
A Review of Research on SLAM Technology Based on the Fusion of LiDAR and Vision

 , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
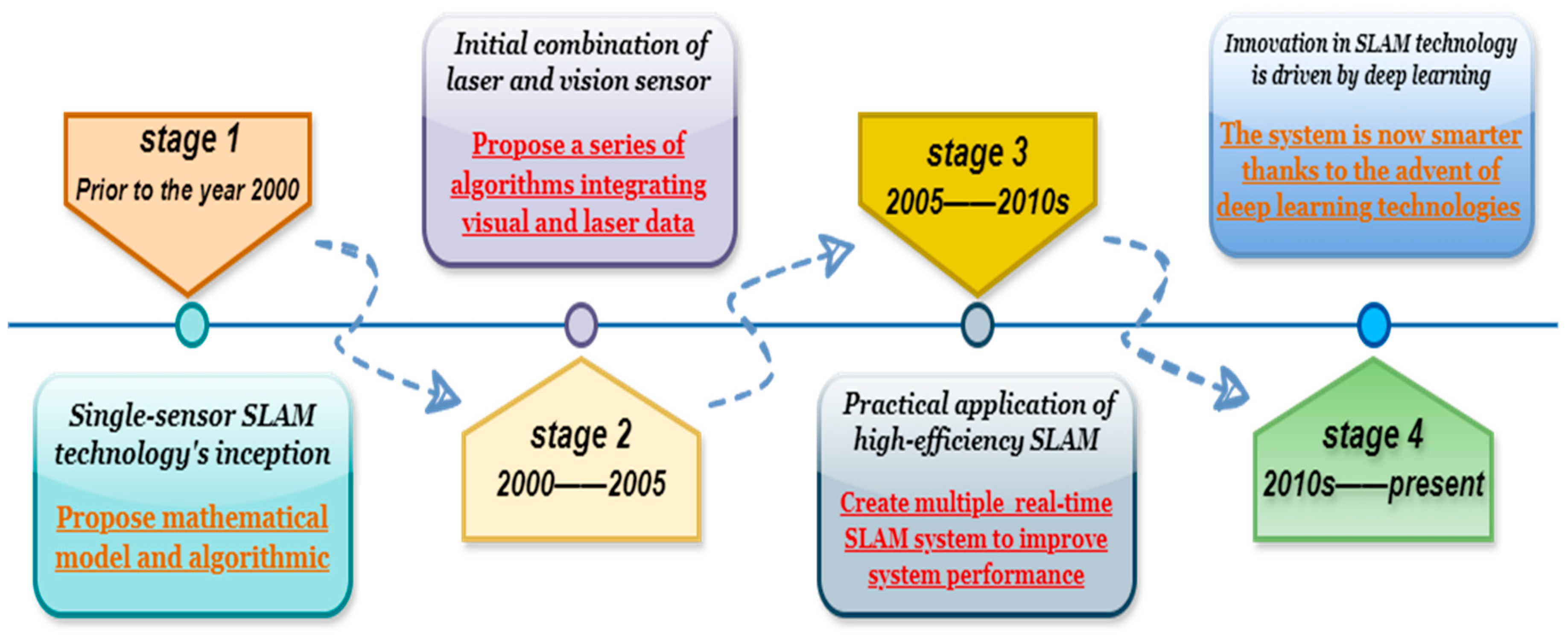
2. The History of SLAM Technology Development
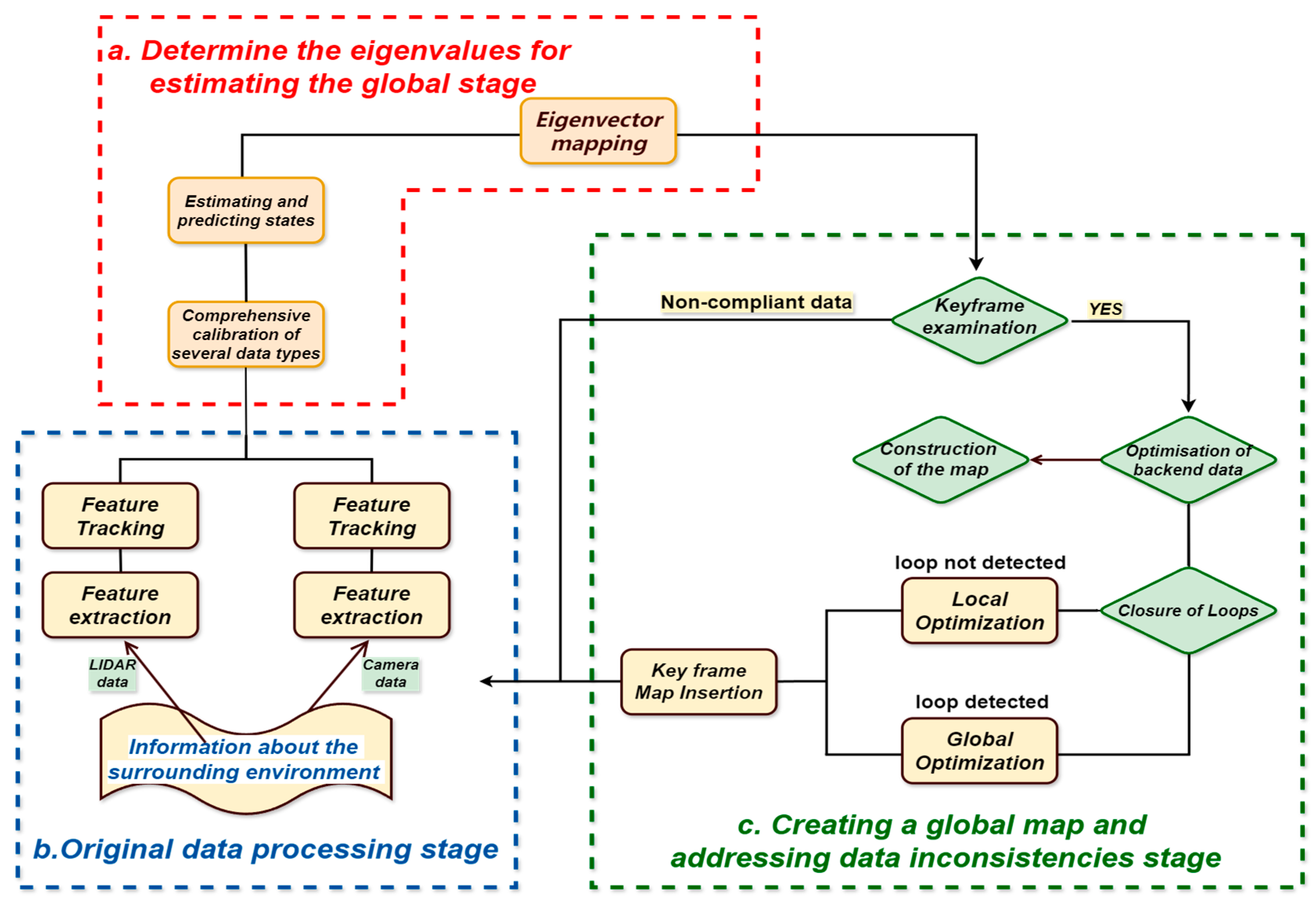
3. The Primary Techniques for SLAM Technology Study
3.1. A Multimodal Data-Based Fusion Technique
3.2. Methods of Feature-Based Fusion
3.3. SLAM Technique with Semantic Information Assistance
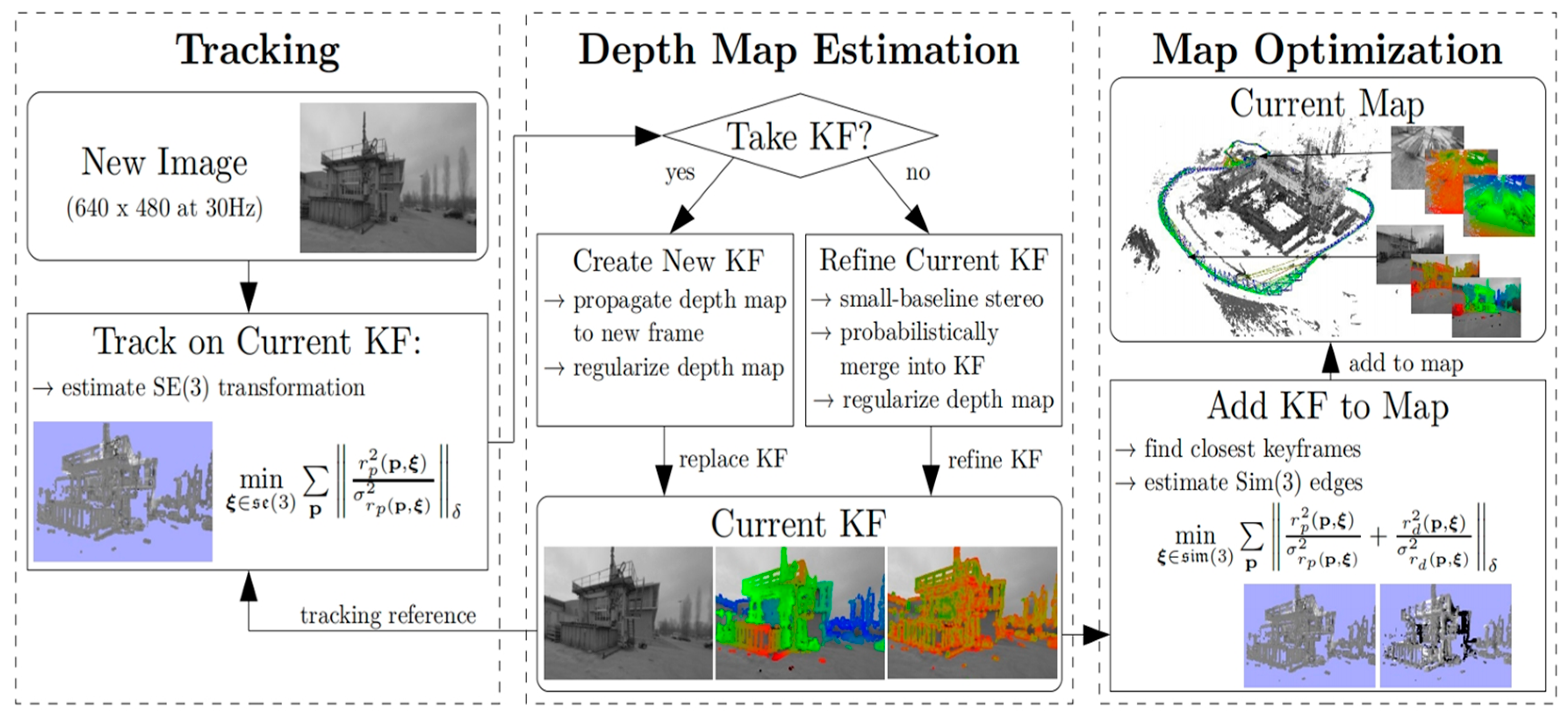
3.4. Direct Method-Based Fusion Method
- (1)
- In addition to being complementary, multimodal data fusion techniques create a broad framework that can offer an integrated platform for many sensors. This includes feature-based, direct, and semantic aid techniques, all of which can be used in multimodal SLAM to make use of the benefits of many sensors and enhance system performance;
- (2)
