
A Review on Face Mask Recognition


 and
and 
Abstract
1. Introduction
- (1)
- A comprehensive evaluation of public datasets: This review offers an exhaustive categorization and evaluation of publicly available datasets for face mask detection, with a particular focus on their scale, diversity, and annotation granularity. By identifying critical challenges, such as data insufficiency and inherent biases, we provide actionable strategies to enhance dataset diversity, reduce bias, and improve fairness in the training and evaluation of face mask detection models. This contribution is novel in its comprehensive approach to dataset assessment, a subject which has been insufficiently explored in previous literature.
- (2)
- The categorization and in-depth analysis of detection methods: This review classifies existing face mask detection methods into three primary categories: feature-extraction-and-classification-based approaches, object-detection-models-based methods and multi-sensor-fusion-based methods. Through a detailed analysis of their workflows, strengths, limitations, and appropriate application scenarios, we offer a clear, comparative technical overview that highlights the unique advantages and challenges of each approach. This classification, along with its analysis, provides novel insights into the strengths and trade-offs inherent in the choice of method, offering a valuable resource for researchers and practitioners.
- (3)
- An exploration of multimodal techniques for enhanced detection: This review also investigates the use of multimodal techniques, such as depth and infrared imaging, in face mask detection. We explore their potential in addressing complex real-world environments, emphasizing their advantages in improving detection robustness under challenging conditions. Additionally, we identify and discuss the challenges associated with these techniques, including hardware cost, data fusion complexity, and privacy concerns. This contribution is significant as it bridges the gap between traditional visual-based methods and advanced multimodal approaches, offering novel perspectives for future face mask detection research.
2. Datasets
- (1)
- The richness and diversity of dataset sizes: Today’s existing datasets show great diversity in scale, ranging from as small as only a few hundred images (e.g., about 250 images for TFCD) to as large as tens or even hundreds of thousands of images (e.g., MAFA, FMLD, RMFRD, MaskedFace-Net, SMFRD). This multivariate distribution from small to large scale not only facilitates rapid prototyping and exploration under low-resource conditions, but also lays the data foundation for high-complexity training and generalization performance testing of deep models. Researchers can flexibly choose and combine datasets of different sizes according to their own research stages and task attributes, in order to strike a balance between computational overhead and model performance.
- (2)
- Complementary advantages of real images and synthetic datasets: The data sources are both real-world captured images (e.g., MAFA, FMLD, RMFRD) and synthetic and generated images (e.g., BAFMD, Kaggle-FMLD, MaskedFace-Net, SMFRD). Real datasets better reflect the variability and complexity of the actual environment and improve the robustness of the model in real-world scenarios, while synthetic datasets ensure the consistency and diversity of annotations through a controlled data generation process, providing a stable foundation for model pre-training, data enhancement, and domain self-adaptation. Combining the two organically helps to further enhance the applicability and performance ceiling of the model.
