Abstract
In mobile edge computing networks, achieving effective load balancing across edge server nodes is essential for minimizing task processing latency. However, the lack of a priori knowledge regarding the current load state of edge nodes for user devices presents a significant challenge in multi-user, multi-edge node scenarios. This challenge is exacerbated by the inherent dynamics and uncertainty of edge node load variations. To tackle these issues, we propose a deep reinforcement learning-based approach for task offloading and resource allocation, aiming to balance the load on edge nodes while reducing the long-term average cost. Specifically, we decompose the optimization problem into two subproblems, task offloading and resource allocation. The Karush–Kuhn–Tucker (KKT) conditions are employed to derive the optimal strategy for communication bandwidth and computational resource allocation for edge nodes. We utilize Long Short-Term Memory (LSTM) networks to forecast the real-time activity of edge nodes. Additionally, we integrate deep compression techniques to expedite model convergence, facilitating faster execution on user devices. Our simulation results demonstrate that our proposed scheme achieves a 47% reduction in terms of the task drop rate, a 14% decrease in the total system cost, and a 7.6% improvement in the runtime compared to the baseline schemes.
1. Introduction
With the advent of fifth-generation mobile communication technology, there has been an exponential growth in the number of smart devices, giving rise to a plethora of resource-intensive and latency-sensitive applications. These include online video streaming, online education, telemedicine, augmented reality, etc. [1]. Achieving satisfactory Quality of Service (QoS) and Quality of Experience (QoE) for such applications is challenging when relying on the limited computing capabilities of mobile devices alone [2].
Traditional approaches often depend on centralized cloud computing infrastructures, where data processing and storage tasks are managed in distant data centers [3]. However, this method necessitates extensive data transmission between users and data centers, potentially leading to prohibitively high latency. In response, mobile edge computing (MEC) has risen as a compelling alternative, attracting considerable interest from both industry and academia [4].
MEC addresses these challenges by relocating computation and storage resources to the network’s edge, closer to the users. This relocation facilitates real-time processing and significantly reduces latency, making MEC an attractive option for applications that are sensitive to latency [5].
By situating computing resources in close proximity to the end-users, such as at base stations or routers, MEC enables localized data processing. This effectively eliminates the need for data to be sent back to remote data centers [6,7]. This strategy not only enhances the responsiveness of applications but also mitigates network congestion. This is particularly beneficial in scenarios with high traffic volumes and stringent low-latency requirements, such as intelligent transportation systems [8].
In the MEC architecture, edge nodes are tasked with both computation and storage responsibilities. However, in real-world scenarios characterized by unpredictable task arrivals, a sudden surge of tasks offloaded to a single edge node can lead to overloading and prolonged operation over time. Unlike cloud service centers, edge nodes in practical deployments typically have limited computing and storage resources [9]. Consequently, tasks processed on overloaded edge nodes may experience extended queuing delays, potentially resulting in untimely processing or even task abandonment.
To maintain load balancing across edge nodes, it is crucial to establish reasonable and effective task offloading policies. Additionally, when tasks are transmitted to edge nodes via wireless channels, the allocation of communication bandwidth and computational resources becomes pivotal to the overall system performance [10]. Poor resource allocation can lead to high latency and suboptimal resource utilization, which are clearly undesirable. Therefore, the optimization of MEC systems necessitates the design of an effective resource allocation strategy.
Several studies have addressed load balancing across edge nodes in the context of MEC task offloading. In [11], the task offloading problem in a dynamic MEC environment with rapidly moving user devices is considered. The authors use Lyapunov optimization theory and a neural network framework to balance the load across different cloudlets. In [12], to address the computational load imbalance problem on edge nodes, the authors employ a D3QN-based deep reinforcement learning framework to group MEC nodes. The work in [13] proposes a heuristic offloading algorithm to balance computational and traffic load. However, these studies overlook the queuing delays that occur during task offloading. The study in [14] investigates delay estimation and computational task offloading in MEC networks for V2X applications, developing an end-to-end delay prediction framework that integrates various delays using actual round-trip time data. In [15], the authors address the offloading problem in MEC networks with inter-task dependencies by assigning tasks to different waiting queues based on their priority and deadline requirements. While these studies consider queuing delays associated with task offloading, they do not focus on the load balancing problem in dynamic scenarios, neglecting the load state information of each edge node during offloading decisions.
Building on these considerations, this paper proposes a distributed task offloading and resource allocation strategy leveraging deep reinforcement learning to tackle the challenge posed by the dynamic uncertainty of edge node loads in multi-user, multi-edge node environments. The primary objective is to minimize the long-term average cost of the user system in terms of latency and energy consumption. Specifically, each user device predicts the activity state of edge nodes in real time by leveraging historical load information, enabling adaptive offloading decisions. Subsequently, the optimal allocation of communication bandwidth and computational resources is determined to maximize system resource utilization. Furthermore, to reduce the computational complexity and enhance the execution speed of the deep learning model, we incorporate deep compression techniques [16] within the algorithm. These techniques, including pruning and quantization, effectively reduce the model’s storage requirements and computational costs, making them suitable for deployment in resource-constrained environments. Finally, simulation results demonstrate that the proposed scheme outperforms the baseline approaches in reducing the task drop rate, lowering the long-term average cost of the user’s system, and minimizing runtime.
In summary, the primary contributions of this paper are as follows:
- We explore the problem of dynamic task offloading and resource allocation in a multi-user, multi-edge node scenario, considering the uncertainty of edge node load variations in dynamic environments, with the objective of minimizing the long-term average cost of the user system in terms of latency and energy consumption.
- We propose a solution for real-time task offloading and resource allocation. We decompose the optimization problem into two subproblems, task offloading and resource allocation. Using the Karush–Kuhn–Tucker (KKT) conditions, we derive the optimal communication bandwidth and computational resource allocation scheme for edge nodes. We then propose the Balanced Preserve based on Deep Reinforcement Learning (BPDRL) algorithm, which enables each user device to dynamically predict the load of the edge nodes based on historical information and independently make offloading decisions without knowing the load of other devices, achieving load balancing at the edge nodes.
- To expedite model convergence and facilitate efficient deployment on user devices, we incorporate deep compression techniques into the algorithm to reduce model size. Simulation experiments validate the feasibility and effectiveness of the proposed scheme.
The rest of this paper is organized as follows. We review related work in Section 2. In Section 3, we introduce the system model. The corresponding optimization problem is established in Section 4. The BPDRL algorithm is illustrated in Section 5. In Section 6, we give the performance evaluation. Finally, Section 7 summarizes the work of this paper.
2. Related Works
In MEC, the implementation of effective task offloading and resource allocation strategies is crucial for enhancing system efficiency and delivering a satisfactory service experience to users. Consequently, this area has remained a central and consistently emphasized focus within the research community.
A multitude of studies have been conducted on the challenges of computation offloading and resource allocation in MEC environments. For instance, Wu et al. [10] propose a game-theoretic approach to multi-cellular network computing offloading, which effectively reduces the system latency and energy consumption. Peng et al. [17] investigate the problem of task offloading and resource allocation in MEC-enabled dynamic networks, utilizing an actor–critic deep learning algorithm to minimize the long-term average tasks completion delay. Zhang et al. [18] consider two task offloading modes and propose a greedy-based edge node selection strategy to reduce overall task execution delay. Li et al. [19] formulate the computation offloading and resource optimization as a Mixed Integer Nonlinear Programming (MINLP) problem, employing genetic algorithms and Monte Carlo search methods to jointly optimize offloading strategies and bandwidth resources. Zeng et al. [20] maximize the system QoE by jointly optimizing task offloading strategies and multi-dimensional resource allocation. Xia et al. [21] propose a vehicle location-aware task offloading mechanism, differentiating between single-unit and multi-unit offloading scenarios. Chen et al. [22] study multi-user computation offloading in a dynamic MEC environment with energy harvesting capabilities, designing a dynamic offloading algorithm to minimize system energy consumption under delay constraints. Chen et al. [23] model the offloading problem as a Markov decision process and address the state space explosion issue using the Deep Deterministic Policy Gradient (DDPG) algorithm.
However, the aforementioned studies overlook the load status of edge nodes during task offloading. Real network environments are inherently dynamic and uncertain, leading to significant unpredictability in the real-time load of edge nodes. Given the limited computation resources of edge nodes, managing all incoming tasks becomes a complex challenge. Zhu et al. [24] design an immune algorithm-based task offloading scheme aimed at optimizing system task response time, device energy consumption, and server load balance to ensure system service quality and load balancing performance. Yet, this approach does not account for task offloading over continuous time intervals, making it less suitable for dynamic environments. Yan et al. [25] focus on the task offloading problem for unmanned rescue vehicles, aiming to minimize task drop rates, system delay, and energy consumption. They achieve edge server load balancing by equalizing the number of queued tasks. However, this research is conducted in a quasi-static environment and may not be applicable to truly dynamic settings. Tang et al. [26] design a distributed offloading algorithm that addresses the dynamic uncertainty of edge node loads by integrating Long Short-Term Memory (LSTM) networks, Deep Dueling Q Networks, and Double Deep Q-Network (DDQN) techniques. Chen et al. [27] explore the computation offloading problem in ultra-dense software-defined networks, proposing a load balancing algorithm based on load estimation to mitigate the ping-pong effect. These studies simplify the communication model of wireless networks and do not consider the impact of communication resource constraints on the network. While recent studies [12,28,29] have primarily focused on task offloading and load balancing in mobile edge computing, our research emphasizes dynamic task offloading and resource allocation to address the challenges posed by dynamic variations in edge node load, distinguishing it from the aforementioned works.
Deep reinforcement learning (DRL), a prominent subfield of machine learning (ML), has emerged as a potent approach for tackling computation offloading and resource allocation challenges in MEC. This approach integrates deep learning with reinforcement learning, enabling the system to intelligently determine computation task offloading and resource allocation strategies. Wu et al. [30] categorize users into regular and VIP users, proposing a DRL-based task offloading algorithm to adapt the fluctuating task arrival rates in MEC networks. Cao et al. [31] employ fuzzy inference to assess network traffic patterns and propose a reinforcement learning-based algorithm to devise offloading strategies. Zhao et al. [32] present a DRL-based offloading strategy to prevent suboptimal decisions by minimizing state-space dimensions while considering task data dependencies and vehicle mobility. Hu et al. [33] optimize the distribution of system energy and computational resources in a dynamic single MEC environment by refining exploration and experience replay components within a DRL-based algorithm. However, DRL models often require considerable computational resources for both training and execution, posing issues such as high computational complexity, energy consumption, and reduced deployment efficiency on user devices. To counter these challenges, we integrate deep compression techniques into our DRL model. This integration significantly reduces model size and computational complexity, thereby improving deployment efficiency through strategies like pruning and parameter quantization. Table 1 contrasts the salient features and unique aspects of our research against relevant existing studies.

Table 1.
Key features of the related research studies and our research.
3. System Model
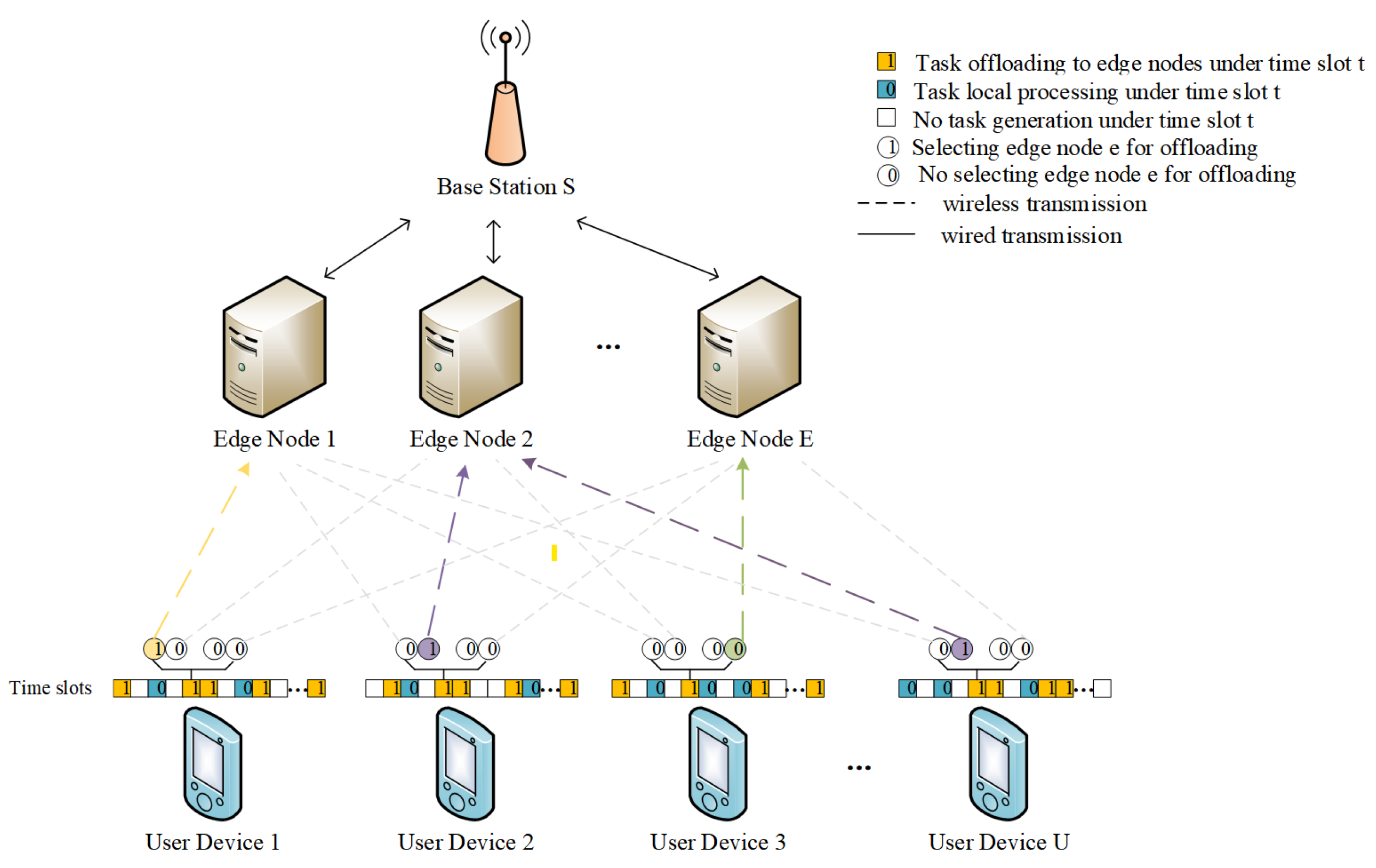
In this paper, we consider a MEC system containing a base station S, a set of edge nodes , and a set of user devices . The base station is equipped with multiple MEC nodes, and user devices make decisions on whether to execute tasks locally or delegate them to the MEC nodes affiliated with the base station, in accordance with predefined task offloading strategies as illustrated in Figure 1. It is presumed that users within the base station’s communication radius access the network via Orthogonal Frequency Division Multiple Access (OFDMA). Moreover, the wireless communication between user devices and the base station is susceptible to path loss and distance-dependent large-scale fading [10]. An in-depth exploration of the communication model is presented in the subsection titled “Communication Model”.
