Abstract
Road object detection technology is a key technology to achieve intelligent assisted driving. The complexity and variability of real-world road environments make the detection of densely occluded objects more challenging in autonomous driving scenarios. This study proposes an occluded object detection algorithm, RE-YOLOv5, based on receptive field enhancement to assist with the difficult identification of occluded objects in complex road environments. To efficiently extract irregular features, such as object deformation and truncation in occluded scenes, deformable convolution is employed to enhance the feature extraction network. Additionally, a receptive field enhancement module is designed using atrous convolution to capture multi-scale contextual information and better understand the relationship between occluded objects and their surrounding environment. Considering that the ordinary non-maximum suppression method in dense occlusion scenarios will incorrectly suppress the prediction box of the occluded object, EIOU was used to optimize the non-maximum suppression method. Experiments were conducted on two benchmark datasets, KITTI and CityPersons. The proposed method achieves a mean average precision (mAP) of 82.04% on KITTI, representing an improvement of 2.34% over the baseline model. For heavily occluded objects on CityPersons, the Log Average Miss Rate () is reduced to 40.31%, which is a decrease of 9.65% compared to the baseline. These results demonstrate that the proposed method significantly outperforms other comparative algorithms in detecting occluded objects across both datasets.
1. Introduction
Currently, Advanced Driver Assistance Systems (ADASs) have been widely applied in automobiles. With their gradually improving application capabilities and operational authority, intelligent assisted driving has become a crucial step toward achieving true autonomous driving [1]. ADAS combines computer vision technology, machine learning technology, and perception technology. It performs real-time monitoring of the vehicle’s surroundings using advanced on-board sensors such as LiDAR and monocular or binocular cameras. These sensors collect environmental information and input it into computing devices. The vehicle’s intelligent algorithms then analyze traffic factors to provide timely feedback through output devices, enhancing safety by identifying hazards and intervening in dangerous situations [2]. As a prerequisite for effective ADAS operation, environmental sensing is fundamental to vehicle decision making and control.
The most common vehicle environment sensors are vision-based. These sensors, which closely mimic human visual perception, can independently perform environmental sensing tasks at low cost. Recent developments in hardware acceleration technology and deep learning-based object detection algorithms have further solidified their technical foundation.
Road object detection, essential for intelligent and autonomous driving, involves identifying vehicles, pedestrians, cyclists, and traffic signs. Accurate detection provides reliable decision-making support for vehicle control systems, ensuring safe driving. This makes road object detection a critical research priority [3]. Recent studies highlight that robust road perception systems not only enhance driving safety but also provide critical data infrastructure for predictive road maintenance analytics. As demonstrated in comprehensive reviews of pavement management systems, machine learning-driven detection frameworks can simultaneously monitor real-time traffic objects and quantify long-term road surface degradation patterns—a dual capability crucial for both vehicle control and infrastructure preservation [4]. However, real-world road scenes are complex and variable. Key challenges include environmental interference from adverse weather or poor lighting as well as widespread occlusion. Occluded objects—whether obscured by backgrounds or other objects—often exhibit deformed or truncated features that general detectors struggle to recognize.
In this paper, we address the challenge of detecting occluded objects in road scenes, which are often characterized by truncation, deformation, and other features that make them difficult for general detectors to identify. Leveraging deep learning-based object detection technology, we investigate road object detection algorithms in intelligent assisted driving scenarios and design an efficient neural network model for the accurate detection of occluded objects in road environments. The main contributions are as follows.
- (1)
- An object detection algorithm RE-YOLOv5 based on receptive field enhancement is proposed, which effectively solves the problem of low accuracy in occluded object detection caused by the difficulty in extracting effective features in complex road scenes.
- (2)
- To improve the feature extraction ability of the backbone network for occluded objects, the CSPLayer with Deformable Convnets (CSPD) module is designed by introducing deformable convolution in the CSPLayer. The Receptive Field Atrous Enhancement (RFAE) module is designed using atrous convolution to obtain richer contextual information.
- (3)
- In the post-processing stage, the network is optimized using an EIOU-NMS algorithm, which is used to improve the accuracy of occluded object detection. Various experiments validate the superiority of this method.
The rest of the paper is organized as follows. Section 2 reviews the methods for occlusion object detection. Section 3 proposes the network structure and optimizes the non-maximal value suppression algorithm. Experimental results and analyses are given in Section 4. Finally, the paper is summarized in Section 5.
2. Related Work
2.1. Occlusion Object Detection
In traffic road scenes, the phenomenon of objects being occluded is widespread. For example, dense pedestrians and dense traffic are typical scenarios where occlusion occurs. The types of occlusion can be generally divided into two categories: inter-class occlusion and intra-class occlusion [5]. Inter-class occlusion occurs between different object categories, such as when background elements obscure objects of interest or when distinct object types overlap. Intra-class occlusion refers to mutual obstruction among objects of the same category, such as multiple pedestrians in a crowd.
Inter-class occlusion can cause changes in object shape and obscure critical features, leading to incomplete feature extraction and missed detections. Intra-class occlusion causes prediction boxes of adjacent objects to cluster closely, which are easily suppressed by standard non-maximum suppression (NMS) algorithms, thereby increasing missed detection rates. To address these challenges, researchers have developed targeted solutions.
