

Indoor Passive Visual Positioning by CNN-Based Pedestrian Detection


Abstract
:1. Introduction
- Our visual localization algorithm is a passive vision scheme. Unlike active visual localization schemes, users do not need to take photos when they want to obtain their position.
- Our visual localization algorithm makes full use of inter-frame detection results and CAD map information. Unlike other visual detection methods, we propose a new spatial attention model that fuses CAD map information and detection results from previous frames. We call this model the region of interest attention model (RIAM).
- Our visual localization algorithm is not limited to the detection results. Compared with other visual detection methods, not only do we know if there are people in the scene, but we also know exactly where the pedestrians are. We recover individual 2D positions from the pedestrian detection pixel results.
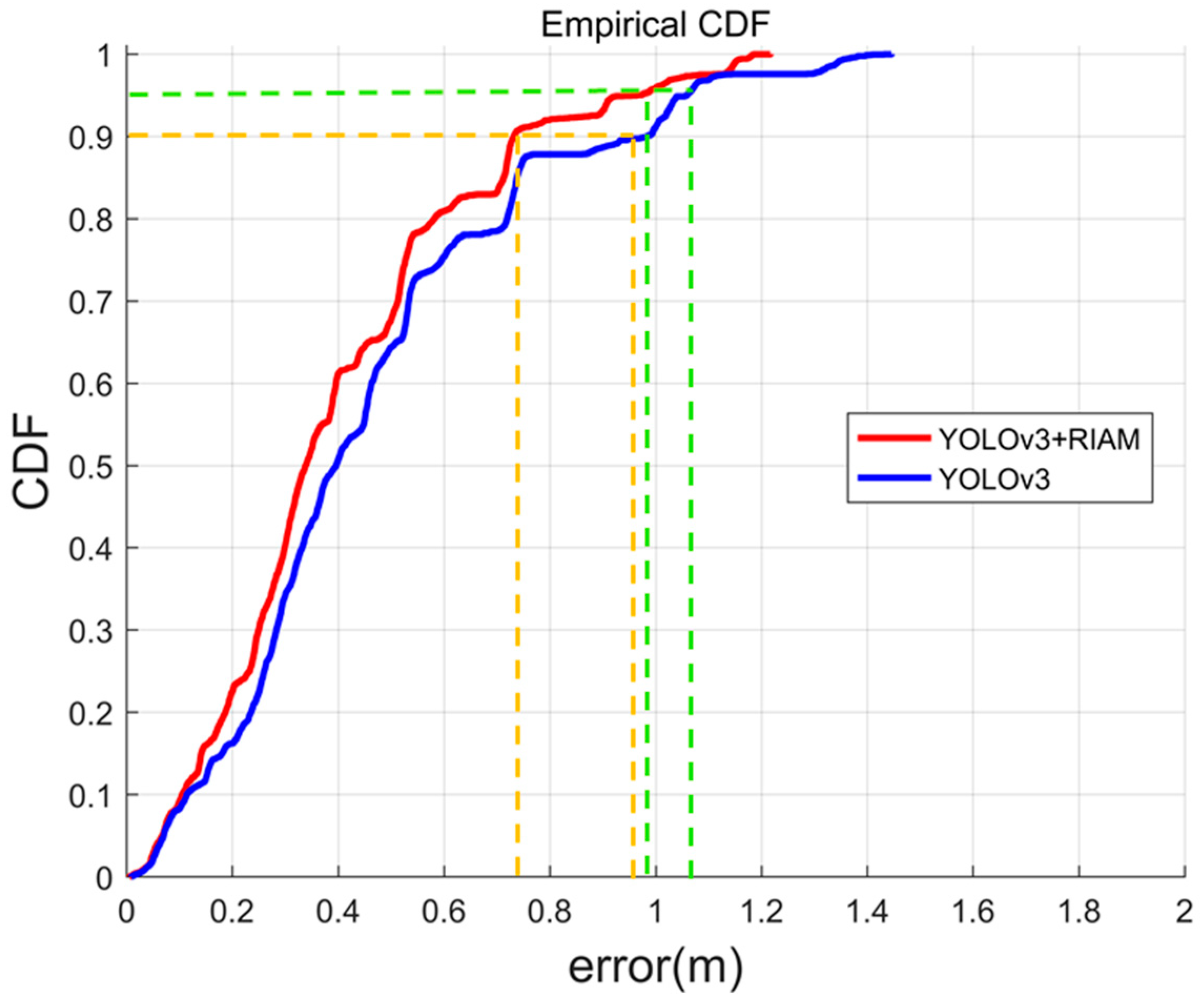
- Our detection method achieved 83.49% detection accuracy, representing an increase of about 1.56% over the YOLOv3 approach. Compared with the YOLOv3 +PT method, our passive visual positioning method increased average accuracy by about 12.2%, achieved an average accuracy of 40.4 cm, and about 90% of the results were less than 73.2 cm from the actual position.
2. Related Work
3. System Overview and Methods
- (1)