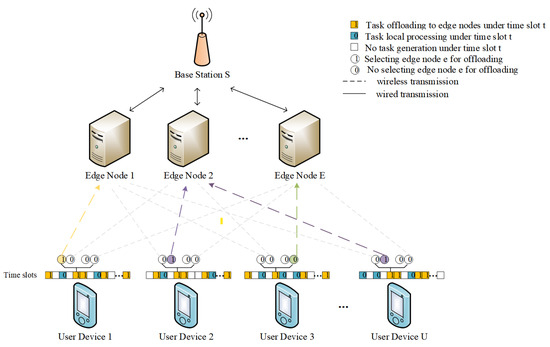
Figure 1.
System model.
To capture the system’s dynamic characteristics more effectively, we concentrate on the system’s functioning across a series of time slots , with each time slot lasting a duration of . Within each time slot, each user device has a probabilistic likelihood of generating a random IoT application task, which requires a decision on whether to process it locally or offload it to a designated MEC node. We adopt a triplet to represent the task generated by user device u at time slot t, where represents the task size in bits, denotes the task processing density, i.e., the CPU cycles required to process each bit of data, and indicates the maximum acceptable latency for the task. The task is discarded if the processing duration surpasses this threshold. Additionally, we assume that tasks are non-divisible, meaning that each task must either be processed locally or entirely offloaded to an edge node.
We represent the offloading decision for a task arriving at time slot t as , where indicates local task processing and indicates offloading the task to an edge node for processing via wireless channel transmission. When a task is selected for offloading to an edge node, let represent whether the task generated by user device u is allocated for processing at edge node e during time slot t. Specifically, , where confirms that the task is processed at edge node e and confirms that it is not. The variable satisfies the following relation:
This equation indicates that a single edge node must be selected for task offloading.
A summary of the key symbols utilized in this paper is provided in Table 2. In the following, we specify the system in terms of the communication model, the computational model, and the queuing model.
Table 2.
Summary of key notations.
3.1. Communication Model
In the wireless communication process between user device u and base station S, the uplink transmission rate is represented as follows:
where denotes the bandwidth allocated to user device u by the MEC system, denotes the transmit power of user device u, denotes the channel gain between user device u and base station S, and denotes the channel noise power.
When user device u offloads to edge node e for processing, the transmission delay incurred through the wireless channel transmission is
The energy consumption generated by user device u during the transmission process is
In comparison to the uploaded data, the downlink transmission of output data back to the user device is considered negligible, and thus, the downlink transmission delay is disregarded [34].
3.2. Computational Model
3.2.1. Local Computation
When user device u opts to execute the task locally, the computational time required is expressed as
where represents the local computing capability of user device u, i.e., the CPU cycles per second.
The energy consumption generated by the user device u during the local computation is represented as [35]
where is the effective capacitance factor, which is related to the hardware architecture of the user device [36].
3.2.2. Edge Computation
The time required for edge node e to process is
where denotes the computational resources allocated to edge node e in time slot t.
Our focus is on the energy consumption at the user device due to computation. Therefore, we omit the energy consumption by the user device when a task is uploaded to the edge server for processing, as it is typically relatively insignificant.
3.3. Queue Model
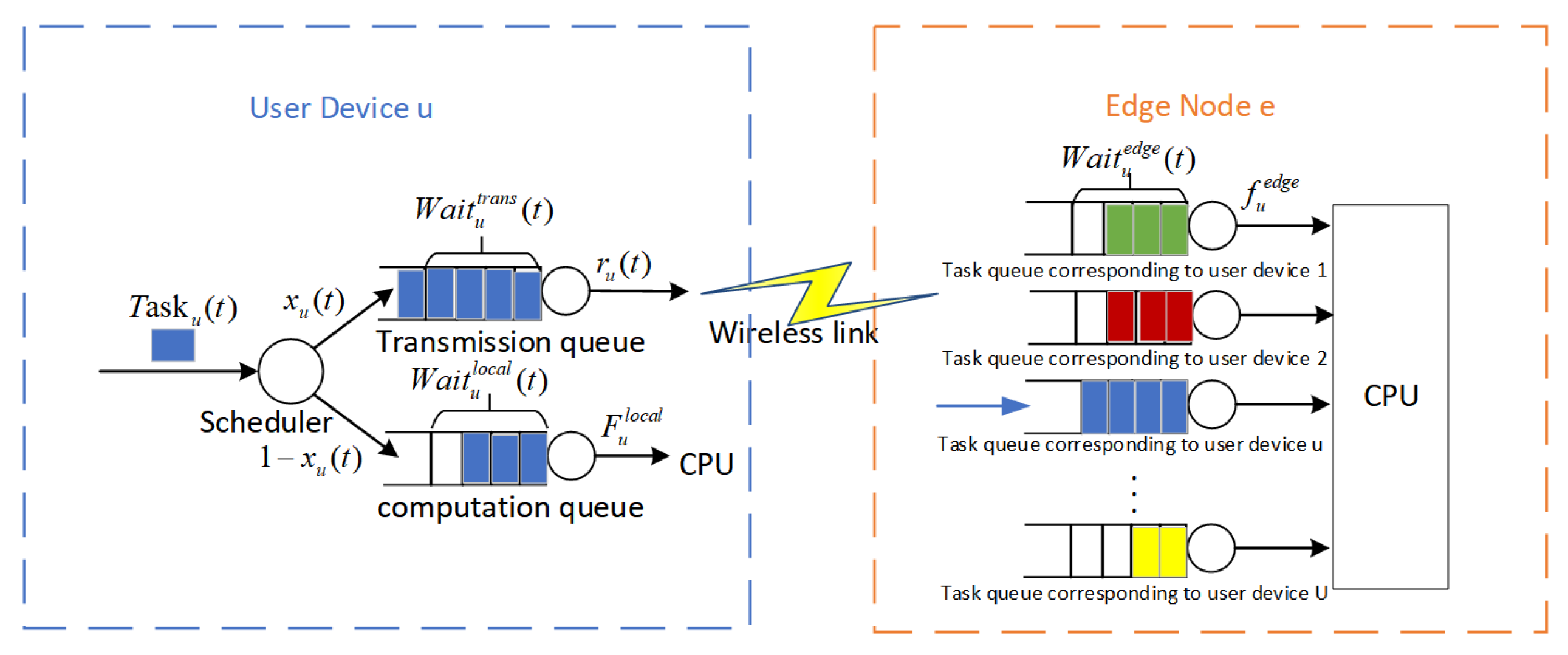
Each user device and edge node is equipped with dedicated task queues that operate on a first-in–first-out basis. Specifically, each user device possesses two separate queues, the computation queue and the transmission queue. In parallel, each edge node manages U task queues, where U represents the number of user devices associated with that edge node.
Prior to the conclusion of time slot t, user device u generates a new task . This task undergoes evaluation by the scheduler, which ascertains the offloading decision, and is then positioned into the appropriate queue at the commencement of the ensuing time slot. If is selected for local processing, it is slotted into the computation queue of user device u for execution. On the other hand, if the task is destined for offloading to edge node e, it is initially placed in the transmission queue of user device u before being relayed to the corresponding queue on edge node e for additional queuing and subsequent processing through the wireless link. This process is illustrated in Figure 2. For the sake of simplicity, we make when no task is generated during time slot t.
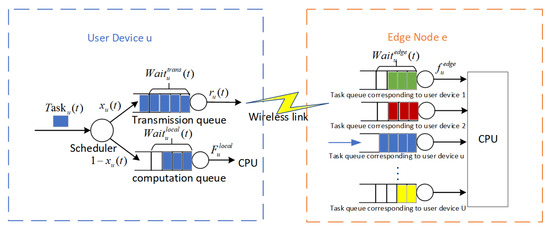
Figure 2.
Queuing model.
3.3.1. Local Queue
- (1)
- Local computational queue.
If , i.e., arrives at the local computation queue during time slot t, the number of time slots required for to be processed from the start to the completion, according to the local computation model, is given by
Before time t when arrives, if there are pending tasks in the local computation queue that have not been completed, will not be processed immediately. Instead, it has to wait until all preceding tasks in the computation queue are finished. We assume that the time slot in which is fully processed in the local computation queue is ; thus, we have the following equation:
where represents the waiting time slots in the local computation queue before begins processing. The waiting time slots are calculated as
Note that if the sum of the waiting time slots and the processing time slots exceeds the maximum tolerable time slots, the task will be discarded.
- (2)
- Local transmission queue.
According to the transmission model, if , i.e., arrives at the local transmission queue in time slot t, the number of time slots required for to be transmitted from the start of transmission until it is completely sent to the designated edge node is
Before the arrival of at time t, if there are still tasks in the local transmission queue that have not been transmitted, we assume the time slot when is fully transmitted in the local transmission queue is . Thus, we have
where represents the waiting time slots in the local transmission queue before begins transmission. The waiting time slots for transmission are determined by
Similarly, if the sum of the waiting time slots and the transmission time slots surpasses the task’s maximum tolerable time slots, will be discarded.
3.3.2. Edge Queue
During time slot t, if there is a task arriving at queue u of the edge node e, the number of time slots required for the task to be processed from the start until completion on edge node e, according to the edge computing model, is
We denote the time slot as when the task is completely processed in edge queue u. Thus, we have
where represents the waiting time slots for the task in the edge queue u. The waiting time in the edge queue is given by
Here, we define the active queues as the set of queues on an edge node e that contain tasks which are either being processed or are waiting to be processed, i.e.,
The number of active queues on edge node e is represented as , and assuming that the edge node employs a resource sharing model [26], the real-time computational resources of edge node e can be articulated as
where denotes the aggregate computational resources available on edge node e.
The active queues on the edge node e fluctuate dynamically in real time. When making offloading decisions, user devices cannot preemptively discern the active queues on an edge node e. If multiple user devices concurrently offload tasks to a specific edge node e, the node might encounter a scarcity of computational resources. This situation could precipitate an increase in the waiting time slots for tasks in the queue and the processing time slots , potentially causing the sum of these time slots to surpass the maximum tolerable time slots for tasks. Consequently, this could lead to a higher rate of task abandonment. In contrast, when fewer tasks are offloaded to edge nodes, their resource utilization decreases. Therefore, it is essential to develop appropriate offloading and resource allocation strategies to balance the load on edge nodes and fully utilize system resources.
4. Problem Formulation
Drawing from the preceding discourse, the cumulative delay encountered by user device u throughout the time period T can be defined as
Similarly, the aggregate energy consumption generated by user device u over the time period T can be expressed as
where denotes the energy consumption from local computation, i.e., , and represents the energy consumption of user device u during transmission, i.e., .
In the context of a multi-user, multi-MEC server scenario, the objective is to minimize the system utility function for user device u, which is the weighted sum of user delay and energy consumption across a time period T. Consequently, the following problem formulation is constructed:
where is a delay weighting parameter used to balance the trade-off between system delay and energy consumption. This parameter governs the relative importance of the two components in the overall system cost and should be selected based on the specific application scenario. For instance, in latency-sensitive applications such as augmented reality or real-time video processing, the parameter should be assigned a higher value to emphasize the time component. Conversely, in scenarios where energy efficiency is critical, such as IoT devices with limited battery capacity, the parameter should be set to a lower value to prioritize energy consumption minimization. W represents the total communication bandwidth allocated to the system. The constraint ensures that the aggregate bandwidth allocated to each user device does not exceed the system’s total communication bandwidth.
5. Algorithm Design
Problem P is inherently complex to solve due to the need to optimize both discrete computational offloading decisions and continuous communication bandwidth resource allocation. We recognize that once the offloading decisions are established, the communication resource allocation problem transforms into a convex function. Thus, our strategy is to decompose Problem P into two subproblems, computational offloading and resource allocation, which are addressed separately.
5.1. Resource Allocation
We focus on the allocation of communication bandwidth at time slot t. Tasks can only be uploaded to the edge node via the wireless channel if they have not been discarded in the transmission queue of the user device. Consequently, we formulate the following problem for the user tasks in the system awaiting transmission at time slot t:
where Au is given by is independent of . Problem P1 is subject to the constraint (22). The derivation of is detailed in Appendix A.
By calculating the second derivative of problem P1 with respect to , we obtain
Formulation (23) confirms that the optimization problem P1 is a convex optimization problem [37]. Therefore, we further construct the Lagrangian function for this optimization problem [38]:
where is the Lagrange multiplier associated with the constraint, and .
Through applying the KKT conditions, we can derive the optimal value and that satisfy the following Equations [39]:
By further derivation, we can obtain the optimal solution as follows:
i.e., the optimal allocated bandwidth for user device u at time slot t.
5.2. Task Offloading
In the preceding section, we derive the optimal communication resource scheme at time slot t when the offloading policies are determined through mathematical formulations. This section is primarily concerned with determining the optimal offloading policies. We convert the task offloading policy solution within the optimization problem into a Markov decision process that operates over a finite number of time slots.
A standard Markov decision process [40] is typically defined as a quaternion , where S represents the set of states observed from the environmental system, A represents the set of actions that the agent can perform depending on the state of the environment, is the state transition probability function, and R is the reward that is obtained by the agent executing an action at state s. The specific details of each element in our Markov decision process problem model are as follows.
5.2.1. State
At the beginning of time slot t, each user device in the system observes the following state information from the environment:
It includes task size , queue situation , , ; and history edge nodes’ active queue information , where .
5.2.2. Action
Upon the arrival of a task during time slot t, user device u, acting as an agent, must decide whether to process the task locally or at an edge node. If the decision is to process the task at an edge node, it also needs to decide which edge node to select for processing. Thus, the action space is defined as
where .
5.2.3. Reward
The goal of reinforcement learning is to maximize the long-term average reward of the system. We define the reward obtained by the user device agent as the negative of the weighted average sum of delay and energy consumption under the time period T, expressed as follows:
The specific algorithm is detailed in the subsequent subsection.
