
An AI-powered Electronic Nose System with Fingerprint Extraction for Aroma Recognition of Coffee Beans


Abstract
:1. Introduction
- To use the extracted aroma data of coffee beans and machine learning techniques to ensure the authenticity of the origin of coffee beans.
- To establish a method for creating individual coffee aroma signatures (i.e., digital fingerprints) to identify their provenance.
2. Related Work
3. System Framework
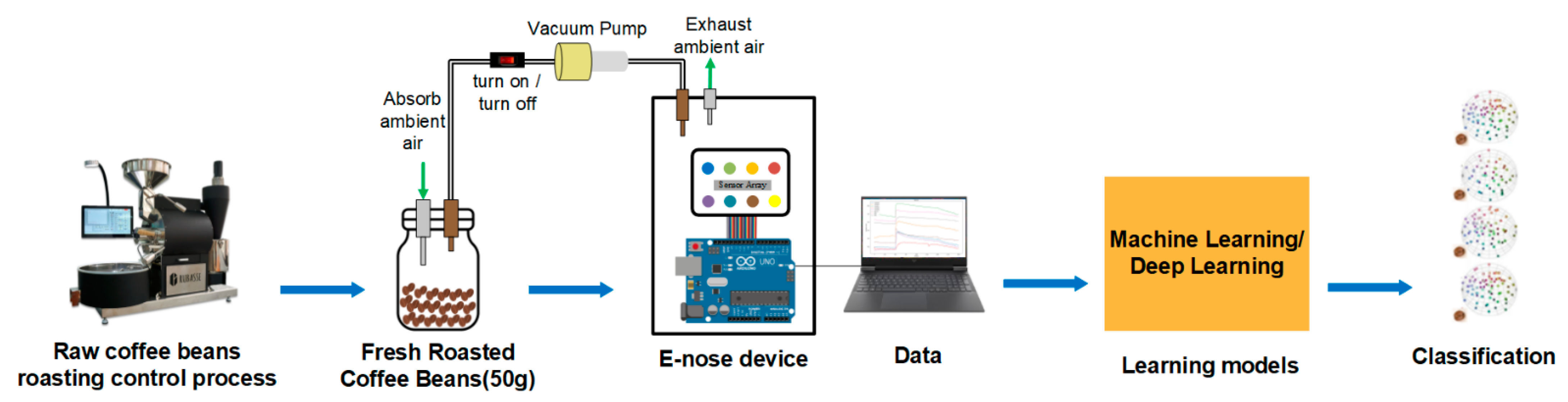
3.1. System Framework and Workflow
3.2. Experimental Processes
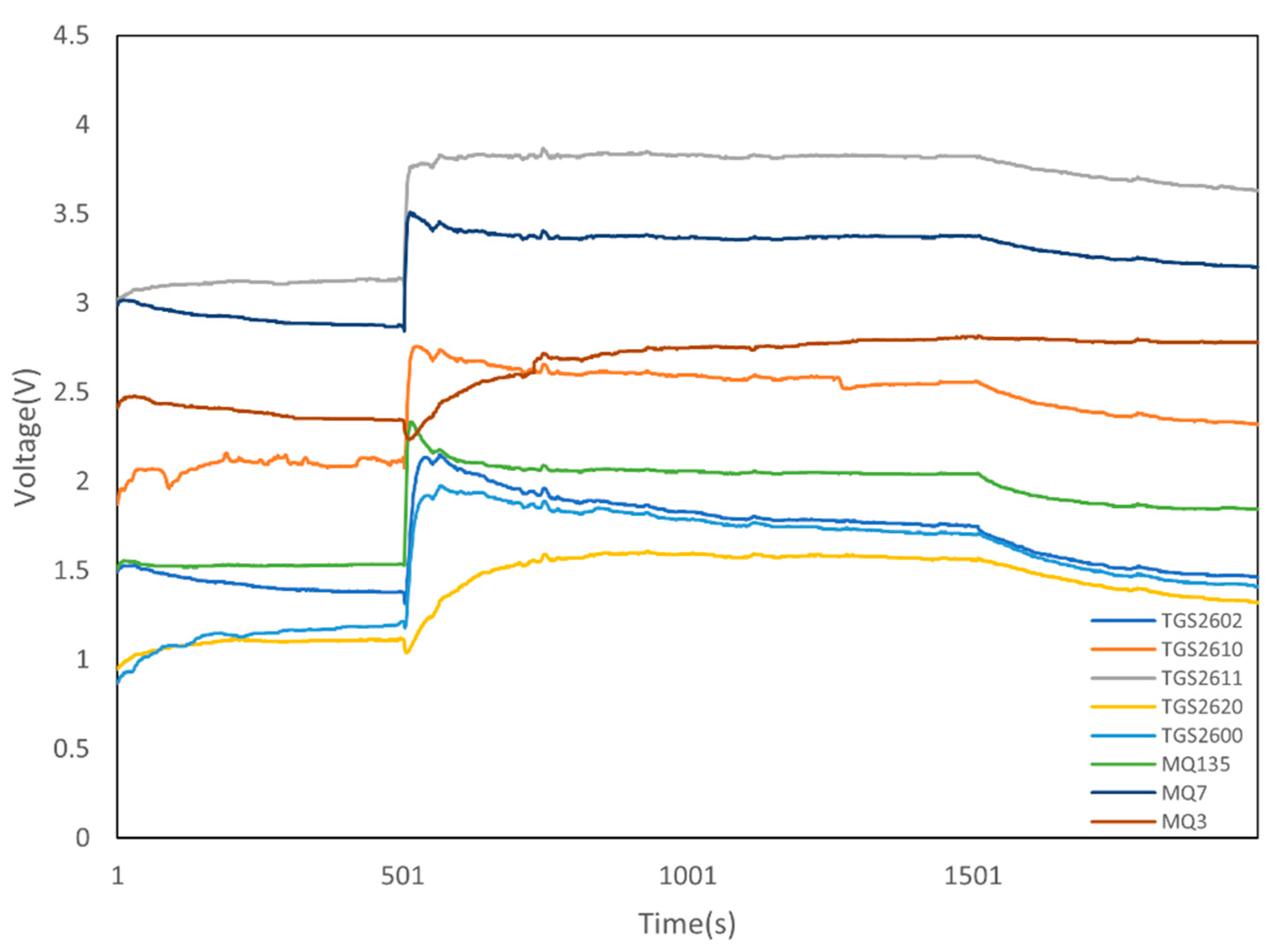
3.3. Coffee Aroma and E-Nose Sensor Array
3.4. Configuration of the E-Nose System
3.5. Humidity Effect on the Output Results
3.6. Sensor Selection and Data Extraction
The Commercial Sensors Chosen for the Developed E-Nose System
4. Feature Extraction of Aroma Data for Digital Fingerprint Generation
Construction of Digital Fingerprints of Measured Coffee Aromas
5. Experiments and Results
5.1. Experiment 1: Coffee Bean Aroma Recognition Using E-Nose with Manual Gas Extraction
5.2. Experiment 2: Coffee Aroma Recognition Using E-Nose with A Vacuum Pump
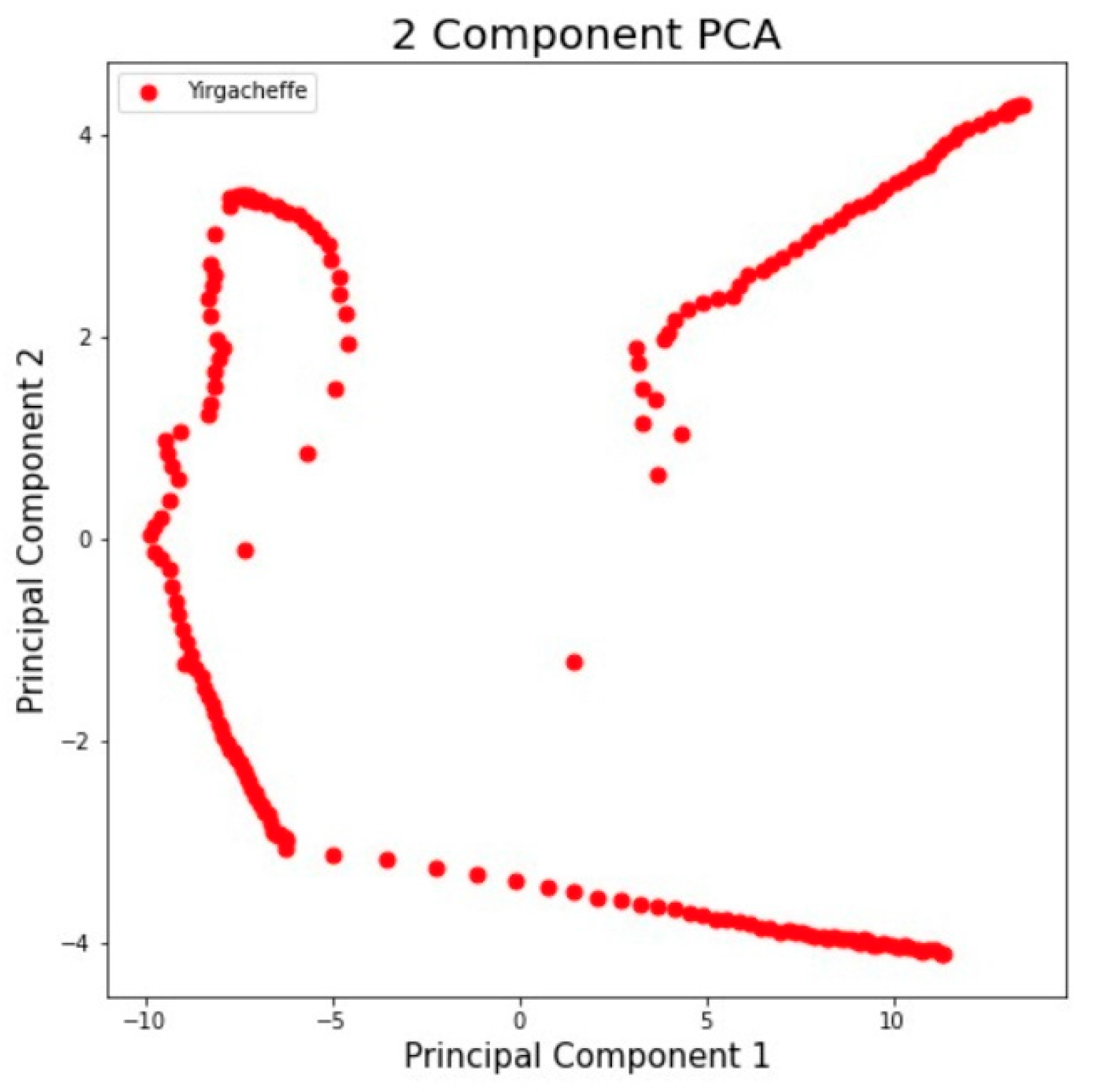
5.3. Digitizing Coffee Aroma with Proposed Fingerprint Generation Technique
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Visualization of Digital Fingerprint Samples of Coffee Aromas from Different Origins
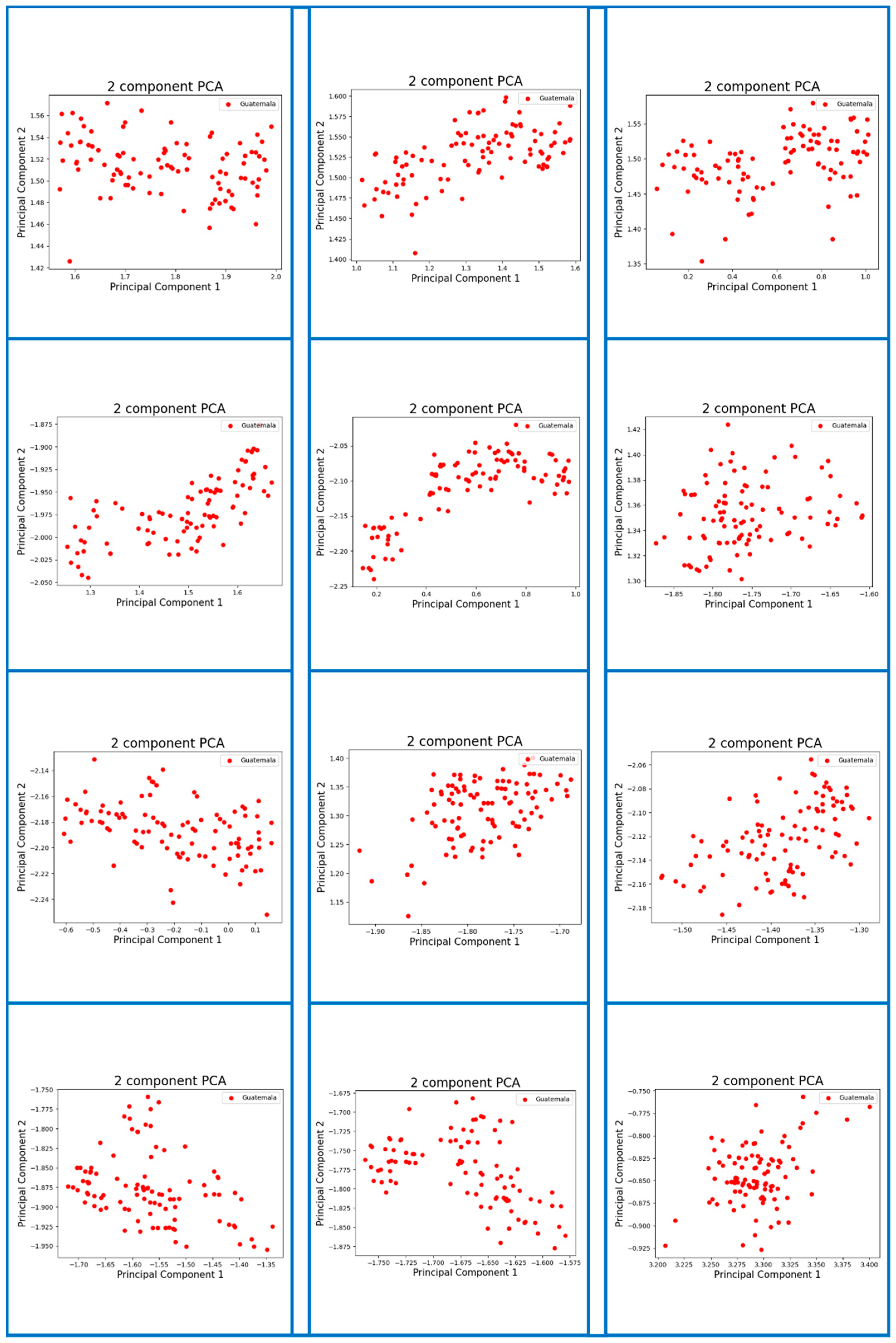
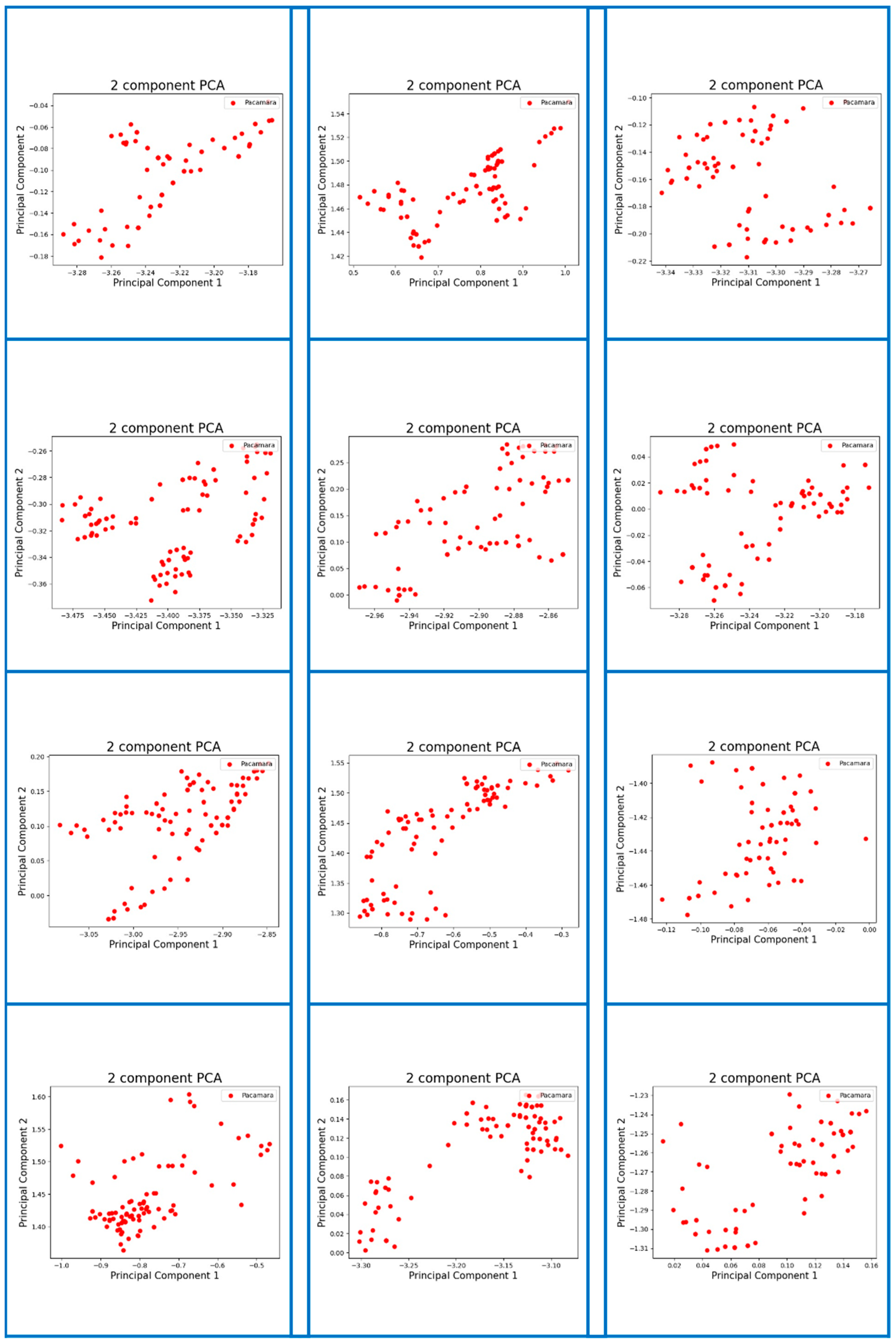
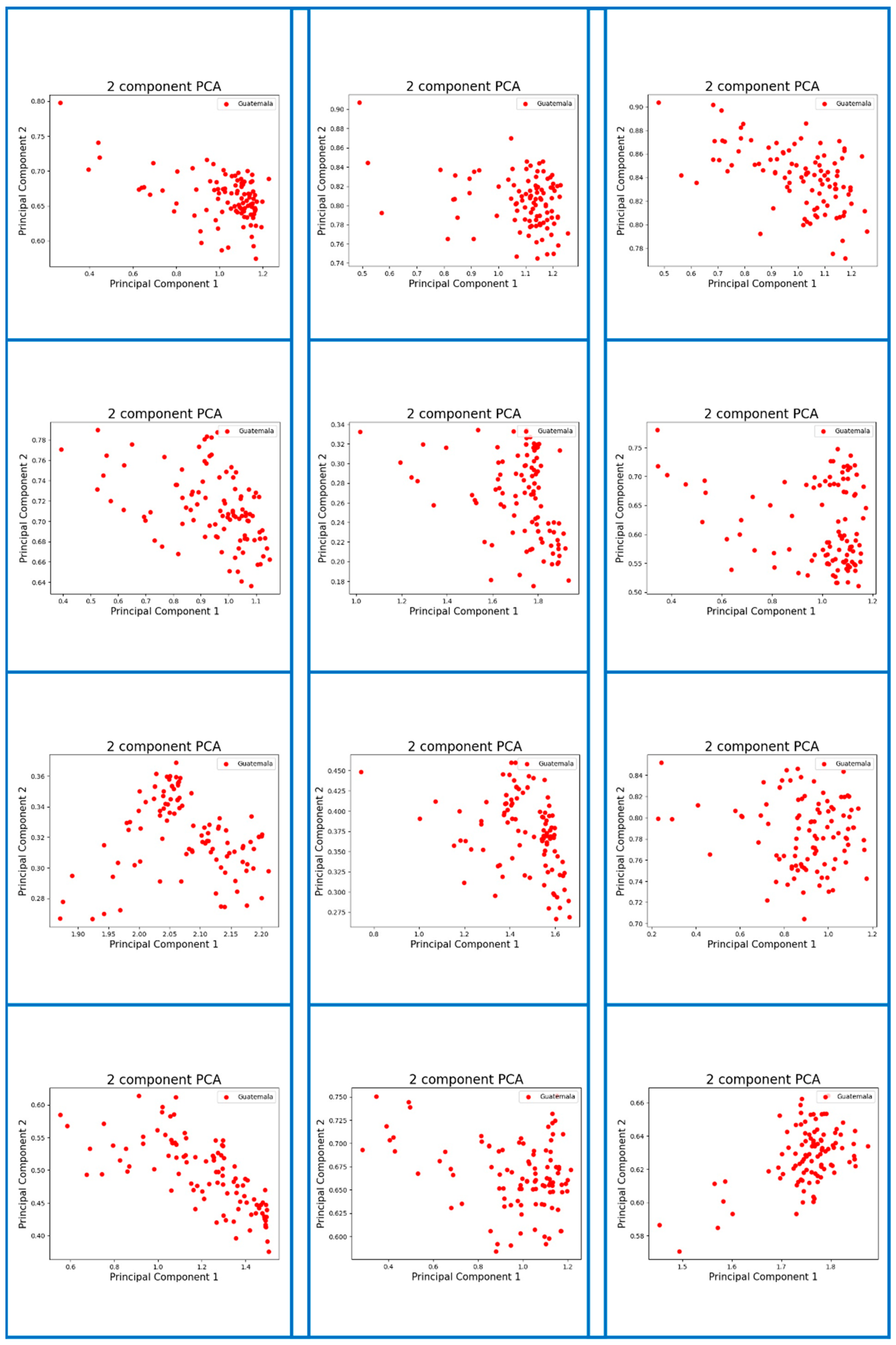
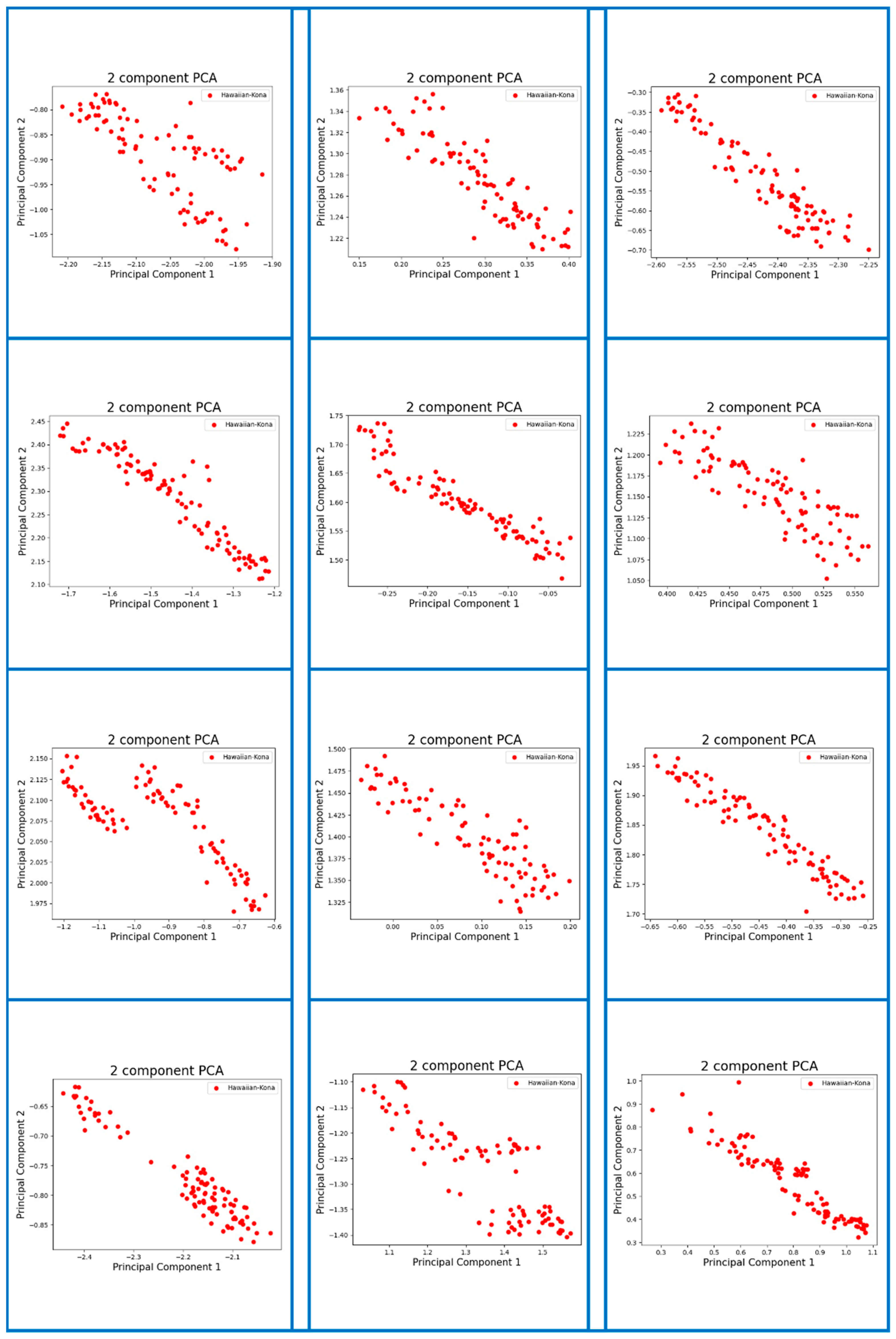
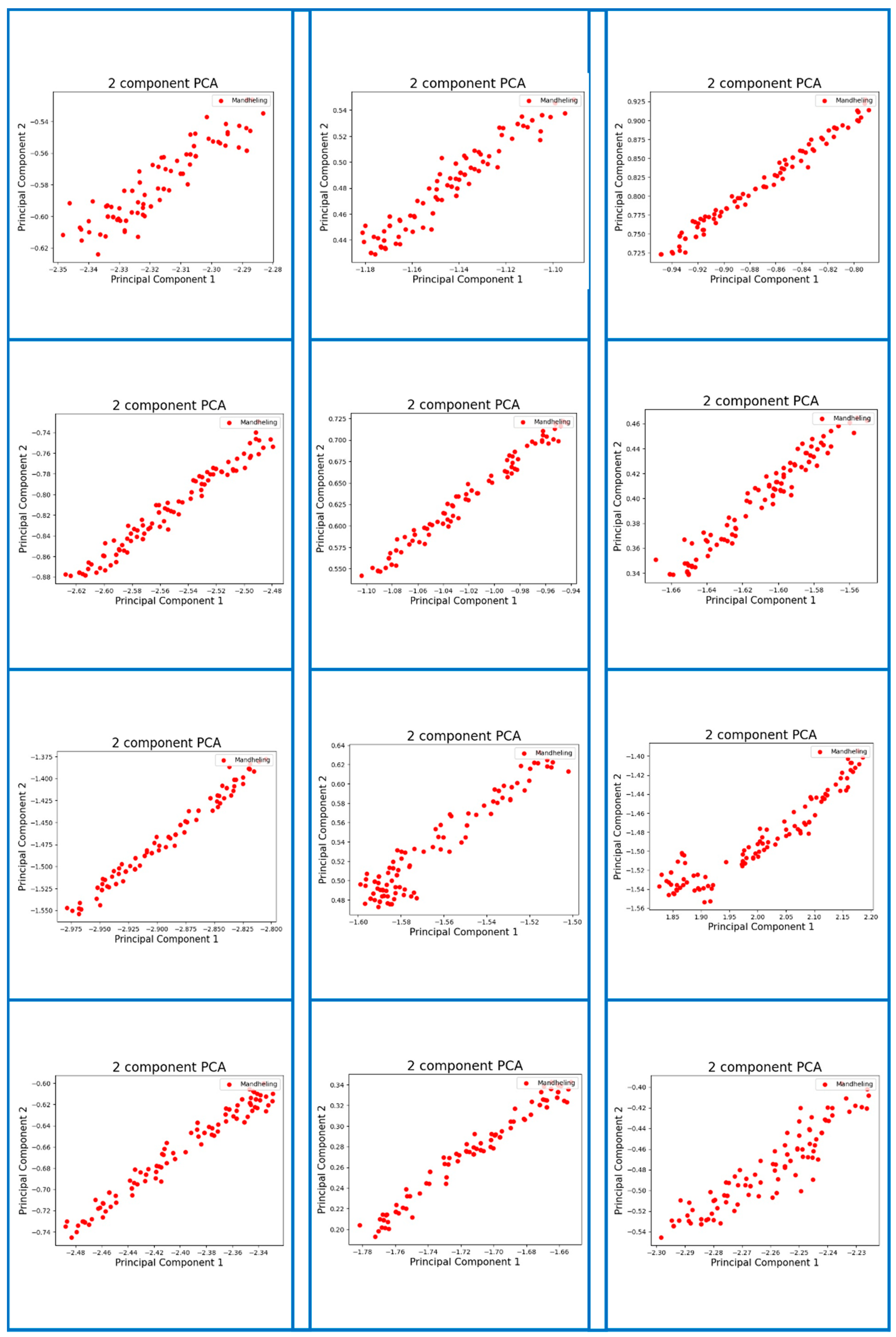
References
- Persaud, K.; Dodd, G. Analysis of discrimination mechanisms in the mammalian olfactory system using a model nose. Nature 1982, 299, 352–355. [Google Scholar] [CrossRef] [PubMed]
- Fuentes, S.; Summerson, V.; Gonzalez Viejo, C.; Tongson, E.; Lipovetzky, N.; Wilkinson, K.L.; Szeto, C.; Unnithan, R.R. Assessment of smoke contamination in grapevine berries and taint in wines due to bushfires using a low-cost E-nose and an artificial intelligence approach. Sensors 2020, 20, 5180. [Google Scholar] [CrossRef]