Kim et al. [6] proposed BBCNet (Bounding-Box Critic Network), which is a plug-in network that uses bounding-box estimators to identify occlusion regions. Through adversarial learning, this approach forces detectors to learn occlusion features. When integrated into Faster R-CNN and SSD frameworks during training and inference, BBCNet significantly improves the detection of occluded vehicles. Mao et al. [7] enhanced YOLOv3 for overlapping object detection in road scenes by redesigning its post-processing stage. Their flexible NMS algorithm, validated on autonomous driving datasets, demonstrates improved performance. Tian et al. [8] developed SA-YOLOv3, which optimizes regression loss functions to enhance the localization of occluded objects. For pedestrian detection under occlusion, Tan et al. [9] designed the Prior-based Receptive Field Block (PRFB). This module aligns receptive fields with pedestrian aspect ratios, effectively reducing background interference during multi-scale feature extraction. Xie et al. [10] introduced a deformable attention-guided network for pedestrian detection. By combining deformable convolutional structures with attention mechanisms, their method samples features from non-rigid locations and aggregates global context through attention maps. Addressing feature degradation in small occluded objects, Liu et al. [11] proposed SE-YOLOv4. This algorithm replaces linear interpolation upsampling with PixelShuffle-based path aggregation and pyramidal convolutional attention, preserving feature integrity through channel-wise periodic shuffling.
2.2. Receptive Field Enhancement
The receptive field defines the spatial region of an input image that influences a neuron’s activation. A larger receptive field enables models to capture global contextual patterns, while a smaller one preserves fine-grained local details. In computer vision, multi-scale receptive field design allows models to jointly model object–environment relationships, thereby improving detection robustness. For occluded object detection, where partial object features are missing, leveraging contextual information through receptive field adaptation becomes critical. This compensates for incomplete features by inferring relationships between visible object parts and their surroundings.
Recent studies have explored various receptive field enhancement strategies for occlusion handling: Chi et al. [12] developed a selective refinement network with multi-branch modules to adaptively fuse features from different receptive fields. Najibi et al. [13] proposed context integration through enlarged convolutional windows around candidate regions, demonstrating that simple architectural changes can improve occlusion reasoning. Wang et al. [14] introduced large-kernel convolutions combined with channel-wise attention mechanisms, simultaneously expanding receptive fields and enhancing directional feature sensitivity. Deng et al. [15] implemented context modeling by deploying independent modules across five feature pyramid levels, enabling multi-scale rigid context fusion. Yu et al. [16] specifically addressed face occlusion through a receptive field enhancement module and designed normalized Wasserstein distance (NWD) loss to mitigate the localization bias for small occluded objects. These works collectively validate that context-aware receptive field design effectively mitigates occlusion challenges, establishing it as a promising research direction.
2.3. Non-Maximum Suppression
In object detection, the non-maximum suppression (NMS) algorithm is typically applied before the network’s final output to select optimal prediction boxes from overlapping candidates. The core principle of NMS involves first ranking all prediction boxes by their confidence scores. The box with the highest confidence is selected as the base, and remaining boxes are iteratively compared against it. If a box’s Intersection-Over-Union (IOU) with the base exceeds a predefined threshold, its confidence is set to zero (suppressed); otherwise, it is retained. This process repeats until all boxes are evaluated.
Most current detection algorithms rely on Greedy-NMS [17], which determines suppression solely through IOU calculations. However, Greedy-NMS overlooks the spatial relationships between boxes. When neighboring boxes surpass the IOU threshold, the algorithm abruptly discards them by zeroing their scores. This aggressive suppression increases missed detections, particularly in occlusion-prone scenarios.
To mitigate this issue, Soft-NMS [18] introduces a graduated penalty mechanism. Instead of outright suppression, it reduces the confidence scores of high-overlap boxes proportionally to their IOU values. Boxes with substantial overlap receive stronger penalties, while distant boxes remain unaffected. Despite this improvement, Soft-NMS may still penalize well-localized boxes with low confidence more harshly than poorly-localized boxes with high confidence—a problematic scenario when localization and classification confidence are mismatched.
Further advancing this field, DIOU-NMS [19] incorporates centroid distance metrics into the suppression criteria via Distance-IOU (DIOU). By jointly considering the overlap area and centroid proximity, the method more effectively resolves conflicts between overlapping predictions. Nevertheless, DIOU-NMS does not account for differences in box aspect ratios, leaving room for improvement in handling objects with significant shape variations.
2.4. Emerging Research Directions
In recent years, multimodal fusion and self-supervised pre-training have emerged as pivotal research directions in intelligent transportation detection. Cross-modal collaborative detection methods have demonstrated significant advantages. Lu et al. [20] proposed a Shared-Specific Feature Transfer Framework, which decouples modality-shared features from modality-specific ones, achieving a 22.5% mAP improvement on the SYSU-MM01 dataset. Similarly, Labbaki et al. [21] innovatively designed an Orthogonal Sequential Fusion Mechanism that mitigates feature redundancy through phased fusion and orthogonal constraints, outperforming traditional parallel fusion approaches. These studies underscore the critical role of inter-modal complementarity mining and structured fusion strategies in enhancing detection robustness.
Self-supervised learning has also achieved breakthroughs in unlabeled data utilization and domain adaptation. Zhang et al. [22] introduced a Pseudo-Label Cross-Teaching Framework for scene adaptation, leveraging background invariance enhancement and hybrid data augmentation to significantly improve detection accuracy in fixed-view scenarios. In monocular depth estimation, Saunders et al. [23] developed a Direction-Aware Convolutional Network that addresses orientation sensitivity through environmental context accumulation, achieving state-of-the-art performance on benchmarks like KITTI. Concurrently, Han et al. [24] constructed a Weather-Augmented Robustness Framework using pseudo-supervised losses and weather-aware augmentation, surpassing existing methods in foggy/nighttime scenarios. These advancements highlight the potential of self-supervised learning for generalization in complex transportation environments.
