
Video-Based Plastic Bag Grabbing Action Recognition: A New Video Dataset and a Comparative Study of Baseline Models

Abstract
1. Introduction
- A benchmark bag-grabbing video dataset is established. We collected 989 video clips for two categories, whereby positive clips contain the action of taking the plastic bag provided, while negative clips reflect other actions besides the said action. To the best of our knowledge, this is the first dataset for this problem, as reviewed in Table 1.
- The plastic bag grabbing is a niche action recognition problem. For that, we designed three baseline approaches, including (i) a hand-crafted feature extraction plus a sequential classification model, (ii) a multiple-frame convolutional neural network (CNN)-based action recognition model, and (iii) a 3D CNN-based deep learning-based action recognition model. We provided a comparative study by evaluating these baseline approaches using our benchmark dataset.
2. Related Works
- Recognition objective: Action video understanding commonly centers on two related but distinct tasks, including action recognition and action detection. Action recognition focuses on classifying an entire video clip based on the action it contains [30]. This can be further divided into trimmed and untrimmed scenarios. In trimmed action recognition, the action extends across the entire duration of the video. In contrast, untrimmed action recognition deals with videos that include additional irrelevant segments before or after the target action. On the other hand, temporal action detection aims to identify not only the type of action but also its precise start and end times within an untrimmed video [19].
- Backbone modeling: The second perspective focuses on the choice of backbone models [20]. Popular approaches have leveraged CNNs to extract spatiotemporal features. Such methods typically stack 2D or 3D convolutions to capture both spatial patterns within individual frames and temporal patterns across frames. Recently, transformer-based architectures have emerged as a compelling alternative. These models first tokenize video frames into a sequence of embeddings and then use multi-head self-attention layers to capture long-range dependencies. The final classification layers map these embeddings to action categories. Representative transformer-based models include a pure Transformer architecture that models video data as a sequence of spatiotemporal tokens [21], a factorized self-attention mechanism to independently process temporal and spatial dimensions [22], a multiscale vision transformer [23], and a video swin transformer that adapts the swin transformer’s shifted windowing strategy to the video domain [24].
- Deployment strategies: There are two types of deployments of action understanding models, including supervised classification (the focus of this paper’s study) and zero-shot classification. In the supervised setting, models are trained on labeled datasets and then applied to testing examples. However, zero-shot classification has emerged to address scenarios where no training examples for a given action class are available. Leveraging auxiliary modalities (e.g., text embeddings), zero-shot models can classify new, unseen action categories without additional supervision [25,26].
3. Dataset
3.1. Data Collection and Organization
- Each process began with an empty counter, followed by placing items on the counter and packing items into plastic bags. The video either recorded the customer taking the plastic bags from the counter or introducing their own bag. Lastly, both items and bags are removed from the counter.
- A variety of “plastic bag taking” actions are represented, which included pinching and grabbing the bag, as well as the use of both left and right hands, as illustrated in Figure 1.
- Only red-coloured bags are used to represent the plastic bags at the self-checkout counter. This is consistent with the observation that a store typically provides a standard design of plastic bags.
- The customer may touch the bag at the self-checkout counter without taking the plastic bags in the end.
3.2. Limitation of This Dataset
4. Three Baseline Approaches and a Comparative Study
4.1. Selection of Three Baseline Approaches
4.2. Approach 1: Hand-Crafted Features + LSTM
- Hand landmark detection. A pre-trained model, Mediapipe Hands [36], is used for hand landmark detection. The model is capable of localising 21 hand landmarks, consisting of coordinates and depth information for each hand. This gives rise to 126 location values when both hands are detected in the frame.