- Liu, H.; Li, Q.; Yan, B.; Zhang, L.; Gu, Y. Bionic electronic nose based on MOS sensors array and machine learning algorithms used for wine properties detection. Sensors 2018, 19, 45. [Google Scholar] [CrossRef]
- Wojnowski, W.; Majchrzak, T.; Dymerski, T.; Gębicki, J.; Namieśnik, J. Electronic noses: Powerful tools in meat quality assessment. Meat Sci. 2017, 131, 119–131. [Google Scholar] [CrossRef] [PubMed]
- Qiu, S.; Gao, L.; Wang, J. Classification and regression of ELM, LVQ and SVM for E-nose data of strawberry juice. J. Food Eng. 2015, 144, 77–85. [Google Scholar] [CrossRef]
- Wu, H.; Yue, T.; Xu, Z.; Zhang, C. Sensor array optimization and discrimination of apple juices according to variety by an electronic nose. Anal. Methods 2017, 9, 921–928. [Google Scholar] [CrossRef]
- Chen, Q.; Zhao, J.; Chen, Z.; Lin, H.; Zhao, D.A. Discrimination of green tea quality using the electronic nose technique and the human panel test, comparison of linear and nonlinear classification tools. Sens. Actuators B Chem. 2011, 159, 294–300. [Google Scholar] [CrossRef]
- Dutta, R.; Hines, E.L.; Gardner, J.W.; Kashwan, K.R.; Bhuyan, M. Tea quality prediction using a tin oxide-based electronic nose: An artificial intelligence approach. Sens. Actuators B Chem. 2003, 94, 228–237. [Google Scholar] [CrossRef]
- Yu, H.; Wang, J.; Yao, C.; Zhang, H.; Yu, Y. Quality grade identification of green tea using E-nose by CA and ANN. LWT-Food Sci. Technol. 2008, 41, 1268–1273. [Google Scholar] [CrossRef]
- Grodniyomchai, B.; Chalapat, K.; Jitkajornwanich, K.; Jaiyen, S. A deep learning model for odor classification using deep neural network. In Proceedings of the 2019 5th International Conference on Engineering, Applied Sciences and Technology (ICEAST), Luang Prabang, Laos, 2–5 July 2019; pp. 1–4. [Google Scholar]
