
Time Series Data Augmentation for Energy Consumption Data Based on Improved TimeGAN

Abstract
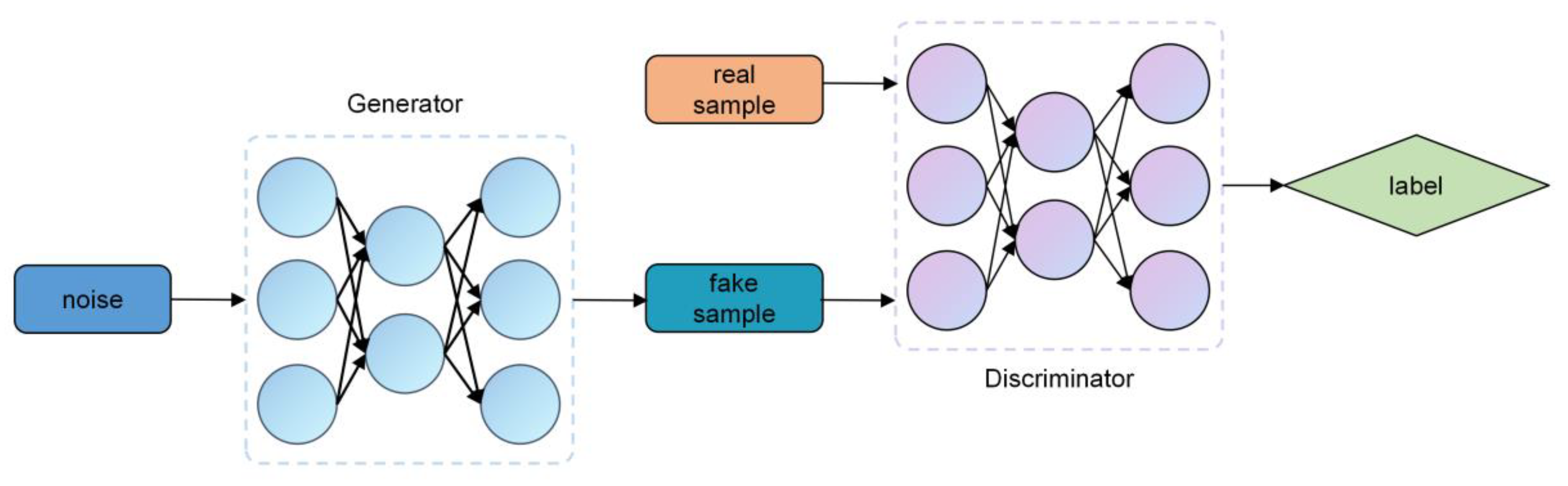
1. Introduction
2. Methodology
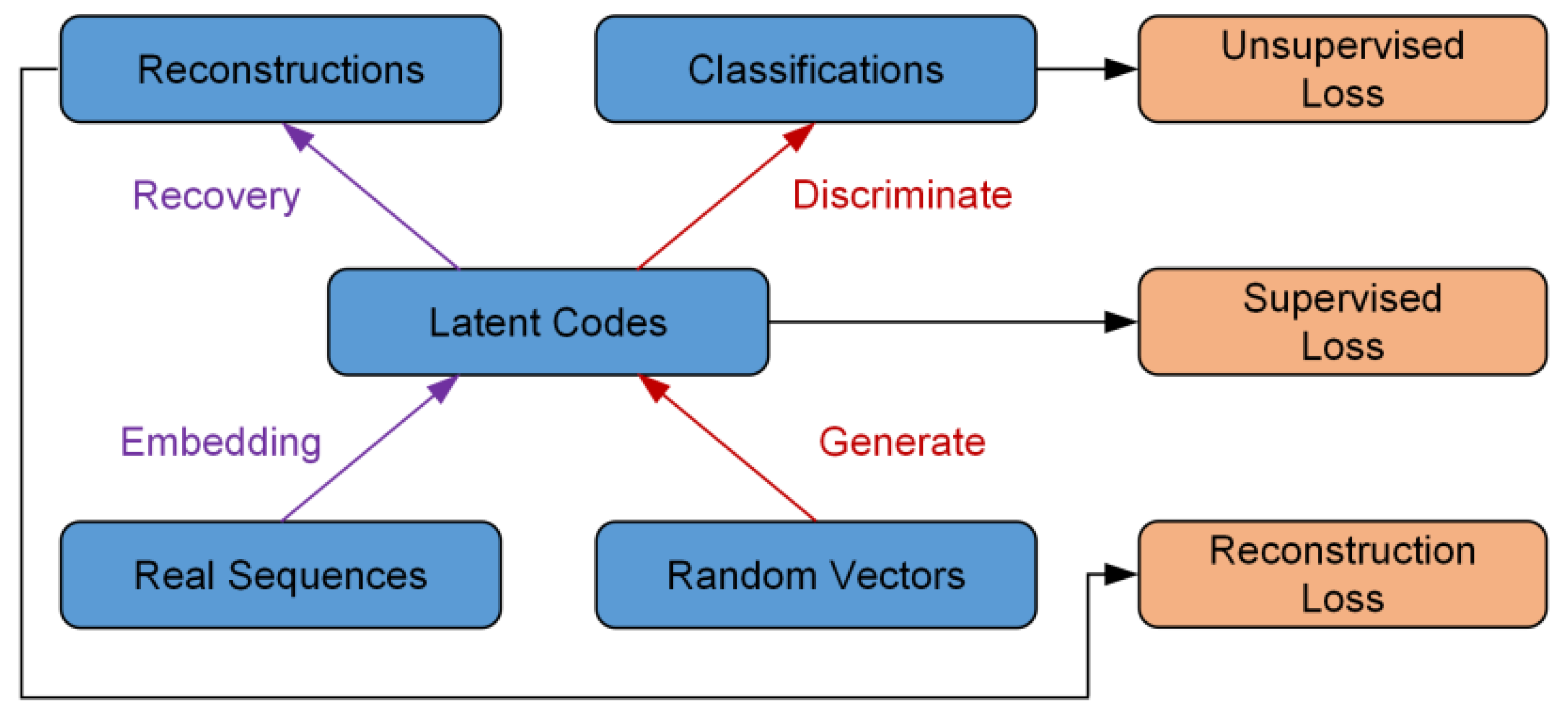
2.1. Overview of the Method
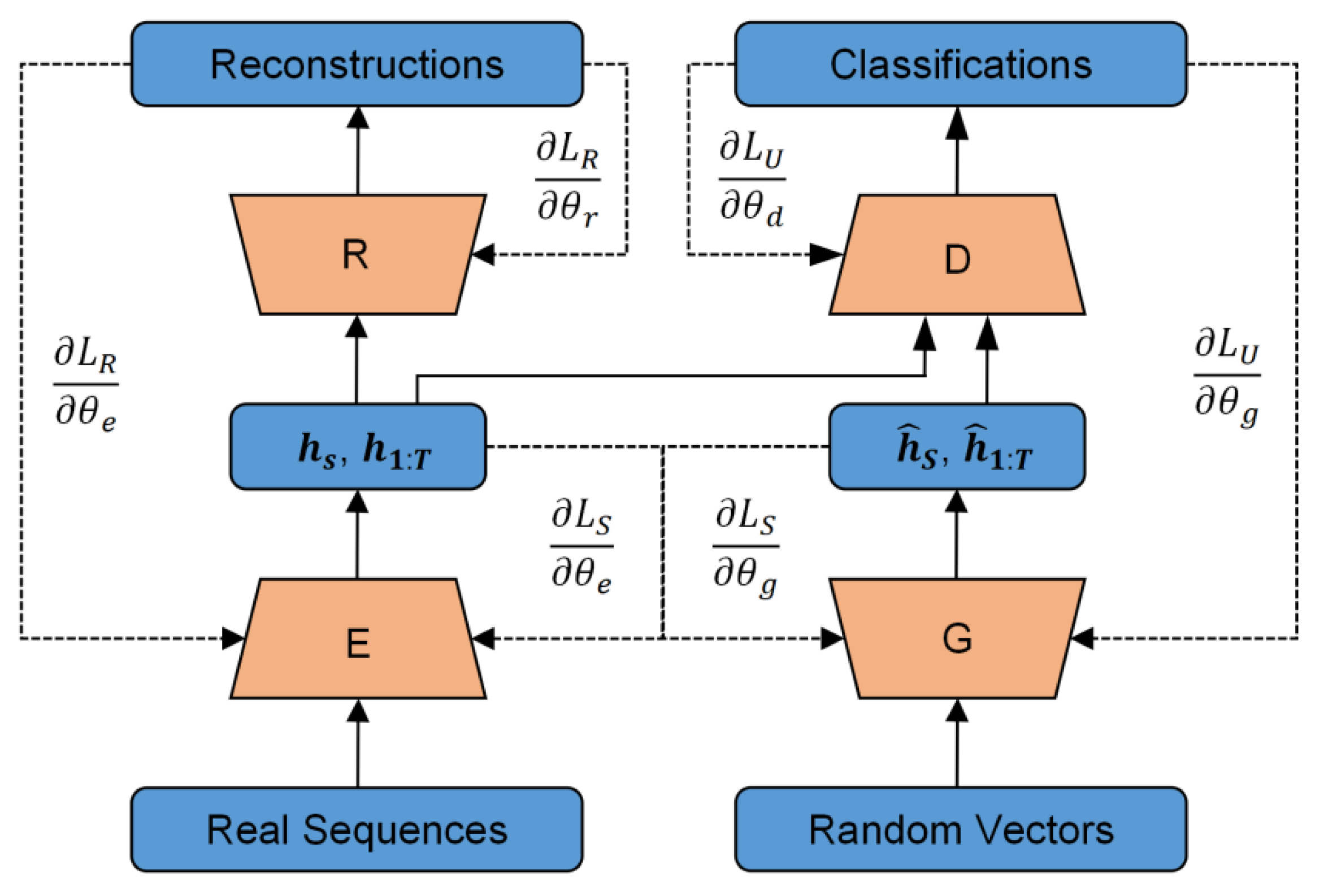
