Abstract
The increasing technology of high-resolution image airborne sensors, including those on board Unmanned Aerial Vehicles, demands automatic solutions for processing, either on-line or off-line, the huge amountds of image data sensed during the flights. The classification of natural spectral signatures in images is one potential application. The actual tendency in classification is oriented towards the combination of simple classifiers. In this paper we propose a combined strategy based on the Deterministic Simulated Annealing (DSA) framework. The simple classifiers used are the well tested supervised parametric Bayesian estimator and the Fuzzy Clustering. The DSA is an optimization approach, which minimizes an energy function. The main contribution of DSA is its ability to avoid local minima during the optimization process thanks to the annealing scheme. It outperforms simple classifiers used for the combination and some combined strategies, including a scheme based on the fuzzy cognitive maps and an optimization approach based on the Hopfield neural network paradigm.
1. Introduction
Nowadays the increasing technology of airborne sensors with their capabilities for capturing images, including those on board the new generations of Unmanned Aerial Vehicles, demands solutions for different image-based applications. Natural spectral signature classification is one of such applications because of the high image spatial resolution. The areas where the identification of spectral signatures are suitable include agricultural crop ordination, forest areas determination, urban identification and damage evaluation in catastrophes or dynamic path planning during rescue missions or intervention services also in catastrophes (fires, floods, etc.), among others. This justifies the choice of the images with different spectral signatures as the data where the proposed approach is to be applied, providing an application for this kind of sensors.
All classification problems need the selection of features to be classified and their associated attributes or properties, where a feature and its attributes describe a pattern. The behaviour of different features has been studied in texture classifications [1–3]. There are two categories depending on the nature of the features used: pixel-based [4–6] and region-based [2,7–10]. A pixel-based classification tries to classify each pixel as belonging to one of the clusters. The region-based identifies patterns of textures within the image and describes each pattern by applying filtering (laws masks, Gabor filters, wavelets, etc.), it is assumed that each texture displays different levels of energy allowing its identification at different scales. The aerial images used in our experiments do not display texture patterns. This implies that textured regions cannot be identified. In this paper we focus on the pixel-based category. Taking into account that we are classifying multi-spectral textured images, we use as attributes the three visible spectral Red-Green-Blue components, i.e., the RGB colour mapping. The RGB map performs better than other colour representations [11]; we have verified this assertion in our experiments, justifying its choice.
An important issue reported in the literature is that the combination of classifiers performs better than simple classifiers [1,12–16]. Particularly, the studies in [17] and [18] report the advantages of using combined classifiers against simple ones. This is because each classifier produces errors on a different region of the input pattern space [19].
Nevertheless, the main problem is: what strategy to choose for combining individual classifiers? This is still an open issue. Indeed in [13] it is stated that the same method can work appropriately in one application and produce poor results in another. Hence, our goal is to find a combined strategy that works conveniently for classifying spectral signatures in images. In [15] and [20] a revision of different approaches is reported including the way in which the classifiers are combined. Some important conclusions are: 1) if only labels are available, a majority vote should be suitable; 2) if continuous outputs like posterior probabilities are supplied, an average or some other linear combinations are suggested; 3) if the classifier outputs are interpreted as fuzzy membership values, fuzzy approaches, such as aggregation operators, could be used; 4) also it is possible to train the output classifier separately using the outputs of the input classifiers as new patterns, where a hierarchical approach can be used [1].
We propose a new approach which combines two individual classifiers: the probabilistic parametric Bayesian (BP) approach [21] and the fuzzy clustering (FC) [21,22]. The following two phases are involved during any classification process: training and decision. Really, the combination of the outputs provided by the two individual classifiers is carried out during the decision phase, as we will explain later. Given a set of training data, scattered through the tri-dimensional RGB data space and assuming known the number of clusters and the distribution of the samples into the clusters, both BP and FC individual classifiers estimate their associated parameters. Based on these estimated parameters, during the decision phase, each individual classifier provides for each pixel to be classified, a support of belonging to a cluster, BP provides probabilities and FC membership degrees, i.e., continuous outputs.
Because the number of classes is known, we build a network of nodes netj for each class wj, where each node i in the netj is identified as a pixel location i ≡ (x, y) in the image which is to be classified. Each node i is initialized in the netj with the output probability, provided by BP, that the node belongs to the class wj. This is the initial state value for the node i in the netj. Each state is later iteratively updated through the Deterministic Simulated Annealing (DSA) optimization strategy taking into account the previous states and two types of external influences exerted by other nodes on its neighbourhood. The external influences are mapped as consistencies under two terms: regularization and contextual. These terms are clique potentials of an underlying Markov Random Field model [23] and they both involve a kind of human perception. Indeed, the tri-dimensional scenes are captured by the imaging sensor and mapped in the bi-dimensional space, although the third dimension is lost under this mapping, the spatial grouping of the regions is preserved, and they are visually perceived grouped together like in the real scene.
The above allows the application of the Gestalt principles of psychology [24,25], specifically: similarity, proximity and connectedness. The similarity principle states that similar pixels tend to be grouped together. The proximity principle states that pixels near to one another tend to be grouped together. The connectedness states that the pixels belonging to the same region are spatially connected. The proximity and connectedness principles justify the choice of the neighbourhood for defining the regularization and contextual terms and the similarity establishes the analogies in the supports received by the pixels in the neighbourhood coming from the individual classifiers. From the point of view of the combination of classifiers the most relevant term is the regularization one. This is because it compares the supports provided by the individual classifier FC as membership degrees and the states of the nodes in the networks, which, as aforementioned, initially are the probabilities supplied by the individual classifier BP as supports. Therefore, this is the term where the combination of classifiers is really carried out making an important contribution of this paper.
