Spectral and Spatial-Based Classification for Broad-Scale Land Cover Mapping Based on Logistic Regression



Abstract
:1. Introduction
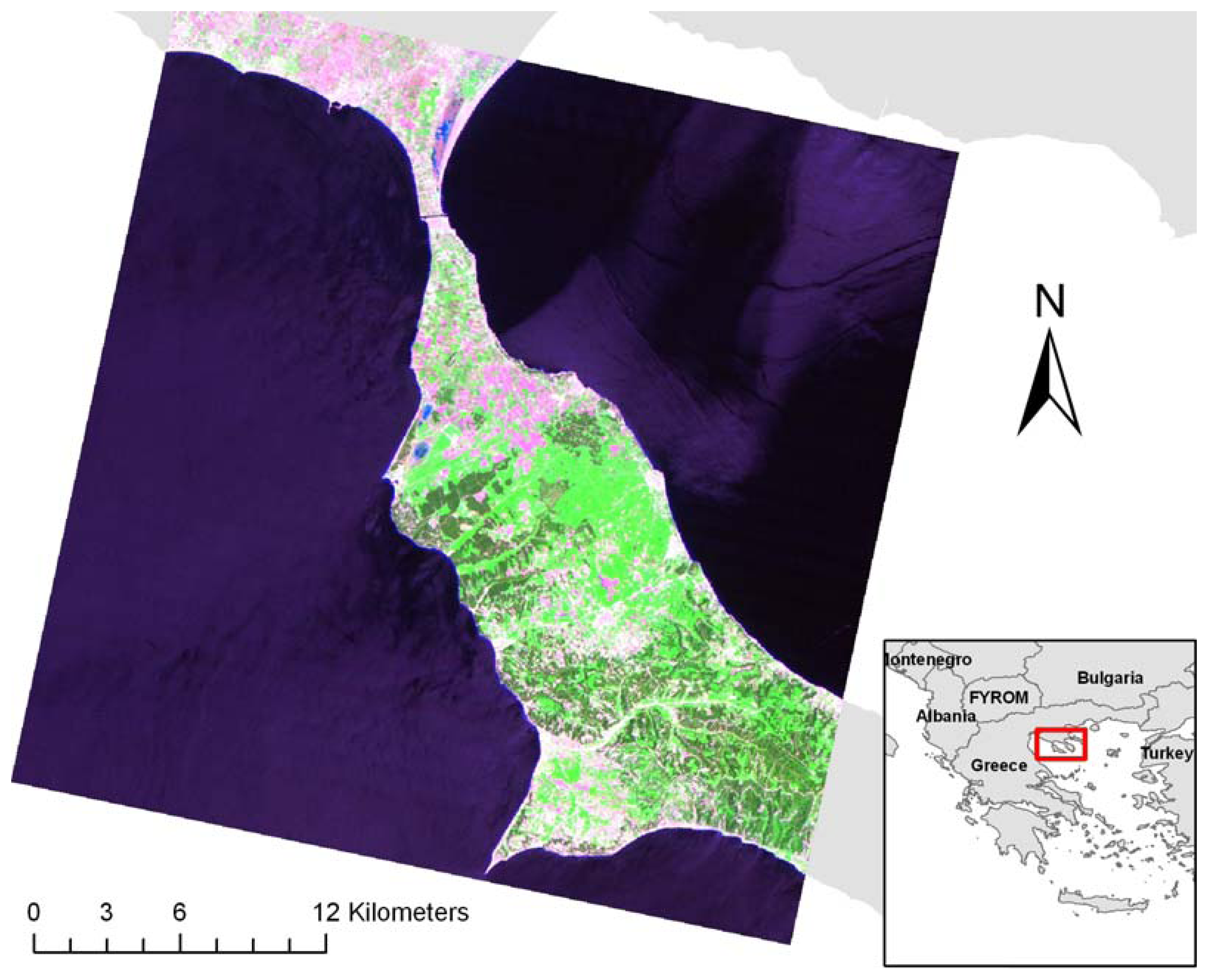
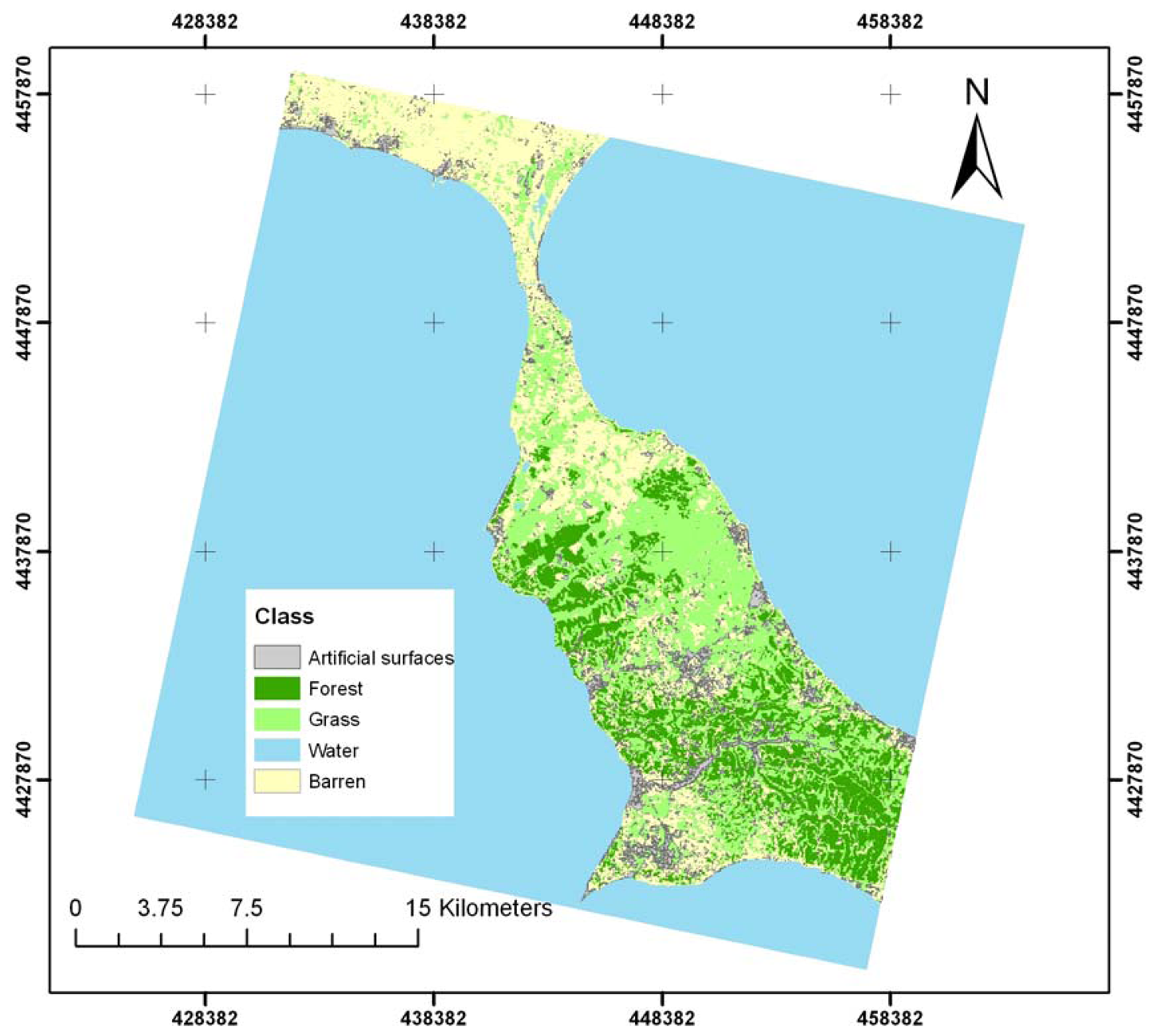
2. Study Area
3. Materials and Methods
3.1. Image Data Preprocessing
3.2. Data analysis
3.2.1. Classification Scheme
3.2.2. Maximum Likelihood (ML) Classification