- Estakhroueiyeh, H.R.; Rashedi, E. Detecting moldy Bread using an E-nose and the KNN classifier. In Proceedings of the 2015 5th International Conference on Computer and Knowledge Engineering (ICCKE), Sanya, China, 29 October 2015; pp. 251–255. [Google Scholar]
- Xie, L.; Wang, X. Gas quantitative analysis with support vector machine. In Proceedings of the 2009 Chinese Control and Decision Conference, Guilin, China, 17–19 June 2009; pp. 5148–5151. [Google Scholar]
- Wang, S.H.; Chou, T.I.; Chiu, S.W.; Tang, K.T. Using a hybrid deep neural network for gas classification. IEEE Sens. J. 2020, 21, 6401–6407. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Bashar, A. Survey on evolving deep learning neural network architectures. J. Artif. Intell. 2019, 1, 73–82. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2015; Springer: Berlin/Heidelberg, Germany; pp. 234–241. [Google Scholar]
- Asgari Taghanaki, S.; Abhishek, K.; Cohen, J.P.; Cohen-Adad, J.; Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 2021, 54, 137–178. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Z.; Lai, R.; Kong, X.; Tan, Z.; Shi, W. Deep learning based emotion analysis of microblog texts. Inf. Fusion 2020, 64, 1–11. [Google Scholar] [CrossRef]
- Wu, P.; Li, X.; Shen, S.; He, D. Social media opinion summarization using emotion cognition and convolutional neural networks. Int. J. Inf. Manag. 2020, 51, 101978. [Google Scholar] [CrossRef]
- Zhang, S.; Wei, Z.; Wang, Y.; Liao, T. Sentiment analysis of Chinese micro-blog text based on extended sentiment dictionary. Future Gener. Comput. Syst. 2018, 81, 395–403. [Google Scholar] [CrossRef]
- Wakhid, S.; Sukolilo, I.T.S.N.; Sarno, R.; Sabilla, S.; Maghfira, D. Detection and Classification of Indonesian Civet and Non-Civet Coffee Based on Statistical Analysis Comparison Using E-Nose. Int. J. Intell. Eng. Syst. 2020, 13, 56–65. [Google Scholar] [CrossRef]
- Harsono, W.; Sarno, R.; Sabilla, S.I. Recognition of original arabica civet coffee based on odor using electronic nose and machine learning. In Proceedings of the 2020 International Seminar on Application for Technology of Information and Communication (iSemantic), Semarang, Indonesia, 19–20 September 2020; pp. 333–339. [Google Scholar]
