Abstract
Semi-supervised clustering can be viewed as a clustering paradigm that exploits both labeled and unlabeled data to steer learning accurate data clusters and avoid local minimum solutions. Nonetheless, the attempts to refine existing semi-supervised clustering methods are relatively limited when compared to the advancements witnessed in the current benchmark methods in fully unsupervised clustering. This research introduces a novel semi-supervised method for deep clustering that leverages deep neural networks and fuzzy memberships to better capture the data partitions. In particular, the proposed Dual-Constraint-based Semi-Supervised Deep Clustering (DC-SSDEC) method utilizes two sets of pairwise soft constraints; “should-link” and “shouldNot-link”, to guide the clustering process. The intended clustering task is expressed as an optimization of a newly designed objective function. Additionally, DC-SSDEC performance was evaluated through comprehensive experiments using three real-world and benchmark datasets. Moreover, a comparison with related state-of-the-art clustering techniques was conducted to showcase the DC-SSDEC outperformance. In particular, DC-SSDEC significance consists of the proposed dual-constraint formulation and its integration into a novel objective function. This contribution yielded an improvement in the resulting clustering performance compared to relevant state-of-the-art approaches. In addition, the assessment of the proposed model using real-world datasets represents another contribution of this research. In fact, increases of 3.25%, 1.44%, and 1.82% in the clustering accuracy were gained by DC-SSDEC over the best performing single-constraint-based approach, using MNIST, STL-10, and USPS datasets, respectively.
1. Introduction
Typically, supervised learning approaches require accurate labeled collections of data to build accurate inference models [1]. However, the increasing size of data repositories has rendered the labeling process even more time-consuming and labor-intensive. On the other hand, contending with only relatively small datasets makes the intended models prone to overfitting. This promoted researchers’ efforts to investigate further unsupervised machine learning approaches. The motive is to cope better with unlabeled datasets as they relax the need for labeled training sets. In fact, cluster analysis has been employed to address problems in various areas, such as data mining, pattern recognition, and computer vision [2,3]. The goal of clustering consists of discovering homogeneous groups of data objects. Specifically, the instances assigned to the same cluster should exhibit similar features in comparison to the instances that belong to other clusters. Thus, clustering similar data samples together reveals the true data partition and provides insights into the hidden patterns beneath the distinct categories. Conventional clustering techniques are typically preceded with feature extraction to encode and capture data properties that reveal hidden patterns. However, this feature extraction can result in a high-dimensional representation of data, which can lead to a curse of dimensionality problem [4]. Consequently, several dimensionality reduction techniques [5,6] have been introduced to transform the data into a lower dimensionality feature space. Despite these advances, clustering data with complex latent structures remains challenging using existing methods [2].
The rise and rapid advancement of deep neural networks (DNNs) have triggered a reinvestigation of the research related to clustering. In particular, researchers have exploited the deep networks’ capability to automatically extract the most related data features and discard the need for feature engineering [2,7], for a more accurate clustering performance. Moreover, deep clustering paradigms aim to overcome challenges like handling nonlinear datasets, dealing with high-dimensional data, and reducing sensitivity to data noise [8,9].
Basically, early deep clustering works [10,11] considered feature transformation and clustering as two separate processes. Specifically, the data were first transformed into a new feature space and then fed into a clustering algorithm. Recently, deep clustering has improved to perform feature learning, transformation, and clustering of highly complex data in a joint manner [2]. Deep clustering approaches rely on deep neural network architectures [12], the network loss, and the clustering loss optimization [3]. This progress boosted the researchers’ efforts to inject some supervision to guide the clustering process, i.e., the semi-supervised learning paradigm. Specifically, semi-supervised learning uses both labeled and unlabeled data to train a model. In particular, it exploits prior knowledge and formulates it as constraints to ease the learning process. Pairwise constraints are a type of instance-level constraints that are used to represent prior knowledge. In fact, such constraints are induced by the perceived similarities between data instances. Several semi-supervised deep clustering approaches were recently proposed, including works based on graph clustering [13,14], density-based clustering [15], multi-view clustering [16], KL divergence clustering [17,18], and contrastive clustering [19]. While the side information in [20] is included in the model as a prior on the class proportions, the must-link and cannot-link pairwise constraint pairs in [21] are employed to define the thresholds for distinguishing between similar and dissimilar data points.
Despite ongoing efforts by researchers, the body of work on state-of-the-art semi-supervised deep clustering approaches remains considerably limited in comparison to the research conducted on unsupervised approaches [22]. In this paper, we propose DC-SSDEC to overcome the limitations of the current approaches. DC-SSDEC relies on a deep neural network architecture for feature learning and performs fuzzy membership-based clustering to mine the true partition of the data. In particular, DC-SSDEC introduces two sets of soft constraints within a novel objective function. This function is devised to learn the concealed data clusters and optimize the deep neural network in a simultaneous manner.
Additionally, fuzzy logic has been used in clustering to better represent data groupings [17,23]. This is attributed to the fact that fuzzy clustering allows individual data samples to belong to multiple clusters with varying probabilities, offering more flexibility. The fuzzy membership function assigns values between 0 and 1, indicating the similarity degree between a data sample and a cluster’s centroid. A higher probability suggests stronger confidence in the cluster assignment. Moreover, unlike overlapping clustering methods, the sum of membership values for a data instance must equal 1.
Furthermore, the majority of research in the literature on semi-supervised deep clustering utilizes “must-link”, and “cannot-link” pairwise constraints [24,25,26,27]. These constraints are considered hard as they enforce the data sample belonging to a certain cluster. On the other hand, soft “should-link” and “shouldNot-link” pairwise constraints are incorporated within the objective function of the proposed (DC-SSDEC) to express the supervision in hand. These constraints are formulated in a relaxing way in which the compliance with a constraint is not strictly obligated. The constraints are formulated in a relaxed manner, wherein strict compliance is not required. This flexible formulation enhances the applicability of the proposed approach to real-world data clustering tasks, where side information can be incomplete or unreliable, and thus cannot be firmly enforced.
2. Related Works
Different deep clustering frameworks based on various DNN architectures have been recently released [2]. Namely, deep clustering applications have adopted autoencoders (AEs), deep belief networks (DBNs) [28], convolutional neural networks (CNNs) [29,30], and generative adversarial networks (GANs) [31] as DNN architectures for feature learning and extraction. In fact, autoencoders have been widely used to tackle challenges relevant to deep clustering models [12,32,33,34]. Generally, AE-based deep clustering approaches leverage the trained encoder layers to transform the original data input into a lower-dimensional embedded representation. Recently, a deep embedding clustering (DEC) [12] method was introduced and then extended through a number of contributions [33,35,36,37,38,39]. One should mention that the DNN architecture in DEC [12] consists of a deep stacked autoencoder (SAE) network intended to automatically learn the feature representations through nonlinear data embedding. Note that the autoencoder is fine-tuned in order to minimize the reconstruction loss. The authors reported DEC accuracies of 84.3% and 75.63% using MNIST [40] and REUTERS [41] datasets, respectively. Later, DEC was adopted as a baseline for the empirical comparison of several deep clustering approaches [34,42,43]. Furthermore, other deep clustering works were proposed to address DEC limitations [12]. Namely, Improved Deep Embedded Clustering (IDEC) [38] was outlined as a DEC variant that maintains the valuable local structure of the data by freezing the decoder layers. Moreover, IDEC integrates and jointly optimizes the autoencoder’s reconstruction and clustering losses. In fact, keeping the decoder layers by IDEC helps in avoiding feature space distortion by clustering loss. Pursuing IDEC, several works take advantage of the decoder part of the autoencoder [10,44,45].
Specifically, DCEC was introduced in [32] as an extension of IDEC [38] for image clustering applications. DCEC relies on a convolutional autoencoder (CAE) as a deep network. This extension targets feature learning and embedding in an end-to-end-fashion. This contribution makes the model more suitable for clustering image data. Furthermore. Following DCEC, the Deep Continuous Clustering (DCC) approach was outlined in [34] to address two key limitations. Specifically, it relaxed the needs to (i) predefine the number of clusters for classical center-based approaches, and (ii) use discrete objective reconfigurations during optimization. DCC tackled these issues by optimizing a continuous objective using scalable gradient-based solvers. Later, another CAE-based deep clustering algorithm was proposed in [46]. It relaxed the need for pre-setting the number of clusters by adopting density-based distributions to discover homogenous clusters.
The authors in [24] observed that DEC [12] does not exploit prior knowledge to guide the learning process. In particular, they extended DEC [12] and proposed a new scheme of Semi-Supervised Deep Embedded Clustering (SDEC) to overcome this limitation. Specifically, SDEC incorporates pairwise constraints in the feature learning process. Its overall loss function is composed of two parts: the first consists of an unsupervised KL divergence loss, while the second part represents a semi-supervised loss that denotes the consistency between the learned representation with the prior information that is formed as pairwise constraints. SDEC’s best performance attained 86.11% in clustering accuracy and 82.89% in NMI for the MNIST image dataset. Since then, Semi-Supervised Deep Embedded Clustering (SS-DEC) has become a growing research field [47,48,49].
An earlier semi-supervised approach that employs supervision as constraints to learn the clustering metric was introduced in [50]. One should note that the proposed DC-SSDEC differs in two key aspects: (i) It uses deep neural networks to learn relevant feature representations and uncover hidden data partitions. In contrary, the approach in [50] that is not deep neural network-based uses hand-crafted features to encode the data into numerical vectors. (ii) The side information is incorporated into a DC-SSDEC objective function as a reward and penalty terms to govern the coherence between the learned representation and side information. As for the study in [50], the constraints are used to learn a Mahalanobis distance measure, and then cluster the data according to that metric (i.e., under similarity and dissimilarity constraints).