3.2.3. Contextual Classification Based on Mahalanobis Distance
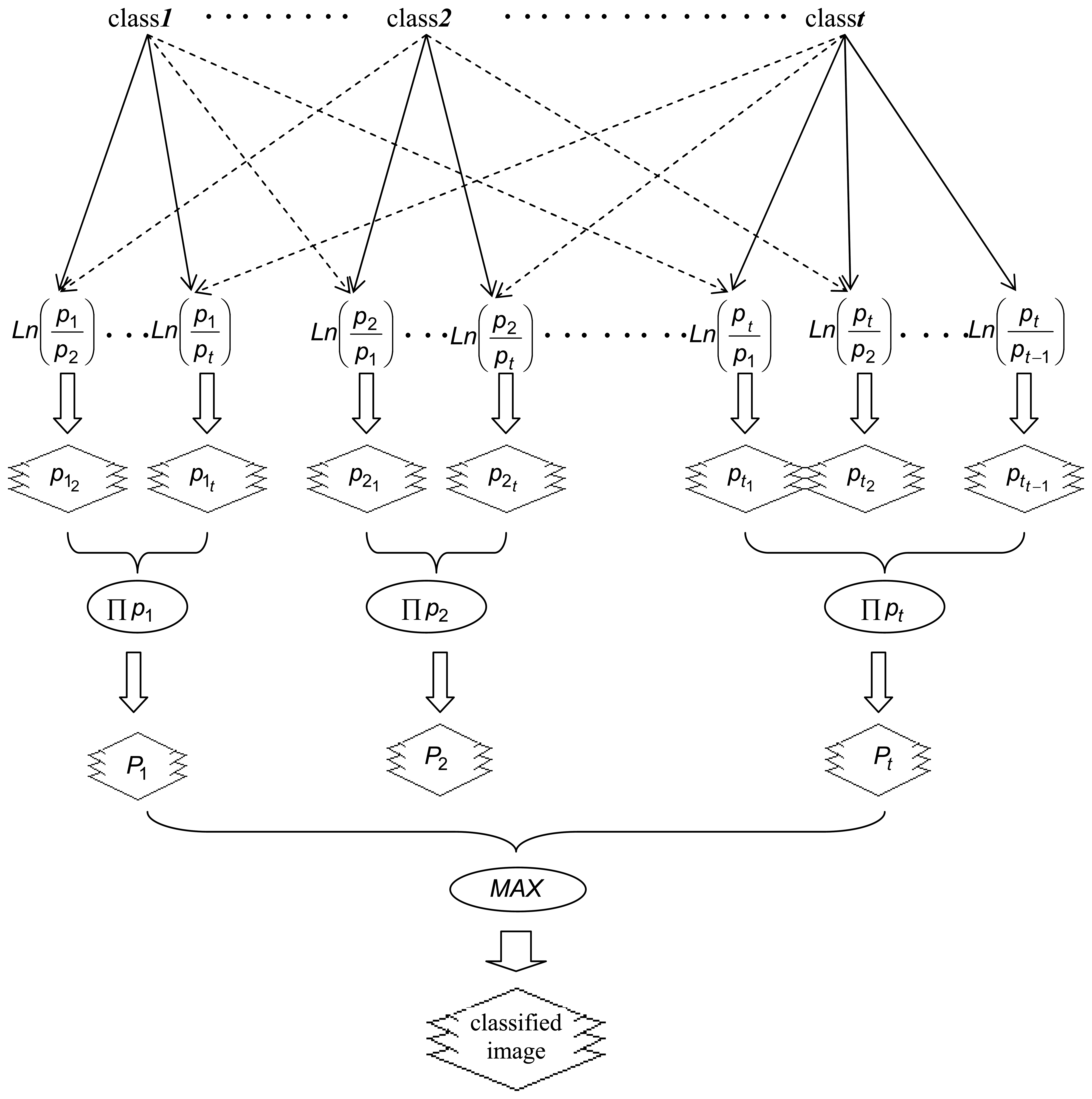
3.2.4. Logistic Regression Modelling
- Assessment of training areas for each informational class and extraction of DN values. The spectral channels of TM imagery are perceived as independent variables while the land cover category is the dependent variable.
