1. Introduction
A USV inherently constitutes a complex nonlinear system, being subject to disturbances and influences from the environment during navigation. Consequently, enhancing the path-tracking accuracy of unmanned ship motion control is a pressing concern.
At present, common methods for achieving such control include the PID [
1,
2], which is the most widely used, feedback control [
3,
4], fuzzy control [
5,
6], module predictive control (MPC) [
7,
8], and reinforcement learning (RL)-based control [
9,
10] methods. Of the aforementioned approaches, the PID control method stands out for its advantages. Notably, it eliminates the necessity for modeling the unmanned ship, rendering it a robust and easily implementable controller. However, a challenge lies in ensuring the optimality of specific performance indices. While the fuzzy controller exhibits the capability to deduce and generate expert behavior, its application is challenged by the intricacies of crafting fuzzy rules that primarily arise from the complexity inherent in the navigation environment.
The feedback controller, in its typical operation, computes heading and lateral deviations by analyzing the geometric relationship between the USV and the desired path. Based on this, it directly determines the steering wheel angle for precise steering control. The methods used for tracking, which involve deriving the correlation between the selected path anchor point and the USV position, are the single-point tracking method, pre-sight distance method, and the Stanley method. Both the single-point tracking method [
11] and pre-viewing distance method [
12,
13] offer the advantages of simplicity in algorithms and ease of implementation. However, a notable consideration lies in the fact that the selection of pre-viewing distance is contingent upon the experiential judgment of designers. The Stanley method, initially introduced by Stanford University for an unmanned vehicle fleet, is well suited for lower vehicle speeds. It necessitates a continuous curvature in the reference trajectory for optimal implementation.
A plethora of research findings have emerged concerning the application of MPC in vehicle motion control, as documented in the literature [
14,
15,
16,
17]. Of the achievements in these cited works, Falcone et al. [
15] introduced an MPC motion controller grounded in the continuous linearization model, and their simulation results underscore the efficacy of the continuous linearization MPC design approach in minimizing computational costs. Carvalho et al. [
17] studied an algorithm for local path planning using locally linearized MPC, carrying out linearization and convex approximation of nonlinear obstacle avoidance boundaries. Liniger et al. [
18] proposed a lateral motion method of model predictive controlling control (MPCC). Using this method, the lateral deviation is calculated by estimating the position of the projection point, which reduces the computational complexity to a certain extent. Ostafew et al. [
19] adopted Gaussian process regression to build a nonparametric model of a mobile robot. In the realm of unmanned surface vehicles, the trajectory tracking controller, employing the MPC method, typically necessitates real-time numerical calculations for solving an open-loop control sequence. The performance of this approach can be influenced by the precision of the model in addition to the unavoidable challenge of managing the complexity inherent in online calculations. Collectively, the current control strategies have various limitations characterized by suboptimal tracking accuracy and constrained computational efficiency.
In recent years, approximate dynamic programming (ADP) as well as reinforcement learning (RL) have experienced widespread adoption in the design of robot decision and control algorithms, thanks to their remarkable efficiency in solving optimization problems and adaptive learning capabilities [
20,
21]. Yang [
22] developed a learning method which is based on PID control for the tracking control of vehicles. Aiming at optimizing the tracking deviation of robots, the DHP algorithm was employed for real-time adjustment of PID parameters, enhancing path-tracking accuracy. Gong et al. [
23] designed a finite-time dynamic positioning controller for surface vessels. Shen et al. [
24] introduced an innovative LMPC framework aiming to enhance trajectory tracking performance. Jiang et al. [
25] also proposed sliding mode control to improve the tracking performance of USVs.
Recent advancements include noteworthy works employing deep learning and deep reinforcement learning to design controllers based on image or state information, facilitating trajectory control for USVs [
26,
27,
28]. A key advantage of this approach lies in leveraging deep networks to enhance the feature representation capabilities of both reinforcement learning and supervised learning. Notably, the training process is entirely data driven, eliminating the need for dynamic model information. However, it has the following disadvantages:
- (1)
Due to the inherent complexity of deep networks, application of this method is limited to offline training control strategies for online deployment. Moreover, its control performance is susceptible to the influence of factors such as the quantity and distribution of training samples.
- (2)
In the context of deep network learning, the analysis of theoretical characteristics, such as convergence and robustness, remains a crucial and challenging issue for the academic community to address.
