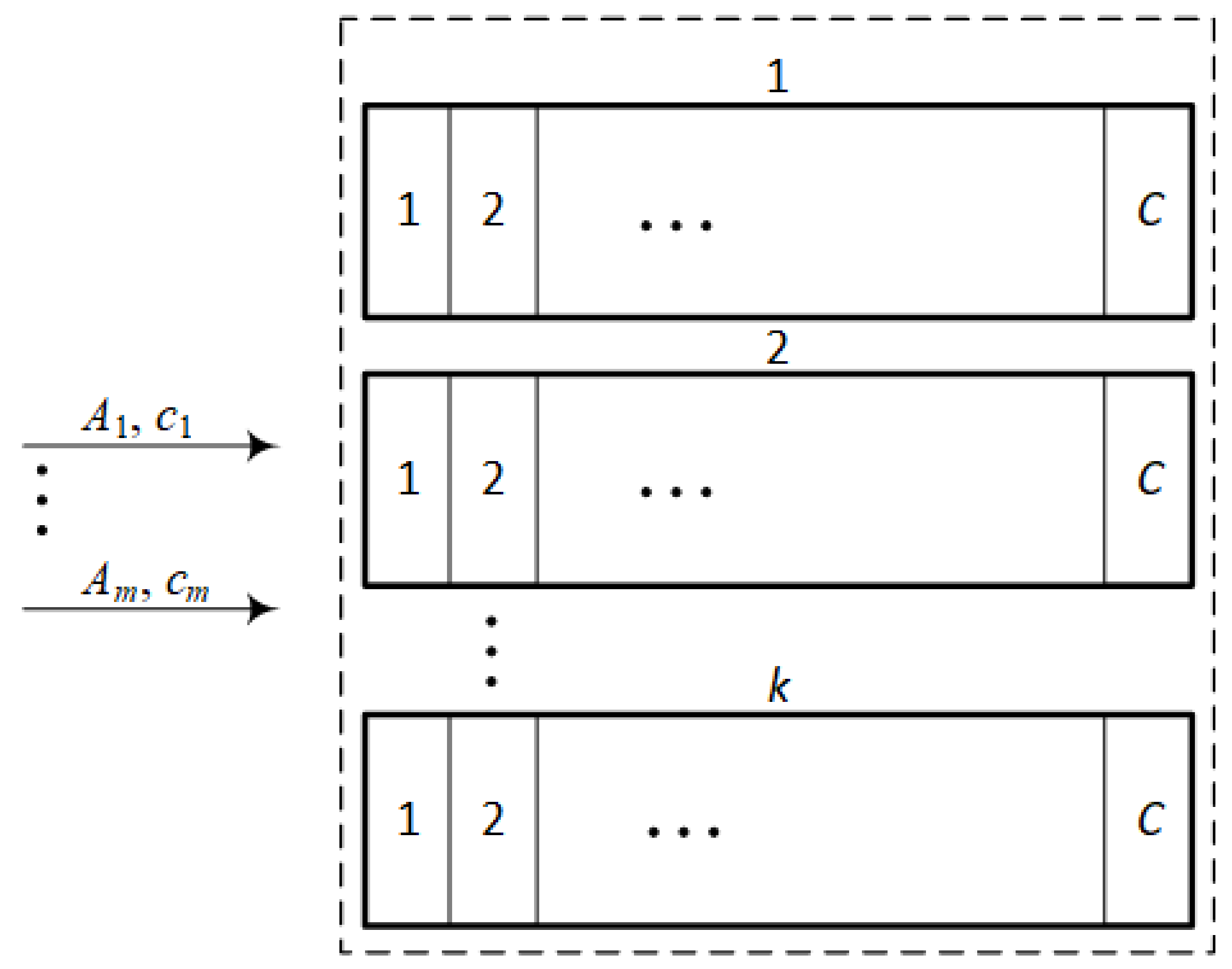
3. Model
3.1. Basic Analytical Models
3.2. Full Availability System
3.2.1. Limited Availability System
- —the traffic intensity of traffic class i offered to a LAS;
- —the occupancy probability of n AUs in a LAS with a total capacity of units, where C is the capacity of single subsystem;
- —the so-called conditional passage probability for transitions between neighboring occupancy states in a LAS:where is the number of possible distributions of x free (unoccupied) AUs in k separate resources, where each of the resources has a capacity of C units:
3.2.2. Fixed-Point Method
- Initialization of the iteration step: .