- Pardo, M.; Sberveglieri, G. Coffee analysis with an electronic nose. IEEE Trans. Instrum. Meas. 2002, 51, 1334–1339. [Google Scholar] [CrossRef]
- Magfira, D.B.; Sarno, R. Classification of Arabica and Robusta coffee using electronic nose. In Proceedings of the 2018 In-ternational Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 6–7 March 2018; pp. 645–650. [Google Scholar]
- Omatu, S.; Ikeda, Y.; Yano, M. Odor measurement and intelligent classification. In Proceedings of the 2015 10th Asian Control Conference (ASCC), Kota Kinabalu, Malaysia, 31 May–3 June 2015; pp. 1–6. [Google Scholar]
- Thazin, Y.; Pobkrut, T.; Kerdcharoen, T. Prediction of acidity levels of fresh roasted coffees using e-nose and artificial neural network. In Proceedings of the 2018 10th International Conference on Knowledge and Smart Technology (KST), Chiang Mai, Thailand, 31 January–3 February 2018; pp. 210–215. [Google Scholar]
- Tisan, A.; Cirstea, M.; Oniga, S.; Buchman, A. Artificial olfaction system with hardware on-chip learning neural networks. In Proceedings of the 2010 12th International Conference on Optimization of Electrical and Electronic Equipment, Brasov, Romania, 20–22 May 2010; pp. 884–889. [Google Scholar]
- Rodríguez, J.; Durán, C.; Reyes, A. Electronic nose for quality control of Colombian coffee through the detection of defects in “Cup Tests”. Sensors 2009, 10, 36–46. [Google Scholar] [CrossRef] [PubMed]
- Macasaet, D.; Bandala, A.; Illahi, A.A.; Dadios, E.; Lauguico, S.; Alejandrino, J. Development of an Electronic Nose for Smell Categorization U sing Artificial Neural Network. J. Adv. Inf. Technol. 2021, 12, 36–44. [Google Scholar]
- Brudzewski, K.; Osowski, S.; Dwulit, A. Recognition of coffee using differential electronic nose. IEEE Trans. Instrum. Meas. 2012, 61, 1803–1810. [Google Scholar] [CrossRef]