5.3. BPDRL Algorithm
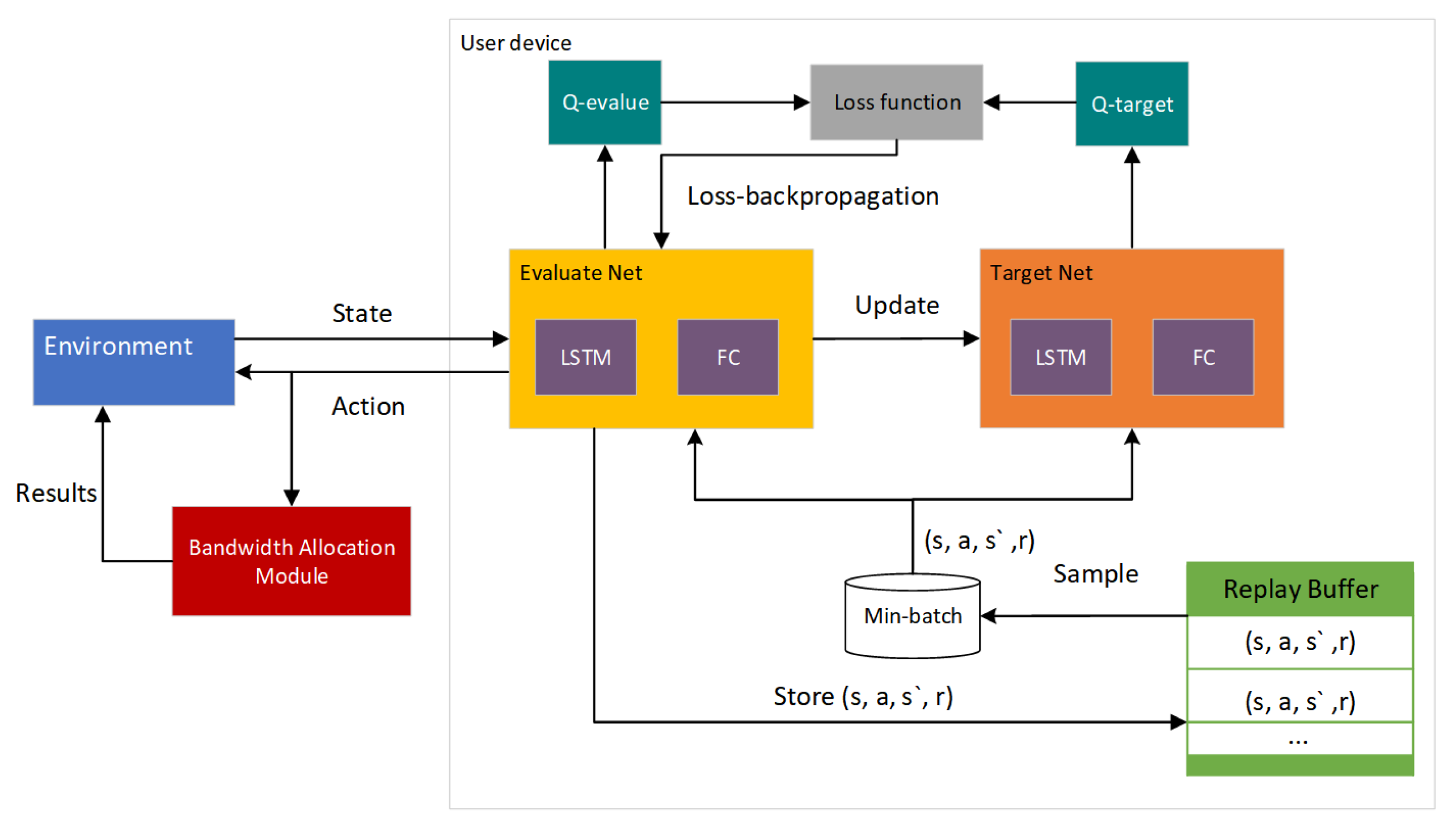
In this section, we propose a deep reinforcement learning-based approach to obtain task offloading policies and an optimal resource allocation scheme. Each user device observes the state from the environment at the inception of each time slot. Firstly, the user device anticipates the current active state of edge nodes predicated on historical active information of edge nodes. Secondly, the user device selects an appropriate action per the state and receives the corresponding bandwidth allocation. Subsequently, the tuples of state, action, and reward information, along with the historical active level information of edge nodes, are stored in an experience repository. Small batches of data are extracted from this experience repository, and the sampled data are then used to train the network. Through iterative learning, the network learns the mapping policy from state–action pairs to Q-values to obtain the offloading strategy that maximizes the long-term cumulative rewards. The entire process is shown in Figure 3.
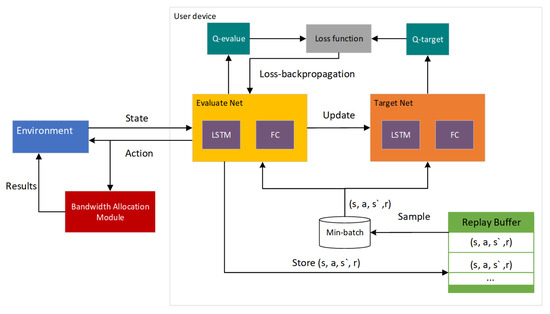
Figure 3.
Algorithmic framework.
Our model is constructed on the architecture of deep Q-learning, an effective approach for addressing complex, high-dimensional problems characterized by long-term temporal dependencies. The deep Q-learning technique employs a deep neural network with initialized parameters to forecast the Q-values of state–action pairs. By leveraging mechanisms such as a replay buffer and a dedicated target network, the neural network is trained to refine its predictions of Q-values. By continuous iterative updating, the optimal policy is obtained. Its loss function is calculated as , where represents the discount factor for future rewards, represents the neural network parameters, which are periodically updated, and signifies the most current neural network parameters [41].
To tackle the challenge faced by user devices in not being aware of the dynamic load status of edge nodes, we integrate an LSTM prediction layer into the neural network. This enables user devices to anticipate the real-time state of edge nodes based on their historical load data, thus ensuring a potential load balance among edge nodes. Furthermore, following the task offloading decision, user devices acquire the optimal communication bandwidth allocation value according to the system conditions in the current time slot, ensuring maximum utilization of network resources. Algorithm 1 delineates the detailed procedure of our proposed dynamic computation offloading and resource allocation algorithm, BPDRL. The proposed BPDRL algorithm is a distributed approach, where each user device independently makes offloading decisions based on its local observations and historical information. This distributed nature ensures that the algorithm can scale efficiently with the number of user devices and edge nodes, without requiring a centralized controller to manage all decisions.
The algorithm initiates by initializing the parameters of the primary evaluation network and the target network. It ascertains the current active status of edge nodes via an LSTM prediction layer. Thereafter, based on the obtained current state s, it employs an strategy to select offloading actions. The user device opting to offload its task to an edge node broadcasts the task status information to other user devices within the network and concurrently receives task information from other user devices offloading their tasks to edge nodes. Based on formulation (26), the optimal communication bandwidth allocation scheme is established. Subsequently, the user device carries out the offloading action and interacts with the environment to garner the reward r and the subsequent state information under action a. The experience tuple is then stored into the experience replay buffer, and learning is conducted by randomly sampling from the experience replay memory. The target Q-value is computed using the target network. The parameters of the primary evaluation network are updated in accordance with the loss function , and the parameters of the target network are periodically updated.
Our algorithm not only considers the computation offloading and resource allocation problems in the MEC scenarios but also proposes an adaptive task offloading and resources allocation scheme based on the unknown load status of edge nodes in the current dynamic scenario. In this scheme, each user device can fully utilize the computational resources of edge nodes and the system’s communication resources while maintaining system stability through load balancing on edge nodes.
| Algorithm 1 Algorithm of BPDRL. |
|
Divergent from traditional reinforcement learning methods, our approach encompasses personalized training networks for each user agent to make independent offloading decisions and engage with the environment. Moreover, we utilize the long-term weighted cost of the system as the optimization objective to gauge the QoS for users. Furthermore, to ensure the implementation of training networks on the user side, we incorporate deep compression techniques, which involve quantizing and pruning the parameters within the training network to reduce network size and expedite model convergence. Algorithm 2 outlines the specific steps of quantization and pruning.
| Algorithm 2 Pruning and parameters quantization. |
|
5.4. Complexity Analysis
The complexity of the BPDRL algorithm can be broken down into two main components: the training phase and the inference phase. We define N as the quantity of multiplication operations necessary for a single training iteration of the deep neural network, E as the total number of training episodes, and B as the batch size of samples utilized for training in each episode. Given that K tasks are stochastically generated by user device u over the time period T, the computational complexity of the proposed BPDRL algorithm during the training phase can be articulated as . During the inference phase, each user device uses the trained neural network to make offloading decisions in real time. The complexity of this phase is O(N) per time slot, as it involves a single forward pass through the neural network. It should be noted that the training and inference of neural networks introduce additional computational overhead. However, as this study focuses on optimizing the long-term average system cost, these additional computational costs are not explicitly considered in the analysis.
6. Experimental Results
Simulation experiments were carried out on a personal computer with a 3.20 GHz AMD Ryzen 7 5800H processor. PyCharm 2022.1.3 (Community Edition) served as the integrated development environment for implementing the experiments, and TensorFlow was utilized to construct the deep neural network model in Python.
In this section, we initially present the simulation experiment’s parameter settings and the benchmark methods for comparative analysis. Subsequently, we assess the convergence of the proposed algorithm and compare its performance with the baseline approaches under various scenarios, thereby highlighting the efficacy of our algorithm. Lastly, we discuss the influence of deep compression techniques on the proposed algorithm.
6.1. Parameter Settings
We simulate a circular area with a 50 m coverage radius, housing a base station equipped with multiple MEC nodes [10]. User devices are uniformly distributed across the area, engaging in wireless communication with the base station. The channel gain from user device u to the base station S is defined as , where d denotes the Euclidean distance between user device u and the base station S, and is the path loss factor [42]. Other specific parameter settings are detailed in Table 3.
Table 3.
Parameter settings.
To demonstrate the advantages of our proposed algorithm in maintaining system load balancing performance, we compare it with the following baseline algorithms:
- (1)
- Random Offloading (Random): For arriving tasks, each user device randomly chooses an offloading strategy, either processing the task locally or uploading it to an edge node for MEC server processing. This scheme can achieve load balancing of edge nodes in a static environment.
- (2)
- Deep Q-Network Offloading [26] (DQN): In a static communication environment, this algorithm considers the impact of latency and dynamic edge node loads on the system, employing a DQN-based approach to determine the offloading strategy.
- (3)
- Hybrid Artificial Bee Colony Algorithm [44] (HABC): The algorithm employs a heuristic approach that integrates the strengths of genetic algorithms and simulated annealing to address the task offloading problem under constrained edge server resources.
6.2. Algorithm Convergence
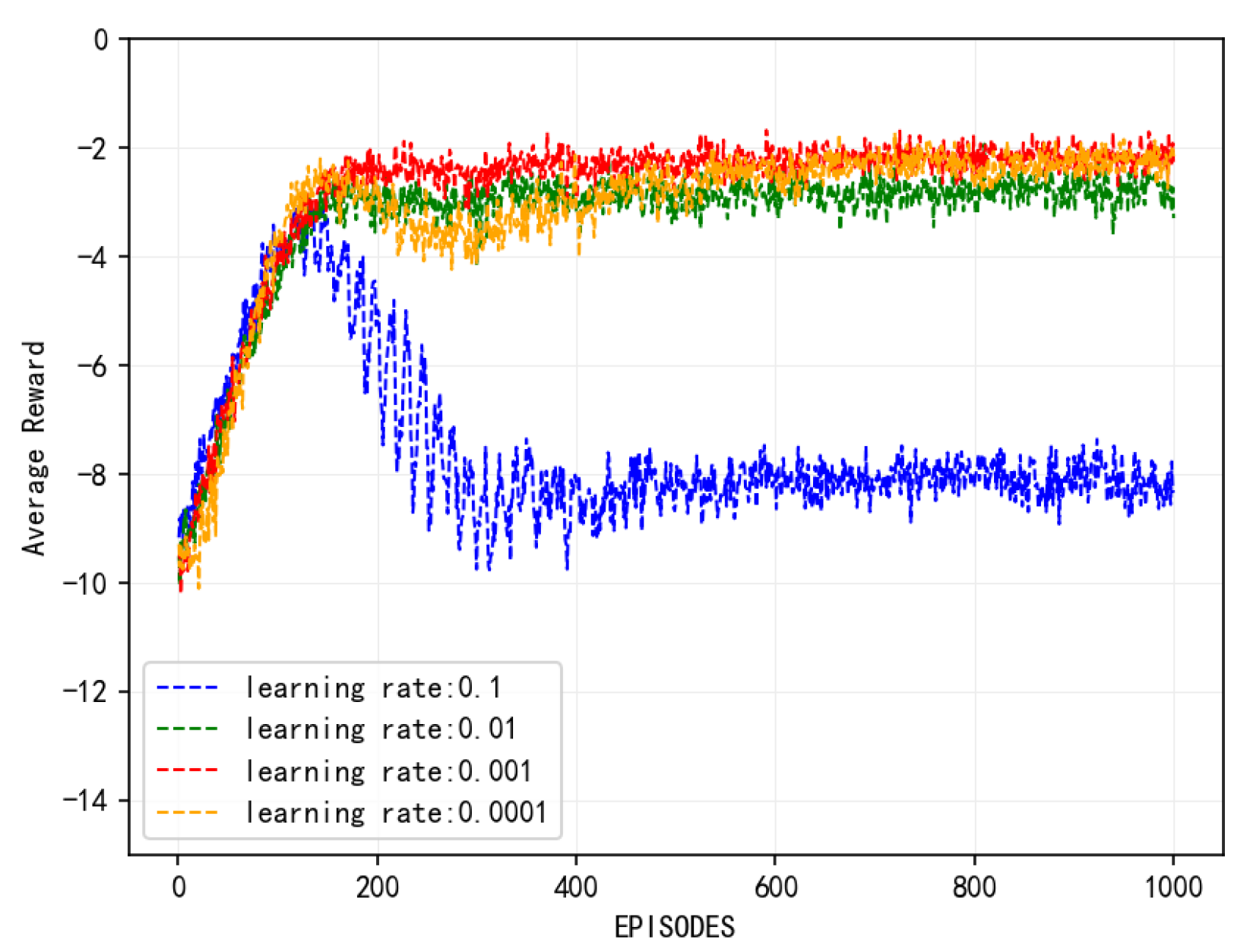
Figure 4 illustrates the convergence behavior of the proposed algorithm under various learning rates. It is evident that the algorithm converges across all tested learning rates. Specifically, at a learning rate of 0.1, the algorithm exhibits the lowest convergence reward and the poorest performance. With a learning rate of 0.0001, the algorithm converges slowly, stabilizing at around 400 iterations. At a learning rate of 0.001, the algorithm converges more rapidly and achieves the peak reward value. The comparative results indicate that an excessively high learning rate can result in training oscillations, preventing the model from reaching the global optimal solution. Conversely, an overly low learning rate can lead to slow convergence and potential overfitting, thereby diminishing the model’s generalization capability. Therefore, selecting an appropriate and effective learning rate is crucial for algorithm performance.
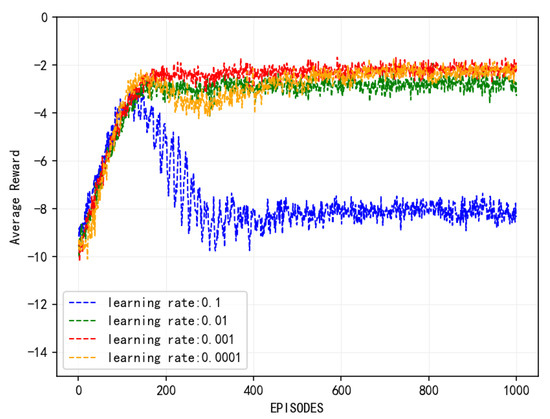
Figure 4.
Convergence of algorithm at different learning rates.