Recently, a semi-supervised deep embedding approach named SC-DEC was presented in [17]. SC-DEC leverages a deep neural network architecture and generates fuzzy membership degrees that better reveal the data partitioning. In particular, SC-DEC uses side information and formulates it as a set of soft pairwise constraints to steer the machine learning process. This supervision is expressed using relaxed “should-link” pairwise constraints. Such constraints determine whether the pairs of data instances should be assigned to the same or different cluster(s). In fact, the clustering task in SC-DEC was formulated as an optimization problem via the minimization of a designed objective function. SC-DEC reported clustering accuracy of 92.11% on MNIST, 76.62% on USPS, and 91.65% on STL-10 datasets, outperforming other relevant models. However, the effect of dual pairwise constraints was not investigated in SC-DEC. Moreover, studying the model was limited to benchmark datasets. In fact, the proposed DC-SSDEC differs from SC-DEC [17] in the prior knowledge considered to guide the clustering process. Specifically, soft “shouldNot-link” constraints are further designed to encode side information intended to further attend the clustering process. Additionally, unlike [17], which used only benchmark datasets, DC-SSDEC was tested on real-world datasets to solve factual problems. In particular, the Chest X-Ray dataset images were used for pneumonia detection. Moreover, DermaMNIST and American Digits Sign Language datasets were used to further investigate the proposed contributions. Table 1 below shows a summary of semi-supervised deep clustering works.

Table 1.
Summary of related semi-supervised deep clustering works.
3. Dual-Constraint-Based Semi-Supervised Deep Clustering Approach
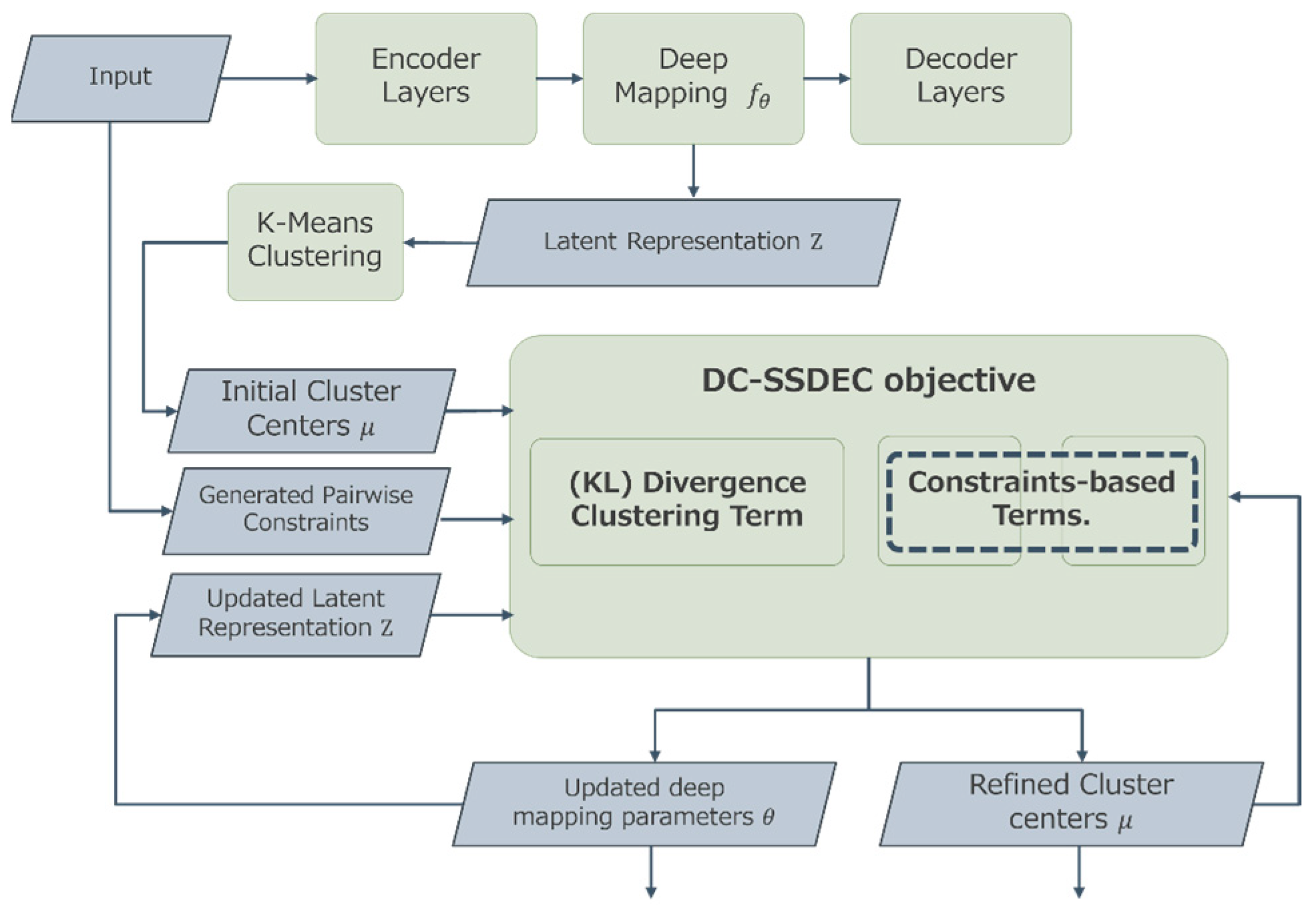
The proposed Dual-Constraint-based Semi-Supervised Deep Clustering (DC-SSDEC) approach utilizes a deep neural network architecture to carry out feature learning and clustering using fuzzy membership values. Specifically, the intended clustering problem is expressed as the optimization of a novel objective function. This function is designed to simultaneously uncover the hidden data clustering and optimize the deep neural network model. Additionally, the supervision information is integrated into the objective function as soft pairwise constraints, aiming to guide the partitioning process without being strictly enforced. Moreover, the data partition is represented using fuzzy membership functions to reflect the natural data grouping into homogeneous clusters. The proposed DC-SSDEC considers “should-link” and “shouldNot-link” pairwise constraints. As shown in Figure 1, DC-SSDEC relies on two main components: (i) an autoencoder AE architecture that learns the distinctive representation of the original data, and (ii) an objective function that performs the clustering tasks as advised.
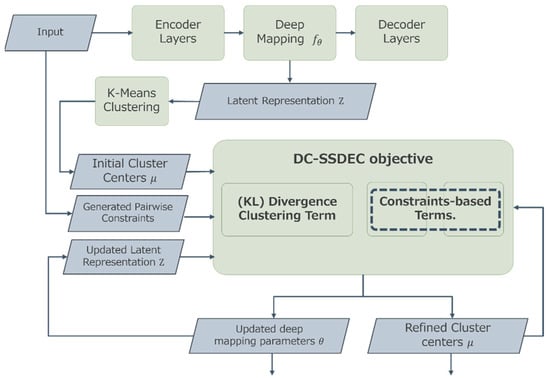
Figure 1.
Overview of the proposed DC-SSDEC approach.
As shown in Figure 1, the data input first passes through the first component, where the autoencoder layers are trained to initialize its parameters and learn the embedded data representation. The learned latent representation is then processed by a K-means clustering layer for cluster centers initialization. Subsequently, along with the generated pairwise constraints, the latent representation undergoes the second component (DC-SSDEC objective), where the deep network parameters and cluster centers are jointly optimized. This process continues until a specified threshold is met.
Let be the unlabeled dataset that represents the input to the devised clustering algorithm. Accordingly, constitute the data instances, and represents the dimensions size of the original feature space. Rather than conducting the clustering task directly in the original data space, we define a nonlinear mapping function to transform the original input data into a latent feature space ; , where represents the corresponding learnable parameters. One should note that the dimensionality of the embedded space is considerably lower than the dimensionality of the original data space. Accordingly, the primary purpose of the proposed DC-SSDEC algorithm is to learn an accurate data clustering in the latent feature space . This goal is mainly achieved using unlabeled data as well as some infused supervision. Specifically, it aims at partitioning the data into clusters, where each cluster is defined using a -dimensional centroid . Note that represents the dimensionality of the embedded space . Basically, we intend to find a cluster-friendly such that the learned parameters are biased towards the clustering task and the available prior knowledge. Further details on the autoencoder architecture can be found in [17].