Motivated by the challenges outlined above, we propose a RHRL-based control method, aiming at achieving high-precision lateral control for USVs. The initial step involves constructing a dynamic deviation model for a USV. The steering control of such vehicles comprises two parts, which are feedforward and feedback. Feedforward control is derived directly from the curvature and deviation model for the reference path. In parallel, the establishment of feedback control is achieved by addressing the problem of optimal tracking through application of the RHRL algorithm proposed in this paper. Diverging from conventional optimal control methods rooted in reinforcement learning, RHRL employs a rolling horizon optimization mechanism. This transformation converts infinite time domain optimal control problems into a sequence of finite time domain heuristic dynamic programming problems for resolution. In contrast to the MPC method for unwinding the loop control sequence, the strategy learned by this method is an explicit state feedback control law, which is amenable to offline direct deployment and online learning. Furthermore, in
Section 3, the convergence and stability of the closed-loop associated with the proposed RHRL algorithm are theoretically analyzed within each prediction time domain. Finally, simulation and comparative experiments for USV trajectory control using the RHRL algorithm are conducted. Through simulation tests, the control performance is found to be comparable to that of LMPC, with notable advantages in terms of computational efficiency, lower sample complexity, and higher learning efficiency. To verify the algorithm’s robustness and anti-interference capabilities, simulation incorporating disturbances are also conducted.
The remaining sections of this manuscript are arranged as follows. In
Section 2, a dynamic model of a USV is built. Then, a USV trajectory control algorithm based on RHRL is proposed and shown to be stable. In
Section 3, the simulation and comparison experiments are carried out, and disturbances are added.
Section 4 contains the conclusions.
2. Materials and Methods
2.1. Modeling
In contemporary vehicle modeling, the utilization of three degrees of freedom (DOF) and six DOF predominates. However, considering the environment of the USV investigated in this study, which navigates on the sea surface, we opt for three degrees of freedom in the modeling process to avoid unnecessary complexity.
In the process of establishing dynamical equations, a crucial decision lies in selecting the coordinate system for their formulation. Direct application of Newton’s laws of motion necessitates the expansion of equations in an inertial coordinate system. Nevertheless, various considerations compel us to derive the dynamic equations in a satellite coordinate system. One such reason is to establish dynamic equations that are direction independent. Additionally, employing the satellite coordinate system facilitates the direct assignment of forces and control moments. However, this would result in the current frame of reference not being an inertial frame of reference. Hence, to account for the non-inertial reference frame, Coriolis and centripetal forces are artificially introduced. This allows us to derive the remaining dynamics as if they were in an inertial reference frame.
The USV under investigation features a catamaran-like structure, incorporating two fixed propellers positioned at the extremities of each hull. In
Figure 1, variables
and
denote the speeds of the two thrusters, while
represents the heading angle.
Considering its actual working environment, trajectory tracking control of the USV on the horizontal plane will be the focus of our study.
There is a reference frame called the BF (body frame) that is securely fixed to the USV, with the point of origin deliberately chosen to coincide with the center of gravity. Global information is recorded by the IF (inertial frame). Thus, the USV’s motion can be accurately described via the kinematic equation and dynamic equation of the coordinate transformation between these two frames.
The kinematic equation is
where
represents the USV’s position and heading in the IF;
represents the USV’s velocity in the BF; and the rotation matrix
depends on
, which is the heading angle.
can be expressed by the follow equation:
According to the Newton’s law of motion, the dynamic equation can be established as follows:
where
represents the thrust force of each propeller. The matrix
takes the mass (which is added) into consideration;
represents the Coriolis and centripetal matrix. Concrete forms of the above three matrices are shown as follows:
where
is the USV’s damping matrix;
denotes the specific restoring force.
The thrusters
generate thrust force
, and the
comes from
.
denoting the thrusters’ azimuth vector in the BF. We can obtain the distribution of the thruster:
where
denotes an input matrix that is constant.
is a
matrix that distributes power to the thrusters in three directions, and
satisfies the condition that
is not singular.
are the thrusters’ efficiency factors.
Therefore, we can derive the dynamic model of the USV for trajectory tracking by combining Equations (1), (3), and (5):
where
is the defined state, and input control is expressed as
. At the end of this section, we successfully derive the dynamic equation governing USV operation on the water surface.