- T groups (t classification classes) of t-1 data files each, are formed and the main or baseline informational class is encoded to value 1. This set of files is the final input to the multiple logistic regression modelling process.
- Using a forward multiple logistic procedure based on the likelihood ratio statistic, the coefficients of each model are estimated by considering three explanatory variables maximum. The independent variables of each model are the best-performing out of the seven available to discriminate each informational class.
- The logistic regression models are applied and t x (t-1) new images are produced and organized in t groups according to the original file scheme. Within each group, the four images are combined through multiplication to produce a final probability image for each class.
- The final classified image results by assigning to each pixel the land-cover category which corresponds to the highest probability value.
3.2.5. Autologistic regression modeling
- Estimation of the predicted probabilities of the binary response variable using the ordinary multiple logistic regression model.
- Estimation of the autocovariate component from the predicted probabilities using a moving window. The autocovariate component is then incorporated into the ordinary multiple logistic regression model as a new covariate.
- Estimation of the coefficients of the autologistic multiple regression model including the original covariates (three spectral channels) and the autocovariate component. The procedure can be repeated from step 2 using the estimated probabilities of step 3.
3.3. Assessment of the different classification procedures
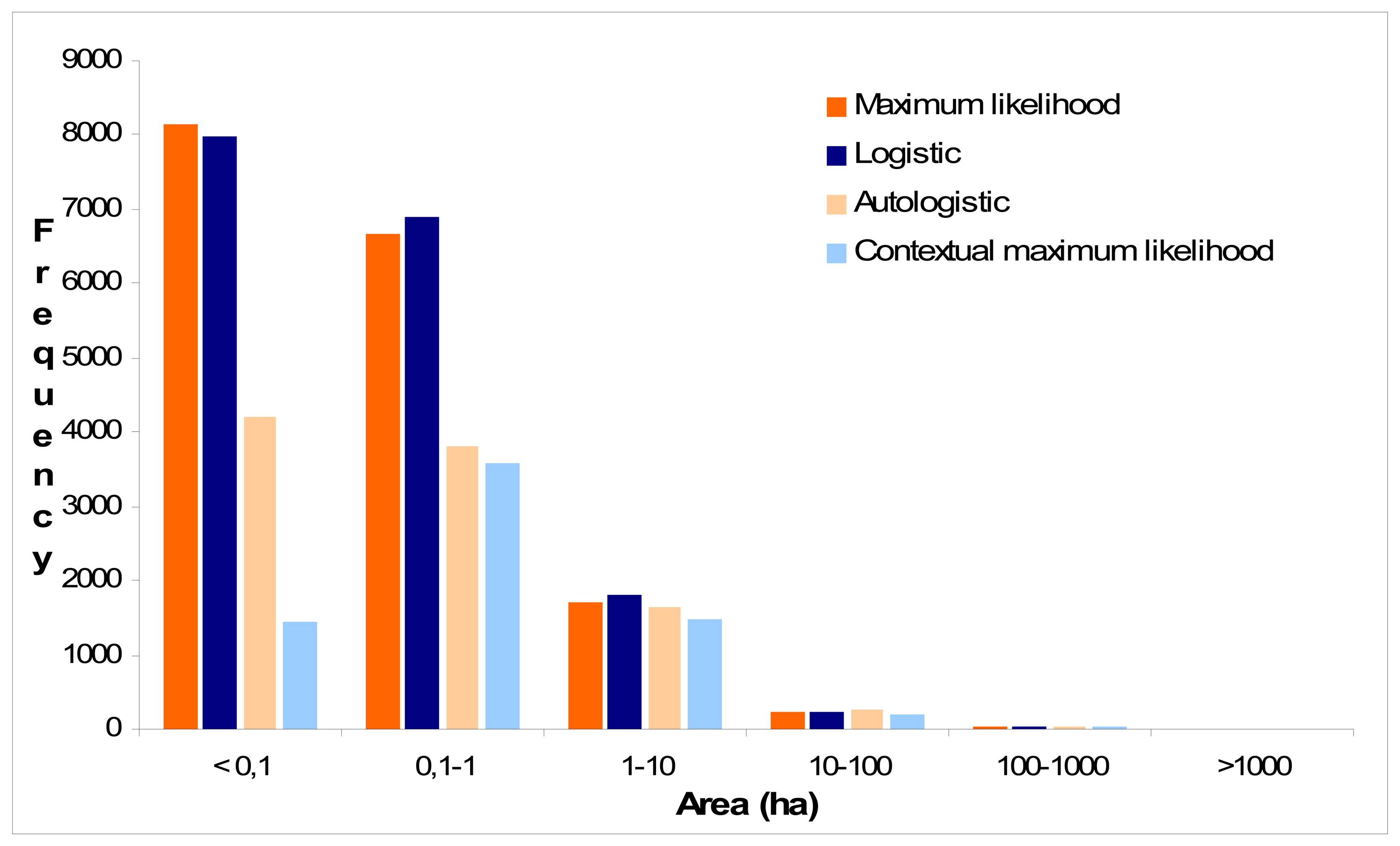
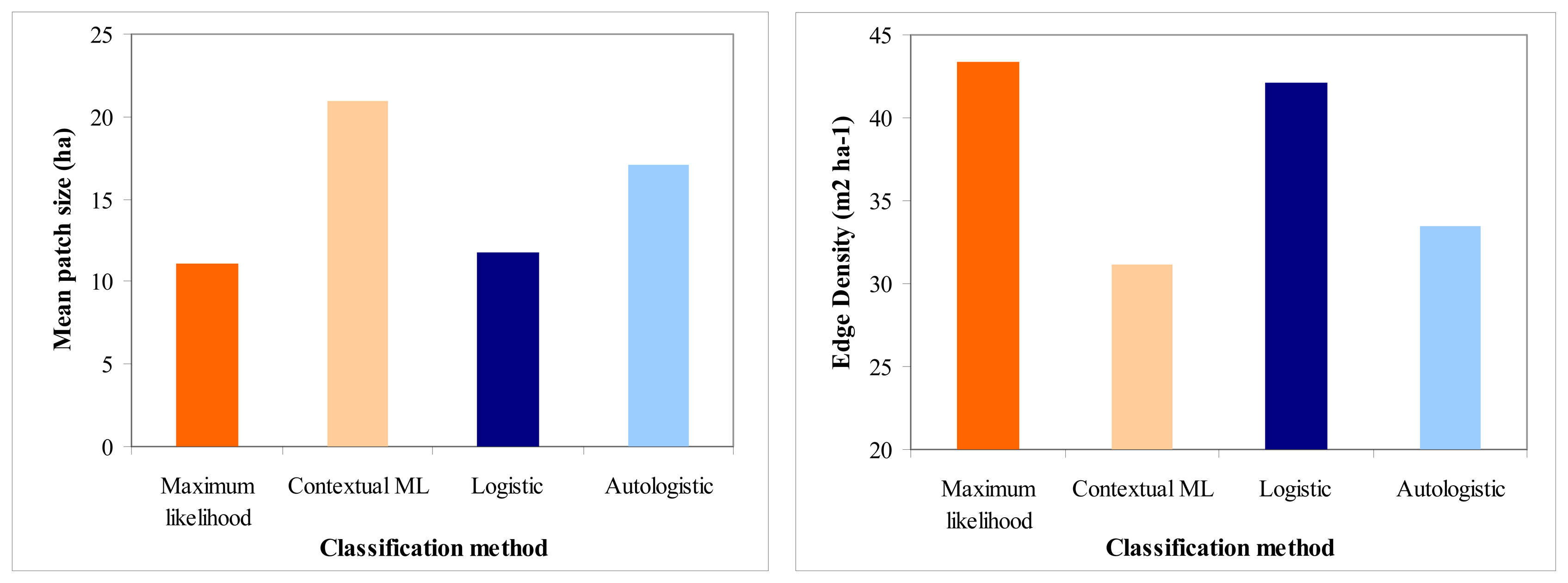
4. Results and Discussion
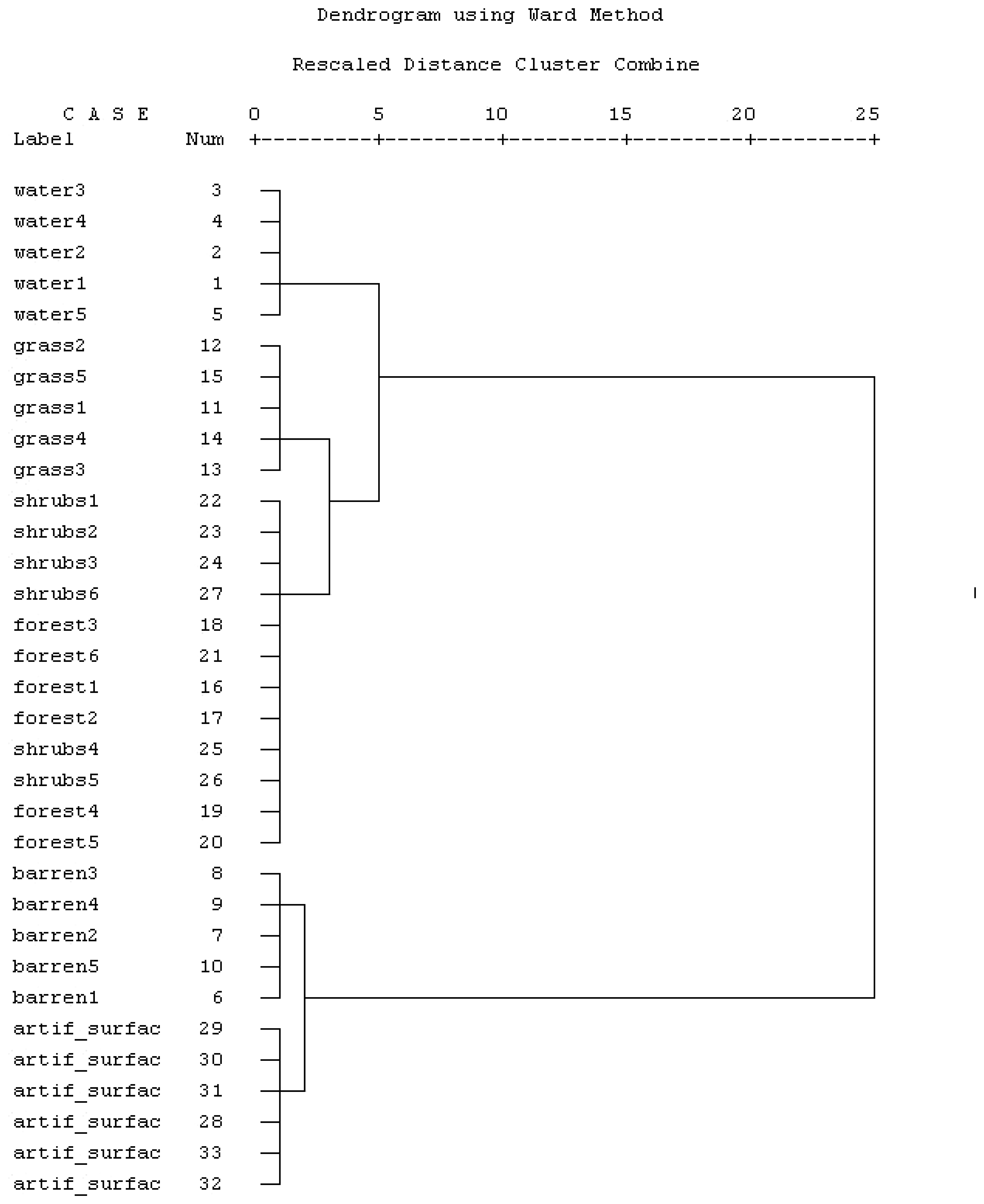
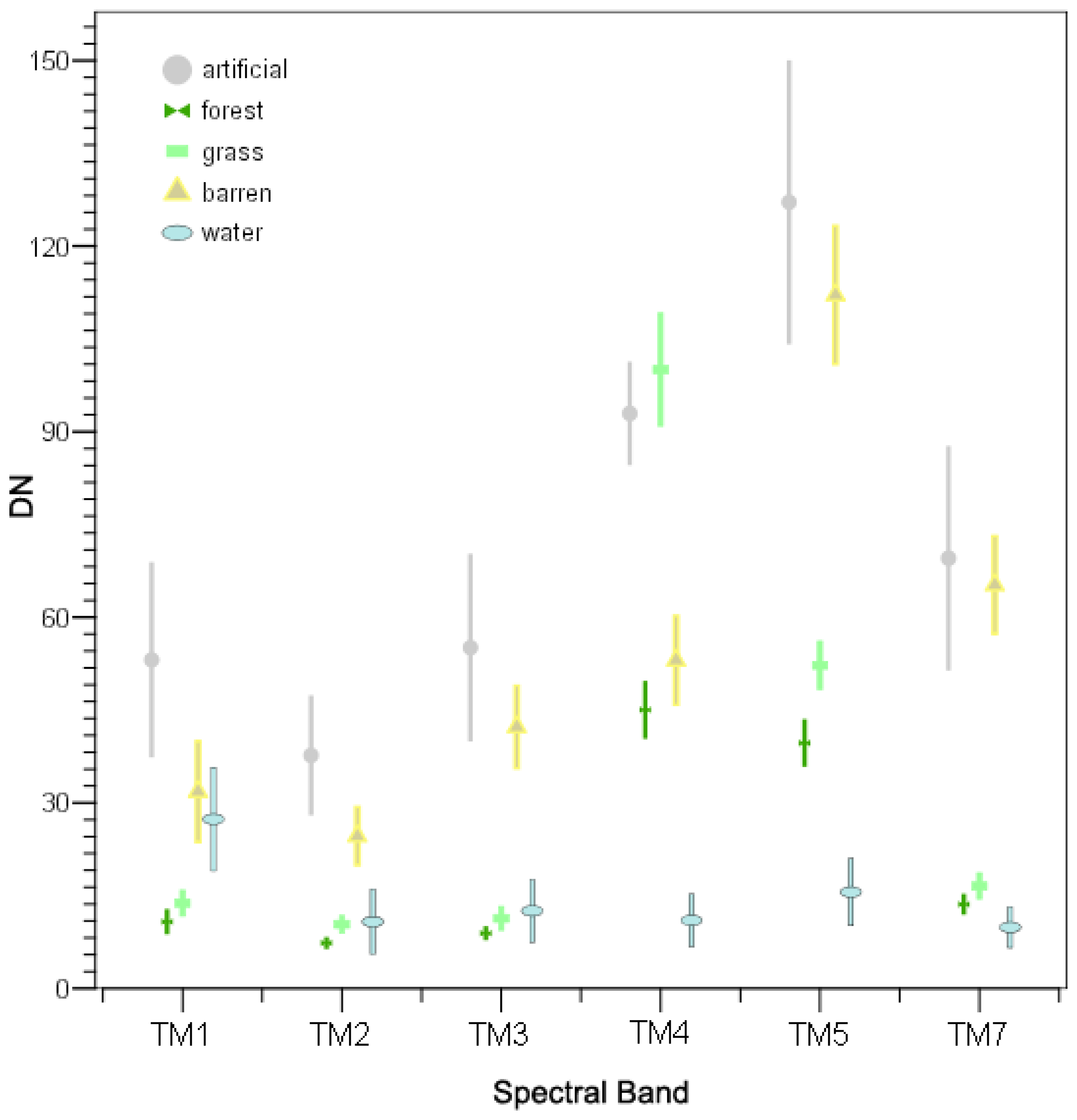
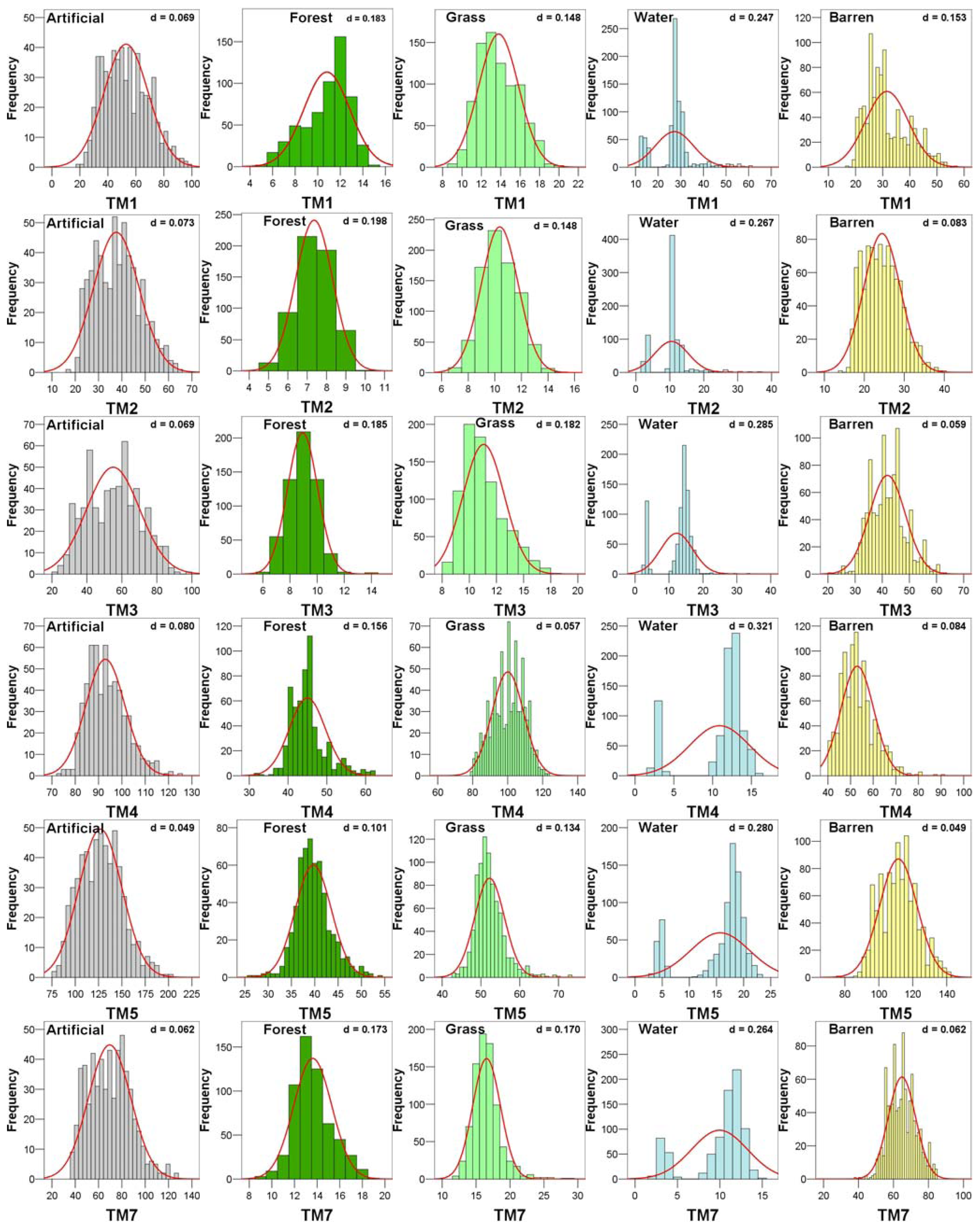
4.1. Purification of classification categories
5. Conclusions
References and Notes
- Aplin, P. Remote sensing: Land cover. Prog. Phys. Geog. 2004, 28, 283–293. [Google Scholar]
