Abstract
Inferring a complete 3D shape from a single-view image is an ill-posed problem. The proposed methods often have problems such as insufficient feature expression, unstable training and limited constraints, resulting in a low accuracy and ambiguity reconstruction. To address these problems, we propose a prior-guided adaptive probabilistic network for single-view 3D reconstruction, called PAPRec. In the training stage, PAPRec encodes a single-view image and its corresponding 3D prior into image feature distribution and point cloud feature distribution, respectively. PAPRec then utilizes a latent normalizing flow to fit the two distributions and obtains a latent vector with rich cues. PAPRec finally introduces an adaptive probabilistic network consisting of a shape normalizing flow and a diffusion model in order to decode the latent vector as a complete 3D point cloud. Unlike the proposed methods, PAPRec fully learns the global and local features of objects by innovatively integrating 3D prior guidance and the adaptive probability network under the optimization of a loss function combining prior, flow and diffusion losses. The experimental results on the public ShapeNet dataset show that PAPRec, on average, improves CD by 2.62%, EMD by 5.99% and F1 by 4.41%, in comparison to several state-of-the-art methods.
1. Introduction
Three-dimensional reconstructions based on computer vision aim to generate complete 3D models of objects or scenes from images. Three-dimensional reconstruction technology has been widely used in both academia and industry due to its extensive applications in robotics [1], autonomous driving [2,3], augmented reality and virtual reality [4,5]. With the disclosure of large-scale 3D datasets [6,7,8] and the progress of deep learning, a growing number of researchers are trying to apply deep learning into the analysis and understanding of 3D objects. According to the common representation forms of 3D models, 3D reconstruction methods are mainly based on point cloud [9,10,11,12], mesh [13,14,15,16] and voxel [17,18,19,20,21,22,23,24,25,26,27]. These methods have undergone extensive study in order to provide effective tools for building 3D models.
Different from voxel and mesh representations, the point cloud representation is easy to obtain and has the characteristics of simplicity and irregularity. Previous studies [9,28,29,30] reconstruct point clouds by generative models including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs) [31], Autoregressive (AR) models, likelihood-based models and flow-based models. Although these studies have made significant progress, they have some inherent limitations. GANs often suffer from unstable training and model collapse, and AR models are not flexible. Unlike GANs, likelihood-based models and flow-based models optimize a negative log-likelihood function on training data. This function compares and measures their ability to generalize to unseen data. Moreover, likelihood-based models assign a maximum probability to all samples in the training data, so the models can theoretically cover all the patterns of the data without the problems of pattern collapse and loss of diversity that occur in GANs. Some studies utilize Neural Radiance Fields (NeRF) [32,33], which leverages the spatial and light interactions within the captured images to produce realistic 3D representations. Gaussian Splatting [34,35] further enhances this process by refining and smoothing the spatial data points, and achieves better reconstruction.
Recently, denoising diffusion probabilistic models (DDPM) [36,37] have emerged as a new class of generative models, achieving impressive performance in point cloud generation [38,39,40,41]. Based on non-equilibrium thermodynamics, DDPM is a parameterized Markov chain established by variational reasoning. It is designed to produce samples that match the real data after a finite amount of time, and the reverse process is used to learn the diffusion from the noise distribution to the real data distribution. Similarly, a point cloud can also be regarded as particles in a non-equilibrium thermodynamic system in contact with a hot bath. Therefore, the point cloud generation process can be modeled as the particle reverse diffusion process from a noise distribution to the real point cloud distribution. Subsequently, some studies combine diffusion models and Gaussian Splatting. For example, DiffGs [35] utilizes a general Gaussian generator based on latent diffusion models to reconstruct objects.
Inspired by this, we study the adaptive probabilistic network based on point cloud prior for the single-view point cloud reconstruction task. We design an adaptive decoding network consisting of a shape normalizing flow model that achieves a reversible mapping process from the Gaussian distribution to target point cloud distribution, and a diffusion model that uses the particle reverse diffusion process to transform the noise distribution into target point cloud distribution. Furthermore, we introduce an image encoder and a point encoder to obtain a shape latent vector as the noise from a single-view image before decoding. The vector is taken as the condition of a transition kernel, so as to realize high-precision 3D reconstruction.
The remainder of this paper is structured as follows. Section 2 reviews the related work on 3D reconstruction methods. Section 3 introduces the architecture and objective functions of PAPRec. Section 4 conducts comparative experiments of PAPRec with state-of-the-art methods on the ShapeNet dataset, as well as the ablation studies of PAPRec. Section 5 concludes this paper.
2. Related Work
2.1. Single-View 3D Reconstruction
In recent years, single-view 3D reconstruction has been a very challenging research hotspot in the field of computer vision. Researchers have achieved certain results by introducing prior knowledge and imposing appropriate constraints for 3D reconstruction [42,43,44,45,46,47,48,49,50]. Fan et al. [9] used a direct form of 3D model output—point cloud coordinates—which outperforms voxel-based methods. Mandikal et al. [51] trained a 3D point cloud autoencoder and then learned the mapping from the 2D image to the corresponding potential embedding space. Recently, Zhang et al. [49] proposed an encoder–decoder architecture for view-aware joint geometry and structure learning, which jointly learns multi-modal feature representations to reconstruct geometric shapes and structural details from a single-view image. Wen et al. [29] proposed a 3DAttriFlow network, which focuses on the separation and extraction of semantic attributes of different semantic levels in input images and integrates them into the process of 3D shape reconstruction. The network provides clear guidance for the reconstruction of specific attributes on 3D shapes, so as to reconstruct more accurate 3D shapes. Most of the above methods use the Chamfer distance (CD) and the Earth Mover’s distance (EMD) as loss functions to optimize neural network models. However, the loss functions have some shortcomings [52,53] because they do not guarantee that the predicted points follow the geometry of an object, and these points may exist outside the real 3D shape of an object. Zhou et al. [35] proposed a general Gaussian generator based on latent diffusion models, and achieved better reconstruction results. However, the method has a higher computational complexity and finds it difficult to preserve the details of an object.