- (3)
- The increasing granularity of labeling versus task complexity: The dataset annotation extends from the initial binary categorization (masked/unmasked) to more complex category and attribute annotations, such as considering wrongly worn (wrongly worn), diverse mask types, and facial keypoint localization (e.g., FMLD, WearMask, PWMFD). Fine-grained annotations help researchers to deeply explore mask-wearing behavior and its impact on face recognition and detection performance, and provide support for subsequent attribute prediction, bias analysis, segmented scene response, and more fine-grained tasks (e.g., distinguishing between different types of mask materials and wearing styles).
- (4)
- Real-world scenario applicability with domain-specific applications: Most datasets introduce diverse scenes, lighting conditions, crowd composition and ingestion angles (e.g., FaceMask, AIZOO, WearMask, etc.) into the data collection and screening, so as to make the data more suitable for the actual application environment. This is especially critical for face monitoring during epidemics, security monitoring in public places, and personnel protection detection in healthcare scenarios. Researchers can select datasets based on the specific needs of their application domains to ensure that the constructed models will perform robustly in field deployments.
- (5)
- Data diversity and equity concerns: Some datasets (e.g., BAFMD) emphasize a balanced distribution of different races, genders, and ages in their data collection and labeling, reflecting the growing attention of academics to the issue of potential bias and fairness in datasets. Ensuring that datasets are sufficiently diverse and balanced can help reduce model performance bias in specific populations or particular scenarios, thereby enabling more inclusive and equitable decision-making in real-world applications.
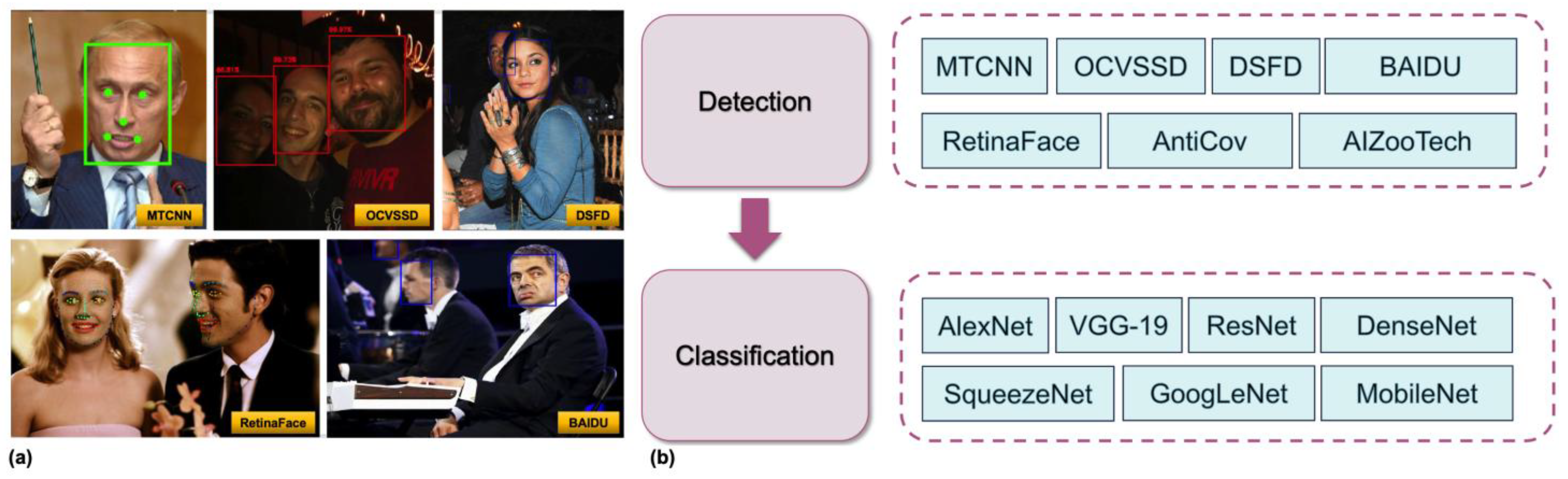
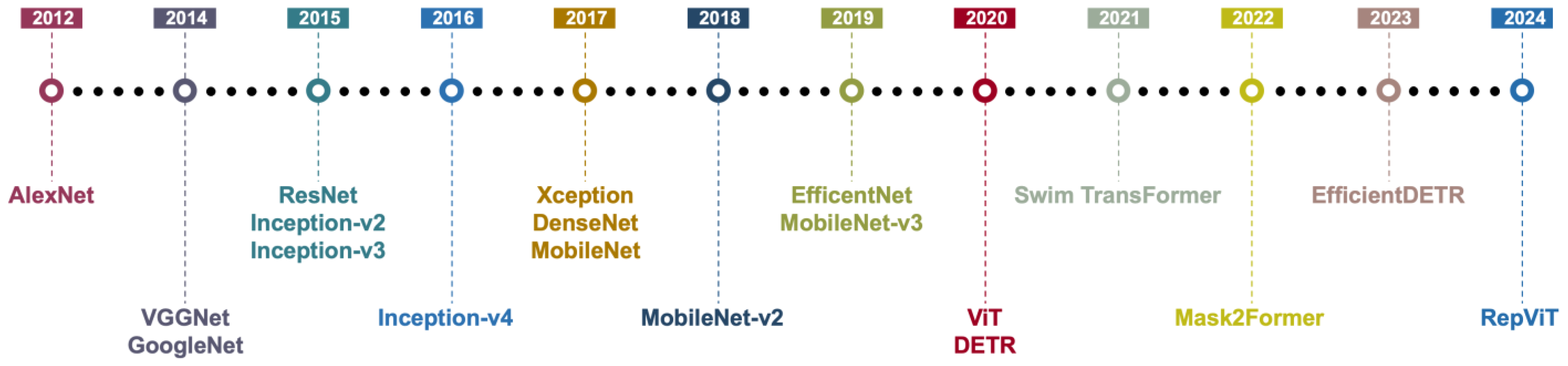
3. Methods for Face Mask Detection and Recognition
3.1. Feature-Extraction-and-Classification-Based Methods
3.1.1. Traditional Feature Extraction
3.1.2. Facial Feature Extraction
3.2. Object-Detection-Model-Based Methods
3.2.1. Based on Single-Stage Object Detection
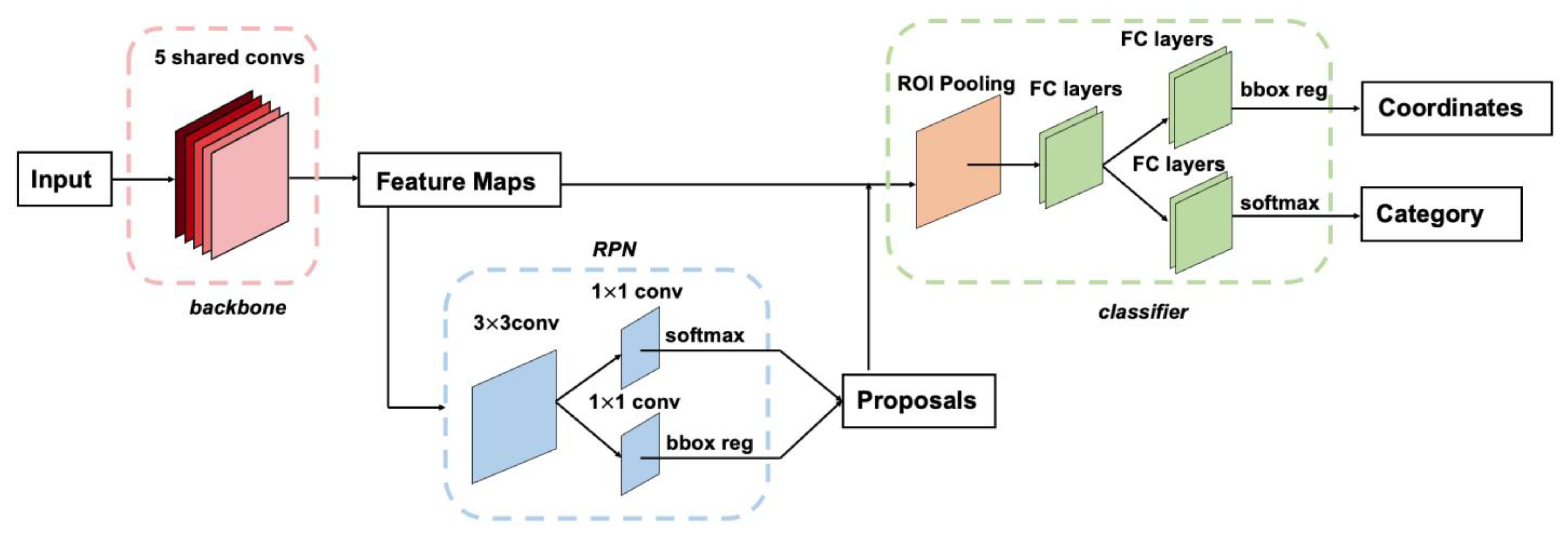
3.2.2. Based on Two-Stage Object Detection
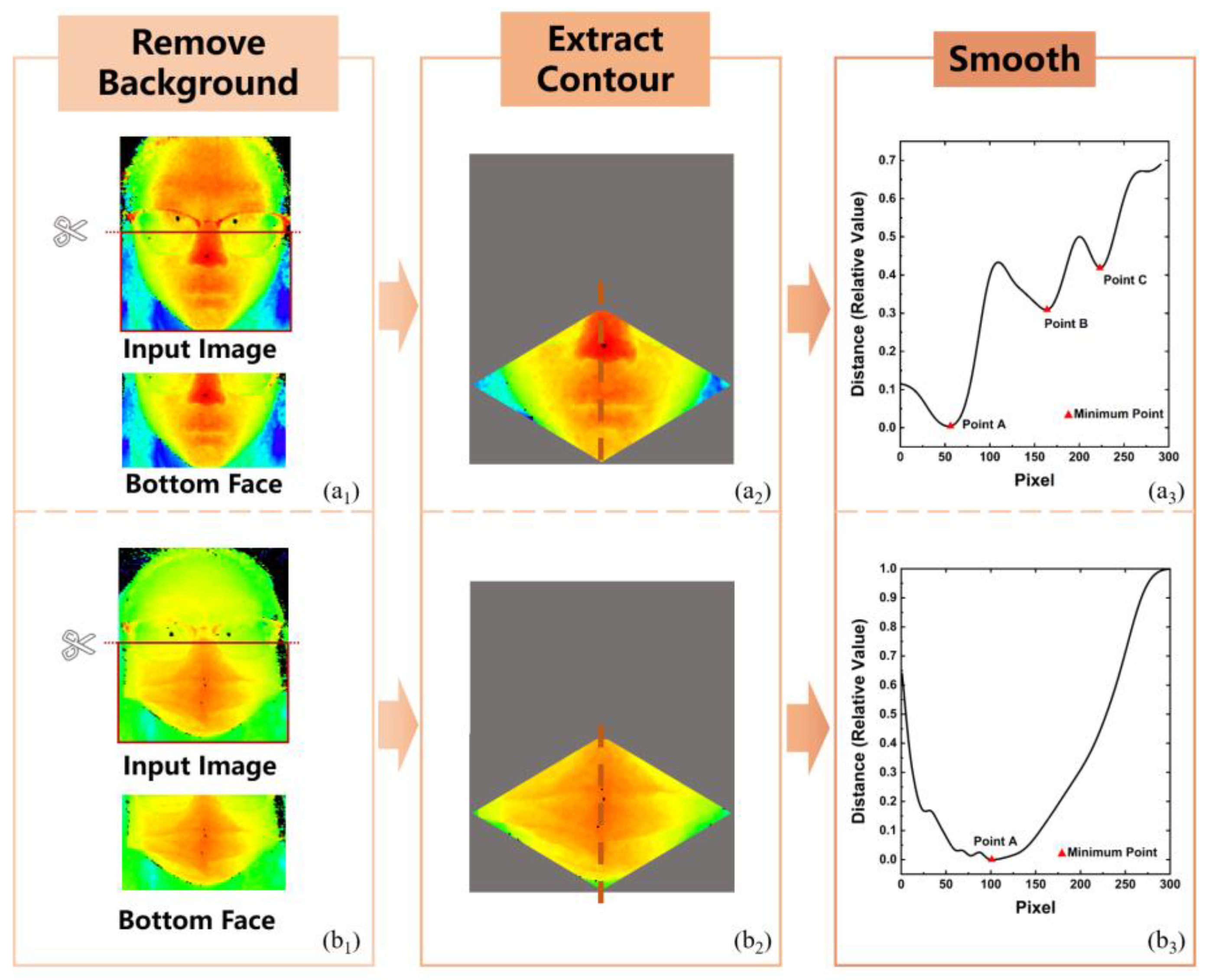
3.3. Multi-Sensor-Fusion-Based Methods
4. Discussion
4.1. Coexistence of “Face-Detection-and-Classification” and “Object-Detection-Models”
- (1)
- Advantages and limitations of face detection and classification: This two-stage approach excels in scenarios requiring fine-grained analysis of face mask usage. In medical settings, for instance, high protective standards necessitate precise evaluations of whether medical or N95 masks adequately cover the nose and mouth. This method allows for more detailed annotation of facial regions and associated features. However, it relies heavily on the reliability of the face detection module; any errors in face localization can directly affect the subsequent classification accuracy, leading to reduced overall precision or increased false positives. Additionally, in densely populated environments, the computational burden of sequentially detecting and classifying faces frame by frame poses challenges to real-time processing, necessitating optimization in network architecture or inference speed.