- Foody, G.M.; Mathur, A. A relative evaluation of multiclass image classification by support vector machines. IEEE T Geosci. Remote 2004, 42, 1335–1343. [Google Scholar]
- Avery, T.E.; Berlin, G.L. Fundamentals of Remote Sensing and Air Photo Interpretation, 5th Ed. ed; Macmillan Publishing Company: New York, USA, 1992; pp. 51–57. [Google Scholar]
- Kanellopoulos, I.; Varfis, A.; Wilkinson, G.G.; Megier, J. Land-cover discrimination in SPOT HRV imagery using an artificial neural network-a 20-class experiment. Int. J. Remote Sens. 1992, 13, 917–924. [Google Scholar]
- Liu, X.; Skidmore, A.K.; Oosten, H.V. Integration of classification methods for improvement of land-cover map accuracy. ISPRS J. Photogramm. 2002, 56, 257–268. [Google Scholar]
- Liu, W.; Gopal, S.; Woodcock, C.E. Uncertainty and confidence in land cover classification using a hybrid classifier approach. Photogramm. Eng. 2004, 70, 963–971. [Google Scholar]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar]
- Chen, D. A standardized probability comparison approach for evaluating and combining pixel-based classification procedures. Photogramm. Eng. 2008, 74, 601–609. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: New York, USA, 2001; pp. 182–187. [Google Scholar]
- Carpenter, G.A.; Gopal, S.; Macomber, S.; Martens, S.; Woodcock, C.E. A neural network method for mixture estimation for vegetation mapping. Remote Sens. Environ. 1999, 70, 138–152. [Google Scholar]
- Koutsias, N.; Karteris, M. Burned area mapping using logistic regression modeling of a single post-fire Landsat-5 Thematic Mapper image. Int. J. Remote Sens. 1998, 21, 673–687. [Google Scholar]
- Mallinis, G.; Koutsias, N.; Makras, A.; Karteris, M. Forest parameters estimation in a European Mediterranean landscape using remotely sensed data. Forest Sci. 2004, 50, 450–460. [Google Scholar]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ. 2003, 82, 554–565. [Google Scholar]
- Mallinis, G.; Koutsias, N.; Tsakiri, M.; Karteris, M. Object-based classification using Quickbird imagery for delineating forest vegetation polygons in a Mediterranean test site. ISPRS J. Photogramm. 2008, 63, 237–250. [Google Scholar]