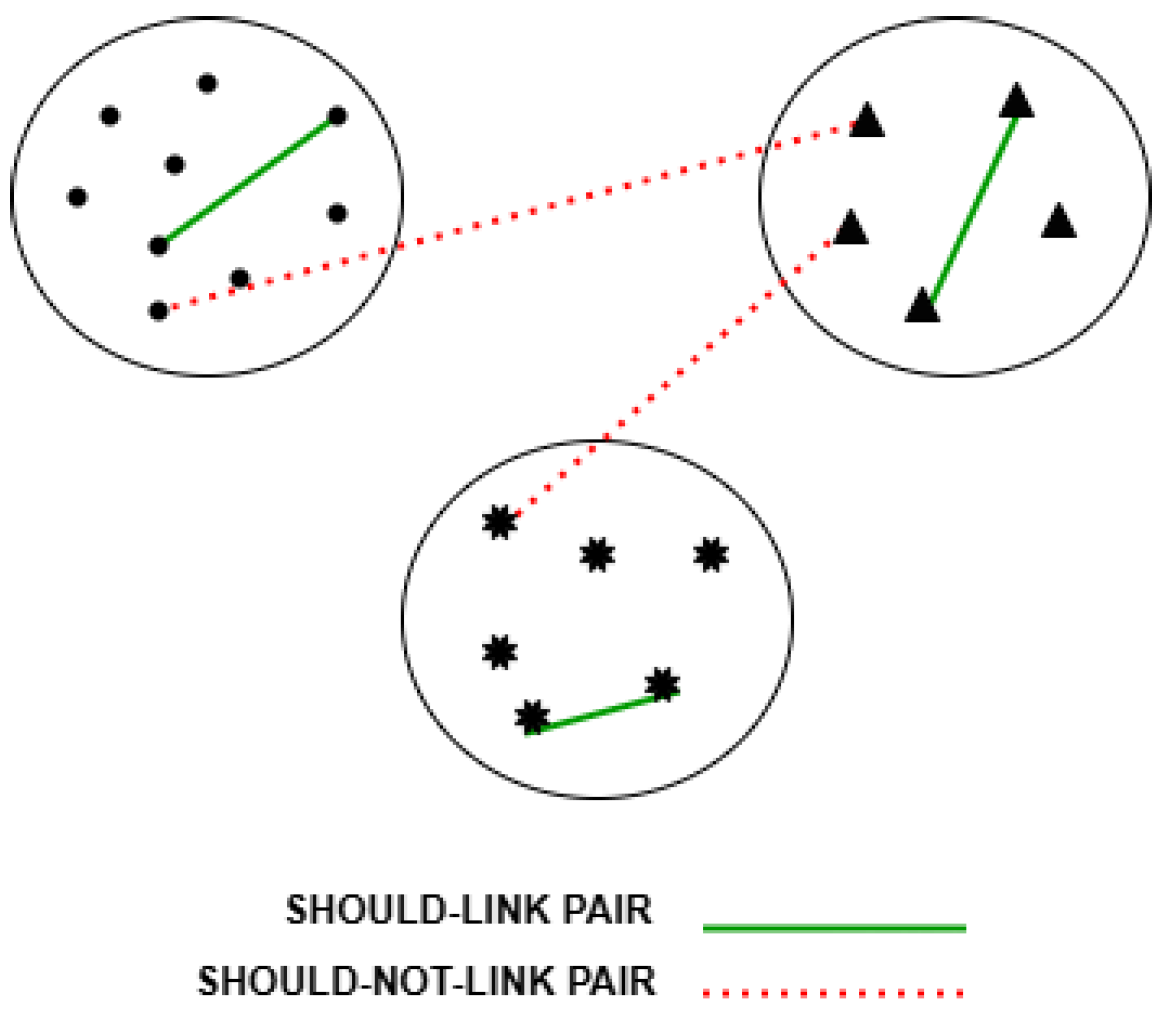
To guide the learning process, and escape local minima, side information is considered by the proposed DC-SSDEC. Specifically, it is expressed as two sets of pairwise constraints: (i) a set of “should-link” pairwise soft constraints denoted by {: and should be assigned to the same cluster, }; and (ii) a set of “shouldNot-link” soft pairwise constraints denoted by {: and should not be assigned to the same cluster, }. Figure 2 shows an illustrative example of the considered pairwise constraints links.
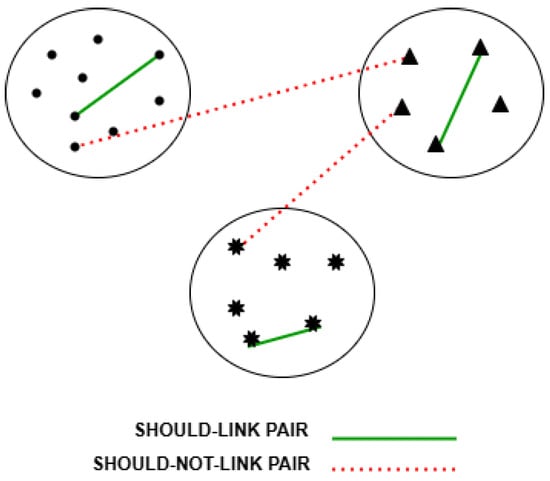
Figure 2.
Illustration of the “should-link” and “shouldNot-link” pairwise constraints. Different symbols (circle, triangle and star) denote different clusters.
Typically, the supervision information is associated with a subset of the dataset only. One should note that these soft constraint sets are preset and produced from the dataset in a random way. In particular, the pairwise constraints are generated with a size equal to , where is the (ratio) of the pairwise constraints to the dataset size . Specifically, for every pair of data points randomly drawn, we check their corresponding ground-truth labels. Accordingly, if the ground-truth labels of the samples pair are similar, a “should-link” pairwise link is generated between these samples and represented by 1. Otherwise, the pairwise link is represented by 0. Conversely, an opposing scenario takes place for the “shouldNot-link” pairwise link generation.
In this research, the clustering task is formulated as an optimization problem. Specifically, the proposed DC-SSDEC objective function encloses “should-link” and “shouldNot-link” constraints terms within the clustering objective function. More specifically, we designed the objective function below to learn the data partition along with its optimal parameters:
where is the number of data points and represents the number of clusters. On the other hand, denotes the fuzziness parameter (a constant > 1) that reflects the fuzzy-based representation of the data clusters. Finally, and are the sets that represent the considered soft constraints. One should mention that the constraint term weights , in (1) are the preset trade-off factors that balance the influence of the second and third terms (i.e., the constraint-based terms). Specifically, they balance the amount of penalty applied on the data batch in response to clustering errors. Additionally, in (1) represents the soft assignment of the embedded data instances to the clusters.
The first term in (1) is inherited from the unsupervised deep embedded clustering term of DEC [12], which is expressed as the Kullback–Leibler (KL) divergence [67] based on the computed soft assignments to the computed auxiliary target distribution . On the other hand, the second and third terms are the constraint-based terms that are intended to learn the compact, fuzzy-based clusters with the supervision guidance. This supervision is in the form of “should-link” and “shouldNot-link” soft pairwise constraints, respectively. In other words, the second and third terms are intended to reward/penalize the model for correct clustering, i.e., assigning a high membership value to a “should-link” pair of samples, to the same cluster.
Furthermore, the soft assignment value in (1) is calculated using Student’s t-distribution as the kernel to compute the similarity between embedded point and cluster center :
where = () represents the embedded representation of . Additionally, is the jth cluster center in the latent data space, ‖ . ‖ denotes the L2-norm and refers to all cluster centroids including the one in the numerator. The denominator is for the purpose of normalization, so that values per data point can sum to one. Furthermore, α is the degrees of freedom of the Student’s t-distribution. We set α = 1 for all experiments. Hence, is computed as follows:
Additionally, in (1) represents the auxiliary target distribution used to update the deep mapping and refine the cluster centroids. This update is implemented through learning from the current high confidence assignments in a self-training manner. Moreover, we compute based on from (3) by first squaring and subsequently normalizing it based on cluster-wise frequency, as detailed below:
where are the soft cluster frequencies and are the soft frequencies for all clusters, including the one in the numerator. Unlike hard clustering, fuzzy-based clustering approaches allow every data instance to belong to every cluster. This adds more flexibility to the proposed solution and facilitates the partitioning of data with vague boundaries. Typically, the membership value should be between 0 to 1, where 0 means the data instance does not belong to a specific cluster and 1 means it entirely belongs to that cluster. Moreover, the membership values of a data instance should sum up to 1. Fuzzy clustering is also known as probabilistic clustering. In fact, the fuzziness is introduced in DC-SSDEC by incorporating the fuzziness parameter (1 ) in the objective function to regulate the degree of data sharing between fuzzy clusters. On top of the AE encoder layers of the DC-SSDEC model, a custom clustering layer is added. Typically, it converts the data sample (the embedded features) to a soft label, i.e., a vector that reflects the fuzzy probability degree of the sample belonging to each cluster. This probability is computed with Student’s t-distribution.
Furthermore, in contrast to the rigid “must-link” and “cannot-link” constraints, the proposed formulation incorporates soft constraints. These constraints function as a reward for correctly clustering a data point, making this approach more suitable for the imprecise labeling commonly found in real-world datasets. The soft constraint term within the objective function governs the alignment between the learned representations and the clustering guided by the provided supervision.
Concretely, for a certain cluster , , and given that the membership has a fuzzy probabilistic value ( [0, 1]): if and are both high, then the value of the resulting constraints term becomes high, thus promoting the minimization of the objective function; if and are both low, then the value of the resulting constraints term becomes quite low, thus having a neutral effect on the total of the objective function; if is low and is high (or vice versa), then the value of the resulting constraints term becomes relatively low, thus obstructing the objective function minimization.
The minimization of the objective function in (1) is preceded by the pretraining of an autoencoder AE for DNN parameter initialization. The AE training is performed based on the minimization of the following objective function:
where is the Euclidean norm of the difference between data sample vector and its reconstructed sample vector . On the other hand, is the size of the dataset.
The proposed algorithm minimizes the objective function in (1) iteratively and converges into the optimal clustering results, constrained by a tolerance threshold (%). Concretely, the proposed clustering approach encloses two phases: (i) A model parameter initialization where the DNN embedding parameters are initialized through the training of the deep autoencoder. Then, a K-means clustering algorithm [68] is deployed within the latent space Z for the initialization of the cluster centers . (ii) A model parameter optimization intended to update the deep mapping and refine the cluster centers . In this phase, the devised objective function is optimized through minimization. This minimization aims to learn from the upright high-confidence predictions. In particular, the objective iterates between the computation of the auxiliary target distribution and the minimization of the KL divergence objective term. Thus, the cluster assignment distribution is achieved through the minimization of the KL divergence with an auxiliary distribution.
