1. Introduction
In recent years, there has been considerable progress in microrobotics applications across many fields, including but not limited to medicine and the food industry [
1,
2,
3]. The significant potential that microrobots carry for use in the general scientific field has gained significant interest in the scientific community. Since the structure of the microrobots is very small, they can be utilized in medicinal fields as they can reach inaccessible areas [
4].
Nevertheless, one major challenge in microrobotics is achieving autonomous, intelligent, and precise control and navigation of microrobots toward target positions [
5,
6]. A microrobot control system aims to manipulate the shape and size of the actuation energy field, focusing on providing navigation for the microrobot toward a desired dynamic behavior. To this end, the microrobots must have the necessary capabilities and tools for sensing the environment, enabling propulsion, and decision-making. While these functionalities are common in macro-robots through the integration of software and hardware tools [
7], the tiny size of micro-dimensions will prohibit the integration of hardware tools like sensors, power sources, communication equipment, and more [
8]. Therefore, microrobots often come with relatively simple structures. This limitation lays the ground for alternative actuation and navigation approaches. Magnetic microrobots remotely actuated via magnetic fields are approved as a feasible solution to micro-scale propulsion challenges. Due to their safety, especially in medical applications, these microrobots encompass a wide range of navigation and swimming mechanisms in fluidic environments. They also offer other complementary functionalities like cell, drug, and gene delivery [
9], biopsy [
10], and disease diagnosis [
11].
However, the efficient and autonomous motion control and navigation of these magnetic microrobots in fluidic environments require intelligent, precise, and optimal methods. Traditional methods for microrobots’ control and navigation typically employ approximate and experimental methods, which ultimately need complex dynamic modeling of the whole system including microrobot dynamics, environmental conditions, and actuation systems [
12]. This limitation restricts the flexibility and adaptability of these approaches for implementation in various control situations, especially within complex and unpredictable environments.
Recent developments in artificial intelligence (AI) and deep learning (DL) technologies [
13] have introduced reinforcement learning (RL) algorithms as a possible solution to the problem of microrobot motion control [
14]. The combination of RL with DL called Deep RL (DRL), is most useful in complex decision-making tasks where effectively learning complex behaviors and features is essential [
15]. The main advantage of model-free DRL algorithms relies on the fact that they do not need a predefined model for the prediction of various environmental states. This, therefore, simplifies their implementation, particularly in unpredictable environments.
Considering the promising success demonstrated by RL algorithms in a wide range of robotic control problems [
16,
17] as well as the inherent complexity of environments in which microrobots operate, recent studies have focused on the use of RL algorithms in microrobot control and navigation. For instance, Q-learning as a value-based RL algorithm has been employed to learn appropriate policies for movement in steady flow [
18], optimization of the propulsion policies for three-sphere microswimmers [
19], motion control in simulated blood vessels environments [
20], and support microrobot real-time path planning in navigation [
21]. However, Q-learning not only lacks performance efficiency in systems with continuous action spaces [
22] but also exhibits a high degree of sample inefficiency [
23,
24]. This limitation results in multiple challenges in practical, real-world scenarios that typically require continuous action spaces and sample efficiency.
The actor-critic approach is introduced to overcome these limitations. Recent studies have reported that microrobots can be controlled and guided properly within complex environments using the actor-critic strategy. So far, this approach has been applied for the gait learning in microrobots to swim into predefined directions [
25], guiding microrobots to target areas under diverse environmental conditions [
26], and learning how to use hydrodynamic forces to move in a controlled direction [
27]. Nevertheless, most of these studies have been dedicated to deploying RL approaches only under very simple settings and assumptions in computational modeling and simulation.
