

Biosensor-Based Multimodal Deep Human Locomotion Decoding via Internet of Healthcare Things

Abstract
:1. Introduction
- A novel approach to filtering the ambient-based data that includes infrared cameras and switches attached to the environment;
- Efficient ambient sensor descriptor extraction based on a unique and novel graph representation;
2. Related Work
2.1. Sensor-Based Locomotion Decoding
2.2. Multimodal Locomotion Decoding
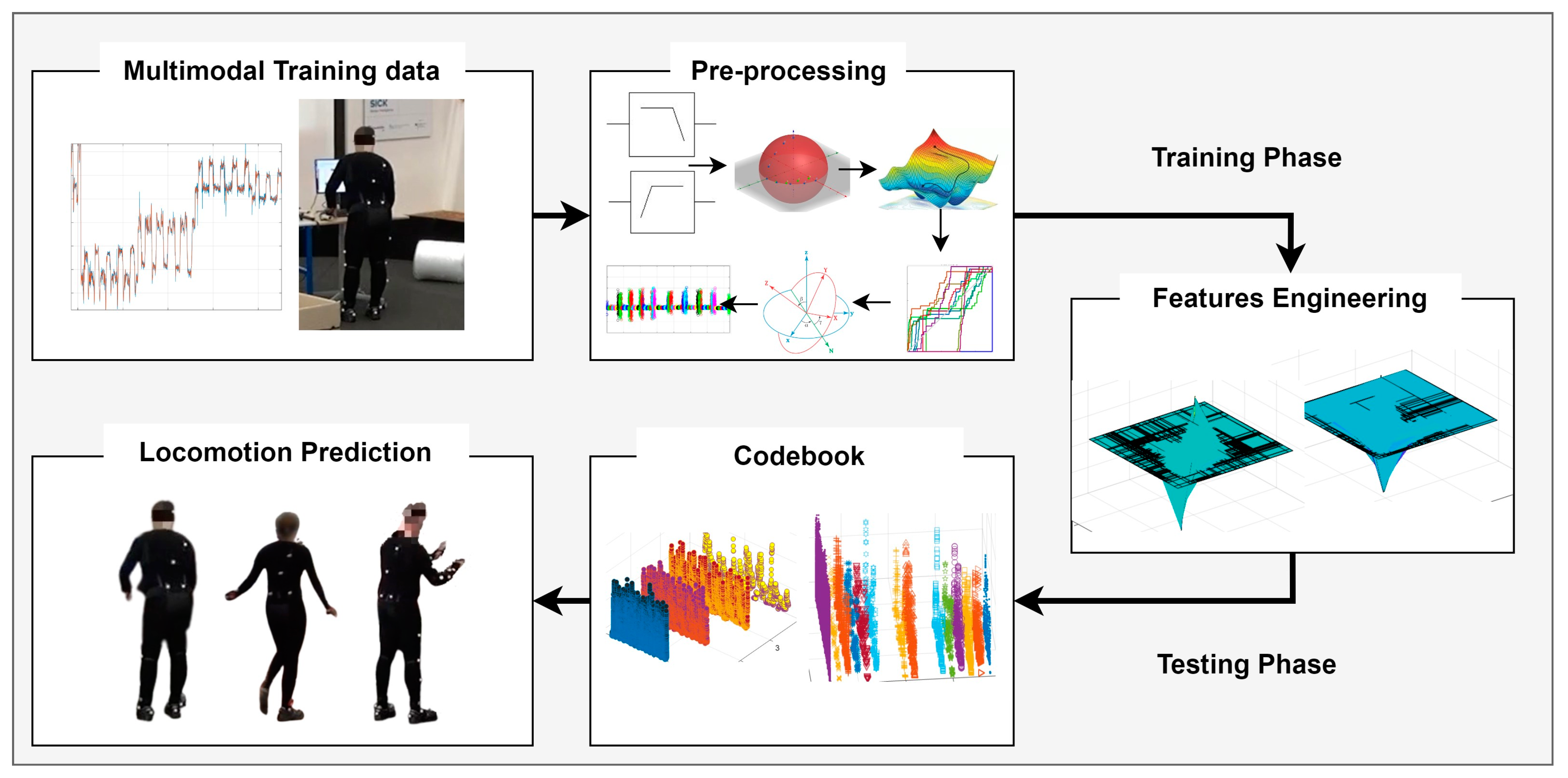
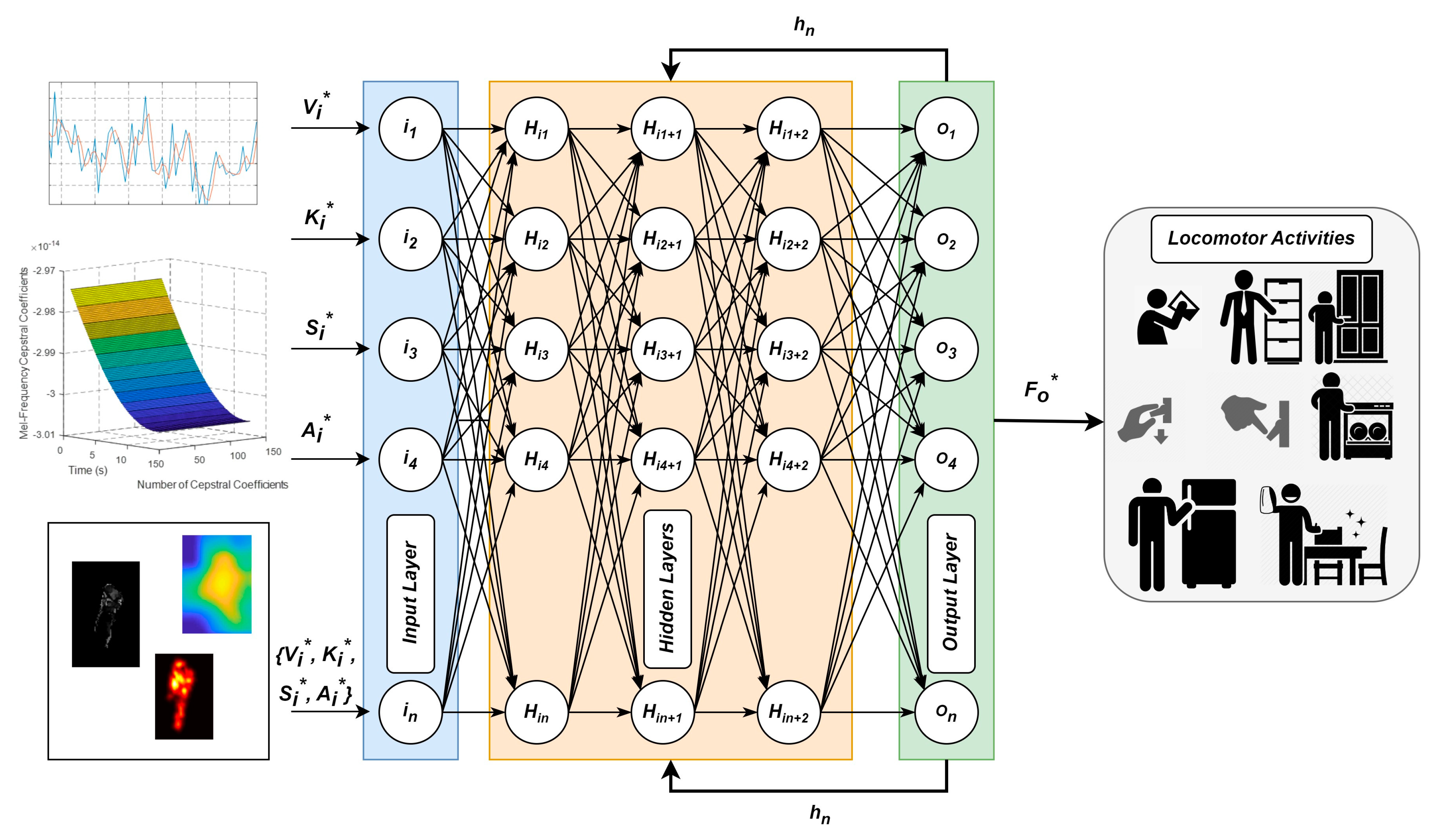
3. Materials and Methods
| Algorithm 1 HLD Algorithm |
| Input: physical IMU signals {pi}, ambient signals {pa}, visual frame sequences {pv}; Output: recognized activities {A*};
|
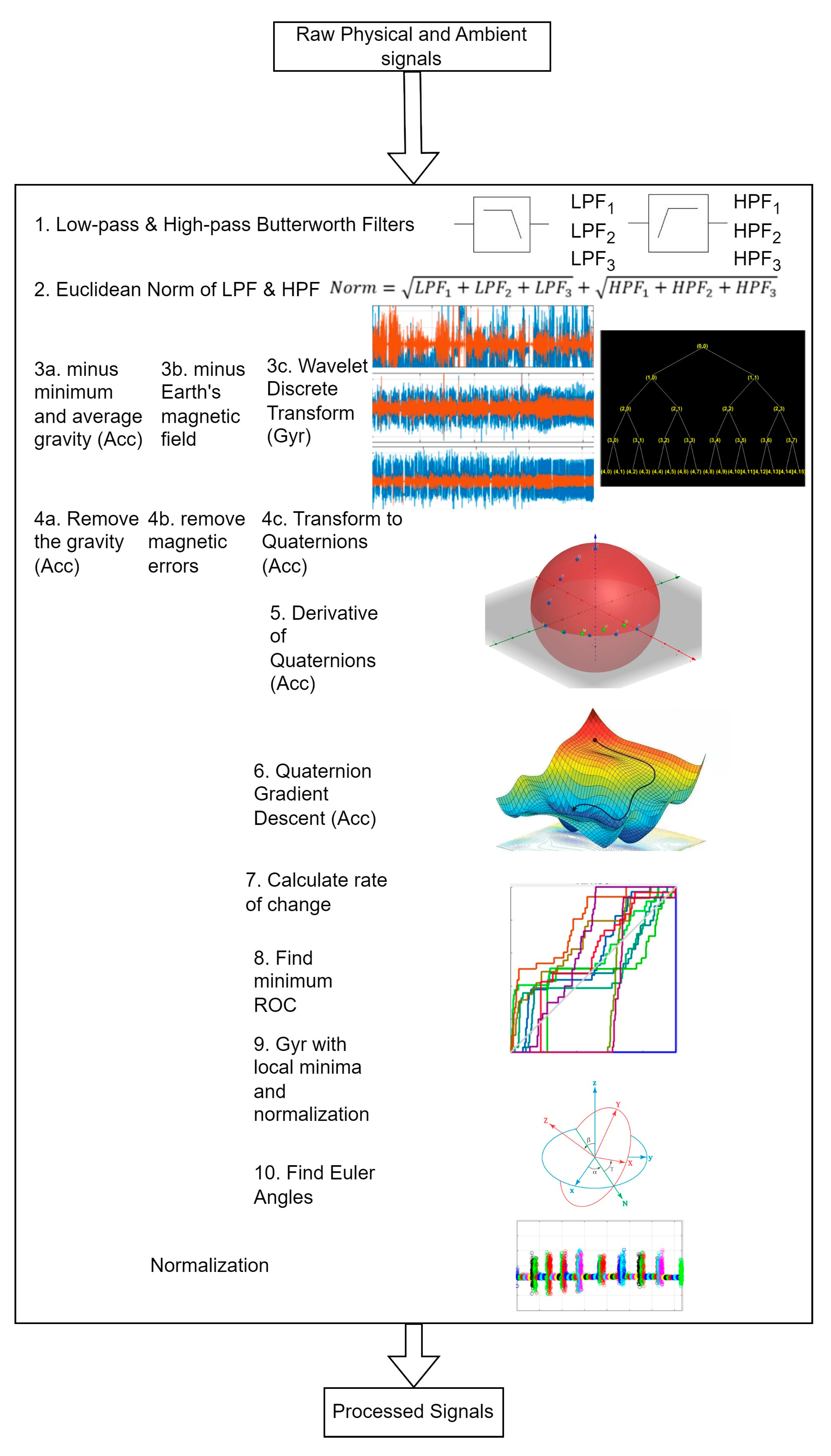
3.1. Pre-Processing Motion and Ambient Data
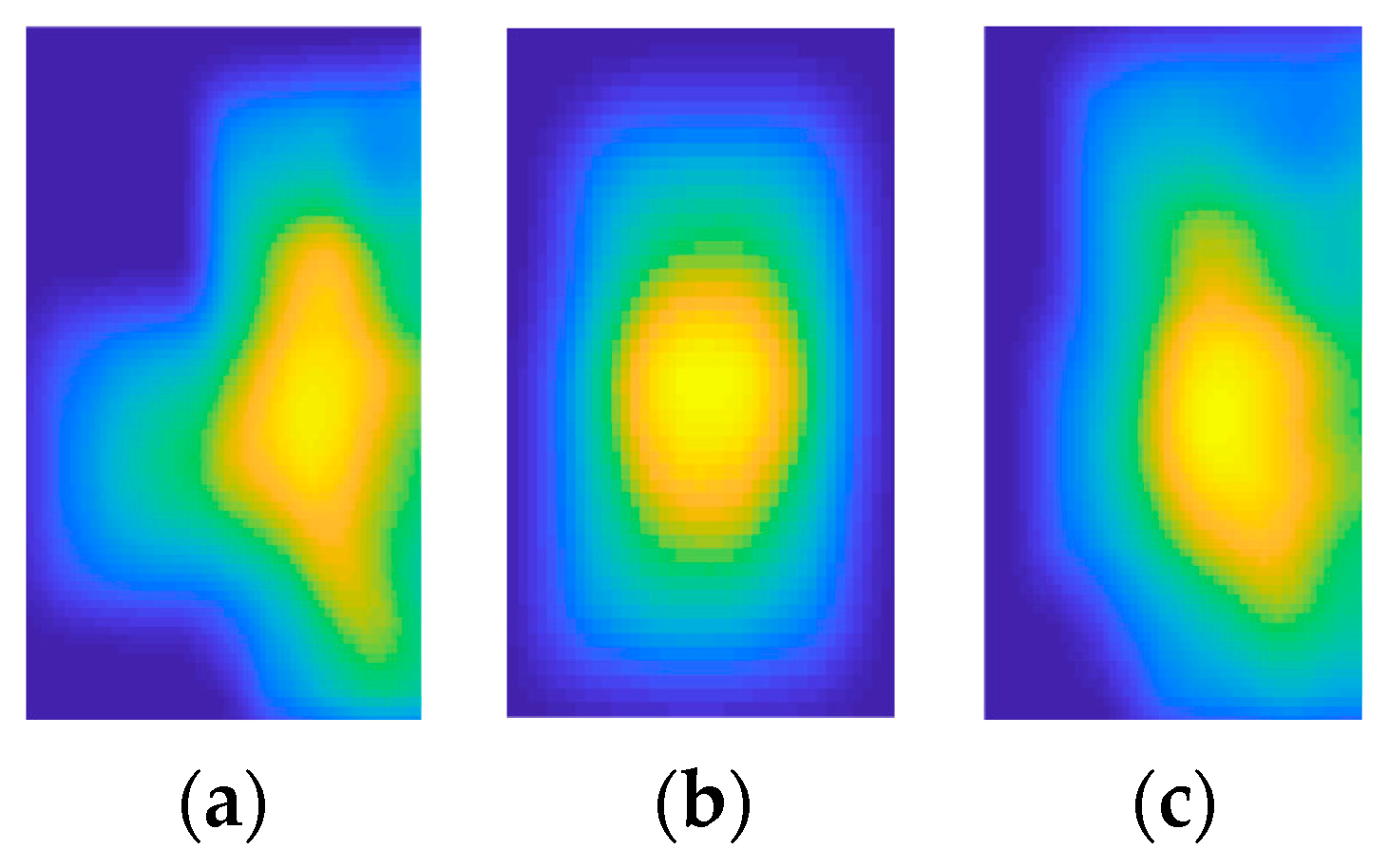
3.2. Pre-Processing Visual Data
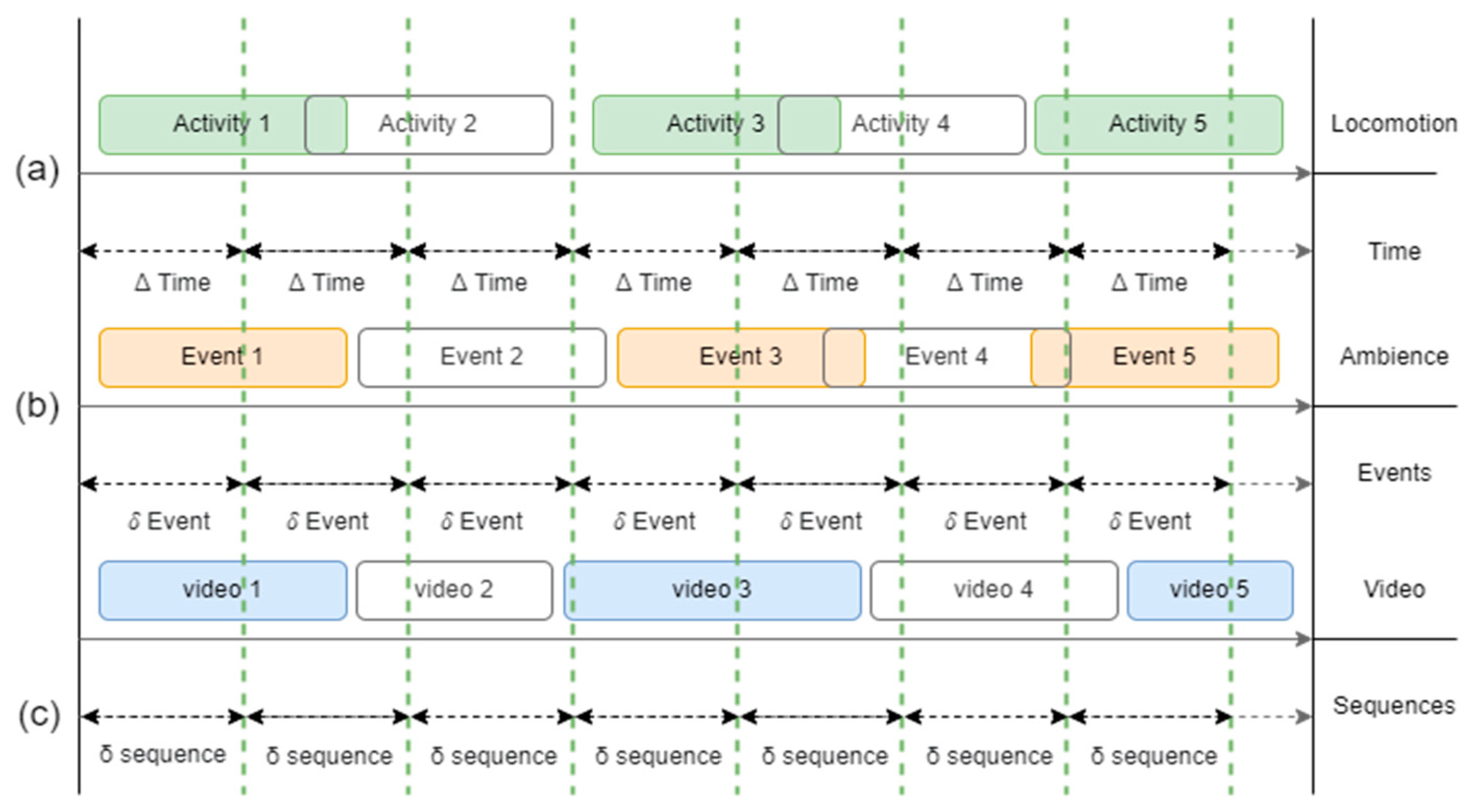
3.3. Data Segmentation
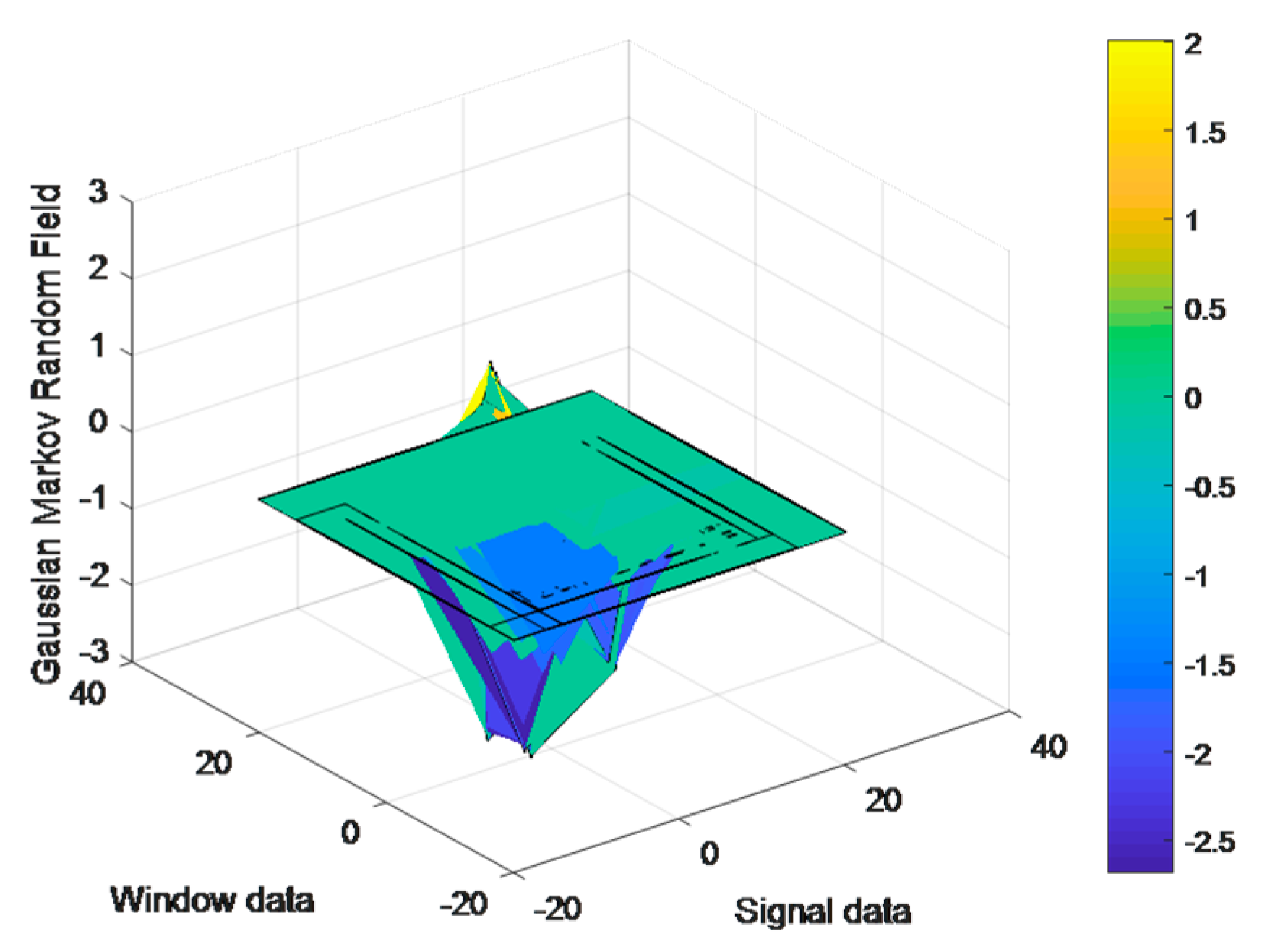
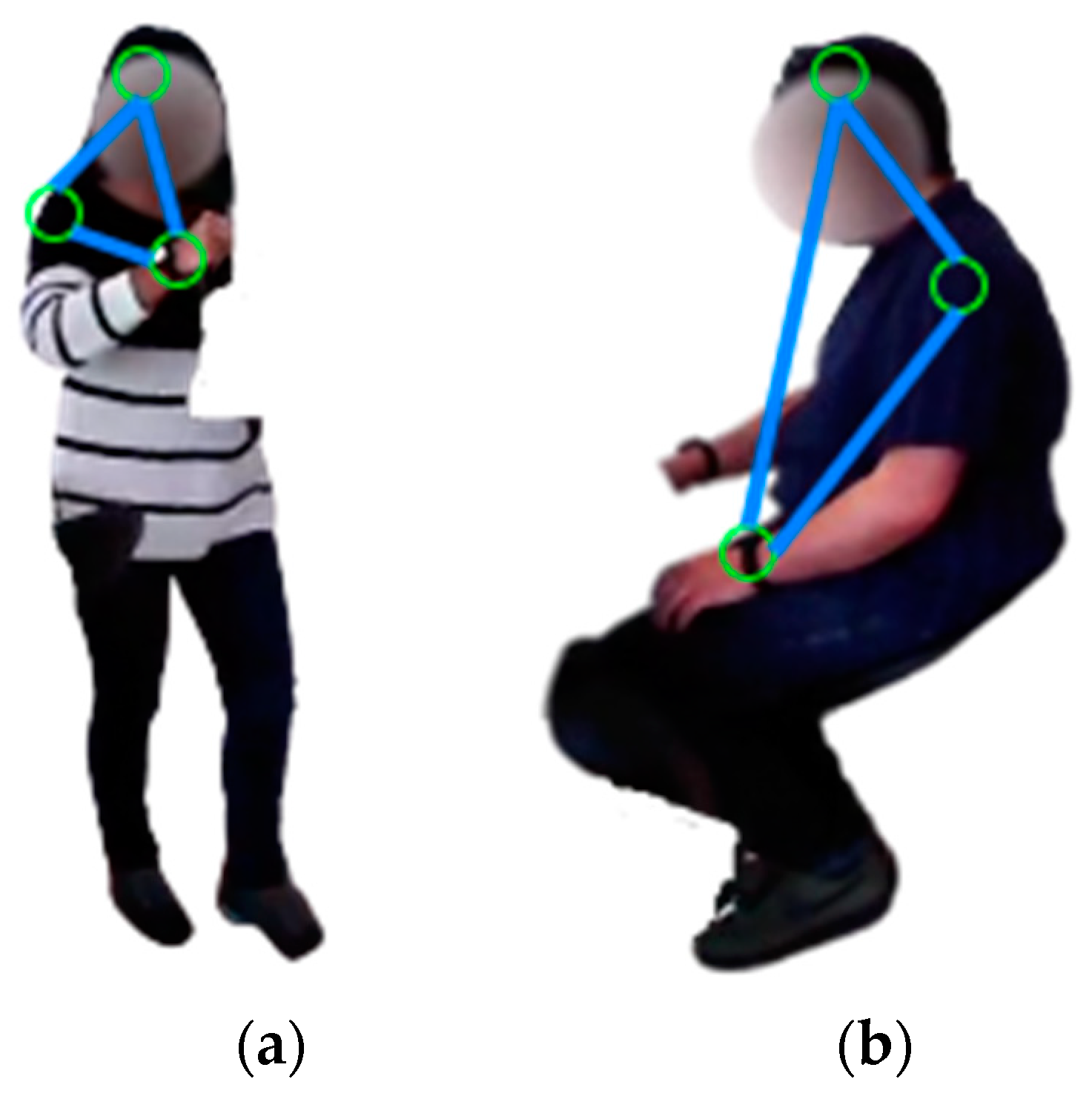
3.4. Motion Descriptor Extraction
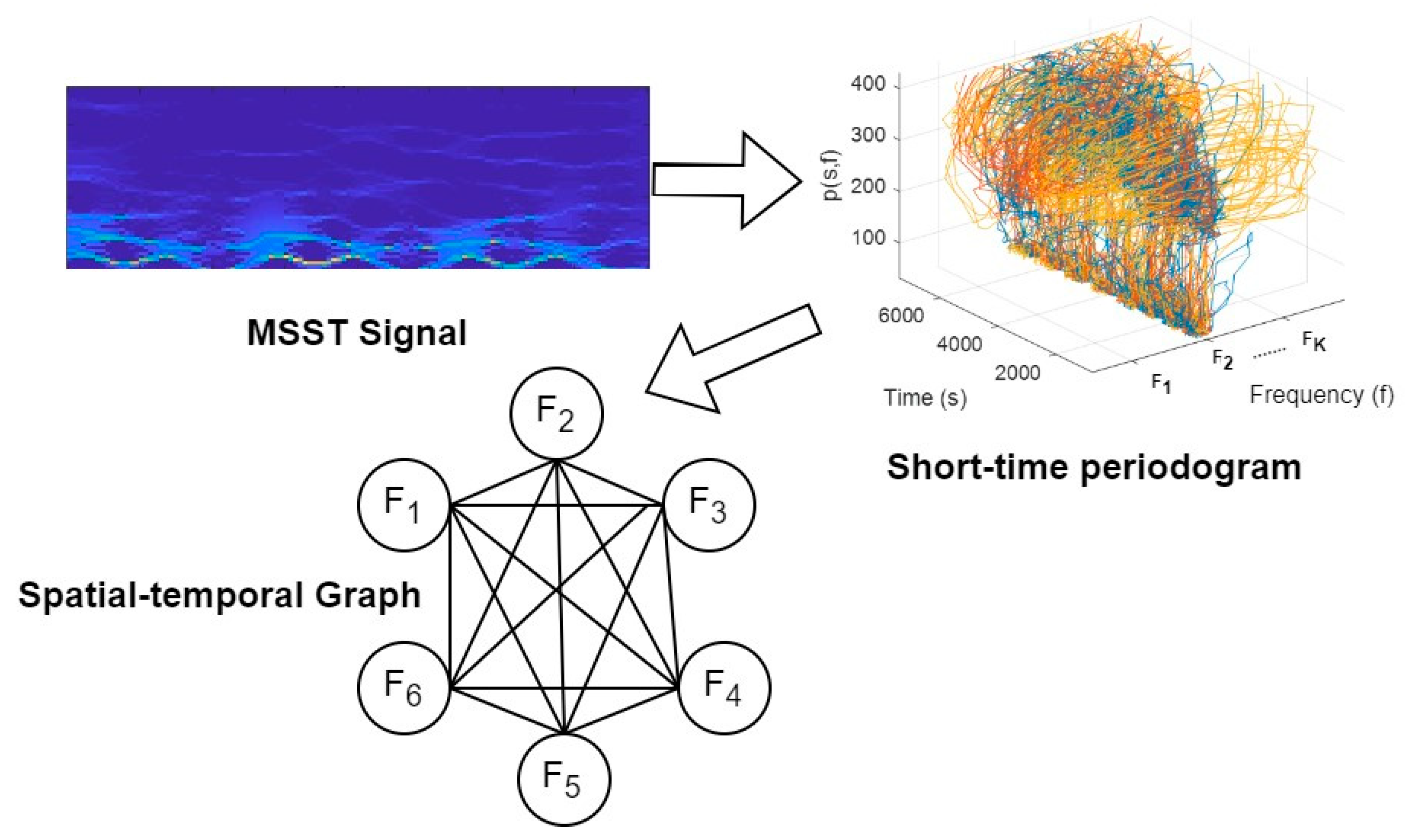
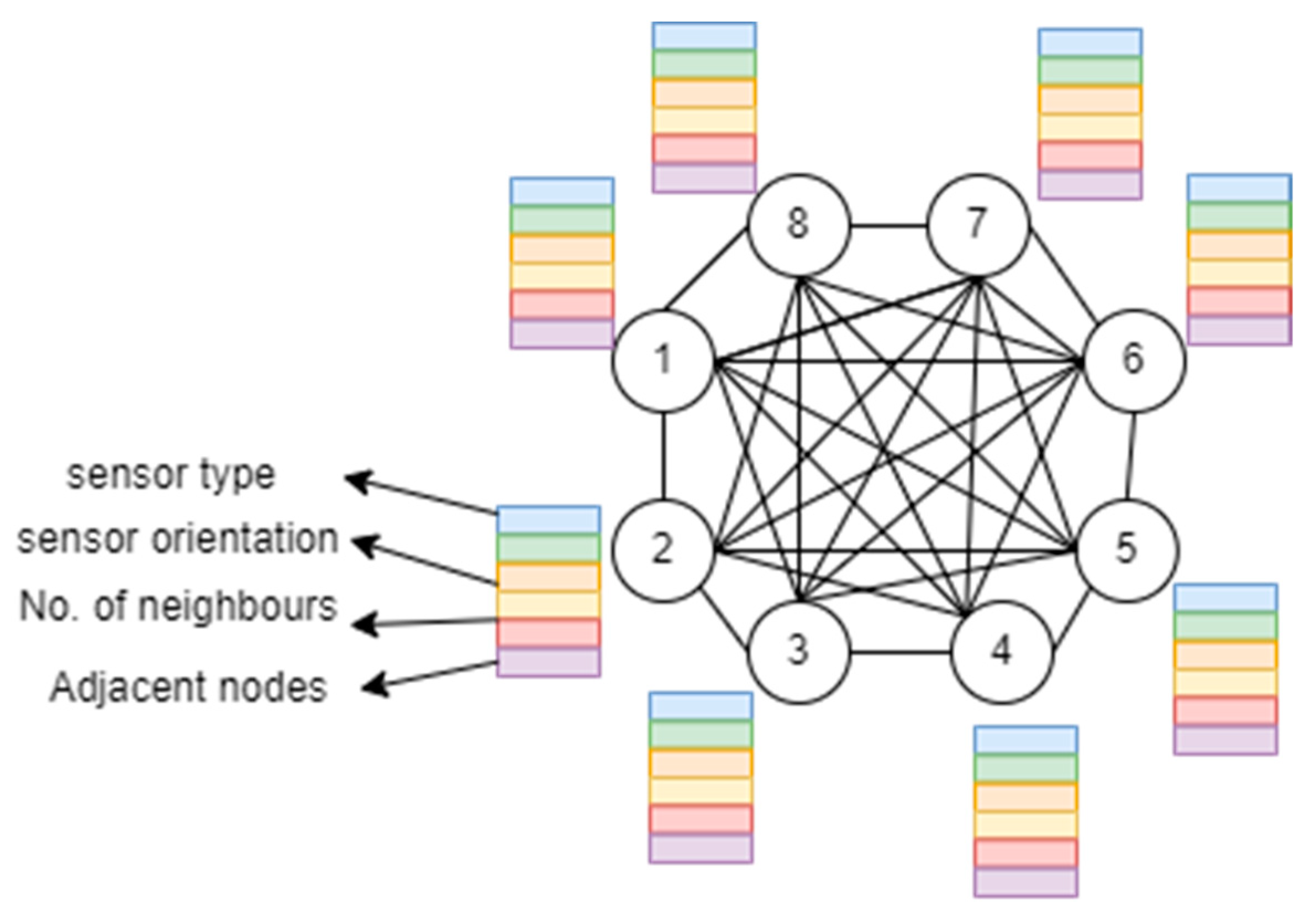
3.5. Ambient Descriptor Extraction
3.6. Vision Descriptor Extraction
3.7. Codebook Generation
3.8. Locomotion Decoding
4. Performance Evaluation
4.1. Dataset Descriptions
4.2. Experiment 1: Evaluation Protocol
4.3. Experiment 2: Comparison with Baseline HLD Systems
4.4. Experiment 3: Comparison with Other Works Utilizing Filtration and Descriptors
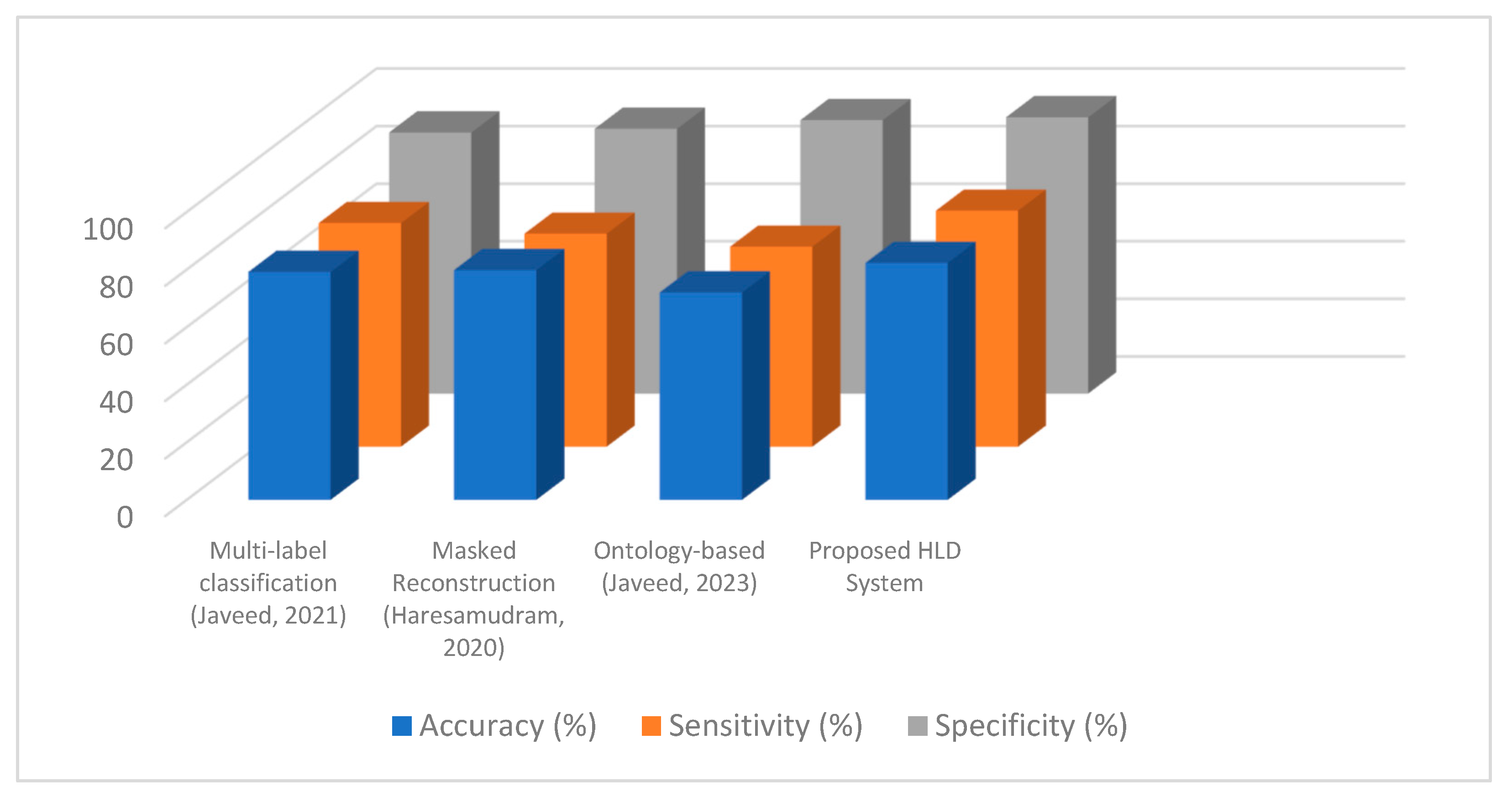
4.5. Experiment 4: Comparisons with Existing Works
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ramanujam, E.; Perumal, T.; Padmvavathi, S. Human Activity Recognition with Smartphone and Wearable Sensors Using Deep Learning Techniques: A Review. IEEE Sens. J. 2021, 21, 13029–13040. [Google Scholar] [CrossRef]
- Ouyed, O.; Allili, M.S. Group-of-features relevance in multinomial kernel logistic regression and application to human interaction recognition. Expert Syst. Appl. 2020, 148, 113247. [Google Scholar] [CrossRef]
- Abid Hasan, S.M.; Ko, K. Depth edge detection by image-based smoothing and morphological operations. J. Comput. Des. Eng. 2016, 3, 191–197. [Google Scholar] [CrossRef]
- Batool, M.; Jalal, A.; Kim, K. Telemonitoring of daily activity using Accelerometer and Gyroscope in smart home environments. J. Electr. Eng. Technol. 2020, 15, 2801–2809. [Google Scholar] [CrossRef]
- Javeed, M.; Mudawi, N.A.; Alabduallah, B.I.; Jalal, A.; Kim, W. A Multimodal IoT-Based Locomotion Classification System Using Features Engineering and Recursive Neural Network. Sensors 2023, 23, 4716. [Google Scholar] [CrossRef] [PubMed]
- Shen, X.; Du, S.-C.; Sun, Y.-N.; Sun, P.Z.H.; Law, R.; Wu, E.Q. Advance Scheduling for Chronic Care Under Online or Offline Revisit Uncertainty. IEEE Trans. Autom. Sci. Eng. 2023, 1–14. [Google Scholar] [CrossRef]
- Wang, N.; Chen, J.; Chen, W.; Shi, Z.; Yang, H.; Liu, P.; Wei, X.; Dong, X.; Wang, C.; Mao, L.; et al. The effectiveness of case management for cancer patients: An umbrella review. BMC Health Serv. Res. 2022, 22, 1247. [Google Scholar] [CrossRef]
- Hu, S.; Chen, W.; Hu, H.; Huang, W.; Chen, J.; Hu, J. Coaching to develop leadership for healthcare managers: A mixed-method systematic review protocol. Syst. Rev. 2022, 11, 67. [Google Scholar] [CrossRef]