4. Experiments
The proposed DC-SSDEC was first assessed using three benchmark datasets widely adopted by deep clustering researchers. The first is the MNIST dataset [40], which comprises 70,000 grayscale images of handwritten digits. Each image is represented as a 28 × 28-pixel grid, resulting in a 784-dimensional feature vector. The second dataset is USPS [69], which consists of 9298 grayscale images of handwritten digits, each with a resolution of 16 × 16 pixels. Lastly, the STL-10 dataset [70], which contains 13,000 color images of natural scenes with a resolution of 96 × 96 pixels, was also considered in this research. Furthermore, to verify the performance of the proposed method in real-world applications, DC-SSDEC was associated with three real datasets. Namely, Chest X-Ray [71], DermaMNIST [72,73], and American Digits Sign Language [74] datasets were used in this research. Specifically, the Chest X-Ray radiographic imagery dataset [71] was considered for pneumonia disease detection and classification. More specifically, 5863 X-ray images from two categories—”Pneumonia” and “Normal”—were utilized. DermaMNIST [72,73] is a colored image collection including common pigmented skin lesions. The images size is 28 × 28 × 3 pixels. Finally, the American Sign Language digits dataset (Digits_SL) [74], which is relatively smaller, contains ten categories, representing the digits from 0 to 9. Table 2 reports the details of those datasets, along with the ground-truth information relevant to the intended clustering task. Sample images from the datasets used in this research are shown in Figure 3.
Table 2.
Description of the datasets considered.

Figure 3.
Sample images from: (a) MNIST, (b) STL-10, (c) USPS, (d) Pneumonia chest X-Ray, (e) DermaMNIST and (f) Digits-SL datasets.
The performance of the proposed DC-SSDEC and those achieved by the challenger approaches were evaluated using standard metrics. The first one is the clustering accuracy (ACC), that measures the percentage of correctly grouped data points. It is computed using:
where is the ground truth, is the cluster assignment, is the number of data points, and spans over all possible one-to-one correspondences between the clusters and the predefined labels.
The second metric consists of the Normalized Mutual Information (NMI) measured using:
where represents the entropy of the ground truth , is the entropy of the cluster assignment , and is the mutual information of and . NMI values range from 0 to 1, where a score of 1 implies that the two clustering outcomes are identical.
Regarding the non-linear mapping , a fully connected stacked deep autoencoder network was adopted. For all experiments, the dimension size of the autoencoder layers is d–500–500–2000–10 dimensions, where represents the dimensions of the input data space. Furthermore, the ReLU nonlinearity function [75] was selected as activation function for the internal layers of the autoencoder, with the exception of the input, output, and embedding layers. The initialization of the autoencoder weights was carried out through a greedy layer-wise pretraining. During the pretraining of the model using all datasets, “Adam” [76] was employed as the optimizer, with a default learning rate of 0.001, and the stopping threshold was set to 0.001. To initialize the cluster centers , K-means clustering was run 20 times and the best result was exploited to set the initial centers.
4.1. Results Obtained Using Benchmark Datasets
These experiments aimed at assessing the performance of DC-SSDEC using benchmark datasets. Specifically, the objective function introduced in (1) was validated using MNIST [40], USPS [69], and STL-10 datasets. One should note that the model hyper-parameters went through a tuning process to obtain better settings and initialization. In particular, the optimal hyper-parameter values were set using a validation set and the accuracy as performance measure. Namely, we investigated the best number of pretraining epochs, the amount of supervision , the fuzziness parameter , the “should-link” constraint term weight , the “shouldNot-link” constraint term weight , and the data batch size. The following details the valid ranges for the model’s hyper-parameters: the size of the data batch size ϵ {| , }, β ϵ {| , }, and ϵ {| } and ϵ {| }. In fact, these ranges were selected based on the best practices from the related literature and the considered benchmark datasets. Moreover, hyper-parameter tuning was carried out by allocating one experiment for each selected hyper-parameter value. After each hyper-parameter set of experiments, the value that resulted in the highest accuracy was saved and used for the rest of the experiments. Table 3 reports the hyper-parameter values that achieved the highest clustering accuracy for the proposed DC-SSDEC across the benchmark datasets.
Table 3.
Hyper-parameter values that yielded the highest accuracy of DC-SSDEC for the different datasets.
The results achieved using DC-SSDEC were compared to those yielded by the relevant unsupervised and semi-supervised deep clustering algorithms. Specifically, the proposed method was compared with DEC [12], Semi-Supervised Deep Embedded Clustering (SDEC) [24], Improved Deep Embedded Clustering with Local Structure Preservation (IDEC) [38], K-means [77] applied to the deep embeddings of the considered datasets (DL + K-means), and the single-constraint based deep clustering approach (SC-DEC) [17]. One should note that the approach in [50] was not considered among the set of benchmark approaches because it failed to converge when associated with the datasets used in our experiments.
Table 4 reports the results achieved by DC-SSDEC, along with those obtained using the latter state-of-the-art methods along with MNIST, USPS, and STL-10 benchmark datasets. As can be seen in Table 4, the outperforming results obtained using DC-SSDEC showcase the advantage of enriching the prior knowledge by including the soft “shouldNot-link” constraints to guide the clustering process.
Table 4.
Clustering results in terms of ACC and NMI, achieved using the different approaches and datasets.
It can be noticed from Table 4 that DC-SSDEC overtook the other deep clustering approaches using all datasets in terms of the ACC metric. Regarding NMI, DC-SSDEC outperformed the relevant approaches, except SDEC [24], using the USPS [69] dataset. In fact, the results showed the positive effect of utilizing side information, as the proposed DC-SSDEC outperforms the unsupervised approach DEC [12]. Moreover, the fact that DC-SSDEC surpassed SC-DEC [17] demonstrates that coupling the set of “should-link” pairwise constraints with the set of “shouldNot-link” constraints let the clustering process escape local minima and yielded a better overall clustering accuracy. Although the designed objective function is different from the one in SC-DEC [17], the proposed dual constraints are expected to reduce the hypothesis and the search space, which reduces the risk of converging to local minima.
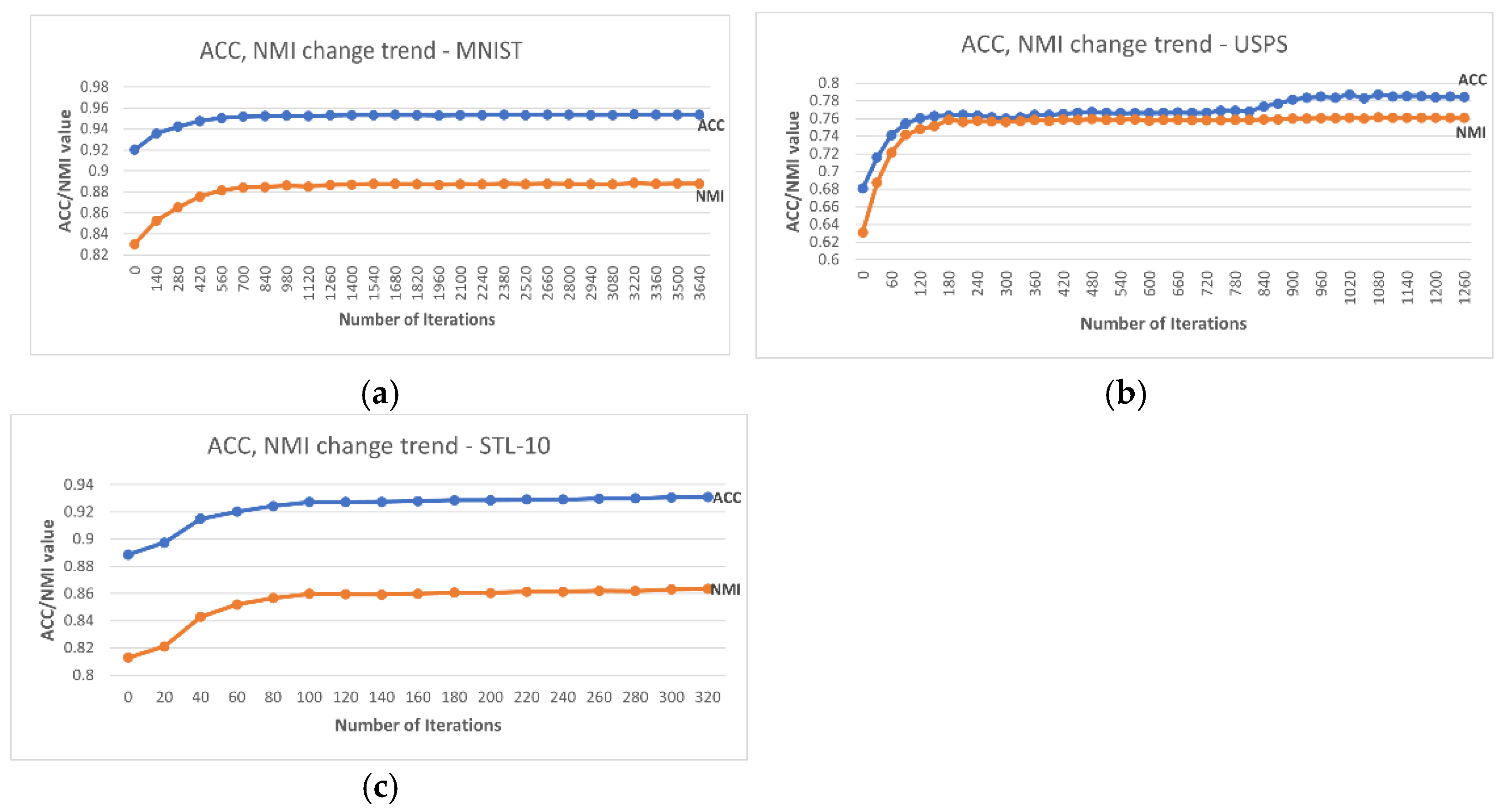
Furthermore, at the individual class level, the lowest accuracy reported by DC-SSDEC increased by 11.9% in MNIST, 13.0% in USPS, and 10.5% in STL-10 compared to the single-constraint version in [17]. Additionally, DC-SSDEC exceeds the results obtained using DL + K-means for all three considered datasets. This demonstrates the importance of the joint optimization of deep embedding and clustering. The results also proved the importance of the fuzzy membership-based representations in enhancing the data partitioning. In fact, the proposed DC-SSDEC outperformed the non-fuzzy method SDEC [33]. In addition, Figure 4 shows the ACC and NMI trends for DC-SSDEC on the considered benchmark datasets. It is notable that the improvement in both ACC and NMI attainments is steadied after about 30% of the training time.