- The pretreatment component is shown in Figure 1a. The interior orientation element and lens distortion parameters of a camera are digitized through camera calibration. A security camera is installed with stable localization.
- (2)
- The target detection component is shown in Figure 1b. This includes offline training and online pedestrian detection. Offline training employs a new attention mechanism known as the region of interest attention model (RIAM), which fuses existing detection results and map information.
- (3)
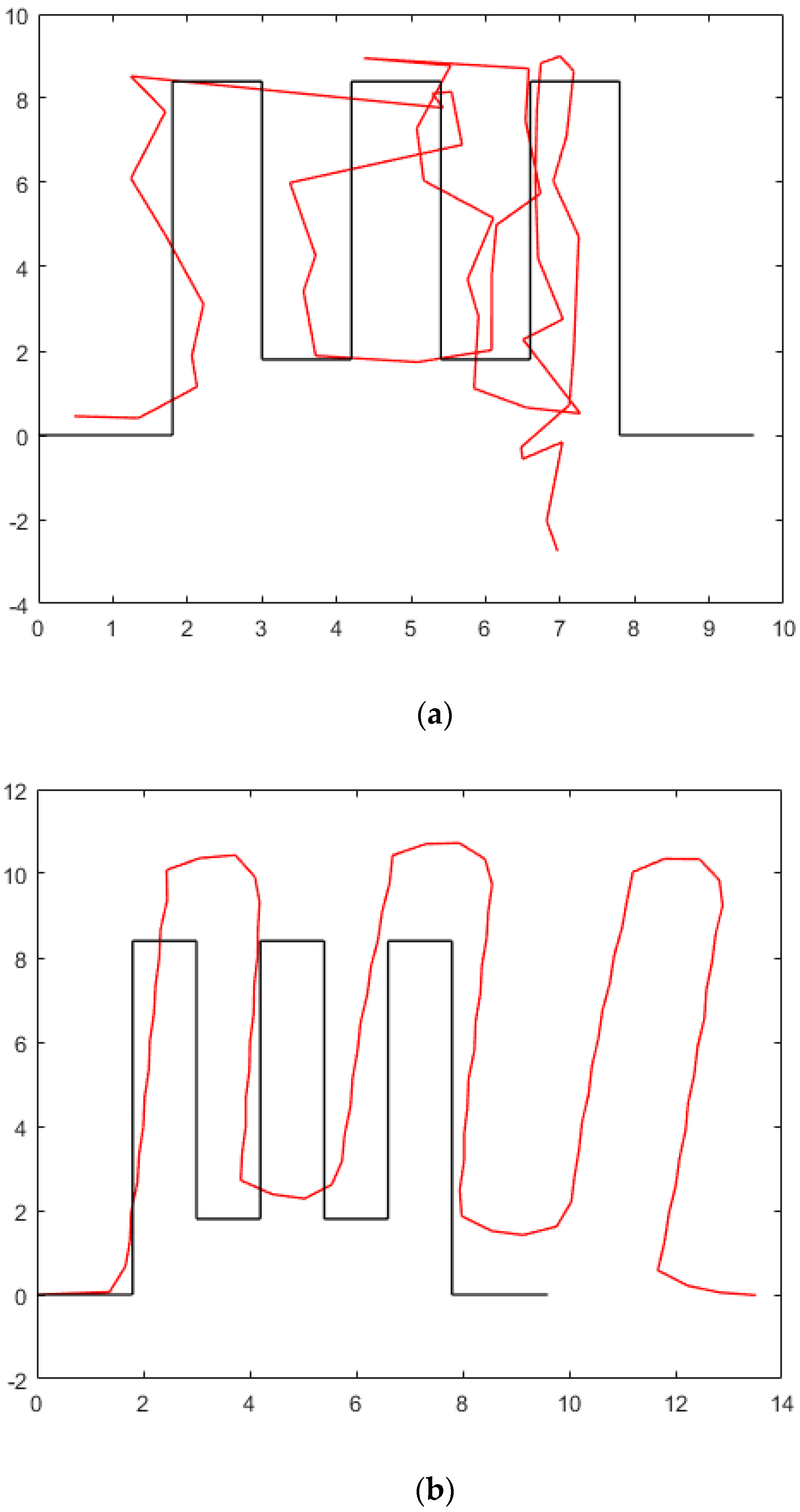
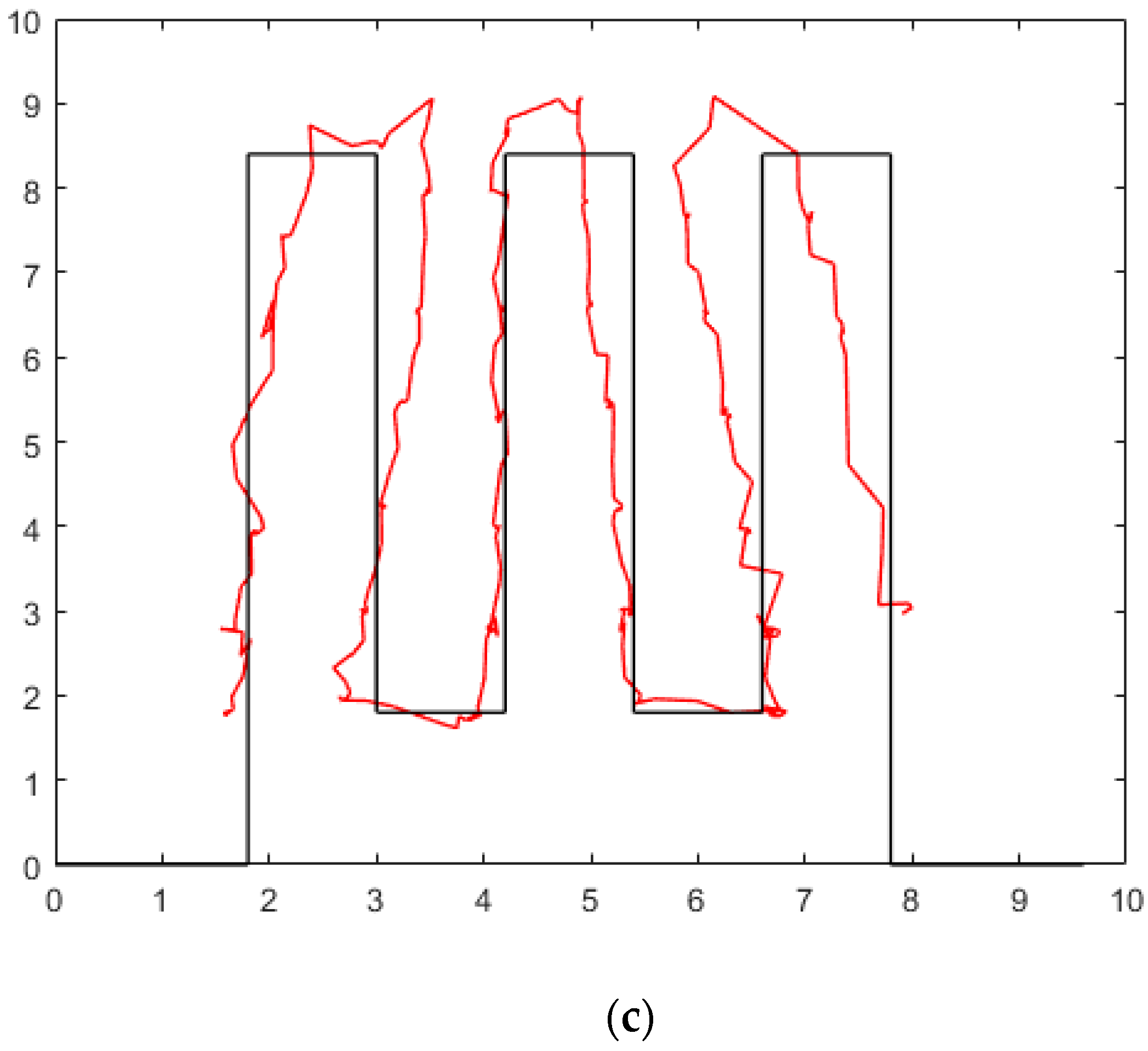
- The position estimation component is shown in Figure 1c. The camera is positioned to look downward so that what is shown in the picture is totally different from the usual pedestrian detection database. After pedestrian detection from the overhead view, the 2D pixel result is used to calculate the location of a pedestrian in plane 2D coordinates, assuming that pedestrians are standing on the ground.
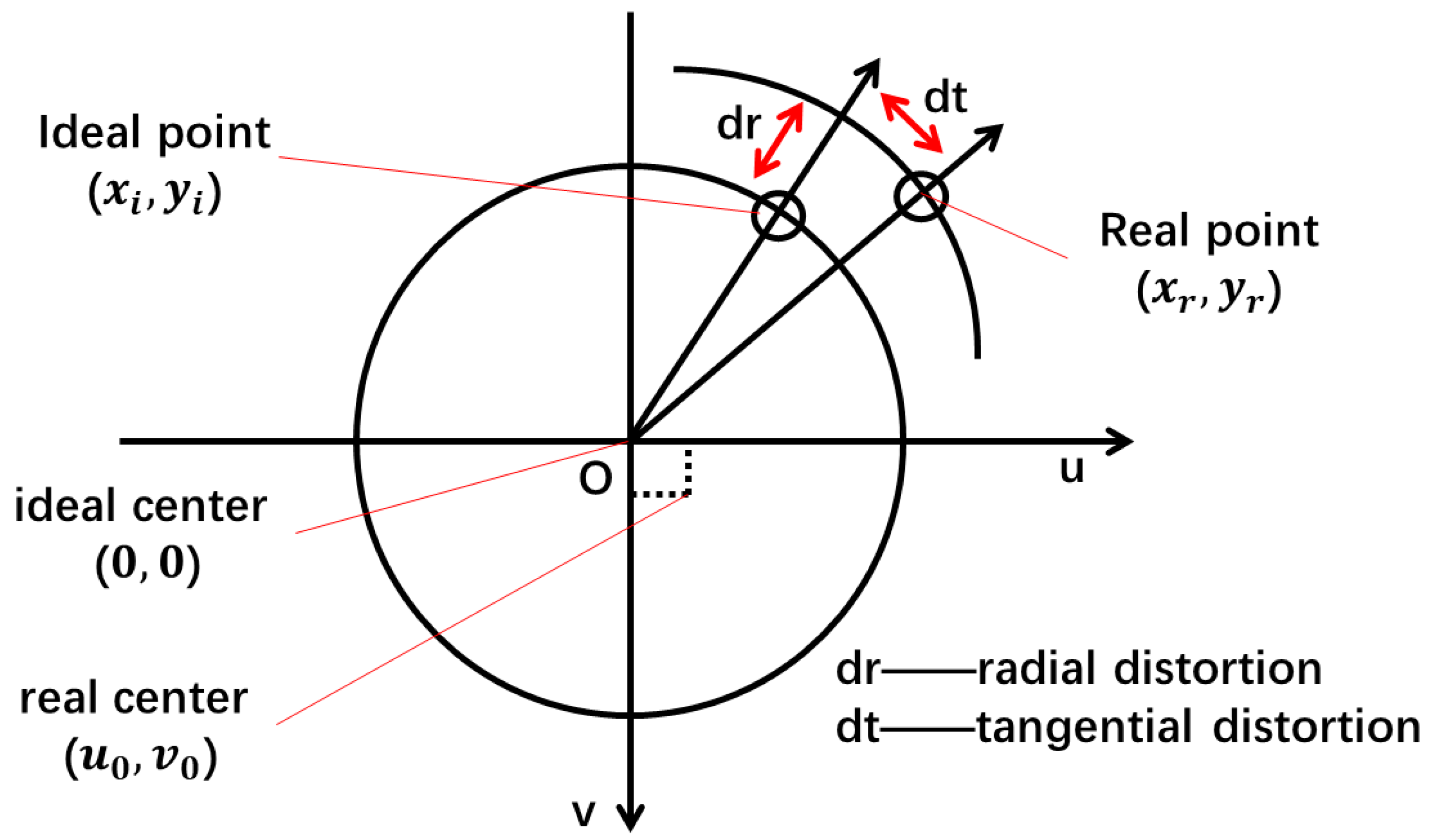
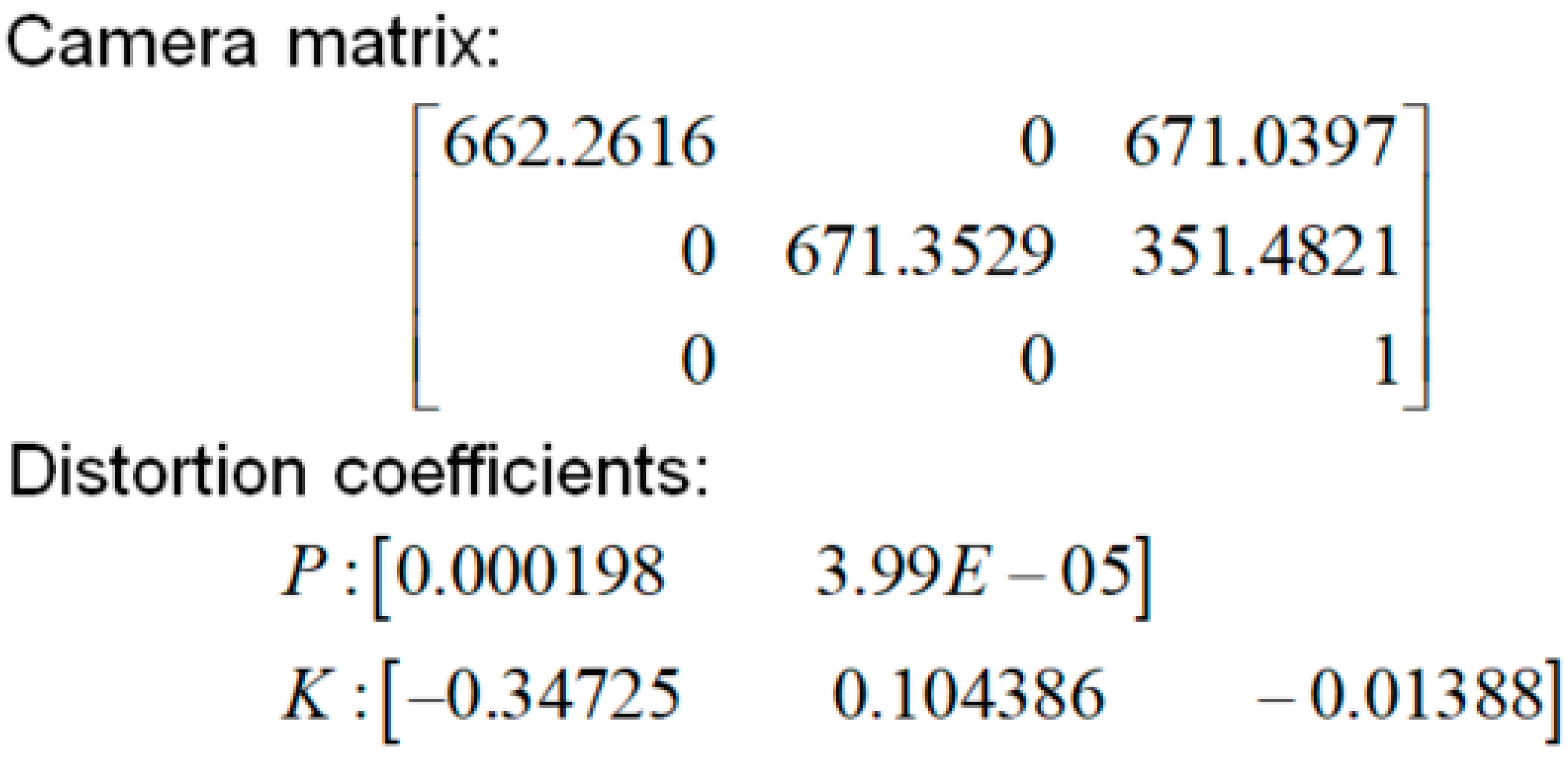
3.1. Pretreatment
3.2. Target Detection
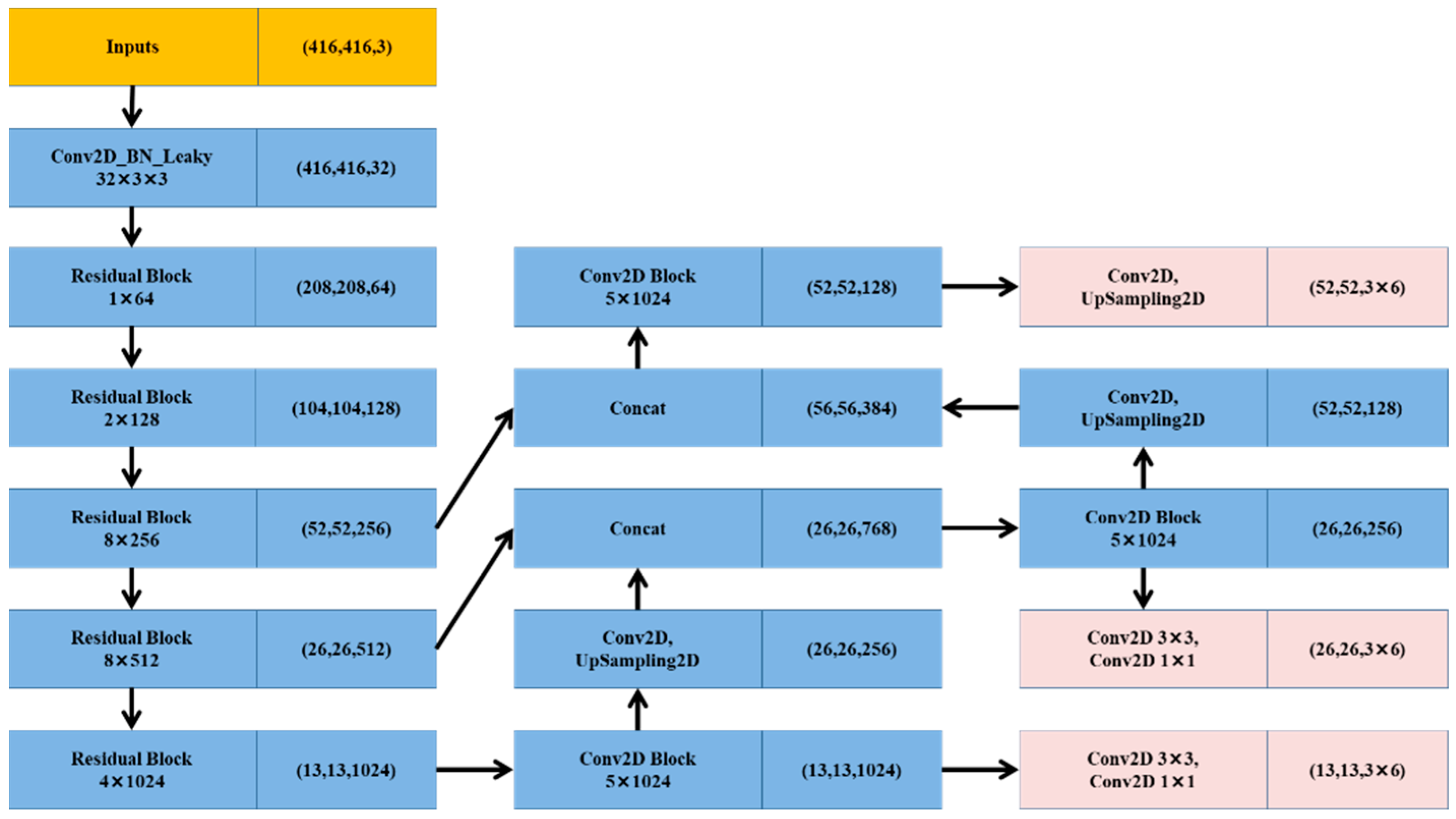
3.2.1. Deep Convolutional Neural Networks
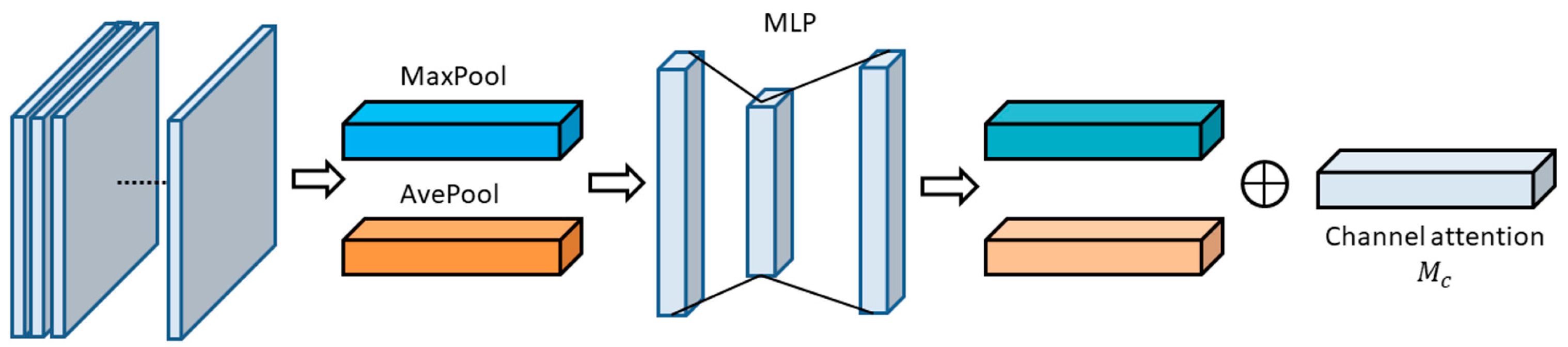
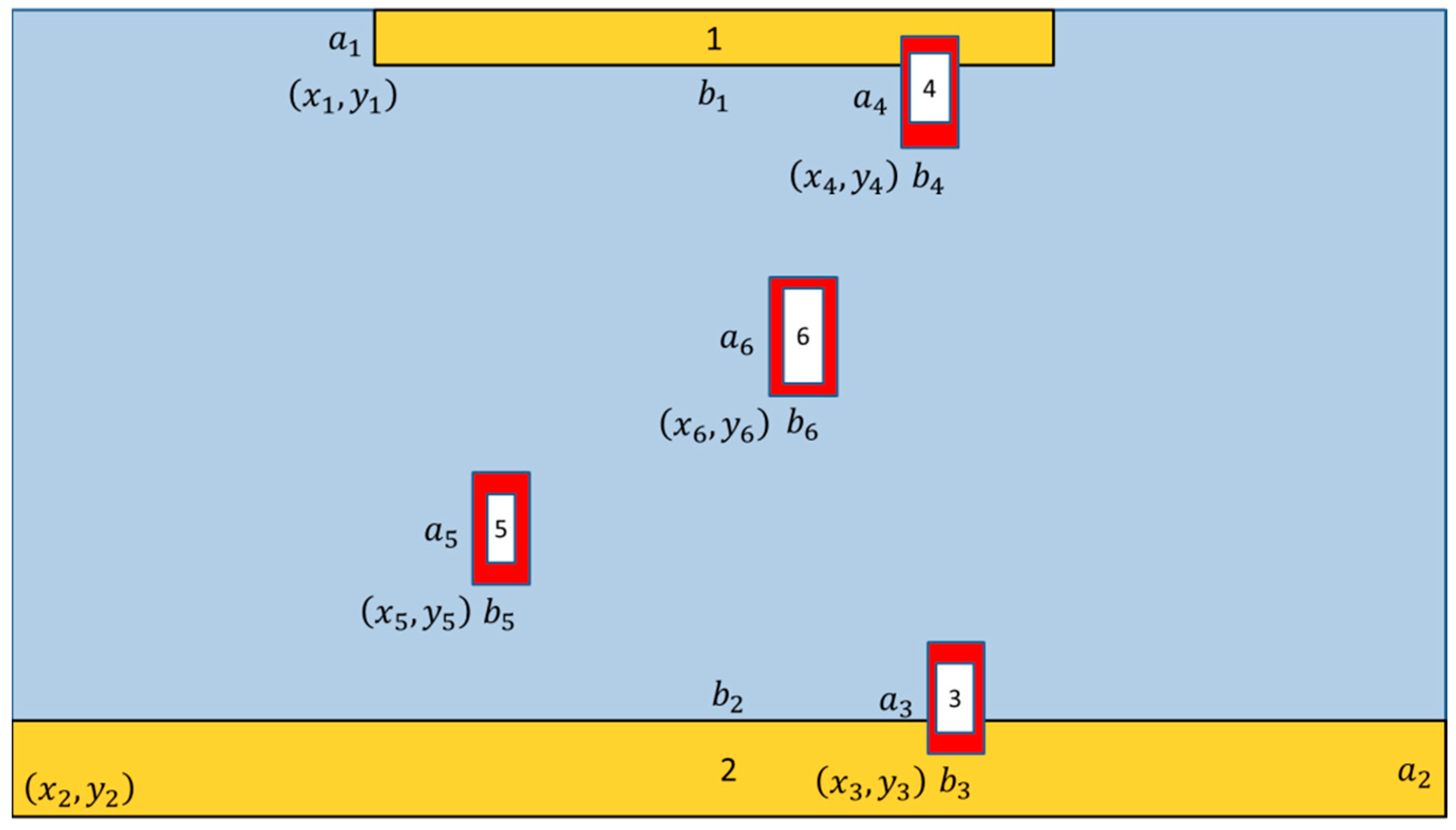
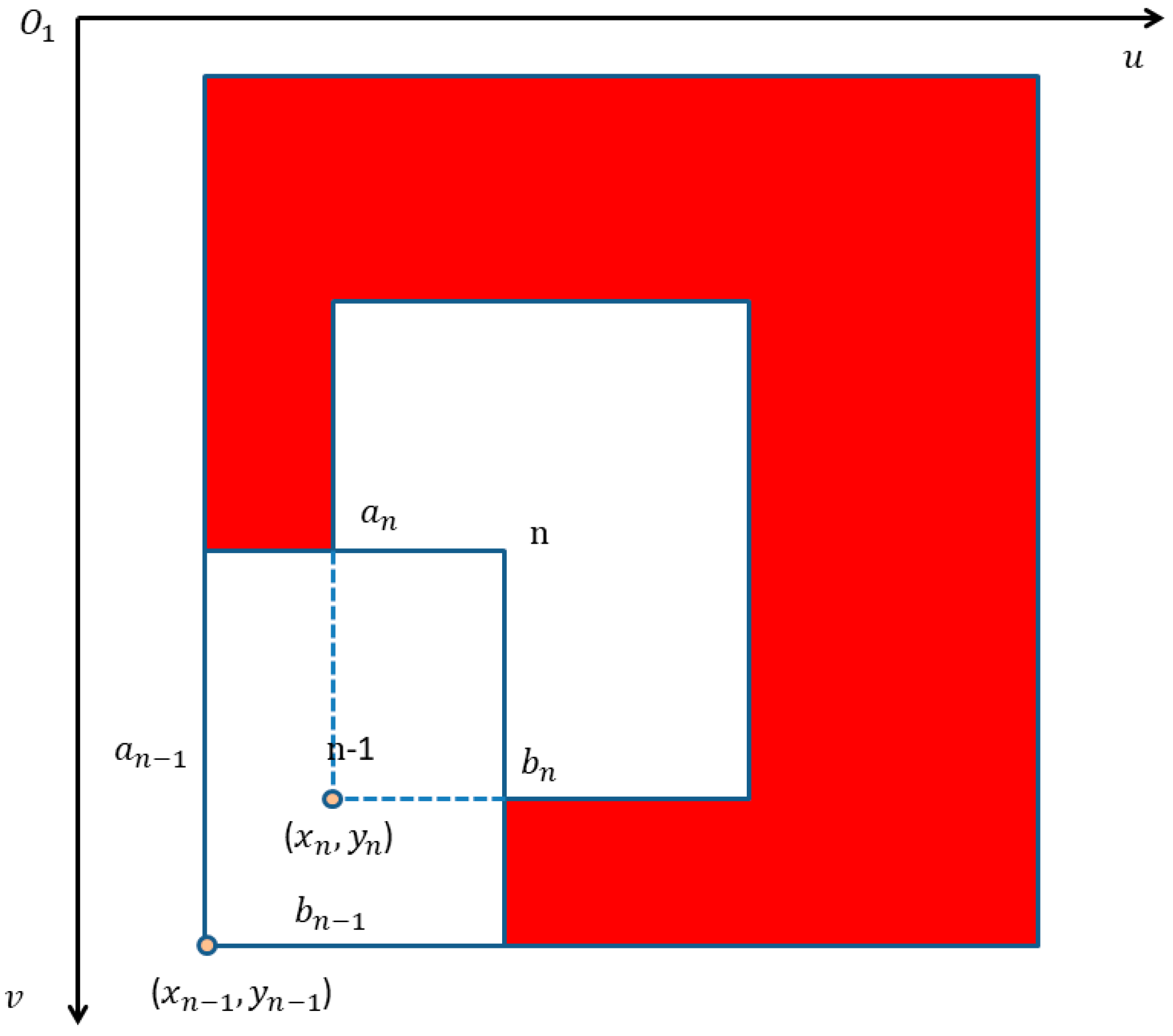
3.2.2. Region of Interest Attention Module
3.3. Position Estimation
4. Experiments
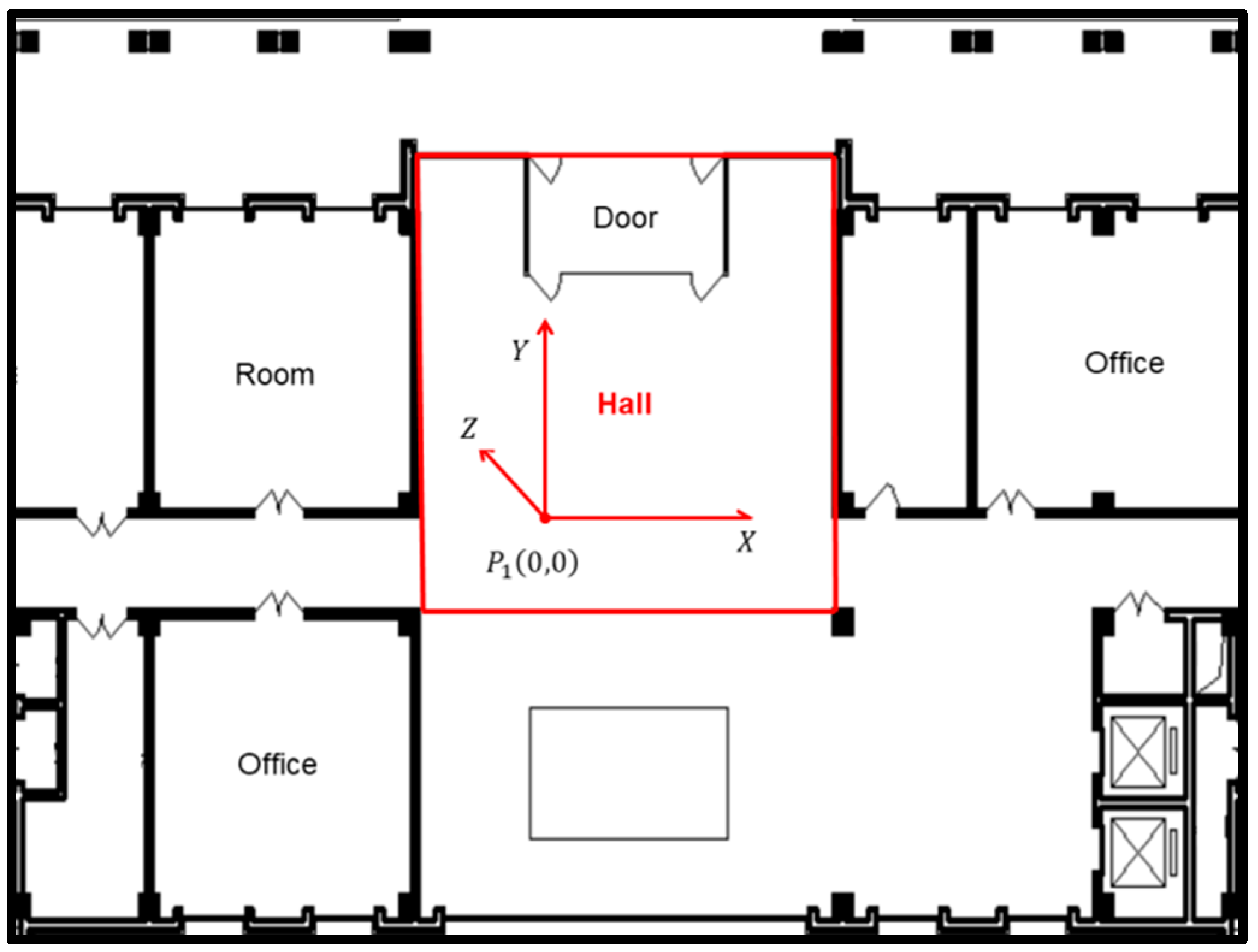
4.1. Experimental Environment and Setup
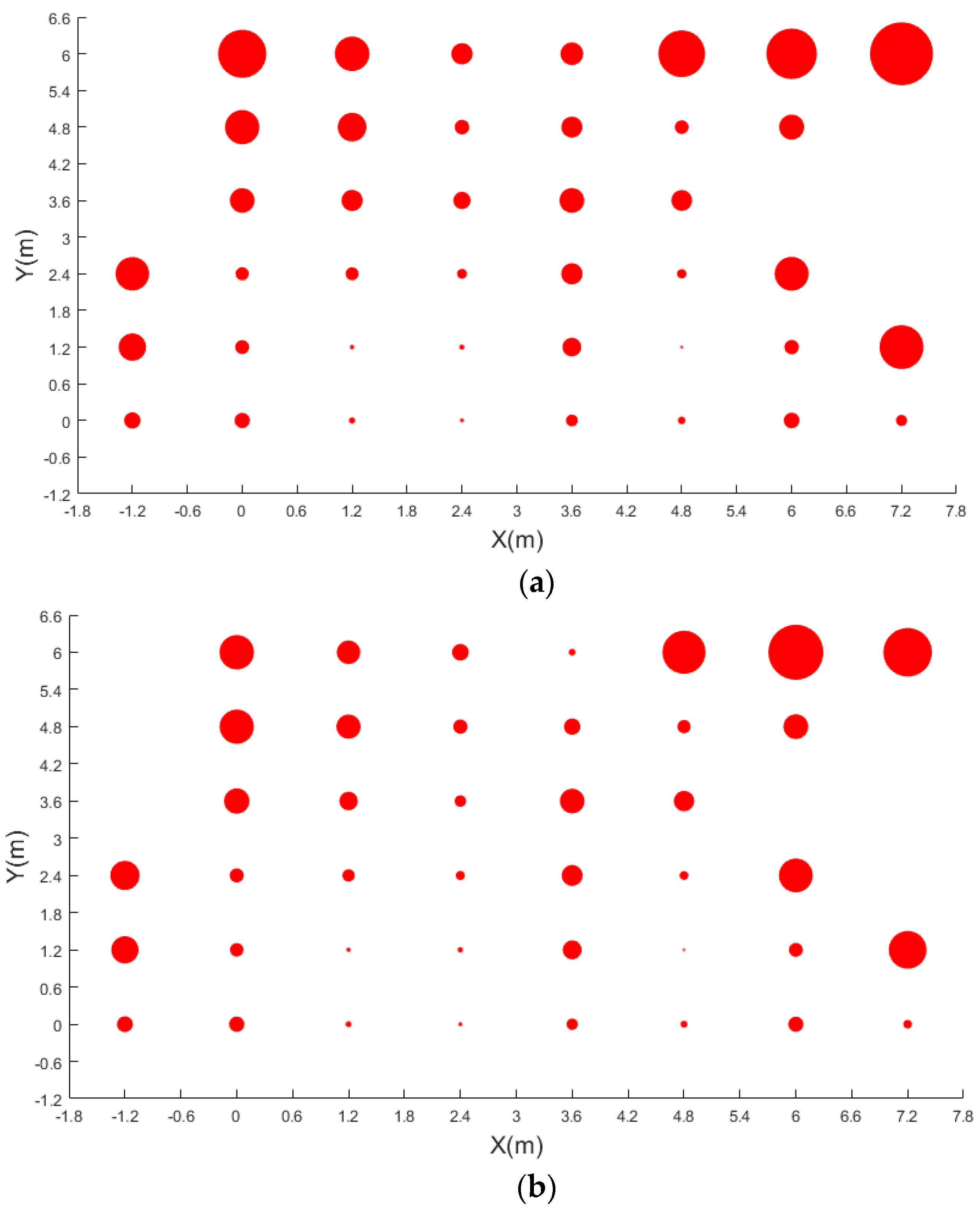
