
QGWFQS: A Queue-Group-Based Weight Fair Queueing Scheduler on FPGA


Abstract
:1. Introduction
1.1. Motivation
1.2. Limitations of Prior Art
1.3. Proposed Approach
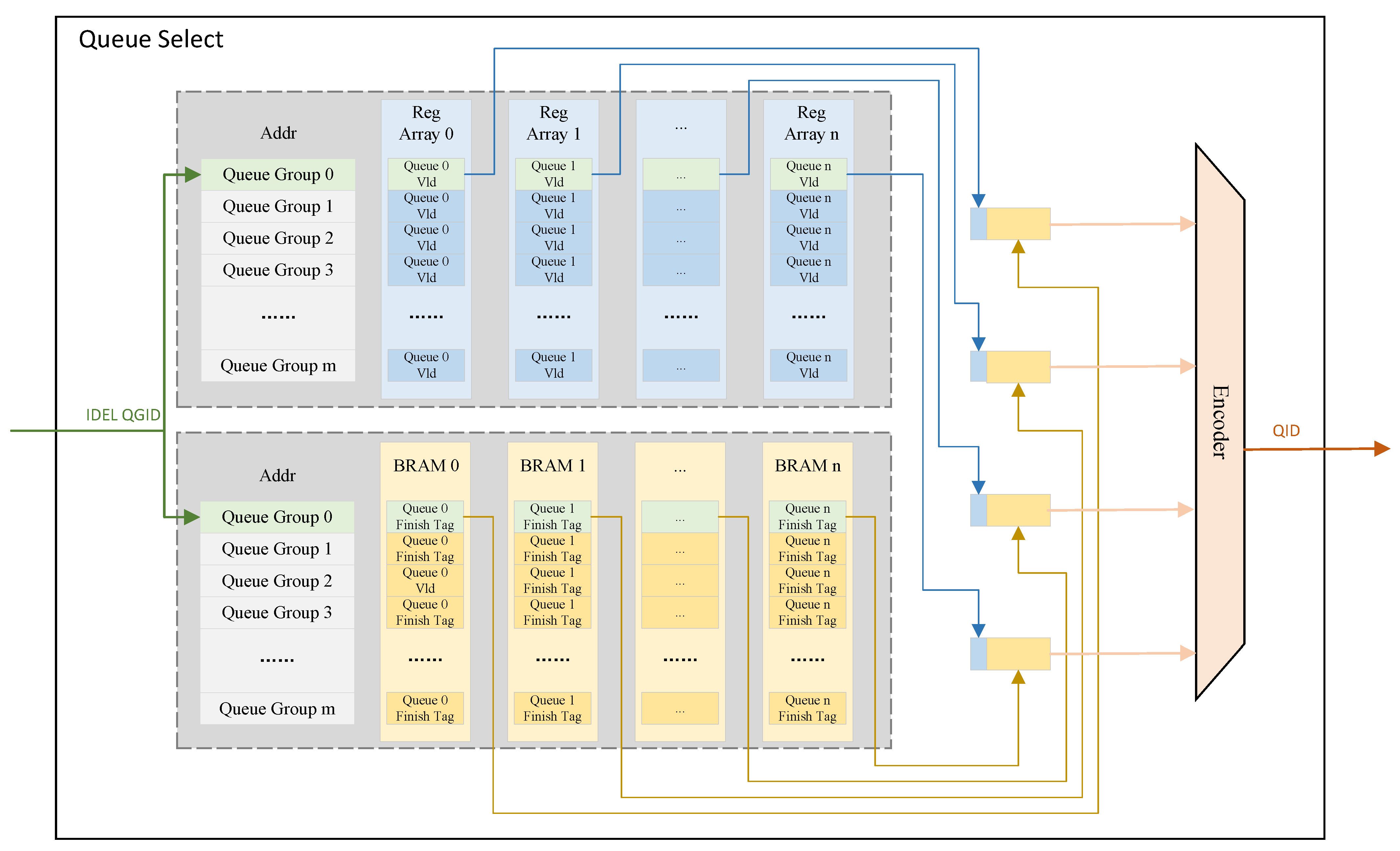
- Less Resource Consumption. Only the packet at the head of each WFQ queue is eligible for potential scheduling. When the head packet of a queue is scheduled and there are remaining packets in the same queue, the new head packet of that queue is then subjected to tag calculation and potential scheduling. With this Queue Head Packet Scheduling Model (QHPSM), when selecting a queue for scheduling from a queue group, the number of tags to be compared is reduced to no more than the maximum number of backlogged queues within the queue group. This implies that it is unnecessary to maintain tag sorting within each queue group continuously. Once a new tag is computed, it is temporarily stored in a buffer. When queue selection for scheduling is required, the tags corresponding to the head packets of all backlogged queues in the queue group are compared, and the minimum tag is determined. This comparison circuitry can be reused for each queue group, which results in the scheduler occupying only a minimal amount of resources.