- Okur, S.; Zhang, Z.; Sarheed, M.; Nick, P.; Lemmer, U.; Heinke, L. Towards a MOF e-Nose: A SURMOF sensor array for detection and discrimination of plant oil scents and their mixtures. Sens. Actuators B Chem. 2020, 306, 127502. [Google Scholar] [CrossRef]
- Kukade, M.; Karve, T.; Gharpure, D. Identification and classification of spices by Machine Learning. In Proceedings of the 2019 IEEE International Conference on Intelligent Systems and Green Technology (ICISGT), Visakhapatnam, India, 29–30 June 2019; pp. 1–13. [Google Scholar]
- Liu, M.; Han, X.; Tu, K.; Pan, L.; Tu, J.; Tang, L.; Liu, P.; Zhan, G.; Zhoung, Q.; Xiong, Z. Application of electronic nose in Chinese spirits quality control and flavour assessment. Food Control. 2012, 26, 564–570. [Google Scholar] [CrossRef]
- Li, L.; Li, H.Y.; Hu, Z.; Liu, J.; Zhou, L.; Tian, Z.; Liu, H. Construction and simple application of a primary electronic nose system. In Proceedings of the 2019 IEEE International Symposium on Olfaction and Electronic Nose (ISOEN), Fukuoka, Japan, 26–29 May 2019; pp. 1–4. [Google Scholar]
- Yu, D.; Wang, X.; Liu, H.; Gu, Y. A multitask learning framework for multi-property detection of wine. IEEE Access. 2019, 7, 123151–123157. [Google Scholar] [CrossRef]
- Wu, D.; Luo, D.; Wong, K.Y.; Hung, K. POP-CNN: Predicting odor pleasantness with convolutional neural network. IEEE Sens. J. 2019, 19, 11337–11345. [Google Scholar] [CrossRef]
- Tang, K.T.; Chiu, S.W.; Pan, C.H.; Hsieh, H.Y.; Liang, Y.S.; Liu, S.C. Development of a portable electronic nose system for the detection and classification of fruity odors. Sensors 2010, 10, 9179–9193. [Google Scholar] [CrossRef]
- Sanchez-Lengeling, B.; Wei, J.N.; Lee, B.K.; Gerkin, R.C.; Aspuru-Guzik, A.; Wiltschko, A.B. Machine learning for scent: Learning generalizable perceptual representations of small molecules. arXiv 2019, arXiv:1910.10685. [Google Scholar]
- Wijaya, D.R.; Sarno, R.; Zulaika, E. DWTLSTM for electronic nose signal processing in beef quality monitoring. Sens. Actuators B Chem. 2021, 326, 128931. [Google Scholar] [CrossRef]