4.2. Pedestrian Detection Results
4.3. Indoor Positioning Result
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, D.; Shan, J.; Shao, Z.; Zhou, X.; Yao, Y. Geomatics for smart cities-concept, key techniques, and applications. Geo-Spat. Inf. Sci. 2013, 16, 13–24. [Google Scholar] [CrossRef]
- Mautz, R. Overview of current indoor positioning systems. Geod. Ir. Kartogr. 2009, 35, 18–22. [Google Scholar] [CrossRef]
- Mautz, R. Indoor Positioning Technologies. Ph.D. Thesis, ETH Zürich, Zürich, Switzerland, 2012. [Google Scholar]
- Liu, J.; Chen, R.; Pei, L. A hybrid smartphone indoor positioning solution for mobile LBS. Sensors 2012, 12, 17208–17233. [Google Scholar] [CrossRef] [PubMed]
- Youssef, M.; Agrawala, A. The horus WLAN location determination system. In Proceedings of the Third International Conference on Mobile Systems, Applications, and Services, Seattle, WA, USA, 6–8 June 2005; pp. 205–218. [Google Scholar]
- Yang, S.; Dessai, P.; Verma, M. Freeloc: Calibration-free crowdsourced indoor localization. In Proceedings of the 32nd IEEE International Conference on Computer Communications, Turin, Italy, 14–19 April 2013; pp. 2481–2489. [Google Scholar]
- Wei, M. Secure and robust Wi-Fi fingerprinting indoor localization. In Proceedings of the 2011 International Conference on Indoor Positioning and Indoor Navigation, Guimarães, Portugal, 21–23 September 2011; pp. 21–23. [Google Scholar]