In addition to the learning rate, the discount factor is another critical hyperparameter that directly influences the agent’s performance by determining the weight given to future rewards. We tested values in the range of 0.8 to 0.99. A smaller value (e.g., 0.8) biases the agent toward immediate rewards, leading to suboptimal solutions in tasks requiring long-term planning. Conversely, a larger value (e.g., 0.99) encourages the agent to prioritize long-term rewards but may result in slow convergence due to overemphasis on distant outcomes. Empirical results indicate that = 0.9 strikes a good balance, enabling efficient exploration of long-term strategies without sacrificing convergence speed. Based on these analyses, subsequent experiments were conducted using the hyperparameter settings of = 0.001, = 0.9, a batch size of 32, and a replay buffer size of 500.
6.3. Algorithmic Comparison
In this segment, we assess the comparative performance of various algorithms with respect to system load balancing as the task arrival rate changes. Additionally, we evaluate the scalability of different algorithms under varying numbers of user devices. To quantify the load balancing efficacy in a dynamic MEC environment, we employ metrics such as the task drop rate, the average system cost, and the ratio of tasks processed locally or offloaded to edge nodes against the total number of tasks generated over a defined period. These metrics are widely recognized and utilized in numerous research studies [25,26,32].
6.3.1. Impact of Varying Task Arrival Rates
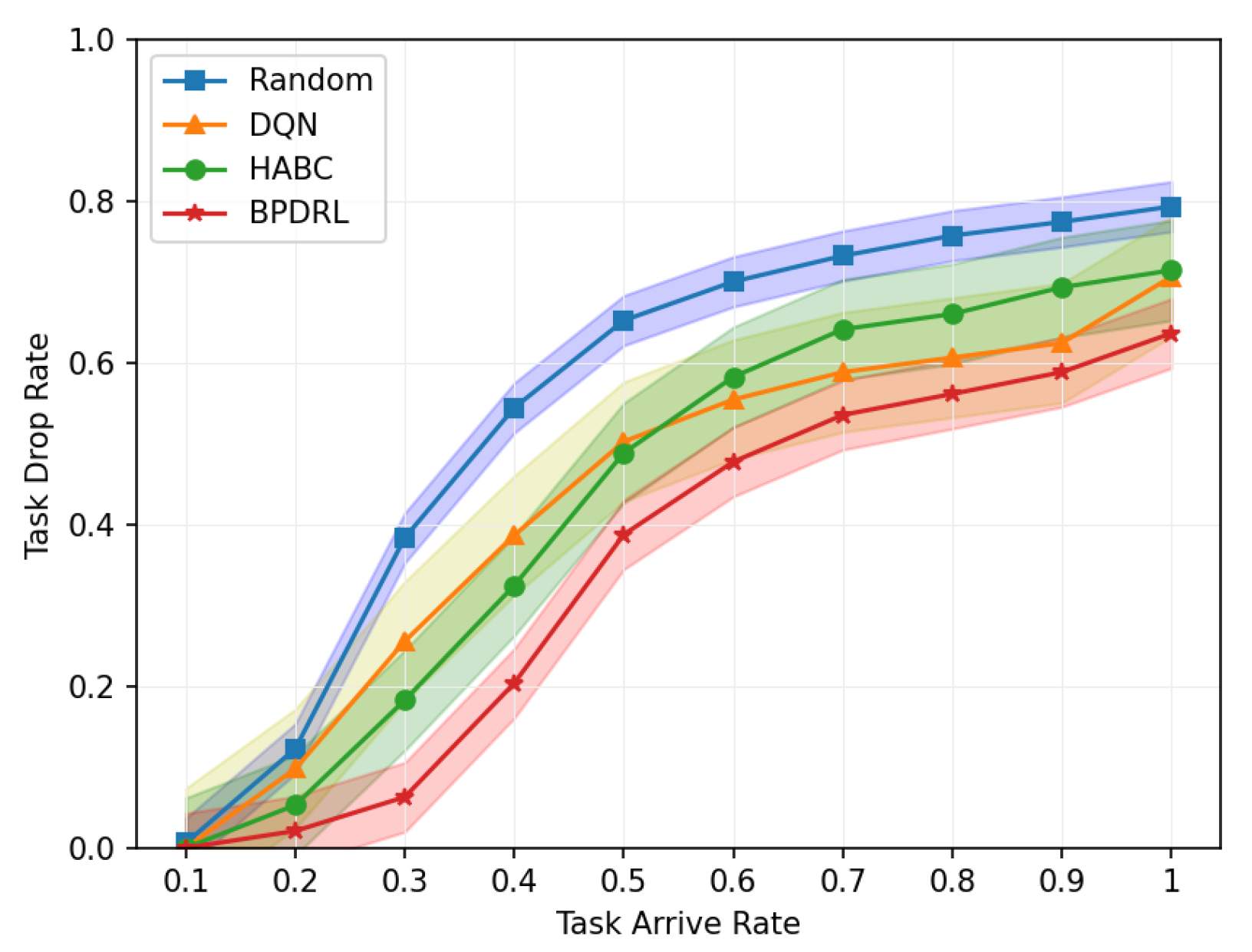
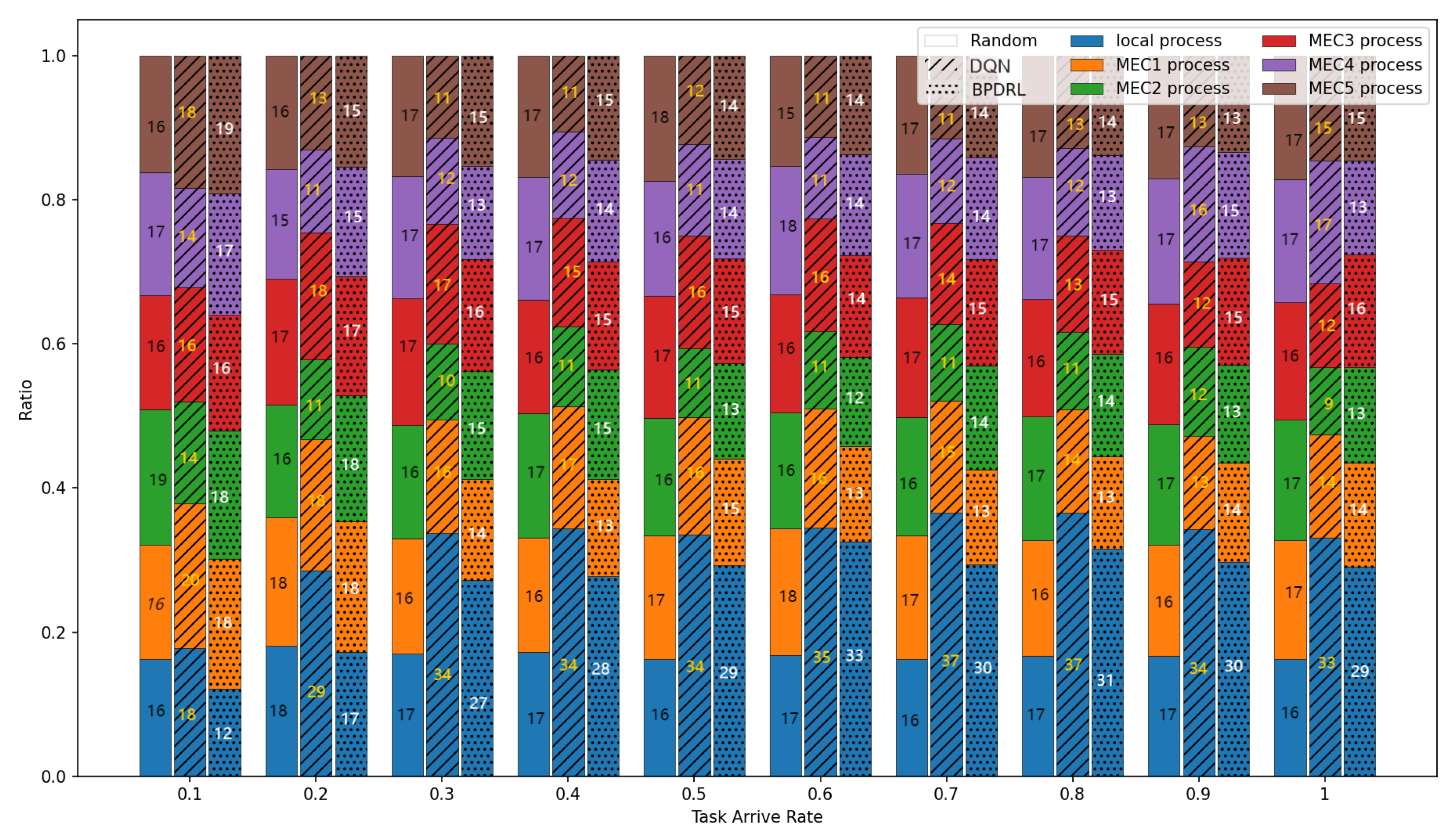
Figure 5 delineates the comparison of task drop rate across varying task arrival rates. As the task arrival rate escalates, the task drop rates for all algorithms increase correspondingly. The proposed BPDRL algorithm effectively predicts the load levels of edge nodes in advance, ensuring optimal utilization of computational resources while avoiding excessive load. Consequently, it achieves the lowest task drop rate, even at a task arrival rate of 1. Notably, at a task arrival rate of 0.4, the BPDRL algorithm reduces the task drop rate by 47% compared to the DQN algorithm and by 37% compared to the HABC algorithm. These results highlight the superior robustness and stability of the BPDRL algorithm in high-load environments. Figure 6 presents the comparative distribution of tasks processed locally or offloaded to edge nodes as a percentage of the total tasks generated over a specified period under varying task arrival rates. It is evident that under the Random approach, user devices indiscriminately offload tasks to edge nodes. However, this strategy overlooks the system’s dynamic attributes, leading to elevated task drop rates. In contrast to the DQN algorithm, our BPDRL algorithm demonstrates a reduced proportion of tasks processed locally and a more equitable distribution of tasks offloaded to various edge nodes. This outcome can be credited to our algorithm’s implementation of a more efficient offloading strategy coupled with an optimal resource allocation scheme, which stabilizes loads across different edge nodes and ensures consistent system performance.
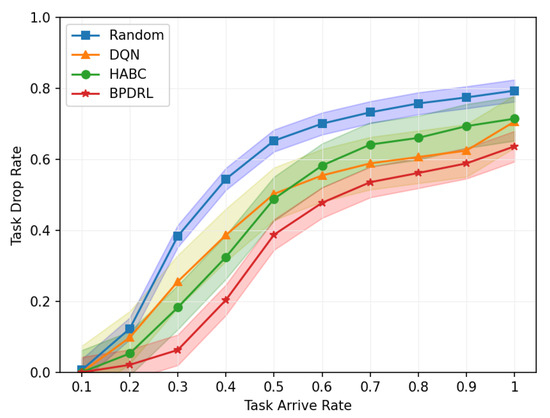
Figure 5.
Comparison of task drop rates under different task arrival rates.
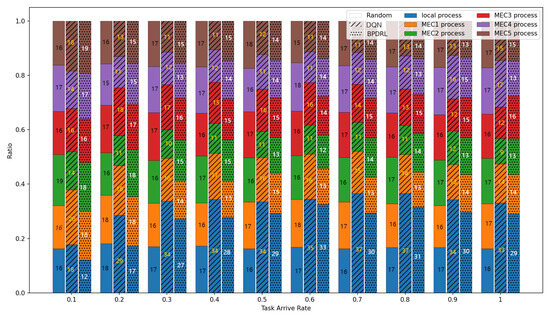
Figure 6.
Comparison of proportion of tasks with different offloading methods under different task arrival rates.
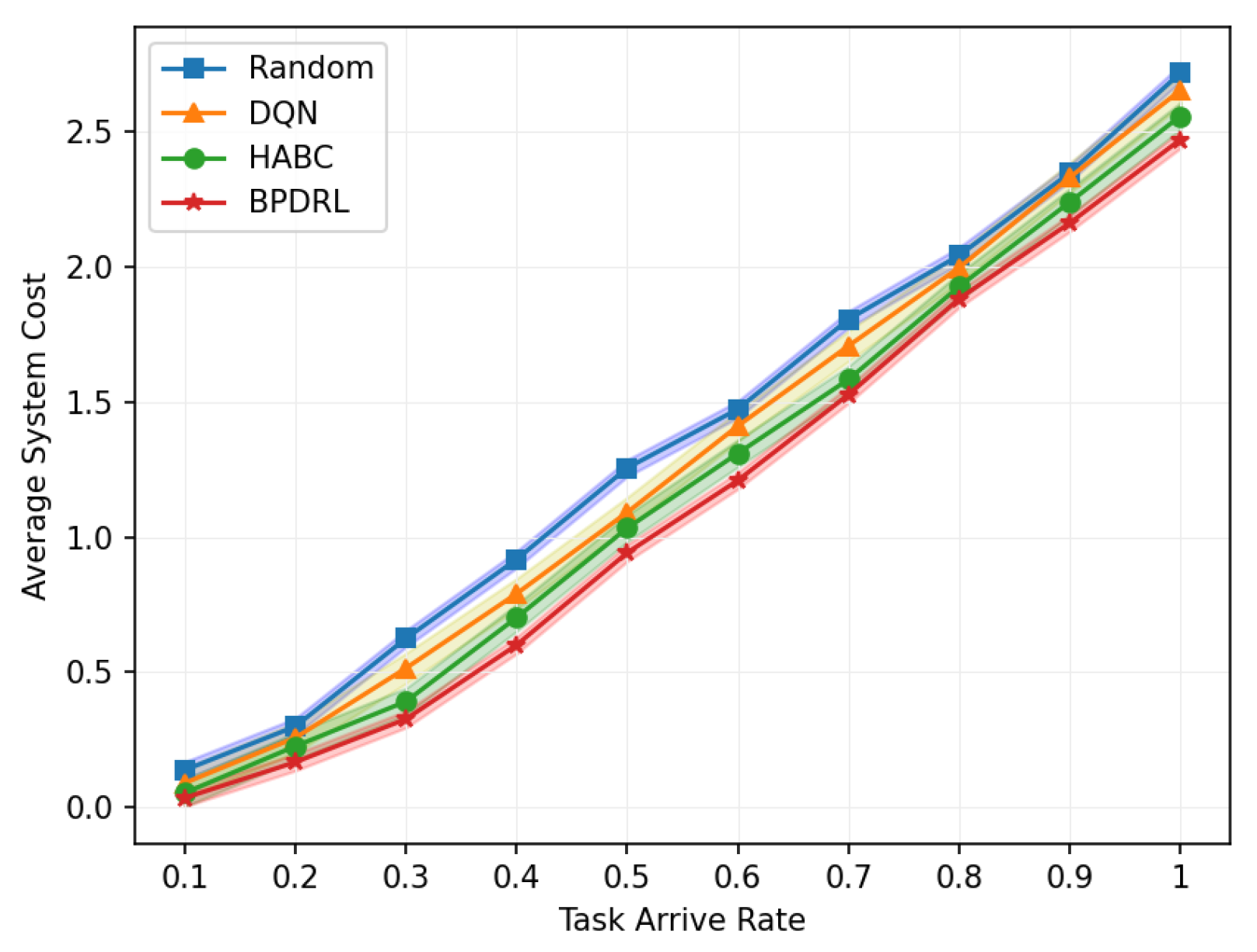
Figure 7 illustrates the average system cost under different task arrival rates with the delay weighting parameter set to 0.9. As the system’s task processing demands increase, the average system cost rises accordingly. The figure indicates that our proposed method consistently achieves the lowest average system cost compared to the other three algorithms. At a task arrival rate of 0.6, our proposed algorithm reduces the overall system cost by 14%, 18%, and 8% compared to the DQN, Random, and HABC algorithms, respectively. This reduction is due to our algorithm’s capability to dynamically devise offloading strategies based on the projected load status of the edge nodes and to adjust resource allocation in real time according to different offloading strategies employed by user devices.