2.2. Generative Models for Point Cloud
The point cloud generation task is the basis for various 3D vision tasks. Early generative models such as VAE [54], AR models [55], GAN [24,56,57,58] and flow model [29,59] have been applied to point cloud generation. However, the main drawback of these models is that they are limited to generating point clouds with a fixed number of points and lack the property of permutation invariance. Recently, researchers have proposed to treat point clouds as samples from a point distribution. Cheng et al. [55] proposed an autoregressive model that generates diverse and realistic point cloud samples under certain conditions, making good use of point-to-point correlations. Yang et al. [60] took full advantage of the reversibility of continuous normalized flow to learn two levels of distribution: the distribution of shapes and the distribution of points with a given shape. Cai et al. [52] modeled a noisy point cloud as a sample from a noisy convolution distribution, designed a network to estimate the fraction of the distribution and used the fraction to denoise the point cloud through gradient rise. Klokov et al. [61] built normalized streams with affine coupled layers to generate arbitrarily sized 3D point clouds given potential shape representations. In addition, other works developed C-Flow [62] and NeRF [32,33] to improve 3D presentation performance and obtain fine reconstruction results.
2.3. Diffusion Probabilistic Models
Diffusion models were applied early on in image generation and image restoration tasks [36,37,63]. Recently, these models have also shown great advantages in 3D point clouds [38,39,40,41,64,65]. The main idea is to model the reverse diffusion process of point cloud generation as a Markov chain with a specific shape. The diffusion model is easy to derive from the variable boundary of the probability of point clouds, which outperforms the previous generation model. Jiang et al. [66] proposed SDFDiff which achieves unsupervised 3D shape reconstruction. However, most of these approaches still suffer from problems, such as failing to recover occluded parts of objects completely and accurately, producing noise. Li et al. [67] used point cloud diffusion to aggregate the intermediate features of the generator into semantic labels for annotating point clouds. Lyu et al. [68] used diffusion and refinement models to complete partial point clouds. In addition, Melas et al. [69] took a single-view image and its camera parameters as inputs, and projected the local features of the image onto a partially denoised point cloud during the diffusion process, and achieved high-resolution reconstruction results. Wu et al. [70] proposed a probabilistic diffusion model that combines a hand-drawn sketch of an object and its text description to generate colored point clouds. Wei et al. [71] also applied the conditional diffusion model to the 3D reconstruction task and achieved good results. Liu et al. [72] proposed Zero-1-to-3 which uses a viewpoint-conditioned diffusion approach for 3D reconstruction from a single image. Hong et al. [73] proposed LRM which adopts a highly scalable transformer-based architecture to predict a neural radiance field from an input image.
3. PAPRec
As shown in Figure 1, PAPRec contains three parts: prior feature extraction, latent shape learning and adaptive probabilistic decoding. PAPRec incorporates 3D prior knowledge and adopts an adaptive probabilistic decoder to learn the global and local information of an object, which is conductive to capture the mapping between an input image and the corresponding 3D point cloud. The training and testing details are shown in Algorithm 1.
| Algorithm 1: Training and testing process |
 |
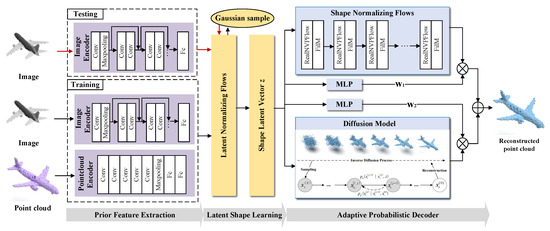
Figure 1.
The architecture of our proposed PAPRec. In the training stage, PAPRec encodes a single-view image and its corresponding 3D shape into feature distributions. PAPRec then utilizes a latent normalizing flow to fit the distributions and obtain a shape latent vector. PAPRec finally introduces an adaptive probabilistic network, which consists of a flow model and a diffusion model for fully learning the global and local features of objects, to decode the latent vector as a complete 3D point cloud. In the testing stage, PAPRec utilizes the trained image encoder, latent normalizing flow and adaptive decoder to reconstruct the 3D point cloud from a single-view image.
3.1. Prior Feature Extraction
In the single-view 3D point cloud reconstruction task, we regard a point cloud as a conditional probabilistic distribution. As a result, the goal is to learn a distribution , where I is an input image. In order to obtain rich cues given few inputs, we introduce a point cloud-based prior to guide the learning of the mapping between the input and the real point cloud during training.
Specifically, we utilize a point cloud encoder to parameterize a real point cloud X as a feature vector . The encoder consists of five convolutional layers with feature channels of {3, 64, 128, 256, 512}, a max-pooling layer and two fully connected layers with 512 channels. Meanwhile, we also utilize an image encoder consisting of ResNet18 [74] to parameterize an input image I as a feature vector . Then, we obtain the point cloud and image latent conditional distributions and . and are modeled as normal distributions.
3.2. Latent Shape Learning
In order to fully learn the latent distribution of an object, we introduce a latent normalizing flow model f to approximate and . The flow model provides a trainable bijector that maps isotropic Gaussian distribution to a complex distribution.
The latent normalizing flow model consists of 14 affine coupling layers, each of which is followed by batch normalization and the ReLU activation function. The channels are set as {128, 256, 256, 128}. The model finally outputs a shape representation for 3D generation tasks and single-view 3D reconstruction tasks.
The prior loss is used to minimize the distance between the image distribution and the point cloud distribution, and it is defined as follows:
where X denotes the true point cloud. denotes the calculation of the approximate posterior entropy loss, and it can prevent the latent distribution from being either too concentrated or too dispersed, and also prevent the model from overfitting the training data. denotes the calculation of the mathematical expectation. denotes the sampling from a Gaussian distribution, denotes a trainable bijector with a normalized flow conditioned on image eigenvectors, denotes the calculation of the determinant, and denotes the calculation of Jacobian determinant.
In the training process, we combine the prior distribution of the image with the posterior distribution of the point cloud, and fit the posterior and the prior as Gaussian distributions, thus improving the generation performance. Therefore, we obtain the distribution of the shape latent vector :
where denotes the isotropic Gaussian distribution .