- (2)
- Flexibility of one-step object detection methods: Treating masked faces as a category within general object detection enables face mask detection to leverage the latest advancements in object detection. Single-stage detectors, known for their high inference speeds, are well-suited for scenarios requiring real-time monitoring, such as surveillance systems in train stations, airports, and shopping malls. Two-stage detectors, on the other hand, excel in high-precision applications, making them suitable for scenarios demanding detailed analysis. This “one-step” detection approach offers significant advantages in handling multi-target and multi-scale scenarios. Additionally, it integrates seamlessly with emerging technologies such as attention mechanisms and transformer architectures and benefits from pre-training on large-scale general datasets, achieving strong generalization even on smaller face mask datasets.
- (3)
- Balancing speed, accuracy, and hardware resources: Both two-stage and one-stage methods require a careful balance between speed, accuracy, and resource efficiency. In resource-constrained environments, such as embedded devices, lightweight optimization techniques, like model pruning, quantization, and knowledge distillation, can significantly reduce computational overhead. Pruning and quantization compress network structures and represent model parameters with lower bit-widths, improving inference speed. Knowledge distillation enables a teacher model to transfer feature representations to a student model, maintaining high accuracy while reducing model size.
- (4)
- Scalability and multi-task integration: Face mask detection is often combined with other tasks, such as face recognition or behavior analysis. The two-stage approach allows for additional classification or regression modules to be stacked on cropped ROIs, while one-step detection methods can leverage multi-task learning to simultaneously predict masks and other attributes or targets. However, increasing the number of tasks raises model complexity, requiring trade-offs between interpretability, real-time performance, and resource consumption.
- (5)
- Future research directions: Future research may focus on few-shot learning and incremental learning to quickly adapt to new face mask types. Domain adaptation and transfer learning approaches can enhance model generalization across varying environments, such as differing camera setups or lighting conditions. Furthermore, ensuring robust performance while addressing privacy protection and fairness concerns remains critical. Balancing detection efficiency with minimal invasiveness in privacy-sensitive applications, and ensuring equitable representation across diverse demographic groups in datasets, are essential priorities.
4.2. Diversity and Application Requirements of Datasets
- (1)
- Refinement of annotation schemes: Beyond merely distinguishing between “correct” and “incorrect” mask wearing, further distinctions should be made regarding mask types, levels of occlusion, and related attributes. Such detailed annotations would better support high-precision or interpretable applications.
- (2)
- Cross-domain integration and scenario coverage: Collecting more representative image data from diverse domains, such as urban transportation, medical protection, and industrial environments, while leveraging synthetic data for targeted transfer learning and generalization testing, will enhance the adaptability of models across varied application scenarios.