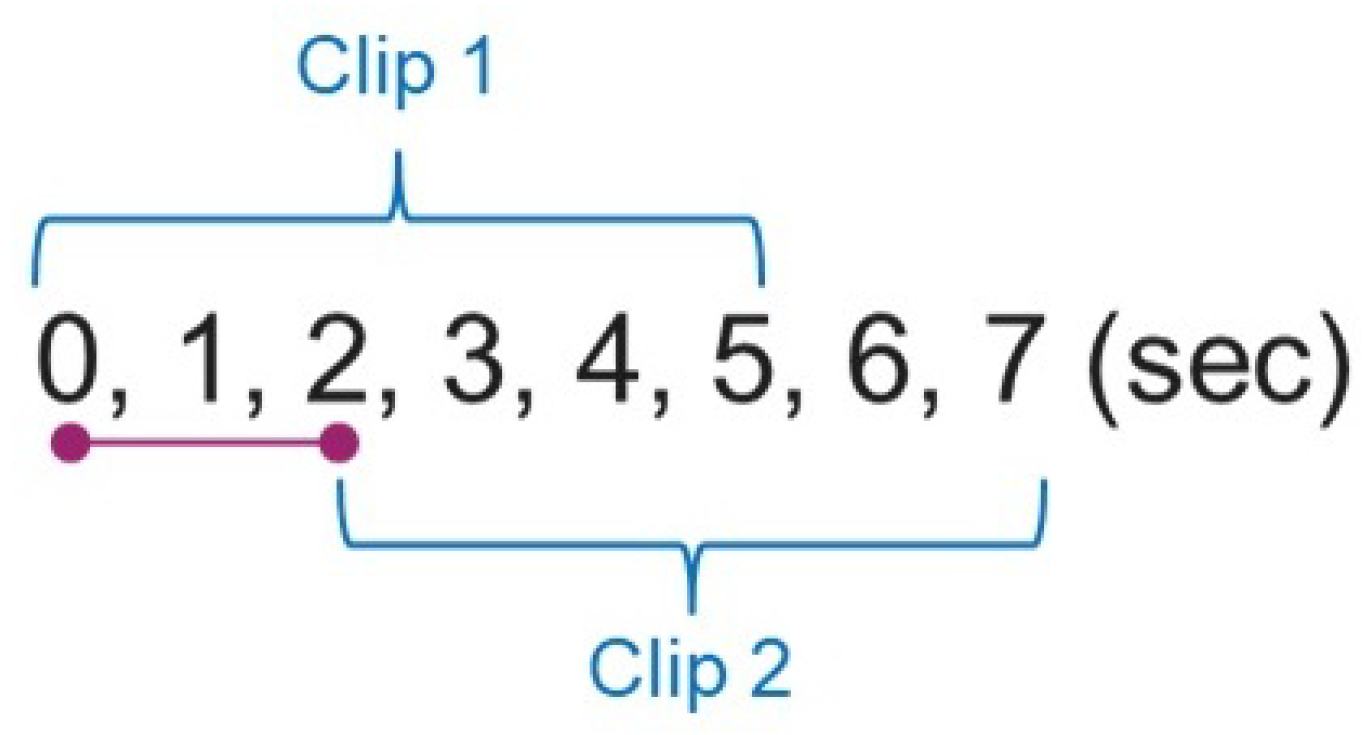
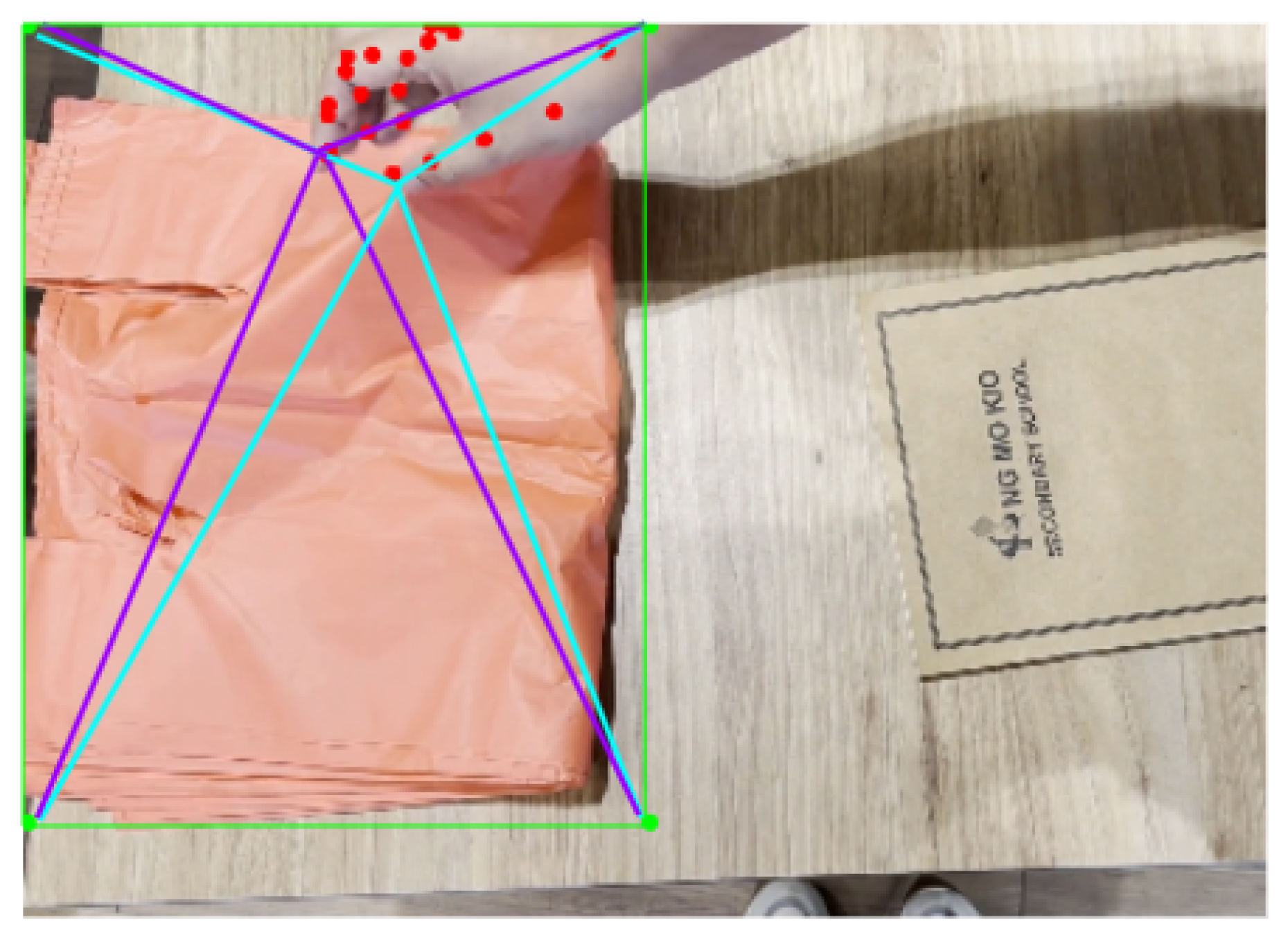
- Relational feature extraction. The relation feature is then extracted by calculating the distances between the index and thumb of the hand and the four corners of the bounding box of the detected plastic bag, as illustrated in Figure 4. The relationship information is extracted from each frame, and the sequence of such features is used as inputs for the next classification model. This gives rise to 16 values in each frame.
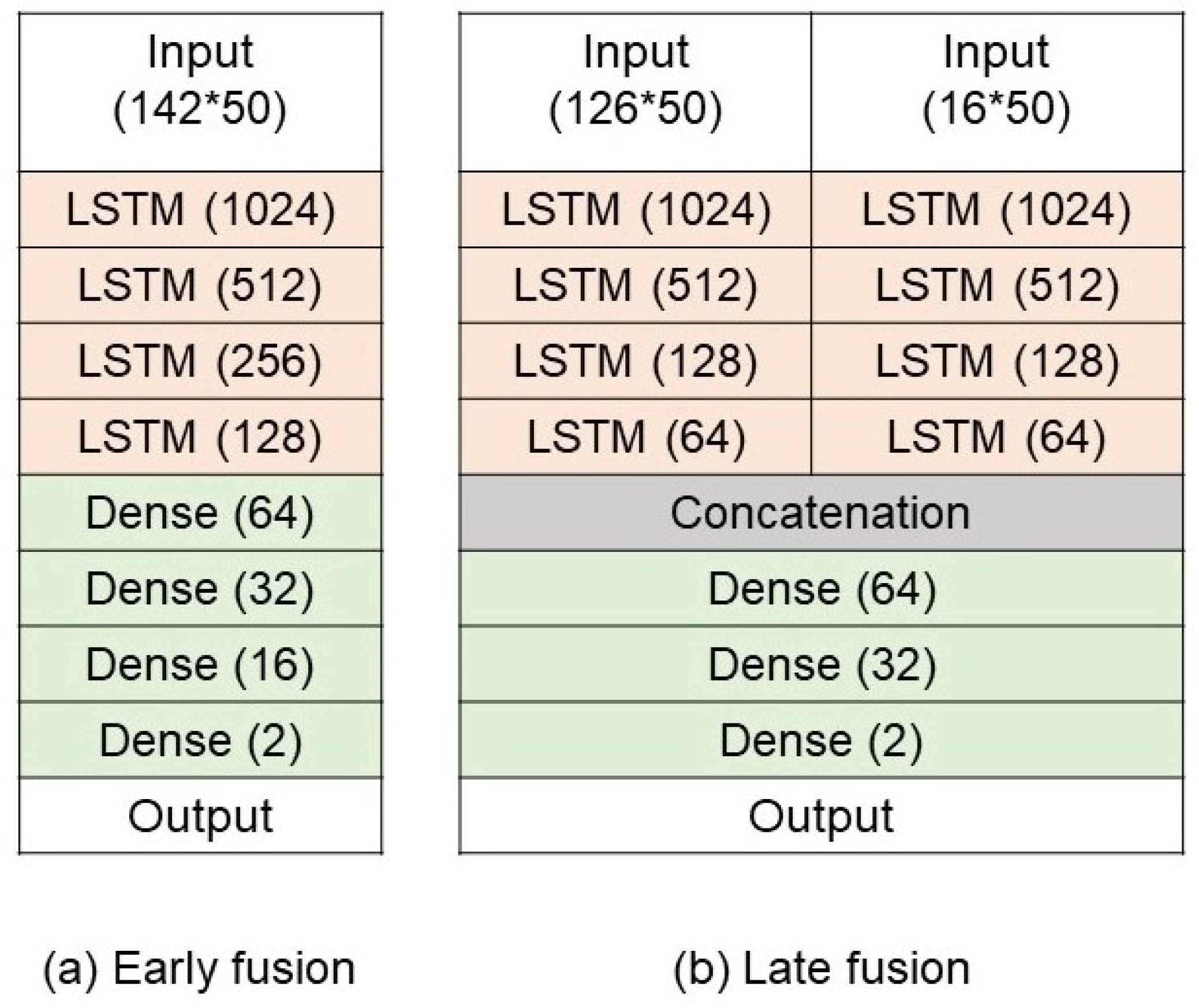
- Action classification. Two variations are explored for the technique of using the hand-crafted features and LSTM, mainly early fusion and late fusion, as presented in Figure 5. The key difference between early and late fusion is the inputs for the LTSM model. To be more specific, early fusion uses both hand keypoints and relationships between the hand and plastic bag within the same LSTM model, while there are separate LSTM models for hand keypoints and relationships between the hand and plastic bag in late fusion. In early fusion, the hand keypoints and relational features are combined into a single input vector before being fed into a single LSTM model. This means that the model learns an integrated representation of hand pose and the spatial relationship to the plastic bag from the very beginning. In contrast, late fusion maintains two separate independent LSTM models, including one for the hand keypoints and another for the relational features. Only after both models have processed their individual feature streams do their outputs get merged. This approach allows each LSTM to specialize in a particular feature domain and reduces the complexity of the data representation.
4.3. Approach 2: Energy Motion Image + Image Classification
- Motion energy map. Hand skeletal structures, if any, are generated using Hand Landmark Detection for every frame in the input video clip. Thus, each EMI comprises a maximum overlay of 150 frames, rendering the latest frame in the video clip to have the greatest weight in the final EMI. These EMIs are used as inputs for an image classification model that determines if the clip reflects the plastic bags taking action.
- Action classification. In consideration of the fact that the energy motion image is grayscale, a single-channel image classification model (i.e., ResNet model) is explored. In addition, the EMI image has been downsized to a resolution of to reduce the number of parameters.