- Hubert-Moy, L.; Cotonnec, A.; Le Du, L.; Chardin, A.; Pιrez, P. A comparison of parametric classification procedures of remotely sensed data applied on different landscape units. Remote Sens. Environ. 2001, 75, 174–187. [Google Scholar]
- Chen, D.; Stow, D.A.; Gong, P. Examining the effect of spatial resolution and texture window size on classification accuracy, an urban environment case. Int. J. Remote Sens. 2004, 25, 2177–2192. [Google Scholar]
- Hay, G.J.; Niemann, K.O.; McLean, G.F. An object-specific image-texture analysis of H-resolution forest imagery. Remote Sens. Environ. 1996, 55, 108–122. [Google Scholar]
- Cushnie, J.L. The interactive effect of spatial resolution and degree of internal variability within land-cover types on classification accuracies. Int. J. Remote Sens. 1987, 8, 15–29. [Google Scholar]
- Gong, P.B.; Xu, B. Contextual classification methods for land cover and land use mapping. In Remote Sensing Image Analysis including the Spatial Domain; de Jong, S.M., van der Meer, F.D., Eds.; Kluwer Press: Amsterdam, Netherlands, 2004; pp. 137–152. [Google Scholar]
- Gong, P.; Howarth, P.J. Performance analyses of probabilistic relaxation methods for land-cover classification. Remote Sens. Environ. 1989, 30, 33–42. [Google Scholar]
- Kontoes, C.C.; Rokos, D. The integration of spatial context information in an experimental knowledge-based system and the supervised relaxation algorithm-Two successful approaches to improving SPOT-XS classification. Int. J. Remote Sens. 1999, 17, 3093–3106. [Google Scholar]
- Solberg, A.H.; Taxt, T.; Jain, A.K. A Markov random field model for classification of multisource satellite imagery. IEEE T. Geosci. Remote 1996, 34, 100–113. [Google Scholar]
- Tso, B.C.K.; Mather, P.M. Classification of multisource remote sensing imagery using a Genetic Algorithm and Markov Random Fields. IEEE T. Geosci. Remote 1999, 37, 1255–1260. [Google Scholar]
- Magnussen, S.; Boudewyn, P.; Wulder, M. Contextual classification of Landsat TM images to forest inventory cover types. Int. J. Remote Sens. 2004, 25, 3093–3104. [Google Scholar]
- Lillesand, T.M.; Kiefer, R.W.; Chipman, J.W. Remote Sensing and Image Interpretation, 5th Ed. ed; J. Wiley and Sons: New York, USA, 2004; p. 551. [Google Scholar]