The choice of BP and FC as the simple classifiers for the combination is based on their well tested performance in the literature and also in the possibility of combining continuous outputs during the decision phase under a mechanism different from the classical one used in [15]. Nevertheless, different classifiers providing continuous outputs or some others where this can be obtained could be used. As mentioned before, we have focused the combination on the decision phase; this implies that other strategies that apply the combination based on the training one are out of the scope of this paper. One of them is proposed in [26], which has been used in various classification problems. In this model, a selector makes use of a separate classifier, which determines the participation of the experts in the final decision for an input pattern. This architecture has been proposed in the neural network context. The experts are neural networks, which are trained so that each network is responsible for a part of the feature space. The selector uses the output of another neural network called the gating network [15]. The input of the gating network is the pattern to be classified and the output is a set of outputs determining the competences for each expert. These competences are used together during the decision with the classifier outputs provided by the experts. Under the above considerations we justify the choice of BP and FC as the base classifiers for the proposed combined strategy.
We have designed similar combined strategies. The first one is based on the fuzzy cognitive maps (FCM) framework [27] and the second in the analog Hopfield neural network (HNN) paradigm [28], where in the latter an energy minimization approach is also carried out. The best performance achieved, considering both strategies, is about an 85% success. After additional experiments with the HNN, we have verified that this is because the energy falls some times in local minima that are not global optima. This behaviour of HNN is reported in [29]. The DSA is also an energy optimization approach with the advantage that it can avoid local minima. Indeed, according to [23] and reproduced in [29], when the temperature involved in the simulated annealing process satisfies some constraints (explained in the section 2.2) the system converges to the minimum global energy which is controlled by the annealing scheduling instead of the nonlinear first-order differential equation used in HNN. This is the main difference of the proposed DSA technique with respect to the HNN approach. The FCM does not work with energy minimization, but because it does not improve the results of HNN, we think that it is unable to solve this problem. Hence, we exploit the capability of the DSA for avoiding local minima, making the main contribution of this paper. The DSA outperforms the FCM and HNN combined strategies, also the classical ones and the simple classifiers.
The paper is organized as follows. In Section 2 we give details about the proposed combined classifier, describing the training and decision phases, specially the last one where the DSA mechanism is involved. In Section 3 we give details about the performance of the proposed strategy applied to natural images displaying different spectral signatures. Finally, the conclusions are presented in Section 4.
2. Design of the Classifier
The system works in two phases: training and decision. As mentioned before, we have available a set of scattering patterns for training, partitioned into a known number of classes, c. With such purpose, the training patterns are supplied to the BP and FC classifiers for computing their parameters. These parameters are later recovered during the decision phase for making decisions about the new incoming samples, which are to be classified.
2.1. Training Phase
During the training phase, we start with the observation of a set X of n training samples, i.e., X = {x1,x2,…,xn} ∈ ℜd, where d is the data dimensionality, which is set to 3 because the samples represent the R,G and B spectral components of each pixel. Each sample is to be assigned to a given class wj, where the number of possible classes is c, i.e., j = 1, 2,…,c.
a) Fuzzy Clustering (FC)
This process receives the input training patterns and computes for each xi ∈ X at the iteration t its membership grade
and updates the class centres, vj ∈ ℜd as follows [20,22]:
is the squared Euclidean distance between xi and vj and equivalently
between xi and vr. The number m is called the exponent weight [22,30]. The stopping criterion of the iteration process is achieved when
or a number tmax of iterations is reached, set to 50 in our experiments; ε has been fixed to 0.01 after experimentation. Once the fuzzy clustering process is carried out, each class wj has associated its centre vj.
b) Bayesian Parametric (BP) estimation
Assuming known the distribution (Gaussian) for each class wj, the probability density function is expressed as follows:
where the parameters to be estimated are the mean mj and the covariance Cj, both for each class wj with nj samples. They are estimated through maximum likelihood as given by equation (3):
where T denotes transpose. The parameters vj, mj and Cj are stored to be recovered during the next decision phase.
2.2. Decision Phase
Given a new sample xi, the problem is to decide which the cluster it belongs is. We make the decision based on the final state values after the DSA optimization process. As mentioned before, the DSA is an energy optimization based approach with the advantage that it can avoid local minima. Indeed, in accordance with [23] and reproduced in [29], when the temperature involved in the simulated annealing process satisfies some constraints, explained below, the system converges to the minimum global energy which is controlled by the annealing. The minimization is iteratively achieved by modifying the state of each node through the external influences exerted by other nodes and its own state on the previous iteration.
As mentioned during the introduction, for each cluster wj, we build a network of nodes, netj. Each node i in the netj is associated to the pixel location i ≡ (x, y)in the image, which is to be classified; the node i in the netj is initialized with the probability
provided by BP according to the equation (2), but mapped linearly to the range [−1,+1] instead of [0,+1]. The probabilities are the initial network states associated to the nodes. As it is known, the simple BP method classifies each pixel i as belonging to the cluster wj according to the maximum network state value associated to the pixel i in the j networks, i.e., i ∈ wj if
, ∀ j ≠ h. Through the DSA these network states are reinforced or punished iteratively based on the influences exerted by their neighbours. The goal is to make better decisions based on more stable state values.
Suppose a network with N nodes. The simulated annealing optimization problem is: modify the analogue values
so as to minimize the energy [21,29]:
where
is the symmetric weight interconnecting two nodes i and k in the netj and can be positive or negative ranging in [−1,+1];
is the state of the neighbouring node k in the netj. Each
determines the influence that the node k exerts on i trying to modify the state
. According to [21] the self-feedback weights must be null (i.e.,
). The DSA approach tries to achieve the most network stable configuration based on the energy minimization. From equation (4) one can see that this expression requires the computation of
and the states of the nodes
and
;
will be defined later in the equation (7); both
and
are obtained after the corresponding updating process.
