
Lightweight Multi-Scale Asymmetric Attention Network for Image Super-Resolution


Abstract
:1. Introduction
- We employ fine-grained feature blocks (FFBs) as the backbone module of our framework implementation, which accesses reasonable SR performance with fewer parameters. The multi-scale attention residual block (MARB) of FFBs extracts sufficient multi-scale features for global feature fusion. It enhances asymmetric attention neurons in a larger receptive field to capture richer multi-frequency information features significantly.
- We propose an asymmetric multi-weights attention block (AMAB) to enhance feature propagation and further extract high-frequency detail features by adaptive selection among the layers.
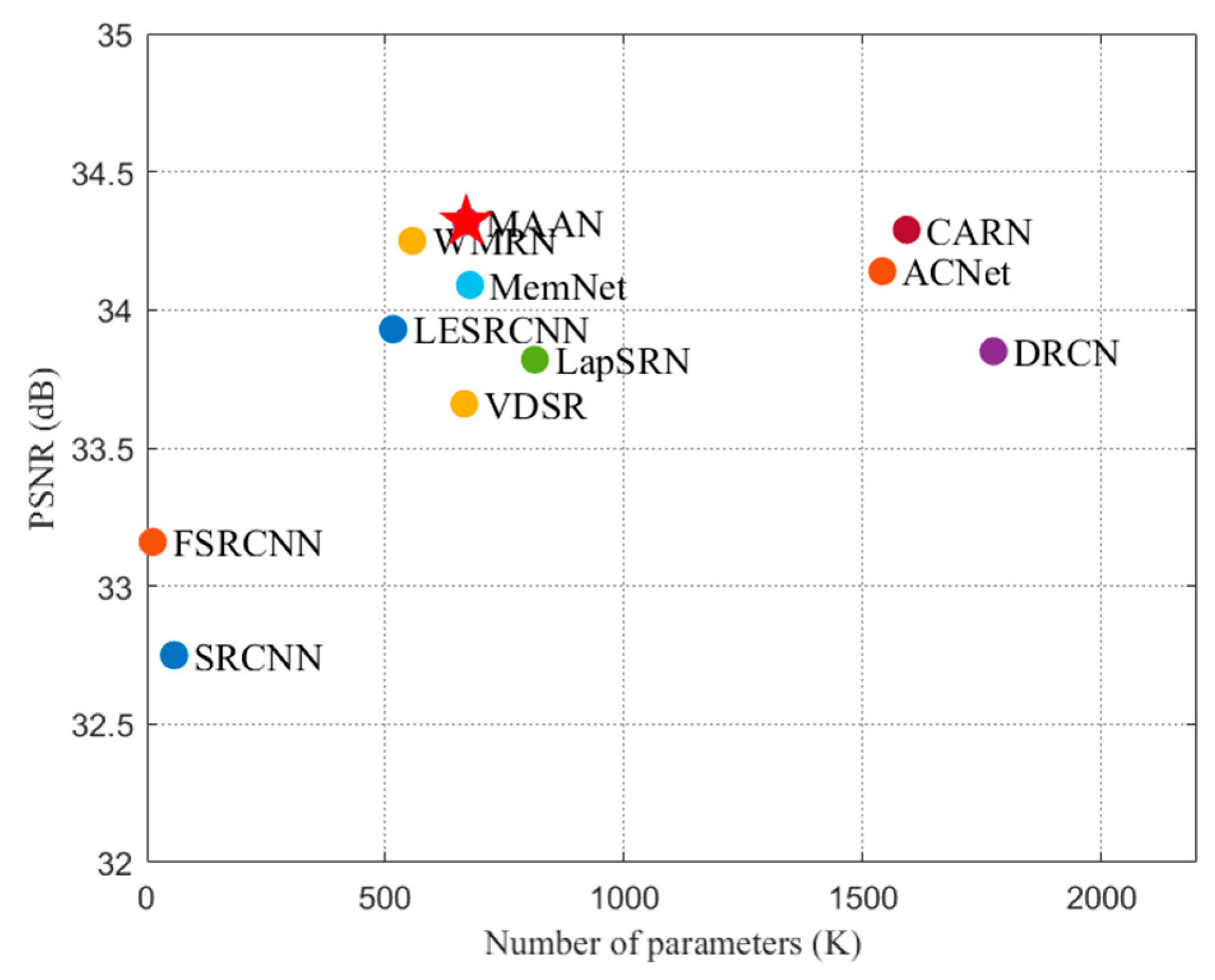
- MAAN acquires a better trade-off between performance and lightweight compared to the popular models.