- Koutsias, N. An autologistic regression model for increasing the accuracy of burned surface mapping using Landsat Thematic Mapper data. Int. J. Remote Sens. 2003, 24, 2199–2204. [Google Scholar]
- Atkinson, P.M. Autologistic regression for flood zonation using SAR imagery. Proceedings of the 26th Annual Conference of the Remote Sensing Society, Adding Value to Remotely Sensed Data; Remote Sensing Society: Nottingham, UK, September 2000. [Google Scholar]
- Foody, G.M.; Campbell, N.A.; Trodd, N.M.; Wood, T.F. Derivation and applications of probabilistic measures of class membership from the maximum likelihood classification. Photogramm. Eng. 1992, 58, 1335–1341. [Google Scholar]
- Richards, J.A. Remote Sensing Digital Image Analysis: An Introduction, 2nd Ed. ed; Springer-Verlag: New York, USA, 1993; pp. 46–47. [Google Scholar]
- Chuvieco, E.; Congalton, R.G. Using cluster analysis to improve the selection of training statistics in classifying remotely sensed data. Photogramm. Eng. 1988, 54, 1275–1281. [Google Scholar]
- Milligan, G.W. An examination of the effects of six types of error perturbations on fifteen clustering algorithms. Psychometrika 1981, 45, 325–342. [Google Scholar]
- Hair, J.F., Jr.; Anderson, R.E.; Tatham, R.L.; Black, W.C. Multivariate Data Analysis, 5th Ed. ed; Prentice-Hall Inc.: New Jersey, USA, 1998; pp. 469–502. [Google Scholar]
- Wilson, M.D.; Atkinson, P.M. The use of remotely sensed land cover to derive floodplain friction coefficients for flood inundation modelling. Hydrol. Proc. 2007, 21, 3576–3586. [Google Scholar]
- Atkinson, P.M.; Lewis, P. Geostatistical classification for remote sensing, an introduction. Comput. Geosci. 2000, 26, 361–371. [Google Scholar]
- Foody, G.M.; Sargent, I.M.J.; Atkinson, P.M.; Williams, J. Thematic labelling from hyperspectral remotely sensed imagery, trade-offs in image properties. Int. J. Remote Sens. 2004, 25, 2337–2363. [Google Scholar]
- Pedroni, L. Improved classification of Landsat Thematic Mapper data using modified prior probabilities in large and complex landscapes. Int. J. Remote Sens. 2003, 24, 91–113. [Google Scholar]