The term
is a combination of two coefficients representing the mutual influence exerted by the k neighbours over i, namely: a) a regularization coefficient which computes the consistency between the states of the nodes and the membership degrees provided by FC in a given neighbourhood for each netj; b) a contextual coefficient which computes the consistency between the class labels obtained after a previous classification phase. Both consistencies are based on the similarity Gestalt’s principle [24,25], as explained in the introduction. The neighbourhood is defined as the m-connected spatial region,
, where m is set to 8 in this paper and allows the implementation of the proximity and connectedness Gestalt’s principles [24,25], also explained in the introduction The regularization coefficient is computed at the iteration t according to the equation (5):
where
is the membership degree, supplied by FC, that a node (pixel) k with attributes xk belongs to the class wj, computed through the equation (1). These values are also mapped linearly to range in [−1,+1] instead of [0,+1]. From (5) we can see that
ranges in [−1,+1] where the lower/higher limit means minimum/maximum influence respectively.
The contextual coefficient at the iteration t is computed taking into account the class labels li and lj as follows, where values of −1 and +1 mean negative and positive influence respectively:
Labels li and lk are obtained as follows: given the node i, at each iteration t, we know its state at each netj as given by the next equation (8), initially through the supports provided by BP; we determine that the node i belongs to the cluster wj if
, ∀ j≠h, so we set li to the j value which identifies the cluster, j = 1,..., c. The label lk is set similarly. Thus, this coefficient is independent of the netj, because it is the same for all networks. Both coefficients are combined as the averaged sum, taking into account the signs:
γ ∈ [0,1] represents the trade-off between both coefficients. After a set of experiments we have chosen γ = 0.80 because cik(t) considers the state values which are directly involved in the energy computation through the equation (4). This avoids the over contribution of the state values in the energy value; sgn is the signum function and v is the number of negative values in the set
, i.e., given S ≡ {q ∈ C/q < 0} ⊆ C, v = card (S). Note that cik(t) after a previous decision phase.
The simulated annealing process was originally developed in [31,32] under a stochastic approach. In this paper we have implemented the deterministic one described in [21,33] because, as reported here, the stochastic is slow due to its discrete nature as compared to the analogue nature of the deterministic. Following the notation in [21], let
be the force exerted on node i by the other nodes
at the iteration t; then the new state
is obtained by adding the fraction f(·,·) to the previous one as follows:
Where, as always, t represents the iteration index. The fraction f(·,·) depends upon
and the temperature T at the iteration t.
The equation (8) differs from the updating process in [21] because we have added the term
to the fraction f(·,·). This modification represents the contribution of the self-support from node i to its updating process. This implies that the updated value for each node i is obtained by taking into account its own previous state value and also the previous state values and membership degrees of its neighbours. The introduction of the self support tries to minimize the impact of an excessive neighbouring influence. Hence, the updating process tries to achieve a trade-off between its own influence and the influence exerted by the nodes j by averaging both values.
One can see from equation (7) that if a node i is surrounded by nodes with similar state values and labels,
should be high. This implies that the
value should be reinforced through equation (8) and the energy given by equation (4) is minimum and vice versa. Moreover, at high T, the value of f(·,·) is lower for a given value of the forces
. Details about the behaviour of T are given in [21]. We have verified that the fraction
must be small as compared to
in order to avoid that the updating is controlled only by
. Under the above considerations and based on [23,30,33], the following annealing schedule suffices to obtain a global minimum: T(t) = T0/log(t+1), with T0 being a sufficiently high initial temperature. T0 is computed as follows [34]: 1) we select four images to be classified, computing the energy in (4) for each image after the initialization of the networks; 2) we choose an initial temperature that permits about 80% of all transitions to be accepted (i.e., transitions that decrease the energy function), and the temperature value is changed until this percentage is achieved; 3) we compute the M transitions ΔEk and we look for a value for T for which
, after rejecting the higher order terms of the Taylor expansion of the exponential, T = 8⟨ΔEk⟩, where ⟨·⟩ is the mean value. In our experiments, we have obtained ⟨ΔEk⟩ = 1.22, giving T0 = 9.76 (with a similar order of magnitude as that reported in [33]). We have also verified that a value of tmax = 200 suffices, although the expected condition T(t) = 0, t → +∞ in the original algorithm is not fully fulfilled. The assertion that it suffices is based on the fact that this limit was never reached in our experiments as shown later in the section 3, hence this value does not affect the results. The DSA process is synthesized as follows [21]:
- Initialization: load each node with according to the equation (2); set ε = 0.01 (constant to accelerate the convergence, section 3.1); tmax = 100. Define nc as the number of nodes that change their state values at each iteration.
- DSA process:t = 0while t < tmax or nc ≠ 0
- t = t + 1; nc = 0;
- for each node i
- if
- then
- nc = nc + 1; else nc = nc
- end if; end for; end while
- Outputs: the states for all nodes updated.
The decision about the classification of a node i with attributes xi as belonging to the class wj is made as follows: i ∈ wj if
, ∀ wj ≠ wh.
3. Comparative Analysis and Performance Evaluation
To assess the validity and performance of the proposed approach we describe the tests carried out according to both processes: training and classification. First, we give details about the setting of some free parameters involved in the proposed method.