- Feature-based fusion approaches provide a versatile way to manage feature points, providing extra pose constraints through feature matching, which are useful for merging with other methods to create a more efficient SLAM. This technique offers a versatile approach to managing feature points that are part of the feature layer fusion level. Through feature matching, this degree of fusion can offer extra pose restrictions, hence enhancing the SLAM system’s positioning precision and map-building capabilities in many contexts. It can be used with other techniques to produce a SLAM that is more effective. Combining these techniques allows us to create SLAM systems that are more robust, adaptable, and effective for a range of application scenarios and surroundings with various needs. The algorithm has more alternatives thanks to multimodal fusion, which helps it function well in a variety of challenging situations. By integrating these methodologies, we may create more powerful, adaptable, and efficient SLAM systems for diverse types of surroundings and application scenarios with different needs. The algorithm has more alternatives thanks to multimodal fusion, which helps it function well in a variety of challenging situations;
- (3)
- By providing high-level contextual information, semantic information-assisted SLAM techniques can aid the system in comprehending the scene, particularly in complex environments. They can also be used in conjunction with feature-based and direct techniques to improve positioning accuracy and system stability;
- (4)
- In order to create a hybrid approach, the direct technique combines features with semantic information. By optimizing the original data using these sensible techniques and using the depth information of the direct method to improve feature matching, it increases the SLAM system’s accuracy and resilience in a variety of settings.