- Support Variable Port Link Rate. The schedule algorithm does not care about the correspondence between virtual time and real time, and the growth rate of virtual time remains unaffected by the link rate. The scheduler solely requires the detection of port idleness and the presence of a queue in need of scheduling, which is easy to implement in FPGA.
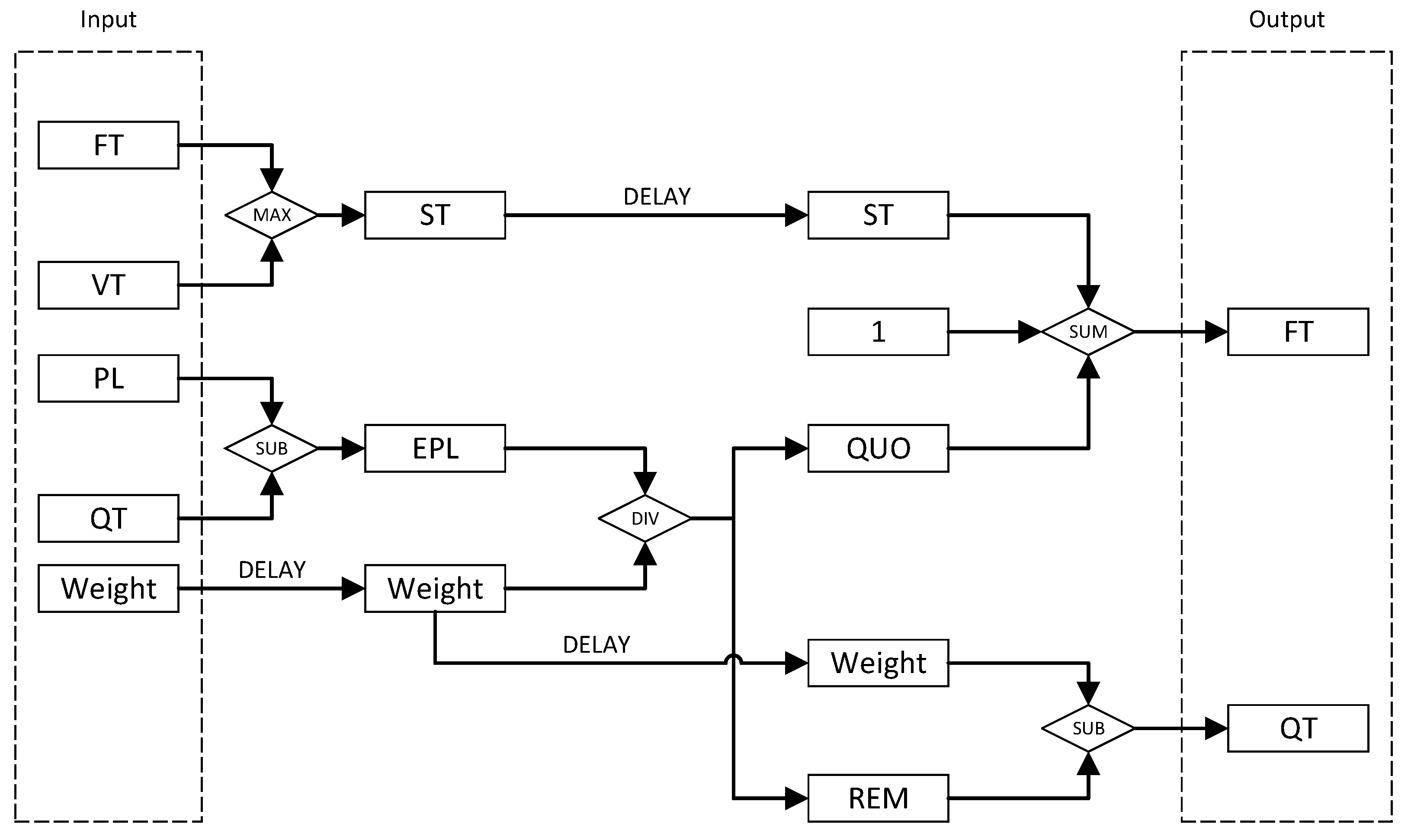
- Fairness. During each division calculation, the remainder is considered. The generated remainder from the tag calculation of the last packet within the same queue is recorded, and this previously recorded remainder is utilized to compensate and rectify the tag calculation for subsequent packets in the queue. This approach enhances the fairness of the implemented scheduling algorithm.
2. Related Work
2.1. Tag Sorting Circuit
2.2. Tag Calculation Method
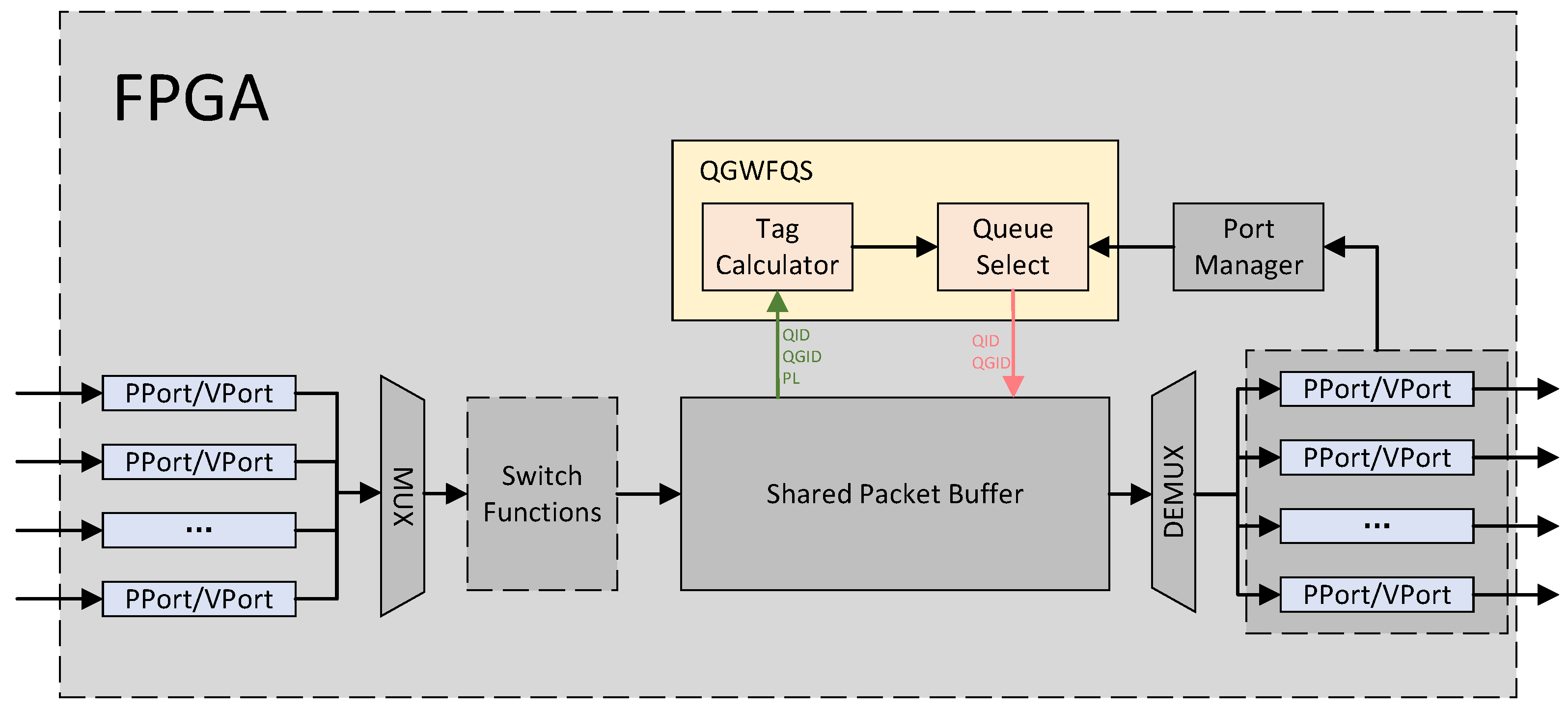
3. Proposed Scheduler
3.1. Shared Packet Buffer
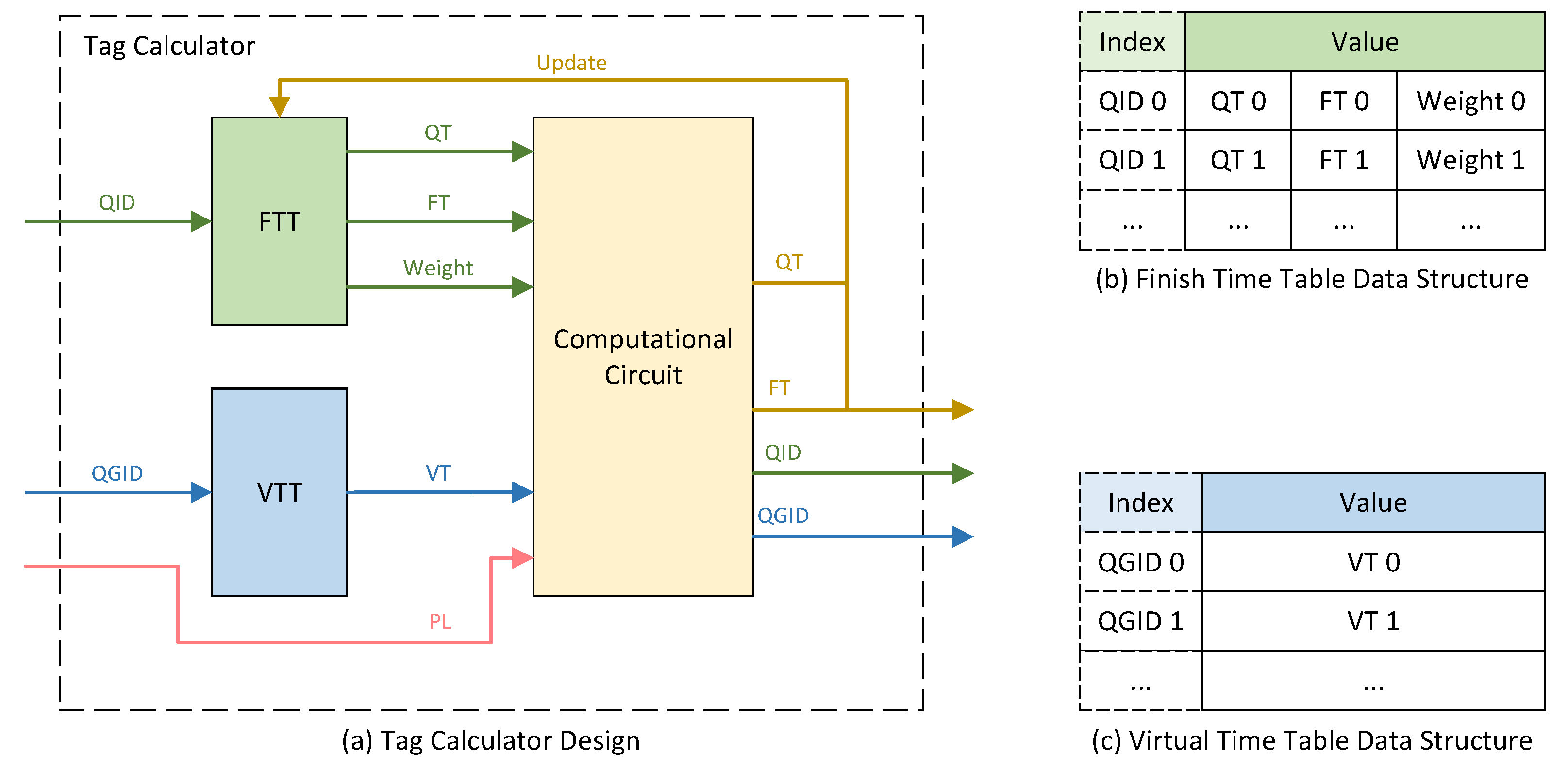
3.2. Tag Calculator
3.2.1. Tag Calculation Algorithm