- Liu, M. Scene recognition for indoor localization using a multi-sensor fusion approach. Sensors 2017, 17, 2847. [Google Scholar] [CrossRef] [PubMed]
- Bozorgasl, Z.; Dehghani, M.J. 2-D DOA estimation in wireless location system via sparse representation. In Proceedings of the 4th International Conference Computer Knowledge Engineering, Mashhad, Iran, 29–30 October 2014; pp. 86–89. [Google Scholar]
- Hightower, J.; Borriello, G. Location systems for ubiquitous computing. Computer 2001, 34, 57–66. [Google Scholar] [CrossRef]
- Lee, N.; Kim, C.; Choi, W.; Pyeon, M.; Kim, Y.x. Development of indoor localization system using a mobile data acquisition platform and BoW image matching. KSCE J. Civ. Eng. 2017, 21, 418–430. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, R.; Liu, M. Indoor visual positioning aided by CNN-based image retrieval: Training-free, 3D modeling-free. Sensors 2018, 18, 2692. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Zhang, L.; Koch, R. An efficient and robust line segment matching approach based on LBD descriptor and pairwise geometric consistency. J. Vis. Commun. Image Represent. 2013, 24, 794–805. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, H.; Wu, F. HLD: A robust descriptor for line matching. In Proceedings of the 11th IEEE International Conference on Computer-Aided Design and Computer Graphics, Huangshan, China, 19–21 August 2009; pp. 19–21. [Google Scholar]