3.1. Setting Free Parameters
We have used several data sets for setting the free parameters; these are: 1) nine data sets from the Machine Learning Repository [35]: (bupa, cloud, glass, imageSegm, iris, magi4, thyroid, pimaIndians and wine); 2) three synthetic data sets manually generated with different numbers of classes and 3) four data sets coming from outdoor natural images, also with different numbers of classes. The use of these data, some of them different from the images with different spectral signatures, is justified under the idea that the values of the parameters to be set must have so much general validity as it is possible.
a) Parameters involved in the FC training phase
They are the exponential weight m in equation (1) and the convergence parameters ε and tmax used for its convergence. The number of classes and the distribution of the patterns on the clusters are assumed to be known. We apply the following cross-validation procedure [21]. We randomly split each data set into two parts. The first (90% of the patterns) is used as the training set. The other set (validation set) is used to estimate the global classification error based on the single FC classifier. We set m = 2.0 (which is a usual value) and vary ε from 0.01 to 0.1 in steps of 0.015 and estimate the cluster centres and membership degrees for each training set. Then, we compute the error rate for each validation set. The maximum error was obtained with ε = 0.1 for 10 iterations and the minimum with ε = 0.01 and 47 iterations. Fixed those values, we vary m from 1.1 to 4.0 in steps of 0.1 and estimate once again the cluster centres and the membership degrees with the training set. Once again the validation sets are used for computing the error rates, the minimum error value is obtained for m = 2.0. The settings are finally fixed to m = 2.0, ε = 0.01 and tmax = 50 (expanding the limit of 47).
b) DSA convergence
The ε used for accelerating the convergence in the DSA optimization approach is set to 0.01 by using the validation set for the four data sets coming from the outdoor natural images mentioned above. Verifying, that tmax = 20 suffices.
3.2. Training Phase
We have available a set of 36 digital aerial images acquired during May in 2006 from the Abadin region located at Lugo (Spain). They are images in the visible range of the spectra, i.e., red-green-blue, 512 × 512 pixels in size. The images were taken during different days from an area with several natural spectral signatures. We select randomly 12 images from the set of 36 available. Each image is down sampled by two, eliminating a row and column of every two; so, the number of training samples provided by each image is the number of pixels. The total number of training samples is n = 12 × 256 × 256 = 786,432.
We have considered that the images have four clusters, i.e., c = 4. Table 1 displays the number of patterns used for training and the cluster centres estimated by the individual classifiers, which are vi for FC and mi for BP, equations (1) and (3) respectively.

Table 1.
Number of patterns used for training and class centres obtained for each class according to the simple classifiers FC and BP.
3.3. Decision Phase and Comparative Analysis
The remaining 24 images from the set of 36 are used as images for testing. Four sets, S0, S1 S2 and S3 of six images each, are processed during the test according to the strategy described below. The images assigned to each set are randomly selected from the 24 images available.
a) Design of a test strategy
In order to assess the validity and performance of the proposed approach we have designed a test strategy with two purposes: 1) to verify the performance of our approach as compared against some existing strategies (simple and combined); 2) to study the behaviour of the method as the training (i.e., the learning) increases.
Our proposed combined DSA (DS) method is compared against the base classifiers used for the combination (BP and FC). It is also compared against the following classical combiners that apply the decision as described immediately after [15,20]. Consider the pixel i to be classified. BP and FC provide the probability
and membership degree
respectively, that the pixel i belongs to the class wj. After applying a rule, a new support
is obtained for that pixel of belonging to wj as follows: a) Mean rule (ME)
; b) Maximum rule (MA)
; c) Minimum rule (MI)
and d) Product rule (PD)
. These rules have been studied in terms of reliability [36]. Yager [37] proposed a multi-criteria decision making approach based on fuzzy sets aggregation. It follows the general rule and the scheme of the combiners described in [21]. So, DS is also compared against the fuzzy aggregation (FA) where the final support that the pixel i belongs to the class wj is given by the following aggregation rule:
The parameter a has been fixed to 4 by applying a cross-validation procedure as the described in section 3.1a). Given the supports, according to each rule, the decision about the pixel i is made as follows: i ∈ wj if.
Finally, and what it is more important, DS is compared against the optimization strategy based on the Fuzzy cognitive Maps (FM) [27] and the Hopfield neural Network (HN) [28] paradigms. Both are based on the same network topology like the used in this paper and compute the regularization and contextual coefficients similarly to the proposed in this paper through the equations (5) and (6), but using the membership degrees provided by FC for the networks initializations. Nevertheless, for comparison purposes, we have changed the roles in the experiments carried out here, so that the nodes in both FM and HN are initially loaded with the probabilities as in the proposed DS approach.
In order to verify the behaviour of each method as the learning degree increases, we have carried out the experiments according to the following three STEPs described below
STEP 1: given the images in S0 and S1, classify each pixel as belonging to a class, according to the number of classes established during the training phase. Compute the percentage of successes according to the ground truth defined for each class at each image. The classified pattern samples from S1 are added to the previous training samples and a new training process is carried out (Section 2.1) with the same number of clusters. The parameters associated to each classifier are updated. The set S0 is used as a pattern set in order to verify the performance of the training process as the learning increases. Note that it is not considered for training.
STEPs 2 and 3: perform the same process but using the sets S2 and S3 respectively instead of S1; S0 is also processed as before.
As one can see the number of training samples added at each STEP is 6 × 512 × 512 because this is the number of pixels classified during the STEPs 1 to 3 belonging to the sets S1, S2 and S3.
To verify the performance for each method we have built a ground truth for each image processed under the supervision of expert human criteria. Based on the assumption that the automatic training process determines four clusters, we classify each image pixel with the simple classifiers obtaining a labelled image with four expected clusters, and then we select the image with the best results, always according to the expert.