- Augustin, N.H.; Mugglestone, M.A.; Buckland, S.T. An autologistic model for the spatial distribution of wildlife. J. Appl. Ecol. 1996, 33, 339–347. [Google Scholar]
- Osborne, P.E.; Alonso, J.C.; Bryant, R.G. Modelling landscape-scale habitat use using GIS and remote sensing, a case study with great bustards. J. Appl. Ecol. 2001, 38, 458–471. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–40. [Google Scholar]
- Steele, B.M. Maximum posterior probability estimators of map accuracy. Remote Sens. Environ. 2005, 99, 254–270. [Google Scholar]
- Turner, M.G.; Ruscher, C.L. Changes in landscape patterns in Georgia, USA. Landscape Ecol. 1988, 1, 241–251. [Google Scholar]
- Saura, S.; Martínez-Millán, J. Sensitivity of landscape pattern metrics to map spatial extent. Photogramm. Eng. 2001, 67, 1027–1036. [Google Scholar]
- Hudson, W.D. Evaluation of several classification schemes for mapping cover types in Michigan. Int. J. Remote Sens. 1987, 8, 1785–1796. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Land cover type | Description | Number of training plots / pixels |
|---|---|---|
| Artificial surfaces | Urban areas and man-made structures (roads, camps) | 6 / 572 |
| Forest | Coniferous forests (Pinus halepensis) | 6 / 632 |
| Shrubs | Shrublands mixed with interspersed P. halepensis (maquis, including Q. coccifera, Q. ilex and Arbutus unedo) | 5 / 575 |
| Grass | Cultivated crops and pastures which at the time of image acquisition, due to the vegetation phenology and the area's climatic conditions, are in full bloom | 6 / 812 |
| Barren | Bare rocks, very sparsely vegetated areas, and non-cultivated farmlands | 5 / 962 |
| Water | Wetlands and sea | 5 / 732 |
| 1. Maximum likelihood | 2. Contextual ML | 3. Logistic regression | 4. Autologistic regression | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Area of the map (km2)/Reference points | Producers | Users | Producers | Users | Producers | Users | Producers | Users | |
| Artificial surfaces | 37.9/13 | 100.00 | 27.08 | 100.00 | 28.26 | 38.46 | 55.56 | 46.15 | 40.00 |
| Forest | 48/29 | 82.76 | 88.89 | 89.66 | 89.66 | 89.66 | 86.67 | 86.21 | 96.15 |