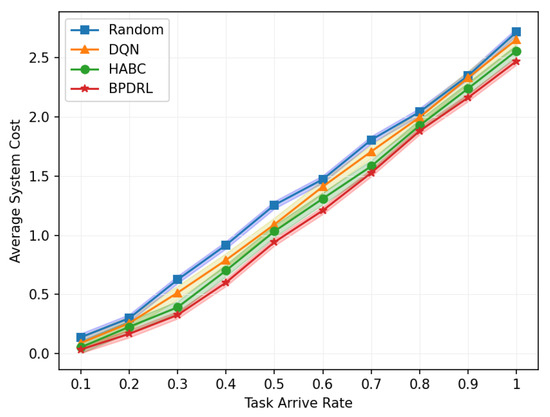
Figure 7.
Comparison of average system cost under different task arrival rates.
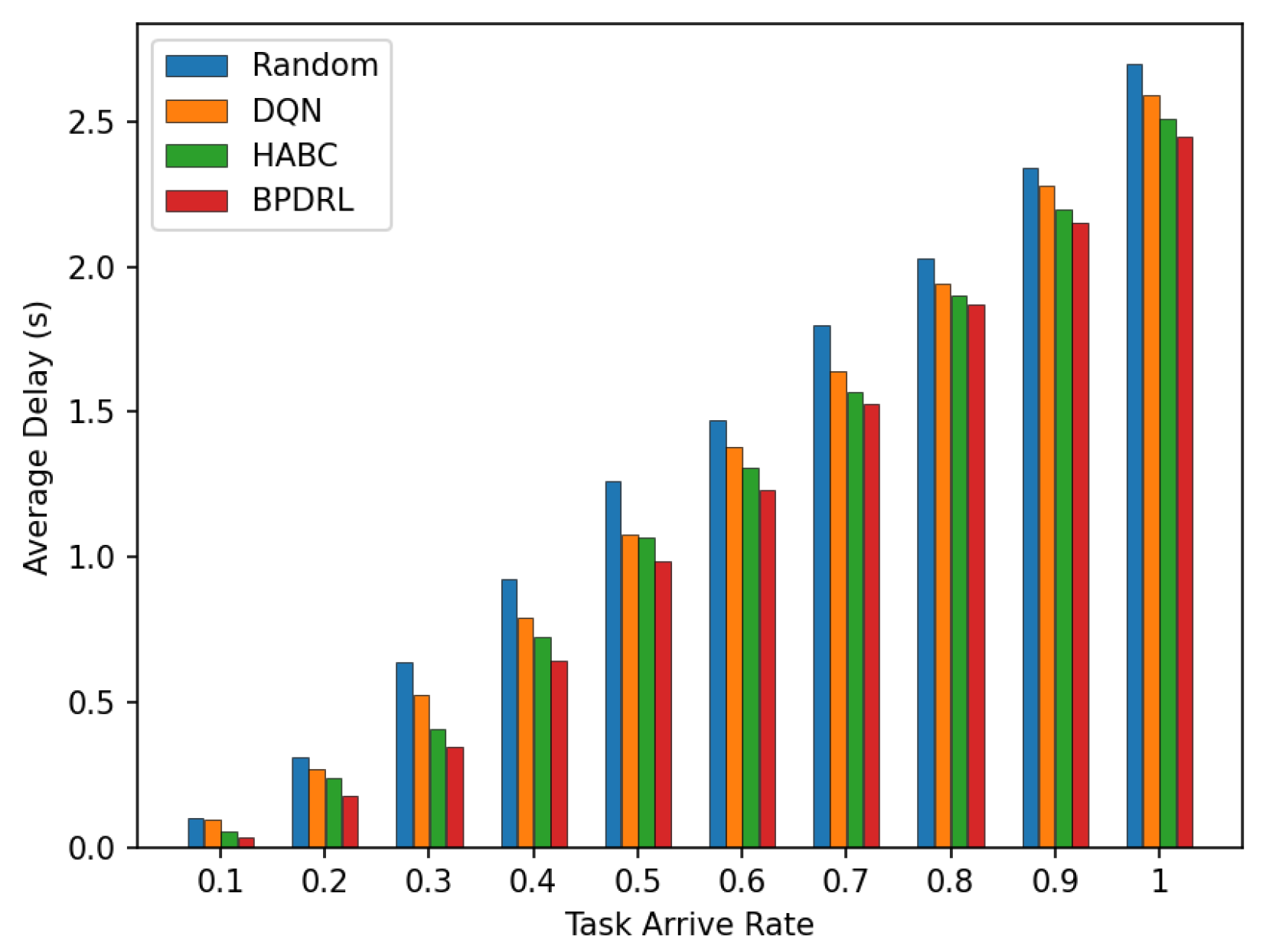
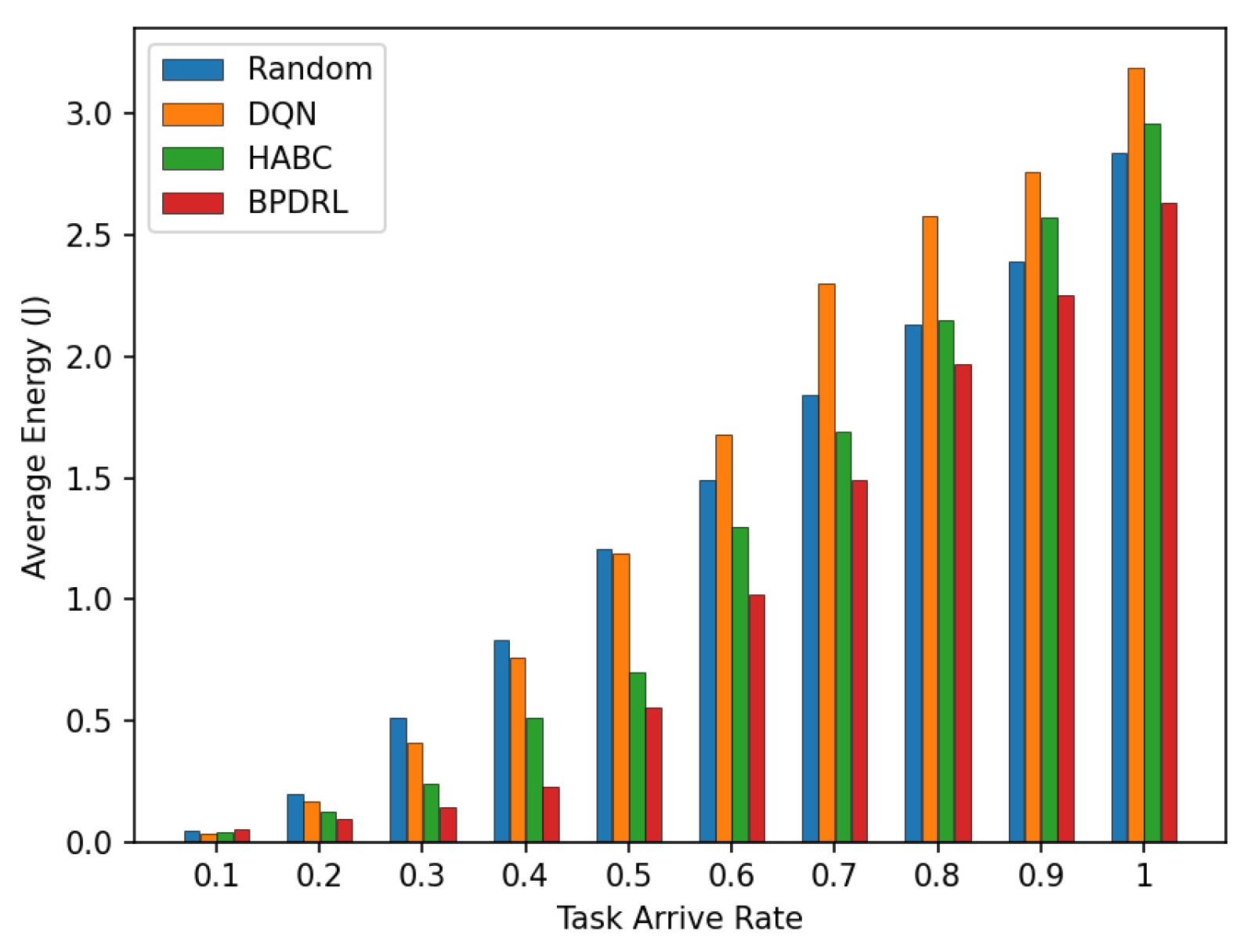
Figure 8 compares the average delay per time slot under various task arrival rates. Our approach consistently achieves the lowest average delay compared to the three baseline schemes. This advantage is attributed to our method’s priority selection to offload tasks to less burdened edge nodes for real-time tasks. Specifically, the incorporation of an LSTM-based prediction module into our algorithm enables user devices to predict the current load of each system node based on historical offloading data, thereby facilitating more accurate and efficient offloading decisions. Moreover, by optimally allocating real-time communication bandwidth to user devices, our approach enhances task transmission rates, leading to further improving the latency performance. Figure 9 illustrates the comparison of average energy consumption per time slot for different task arrival rates. As the task arrival rate increases, our proposed scheme consistently exhibits the lowest average energy consumption compared to the three baseline schemes. This superior performance is attributed to the ability of our scheme to maintain the lowest task drop rate across varying arrive rates by preferentially offloading tasks to edge nodes with greater available resources. This strategy minimizes energy wastage due to task drops and reduces the energy consumption of local devices.
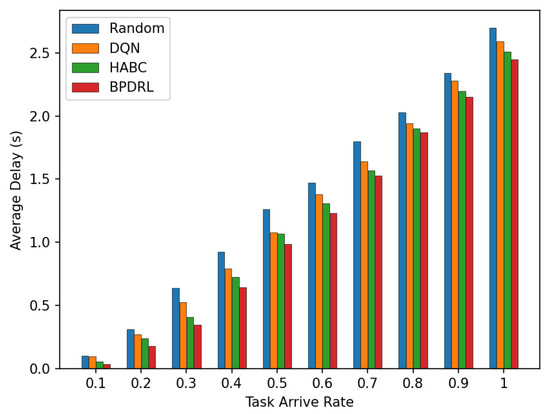
Figure 8.
Comparison of average delay under different task arrival rates.
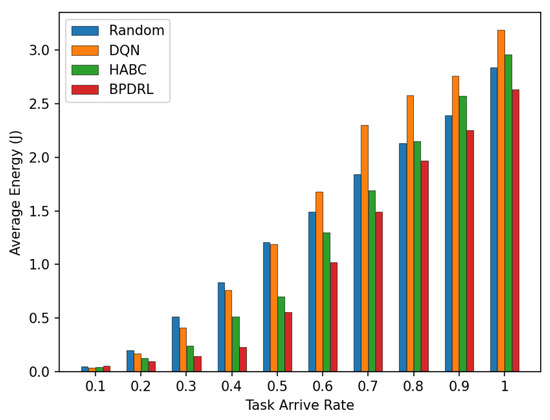
Figure 9.
Comparison of average energy under different task arrival rates.