The labels for each cluster, from the selected labelled image, are manually touched up until a satisfactory classification is obtained under the human supervision. This implies that each pixel has assigned a unique label in the ground truth, which serves as the reference one for comparing the performances.
Figure 1(a) displays an original image belonging to the set S0; Figure 1(b) displays the correspondence between clusters and labels, in the left column the colour according to the values of the corresponding cluster centre and in the right column the artificial colour labels, both in the tri-dimensional RGB colour space; (c) labelled image for the four clusters obtained by our proposed DS approach.

Figure 1.
(a) original image belonging to the set S0; (b) correspondence between classes and labels; (c) labelled image with the four classes according to the labels in (b).
The correspondence between labels and the different spectral signatures is: 1.-yellow, forest vegetation displaying obscure tones; 2.-blue, ochre tones without the spectral saturation of the sensor; 3.-green, agricultural crop vegetation; 4.-red, ochre tones with a clear tendency towards the spectral saturation of the sensor. In clusters 3 and 4 are included buildings, man made structures and also bare soils.
Figure 2 displays the distribution of a representative subset of 4,096 patterns from the image of the Figure 1(a), obtained by down sampling the image by eight, into the clusters in the tri-dimensional RGB colour space, where the centres of the classes, obtained through the BP classifier during the training phase, are also displayed; they are the four mj cluster centres, displayed in the same colour as the labels in the Figure 1(b). As one can see, there is no a clear partition into the four clusters because the samples appear scattered in the whole space following the diagonal. Hence, the classification of the borders patterns becomes a difficult task because they can belong to more than one cluster depending on their proximity to the centres.
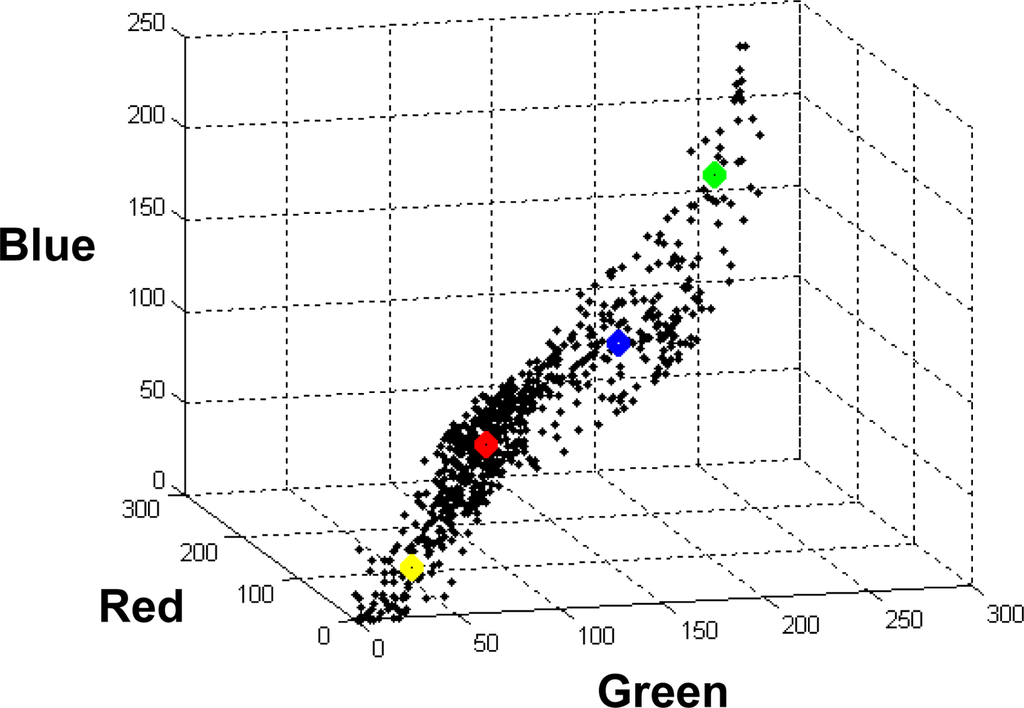
Figure 2.
Distribution of a subset of 4,096 patterns into the four estimated classes around the cluster centres of the classes in the colour space RGB. The centres are displayed in the same colour as the labels in Figure 1(b).
b) Results
Table 2 shows the percentage of error during the decision for the different classifiers. For each STEP from 1 to 3, we show the results obtained for both sets of tested images S0 and either S1 or S2 or S3.
Table 2.
Average percentages of error and standard deviations at each STEP for the four sets of tested images S0, S1, S2 and S3.
These percentages are computed as follows. Let
an image r (r = 1,…,6) belonging to the set SN (N = 0,1,2,3); i is the node at the pixel location (x,y) in
. An error counter
is initially set to zero for each image r in the set SN at each STEP and for each classifier. Based on the corresponding decision process, each classifier determines the class to which the node i belongs, i ∈ wj. If the same pixel location on the corresponding ground truth image is black then the pixel is incorrectly classified and
. The error rate of the image
is:
, where Z is the image size, i.e., 512 × 512. The average error rate for the set SN at each STEP is given by:
and the standard deviation by:
In the Table 2 they are displayed as percentages, i.e., ẽN = 100 ēN and σ̃N = 100 σ̄N. The numbers in square brackets indicate the rounded and averaged number of iterations required by DS, HN and FM for each set (S0, S1, S2 and S3) at each STEP (1, 2 and 3).
Figure 3 displays the ground truth image for the one in Figure 1(a) which has been manually rectified from the results obtained through the BP classifier. As in the image of Figure 1(c), each colour identifies the corresponding label for the four clusters represented in Figure 1.