2.2. The USV Trajectory Control Algorithm Based on RHRL
In this section, the USV trajectory control algorithm utilizing RHRL is elaborated. We initially formulate the performance index for the finite time domain trajectory control problem of the USV. Subsequently, we outline the core concepts of the associated reinforcement learning algorithm along with the design and implementation process of the controller. Also included is a detailed analysis of convergence based on this approach.
When conducting tracking control, it is necessary to describe the relative position between the USV and the desired path, as shown in
Figure 2. The point
P represents the closet point from the desired path, which is called the road projection point.
is denoted as the path information at the projection point, where
are the global coordinates of
P.
is the angle between the tangent line of
P and the
X-axis, also known as the direction of the path;
is the curvature of the path at point
P.
The distance between
P and the USV centroid is called the lateral deviation
, and
is specified for when the USV is located on the left side of the path, and
when the USV is on the right side. Therefore, the lateral deviation can be expressed as
The path deviation
of the USV is defined as the difference between the path and the direction, which is
.
. The first derivative of
and
are shown below:
where
.
. It is assumed that
remains constant and there is no sidescale phenomenon in the moving process, and that the expected yaw velocity of the USV’s desired path is constant; then, the lateral acceleration of the USV when it stably tracks the path is
.
Assuming that the course deviation
is small, then according to the small angle theorem,
. Then, the second derivative of the lateral deviation with respect to time can be expressed as
The first derivative can be approximated as
Combining Equations (1), (3) and (4), also (8)–(10); the following equation can be derived as
where
, and the control quantity
.
Given a sampling period
, the discrete time model of Equation (11a) can be discretized as
where
, and
k is a discrete time point.
For the above model Equation (
12), it is assumed that path information
, and the purpose of this paper is to design a lateral control algorithm based on RHRL (as shown in
Figure 3) such that during the control process, the above-mentioned lateral error state quantity gradually converges to 0, that is,
.
2.2.1. Design of Performance Index for the Finite Time Domain Trajectory Control Problem
In this section, a detailed control algorithm based on RHRL is presented. We commence by designing the performance index for the USV finite time domain lateral control problem. Subsequently, we outline the core concept of the RHRL algorithm and delve into the design implementation and convergence analysis based on the actuator–evaluator. For the system deviation model of Equation (
12), the control quantity can be decomposed into the form of a feedforward component
plus a feedback component
such that
, which is shown in
Figure 3. The feedforward control quantity represents the expected control input during steady-state vehicle operation and is applicable when the vehicle is stably following the reference path.At the same time
holds,
as well. The feedforward control quantity
can be determined as follows:
The value in the above formula can be obtained by . are discrete time coefficient matrices.
Since
can be easily solved at any current time value
k, we assume that
remains constant throughout the prediction time domain
, then the feedback control quantity
to be solved needs to meet the following constraints:
where
represents the maximum of
u,
is the minimum of
u. The RHRL algorithm, introduced in this paper, seeks to minimize the following performance indicator function by optimizing
in each prediction time domain:
where the cost function
is a matrix which is positive definite,
P is a preset positive real number, and the cost function of the predictive time domain terminal is
where the penalty matrix
is a positive definite matrix, which can be solved using the following Lyapunov equation:
where
is the feedback gain matrix satisfying the conditions indicating that
F is Schur-stable. (The characteristic polynomial ‘F’ for discrete linear systems is such that the roots are located within the unit circle. This property results in the system being classified as Schur-stable).
2.2.2. Path Control Algorithm Based on RHRL
The implementation of the finite time domain reinforcement learning algorithm using the executive–evaluator involves the following main steps:
First of all, according to Equation (
15), in any
, we can express the value function as a differential form:
where
. At the
l-th prediction moment,
would be defined as the optimal value function, and we obtain the HJB equation of the above finite time domain optimization control problem as
and the optimal control strategy:
In fact, due to the control constraints, it is difficult to obtain analytical solutions for and using Equations (19) and (20). In principle, we can approximate the optimal solution of the value function and the control strategy through the method of value iteration. For any , at given initial values where , then iterate steps . This needs to be repeated until to resolve the following two steps.
In conclusion, the task of trajectory tracking is accomplished through continuous updating of the strategy and feedback values.
2.2.3. Rolling Time Domain Executor–Evaluator Learning Implementation
We employ the executive–evaluator structure to implement the finite time domain value function iteration algorithm described above. In existing finite time domain reinforcement learning control algorithms [
17], the value function in the prediction time domain is regarded as a time-dependent function.