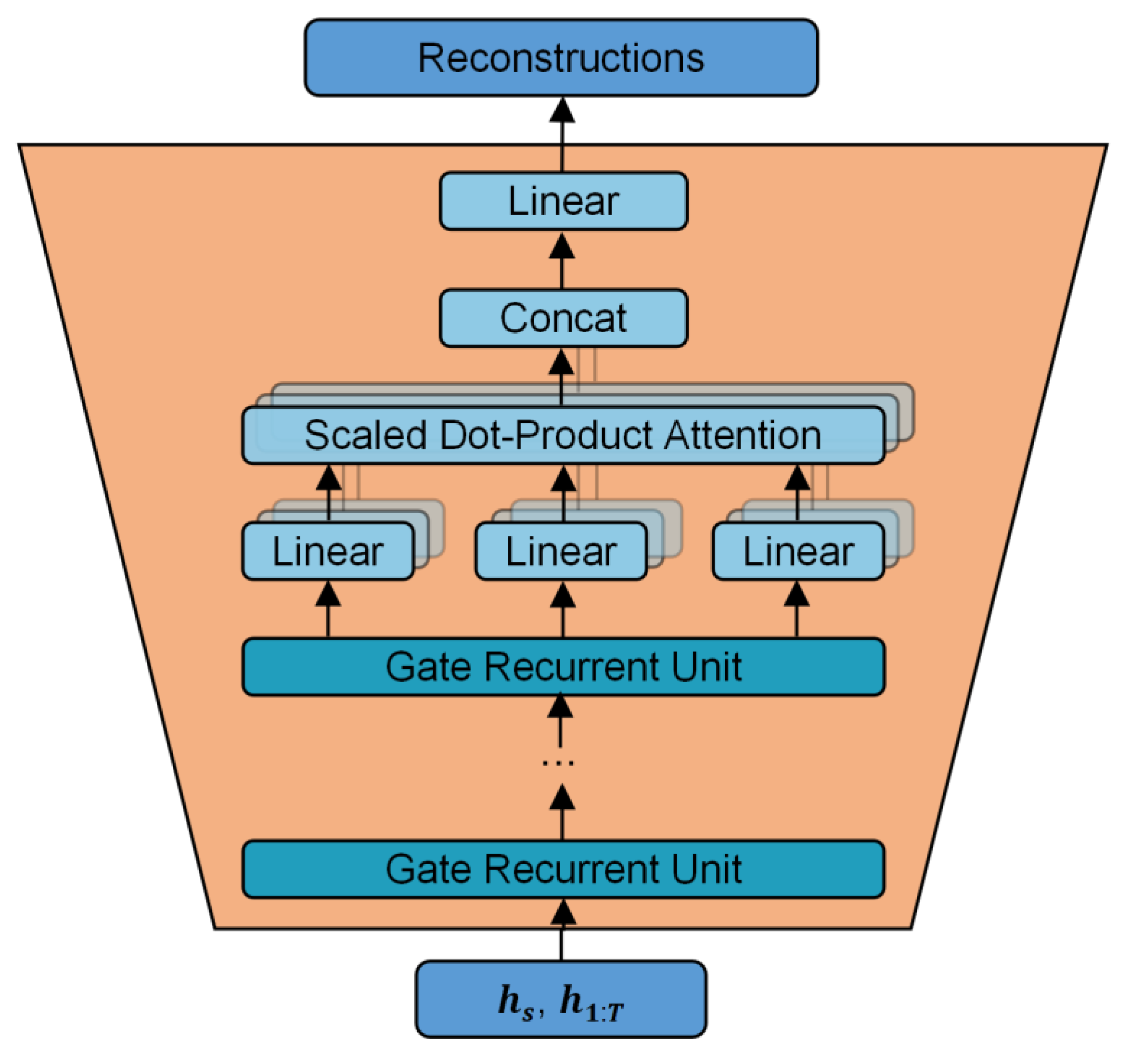
2.2. Improved TimeGAN Model
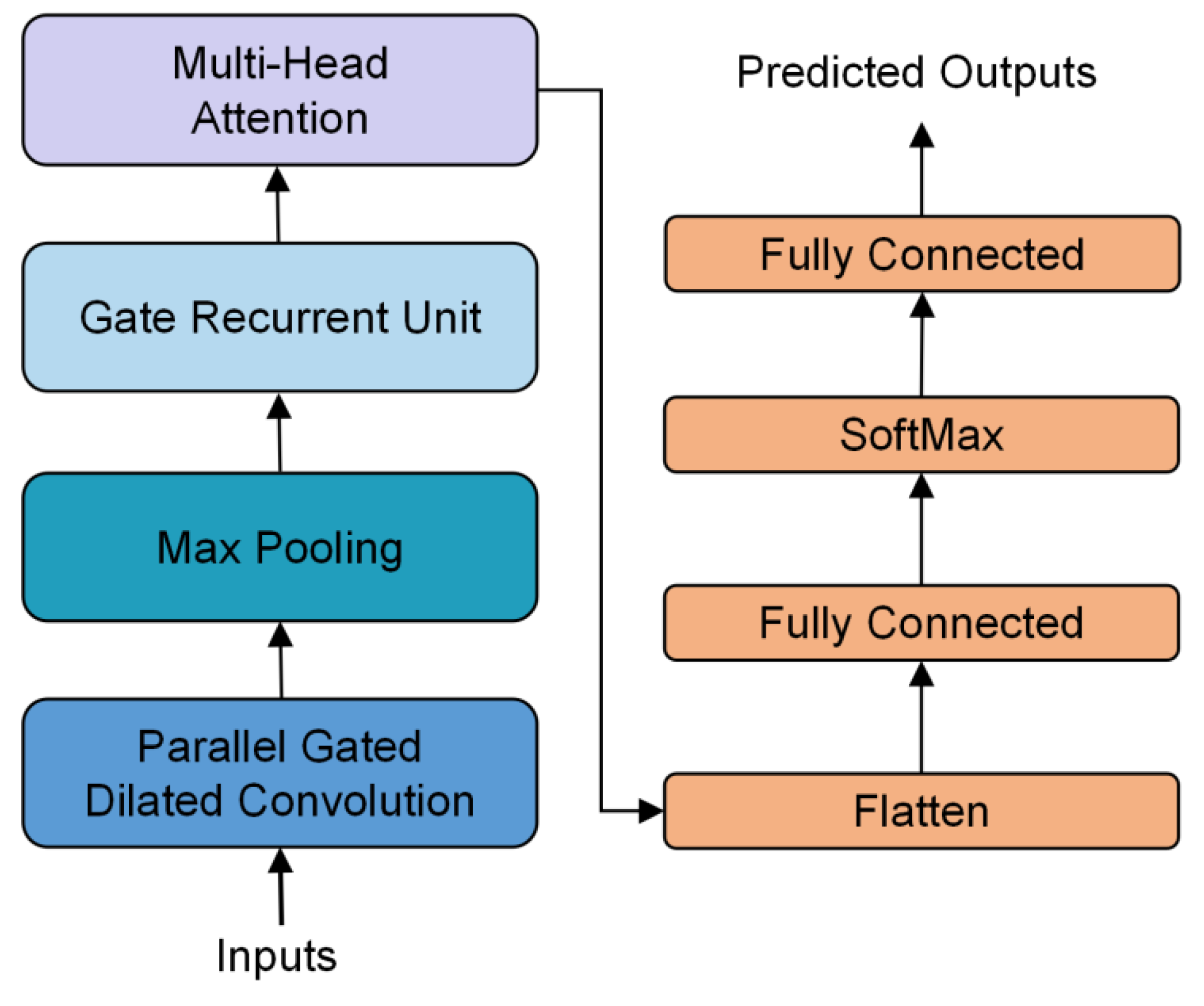
2.3. Prediction Model
3. Experiment
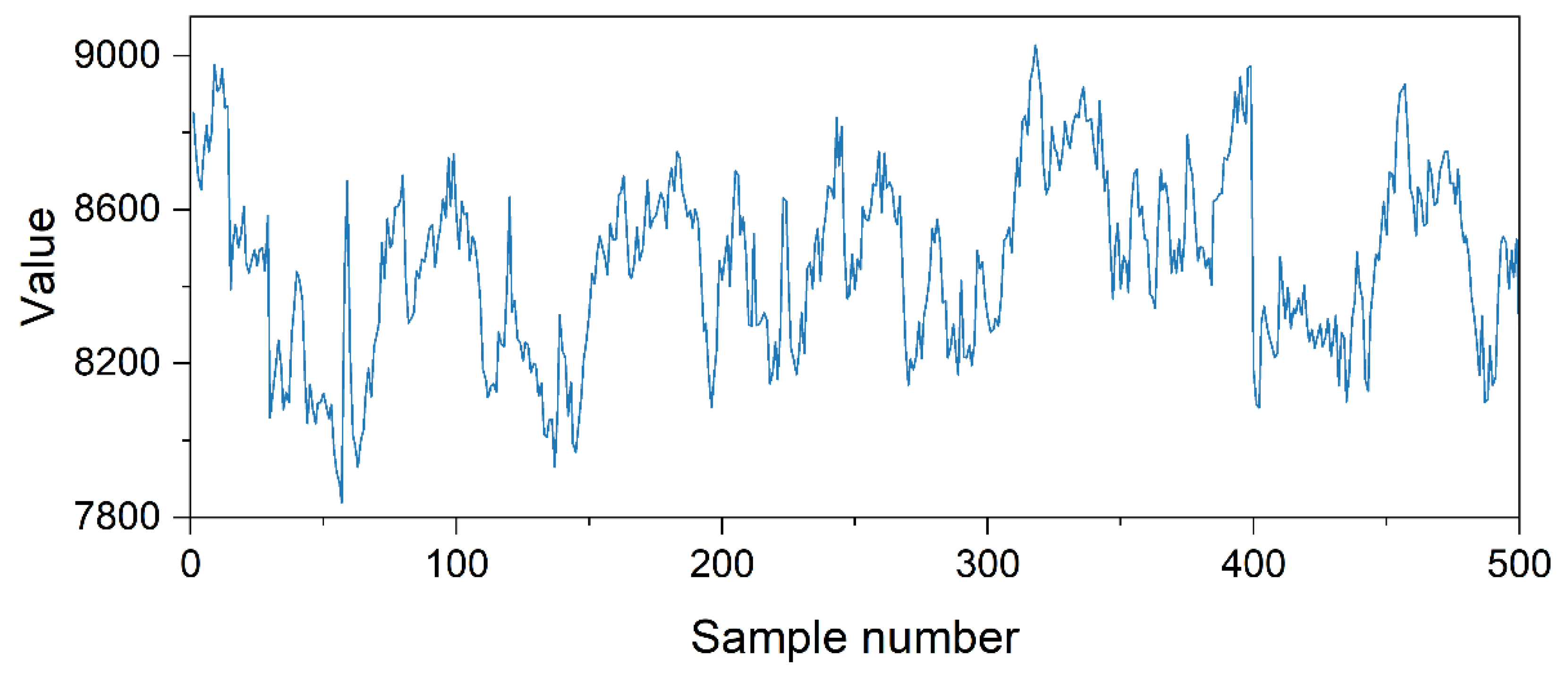
3.1. Data Source
3.2. Data Preprocessing
3.3. Evaluation Metrics
3.4. Hyperparameters and Benchmarks
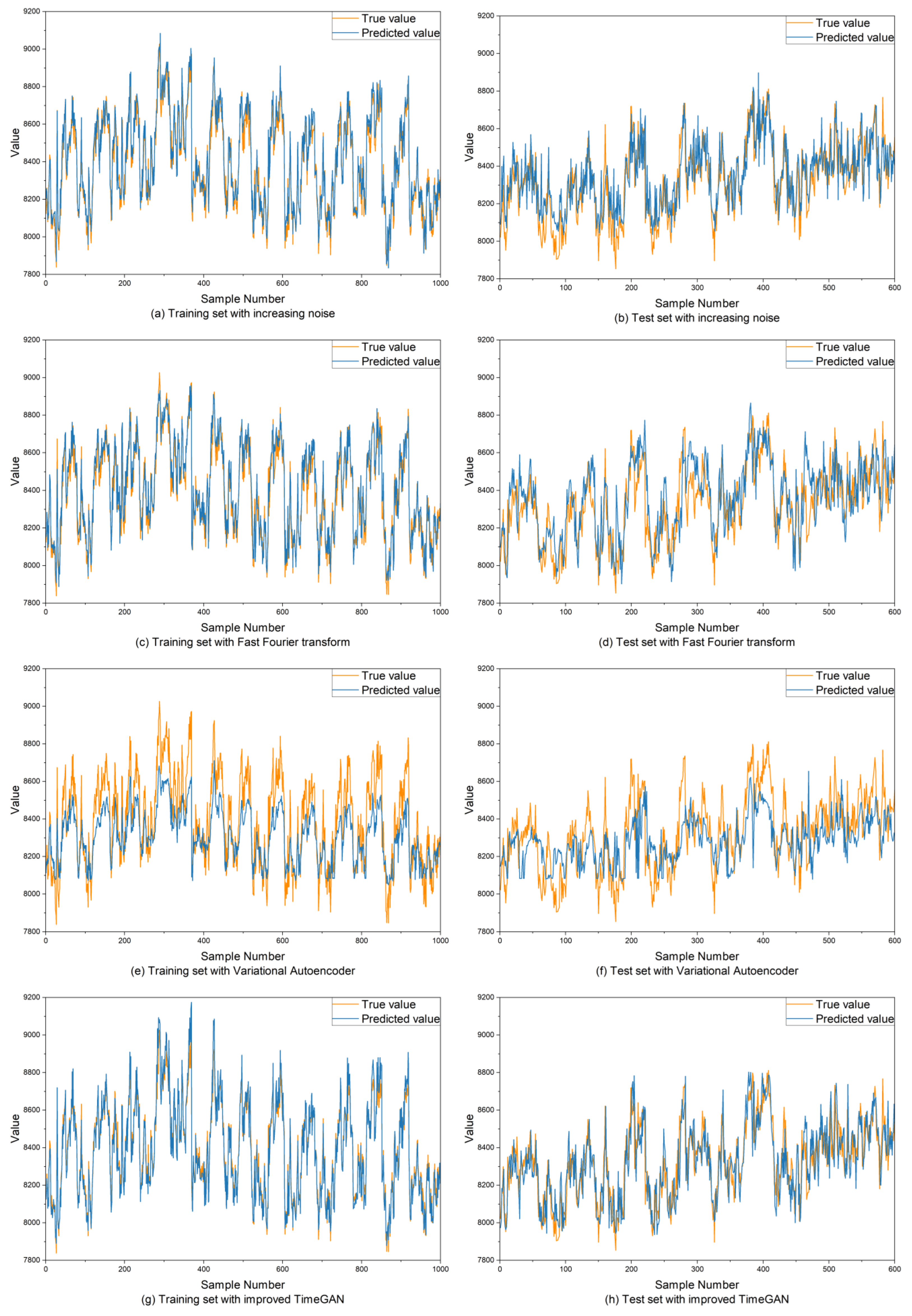