2. Related Work
2.1. Lightweight Super-Resolution Networks
2.2. Attention Mechanism
3. Methods
3.1. Network Architecture
3.2. Fine-Grained Feature Block
3.3. Multi-Scale Attention Residual Block
3.4. Asymmetric Multi-Weights Attention Block
| Algorithm 1: The implementation of asymmetric multi-weights attention. |
| Input X: The feature matrix of H × W × C size. |
| Output X: The resultant matrix of H × W × C size. |
|
4. Experiments
4.1. Datasets and Metrics
4.2. Model Analysis
4.2.1. Number of FFBs
4.2.2. Effect of Reduction Ratio R Setting in AMAB
4.2.3. Effect of AMAB
4.3. Comparison with State-of-the-Art Methods
4.3.1. Quantitative Evaluation
4.3.2. Qualitative Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.-H.; Liao, Q. Deep learning for single image super-resolution: A brief review. IEEE Trans. Multimed. 2019, 21, 3106–3121. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Liu, J.; Tang, J.; Wu, G. Residual feature distillation network for lightweight image super-resolution. In Computer Vision—ECCV 2020 Workshops, Proceedings of the ECCV 2020: European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 41–55. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual feature aggregation network for image super-resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2359–2368. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.-A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, S.C. Deep learning for image super-resolution: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 49, 3365–3387. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tong, W.; Chen, W.; Han, W.; Li, X.; Wang, L. Channel-attention-based DenseNet network for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1637–1645. [Google Scholar]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Hui, Z.; Wang, X.; Gao, X. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 723–731. [Google Scholar]
- Tian, C.; Zhuge, R.; Wu, Z.; Xu, Y.; Zuo, W.; Chen, C.; Lin, C.W. Lightweight image super-resolution with enhanced CNN. Knowl.-Based Syst. 2020, 205, 106235. [Google Scholar] [CrossRef]
- Tian, C.; Xu, Y.; Zuo, W.; Lin, C.-W.; Zhang, D. Asymmetric CNN for Image Superresolution. IEEE Trans. Syst. Man Cybern. Syst. 2021, 1–13. [Google Scholar] [CrossRef]
- Wang, L.; Shen, J.; Tang, E.; Zheng, S.; Xu, L. Multi-scale attention network for image super-resolution. J. Vis. Commun. Image Represent. 2021, 80, 103300. [Google Scholar] [CrossRef]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Computer Vision—ECCV 2020 Workshops, Proceedings of the ECCV 2020: European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 191–207. [Google Scholar]
- Anwar, S.; Barnes, N. Densely residual laplacian super-resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Dong, X.; Wang, Y.; Ying, X.; Lin, Z.; An, W.; Guo, Y. Exploring Sparsity in Image Super-Resolution for Efficient Inference. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4917–4926. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 801–818. [Google Scholar]
- Borst, A.; Haag, J.; Mauss, A.S. How fly neurons compute the direction of visual motion. J. Comp. Physiol. A 2020, 206, 109–124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lo, S.-Y.; Hang, H.-M.; Chan, S.-W.; Lin, J.-J. Efficient dense modules of asymmetric convolution for real-time semantic segmentation. In Proceedings of the 2019 ACM Multimedia Asia, Beijing, China, 15–18 December 2019; pp. 1–6. [Google Scholar]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.-H.; Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 114–125. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the 23rd British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Curves and Surfaces, Proceedings of the 7th International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; Springer: Berlin/Heidelberg, Germany, 2012; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the ICCV 2001: Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 391–407. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4539–4547. [Google Scholar]