- Salaun, Y.; Marlet, R.; Monasse, P. Multiscale line segment detector for robust and accurate SFM. In Proceedings of the 23rd International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 4–8. [Google Scholar]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981. [Google Scholar]
- Fischer, P.; Dosovitskiy, A.; Ilg, E.; Häusser, P.; Hazırbaş, C.; Golkov, V.; van der Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Version, Santiago, Chile, 7–13 December 2015; pp. 7–13. [Google Scholar]
- Sattler, T.; Torii, A.; Sivic, J.; Pollefeys, M.; Taira, H.; Okutomi, M.; Pajdla, T. Are large-scale 3D models really necessary for accurate visual localization? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6175–6184. [Google Scholar]
- Zhang, H.; Jin, L.; Ye, C. An RGB-D camera based visual positioning system for assistive navigation by a robotic navigation aid. IEEE/CAA J. Autom. Sin. 2022, 8, 1389–1400. [Google Scholar] [CrossRef]
- Zamir, A.R.; Hakeem, A.; Gool, L.V.; Shah, M.; Szeliski, R. Introduction to large-scale visual geo-localization, in large-scale visual geo-localization. In Larger-Scale Visual Geo-Localization; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Zamir, A.R.; Shah, M. Image geo-localization based on multiple nearest neighbor feature matching using generalized graphs. IEEE Trans. Pattern. Anal. Mach. Intel. 2014, 36, 1546–1558. [Google Scholar] [CrossRef] [PubMed]