| Grass | 93.3/32 | 62.50 | 83.33 | 68.75 | 88.00 | 75.00 | 75.00 | 87.50 | 82.35 |
| Water | 817.7/16 | 93.75 | 100.0 | 93.75 | 100.0 | 100.00 | 100.0 | 100.00 | 100.0 |
| Barren | 97/33 | 21.21 | 77.78 | 18.18 | 75.00 | 66.67 | 61.11 | 72.73 | 75.00 |
| Overall accuracy | 64.23 | 66.67 | 75.61 | 80.49 | |||||
| Kappa | 0.56 | 0.59 | 0.68 | 0.75 | |||||
| Maximum likelihood | Logistic regression | |||||
|---|---|---|---|---|---|---|
| Probabilities threshold | Number of pixels | Percent (%) | Cumulative percent (%) | Number of pixels | Percent (%) | Cumulative percent (%) |
| 0,1 | 32556 | 2.68 | 2.68 | 1514 | 0.12 | 0.12 |
| 0,2 | 35805 | 0.27 | 2.95 | 1514 | 0 | 0.12 |
| 0,3 | 39052 | 0.27 | 3.21 | 1514 | 0 | 0.12 |
| 0,4 | 42838 | 0.31 | 3.52 | 1716 | 0.02 | 0.14 |
| 0,5 | 47126 | 0.35 | 3.88 | 3780 | 0.17 | 0.31 |
| 0,6 | 52670 | 0.46 | 4.33 | 20393 | 1.37 | 1.68 |
| 0,7 | 59719 | 0.58 | 4.91 | 39632 | 1.58 | 3.26 |
| 0,8 | 69963 | 0.84 | 5.76 | 62503 | 1.88 | 5.14 |
| 0,9 | 90133 | 1.66 | 7.41 | 98830 | 2.99 | 8.13 |
| 1,0 | 1215609 | 92.59 | 100.00 | 1215609 | 91.87 | 100.00 |
| Maximum Likelihood (ML) | Logistic | Autologistic | |
|---|---|---|---|
| Logistic | 1.58 | ||
| Autologistic | 2.55 | 0.93 | |
| Contextual ML | 0.40 | 1.28 | 2.30 |
© 2008 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Mallinis, G.; Koutsias, N. Spectral and Spatial-Based Classification for Broad-Scale Land Cover Mapping Based on Logistic Regression. Sensors 2008, 8, 8067-8085. https://doi.org/10.3390/s8128067
Mallinis G, Koutsias N. Spectral and Spatial-Based Classification for Broad-Scale Land Cover Mapping Based on Logistic Regression. Sensors. 2008; 8(12):8067-8085. https://doi.org/10.3390/s8128067
Chicago/Turabian StyleMallinis, Georgios, and Nikos Koutsias. 2008. "Spectral and Spatial-Based Classification for Broad-Scale Land Cover Mapping Based on Logistic Regression" Sensors 8, no. 12: 8067-8085. https://doi.org/10.3390/s8128067
APA StyleMallinis, G., & Koutsias, N. (2008). Spectral and Spatial-Based Classification for Broad-Scale Land Cover Mapping Based on Logistic Regression. Sensors, 8(12), 8067-8085. https://doi.org/10.3390/s8128067