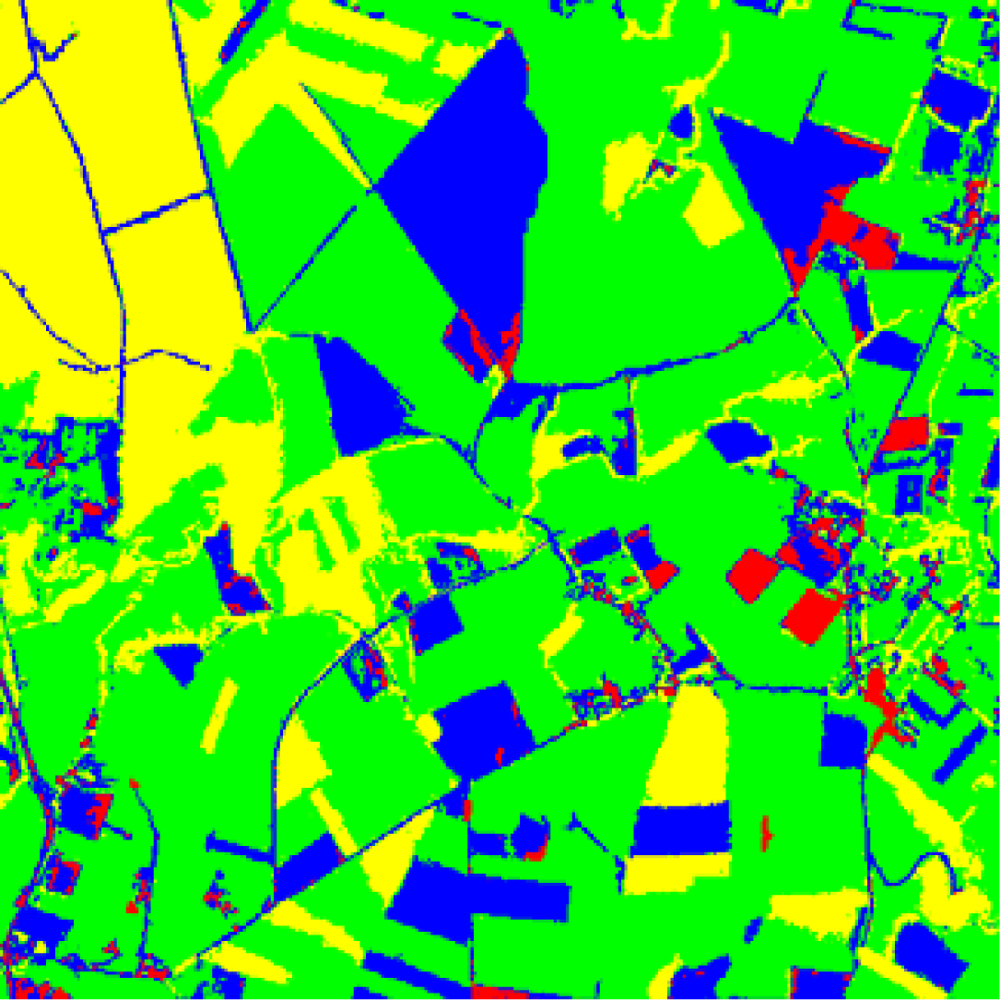
Figure 3.
Ground truth image where the labels for the four clusters displayed in Figure 1 have been manually rectified.
c) Discussion
Based on the error rates displayed in Table 2, we can see that in general, the proposed DS approach outperforms the other methods and achieves the less error rates for STEP 3 in both sets S0 and S1. All strategies achieve the best performance in the STEP 3. Of particular interest is the improvement achieved for the set S0 in STEP 3 with respect the results obtained in STEPs 1 and 2 for that set. Based on the above observations, we can conclude that the learning improves the results, i.e., better decisions can be made as the learning increases. A detailed analysis for groups of classifiers is the following:
- Simple classifiers: the best performance is achieved by BP as compared to FC. This suggests that the network initialization, through the probabilities supplied by BP, is acceptable.
- Combined rules: the mean and product rules achieve both similar averaged errors. The performance of the mean is slightly better than the product. This is because, as reported in [38], combining classifiers which are trained in independent feature spaces result in improved performance for the product rule, while in completely dependent feature spaces the performance is the same. We think that this occurs in our RGB feature space because of the high correlation among the R, G and B spectral components [39,40]. High correlation means that if the intensity changes, all the three components will change accordingly.
- Fuzzy combination: this approach outperforms the simple classifiers and the combination rules. Nevertheless, this improvement requires the convenient adjusting of the parameter a, with other values the results get worse.
- Optimization and relaxation approaches: once again, the best performance is achieved by DS, which with a similar number of iterations that HN obtains better percentages of successes, the improvement is about 3.6 percentage points. DS also outperforms FM. This is because DS avoids satisfactorily some minima of energy, as expected.
For clarity, in Figure 4(a) the performance of the proposed DS approach for the set S0 is displayed against HN, because both are optimization approaches based on energy minimization; ME which is the best method of the combination rules and BP, the best method of simple combiners. Figure 4(b) shows the energy behaviour for the four sets (S1, S2, S3 and S0 in STEP 3) against the averaged number of iterations required to reach the convergence. The energy decreases as the optimization process increases, as expected according to the equation (4). Similar slopes can be observed for the sets S0, S2 and S3. On the contrary, the slope for S1 is smoother; this explains the greater number of iterations required for this set during the convergence.