4. Main Research Achievements and Evaluation Analysis
4.1. Analysis of Accuracy and Robustness
4.2. Analysis of Real-Time and Adaptability
4.3. Evaluation of SLAM’s Performance in Difficult Surroundings
4.3.1. Evaluation of SLAM’s Performance in Dynamic Settings
4.3.2. SLAM Performance in Situations with Limited Features
5. Limitations and Trends in the Development of Current Research
5.1. The Limitations of the Research
- (1)
- Handling of dynamic environments
- (2)
- Dependency on the sensors
- (3)
- Complexity of computation
- (4)
- Adaptability to the environment
5.2. Trends in Research
- (1)
- Fusion of many sensors
- (2)
- Optimization of algorithms
- (3)
- Improvement of performance in real time
- (4)
- Extension of application scenarios
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Merzlyakov, A.; Macenski, S. A Comparison of Modern General-Purpose Visual SLAM Approaches. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 9190–9197. [Google Scholar] [CrossRef]
- Lu, Y.; Song, D. Visual Navigation Using Heterogeneous Landmarks and Unsupervised Geometric Constraints. IEEE Trans. Robot. 2015, 31, 736–749. [Google Scholar] [CrossRef]
- Yang, S.; Scherer, S. CubeSLAM: Monocular 3-D Object SLAM. IEEE Trans. Robotics 2019, 35, 925–938. [Google Scholar] [CrossRef]
- Qiu, Y.; Wang, C.; Wang, W.; Henein, M.; Scherer, S. AirDOS: Dynamic SLAM Benefits from Articulated Objects. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 8047–8053. [Google Scholar] [CrossRef]
- Shin, Y.-S.; Park, Y.S.; Kim, A. Direct Visual SLAM Using Sparse Depth for Camera-LiDAR System. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 5144–5151. [Google Scholar] [CrossRef]
- Droeschel, D.; Schwarz, M.; Behnke, S. Continuous Mapping and Localization for Autonomous Navigation in Rough Terrain Using a 3D Laser Scanner. Robot. Auton. Syst. 2017, 88, 104–115. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef]
- Cattaneo, D.; Vaghi, M.; Valada, A. LCDNet: Deep Loop Closure Detection and Point Cloud Registration for LiDAR SLAM. IEEE Trans. Robot. 2022, 38, 2074–2093. [Google Scholar] [CrossRef]
- Endres, F.; Hess, J.; Engelhard, N.; Sturm, J.; Cremers, D.; Burgard, W. An Evaluation of the RGB-D SLAM System. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1691–1696. [Google Scholar] [CrossRef]
- Shin, Y.S.; Park, Y.S.; Kim, A. DVL-SLAM: Sparse Depth Enhanced Direct Visual-LiDAR SLAM. Auton. Robot 2020, 44, 115–130. [Google Scholar] [CrossRef]
- Wang, J.; Rünz, M.; Agapito, L. DSP-SLAM: Object Oriented SLAM with Deep Shape Priors. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 7–10 June 2021; pp. 1362–1371. [Google Scholar] [CrossRef]
- Debeunne, C.; Vivet, D. A Review of Visual-LiDAR Fusion based Simultaneous Localization and Mapping. Sensors 2020, 20, 2068. [Google Scholar] [CrossRef] [PubMed]
- Jiang, G.; Yin, L.; Jin, S.; Tian, C.; Ma, X.; Ou, Y. A Simultaneous Localization and Mapping (SLAM) Framework for 2.5D Map Building Based on Low-Cost LiDAR and Vision Fusion. Appl. Sci. 2019, 9, 2105. [Google Scholar] [CrossRef]
- Covolan, J.P.M.; Sementille, A.C.; Sanches, S.R.R. A Mapping of Visual SLAM Algorithms and Their Applications in Augmented Reality. In Proceedings of the 2020 22nd Symposium on Virtual and Augmented Reality (SVR), Porto de Galinhas, Brazil, 10–13 November 2020; pp. 20–29. [Google Scholar] [CrossRef]
- Arshad, S.; Kim, G.-W. Role of Deep Learning in Loop Closure Detection for Visual and Lidar SLAM: A Survey. Sensors 2021, 21, 1243. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Shang, G.; Ji, A.; Zhou, C.; Wang, X.; Xu, C.; Li, Z.; Hu, K. An Overview on Visual SLAM: From Tradition to Semantic. Remote Sens. 2022, 14, 3010. [Google Scholar] [CrossRef]
- Whelan, T.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J.; Leutenegger, S. ElasticFusion: Real-Time Dense SLAM and Light Source Estimation. Int. J. Robot. Res. 2016, 35, 1697–1716. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, H.; Li, Y.; Nakamura, Y.; Zhang, L. FlowFusion: Dynamic Dense RGB-D SLAM Based on Optical Flow. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–4 June 2020; pp. 7322–7328. [Google Scholar] [CrossRef]