Soft actor-critic (SAC) [
28], a prominent actor-critic approach, has recently shown promising results in the control of microrobots in real-world environments. For example, Behrens and Ruder (2022) applied this algorithm to control the movement of an intelligent helical magnetic microrobot [
29]. In their study, a rotating electromagnetic system was used to obtain a nonlinear actuation. The optimal swimming behaviors were acquired autonomously in the fluid environments; thus, the need for prior knowledge of the environmental conditions was eliminated. In this way, the development time and resource utilization required for designing the system was minimized accordingly. The RL agent’s objective was to learn an action policy that maximizes overall reward for guiding the microrobot in a circular workspace toward the target position. The results showed that the SAC algorithm successfully learned a nearly optimal policy for the circular motion of the microrobot around a fixed point within the fluid environment [
29]. In a separate study, the SAC algorithm was used to control a soft magnetic microrobot to reach a target point for simulating drug delivery and then float within the fluid for simulating drug release [
30].
Despite the acceptable results of the SAC in controlling microrobots in real-world environments, one limitation of the SAC is training instability, in which one can observe a huge degradation in performance during the training process. This limitation seems to be responsible for non-optimal behaviors, such as the negative backward movement of the microrobot reported by Behrens and Ruder (2022) [
29]. To address this issue, the Trust Region Policy Optimization (TRPO) algorithm [
31] is a feasible solution because it utilizes the concept of trust region to prevent large updates during each iteration. To the best of our knowledge, none of the previous studies employed this algorithm for the position control of microrobots.
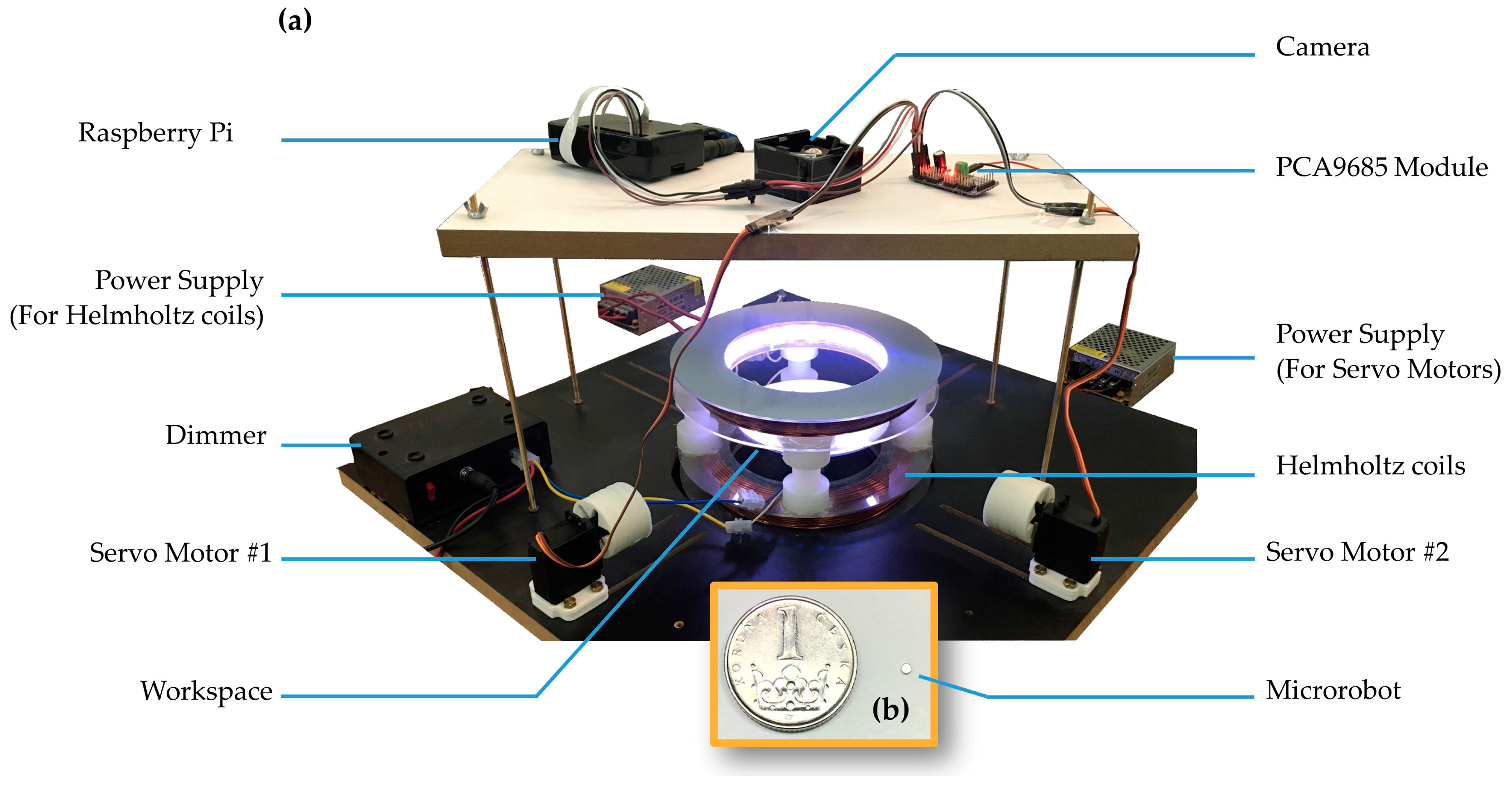
In the present study, both the TRPO and SAC algorithms were independently employed to control a single magnetic disk-shaped microrobot within the physical system, and their respective results were subsequently compared. For this purpose, a magnetic actuation system with two rotating permanent magnets and a uniaxial Helmholtz coil was assembled. RL algorithms enable the microrobot to efficiently navigate from an initial position to an arbitrary goal position in the shortest path. The microrobot’s task was to determine the optimal or near-optimal policy for reaching the target positions on an air-water interface. The primary contribution of this paper is to provide a framework for implementing two different DRL algorithms to enable microrobot operations in such circumstances. In order to compare the results, the evaluations were performed for each algorithm. In this research, we did not involve any analysis of the magnetic field modeling generated by the actuation system or the dynamic modeling of microrobot behavior within the fluid environment. The hypothesis of this study revolves around the development of an RL-based control system that does not need to develop a specialized model of the whole physical system.