6.3.2. Impact of Varying User Device Populations
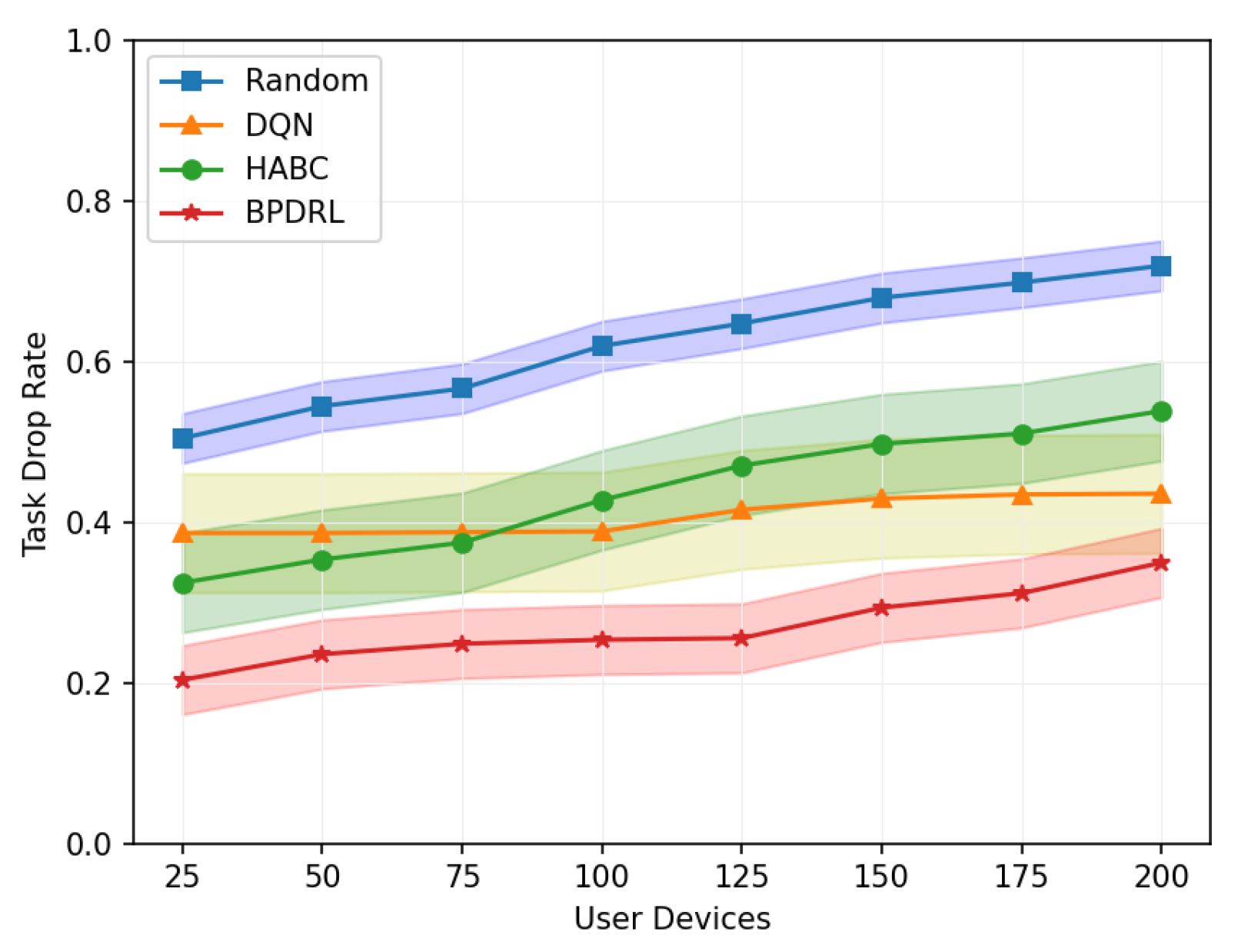
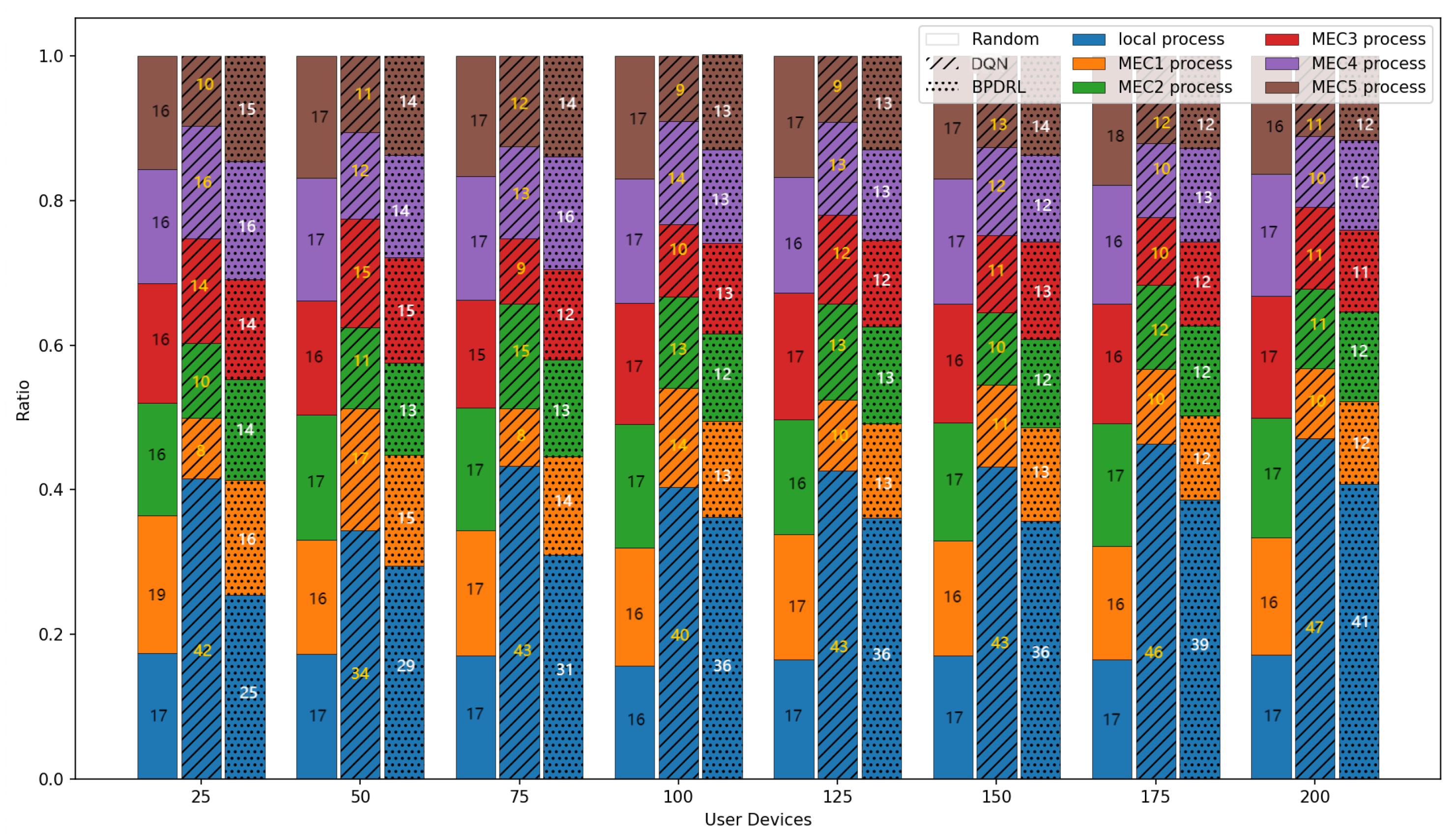
Figure 10 shows the comparison of the system task drop rate under different network scales defined by user device quantities. As the number of user devices increases, task drop rates for all schemes rise accordingly. However, our proposed approach consistently achieves the lowest task drop rates in scenarios with a large user base. This is due to the algorithm’s capability for each user to effectively predict real-time load dynamics at edge nodes, thereby fully utilizing the system’s communication and computing resources. This ensures dynamic load balancing and optimal resource utilization. When the number of user devices reaches 200, our approach reduces the task drop rate by 51.4%, 19.7%, and 35% compared to the Random, DQN, and HABC algorithms. Figure 11 compares the percentage of tasks processed locally or offloaded to the edge nodes relative to the total tasks generated over a given time period under different network scales. While the Random strategy distributes tasks evenly, it overlooks system dynamics, leading to higher task drop rates. In contrast, our approach dynamically maintains load balance among edge nodes based on real-time load levels, achieving a lower task drop rate. Compared with the DQN strategy, our approach tends to offload more tasks to the edge nodes and achieves a more balanced distribution of offloading decisions among the edge nodes, offering a significant advantage in addressing the load balancing challenges of edge nodes.
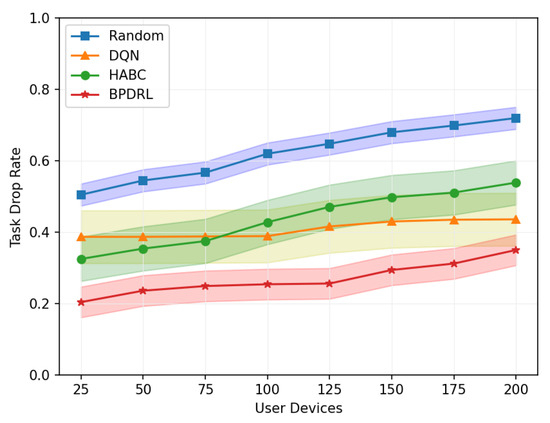
Figure 10.
Comparison of task drop rates under different user devices.

Figure 11.
Comparison of proportion of tasks with different offloading methods under different user devices.
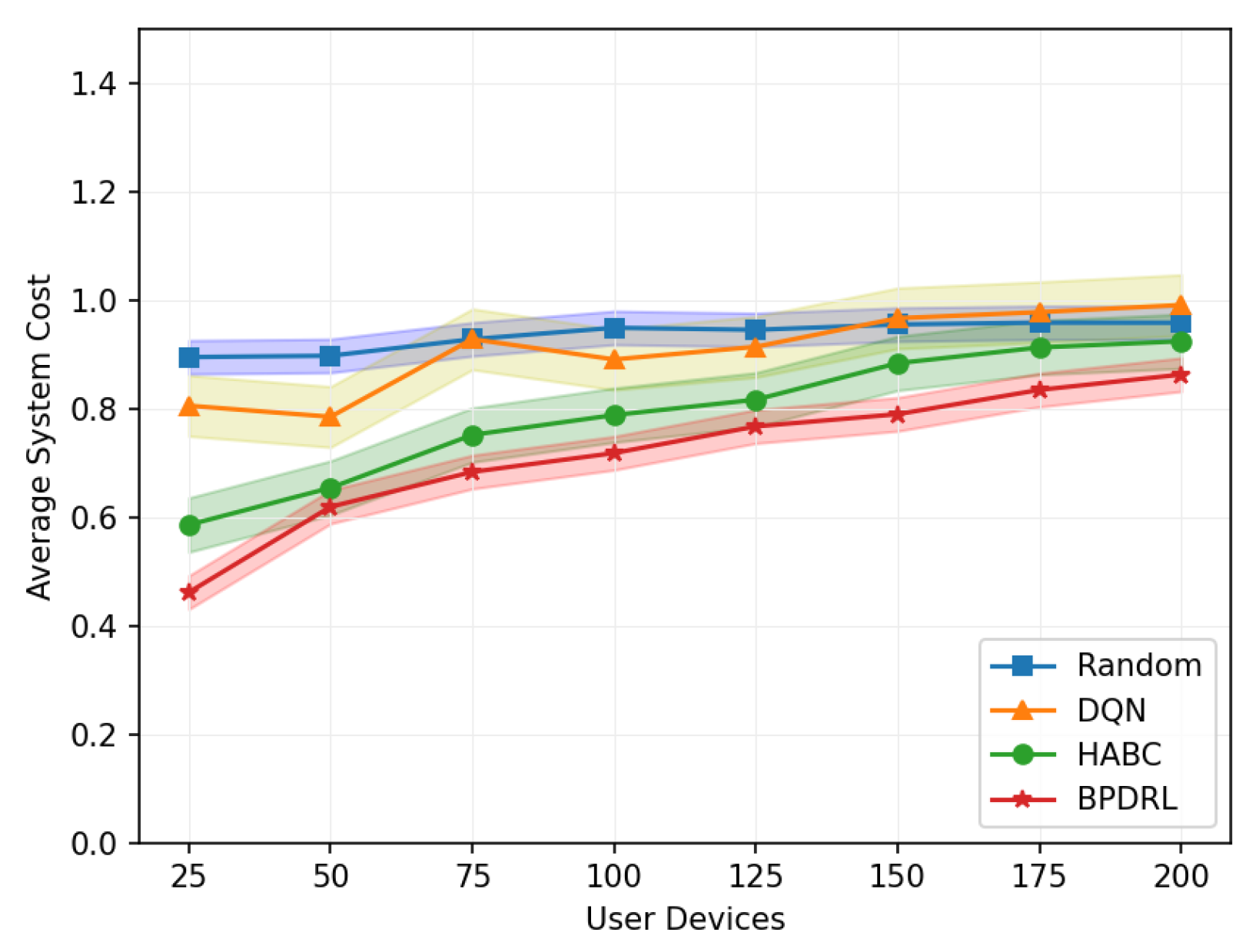
Figure 12 illustrates the variation in average system cost across different network sizes when the delay weighting parameter is set to 0.7. The Random algorithm consistently maintains a high system cost, reflecting its suboptimal performance in resource utilization and task allocation. While the DQN algorithm achieves a lower system cost compared to the Random algorithm, its performance deteriorates significantly as the number of user devices increases, indicating limited adaptability to large-scale user networks. In contrast, the HABC algorithm demonstrates greater stability across varying network sizes, with only a slight increase in system cost as the number of user devices grows. However, the BPDRL algorithm consistently achieves the lowest system cost among all the baseline methods, with the most moderate growth trend as network size expands. These findings underscore the superior efficiency and robustness of the BPDRL algorithm in optimizing resource allocation and task offloading, effectively mitigating the impact of increased network scale on system performance.
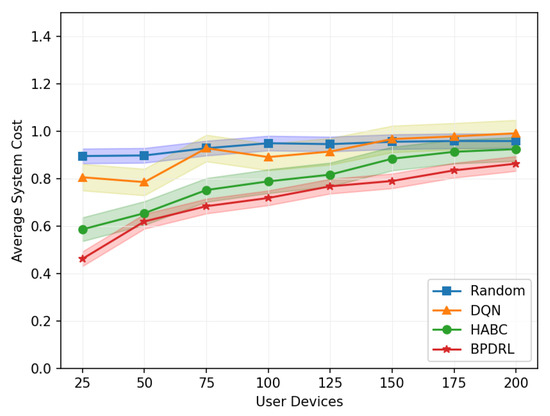
Figure 12.
Comparison of average system cost under different user devices.
