
TILLING-by-Sequencing+ Reveals the Role of Novel Fatty Acid Desaturases (GmFAD2-2s) in Increasing Soybean Seed Oleic Acid Content


 , ,
, ,  ,
, 

Abstract
1. Introduction
2. Material and Methods
2.1. Development of an EMS Mutagenized Forrest Population
2.2. FAD2 Sequences and Phylogenetic Analysis
2.3. Chromosomal Distribution and Synteny Analysis
2.4. Library Preparation, Probe Design and TILLING-by-Sequencing+
2.5. Variant Calling for Mutation Detection
2.6. Mutation Density Evaluation
2.7. Analysis of Seed Fatty Acids
2.8. Confirmation of the Mutants by SANGER Sequencing
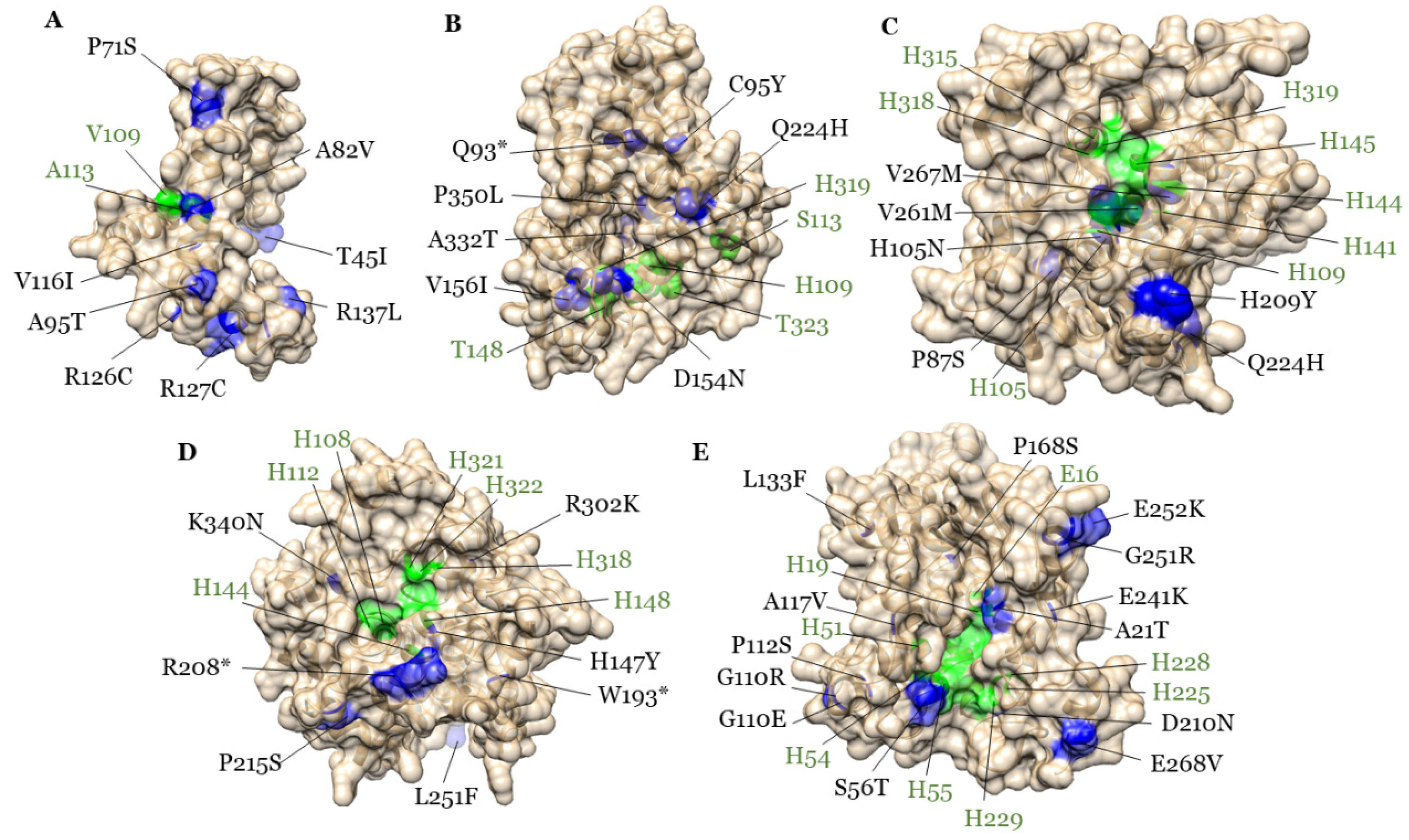
2.9. Homology Modeling of GmFAD2-2 Proteins and Mutational Analysis
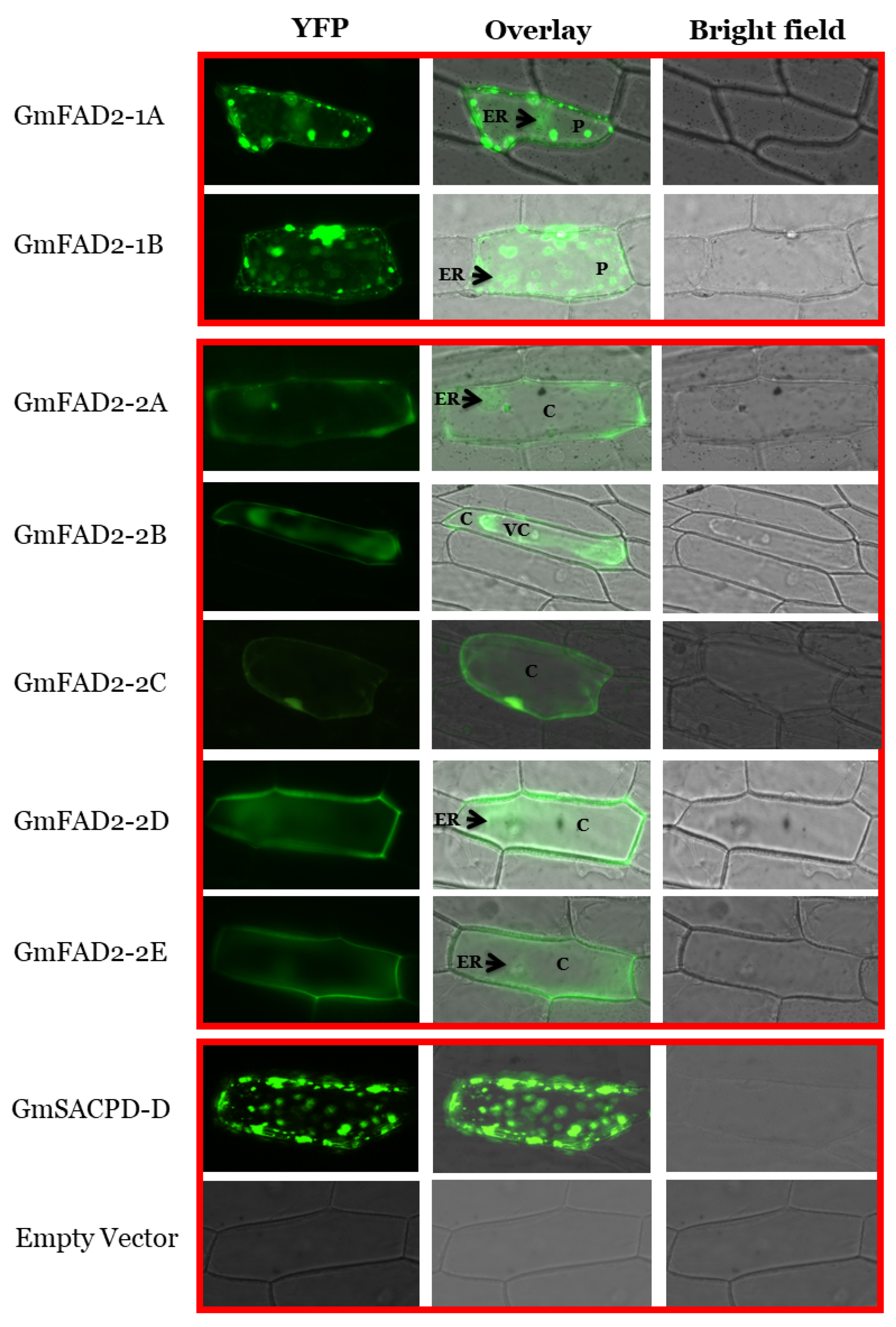
2.10. GmFAD2-1 and GmFAD2-2 Subcellular Localization and Cloning
2.11. Analysis of Putative Cis-Elements at the GmFAD2-1 and GmFAD2-2 Promoters
2.12. Statistical Analysis
2.13. RNA-seq Library Preparation and Analysis
3. Results
3.1. FAD2 Duplication within the Soybean Genome
3.2. Evolution of the GmFAD2 Gene Family
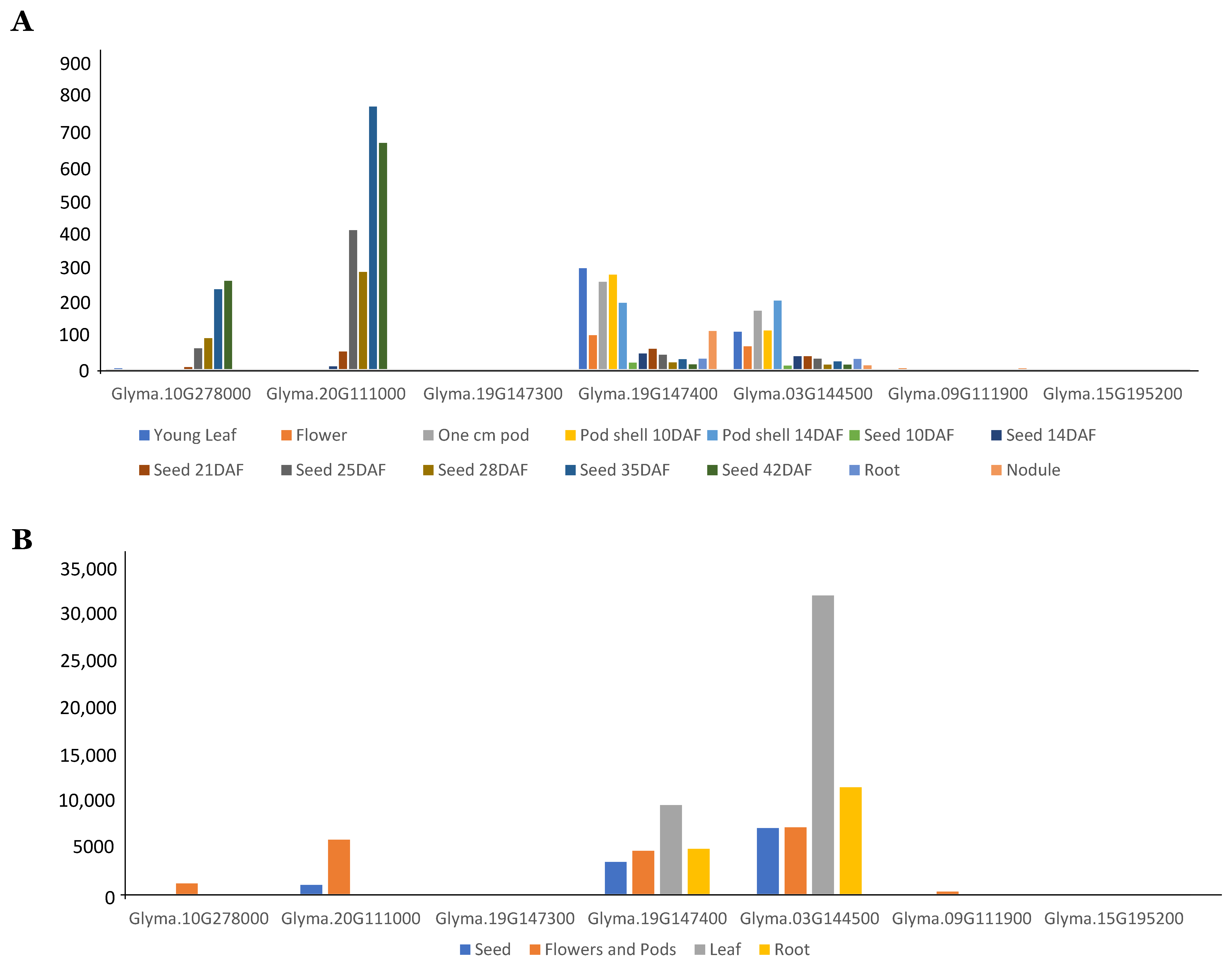
3.3. Expression Analysis of GmFAD2 Gene Family
3.4. TILLING by Target Capture Sequencing
3.5. Mutation Density of the “Forrest” EMS Mutagenized Soybean Population
3.6. All Five GmFAD2-2s Are Involved in High Oleic Acid Content
3.7. Subcellular Localization of GmFAD2-1 and GmFAD2-2 Subfamily Members
3.8. Analysis of Putative Cis-Elements in the Promoter Region of GmFAD2-1 and GmFAD2-2 Gene Members
4. Discussion
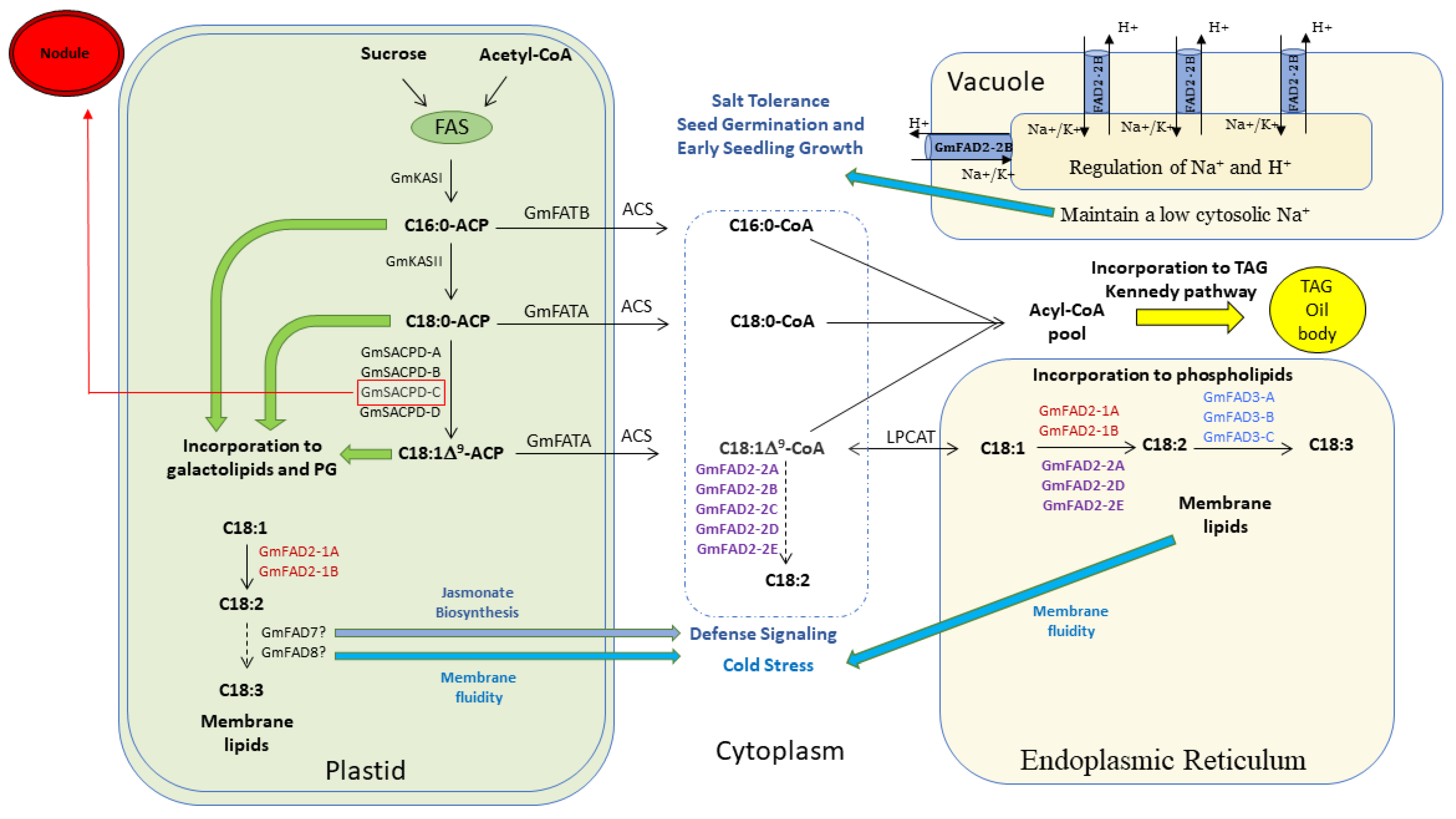
4.1. Involvement of the Five GmFAD2-2 Members in the Unsaturated Fatty Acid Pathway
4.2. Subfunctionalization of GmFAD2-2 Gene Family during Whole Genome Duplication
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Fehr, W.R. Breeding for Modified Fatty Acid Composition in Soybean. Crop. Sci. 2007, 47, S-72–S-87. [Google Scholar] [CrossRef]
- Ascherio, A.; Willett, W.C. Health effects of trans fatty acids. Am. J. Clin. Nutr. 1997, 66, 1006S–1010S. [Google Scholar] [CrossRef]
- Raneses, A.R.; Glaser, L.K.; Price, J.M.; Duffield, J.A. Potential biodiesel markets and their economic effects on the agricultural sector of the United States. Ind. Crop. Prod. 1999, 9, 151–162. [Google Scholar] [CrossRef]
- Heffner, E.L.; Sorrells, M.E.; Jannink, J.-L. Genomic Selection for Crop Improvement. Crop. Sci. 2009, 49, 1–12. [Google Scholar] [CrossRef]
- Pham, A.-T.; Lee, J.-D.; Shannon, J.G.; Bilyeu, K.D. Mutant alleles of FAD2-1A and FAD2-1Bcombine to produce soybeans with the high oleic acid seed oil trait. BMC Plant. Biol. 2010, 10, 195. [Google Scholar] [CrossRef] [PubMed]
- Pham, A.-T.; Shannon, J.G.; Bilyeu, K.D. Combinations of mutant FAD2 and FAD3 genes to produce high oleic acid and low linolenic acid soybean oil. Theor. Appl. Genet. 2012, 125, 503–515. [Google Scholar] [CrossRef] [PubMed]
- Lakhssassi, N.; Colantonio, V.; Flowers, N.D.; Zhou, Z.; Henry, J.; Liu, S.; Meksem, K. Stearoyl-Acyl Carrier Protein Desaturase Mutations Uncover an Impact of Stearic Acid in Leaf and Nodule Structure. Plant. Physiol 2017, 174, 1531–1543. [Google Scholar] [CrossRef] [PubMed]