3. Results
In this study, two different model-free DRL algorithms, TRPO (an on-policy algorithm) and SAC (an off-policy algorithm) were employed to find optimal policies for closed-loop control of a magnetic microrobot on a fluid surface with no prior knowledge of the system dynamic. Frequency distribution diagrams of actions were plotted to gain insights into the SAC and TRPO algorithms’ behavior and performance. These diagrams provide a visual representation of how frequently certain actions are chosen during the learning process.
Figure 6 and
Figure 7 depict frequency distribution diagrams of the SAC and TRPO algorithm action outputs, respectively, displaying angle 1 (the angle of the first magnet rotated by the servo motor #1) and angle 2 (the angle of the second magnet rotated by the servo motor #2). These histograms are categorized into five intervals: 0–20 k time steps, 20 k–40 k time steps, 40 k–60 k time steps, 60 k–80 k time steps, and 80 k–100 k time steps. These five distinct intervals allow us to analyze the evolution of action distributions over different training phases. Over the initial 20 k time steps, the action distributions are concentrated around a peak, except for angle #2 in the SAC (
Figure 6b), which displays two sharp peaks. This indicates that the SAC network tended to rotate the second magnet more frequently with angles exceeding 90°, while the TRPO network tried to rotate both magnets similarly, exploring the entire action space and identifying patterns related to state changes. In this phase, the microrobot explored all possible states within the workspace and exhibited the lowest success rate in reaching the target positions. In the subsequent time steps, from 20 k to 60 k, both networks explore a wider range of angles. Between 60 k and 100 k time steps, the action distributions become more skewed, with some histograms shifted on one side. This implies that both networks discovered near-optimal policies and learned to favor certain angles over others. Notably, at the final 20 k time steps, the action distributions became more uniform and flat (except for angle #2 in the TRPO, as shown in
Figure 7b), with some histograms showing almost no peaks. In this phase, the microrobot exhibited more precise and successful navigation toward the target positions. It is important to highlight that in the initial steps, the agents generated non-valid angles (less than zero degrees and more than 180°), which is a natural part of the exploration process for the algorithms. However, as learning progressed, both algorithms effectively learned to avoid selecting invalid angles. In the last 20 k time steps, particularly in the case of the TRPO, they even avoided choosing angles between 170 to 180°.