- (3)
- Privacy and fairness considerations: Striking a balance between the need to detect critical facial regions and protecting individual privacy is essential. Additionally, ensuring balanced representation of different races, genders, and age groups within datasets will mitigate systemic biases and prevent unintended disparities in real-world deployments of face mask detection systems.
4.3. Multimodal Fusion and Boundary Challenges
- (1)
- Hardware costs and system complexity: Multimodal systems typically require multiple sensors (e.g., RGB cameras, depth cameras, infrared cameras) to work in tandem. The hardware acquisition costs for such systems are substantially higher than those for single-modal systems. Additionally, to ensure temporal and spatial alignment among multiple sensors, high-precision synchronization mechanisms and dedicated calibration algorithms are required. These demands not only increase system complexity but also raise operational and maintenance costs.
- (2)
- Data fusion and computational efficiency: Multimodal data differ significantly in terms of physical properties, resolution, frame rate, and data formats, making the fusion process highly complex. Effective fusion strategies must address cross-modal alignment issues, such as spatial overlapping between depth and RGB images, while maintaining computational efficiency. For instance, directly inputting multimodal data into multi-stream CNNs or transformer-based models may lead to excessive resource requirements, making real-time applications infeasible. To address this, researchers have proposed strategies such as feature-level fusion and decision-level fusion. These methods integrate multimodal information either during feature extraction or at the classification stage. However, the choice of fusion method often requires balancing precision and speed based on the application scenario.
- (3)
- Annotation and data scarcity: Multimodal datasets require annotations across multiple dimensions, and semantic consistency among modalities must be ensured, which increases the cost and complexity of dataset construction. Furthermore, modalities such as infrared and depth imaging are not yet widely used in real-world applications, resulting in a scarcity of publicly available multimodal datasets. This limitation constrains the training and evaluation of multimodal models and may reduce their generalizability in real-world scenarios.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Eyiokur, F.I.; Kantarcı, A.; Erakın, M.E.; Damer, N.; Ofli, F.; Imran, M.; Križaj, J.; Salah, A.A.; Waibel, A.; Štruc, V.; et al. A Survey on Computer Vision Based Human Analysis in the COVID-19 Era. Image Vis. Comput. 2023, 130, 104610. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Ma, N.; Witt, C.; Rapp, S.; Wild, P.S.; Andreae, M.O.; Pöschl, U.; Su, H. Face Masks Effectively Limit the Probability of SARS-CoV-2 Transmission. Science 2021, 372, 1439–1443. [Google Scholar] [CrossRef] [PubMed]
- Mbunge, E.; Chitungo, I.; Dzinamarira, T. Unbundling the Significance of Cognitive Robots and Drones Deployed to Tackle COVID-19 Pandemic: A Rapid Review to Unpack Emerging Opportunities to Improve Healthcare in Sub-Saharan Africa. Cogn. Robot. 2021, 1, 205–213. [Google Scholar] [CrossRef]
- Sharma, A.; Gautam, R.; Singh, J. Deep Learning for Face Mask Detection: A Survey. Multimed. Tools Appl. 2023, 82, 34321–34361. [Google Scholar] [CrossRef]
- Shatnawi, M.; Alhanaee, K.; Alhammadi, M.; Almenhali, N. Advancements in Machine Learning-Based Face Mask Detection: A Review of Methods and Challenges. Int. J. Electr. Electron. Res. 2023, 11, 844–850. [Google Scholar] [CrossRef]
- Alturki, R.; Alharbi, M.; AlAnzi, F.; Albahli, S. Deep Learning Techniques for Detecting and Recognizing Face Masks: A Survey. Front. Public Health 2022, 10, 955332. [Google Scholar] [CrossRef]
- Abbas, S.F.; Shaker, S.H.; Abdullatif, F.A. Face Mask Detection Based on Deep Learning: A Review. J. Soft Comput. Comput. Appl. 2024, 1, 7. [Google Scholar] [CrossRef]
- Batagelj, B.; Peer, P.; Štruc, V.; Dobrišek, S. How to Correctly Detect Face-Masks for COVID-19 from Visual Information? Appl. Sci. 2021, 11, 2070. [Google Scholar] [CrossRef]
- Himeur, Y.; Al-Maadeed, S.; Varlamis, I.; Al-Maadeed, N.; Abualsaud, K.; Mohamed, A. Face Mask Detection in Smart Cities Using Deep and Transfer Learning: Lessons Learned from the COVID-19 Pandemic. Systems 2023, 11, 107. [Google Scholar] [CrossRef]
- Roy, S.; Menapace, W.; Oei, S.; Luijten, B.; Fini, E.; Saltori, C.; Huijben, I.; Chennakeshava, N.; Mento, F.; Sentelli, A.; et al. Deep Learning for Classification and Localization of COVID-19 Markers in Point-of-Care Lung Ultrasound. IEEE Trans. Med. Imaging 2020, 39, 2676–2687. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Esi Nyarko, B.N.; Bin, W.; Zhou, J.; Agordzo, G.K.; Odoom, J.; Koukoyi, E. Comparative Analysis of AlexNet, Resnet-50, and Inception-V3 Models on Masked Face Recognition. In Proceedings of the 2022 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 6–9 June 2022; IEEE: Seattle, WA, USA, 2022; pp. 337–343. [Google Scholar]