- Lakhssassi, N.; Zhou, Z.; Liu, S.; Colantonio, V.; AbuGhazaleh, A.; Meksem, K. Characterization of the FAD2 Gene Family in Soybean Reveals the Limitations of Gel-Based TILLING in Genes with High Copy Number. Front. Plant. Sci 2017, 8, 324. [Google Scholar] [CrossRef] [PubMed]
- Kavithamani, D.K.; Vanniarajan, C.A.; Uma, D. Development of new vegetable soybean (Glycine max L. Merill) mutants.with high protein and less fibre content. Electron. J. Plant. Breed. 2010, 1, 1060–1065. [Google Scholar]
- Dierking, E.C.; Bilyeu, K.D. New sources of soybean seed meal and oil composition traits identified through TILLING. BMC Plant. Biol. 2009, 9, 89. [Google Scholar] [CrossRef]
- Taylor, D.C.; Katavic, V.; Zou, J.; MacKenzie, S.L.; Keller, W.A.; An, J.; Friesen, W.; Barton, D.L.; Pedersen, K.K.; Michael Giblin, E.; et al. Field testing of transgenic rapeseed cv. Hero transformed with a yeast sn-2 acyltransferase results in increased oil content, erucic acid content and seed yield. Mol. Breed. 2002, 8, 317–322. [Google Scholar] [CrossRef]
- Anai, T.; Yamada, T.; Hideshima, R.; Kinoshita, T.; Rahman, S.M.; Takagi, Y. Two high-oleic-acid soybean mutants, M23 and KK21, have disrupted microsomal omega-6 fatty acid desaturase, encoded by GmFAD2-1a. Breed. Sci. 2008, 58, 447–452. [Google Scholar] [CrossRef]
- Bachleda, N.; Grey, T.; Li, Z. Effects of high oleic acid soybean on seed yield, protein and oil contents, and seed germination revealed by near-isogeneic lines. Plant. Breed. 2017, 136, 539–547. [Google Scholar] [CrossRef]
- Cahoon, E.B.; Carlson, T.J.; Ripp, K.G.; Schweiger, B.J.; Cook, G.A.; Hall, S.E.; Kinney, A.J. Biosynthetic origin of conjugated double bonds: Production of fatty acid components of high-value drying oils in transgenic soybean embryos. Proc. Natl. Acad. Sci. USA 1999, 96, 12935. [Google Scholar] [CrossRef]
- Dyer, J.M.; Chapital, D.C.; Kuan, J.-C.W.; Mullen, R.T.; Turner, C.; McKeon, T.A.; Pepperman, A.B. Molecular Analysis of a Bifunctional Fatty Acid Conjugase/Desaturase from Tung. Implications for the Evolution of Plant Fatty Acid Diversity. Plant Physiol. 2002, 130, 2027–2038. [Google Scholar] [CrossRef]
- Cahoon, E.B.; Kinney, A.J. Dimorphecolic Acid Is Synthesized by the Coordinate Activities of Two Divergent Δ12-Oleic Acid Desaturases*. J. Biol. Chem. 2004, 279, 12495–12502. [Google Scholar] [CrossRef] [PubMed]
- Clark, K.J.; Makrides, M.; Neumann, M.A.; Gibson, R.A. Determination of the optimal ratio of linoleic acid to α-linolenic acid in infant formulas. J. Pediatrics 1992, 120, S151–S158. [Google Scholar] [CrossRef]
- Wei, C.-C.; Yen, P.-L.; Chang, S.-T.; Cheng, P.-L.; Lo, Y.-C.; Liao, V.H.-C. Antioxidative Activities of Both Oleic Acid and Camellia tenuifolia Seed Oil Are Regulated by the Transcription Factor DAF-16/FOXO in Caenorhabditis elegans. PLoS ONE 2016, 11, e0157195. [Google Scholar] [CrossRef]
- Sahari, M.A.; Ataii, D.; Hamedi, M. Characteristics of tea seed oil in comparison with sunflower and olive oils and its effect as a natural antioxidant. J. Am. Oil Chem. Soc. 2004, 81, 585–588. [Google Scholar] [CrossRef]