- Urban, S.; Hinz, S. MultiCol-SLAM—A Modular Real-Time Multi-Camera SLAM System. arXiv 2016, arXiv:1610.07336. [Google Scholar] [CrossRef]
- Kolar, P.; Benavidez, P.; Jamshidi, M. Survey of Datafusion Techniques for Laser and Vision Based Sensor Integration for Autonomous Navigation. Sensors 2020, 20, 2180. [Google Scholar] [CrossRef] [PubMed]
- Zheng, C.; Zhu, Q.; Xu, W.; Liu, X.; Guo, Q.; Zhang, F. FAST-LIVO: Fast and Tightly-Coupled Sparse-Direct LiDAR-Inertial-Visual Odometry. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–October 2022; pp. 4003–4009. [Google Scholar] [CrossRef]
- Cao, K.; Liu, R.; Wang, Z.; Peng, K.; Zhang, J.; Zheng, J.; Teng, Z.; Yang, K.; Stiefelhagen, R. Tightly-Coupled LiDAR-Visual SLAM Based on Geometric Features for Mobile Agents. In Proceedings of the 2023 IEEE International Conference on Robotics and Biomimetics (ROBIO), Koh Samui, Thailand, 10–13 December 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Liang, T.; Xie, H.; Yu, K.; Xia, Z.; Lin, Z.; Wang, Y.; Wang, B.; Tang, Z. BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework. arXiv 2019, arXiv:2205.13790. [Google Scholar] [CrossRef]
- Johari, M.M.; Carta, C.; Fleuret, F. ESLAM: Efficient Dense SLAM System Based on Hybrid Representation of Signed Distance Fields. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 17408–17419. [Google Scholar] [CrossRef]
- Li, D.; Shi, X.; Long, Q.; Liu, S.; Yang, W.; Wang, F.; Wei, Q.; Qiao, F. DXSLAM: A Robust and Efficient Visual SLAM System with Deep Features. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24–27 October 2020; pp. 4958–4965. [Google Scholar] [CrossRef]
- Li, R.; Wang, S.; Gu, D. Ongoing Evolution of Visual SLAM from Geometry to Deep Learning: Challenges and Opportunities. Cogn. Comput. 2018, 10, 875–889. [Google Scholar] [CrossRef]
- Civera, J.; Davison, A.J.; Montiel, J.M.M. Inverse Depth Parametrization for Monocular SLAM. IEEE Trans. Robot. 2008, 24, 932–945. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, S. SaD-SLAM: A Visual SLAM Based on Semantic and Depth Information. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24–27 October 2020; pp. 4930–4935. [Google Scholar] [CrossRef]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V.; et al. DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 17161–17170. [Google Scholar] [CrossRef]
- Zhang, Y.; Kang, J.; Sohn, G. PVL-Cartographer: Panoramic Vision-Aided LiDAR Cartographer-Based SLAM for Maverick Mobile Mapping System. Remote Sens. 2023, 15, 3383. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Liu, Y.; Miura, J. RDS-SLAM: Real-Time Dynamic SLAM Using Semantic Segmentation Methods. IEEE Access 2021, 9, 23772–23785. [Google Scholar] [CrossRef]
- Lou, L.; Li, Y.; Zhang, Q.; Wei, H. SLAM and 3D Semantic Reconstruction Based on the Fusion of Lidar and Monocular Vision. Sensors 2023, 23, 1502. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Schöps, T.; Pollefeys, M. Illumination Change Robustness in Direct Visual SLAM. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4523–4530. [Google Scholar] [CrossRef]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef]
- Usenko, V.; Engel, J.; Stückler, J.; Cremers, D. Direct Visual-Inertial Odometry with Stereo Cameras. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1885–1892. [Google Scholar] [CrossRef]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, Mapping, and Inpainting in Dynamic Scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Computer Vision–ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8690, pp. 834–849. [Google Scholar] [CrossRef]
- Tan, W.; Liu, H.; Dong, Z.; Zhang, G.; Bao, H. Robust Monocular SLAM in Dynamic Environments. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, SA, Australia, 1–4 October 2013; pp. 209–218. [Google Scholar] [CrossRef]
- Palazzolo, E.; Behley, J.; Lottes, P.; Giguère, P.; Stachniss, C. ReFusion: 3D Reconstruction in Dynamic Environments for RGB-D Cameras Exploiting Residuals. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 7855–7862. [Google Scholar] [CrossRef]
- Zhou, Z.; Yang, M.; Wang, C.; Wang, B. ROI-Cloud: A Key Region Extraction Method for LiDAR Odometry and Localization. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–4 June 2020; pp. 3312–3318. [Google Scholar] [CrossRef]