- Qi, P.F.; Meng, Q.H.; Zeng, M. A CNN-based simplified data processing method for electronic noses. In Proceedings of the 2017 ISOCS/IEEE International Symposium on Olfaction and Electronic Nose (ISOEN), Montreal, QC, Canada, 28–31 May 2017; pp. 1–3. [Google Scholar]
- Jong, G.J.; Wang, Z.H.; Hsieh, K.S.; Horng, G.J. A novel feature extraction method an electronic nose for aroma classification. IEEE Sens. J. 2019, 19, 10796–10803. [Google Scholar] [CrossRef]
- Shi, Y.; Gong, F.; Wang, M.; Liu, J.; Wu, Y.; Men, H. A deep feature mining method of electronic nose sensor data for identifying beer olfactory information. J. Food Eng. 2019, 263, 437–445. [Google Scholar] [CrossRef]
- Müller, P.; Salminen, K.; Nieminen, V.; Kontunen, A.; Karjalainen, M.; Isokoski, P.; Rantala, J.; Savia, M.; Väliaho, J.; Kallio, P.; et al. Scent classification by K nearest neighbors using ion-mobility spectrometry measurements. Expert Syst. Appl. 2019, 115, 593–606. [Google Scholar] [CrossRef]
- Ma, D.; Gao, J.; Zhang, Z.; Zhao, H. Gas recognition method based on the deep learning model of sensor array response map. Sens. Actuators B Chem. 2021, 330, 129349. [Google Scholar] [CrossRef]
- Liu, H.; Yu, D.; Gu, Y. Classification and evaluation of quality grades of organic green teas using an electronic nose based on machine learning algorithms. IEEE Access 2019, 7, 172965–172973. [Google Scholar] [CrossRef]
- Bhattacharyya, N.; Seth, S.; Tudu, B.; Tamuly, P.; Jana, A.; Ghosh, D.; Bandyopadhyay, R.; Bhuyan, M.; Sabhapandit, S. Detection of optimum fermentation time for black tea manufacturing using electronic nose. Sens. Actuators B Chem. 2007, 122, 627–634. [Google Scholar] [CrossRef]
- Wang, Y.; Diao, J.; Wang, Z.; Zhan, X.; Zhang, B.; Li, N.; Li, G. An optimized deep convolutional neural network for dendrobium classification based on electronic nose. Sens. Actuators A Phys. 2020, 307, 111874. [Google Scholar] [CrossRef]
- Zhang, S.; Cheng, Y.; Luo, D.; He, J.; Wong, A.K.; Hung, K. Channel Attention Convolutional Neural Network for Chinese Baijiu Detection With E-nose. IEEE Sens. J. 2021, 14, 16170–16182. [Google Scholar] [CrossRef]