- Hays, J.; Efros, A.A. IM2GPS: Estimating geographic information from a single image. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Gronat, P.; Obozinski, G.; Sivic, J.; Padjla, T. Learning and calibrating per-location classifiers for visual place recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 907–914. [Google Scholar]
- Jung, T.-W.; Jeong, C.-S.; Kwon, S.-C.; Jung, K.-D. Point-graph neural network based novel visual positioning system for indoor navigation. Appl. Sci. 2021, 11, 9187. [Google Scholar] [CrossRef]
- Smeulders, A.W.M.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Zhang, L.; Xia, H.; Liu, Q.; Wei, C.; Fu, D.; Qiao, Y. Visual positioning in indoor environments using RGB-D images and improved vector of local aggregated descriptors. Int. J. Geo-Inf. 2021, 10, 195. [Google Scholar] [CrossRef]
- Araujo, A.; Girod, B. Large-scale video retrieval using image queries. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1406–1420. [Google Scholar] [CrossRef]
- Tolias, G.; Avrithis, Y.; Jégou, H. Erratum to: Image search with selective match kernels: Aggregation across single and multiple images. Int. J. Comput. Vis. 2016, 116, 262. [Google Scholar] [CrossRef]
- Tolias, G.; Jégou, H. Visual query expansion with or without geometry: Refining local descriptors by feature aggregation. Pattern Recognit. 2014, 47, 3466–3476. [Google Scholar] [CrossRef]
- Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. arXiv 2015, arXiv:1511.05879. Available online: https://arxiv.org/abs/1511.05879 (accessed on 1 February 2021).