3.3. Adaptive Probabilistic Decoder
We design a decoder which is an adaptive probabilistic model consisting of a diffusion model and a shape normalizing flow for learning the local and global information of objects. In particular, we set adaptive weights and for the two models to represent the entire shape of an object. The weights are obtained by two Multi-Layer Perceptrons (MLPs), each of which contains two fully connected layers with 512 channels, batch normalization, and the Swish activation function. Therefore, we can express the conditional distribution of the predicted point cloud as :
where, the former and the latter represent the diffusion model and the shape normalizing flow model, respectively. S is the diffusion step.
For the diffusion model, it is a variant of MLP consisting of a series of concatenation and squash layers to achieve the reverse diffusion kernel. The point cloud is represented as , where represents the ith point at the jth step, which is regarded as a set of particles in the evolutionary thermodynamic system. The initial point can be regarded as a sample independent of the true point distribution. Over time, the points gradually spread out into a chaotic set of points, which converts the original meaningful distribution of points into a noise distribution. The reverse process aims to recover the desired shape from the input noise. The process can be formulated as follows:
where the starting distribution in the reverse diffusion process is set to the standard normal distribution , and is the estimated value by the neural network. are the variance scheduling parameters controlling the rate of the diffusion process, and they are set by the common linear scheduling formula .
The goal of training the reverse diffusion process is to maximize the log-likelihood of the point cloud. However, the direct optimization of the log-likelihood is difficult to solve. Therefore, we maximize its variational lower bound, and the diffusion loss is defined as follows:
where denotes the calculation of KL divergence and and this divergence is used to measure the difference between two probability distributions, which helps the reverse diffusion process to better restore the real point cloud state.
For the shape normalizing flow model, we use the same network as the latent normalizing flow, and the network consists of 14 RealNVPFlow and FilM layers [75]. The reconstructed 3D point cloud distribution of the model is defined as follows:
The loss of the shape normalizing flow is defined as follows:
where denotes the transpose of .
Our PAPRec is optimized in an end-to-end way by minimizing the total loss L, which is defined as follows:
4. Experiments
In this section, we describe the datasets, evaluation metrics and the experimental implementation details. We then discuss and analyze the comparison with the most relevant works based on quantitative and qualitative results.
4.1. Dataset
Following [61], we use the ShapeNet dataset [76] to evaluate the performance of PAPRec. In particular, for the 3D point cloud generation task, we adopt 51,127 shapes from 55 categories in the ShapeNet dataset. For the single-view 3D reconstruction task, we adopt 13 object categories {airplane, bench, cabinet, car, chair, monitor, lamp, speaker, rifle, sofa, table, telephone, vessel} from ShapeNet provided by 3D-R2N2 [77], and obtain the data pairs of images and point clouds. The above datasets are randomly divided into 80% training set and 20% testing set.
4.2. Evaluation Metric
In order to compare the reconstruction performance of different methods on public datasets, we use the Chamfer distance (CD) and the Earth Mover’s distance (EMD) to measure the reconstruction quality. In addition, we also use the F1-score to evaluate the reconstruction accuracy at the point cloud level.
CD is used to measure the distance between two point clouds by calculating the square distance between each point p in the predicted point cloud set and the nearest neighbor of each point q in the true point cloud X set:
The lower (denoted by ↓) the CD is, the better the reconstructed 3D shape is.
EMD is used to measure the heterogeneity between two multi-dimensional distributions in a certain feature space by calculating the point-to-point L1 distance between two point clouds.
The lower (denoted by ↓) the EMD is, the better the reconstructed 3D shape is.
The F1-score is used to measure the correct percentage of reconstructed points by calculating the harmonic average of accuracy P and recall R at a threshold.
The higher (denoted by ↑) the F1 is, the better the reconstructed 3D shape is.
4.3. Parameter Setting
We optimize all the losses under the Pytorch (https://pytorch.org/) framework using the Adam algorithm [78] with default values. The learning rate is set to by following [33]. The size of a point cloud is set as (for the 3D generation task) and (for the single-view reconstruction task). The diffusion step is set as to balance between computational resources and the generation effect. The variance scheduling parameters are set as . The former is to preserve the features and structure of the original data well and the latter is so that the data reach a certain level of noise, but do not transform completely into random noise without any pattern.
4.4. Comparisons with State-of-the-Art Methods
We conduct two kinds of experiments to evaluate the performance of PAPRec: a 3D generation task and a single-view 3D reconstruction task. The former aims to demonstrate the advantage of our autoencoder, and the comparison results are shown in Figure 2 and Table 1. The latter is designed to demonstrate our performance in the single-view reconstruction task, and the comparison results are shown in Figure 3 and Table 2 and Table 3.