To enable a systematic analysis of advancements and limitations in occlusion handling for object detection, we provide a structured summary of existing methodologies in Table 1. As illustrated, each approach employs distinct technical strategies to address specific challenges in this domain. Although the above method improves the detection accuracy of occluded objects to a certain extent, there are still many problems, such as the more serious situations of missed detection and misdetection. To address these issues, this paper designs a method of receptive field enhancement and uses this method to experimentally validate and analyze the method with YOLOv5 as the baseline model.

Table 1.
Comparative analysis of methodologies.
3. System Model
3.1. RE-YOLOv5 Overall Structure
The overall network framework of the detection model RE-YOLOv5 in this paper is based on YOLOv5, as shown in Figure 1. In the backbone network, we replace a portion of the standard convolutions in YOLOv5’s CSPLayer with deformable convolutions better suited for occluded object feature extraction. Each modified CSPLayer is renamed as CSPD (CSPLayer with Deformable Convolutions, CSPD). To enhance the network’s contextual information capture capability, Receptive Field Augmentation Modules (RFAMs) are introduced to the last three feature layers of the feature extraction network for multi-scale context modeling. Finally, prior to detection output, an EIOU-based non-maximum suppression (NMS) algorithm is employed to suppress redundant prediction boxes. The following subsections will elaborate on the aforementioned methodology, with Table 2 providing the notation definitions used in subsequent subsections.
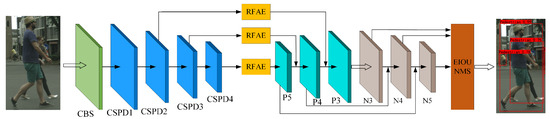
Figure 1.
Model overall structure of RE-YOLOv5.
Table 2.
List of key notations.
3.2. CSPLayer with Deformable Convnets
In order to enhance the feature extraction ability of the model for occluded objects, this study uses a 3 × 3 sized DCNv2 to replace some of the convolutional layers. Deformable Convnets v2 (DCNv2) [25] is a new type of convolution operation, which aims to improve the CNN’s ability to adapt to changes in object shape. The shape of the convolution kernel is fixed in ordinary convolution operations, while the shape and position of the DCNv2 convolution kernel can be automatically adjusted according to the differences in its object shape. In road occlusion environments, there is extensive occlusion between objects, and thus their effective features are characterized by multiple states. In addition, the pose of the pedestrian object in the road changes at any time, and it is difficult to extract features effectively by ordinary convolution. Therefore, in road occlusion environments, DCNv2 has a better feature extraction capability than ordinary convolution.
As illustrated in Figure 2, the CSPDLayer of RE-YOLOv5 comprises a combination of a CBS component and a DCNv2-Residual Unit. The CBS’s convolutional layers, all featuring 1 × 1 convolutional kernels, primarily control the channel relationships between layers. Meanwhile, the DCNv2-Res Unit, serving as the smallest residual unit within the CSPDLayer, is obtained by cascading a CBS with a Direction-wise Batch Splitting (DBS) and then connecting the residuals. In this structure, the DCNv2 within the DBS is of size 3 × 3. This size is chosen because it provides a sufficient receptive field, making it well suited for feature extraction in the backbone network.
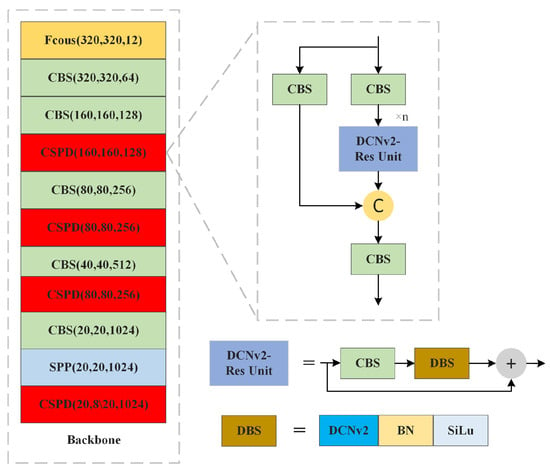
Figure 2.
Schematic diagram of backbone network improvement.
3.3. Receptive Field Atrous Enhancement Module
In occluded object detection, the presence of occlusion prevents the effective extraction of some object information, creating challenges for detection. Utilizing contextual information effectively helps the model learn the relationship between the visible parts of the object and the surrounding environment, thereby improving the detection performance for occluded objects. In this paper, a Receptive Field Atrous Enhancement (RFAE) module based on atrous convolution (AC) is designed. The structure of RFAE is illustrated in Figure 3.
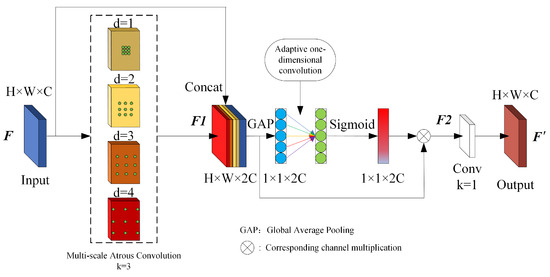
Figure 3.
Schematic diagram of RFAE structure.
Atrous convolution (AC) [26] alters the size of the convolution kernel by introducing voids in the middle of the kernel. This modification allows for the acquisition of different receptive fields and corresponding contextual information. In contrast to regular convolution, AC’s feature extraction process no longer involves convolving the convolution kernel with neighboring pixels for every element. Instead, it skips certain pixels based on a specified dilation ratio before performing convolution with the input pixels. Although the size of the receptive field can be controlled by adjusting the kernel size and stride, increasing the kernel size introduces additional computational overhead, while increasing the stride results in sparser feature extraction. In contrast, AC allows for the extraction of rich contextual information using the same size of the convolutional kernel without causing excessive sparsity in the extracted features.