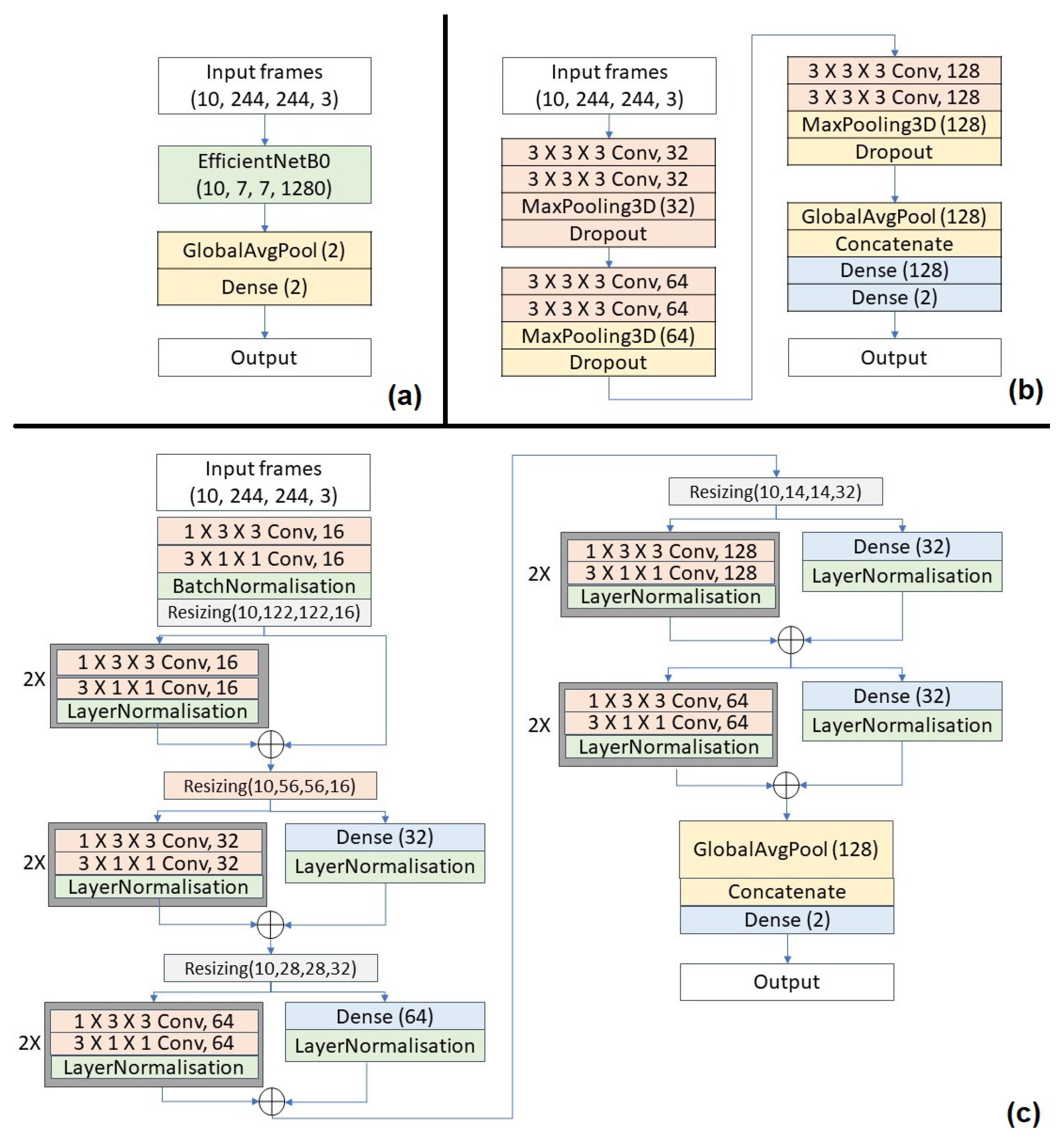
4.4. Approach 3: 3D CNN Model
- EfficientNet model [38]. It is re-trained on our benchmark video dataset.
- 3D CNN model [39]. It generally performs better than 2D networks as it is able to model temporal information better on top of the spatial information that 2D networks capture.
- (2 + 1)D ResNet model [40]. The use of (2 + 1)D convolutions over regular 3D convolutions reduces computational complexity by decomposing the spatial and temporal dimensions to reduce parameters. It also prevents overfitting and introduces more non-linearity that allows for a better functional relationship to be modeled.
5. Experimental Results
5.1. Performance Metrics
5.2. Implementation Details
5.3. Experimental Results
5.4. Ablation Study
5.5. Overall Evaluation
6. Limitations and Potential Impacts
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Single-Use Plastic Bags and Their Alternatives: Recommendations from Life Cycle Assessments; United Nations Environment Programme: New York, NY, USA, 2020.