- Determining the initial approximations (z = 0) for the blocking probabilities of all traffic classes in all subsystems:where
- Increasing the iteration step:
- Determining , i.e., the effective traffic intensities of individual classes offered to subsystem j in step z:where each element of set is determined according to the formula:
- Determining , , i.e., the occupancy distributions and blocking probabilities of individual classes in subsystem j at step z:where each element of the and sets is determined, respectively, based on (3):where is a set of requests for individual traffic classes in subsystem j with capacity :
- Determining the total blocking probability , i.e., the blocking probability values of individual classes in the entire system at step z:where each element of the set is determined by the formula:
- Checking the accuracy of the calculations:If the condition is not met for all i, go to Step 3; otherwise, , and the calculations end.
3.3. Proposed Model
ARU Method
- ARU METHOD:
- Determination, based on (35), of the distributions in a single PM for each type of resource (). It is assumed that the resources handle VMs with requests (), independently of the handling of these VMs in the other resources .
- Determination—based on (38)—of the average resource utilization for each type of PM resource ().
- Determination—based on (42)—of the average resource utilization for each type of resource () in a group of k PMs.
- Calculation, for each type of resource X, of the resource utilization coefficient (Formula (42)).
- Determination—based on (44)—of the actual average resource utilization in a single PM for each type of resource X ().
- Determination of the actual average resource utilization in a group of k PMs for each type of resource X () (Formula (46)).
4. Results
The Use of Individual Physical Machine Resources in the System
5. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ericsson. Ericsson Mobility Report; Ericsson Technical Report; Ericsson: Stockholm, Sweden, 2023; Available online: https://www.ericsson.com/en/reports-and-papers/mobility-report/reports (accessed on 15 February 2024).
- Mell, P.; Grance, T. The NIST Definition of Cloud Computing; Technical Reports 800-145; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2011.
- Foster, I.; Zhao, Y.; Raicu, I.; Lu, S. Cloud Computing and Grid Computing 360-Degree Compared. In Proceedings of the 2008 Grid Computing Environments Workshop, Austin, TX, USA, 16 November 2008; pp. 1–10. [Google Scholar] [CrossRef]
- Avgerinou, M.; Bertoldi, P.; Castellazzi, L. Trends in Data Centre Energy Consumption under the European Code of Conduct for Data Centre Energy Efficiency. Energies 2017, 10, 1470. [Google Scholar] [CrossRef]
- Khalil, I.M.; Khreishah, A.; Azeem, M. Cloud Computing Security: A Survey. Computers 2014, 3, 1–35. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Cao, K.; Liu, Y.; Meng, G.; Sun, Q. An Overview on Edge Computing Research. IEEE Access 2020, 8, 85714–85728. [Google Scholar] [CrossRef]
- Oueida, S.; Kotb, Y.; Aloqaily, M.; Jararweh, Y.; Baker, T. An Edge Computing Based Smart Healthcare Framework for Resource Management. Sensors 2018, 18, 4307. [Google Scholar] [CrossRef] [PubMed]
- Naha, R.K.; Garg, S.; Georgakopoulos, D.; Jayaraman, P.P.; Gao, L.; Xiang, Y.; Ranjan, R. Fog Computing: Survey of Trends, Architectures, Requirements, and Research Directions. IEEE Access 2018, 6, 47980–48009. [Google Scholar] [CrossRef]
- Villegas, N.; Diez, L.; Iglesia, I.D.L.; González-Hierro, M.; Agüero, R. Energy-Aware Optimum Offloading Strategies in Fog-Cloud Architectures: A Lyapunov Based Scheme. IEEE Access 2023, 11, 73116–73126. [Google Scholar] [CrossRef]
- Basir, R.; Qaisar, S.; Ali, M.; Aldwairi, M.; Ashraf, M.I.; Mahmood, A.; Gidlund, M. Fog Computing Enabling Industrial Internet of Things: State-of-the-Art and Research Challenges. Sensors 2019, 19, 4807. [Google Scholar] [CrossRef] [PubMed]
- Moysiadis, V.; Sarigiannidis, P.; Moscholios, I. Towards distributed data management in fog computing. Wirel. Commun. Mob. Comput. (Online) 2018, 2018, 7597686. [Google Scholar] [CrossRef]
- International Energy Agency Global data centre energy demand by end use and data centre type, 2014–2020—Charts—Data & Statistics. Available online: https://www.iea.org/data-and-statistics/charts/global-data-centre-energy-demand-by-end-use-and-data-centre-type-2014-2020 (accessed on 15 February 2024).