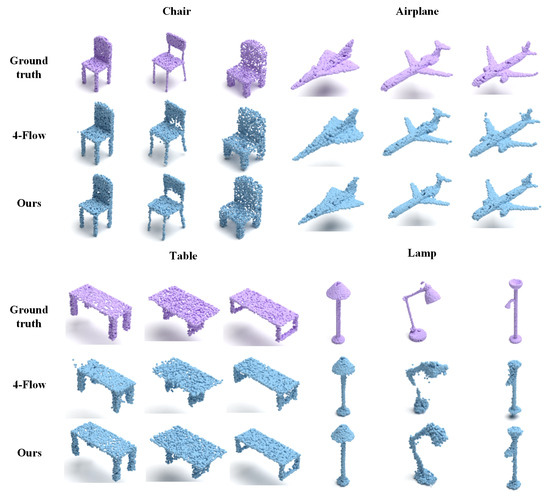
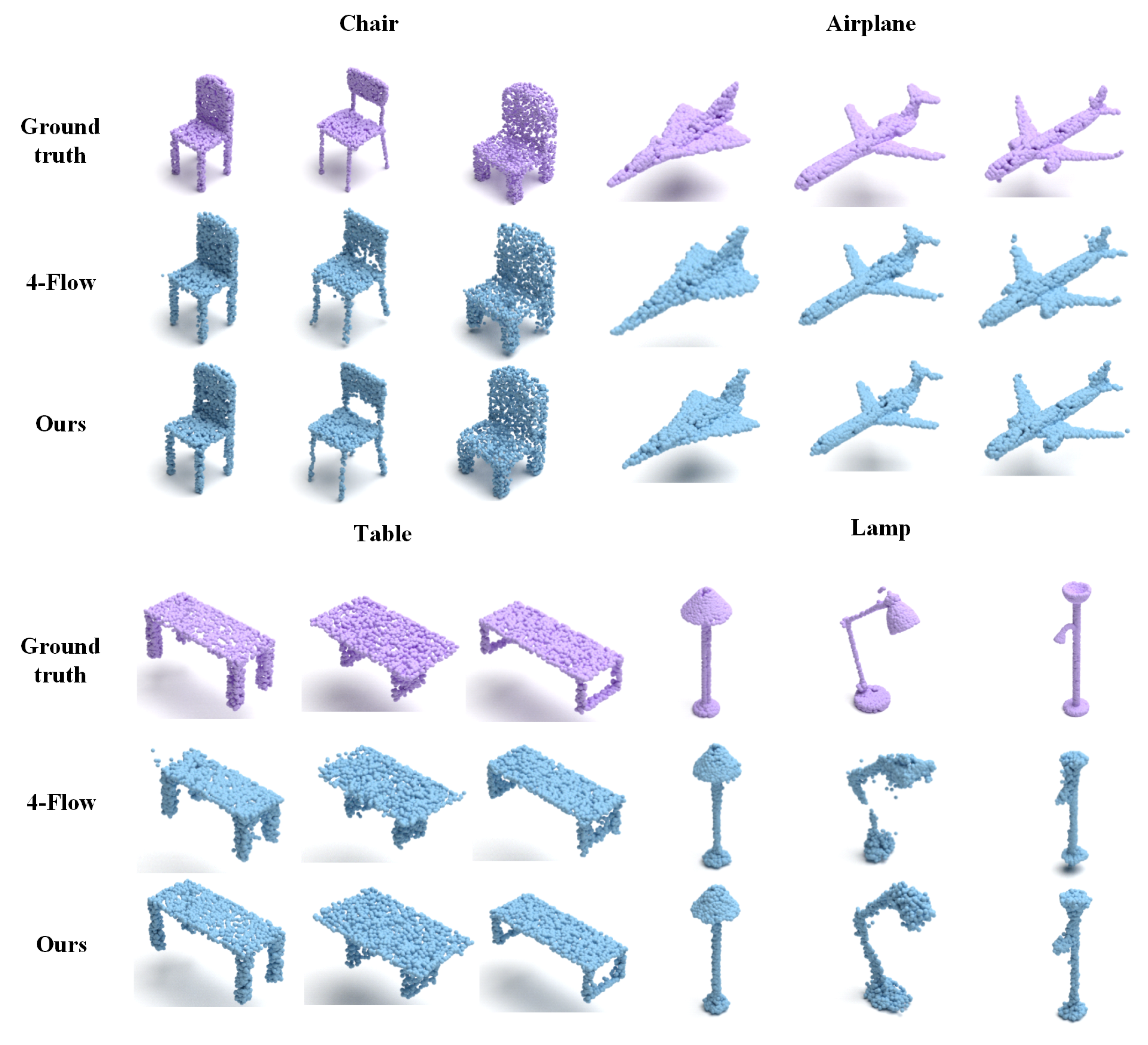
Figure 2.
The qualitative comparison results of different autoencoders. Our reconstructed chairs and airplanes exhibit higher accuracy, while the reconstructed tables and lamps are more complete. This clearly demonstrates that PAPRec has greater effectiveness and a stronger capacity to represent diverse shapes.

Table 1.
The quantitative comparison results of different autoencoders on the full ShapeNet dataset. The bold numbers denote the best results.

Figure 3.
The qualitative comparison results of the single-view reconstruction methods. Our reconstructed monitors, benches and cars exhibit more details, while the reconstructed tables, planes and chairs are more accurate. This clearly demonstrates that PAPRec has better robustness.
Table 2.
The quantitative comparison results of a single-view 3D reconstruction on the 13 object categories of ShapeNet. The bold numbers denote the best results.
Table 3.
The quantitative comparison results of single-view reconstruction on each category of ShapeNet. The bold numbers denote the best results.
Specifically, for the 3D generation task, we compare the current mainstream generative models, such as the GAN [58] and flow-based [33,60,61] methods. From Table 1, it is observed that our PAPRec outperforms the others in both CD and EMD. From Figure 2, the improvement of the lamp category is particularly obvious, which indicates that PAPRec has greater effectiveness and a stronger capacity to represent diverse shapes.
For the single-view reconstruction task, we compare several reconstruction methods [33,42,43,61,79]. Among them, DPF [61] is closest to us, and it also regards the point cloud as the distribution of samples and uses the normalized flow model for decoding. 4-Flow [33] realizes the parallel decoding of four normalized flows to reconstruct the overall shape and makes a slight improvement on DPF, showing better optimization. However, 4-Flow cannot generate good details. From Figure 3 and Table 2 and Table 3, it can be ssen that PAPRec is superior to the current mainstream single-view reconstruction methods in both quantitative and qualitative results. PAPRec owes its superiority to two key aspects. It uses a diffusion probability decoding network for the gradual refinement of point cloud reconstruction, and integrates a flow model to learn features of the point cloud’s overall distribution. Moreover, PAPRec uses 3D point cloud priors to guide single-view image reconstruction and accurately capture local and global information during 3D point cloud generation.