- Wei, H.; Gu, Y. A Machine Learning Method for the Detection of Brown Core in the Chinese Pear Variety Huangguan Using a MOS-Based E-Nose. Sensors 2020, 20, 4499. [Google Scholar] [CrossRef]
- Ansari, A.Q.; Khusro, A.; Ansari, M.R. Performance evaluation of classifier techniques to discriminate odors with an E-Nose. In Proceedings of the 2015 Annual IEEE India Conference (INDICON), New Delhi, India, 17–20 December 2015. [Google Scholar]
- Zhu, P.; Zhang, Y.; Chou, Y.; Gu, Y. Recognition of the storage life of mitten crab by a machine olfactory system with deep learning. J. Food Process. Eng. 2019, 42, e13095. [Google Scholar] [CrossRef]
- Shen, H.; Tao, J. Applying Electronic Nose Based on Odour Classification and Identification Technology in Detecting the Shelf Life of Fresh Fruits. Chem. Eng. Trans. 2018, 68, 217–222. [Google Scholar]
- Kit, C.K.; Soh, A.C.; Yusof, U.K.M.; Ishak, A.J.; Hassan, M.K.; Khamis, S. E-nose herbs recognition system based on Artificial Neural Network technique. In Proceedings of the 2013 IEEE International Conference on Control System, Computing and Engineering, Penang, Malaysia, 29 November–1 December 2013. [Google Scholar]
- Ayari, F.; Mirzaee-Ghaleh, E.; Rabbani, H.; Heidarbeigi, K. Using an E-nose machine for detection the adulteration of margarine in cow ghee. J. Food Process. Eng. 2018, 41, e12806. [Google Scholar] [CrossRef]
- Xu, M.; Wang, J.; Gu, S. Rapid identification of tea quality by E-nose and computer vision combining with a synergetic data fusion strategy. J. Food Eng. 2019, 241, 10–17. [Google Scholar] [CrossRef]
- Rasekh, M.; Karami, H. E-nose coupled with an artificial neural network to detection of fraud in pure and industrial fruit juices. Int. J. Food Prop. 2021, 24, 592–602. [Google Scholar] [CrossRef]
- Rao, S. The Coffee Roaster’s Companion. Scott Rao. 2014. Available online: https://www.scottrao.com/the-coffee-roasters-companion (accessed on 24 June 2022).