- Azmat, U.; Ahmad, J. Smartphone inertial sensors for human locomotion activity recognition based on template matching and codebook generation. In Proceedings of the IEEE International Conference on Communication Technologies, Rawalpindi, Pakistan, 21–22 September 2021. [Google Scholar]
- Lv, Z.; Chen, D.; Feng, H.; Zhu, H.; Lv, H. Digital Twins in Unmanned Aerial Vehicles for Rapid Medical Resource Delivery in Epidemics. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25106–25114. [Google Scholar] [CrossRef] [PubMed]
- İnce, Ö.F.; Ince, I.F.; Yıldırım, M.E.; Park, J.S.; Song, J.K.; Yoon, B.W. Human activity recognition with analysis of angles between skeletal joints using a RGB-depth sensor. ETRI J. 2020, 42, 78–89. [Google Scholar] [CrossRef]
- Cheng, B.; Zhu, D.; Zhao, S.; Chen, J. Situation-Aware IoT Service Coordination Using the Event-Driven SOA Paradigm. IEEE Trans. Netw. Serv. Manag. 2016, 13, 349–361. [Google Scholar] [CrossRef]
- Sun, Y.; Xu, C.; Li, G.; Xu, W.; Kong, J.; Jiang, D.; Tao, B.; Chen, D. Intelligent human computer interaction based on non-redundant EMG signal. Alex. Eng. J. 2020, 59, 1149–1157. [Google Scholar] [CrossRef]
- Muneeb, M.; Rustam, H.; Ahmad, J. Automate Appliances via Gestures Recognition for Elderly Living Assistance. In Proceedings of the 2023 4th International Conference on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, 20–22 February 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Nguyen, N.; Bui, D.; Tran, X. A novel hardware architecture for human detection using HOG-SVM co-optimization. In Proceedings of the APCCAS, Bangkok, Thailand, 11–14 November 2019. [Google Scholar] [CrossRef]
- Nadeem, A.; Jalal, A.; Kim, K. Automatic human posture estimation for sport activity recognition with robust body parts detection and entropy markov model. Multimed. Tools Appl. 2021, 80, 21465–21498. [Google Scholar] [CrossRef]
- Zank, M.; Nescher, T.; Kunz, A. Tracking human locomotion by relative positional feet tracking. In Proceedings of the IEEE Virtual Reality (VR), Arles, France, 23–27 March 2015. [Google Scholar] [CrossRef]
- Jalal, A.; Mahmood, M. Students’ behavior mining in e-learning environment using cognitive processes with information technologies. Educ. Inf. Technol. 2019, 24, 2797–2821. [Google Scholar] [CrossRef]
- Batool, M.; Jalal, A.; Kim, K. Sensors Technologies for Human Activity Analysis Based on SVM Optimized by PSO Algorithm. In Proceedings of the 2019 International Conference on Applied and Engineering Mathematics (ICAEM), Taxila, Pakistan, 27–29 August 2019; pp. 145–150. [CrossRef]
- Prati, A.; Shan, C.; Wang, K.I.-K. Sensors, vision and networks: From video surveillance to activity recognition and health monitoring. J. Ambient Intell. Smart Environ. 2019, 11, 5–22. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, N.; Liu, A.-A.; Li, W.; Zhang, Y. High-Order Interaction Learning for Image Captioning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 4417–4430. [Google Scholar] [CrossRef]
- Zhang, C.; Xiao, P.; Zhao, Z.-T.; Liu, Z.; Yu, J.; Hu, X.-Y.; Chu, H.-B.; Xu, J.-J.; Liu, M.-Y.; Zou, Q.; et al. A Wearable Localized Surface Plasmons Antenna Sensor for Communication and Sweat Sensing. IEEE Sens. J. 2023, 23, 11591–11599. [Google Scholar] [CrossRef]
- Lin, Q.; Xiongbo, G.; Zhang, W.; Cai, L.; Yang, R.; Chen, H.; Cai, K. A Novel Approach of Surface Texture Mapping for Cone-beam Computed Tomography in Image-guided Surgical Navigation. IEEE J. Biomed. Health Inform. 2023, 1–10. [Google Scholar] [CrossRef]