- Su, M.H.; Shih, M.C.; Lin, K.H. Chemical composition of seed oils in native Taiwanese Camellia species. Food Chem. 2014, 156, 369–373. [Google Scholar] [CrossRef]
- O’Keefe, S.F.; Wiley, V.A.; Knauft, D.A. Comparison of oxidative stability of high- and normal-oleic peanut oils. J. Am. Oil Chem. Soc. 1993, 70, 489–492. [Google Scholar] [CrossRef]
- Tang, G.Q.; Novitzky, W.P.; Carol Griffin, H.; Huber, S.C.; Dewey, R.E. Oleate desaturase enzymes of soybean: Evidence of regulation through differential stability and phosphorylation. Plant J. 2005, 44, 433–446. [Google Scholar] [CrossRef]
- Al Amin, N.; Ahmad, N.; Wu, N.; Pu, X.; Ma, T.; Du, Y.; Bo, X.; Wang, N.; Sharif, R.; Wang, P. CRISPR-Cas9 mediated targeted disruption of FAD2–2 microsomal omega-6 desaturase in soybean (Glycine max. L). BMC Biotechnol. 2019, 19, 9. [Google Scholar] [CrossRef]
- Wu, N.; Lu, Q.; Wang, P.; Zhang, Q.; Zhang, J.; Qu, J.; Wang, N. Construction and Analysis of GmFAD2-1A and GmFAD2-2A Soybean Fatty Acid Desaturase Mutants Based on CRISPR/Cas9 Technology. Int. J. Mol. Sci. 2020, 21, 1104. [Google Scholar] [CrossRef]
- Buhr, T.; Sato, S.; Ebrahim, F.; Xing, A.; Zhou, Y.; Mathiesen, M.; Schweiger, B.; Kinney, A.; Staswick, P. Ribozyme termination of RNA transcripts down-regulate seed fatty acid genes in transgenic soybean. Plant J. 2002, 30, 155–163. [Google Scholar] [CrossRef]
- Hoshino, T.; Takagi, Y.; Anai, T. Novel GmFAD2-1b mutant alleles created by reverse genetics induce marked elevation of oleic acid content in soybean seeds in combination with GmFAD2-1a mutant alleles. Breed. Sci. 2010, 60, 419–425. [Google Scholar] [CrossRef]
- Pham, A.-T.; Lee, J.-D.; Shannon, J.G.; Bilyeu, K.D. A novel FAD2-1 A allele in a soybean plant introduction offers an alternate means to produce soybean seed oil with 85% oleic acid content. Theor. Appl. Genet. 2011, 123, 793–802. [Google Scholar] [CrossRef] [PubMed]
- Haun, W.; Coffman, A.; Clasen, B.M.; Demorest, Z.L.; Lowy, A.; Ray, E.; Retterath, A.; Stoddard, T.; Juillerat, A.; Cedrone, F.; et al. Improved soybean oil quality by targeted mutagenesis of the fatty acid desaturase 2 gene family. Plant Biotechnol. J. 2014, 12, 934–940. [Google Scholar] [CrossRef]
- Lakhssassi, N.; Zhou, Z.; Liu, S.; Piya, S.; Cullen, M.A.; El Baze, A.; Knizia, D.; Patil, G.B.; Badad, O.; Embaby, M.G.; et al. Soybean TILLING-by-Sequencing + reveals the role of novel GmSACPD members in the unsaturated fatty acid biosynthesis while maintaining healthy nodules. J. Exp. Bot. 2020. [Google Scholar] [CrossRef]
- Lakhssassi, N.; Zhou, Z.; Cullen, M.A.; Badad, O.; El Baze, A.; Chetto, O.; Embaby, M.G.; Knizia, D.; Liu, S.; Neves, L.G.; et al. TILLING-by-Sequencing+ to Decipher Oil Biosynthesis Pathway in Soybeans: A New and Effective Platform for High-Throughput Gene Functional Analysis. Int. J. Mol. Sci. 2021, 22, 4219. [Google Scholar] [CrossRef]