Assumption 1. If there has a control strategy so that system (Equation (12)) is asymptotically stable under control strategy , where is a continuous function satisfying . The aforementioned assumptions essentially represent another aspect of the stabilizability of the system Equation (
12). Simultaneously, it is worth noting that the dynamic model Equation (
12) presented in this paper is controllable, so there must be a continuous equation
that renders Equation (
16) asymptotically stable under the control strategy
. Therefore, the above assumptions are reasonable.
We define as a control invariant set under the control law , then we can state the following theorem.
Theorem 1. (Time-independent value function) If the value of the prediction time domain N satisfies in any prediction time domain, for any initial state , the terminal state is driven by the control strategy of system Equation (9) such that there is such a control strategy that , and is a function that is independent of time. Proof of Theorem 1. Firstly, consider the case of
. Based on the definition of
, there is a control law
that ensures the quantity of states at any time in the future satisfy
. From that, we can solve and obtain the following function:
For the case of
, according to Assumption 1, there is such a control strategy
and a finite prediction step
N that
. In particular, let
, then
where
.
Hence, a value function and a strategy independent of time exist. Drawing inspiration from this, we adopt a time-independent executive–evaluator structure to execute the finite time-domain value function iteration process described above. Initially, a network of evaluators is designed to approximate the value function:
where
represents the weight of the evaluator network,
denotes network node number;
is the network’s basis function. According to the definition of the evaluator network, the resulting errors
E and the end error
can be expressed as
Therein,
, which can be randomly valued around 0. By minimizing
, the equation for updating the weights of the evaluator network is derived as follows:
where
is the learning rate of the evaluator network.
Next, to deal with control constraints, we construct the network of actuators as follows:
where
,
, including
is the weight of actuator network;
is the basis function vector of the network.
indicates the node number, which is on network. Given that the actuator network aims to approximate the optimal strategy of control, we define the control quantity deviation as follows:
By minimizing
, we can obtain the update rule of the network weight as
where
represents the learning rate of the actuator network.
| Algorithm 1 The main steps of implementing the above finite time domain reinforcement learning algorithm, which makes use of the executive–evaluator. |
- (I)
Initialize the weights , , and obtain the initial state . - (II)
When the time , the projection point P is found according to the state , and the deviation state is calculated. - (III)
, repeat the following process 1–3: - (1)
According to Equations (17) and (28), and are respectively calculated. - (2)
Update , according to Equations (27) and (30). - (3)
Calculate according to Equations (13) and (28), and apply the prediction model for .
- (IV)
Calculate and according to Equations (12) and (27), respectively. - (V)
In the time period , apply quantity directly to the USV, and update the system states . - (VI)
Set and repeat operations II-V based on the receding time domain optimization strategy.
|
□
2.2.4. Convergence Analysis of the Weight of Finite Time Domain Actuator and Evaluator
Next, we present the convergence analysis of the above RHRL algorithm in each prediction domain
. First, the (local) optimal value function and control strategy can be represented as a network:
where both
and
are weight matrices, and
and
are the errors of reconstruction.
Assumption 2. (Network reconstruction error)
- (1)
- (2)
Assumption 3. (Continuous excitation)
There are positive real numbers such thatwhere . In order to more compactly describe the following theorem, define are tunable positive real numbers.
Theorem 2. Under Assumptions 2 and 3, if the appropriate learning laws and and are chosen so that and , then the network weights and of Equations (27) and (30) will asymptotically converge to the following region when using the above strategy:where , and is the error. Furthermore, if , then and converge asymptotically to 0.
Proof of Theorem 2. The Lyapunov function is defined as follows:
where
, and
. They can be calculated based on Equation (
26).
where
.
where
, then according to Equations (27), (35) and (36):
where
,
.
Similarly,
can be expressed as
In consideration of
,
,
, and
, then
where
. According to Young’s inequality theorem,
where
. Then, by defining
, we obtain
On this basis, if
,
is obtained, then
and
asymptotically converge to 0.