- Hu, Z.; Ren, L.; Wei, G.; Qian, Z.; Liang, W.; Chen, W.; Lu, X.; Ren, L.; Wang, K. Energy Flow and Functional Behavior of Individual Muscles at Different Speeds During Human Walking. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 294–303. [Google Scholar] [CrossRef]
- Zhang, R.; Li, L.; Zhang, Q.; Zhang, J.; Xu, L.; Zhang, B.; Wang, B. Differential Feature Awareness Network within Antagonistic Learning for Infrared-Visible Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2023. [Google Scholar] [CrossRef]
- Mahmood, M.; Ahmad, J.; Kim, K. WHITE STAG model: Wise human interaction tracking and estimation (WHITE) using spatio-temporal and angular-geometric (STAG) descriptors. Multimed. Tools Appl. 2020, 79, 6919–6950. [Google Scholar] [CrossRef]
- Zheng, M.; Zhi, K.; Zeng, J.; Tian, C.; You, L. A hybrid CNN for image denoising. J. Artif. Intell. Technol. 2022, 2, 93–99. [Google Scholar] [CrossRef]
- Gao, Z.; Pan, X.; Shao, J.; Jiang, X.; Su, Z.; Jin, K.; Ye, J. Automatic interpretation and clinical evaluation for fundus fluorescein angiography images of diabetic retinopathy patients by deep learning. Br. J. Ophthalmol. 2022, 107, 1852–1858. [Google Scholar] [CrossRef]
- Wang, W.; Qi, F.; Wipf, D.P.; Cai, C.; Yu, T.; Li, Y.; Zhang, Y.; Yu, Z.; Wu, W. Sparse Bayesian Learning for End-to-End EEG Decoding. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15632–15649. [Google Scholar] [CrossRef] [PubMed]
- Lu, S.; Liu, S.; Hou, P.; Yang, B.; Liu, M.; Yin, L.; Zheng, W. Soft Tissue Feature Tracking Based on Deep Matching Network. Comput. Model. Eng. Sci. 2023, 136, 363–379. [Google Scholar] [CrossRef]
- Sreenu, G.; Saleem Durai, M.A. Intelligent video surveillance: A review through deep learning techniques for crowd analysis. J. Big Data 2019, 6, 48. [Google Scholar] [CrossRef]
- Xu, H.; Pan, Y.; Li, J.; Nie, L.; Xu, X. Activity recognition method for home-based elderly care service based on random forest and activity similarity. IEEE Access 2019, 7, 16217–16225. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Nini, B.; Sabokrou, M.; Hadid, A. Vision-based human activity recognition: A survey. Multimed. Tools Appl. 2020, 79, 30509–30555. [Google Scholar] [CrossRef]
- Hu, X.; Kuang, Q.; Cai, Q.; Xue, Y.; Zhou, W.; Li, Y. A Coherent Pattern Mining Algorithm Based on All Contiguous Column Bicluster. J. Artif. Intell. Technol. 2022, 2, 80–92. [Google Scholar] [CrossRef]
- Quaid, M.A.K.; Ahmad, J. Wearable sensors based human behavioral pattern recognition using statistical features and reweighted genetic algorithm. Multimed. Tools Appl. 2020, 79, 6061–6083. [Google Scholar] [CrossRef]
- Ahmad, F. Deep image retrieval using artificial neural network interpolation and indexing based on similarity measurement. CAAI Trans. Intell. Technol. 2022, 7, 200–218. [Google Scholar] [CrossRef]
- Zhang, J.; Ye, G.; Tu, Z.; Qin, Y.; Qin, Q.; Zhang, J.; Liu, J. A spatial attentive and temporal dilated (SATD) GCN for skeleton-based action recognition. CAAI Trans. Intell. Technol. 2022, 7, 46–55. [Google Scholar] [CrossRef]
- Lu, S.; Yang, J.; Yang, B.; Yin, Z.; Liu, M.; Yin, L.; Zheng, W. Analysis and Design of Surgical Instrument Localization Algorithm. Comput. Model. Eng. Sci. 2023, 137, 669–685. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, C.; Zheng, L.; Xu, K. ROSEFusion: Random optimization for online dense reconstruction under fast camera motion. ACM Trans. Graph. 2021, 40, 1–17. [Google Scholar] [CrossRef]