- Gong, Y.; Wang, L.; Guo, R. Multi-scale orderless pooling of deep convolutional activation features. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 392–407. [Google Scholar]
- Yandex, A.B.; Lempitsky, V. Aggregating local deep features for image retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1269–1277. [Google Scholar]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar]
- Meng, Y.; Lin, K.-J.; Tsai, B.-L.; Chuang, C.-C.; Cao, Y.; Zhang, B. Visual-based localization using pictorial planar objects in indoor environment. Appl. Sci. 2020, 10, 8583. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. Available online: https://arxiv.org/abs/1905.05055 (accessed on 1 February 2021).
- Viola, P.A.; Jones, M.J. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; p. 1. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Mcallester, D.A.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Forsyth, D. Object detection with discriminatively trained part-based models. Computer 2014, 47, 6–7. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Kuang, J.; Niu, X.; Zhang, P.; Chen, X. Indoor positioning based on pedestrian dead reckoning and magnetic field matching for smartphones. Sensors 2018, 18, 4142. [Google Scholar] [CrossRef]
- Kuang, J.; Li, T.; Niu, X. Magnetometer bias insensitive magnetic field matching based on pedestrian dead reckoning for smartphone indoor positioning. IEEE Sens. J. 2021, 22, 4790–4799. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP | Running Time |
|---|---|---|
| Faster-RCNN | 78.33% | 196.2 ms |
| SSD | 75.59% | 64.9 ms |
| YOLOv3 | 81.63% | 29.3 ms |
| YOLOv3 + RIAM | 83.49% | 38.3 ms |
| Num | YOLOv3|YOLOv3 + RIAM Errors (m) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMS | Mean | Max | Min | Range | ||||||
| Test-Point 1 | 0.32 | 0.33 | 0.32 | 0.33 | 0.34 | 0.35 | 0.31 | 0.31 | 0.04 | 0.04 |
| Test-Point 2 | 0.29 | 0.30 | 0.29 | 0.30 | 0.36 | 0.38 | 0.25 | 0.26 | 0.11 | 0.12 |
| Test-Point 3 | 0.30 | 0.28 | 0.30 | 0.28 | 0.31 | 0.30 | 0.29 | 0.27 | 0.03 | 0.03 |
| Test-Point 4 | 0.53 | 0.53 | 0.53 | 0.53 | 0.55 | 0.55 | 0.52 | 0.52 | 0.02 | 0.03 |
| Test-Point 5 | 0.72 | 0.73 | 0.72 | 0.73 | 0.74 | 0.76 | 0.70 | 0.71 | 0.04 | 0.04 |
| Test-Point 6 | 0.72 | 1.03 | 0.72 | 1.03 | 0.74 | 1.04 | 0.72 | 1.02 | 0.02 | 0.02 |
| Test-Point 7 | 0.49 | 0.74 | 0.49 | 0.74 | 0.52 | 0.76 | 0.46 | 0.71 | 0.06 | 0.06 |
| Test-Point 8 | 0.51 | 0.62 | 0.51 | 0.62 | 0.53 | 0.64 | 0.49 | 0.59 | 0.05 | 0.05 |
| Test-Point 9 | 0.39 | 0.45 | 0.39 | 0.45 | 0.40 | 0.46 | 0.38 | 0.44 | 0.02 | 0.02 |
| Test-Point 10 | 0.26 | 0.28 | 0.26 | 0.28 | 0.29 | 0.30 | 0.24 | 0.26 | 0.05 | 0.05 |
| Test-Point 11 | 0.08 | 0.08 | 0.08 | 0.08 | 0.11 | 0.11 | 0.04 | 0.05 | 0.07 | 0.07 |
| Test-Point 12 | 0.12 | 0.12 | 0.11 | 0.12 | 0.16 | 0.17 | 0.09 | 0.10 | 0.07 | 0.07 |
| Test-Point 13 | 0.06 | 0.07 | 0.06 | 0.07 | 0.10 | 0.11 | 0.03 | 0.04 | 0.07 | 0.07 |
| Test-Point 14 | 0.11 | 0.11 | 0.10 | 0.10 | 0.20 | 0.19 | 0.04 | 0.03 | 0.17 | 0.16 |
| Test-Point 15 | 0.20 | 0.21 | 0.20 | 0.21 | 0.21 | 0.23 | 0.18 | 0.20 | 0.03 | 0.03 |
| Test-Point 16 | 0.25 | 0.37 | 0.25 | 0.37 | 0.27 | 0.40 | 0.22 | 0.35 | 0.05 | 0.05 |
| Test-Point 17 | 0.30 | 0.32 | 0.30 | 0.32 | 0.38 | 0.40 | 0.24 | 0.25 | 0.15 | 0.15 |
| Test-Point 18 | 0.35 | 0.46 | 0.35 | 0.46 | 0.40 | 0.51 | 0.29 | 0.40 | 0.11 | 0.11 |