- Lekavičius, V.; Bobinaitė, V.; Balsiūnaitė, R.; Kliaugaitė, D.; Rimkūnaitė, K.; Vasauskaitė, J. Socioeconomic Impacts of Sustainability Practices in the Production and Use of Carrier Bags. Sustainability 2023, 15, 12060. [Google Scholar] [CrossRef]
- Geetha, R.; Padmavathy, C. The Effect of Bring Your Own Bag on Pro-environmental Behaviour: Towards a Comprehensive Conceptual Framework. Vision J. Bus. Perspect. 2023. [Google Scholar] [CrossRef]
- Nielsen, T.D.; Holmberg, K.; Stripple, J. Need a bag? A review of public policies on plastic carrier bags—Where, how and to what effect? Waste Manag. 2019, 87, 428–440. [Google Scholar] [CrossRef] [PubMed]
- Kua, I. Singapore Supermarkets Start Charging for Plastic Bags. 2023. Available online: https://www.bloomberg.com/news/articles/2023-07-03/singapore-supermarkets-start-charging-for-plastic-bags (accessed on 1 January 2025).
- Hong, L. What Happens If You Take a Plastic Bag Without Paying from July 3? 2023. Available online: https://www.straitstimes.com/singapore/environment/pay-for-plastic-bags-at-supermarkets-from-july-3-or-you-might-be-committing-theft-legal-experts (accessed on 1 January 2025).
- Ahn, Y. Plastic Bag Charge: Some Customers Say They Will Pay or Switch to Reusables, but Scepticism Abounds over “Honour System”. 2023. Available online: https://www.todayonline.com/singapore/supermarket-plastic-bag-honour-system-sceptical-2197591 (accessed on 1 January 2025).
- Ting, K.W. Barcodes and Dispensers: How Supermarkets in Singapore Are Gearing Up for the Plastic Bag Charge. 2023. Available online: https://www.channelnewsasia.com/singapore/plastic-bag-charges-singapore-supermarkets-dispensers-barcodes-3573671 (accessed on 1 January 2025).
- Chua, N. Shop Theft Cases Jump 25 Percent in First Half of 2023 as Overall Physical Crime Rises. 2023. Available online: https://www.straitstimes.com/singapore/courts-crime/physical-crime-increases-in-first-half-of-2023-as-shop-theft-cases-jump-25 (accessed on 1 January 2025).
- Reid, S.; Coleman, S.; Vance, P.; Kerr, D.; O’Neill, S. Using Social Signals to Predict Shoplifting: A Transparent Approach to a Sensitive Activity Analysis Problem. Sensors 2021, 21, 6812. [Google Scholar] [CrossRef] [PubMed]
- Koh, W.T. Some Customers Take Plastic Bags Without Paying at Supermarkets Based on Honour System—CNA. 2023. Available online: https://www.channelnewsasia.com/singapore/some-customers-not-paying-plastic-bag-ntuc-fairprice-honour-system-3745016 (accessed on 1 January 2025).
- Dataset. Plastic Bags Dataset. 2022. Available online: https://universe.roboflow.com/dataset-t7hz7/plastic-bags-0qzjp (accessed on 1 August 2024).
- Marionette. Plastic Paper Garbage Bag Synthetic Images. 2022. Available online: https://www.kaggle.com/datasets/vencerlanz09/plastic-paper-garbage-bag-synthetic-images (accessed on 1 January 2025).
- Nazarbayev University. Plastic and Paper Bag Dataset. 2023. Available online: https://universe.roboflow.com/nazarbayev-university-dbpei/plastic-and-paper-bag (accessed on 1 January 2025).