4.5. Ablation Study
We conduct the experiments to analyse the importance of each component from PAPRec. We denote
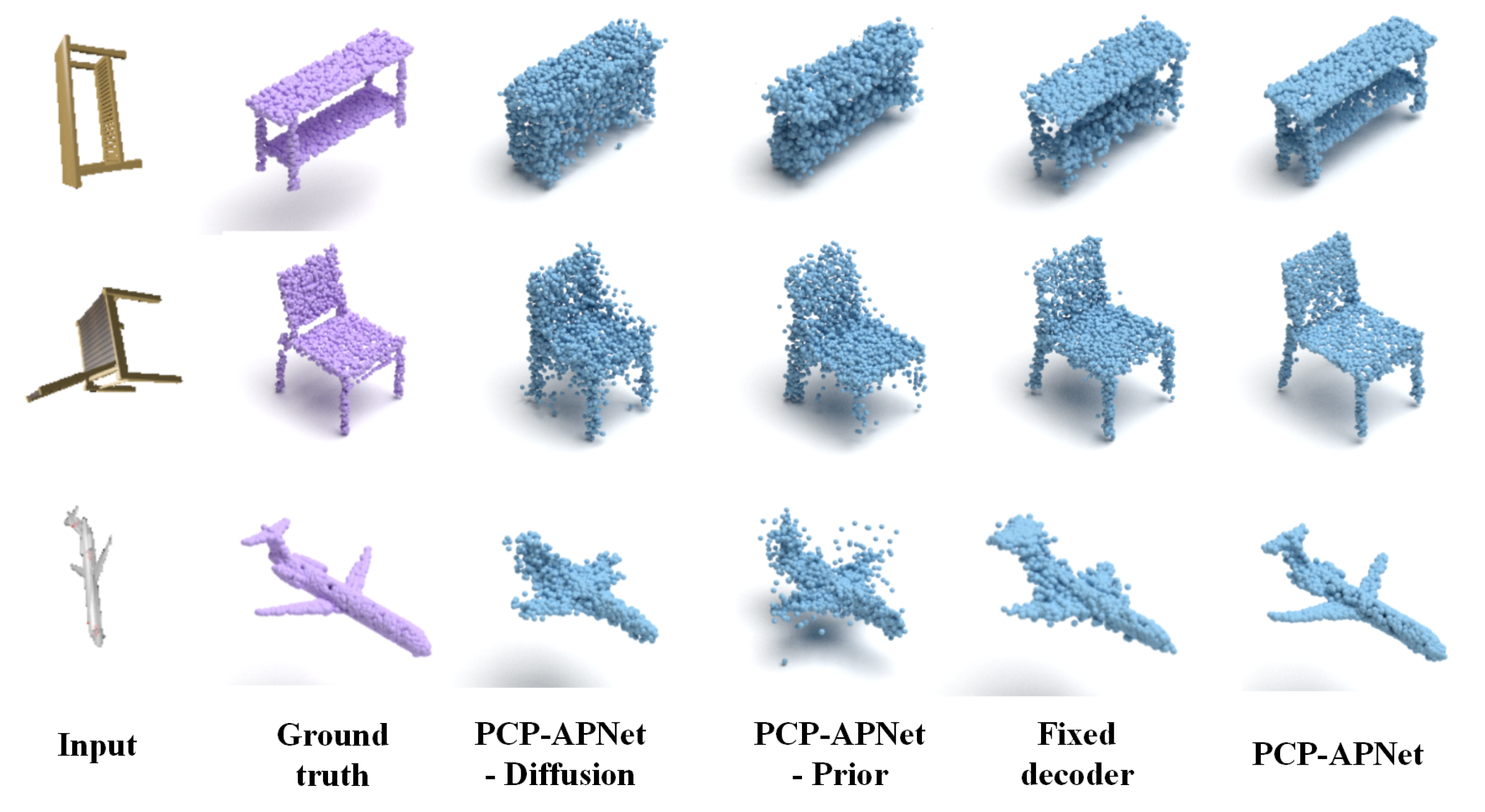
Table 4 and Figure 4, respectively, present the quantitative and qualitative results of the ablation study. As can be seen from Figure 4, when only image features are employed as the shape latent vector for decoding, the reconstruction effect is evidently subpar. For instance, when dealing with a chair that has severe self-occlusion, the model fails to reconstruct the details of its legs. Similarly, for other object categories, the reconstruction results have noise. Moreover, neither a single flow model nor a diffusion model alone can achieve faithful reconstruction; instead, they tend to generate noise. Additionally, while a non-adaptive probabilistic decoder can reconstruct the general shape, it performs poorly in capturing details. Thus, both the quantitative and qualitative results verify that the full model is innovative and effective.
Table 4.
Quantitative results of ablation study. ‘-Prior’, ‘-Flow’ and ‘-Diffusion’ denote PAPRec without the point cloud learning, the shape normalizing flow and the diffusion model, respectively. ‘Fixed decoder’ denotes PAPRec adopts fixed weights in the decoder. The bold numbers denote the best results.
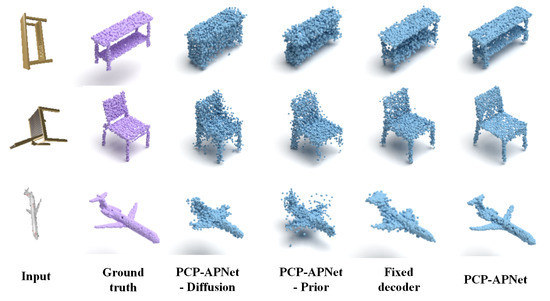
Figure 4.
The qualitative comparison results of ablation study. ‘-Prior’, ‘-Flow’ and ‘-Diffusion’ denote PAPRec without the point cloud learning, the shape normalizing flow and the diffusion model, respectively. ‘Fixed decoder’ denotes PAPRec adopts fixed weights in the decoder. The full model achieves superior performance in handling noise and reproducing details.
5. Conclusions
We propose a novel framework, PAPRec, that reconstructs the complete 3D point cloud of an object from a single-view image. Different from the proposed methods, the main contributions of our work can be summarized as follows:
- PAPRec introduces point cloud models to guide a corresponding single-view image to express the potential space of an object by optimizing a prior loss. This makes up for insufficient feature expression of a single image and effectively improves the ambiguity reconstruction.