- Budryn, G.; Nebesny, E.; Oracz, J. Correlation between the stability of chlorogenic acids, antioxidant activity and acrylamide content in coffee beans roasted in different conditions. Int. J. Food Prop. 2015, 18, 290–302. [Google Scholar] [CrossRef]
- Blank, T.A.; Eksperiandova, L.P.; Belikov, K.N. Recent trends of ceramic humidity sensors development: A review. Sens. Actuators B Chem. 2016, 228, 416–442. [Google Scholar] [CrossRef]
- Illy, A.; Viani, R. Espresso Coffee: The Science of Quality, 2nd ed.; Elsevier: Amsterdam, The Netherlands; Academic Press: London, UK, 2005. [Google Scholar]
- Gardner, J.W.; Bartlett, P.N. Electronic Noses: Principles and Applications; Oxford University Press: Oxford, UK, 1999; pp. 221–245. [Google Scholar]
- Wilson, A.D.; Baietto, M. Applications and advances in electronic-nose technologies. Sensors 2009, 9, 5099–5148. [Google Scholar] [CrossRef] [PubMed]
- Röck, F.; Barsan, N.; Weimar, U. Electronic nose: Current status and future trends. Chem. Rev. 2008, 108, 705–725. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor Name | Measured Gas Contents |
|---|---|
| TGS2600 | Air pollutants (hydrogen, ethanol) |
| TGS2602 | Air pollutants (VOCs, ammonia, H2S) |
| TGS2610 | Butane, Propane |
| TGS2611 | Methane |
| TGS2620 | Alcohol, Solvent vapors |
| MQ135 | Ammonia, Sulfide, Benzene |
| MQ3 | Alcohol, Ethanol |
| MQ7 | Carbon monoxide (CO) |
| Origin (Growing Area) | Samples | Decision Tree | Random Forest | XGBoost | SVM | CNN | CNN + LSTM |
|---|---|---|---|---|---|---|---|
| Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | ||
| La Flor del (Guatemala) | Training: 144 Test: 36 | 0.997 | 0.988 | 0.998 | 0.983 | 0.758 | 0.821 |
| Kona (Hawaiian) | Training: 144 Test: 36 | 0.971 | 0.978 | 0.969 | 0.934 | 0.747 | 0.80 |
| Mandheling (Indonesia) | Training: 144 Test: 36 | 0.993 | 0.984 | 0.995 | 0.986 | 0.942 | 0.989 |
| Sigri (Papua New Guinea) | Training: 144 Test: 36 | 0.989 | 0.973 | 0.975 | 0.964 | 0.885 | 0.844 |
| Bunum Wo (Papua New Guinea) | Training: 144 Test: 36 | 0.969 | 0.971 | 0.969 | 0.953 | 0.867 | 0.924 |
| Ipanema (Brazil) | Training: 144 Test: 36 | 0.952 | 0.966 | 0.944 | 0.895 | 0.923 | 0.971 |
| Yirgacheffe (Ethiopia) | Training: 144 Test: 36 | 0.951 | 0.971 | 0.941 | 0.886 | 0.954 | 0.983 |
| Dongshan (Taiwan) | Training: 144 Test: 36 | 0.942 | 0.964 | 0.944 | 0.889 | 0.867 | 0.657 |
| Tolima (Colombia) | Training: 144 Test: 36 | 0.989 | 0.991 | 0.985 | 0.950 | 0.987 | 0.835 |
| Origin (Growing Area) | Samples | Decision Tree | Random Forest | XGBoost | SVM | CNN | CNN + LSTM |
|---|---|---|---|---|---|---|---|
| Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | ||
| La Flor del (Guatemala) | Training:144 Test:36 | 0.86 | 0.91 | 0.86 | 0.86 | 0.8 | 0.8 |
| Kona (Hawaiian) | Training:144 Test:36 | 0.9 | 0.83 | 0.88 | 0.85 | 0.95 | 0.89 |
| Mandheling (Indonesia) | Training:144 Test:36 | 0.94 | 0.81 | 0.89 | 0.72 | 0.67 | 0.67 |
| Sigri (Papua New Guinea) | Training: 144 Test: 36 | 0.79 | 0.91 | 0.75 | 0.91 | 0.7 | 0.71 |
| Bunum Wo (Papua New Guinea) | Training: 144 Test: 36 | 0.83 | 0.86 | 0.88 | 0.84 | 0.76 | 0.76 |
| Ipanema (Brazil) | Training: 144 Test: 36 | 0.8 | 0.87 | 0.88 | 0.91 | 0.93 | 0.96 |
| Yirgacheffe (Ethiopia) | Training: 144 Test: 36 | 0.85 | 0.92 | 0.73 | 0.93 | 0.66 | 0.73 |
| Dongshan (Taiwan) | Training: 144 Test: 36 | 0.73 | 0.95 | 0.93 | 0.85 | 0.97 | 0.86 |
| Tolima (Colombia) | Training: 144 Test: 36 | 0.76 | 0.84 | 0.79 | 0.83 | 0.94 | 0.94 |
| Origin (Growing Area) | Samples | Decision Tree | Random Forest | XGBoost | SVM | CNN | CNN + LSTM |
|---|---|---|---|---|---|---|---|
| Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | ||
| PacaMara (Nicaragua) | Training: 320 Test: 80 | 0.990 | 0.985 | 0.988 | 0.967 | 0.904 | 0.889 |
| Huehuetenango (Guatemala) | Training: 320 Test: 80 | 0.968 | 0.995 | 0.966 | 0.952 | 0.897 | 0.928 |
| Yirgacheffe (Ethiopia) | Training: 320 Test: 80 | 0.986 | 0.982 | 0.982 | 0.963 | 0.997 | 0.992 |
| Mandheling (Indonesia) | Training: 320 Test: 80 | 0.985 | 0.985 | 0.986 | 0.979 | 0.989 | 0.972 |
| Kona (Hawaiian) | Training: 320 Test: 80 | 0.986 | 0.992 | 0.987 | 0.987 | 0.985 | 0.829 |
| Guji Uraga (Ethiopia) | Training: 320 Test: 80 | 0.992 | 0.987 | 0.982 | 0.986 | 0.998 | 0.966 |
| Origin (Growing Area) | Samples | Decision Tree | Random Forest | XGBoost | SVM | CNN | CNN + LSTM |
|---|---|---|---|---|---|---|---|
| Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | ||
| PacaMara (Nicaragua) | Training: 320 Test: 80 | 0.72 | 0.7 | 0.71 | 0.75 | 0.7 | 0.7 |
| Huehuetenango (Guatemala) | Training: 320 Test: 80 | 0.83 | 0.88 | 0.83 | 0.87 | 0.92 | 0.75 |
| Yirgacheffe (Ethiopia) | Training: 320 Test: 80 | 0.94 | 0.84 | 0.84 | 0.88 | 0.74 | 0.79 |
| Mandheling (Indonesia) | Training: 320 Test: 80 | 0.63 | 0.72 | 0.81 | 0.73 | 0.72 | 0.82 |
| Kona (Hawaiian) | Training: 320 Test: 80 | 0.82 | 0.86 | 0.8 | 0.77 | 0.93 | 0.71 |
| Guji Uraga (Ethiopia) | Training: 320 Test: 80 | 0.79 | 0.81 | 0.89 | 0.91 | 0.96 | 0.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, C.-H.; Chen, I.-T.; Yang, H.-C.; Chen, Y.J. An AI-powered Electronic Nose System with Fingerprint Extraction for Aroma Recognition of Coffee Beans. Micromachines 2022, 13, 1313. https://doi.org/10.3390/mi13081313
Lee C-H, Chen I-T, Yang H-C, Chen YJ. An AI-powered Electronic Nose System with Fingerprint Extraction for Aroma Recognition of Coffee Beans. Micromachines. 2022; 13(8):1313. https://doi.org/10.3390/mi13081313
Chicago/Turabian StyleLee, Chung-Hong, I-Te Chen, Hsin-Chang Yang, and Yenming J. Chen. 2022. "An AI-powered Electronic Nose System with Fingerprint Extraction for Aroma Recognition of Coffee Beans" Micromachines 13, no. 8: 1313. https://doi.org/10.3390/mi13081313
APA StyleLee, C.-H., Chen, I.-T., Yang, H.-C., & Chen, Y. J. (2022). An AI-powered Electronic Nose System with Fingerprint Extraction for Aroma Recognition of Coffee Beans. Micromachines, 13(8), 1313. https://doi.org/10.3390/mi13081313