3.5. Data Augmentation Result Analysis
3.6. Prediction Model Result Analysis
4. Conclusions
- (1)
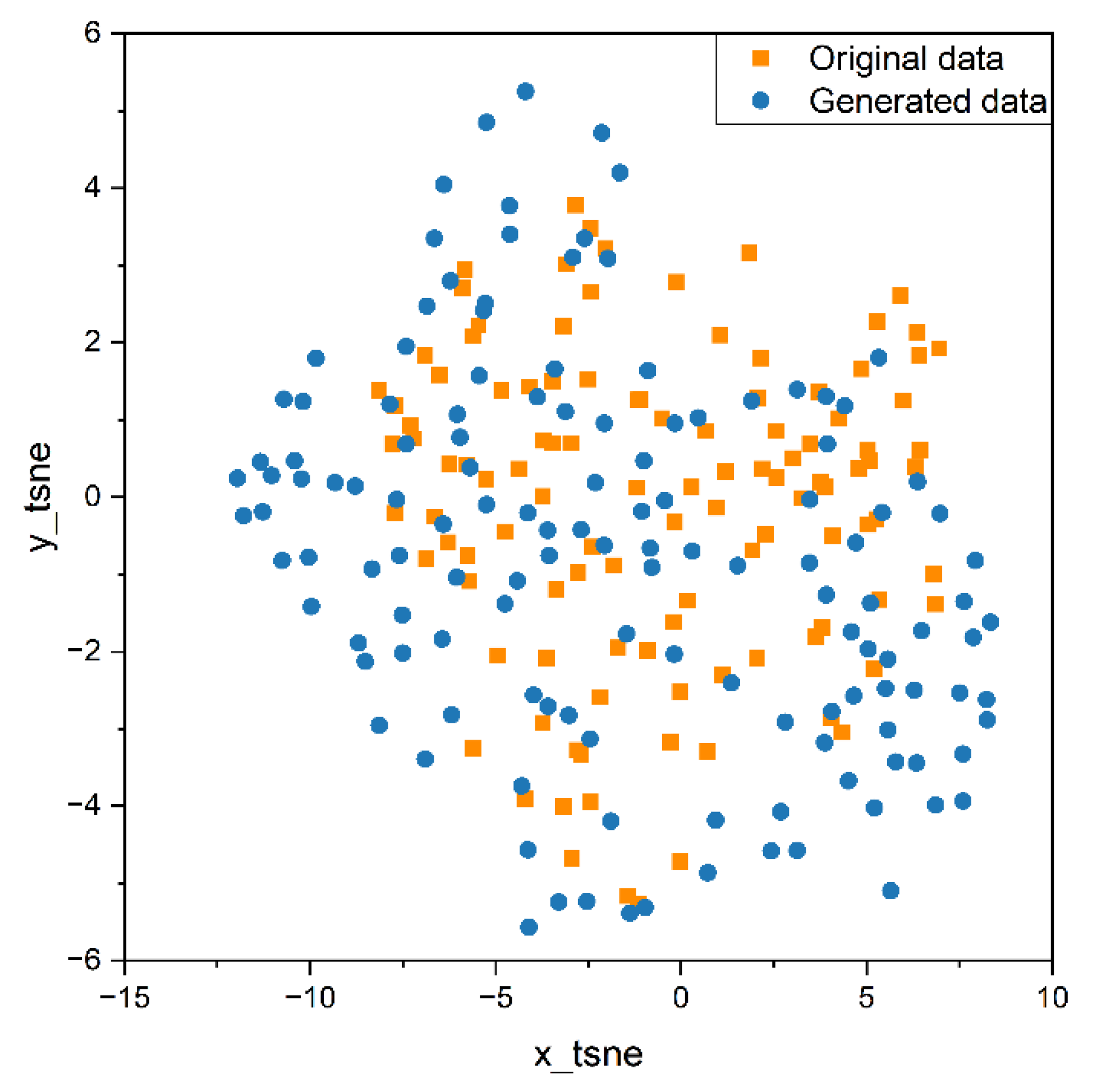
- The structure of the TimeGAN model is improved by incorporating a multi-head self-attention mechanism layer into the recovery module. As a