- Meng, J.; Li, Y.; Liang, H.; Ma, Y. Single-image Dehazing based on two-stream convolutional neural network. J. Artif. Intell. Technol. 2022, 2, 100–110. [Google Scholar] [CrossRef]
- Ma, K.; Li, Z.; Liu, P.; Yang, J.; Geng, Y.; Yang, B.; Guan, X. Reliability-Constrained Throughput Optimization of Industrial Wireless Sensor Networks With Energy Harvesting Relay. IEEE Internet Things J. 2021, 8, 13343–13354. [Google Scholar] [CrossRef]
- Zhuang, Y.; Jiang, N.; Xu, Y.; Xiangjie, K.; Kong, X. Progressive Distributed and Parallel Similarity Retrieval of Large CT Image Sequences in Mobile Telemedicine Networks. Wirel. Commun. Mob. Comput. 2022, 2022, 6458350. [Google Scholar] [CrossRef]
- Miao, Y.; Wang, X.; Wang, S.; Li, R. Adaptive Switching Control Based on Dynamic Zero-Moment Point for Versatile Hip Exoskeleton Under Hybrid Locomotion. IEEE Trans. Ind. Electron. 2023, 70, 11443–11452. [Google Scholar] [CrossRef]
- He, B.; Lu, Q.; Lang, J.; Yu, H.; Peng, C.; Bing, P.; Li, S.; Zhou, Q.; Liang, Y.; Tian, G. A New Method for CTC Images Recognition Based on Machine Learning. Front. Bioeng. Biotechnol. 2020, 8, 897. [Google Scholar] [CrossRef]
- Li, Z.; Kong, Y.; Jiang, C. A Transfer Double Deep Q Network Based DDoS Detection Method for Internet of Vehicles. IEEE Trans. Veh. Technol. 2023, 72, 5317–5331. [Google Scholar] [CrossRef]
- Hassan, F.S.; Gutub, A. Improving data hiding within colour images using hue component of HSV colour space. CAAI Trans. Intell. Technol. 2022, 7, 56–68. [Google Scholar] [CrossRef]
- Zheng, W.; Xun, Y.; Wu, X.; Deng, Z.; Chen, X.; Sui, Y. A Comparative Study of Class Rebalancing Methods for Security Bug Report Classification. IEEE Trans. Reliab. 2021, 70, 1658–1670. [Google Scholar] [CrossRef]
- Zheng, C.; An, Y.; Wang, Z.; Wu, H.; Qin, X.; Eynard, B.; Zhang, Y. Hybrid offline programming method for robotic welding systems. Robot. Comput.-Integr. Manuf. 2022, 73, 102238. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Y.; Yang, M.; Geng, G. Toward Concurrent Video Multicast Orchestration for Caching-Assisted Mobile Networks. IEEE Trans. Veh. Technol. 2021, 70, 13205–13220. [Google Scholar] [CrossRef]
- Qi, M.; Cui, S.; Chang, X.; Xu, Y.; Meng, H.; Wang, Y.; Yin, T. Multi-region Nonuniform Brightness Correction Algorithm Based on L-Channel Gamma Transform. Secur. Commun. Netw. 2022, 2022, 2675950. [Google Scholar] [CrossRef]
- Zhao, W.; Lun, R.; Espy, D.D.; Reinthal, M.A. Rule based real time motion assessment for rehabilitation exercises. In Proceedings of the IEEE Symposium Computational Intelligence in Healthcare and E-Health, Orlando, FL, USA, 9–12 December 2014. [Google Scholar] [CrossRef]
- Hao, S.; Jiali, P.; Xiaomin, Z.; Xiaoqin, W.; Lina, L.; Xin, Q.; Qin, L. Group identity modulates bidding behavior in repeated lottery contest: Neural signatures from event-related potentials and electroencephalography oscillations. Front. Neurosci. 2023, 17, 1184601. [Google Scholar] [CrossRef]
- Barnachon, M.; Bouakaz, S.; Boufama, B.; Guillou, E. Ongoing human action recognition with motion capture. Pattern Recognit. 2014, 47, 238–247. [Google Scholar] [CrossRef]
- Lu, S.; Yang, B.; Xiao, Y.; Liu, S.; Liu, M.; Yin, L.; Zheng, W. Iterative reconstruction of low-dose CT based on differential sparse. Biomed. Signal Process. Control 2023, 79, 104204. [Google Scholar] [CrossRef]