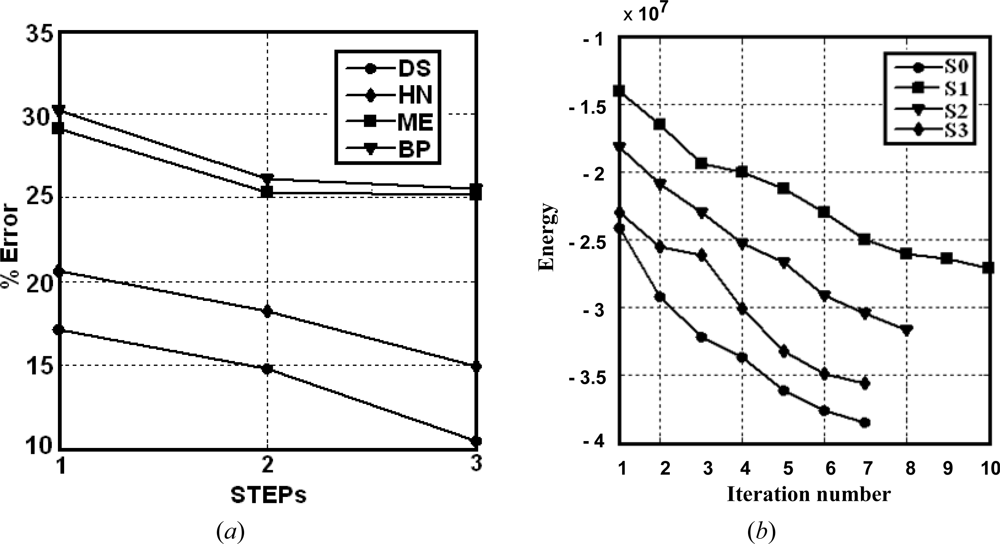
Figure 4.
(a) percentage of error for DS, HN, ME and BP against the three STEPs; (b) energy behaviour for S0 to S3 against the number of iterations.
Overall, the results show that the combined approaches perform favourably for the data sets used. The MA and ME fusion methods also provide best results than the individual ones. This means that combined strategies are suitable for classification tasks. This agrees with the conclusion reported in [13] or [15] about the choice of combined classifiers. Moreover, as the learning increases through STEPs 1 to 3 the performance improves and the number of iterations for S0 decreases, because part of the learning has been achieved at this stage. This means that the learning phase is important and that the number of samples affects the performance.
The main drawback of the DS, as well as also for the HN and FM approaches, is its execution time, which is greater than the methods that do not apply relaxation processes. This is a general problem for all kind of relaxation or optimization approaches.
All tests have been implemented in MATLAB and executed on an Intel Core 2 Duo, 2.40 GHz PC with 2.87 GB RAM operating under Microsoft Windows XP service pack 3. On average, the execution time per iteration and per image is 10.1 seconds.
4. Conclusions
During the decision phase, we have proposed a combined strategy under the DSA framework performing favourably as compared against other existing combined strategies including those with similar design and based on optimization and also against the individual classifiers. The application of the similarity, proximity and connectedness Gestalt’s principles allows combining probabilities and membership degrees, supplied by the BP and FC classifiers respectively, by means of the regularization and contextual coefficients. The probabilities supplied by BP are used as initial states in a set of neural networks, which are specifically designed with such purpose. These states are iteratively updated under the DSA optimization process through the external influences exerted by the nodes in the neighbourhood thanks to the application of the Gestalt’s principles.
In future works the updating through the DSA of both probabilities and membership degrees could be considered. With the proposed combined approach, we have established the bases to be able for combine more than two classifiers. This can be made by re-defining the regularization coefficient.
Also, if we try to combine classifiers providing outputs in different ranges always it should be possible to map all outputs in the same range. This allows the combination of different kinds of classifiers including self-organizing maps or vector quantization with BP or FC by example.
Acknowledgments
The authors would like to thank to SITGA (Servicio Territorial de Galicia) in collaboration with the Dimap Company ( http://www.dimap.es/) for the original aerial images supplied and used in this paper. The authors are also grateful to the referees for their constructive criticism and suggestions on the original version of this paper.
References and Notes
- Valdovinos, R.M.; Sánchez, J.S.; Barandela, R. Dynamic and static weighting in classifier fusion. In Pattern Recognition and Image Analysis, Lecture Notes in Computer Science; Marques, J.S., Pérez de la Blanca, N., Pina, P., Eds.; Springer Berlin/Heidelberg: Berlin, Germany, 2005; pp. 59–66. [Google Scholar]
- Puig, D.; García, M.A. Automatic texture feature selection for image pixel classification. Patt. Recog 2006, 39, 1996–2009. [Google Scholar]
- Hanmandlu, M.; Madasu, V.K.; Vasikarla, S. A Fuzzy Approach to Texture Segmentation. Proceedings of the IEEE International Conference on Information Technology: Coding and Computing (ITCC’04), Las Vegas, NV, USA, April 5–7, 2004; pp. 636–642.
- Rud, R.; Shoshany, M.; Alchanatis, V.; Cohen, Y. Application of spectral features’ ratios for improving classification in partially calibrated hyperspectral imagery: a case study of separating Mediterranean vegetation species. J. Real-Time Image Process 2006, 1, 143–152. [Google Scholar]
- Kumar, K.; Ghosh, J.; Crawford, M.M. Best-bases feature extraction for pairwise classification of hyperspectral data. IEEE Trans. Geosci. Remot. Sen 2001, 39, 1368–1379. [Google Scholar]
- Yu, H.; Li, M.; Zhang, H.J.; Feng, J. Color texture moments for content-based image retrieval. Proceedings of International Conference on Image Processing, Rochester, NY, USA, September 22–25, 2002; pp. 24–28.