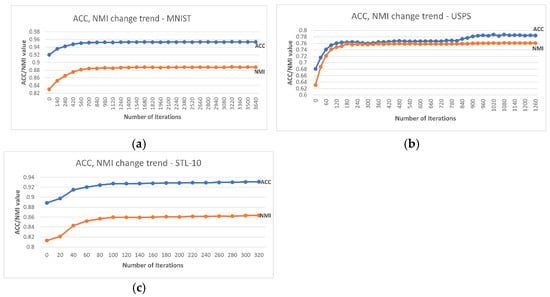
Figure 4.
Accuracy and NMI trends recorded using DC-SSDEC and (a) MNIST, (b) USPS, and (c) STL-10 datasets.
Further investigations show that the change in accuracy as a response to the increase in the value was trivial for USPS and STL-10 datasets, as the difference between the highest and lowest accuracy did not exceed 0.14% and 0.81% for STL-10 and USPS datasets. On the other hand, this variance reached 8.84% for the MNIST dataset. The same observation holds for the effect of the weights and associated with both constraint terms. Additionally, the highest DC-SSDEC accuracy was achieved using the fuzzifier set to 2 for the three datasets. One should also note that training DC-SSDEC on the USPS dataset using a 128-batch size resulted in better performance in comparison to using the default 256-batch size.
4.2. Results Obtained Using Real-World Datasets
In the next experiments, we assess the performance of DC-SSDEC using real-world datasets. Specifically, DC-SSDEC was deployed for medical image analysis and sign language recognition. In particular, these experiments included the assessment of DC-SSDEC performance when associated with two medical imagery datasets. Namely, the Chest X-Ray image dataset [71] was considered for pneumonia disease detection and the DermaMNIST image dataset [72,73] was used for dermatology disease detection. Moreover, similar experiments were carried out using the American Sign Language digits dataset, Digits_SL [74]. Furthermore, the results of DC-SSDEC using these datasets were evaluated against the results obtained from state-of-the-art approaches. Table 5 details the hyper-parameter values that yielded the best clustering accuracy for DC-SSDEC when associated with the Chest X-Ray dataset for pneumonia detection.
Table 5.
Hyper-parameter values that yielded the highest accuracy for DC-SSDEC and the Chest X-Ray dataset.
Generally, hyper-parameter tuning results show that the change in accuracy in response to the increased β value was not trivial, as the difference between the highest and lowest accuracy equaled 15.91%. Moreover, the effect of the size of constraints β on the performance of the proposed DC-SSDEC was relatively random. This may be influenced by the pairwise constraints generated, as their formation is randomized for each new value of β. Furthermore, the highest accuracy value for DC-SSDEC was gained when the value of the fuzzy parameter m equaled 2. This result is consistent with earlier experiments. In addition, training DC-SSDEC on the Chest X-Ray dataset using a 64-batch size yielded the highest results. This can be related to the small size of the dataset.
Table 6 reports the pneumonia detection performance achieved using DC-SSDEC and the considered state-of-the-art methods along with the Chest X-Ray dataset. As can be seen, improvements of approximately 10% and 7% were achieved by DC-SSDEC compared to the other methods, for the accuracy and NMI, respectively.
Table 6.
Clustering results obtained using the Chest X-Ray dataset.
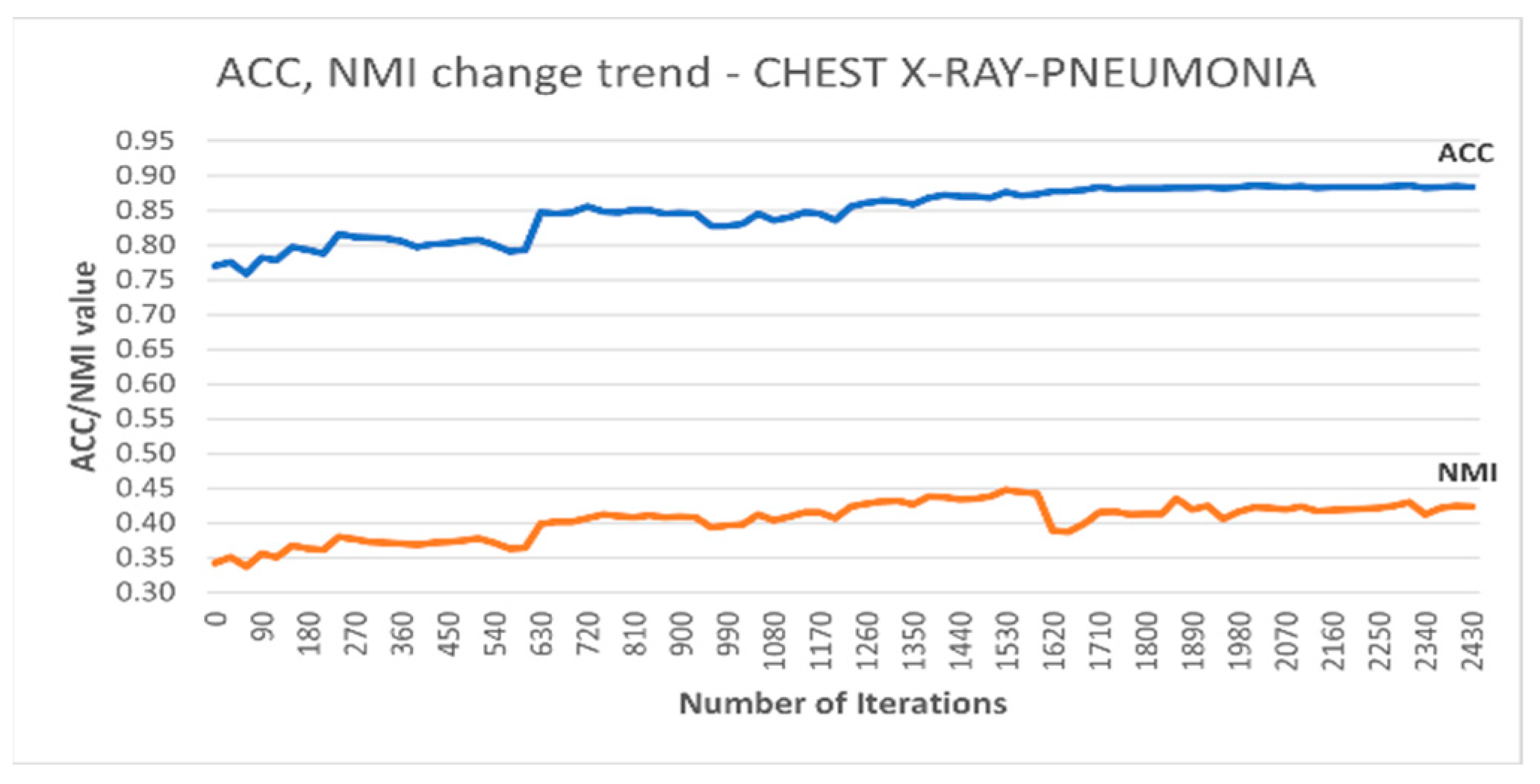
Additionally, Figure 5 depicts the accuracy and NMI trends for DC-SSDEC on the Chest X-Ray dataset. It is notable that the improvement in terms of both accuracy and NMI measures is steadied after around 60% of the training time.
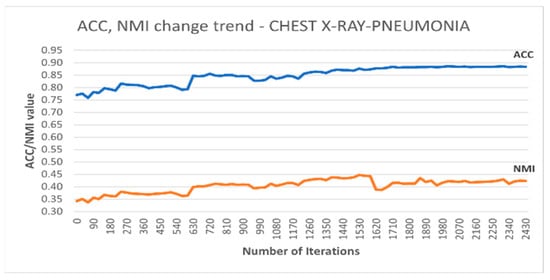
Figure 5.
Trends recorded for the performance metrics achieved using DC-SSDEC on the Chest X-Ray dataset.
In the following, we outline the results obtained using the proposed DC-SSDEC when associated with the DermaMNIST dataset [72,73] for dermatological disease detection. The assessment began with running a set of experiments to calibrate the relevant hyper-parameters. After tuning the model hyper-parameters to their best values in terms of clustering accuracy, we ran 20 experiments using these values. Hyper-parameter values that yielded the highest accuracy of DC-SSDEC for the DermaMNIST dataset are reported in Table 7. In particular, hyper-parameter tuning results show that with only a ratio of 0.3 of the pairwise constraints (β hyper-parameter), DC-SSDEC yielded the highest accuracy. This result is similar to the one obtained when evaluating DC-SSDEC on MNIST. Also, consistent with past experiments, the results show that tuning the fuzzifier to the value of 2 returns the highest accuracy on DermaMNIST.
Table 7.
Hyper-parameter values that yielded the highest accuracy of DC-SSDEC for the DermaMNIST dataset.
The results achieved by DC-SSDEC in these experiments are reported in Table 8. The results show that our approach outperformed the other state-of-the-art approaches, with an increase of approximately 13.3% in terms of clustering accuracy. Furthermore, all of the considered methods yielded rather weak results in terms of the NMI score.
Table 8.
Clustering results obtained using the DermaMNIST dataset.