- Park, Y.S.; Jang, H.; Kim, A. I-LOAM: Intensity Enhanced LiDAR Odometry and Mapping. In Proceedings of the 2020 17th International Conference on Ubiquitous Robots (UR), Kyoto, Japan, 15–18 July 2020; pp. 455–458. [Google Scholar] [CrossRef]
- Lamarca, J.; Parashar, S.; Bartoli, A.; Montiel, J.M.M. DefSLAM: Tracking and Mapping of Deforming Scenes from Monocular Sequences. IEEE Trans. Robot. 2021, 37, 291–303. [Google Scholar] [CrossRef]
- Ahmadi, M.; Naeini, A.A.; Sheikholeslami, M.M.; Arjmandi, Z.; Zhang, Y.; Sohn, G. HDPV-SLAM: Hybrid Depth-Augmented Panoramic Visual SLAM for Mobile Mapping System with Tilted LiDAR and Panoramic Visual Camera. In Proceedings of the 2023 IEEE 19th International Conference on Automation Science and Engineering (CASE), Auckland, New Zealand, 22–25 August 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Maddern, W.; Milford, M.; Wyeth, G. Continuous Appearance-Based Trajectory SLAM. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3595–3600. [Google Scholar] [CrossRef]
- Zou, D.; Tan, P. CoSLAM: Collaborative Visual SLAM in Dynamic Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 354–366. [Google Scholar] [CrossRef]
- Bescos, B.; Campos, C.; Tardós, J.D.; Neira, J. DynaSLAM II: Tightly-Coupled Multi-Object Tracking and SLAM. IEEE Robotics Autom. Lett. 2021, 6, 5191–5198. [Google Scholar] [CrossRef]
- Joo, K.; Kim, P.; Hebert, M.; Kweon, I.S.; Kim, H.J. Linear RGB-D SLAM for Structured Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8403–8419. [Google Scholar] [CrossRef]
- Kerl, C.; Sturm, J.; Cremers, D. Dense Visual SLAM for RGB-D Cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2100–2106. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar] [CrossRef]
- Ma, L.; Kerl, C.; Stückler, J.; Cremers, D. CPA-SLAM: Consistent Plane-Model Alignment for Direct RGB-D SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1285–1291. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.-J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM Towards Dynamic Environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar] [CrossRef]
- Blochliger, F.; Fehr, M.; Dymczyk, M.; Schneider, T.; Siegwart, R. Topomap: Topological Mapping and Navigation Based on Visual SLAM Maps. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3818–3825. [Google Scholar] [CrossRef]
- Laidlow, T.; Czarnowski, J.; Leutenegger, S. DeepFusion: Real-Time Dense 3D Reconstruction for Monocular SLAM Using Single-View Depth and Gradient Predictions. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4068–4074. [Google Scholar] [CrossRef]
- Wasenmüller, O.; Meyer, M.; Stricker, D. CoRBS: Comprehensive RGB-D Benchmark for SLAM Using Kinect v2. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Nicholson, L.; Milford, M.; Sünderhauf, N. QuadricSLAM: Dual Quadrics from Object Detections as Landmarks in Object-Oriented SLAM. IEEE Robot. Autom. Lett. 2019, 4, 1–8. [Google Scholar] [CrossRef]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.J.; Davison, A.J. SLAM++: Simultaneous Localization and Mapping at the Level of Objects. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1352–1359. [Google Scholar] [CrossRef]
- Ibragimov, I.Z.; Afanasyev, I.M. Comparison of ROS-Based Visual SLAM Methods in Homogeneous Indoor Environment. In Proceedings of the 2017 14th Workshop on Positioning, Navigation and Communications (WPNC), Bremen, Germany, 22–23 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, Y.; Miura, J. RDMO-SLAM: Real-Time Visual SLAM for Dynamic Environments Using Semantic Label Prediction with Optical Flow. IEEE Access 2021, 9, 106981–106997. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, M.; Meng, M.Q.H. Motion Removal for Reliable RGB-D SLAM in Dynamic Environments. Robot. Auton. Syst. 2018, 108, 115–128. [Google Scholar] [CrossRef]
- Chen, W.; Zhou, C.; Shang, G.; Wang, X.; Li, Z.; Xu, C.; Hu, K. SLAM Overview: From Single Sensor to Heterogeneous Fusion. Remote Sens. 2022, 14, 6033. [Google Scholar] [CrossRef]
- Yang, S.; Song, Y.; Kaess, M.; Scherer, S. Pop-up SLAM: Semantic Monocular Plane SLAM for Low-Texture Environments. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 1222–1229. [Google Scholar] [CrossRef]