- Oumina, A.; El Makhfi, N.; Hamdi, M. Control The COVID-19 Pandemic: Face Mask Detection Using Transfer Learning. In Proceedings of the 2020 IEEE 2nd International Conference on Electronics, Control, Optimization and Computer Science (ICECOCS), Kenitra, Morocco, 2–3 December 2020; IEEE: Kenitra, Morocco, 2020; pp. 1–5. [Google Scholar]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. A Hybrid Deep Transfer Learning Model with Machine Learning Methods for Face Mask Detection in the Era of the COVID-19 Pandemic. Measurement 2021, 167, 108288. [Google Scholar] [CrossRef] [PubMed]
- Walia, I.S.; Kumar, D.; Sharma, K.; Hemanth, J.D.; Popescu, D.E. An Integrated Approach for Monitoring Social Distancing and Face Mask Detection Using Stacked ResNet-50 and YOLOv5. Electronics 2021, 10, 2996. [Google Scholar] [CrossRef]
- Meena, S.D.; Siri, C.S.; Lakshmi, P.S.; Doondı, N.S.; Sheela, J. Real Time DNN-Based Face Mask Detection System Using MobileNetV2 and ResNet50. In Proceedings of the 2023 International Conference on Inventive Computation Technologies (ICICT), Lalitpur, Nepal, 26–28 April 2023; IEEE: Lalitpur, Nepal, 2023; pp. 1007–1015. [Google Scholar]
- Rayapati, N.; Reddy Madhavi, K.; Anantha Natarajan, V.; Goundar, S.; Tangudu, N. Face Mask Detection Using Multi-Task Cascaded Convolutional Neural Networks. In Proceedings of the Fourth International Conference on Computer and Communication Technologies; Reddy, K.A., Devi, B.R., George, B., Raju, K.S., Sellathurai, M., Eds.; Springer Nature: Singapore, 2023; Volume 606, pp. 521–530. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 5202–5211. [Google Scholar]
- Chavda, A.; Dsouza, J.; Badgujar, S.; Damani, A. Multi-Stage CNN Architecture for Face Mask Detection. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; IEEE: Maharashtra, India, 2021; pp. 1–8. [Google Scholar]
- Militante, S.V.; Dionisio, N.V. Deep Learning Implementation of Facemask and Physical Distancing Detection with Alarm Systems. In Proceedings of the 2020 Third International Conference on Vocational Education and Electrical Engineering (ICVEE), Surabaya, Indonesia, 3–4 October 2020; IEEE: Surabaya, Indonesia, 2020; pp. 1–5. [Google Scholar]
- Magistris, G.D.; Iacobelli, E.; Brociek, R.; Napoli, C. An Automatic CNN-Based Face Mask Detection Algorithm Tested During the COVID-19 Pandemics. In Proceedings of the International Conference of Yearly Reports on Informatics, Mathematics, and Engineering (ICYRIME 2022), Catania, Italy, 26–29 August 2022. [Google Scholar]
- Alnaim, N.M.; Almutairi, Z.M.; Alsuwat, M.S.; Alalawi, H.H.; Alshobaili, A.; Alenezi, F.S. DFFMD: A Deepfake Face Mask Dataset for Infectious Disease Era with Deepfake Detection Algorithms. IEEE Access 2023, 11, 16711–16722. [Google Scholar] [CrossRef]
- Aydemir, E.; Yalcinkaya, M.A.; Barua, P.D.; Baygin, M.; Faust, O.; Dogan, S.; Chakraborty, S.; Tuncer, T.; Acharya, U.R. Hybrid Deep Feature Generation for Appropriate Face Mask Use Detection. IJERPH 2022, 19, 1939. [Google Scholar] [CrossRef]
- Xu, M.; Wang, H.; Yang, S.; Li, R. Mask Wearing Detection Method Based on SSD-Mask Algorithm. In Proceedings of the 2020 International Conference on Computer Science and Management Technology (ICCSMT), Shanghai, China, 20–22 November 2020; IEEE: Shanghai, China, 2020; pp. 138–143. [Google Scholar]
- Farouk, S.; Sabir, M.; Mehmood, I.; Adnan Alsaggaf, W.; Fawai Khairullah, E.; Alhuraiji, S.; Alghamdi, A.S.; Abd El-Latif, A.A. An Automated Real-Time Face Mask Detection System Using Transfer Learning with Faster-RCNN in the Era of the COVID-19 Pandemic. Comput. Mater. Contin. 2022, 71, 4151–4166. [Google Scholar] [CrossRef]
- Cao, R.; Mo, W.; Zhang, W. FMDet: Face Mask Detection Based on Improved Cascade Rcnn. In Proceedings of the 2023 IEEE 4th International Conference on Pattern Recognition and Machine Learning (PRML), Urumqi, China, 4–6 August 2023; IEEE: Urumqi, China, 2023; pp. 1–6. [Google Scholar]
- Cao, R.; Mo, W.; Zhang, W. MFMDet: Multi-Scale Face Mask Detection Using Improved Cascade Rcnn. J. Supercomput. 2024, 80, 4914–4942. [Google Scholar] [CrossRef]
- Pham, T.-N.; Nguyen, V.-H.; Huh, J.-H. Integration of Improved YOLOv5 for Face Mask Detector and Auto-Labeling to Generate Dataset for Fighting against COVID-19. J. Supercomput. 2023, 79, 8966–8992. [Google Scholar] [CrossRef]
- Sharma, A.; Gautam, R.; Singh, J. Real Time Face Mask Detection on a Novel Dataset for COVID-19 Prevention. Multimed. Tools Appl. 2023, 83, 32387–32410. [Google Scholar] [CrossRef]
- Pham, T.-N.; Nguyen, V.-H.; Huh, J.-H. COVID-19 Monitoring System: In-Browser Face Mask Detection Application Using Deep Learning. Multimed. Tools Appl. 2023, 83, 61943–61970. [Google Scholar] [CrossRef]
- Ferreira, F.R.T.; Do Couto, L.M.; De Melo Baptista Domingues, G. Exploring the Potential of YOLOv8 in Hybrid Models for Facial Mask Identification in Diverse Environments. Neural Comput. Applic 2024, 36, 22037–22052. [Google Scholar] [CrossRef]
- Sinha, D.; El-Sharkawy, M. Thin MobileNet: An Enhanced MobileNet Architecture. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; IEEE: New York, NY, USA, 2019; pp. 0280–0285. [Google Scholar]
- Lin, B.; Hou, M. Face Mask Detection Based on Improved YOLOv8. J. Electr. Syst. 2024, 20, 365–375. [Google Scholar] [CrossRef]
- Iyer, R.V.; Ringe, P.S.; Bhensdadiya, K.P. Comparison of YOLOv3, YOLOv5s and MobileNet-SSD V2 for Real-Time Mask Detection. 2021, 8, 1156–1160. Artic. Int. J. Res. Eng. Technol. 2021, 8, 1156–1160. [Google Scholar]