3.2.2. Tag Calculator Design
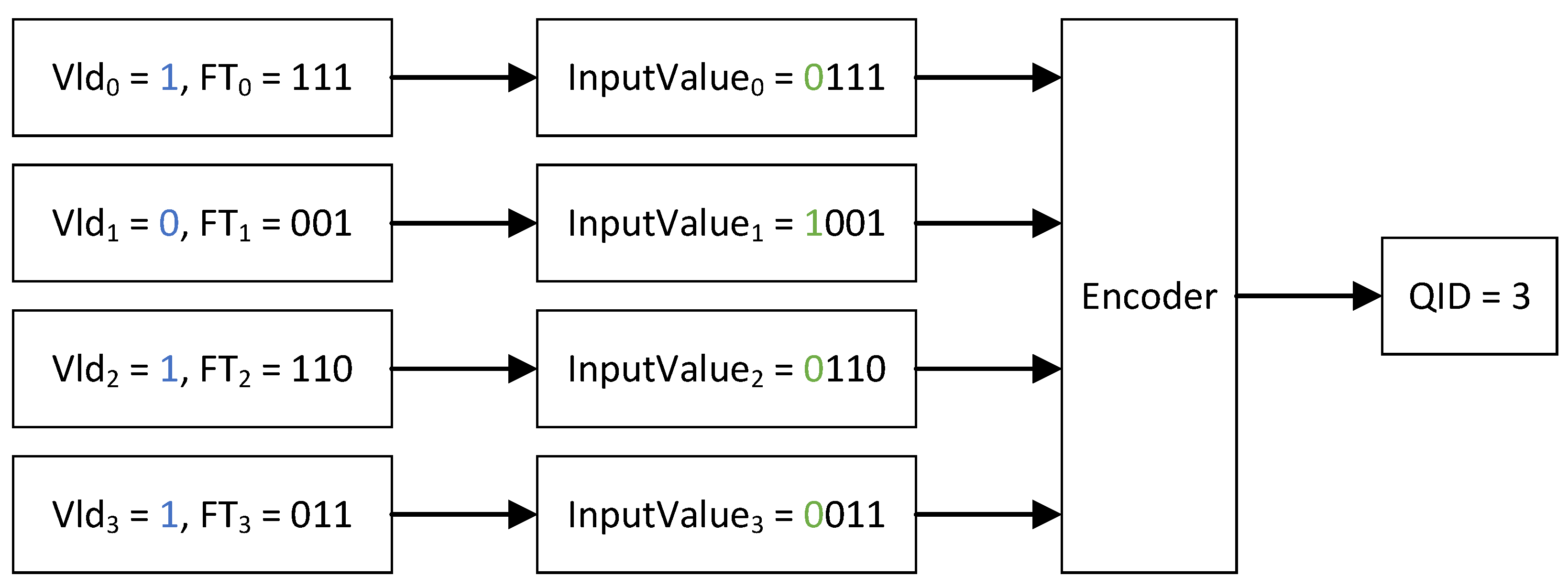
3.3. Queue Select
4. Implementation and Result
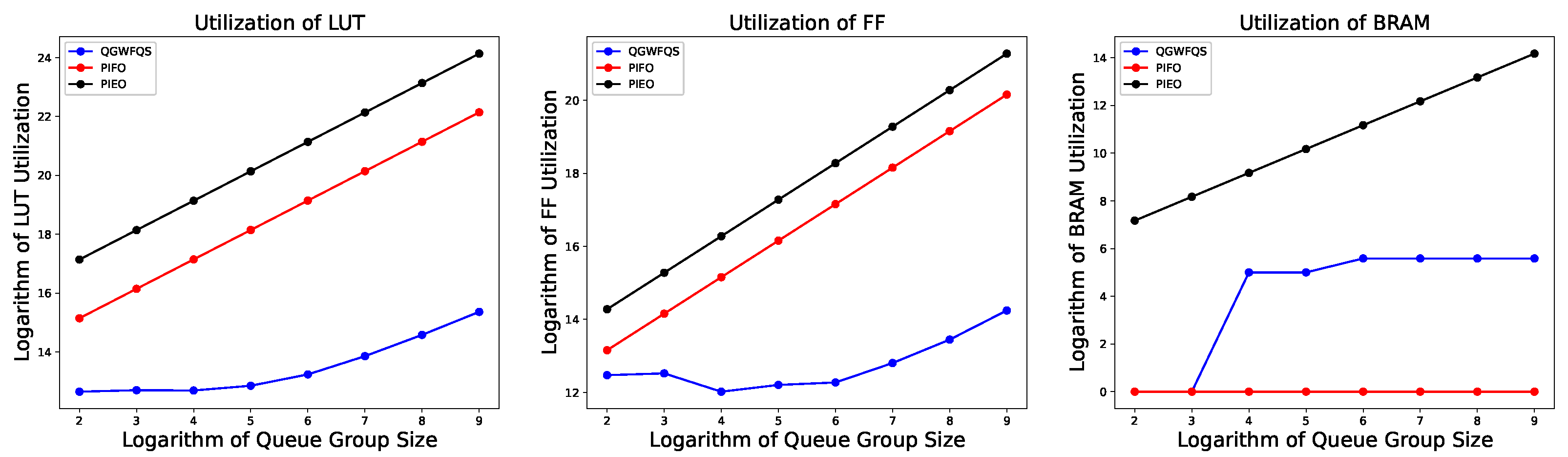
4.1. Hardware Resource Evaluation
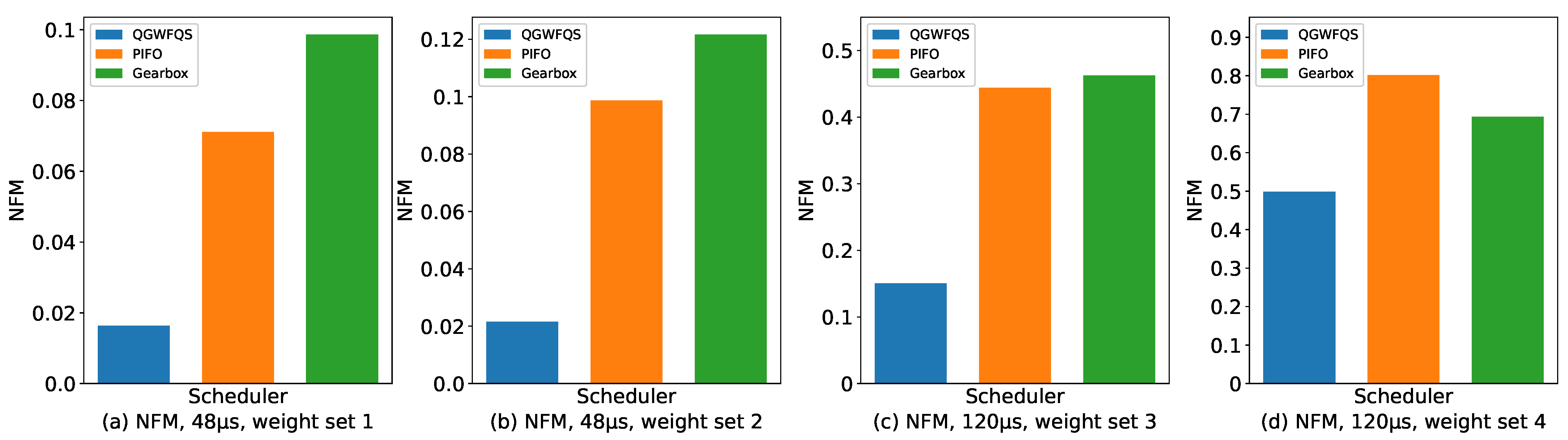
4.2. Fairness of Bandwidth Allocation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- MacDavid, R.; Chen, X.; Rexford, J. Scalable Real-Time Bandwidth Fairness in Switches. In Proceedings of the IEEE INFOCOM 2023—IEEE Conference on Computer Communications, New York, NY, USA, 17–20 May 2023; pp. 1–10. [Google Scholar]
- Ruan, L.; Wong, E. Addressing Concept Drift of Dynamic Traffic Environments through Rapid and Self-Adaptive Bandwidth Allocation. In Proceedings of the 2023 32nd International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 24–27 July 2023; pp. 1–7. [Google Scholar]
- Shreedhar, M.; Varghese, G. Efficient fair queuing using deficit round-robin. IEEE/ACM Trans. Netw. 1996, 4, 375–385. [Google Scholar] [CrossRef]