- PAPRec intorduces an adaptive probabilistic decoding network. The network adopts adaptive weights to combine two models and utilizes a flow loss and a diffusion loss to optimize them. One model is a shape normalizing flow model, which is used to interpret the overall distribution of a point cloud for obtaining global information. Another model is diffusion model, which is used to extract local information. The network is inductive to stable training and adaptive constrains, thus generating high-quality reconstruction.
- The experimental results show that PAPRec improves average CD by 2.62%, EMD by 5.99% and F1 by 4.41% on the ShapeNet dataset for the single-view 3D reconstruction.
Although PAPRec achieves better reconstruction by innovatively integrating 3D prior guidance and the adaptive probability network, there is still room for improvement in generating details. Based on the fact that accurate 3D models are very important for some high-level multimedia applications, we will conduct more research on improving the reconstruction accuracy by using prior-based diffusion models.
Author Contributions
Conceptualization, C.L., Y.C. and H.L.; methodology C.L., M.Z. and Y.C.; software, M.Z. and Y.C.; formal analysis, M.Z.; resources, H.L.; writing—original draft, C.L., M.Z., Y.C. and X.W.; writing—review & editing, C.L., X.W. and H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (No.62402018, 62277001), Beijing Natural Science Foundation (L233026), R&D Program of Beijing Municipal Education Commission (No.KM202410011017), and Beijing Technology and Business University 2024 postgraduate research ability improvement program project.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The details of the data are shown in Section 3.1.
Conflicts of Interest
The authors declare no conflicts of interest. The funders (Caixia Liu, Haisheng Li) had a role in the design of the study; in the collection, analyses or interpretation of data; in the writing of the manuscript; and in the decision to publish the results. Please refer to the above “Author Contributions” for details.
References
- Mees, O.; Tatarchenko, M.; Brox, T.; Burgard, W. Self-supervised 3d shape and viewpoint estimation from single images for robotics. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 6083–6089. [Google Scholar]
- Ye, J.; Chen, Y.; Wang, N.; Wang, X. Online adaptation for implicit object tracking and shape reconstruction in the wild. IEEE Robot. Autom. Lett. 2022, 7, 8909–8916. [Google Scholar] [CrossRef]
- Qian, X.; Wang, L.; Zhu, Y.; Zhang, L.; Fu, Y.; Xue, X. Impdet: Exploring implicit fields for 3d object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 4260–4270. [Google Scholar]
- Sun, Y.; Kantareddy, S.N.R.; Bhattacharyya, R.; Sarma, S.E. X-vision: An augmented vision tool with real-time sensing ability in tagged environments. In Proceedings of the 2018 IEEE International Conference on Rfid Technology & Application (Rfid-TA), Macau, Macao, 26–28 September 2018; pp. 1–6. [Google Scholar]
- Stets, J.D.; Sun, Y.; Corning, W.; Greenwald, S.W. Visualization and labeling of point clouds in virtual reality. In Proceedings of the SIGGRAPH Asia 2017 Posters, Bangkok, Thailand, 27–30 November 2017; pp. 1–2. [Google Scholar]
- Koch, S.; Matveev, A.; Jiang, Z.; Williams, F.; Artemov, A.; Burnaev, E.; Alexa, M.; Zorin, D.; Panozzo, D. ABC: A Big CAD Model Dataset for Geometric Deep Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9593–9603. [Google Scholar]
- Sun, X.; Wu, J.; Zhang, X.; Zhang, Z.; Zhang, C.; Xue, T.; Tenenbaum, J.B.; Freeman, W.T. Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2974–2983. [Google Scholar]
- Reizenstein, J.S. Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction. In Proceedings of the International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10881–10891. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J.G. A point Set Generation Network for 3D object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2463–2471. [Google Scholar]
- Lin, C.H.; Kong, C.; Lucey, S. Learning efficient point cloud generation for dense 3D object reconstruction. In Proceedings of the AAAI, New Orleans, LA, USA, 2–7 February 2018; pp. 7114–7121. [Google Scholar]
- Zheng, Y.; Zeng, G.; Li, H.; Cai, Q.; Du, J. Colorful 3D reconstruction at high resolution using multi-view representation. J. Vis. Commun. Image Represent. 2022, 85, 103486. [Google Scholar] [CrossRef]
- Cui, R.; Qiu, S.; Anwar, S.; Liu, J.; Xing, C.; Zhang, J.; Barnes, N. P2C: Self-Supervised Point Cloud Completion from Single Partial Clouds. In Proceedings of the International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 1–10. [Google Scholar]
- Kanazawa, A.; Tulsiani, S.; Efros, A.A.; Malik, J. Learning Category-Specific Mesh Reconstruction from Image Collections. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Volume 15, pp. 386–402. [Google Scholar]
- Ranjan, A.; Bolkart, T.; Sanyal, S.; Black, M.J. Generating 3D Faces using Convolutional Mesh Autoencoders. In Proceedings of the European Conference on Computer Vision, 8–14 September 2018; Volume 3, pp. 725–741. [Google Scholar]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.G. Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images. In Proceedings of the European Conference on Computer Vision, 8–14 September 2018; Volume 11, pp. 55–71. [Google Scholar]
- Thayyil, S.B.; Yadav, S.K.; Polthier, K.; Muthuganapathy, R. Local Delaunay-based high fidelity surface reconstruction from 3D point sets. Comput. Aided Geom. Des. 2021, 86, 101973. [Google Scholar] [CrossRef]
- Smith, E.; Meger, D. Improved Adversarial Systems for 3D Object Generation and Reconstruction. In Proceedings of the Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 87–96. [Google Scholar]
- Varley, J.; DeChant, C.; Richardson, A.; Ruales, J.; Allen, P.K. Shape completion enabled robotic grasping. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 2442–2447. [Google Scholar]