- Deschaud, J.-E. IMLS-SLAM: Scan-to-Model Matching Based on 3D Data. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2480–2485. [Google Scholar] [CrossRef]
- Xu, Y.; Ou, Y.; Xu, T. SLAM of Robot Based on the Fusion of Vision and LIDAR. In Proceedings of the 2018 IEEE International Conference on Cyborg and Bionic Systems (CBS), Shenzhen, China, 31 October–3 November 2018; pp. 121–126. [Google Scholar] [CrossRef]
- Pumarola, A.; Vakhitov, A.; Agudo, A.; Sanfeliu, A.; Moreno-Noguer, F. PL-SLAM: Real-Time Monocular Visual SLAM with Points and Lines. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4503–4508. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Fox, D.; Seitz, S.M. DynamicFusion: Reconstruction and Tracking of Non-Rigid Scenes in Real-Time. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 343–352. [Google Scholar] [CrossRef]
- Ji, T.; Wang, C.; Xie, L. Towards Real-Time Semantic RGB-D SLAM in Dynamic Environments. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11175–11181. [Google Scholar] [CrossRef]
- Whelan, T.; Leutenegger, S.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J. ElasticFusion: Dense SLAM without a Pose Graph. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 12–16 July 2015; MIT Press: Cambridge, MA, USA, 2015; Volume 11. [Google Scholar] [CrossRef]
- Li, R.; Wang, S.; Gu, D. DeepSLAM: A Robust Monocular SLAM System with Unsupervised Deep Learning. IEEE Trans. Ind. Electron. 2021, 68, 3577–3587. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Probabilistic Semi-Dense Mapping from Highly Accurate Feature-Based Monocular SLAM. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 12–16 July 2015. [Google Scholar] [CrossRef]
- Burgard, W.; Stachniss, C.; Grisetti, G.; Steder, B.; Kummerle, R.; Dornhege, C.; Ruhnke, M.; Kleiner, A.; Tardos, J.D. A Comparison of SLAM Algorithms Based on a Graph of Relations. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 2089–2095. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B.; Ratti, C.; Rus, D. LVI-SAM: Tightly-Coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 5692–5698. [Google Scholar] [CrossRef]
- Sturm, J.; Magnenat, S.; Engelhard, N.; Pomerleau, F.; Colas, F.; Cremers, D.; Siegwart, R.; Burgard, W. Towards a Benchmark for RGB-D SLAM Evaluation. In Proceedings of the RGB-D Workshop on Advanced Reasoning with Depth Cameras at Robotics: Science and Systems Conference (RSS), Los Angeles, CA, USA, 27 June–1 July 2011. [Google Scholar]
- Greene, W.N.; Ok, K.; Lommel, P.; Roy, N. Multi-Level Mapping: Real-Time Dense Monocular SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 833–840. [Google Scholar] [CrossRef]
- Sucar, E.; Liu, S.; Ortiz, J.; Davison, A.J. iMAP: Implicit Mapping and Positioning in Real-Time. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 17 2021; pp. 6209–6218. [Google Scholar] [CrossRef]
- Vincent, J.; Labbé, M.; Lauzon, J.-S.; Grondin, F.; Comtois-Rivet, P.-M.; Michaud, F. Dynamic Object Tracking and Masking for Visual SLAM. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24–27 October 2020; pp. 4974–4979. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast Semi-Direct Monocular Visual Odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Nardi, L.; Bodin, B.; Zia, M.Z.; Mawer, J.; Nisbet, A.; Kelly, P.H.J.; Davison, A.J.; Lujan, M.; O’Boyle, M.F.P.; Riley, G.; et al. Introducing SLAMBench, a Performance and Accuracy Benchmarking Methodology for SLAM. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 5783–5790. [Google Scholar] [CrossRef]
- Yan, J.; Zheng, Y.; Yang, J.; Mihaylova, L.; Yuan, W.; Gu, F. PLPF-VSLAM: An Indoor Visual SLAM with Adaptive Fusion of Point-Line-Plane Features. J. Field Robot. 2024, 41, 50–67. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Visual-Inertial Monocular SLAM with Map Reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Zhu, Z.; Peng, S.; Larsson, V.; Xu, W.; Bao, H.; Cui, Z.; Oswald, M.R.; Pollefeys, M. NICE-SLAM: Neural Implicit Scalable Encoding for SLAM. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 12776–12786. [Google Scholar] [CrossRef]