- Mohammed, A.A.; Madani, G.A. Comparison of Schecduling Schemes in IPV4 and IPV6 to Achieve High QoS. In Proceedings of the 2022 IEEE 2nd International Maghreb Meeting of the Conference on Sciences and Techniques of Automatic Control and Computer Engineering (MI-STA), Sabratha, Libya, 23–25 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 238–241. [Google Scholar]
- Bianco, A.; QoS Scheduling. TNG Group-Politecnico di Torino QoS Issues in Telecommunication Networks—1. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=196a91b9a1c9f332b33cf393142536b1afcec9e1 (accessed on 6 October 2023).
- McKillen, C.; Sezer, S. A weighted fair queuing finishing tag computation architecture and implementation. In Proceedings of the IEEE International SOC Conference, Santa Clara, CA, USA, 12–15 September 2004; IEEE: Piscataway, NJ, USA, 2004; pp. 270–273. [Google Scholar]
- Sharma, N.K.; Liu, M.; Atreya, K.; Krishnamurthy, A. Approximating fair queueing on reconfigurable switches. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), Renton, WA, USA, 9–11 April 2018; pp. 1–16. [Google Scholar]
- Sivaraman, A.; Subramanian, S.; Alizadeh, M.; Chole, S.; Chuang, S.T.; Agrawal, A.; Balakrishnan, H.; Edsall, T.; Katti, S.; McKeown, N. Programmable packet scheduling at line rate. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianopolis, Brazil, 22–26 August 2016; pp. 44–57. [Google Scholar]
- Shrivastav, V. Fast, scalable, and programmable packet scheduler in hardware. In Proceedings of the ACM Special Interest Group on Data Communication, Beijing, China, 19–23 August 2019; pp. 367–379. [Google Scholar]
- Gao, P.; Dalleggio, A.; Xu, Y.; Chao, H.J. Gearbox: A hierarchical packet scheduler for approximate weighted fair queuing. In Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), Renton, WA, USA, 4–6 April 2022; pp. 551–565. [Google Scholar]
- McLaughlin, K.; Sezer, S.; Blume, H.; Yang, X.; Kupzog, F.; Noll, T. A scalable packet sorting circuit for high-speed WFQ packet scheduling. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2008, 16, 781–791. [Google Scholar] [CrossRef]