On the other hand, the mean episode length and the mean episode reward over the time steps are important criteria for evaluating the RL effectiveness. Based on the configuration of the system, shorter episode lengths and higher episode rewards are expected to result in better learning efficiency. As illustrated in
Figure 8, the TRPO network was able to attain a convergence to an optimal reward at an early stage. In contrast, the SAC algorithm exhibited negative rewards within the first 5000 time steps and then followed by unstable reward values.
Figure 8 and
Figure 9 illustrate that in the initial episodes for both algorithms, the mean episode length is long, while the mean reward remains low. This is typical for the learning process, where the agent explores the environment and seeks to reach the targets through random actions.
Furthermore, a discernible trend of decreasing episode length and increasing episode reward can be observed with the advancement of training, suggesting that the microrobot’s performance improves with experience. After approximately 30 k time steps, the TRPO succeeded in the task of finding a stable and optimal policy with the maximum possible reward. The SAC, on the other hand, not only took more time steps to reach the maximum possible reward but also exhibited more fluctuations during the training. This indicates that the SAC network does not exhibit the same degree of consistency as the TRPO network. As shown in
Figure 9, the mean episode length of the TRPO mostly remained considerably lower than that of the SAC over time, showing that the TRPO reached the target positions more rapidly with less number of time steps.
In the final time steps, both episode length and reward seem to stabilize toward relatively constant values. At this point, the agent was converging to an almost optimal policy with a high degree of robustness, especially in the case of the TRPO. These results suggest that the TRPO is more stable during the learning process compared to the SAC since there are fewer fluctuations in the reward curve throughout training. This could be caused by the SAC’s stochasticity and regularization, which can cause learning curve fluctuations. Another factor attributable to the observed fluctuations on the learning curve could be the off-policy nature of the SAC, which might make it more sensitive to the quality and diversity of the experience data it collects.
Figure 10 depicts the algorithms’ performance in the initial episode and final episodes. As anticipated with RL algorithms, in the initial episode, the agent interacted with the environment by generating random actions to explore it. As illustrated in
Figure 10a, the first episode had the longest duration (i.e., 100 time steps) and the lowest reward for both SAC and TRPO algorithms. The microrobot learned to find the optimal policy for reaching the target points during the learning process.
Figure 10b–f illustrates the trajectories of the microrobot to reach five different targets (green circles) in the final episodes, using both the SAC and TRPO algorithms. This figure shows that both algorithms discover near-optimal policies to reach different targets solely through trial and error and interaction with the environment.
Furthermore, it is worth noting that after the entire learning experience was completed, the TRPO managed to achieve higher success rates in completing episodes compared to the SAC. The results revealed that the TRPO performed 7797 episodes in the learning phase and successfully reached the target positions in 7633 episodes (97.9%). In contrast, the SAC completed 3968 episodes, with 3541 of them successfully reaching the target positions (89%). It appears that the TRPO was able to make more efficient use of the episodes it experienced. This observation is also supported by the success rates of each agent in the initial time steps. In the first 30k time steps especially, the TRPO algorithm saw the microrobot failing to reach the target positions only 21% of the time, whereas the SAC algorithm exhibited a failure rate of 52%. Therefore, the results imply that the TRPO is more sample-efficient than the SAC, which means it requires less sample to reach an optimal policy. Having a sample efficient agent is critical for implementing RL in microrobotics, especially when training with physical systems.