- Ordóñez, F.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Franco, A.; Magnani, A.; Maio, D. A multimodal approach for human activity recognition based on skeleton and RGB data. Pattern Recognit. Lett. 2020, 131, 293–299. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Mujtaba, G.; Alo, U.R.; Al-Garadi, M.A. Multi-sensor fusion based on multiple classifier systems for human activity identification. Hum. Cent. Comput. Inf. Sci. 2019, 9, 34. [Google Scholar] [CrossRef]
- Ehatisham-Ul-Haq, M.; Javed, A.; Azam, M.A.; Malik, H.M.A.; Irtaza, A.; Lee, I.H.; Mahmood, M.T. Robust Human Activity Recognition Using Multimodal Feature-Level Fusion. IEEE Access 2019, 7, 60736–60751. [Google Scholar] [CrossRef]
- Chung, S.; Lim, J.; Noh, K.J.; Kim, G.; Jeong, H. Sensor Data Acquisition and Multimodal Sensor Fusion for Human Activity Recognition Using Deep Learning. Sensors 2019, 19, 1716. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Guo, S.; Chen, Z.; Shen, Q.; Meng, Z.; Xu, H. Marfusion: An Attention-Based Multimodal Fusion Model for Human Activity Recognition in Real-World Scenarios. Appl. Sci. 2022, 12, 5408. [Google Scholar] [CrossRef]
- Niemann, F.; Reining, C.; Rueda, F.M.; Nair, N.R.; Steffens, J.A.; Fink, G.A.; Hompel, M.T. LARa: Creating a Dataset for Human Activity Recognition in Logistics Using Semantic Attributes. Sensors 2020, 20, 4083. [Google Scholar] [CrossRef] [PubMed]
- Ranieri, C.M.; MacLeod, S.; Dragone, M.; Vargas, P.A.; Romero, R.A.F. Activity Recognition for Ambient Assisted Living with Videos, Inertial Units and Ambient Sensors. Sensors 2021, 21, 768. [Google Scholar] [CrossRef]
- Bersch, S.D.; Azzi, D.; Khusainov, R.; Achumba, I.E.; Ries, J. Sensor data acquisition and processing parameters for human activity classification. Sensors 2014, 14, 4239–4270. [Google Scholar] [CrossRef]
- Huang, H.; Liu, L.; Wang, J.; Zhou, Y.; Hu, H.; Ye, X.; Liu, G.; Xu, Z.; Xu, H.; Yang, W.; et al. Aggregation caused quenching to aggregation induced emission transformation: A precise tuning based on BN-doped polycyclic aromatic hydrocarbons toward subcellular organelle specific imaging. Chem. Sci. 2022, 13, 3129–3139. [Google Scholar] [CrossRef]
- Schrader, L.; Vargas Toro, A.; Konietzny, S.; Rüping, S.; Schäpers, B.; Steinböck, M.; Krewer, C.; Müller, F.; Güttler, J.; Bock, T. Advanced sensing and human activity recognition in early intervention and rehabilitation of elderly people. Popul. Ageing 2020, 13, 139–165. [Google Scholar] [CrossRef]
- Lee, M.; Kim, S.B. Sensor-Based Open-Set Human Activity Recognition Using Representation Learning with Mixup Triplets. IEEE Access 2022, 10, 119333–119344. [Google Scholar] [CrossRef]
- Patro, S.G.K.; Mishra, B.K.; Panda, S.K.; Kumar, R.; Long, H.V.; Taniar, D.; Priyadarshini, I. A Hybrid Action-Related K-Nearest Neighbour (HAR-KNN) Approach for Recommendation Systems. IEEE Access 2020, 8, 90978–90991. [Google Scholar] [CrossRef]
- Li, J.; Tian, L.; Wang, H.; An, Y.; Wang, K.; Yu, L. Segmentation and recognition of basic and transitional activities for continuous physical human activity. IEEE Access 2019, 7, 42565–42576. [Google Scholar] [CrossRef]
- Chen, D.; Wang, Q.; Li, Y.; Li, Y.; Zhou, H.; Fan, Y. A general linear free energy relationship for predicting partition coefficients of neutral organic compounds. Chemosphere 2020, 247, 125869. [Google Scholar] [CrossRef] [PubMed]