- McLaughlin, K.; Burns, D.; Toal, C.; McKillen, C.; Sezer, S. Fully hardware based WFQ architecture for high-speed QoS packet scheduling. Integration 2012, 45, 99–109. [Google Scholar] [CrossRef]
- Parekh, A.K.; Gallager, R.G. A generalized processor sharing approach to flow control in integrated services networks: The single-node case. IEEE/ACM Trans. Netw. 1993, 1, 344–357. [Google Scholar] [CrossRef] [PubMed]
- Demers, A.; Keshav, S.; Shenker, S. Analysis and simulation of a fair queueing algorithm. ACM SIGCOMM Comput. Commun. Rev. 1989, 19, 1–12. [Google Scholar] [CrossRef]
- Golestani, S.J. A self-clocked fair queueing scheme for broadband applications. In Proceedings of the INFOCOM’94 Conference on Computer Communications, Toronto, ON, Canada, 12–16 June 1994; IEEE: Piscataway, NJ, USA, 1994; pp. 636–646. [Google Scholar]
- McAllister, B.; Sezer, S.; Toal, C. Custom tag computation circuit for a 10Gbps SCFQ scheduler. In Proceedings of the Field Programmable Logic and Application: 13th International Conference, FPL 2003, Lisbon, Portugal, 1–3 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 1149–1152. [Google Scholar]