- Tamura, K.; Stecher, G.; Peterson, D.; Filipski, A.; Kumar, S. MEGA6: Molecular Evolutionary Genetics Analysis version 6.0. Mol. Biol. Evol. 2013, 30, 2725–2729. [Google Scholar] [CrossRef]
- Saitou, N.; Nei, M. The neighbor-joining method: A new method for reconstructing phylogenetic trees. Mol. Biol. Evol. 1987, 4, 406–425. [Google Scholar]
- Chen, X.; Chen, Z.; Zhao, H.; Zhao, Y.; Cheng, B.; Xiang, Y. Genome-Wide Analysis of Soybean HD-Zip Gene Family and Expression Profiling under Salinity and Drought Treatments. PLoS ONE 2014, 9, e87156. [Google Scholar] [CrossRef] [PubMed]
- Bolger, A.M.; Lohse, M.; Usadel, B. Trimmomatic: A flexible trimmer for Illumina sequence data. Bioinformatics 2014, 30, 2114–2120. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Durbin, R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics 2009, 25, 1754–1760. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Handsaker, B.; Wysoker, A.; Fennell, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G.; Durbin, R.; Genome Project Data Processing, S. The Sequence Alignment/Map format and SAMtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef] [PubMed]
- Garrison, E.; Marth, G. Haplotype-based variant detection from short-read sequencing. arXiv 2012, arXiv:1207.3907. [Google Scholar]
- Bansal, V. A statistical method for the detection of variants from next-generation resequencing of DNA pools. Bioinformatics 2010, 26, i318–i324. [Google Scholar] [CrossRef]
- Danecek, P.; Auton, A.; Abecasis, G.; Albers, C.A.; Banks, E.; DePristo, M.A.; Handsaker, R.E.; Lunter, G.; Marth, G.T.; Sherry, S.T.; et al. The variant call format and VCFtools. Bioinformatics 2011, 27, 2156–2158. [Google Scholar] [CrossRef]
- Robinson, J.T.; Thorvaldsdóttir, H.; Winckler, W.; Guttman, M.; Lander, E.S.; Getz, G.; Mesirov, J.P. Integrative genomics viewer. Nat. Biotechnol. 2011, 29, 24–26. [Google Scholar] [CrossRef]
- Cooper, J.L.; Till, B.J.; Laport, R.G.; Darlow, M.C.; Kleffner, J.M.; Jamai, A.; El-Mellouki, T.; Liu, S.; Ritchie, R.; Nielsen, N.; et al. TILLING to detect induced mutations in soybean. BMC Plant. Biol. 2008, 8, 9. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Lakhssassi, N.; Cullen, M.A.; El Baz, A.; Vuong, T.D.; Nguyen, H.T.; Meksem, K. Assessment of Phenotypic Variations and Correlation among Seed Composition Traits in Mutagenized Soybean Populations. Genes (Basel) 2019, 10, 975. [Google Scholar] [CrossRef]
- Kramer, J.K.; Fellner, V.; Dugan, M.E.; Sauer, F.D.; Mossoba, M.M.; Yurawecz, M.P. Evaluating acid and base catalysts in the methylation of milk and rumen fatty acids with special emphasis on conjugated dienes and total trans fatty acids. Lipids 1997, 32, 1219–1228. [Google Scholar] [CrossRef] [PubMed]
- Kelley, L.A.; Mezulis, S.; Yates, C.M.; Wass, M.N.; Sternberg, M.J.E. The Phyre2 web portal for protein modeling, prediction and analysis. Nat. Protoc. 2015, 10, 845–858. [Google Scholar] [CrossRef] [PubMed]
- Finn, R.D.; Bateman, A.; Clements, J.; Coggill, P.; Eberhardt, R.Y.; Eddy, S.R.; Heger, A.; Hetherington, K.; Holm, L.; Mistry, J.; et al. Pfam: The protein families database. Nucleic Acids Res. 2014, 42, D222–D230. [Google Scholar] [CrossRef] [PubMed]