- Yang, B.; Rosa, S.; Markham, A.; Trigoni, N.; Wen, H. 3D Object Dense Reconstruction from a Single Depth View. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2820–2834. [Google Scholar] [CrossRef] [PubMed]
- Gwak, J.; Choy, C.B.; Chandraker, M.; Garg, A.; Savarese, S. Weakly supervised 3D reconstruction with adversarial constraint. In Proceedings of the 3DV, Qingdao, China, 10–12 October 2017; pp. 263–272. [Google Scholar]
- Wang, L.; Fang, Y. Unsupervised 3D Reconstruction from a Single Image via Adversarial Learning. arXiv 2017, arXiv:1711.09312. [Google Scholar]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, B.; Tenenbaum, J. Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling. In Proceedings of the Annual Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 82–90. [Google Scholar]
- Yang, B.; Wen, H.; Wang, S.; Clark, R.; Markham, A.; Trigoni, N. 3D object reconstruction from a single depth view with adversarial learning. Int. Conf. Comput. Vis. Workshop 2017, 112, 679–688. [Google Scholar]
- Li, H.; Zheng, Y.; Wu, X.; Cai, Q. 3D model generation and reconstruction using conditional generative adversarial network. Int. J. Comput. Intell. Syst. 2019, 12, 697–705. [Google Scholar] [CrossRef]
- Liu, C.; Kong, D.; Wang, S.; Li, J.; Yin, B. Latent Feature-Aware and Local Structure-Preserving Network for 3D Completion from a Single Depth View. In Proceedings of the Internet Corporation for Assigned Names and Numbers (ICANN), Online, 1 December 2020–30 November 2021; pp. 67–79. [Google Scholar]
- Liu, C.; Kong, D.; Wang, S.; Li, J.; Yin, B. A Spatial Relationship Preserving Adversarial Network for 3D Reconstruction from a Single Depth View. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–22. [Google Scholar] [CrossRef]
- Liu, C.; Kong, D.; Wang, S.; Li, Q.; Li, J.; Yin, B. Multi-scale latent feature-aware network for logical partition based 3D voxel reconstruction. Neurocomputing 2023, 533, 22–34. [Google Scholar] [CrossRef]
- Gadelha, M.; Wang, R.; Maji, S. Multiresolution Tree Networks for 3D Point Cloud Processing. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 105–122. [Google Scholar]
- Xin, W.; Junsheng, Z.; YuShen, L.; Hua, S.; Zhen, D.; Zhizhong, H. 3D Shape Reconstruction from 2D Images with Disentangled Attribute Flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3793–3803. [Google Scholar]
- Wei, Y.; Vosselman, G.; Yang, M.Y. Flow-based GAN for 3D Point Cloud Generation from a Single Image. In Proceedings of the British Machine Vision Conference, London, UK, 21–24 November 2022. [Google Scholar]
- Yu, M.S.; Jung, T.W.; Yun, D.Y.; Hwang, C.G.; Park, S.Y.; Kwon, S.C.; Jung, K.D. A Variational Autoencoder Cascade Generative Adversarial Network for Scalable 3D Object Generation and Reconstruction. Sensors 2024, 24, 751. [Google Scholar] [CrossRef]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3D Gaussian Splatting for Real-time Radiance Field Rendering. ACM Trans. Graph. 2023, 42, 139. [Google Scholar] [CrossRef]
- Postels, J.; Liu, M.; Spezialetti, R.; Van Gool, L.; Tombari, F. Go with the Flows: Mixtures of Normalizing Flows for Point Cloud Generation and Reconstruction. In Proceedings of the International Conference on 3D Vision, Virtual, 1–3 December 2021; pp. 1249–1258. [Google Scholar]
- Surmen, H.K. Photogrammetry for 3D Reconstruction of Objects: Effects of Geometry, Texture and Photographing. Image Anal. Stereol. 2023, 42, 51–63. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, W.; Liu, Y.S. DiffGS: Functional Gaussian Splatting Diffusion. Adv. Neural Inf. Process. Syst. 2025, 37, 37535–37560. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Proceedings of the International Conference on Neural Information Processing Systems, Online, 6–12 December 2020; pp. 6840–6851. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10674–10685. [Google Scholar]
- Luo, S.; Hu, W. Diffusion Probabilistic Models for 3D Point Cloud Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2836–2844. [Google Scholar]
- Zhou, L.; Du, Y.; Wu, J. 3D Shape Generation and Completion through Point-Voxel Diffusion. In Proceedings of the International Conference on Computer Vision, Virtual, 1–17 October 2021; pp. 5826–5835. [Google Scholar]
- Nichol, A.; Jun, H.; Dhariwal, P.; Mishkin, P.; Chen, M. Point-E: A System for Generating 3D Point Clouds from Complex Prompts. arXiv 2022, arXiv:2212.08751. [Google Scholar]
- Zeng, X.; Vahdat, A.; Williams, F.; Gojcic, Z.; Litany, O.; Fidler, S.; Kreis, K. LION: Latent Point Diffusion Models for 3D Shape Generation. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; pp. 10021–10039. [Google Scholar]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Yu, H.; Liu, W.; Xue, X.; Jiang, Y.G. Pixel2Mesh: 3D Mesh Model Generation via Image Guided Deformation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3600–3613. [Google Scholar] [CrossRef]
- Groueix, T.; Fisher, M.; Kim, V.G.; Russell, B.C.; Aubry, M. A Papier-Mache Approach to Learning 3D Surface Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 216–224. [Google Scholar]
- Xu, Q.; Wang, W.; Ceylan, D.; Mech, R.; Neumann, U. DISN: Deep Implicit Surface Network for High-Quality Single-View 3D Reconstruction. In Proceedings of the Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 490–500. [Google Scholar]
- Duggal, S.; Pathak, D. Topologically-Aware Deformation Fields for Single-View 3D Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1536–1546. [Google Scholar]
- Mao, A.; Dai, C.; Liu, Q.; Yang, J.; Gao, L.; He, Y.; Liu, Y.J. STD-Net: Structure-Preserving and Topology-Adaptive Deformation Network for Single-View 3D Reconstruction. IEEE Trans. Vis. Comput. Graph. 2023, 29, 1785–1798. [Google Scholar] [CrossRef]