Hence, at this juncture, we have successfully concluded the proof of Theorem 2. □
The conclusion of the above theorem indicates that we can make u converge to
with an arbitrarily small error by increasing the number of base function nodes in the actuator and the evaluator. Therefore, under the premise that Assumption 1 is true, if a sufficiently large
N is chosen, the equation of system (12) satisfies the terminal state
in the prediction time domain
driven by strategy
,
. Thus, the next prediction time domain
,
,
is a feasible control strategy. We define the loss function produced by the feasible strategy for
, and referring to Rawling’s [
29],
is available. Due to
being suboptimal, we may safely derive
which can be obtain by using Lyapunov stability analysis of the stability of the system, which is a closed-loop system.
3. Simulation Analysis
To ensure a precise comparison of the control performance between RHRL, Lyapunov-based MPC (LMPC), and sliding mode control (SMC), the control variable method was adopted using experimental parameters from [
24,
25]. In the simulations, all of the hydrodynamic parameters in the equations are based on the Falcon model [
30].
The simulation results are presented in this section in showcasing the advantages of the RHRL method. In addition, the operating environment is Matlab 2021b, and the core is R7-5800H.
3.1. Parameter Selection
Two distinct desired trajectories are employed. Refer to the article of Li [
31], where one trajectory (Path I) is a typical sinusoidal path:
The other trajectory, Path II, is based on [
32] and is an S-shaped path:
For the RHRL controller, the following parameters are utilized: the prediction horizon is set such that , where [s] represents the time period; three matrices are set for weighting as , , and . The gains of the control are .And the .
In this section, the desired trajectory tracking simulation of a USV based on RHRL will be executed as described to emphasize the feasibility and efficiency of RHRL algorithm proposed earlier. The parameters for USV simulation are presented in
Table 1.
3.2. Tracking Performance
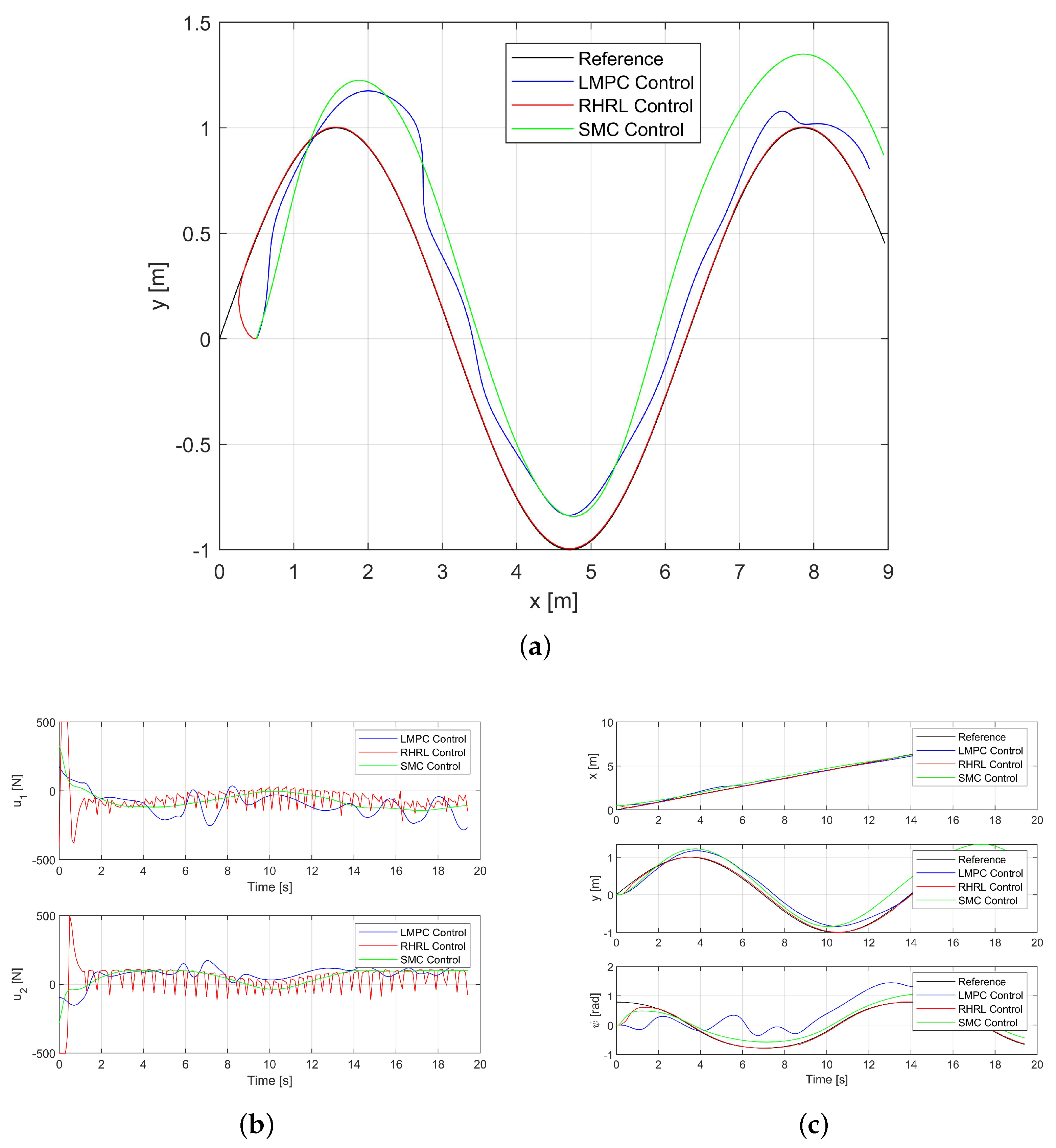
Both
Figure 4a,c depict the tracking results for Path I. The USV trajectories are represented by the blue curve for the LMPC control method, the green curve for the SMC controller, and the red curve for the USV RHRL controller, and the black curve illustrates the sinusoidal trajectory, which is the desired trajectory. The results demonstrate that all controllers are successful in guiding the USV along the desired trajectory, affirming the stability of the closed loop. However, the RHRL method notably exhibits a considerably accelerated convergence compared to the LMPC and SMC methods. This acceleration in convergence is attributed to the selection of control gain matrices
and
, which are small. The simulation results show that the improvement of tracking accuracy is due to synchronous online incremental learning and deployment.