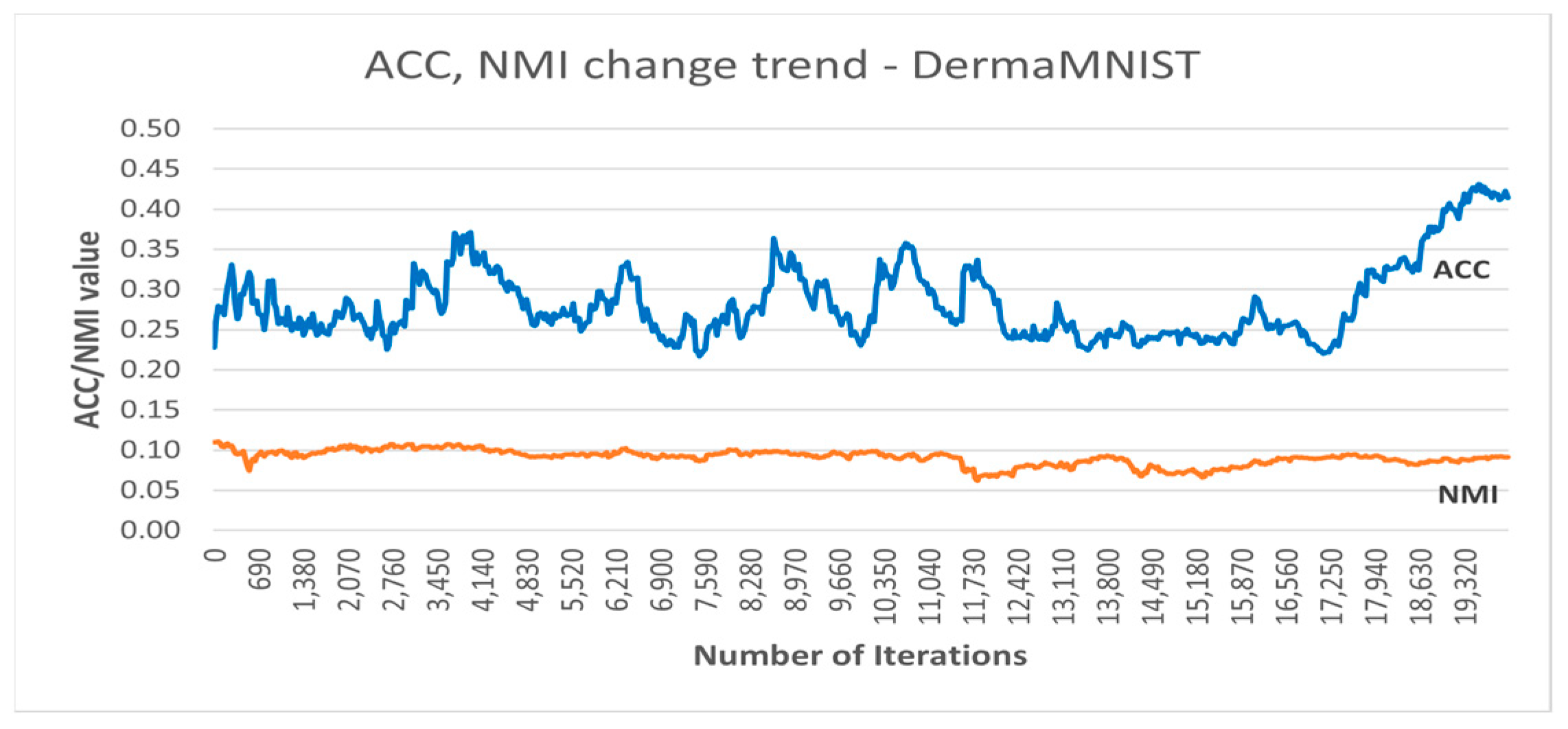
Figure 6 shows the accuracy and NMI trends over the training iterations of the best DC-SSDEC run on the DermaMNIST dataset. As can be seen, after some fluctuation during the training, the accuracy improved by almost 19% from the initial accuracy recorded.
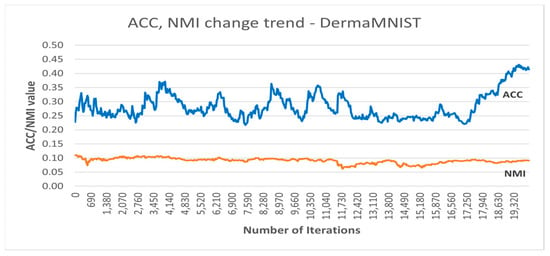
Figure 6.
Accuracy and NMI trends recorded using DC-SSDEC and the DermaMNIST dataset.
Hyper-parameter values that yielded the highest accuracy of DC-SSDEC on the Digits-SL dataset are reported in Table 9. Generally, the results of this hyper-parameter tuning show that the highest accuracy was attained at values of −1 and 1 for γ1 and γ2, respectively. This is consistent with the initial structure of the proposed objective function. Furthermore, the accuracy results had an inverse relationship with the data batch size adopted for pretraining, where training DC-SSDEC on the Digits-SL dataset using a 32-batch size yielded the highest results. This can be related to the small scale of the dataset.
Table 9.
Hyper-parameter values that yielded the highest accuracy of DC-SSDEC for the Digits-SL dataset.
Finally, Table 10 reports the results achieved by DC-SSDEC and the considered state-of-the-art approaches using the Digits_SL dataset [74] for sign language detection. The results shown in the table demonstrate the dominance of the proposed approach. Specifically, an improvement of approximately 9.3% over other methods was recorded in terms of clustering accuracy.
Table 10.
Clustering results obtained using the Digits_SL dataset.
Also, an improvement near 8.77% was achieved by DC-SSDEC in terms of the NMI metric. In addition, the relatively low accuracy values in Table 10 can be attributed to the small size of the highly dimensional Digits_SL dataset.
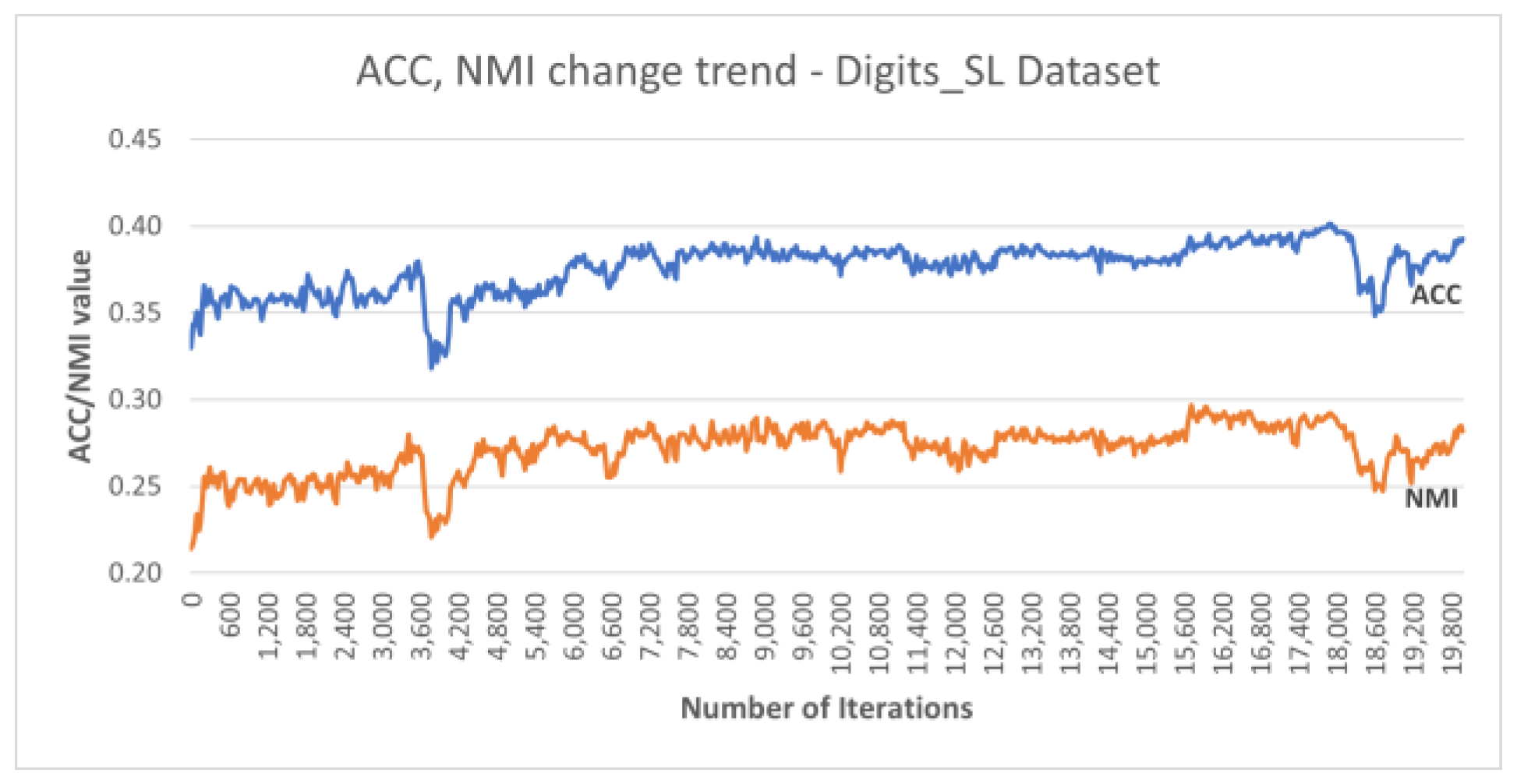
Additionally, Figure 7 plots the accuracy and NMI trends over the training iterations for the best run of DC-SSDEC using the Digits_SL dataset. It is notable that both metrics improved by 6% from the initial accuracy recorded, with some fluctuation throughout the training process.