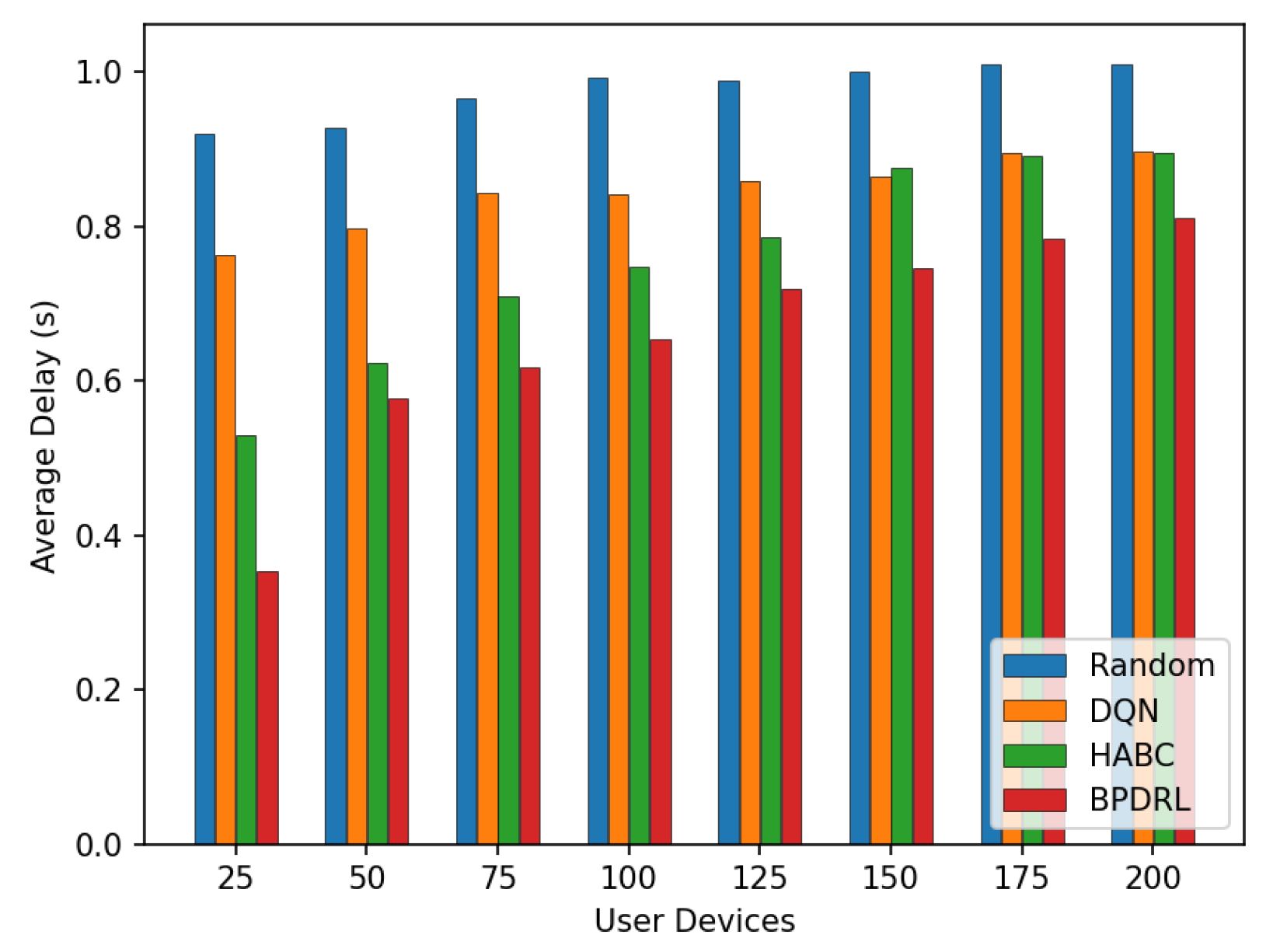
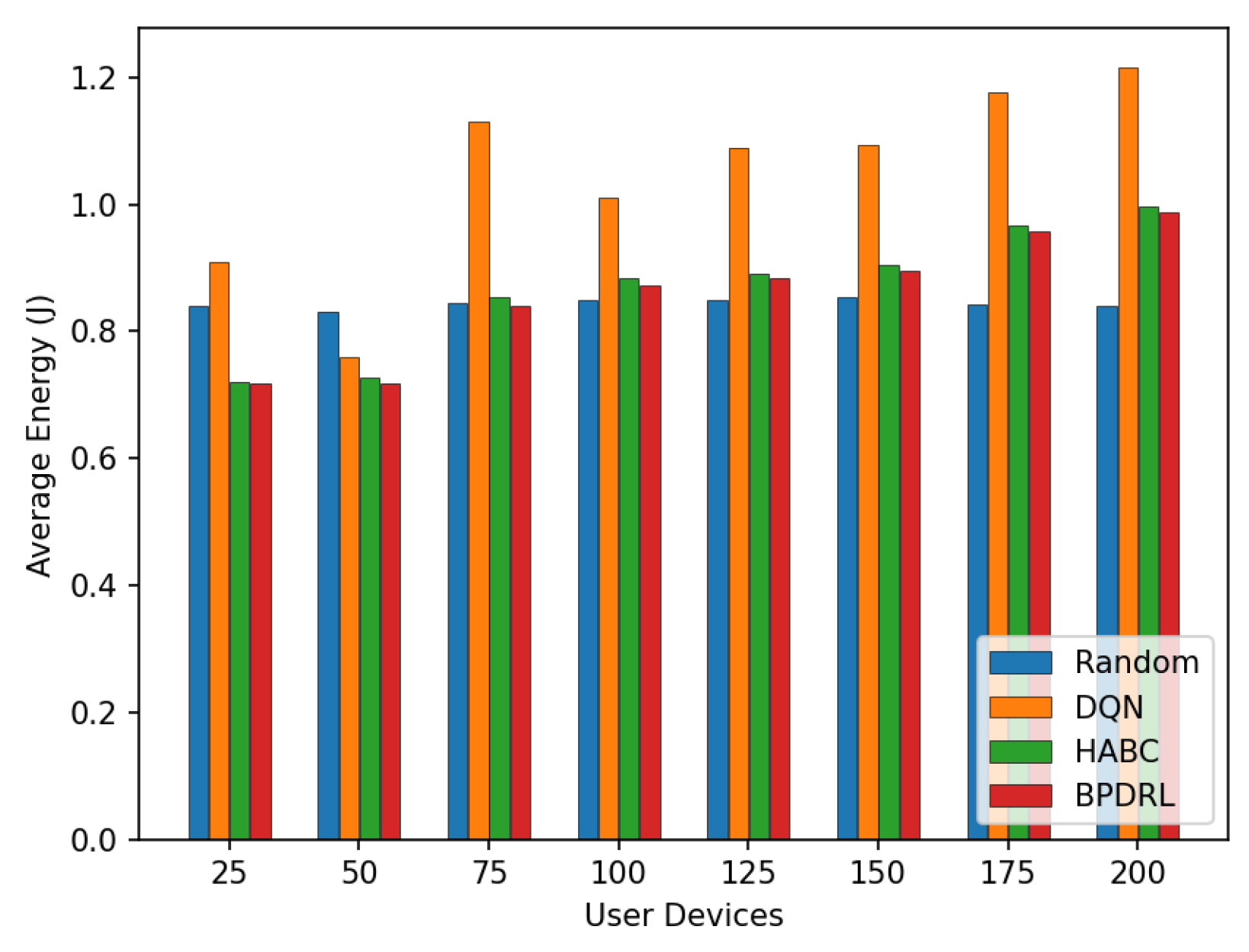
Figure 13 compares the average delay per time slot under varying user device populations. As the number of user devices increases, the average delay rises for all schemes. Notably, the proposed method achieves the lowest average delay compared to the baseline schemes. This performance disparity arises because mobile edge nodes have limited computational resources. As the number of user devices grows, more tasks are offloaded to the edge nodes for processing. This surge in task volume often leads to overloaded edge nodes, causing a significant number of tasks to be dropped and thereby increasing the average delay. In contrast, the proposed algorithm enables each user device to predict the current load of edge nodes based on the system’s historical states. This predictive capability ensures that computational resources across edge nodes are utilized efficiently without causing overloads. As a result, tasks are processed more effectively within shorter time frames, significantly reducing the average delay. Figure 14 presents the average energy consumption per time slot under different network scales. With an increasing number of user devices, our scheme consistently maintains the lowest average energy consumption. When the number of user devices is 200, our method reduces the average system energy consumption by 18.8% and 1% compared to the DQN and HABC schemes.
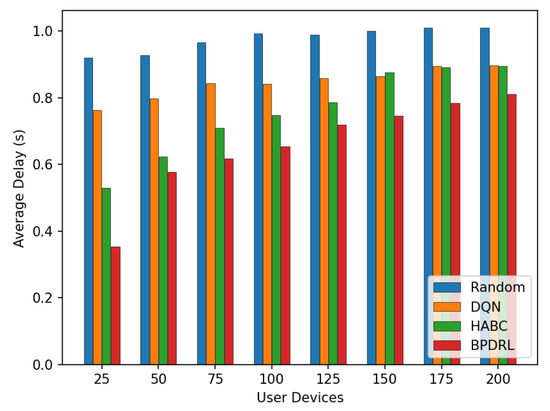
Figure 13.
Comparison of average delay under different user devices.
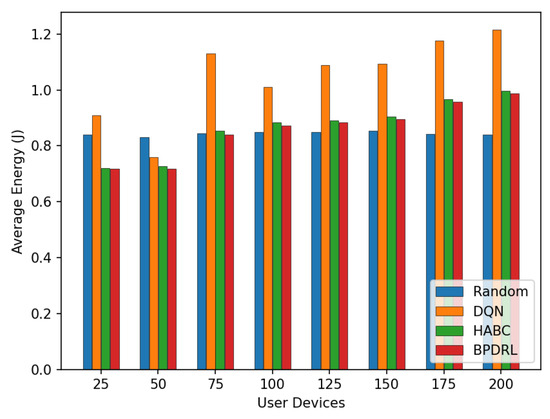
Figure 14.
Comparison of average energy under different user devices.
6.3.3. The Comparison of Runtime
To enhance the convergence performance of our proposed algorithm on user devices, we employ deep compression techniques to prune the model and quantize parameters. The model achieves pruning by removing parameters with smaller weights based on a predefined pruning threshold, thereby reducing the number of parameters and the associated computational complexity. Subsequently, an 8-bit quantization technique is employed to convert the pruned parameters from floating-point representations to low-precision 8-bit signed integers, effectively minimizing storage requirements while further reducing computational complexity.
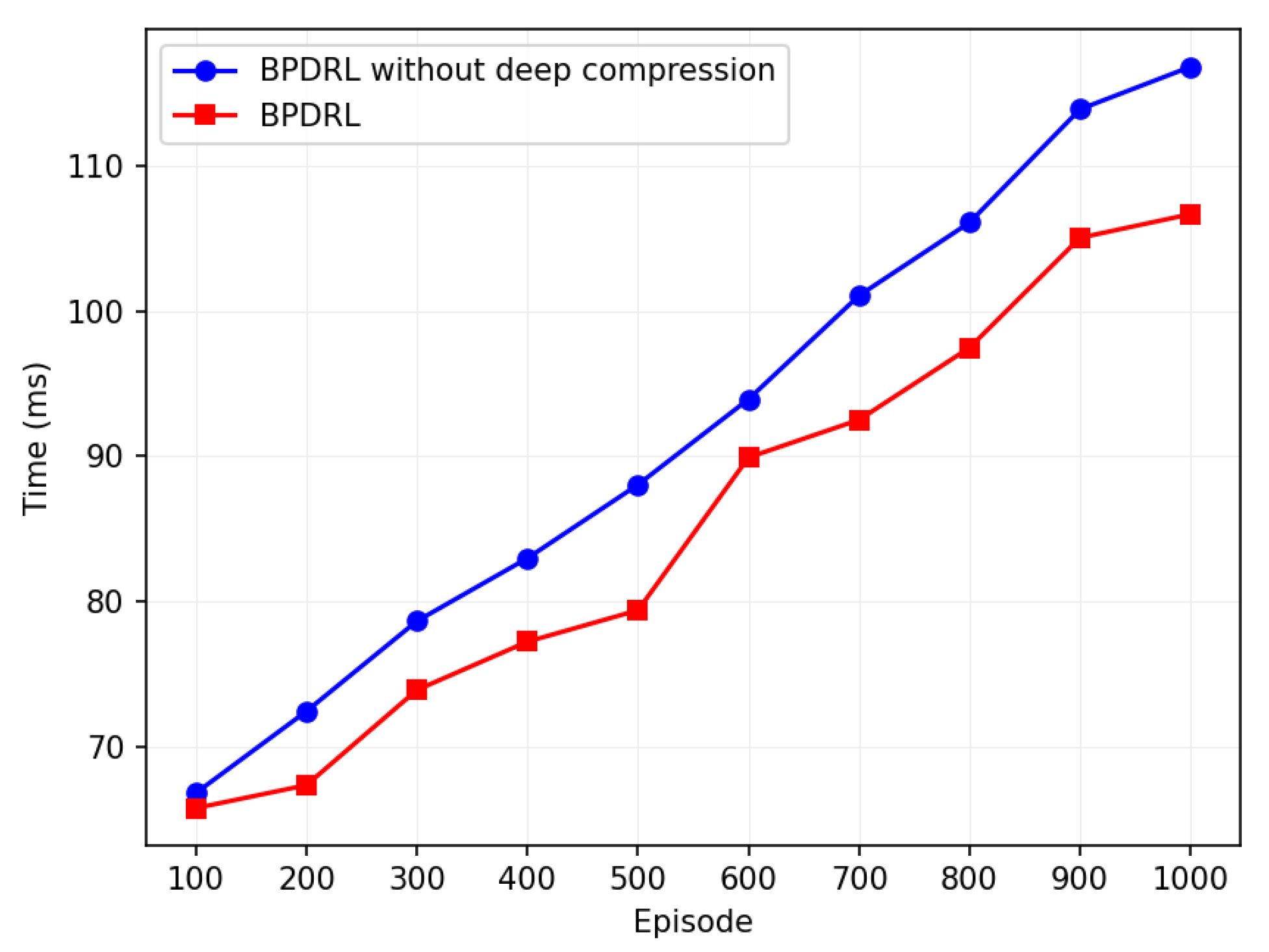
Figure 15 compares the runtime of the algorithm with and without deep compression techniques. The horizontal axis represents training episodes, and the vertical axis indicates the average runtime per training episode every 100 episodes. The average runtime increases with training episodes, but the model with deep compression consistently shows lower runtime. Over 1000 training episodes, the algorithm with deep compression reduces runtime by 7.6% compared to the non-compressed version, with only a 3.5% reduction in task drop rate. The results demonstrate that the deep compression technique enhances the operational efficiency of the model while preserving its performance. Although pruning and quantization remove certain parameters, potentially impacting model accuracy, experimental verification reveals that the pruned and quantized model maintains a low task discard rate even under high task arrival rates. This highlights the model’s ability to sustain both accuracy and stability. Furthermore, as a 32-bit floating-point number requires 4 bytes of storage while an 8-bit integer requires only 1 byte, 8-bit quantization significantly reduces the model’s storage requirements and runtime memory footprint. This compression makes the model more suitable for deployment on resource-constrained devices. Thus, we deem the integration of deep compression techniques into the model to be beneficial.
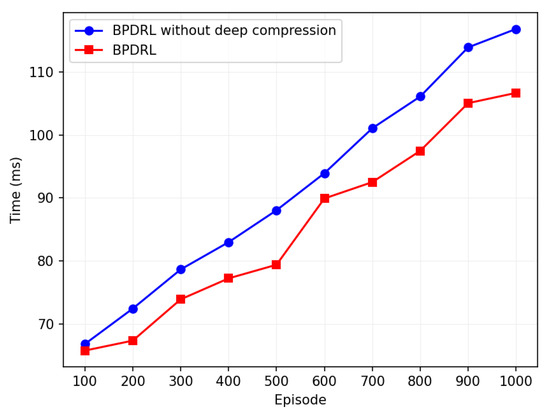
Figure 15.
Comparison of whether to use deep compression.
6.4. Analysis of Statistical Significance
To evaluate the performance enhancements achieved by the BPDRL algorithm in task offloading and resource allocation within mobile edge computing environments, a comparative analysis was conducted against the HABC algorithm, DQN algorithm, and Random Offloading strategy. The evaluation focused on key performance metrics, including task drop rate and system latency. To ensure the reliability and consistency of the results, the experiment was repeated 10 times under identical conditions. A two-sample t-test was then performed to assess the statistical significance of the findings.
Table 4, Table 5 and Table 6 demonstrate that the BPDRL algorithm achieves a substantial improvement in task drop rate, with an average reduction of 37% compared to the HABC algorithm (p-value = 0.005). This result highlights the BPDRL algorithm’s enhanced ability to handle high-load tasks and mitigate task losses caused by insufficient resources. Furthermore, when compared to the DQN algorithm, the BPDRL algorithm achieves a 47% reduction in task drop rate (p-value = 0.000), further underscoring its superior performance in resource-constrained environments. Notably, the BPDRL algorithm reduces the task discard rate by 63% relative to the Random Offloading strategy (p-value = 0.000), a significant improvement that emphasizes its capability to make intelligent task offloading decisions in dynamic and complex environments. The BPDRL algorithm also demonstrates significant advantages in reducing system latency. Compared to the HABC algorithm, it achieves an average latency reduction of 9% (p-value = 0.010), indicating its ability to expedite task processing and thereby minimize user waiting times. Similarly, the BPDRL algorithm reduces system latency by 9% compared to the DQN algorithm (p-value = 0.008), further validating its effectiveness in optimizing task processing times. Moreover, the BPDRL algorithm achieves a substantial 20% reduction in system latency relative to the Random Offloading strategy (p-value = 0.000), highlighting its notable superiority in minimizing latency in dynamic and resource-constrained environments.
Table 4.
Significance analysis of BPDRL vs. HABC.
Table 5.
Significance analysis of BPDRL vs. DQN.
Table 6.
Significance analysis of BPDRL vs. Random.