The RFAE consists of three parts. The first part consists of four groups of AC; here, the RFAE sets four void rates of AC that are used to provide multi-scale receptive field information for the feature map, while the number of each group of AC is set to 1/4 of the input feature map, and the size of the convolution kernel k is 3. In the RFAE, the dilated ratios are set to 1, 2, 3, and 4, at which time the equivalent receptive field size can be obtained according to Equation (1).
in the above equation, is the receptive field size, d is the dilation ratio, and k denotes the size of the convolution kernel.
Since the size of the convolution kernel used is 3 × 3, the receptive field sizes are 3, 5, 7 and 9 according to Equation (1). In addition, in order to reduce the information loss caused by the voids of the atrous convolution, RFAE contacts the input feature maps with the feature maps of the AC outputs in the channel direction, which retains the original information and at the same time introduces the information of the receptive fields of different sizes. Assuming that the input feature map is denoted by F, the output feature map after the above process can be described as shown in Equation (2).
the second part uses the Efficient Channel Attention (ECA) [27] mechanism to enhance the feature map channel correlations in the first part and suppress useless channel information to some extent. ECA first compresses the feature map in the spatial dimension using global average pooling (GAP), obtaining a set of feature information related to the channel dimension. Then, adaptive one-dimensional convolution with convolution kernel size k is used to generate the channel weights, which are channel-weighted to the input feature map after Sigmoid normalization. Assuming that the output feature map of the above process is , it can be described as shown in Equation (3).
where denotes adaptive one-dimensional convolution with convolution kernel size k. GAP denotes the global average pooling of the feature map, and since the number of feature map channels in the network is an integer power of 2, the value of k can be determined by Equation (4).
In the above equation, C denotes the number of channels in the input feature map. denotes the nearest odd number taken when it is not possible to divide , and the values of and b are taken by default to be 2 and 1. Longer interactions are guaranteed for high-dimensional channels, and shorter interactions are guaranteed for low-dimensional channels by the mapping . The mapping is based on the fact that the channels have longer interactions, and the lower-dimensional channels are able to perform shorter interactions.
The last part of the RFAE is to update the number of channels of the input feature map using a convolutional layer of 1 × 1 size, which keeps the number of channels of the input and output feature maps of the RFAE unchanged so that the number of channels of the feature layer will not be changed when the RFAE is integrated into the original model, and the final feature map output from the RFAE is denoted by Equation (5).
3.4. EIOU-NMS: Enhanced Post-Processing
In this paper, EIOU (Efficient IOU) [28] is used as a method for updating the confidence level of NMS, which is called EIOU-NMS. EIOU-NMS takes into account the overlapping area of the prediction boxes, the center distance of the prediction boxes, and the difference between the width and height of the prediction boxes. The EIOU-NMS algorithm is shown in Algorithm 1.
| Algorithm 1 EIOU-NMS. |
|
The confidence updating formula optimized by EIOU is denoted as Equation (6).
In the above equation, is the updated confidence value, is used to measure the spatial positional relationship between the two boxes, and its expression is shown in Equation (7).
where w is the width of the baseline prediction box, h is the height of the baseline prediction box, is the width of the remaining prediction box, is the height of the remaining prediction box, c denotes the diagonal length of the smallest outer bounding rectangle of the two prediction boxes, and and denote the width and height of the smallest outer bounding rectangle, respectively. Figure 4 shows a schematic illustration of EIOU.
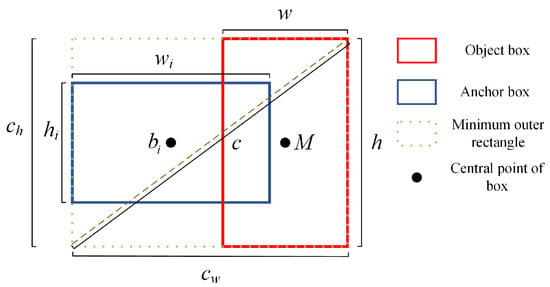
Figure 4.
The schematic diagram of EIOU.
Compared with the traditional NMS, using EIOU to update the confidence level allows NMS to measure the positional relationship between two prediction boxes more comprehensively in the process of suppressing redundant prediction boxes, and thus it is more suitable for object detection in dense occlusion scenarios. Algorithm 1 shows the steps of the EIOU-NMS algorithm execution.
4. Experiments and Discussion
4.1. Experimental Setup
4.1.1. Datasets and Data Preprocessing
In this paper, we use KITTI [29] and CityPersons [30] datasets for occlusion object detection experiments. The KITTI dataset contains nine categories of labeled information: Car, Van, Truck, Pedestrian, Person-sitting, Cyclist, Tram, Misc, and DontCare, with DontCare denoting unlabeled regions and Misc as irrelevant miscellaneous items. Its training set contains 7481 images, the test set includes 7518 images, and the test set provides no labeling information. In this paper, the experimental setup removes the unlabeled test set, mixes the training set with the validation set, and then reclassifies the training set, validation set, and test set as 8:1:1. Meanwhile, the categories of the KITTI dataset are reclassified: the four categories of Car, Van, Truck, and Tram are merged into the category of Car; Pedestrain and Person-sitting are merged into Pedestrian; and Pedestrain and Person-sitting are merged into Pedestrian. The Cyclist category remained unchanged, and the other irrelevant categories were removed. The percentage of cars, pedestrians, and cyclists that are occluded in the KITTI dataset is 53.4%,40.6%, and 44.5%, respectively. The number of instances in the KITTI dataset as well as the number of instances that are occluded are given in Table 3.