result, the errors in the mean and quartiles between the generated data and the original data are maintained within 0.5%, while the variance error is kept within 10%. Additionally, the PCA and t-SNE dimensionality reduction analyses indicated that the trends in the data segments of the original data and the generated data are similar.
- (2)
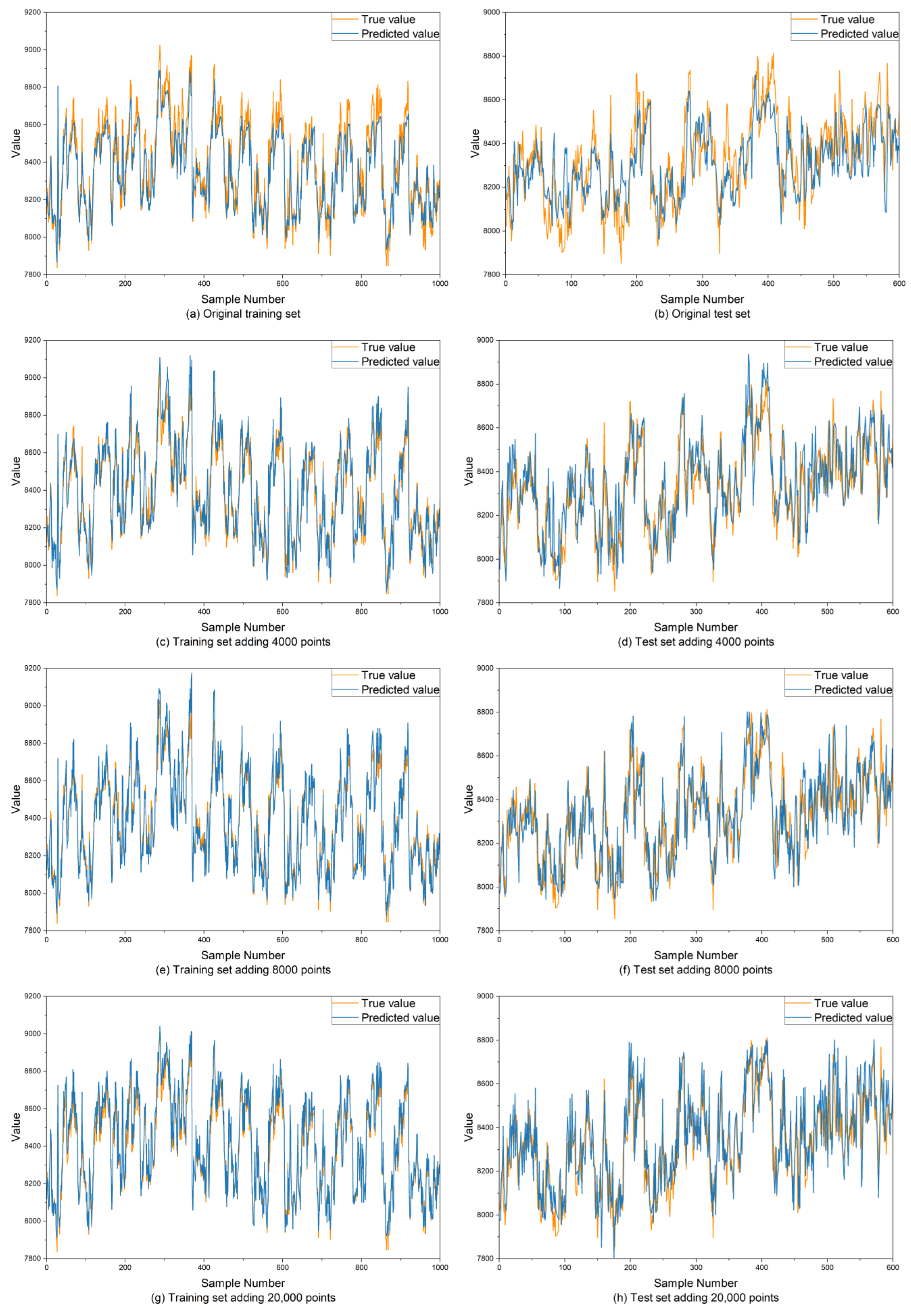
- After augmenting the training set size of the energy consumption time series prediction model with the generated data, the performance of the prediction model is significantly improved. Compared to the original model, the RMSE and MAE on the training set decrease by over 60%, while on the test set, they decrease by more than 9%. Additionally, the R2 score is also improved. The model trained after data augmentation better meets the requirements of model accuracy in the actual production process.