- Wang, L.; Lin, Y.; Sun, W.; Wu, Y. Improved Faster-RCNN Algorithm for Mask Wearing Detection. In Proceedings of the 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 18–20 June 2021; IEEE: Chongqing, China, 2021; pp. 1119–1124. [Google Scholar]
- Addagarla, S.K. Real Time Multi-Scale Facial Mask Detection and Classification Using Deep Transfer Learning Techniques. IJATCSE 2020, 9, 4402–4408. [Google Scholar] [CrossRef]
- Gao, X.; Gupta, B.B.; Colace, F. Human Face Mask Detection Based on Deep Learning Using YOLOv7+CBAM in Deep Learning. Handbook of Research on AI and ML for Intelligent Machines and Systems; Gupta, B.B., Colace, F., Eds.; IGI Global: Hershey, PA, USA, 2024; pp. 94–106. [Google Scholar] [CrossRef]
- Ragunthar, T.; Mukherjee, A.; Sati, S. Face Mask Detection Using SSD-Mobilenet-V2. In Proceedings of the 2023 13th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 19–20 January 2023; IEEE: Noida, India, 2023; pp. 366–372. [Google Scholar]
- Endris, A.; Yang, S.; Zenebe, Y.A.; Gashaw, B.; Mohammed, J.; Bayisa, L.Y.; Abera, A.E. Efficient Face Mask Detection Method Using YOLOX: An Approach to Reduce Coronavirus Spread. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022; IEEE: Chengdu, China, 2022; pp. 568–573. [Google Scholar]
- Anggraini, N.; Ramadhani, S.H.; Wardhani, L.K.; Hakiem, N.; Shofi, I.M.; Rosyadi, M.T. Development of Face Mask Detection Using SSDLite MobilenetV3 Small on Raspberry Pi 4. In Proceedings of the 2022 5th International Conference of Computer and Informatics Engineering (IC2IE), Jakarta, Indonesia, 13–14 September 2022; IEEE: Jakarta, Indonesia, 2022; pp. 209–214. [Google Scholar]
- Dewi, C.; Manongga, D.; Hendry; Mailoa, E. Deep Learning-Based Face Mask Recognition System with YOLOv8. In Proceedings of the 2024 16th International Conference on Computer and Automation Engineering (ICCAE), Melbourne, Australia, 14–16 March 2024; IEEE: Melbourne, Australia, 2024; pp. 418–422. [Google Scholar]
- Yadav, S. Deep Learning Based Safe Social Distancing and Face Mask Detection in Public Areas for COVID-19 Safety Guidelines Adherence. Int. J. Res. Appl. Sci. Eng. Technol. 2020, 8, 1368–1375. [Google Scholar] [CrossRef]
- Tong, B.; Zhang, M. Comparison of YOLO Series Algorithms in Mask Detection. In Proceedings of the 2023 International Workshop on Intelligent Systems (IWIS), Ulsan, Republic of Korea, 9–11 August 2023; IEEE: Ulsan, Republic of Korea, 2023; pp. 1–5. [Google Scholar]
- Jovanovic, L.; Bacanin, N.; Zivkovic, M.; Mani, J.; Strumberger, I.; Antonijevic, M. Comparison of YOLO Architectures for Face Mask Detection in Images. In Proceedings of the 2023 16th International Conference on Advanced Technologies, Systems and Services in Telecommunications (TELSIKS), Nis, Serbia, 25–27 October 2023; IEEE: Nis, Serbia, 2023; pp. 179–182. [Google Scholar]
- Dewi, C.; Manongga, D.; Hendry; Mailoa, E.; Hartomo, K.D. Deep Learning and YOLOv8 Utilized in an Accurate Face Mask Detection System. Big Data Cogn. Comput. 2024, 8, 9. [Google Scholar] [CrossRef]
- Kolosov, D.; Kelefouras, V.; Kourtessis, P.; Mporas, I. Anatomy of Deep Learning Image Classification and Object Detection on Commercial Edge Devices: A Case Study on Face Mask Detection. IEEE Access 2022, 10, 109167–109186. [Google Scholar] [CrossRef]
- Anithadevi, N.; Abinisha, J.; Akalya, V.; Haripriya, V. An Improved SSD Object Detection Algorithm for Safe Social Distancing and Face Mask Detection in Public Areas Through Intelligent Video Analytics. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; IEEE: Kharagpur, India, 2021; pp. 1–7. [Google Scholar]
- Balaji, K.; Gowri, S. A Real-Time Face Mask Detection Using SSD and MobileNetV2. In Proceedings of the 2021 4th International Conference on Computing and Communications Technologies (ICCCT), Chennai, India, 16–17 December 2021; IEEE: Chennai, India, 2021; pp. 144–148. [Google Scholar]
- Xiao, H.; Wang, B.; Zheng, J.; Liu, L.; Chen, C.L.P. A Fine-Grained Detector of Face Mask Wearing Status Based on Improved YOLOX. IEEE Trans. Artif. Intell. 2024, 5, 1816–1830. [Google Scholar] [CrossRef]
- Han, W.; Huang, Z.; Kuerban, A.; Yan, M.; Fu, H. A Mask Detection Method for Shoppers Under the Threat of COVID-19 Coronavirus. In Proceedings of the 2020 International Conference on Computer Vision, Image and Deep Learning (CVIDL), Chongqing, China, 10–12 July 2020; IEEE: Chongqing, China, 2020; pp. 442–447. [Google Scholar]
- Nithin, A.; Jaisharma, K. A Deep Learning Based Novel Approach for Detection of Face Mask Wearing Using Enhanced Single Shot Detector (SSD) over Convolutional Neural Network (CNN) with Improved Accuracy. In Proceedings of the 2022 International Conference on Business Analytics for Technology and Security (ICBATS), Dubai, United Arab Emirates, 16–17 February 2022; IEEE: Dubai, United Arab Emirates, 2022; pp. 1–5. [Google Scholar]
- Cheng, C. Real-Time Mask Detection Based on SSD-MobileNetV2. In Proceedings of the 2022 IEEE 5th International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 18–20 November 2022; IEEE: Shenyang, China, 2022; pp. 761–767. [Google Scholar]
- Zhang, B.; Li, S.; Wang, Z.; Wu, L. Attention-Guided Neural Network for Face Mask Detection. Image Graph. Technol. Appl. 2023, 1910, 194–207. [Google Scholar] [CrossRef]
- Al-Shamdeen, M.J.; Ramo, F.M. Deployment Yolov8 Model for Face Mask Detection Based on Amazon Web Service. Emerg. Trends Appl. Artif. Intell. 2024, 960, 404–413. [Google Scholar] [CrossRef]