Table 3.
KITTI dataset occlusion count statistics.
Moreover, the KITTI dataset also grades the detection difficulty of the dataset according to the occlusion rate of the object and the size of the object, and its detection difficulty can be categorized into easy, moderate, and hard. Table 4 shows the basis of the KITTI dataset’s judgment for detection difficulty.
Table 4.
Criteria for dividing the detection difficulty of KITTI dataset.
The CityPersons dataset is used for the study of pedestrian detection in autonomous driving scenarios with annotations provided exclusively for the pedestrian class. The dataset consists of 2975 images for training, 500 for model validation, and 1575 for testing. Notably, the test set is unlabeled. In the CityPersons dataset, pedestrians with over 65% visibility are labeled as “Reasonable” (i.e., largely visible), those with 65–90% visibility are labeled as “Partial occlusion” (partially obscured), and those with 20–65% visibility are labeled as “Heavy occlusion” (severely obscured). Pedestrians with no occlusion are labeled as “Bare”. In this paper, 2975 images are used for training, quantitative analysis is conducted on a validation set of 500 images, and visualization is performed on the test set.
In the perspective of data preprocessing, considering the specificity of the occluded scene, this paper uses the Mixup [31] data enhancement method. The idea of the implementation of the Mixup enhancement method is to fuse two scenes into one scene. Before the network training, two samples will be randomly selected from each batch of training samples, and then the information in the images will be blended in a certain ratio to generate a new image. The Mixup method simulates the complex background of the image and also simulates the occluded state to some extent for the objects to be detected, thus indirectly providing the detector with more learning samples of the occluded objects.
4.1.2. Experimental Parameter Settings
The experimental configuration was set as follows: all models were trained for 300 epochs using the Stochastic Gradient Descent (SGD) optimizer with an initial learning rate of 0.01. The implementation leveraged an NVIDIA GeForce RTX 3090 GPU (24 GB VRAM) with CUDA 11.3 acceleration, which was accompanied by an Intel® Core™ i5-12500 CPU. The software stack included PyTorch 2.0.1 and Python 3.9. The training method is freeze training, the pre-training weight file is loaded first for freeze training, the parameters of the backbone network are unchanged in the freezing phase, and all the parameters will be involved in the training in the unfreezing phase.
4.1.3. Evaluation Indicators
The selection of performance metrics is rigorously justified based on dataset characteristics and established practices within the research community. For the KITTI dataset, we adopt mean Average Precision (mAP) as it holistically evaluates multi-class detection performance (cars, pedestrians, cyclists) across diverse occlusion levels and object scales. As the de facto standard for autonomous driving benchmarks, mAP effectively balances localization accuracy, via IOU threshold and occlusion tolerance, aligning with the practical requirements of traffic scenario analysis. For the CityPersons dataset, we employ the Log Average Miss Rate () to specifically address pedestrian detection challenges under severe occlusion. This metric, formally endorsed by the benchmark protocol, quantifies algorithmic robustness to partial visibility by emphasizing missed detection rates in densely occluded scenarios. The dual-metric strategy provides complementary evaluations, mAP reflects comprehensive performance improvements, while validates targeted optimizations for occlusion handling. Together, these metrics demonstrate both generalized accuracy enhancements and domain-specific advancements in safety-critical applications.
4.2. Comparative Experimental Analysis
This study first conducts comparative experiments on the KITTI dataset. As shown in Table 5, where “E” denotes Easy, “M” Moderate, and “H” Hard scenarios, the following observations are made. For the Car category, RE-YOLOv5 outperforms the other listed algorithms in general and moderately occluded scenarios, while BBCNet achieves the highest precision of 86.2% under severe occlusion with RE-YOLOv5 ranking second. For Pedestrian detection, RE-YOLOv5 demonstrates superior accuracy with AP values of 86.56%, 75.56%, and 69.01% across the three scenarios, respectively. Similarly, for Cyclist detection, while PSNS-SSD achieves the highest AP of 88.48% in general scenarios with RE-YOLOv5 following closely, RE-YOLOv5 attains higher precision in partially and severely occluded scenarios at 76.44% and 73.13% AP, respectively, surpassing all compared methods. Furthermore, the mean average precision (mAP) of RE-YOLOv5 exceeds that of the classical detection model Faster-RCNN by 19.94%, and it outperforms state-of-the-art road object detection models PSNS-SSD and PointRCNN by 7.63% and 11.93%, respectively. Overall, RE-YOLOv5 demonstrates superior performance in occluded object detection accuracy on the KITTI dataset.
Table 5.
Comparison of different methods on KITTI dataset (%).
To further validate the detection performance of RE-YOLOv5, experiments were conducted using the CityPersons dataset, and RE-YOLOv5 was also compared with some of the methods in the literature. Table 6 demonstrates the comparison of the results of RE-YOLOv5 with other methods on the CityPersons validation set.
Table 6.
Comparison of different methods on CityPersons verification set ().
According to Table 6, it can be seen that the detection of RE-YOLOv5 is improved relative to YOLOv5 in all four conditions. In the case of no occlusion (Bare), the MR-2 of YOLOv5 is 7.80%, while that of RE-YOLOv5 is 5.16%, which is a decrease of 2.64%. In the case of a small amount of occlusion (Reasonable), YOLOv5 is 15.24%, while that of RE-YOLOv5 is 10.98%, which is a decrease of 4.26% in the value. In the case of an occlusion more severe (Partial) scenario, YOLOv5 is 18.19% and RE-YOLOv5 is 13.49%, which is a decrease of 4.7%. For the severe occlusion (Heavy) scenario, YOLOv5 is 49.96% and RE-YOLOv5 is 40.31%, which is the most significant enhancement with a decrease of 9.65%. The synthesis of the above experimental results shows that the RE-YOLOv5 algorithm proposed in this paper is effective.