The performance of each agent was then tested under scenarios in which they had not been trained, such as different initial positions for the microrobot and different target positions, to evaluate the generalization of the algorithms. From the mean reward and accuracy results, it is observed that both SAC and TRPO methods can accomplish the goal-reaching task effectively. Additionally, there is not much difference between the SAC and TRPO in achieving the optimal policy, as shown in
Table 2. However, the SAC has an immensely lower standard deviation than the TRPO. Standard deviation measures the spread or variability in rewards. This could be due to the SAC’s ability to explore and exploit the policy more effectively. These results provide insights into agents’ generalization and adaptation capabilities, as well as their robustness to uncertainty and noise.
Figure 11 illustrates a time-lapse image of the magnetic microrobot’s trajectory during one of the episodes of the evaluation process of the SAC (
Figure 11a) and TRPO (
Figure 11b) algorithms in the physical environment. Each episode consists of seven time steps. As is evident from the figure, both algorithms successfully applied their experience gained during the training to navigate the microrobot to the target position. It is important to highlight that to assess the algorithms’ performance in scenarios where they had not been trained, the microrobot’s initial position and the target positions during the evaluation differed from those in the training phase.
4. Discussion
The SAC and TRPO algorithms were individually implemented within 100,000 time steps, and their performances were compared. Both algorithms were able to discover and learn optimal policies for their control task. The implementation outcomes of both algorithms demonstrate that the microrobot can effectively learn to navigate through the environment. Compared to other studies focused on closed-loop control of microrobots [
22,
37], which often rely on complex models, the DRL-based control systems presented in this study require no prior knowledge of microrobot dynamics, the environment, or the actuation system to perform navigation tasks. This adaptability is one of the key advantages of the control systems presented in this study. Additionally, they hold the potential to surpass classical control systems because DRL agents learned from the actual physical behaviors of the system and leveraged deep neural networks to model any observed nonlinearities inherent to the microrobotic systems. Therefore, the current paper can serve as a foundational framework for leveraging DRL to enable microrobots to operate in environments where their models are unavailable.
It was also demonstrated that the SAC algorithm requires a limited number of samples to discover the optimal policy. This high efficiency was also reported by Behrens and Ruder (2022) [
29] and Cai et al. (2022) [
30], who utilized the SAC algorithm for microrobotic control tasks within physical systems. Nonetheless, in our specific experimental setup, the TRPO algorithm proved to be more sample-efficient than the SAC under the same conditions. One major reason behind the difference in sample efficiency may be found in the design principles of the two algorithms. SAC is known to make use of off-policy learning so that it can efficiently use data collected throughout training. The TRPO, on the other hand, builds on inherently conservative trust region methods. This conservativeness can hence lead to even better sample efficiency in some scenarios.
During the training, the SAC algorithm exhibited frequent fluctuations and huge drops in performance, while the TRPO algorithm maintained greater stability and demonstrated relatively fewer fluctuations. SAC uses stochastic policies that add randomness to actions by including an entropy term. Although this may improve exploration, it also can result in fluctuations in performance. The TRPO, on the other hand, optimizes deterministic policies, which generally exhibit less variability in behavior.
Considering factors such as sample efficiency, learning stability, and no need for prior knowledge about the environmental dynamics or the actuation systems, we encourage the utilization of the TRPO algorithm for microrobotic applications in physical systems, such as drug delivery. Future research should focus on varying environmental conditions encompassing fluid dynamics, obstacle avoidance, path tracking, and navigation in complex environments. Extending the control of microrobots into three dimensions promises more realistic applications. Moreover, exploring alternative microrobots like helical microrobots, distinct actuation methods such as ultrasound, and diverse imaging systems such as MRI should be considered for future studies. This research also has the potential for extension into multi-agent systems, where the learning capabilities can facilitate microrobots in collaborative tasks.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}