- Kaur, R.; Luthra, P. Load balancing in cloud computing. In Proceedings of the International Conference on Recent Trends in Information, Telecommunication and Computing, ITC, Kochi, India, 3–4 August 2012. [Google Scholar]
- Nuaimi, K.; Mohamed, N.; Alnuaimi, M.; Al-Jaroodi, J. A survey of load balancing in cloud computing: Challenges and algorithms. In Proceedings of the Second Symposium on Network Cloud Computing and Applications, London, UK, 3–4 December 2012; Volume 12, pp. 137–142. [Google Scholar]
- Panwar, R.; Mallick, B. A Comparative Study of Load Balancing Algorithms in Cloud Computing. in Int. J. Comput. Appl. 2015, 117, 33–37. [Google Scholar] [CrossRef]
- Rai, H.; Ojha, S.K.; Nazarov, A. A survey of load balancing in cloud computing: Challenges and algorithms. In Proceedings of the 2nd IEEE International Conference on Advances in Computing, Greater Noida, India, 18–19 December 2020; pp. 861–865. [Google Scholar]
- Kaur, G.; Bala, A.; Chana, I. An intelligent regressive ensemble approach for predicting resource usage in cloud computing. J. Parallel Distrib. Comput. 2019, 123, 1–12. [Google Scholar] [CrossRef]
- Farahnakian, F.; Liljeberg, P.; Plosila, J. LiRCUP: Linear Regression Based CPU Usage Prediction Algorithm for Live Migration of Virtual Machines in Data Centers. In Proceedings of the 2013 39th Euromicro Conference on Software Engineering and Advanced Applications, Santander, Spain, 4–6 September 2013; pp. 357–364. [Google Scholar] [CrossRef]
- Li, R.; Wang, X.; Xiao, D.; Huang, C. Cloud Instance Resources Prediction Based on Hidden Markov Model. In Proceedings of the 2023 IEEE 9th International Conference on Cloud Computing and Intelligent Systems (CCIS), Dali, China, 12–13 August 2023; pp. 516–520. [Google Scholar] [CrossRef]
- Subirats, J.; Guitart, J. Assessing and forecasting energy efficiency on Cloud computing platforms. Future Gener. Comput. Syst. 2015, 45, 70–94. [Google Scholar] [CrossRef]
- Islam, S.; Jacky, J.; Lee, K.; Liu, A. Empirical prediction models for adaptive resource provisioning in the cloud. Future Gener. Comput. Syst. 2012, 20, 155–162. [Google Scholar] [CrossRef]
- Ullah, Q.Z.; Hassan, S.; Khan, G.M. Adaptive Resource Utilization Prediction System for Infrastructure as a Service Cloud. Comput. Intell. Neurosci. 2017, 2017, 4873459. [Google Scholar]
- Mehmood, T.; Latif, S.; Malik, S. Prediction Of Cloud Computing Resource Utilization. In Proceedings of the 2018 15th International Conference on Smart Cities: Improving Quality of Life Using ICT & IoT (HONET-ICT), Islamabad, Pakistan, 8–10 October 2018; pp. 38–42. [Google Scholar] [CrossRef]