- Chen, G.; Hong, L. Research on Environment Perception System of Quadruped Robots Based on LiDAR and Vision. Drones 2023, 7, 329. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Frosi, M.; Matteucci, M. ART-SLAM: Accurate Real-Time 6DoF LiDAR SLAM. IEEE Robot. Autom. Lett. 2022, 7, 2692–2699. [Google Scholar] [CrossRef]
- Gálvez-López, D.; Salas, M.; Tardós, J.D.; Montiel, J.M.M. Real-Time Monocular Object SLAM. Robot. Auton. Syst. 2016, 75, 435–449. [Google Scholar] [CrossRef]
- Chaplot, D.S.; Gandhi, D.; Gupta, S.; Gupta, A.; Salakhutdinov, R. Learning to Explore Using Active Neural SLAM. In Proceedings of the 8th International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar] [CrossRef]
- Chen, X.; Läbe, T.; Milioto, A.; Röhling, T.; Vysotska, O.; Haag, A.; Behley, J.; Stachniss, C. OverlapNet: Loop Closing for LiDAR-based SLAM. arXiv 2021, arXiv:2105.11344. [Google Scholar] [CrossRef]
- Teed, Z.; Deng, J. DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras. Neural Inf. Process. Syst. 2021, 34, 16558–16569. [Google Scholar] [CrossRef]
- Bruno, H.M.S.; Colombini, E.L. LIFT-SLAM: A Deep-Learning Feature-Based Monocular Visual SLAM Method. Neurocomputing 2021, 455, 97–110. [Google Scholar] [CrossRef]
- Ai, Y.; Rui, T.; Lu, M.; Fu, L.; Liu, S.; Wang, S. DDL-SLAM: A Robust RGB-D SLAM in Dynamic Environments Combined with Deep Learning. IEEE Access 2020, 8, 162335–162342. [Google Scholar] [CrossRef]
- Chung, C.-M.; Tseng, Y.-C.; Hsu, Y.-C.; Shi, X.-Q.; Hua, Y.-H.; Yeh, J.-F.; Chen, W.-C.; Chen, Y.-T.; Hsu, W.H. Orbeez-SLAM: A Real-Time Monocular Visual SLAM with ORB Features and NeRF-Realized Mapping. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 9400–9406. [Google Scholar] [CrossRef]
- Zhu, Z.; Peng, S.; Larsson, V.; Cui, Z.; Oswald, M.R.; Geiger, A.; Pollefeys, M. NICER-SLAM: Neural Implicit Scene Encoding for RGB SLAM. In Proceedings of the 2024 International Conference on 3D Vision (3DV), Davos, Switzerland, 9–12 September 2024; pp. 42–52. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, J.; Liu, J. A Survey of Simultaneous Localization and Mapping with an Envision in 6G Wireless Networks. J. Glob. Position. Syst. 2021, 17, 206–236. [Google Scholar] [CrossRef]
- Shu, F.; Lesur, P.; Xie, Y.; Pagani, A.; Stricker, D. SLAM in the Field: An Evaluation of Monocular Mapping and Localization on Challenging Dynamic Agricultural Environment. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2021; pp. 1760–1770. [Google Scholar] [CrossRef]
- Schöps, T.; Sattler, T.; Pollefeys, M. BAD SLAM: Bundle Adjusted Direct RGB-D SLAM. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 134–144. [Google Scholar] [CrossRef]
- Keetha, N.; Karhade, J.; Jatavallabhula, K.M.; Yang, G.; Scherer, S.; Ramanan, D.; Luiten, J. SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–20 June 2024; pp. 21357–21366. [Google Scholar] [CrossRef]
- Kim, G.; Kim, A. LT-mapper: A Modular Framework for LiDAR-based Lifelong Mapping. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 7995–8002. [Google Scholar] [CrossRef]
- Tiwari, L.; Ji, P.; Tran, Q.H.; Zhuang, B.; Anand, S.; Chandraker, M. Pseudo RGB-D for Self-improving Monocular SLAM and Depth Prediction. In Computer Vision–ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12356, pp. 437–455. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Zhao, X.; Zeng, L.; Liu, L.; Liu, S.; Sun, L.; Li, Z.; Chen, H.; Liu, G.; Qiao, Z.; et al. A Review of Research on SLAM Technology Based on the Fusion of LiDAR and Vision. Sensors 2025, 25, 1447. https://doi.org/10.3390/s25051447
Chen P, Zhao X, Zeng L, Liu L, Liu S, Sun L, Li Z, Chen H, Liu G, Qiao Z, et al. A Review of Research on SLAM Technology Based on the Fusion of LiDAR and Vision. Sensors. 2025; 25(5):1447. https://doi.org/10.3390/s25051447
Chicago/Turabian StyleChen, Peng, Xinyu Zhao, Lina Zeng, Luxinyu Liu, Shengjie Liu, Li Sun, Zaijin Li, Hao Chen, Guojun Liu, Zhongliang Qiao, and et al. 2025. "A Review of Research on SLAM Technology Based on the Fusion of LiDAR and Vision" Sensors 25, no. 5: 1447. https://doi.org/10.3390/s25051447
APA StyleChen, P., Zhao, X., Zeng, L., Liu, L., Liu, S., Sun, L., Li, Z., Chen, H., Liu, G., Qiao, Z., Qu, Y., Xu, D., Li, L., & Li, L. (2025). A Review of Research on SLAM Technology Based on the Fusion of LiDAR and Vision. Sensors, 25(5), 1447. https://doi.org/10.3390/s25051447