- Marchler-Bauer, A.; Derbyshire, M.K.; Gonzales, N.R.; Lu, S.; Chitsaz, F.; Geer, L.Y.; Geer, R.C.; He, J.; Gwadz, M.; Hurwitz, D.I.; et al. CDD: NCBI’s conserved domain database. Nucleic Acids Res. 2015, 43, D222–D226. [Google Scholar] [CrossRef]
- Pettersen, E.F.; Goddard, T.D.; Huang, C.C.; Couch, G.S.; Greenblatt, D.M.; Meng, E.C.; Ferrin, T.E. UCSF Chimera—A visualization system for exploratory research and analysis. J. Comput. Chem. 2004, 25, 1605–1612. [Google Scholar] [CrossRef] [PubMed]
- Hewezi, T.; Howe, P.J.; Maier, T.R.; Hussey, R.S.; Mitchum, M.G.; Davis, E.L.; Baum, T.J. Arabidopsis Spermidine Synthase Is Targeted by an Effector Protein of the Cyst Nematode Heterodera schachtii. Plant. Physiol. 2010, 152, 968. [Google Scholar] [CrossRef]
- Higo, K.; Ugawa, Y.; Iwamoto, M.; Korenaga, T. Plant cis-acting regulatory DNA elements (PLACE) database: 1999. Nucleic Acids Res. 1999, 27, 297–300. [Google Scholar] [CrossRef] [PubMed]
- Cartharius, K.; Frech, K.; Grote, K.; Klocke, B.; Haltmeier, M.; Klingenhoff, A.; Frisch, M.; Bayerlein, M.; Werner, T. MatInspector and beyond: Promoter analysis based on transcription factor binding sites. Bioinformatics 2005, 21, 2933–2942. [Google Scholar] [CrossRef]
- Chang, W.C.; Lee, T.Y.; Huang, H.D.; Huang, H.Y.; Pan, R.L. PlantPAN: Plant promoter analysis navigator, for identifying combinatorial cis-regulatory elements with distance constraint in plant gene groups. BMC Genom. 2008, 9, 561. [Google Scholar] [CrossRef]
- Dobin, A.; Gingeras, T.R. Mapping RNA-seq Reads with STAR. Curr. Protoc. Bioinform. 2015, 51, 11.14.11–11.14.19. [Google Scholar] [CrossRef] [PubMed]
- Trapnell, C.; Pachter, L.; Salzberg, S.L. TopHat: Discovering splice junctions with RNA-Seq. Bioinformatics 2009, 25, 1105–1111. [Google Scholar] [CrossRef]
- Anders, S.; Pyl, P.T.; Huber, W. HTSeq—A Python framework to work with high-throughput sequencing data. Bioinformatics 2015, 31, 166–169. [Google Scholar] [CrossRef]
- Love, M.I.; Huber, W.; Anders, S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 2014, 15, 550. [Google Scholar] [CrossRef]
- Li, W.-H.; Gojobori, T.; Nei, M. Pseudogenes as a paradigm of neutral evolution. Nature 1981, 292, 237–239. [Google Scholar] [CrossRef]
- Juretic, N.; Hoen, D.R.; Huynh, M.L.; Harrison, P.M.; Bureau, T.E. The evolutionary fate of MULE-mediated duplications of host gene fragments in rice. Genome Res. 2005, 15, 1292–1297. [Google Scholar] [CrossRef]
- Schmutz, J.; Cannon, S.B.; Schlueter, J.; Ma, J.; Mitros, T.; Nelson, W.; Hyten, D.L.; Song, Q.; Thelen, J.J.; Cheng, J.; et al. Genome sequence of the palaeopolyploid soybean. Nature 2010, 463, 178–183. [Google Scholar] [CrossRef] [PubMed]
- Dyer, J.M.; Mullen, R.T. Immunocytological localization of two plant fatty acid desaturases in the endoplasmic reticulum. FEBS Lett. 2001, 494, 44–47. [Google Scholar] [CrossRef]