- Borkowski, M.; Schulte, S.; Hochreiner, C. Predicting Cloud Resource Utilization. In Proceedings of the 2016 IEEE/ACM 9th International Conference on Utility and Cloud Computing (UCC), Shanghai, China, 6–9 December 2016; pp. 37–42. [Google Scholar]
- Hanczewski, S.; Weissenberg, M. Concept of an analytical model for cloud computing infrastructure. In Proceedings of the 11th International Symposium on Communication Systems, Networks and Digital Signal Processing (CSNDSP), Budapest, Hungary, 18–20 July 2018; pp. 1–4. [Google Scholar]
- Hanczewski, S.; Stasiak, M.; Weissenberg, M. Determining Resource Utilization in Cloud Systems: An Analytical Algorithm for IaaS Architecture. In Proceedings of the 2023 17th International Conference on Telecommunications (ConTEL), Graz, Austria, 11–13 July 2023. [Google Scholar]
- Hanczewski, S.; Stasiak, M.; Weissenberg, M. A Multiparameter Analytical Model of the Physical Infrastructure of a Cloud-Based System. IEEE Access 2021, 9, 100981–100990. [Google Scholar] [CrossRef]
- Kaufman, J. Blocking in a shared resource environment. IEEE Trans. Commun. 1981, 29, 1474–1481. [Google Scholar] [CrossRef]
- Roberts, J. A service system with heterogeneous user requirements—application to multi-service telecommunications systems. In Proceedings of the International Conference on Performance Data Communication Systems and Their Applications, Paris, France, 14–16 September 1981; pp. 423–431. [Google Scholar]
- Stasiak, M. Blocking probability in a limited-availability group carrying a mixture of different multichannel traffic streams. Ann. Télécommun. 1993, 48, 71–76. [Google Scholar] [CrossRef]
- Głąbowski, M.; Sobieraj, M.; Stasiak, M. Analytical and simulation modeling of limited-availability systems with multi-service sources and bandwidth reservation. Int. J. Adv. Telecommun. 2013, 6, 1–11. [Google Scholar]
- Kelly, F.P. Fixed Point Models of loss networks. J. Aust. Math. Soc. 1989, B31, 319–378. [Google Scholar] [CrossRef]
- Bonald, T.; Virtamo, J. A recursive formula for multirate systems with elastic traffic. IEEE Commun. Lett. 2005, 9, 753–755. [Google Scholar] [CrossRef]
- Roberts, J.W.; Mocci, U.; Virtamo, J.T. Broadband Network Teletraffic, Performance Evaluation and Design of Broadband Multiservice Networks. Final Report of Action COST 242; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RAM | 1 AU = 16 GB |
| Processor | 1 AU = 8 cores |
| Disk | 1 AU = 64 GB |