- (3)
- This article validates that, when augmenting the training set of deep learning models using data augmentation, the quantity of generated data does not necessarily need to be maximized; rather, it should be analyzed based on the specific conditions of the dataset and the training model. In the context of the energy consumption time series in this paper, the prediction model performs optimally when the amount of generated data is set to 8000.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Amasyali, K.; El-Gohary, N.M. A review of data-driven building energy consumption prediction studies. Renew. Sustain. Energy Rev. 2018, 81, 1192–1205. [Google Scholar] [CrossRef]
- Weigend, A.S. Time Series Prediction: Forecasting the Future and Understanding the Past; Routledge: Oxfordshire, UK, 2018. [Google Scholar]
- Han, Z.; Zhao, J.; Leung, H.; Ma, K.F.; Wang, W. A review of deep learning models for time series prediction. IEEE Sens. J. 2019, 21, 7833–7848. [Google Scholar] [CrossRef]
- Turowski, M.; Heidrich, B.; Weingärtner, L.; Springer, L.; Phipps, K.; Schäfer, B.; Mikut, R.; Hagenmeyer, V. Generating synthetic energy time series: A review. Renew. Sustain. Energy Rev. 2024, 206, 114842. [Google Scholar] [CrossRef]
- Hu, C.; Sun, Z.; Li, C.; Zhang, Y.; Xing, C. Survey of Time Series Data Generation in IoT. Sensors 2023, 23, 6976. [Google Scholar] [CrossRef]
- Kang, Y.; Hyndman, R.J.; Li, F. GRATIS: GeneRAting TIme Series with diverse and controllable characteristics. Stat. Anal. Data Min. ASA Data Sci. J. 2020, 13, 354–376. [Google Scholar] [CrossRef]
- Zhou, Y.; Guo, Q.; Sun, H.; Yu, Z.; Wu, J.; Hao, L. A novel data-driven approach for transient stability prediction of power systems considering the operational variability. Int. J. Electr. Power Energy Syst. 2019, 107, 379–394. [Google Scholar] [CrossRef]
- Steven Eyobu, O.; Han, D.S. Feature representation and data augmentation for human activity classification based on wearable IMU sensor data using a deep LSTM neural network. Sensors 2018, 18, 2892. [Google Scholar] [CrossRef]
- Raychaudhuri, S. Introduction to monte carlo simulation. In Proceedings of the 2008 Winter Simulation Conference, Miami, FL, USA, 7–10 December 2008; pp. 91–100. [Google Scholar]
- Talbot, P.W.; Rabiti, C.; Alfonsi, A.; Krome, C.; Kunz, M.R.; Epiney, A.; Wang, C.; Mandelli, D. Correlated synthetic time series generation for energy system simulations using Fourier and ARMA signal processing. Int. J. Energy Res. 2020, 44, 8144–8155. [Google Scholar] [CrossRef]
- Ravi, N.; Scaglione, A.; Kadam, S.; Gentz, R.; Peisert, S.; Lunghino, B.; Levijarvi, E.; Shumavon, A. Differentially private K-means clustering applied to meter data analysis and synthesis. IEEE Trans. Smart Grid 2022, 13, 4801–4814. [Google Scholar] [CrossRef]
- Tadayon, M.; Pottie, G. Tsbngen: A python library to generate time series data from an arbitrary dynamic bayesian network structure. arXiv 2020, arXiv:2009.04595. [Google Scholar]
- Shamshad, A.; Bawadi, M.; Hussin, W.W.; Majid, T.A.; Sanusi, S. First and second order Markov chain models for synthetic generation of wind speed time series. Energy 2005, 30, 693–708. [Google Scholar] [CrossRef]
- Li, Y.; Hu, B.; Niu, T.; Gao, S.; Yan, J.; Xie, K.; Ren, Z. GMM-HMM-based medium-and long-term multi-wind farm correlated power output time series generation method. IEEE Access 2021, 9, 90255–90267. [Google Scholar] [CrossRef]
- Kingma, D.P. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Chung, J.; Kastner, K.; Dinh, L.; Goel, K.; Courville, A.C.; Bengio, Y. A recurrent latent variable model for sequential data. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://webofscience.clarivate.cn/wos/alldb/full-record/WOS:000450913100021 (accessed on 12 January 2025).