- Cao, Z.; Li, W.; Zhao, H.; Pang, L. YoloMask: An Enhanced YOLO Model for Detection of Face Mask Wearing Normality, Irregularity and Spoofing. Biom. Recognit. 2022, 13628, 205–213. [Google Scholar] [CrossRef]
- Xu, S.; Guo, Z.; Liu, Y.; Fan, J.; Liu, X. An Improved Lightweight YOLOv5 Model Based on Attention Mechanism for Face Mask Detection. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2022; Pimenidis, E., Angelov, P., Jayne, C., Papaleonidas, A., Aydin, M., Eds.; Springer: Cham, Switzerland, 2022; Volume 13531, pp. 531–543. [Google Scholar]
- Koklu, M.; Cinar, I.; Taspinar, Y.S. CNN-Based Bi-Directional and Directional Long-Short Term Memory Network for Determination of Face Mask. Biomed. Signal Process. Control 2022, 71, 103216. [Google Scholar] [CrossRef] [PubMed]
- Naseri, R.A.S.; Kurnaz, A.; Farhan, H.M. Optimized Face Detector-Based Intelligent Face Mask Detection Model in IoT Using Deep Learning Approach. Appl. Soft Comput. 2023, 134, 109933. [Google Scholar] [CrossRef]
- Sethi, S.; Kathuria, M.; Kaushik, T. Face Mask Detection Using Deep Learning: An Approach to Reduce Risk of Coronavirus Spread. J. Biomed. Inform. 2021, 120, 103848. [Google Scholar] [CrossRef]
- Wu, P.; Li, H.; Zeng, N.; Li, F. FMD-Yolo: An Efficient Face Mask Detection Method for COVID-19 Prevention and Control in Public. Image Vis. Comput. 2022, 117, 104341. [Google Scholar] [CrossRef]
- Kumar, A.; Kalia, A.; Kalia, A. ETL-YOLO v4: A Face Mask Detection Algorithm in Era of COVID-19 Pandemic. Optik 2022, 259, 169051. [Google Scholar] [CrossRef]
- Mostafa, S.A.; Ravi, S.; Asaad Zebari, D.; Asaad Zebari, N.; Abed Mohammed, M.; Nedoma, J.; Martinek, R.; Deveci, M.; Ding, W. A YOLO-Based Deep Learning Model for Real-Time Face Mask Detection via Drone Surveillance in Public Spaces. Inf. Sci. 2024, 676, 120865. [Google Scholar] [CrossRef]
- Nagrath, P.; Jain, R.; Madan, A.; Arora, R.; Kataria, P.; Hemanth, J. SSDMNV2: A Real Time DNN-Based Face Mask Detection System Using Single Shot Multibox Detector and MobileNetV2. Sustain. Cities Soc. 2021, 66, 102692. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, W. Face Mask Wearing Detection Algorithm Based on Improved YOLO-V4. Sensors 2021, 21, 3263. [Google Scholar] [CrossRef]
- Asha, V. Real-Time Face Mask Detection in Video Streams Using Deep Learning Technique. In Proceedings of the 2023 4th International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 20–22 September 2023; IEEE: Trichy, India, 2023; pp. 1254–1259. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Bisht, A.S.; Jha, A.K.; Sachdeva, A.; Sharma, N. Role of Artificial Intelligence in Object Detection: A Review. In Proceedings of the 2022 4th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 16–17 December 2022; IEEE: Greater Noida, India, 2022; pp. 1020–1026. [Google Scholar]
- Mahadevkar, S.V.; Khemani, B.; Patil, S.; Kotecha, K.; Vora, D.R.; Abraham, A.; Gabralla, L.A. A Review on Machine Learning Styles in Computer Vision—Techniques and Future Directions. IEEE Access 2022, 10, 107293–107329. [Google Scholar] [CrossRef]
- Tang, H.-M.; You, F.-C. Face Mask Recognition Based on MTCNN and MobileNet. In Proceedings of the 2021 3rd International Academic Exchange Conference on Science and Technology Innovation (IAECST), Guangzhou, China, 10–12 December 2021; IEEE: Guangzhou, China, 2021; pp. 471–474. [Google Scholar]
- Li, J.; Wang, Y.; Wang, C.; Tai, Y.; Qian, J.; Yang, J.; Wang, C.; Li, J.; Huang, F. DSFD: Dual Shot Face Detector. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Long Beach, CA, USA, 2019; pp. 5055–5064. [Google Scholar]
- Tang, X.; Du, D.K.; He, Z.; Liu, J. PyramidBox: A Context-Assisted Single Shot Face Detector. In Proceedings of the Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11213, pp. 812–828. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2018, arXiv:1608.06993. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. arXiv 2014, arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. Computer Vision—ECCV 2016 2016, 9905, 21–37. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. arXiv 2018, arXiv:1708.02002. [Google Scholar]
- Mohammed Ali, F.; AlTamimi, M. Face Mask Detection Methods and Techniques: A Review. IJNAA 2022, 13, 3811–3823. [Google Scholar] [CrossRef]
- Vibhuti; Jindal, N.; Singh, H.; Rana, P.S. Face Mask Detection in COVID-19: A Strategic Review. Multimed. Tools Appl. 2022, 81, 40013–40042. [Google Scholar] [CrossRef]
- Nowrin, A.; Afroz, S.; Rahman, M.S.; Mahmud, I.; Cho, Y.-Z. Comprehensive Review on Facemask Detection Techniques in the Context of COVID-19. IEEE Access 2021, 9, 106839–106864. [Google Scholar] [CrossRef]
- Ge, S.; Li, J.; Ye, Q.; Luo, Z. Detecting Masked Faces in the Wild With LLE-CNNs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Su, X.; Gao, M.; Ren, J.; Li, Y.; Dong, M.; Liu, X. Face Mask Detection and Classification via Deep Transfer Learning. Multimed. Tools Appl. 2022, 81, 4475–4494. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, P.; Louis, P.C.; Wheless, L.E.; Huo, Y. WearMask: Fast In-Browser Face Mask Detection with Serverless Edge Computing for COVID-19. Electron. Imaging 2023, 35, 229-1–229-6. [Google Scholar] [CrossRef]
- Jiang, X.; Gao, T.; Zhu, Z.; Zhao, Y. Real-Time Face Mask Detection Method Based on YOLOv3. Electronics 2021, 10, 837. [Google Scholar] [CrossRef]