- Division in Verilog. 2020. Available online: https://projectf.io/posts/division-in-verilog (accessed on 1 March 2023).
- Bosshart, P.; Gibb, G.; Kim, H.S.; Varghese, G.; McKeown, N.; Izzard, M.; Mujica, F.; Horowitz, M. Forwarding metamorphosis: Fast programmable match-action processing in hardware for SDN. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 99–110. [Google Scholar] [CrossRef]
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming protocol-independent packet processors. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Stephens, B.; Singhvi, A.; Akella, A.; Swift, M. Titan: Fair Packet Scheduling for Commodity Multiqueue {NICs}. In Proceedings of the 2017 USENIX Annual Technical Conference (USENIX ATC 17), Santa Clara, CA, USA, 11–13 July 2017; pp. 431–444. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Our Work | Comparative Work [6] | |
|---|---|---|
| LUTs | 1302 | 284,672 |
| Flip Flops | 883 | 338,944 |
| BRAMs | 45.5 | 768 |
| Weight Set | Weight |
|---|---|
| Weight Set 1 | 1:1:1:1 |
| Weight Set 2 | 2:2:1:1 |
| Weight Set 3 | 50:50:1:1 |
| Weight Set 4 | 100:100:1:1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Guo, Z.; Song, X.; Song, M. QGWFQS: A Queue-Group-Based Weight Fair Queueing Scheduler on FPGA. Micromachines 2023, 14, 2100. https://doi.org/10.3390/mi14112100
Guo Y, Guo Z, Song X, Song M. QGWFQS: A Queue-Group-Based Weight Fair Queueing Scheduler on FPGA. Micromachines. 2023; 14(11):2100. https://doi.org/10.3390/mi14112100
Chicago/Turabian StyleGuo, Yunfei, Zhichuan Guo, Xiaoyong Song, and Mangu Song. 2023. "QGWFQS: A Queue-Group-Based Weight Fair Queueing Scheduler on FPGA" Micromachines 14, no. 11: 2100. https://doi.org/10.3390/mi14112100
APA StyleGuo, Y., Guo, Z., Song, X., & Song, M. (2023). QGWFQS: A Queue-Group-Based Weight Fair Queueing Scheduler on FPGA. Micromachines, 14(11), 2100. https://doi.org/10.3390/mi14112100