- Fraccaro, M.; Sønderby, S.K.; Paquet, U.; Winther, O. Sequential neural models with stochastic layers. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Desai, A.; Freeman, C.; Wang, Z.; Beaver, I. Timevae: A variational auto-encoder for multivariate time series generation. arXiv 2021, arXiv:2111.08095. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Hadley, A.J.; Pulliam, C.L. Enhancing Activity Recognition After Stroke: Generative Adversarial Networks for Kinematic Data Augmentation. Sensors 2024, 24, 6861. [Google Scholar] [CrossRef]
- Ramponi, G.; Protopapas, P.; Brambilla, M.; Janssen, R. T-cgan: Conditional generative adversarial network for data augmentation in noisy time series with irregular sampling. arXiv 2018, arXiv:1811.08295. [Google Scholar]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (medical) time series generation with recurrent conditional gans. arXiv 2017, arXiv:1706.02633. [Google Scholar]
- Yoon, J.; Jarrett, D.; Van der Schaar, M. Time-series generative adversarial networks. Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://webofscience.clarivate.cn/wos/alldb/full-record/WOS:000534424305049 (accessed on 12 January 2025).
- Xu, T.; Wenliang, L.K.; Munn, M.; Acciaio, B. Cot-gan: Generating sequential data via causal optimal transport. Adv. Neural Inf. Process. Syst. 2020, 33, 8798–8809. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Lin, Z.; Jain, A.; Wang, C.; Fanti, G.; Sekar, V. Using gans for sharing networked time series data: Challenges, initial promise, and open questions. In Proceedings of the ACM Internet Measurement Conference, New York, NY, USA, 27–29 October 2020; pp. 464–483. [Google Scholar]
- Pei, H.; Ren, K.; Yang, Y.; Liu, C.; Qin, T.; Li, D. Towards generating real-world time series data. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021; pp. 469–478. [Google Scholar]
- Cyriac, R.; Balasubaramanian, S.; Balamurugan, V.; Karthikeyan, R. DCCGAN based intrusion detection for detecting security threats in IoT. Int. J. Bio Inspired Comput. 2024, 23, 111–124. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Guo, L.; Li, N.; Zhang, T. EEG-based emotion recognition via improved evolutionary convolutional neural network. Int. J. Bio Inspired Comput. 2024, 23, 203–213. [Google Scholar] [CrossRef]
- Zhu, X.; Xia, P.; He, Q.; Ni, Z.; Ni, L. Coke price prediction approach based on dense GRU and opposition-based learning salp swarm algorithm. Int. J. Bio Inspired Comput. 2023, 21, 106–121. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Gulçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Cooley, J.W.; Tukey, J.W. An algorithm for the machine calculation of complex Fourier series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Original Data | Generated Data |
|---|---|---|
| Average | 8401.65 | 8396.60 |
| Standard deviation | 225.00 | 203.86 |
| 1st quartile | 8231.02 | 8248.70 |
| 2nd quartile | 8401.27 | 8392.21 |
| 3rd quartile | 8567.21 | 8537.59 |
| Skewness | 0.0652 | 0.0790 |
| Kurtosis | 0.5908 | 0.7221 |
| Generated Data Size | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|
| RMSE | MAE | R2 | RMSE | MAE | R2 | |
| 0 | 88.6316 | 70.0475 | 0.8465 | 131.3622 | 101.3626 | 0.5653 |
| 4000 | 58.0971 | 40.9832 | 0.9238 | 123.5372 | 96.989 | 0.6296 |
| 8000 | 35.0361 | 24.4527 | 0.9728 | 118.445 | 91.8783 | 0.6327 |
| 12,000 | 46.8471 | 38.7948 | 0.9506 | 128.5719 | 100.243 | 0.5757 |
| 16,000 | 33.1651 | 22.4858 | 0.9745 | 129.3287 | 100.1522 | 0.6132 |
| 20,000 | 28.1058 | 22.7874 | 0.9814 | 133.4881 | 102.5445 | 0.6263 |
| Data Augmentation Methods | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|
| RMSE | MAE | R2 | RMSE | MAE | R2 | |
| Increasing noise | 62.8416 | 48.9257 | 0.9348 | 121.9678 | 95.273 | 0.6105 |
| Fast Fourier transform | 54.1052 | 41.3113 | 0.9547 | 139.6714 | 108.2355 | 0.4892 |
| Variational Autoencoder | 146.1772 | 98.5957 | 0.8288 | 155.2344 | 124.1232 | 0.3691 |
| Improved TimeGAN | 35.0361 | 24.4527 | 0.9728 | 118.445 | 91.8783 | 0.6327 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, P.; Li, Z.; Wang, X.; Liu, X.; Mou, P. Time Series Data Augmentation for Energy Consumption Data Based on Improved TimeGAN. Sensors 2025, 25, 493. https://doi.org/10.3390/s25020493
Tang P, Li Z, Wang X, Liu X, Mou P. Time Series Data Augmentation for Energy Consumption Data Based on Improved TimeGAN. Sensors. 2025; 25(2):493. https://doi.org/10.3390/s25020493
Chicago/Turabian StyleTang, Peihao, Zhen Li, Xuanlin Wang, Xueping Liu, and Peng Mou. 2025. "Time Series Data Augmentation for Energy Consumption Data Based on Improved TimeGAN" Sensors 25, no. 2: 493. https://doi.org/10.3390/s25020493
APA StyleTang, P., Li, Z., Wang, X., Liu, X., & Mou, P. (2025). Time Series Data Augmentation for Energy Consumption Data Based on Improved TimeGAN. Sensors, 25(2), 493. https://doi.org/10.3390/s25020493