- Maillard, P. Comparing texture analysis methods through classification. Photogramm. Eng. Remote Sens 2003, 69, 357–367. [Google Scholar]
- Randen, T.; Husøy, J.H. Filtering for texture classification: a comparative study. IEEE Trans. Patt. Anal. Mach. Int 1999, 21, 291–310. [Google Scholar]
- Wagner, T. Texture Analysis. Signal Processing and Pattern Recognition. In Handbook of Computer Vision and Applications; Jähne, B., Hauβecker, H., Geiβler, P., Eds.; Academic Press: St. Louis, MO, USA, 1999. [Google Scholar]
- Smith, G.; Burns, I. Measuring texture classification algorithms. Patt. Recog. Lett 1997, 18, 1495–1501. [Google Scholar]
- Drimbarean, A.; Whelan, P.F. Experiments in colour texture analysis. Patt. Recog. Lett 2003, 22, 1161–1167. [Google Scholar]
- Kong, Z.; Cai, Z. Advances of Research in Fuzzy Integral for Classifier’S Fusion. Proceedings of 8th ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, Tsingtao, China, July 30–August 1, 2007; pp. 809–814.
- Kuncheva, L.I. “Fuzzy” vs “non-fuzzy” in combining classifiers designed by boosting. IEEE Trans. Fuzzy Syst 2003, 11, 729–741. [Google Scholar]
- Kumar, S.; Ghosh, J.; Crawford, M.M. Hierarchical fusion of multiple classifiers for hyperspectral data analysis. Patt. Anal. Appl 2002, 5, 210–220. [Google Scholar]
- Kittler, K.; Hatef, M.; Duin, R.P.W.; Matas, J. On combining classifiers. IEEE Trans. Patt. Anal. Mach. Int 1998, 20, 226–239. [Google Scholar]
- Cao, J.; Shridhar, M.; Ahmadi, M. Fusion of Classifiers with Fuzzy Integrals. Proceedings of 3rd Int. Conf. Document Analysis and Recognition (ICDAR’95), Montreal, Canada, August 14–15, 1995; pp. 108–111.
- Partridge, D.; Griffith, N. Multiple classifier systems: software engineered, automatically modular leading to a taxonomic overview. Patt. Anal. Appl 2002, 5, 180–188. [Google Scholar]
- Deng, D.; Zhang, J. Combining Multiple Precision-Boosted Classifiers for Indoor-Outdoor Scene Classification. Inform. Technol. Appl 2005, 1, 720–725. [Google Scholar]
- Alexandre, L.A.; Campilho, A.C.; Kamel, M. On combining classifiers using sum and product rules. Patt. Recog. Lett 2001, 22, 1283–1289. [Google Scholar]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms; Wiley: New York, NY, USA, 2004. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.S. Pattern Classification; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Zimmermann, H.J. Fuzzy Set Theory and its Applications; Kluwer Academic Publishers: Norwell, MA, USA, 1991. [Google Scholar]
- Geman, S.; Geman, G. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Patt. Anal. Mach. Int 1984, 6, 721–741. [Google Scholar]
- Koffka, K. Principles of Gestalt Psychology; Harcourt Brace & Company: New York, NY, USA, 1935. [Google Scholar]
- Palmer, S.E. Vision Science; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Xu, L.; Amari, S.I. Encyclopedia of Artificial Intelligence. In Combining Classifiers and Learning Mixture-of-Experts; Rabuñal-Dopico, J. R., Dorado, J., Pazos, A., Eds.; IGI Global (IGI) publishing company: Hershey, PA, USA, 2008; pp. 318–326. [Google Scholar]
- Pajares, G.; Guijarro, M.; Herrera, P.J.; Ribeiro, A. IET Comput. Vision 2009, in press.. [CrossRef]
- Pajares, G.; Guijarro, M.; Herrera, P.J.; Ribeiro, A. A hopfield neural network for combining classifiers applied to textured images. Neural Networks 2009, in press.. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: a comprehensive foundation; Macmillan College Publishing Co.: New York, NY, USA, 1994. [Google Scholar]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Kluwer-Plenum Press: New York, NY, USA, 1981. [Google Scholar]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar]
- Kirkpatrick, S. Optimization by simulated annealing: quantitative studies. J. Statist. Phys 1984, 34, 975–984. [Google Scholar]
- Hajek, B. Cooling schedules for optimal annealing. Math. Oper. Res 1988, 13, 311–329. [Google Scholar]
- Laarhoven, P.M.J.; Aarts, E.H.L. Simulated Annealing: Theory and Applications; Kluwer Academic: Norwell, MA, USA, 1989. [Google Scholar]
- Asuncion, A.; Newman, D.J. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA; website http://archive.ics.uci.edu/ml/ (accessed September 7, 2009).
- Cabrera, J.B.D. On the impact of fusion strategies on classification errors for large ensambles of classifiers. Patt. Recog 2006, 39, 1963–1978. [Google Scholar]
- Yager, R.R. On ordered weighted averaging aggregation operators in multicriteria decision making. IEEE Trans. Syst. Man Cybern 1988, 18, 183–190. [Google Scholar]
- Tax, D.M.J.; Breukelen, M.; Duin, R.P.W.; Kittler, J. Combining multiple classifiers by averaging or by multiplying? Patt. Recog 2000, 33, 1475–1485. [Google Scholar]
- Littmann, E.; Ritter, H. Adaptive color segmentation -A comparison of neural and statistical methods. IEEE Trans. Neural Networks 1997, 8, 175–185. [Google Scholar]
- Cheng, H.D.; Jiang, X.H.; Sun, Y.; Wang, J. Color image segmentation: advances and prospects. Patt. Recog 2001, 34, 2259–2281. [Google Scholar]
© 2009 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).