- Miao, X.; Zhang, L.; Hu, X.; Nan, S.; Chen, X.; Fu, H. Cloning and functional analysis of the FAD2 gene family from desert shrub Artemisia sphaerocephala. BMC Plant Biol. 2019, 19, 481. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.-J.; Cao, N.; Zhang, Z.-G.; Shang, Q.-M. Characterization of the Fatty Acid Desaturase Genes in Cucumber: Structure, Phylogeny, and Expression Patterns. PLoS ONE 2016, 11, e0149917. [Google Scholar] [CrossRef]
- Todorova, R. Expression and localization of FAD2 desaturase from spinach in tobacco cells. Russ. J. Plant Physiol. 2008, 55, 513. [Google Scholar] [CrossRef]
- Javelle, M.; Vernoud, V.; Depège-Fargeix, N.; Arnould, C.; Oursel, D.; Domergue, F.; Sarda, X.; Rogowsky, P.M. Overexpression of the Epidermis-Specific Homeodomain-Leucine Zipper IV Transcription Factor outer cell layer1 in Maize Identifies Target Genes Involved in Lipid Metabolism and Cuticle Biosynthesis. Plant Physiol. 2010, 154, 273. [Google Scholar] [CrossRef]
- Walsh, T.A.; Bevan, S.A.; Gachotte, D.J.; Larsen, C.M.; Moskal, W.A.; Merlo, P.A.; Sidorenko, L.V.; Hampton, R.E.; Stoltz, V.; Pareddy, D.; et al. Canola engineered with a microalgal polyketide synthase-like system produces oil enriched in docosahexaenoic acid. Nat. Biotechnol. 2016, 34, 881–887. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Liu, H.; Sun, J.; Li, B.; Zhu, Q.; Chen, S.; Zhang, H. Arabidopsis fatty acid desaturase FAD2 is required for salt tolerance during seed germination and early seedling growth. PLoS ONE 2012, 7, e30355. [Google Scholar] [CrossRef] [PubMed]
- Alfonso, M. Improving soybean seed oil without poor agronomics. J. Exp. Bot. 2020, 71, 6857–6860. [Google Scholar] [CrossRef]
- Román, Á.; Andreu, V.; Hernández, M.L.; Lagunas, B.; Picorel, R.; Martínez-Rivas, J.M.; Alfonso, M. Contribution of the different omega-3 fatty acid desaturase genes to the cold response in soybean. J. Exp. Bot. 2012, 63, 4973–4982. [Google Scholar] [CrossRef] [PubMed]
- Almeida, D.M.; Oliveira, M.M.; Saibo, N.J.M. Regulation of Na+ and K+ homeostasis in plants: Towards improved salt stress tolerance in crop plants. Genet. Mol. Biol. 2017, 40, 326–345. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Chen, N.; Grant, J.N.; Cheng, Z.M.; Stewart, C.N., Jr.; Hewezi, T. Soybean kinome: Functional classification and gene expression patterns. J. Exp. Bot. 2015, 66, 1919–1934. [Google Scholar] [CrossRef]
- Gepts, P. Ten thousand years of crop evolution. In Plants, Genes, and Crop Biotechnology; Chrispeels, M.J., Sadava, D.E., Eds.; Jones and Bartlett: Sudbury, MA, USA, 2003; pp. 328–359. [Google Scholar]
- Eckardt, N.A. Two genomes are better than one: Widespread paleopolyploidy in plants and evolutionary effects. Plant Cell 2004, 16, 1647–1649. [Google Scholar] [CrossRef]
- Lakhssassi, N.; Liu, S.; Bekal, S.; Zhou, Z.; Colantonio, V.; Lambert, K.; Barakat, A.; Meksem, K. Characterization of the Soluble NSF Attachment Protein gene family identifies two members involved in additive resistance to a plant pathogen. Sci. Rep. 2017, 7, 45226. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gene ID | Amplicon Size (bp) | Base Changes | Type of Base Changes | InDel | Mutation Density (Kb) | AA Changes | Missense Mutations | Nonsense Mutations | Silent Mutations | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| G > A | C > T | Others | |||||||||