- Vrigkas, M.; Kourfalidou, E.-A.; Plissiti, M.E.; Nikou, C. FaceMask: A New Image Dataset for the Automated Identification of People Wearing Masks in the Wild. Sensors 2022, 22, 896. [Google Scholar] [CrossRef]
- Kantarcı, A.; Ofli, F.; Imran, M.; Ekenel, H.K. Bias-Aware Face Mask Detection Dataset. Multimed. Tools Appl. 2024. [Google Scholar] [CrossRef]
- Cabani, A.; Hammoudi, K.; Benhabiles, H.; Melkemi, M. MaskedFace-Net—A Dataset of Correctly/Incorrectly Masked Face Images in the Context of COVID-19. Smart Health 2021, 19, 100144. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wang, G.; Huang, B.; Xiong, Z.; Hong, Q.; Wu, H.; Yi, P.; Jiang, K.; Wang, N.; Pei, Y.; et al. Masked Face Recognition Dataset and Application. arXiv 2020, arXiv:2003.09093. [Google Scholar] [CrossRef]
- Ward, R.J.; Mark Jjunju, F.P.; Kabenge, I.; Wanyenze, R.; Griffith, E.J.; Banadda, N.; Taylor, S.; Marshall, A. FluNet: An AI-Enabled Influenza-Like Warning System. IEEE Sens. J. 2021, 21, 24740–24748. [Google Scholar] [CrossRef]
- Wang, X.; Xu, T.; An, D.; Sun, L.; Wang, Q.; Pan, Z.; Yue, Y. Face Mask Identification Using Spatial and Frequency Features in Depth Image from Time-of-Flight Camera. Sensors 2023, 23, 1596. [Google Scholar] [CrossRef]
- Cao, Z.; Shao, M.; Xu, L.; Mu, S.; Qu, H. MaskHunter: Real-time Object Detection of Face Masks during the COVID-19 Pandemic. IET Image Process 2020, 14, 4359–4367. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Mask Types | Scales | Annotation Classes | Resolution | Year | Data Link |
|---|---|---|---|---|---|---|
| TFCD | Real | 250 | 2 (masked/unmasked) | 320 × 240 | 2021 | https://zenodo.org/records/4739682#.YUmyrrhKgWc (accessed on 6 January 2025) |
| Kaggle-853 | Real | 853 | 3 (masked/not masked/wrongly worn) | Multi | 2020 | https://www.kaggle.com/datasets/andrewmvd/face-mask-detection (accessed on 6 January 2025) |
| FMCD | Real | 3241 | 2 (masked/unmasked) | 224 × 224 | 2022 | https://github.com/Kyrie-leon/Face-Mask-Classification-Dataset?tab=readme-ov-file (accessed on 6 January 2025) |
| FaceMask | Real | 4866 | 2 (masked/unmasked) | Multi | 2022 | https://mvrigkas.github.io/FaceMaskDataset/ (accessed on 6 January 2025) |
| BAFMD | Artificial | 6264 | 2 (masked/unmasked) | Multi | 2022 | https://github.com/Alpkant/BAFMD (accessed on 6 January 2025) |
| AIZOO | Real | 7971 | 2 (masked/unmasked) | Multi | 2021 | https://github.com/AIZOOTech/FaceMaskDetection (accessed on 6 January 2025) |
| WearMask | Real | 9097 | 3 (masked/not masked/wrongly worn) | Multi | 2020 | https://facemask-detection.com/ (accessed on 6 January 2025) |
| PWMFD | Real | 9205 | 3 (masked/unmasked) | Multi | 2021 | https://github.com/ethancvaa/Properly-Wearing-Masked-Detect-Dataset (accessed on 6 January 2025) |
| Kaggle-12k | Real | 12,000 | 2 (masked/unmasked) | Multi | 2020 | https://www.kaggle.com/datasets/ashishjangra27/face-mask-12k-images-dataset (accessed on 6 January 2025) |
| Kaggle-FMLD | Artificial | 20,000 | 2 (masked/unmasked) | 1024 × 1024 | 2020 | https://www.kaggle.com/datasets/prasoonkottarathil/face-mask-lite-dataset (accessed on 6 January 2025) |
| MAFA | Real | 30,811 | Multiple (face frames, mask types) | Multi | 2017 | https://www.kaggle.com/datasets/revanthrex/mafadataset (accessed on 6 January 2025) |
| FMLD | Real | 41,934 | 3 (masked/not masked/wrongly worn) | Multi | 2021 | https://github.com/borutb-fri/FMLD (accessed on 6 January 2025) |
| RMFRD | Real | 92,671 | 2 (masked/unmasked) | Multi | 2020 | https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset (accessed on 6 January 2025) |
| MaskedFace-Net | Artificial | 137,016 | 3 (masked/not masked/wrongly worn) | 1024 × 1024 | 2020 | https://github.com/cabani/MaskedFace-Net (accessed on 6 January 2025) |
| SMFRD | Artificial | 500,000 | 2 (masked/unmasked) | Multi | 2020 | https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset (accessed on 6 January 2025) |
| Work | Method | Data | Distinguished Type | Accuracy | Efficiency |
|---|---|---|---|---|---|
| Cao et al. [98] | YOLOv4-large | 2D RGB | With/without Nighttime | 94% 77.9% | 18 FPS |
| Nagrath et al. [63] | SSDMNV2 | 2D RGB | With/without | 92.64% | 15.71 FPS |
| Yu et al. [64] | YOLO-v4 | 2D RGB | With/without | 98.3% | 54.57 FPS |
| Walia et al. [15] | ResNet-50 | 2D RGB | With/without | 98% | 32 FPS |
| Jiang et al. [91] | SE-YOLOv3 | 2D RGB | With/without /Correct wearing | 73.7% | 15.63 FPS |
| Su et al. [63] | Transfer learning and efficient-Yolov3 | 2D RGB | with/without Mask type | 96.03% | 15 FPS |
| 97.84% | |||||
| Wang et al. [97] | Feature-based | 3D Depth | With/without Mask Type | 96.9% 87.85% | 31.55 FPS |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; An, D.; Zhang, Y.; Wang, X.; Wang, X.; Wang, Q.; Pan, Z.; Yue, Y. A Review on Face Mask Recognition. Sensors 2025, 25, 387. https://doi.org/10.3390/s25020387
Zhang J, An D, Zhang Y, Wang X, Wang X, Wang Q, Pan Z, Yue Y. A Review on Face Mask Recognition. Sensors. 2025; 25(2):387. https://doi.org/10.3390/s25020387
Chicago/Turabian StyleZhang, Jiaonan, Dong An, Yiwen Zhang, Xiaoyan Wang, Xinyue Wang, Qiang Wang, Zhongqi Pan, and Yang Yue. 2025. "A Review on Face Mask Recognition" Sensors 25, no. 2: 387. https://doi.org/10.3390/s25020387
APA StyleZhang, J., An, D., Zhang, Y., Wang, X., Wang, X., Wang, Q., Pan, Z., & Yue, Y. (2025). A Review on Face Mask Recognition. Sensors, 25(2), 387. https://doi.org/10.3390/s25020387