| Bandwidth | 1 AU = 100 Mbps |
| System 0 | ||||
| Servers | ||||
| No. of PMs | Capacity of Server Components in AUs | |||
| Virtual Machines | ||||
| VM Class | VM Demands in AUs | |||
| 1 | ||||
| 2 | ||||
| 3 | ||||
| System 1 | ||||
| Servers | ||||
| No. of PMs | Capacity of Server Components in AUs | |||
| Virtual Machines | ||||
| VM Class | VM Demands in AUs | |||
| 1 | ||||
| 2 | ||||
| 3 | ||||
| System 2 | ||||
| Servers | ||||
| No. of PMs | Capacity of Server Components in AUs | |||
| Virtual Machines | ||||
| VM Class | VM Demands in AUs | |||
| 1 | ||||
| 2 | ||||
| 3 | ||||
| System 3 | ||||
| Servers | ||||
| No. of PMs | Capacity of Server Components in AUs | |||
| Virtual Machines | ||||
| VM Class | VM Demands in AUs | |||
| 1 | ||||
| 2 | ||||
| 3 | ||||
| System 4 | ||||
| Servers | ||||
| Traffic [Erl] | Capacity of Server Components in AUs | |||
| Virtual Machines | ||||
| VM Class | VM Demands in AU | |||
| 1 | ||||
| 2 | ||||
| 3 | ||||
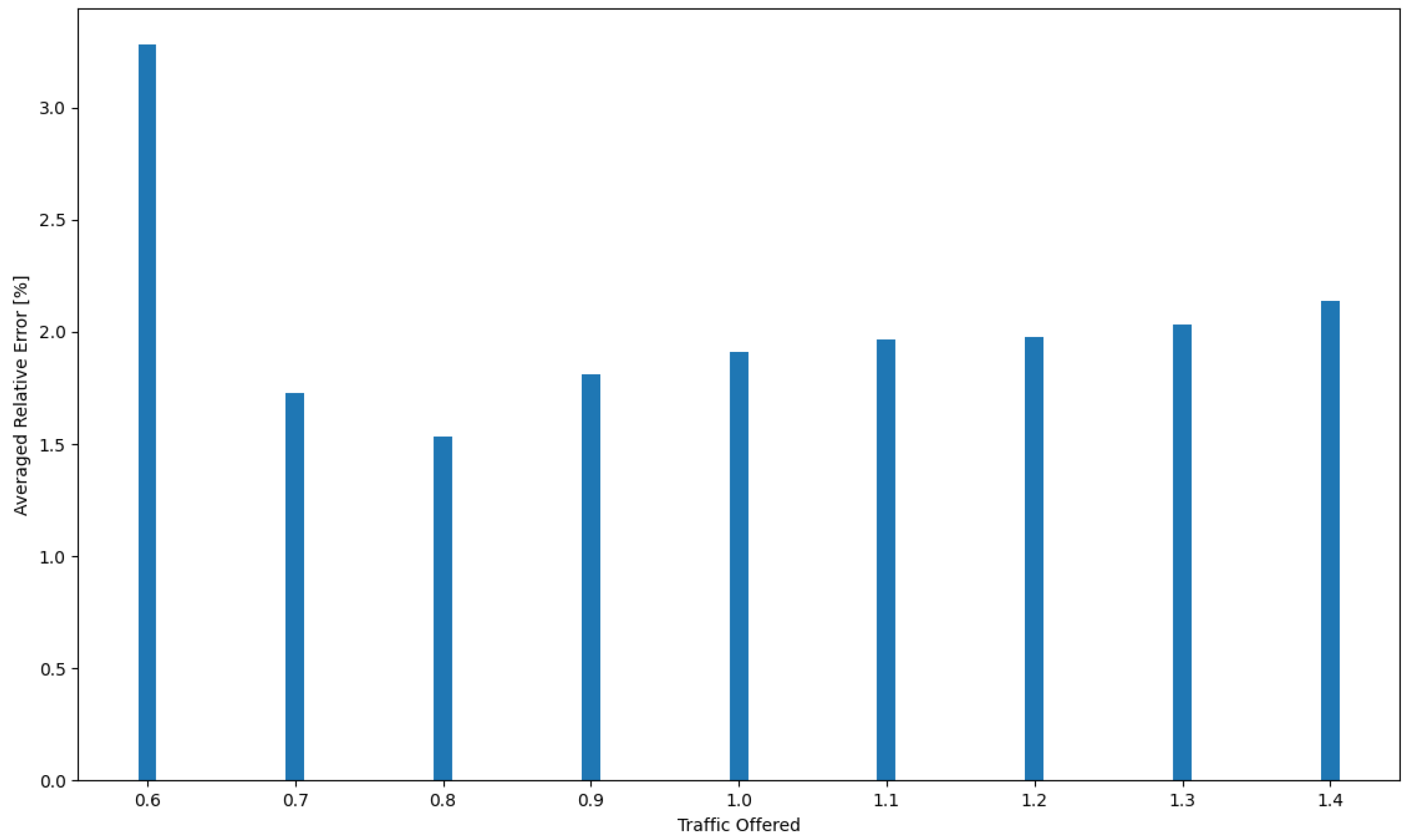
| Relative Error [%] | ||||
|---|---|---|---|---|
| Traffic Offered | RAM | CPU | HDD | B |
| 0.6 | 2.23649795 | 5.302968054 | 2.348080821 | 3.23421324 |
| 0.7 | 0.603117214 | 3.974417961 | 0.296085737 | 2.048389148 |
| 0.8 | 0.912760692 | 3.015055681 | 0.242153371 | 1.973825727 |
| 0.9 | 1.875510402 | 2.48183634 | 1.001852035 | 1.890306685 |
| 1 | 2.411807539 | 2.267414437 | 1.431078475 | 1.533685952 |
| 1.1 | 2.813128107 | 2.281697061 | 1.482090429 | 1.278598927 |
| 1.2 | 2.912439866 | 2.389068886 | 1.465307318 | 1.142268669 |
| 1.3 | 2.938155722 | 2.572646504 | 1.492920088 | 1.128719787 |
| 1.4 | 2.909306255 | 2.777580047 | 1.622203661 | 1.236359382 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hanczewski, S.; Stasiak, M.; Weissenberg, M. An Analytical Model of IaaS Architecture for Determining Resource Utilization. Sensors 2024, 24, 2758. https://doi.org/10.3390/s24092758
Hanczewski S, Stasiak M, Weissenberg M. An Analytical Model of IaaS Architecture for Determining Resource Utilization. Sensors. 2024; 24(9):2758. https://doi.org/10.3390/s24092758
Chicago/Turabian StyleHanczewski, Slawomir, Maciej Stasiak, and Michal Weissenberg. 2024. "An Analytical Model of IaaS Architecture for Determining Resource Utilization" Sensors 24, no. 9: 2758. https://doi.org/10.3390/s24092758
APA StyleHanczewski, S., Stasiak, M., & Weissenberg, M. (2024). An Analytical Model of IaaS Architecture for Determining Resource Utilization. Sensors, 24(9), 2758. https://doi.org/10.3390/s24092758