| Glyma.10G278000 | 1928 | 50 | 13 | 29 | 8 | 0 | 1/155 | 28 | 17 | 0 | 11 |
| Glyma.20G111000 | 3403 | 89 | 22 | 29 | 38 | 3 | 1/154 | 25 | 11 | 1 | 13 |
| Glyma.19G147300 | 889 | 28 | 13 | 12 | 3 | 1 | 1/128 | 13 | 9 | 1 | 3 |
| Glyma.19G147400 | 2711 | 79 | 26 | 39 | 14 | 5 | 1/138 | 39 | 28 | 2 | 9 |
| Glyma.03G144500 | 2210 | 87 | 29 | 35 | 23 | 3 | 1/102 | 28 | 15 | 1 | 12 |
| Glyma.09G111900 | 1663 | 55 | 18 | 23 | 14 | 2 | 1/121 | 33 | 25 | 2 | 6 |
| Glyma.15G195200 | 881 | 53 | 16 | 24 | 13 | 2 | 1/67 | 30 | 25 | 0 | 5 |
| Total | 441 | 137 | 191 | 113 | 16 | 196 | 130 | 7 | 59 | ||
| Gene ID | Plant ID | Nucleotide Change | Amino Acid Substitution | C16:0 | C18:0 | C18:1 | C18:2 | C18:3 |
|---|---|---|---|---|---|---|---|---|
| GmFAD2-2A Glyma.19g147300 | F490 | G410T | R137L | 10.4 | 3.5 | 29.6 | 50.1 | 6.4 |
| F601 | G283A | A95T | 9.6 | 4.8 | 24.8 | 54.3 | 6.4 | |
| F300 | C134T | T45I | 10.7 | 4.1 | 25.1 | 54.0 | 6.1 | |
| F1410 | C38A | P13H | 10.6 | 5.1 | 27.8 | 50.9 | 5.6 | |
| F960 | C91T | R31C | 10.2 | 3.6 | 24.2 | 54.3 | 7.6 | |
| F935 | C103T | R35C | 10.3 | 3.7 | 25.1 | 53.4 | 7.5 | |
| F239 | C211T | P71S | 11.1 | 4.2 | 26.8 | 53.3 | 4.6 | |
| F1044 | C245T | A82V | 10.0 | 5.2 | 26.1 | 54.1 | 4.6 | |
| F1202 | C331T | H11Y | 9.4 | 4.1 | 31.9 | 49.0 | 5.5 | |
| F141 | G346A | V116I | 10.8 | 5.1 | 27.9 | 50.3 | 5.8 | |
| F1581 | C376T | R126C | 10.5 | 4.5 | 28.6 | 51.2 | 5.2 | |
| F1493 | C379T | R127C | 9.7 | 3.4 | 25.8 | 54.5 | 6.6 | |
| GmFAD2-2B Glyma.19g147400 | F211 | G994A | A332T | 10.7 | 3.9 | 25.1 | 52.0 | 8.4 |
| F185 | C277T | Q93 * | 9.6 | 3.5 | 25.6 | 50.6 | 10.7 | |
| F45 | G1118A | S373N | 10.8 | 3.7 | 26.3 | 52.1 | 7.1 | |
| F1103 | G284A | C95Y | 10.3 | 3.5 | 28.1 | 51.3 | 6.9 | |
| F1496 | G460A | D154N | 9.7 | 4.8 | 27.8 | 51.3 | 6.4 | |
| F1562 | G466A | V156I | 9.9 | 4.2 | 27.3 | 52.2 | 6.4 | |
| F253 | A672T | Q224H | 10.1 | 4.2 | 27.4 | 52.7 | 5.6 | |
| F921 | C1049T | P350L | 10.2 | 3.7 | 24.1 | 53.5 | 8.5 | |
| GmFAD2-2C Glyma.03G144500 | 496 | C625T | H209Y | 9.9 | 3.1 | 28.3 | 50.5 | 8.3 |
| 1106 | G1114A | E372K | 10.2 | 4.2 | 29.6 | 50.8 | 5.3 | |
| 468 | C88T | P30S | 9.9 | 5.6 | 28.2 | 50.0 | 6.2 | |
| 595 | G781A | V261M | 10.4 | 5.1 | 25.7 | 53.5 | 5.3 | |
| F408 | G49A | E17K | 10.3 | 4.3 | 28.9 | 51.3 | 5.2 | |
| F1222 | G175A | D59N | 10.4 | 4.0 | 25.2 | 52.7 | 7.7 | |
| F1748 | C259T | P87S | 10.3 | 4.7 | 26.1 | 51.0 | 7.9 | |
| F1111 | C313A | H105N | 10.5 | 5.3 | 25.5 | 52.7 | 6.0 | |
| F58 | A672T | Q224H | 10.2 | 4.9 | 24.4 | 53.7 | 6.9 | |
| F1165 | G799A | V267M | 9.3 | 3.2 | 27.9 | 50.2 | 9.4 | |
| GmFAD2-2D Glyma.09G111900 | 313 | C643T | P215S | 11.0 | 4.9 | 26.9 | 48.8 | 8.4 |
| 81 | A622T | R208 * | 10.3 | 5.2 | 32.7 | 46.5 | 5.2 | |
| 369 | C751T | L251F | 10.7 | 5.0 | 25.3 | 53.1 | 5.9 | |
| 1436 | G1094T | C365F | 10.4 | 5.2 | 27.7 | 50.0 | 6.7 | |