Figure 4b illustrates the thrust output of each propeller. It is evident that at the commencement of tracking, the RHRL controller maximally utilizes the onboard thrust capability to achieve convergence as swiftly as possible. In essence, the state remains within the prescribed boundary, aligning with expectations. It is also notable that RHRL demonstrates superior adjustment capability and undergoes more rapid adjustments.
The outcomes for Path II are presented in
Figure 5. Similarities arise from the observations: The USV exhibits quicker convergence to the desired trajectory through RHRL.
3.3. Robustness Experiment with Disturbance
The incorporation of the receding horizon implementation introduces feedback into the closed-loop system. One of the inherent advantages of the RHRL controller is its robustness toward disturbances and emergencies, making it particularly well-suited for control systems in marine and submarine environments.The RHRL’s robustness is thoroughly examined and demonstrated through simulations. The definite simulated disturbance of magnitude was added. To provide a clearer visualization of the deviation between the three algorithms, the reference trajectory, indicated by a black line, is also included in this experiment.
In analyzing the outcomes shown from
Figure 5 to
Figure 6, it is evident that RHRL tracking control consistently guides the USV to adequately converge toward the desired trajectory. In contrast, substantial tracking errors are exhibited when conducting tracking control using LMPC, the even greater errors are associated with SMC.
Figure 6b and
Figure 7b illustrate that the RHRL controller consistently provides feedback for responding within a small time domain, ensuring minimal deviation.
The MSEs (mean square errors) for both paths are consolidated in
Table 2 and
Table 3. Generally, the MSEs are approximately 10 times smaller for RHRL compared to LMPC and SMC, especially in the case of Path II. Indeed, it is widely acknowledged that smaller MSEs correspond to reduced tracking error, thereby resulting in higher tracking accuracy; thus, it is evident that the RHRL algorithm significantly enhances tracking accuracy.
In order to more objectively demonstrate the excellent performance of the algorithm, we propose conducting quantitative analysis based on a new factor, namely thrust output. It is known that a smaller average value of thrust corresponds to lower energy consumption and enhanced cost-effectiveness. The specific data are shown in
Table 4 and
Table 5. As can be seen from the tables, the energy consumption of RHRL compared with LMPC is reduced by 43.85% and 41.65% for Paths I and II, respectively. The data show that RHRL is much more economical than LMPC. However, due to the algorithm characteristics, RHRL does not have a significant advantage over SMC based on this analysis.
The observed disparity stems from RHRL’s ability to learn and adapt online, utilizing online optimization to dynamically adjust control gains and effectively compensate for interference. Conversely, both LMPC and SMC lack this flexibility. Consequently, robustness is significantly enhanced by RHRL control.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}