- Hou, X.; Zhang, L.; Su, Y.; Gao, G.; Liu, Y.; Na, Z.; Xu, Q.; Ding, T.; Xiao, L.; Li, L.; et al. A space crawling robotic bio-paw (SCRBP) enabled by triboelectric sensors for surface identification. Nano Energy 2023, 105, 108013. [Google Scholar] [CrossRef]
- Hou, X.; Xin, L.; Fu, Y.; Na, Z.; Gao, G.; Liu, Y.; Xu, Q.; Zhao, P.; Yan, G.; Su, Y.; et al. A self-powered biomimetic mouse whisker sensor (BMWS) aiming at terrestrial and space objects perception. Nano Energy 2023, 118, 109034. [Google Scholar] [CrossRef]
- Mi, W.; Xia, Y.; Bian, Y. Meta-analysis of the association between aldose reductase gene (CA)n microsatellite variants and risk of diabetic retinopathy. Exp. Ther. Med. 2019, 18, 4499–4509. [Google Scholar] [CrossRef] [PubMed]
- Ye, X.; Wang, J.; Qiu, W.; Chen, Y.; Shen, L. Excessive gliosis after vitrectomy for the highly myopic macular hole: A Spectral Domain Optical Coherence Tomography Study. Retina 2023, 43, 200–208. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liu, S. Detection and Segmentation of Occluded Vehicles Based on Skeleton Features. In Proceedings of the 2012 Second International Conference on Instrumentation, Measurement, Computer, Communication and Control, Harbin, China, 8–10 December 2012; pp. 1055–1059. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A survey of depth and inertial sensor fusion for human action recognition. Multimed. Tools Appl. 2017, 76, 4405–4425. [Google Scholar] [CrossRef]
- Amir, N.; Ahmad, J.; Kibum, K. Human Actions Tracking and Recognition Based on Body Parts Detection via Artificial Neural Network. In Proceedings of the 2020 3rd International Conference on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, 17–19 February 2020. [Google Scholar]
- Zhou, B.; Wang, C.; Huan, Z.; Li, Z.; Chen, Y.; Gao, G.; Li, H.; Dong, C.; Liang, J. A Novel Segmentation Scheme with Multi-Probability Threshold for Human Activity Recognition Using Wearable Sensors. Sensors 2022, 22, 7446. [Google Scholar] [CrossRef]
- Yao, Q.-Y.; Fu, M.-L.; Zhao, Q.; Zheng, X.-M.; Tang, K.; Cao, L.-M. Image-based visualization of stents in mechanical thrombectomy for acute ischemic stroke: Preliminary findings from a series of cases. World J. Clin. Cases 2023, 11, 5047–5055. [Google Scholar] [CrossRef]
- Su, W.; Ni, J.; Hu, X.; Fridrich, J. Image Steganography With Symmetric Embedding Using Gaussian Markov Random Field Model. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1001–1015. [Google Scholar] [CrossRef]
- Li, X.; Zhao, H.; Yu, L.; Chen, H.; Deng, W.; Deng, W. Feature Extraction Using Parameterized Multisynchrosqueezing Transform. IEEE Sens. J. 2022, 22, 14263–14272. [Google Scholar] [CrossRef]
- Jin, K.; Gao, Z.; Jiang, X.; Wang, Y.; Ma, X.; Li, Y.; Ye, J. MSHF: A Multi-Source Heterogeneous Fundus (MSHF) Dataset for Image Quality Assessment. Sci. Data 2023, 10, 286. [Google Scholar] [CrossRef] [PubMed]
- Amir, N.; Ahmad, J.; Kim, K. Accurate Physical Activity Recognition using Multidimensional Features and Markov Model for Smart Health Fitness. Symmetry 2020, 12, 1766. [Google Scholar]
- Kanan, C.; Cottrell, G. Robust Classification of Objects, Faces, and Flowers Using Natural Image Statistics. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2472–2479. [Google Scholar] [CrossRef]