Additionally, this study compares RE-YOLOv5 with other methods on the CityPersons validation set. For example, MF-CSP utilizes a semantic feature enhancement module to fuse multi-level feature maps for semantic enhancement. MF-CSP demonstrates acceptable detection performance in Bare, Reasonable, and Partial scenarios, but it shows limited effectiveness in Heavy scenarios with an of 47.9%, while RE-YOLOv5 achieves a 7.59% lower under the same conditions. As shown in Table 6, MAFA-Net achieves the best performance in Partial scenarios with an of 10.05%, whereas RE-YOLOv5 exhibits a 3.44% higher . However, under Heavy conditions, MAFA-Net’s rises to 43.84%, surpassing RE-YOLOv5 by 3.53%. In Bare and Reasonable scenarios, RE-YOLOv5 still maintains lower Miss Rates. Compared to state-of-the-art (SOTA) models in road object detection, FA-Net achieves an of 11.6% in Reasonable scenarios, which is 6.02% higher than RE-YOLOv5. CCFA-Net attains an of 5.66% in Bare scenarios yet still underperforms RE-YOLOv5 by 0.5%.
4.3. Qualitative Analysis of Occlusion Object Detection
In order to more intuitively compare the detection effect of YOLOv5 as well as in occluded environments, the experiments were carried out by selecting part of the data from the KITTI test set as well as from the CityPersons test set, and in order to better reflect the detection differences between the two algorithms, the regions used for the comparisons have been additionally labeled out in the figure, in which the results of the KITTI dataset on the KITTI dataset are as demonstrated in Figure 5.

Figure 5.
Comparison of KITTI dataset detection results.
Two common occlusion scenarios were selected as examples for the experiment. The first row of Figure 5 shows intra-category occlusion, where cars are closely aligned at both ends of the road, and there is a white car on its left side that is occluded by other vehicles, which is not detected by YOLOv5, but in (b) in the figure, we can see that RE-YOLOv5 can detect it. In the second row of inter-category occlusion, the car in the labeled area in the figure is not only occluded by the car in front of it but also by pedestrians, which is not detected by YOLOv5 in this scenario; however, in figure (b), we can see that RE-YOLOv5 can still detect it. Through the above visualized results, it is easy to find that RE-YOLOv5 has a better detection effect compared to YOLOv5 in the occlusion scenario of the KITTI dataset.
Figure 6 shows a comparison of the actual detection results on the CityPersons test set. In the detection scenario in the first row, there is an obscured pedestrian behind the pram that is not detected, whereas in figure (b), it can be seen that RE-YOLOv5 can be detected; in the second row of the comparison results, there is an obscured pedestrian on the left side that is not detected by YOLOv5, but it can be detected by RE-YOLOv5. Comparing the two results, we can see that RE-YOLOv5 is better at overall detection.

Figure 6.
Comparison of CityPersons dataset detection results.
To further validate the real-world occlusion detection performance and hardware compatibility of RE-YOLOv5, we conducted practical testing using dashcam video data. The experiments leveraged the KITTI-trained model deployed on a system with NVIDIA GeForce RTX 2060 (12 GB VRAM) and Intel® Core™ i5-10400F CPU @ 2.90 GHz. The video data were also sourced from publicly available internet repositories with two randomly selected frames undergoing comparative detection analysis. The results are shown in Figure 7, and it can be seen that the FPS of RE-YOLOv5 is also reduced compared to YOLOv5 detection because deformable convolution increases the inference time, but it is better than YOLOv5 for occluded object detection in real driving scenarios.

Figure 7.
Detection results of occluded objects in video data.
To visually evaluate the effectiveness of CSPD and RFAE modules, we present feature heatmap visualizations of their outputs on the CityPersons dataset in Figure 8, which includes three columns: (a) input images, (b) CSPD output heatmaps, and (c) RFAE output heatmaps. The visualization reveals strong activations (red regions) in densely occluded object areas, while moderate background responses (yellow regions) indicate a computational trade-off inherent to contextual feature extraction.
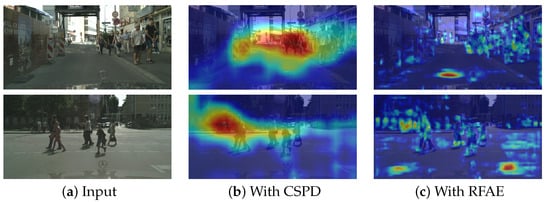
Figure 8.
Feature heatmap visualization.
4.4. Ablation Experiment
In order to verify the effectiveness of the CSPD, RFAE, and EIOU-NMS used in this paper for occluded object detection, ablation experiments were conducted on each module separately. Method 1 is YOLOv5, replacing the CSPLayer in the backbone network. CSPD is recorded as Method 2. After introducing RFAE in YOLOv5, it is recorded as Method 3. Replacing the Greedy-NMS of YOLOv5 with the EIOU-NMS is recorded as Method 4. The use of CSPD and RFAE at the same time is recorded as Method 5. Last, Method 6 is recorded as RE-YOLOv5. The results of its ablation experiments on the CityPersons dataset as well as the KITTI dataset are shown in Table 7 and Table 8.
Table 7.
Results of ablation experiments on the CityPersons dataset ().
Table 8.
Results of ablation experiments on the KITTI dataset (%).