- Molchanov, P.; Yang, X.; Gupta, S.; Kim, K.; Tyree, S.; Kautz, J. Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4207–4215. [Google Scholar]
- Zhang, Y.; Cao, C.; Cheng, J.; Lu, H. EgoGesture: A New Dataset and Benchmark for Egocentric Hand Gesture Recognition. IEEE Trans. Multimed. 2018, 20, 1038–1050. [Google Scholar] [CrossRef]
- Avola, D.; Bernardi, M.; Cinque, L.; Foresti, G.L.; Massaroni, C. Exploiting Recurrent Neural Networks and Leap Motion Controller for the Recognition of Sign Language and Semaphoric Hand Gestures. IEEE Trans. Multimed. 2019, 21, 234–245. [Google Scholar] [CrossRef]
- Gao, C.; Li, Z.; Gao, H.; Chen, F. Iterative Interactive Modeling for Knotting Plastic Bags. In Proceedings of the International Conference on Robot Learning; Liu, K., Kulic, D., Ichnowski, J., Eds.; PMLR: Cambridge, MA, USA, 2023; Volume 205, pp. 571–582. [Google Scholar]
- Hu, K.; Shen, C.; Wang, T.; Xu, K.; Xia, Q.; Xia, M.; Cai, C. Overview of temporal action detection based on deep learning. Artif. Intell. Rev. 2024, 57, 26. [Google Scholar] [CrossRef]
- Selva, J.; Johansen, A.S.; Escalera, S.; Nasrollahi, K.; Moeslund, T.B.; Clapes, A. Video Transformers: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12922–12943. [Google Scholar] [CrossRef] [PubMed]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lucic, M.; Schmid, C. ViViT: A Video Vision Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Los Alamitos, CA, USA, 27 October–2 November 2021; pp. 6816–6826. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is Space-Time Attention All You Need for Video Understanding? In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021.
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6804–6815. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video Swin Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3192–3201. [Google Scholar]
- Madan, N.; Moegelmose, A.; Modi, R.; Rawat, Y.S.; Moeslund, T.B. Foundation Models for Video Understanding: A Survey. arXiv 2024, arXiv:2405.03770. [Google Scholar]
- Liu, X.; Zhou, T.; Wang, C.; Wang, Y.; Wang, Y.; Cao, Q.; Du, W.; Yang, Y.; He, J.; Qiao, Y.; et al. Toward the unification of generative and discriminative visual foundation model: A survey. Vis. Comput. 2024. [Google Scholar] [CrossRef]
- Pareek, P.; Thakkar, A. A survey on video-based Human Action Recognition: Recent updates, datasets, challenges, and applications. Artif. Intell. Rev. 2021, 54, 2259–2322. [Google Scholar] [CrossRef]
- Dang, L.; Min, K.; Wang, H.; Piran, M.; Lee, C.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Bandini, A.; Zariffa, J. Analysis of the Hands in Egocentric Vision: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6846–6866. [Google Scholar] [CrossRef] [PubMed]
- Hutchinson, M.S.; Gadepally, V.N. Video Action Understanding. IEEE Access 2021, 9, 134611–134637. [Google Scholar] [CrossRef]
- Satyamurthi, S.; Tian, J.; Chua, M.C.H. Action recognition using multi-directional projected depth motion maps. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 14767–14773. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Xie, T.; Tian, J.; Ma, L. A vision-based hand hygiene monitoring approach using self-attention convolutional neural network. Biomed. Signal Process. Control 2022, 76, 103651. [Google Scholar] [CrossRef]
- Wu, Y.; Lin, Q.; Yang, M.; Liu, J.; Tian, J.; Kapil, D.; Vanderbloemen, L. A Computer Vision-Based Yoga Pose Grading Approach Using Contrastive Skeleton Feature Representations. Healthcare 2022, 10, 36. [Google Scholar] [CrossRef] [PubMed]
- Mediapipe. Hand Landmark Model. 2023. Available online: https://github.com/google/mediapipe/blob/master/docs/solutions/hands.md (accessed on 1 January 2025).
- Ultralytics. Ultralytics/yolov5: V7.0—YOLOv5 SOTA Realtime Instance Segmentation. 2022. Available online: https://zenodo.org/records/7347926 (accessed on 1 January 2025).