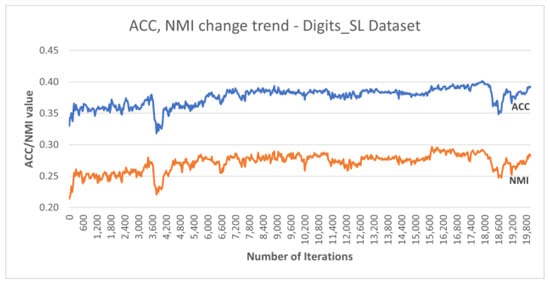
Figure 7.
Performance trends recorded for DC-SSDEC using the Digits_SL dataset.
5. Conclusions
This research introduced a novel semi-supervised deep clustering approach that associates deep neural networks and fuzzy membership functions for an improved clustering performance. The proposed Dual-Constraint-based Semi-Supervised Deep Clustering approach, DC-SSDEC, exploits “should-link” and “shouldNot-link” pairwise soft constraints to guide the clustering process. In particular, the intended clustering task was expressed as an optimization problem through the minimization of a newly objective function. Comprehensive experiments were conducted to validate and assess DC-SSDEC performance. The results obtained demonstrated DC-SSDEC outperformance compared to relevant deep clustering approaches. Specifically, when evaluated against the state-of-the-art approaches, DC-SSDEC yielded competitive clustering results using the STL-10 dataset and exceeded the performance of the state-of-the-art methods using MNIST, USPS, Chest X-Ray, DermaMNIST, and Digits-SL datasets. Typically, the obtained results showcased the added value of the proposed formulation of the soft pairwise constraints considered. Specifically, enriching the set of “should-link” pairwise constraints with another set of “shouldNot-link” constraints further enhanced the clustering performance. Additionally, the superior performance of DC-SSDEC in comparison to (DL + K-means) on all datasets demonstrated the efficiency of the proposed simultaneous optimization of (i) the clustering objective function and (ii) the deep network loss function.
In fact, whereas crisp clustering mandates that each data sample be assigned to a single cluster, soft clustering allows data points to belong to multiple clusters simultaneously. This flexibility enables soft clustering to handle clusters with unclear boundaries more effectively. In contrast, crisp clustering methods often struggle to identify clusters with irregular shapes, making them more prone to local minima. As a result, the performance of DC-SSDEC highlighted the positive impact of adopting soft clustering, in comparison to crisp clustering methods. As an application of soft clustering, fuzzy membership representations boosted the performance of the proposed approach over the non-fuzzy approach, SDEC [24], for all datasets.
The proposed approach, DC-SSDEC, can be coupled with any image datasets. In particular, medical imaging analysis, information security purposes such as surveillance and intrusion detection, and Content-Based Image Retrieval (CBIR) represent typical applications for the proposed approach. Furthermore, we should state some limitations of the proposed approach, such as its sensitivity to the predetermined number of clusters and its dependence on trial-and-error methods for hyper-parameter tuning. To address these issues and improve performance, future research directions are suggested: (i) automating cluster number determination by incorporating an additional term into the proposed objective function; (ii) exploring advanced heuristics for selecting hyper-parameters (β, γ); (iii) expanding the range of tunable hyper-parameters, such as those for autoencoder settings and the optimizer’s learning rate; (iv) managing noise and outliers using a possibilistic logic-based clustering approach; (v) incorporating weights into the labeled instances associated with the pairwise constraints; and (vi) analyzing the computational complexity of the algorithm.
Author Contributions
Conceptualization, M.S.A., M.M.B.I. and O.B.; methodology, M.S.A., M.M.B.I. and O.B.; software, M.S.A.; validation, M.S.A. and M.M.B.I.; formal analysis, M.S.A. and M.M.B.I.; investigation, M.S.A. and M.M.B.I.; resources, M.S.A. and M.M.B.I.; data curation, M.S.A.; writing—original draft preparation, M.S.A.; writing—review and editing, M.S.A., M.M.B.I. and O.B.; visualization, M.S.A. and M.M.B.I.; supervision, O.B. and M.M.B.I. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. The MNIST data can be found at https://www.kaggle.com/datasets/hojjatk/mnist-dataset/data. The USPS data can be found at https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/multiclass.html#usps. The STL-10 data can be found at https://cs.stanford.edu/~acoates/stl10/. The Chest X-Ray data can be found at https://www.kaggle.com/datasets/paultimothymooney/chest-xray-pneumonia. The DermaMNIST data can be found at https://zenodo.org/records/10519652. The Digits_SL data can be found at https://www.kaggle.com/datasets/ardamavi/sign-language-digits-dataset. (All data sources above were accessed on 22 January 2025.)
Acknowledgments
The authors would like to thank the Deanship of Scientific Research at King Saud University for supporting this research through the initiative of Graduate Students Research Support (GSR).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Talabis, M.; McPherson, R.; Miyamoto, I.; Martin, J. Information Security Analytics: Finding Security Insights, Patterns, and Anomalies in Big Data; Syngress: Burlington, MA, USA, 2014. [Google Scholar]
- Min, E.; Guo, X.; Liu, Q.; Zhang, G.; Cui, J.; Long, J. A survey of clustering with deep learning: From the perspective of network architecture. IEEE Access 2018, 6, 39501–39514. [Google Scholar] [CrossRef]
- Dahal, P. “Deep Clustering”, DeepNotes. Available online: http://deepnotes.io/deep-clustering (accessed on 18 November 2023).
- Steinbach, M.; Ertöz, L.; Kumar, V. The challenges of clustering high dimensional data. In New Directions in Statistical Physics; Springer: Berlin/Heidelberg, Germany, 2004; pp. 273–309. [Google Scholar]
- Saul, L.K.; Weinberger, K.Q.; Sha, F.; Ham, J.; Lee, D.D. Spectral methods for dimensionality reduction. Semi-Supervised Learn. 2006, 3, 566–806. [Google Scholar]
- Vasan, K.K.; Surendiran, B. Dimensionality reduction using principal component analysis for network intrusion detection. Perspect. Sci. 2016, 8, 510–512. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Rolnick, D.; Veit, A.; Belongie, S.; Shavit, N. Deep learning is robust to massive label noise. arXiv 2017, arXiv:1705.10694. [Google Scholar]
- Aljalbout, E.; Golkov, V.; Siddiqui, Y.; Strobel, M.; Cremers, D. Clustering with deep learning: Taxonomy and new methods. arXiv 2018, arXiv:1801.07648. [Google Scholar]
- Yang, B.; Fu, X.; Sidiropoulos, N.D.; Hong, M. Towards k-means-friendly spaces: Simultaneous deep learning and clustering. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 3861–3870. [Google Scholar]
- Shaham, U.; Stanton, K.; Li, H.; Nadler, B.; Basri, R.; Kluger, Y. SpectralNet: Spectral Clustering using Deep Neural Networks. arXiv 2018, arXiv:1801.01587. [Google Scholar] [CrossRef]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 478–487. [Google Scholar]
- Berahmand, K.; Bahadori, S.; Abadeh, M.N.; Li, Y.; Xu, Y. Sdac-da: Semi-supervised deep attributed clustering using dual autoencoder. IEEE Trans. Knowl. Data Eng. 2024, 36, 6989–7002. [Google Scholar] [CrossRef]
- Ding, S.; Hou, H.; Xu, X.; Zhang, J.; Guo, L.; Ding, L. Graph-Based Semi-Supervised Deep Image Clustering with Adaptive Adjacency Matrix. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 18828–18837. [Google Scholar] [CrossRef]
- Xu, X.; Hou, H.; Ding, S. Semi-supervised deep density clustering. Appl. Soft Comput. 2023, 148, 110903. [Google Scholar] [CrossRef]
- Chen, R.; Tang, Y.; Zhang, W.; Feng, W. Deep multi-view semi-supervised clustering with sample pairwise constraints. Neurocomputing 2022, 500, 832–845. [Google Scholar] [CrossRef]
- AlZuhair, M.S.; Ismail, M.M.B.; Bchir, O. Soft Semi-Supervised Deep Learning-Based Clustering. Appl. Sci. 2023, 13, 9673. [Google Scholar] [CrossRef]
- Li, J.; Lin, C.; Huang, R.; Qin, Y.; Chen, Y. Intention-guided deep semi-supervised document clustering via metric learning. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 416–425. [Google Scholar]
- La Rosa, L.E.C.; Oliveira, D.A.B. Learning from label proportions with prototypical contrastive clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; pp. 2153–2161. [Google Scholar]
- Genevay, A.; Dulac-Arnold, G.; Vert, J.-P. Differentiable deep clustering with cluster size constraints. arXiv 2019, arXiv:1910.09036. [Google Scholar]
- Qin, X.; Yuan, C.; Jiang, J.; Chen, L. Deep semi-supervised clustering based on pairwise constraints and sample similarity. Pattern Recognit. Lett. 2024, 178, 1–6. [Google Scholar] [CrossRef]
- Ren, Y.; Pu, J.; Yang, Z.; Xu, J.; Li, G.; Pu, X.; Yu, P.S.; He, L. Deep clustering: A comprehensive survey. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 5858–5878. [Google Scholar] [CrossRef]
- Zhao, X.; Jia, M. A novel deep fuzzy clustering neural network model and its application in rolling bearing fault recognition. Meas. Sci. Technol. 2018, 29, 125005. [Google Scholar] [CrossRef]
- Ren, Y.; Hu, K.; Dai, X.; Pan, L.; Hoi, S.C.H.; Xu, Z. Semi-supervised deep embedded clustering. Neurocomputing 2019, 325, 121–130. [Google Scholar] [CrossRef]