The ablation results in Table 7 and Table 8 indicate that replacing the CSPLayer with CSPD in YOLOv5’s backbone network yields more significant improvements compared to RFAE and EIOU-NMS, primarily due to the deformable offsets introduced in CSPD’s convolutional process, which enhance feature extraction for occluded objects. However, CSPD increases model parameters by 0.62 MB and reduces FPS by 10. Similarly, RFAE improves detection accuracy but introduces an additional 1.714 MB of parameters and reduces FPS by 6. While EIOU-NMS contributes less to precision than CSPD and RFAE, it adds no extra parameters and minimally impacts FPS. Overall, RE-YOLOv5, despite its higher parameter count, achieves superior accuracy in occlusion scenarios while maintaining real-time detection capability at 43 FPS, which remains sufficient for practical applications.
4.5. Comparison of Different Reprocessing Methods
To further validate the post-processing effect of the EIOU-NMS used in this section, experiments were conducted to compare the EIOU-NMS with the Greedy-NMS and the more advanced DIOU-NMS on KITTI as well as CityPersons data, and the results of the experiments are shown in Table 9 and Table 10.
Table 9.
Results of ablation experiments on the KITTI dataset (%).
Table 10.
A comparison of different post-processing methods on CityPersons ().
According to Table 9 and Table 10, it can be seen that the overall effect is better when using EIOU-NMS, which verifies that the use of EIOU-NMS can suppress the redundant prediction boxes more effectively and help improve the detection accuracy of the model. The performance improvement is due to the EIOU metric, which makes the suppression criterion not only limited to the overlap region between two prediction boxes and the distance between the centroids but also focuses on the differences in width and height between the boxes. In addition, the EIOU-NMS method can be easily added to different models without additional training.
5. Conclusions
In this paper, an occlusion object detection algorithm RE-YOLOv5 based on receptive field enhancement is proposed for the road occlusion object detection problem in intelligent assisted driving scenarios. Firstly, in the perspective of feature extraction, considering that the features of the objects under the occlusion conditions will be truncated and deformed, the use of deformable convolution to replace the ordinary convolution can be more effective in the extraction of the features of the objects in the occlusion environment. In addition, in order to more effectively establish the connection between the occluded object and the surrounding background information, and to enrich the contextual information, this paper designs the receptive field enhancement module through the atrous convolution and channel attention mechanism to obtain the contextual information of multiple scales and improve the detection effect of the occluded object. In the perspective of non-maximum suppression, the problems that Greedy-NMS would have in occluded environment detection are analyzed, and it is proposed to use the more advanced EIOU-NMS for non-maximum suppression of the detection results to prevent overlapping objects from being suppressed incorrectly. Finally, experiments are conducted on the KITTI dataset and the CityPersons dataset, the mAP on KITTI reaches 82.04%, and the Log Average Miss Rate of heavy occluded objects on CityPersons is only 40.31%. The experimental results show that RE-YOLOv5 has better results than the baseline scheme as well as other detection algorithms in occluded object detection.
Author Contributions
Conceptualization, T.L.; Supervision, Y.Z. (Yuan Zhang) and Z.L.; methodology, T.L. and X.X.; Investigation, X.F. and Y.Z. (Yushu Zhang); software, H.H. and D.H.; validation, Y.Z. (Yuan Zhang); formal analysis, X.F. and M.H.; writing—original draft preparation, T.L. and X.X.; writing—review and editing, T.L.; visualization, T.L.; project administration, X.X.; funding acquisition, Y.Z. (Yuan Zhang). All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Science and Technology Research Program of Chongqing Municipal Education Commission (Grant No. KJQN202301902).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available upon request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Yu, H. Where will automotive intelligent driving technology go. Automob. Accessories 2022, 2022, 40–41. [Google Scholar]
- Razi, A.; Chen, X.; Li, H.; Wang, H.; Russo, B.; Chen, Y.; Yu, H. Deep learning serves traffic safety analysis: A forward-looking review. IET Intell. Transp. Syst. 2023, 17, 22–71. [Google Scholar] [CrossRef]
- Li, A.; Guo, C.; Huang, X.; Cao, J.; Liu, G. A review of object detection methods for self-driving cars. J. Shandong Jiaotong Inst. 2022, 30, 20–29. [Google Scholar]
- Basnet, K.S.; Shrestha, J.K.; Shrestha, R.N. Pavement performance model for road maintenance and repair planning: A review of predictive techniques. Digit. Transp. Saf. 2023, 2, 253–267. [Google Scholar] [CrossRef]
- Kaur, J.; Singh, W. Tools, techniques, datasets and application areas for object detection in an image: A review. Multimed. Tools Appl. 2022, 81, 38297–38351. [Google Scholar] [CrossRef]
- Kim, J.U.; Kwon, J.; Kim, H.G.; Ro, Y.M. Bbc net: Bounding-box critic network for occlusion-robust object detection. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1037–1050. [Google Scholar] [CrossRef]
- Mao, Q.C.; Sun, H.M.; Zuo, L.Q.; Jia, R.S. Finding every car: A traffic surveillance multi-scale vehicle object detection method. Appl. Intell. 2020, 50, 3125–3136. [Google Scholar] [CrossRef]
- Tian, D.; Lin, C.; Zhou, J.; Duan, X.; Cao, Y.; Zhao, D.; Cao, D. Sa-yolov3: An efficient and accurate object detector using self-attention mechanism for autonomous driving. IEEE Trans. Intell. Transp. Syst. 2020, 23, 4099–4110. [Google Scholar] [CrossRef]