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6450–6459. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Ye, N.; Zeng, Z.; Zhou, J.; Zhu, L.; Duan, Y.; Wu, Y.; Wu, J.; Zeng, H.; Gu, Q.; Wang, X.; et al. OoD-Control: Generalizing Control in Unseen Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 7421–7433. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Bag Object | Hand Gesture | Hand Bag Interaction | Available to Public | Remarks | |
|---|---|---|---|---|---|---|---|
| Plastic bag object detection | [12] | 2022 | √ | - | - | √ | 1 class (plastic bag or not) and 283 images. |
| [13] | 2022 | √ | - | - | √ | 3 classes (Plastic, Paper, and Garbage Bag) and 5000 instances | |
| [14] | 2023 | √ | - | - | √ | 6 classes (anorganic, paper bag, shopping bag, smoke, stretch, trashbag) and 400 images | |
| Hand bag interaction | [15] | 2016 | - | √ | - | √ | 25 types of gestures and 1532 samples |
| [16] | 2018 | - | √ | - | √ | 83 types of gestures and 24,161 samples | |
| [17] | 2019 | - | √ | - | √ | 30 types of gestures and 1200 samples | |
| [18] | 2023 | √ | √ | √ | - | 4 types of bags and 43,000 images | |
| Our dataset | - | √ | √ | √ | √ | 2 classes and 989 clips | |
| Approach 1 | Approach 2 | Approach 3 | ||||
|---|---|---|---|---|---|---|
| Early Fusion | Late Fusion | EfficientNet | 3D CNN | (2 + 1)D CNN | ||
| Optimizer | Adam | Adam | Adam | Adam | Adam | Adam |
| Learning rate | 0.001 | 0.001 | 0.005–0.00005 | − | 0.0001 | 0.0001 |
| Batch size | 32 | 32 | 32 | 8 | 8 | 8 |
| Epoch | 30 | 30 | 200 | 20 | 20 | 20 |
| Option | Precision | Recall | F1 Score | Accuracy | |
|---|---|---|---|---|---|
| Early Fusion | 0.62 | 0.52 | 0.57 | 0.59 | |
| Approach 1 | Late Fusion | 0.85 | 0.33 | 0.47 | 0.62 |
| Approach 2 | 0.89 | 0.76 | 0.82 | 0.88 | |
| EfficientNet | 0.82 | 0.69 | 0.76 | 0.86 | |
| Approach 3 | 3D CNN | 0.78 | 0.88 | 0.82 | 0.88 |
| (2 + 1)D ResNet | 0.92 | 0.91 | 0.91 | 0.94 | |
| Option | Frame Resolution | Inference Frame Rate | # Parameters | FLOPs | |
|---|---|---|---|---|---|
| Approach 1 | Early Fusion | 15 | 8,968,594 | 17,955,137 | |
| Late Fusion | 15 | 16,056,098 | 31,927,660 | ||
| Approach 2 | 30 | 279,778 | 4,003,459,372 | ||
| EfficientNet | 2 | 4,052,133 | 8,011,611,411 | ||
| Approach 3 | 3D CNN | 2 | 876,898 | 59,520,912,012 | |
| (2 + 1)D CNN | 2 | 586,226 | 9,160,758,184 |
| Hand Keypoints | Relational Feature | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|---|
| √ | - | 0.81 | 0.25 | 0.38 | 0.58 |
| √ | √ | 0.62 | 0.52 | 0.57 | 0.59 |
| Skeleton Thickness | Frame Combination | Precision | Recall | F1 Score | Accuracy | ||
|---|---|---|---|---|---|---|---|
| Small Value | Large Value | Linear Weighting | Quadratic Weighting | ||||
| √ | √ | 0.79 | 0.75 | 0.77 | 0.82 | ||
| √ | √ | 0.89 | 0.76 | 0.82 | 0.88 | ||
| √ | √ | 0.81 | 0.73 | 0.77 | 0.82 | ||
| √ | √ | 0.83 | 0.81 | 0.82 | 0.77 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Low, P.J.; Ng, B.Y.; Mahzan, N.I.; Tian, J.; Leung, C.-C. Video-Based Plastic Bag Grabbing Action Recognition: A New Video Dataset and a Comparative Study of Baseline Models. Sensors 2025, 25, 255. https://doi.org/10.3390/s25010255
Low PJ, Ng BY, Mahzan NI, Tian J, Leung C-C. Video-Based Plastic Bag Grabbing Action Recognition: A New Video Dataset and a Comparative Study of Baseline Models. Sensors. 2025; 25(1):255. https://doi.org/10.3390/s25010255
Chicago/Turabian StyleLow, Pei Jing, Bo Yan Ng, Nur Insyirah Mahzan, Jing Tian, and Cheung-Chi Leung. 2025. "Video-Based Plastic Bag Grabbing Action Recognition: A New Video Dataset and a Comparative Study of Baseline Models" Sensors 25, no. 1: 255. https://doi.org/10.3390/s25010255
APA StyleLow, P. J., Ng, B. Y., Mahzan, N. I., Tian, J., & Leung, C.-C. (2025). Video-Based Plastic Bag Grabbing Action Recognition: A New Video Dataset and a Comparative Study of Baseline Models. Sensors, 25(1), 255. https://doi.org/10.3390/s25010255