6.5. Real-World Deployment and Limitations of the BPDRL Algorithm
The implementation of the proposed algorithm involves several critical steps, including edge node deployment, user device integration, and system configuration. Specifically, edge nodes must be strategically deployed in proximity to user devices, such as base stations or routers, to minimize latency. Each edge node should be provisioned with adequate computational and storage resources to efficiently manage task offloading. User devices must be equipped with the requisite software to interface with the MEC system, enabling them to make offloading decisions based on the BPDRL algorithm. These devices should also be capable of monitoring their computational workload and communicating with the MEC system to receive bandwidth and computational resource allocations. The MEC system must be optimized to support the BPDRL algorithm, including the establishment of communication channels, resource allocation mechanisms, and the integration of the LSTM-based prediction layer. The system should be designed to accommodate dynamic variations in user workloads and task arrival rates, ensuring real-time adaptability and efficient resource utilization.
While the proposed BPDRL algorithm demonstrates feasibility in realistic MEC scenarios, several challenges persist when it is deployed under conditions of high user mobility and heterogeneous devices (HetDev). High user mobility results in frequent fluctuations in network conditions, particularly when users transition between different base stations or edge nodes. In such cases, efficient handover mechanisms are critical to ensuring seamless task offloading. Although the algorithm performs effectively in environments with stable communication link quality, it struggles to maintain low latency and high reliability in scenarios characterized by rapidly changing communication link conditions. In heterogeneous networks, user devices often possess varying computational capabilities, which can significantly impact their ability to process tasks locally or offload tasks to edge nodes. Ensuring that the algorithm operates seamlessly across devices with diverse hardware and software configurations poses an additional challenge. The experiments conducted in this study were performed within a homogeneous network setting, potentially limiting the algorithms’ compatibility and adaptability to heterogeneous network scenarios.
7. Conclusions
In this paper, we investigate the problem of task offloading and resource allocation in a multi-user multi-MEC system with the aim of minimizing the system long-term average cost. We propose a distributed scheme for offloading and resource allocation that takes into account queuing delays during task offloading. This strategy adeptly handles the dynamic and unpredictable load of edge nodes, optimizing the utilization of system resources. For tasks that newly arrive, user devices make adaptive offloading decisions to edge nodes based on the current system state, followed by the allocation of system bandwidth and computational resources. Simulation results demonstrate that our proposed approach markedly reduces the system’s task drop rate and long-term average cost while also sustaining commendable performance with respect to scalability across varying network sizes.
However, there are several limitations to our work. Firstly, the simulation experiments presuppose that users are stationary or exhibit low-speed mobility, thereby neglecting the impact of user mobility within the base station’s coverage area. This assumption may limit the applicability of our model to real-world scenarios where user mobility significantly affects task offloading and resource allocation decisions. Secondly, the task density parameter used in the simulations is set within a range of 20–51 cycles/bit, which may not fully reflect the task characteristics in modern computing systems, where tasks may exhibit much higher density values due to more complex computations or higher data requirements. This limitation could affect the generalizability of our results to real-world applications with different task profiles. Thirdly, our study does not consider inter-task dependencies, which are often present in practical scenarios. Additionally, data security and user privacy, which are crucial in MEC environments, are not explicitly addressed in this paper.
To address these limitations, future work will focus on integrating user mobility patterns and dynamic location changes into task offloading and resource allocation decisions. We will develop models and algorithms that incorporate inter-task dependencies to ensure more efficient and practical scheduling. Furthermore, future studies will investigate mechanisms to optimize task offloading and resource allocation while ensuring robust data security and user privacy, which are indispensable for the broader adoption of MEC systems. Additionally, we aim to refine the task density model to better reflect the requirements of modern computing systems.
Author Contributions
Conceptualization, W.C. and S.L.; methodology and software, S.L.; supervision, W.C.; writing—review and editing, W.C., S.L., Y.Y., W.H. and J.Y.; validation, W.C., S.L., Y.Y., W.H. and J.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Once the offloading decision is determined, Equation (21) simplifies to a convex function that depends solely on the bandwidth allocated to user device u. The terms and are independent of . Therefore, they can be represented by the constants and , respectively.
Given that we focus on bandwidth allocation for user devices with tasks that are not discarded within time slot t, the discarded tasks do not occupy bandwidth or computational resources. Consequently, only the tasks remaining in the transmission queue of user device u during time slot t need to be considered for communication bandwidth and edge computational resource allocation. Thus, Equation (21) can be further simplified as follows:
We consider real-time resource allocation within time slot t, which is derived by processing Equation (30) as follows:
For simplicity in representation, we define to represent the coefficients in Equation (30) that are independent of .
References
- Chen, Y.; Xu, J.; Wu, Y.; Gao, J.; Zhao, L. Dynamic task offloading and resource allocation for noma-aided mobile edge computing: An energy efficient design. IEEE Trans. Serv. Comput. 2024, 17, 1492–1503. [Google Scholar] [CrossRef]
- Ren, J.; Hou, T.; Wang, H.; Tian, H.; Wei, H.; Zheng, H.; Zhang, X. Collaborative task offloading and resource scheduling framework for heterogeneous edge computing. Wirel. Netw. 2024, 30, 3897–3909. [Google Scholar] [CrossRef]
- Wei, Y.; Blake, M.B. Service-oriented computing and cloud computing: Challenges and opportunities. IEEE Internet Comput. 2010, 14, 72–75. [Google Scholar] [CrossRef]
- Kekki, S.; Featherstone, W.; Fang, Y.; Kuure, P.; Li, A.; Ranjan, A.; Purkayastha, D.; Jiangping, F.; Frydman, D.; Verin, G.; et al. MEC in 5G networks. ETSI White Paper 2018, 28, 1–28. [Google Scholar]
- Xu, L.; Liu, Y.; Fan, B.; Xu, X.; Mei, Y.; Feng, W. An Improved Gravitational Search Algorithm for Task Offloading in a Mobile Edge Computing Network with Task Priority. Electronics 2024, 13, 540. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile edge computing: A survey on architecture and computation offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Maia, A.; Boutouchent, A.; Kardjadja, Y.; Gherari, M.; Soyak, E.G.; Saqib, M.; Boussekar, K.; Cilbir, I.; Habibi, S.; Ali, S.O.; et al. A survey on integrated computing, caching, and communication in the cloud-to-edge continuum. Comput. Commun. 2024, 219, 128–152. [Google Scholar] [CrossRef]
- Xiong, R.; Cheng, J.; Yuan, Q.; Ma, K.; Li, L.; Zhang, C.; Zeng, H. Reducing Power Consumption and Latency of Autonomous Vehicles With Efficient Task and Path Assignment in the V2X-MEC Based on Nash Equilibrium. IEEE Trans. Intell. Transp. Syst. 2024, 25, 12954–12967. [Google Scholar] [CrossRef]
- Li, F.; Yao, H.; Du, J.; Jiang, C.; Qian, Y. Stackelberg game-based computation offloading in social and cognitive industrial Internet of Things. IEEE Trans. Ind. Inform. 2019, 16, 5444–5455. [Google Scholar] [CrossRef]
- Wu, L.; Sun, P.; Wang, Z.; Li, Y.; Yang, Y. Computation offloading in multi-cell networks with collaborative edge-cloud computing: A game theoretic approach. IEEE Trans. Mob. Comput. 2023, 23, 2093–2106. [Google Scholar] [CrossRef]
- Li, Y.; Cheng, S.; Zhang, H.; Liu, J. Dynamic adaptive workload offloading strategy in mobile edge computing networks. Comput. Netw. 2023, 233, 109878. [Google Scholar] [CrossRef]
- Duan, S.; Lyu, F.; Wu, H.; Chen, W.; Lu, H.; Dong, Z.; Shen, X. MOTO: Mobility-Aware Online Task Offloading With Adaptive Load Balancing in Small-Cell MEC. IEEE Trans. Mob. Comput. 2024, 23, 645–659. [Google Scholar] [CrossRef]
- Xin, J.; Li, X.; Zhang, L.; Zhang, Y.; Huang, S. Joint Computation and Traffic Loads Balancing Task Offloading in Multi-Access Edge Computing Systems Interconnected by Elastic Optical Networks. IEEE Commun. Lett. 2023, 27, 2378–2382. [Google Scholar] [CrossRef]
- Zhang, W.; Feng, M.; Krunz, M. Latency Estimation and Computational Task Offloading in Vehicular Mobile Edge Computing Applications. IEEE Trans. Veh. Technol. 2024, 73, 5808–5823. [Google Scholar] [CrossRef]
- Maray, M.; Mustafa, E.; Shuja, J.; Bilal, M. Dependent task offloading with deadline-aware scheduling in mobile edge networks. Internet Things 2023, 23, 100868. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Peng, Z.; Wang, G.; Nong, W.; Qiu, Y.; Huang, S. Task offloading in Multiple-Services Mobile Edge Computing: A deep reinforcement learning algorithm. Comput. Commun. 2023, 202, 1–12. [Google Scholar] [CrossRef]
- Zhang, R.; Wu, L.; Cao, S.; Hu, X.; Xue, S.; Wu, D.; Li, Q. Task offloading with task classification and offloading nodes selection for MEC-enabled IoV. ACM Trans. Internet Technol. (TOIT) 2021, 22, 1–24. [Google Scholar] [CrossRef]
- Li, B.; Wu, R. Joint perception data caching and computation offloading in MEC-enabled vehicular networks. Comput. Commun. 2023, 199, 139–152. [Google Scholar] [CrossRef]
- Zeng, C.; Wang, X.; Zeng, R.; Li, Y.; Shi, J.; Huang, M. Joint optimization of multi-dimensional resource allocation and task offloading for QoE enhancement in Cloud-Edge-End collaboration. Future Gener. Comput. Syst. 2024, 155, 121–131. [Google Scholar] [CrossRef]
- Xia, Y.; Zhang, H.; Zhou, X.; Yuan, D. Location-aware and delay-minimizing task offloading in vehicular edge computing networks. IEEE Trans. Veh. Technol. 2023, 72, 16266–16279. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, F.; Lu, Y.; Chen, X. Dynamic task offloading for mobile edge computing with hybrid energy supply. Tsinghua Sci. Technol. 2022, 28, 421–432. [Google Scholar] [CrossRef]
- Chen, M.; Wang, T.; Zhang, S.; Liu, A. Deep reinforcement learning for computation offloading in mobile edge computing environment. Comput. Commun. 2021, 175, 1–12. [Google Scholar] [CrossRef]
- Zhu, S.f.; Cai, J.h.; Sun, E.l. Mobile edge computing offloading scheme based on improved multi-objective immune cloning algorithm. Wirel. Netw. 2023, 29, 1737–1750. [Google Scholar] [CrossRef]
- Yan, L.; Chen, H.; Tu, Y.; Zhou, X. A task offloading algorithm with cloud edge jointly load balance optimization based on deep reinforcement learning for unmanned surface vehicles. IEEE Access 2022, 10, 16566–16576. [Google Scholar] [CrossRef]
- Tang, M.; Wong, V.W. Deep reinforcement learning for task offloading in mobile edge computing systems. IEEE Trans. Mob. Comput. 2020, 21, 1985–1997. [Google Scholar] [CrossRef]
- Chen, W.; Zhu, Y.; Liu, J.; Chen, Y. Enhancing mobile edge computing with efficient load balancing using load estimation in ultra-dense network. Sensors 2021, 21, 3135. [Google Scholar] [CrossRef]
- Kumar, S.; Maurya, V.; Gupta, R. A Distributed Load Balancing Technique for Multitenant Edge Servers With Bottleneck Resources. IEEE Trans. Reliab. 2023, 73, 1147–1159. [Google Scholar] [CrossRef]
- Yahya, M.; Conzelmann, A.; Maghsudi, S. Decentralized Task Offloading and Load-Balancing for Mobile Edge Computing in Dense Networks. IEEE Commun. Lett. 2024, 28, 1954–1958. [Google Scholar] [CrossRef]
- Wu, H.; Geng, J.; Bai, X.; Jin, S. Deep reinforcement learning-based online task offloading in mobile edge computing networks. Inf. Sci. 2024, 654, 119849. [Google Scholar] [CrossRef]
- Cao, S.; Liu, D.; Dai, C.; Wang, C.; Yang, Y.; Zhang, W.; Zheng, D. Reinforcement learning based tasks offloading in vehicular edge computing networks. Comput. Netw. 2023, 234, 109894. [Google Scholar] [CrossRef]
- Zhao, L.; Zhang, E.; Wan, S.; Hawbani, A.; Al-Dubai, A.Y.; Min, G.; Zomaya, A.Y. MESON: A mobility-aware dependent task offloading scheme for urban vehicular edge computing. IEEE Trans. Mob. Comput. 2023, 23, 4259–4272. [Google Scholar] [CrossRef]
- Hu, Z.; Niu, J.; Ren, T.; Dai, B.; Li, Q.; Xu, M.; Das, S.K. An efficient online computation offloading approach for large-scale mobile edge computing via deep reinforcement learning. IEEE Trans. Serv. Comput. 2021, 15, 669–683. [Google Scholar] [CrossRef]
- Sun, Y.; He, Q. Joint task offloading and resource allocation for multi-user and multi-server MEC networks: A deep reinforcement learning approach with multi-branch architecture. Eng. Appl. Artif. Intell. 2023, 126, 106790. [Google Scholar] [CrossRef]
- Zhang, J.; Du, J.; Shen, Y.; Wang, J. Dynamic computation offloading with energy harvesting devices: A hybrid-decision-based deep reinforcement learning approach. IEEE Internet Things J. 2020, 7, 9303–9317. [Google Scholar] [CrossRef]
- Tan, L.; Kuang, Z.; Zhao, L.; Liu, A. Energy-efficient joint task offloading and resource allocation in OFDMA-based collaborative edge computing. IEEE Trans. Wirel. Commun. 2021, 21, 1960–1972. [Google Scholar] [CrossRef]
- Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Powell, M.J. Algorithms for nonlinear constraints that use Lagrangian functions. Math. Program. 1978, 14, 224–248. [Google Scholar] [CrossRef]
- Ghojogh, B.; Ghodsi, A.; Karray, F.; Crowley, M. KKT conditions, first-order and second-order optimization, and distributed optimization: Tutorial and survey. arXiv 2021, arXiv:2110.01858. [Google Scholar]
- Garcia, F.; Rachelson, E. Markov decision processes. In Markov Decision Processes in Artificial Intelligence; Wiley Online Library: Hoboken, NJ, USA, 2013; pp. 1–38. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Wu, L.; Liu, Z.; Sun, P.; Chen, H.; Wang, K.; Zuo, Y.; Yang, Y. Dot: Decentralized offloading of tasks in ofdma-based heterogeneous computing networks. IEEE Internet Things J. 2022, 9, 20071–20082. [Google Scholar] [CrossRef]
- Tong, Z.; Wang, J.; Mei, J.; Li, K.; Li, W.; Li, K. Multi-type task offloading for wireless internet of things by federated deep reinforcement learning. Future Gener. Comput. Syst. 2023, 145, 536–549. [Google Scholar] [CrossRef]
- Huo, Q.; Zhang, W.; Wu, Z.; Song, G.; Wang, B. Collaborative Offloading Strategy for Dependent Tasks in Mobile Edge Computing. Wirel. Pers. Commun. 2024, 134, 267–292. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).