- Pang, H.; Biljecki, F. 3D Building Reconstruction from Single Street View Images using Deep Learning. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102859. [Google Scholar] [CrossRef]
- Boulch, A.; Marlet, R. POCO: Point Convolution for Surface Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6292–6304. [Google Scholar]
- Zhang, X.; Ma, R.; Zou, C.; Zhang, M.; Zhao, X.; Gao, Y. View-Aware Geometry-Structure Joint Learning for Single-View 3D Shape Reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 6546–6561. [Google Scholar] [CrossRef]
- Liu, F.; Liu, X. 2D GANs Meet Unsupervised Single-View 3D Reconstruction. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 497–514. [Google Scholar]
- Mandikal, P.; Murthy, N.; Agarwal, M.; Babu, R. 3D-LMNet: Latent Embedding Matching for Accurate and Diverse 3D Point Cloud Reconstruction from a Single Image. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; pp. 1–19. [Google Scholar]
- Cai, R.; Yang, G.; Averbuch-Elor, H.; Hao, Z.; Belongie, S.; Snavely, N.; Hariharan, B. Learning Gradient Fields for Shape Generation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 364–381. [Google Scholar]
- Huang, T.; Yang, X.; Zhang, J.; Cui, J.; Zou, H.; Chen, J.; Zhao, X.; Liu, Y. Learning to Train a Point Cloud Reconstruction Network Without Matching. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 179–194. [Google Scholar]
- Rezende, D.J.; Mohamed, S. Variational Inference with Normalizing Flows. In Proceedings of the International Conference on International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1530–1538. [Google Scholar]
- Cheng, A.C.; Li, X.; Liu, S.; Sun, M.; Yang, M.H. Autoregressive 3D Shape Generation via Canonical Mapping. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 89–104. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Tang, Y.; Qian, Y.; Zhang, Q.; Zeng, Y.; Hou, J.; Zhe, X. WarpingGAN: Warping Multiple Uniform Priors for Adversarial 3D Point Cloud Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6387–6395. [Google Scholar]
- Achlioptas, P.; Diamanti, O.; Mitliagkas, I.; Guibas, L. Learning Representations and Generative Models for 3D Point Clouds. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 40–49. [Google Scholar]
- Mao, A.; Du, Z.; Hou, J.; Duan, Y.; Liu, Y.J.; He, Y. PU-Flow: A Point Cloud Upsampling Network With Normalizing Flows. IEEE Trans. Vis. Comput. Graph. 2023, 29, 4964–4977. [Google Scholar] [CrossRef]
- Yang, G.; Huang, X.; Hao, Z.; Liu, M.Y.; Belongie, S.; Hariharan, B. PointFlow: 3D Point Cloud Generation With Continuous Normalizing Flows. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4540–4549. [Google Scholar]
- Klokov, R.; Boyer, E.; Verbeek, J. Discrete Point Flow Networks for Efficient Point Cloud Generation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 694–710. [Google Scholar]
- Pumarola, A.; Popov, S.; Moreno-Noguer, F.; Ferrari, V. C-Flow: Conditional Generative Flow Models for Images and 3D Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7946–7955. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Cheng, S.I.; Chen, Y.J.; Chiu, W.C.; Tseng, H.Y.; Lee, H.Y. Adaptively-Realistic Image Generation from Stroke and Sketch with Diffusion Model. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 4043–4051. [Google Scholar]
- Feng, M.; Hou, H.; Zhang, L.; Guo, Y.; Yu, H.; Wang, Y.; Mian, A. Exploring Hierarchical Spatial Layout Cues for 3D Point Cloud based Scene Graph Prediction. IEEE Trans. Multimed. 2023, 1–13. [Google Scholar] [CrossRef]
- Yue, J.; Dantong, J.; Zhizhong, H.; Matthias, Z. SDFDiff: Differentiable Rendering of Signed Distance Fields for 3D Shape Optimization. In Proceedings of the Conference on Computer Vision and Pattern Recognition CVPR, Seattle, WA, USA, 14–19 June 2020; pp. 1248–1258. [Google Scholar]
- Li, T.; Fu, Y.; Han, X.; Liang, H.; Zhang, J.J.; Chang, J. DiffusionPointLabel: Annotated Point Cloud Generation with Diffusion Model. Comput. Graph. Forum 2022, 41, 131–139. [Google Scholar] [CrossRef]
- Lyu, Z.; Kong, Z.; Xu, X.; Pan, L.; Lin, D. A Conditional Point Diffusion-Refinement Paradigm for 3D Point Cloud Completion. arXiv 2021, arXiv:2112.03530. [Google Scholar]
- Melas-Kyriazi, L.; Rupprecht, C.; Vedaldi, A. PC2: Projection-Conditioned Point Cloud Diffusion for Single-Image 3D Reconstruction. In Proceedings of the Conference on Computer Vision and Pattern Recognition CVPR, Vancouver, BC, Canada, 18–22 June 2023; pp. 12923–12932. [Google Scholar]
- Wu, Z.; Wang, Y.; Feng, M.; Xie, H.; Mian, A. Sketch and Text Guided Diffusion Model for Colored Point Cloud Generation. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 8929–8939. [Google Scholar]
- Yao, W.; George, V.; Ying, Y.M. BuilDiff: 3D Building Shape Generation using Single-Image Conditional Point Cloud Diffusion Models. In Proceedings of the International Conference on Computer Vision ICCV Workshops, Paris, France, 2–3 October 2023; pp. 2902–2911. [Google Scholar]
- Ruoshi, L.; Rundi, W.; Van, H.B.; Pavel, T.; Sergey, Z.; Carl, V. Zero-1-to-3: Zero-Shot One Image to 3D Object. In Proceedings of the International Conference on Computer Vision ICCV, Paris, France, 2–6 October 2023; pp. 9264–9275. [Google Scholar]
- Yicong, H.; Kai, Z.; Jiuxiang, G.; Sai, B.; Yang, Z.; Difan, L.; Feng, L.; Kalyan, S.; Trung, B.; Hao, T. LRM: Large Reconstruction Model for Single Image to 3D. In Proceedings of the International Conference on Learning Representations ICLR, Kigali, Rwanda, 1–5 May 2023; pp. 1–25. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using Real NVP. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–30. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 628–644. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Wang, K.; Chen, K.; Jia, K. Deep Cascade Generation on Point Sets. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3726–3732. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).