- Yong, Z.X.; Torrent, T.T. Semi-supervised deep embedded clustering with anomaly detection for semantic frame induction. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 3509–3519. [Google Scholar]
- Vilhagra, L.A.; Fernandes, E.R.; Nogueira, B.M. TextCSN: A semi-supervised approach for text clustering using pairwise constraints and convolutional siamese network. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3 April 2020; pp. 1135–1142. [Google Scholar]
- Shukla, A.; Cheema, G.S.; Anand, S. Semi-supervised clustering with neural networks. In Proceedings of the 2020 IEEE Sixth International Conference on Multimedia Big Data (BigMM), New Delhi, India, 24–26 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 152–161. [Google Scholar]
- Chen, G. Deep learning with nonparametric clustering. arXiv 2015, arXiv:1501.03084. [Google Scholar]
- Kampffmeyer, M.; Løkse, S.; Bianchi, F.M.; Livi, L.; Salberg, A.-B.; Jenssen, R. Deep divergence-based approach to clustering. Neural Netw. 2019, 113, 91–101. [Google Scholar] [CrossRef]
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 132–149. [Google Scholar]
- de Mello, D.P.; Assunção, R.M.; Murai, F. Top-Down Deep Clustering with Multi-Generator GANs. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 7770–7778. [Google Scholar]
- Guo, X.; Liu, X.; Zhu, E.; Yin, J. Deep clustering with convolutional autoencoders. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 373–382. [Google Scholar]
- Guo, X.; Zhu, E.; Liu, X.; Yin, J. Deep embedded clustering with data augmentation. In Proceedings of the Asian Conference on Machine Learning, Beijing, China, 14–16 November 2018; pp. 550–565. [Google Scholar]
- Shah, S.A.; Koltun, V. Deep continuous clustering. arXiv 2018, arXiv:1803.01449. [Google Scholar]
- Zhang, H.; Zhan, T.; Basu, S.; Davidson, I. A framework for deep constrained clustering. Data Min. Knowl. Discov. 2021, 35, 593–620. [Google Scholar] [CrossRef]
- Dizaji, K.G.; Herandi, A.; Deng, C.; Cai, W.; Huang, H. Deep clustering via joint convolutional autoencoder embedding and relative entropy minimization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5736–5745. [Google Scholar]
- Jiang, Z.; Zheng, Y.; Tan, H.; Tang, B.; Zhou, H. Variational deep embedding: An unsupervised and generative approach to clustering. arXiv 2016, arXiv:1611.05148. [Google Scholar]
- Guo, X.; Gao, L.; Liu, X.; Yin, J. Improved deep embedded clustering with local structure preservation. In Proceedings of the IJCAI, Melbourne, VIC, Australia, 19–25 August 2017; pp. 1753–1759. [Google Scholar]
- Moreno, J.G. Point Symmetry-based deep clustering. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 1747–1750. [Google Scholar]
- LeCun, Y. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 17 August 2023).
- Lewis, D.D.; Yang, Y.; Russell-Rose, T.; Li, F. Rcv1: A new benchmark collection for text categorization research. J. Mach. Learn. Res. 2004, 5, 361–397. [Google Scholar]
- Peng, X.; Feng, J.; Zhou, J.T.; Lei, Y.; Yan, S. Deep subspace clustering. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5509–5521. [Google Scholar] [CrossRef]
- Diallo, B.; Hu, J.; Li, T.; Khan, G.A.; Liang, X.; Zhao, Y. Deep embedding clustering based on contractive autoencoder. Neurocomputing 2021, 433, 96–107. [Google Scholar] [CrossRef]
- Fard, M.M.; Thonet, T.; Gaussier, E. Deep k-means: Jointly clustering with k-means and learning representations. Pattern Recognit. Lett. 2020, 138, 185–192. [Google Scholar] [CrossRef]
- Sadeghi, M.; Armanfard, N. IDECF: Improved deep embedding clustering with deep fuzzy supervision. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1009–1013. [Google Scholar]
- Ren, Y.; Wang, N.; Li, M.; Xu, Z. Deep density-based image clustering. Knowl.-Based Syst. 2020, 197, 105841. [Google Scholar] [CrossRef]
- Enguehard, J.; O’Halloran, P.; Gholipour, A. Semi-supervised learning with deep embedded clustering for image classification and segmentation. IEEE Access 2019, 7, 11093–11104. [Google Scholar] [CrossRef]
- Carr, O.; Jovanovic, S.; Albergante, L.; Andreotti, F.; Dürichen, R.; Lipunova, N.; Baxter, J.; Khan, R.; Irving, B. Deep Semi-Supervised Embedded Clustering (DSEC) for Stratification of Heart Failure Patients. arXiv 2020, arXiv:2012.13233. [Google Scholar]
- Ienco, D.; Pensa, R.G. Deep triplet-driven semi-supervised embedding clustering. In Proceedings of the International Conference on Discovery Science, Split, Croatia, 28–30 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 220–234. [Google Scholar]
- Xing, E.; Jordan, M.; Russell, S.J.; Ng, A. Distance metric learning with application to clustering with side-information. Adv. Neural Inf. Process. Syst. 2002, 15, 505–512. [Google Scholar]
- Chen, G. Deep transductive semi-supervised maximum margin clustering. arXiv 2015, arXiv:1501.06237. [Google Scholar]
- Huang, D.; Hu, J.; Li, T.; Du, S.; Chen, H. Consistency regularization for deep semi-supervised clustering with pairwise constraints. Int. J. Mach. Learn. Cybern. 2022, 13, 3359–3372. [Google Scholar] [CrossRef]
- Wang, Z.; Mi, H.; Ittycheriah, A. Semi-supervised clustering for short text via deep representation learning. arXiv 2016, arXiv:1602.06797. [Google Scholar]
- Chen, T.; Lu, S.; Fan, J. SS-HCNN: Semi-supervised hierarchical convolutional neural network for image classification. IEEE Trans. Image Process. 2018, 28, 2389–2398. [Google Scholar] [CrossRef]
- Li, X.; Yin, H.; Zhou, K.; Zhou, X. Semi-supervised clustering with deep metric learning and graph embedding. World Wide Web 2020, 23, 781–798. [Google Scholar] [CrossRef]
- Ohi, A.Q.; Mridha, M.; Safir, F.B.; Hamid, M.A.; Monowar, M.M. Autoembedder: A semi-supervised DNN embedding system for clustering. Knowl.-Based Syst. 2020, 204, 106190. [Google Scholar] [CrossRef]
- Ruff, L.; Vandermeulen, R.A.; Görnitz, N.; Binder, A.; Müller, E.; Müller, K.-R.; Kloft, M. Deep semi-supervised anomaly detection. arXiv 2019, arXiv:1906.02694. [Google Scholar]
- de Lima, B.V.A.; Neto, A.D.D.; Silva, L.E.S.; Machado, V.P. Deep semi-supervised classification based in deep clustering and cross-entropy. Int. J. Intell. Syst. 2021, 36, 3961–4000. [Google Scholar] [CrossRef]
- Śmieja, M.; Wołczyk, M.; Tabor, J.; Geiger, B.C. SeGMA: Semi-Supervised Gaussian Mixture Autoencoder. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3930–3941. [Google Scholar] [CrossRef]
- Hazratgholizadeh, R.; Balafar, M.; Derakhshi, M. Active constrained deep embedded clustering with dual source. Appl. Intell. 2023, 53, 5337–5367. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, R.; Zhou, J.; Han, S.; Du, T.; Ji, K.; Zhao, Y.O.; Zhang, K.; Chen, Y. Semi-Supervised Deep Clustering with Soft Membership Affinity. In Proceedings of the 2021 8th International Conference on Information, Cybernetics, and Computational Social Systems (ICCSS), Beijing, China, 10–12 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 521–524. [Google Scholar]
- Zhang, H.; Basu, S.; Davidson, I. A framework for deep constrained clustering-algorithms and advances. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Würzburg, Germany, 16–20 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 57–72. [Google Scholar]
- Chen, Z.; Li, C.; Gao, J.; Zhang, J.; Li, P. Semisupervised Deep Embedded Clustering with Adaptive Labels. Sci. Program. 2021, 2021, 6613452. [Google Scholar] [CrossRef]
- Amirizadeh, E.; Boostani, R. CDEC: A constrained deep embedded clustering. Int. J. Intell. Comput. Cybern. 2021, 14, 686–701. [Google Scholar] [CrossRef]
- Ay, D.; Tastan, O. Identifying Cross-Cancer Similar Patients via a Semi-Supervised Deep Clustering Approach. 2021. Available online: https://www.biorxiv.org/content/10.1101/2020.11.07.372672v3.full (accessed on 16 April 2025).
- Fogel, S.; Averbuch-Elor, H.; Cohen-Or, D.; Goldberger, J. Clustering-driven deep embedding with pairwise constraints. IEEE Comput. Graph. Appl. 2019, 39, 16–27. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. A k-means clustering algorithm. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Hull, J.J. A database for handwritten text recognition research. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 550–554. [Google Scholar] [CrossRef]
- Coates, A.; Ng, A.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; JMLR Workshop and Conference Proceedings. pp. 215–223. [Google Scholar]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.S.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 2018, 172, 1122–1131. [Google Scholar] [CrossRef]
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, K.; Marchetti, M.; et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). arXiv 2019, arXiv:1902.03368. [Google Scholar]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 180161. [Google Scholar] [CrossRef]
- Mavi, A. A new dataset and proposed convolutional neural network architecture for classification of American sign language digits. arXiv 2020, arXiv:2011.08927. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; JMLR Workshop and Conference Proceedings. pp. 315–323. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).