- Tan, Y.; Yao, H.; Li, H.; Lu, X.; Xie, H. Prf-ped: Multi-scale pedestrian detector with prior-based receptive field. In Proceedings of the International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6059–6064. [Google Scholar]
- Xie, H.; Zhang, W.; Shin, H. Occluded pedestrian detection techniques by deformable attention-guided network (dang). Appl. Sci. 2021, 11, 6025. [Google Scholar] [CrossRef]
- Liu, M.; Wan, L.; Wang, B.; Wang, T. Se-yolov4: Shuffle expansion yolov4 for pedestrian detection based on pixelshuffle. Appl. Intell. 2023, 53, 18171–18188. [Google Scholar] [CrossRef]
- Chi, C.; Zhang, S.; Xing, J. Selective Refinement Network for High Performance Face Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8231–8238. [Google Scholar]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. Ssh: Single stage headless face detector. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4875–4884. [Google Scholar]
- Wang, W.; Li, S.; Shao, J.; Jumahong, H. LKC-Net: Large kernel convolution object detection network. Sci. Rep. 2023, 13, 9535. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Guo, J.; Zhou, Y.; Yu, J.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-stage dense face localisation in the wild. arXiv 2019, arXiv:1905.00641. [Google Scholar]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X. Yolo-facev2: A scale and occlusion aware face detector. Pattern Recognit. 2024, 155, 110714. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 22–24 August 2006; pp. 850–855. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Lu, Y.; Wu, Y.; Liu, B.; Zhang, T.; Li, B.; Chu, Q.; Yu, N. Cross-modality person re-identification with shared-specific feature transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13379–13389. [Google Scholar]
- Labbaki, S.; Minary, P. Orthogonal Sequential Fusion in Multimodal Learning. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Zhang, Z.; Hoai, M. Object detection with self-supervised scene adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21589–21599. [Google Scholar]
- Saunders, K.; Vogiatzis, G.; Manso, L.J. Self-supervised monocular depth estimation: Let’s talk about the weather. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 17–24 June 2023; pp. 8907–8917. [Google Scholar]
- Han, W.; Yin, J.; Shen, J. Self-supervised monocular depth estimation by direction-aware cumulative convolution network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 8613–8623. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Ma, J.; Dai, Y.; Tan, Y.P. Atrous convolutions spatial pyramid network for crowd counting and density estimation. Neurocomputing 2019, 350, 91–101. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient iou loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A diverse dataset for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3213–3221. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]
- Choi, J.; Chun, D.; Kim, H.; Lee, H.J. Gaussian yolov3: An accurate and fast object detector using localization uncertainty for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 502–511. [Google Scholar]
- Ke, X.; Li, J. U-fpndet: A one-shot traffic object detector based on u-shaped feature pyramid module. IET Image Process. 2021, 15, 2146–2156. [Google Scholar] [CrossRef]
- Gasperini, S.; Haug, J.; Mahani, M.A.N.; Marcos-Ramiro, A.; Navab, N.; Busam, B.; Tombari, F. Certainnet: Sampling-free uncertainty estimation for object detection. IEEE Robot. Autom. Lett. 2021, 7, 698–705. [Google Scholar] [CrossRef]
- Yi, J.; Wu, P.; Metaxas, D.N. Assd: Attentive single shot multibox detector. Comput. Vis. Image Underst. 2019, 189, 102827–102835. [Google Scholar] [CrossRef]
- Song, X.; Zhou, Z.; Zhang, L.; Lu, X.; Hei, X. Psns-ssd: Pixel-level suppressed nonsalient semantic and multicoupled channel enhancement attention for 3d object detection. IEEE Robot. Autom. Lett. 2024, 9, 603–610. [Google Scholar] [CrossRef]
- Mushtaq, H.; Deng, X.; Jiang, P.; Wan, S.; Ali, M.; Ullah, I. GFA-SMT: Geometric Feature Aggregation and Self-Attention in a Multi-Head Transformer for 3D Object Detection in Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2025, 26, 3557–3573. [Google Scholar] [CrossRef]
- Ruan, B.; Zhang, C. Occluded pedestrian detection combined with semantic features. IET Image Process. 2021, 15, 2292–2300. [Google Scholar] [CrossRef]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Occlusion-aware r-cnn: Detecting pedestrians in a crowd. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 637–653. [Google Scholar]
- Ma, J.; Wan, H.; Wang, J.; Xia, H.; Bai, C. An improved one-stage pedestrian detection method based on multi-scale attention feature extraction. J. Real-Time Image Process. 2021, 18, 1–14. [Google Scholar] [CrossRef]
- Ma, J.; Wan, H.; Wang, J.; Xia, H.; Bai, C. An improved scheme of deep dilated feature extraction on pedestrian detection. Signal Image Video Process. 2021, 15, 231–239. [Google Scholar] [CrossRef]
- Xia, H.; Wan, H.; Ou, J.; Ma, J.; Lv, X.; Bai, C. Mafa-net: Pedestrian detection network based on multi-scale attention feature aggregation. Appl. Intell. 2022, 52, 1–14. [Google Scholar] [CrossRef]
- Zhang, T.; Ye, Q.; Zhang, B.; Liu, J.; Zhang, X.; Tian, Q. Feature Calibration Network for Occluded Pedestrian Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4151–4163. [Google Scholar] [CrossRef]
- Li, Z.; Luo, N.; Zhang, X.; Guo, Z.; Fang, X.; Qiao, Y. Crowdassign: A Label Assignment Scheme for Pedestrian Detection in Crowded Scenes. In Proceedings of the 2024 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 27–30 October 2024; pp. 326–331. [Google Scholar]
- Zou, F.; Li, X.; Xu, Q.; Sun, Z.; Zhu, J. Correlation-and-Correction Fusion Attention Network for Occluded Pedestrian Detection. IEEE Sens. J. 2023, 23, 6061–6073. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).