| F1381 | A1020T | K340N | 10.1 | 4.1 | 28.9 | 50.2 | 6.7 | |
| F275 | G905A | R302K | 10.5 | 6.4 | 29.2 | 47.7 | 6.2 | |
| F1117 | G579A | W193 * | 10.6 | 4.4 | 27.7 | 50.6 | 6.7 | |
| F470 | G510A | W170 * | 9.7 | 4.7 | 30.5 | 48.1 | 6.9 | |
| F1268 | C439T | H147Y | 9.8 | 4.0 | 26.0 | 52.5 | 7.6 | |
| GmFAD2-2E Glyma.15g195200 | F1087 | G329A | G110E | 10.3 | 3.8 | 21.3 | 55.7 | 8.9 |
| F380 | C502T | P168S | 9.9 | 4.2 | 24.6 | 53.5 | 7.7 | |
| F9 | C829T | P277S | 10.9 | 4.3 | 24.0 | 53.6 | 7.3 | |
| F1215 | A803T | E268V | 10.6 | 4.9 | 29.9 | 48.4 | 6.2 | |
| F602 | G754A | E252K | 10.4 | 4.2 | 25.2 | 54.0 | 6.2 | |
| F1328 | G751A | G251R | 10.2 | 4.7 | 27.2 | 52.4 | 5.5 | |
| F1285 | G721A | E241K | 10.4 | 3.9 | 24.4 | 52.5 | 8.8 | |
| F1065 | C706T | H236Y | 11.3 | 4.8 | 29.8 | 47.6 | 6.5 | |
| F226 | G628A | D210N | 11.3 | 5.0 | 33.7 | 44.9 | 5.1 | |
| F69 | G626A | R209k | 10.5 | 4.5 | 25.9 | 52.1 | 7.0 | |
| F1803 | G605A | G202E | 12.3 | 5.0 | 32.0 | 45.5 | 5.2 | |
| F480 | T595A | W199R | 10.9 | 4.5 | 26.4 | 51.6 | 6.6 | |
| F372 | C397T | L133F | 10.5 | 3.6 | 25.7 | 53.9 | 6.3 | |
| F1180 | C350T | A117V | 10.5 | 4.2 | 24.0 | 54.5 | 6.9 | |
| F123 | C334T | P112S | 10.4 | 5.3 | 28.6 | 50.4 | 5.3 | |
| F238 | G328A | G110R | 10.2 | 6.3 | 27.2 | 50.5 | 5.8 | |
| F1480 | C167T | S56F | 9.8 | 4.2 | 25.7 | 53.0 | 7.3 | |
| F1711 | T166A | S56T | 9.4 | 5.1 | 35.7 | 43.5 | 6.3 | |
| F1462 | G61A | A21T | 9.7 | 3.8 | 33.3 | 47.8 | 5.4 | |
| FWT | 11.6 | 3.32 | 18 | 54.5 | 6.19 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lakhssassi, N.; Lopes-Caitar, V.S.; Knizia, D.; Cullen, M.A.; Badad, O.; El Baze, A.; Zhou, Z.; Embaby, M.G.; Meksem, J.; Lakhssassi, A.; et al. TILLING-by-Sequencing+ Reveals the Role of Novel Fatty Acid Desaturases (GmFAD2-2s) in Increasing Soybean Seed Oleic Acid Content. Cells 2021, 10, 1245. https://doi.org/10.3390/cells10051245
Lakhssassi N, Lopes-Caitar VS, Knizia D, Cullen MA, Badad O, El Baze A, Zhou Z, Embaby MG, Meksem J, Lakhssassi A, et al. TILLING-by-Sequencing+ Reveals the Role of Novel Fatty Acid Desaturases (GmFAD2-2s) in Increasing Soybean Seed Oleic Acid Content. Cells. 2021; 10(5):1245. https://doi.org/10.3390/cells10051245
Chicago/Turabian StyleLakhssassi, Naoufal, Valéria Stefania Lopes-Caitar, Dounya Knizia, Mallory A. Cullen, Oussama Badad, Abdelhalim El Baze, Zhou Zhou, Mohamed G. Embaby, Jonas Meksem, Aicha Lakhssassi, and et al. 2021. "TILLING-by-Sequencing+ Reveals the Role of Novel Fatty Acid Desaturases (GmFAD2-2s) in Increasing Soybean Seed Oleic Acid Content" Cells 10, no. 5: 1245. https://doi.org/10.3390/cells10051245
APA StyleLakhssassi, N., Lopes-Caitar, V. S., Knizia, D., Cullen, M. A., Badad, O., El Baze, A., Zhou, Z., Embaby, M. G., Meksem, J., Lakhssassi, A., Chen, P., AbuGhazaleh, A., Vuong, T. D., Nguyen, H. T., Hewezi, T., & Meksem, K. (2021). TILLING-by-Sequencing+ Reveals the Role of Novel Fatty Acid Desaturases (GmFAD2-2s) in Increasing Soybean Seed Oleic Acid Content. Cells, 10(5), 1245. https://doi.org/10.3390/cells10051245