- Arbain, N.A.; Azmi, M.S.; Muda, A.K.D.; Radzid, A.R.; Tahir, A. A Review of Triangle Geometry Features in Object Recognition. In Proceedings of the 2019 9th Symposium on Computer Applications & Industrial Electronics (ISCAIE), Kota Kinabalu, Malaysia, 27–28 April 2019; pp. 254–258. [Google Scholar] [CrossRef]
- Fausto, F.; Cuevas, E.; Gonzales, A. A New Descriptor for Image Matching Based on Bionic Principles. Pattern Anal. Appl. 2017, 20, 1245–1259. [Google Scholar] [CrossRef]
- Yu, Y.; Yang, J.P.; Shiu, C.-S.; Simoni, J.M.; Xiao, S.; Chen, W.-T.; Rao, D.; Wang, M. Psychometric testing of the Chinese version of the Medical Outcomes Study Social Support Survey among people living with HIV/AIDS in China. Appl. Nurs. Res. 2015, 28, 328–333. [Google Scholar] [CrossRef] [PubMed]
- Ali, H.H.; Moftah, H.M.; Youssif, A.A.A. Depth-based human activity recognition: A comparative perspective study on feature extraction. Future Comput. Inform. J. 2018, 3, 51–67. [Google Scholar] [CrossRef]
- Nguyen, H.-C.; Nguyen, T.-H.; Scherer, R.; Le, V.-H. Deep Learning for Human Activity Recognition on 3D Human Skeleton: Survey and Comparative Study. Sensors 2023, 23, 5121. [Google Scholar] [CrossRef]
- Singh, S.P.; Sharma, M.K.; Lay-Ekuakille, A.; Gangwar, D.; Gupta, S. Deep ConvLSTM With Self-Attention for Human Activity Decoding Using Wearable Sensors. IEEE Sens. J. 2021, 21, 8575–8582. [Google Scholar] [CrossRef]
- Farag, M.M. Matched Filter Interpretation of CNN Classifiers with Application to HAR. Sensors 2022, 22, 8060. [Google Scholar] [CrossRef] [PubMed]
- Husni, N.L.; Sari, P.A.R.; Handayani, A.S.; Dewi, T.; Seno, S.A.H.; Caesarendra, W.; Glowacz, A.; Oprzędkiewicz, K.; Sułowicz, M. Real-Time Littering Activity Monitoring Based on Image Classification Method. Smart Cities 2021, 4, 1496–1518. [Google Scholar] [CrossRef]
- Khatun, M.A.; Abu Yousuf, M.; Ahmed, S.; Uddin, Z.; Alyami, S.A.; Al-Ashhab, S.; Akhdar, H.F.; Khan, A.; Azad, A.; Moni, M.A. Deep CNN-LSTM With Self-Attention Model for Human Activity Recognition Using Wearable Sensor. IEEE J. Transl. Eng. Health Med. 2022, 10, 2700316. [Google Scholar] [CrossRef]
- Javeed, M.; Jalal, A.; Kim, K. Wearable Sensors based Exertion Recognition using Statistical Features and Random Forest for Physical Healthcare Monitoring. In Proceedings of the 2021 International Bhurban Conference on Applied Sciences and Technologies (IBCAST), Islamabad, Pakistan, 12–16 January 2021; pp. 512–517. [Google Scholar] [CrossRef]
- Haresamudram, H.; Beedu, A.; Agrawal, V.; Grady, P.L.; Essa, I. Masked Reconstruction Based Self-Supervision for Human Activity Recognition. In Proceedings of the 24th annual International Symposium on Wearable Computers, Cancun, Mexico, 12–16 September 2020. [Google Scholar]
- Javeed, M.; Mudawi, N.A.; Alazeb, A.; Alotaibi, S.S.; Almujally, N.A.; Jalal, A. Deep Ontology-Based Human Locomotor Activity Recognition System via Multisensory Devices. IEEE Access 2023, 11, 105466–105478. [Google Scholar] [CrossRef]
- Cosoli, G.; Antognoli, L.; Scalise, L. Wearable Electrocardiography for Physical Activity Monitoring: Definition of Validation Protocol and Automatic Classification. Biosensors 2023, 13, 154. [Google Scholar] [CrossRef]
- Ehatisham-ul-Haq, M.; Murtaza, F.; Azam, M.A.; Amin, Y. Daily Living Activity Recognition In-The-Wild: Modeling and Inferring Activity-Aware Human Contexts. Electronics 2022, 11, 226. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D. A depth video sensor-based life-logging human activity recognition system for elderly care in smart indoor environments. Sensors 2014, 14, 11735–11759. [Google Scholar]