| Test-Point 19 | 0.13 | 0.49 | 0.13 | 0.49 | 0.20 | 0.55 | 0.09 | 0.44 | 0.11 | 0.11 |
| Test-Point 20 | 0.35 | 0.45 | 0.35 | 0.45 | 0.42 | 0.52 | 0.26 | 0.36 | 0.16 | 0.17 |
| Test-Point 21 | 0.52 | 0.53 | 0.52 | 0.53 | 0.53 | 0.54 | 0.48 | 0.49 | 0.04 | 0.05 |
| Test-Point 22 | 0.44 | 0.45 | 0.44 | 0.45 | 0.46 | 0.48 | 0.43 | 0.44 | 0.04 | 0.04 |
| Test-Point 23 | 0.40 | 0.40 | 0.40 | 0.40 | 0.46 | 0.46 | 0.38 | 0.38 | 0.08 | 0.08 |
| Test-Point 24 | 0.24 | 0.26 | 0.24 | 0.26 | 0.25 | 0.27 | 0.23 | 0.25 | 0.02 | 0.02 |
| Test-Point 25 | 0.14 | 0.15 | 0.14 | 0.15 | 0.15 | 0.16 | 0.11 | 0.13 | 0.03 | 0.04 |
| Test-Point 26 | 0.05 | 0.05 | 0.04 | 0.05 | 0.08 | 0.09 | 0.01 | 0.01 | 0.08 | 0.08 |
| Test-Point 27 | 0.19 | 0.20 | 0.19 | 0.20 | 0.25 | 0.26 | 0.16 | 0.17 | 0.09 | 0.09 |
| Test-Point 28 | 0.43 | 0.45 | 0.43 | 0.44 | 0.53 | 0.55 | 0.30 | 0.32 | 0.23 | 0.23 |
| Test-Point 29 | 0.28 | 0.30 | 0.28 | 0.30 | 0.35 | 0.37 | 0.22 | 0.23 | 0.13 | 0.13 |
| Test-Point 30 | 0.90 | 1.00 | 0.90 | 1.00 | 0.92 | 1.02 | 0.87 | 0.96 | 0.05 | 0.05 |
| Test-Point 31 | 1.15 | 1.08 | 1.15 | 1.08 | 1.22 | 1.14 | 1.13 | 1.05 | 0.09 | 0.09 |
| Test-Point 32 | 0.52 | 0.54 | 0.52 | 0.54 | 0.54 | 0.56 | 0.51 | 0.52 | 0.04 | 0.04 |
| Test-Point 33 | 0.71 | 0.73 | 0.71 | 0.73 | 0.73 | 0.75 | 0.69 | 0.71 | 0.04 | 0.04 |
| Test-Point 34 | 0.30 | 0.31 | 0.29 | 0.31 | 0.34 | 0.36 | 0.26 | 0.28 | 0.08 | 0.08 |
| Test-Point 35 | 0.32 | 0.34 | 0.32 | 0.34 | 0.36 | 0.38 | 0.29 | 0.30 | 0.07 | 0.07 |
| Test-Point 36 | 1.02 | 1.34 | 1.02 | 1.34 | 1.12 | 1.45 | 0.97 | 1.29 | 0.15 | 0.15 |
| Test-Point 37 | 0.18 | 0.24 | 0.18 | 0.24 | 0.20 | 0.26 | 0.17 | 0.22 | 0.03 | 0.04 |
| Test-Point 38 | 0.80 | 0.94 | 0.79 | 0.94 | 0.99 | 1.14 | 0.72 | 0.86 | 0.27 | 0.28 |
| Test-Point 39 | 0.34 | 0.35 | 0.34 | 0.35 | 0.39 | 0.41 | 0.23 | 0.25 | 0.16 | 0.16 |
| Test-Point 40 | 0.57 | 0.59 | 0.57 | 0.59 | 0.63 | 0.65 | 0.52 | 0.53 | 0.11 | 0.11 |
| Test-Point 41 | 0.61 | 0.72 | 0.61 | 0.72 | 0.66 | 0.77 | 0.56 | 0.67 | 0.10 | 0.10 |
| Passive Visual | Positioning Error (m) | |||||
|---|---|---|---|---|---|---|
| RMS | 95% | 90% | Mean | Max | Min | |
| YOLOv3+PT | 0.549 | 1.056 | 0.952 | 0.460 | 1.446 | 0.013 |
| YOLOv3 + RIAM + PT | 0.480 | 0.964 | 0.732 | 0.404 | 1.217 | 0.006 |
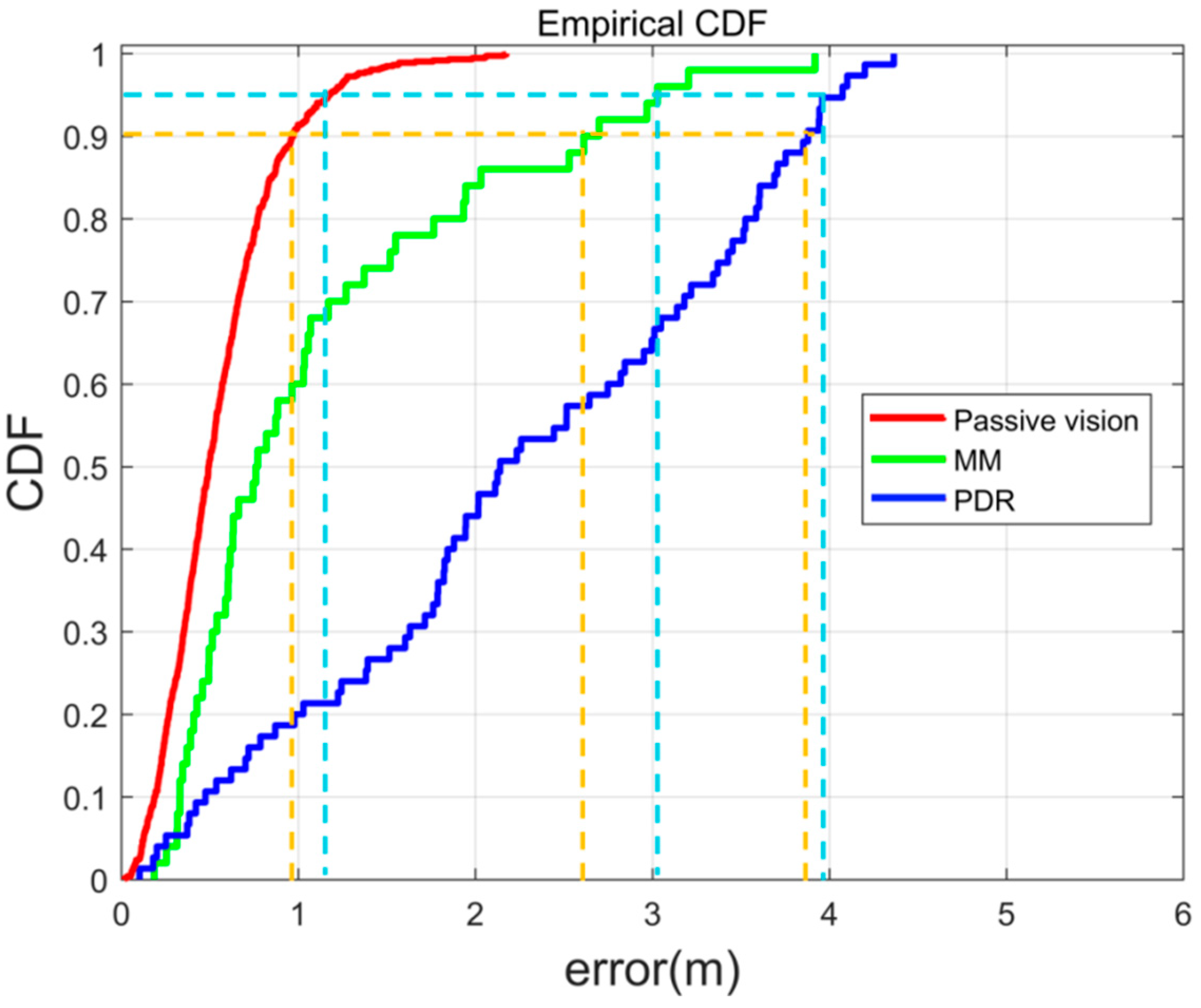
| Passive Method | Positioning Error (m) | |||
|---|---|---|---|---|
| RMS | 95% | 90% | Max | |
| Passive visual | 0.643 | 1.168 | 0.964 | 2.175 |
| PDR | 2.581 | 3.960 | 3.852 | 4.364 |
| MM | 1.435 | 3.029 | 2.610 | 3.919 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, D.; Chen, R.; Yu, Y.; Zheng, X.; Xu, Y.; Liu, Z. Indoor Passive Visual Positioning by CNN-Based Pedestrian Detection. Micromachines 2022, 13, 1413. https://doi.org/10.3390/mi13091413
Wu D, Chen R, Yu Y, Zheng X, Xu Y, Liu Z. Indoor Passive Visual Positioning by CNN-Based Pedestrian Detection. Micromachines. 2022; 13(9):1413. https://doi.org/10.3390/mi13091413
Chicago/Turabian StyleWu, Dewen, Ruizhi Chen, Yue Yu, Xingyu Zheng, Yan Xu, and Zuoya Liu. 2022. "Indoor Passive Visual Positioning by CNN-Based Pedestrian Detection" Micromachines 13, no. 9: 1413. https://doi.org/10.3390/mi13091413
APA StyleWu, D., Chen, R., Yu, Y., Zheng, X., Xu, Y., & Liu, Z. (2022). Indoor Passive Visual Positioning by CNN-Based Pedestrian Detection. Micromachines, 13(9), 1413. https://doi.org/10.3390/mi13091413