- Sun, L.; Liu, Z.; Sun, X.; Liu, L.; Lan, R.; Luo, X. Lightweight Image Super-Resolution via Weighted Multi-Scale Residual Network. IEEE/CAA J. Autom. Sin. 2021, 8, 1271–1280. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Number of FFB | Params | Multi-Adds | PSNR/SSIM |
|---|---|---|---|
| i = 2 | 342K | 39.39G | 27.66/0.8422 |
| i = 4 | 668K | 75.60G | 28.02/0.8498 |
| i = 6 | 993K | 111.82G | 28.20/0.8535 |
| Model | CA | N-AMAB | AMAB | Params | Multi-Adds | PSNR/SSIM |
|---|---|---|---|---|---|---|
| MAAN-CA | ✓ | 668K | 75.60G | 30.25/0.8401 | ||
| MAAN-NOAMAB | ✓ | 639K | 68.52G | 30.17/0.8393 | ||
| MAAN | ✓ | 668K | 75.60G | 30.27/0.8408 |
| Scale | Model | Params | Multi-Adds | Set5 | Set14 | B100 | Urban100 |
|---|---|---|---|---|---|---|---|
| ×2 | SRCNN | 57K | 52.7G | 36.66/0.9524 | 32.42/0.9063 | 31.36/0.8879 | 29.50/0.8946 |
| FSRCNN | 12K | 6.6G | 37.00/0.9558 | 32.63/0.9088 | 31.53/0.8920 | 29.88/0.9020 | |
| VDSR | 665K | 612.6G | 37.53/0.9587 | 33.03/0.9124 | 31.90/0.8960 | 30.76/0.9140 | |
| DRCN | 1774K | 17974G | 37.63/0.9588 | 33.04/0.9118 | 31.85/0.8942 | 30.75/0.9133 | |
| LapSRN | 813K | 29.9G | 37.52/0.9590 | 33.08/0.9130 | 31.80/0.8950 | 30.41/0.9100 | |
| MemNet | 677K | 2662.4G | 37.78/0.9597 | 33.28/0.9142 | 32.08/0.8978 | 31.31/0.9195 | |
| CARN | 1592K | 222.8G | 37.76/0.9590 | 33.52/0.9166 | 32.09/0.8978 | 31.33/0.9200 | |
| LESRCNN | 516K | 110.6G | 37.65/0.9586 | 33.32/0.9148 | 31.95/0.8964 | 31.45/0.9206 | |
| ACNet | 1356K | 501.5G | 37.72/0.9588 | 33.41/0.9160 | 32.06/0.8978 | 31.79/0.9245 | |
| WMRN | 452K | 103G | 37.93/0.9603 | 33.49/0.9169 | 32.13/0.8991 | 31.83/0.9253 | |
| MAAN | 596K | 170G | 37.92/0.9604 | 33.51/0.9174 | 32.14/0.8997 | 31.86/0.9259 | |
| ×3 | SRCNN | 57K | 52.7G | 32.75/0.9090 | 29.28/0.8209 | 28.41/0.7863 | 26.24/0.7989 |
| FSRCNN | 12K | 5.0G | 33.16/0.9140 | 29.43/0.8242 | 28.53/0.7910 | 26.43/0.8080 | |
| VDSR | 665K | 612.6G | 33.66/0.9213 | 29.77/0.8314 | 28.82/0.7976 | 27.14/0.8279 | |
| DRCN | 1774K | 17974G | 33.85/0.9215 | 29.89/0.8317 | 28.81/0.7954 | 27.16/0.8311 | |
| LapSRN | 813K | 149.4G | 33.82/0.9227 | 29.87/0.8320 | 28.82/0.7980 | 27.07/0.8280 | |
| MemNet | 677K | 2662.4G | 34.09/0.9248 | 30.00/0.8350 | 28.96/0.8001 | 27.56/0.8376 | |
| CARN | 1592K | 118.8G | 34.29/0.9255 | 30.29/0.8407 | 29.06/0.8034 | 28.06/0.8493 | |
| LESRCNN | 516K | 49.1G | 33.93/0.9231 | 30.12/0.8380 | 28.91/0.8005 | 27.70/0.84152 | |
| ACNet | 1541K | 369G | 34.14/0.9247 | 30.19/0.8398 | 28.98/0.8023 | 27.97/0.8482 | |
| WMRN | 556K | 57G | 34.25/0.9263 | 30.26/0.8401 | 29.04/0.8033 | 27.95/0.8472 | |
| MAAN | 668K | 75.6G | 34.32/0.9269 | 30.27/0.8408 | 29.05/0.8042 | 28.02/0.8498 | |
| ×4 | SRCNN | 57K | 52.7G | 30.48/0.8628 | 27.49/0.7503 | 26.90/0.7101 | 24.52/0.7221 |
| FSRCNN | 12K | 4.6G | 30.71/0.8657 | 27.59/0.7535 | 26.98/0.7150 | 24.62/0.7280 | |
| VDSR | 665K | 612.6G | 31.35/0.8838 | 28.01/0.7674 | 27.29/0.7251 | 25.18/0.7524 | |
| DRCN | 1774K | 17974G | 31.53/0.8854 | 28.02/0.7670 | 27.23/0.7233 | 25.14/0.7510 | |
| LapSRN | 813K | 149.4G | 31.54/0.8850 | 28.19/0.7720 | 27.32/0.7280 | 25.21/0.7560 | |
| MemNet | 677K | 2662.4G | 31.53/0.8854 | 28.02/0.7670 | 27.23/0.7233 | 25.14/0.7510 | |
| CARN | 1592K | 90.9G | 32.13/0.8937 | 28.60/0.7806 | 27.58/0.7349 | 26.07/0.7837 | |
| LESRCNN | 516K | 28.6G | 31.88/0.8903 | 28.44/0.7772 | 27.45/0.7313 | 25.77/0.7732 | |
| ACNet | 1784K | 347.9G | 31.83/0.8903 | 28.46/0.7788 | 27.48/0.7326 | 25.93/0.7798 | |
| WMRN | 536K | 45.7G | 32.14/0.8944 | 28.58/0.7804 | 27.54/0.7342 | 26.00/0.7816 | |
| MAAN | 653K | 42.6G | 32.21/0.8947 | 28.58/0.7811 | 27.55/0.7355 | 26.01/0.7840 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Wang, H.; Zhang, Z.; Chen, Z.; Shen, J. Lightweight Multi-Scale Asymmetric Attention Network for Image Super-Resolution. Micromachines 2022, 13, 54. https://doi.org/10.3390/mi13010054
Zhang M, Wang H, Zhang Z, Chen Z, Shen J. Lightweight Multi-Scale Asymmetric Attention Network for Image Super-Resolution. Micromachines. 2022; 13(1):54. https://doi.org/10.3390/mi13010054
Chicago/Turabian StyleZhang, Min, Huibin Wang, Zhen Zhang, Zhe Chen, and Jie Shen. 2022. "Lightweight Multi-Scale Asymmetric Attention Network for Image Super-Resolution" Micromachines 13, no. 1: 54. https://doi.org/10.3390/mi13010054