- Aşuroğlu, T. Complex Human Activity Recognition Using a Local Weighted Approach. IEEE Access 2022, 10, 101207–101219. [Google Scholar] [CrossRef]
- Azmat, U.; Ahmad, J.; Madiha, J. Multi-sensors Fused IoT-based Home Surveillance via Bag of Visual and Motion Features. In Proceedings of the 2023 International Conference on Communication, Computing and Digital Systems (C-CODE), Islamabad, Pakistan, 17–18 May 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Ahmad, J.; Kim, Y.-H.; Kim, Y.-J.; Kamal, S.; Kim, D. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar]
- Boukhechba, M.; Cai, L.; Wu, C.; Barnes, L.E. ActiPPG: Using deep neural networks for activity recognition from wrist-worn photoplethysmography (PPG) sensors. Smart Health 2019, 14, 100082. [Google Scholar] [CrossRef]
- Sánchez-Caballero, A.; Fuentes-Jiménez, D.; Losada-Gutiérrez, C. Real-time human action recognition using raw depth video-based recurrent neural networks. Multimed. Tools Appl. 2023, 82, 16213–16235. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Performance | Proposed System with First Novelty | Proposed System with Second Novelty | Proposed System with Both Novelties | CNN | LSTM |
|---|---|---|---|---|---|
| HWU-USP | |||||
| Accuracy | 78.89% | 80.00% | 82.22% | 72.22% | 70.00% |
| Recall | 0.79 | 0.80 | 0.82 | 0.72 | 0.70 |
| Precision | 0.79 | 0.81 | 0.83 | 0.73 | 0.71 |
| F1-Score | 0.79 | 0.81 | 0.82 | 0.72 | 0.70 |
| LARa | |||||
| Accuracy | 80.00% | 77.50% | 82.50% | 78.75% | 76.25% |
| Recall | 0.80 | 0.77 | 0.82 | 0.78 | 0.76 |
| Precision | 0.80 | 0.78 | 0.83 | 0.79 | 0.76 |
| F1-Score | 0.80 | 0.77 | 0.82 | 0.79 | 0.76 |
| Skeleton Body Points | Confidence Levels for HWU-USP | Confidence Levels for LARa |
|---|---|---|
| Head | 0.95 | 0.94 |
| Shoulders | 0.92 | 0.90 |
| Elbows | 0.88 | 0.89 |
| Wrists | 0.91 | 0.90 |
| Torso | 0.85 | 0.88 |
| Knees | 0.89 | 0.92 |
| Ankles | 0.95 | 0.94 |
| Mean Confidence | 0.90 | 0.91 |
| Ref. | Classifier | Descriptor Domain | Modality | Accuracy |
|---|---|---|---|---|
| [96] | Random Forest | Time-based | Multiple | 81.00 |
| [97] | CNN-LSTM | Deep-learning-based | Multiple | 75.00 |
| [98] | HMM | Machine learning | Single | 78.33 |
| [99] | Multi-Layer Perceptron | Frequency and time | Single | 74.20 |
| [100] | Multi-Layer Perceptron | Entropy | Multiple | 75.50 |
| [101] | Markov Chain | Multi-features | Multiple | 74.94 |
| [102] | Recurrent Neural Network | Convolutional | Multiple | 82.00 |
| [103] | Recurrent Neural Network | Raw | Single | 80.43 |
| Proposed | Recurrent Neural Network | Energy, Graph, Frequency, and Time | Multiple | 82.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Javeed, M.; Abdelhaq, M.; Algarni, A.; Jalal, A. Biosensor-Based Multimodal Deep Human Locomotion Decoding via Internet of Healthcare Things. Micromachines 2023, 14, 2204. https://doi.org/10.3390/mi14122204
Javeed M, Abdelhaq M, Algarni A, Jalal A. Biosensor-Based Multimodal Deep Human Locomotion Decoding via Internet of Healthcare Things. Micromachines. 2023; 14(12):2204. https://doi.org/10.3390/mi14122204
Chicago/Turabian StyleJaveed, Madiha, Maha Abdelhaq, Asaad Algarni, and Ahmad Jalal. 2023. "Biosensor-Based Multimodal Deep Human Locomotion Decoding via Internet of Healthcare Things" Micromachines 14, no. 12: 2204. https://doi.org/10.3390/mi14122204